
A Generic Preprocessing Architecture for Multi-Modal IoT Sensor Data in Artificial General Intelligence †

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- RQ1: Can an unsupervised, untrained preprocessing module identify meaningful features in a scene?
- RQ2: Can sensory data from multiple domains be abstracted by the same algorithm?
- RQ3: Is feature abstraction from input data a requirement for AGI?
2. Related Work and Background
2.1. AGI Design Shortcomings
2.2. Sensor Fusion Constraints
2.3. Towards Explainable AGI in IoT
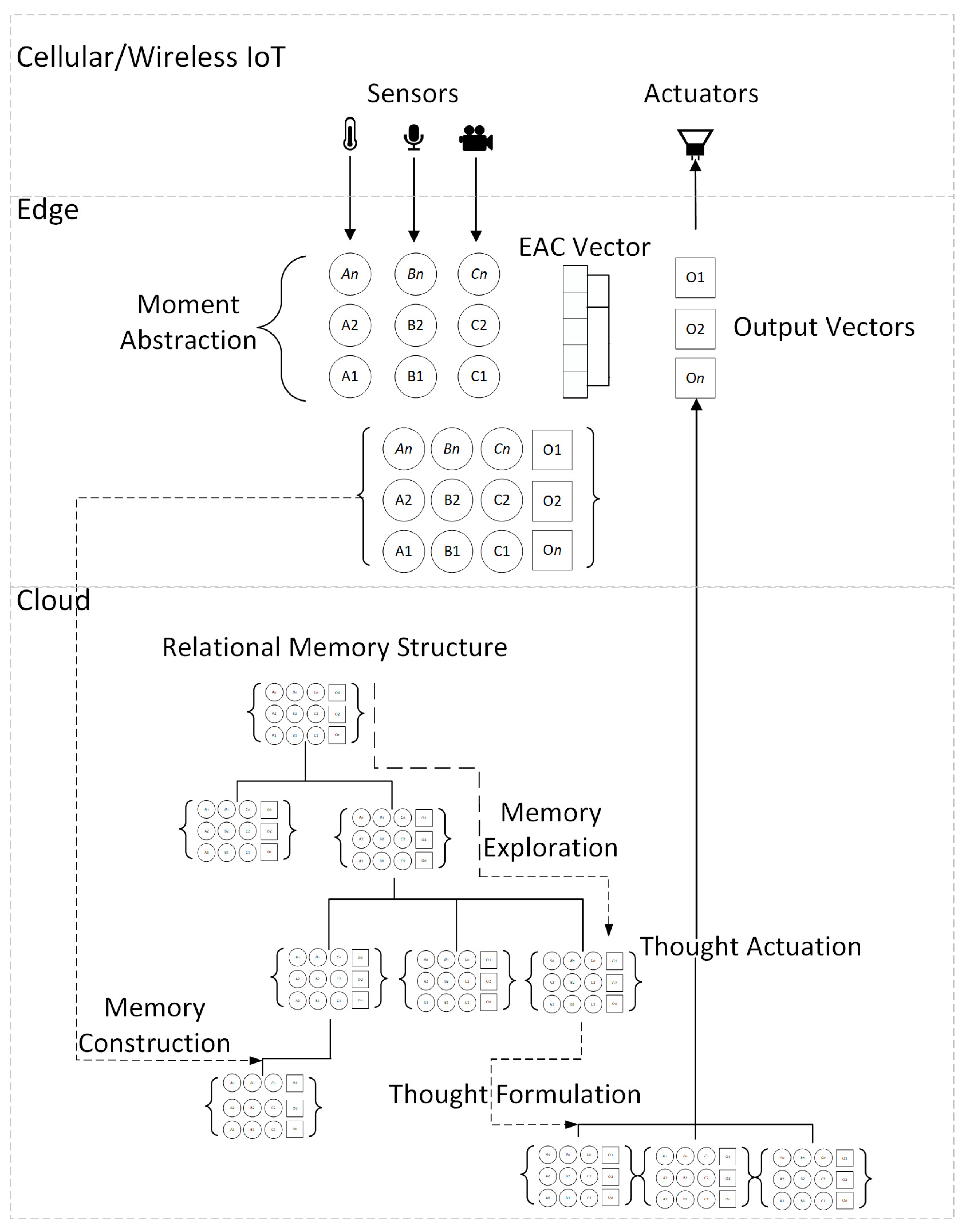
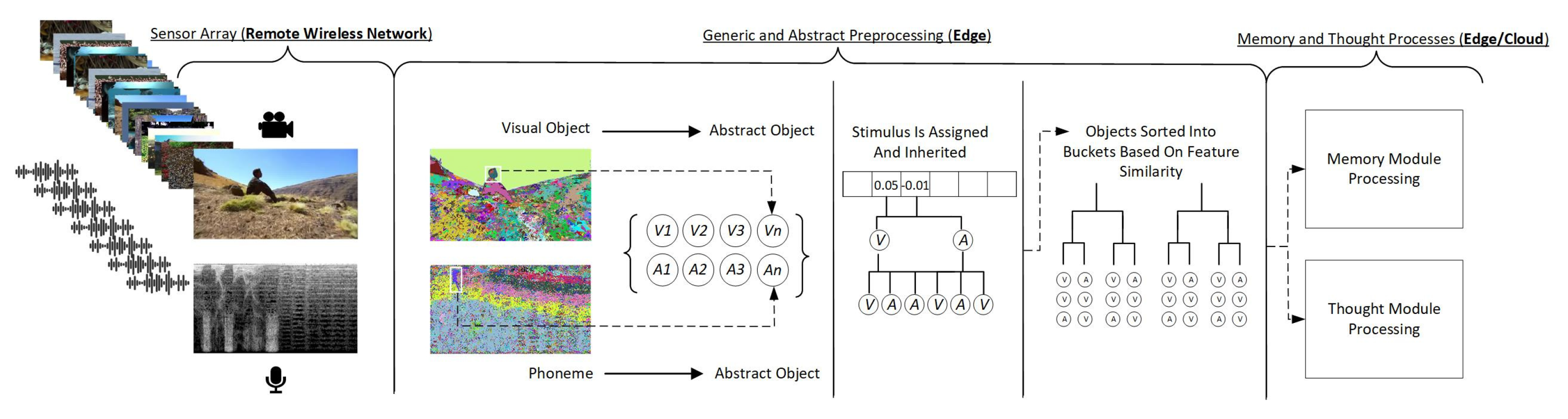
3. Unsupervised and Generic Preprocessing Model
3.1. Input Alignment and Buffering
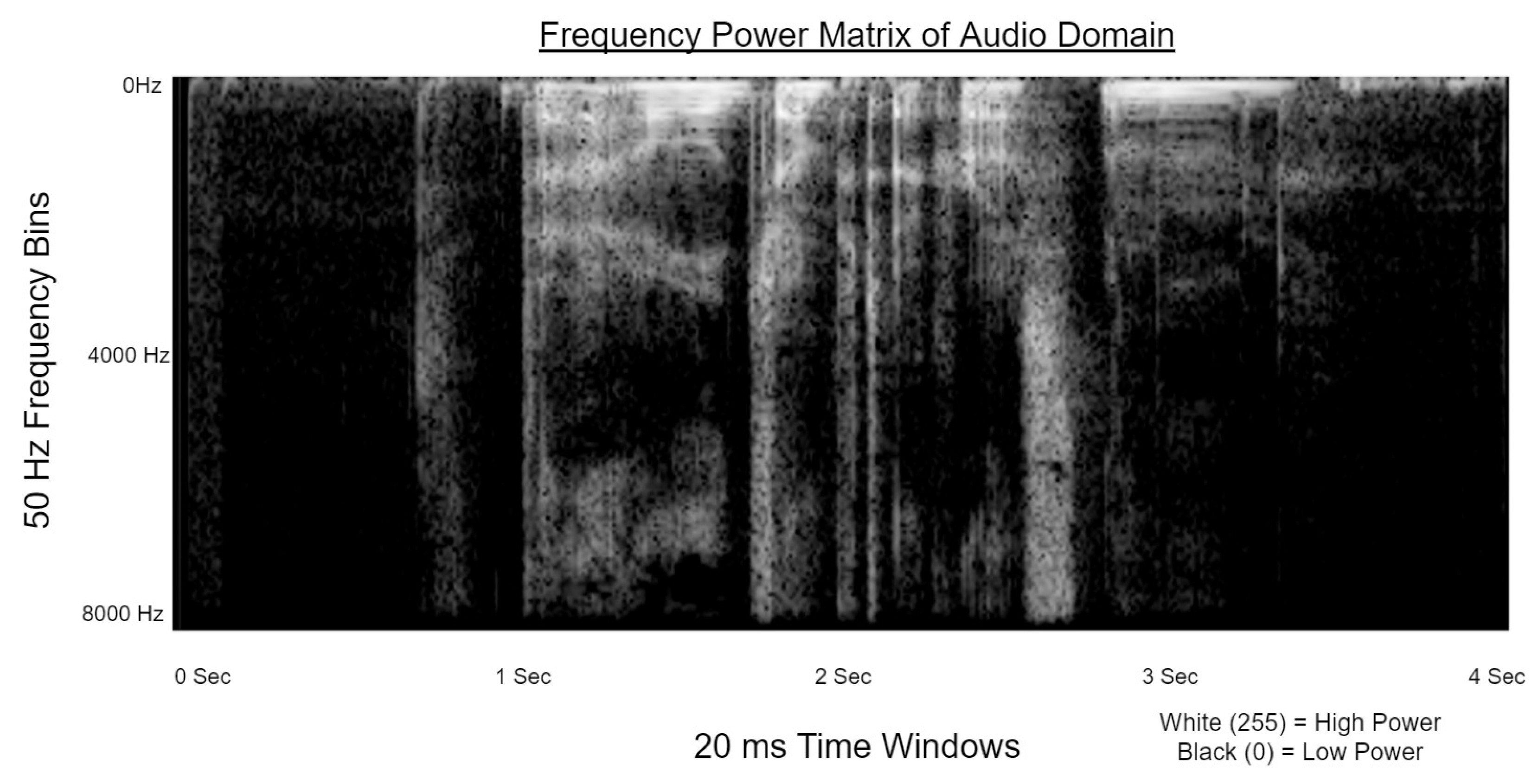
3.2. Transform for 1-D Input Types
- Each 1-D buffer frame in a group is sliced into t number of s (second) sized buckets.
- Fast Fourier transform is performed on each time bucket
- Each frequency domain bucket representing s seconds is transposed and joined to form a 2-D matrix representing the entire length of the buffer group.
3.3. Unsupervised Feature Identification
| Algorithm 1 Deviation- and Neighborhood-Based Clustering |
|
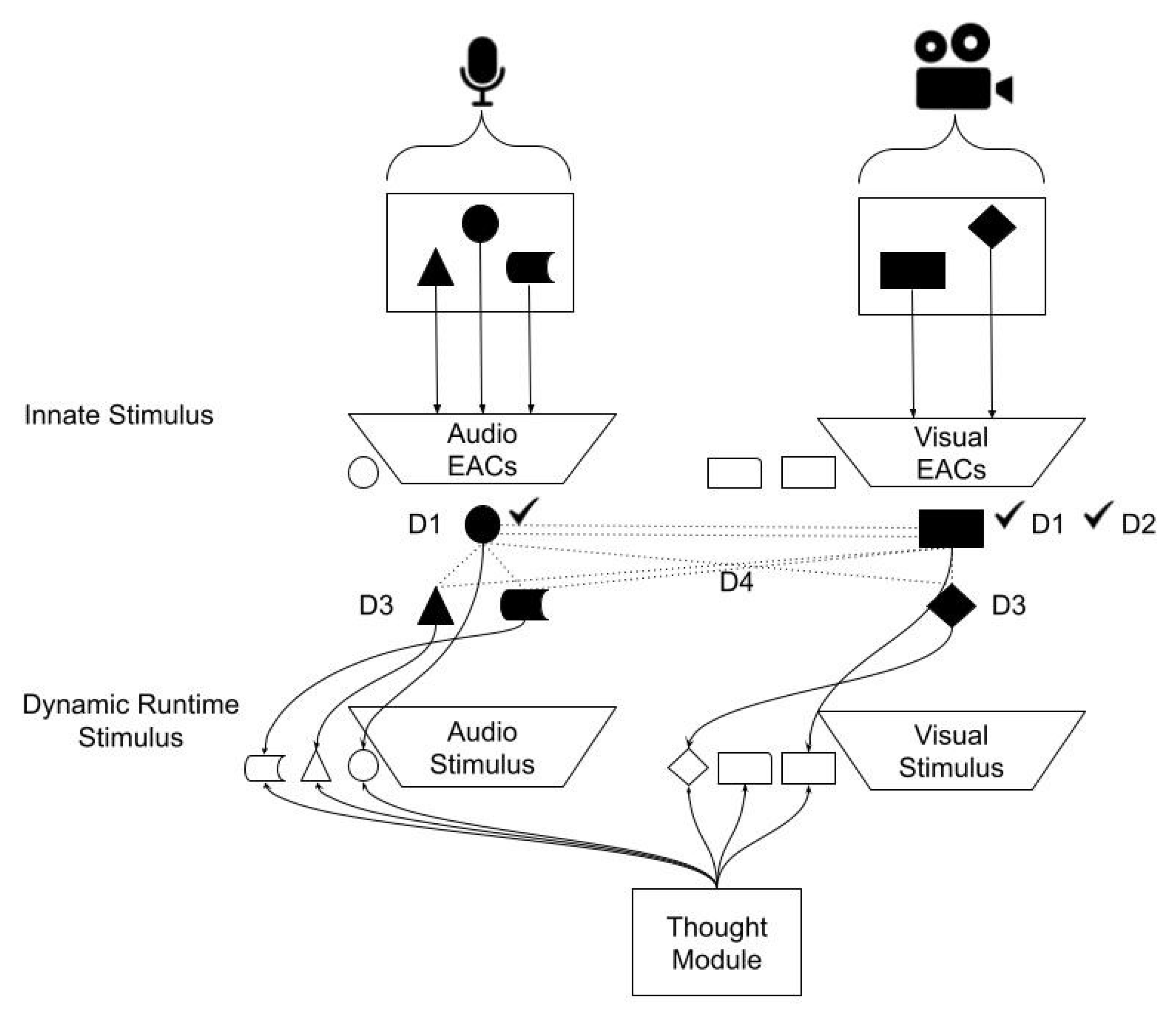
3.4. Feature Abstraction
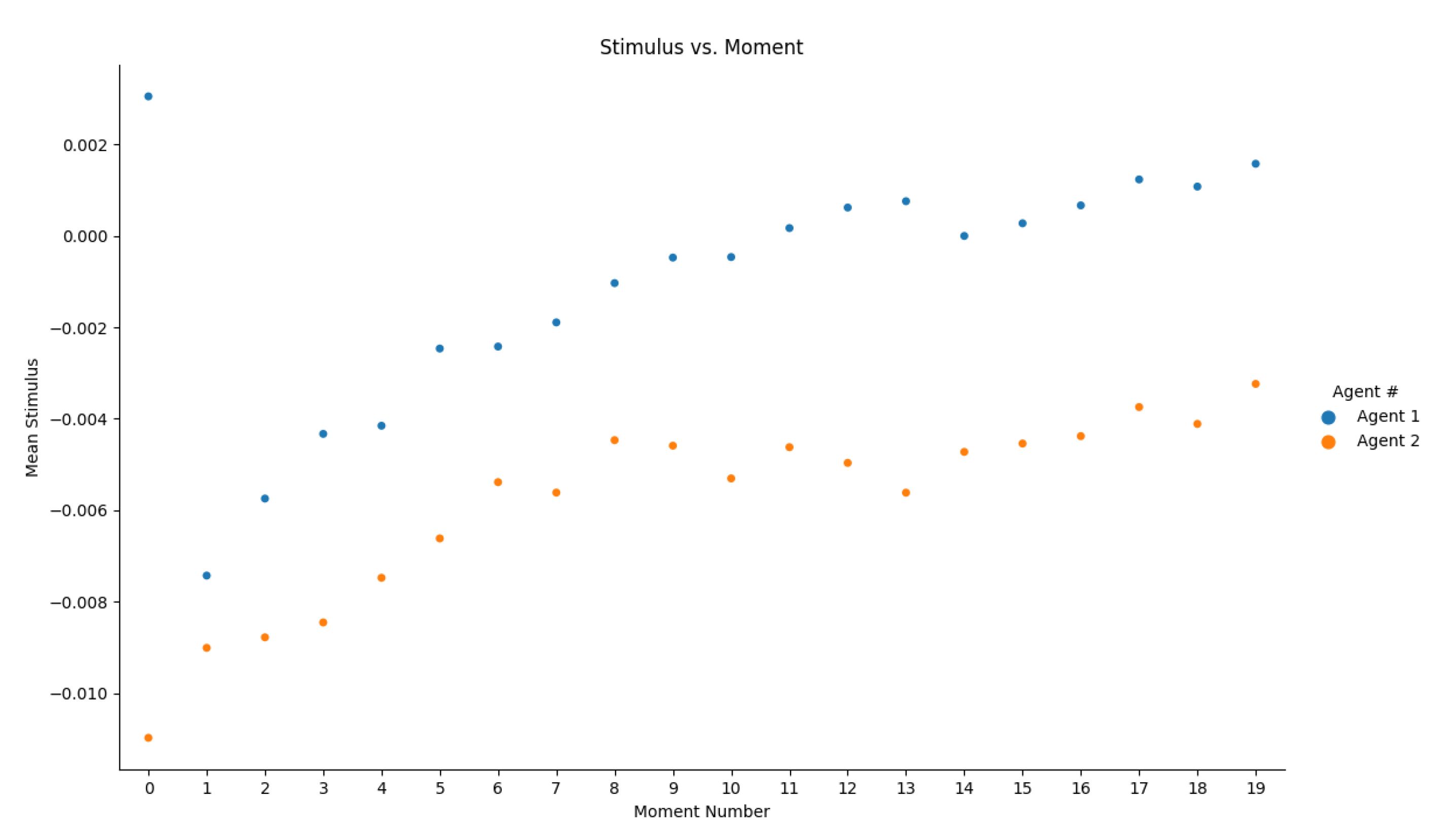
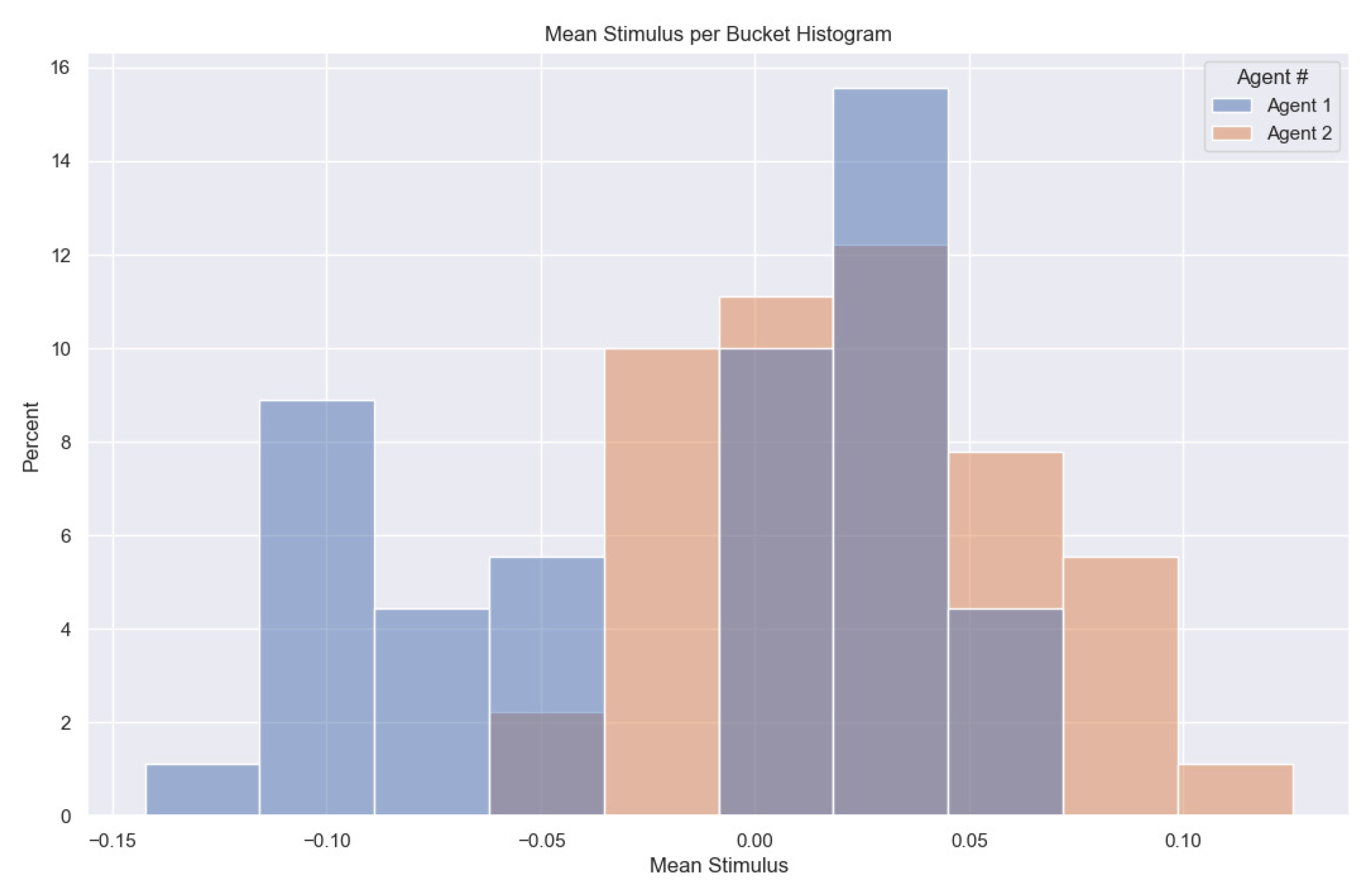
3.5. Stimulus System
3.6. Event Buffering
4. Feature Identification Results and Discussion
4.1. Data Set
4.2. Implementation
- Raw Data Extractor;
- Data Alignment and Buffering;
- 2-D Sensor Transform (to represent 1-D data such as audio in 2 dimensions);
- Deviation- and Neighborhood-Based Clustering (Augmented DBSCAN) Algorithm;
- Cluster to Abstract Feature Algorithm;
- Stimulus Assignation Algorithm;
- Feature Attributes Indexing Algorithm.
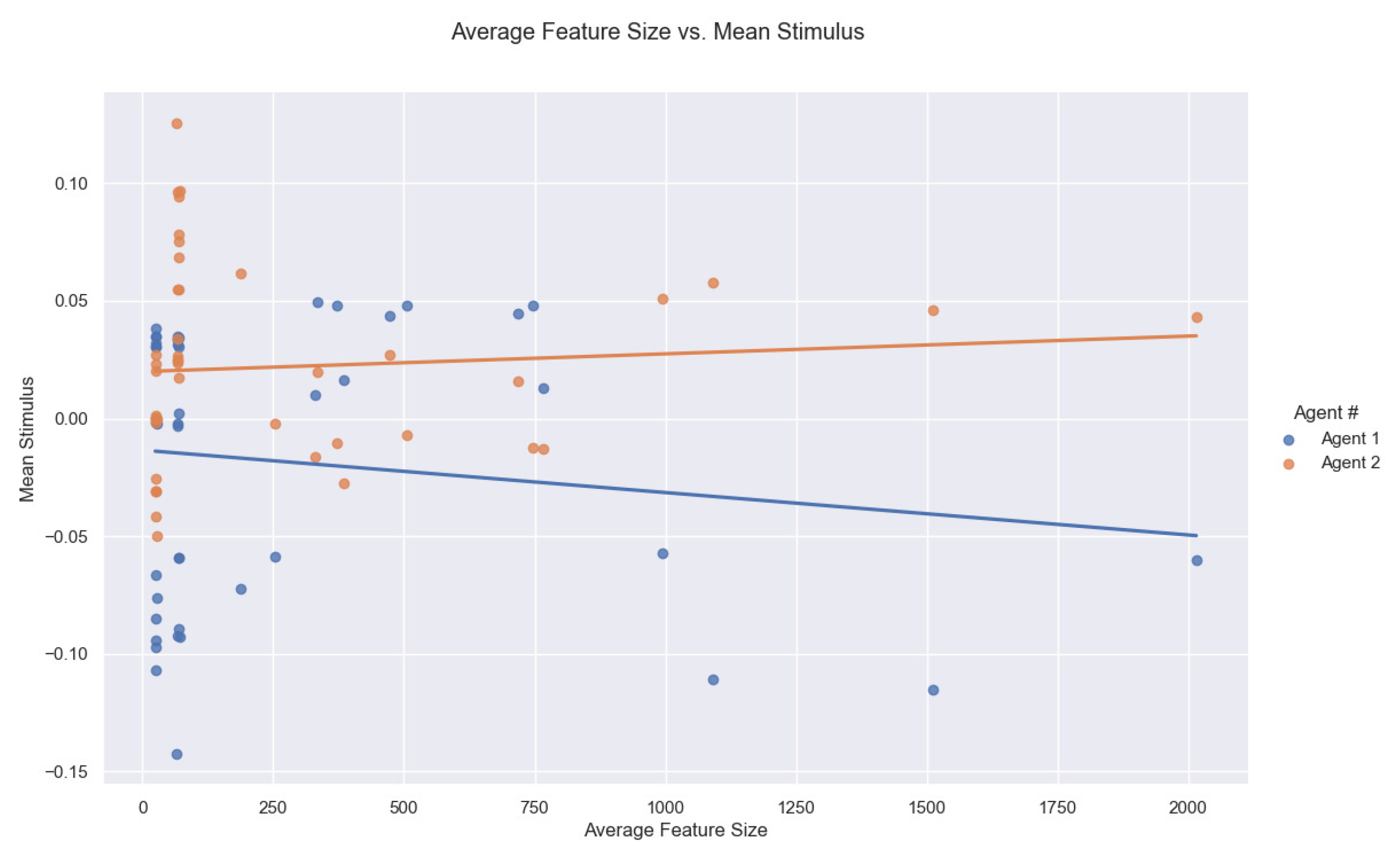
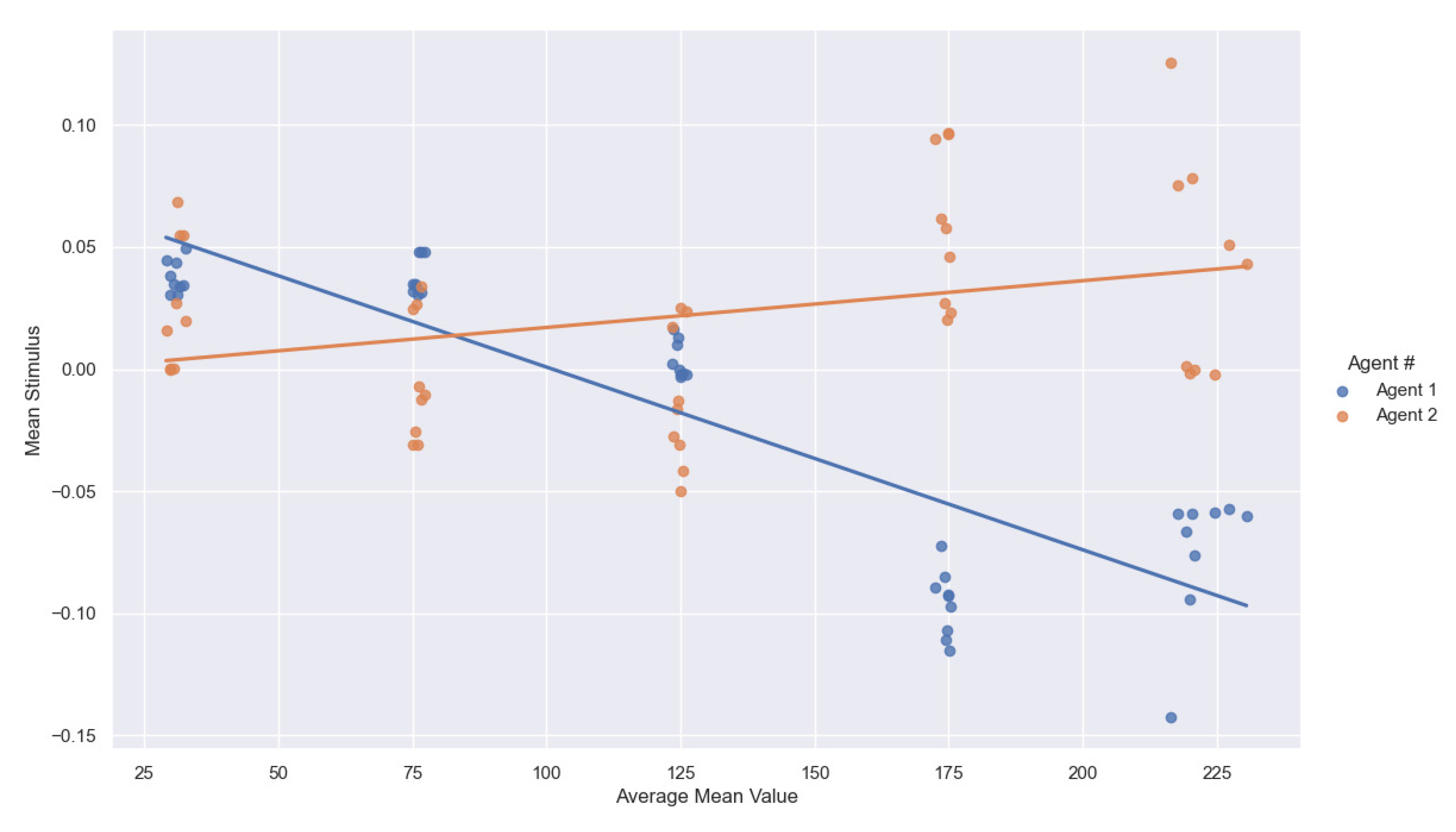
- size (number of pixels);
- min, mean, max value;
- variance, standard deviation;
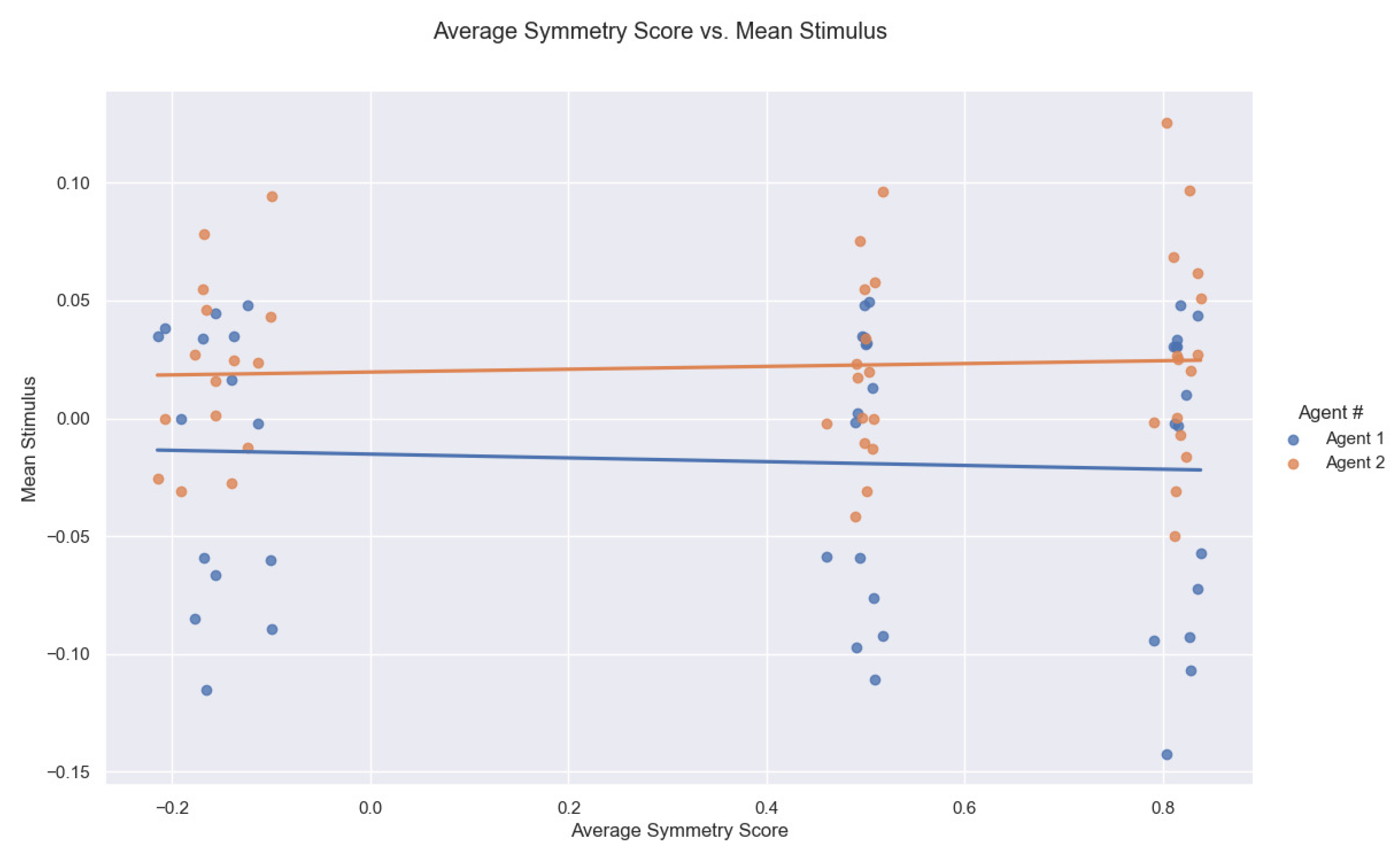
- geometric symmetry score.
- Audio EACs: (“mean”: [0, 100], “activation”: 0.05), (“variance”: [0, 10], “activation”: −0.005);
- Image EACs: (“size”: [150, 250], “activation”: 0.15), (“mean”: [150, 230], “activation”: −0.2).
- Audio EACs: (“mean”: [100, 200], “activation”: 0.05), (“variance”: [10, 20], “activation“: −0.005);
- Image EACs: (“size”: [50, 150], “activation”: 0.15), (“mean”: [80, 150], “activation”: −0.2).
- ID1: 5 tags corresponding to the greyscale range. 1: (0, 51), 2: (51, 102), 3: (102, 153), 4: (153, 204), 5: (204, 255);
- ID2: 3 tags corresponding to geometric symmetry score. 1: (0, 0.33), 2: (0.33, 0.66), 3: (0.66, 1);
- ID3: 3 tags corresponding to the geometric size of the feature. 1: (0, 50), 2: (50, 100), 3: (100, Max).
4.3. Discussion
- RQ1: Can an unsupervised, untrained preprocessing module identify meaningful features in a scene? The preprocessing module implemented was proven to identify features in a scene and turn them into an abstract representation holding descriptive attributes of the raw data.
- RQ2: Can sensory data from multiple domains be abstracted by the same algorithm? Sensory data were abstracted in the audio and visual domain by the same generic feature detection and extraction algorithm. This generic architecture can help manifest AGI as many different IoT sensor types can easily plug into the system with minimum configuration.
- RQ3: Is feature abstraction from input data a requirement for AGI? Feature abstraction is found to be a requirement for intelligence as it diminishes the size of input data, converts large data sets into small discrete abstract representations, and enables the system to be inherently stimulated by features as it experiences complex scenes over time.
4.4. Applications
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mukhopadhyay, S.C.; Tyagi, S.K.S.; Suryadevara, N.K.; Piuri, V.; Scotti, F.; Zeadally, S. Artificial Intelligence-based Sensors for Next Generation IoT Applications: A Review. IEEE Sens. J. 2021, 21, 24920–24932. [Google Scholar] [CrossRef]
- Lin, Z.; Lin, M.; de Cola, T.; Wang, J.B.; Zhu, W.P.; Cheng, J. Supporting IoT With Rate-Splitting Multiple Access in Satellite and Aerial-Integrated Networks. IEEE Internet Things J. 2021, 8, 11123–11134. [Google Scholar] [CrossRef]
- Lin, Z.; An, K.; Niu, H.; Hu, Y.; Chatzinotas, S.; Zheng, G.; Wang, J. SLNR-based secure energy efficient beamforming in Multibeam Satellite Systems. IEEE Trans. Aerosp. Electron. Syst. 2022, 1–4. [Google Scholar] [CrossRef]
- Lin, Z.; Niu, H.; An, K.; Wang, Y.; Zheng, G.; Chatzinotas, S.; Hu, Y. Refracting ris-aided hybrid satellite-terrestrial relay networks: Joint Beamforming Design and optimization. IEEE Trans. Aerosp. Electron. Syst. 2022, 58, 3717–3724. [Google Scholar] [CrossRef]
- Goertzel, B.; Ke, S.; Lian, R.; O’Neill, J.; Sadeghi, K.; Wang, D.; Watkins, O.; Yu, G. The cogprime architecture for embodied Artificial General Intelligence. In Proceedings of the 2013 IEEE Symposium on Computational Intelligence for Human-like Intelligence (CIHLI), Singapore, 16–19 April 2013; pp. 60–67. [Google Scholar] [CrossRef]
- Górriz, J.M.; Ramírez, J.; Ortíz, A.; Martínez-Murcia, F.J.; Segovia, F.; Suckling, J.; Leming, M.; Zhang, Y.-D.; Álvarez-Sánchez, J.R.; Bologna, G.; et al. Artificial intelligence within the interplay between natural and artificial computation: Advances in data science, trends and applications. Neurocomputing 2020, 410, 237–270. [Google Scholar] [CrossRef]
- Chollet, F. On the Measure of Intelligence. arXiv 2019, arXiv:1911.01547. [Google Scholar]
- Rocha, F.M.; Costa, V.S.; Reis, L.P. From Reinforcement Learning Towards Artificial General Intelligence. In Proceedings of the Trends and Innovations in Information Systems and Technologies; Rocha, Á., Adeli, H., Reis, L.P., Costanzo, S., Orovic, I., Moreira, F., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 401–413. [Google Scholar]
- Elton, D.C. Applying Deutsch’s concept of good explanations to artificial intelligence and neuroscience—An initial exploration. Cogn. Syst. Res. 2021, 67, 9–17. [Google Scholar] [CrossRef]
- Zhang, J.; Su, Q.; Tang, B.; Wang, C.; Li, Y. DPSNet: Multitask Learning Using Geometry Reasoning for Scene Depth and Semantics. IEEE Trans. Neural Net. Learn. Syst. 2021, 1–12. [Google Scholar] [CrossRef]
- Zhai, W.; Gao, M.; Souri, A.; Li, Q.; Guo, X.; Shang, J.; Zou, G. An attentive hierarchy ConvNet for crowd counting in Smart City. Clust. Comput. 2022. [Google Scholar] [CrossRef]
- Zhang, P. Multi-source information fusion based on rough set theory: A review. Inf. Fusion 2021, 68, 85–117. [Google Scholar] [CrossRef]
- Vakil, A.; Liu, J.; Zulch, P.; Blasch, E.; Ewing, R.; Li, J. A Survey of Multimodal Sensor Fusion for Passive RF and EO Information Integration. IEEE Aerosp. Electron. Syst. Mag. 2021, 36, 44–61. [Google Scholar] [CrossRef]
- Chung, S.; Lim, J.; Noh, K.J.; Kim, G.; Jeong, H. Sensor Data Acquisition and Multimodal Sensor Fusion for Human Activity Recognition Using Deep Learning. Sensors 2019, 19, 1716. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Lu, Y. Study on artificial intelligence: The state of the art and future prospects. J. Ind. Inf. Integr. 2021, 23, 100224. [Google Scholar] [CrossRef]
- Rababah, B.; Alam, T.; Eskicioglu, R. The Next Generation Internet of Things Architecture Towards Distributed Intelligence: Reviews, Applications, and Research Challenges. J. Telecommun. Electron. Comput. Eng. 2020, 12, 9. [Google Scholar] [CrossRef]
- Pol, M.; Dessalles, J.L.; Diaconescu, A. Explanatory AI for Pertinent Communication in Autonomic Systems. In Intelligent Systems and Applications; Bi, Y., Bhatia, R., Kapoor, S., Eds.; Series Title: Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2020; Volume 1037, pp. 212–227. [Google Scholar] [CrossRef]
- Kelley, D.; Twyman, M. Biasing in an Independent Core Observer Model Artificial General Intelligence Cognitive Architecture. Procedia Comput. Sci. 2020, 169, 535–541. [Google Scholar] [CrossRef]
- Carlson, K.W. Safe Artificial General Intelligence via Distributed Ledger Technology. Big Data Cogn. Comput. 2019, 3, 40. [Google Scholar] [CrossRef] [Green Version]
- Kim, W.; Kanezaki, A.; Tanaka, M. Unsupervised Learning of Image Segmentation Based on Differentiable Feature Clustering. IEEE Trans. Image Process. 2020, 29, 8055–8068. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Grover, A.; Al-Shedivat, M.; Gupta, J.K.; Burda, Y.; Edwards, H. Learning Policy Representations in Multiagent Systems. arXiv 2018, arXiv:1806.06464. [Google Scholar]
- Lo, Y.L.; Woo, C.Y.; Ng, K.L. The necessary roadblock to artificial general intelligence: Corrigibility. AI Matters 2019, 5, 77–84. [Google Scholar] [CrossRef]
- Dmytryk, N.; Leivadeas, A. A Data-Driven Learning System Based on Natural Intelligence for an IoT Virtual Assistant. In Proceedings of the 2020 IEEE 25th International Workshop on Computer Aided Modeling and Design of Communication Links and Networks (CAMAD), Pisa, Italy, 14–16 September 2020; pp. 1–7. [Google Scholar] [CrossRef]
- BBC. Nature Makes You Happy|BBC Earth. 2017. Available online: https://www.youtube.com/watch?v=1wkPMUZ9vX4 (accessed on 31 October 2022).
- Rentschler, I.; Jüttner, M.; Unzicker, A.; Landis, T. Innate and learned components of human visual preference. Curr. Biol. 1999, 9, 665–671. [Google Scholar] [CrossRef] [Green Version]
- Makin, A.D.J.; Poliakoff, E.; Rampone, G.; Bertamini, M. Spontaneous Ocular Scanning of Visual Symmetry Is Similar During Classification and Evaluation Tasks. i-Percept. 2020, 11, 1–12. [Google Scholar] [CrossRef] [PubMed]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dmytryk, N.; Leivadeas, A. A Generic Preprocessing Architecture for Multi-Modal IoT Sensor Data in Artificial General Intelligence. Electronics 2022, 11, 3816. https://doi.org/10.3390/electronics11223816
Dmytryk N, Leivadeas A. A Generic Preprocessing Architecture for Multi-Modal IoT Sensor Data in Artificial General Intelligence. Electronics. 2022; 11(22):3816. https://doi.org/10.3390/electronics11223816
Chicago/Turabian StyleDmytryk, Nicholas, and Aris Leivadeas. 2022. "A Generic Preprocessing Architecture for Multi-Modal IoT Sensor Data in Artificial General Intelligence" Electronics 11, no. 22: 3816. https://doi.org/10.3390/electronics11223816