2. Related Works
There are many studies that have been reported in the field of path planning with both conventional and machine learning approaches but among them, machine learning approaches have gained a lot of popularity [
10]. Wang et al. proposed a globally guided reinforcement learning approach (G2RL) for path planning under dynamic environments which used spatiotemporal environment information to obtain rewards [
11]. Lee et al. proposed Q-Learning-based path planning for optimizing the mobile paths in a warehouse environment. The author performed various simulation tests by varying rewards based on actions and measured path length and path search time and compared the performance with the Dyna-Q learning algorithm [
12]. Dong et al. proposed an improved Deep Deterministic Policy Gradient (DDPG) algorithm for the path planning of a mobile robot by adaptively varying exploration factors. The author also compared it with other reinforcement algorithms such as Q-Learning and SARSA and found that DDPG performed better with less computation time and faster convergence [
13]. Quan et al. proposed Gazebo-simulated path planning of Turtlebot3 using Double Deep Q-Learning Network (DDQN) and Gated recurrent units (GRU)-based Deep Q-Learning. The authors finally compared the performance of reinforcement algorithms with conventional and heuristic algorithms, namely the A* and Ant-colony algorithm [
14]. Yokoyama et al. proposed an autonomous navigation system based on the Double Deep Q-Network using a monocular camera instead of 2D LiDAR [
15], whereas Farias et al. implemented reinforcement learning for position control of the mobile robot by controlling the linear and angular velocity [
16]. Wang et al. reviewed various image processing techniques for weed detection. The various techniques such as color index-based, threshold-based, and learning-based ones were discussed in detail [
17]. Islam et al. used shapes, color, and texture features to detect the objects in Columbia Object Image Library datasets [
18] whereas Attamimi et al. used color and shape-based features as the input to the K Nearest Neighbor classifier to identify the objects for domestic robots [
19].
Based on the above discussion, it can be inferred that reinforcement learning approaches have been implemented mostly for mobile robot navigation with predefined maps with obstacles. The literature available for solving path planning for manipulators using reinforcement learning in unknown environment obtained from a vision sensor is very limited. Hence the main goal of this paperwork was to implement different RL algorithms for vision-based obstacle avoidance using the camera for 5 DOF robotic manipulators in a planar environment. Moreover, to find the optimal training values, different test cases with varying hyperparameters were analyzed. To automate the process of objects detection in workspace, this paper used visual feedback information for determining the start, goal, and obstacle positions. This information was further converted into robot coordinates for tracing the path in real-time which is another contribution of this paper. The main objectives are listed below:
Implementation of image processing techniques to find the start, goal, and obstacle positions to be given as inputs to different RL algorithms;
Implementation of a homogeneous transformation technique to determine the grid world coordinates for corresponding camera coordinates and robot coordinates for respective grid world coordinates;
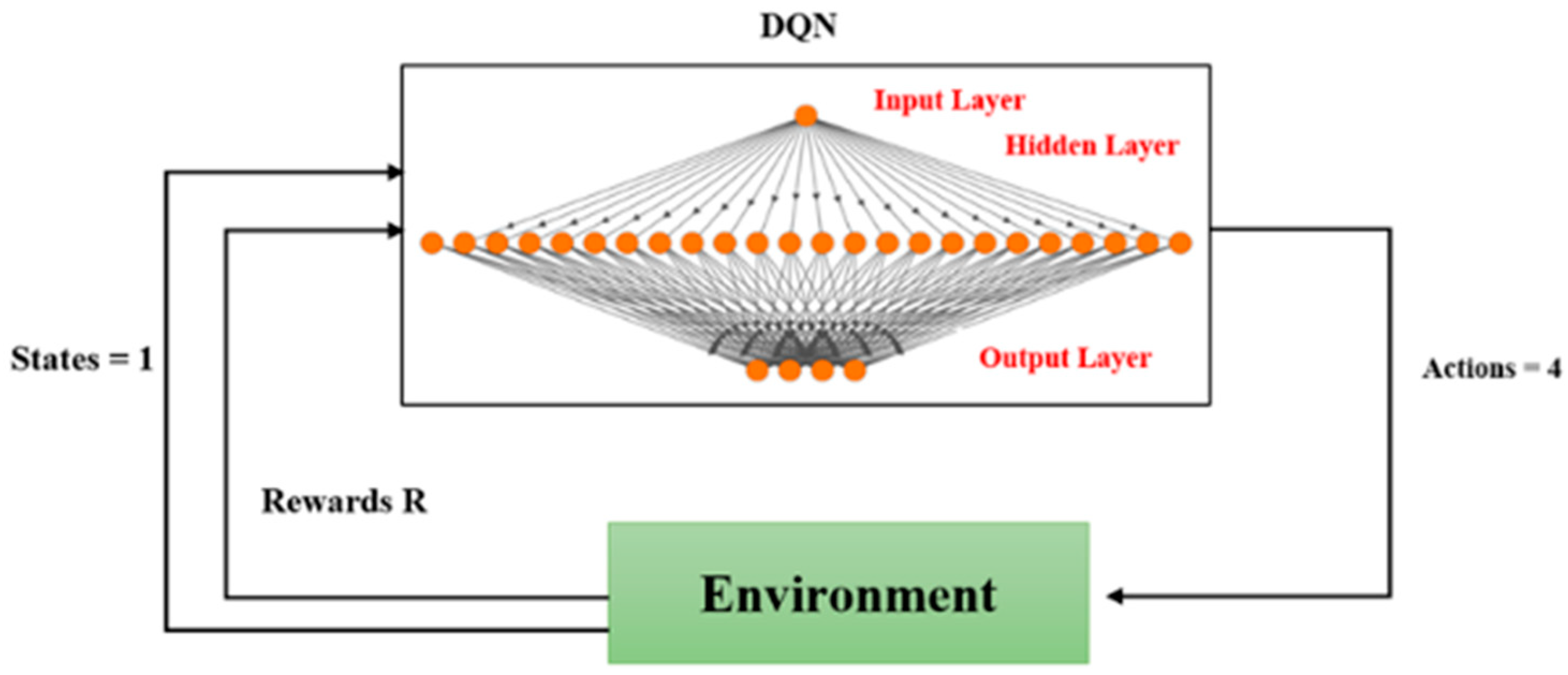
Application of different reinforcement learning algorithms such as Q-Learning, DQN, SARSA, and DDQN for path planning;
Optimization of training hyperparameters using Genetic algorithm and Particle swarm optimization algorithms;
Performance evaluation comparison by varying actions, convergence criteria, obstacle clearance, and episodes to find optimal parameters for Q- learning and noting the pat length and time elapsed for each test case;
Real-time online-based experimental verification for vision-based obstacle avoidance for all the test cases using the input obtained from the live camera feed.
The paper is further divided into four sections.
Section 3 explains vision-based obstacle avoidance using different RL algorithms with camera calibration. This is followed by a performance evaluation of different RL algorithms in
Section 4. The experimental results obtained with their performance analysis are discussed in
Section 5. Finally, the conclusion and future scope of the work are discussed in
Section 6.
5. Results and Discussion
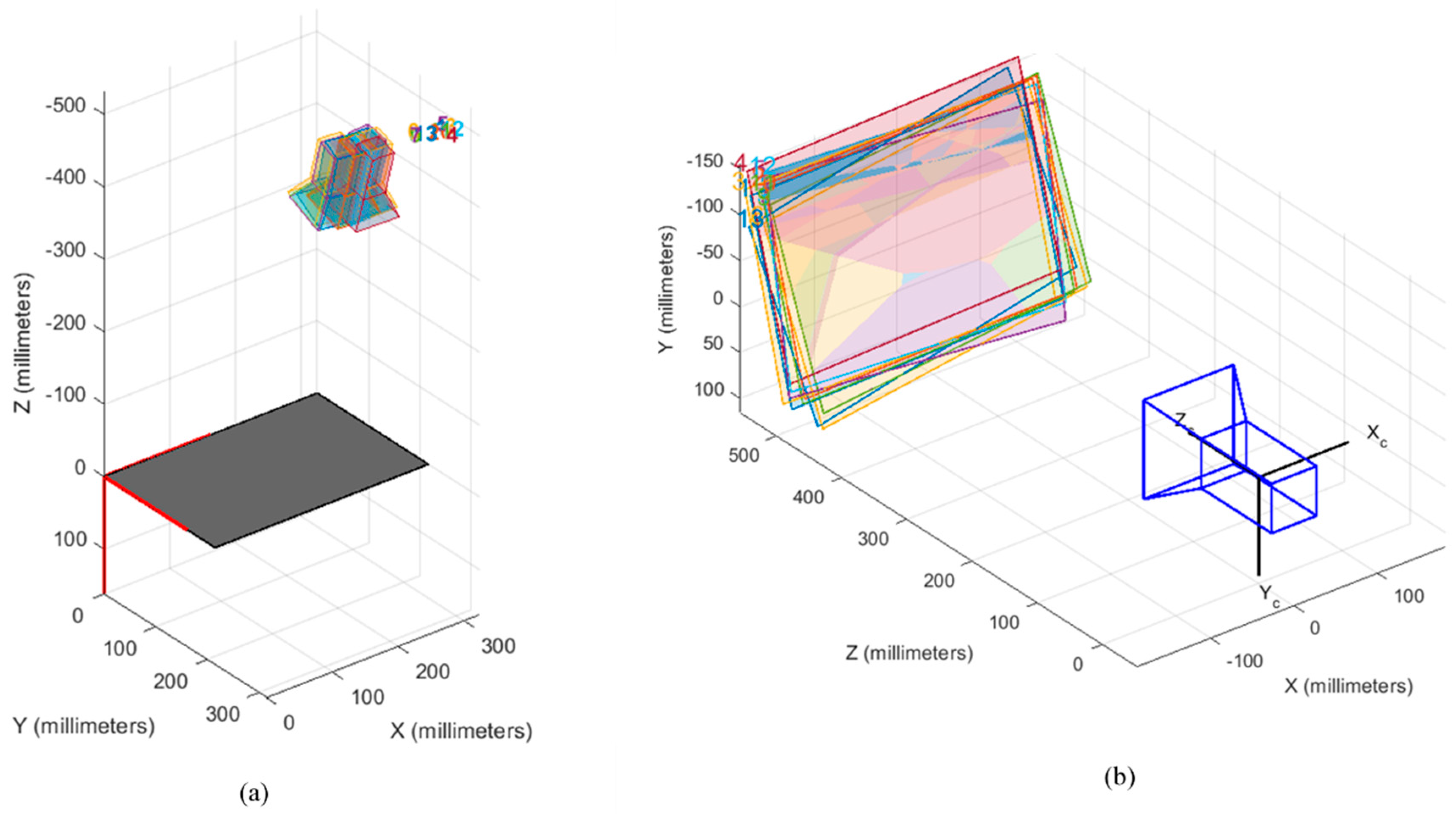
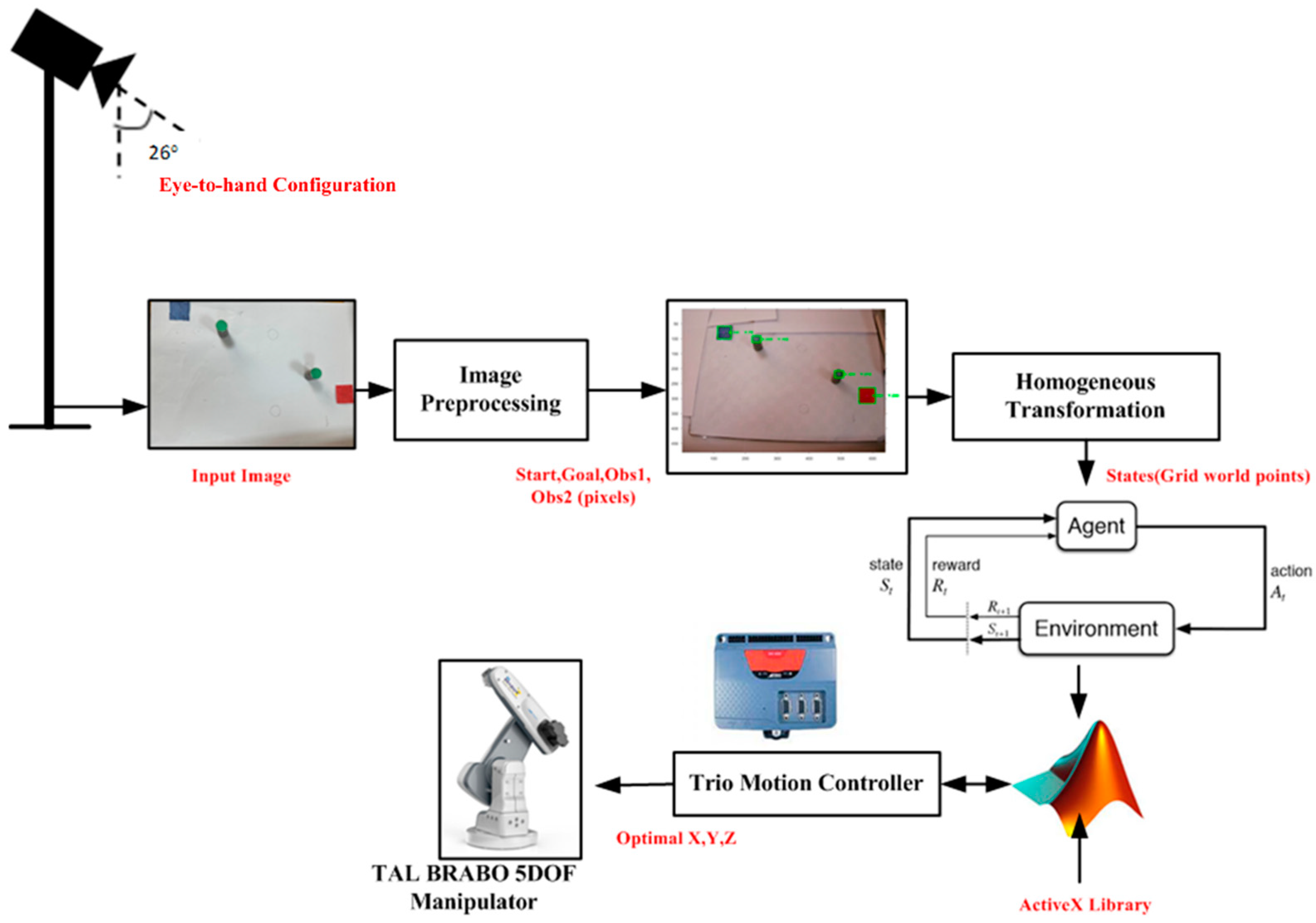
This section presents various results obtained for different test cases for different reinforcement learning algorithms. Their performance was compared, and an optimal set of parameters was chosen for real-time experimentation using TAL BRABO manipulator. The experimental setup for performing vision-based path planning and obstacle avoidance is shown in
Figure 8.
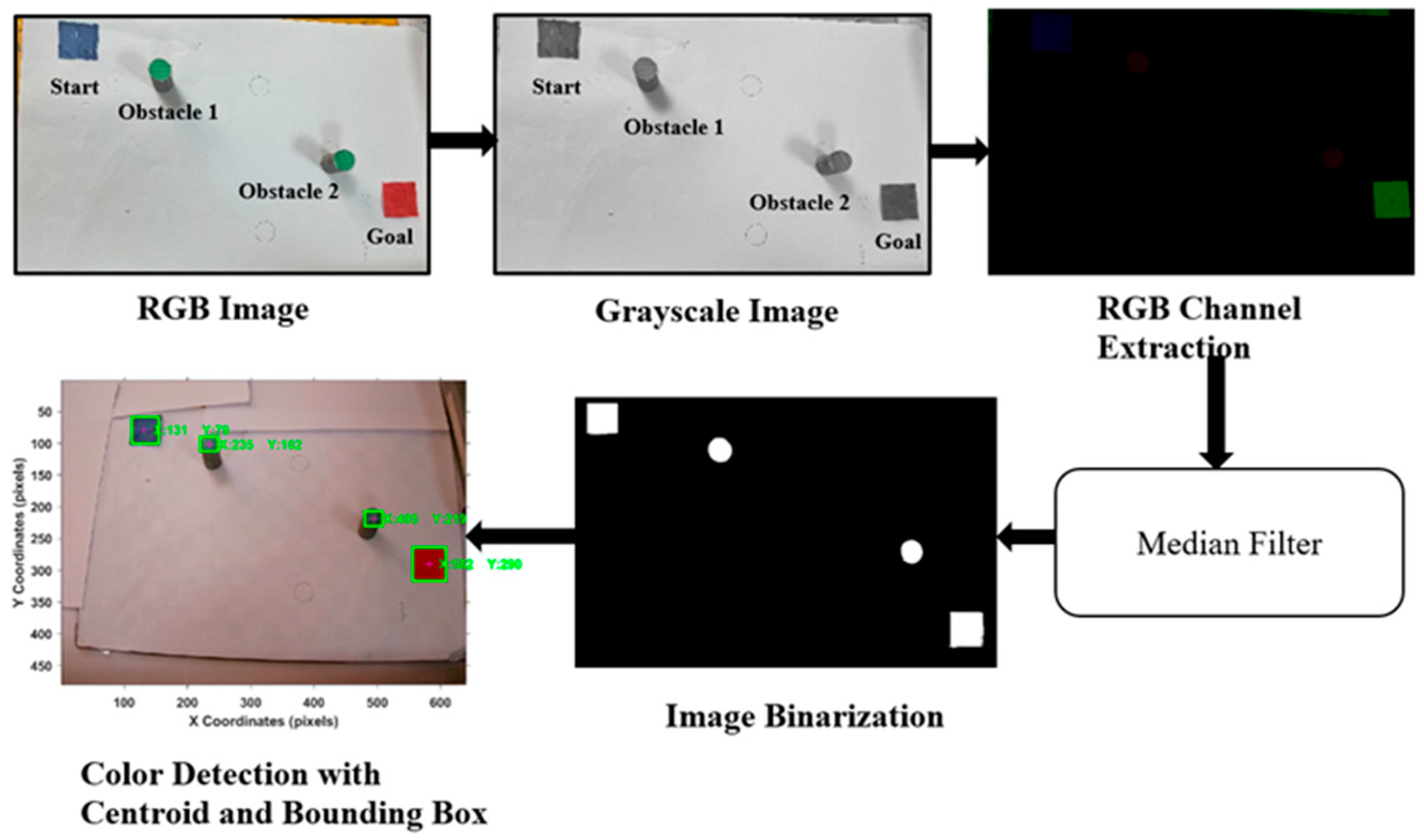
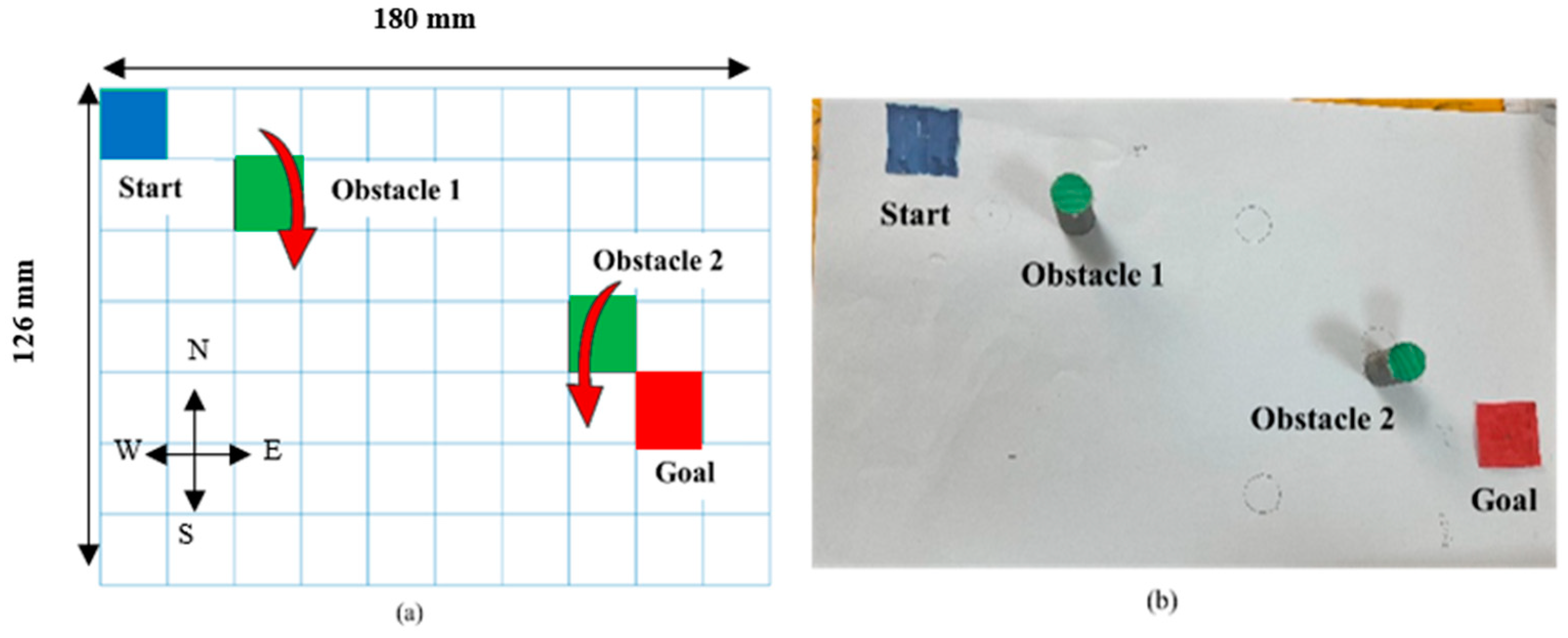
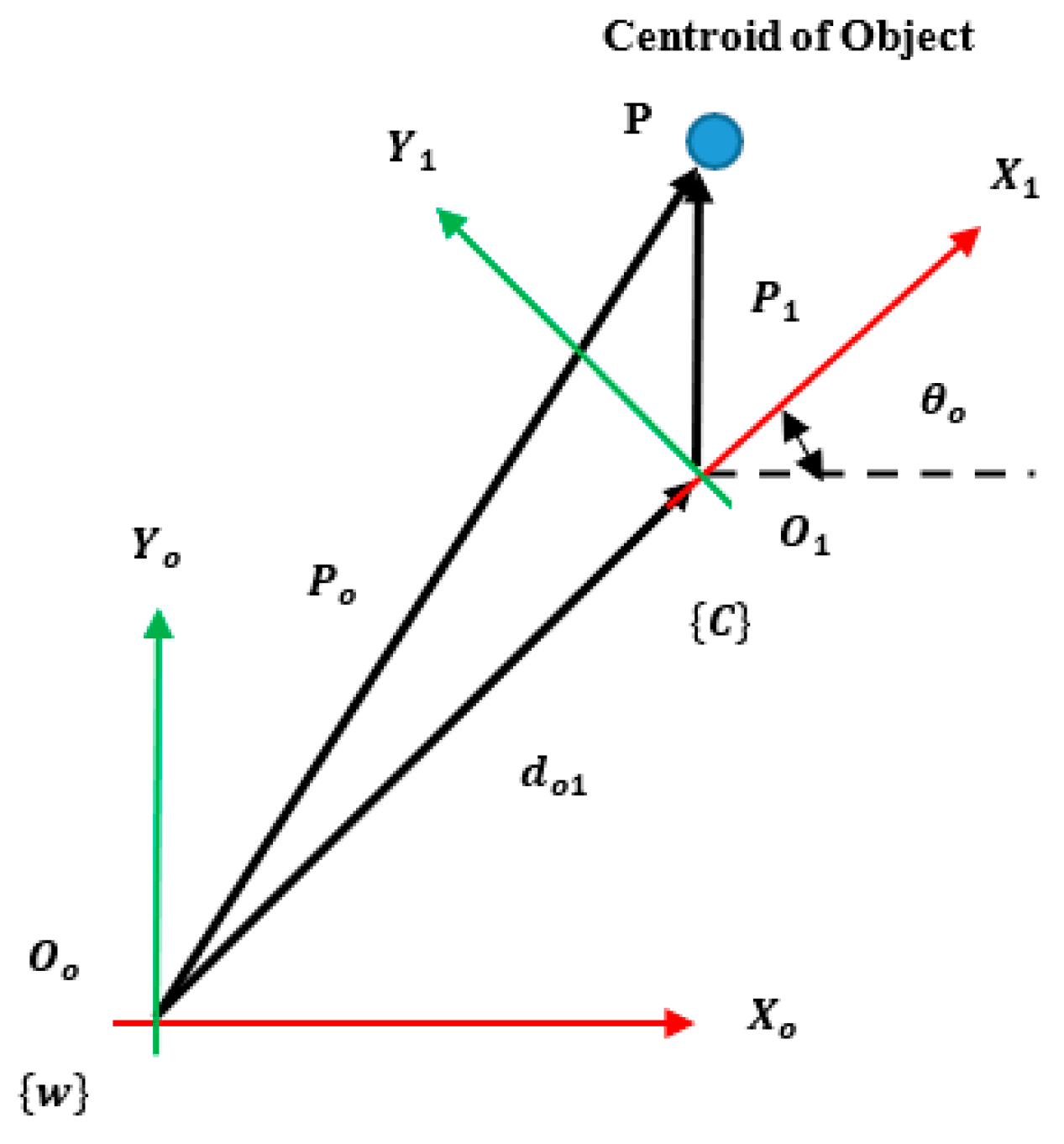
The camera captured the workspace where obstacles were kept and using image processing the colors were segmented and contours and a centroid were drawn over each object. Using the centroid values, corresponding grid world coordinates were obtained using the transformation matrix specified in Equation (8) and fed as input to the reinforcement learning algorithms. The live camera feed capturing the objects placed in the workspace is shown in
Figure 9 and their pixel, grid values, and their robot coordinates are tabulated in
Table 1. The robot coordinates were obtained from Equation (A7) as described in
Appendix A. With the increase in episodes, a better optimal policy can be obtained which leads to better learning. Since the grid world was smaller, episodes of 5000 performed better but based on the environment the episodes needed to be adjusted for better performance. Next, the average rewards were analyzed, and it was seen that the one with a lesser average reward performed better because there was less deviation between the reward given and what the agent received. When the deviation was large, the agent was not able to reach the goal point.
Once the transformed coordinates were obtained, using these parameters, different reinforcement learning algorithms were trained for different episodes namely 1000, 3000, and 5000. The steps per episode were varied as 50, 100, and 300. The learning rate was chosen as 0.0001, 0.2, and 1, whereas the discount rate was chosen as 0.01, 0.5, and 0.99. All these parameters were chosen in such a way that they had low, medium, and high values. Finally, by using different combinations, the length of the path traversed, average reward, average steps per episode, and time taken to reach the goal were calculated for different RL algorithms. Here, the consolidated results of average path length for different reinforcement learning algorithms are tabulated in
Table 2 and the detailed table is described in
Table A2 under
Appendix A.2.
Since the environment was very small for path planning, the maximum episodes were taken as 5000 and steps per episode as 300. It was also observed that with episodes more than 5000, the performance was poor, and the path generated was noisy. From the above table, it can be noted that during the experimental analysis, when the episodes increased from 1000 to 5000, the total elapsed time taken by the agent to reach the goal point also increased. Further, there was no change in path length for all the algorithms and this was the same for different episodes and learning rates. The notable difference in path length was observed while varying the discount factor as this is the important weighting factor which determines the importance of rewards for the future states. From the above analysis, Double DQN was able to reach the goal point exactly with the path length of 216.07 mm while Q-Learning and SARSA were not able to reach the goal point with 5000 episodes. The average steps and elapsed time for training the agent are tabulated in
Table 3 with 5000 episodes, 300 steps per episode, the learning rate of 1, and the discount rate of 0.99.
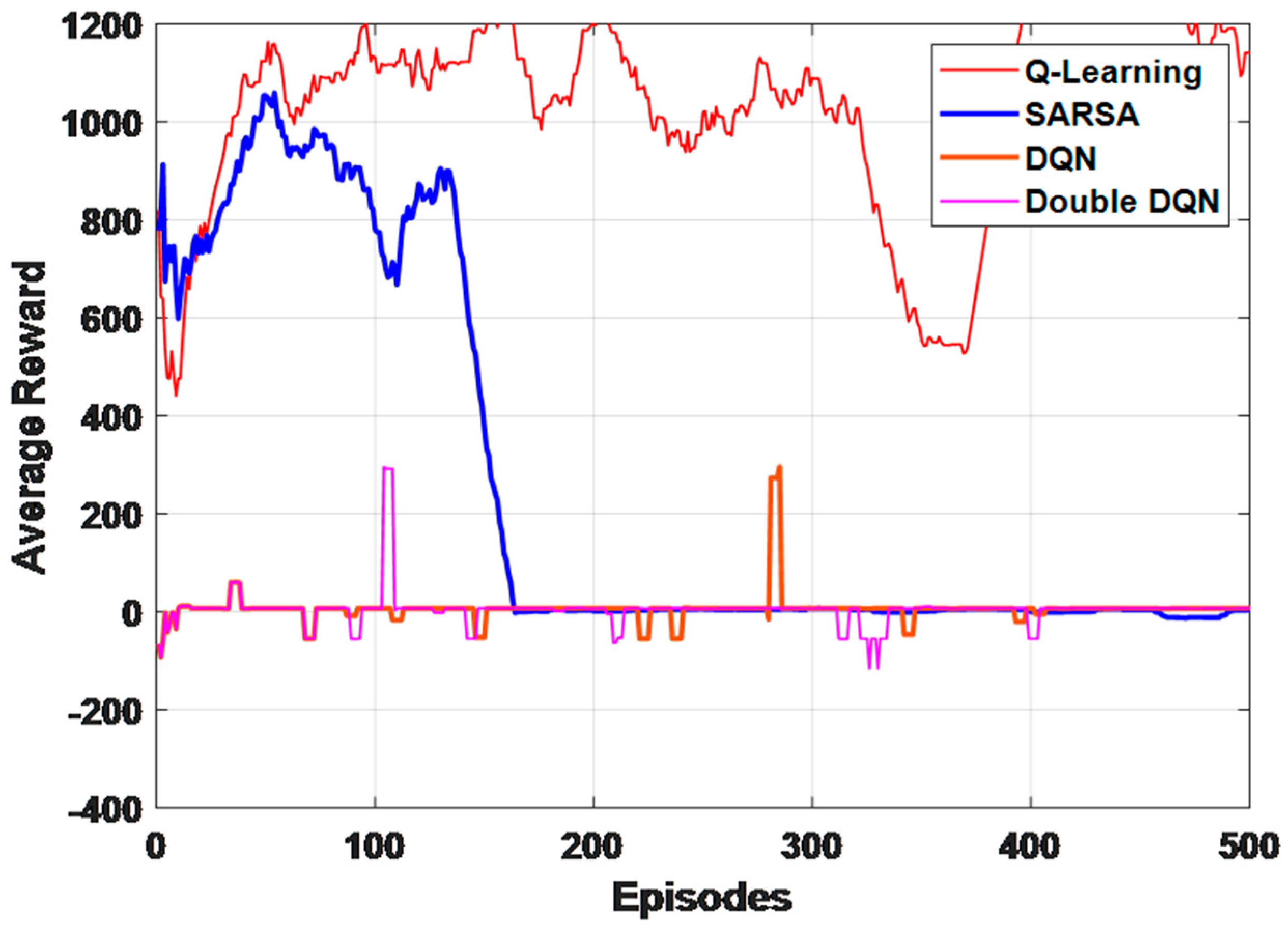
The above table discusses the average steps and total time taken for training for different algorithms in which steps taken by double DQN was less with the value of 10.4 which shows that training converged with the values equal to the stopping criteria whereas Q-Learning had average steps of 206.7. Q-Learning took 2387.2 sto complete the training whereas SARSA completed the training within 2073.9 secs (35 min). Moreover, it was noticed that training was faster with SARSA than any other algorithms. The DQN algorithm took 3957.4 s which is approximately one hour for training which was much slower compared to others. Among deep reinforcement learning algorithms, performance was better for double DQN since it simultaneously ran the DQN for experience replay and calculated the q value using another network whereas in DQN, the Q-value was updated using the reward in the next state. The convergence comparison of different algorithms with respect to the first 500 episodes with a learning rate of 1 is illustrated in
Figure 10. This graph provides an overall idea of which algorithm performance was better as faster convergence is needed.
From the graph, it can be seen that Double DQN converged faster within 40 episodes whereas Q-Learning performed worse since it never seemed to converge. Secondly, DQN and SARSA also converged faster at 150 and 170 episodes, respectively, compared to Q-Learning. It can be inferred that Double DQN performed better among all.
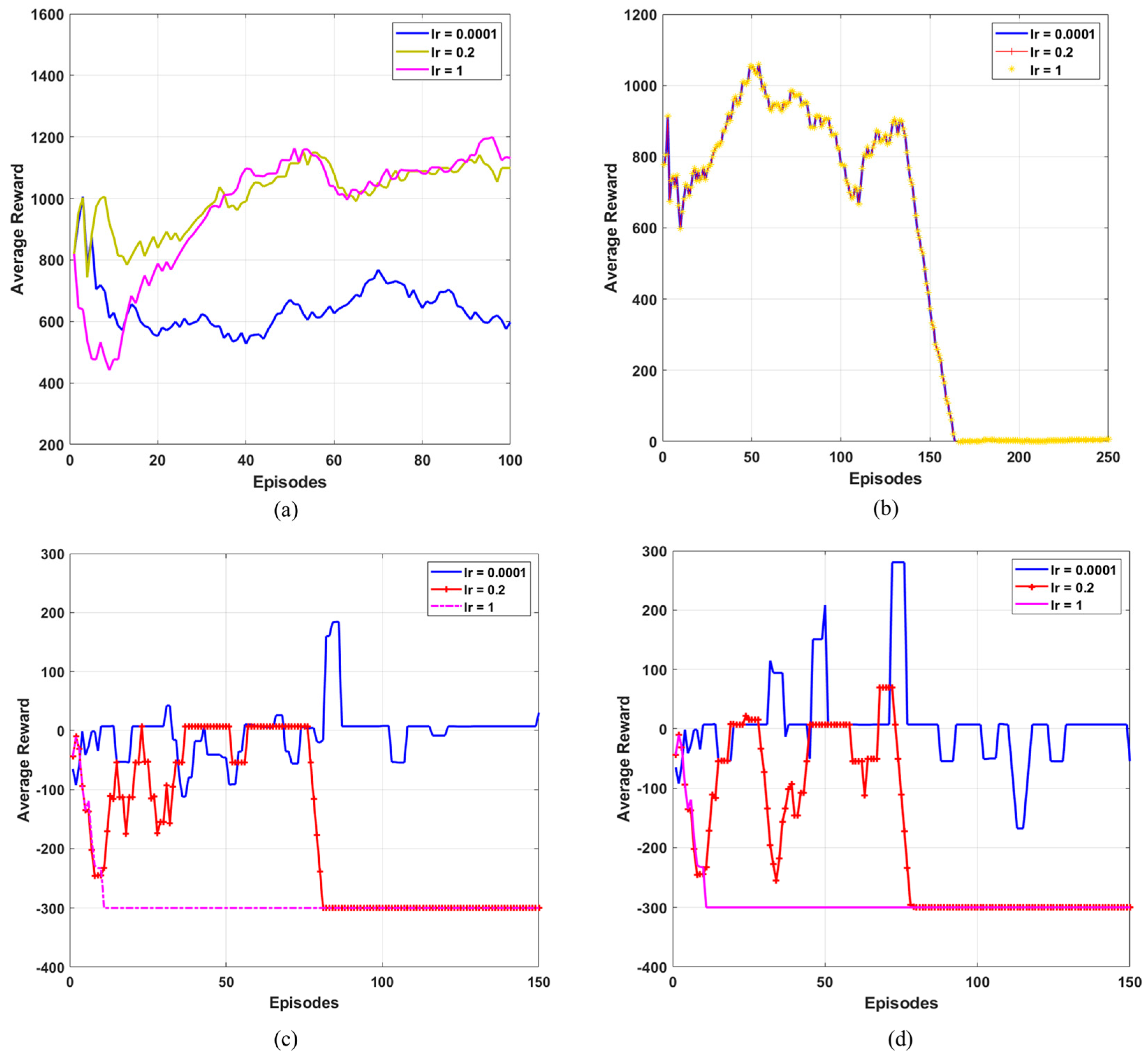
Figure 11a–d depicts the average reward obtained with different learning rates such as 0.0001, 0.2, and 1 for different RL algorithms. It was inferred that the average reward of Q-Learning varied without converging to a specific value but the average reward of SARSA took 155 episodes to converge. However, for DQN and Double DQN it converged within 85 episodes. This shows that the convergence speed was faster for the deep learning-based Q network.
Further,
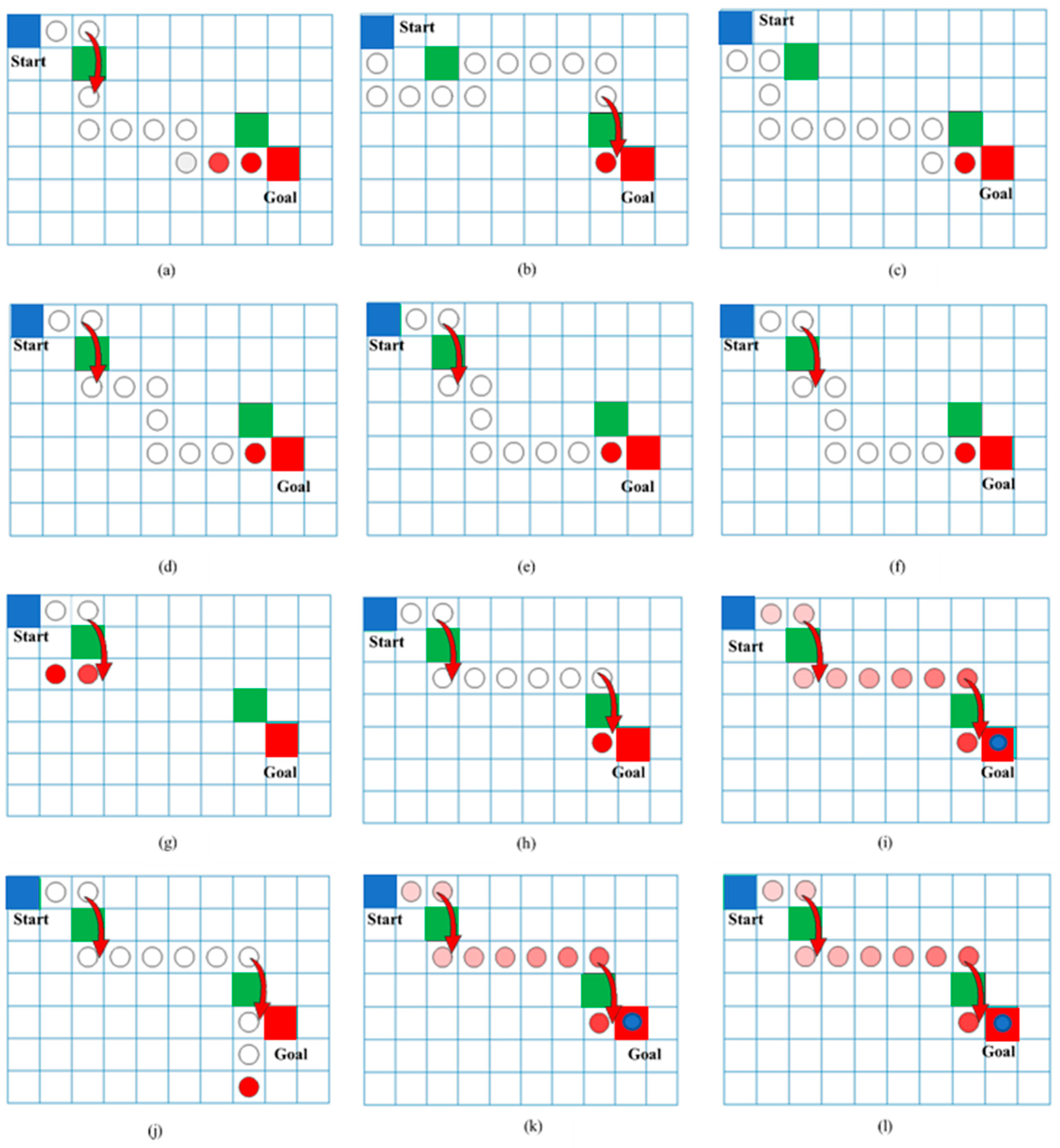
Figure 12a–c denotes the different optimal paths taken by the agent for Q-Learning for steps 50, 100, and 300, respectively. Similarly,
Figure 12d–f shows the agent path using SARSA for 50, 100, and 300 steps, respectively.
Figure 12g–i describes the path using DQN for 50, 100, and 300 steps, respectively and finally
Figure 12j–l shows the path obtained from Double DQN for 50, 100, and 300 steps, respectively. The agent tries to reach the goal point by moving from one grid to another by trial-and-error during learning process. When it encounters an obstacle, a jump is made from one grid to another to find the optimal path in less time which is denoted by red arrow. Here in this paperwork, the agent movement around the obstacle was recorded which could be further used for calculating the probabilities of the future states. The transition jump around the obstacle was taken as 1 and other surrounding grids were made zero so that it did not visit that grid because it was seen that when it reached nearby grids, time to reach goal was more and sometimes it did not reach the goal. Then it was seen that Q-Learning and SARSA were not able to reach the goal point exactly but reached the grid before the goal point which approximated to an 18 mm difference in robot workspace. However, DQN and Double DQN performed better and reached the goal point exactly, which showed that deep reinforcement learning performed better than conventional reinforcement learning algorithms. Hence, steps per episode played a major role as they recorded the state and reward for the state–action pair.
Next by varying the discount rate, the agent’s path was recorded, and its performance was compared. The discount rate considered in this work was 0.01, 0.5, and 0.99, respectively. This is one of the important weighting factors for reinforcement learning apart from learning rate since it reveals the importance of future rewards and adjusts the agent’s behavior accordingly for long-term goals. So, the agent path was recorded which is illustrated in
Figure 13.
Figure 13a–i denotes the different paths taken by the agent for discount rates of 0.01, 0.5, and 0.99, respectively, using different reinforcement learning algorithms such as Q-Learning, SARSA, DQN, and Double DQN. It can be seen that for the higher discount rate, the agent was able to reach the goal efficiently but when the discount rate was 0.01 it never reached the goal, and the learning was poor. It was seen that SARSA reached the goal only when the discount rate was 0.5. Hence, the discount rate of 0.99 should be chosen for a better performance. The total agent steps generated for 5000 episodes with 300 steps per episode are tabulated in
Table 4. This shows the total steps the agent took to reach the goal point.
From the table, it can be inferred that Double DQN took only 3, 80, 299 agent steps to reach the goal point whereas Q-Learning took 12, 27, 734 steps to reach the same goal point. Hence it can be concluded that Double DQN had a superior performance. Further, to find the optimal training hyperparameters, GA and PSO were implemented in this work using MATLAB. The four main input variables considered for optimizing were episodes, steps per episode, learning rate, and discount rate as these variables had a major effect on q value and rewards, and the output variables were chosen as the length of the path traversed by the agent. The GA was run with an initial population size of 50 and 400 generations. The initial swarm matrix for PSO was taken to be 0.5. The lower bound and upper bound values are shown in
Table 5.
The problem was formulated as an unconstrained nonlinear optimization problem. Similarly, a particle swarm optimization algorithm was also used to compare the optimized results of GA and PSO and their effect on agent path traveled. In PSO, the swarm size was taken to be (100, 40) with an initial swarm span of 2000. The total iterations were chosen to be 800. The initial weights of each particle with respect to the neighbors’ particles were taken as 1.49. The optimized parameters were obtained from GA and PSO and one of the solutions is listed in
Table 6. Finally, these parameters were implemented on different reinforcement learning algorithms, and the paths traced were analyzed.
The above discussion was entirely tested in the same environment. Further, to validate the optimized parameters obtained, in this work different environments were created and the agent actions were analyzed using the Double DQN algorithm. Since based on the above analysis Double DQN had the better performance comparatively, it was chosen for further analysis as shown in
Figure 14a–d. The environment was created by adding more obstacles, changing the obstacle positions, and changing the goal point. The analysis was tested with a maximum of four obstacles using the Double DQN algorithm since this gave a better performance than the other RL algorithms.
From the
Figure 14a–d, it can be inferred that the agent was able to reach the goal point under for two and four obstacles. There was some lag in reaching the goal point with three obstacles. The optimal parameters used for this analysis were, namely, episode = 5000, steps = 300, learning rate = 1, and discount rate = 0.99. Since the environment was smaller, the number of obstacles was restricted to four. These training parameters can vary based on the size of the environment and the type of applications chosen. This analysis can be implemented with similar environments and different obstacle sizes. Further, the grid world coordinates were converted to robot coordinates using the transformation Equation (A7) to perform real-time vision-based path planning. The agent path traced in terms of robot coordinates is illustrated for different obstacles and different goal points in
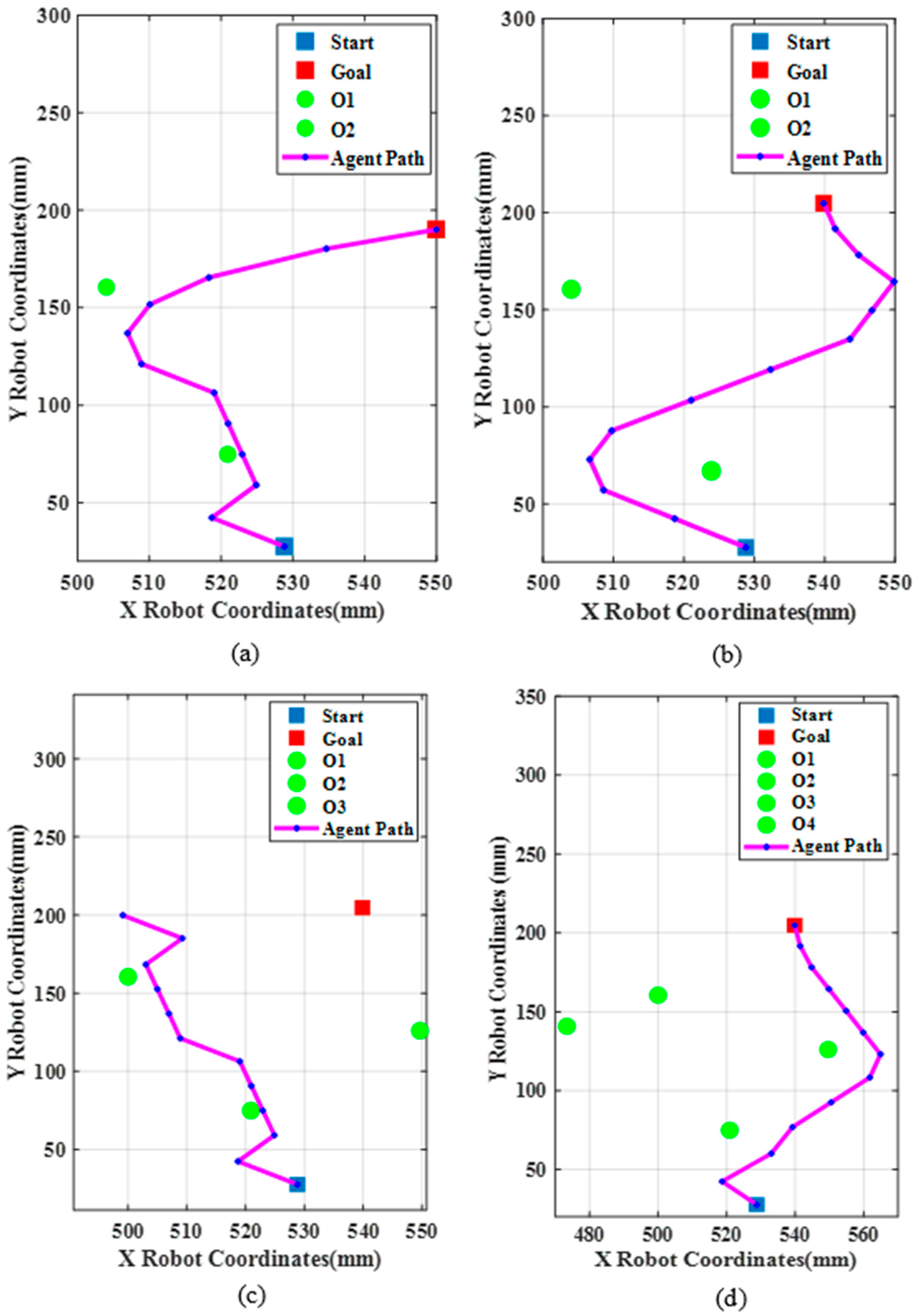
Figure 15a–d. This was analyzed to compare the simulation and real-time robot tracing.
From
Figure 15a,b, the agent was able to reach the goal by the learning process with a path length of 198.16 mm and 252.47 mm. The time taken to reach the goal point was 1455.2 and 1672.66 s, respectively. Next with three obstacles, the robot was made to reach the goal, but the robot was not able to reach the goal point and had an error of about 40 mm along
and 4 mm along
from the goal point as shown in
Figure 15c. The path length was 233.97 mm.
Figure 15d shows the robot’s shortest path with four obstacles with a path length of 252.47 mm. It can be inferred that reinforcement learning algorithms work for any number of obstacles with suitable selection of training parameters. The obstacle considered in the simulation was a square with each side measuring 36 mm but in real time the diameter of the obstacle was 20 mm. Hence, there was a safe distance of 16 mm which was considered in the simulation analysis. The optimal training parameters obtained from GA and PSO were implemented in real-time path planning. The coordinates obtained after coordinate transformation were then sent to the robot via the ActiveX library installed in MATLAB to perform the path planning. In the real time experimentation,
and
coodinates were considered and sent to the robot with
coordinates maintained at a constant 300 mm. The reason was that for a safer operation of the
axis motors of the robot, the analysis was considered in a planar environment but in future, a 3D analysis will be considered. The real-time path planning using TAL BRABO 5 DOF manipulator with two obstacles (
Figure 15b) is shown in
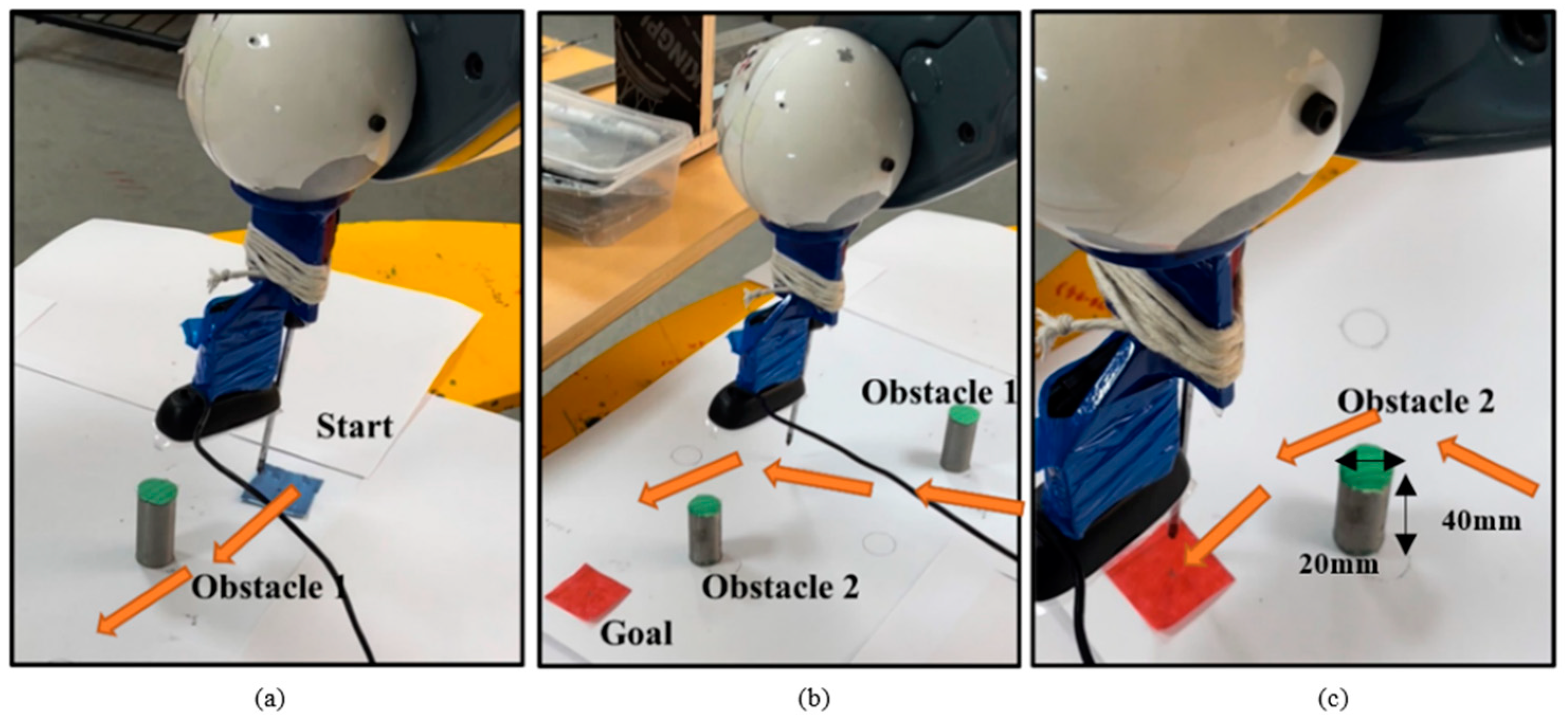
Figure 16a–c.
From the Figure, it can be visualized that the robot tried to follow the path as illustrated in
Figure 15b with two obstacles. The robot started from start position (528.805, 27.553) mm as shown in
Figure 16a and tried to avoid the two obstacles as shown in
Figure 16b and successfully reached the goal point (539.86, 204.84) mm as shown in
Figure 16c. Similarly, the analysis was tested for other conditions with different obstacles and the robot reached the goal point without hitting the obstacles. The speed profile and joint velocities of the TAL BRABO robot while performing online path planning were recorded for case b and shown in
Figure 17a,b.
The above figure shows the linear speed profile and angular velocity generated for the TAL BRABO robot with two obstacles using Double DQN. The velocity was generated for the path illustrated in
Figure 17b to show that the variation of the joint velocities was very minimal while performing path planning. Thereby it shows that the use of Double DQN online-based path planning was smooth.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


















