
Survey of Credit Card Anomaly and Fraud Detection Using Sampling Techniques


Abstract
:1. Introduction
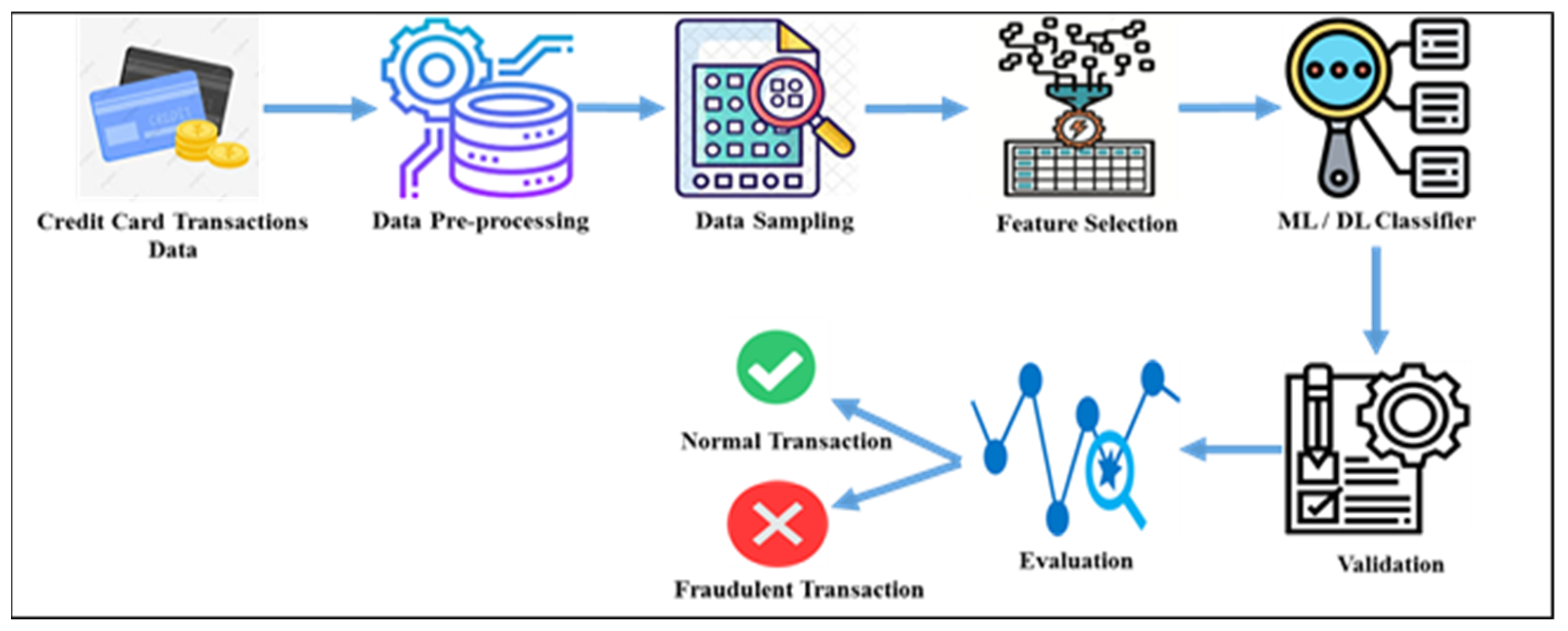
2. Credit Card Fraud Detection
Anomaly Detection
- Contextual attributes Contextual attributes are used to establish the instance’s context (or neighbourhood).
- Behavioural attributes The behavioural features of an instance define its non-contextual qualities.
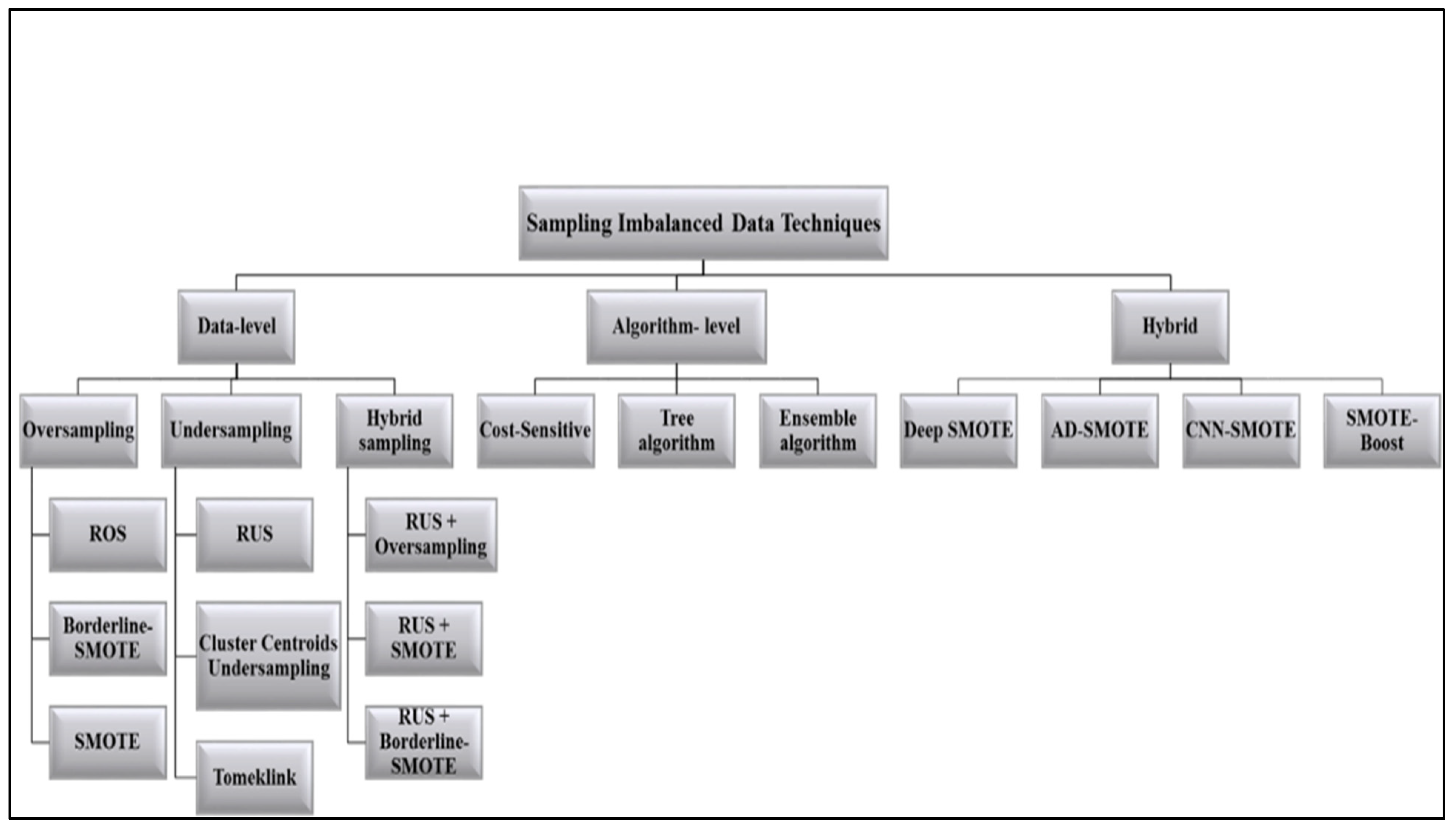
3. Imbalanced Data and Sampling Techniques
3.1. Data-Level Approach
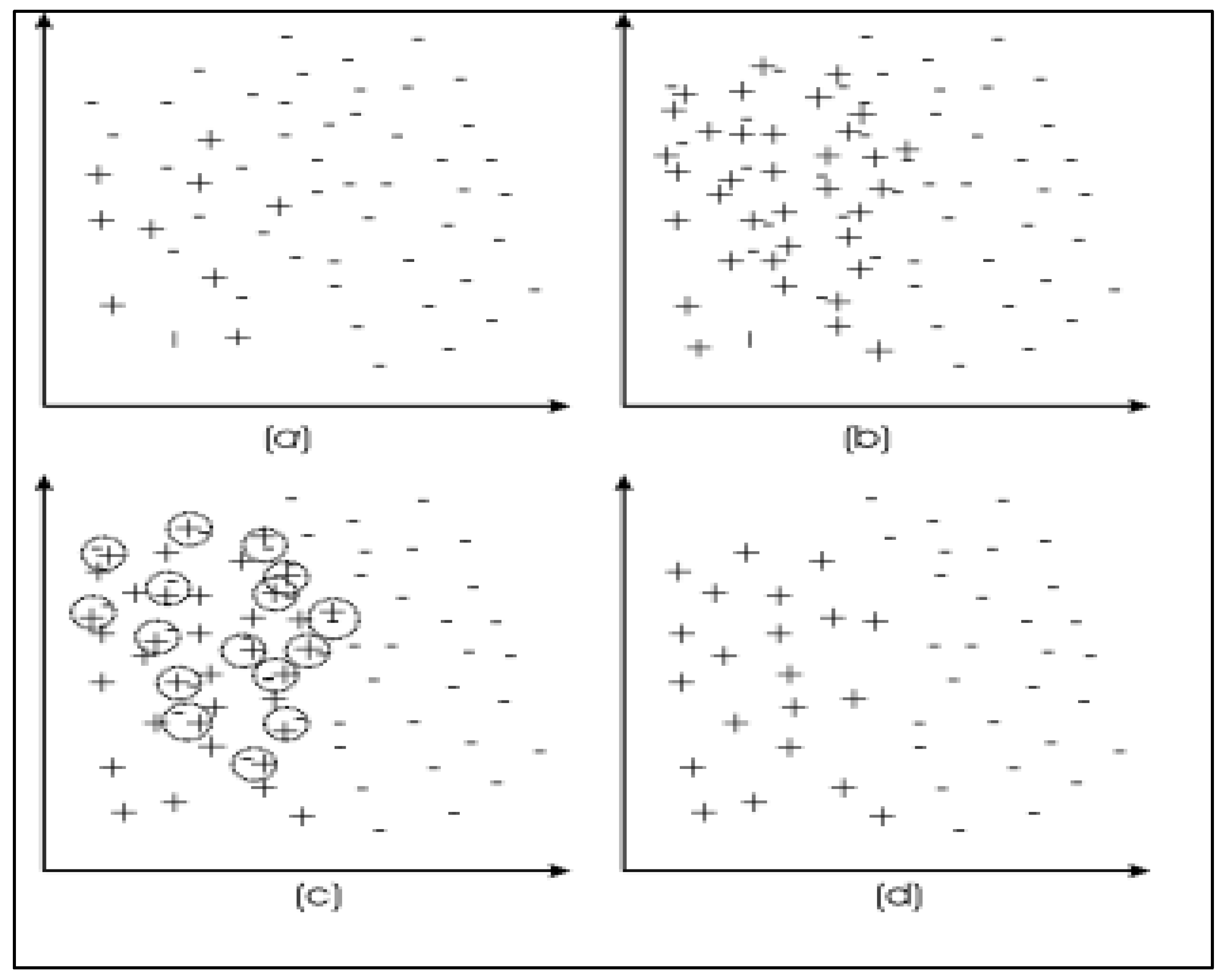
3.1.1. Oversampling
| Algorithm 1: The SMOTE algorithm |
| 1. Identify the minority and majority classes after loading the dataset; 2. Determine the number of instances to be produced depending on the oversampling percentage; 3. Choose a random member of the minority class and determine who its closest neighbors are; 4. Decide which of the closest neighbors to the randomly chosen instance is different from that neighbor; 5. Multiply the difference by a number determined at random, ranging from 0 to 1; 6. Include this distinction with the chosen random instance; 7. Repeat the process from steps 3 to 6 until the specified proportion of instances is generated. |
| Algorithm 2: The Borderline-SMOTE algorithm |
| (1) Compute the closest m samples from the available dataset for each sample in a few classes xi. m′ denotes the number of additional categories in the most recent samples. (2) Organize the samples xi: , are all from distinct categories and are referred to be noise data. As such data will have a negative impact on the generation effect, it is recommended that these samples not be included in the generation. , more than half of the m surrounding samples are of distinct categories. Define Danger as the border sample. , more than half of the surrounding m samples of xi are of the same categories, designated as Safe. (3) After marking, apply the SMOTE method to enlarge the Danger samples. Select xi from the Danger dataset samples and compute k-nearest neighbor samples of the same kind xzi. New samples xn are generated at random using the formula |
3.1.2. Undersampling
| Algorithm 3: Random Undersampling (RUS) algorithm |
| 1. Load the dataset and define the minority and majority classes; 2. Calculate the number of instances to be deleted depending on the undersampling percentage. 3. Select a random instance from the majority class and delete it from the majority class; 4. Continue to step 3 until all occurrences have been eliminated according to the specified percentage. |
3.1.3. Hybrid Sampling
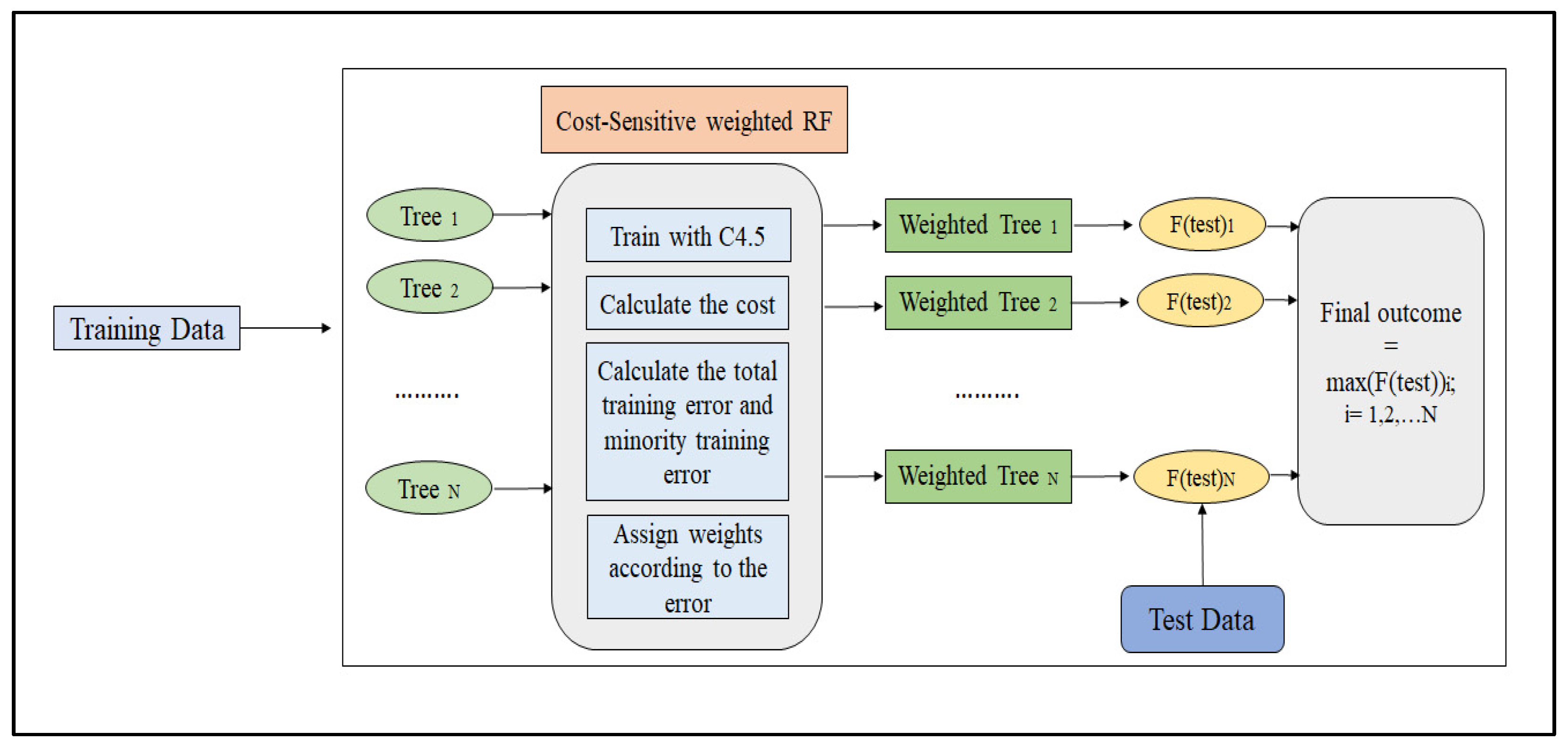
3.2. Algorithm-Level Approach
3.3. Hybrid Approach
| Algorithm 4: Minibatch stochastic gradient descent training of Deep Adversarial SMOTE |
| (1) for number of training iterations do (2) for steps do (3) Sample minibatch of form minority prior and concatenate each selected pairs . (4) Sample minibatch of from data generating distribution . (5) Update the discriminator be ascending its stochastic gradient. (6) end for (7) Sample minibatch of m minority data pairs from minority prior and concatenate each selected pair . (8) (9) end for |
4. Effect of Imbalanced Data on the Classification Performance
5. The Importance of Sampling Techniques
6. Sampling Techniques for Credit Card Transaction Data
7. Taxinomy
8. Discussion
9. Conclusions
10. Future Directions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- John, J.; Naaz, S. Credit Card Fraud Detection using Local Outlier Factor and Isolation. (IJCSE) Int. J. Comput. Sci. Eng. 2019, 7, 1060–1064. [Google Scholar] [CrossRef]
- Nguyen, T.; Tahir, H.; Abdelrazek, M.; Babar, A. Deep Learning Methods for Credit Card Fraud Detection. arXiv 2020, arXiv:2012.03754. [Google Scholar]
- Thabtaha, F.; Hammoudb, S.; Kamalovc, F.; Gonsalves, A.H. Data Imbalance in Classification: Experimental Evaluation. Inf. Sci. 2020, 513, 429–441. [Google Scholar] [CrossRef]
- Asha, R.B.; Suresh Kumar, K.R. Credit Card Fraud Detection Using Artificial Neural Network. Glob. Transit. Proc. 2021, 2, 35–41. [Google Scholar]
- Najadat, H.; Altiti, O.; Abu Aqouleh, A.; Younes, M. Credit Card Fraud Detection Based on Machine. In Proceedings of the 2020 11th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 7–9 April 2020. [Google Scholar]
- Pumsirirat, A.; Yan, L. Credit Card Fraud Detection using Deep Learning. (IJACSA) Int. J. Adv. Comput. Sci. Appl. 2018, 9, 18–25. [Google Scholar]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly Detection: A Survey. ACM Comput. Surv. (CSUR) 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Roy, A.; Sun, J.; Mahoney, R.; Alonzi, L.; Adams, S.; Beling, P. Deep Learning Detecting Fraud in Credit Card Transactions. In Proceedings of the Systems and Information Engineering Design Symposium (SIEDS), Charlottesville, VA, USA, 27 April 2018. [Google Scholar]
- Wen, S.W.; Yusuf, R.M. Predicting Credit Card Fraud on an Imbalanced Data. Int. J. Data Sci. Adv. Anal. 2019, 1, 12–17. [Google Scholar]
- Somasundaram, A.; Reddy, U.S. Data Imbalance: Effects and Solutions for Classification of Large and Highly Imbalanced Data. In Proceedings of the International Conference on Research in Engineering, Computers and Technology (ICRECT), January 2016; pp. 28–34. [Google Scholar]
- Kaur, P.; Gosain, A. Comparing the Behavior of Oversampling and Undersampling Approach of Class Imbalance Learning by Combining Class Imbalance Problem with Noise. In ICT Based Innovations; Springer: Singapore, 2018. [Google Scholar]
- Mînăstireanu, E.-A.; Meşniţ, G. Methods of Handling Unbalanced Datasets in Credit Card Fraud Detection. Brain. Broad Res. Artif. Intell. Neurosci. 2020, 11, 131–143. [Google Scholar] [CrossRef] [PubMed]
- Singh, A.; Ranjan, R.K.; Tiwari, A. Credit Card Fraud Detection under Extreme Imbalanced Data: A Comparative Study of Data-level Algorithms. J. Exp. Theor. Artif. Intell. 2022, 34, 571–598. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.-Y.; Mao, B.-H. Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning. In International Conference on Intelligent Computing; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Sun, Y.; Que, H.; Cai, Q.; Zhao, J.; Li, J.; Kong, Z.; Wang, S. Borderline SMOTE Algorithm and Feature Selection-Based Network Anomalies Detection Strategy. Energies 2022, 15, 4751. [Google Scholar] [CrossRef]
- Batista, G.; Prati, R.; Monard, M. A Study of the Behavior of Several Methods for Balancing Machine Learning Training Data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Xie, Y.; Li, A.; Gao, L.; Liu, Z. A Heterogeneous Ensemble Learning Model Based on Data Distribution for Credit Card Fraud Detection. Wirel. Commun. Mob. Comput. 2021, 2021, 2531210. [Google Scholar] [CrossRef]
- Choirunnisa, S.; Lianto, J. Hybrid Method of Undersampling and Oversampling for Handling Imbalanced Data. In Proceedings of the 2018 International Seminar on Research of Information Technology and Intelligent Systems (ISRITI), Yogyakarta, Indonesia, 21–22 November 2018; pp. 276–280. [Google Scholar]
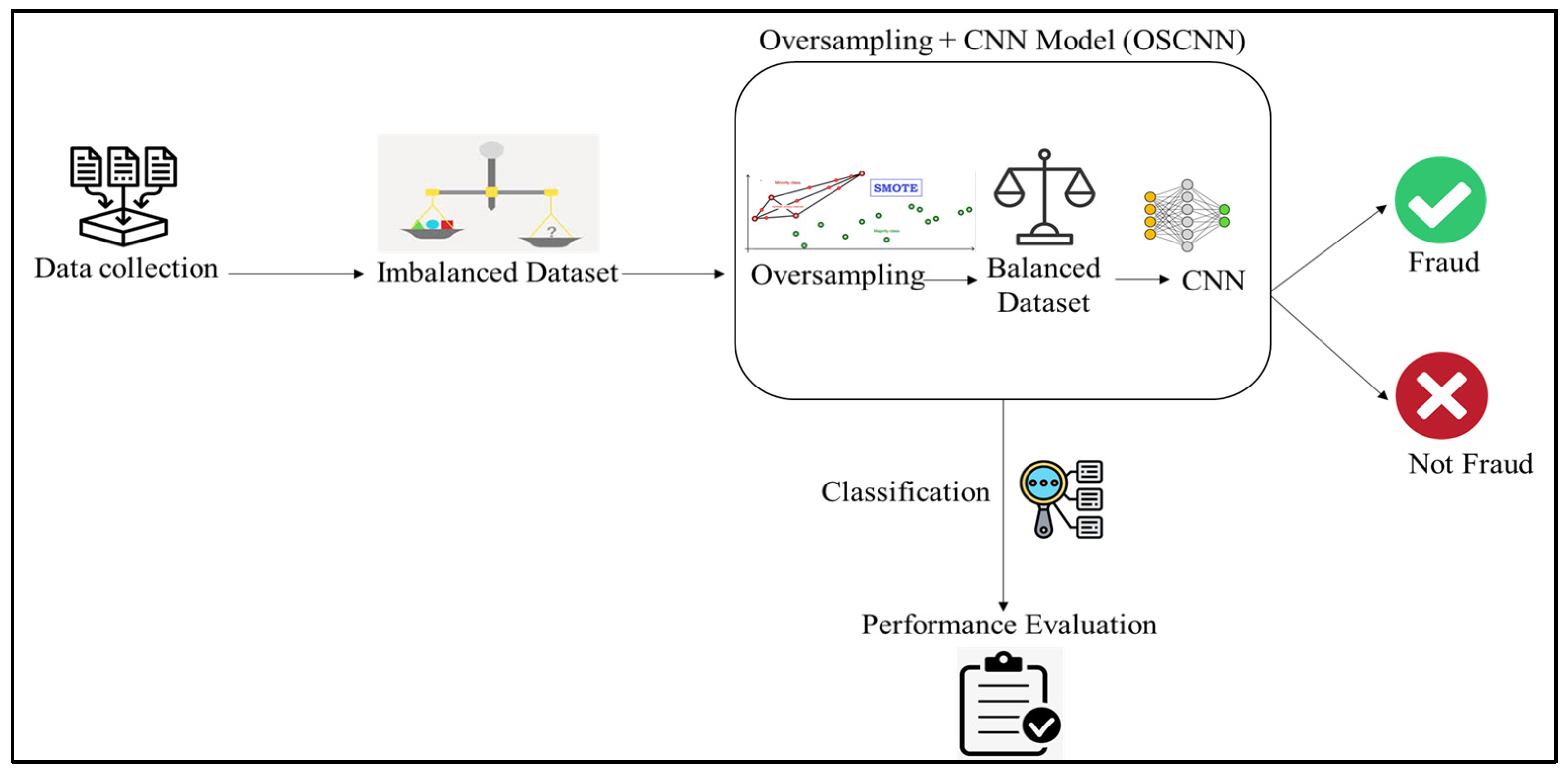
- Abd el Naby, A.; Hemdan, E.E.-D.; El-Sayed, A. Deep Learning Approach for Credit Card Fraud Detection. In Proceedings of the 2nd IEEE International Conference on Electronic Engineering ICEEM2021, Menouf, Egypt, 3–4 July 2021. [Google Scholar]
- Zou, H. Analysis of Best Sampling Strategy in Credit Card Fraud Detection Using Machine Learning. In Proceedings of the 2021 6th International Conference on Intelligent Information Technology (ICIIT ‘21), Ho Chi Minh, Vietnam, 25–28 February 2021. [Google Scholar]
- Mansourifar, H.; Shi, W. Deep Synthetic Minority Over-Sampling Technique. arXiv 2020, arXiv:2003.09788. [Google Scholar]
- Devi, D.; Biswas, S.; Purkayastha, B. A Cost-sensitive weighted Random Forest Technique for Credit Card Fraud Detection. In Proceedings of the 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kanpur, India, 6–8 July 2019. [Google Scholar]
- Wang, Y. An Ensemble Learning Imbalanced Data Classification Method Based on Sample Combination Optimization. J. Phys. Conf. Ser. 2019, 1284, 012035. [Google Scholar] [CrossRef]
- Muaz, A.; Jayabalan, M.; Thiruchelvam, V. Acomparison of Data Sampling Techniques for Credit Card Fraud Detection. Int. J. Adv. Comput. Sci. Appl. (IJACSA) 2020, 11, 477–485. [Google Scholar]
- Varmedja, D.; Karanovic, M.; Sladojev, S.; Arsenovic, M.; Anderla, A. Credit Card Fraud Detection—Machine Learning Methods. In Proceedings of the 18th International Symposium Infotech-Jahorina, Jahorina, Bosnia and Herzegovina, 20–22 March 2019. [Google Scholar]
- Mahesh, K.P.; Afrouz, S.A.; Areeckal, A.S. Detection of fraudulent credit card transactions: A comparative analysis of data sampling and classification techniques. J. Phys. Conf. Ser. 2022, 2161, 012072. [Google Scholar] [CrossRef]
- Li, Q.; Xie, Y. A Behavior-Cluster Based Imbalanced Classification Method for Credit Card Fraud Detection. In Proceedings of the 2nd International Conference on Data Science and Information Technology, Seoul, Republic of Korea, 19–21 July 2019. [Google Scholar]
- Dornadulaa, V.N.; Geetha, S. Credit Card Fraud Detection Using Machine Learning Algorithms. In Proceedings of the International Conference on Recent Trends in Advanced Computing (ICRTAC), Chennai, India, 11–12 November 2019; Volume 165, pp. 631–641. [Google Scholar]
- Itoo, F.; Meenakshi; Singh, S. Comparison and Analysis of Logistic Regression, Naive Bayes and KNN Machine Learning Algorithms for Credit Card Fraud Detection. Int. J. Inf. Technol. 2021, 13, 1503–1511. [Google Scholar] [CrossRef]
- Ahammad, J.; Hossain, N.; Alam, M.S. Credit Card Fraud Detection Using Data Pre-Processing on Imbalanced Data-Both Oversampling and Undersampling. In Proceedings of the International Conference on Computing Advancements, Dhaka, Bangladesh, 10–12 January 2020. [Google Scholar]
- Wibowo, P.; Fatichah, C. An In-Depth Performance Analysis of the Oversampling Techniques for High-Class Imbalanced Dataset. Sci. J. Inf. Syst. Technol. 2021, 7, 63–71. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | Dataset | Sampling Techniques | Classifier | Accuracy |
|---|---|---|---|---|---|
| [11] | 2018 | Synthetic dataset | Random undersampling, SMOTE | C4.5 | NM * |
| [24] | 2020 | Kaggle | Random undersampling, SMOTE, DBSMOTE, SMOTEENN | ANN, GMB, RF, Stacked ensemble | NM * |
| [25] | 2019 | Kaggle | SMOTE | LR, RF, NB, MLP | 97.46%, 99.96%, 99.23%, 99.93% |
| [26] | 2022 | Kaggle | Undersampling, SMOTE, SMOTE-Tomek | KNN, LR, RF, SVM | NM * |
| [27] | 2019 | Financial institution and 18 UCI datasets | behaviour-cluster based imbalanced classification method | NM * | |
| [28] | 2019 | Kaggle | SMOTE, MCC | LOF, Isolation Forest, LR, Decision Tree, RF | 45.8%, 58.8%, 97.18%, 97.08%, 99.98% |
| [29] | 2021 | Kaggle | Random undersampling | LR, KNN, NB | 95.9%, 75.1%, 91.5% |
| [30] | 2020 | NM * | Undersampling, SMOTE | KNN | 81.12% |
| [31] | 2021 | Kaggle | Random oversampling, ADASYN, SMOTE, Borderline-SMOTE | RF, LR, KNN | 99.97% |
| Approaches | Ref. | Advantages | Disadvantages |
|---|---|---|---|
| Data-level approach | [11] |
|
|
| sData-level approach, Hybird approach | [24] |
|
|
| Data-level approach | [25] |
|
|
| Data-level approach | [26] |
|
|
| Data-level approach | [27] |
|
|
| Data-level approach, Algorithm-level approach | [28] |
|
|
| Data-level approach | [29] |
|
|
| Data-level approach | [30] |
|
|
| Data-level approach | [31] |
|
|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alamri, M.; Ykhlef, M. Survey of Credit Card Anomaly and Fraud Detection Using Sampling Techniques. Electronics 2022, 11, 4003. https://doi.org/10.3390/electronics11234003
Alamri M, Ykhlef M. Survey of Credit Card Anomaly and Fraud Detection Using Sampling Techniques. Electronics. 2022; 11(23):4003. https://doi.org/10.3390/electronics11234003
Chicago/Turabian StyleAlamri, Maram, and Mourad Ykhlef. 2022. "Survey of Credit Card Anomaly and Fraud Detection Using Sampling Techniques" Electronics 11, no. 23: 4003. https://doi.org/10.3390/electronics11234003