
Study on Resistant Hierarchical Fuzzy Neural Networks


Abstract
:1. Introduction
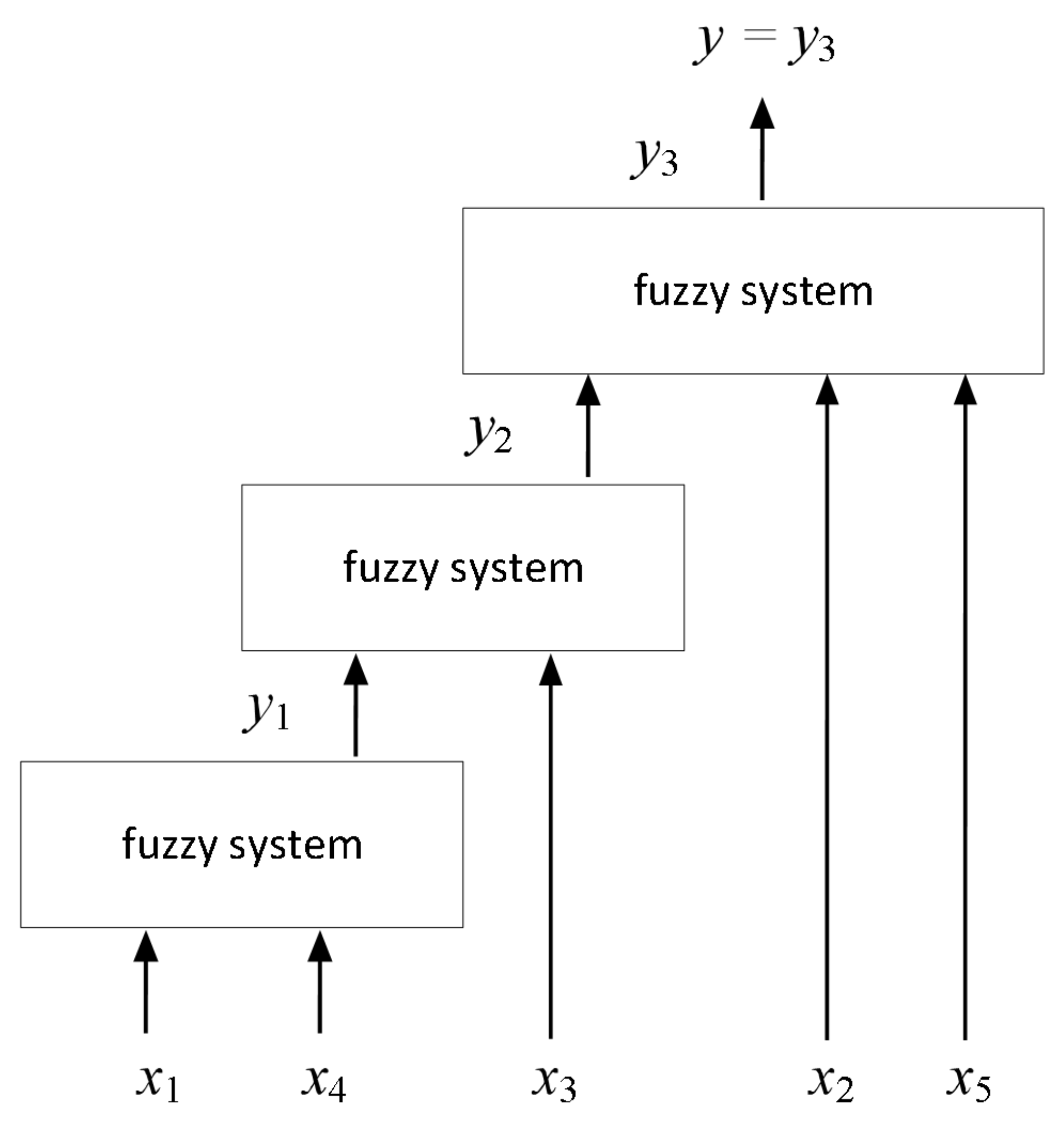
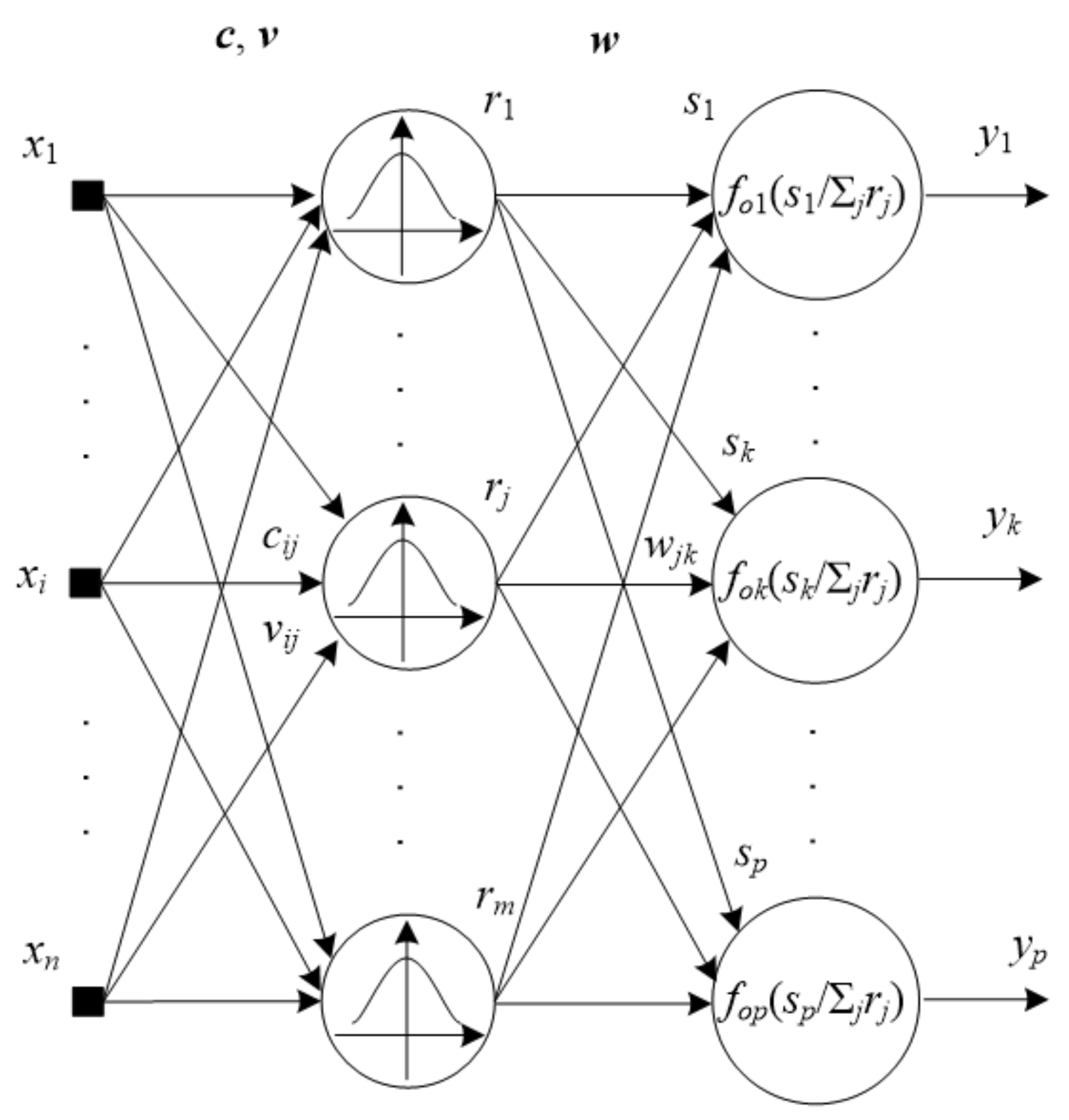
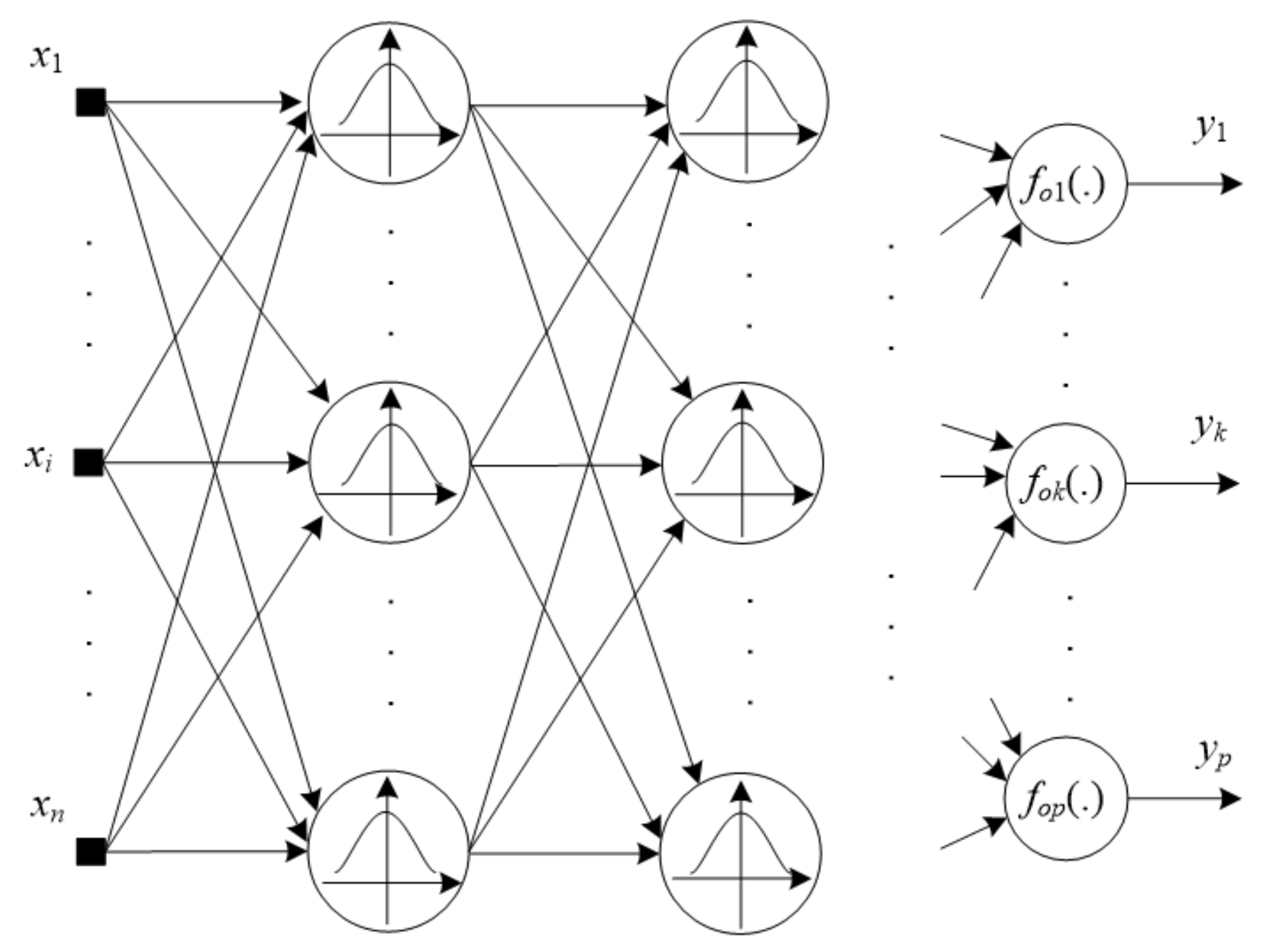
2. Fuzzy Neural Networks
3. Loss Function
4. Partition of Input Variables
- Rule 1:
- Correlation is measured in absolute value (i.e., magnitude).
- Rule 2:
- Put the more correlated predictors in our hierarchical fuzzy neural network as early as possible.
- Rule 3:
- Variables with low correlation will not be used as predictors.
- Rule 4:
- Predictors with about the same level of correlation may be collected in the same group.
5. Illustrative Examples
- (1)
- normal distribution: , ., .
- (2)
- Laplace distribution: , ., ().
- (3)
- Uniform distribution: , .
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Nomenclature
| n-dimensional real space | |
| Cartesian product of sets X and Y |
References
- Knorr, E.M.; Ng, R.T.; Tucakov, V. Distance-based outliers: Algorithms and applications. VLDB J. 2000, 8, 237–253. [Google Scholar] [CrossRef]
- Leys, C.; Ley, C.; Klein, O.; Bernard, P.; Licata, L. Detecting outliers: Do not use standard deviation around mean, use absolute deviation around the median. J. Exp. Soc. Psychol. 2013, 49, 764–766. [Google Scholar] [CrossRef] [Green Version]
- Aguinis, H.; Gottfredson, R.K.; Joo, H. Best-practice recommendations for defining, identifying, and handling outliers. Organ. Res. Methods 2013, 16, 270–301. [Google Scholar] [CrossRef]
- Alfons, A.; Croux, C.; Gelper, S. Sparse least trimmed squares regression for analyzing high-dimensional large data sets. Ann. Appl. Stat. 2013, 7, 226–248. [Google Scholar] [CrossRef]
- Febrero-Bande, M.; Galeano, P.; Gonzále-Manteiga, W. Functional principal component regression and functional partial least-squares regression: An overview and a comparative study. Int. Stat. Rev. 2017, 85, 61–83. [Google Scholar] [CrossRef]
- Lecué, G.; Lerasle, M. Robust machine learning by median-of-means: Theory and practice. Ann. Stat. 2017, 48, 906–931. [Google Scholar] [CrossRef]
- Abonazel, M.R.; Saber, O.M. A comparative study of robust estimators for Poisson regression model with outliers. J. Stat. Appl. Probab 2020, 9, 279–286. [Google Scholar] [CrossRef]
- Lathuilière, S.; Mesejo, P.; Alameda-Pineda, X.; Horaud, R. Deepgum: Learning deep robust regression with a gaussian-uniform mixture model. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 202–217. [Google Scholar]
- Klivans, A.; Kothari, P.K.; Meka, R. Efficient algorithms for outlier-robust regression. In Proceedings of the Conference On Learning Theory, Stockholm, Sweden, 6–9 July 2018; pp. 1420–1430. [Google Scholar]
- Schmidt, A.F.; Chris, F. Linear regression and the normality assumption. J. Clin. Epidemiol. 2018, 98, 146–151. [Google Scholar] [CrossRef] [Green Version]
- Thompson, E.D.; Bowling, B.V.; Markle, R.E. Predicting student success in a major’s introductory biology course via logistic regression analysis of scientific reasoning ability and mathematics scores. Res. Sci. Educ. 2018, 48, 151–163. [Google Scholar] [CrossRef]
- Mahaboob, B.; Praveen, J.P.; Rao, B.A.; Haranadh, Y.; Narayana, C.; Prakash, G.B. A study on multiple linear regression using matrix calculus. Adv. Math. Sci. J. 2020, 9, 4863–4872. [Google Scholar] [CrossRef]
- Steward, P.R.; Dougill, A.J.; Thierfelder, C.; Pittelkow, C.M.; Stringer, L.C.; Kudzala, M.; Shackelford, G.E. The adaptive capacity of maize-based conservation agriculture systems to climate stress in tropical and subtropical environments: A meta-regression of yields. Agric. Ecosyst. Environ. 2018, 251, 194–202. [Google Scholar] [CrossRef]
- Aspuru, J.; Ochoa-Brust, A.; Félix, R.A.; Mata-López, W.; Mena, L.J.; Ostos, R.; Martínez-Peláez, R. Segmentation of the ECG signal by means of a linear regression algorithm. Sensors 2019, 19, 775. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hsieh, J.-G.; Lin, Y.-L.; Jeng, J.-H. Preliminary study on Wilcoxon learning machines. IEEE Trans. Neural Netw. 2008, 19, 201–211. [Google Scholar] [CrossRef] [PubMed]
- Rusiecki, A. Robust learning algorithm based on LTA estimator. Neurocomputing 2008, 120, 624–632. [Google Scholar] [CrossRef]
- Lin, Y.-L.; Hsieh, J.-G.; Jeng, J.-H.; Cheng, W.-C. On least trimmed squares neural networks. Neurocomputing 2015, 161, 107–112. [Google Scholar] [CrossRef]
- Rusiecki, A. Trimmed categorical cross-entropy for deep learning with label noise. Electron. Lett. 2019, 55, 319–320. [Google Scholar] [CrossRef]
- Hsieh, J.-G.; Jeng, J.-H.; Lin, Y.-H.; Kuo, Y.-S. Single index fuzzy neural networks using locally weighted polynomial regression. Fuzzy Sets and Systems. Fuzzy Sets Syst. 2019, 368, 82–100. [Google Scholar] [CrossRef]
- Deng, Z.; Jiang, Y.; Choi, K.S.; Chung, F.L.; Wang, S. Knowledge-leverage-based TSK fuzzy system modeling. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1200–1212. [Google Scholar] [CrossRef]
- Shihabudheen, K.V.; Pillai, G.N. Recent advances in neuro-fuzzy system: A survey. Knowl.-Based Syst. 2018, 152, 136–162. [Google Scholar] [CrossRef]
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-art in artificial neural network applications: A survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef] [Green Version]
- Khodabandelou, G.; Ebadzadeh, M.M. Fuzzy neural network with support vector-based learning for classification and regression. Soft Comput. 2019, 23, 12153–12168. [Google Scholar] [CrossRef]
- Tang, J.; Liu, F.; Zhang, W.; Ke, R.; Zou, Y. Lane-changes prediction based on adaptive fuzzy neural network. Expert Syst. Appl. 2018, 91, 452–463. [Google Scholar] [CrossRef]
- Khashei, M.; Hamadani, A.Z.; Bijari, M. A novel hybrid classification model of artificial neural networks and multiple linear regression models. Expert Syst. Appl. 2012, 39, 2606–2620. [Google Scholar] [CrossRef]
- Zheng, Y.; Jeon, B.; Xu, D. Image segmentation by generalized hierarchical fuzzy C-means algorithm. J. Intell. Fuzzy Syst. 2015, 28, 961–973. [Google Scholar] [CrossRef]
- Deng, Y.; Ren, Z.; Kong, Y.; Bao, F.; Dai, Q. A hierarchical fused fuzzy deep neural network for data classification. IEEE Trans. Fuzzy Syst. 2015, 25, 1006–1012. [Google Scholar] [CrossRef]
- Wang, L.X. Universal approximation by hierarchical fuzzy systems. Fuzzy Sets Syst. 1998, 93, 223–230. [Google Scholar] [CrossRef]
- Chen, W.; Wang, L.X. A note on universal approximation by hierarchical fuzzy systems. Inf. Sci. 2000, 123, 241–248. [Google Scholar] [CrossRef]
- Joo, M.G.; Lee, J.S. Universal approximation by hierarchical fuzzy system with constraints on the fuzzy rule. Fuzzy Sets Syst. 2002, 130, 175–188. [Google Scholar] [CrossRef]
- UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 26 October 2020).
- LIBSVM: A Library for Support Vector Machines. Available online: http://www.csie.ntu.edu.tw/~cjlin/libsvm (accessed on 5 November 2020).
- Kaggle. Available online: https://www.kaggle.com/datasets (accessed on 12 November 2018).




{kind=link}
{kind=link}
{kind=link}
| Dataset | No. of Cases | No. of Predictors | Source |
|---|---|---|---|
| Airfoil self-noise | 1503 | 5 | UCI |
| Boston housing | 506 | 13 | Kaggle |
| Combined cycle power plant | 9568 | 4 | UCI |
| Concrete compressive strength | 1030 | 8 | UCI |
| Cpusmall | 8192 | 12 | LIBSVM |
| Mg | 1385 | 6 | LIBSVM |
| Parkinsons telemonitoring (motor UPDRS) | 5875 | 16 | UCI |
| Parkinsons telemonitoring (total UPDRS) | 5875 | 16 | UCI |
| QSAR fish toxicity | 908 | 6 | UCI |
| Space-GA | 3107 | 6 | LIBSVM |
| Dataset | HFNN | DNN |
|---|---|---|
| Airfoil self-noise | (1,4,3,2) (4,4,3,2) (4,4,3,1) (159) | 5-10-6-4-1 (159) |
| Boston housing | (3,4,3,2) (5,4,3,2) (6,4,3,1) (5,4,3,1) (269) | 13-10-7-5-1 (263) |
| Combined cycle power plant | (1,4,3,2) (3,4,3,2) (4,4,3,1) (151) | 4-8-8-4-1 (153) |
| Concrete compressive strength | (2,4,3,2) (5,4,3,2) (5,4,3,1) (183) | 8-8-7-5-1 (181) |
| Cpusmall | (2,4,3,2) (6,4,3,2) (6,4,3,2) (4,4,3,1) (261) | 12-10-8-4-1 (259) |
| Mg | (2,4,3,2) (4,4,3,2) (4,4,3,1) (167) | 6-8-7-5-1 (165) |
| Parkinsons telemonitoring (motor UPDRS) | (2,4,3,2) (4,4,3,2) (5,4,3,1) (175) | 16-6-5-5-1 (173) |
| Parkinsons telemonitoring (total UPDRS) | (1,4,3,2) (4,4,3,2) (4,4,3,1) (159) | 16-6-5-3-1 (159) |
| QSAR fish toxicity | (1,4,3,2) (4,4,3,2) (3,4,3,2) (4,4,3,1) (213) | 6-9-8-7-1 (214) |
| Space-GA | (1,4,3,2) (3,4,3,2) (5,4,3,2) (3,4,3,1) (213) | 6-9-8-7-1 (214) |
| LTS-HFNN | LTS-DNN | DNN without Noise | |
|---|---|---|---|
| Airfoil self-noise | |||
| LOSS | 0.0919 (±0.0201) | 0.0901 (±0.1667) | |
| MSE | 0.2970 (±0.0600) | 0.2916 (±0.3971) | 0.1039 (±0.4019) |
| MAE | 0.4118 (±0.0410) | 0.4022 (±0.2255) | 0.2374 (±0.2563) |
| Boston housing | |||
| LOSS | 0.3005 (±0.0691) | 0.2220 (±0.0500) | |
| MSE | 0.9877 (±0.3232) | 0.5845 (±0.2183) | 0.1017 (±0.0981) |
| MAE | 0.7745 (±0.0841) | 0.5928 (±0.0817) | 0.2359 (±0.0581) |
| Combined cycle power plant | |||
| LOSS | 0.0260 (±0.0036) | 0.0275 (±0.1481) | |
| MSE | 0.0734 (±0.0107) | 0.0744 (±0.2897) | 0.0570 (±0.4011) |
| MAE | 0.2133 (±0.0124) | 0.2144 (±0.2031) | 0.1850 (±0.2910) |
| Concrete compressive strength | |||
| LOSS | 0.1481 (±0.0352) | 0.1947 (±0.1487) | |
| MSE | 0.3964 (±0.0743) | 0.4904 (±0.3362) | 0.1393 (±0.2216) |
| MAE | 0.4986 (±0.0478) | 0.5574 (±0.1814) | 0.2746 (±0.1489) |
| Cpusmall | |||
| LOSS | 0.0330 (±0.0048) | 0.0327 (±0.0248) | |
| MSE | 0.8737 (±0.1438) | 0.1296 (±0.4685) | 0.0253 (±0.0035) |
| MAE | 0.3928 (±0.0343) | 0.2518 (±0.1383) | 0.1141 (±0.0062) |
| Mg | |||
| LOSS | 0.1538 (±0.0211) | 0.1507 (±0.1192) | |
| MSE | 0.4595 (±0.0747) | 0.4139 (±0.2331) | 0.2920 (±0.2131) |
| MAE | 0.5262 (±0.0435) | 0.5047 (±0.1335) | 0.4157 (±0.1297) |
| Parkinsons telemonitoring (motor UPDRS) | |||
| LOSS | 0.3616 (±0.0319) | 0.4102 (±0.0979) | |
| MSE | 0.9389 (±0.0684) | 0.9262 (±0.1149) | 0.7059 (±0.0996) |
| MAE | 0.7757 (±0.0329) | 0.7952 (±0.0801) | 0.6746 (±0.0637) |
| Parkinsons telemonitoring (total UPDRS) | |||
| LOSS | 0.3333 (±0.0404) | 0.3729 (±0.0578) | |
| MSE | 0.9158 (±0.0686) | 0.9454 (±0.0937) | 0.7011 (±0.1500) |
| MAE | 0.7536 (±0.0393) | 0.7744 (±0.0501) | 0.6689 (±0.0728) |
| QSAR fish toxicity | |||
| LOSS | 0.2175 (±0.0419) | 0.2016 (±0.0671) | |
| MSE | 0.6589 (±0.1362) | 0.6178 (±0.2001) | 0.4719 (±0.1418) |
| MAE | 0.6108 (±0.0463) | 0.5904 (±0.0793) | 0.4779 (±0.0923) |
| Space-GA | |||
| LOSS | 0.1474 (±0.0276) | 0.1145 (±0.0623) | |
| MSE | 0.5002 (±0.1766) | 0.3512 (±0.1806) | 0.2716 (±0.2544) |
| MAE | 0.5074 (±0.0478) | 0.4469 (±0.0890) | 0.3911 (±0.1295) |
| LTS-HFNN | LTS-DNN | DNN without Noise | |
|---|---|---|---|
| Airfoil self-noise | |||
| LOSS | 0.1096 (±0.0273) | 0.2661 (±0.1869) | |
| MSE | 0.3451 (±0.0621) | 0.6195 (±0.4015) | 0.1039 (±0.4019) |
| MAE | 0.4478 (±0.0478) | 0.6258 (±0.2294) | 0.2374 (±0.2563) |
| Boston housing | |||
| LOSS | 0.3600 (±0.1021) | 0.2086 (±0.0765) | |
| MSE | 1.0135 (±0.2562) | 0.8298 (±0.3050) | 0.1017 (±0.0981) |
| MAE | 0.7595 (±0.0897) | 0.6845 (±0.0892) | 0.2359 (±0.0581) |
| Combined cycle power plant | |||
| LOSS | 0.0247 (±0.0016) | 0.0265 (±0.1501) | |
| MSE | 0.0703 (±0.0057) | 0.0711 (±0.2893) | 0.0570 (±0.4011) |
| MAE | 0.2041 (±0.0061) | 0.2103 (±0.2067) | 0.1850 (±0.2910) |
| Concrete compressive strength | |||
| LOSS | 0.1658 (±0.0425) | 0.1507 (±0.1461) | |
| MSE | 0.4358 (±0.0972) | 0.4265 (±0.3083) | 0.1393 (±0.2216) |
| MAE | 0.5256 (±0.0569) | 0.5078 (±0.1754) | 0.2746 (±0.1489) |
| Cpusmall | |||
| LOSS | 0.0205 (±0.0063) | 0.0217 (±0.0279) | |
| MSE | 0.4521 (±0.2958) | 0.0929 (±0.4073) | 0.0253 (±0.0035) |
| MAE | 0.2949 (±0.0819) | 0.2052 (±0.1373) | 0.1141 (±0.0062) |
| Mg | |||
| LOSS | 0.1449 (±0.0367) | 0.1374 (±0.1370) | |
| MSE | 0.4620 (±0.0654) | 0.3965 (±0.2542) | 0.2920 (±0.2131) |
| MAE | 0.5013 (±0.0443) | 0.4823 (±0.1512) | 0.4157 (±0.1297) |
| Parkinsons telemonitoring (motor UPDRS) | |||
| LOSS | 0.3612 (±0.0380) | 0.3407 (±0.0875) | |
| MSE | 0.9004 (±0.0912) | 0.8740 (±0.1118) | 0.7059 (±0.0996) |
| MAE | 0.7605 (±0.0387) | 0.7441 (±0.0763) | 0.6746 (±0.0637) |
| Parkinsons telemonitoring (total UPDRS) | |||
| LOSS | 0.3287 (±0.0300) | 0.3946 (±0.0578) | |
| MSE | 0.8618 (±0.0619) | 0.9758 (±0.0921) | 0.7011 (±0.1500) |
| MAE | 0.7409 (±0.0305) | 0.7943 (±0.0489) | 0.6689 (±0.0728) |
| QSAR fish toxicity | |||
| LOSS | 0.2311 (±0.0651) | 0.1886 (±0.1202) | |
| MSE | 0.7317 (±0.1558) | 0.5801 (±0.2875) | 0.4719 (±0.1418) |
| MAE | 0.6655 (±0.0762) | 0.5735 (±0.1287) | 0.4779 (±0.0923) |
| Space-GA | |||
| LOSS | 0.1379 (±0.0077) | 0.1069 (±0.0862) | |
| MSE | 0.4689 (±0.1199) | 0.3195 (±0.2381) | 0.2716 (±0.2544) |
| MAE | 0.5055 (±0.0152) | 0.4410 (±0.1197) | 0.3911 (±0.1295) |
| LTS-HFNN | LTS-DNN | DNN without Noise | |
|---|---|---|---|
| Airfoil self-noise | |||
| LOSS | 0.0878 (±0.0127) | 0.0801 (±0.1175) | |
| MSE | 0.2787 (±0.0543) | 0.2720 (±0.2748) | 0.1039 (±0.4019) |
| MAE | 0.3961 (±0.0273) | 0.3829 (±0.1545) | 0.2374 (±0.2563) |
| Boston housing | |||
| LOSS | 0.1799 (±0.0378) | 0.1248 (±0.0521) | |
| MSE | 0.6684 (±0.2669) | 0.4135 (±0.1432) | 0.1017 (±0.0981) |
| MAE | 0.5968 (±0.0777) | 0.4861 (±0.0773) | 0.2359 (±0.0581) |
| Combined cycle power plant | |||
| LOSS | 0.0271 (±0.0019) | 0.0295 (±0.1466) | |
| MSE | 0.0761 (±0.0063) | 0.0780 (±0.3029) | 0.0570 (±0.4011) |
| MAE | 0.2155 (±0.0072) | 0.2185 (±0.2044) | 0.1850 (±0.2910) |
| Concrete compressive strength | |||
| LOSS | 0.1160 (±0.0262) | 0.0897 (±0.1117) | |
| MSE | 0.3350 (±0.0706) | 0.2479 (±0.2392) | 0.1393 (±0.2216) |
| MAE | 0.4414 (±0.0468) | 0.3816 (±0.1371) | 0.2746 (±0.1489) |
| Cpusmall | |||
| LOSS | 0.0267 (±0.0062) | 0.0311 (±0.0157) | |
| MSE | 0.8325 (±0.0999) | 0.1182 (±0.3180) | 0.0253 (±0.0035) |
| MAE | 0.3724 (±0.0357) | 0.2518 (±0.0899) | 0.1141 (±0.0062) |
| Mg | |||
| LOSS | 0.1213 (±0.0249) | 0.1249 (±0.1376) | |
| MSE | 0.3826 (±0.0528) | 0.3638 (±0.2730) | 0.2920 (±0.2131) |
| MAE | 0.4662 (±0.0338) | 0.4643 (±0.1566) | 0.4157 (±0.1297) |
| Parkinsons telemonitoring (motor UPDRS) | |||
| LOSS | 0.3412 (±0.0275) | 0.2980 (±0.0684) | |
| MSE | 0.9623 (±0.0748) | 0.8299 (±0.0921) | 0.7059 (±0.0996) |
| MAE | 0.7576 (±0.0291) | 0.7097 (±0.0522) | 0.6746 (±0.0637) |
| Parkinsons telemonitoring (total UPDRS) | |||
| LOSS | 0.3184 (±0.0318) | 0.3892 (±0.0752) | |
| MSE | 0.9121 (±0.0766) | 0.9835 (±0.1188) | 0.7011 (±0.1500) |
| MAE | 0.7326 (±0.0324) | 0.7991 (±0.0644) | 0.6689 (±0.0728) |
| QSAR fish toxicity | |||
| LOSS | 0.1507 (±0.0441) | 0.1246 (±0.0489) | |
| MSE | 0.4986 (±0.1436) | 0.4540 (±0.1513) | 0.4719 (±0.1418) |
| MAE | 0.5347 (±0.0696) | 0.5097 (±0.0838) | 0.4779 (±0.0923) |
| Space-GA | |||
| LOSS | 0.1224 (±0.0073) | 0.0980 (±0.0114) | |
| MSE | 0.4284 (±0.0993) | 0.2986 (±0.0790) | 0.2716 (±0.2544) |
| MAE | 0.4792 (±0.0176) | 0.4196 (±0.0284) | 0.3911 (±0.1295) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, F.; Hsieh, J.-G.; Kuo, Y.-S.; Jeng, J.-H. Study on Resistant Hierarchical Fuzzy Neural Networks. Electronics 2022, 11, 598. https://doi.org/10.3390/electronics11040598
Gao F, Hsieh J-G, Kuo Y-S, Jeng J-H. Study on Resistant Hierarchical Fuzzy Neural Networks. Electronics. 2022; 11(4):598. https://doi.org/10.3390/electronics11040598
Chicago/Turabian StyleGao, Fengyu, Jer-Guang Hsieh, Ying-Sheng Kuo, and Jyh-Horng Jeng. 2022. "Study on Resistant Hierarchical Fuzzy Neural Networks" Electronics 11, no. 4: 598. https://doi.org/10.3390/electronics11040598