
Bringing Emotion Recognition Out of the Lab into Real Life: Recent Advances in Sensors and Machine Learning


Abstract
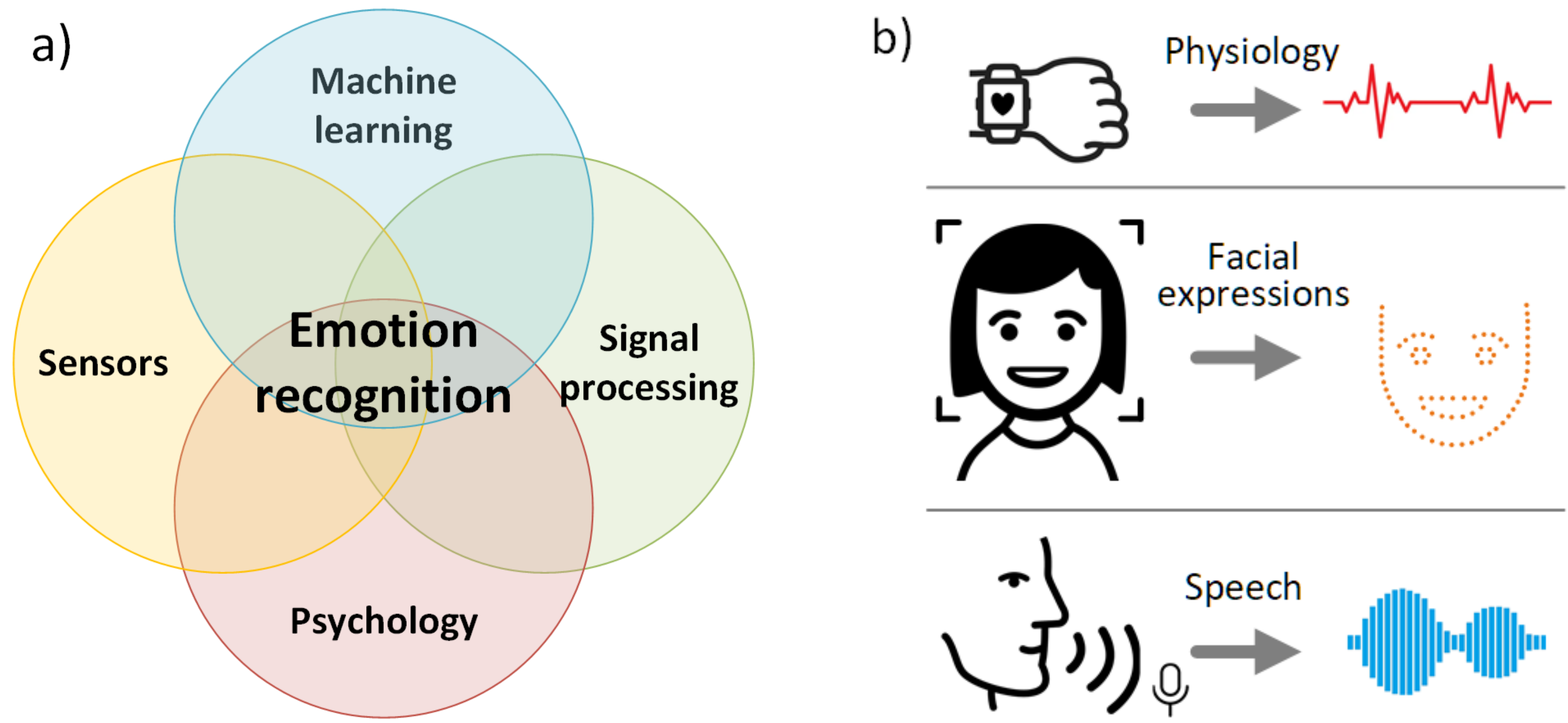
:1. Introduction
2. Sensors and Devices
2.1. Emotion Recognition from Physiology
- What physiological signals do we need to collect? Does the device provide them in a raw format?
- What is the signal recording frequency? Is it appropriate for our problem?
- How portable is the device? What types of physical activities does the device have to handle?
- How are the data obtained from the device? By cable or directly transferred to the cloud? Do we need to integrate the existing study system with the device?
- How convenient and easy to use is the device? How long should the battery last?
2.2. Facial Emotion Recognition
2.3. Speech Emotion Recognition
3. Signal Processing and Transformation
4. Machine Learning Models and Techniques
4.1. Residual Networks
4.2. Long Short-Term Memory
4.3. Convolutional Neural Networks and Fully Convolutional Networks
4.4. End-to-End Deep Learning Approach
4.5. Representation Learning
4.6. Model Personalization
5. Existing Systems
6. Futures of Emotion Recognition
7. Conclusions
Funding
Acknowledgments
Conflicts of Interest
Acronyms
| Signals, Sensors, and Data From Wearables | |
| Acronym | Full Name |
| ACC | accelerometer |
| AL | ambient light |
| ALT | altimeter |
| AT | ambient temperature |
| BAR | barometer |
| BP | blood pressure |
| BVP | blood volume pulse |
| CAL | calories burned |
| ECG | electrocardiogra(ph/m) |
| EEG | electroencephalogra(ph/m) |
| EMG | electromyogra(ph/m) |
| GSR | galvanic skin response |
| GYRO | gyroscope |
| HR | heart rate |
| HRV | heart rate variability |
| IBI | interbit interval |
| MAG | magnetometer |
| MIC | microphone |
| PPG | photoplethysmograph |
| PPI | peak-to-peak interval |
| RRI | R-R interval |
| RSP | respiration rate |
| SKT | skin temperature |
| SpO2 | blood oxygen saturation |
| STP | no. of steps |
| TERM | termometer |
| UV | ultraviolet |
| Deep Learning Architectures and Signal Processing | |
| Acronym | Full Name |
| Bi- | bidirectional- |
| CNN | convolutional neural networks |
| DAE | denoising autoencoder |
| DTD | dynamic threshold difference |
| FCN | fully convolutional networks |
| FFA | fast Fourier transform |
| GAN | generative adversarial networks |
| GRU | gated recurrent unit |
| ICA | independent component analysis |
| LSTM | long short-term memory |
| MCDCNN | multichannel deep convolutional neural networks |
| MLP | multilayer perceptron |
| ResNet | residual networks |
| RNN | recurrent neural networks |
| SPARE | spectral peak recovery |
| StresNet | spectrotemporal residual networks |
| VGG | visual geometry group |
| WT | wavelet transform |
References
- O’Brien, D.T. Thinking, Fast and Slow; Farrar, Straus and Giroux: New York, NY, USA, 2012. [Google Scholar]
- He, C.; Yao, Y.J.; Ye, X.S. An emotion recognition system based on physiological signals obtained by wearable sensors. In Wearable Sensors and Robots; Springer: Berlin, Germany, 2017; pp. 15–25. [Google Scholar]
- Feng, H.; Golshan, H.M.; Mahoor, M.H. A wavelet-based approach to emotion classification using EDA signals. Expert Syst. Appl. 2018, 112, 77–86. [Google Scholar] [CrossRef]
- Pollreisz, D.; TaheriNejad, N. A simple algorithm for emotion recognition, using physiological signals of a smart watch. In Proceedings of the 39th Annual International Conference of the Ieee Engineering in Medicine and Biology Society (EMBC), Jeju Island, Korea, 11–15 July 2017; pp. 2353–2356. [Google Scholar]
- Fernández-Aguilar, L.; Martínez-Rodrigo, A.; Moncho-Bogani, J.; Fernández-Caballero, A.; Latorre, J.M. Emotion detection in aging adults through continuous monitoring of electro-dermal activity and heart-rate variability. In Proceedings of the International Work-Conference on the Interplay Between Natural and Artificial Computation, Tenerife, Spain, 3–7 June 2019; pp. 252–261. [Google Scholar]
- Hu, L.; Yang, J.; Chen, M.; Qian, Y.; Rodrigues, J.J. SCAI-SVSC: Smart clothing for effective interaction with a sustainable vital sign collection. Futur. Gener. Comput. Syst. 2018, 86, 329–338. [Google Scholar] [CrossRef]
- Albraikan, A.; Hafidh, B.; El Saddik, A. iAware: A real-time emotional biofeedback system based on physiological signals. IEEE Access 2018, 6, 78780–78789. [Google Scholar] [CrossRef]
- Schmidt, P.; Reiss, A.; Duerichen, R.; Marberger, C.; Van Laerhoven, K. Introducing wesad, a multimodal dataset for wearable stress and affect detection. In Proceedings of the 20th ACM International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; pp. 400–408. [Google Scholar]
- Setiawan, F.; Khowaja, S.A.; Prabono, A.G.; Yahya, B.N.; Lee, S.L. A framework for real time emotion recognition based on human ans using pervasive device. In Proceedings of the 42nd Annual Computer Software and Applications Conference (COMPSAC), Tokyo, Japan, 23–27 July 2018; pp. 805–806. [Google Scholar]
- Álvarez, P.; Zarazaga-Soria, F.J.; Baldassarri, S. Mobile music recommendations for runners based on location and emotions: The DJ-Running system. Pervasive Mob. Comput. 2020, 67, 101242. [Google Scholar] [CrossRef]
- Tkalčič, M. Emotions and personality in recommender systems: Tutorial. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2 October 2018; pp. 535–536. [Google Scholar]
- Nalepa, G.J.; Kutt, K.; Giżycka, B.; Jemioło, P.; Bobek, S. Analysis and use of the emotional context with wearable devices for games and intelligent assistants. Sensors 2019, 19, 2509. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, T.; Yin, R.; Shu, L.; Xu, X. Emotion recognition using frontal EEG in VR affective scenes. In Proceedings of the MTT-S International Microwave Biomedical Conference (IMBioC), Nanjing, China, 6–8 May 2019; pp. 1–4. [Google Scholar]
- Gross, J.J.; Feldman Barrett, L. Emotion generation and emotion regulation: One or two depends on your point of view. Emot. Rev. 2011, 3, 8–16. [Google Scholar] [CrossRef] [PubMed]
- Damasio, A.R. The Feeling of What Happens: Body and Emotion in the Making of Consciousness; Mariner Books: Boston, MA, USA, 1999. [Google Scholar]
- Ekman, P. Universals and cultural differences in facial expressions of emotions. W: J. Cole (red.). Nebr. Symp. Motiv. 1971, 19, 207–283. [Google Scholar]
- Plutchik, R. A general psychoevolutionary theory of emotion. In Theories of Emotion; Elsevier: Amsterdam, The Netherlands, 1980; pp. 3–33. [Google Scholar]
- Frijda, N.H. The Emotions; Cambridge University Press: Cambridge, UK, 1986. [Google Scholar]
- Gross, J.J. Emotion regulation: Current status and future prospects. Psychol. Sci. 2015, 26, 1–26. [Google Scholar] [CrossRef]
- Barrett, L.F. The future of psychology: Connecting mind to brain. Perspect. Psychol. Sci. 2009, 4, 326–339. [Google Scholar] [CrossRef] [Green Version]
- James, W. The emotions. Nature 1922, 110, 730–731. [Google Scholar]
- Averill, J.R. A constructivist view of emotion. In Theories of Emotion; Elsevier: Amsterdam, The Netherlands, 1980; pp. 305–339. [Google Scholar]
- Mesquita, B.; Boiger, M. Emotions in context: A sociodynamic model of emotions. Emo. Rev. 2014, 6, 298–302. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Yin, H.; Yuan, X.; Gu, Y.; Ren, F.; Sun, X. Emotion recognition based on fusion of long short-term memory networks and SVMs. Digit. Signal Process. 2021, 117, 103153. [Google Scholar] [CrossRef]
- Nakisa, B.; Rastgoo, M.N.; Rakotonirainy, A.; Maire, F.; Chandran, V. Long short term memory hyperparameter optimization for a neural network based emotion recognition framework. IEEE Access 2018, 6, 49325–49338. [Google Scholar] [CrossRef]
- Soroush, M.; Maghooli, K.; Setarehdan, S.; Nasrabadi, A. A Review on EEG signals based emotion recognition. Int. Clin. Neurosc. J. 2017, 4, 118. [Google Scholar] [CrossRef]
- Saganowski, S.; Dutkowiak, A.; Dziadek, A.; Dzieżyc, M.; Komoszyńska, J.; Michalska, W.; Polak, A.; Ujma, M.; Kazienko, P. Emotion recognition using wearables: A systematic literature review-work-in-progress. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Austin, TX, USA, 23–27 March 2020; pp. 1–6. [Google Scholar]
- Schmidt, P.; Reiss, A.; Dürichen, R.; Van Laerhoven, K. Labelling Affective States in the Wild: Practical Guidelines and Lessons Learned. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, Singapore, 8–12 October 2018; pp. 654–659. [Google Scholar]
- Maier, M.; Marouane, C.; Elsner, D. DeepFlow: Detecting Optimal User Experience From Physiological Data Using Deep Neural Networks. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 2108–2110. [Google Scholar]
- Kanjo, E.; Younis, E.M.; Ang, C.S. Deep learning analysis of mobile physiological, environmental and location sensor data for emotion detection. Inf. Fusion. 2019, 49, 46–56. [Google Scholar] [CrossRef]
- Saganowski, S.; Kazienko, P.; Dzieżyc, M.; Jakimów, P.; Komoszyńska, J.; Michalska, W.; Dutkowiak, A.; Polak, A.; Dziadek, A.; Ujma, M. Consumer Wearables and Affective Computing for Wellbeing Support. In Proceedings of the 17th EAI International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services, Darmstadt, Germany, 7–9 December 2020. [Google Scholar]
- Bent, B.; Goldstein, B.A.; Kibbe, W.A.; Dunn, J.P. Investigating sources of inaccuracy in wearable optical heart rate sensors. NPJ Digit. Med. 2020, 3, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Speer, K.E.; Semple, S.; Naumovski, N.; McKune, A.J. Measuring heart rate variability using commercially available devices in healthy children: A validity and reliability study. EJIHPE 2020, 10, 390–404. [Google Scholar] [CrossRef] [Green Version]
- McDuff, D.; Jun, E.; Rowan, K.; Czerwinski, M. Longitudinal Observational Evidence of the Impact of Emotion Regulation Strategies on Affective Expression. IEEE Trans. Affect. Comput. 2019, 12, 636–647. [Google Scholar] [CrossRef]
- Mukhopadhyay, M.; Pal, S.; Nayyar, A.; Pramanik, P.K.D.; Dasgupta, N.; Choudhury, P. Facial emotion detection to assess Learner’s State of mind in an online learning system. In Proceedings of the 5th International Conference on Intelligent Information Technology, Hanoi, Vietnam, 13–22 February 2020; pp. 107–115. [Google Scholar]
- Lu, H.; Frauendorfer, D.; Rabbi, M.; Mast, M.S.; Chittaranjan, G.T.; Campbell, A.T.; Gatica-Perez, D.; Choudhury, T. Stresssense: Detecting stress in unconstrained acoustic environments using smartphones. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5–8 September 2012; pp. 351–360. [Google Scholar]
- Lee, J.; Kim, M.; Park, H.K.; Kim, I.Y. Motion artifact reduction in wearable photoplethysmography based on multi-channel sensors with multiple wavelengths. Sensors 2020, 20, 1493. [Google Scholar] [CrossRef] [Green Version]
- Lee, H.; Chung, H.; Ko, H.; Lee, J. Wearable multichannel photoplethysmography framework for heart rate monitoring during intensive exercise. IEEE Sens. J. 2018, 18, 2983–2993. [Google Scholar] [CrossRef]
- Masinelli, G.; Dell’Agnola, F.; Valdés, A.A.; Atienza, D. SPARE: A spectral peak recovery algorithm for PPG signals pulsewave reconstruction in multimodal wearable devices. Sensors 2021, 21, 2725. [Google Scholar] [CrossRef]
- Zhao, B.; Wang, Z.; Yu, Z.; Guo, B. EmotionSense: Emotion recognition based on wearable wristband. In Proceedings of the Symposia and Workshops on Ubiquitous, Autonomic and Trusted Computing, UIC-ATC, Guangzhou, China, 8–12 October 2018; pp. 346–355. [Google Scholar]
- Awais, M.; Raza, M.; Singh, N.; Bashir, K.; Manzoor, U.; ul Islam, S.; Rodrigues, J.J. LSTM based Emotion Detection using Physiological Signals: IoT framework for Healthcare and Distance Learning in COVID-19. IEEE Internet Things J. 2020, 8, 16863–16871. [Google Scholar] [CrossRef]
- Dar, M.N.; Akram, M.U.; Khawaja, S.G.; Pujari, A.N. Cnn and lstm-based emotion charting using physiological signals. Sensors 2020, 20, 4551. [Google Scholar] [CrossRef] [PubMed]
- Song, T.; Lu, G.; Yan, J. Emotion recognition based on physiological signals using convolution neural networks. In Proceedings of the 12th International Conference on Machine Learning and Computing, Shenzhen, China, 19–21 June 2020; pp. 161–165. [Google Scholar]
- Tizzano, G.R.; Spezialetti, M.; Rossi, S. A Deep Learning Approach for Mood Recognition from Wearable Data. In Proceedings of the IEEE International Symposium on Medical Measurements and Applications (MeMeA), Bari, Italy, 1 June–1 July 2020; pp. 1–5. [Google Scholar]
- Santamaria-Granados, L.; Munoz-Organero, M.; Ramirez-Gonzalez, G.; Abdulhay, E.; Arunkumar, N. Using deep convolutional neural network for emotion detection on a physiological signals dataset (AMIGOS). IEEE Access 2018, 7, 57–67. [Google Scholar] [CrossRef]
- Li, B.; Lima, D. Facial expression recognition via ResNet-50. Int. J. Cogn. Comput. Eng. 2021, 2, 57–64. [Google Scholar] [CrossRef]
- Sepas-Moghaddam, A.; Etemad, A.; Pereira, F.; Correia, P.L. Facial emotion recognition using light field images with deep attention-based bidirectional LSTM. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3367–3371. [Google Scholar]
- Efremova, N.; Patkin, M.; Sokolov, D. Face and emotion recognition with neural networks on mobile devices: Practical implementation on different platforms. In Proceedings of the 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–5. [Google Scholar]
- Cheng, B.; Wang, Z.; Zhang, Z.; Li, Z.; Liu, D.; Yang, J.; Huang, S.; Huang, T.S. Robust emotion recognition from low quality and low bit rate video: A deep learning approach. In Proceedings of the Seventh International Conference on Affective Computing and Intelligent Interaction (ACII), San Antonio, TX, USA, 23–26 October 2017; pp. 65–70. [Google Scholar]
- Bargal, S.A.; Barsoum, E.; Ferrer, C.C.; Zhang, C. Emotion recognition in the wild from videos using images. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 433–436. [Google Scholar]
- Fan, W.; Xu, X.; Xing, X.; Chen, W.; Huang, D. LSSED: A large-scale dataset and benchmark for speech emotion recognition. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 641–645. [Google Scholar]
- Wang, J.; Xue, M.; Culhane, R.; Diao, E.; Ding, J.; Tarokh, V. Speech emotion recognition with dual-sequence LSTM architecture. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6474–6478. [Google Scholar]
- Yu, Y.; Kim, Y.J. Attention-LSTM-attention model for speech emotion recognition and analysis of IEMOCAP database. Electronics 2020, 9, 713. [Google Scholar] [CrossRef]
- Zhang, Y.; Du, J.; Wang, Z.; Zhang, J.; Tu, Y. Attention based fully convolutional network for speech emotion recognition. In Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, USA, 12–15 November 2018; pp. 1771–1775. [Google Scholar]
- Zhao, Z.; Bao, Z.; Zhao, Y.; Zhang, Z.; Cummins, N.; Ren, Z.; Schuller, B. Exploring deep spectrum representations via attention-based recurrent and convolutional neural networks for speech emotion recognition. IEEE Access 2019, 7, 97515–97525. [Google Scholar] [CrossRef]
- Li, Z.; Li, J.; Ma, S.; Ren, H. Speech emotion recognition based on residual neural network with different classifiers. In Proceedings of the IEEE/ACIS 18th International Conference on Computer and Information Science (ICIS), Beijing, China, 17–19 June 2019; pp. 186–190. [Google Scholar]
- Gjoreski, M.; Gams, M.Ž.; Luštrek, M.; Genc, P.; Garbas, J.U.; Hassan, T. Machine learning and end-to-end deep learning for monitoring driver distractions from physiological and visual signals. IEEE Access 2020, 8, 70590–70603. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 18–20 June 2016; pp. 770–778. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; pp. 630–645. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A Database of German Emotional Speech. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.130.8506&rep=rep1&type=pdf (accessed on 1 January 2022).
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Sharma, K.; Castellini, C.; van den Broek, E.L.; Albu-Schaeffer, A.; Schwenker, F. A dataset of continuous affect annotations and physiological signals for emotion analysis. Sci. Data 2019, 6, 1–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Dzieżyc, M.; Gjoreski, M.; Kazienko, P.; Saganowski, S.; Gams, M. Can we ditch feature engineering? end-to-end deep learning for affect recognition from physiological sensor data. Sensors 2020, 20, 6535. [Google Scholar] [CrossRef] [PubMed]
- Schmidt, P.; Dürichen, R.; Reiss, A.; Van Laerhoven, K.; Plötz, T. Multi-target affect detection in the wild: An exploratory study. Proceedings of The 2019 ACM International Joint Conference on Pervasive and Ubiquitous Computing, London, UK, 9–13 September 2019; pp. 211–219. [Google Scholar]
- Zhao, S.; Ma, Y.; Gu, Y.; Yang, J.; Xing, T.; Xu, P.; Hu, R.; Chai, H.; Keutzer, K. An End-to-End visual-audio attention network for emotion recognition in user-generated videos. arXiv 2020, arXiv:2003.00832. [Google Scholar] [CrossRef]
- Sun, T.W. End-to-end speech emotion recognition with gender information. IEEE Access 2020, 8, 152423–152438. [Google Scholar] [CrossRef]
- Harper, R.; Southern, J. A bayesian deep learning framework for end-to-end prediction of emotion from heartbeat. arXiv 2020, arXiv:1902.03043. [Google Scholar] [CrossRef] [Green Version]
- Chiang, H.T.; Hsieh, Y.Y.; Fu, S.W.; Hung, K.H.; Tsao, Y.; Chien, S.Y. Noise reduction in ECG signals using fully convolutional denoising autoencoders. IEEE Access 2019, 7, 60806–60813. [Google Scholar] [CrossRef]
- Adib, E.; Afghah, F.; Prevost, J.J. Synthetic ECG Signal Generation Using Generative Neural Networks. arXiv 2021, arXiv:2112.03268. [Google Scholar]
- Sun, H.; Zhang, F.; Zhang, Y. An LSTM and GAN Based ECG Abnormal Signal Generator. In Advances in Artificial Intelligence and Applied Cognitive Computing; Springer: Berlin, Germany, 2021; pp. 743–755. [Google Scholar]
- Samyoun, S.; Mondol, A.S.; Stankovic, J.A. Stress detection via sensor translation. In Proceedings of the 16th International Conference on Distributed Computing in Sensor Systems (DCOSS), Marina del Rey, CA, USA, 25–27 May 2020; pp. 19–26. [Google Scholar]
- Udovičić, G.; Ðerek, J.; Russo, M.; Sikora, M. Wearable emotion recognition system based on GSR and PPG signals. In Proceedings of the 2nd International Workshop on Multimedia for Personal Health and Health Care, New York, NY, USA, 23 October 2017; pp. 53–59. [Google Scholar]
- Tian, Z.; Huang, D.; Zhou, S.; Zhao, Z.; Jiang, D. Personality first in emotion: A deep neural network based on electroencephalogram channel attention for cross-subject emotion recognition. Royal Soc. Open Sci. 2021, 8, 201976. [Google Scholar] [CrossRef]
- Taylor, S.; Jaques, N.; Nosakhare, E.; Sano, A.; Picard, R. Personalized multitask learning for predicting tomorrow’s mood, stress, and health. IEEE Trans. Affect. Comput. 2017, 11, 200–213. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Can, Y.S.; Chalabianloo, N.; Ekiz, D.; Fernandez-Alvarez, J.; Riva, G.; Ersoy, C. Personal stress-level clustering and decision-level smoothing to enhance the performance of ambulatory stress detection with smartwatches. IEEE Access 2020, 8, 38146–38163. [Google Scholar] [CrossRef]
- iMotions Platform. Available online: https://imotions.com (accessed on 1 January 2022).
- Gloor, P.A.; Colladon, A.F.; Grippa, F.; Budner, P.; Eirich, J. Aristotle said “happiness is a state of activity”—Predicting mood through body sensing with Smartwatches. J. Syst. Sci. Syst. Eng. 2018, 27, 586–612. [Google Scholar] [CrossRef]
- Roessler, J.; Gloor, P.A. Measuring happiness increases happiness. JCSS 2021, 4, 123–146. [Google Scholar] [CrossRef] [Green Version]
- Sun, L.; Gloor, P.A.; Stein, M.; Eirich, J.; Wen, Q. No Pain No Gain: Predicting Creativity Through Body Signals. In Digital Transformation of Collaboration; Springer: Berlin, Germany, 2019; pp. 3–15. [Google Scholar]
- Sun, L.; Gloor, P.A. Measuring Moral Values with Smartwatch-Based Body Sensors. In Digital Transformation of Collaboration; Springer: Berlin, Germany, 2019; pp. 51–66. [Google Scholar]
- Budner, P.; Eirich, J.; Gloor, P.A. Making you happy makes me happy-Measuring Individual Mood with Smartwatches. Available online: http://healthdocbox.com/Psychology_and_Psychiatry/68305189-Making-you-happy-makes-me-happy-measuring-individual-mood-with-smartwatches.html (accessed on 1 January 2022).
- Tripathi, A.; Ashwin, T.; Guddeti, R.M.R. EmoWare: A context-aware framework for personalized video recommendation using affective video sequences. IEEE Access 2019, 7, 51185–51200. [Google Scholar] [CrossRef]
- Fortune, E.; Yusuf, Y.; Zornes, S.; Loyo Lopez, J.; Blocker, R. Assessing Induced Emotions in Employees in a Workplace Setting Using Wearable Devices. In Proceedings of the 2020 Design of Medical Devices Conference, Minneapolis, MA, USA, 6–9 April 2020; p. V001T09A004. [Google Scholar]
- Fortune, E.; Yusuf, Y.; Blocker, R. Measuring Arousal and Emotion in Healthcare Employees Using Novel Devices. In Proceedings of the IEEE 20th International Conference on Bioinformatics and Bioengineering (BIBE), Cincinnati, OH, USA, 26–28 October 2020; pp. 835–838. [Google Scholar]
- Hernandez, J.; Lovejoy, J.; McDuff, D.; Suh, J.; O’Brien, T.; Sethumadhavan, A.; Greene, G.; Picard, R.; Czerwinski, M. Guidelines for Assessing and Minimizing Risks of Emotion Recognition Applications. In Proceedings of the 9th International Conference on Affective Computing and Intelligent Interaction (ACII), Nara, Japan, 28 September–1 October 2021; pp. 1–8. [Google Scholar]
- Emotional Movies-Netflix. Available online: https://ir.netflix.net/ir-overview/profile/default.aspx (accessed on 22 January 2022).
- Panda, R.; Redinho, H.; Gonçalves, C.; Malheiro, R.; Paiva, R.P. How Does the Spotify API Compare to the Music Emotion Recognition State-of-the-Art? In Proceedings of the 18th Sound and Music Computing Conference (SMC 2021), Axea sas/SMC Network. 29 June–1 July 2021; pp. 238–245. [Google Scholar] [CrossRef]
- Álvarez, P.; de Quirós, J.G.; Baldassarri, S. A Web System Based on Spotify for the automatic generation of affective playlists. In Cloud Computing, Big Data & Emerging Topics; Springer: Berlin, Germany, 2020; pp. 124–137. [Google Scholar]
- McDuff, D.; Nishidate, I.; Nakano, K.; Haneishi, H.; Aoki, Y.; Tanabe, C.; Niizeki, K.; Aizu, Y. Non-contact imaging of peripheral hemodynamics during cognitive and psychological stressors. Sci. Rep. 2020, 10, 10884. [Google Scholar] [CrossRef]
- Uchida, M.; Akaho, R.; Ogawa-Ochiai, K.; Tsumura, N. Image-based measurement of changes to skin texture using piloerection for emotion estimation. Artif. Life Robot. 2019, 24, 12–18. [Google Scholar] [CrossRef]
- Zhao, M.; Adib, F.; Katabi, D. Emotion recognition using wireless signals. In Proceedings of the 22nd Annual International Conference on Mobile Computing and Networking, New York, NY, USA, 3–7 October 2016; pp. 95–108. [Google Scholar]
- Richter-Lunn, K. Incognito: Sensorial Interpretations of Covert Physiological Signals for Therapeutic Mediation. Ph.D. Thesis, Harvard University, Cambridge, MA, USA, 2021. [Google Scholar]
- Myin-Germeys, I.; Kuppens, P. The Open Handbook of Experience Sampling Methodology. In The Open Handbook of Experience Sampling Methodology; Independently Publisher: Chicago, IL, USA, 2021; pp. 1–311. [Google Scholar]
- Smyth, J.M.; Stone, A.A. Ecological momentary assessment research in behavioral medicine. J. Happiness Stud. 2003, 4, 35–52. [Google Scholar] [CrossRef]
- Saganowski, S.; Behnke, M.; Komoszyńska, J.; Kunc, D.; Perz, B.; Kazienko, P. A system for collecting emotionally annotated physiological signals in daily life using wearables. In Proceedings of the 9th International Conference on Affective Computing and Intelligent Interaction Workshops and Demos (ACIIW), Nara, Japan, 28 September–1 October 2021; pp. 1–3. [Google Scholar]


{kind=link}
| Device | Type | Release Date | Sensors | Physiological Raw Signals | Other Data |
|---|---|---|---|---|---|
| Apple Watch 7 | Smartwatch | October 2021 | ACC, AL, ALT, BAR, ECG, GPS, GYRO, MIC, PPG | BVP, ECG, SpO2 | ACC, AL, ALT, BAR, BP, GPS, GYRO, HR, MIC, RSP, SKT, STP |
| Fitbit charge 5 | Smartband | September 2021 | ACC, BAR, GPS, GYRO, PPG | - | ACC, BAR, GYRO, HR |
| Samsung Galaxy Watch 4 * | Smartwatch | August 2021 | ACC, AL, BAR, ECG, GPS, GYRO, MIC, PPG | BVP | ACC, AL, BAR, GPS, GYRO, HR, MIC, PPI, STP |
| Huawei Watch 3 | Smartwatch | June 2021 | ACC, AL, BAR, GPS, GYRO, MAG, MIC, PPG, TERM | - | ACC, AL, BAR, GPS, GYRO, HR, MAG, MIC, SKT, STP |
| Fitbit Sense | Smartwatch | September 2020 | ACC, AL, ALT, GPS, GYRO, MIC, PPG, TERM | - | ACC, BAR, GYRO, HR |
| Samsung Galaxy Watch 3 * | Smartwatch | August 2020 | ACC, AL, BAR, ECG, GPS, GYRO, MIC, PPG | BVP | ACC, AL, BAR, GPS, GYRO, HR, MIC, PPI, STP |
| Apple Watch 5 * | Smartwatch | September 2019 | ACC, BAR, ECG, GPS, GYRO, MIC, PPG | - | ACC, BAR, CAL, GPS, GYRO, HR, MIC, STP |
| Fossil Gen 5 * | Smartwatch | August 2019 | ACC, AL, ALT, GPS, GYRO, MIC, PPG | BVP | ACC, AL, ALT, GPS, GYRO, HR, MIC, STP |
| Garmin Fenix 6X Pro | Smartwatch | August 2019 | ACC, AL, ALT, GPS, GYRO, PPG, SpO2 | BVP, SpO2 | ACC, AL, ALT, GPS, GYRO, HR, STP |
| Samsung Galaxy Watch * | Smartwatch | August 2019 | ACC, AL, BAR, GPS, GYRO, MIC, PPG | BVP | ACC, AL, BAR, GPS, GYRO, HR, MIC, STP |
| Polar OH1 | Armband | March 2019 | ACC, PPG | BVP | ACC, PPI |
| Garmin HRM-DUAL | Chest strap | January 2019 | ECG | ECG | RRI |
| Muse 2 * | Headband | January 2019 | ACC, EEG, GYRO, PPG, SpO2 | BVP, EEG, SpO2 | ACC, GYRO, HR |
| Fitbit Charge 3 * | Fitband | October 2018 | ACC, ALT, GYRO, PPG | - | ACC, ALT, HR |
| Garmin VivoActive 3 Music * | Smartwatch | June 2018 | ACC, BAR, GPS, GYRO, PPG | - | ACC, CAL, HR, PPI, RSP, STP |
| Oura ring * | Smart ring | April 2018 | ACC, GYRO, PPG, TERM | - | HR, PPI, SKT |
| Moodmetric * | Smart ring | December 2017 | ACC, EDA | EDA | STP |
| DREEM | Headband | June 2017 | ACC, EEG, PPG, SpO2 | BVP, EEG, SpO2 | ACC, HR |
| Aidlab | Chest strap | March 2017 | ACC, ECG, RSP, TERM | ECG, RSP, SKT | Activities, HR, HRV, STP |
| Polar H10 | Chest strap | March 2017 | ACC, ECG | ECG | ACC, RRI |
| VitalPatch | Chest patch | March 2016 | ACC, ECG, TERM | ECG, SKT | HR, RRI, RSP, STP |
| Emotiv Insight | Headband | October 2015 | ACC, EEG, GYRO, MAG | EEG | ACC, GYRO, MAG |
| Empatica E4* | Wristband | 2015 | ACC, EDA, PPG, TERM | BVP, EDA, SKT | ACC, HR, PPI |
| Microsoft Band 2 | Smartband | October 2014 | ACC, AL, ALT, BAR, EDA, GYRO, PPG, TERM, UV | BVP, EDA, SKT | ACC, AL, ALT, BAR, CAL, GYRO, HR, PPI, STP, UV |
| BodyMedia SenseWear | Armband | 2003 | ACC, EDA, TERM | EDA, SKT | ACC |
| Modality | Reference | Architecture | Classification/Regression Problem Considered |
|---|---|---|---|
| Phys. signals | Awais et al., 2021 [41] | LSTM | 4-class: amused, bored, feared, relaxed |
| Dar et al., 2020 [42] | CNN + LSTM | 4-class: high/low arousal/valence | |
| Song et al., 2020 [43] | CNN | 2 × 3-class: calm/medium/excited arousal; unpleasant/neutral/pleasant valence | |
| Tizzano et al., 2020 [44] | LSTM | 3-class: happy, neutral, sad | |
| Kanjo et al., 2018 [30] | CNN + LSTM | 5-class: level of valence (from 0 to 4) | |
| Nakisa et al., 2018 [25] | LSTM | 4-class: high/low arousal/valence | |
| Santamaria-Granados et al., 2018 [45] | CNN | 2 × binary: high/low arousal/valence | |
| Facial expression | Li and Lima, 2021 [46] | ResNet-50 | 7-class: angry, disgusted, fearful, neutral, happy, sad, surprised |
| Sepas-Moghaddam et al., 2020 [47] | VGG16 + Bi-LSTM + attention | 4-class: angry, happy, neutral, surprised | |
| Efremova et al., 2019 [48] | ResNet-20 | 5-class: positive, weak positive, neutral, weak negative, negative | |
| Cheng et al., 2017 [49] | FCN + CNN | regression: valence value | |
| Bargal et al., 2016 [50] | ResNet-91 with 2 × VGG | 7-class: angry, disgusted, fearful, neutral, happy, sad, surprised | |
| Speech | Fan et al., 2021 [51] | PyResNet: ResNet with pyramid convolution | 4-class: angry, neutral, happy, sad |
| Wang et al., 2020 [52] | dual-sequence LSTM | 4-class: angry, neutral, happy, sad | |
| Yu and Kim, 2020 [53] | attention-LSTM-attention | 4-class: angry, neutral, happy, sad | |
| Zhang et al., 2019 [54] | FCN-attention | 4-class: angry, neutral, happy, sad | |
| Zhao et al., 2019 [55] | attention-Bi-LSTM + attention-FCN | 4-class: angry, neutral, happy, sad; 5-class: angry, emphatic, neutral, positive, resting | |
| Li et al., 2019 [56] | ResNet | 7-class: angry, bored, disgusted, fearful, neutral, happy, sad | |
| Visual + phys. signals | Gjoreski et al., 2020 [57] | StresNet, CNN, LSTM | binary (driver distraction) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saganowski, S. Bringing Emotion Recognition Out of the Lab into Real Life: Recent Advances in Sensors and Machine Learning. Electronics 2022, 11, 496. https://doi.org/10.3390/electronics11030496
Saganowski S. Bringing Emotion Recognition Out of the Lab into Real Life: Recent Advances in Sensors and Machine Learning. Electronics. 2022; 11(3):496. https://doi.org/10.3390/electronics11030496
Chicago/Turabian StyleSaganowski, Stanisław. 2022. "Bringing Emotion Recognition Out of the Lab into Real Life: Recent Advances in Sensors and Machine Learning" Electronics 11, no. 3: 496. https://doi.org/10.3390/electronics11030496