
A Machine Learning Method for Prediction of Stock Market Using Real-Time Twitter Data

 , , and
, , and
Abstract
:1. Introduction
- An efficient framework namely SSWN is proposed with ELM and RNN classifiers for stock market behavior prediction.
- Utilization of SA for stock market prediction and modification of SWN by introducing new terms related to stock market.
- Assignment of sentiment scores to newly introduced stock market-related terms by applying the information gain method, resulting in the development of a new sentiment lexicon SSWN.
- To perform comparative analysis with other methods to show the effectiveness of proposed method.
2. Related Work
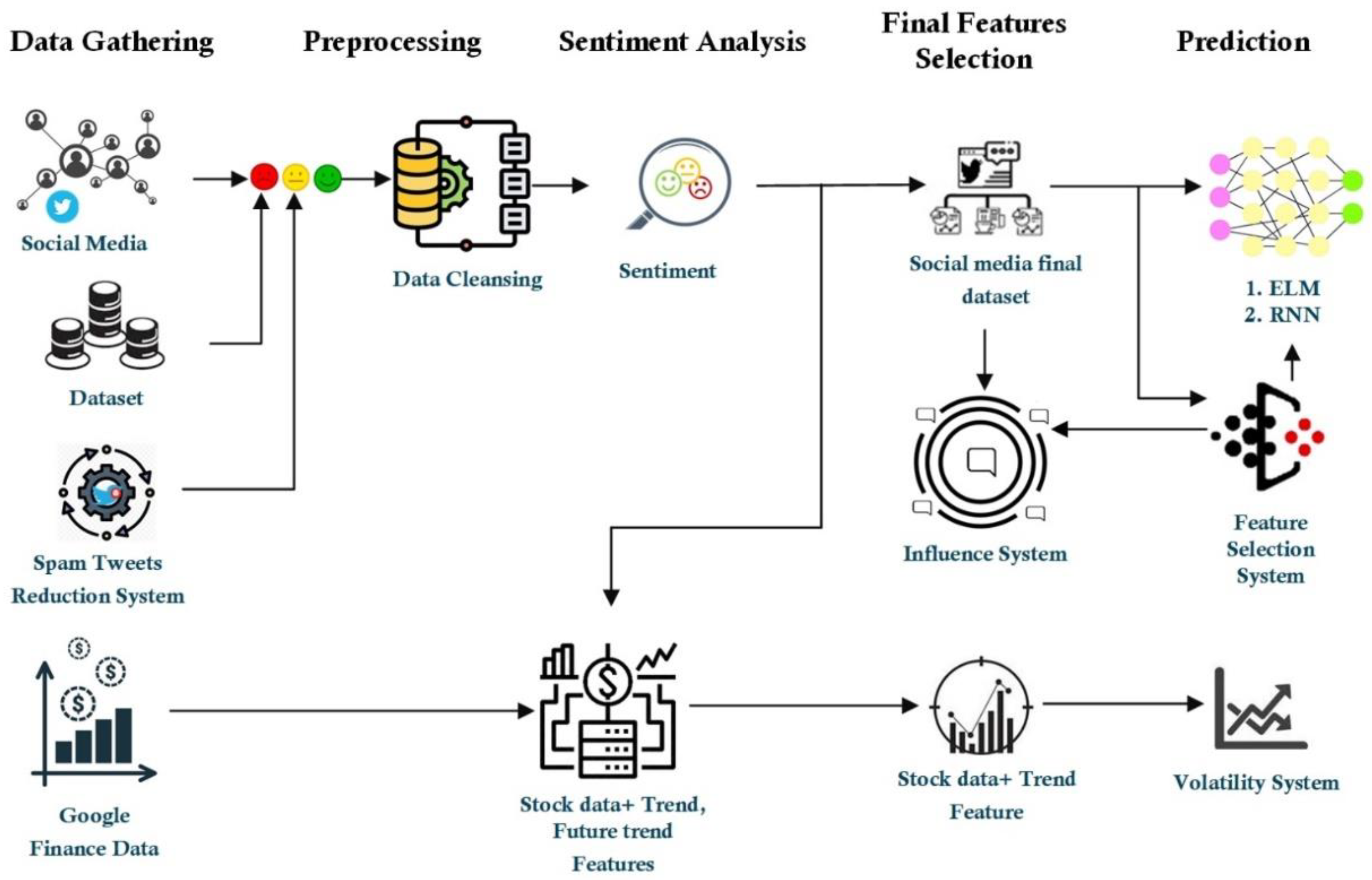
3. Proposed Methodology
3.1. Data Gathering and Cleansing
- Conversion of tweets into word tokens by using bigrams, meaning that the model evaluates two tokens/words at the same time. This means that if a tweet describes something as “not good”, that will be considered as a negative remark, rather than a positive one just because it contains the word “good”.
- Removal of tags like author tag (@). These labels must be eliminated because they contain no valuable knowledge for obtaining sentiments.
- Removal of URLs.
- Elimination of Stop words. Stop words frequently exist in tweets like an, is, are, the, etc.) and have no helpful material for ML classifiers.
- Conversion of words into the identical stems; called word stemming.
- Removal of duplicate tweets.
3.2. Feature Extraction
3.2.1. SWN
3.2.2. SSWN
Information Gain (IG)
Sentiment Knowledge Base (SKB) Generation Procedure
- Take all rows from SSWN one by one.
- Compute synset from each selected row.
- Calculate the sentiment orientation (SO) for each synset.
- If the computed SO is found to be subjective thengo for step 5, else remove the selected synset and jump to step 1 again.
- For each subjective synset, locate and calculate the portions of its speech information.
- Find specific words from the synset.
- Calculate feature vector by combining all individual terms along with speech chunks differentiated with a hash, i.e., term#POS.
- Save the computed key points in the list of nominated features.
- Repeat steps 1–8 for all the rows.
- The same feature can have replicated records with different polarity and sentiment scores in the keypoints list because of its sense ranking-based usage. So, this step is performed to locate the distinctive features.
- The positive and negative occurrences are computed for all the features detected in step 10.
- Based on the count score computed from the step 11, IG is employed to produce sentiment scores.
- Finally, a distinctive identifier (ID) is allocated to each feature.
3.3. Prediction Phase
3.3.1. Extreme Learning Machine
3.3.2. Recurrent Neural Network
4. Experimental Results
4.1. Experimental Setup
4.2. Datasets
4.2.1. The Sentiment140 Dataset
4.2.2. Direct Data from Twitter
4.2.3. Proposed Method Results
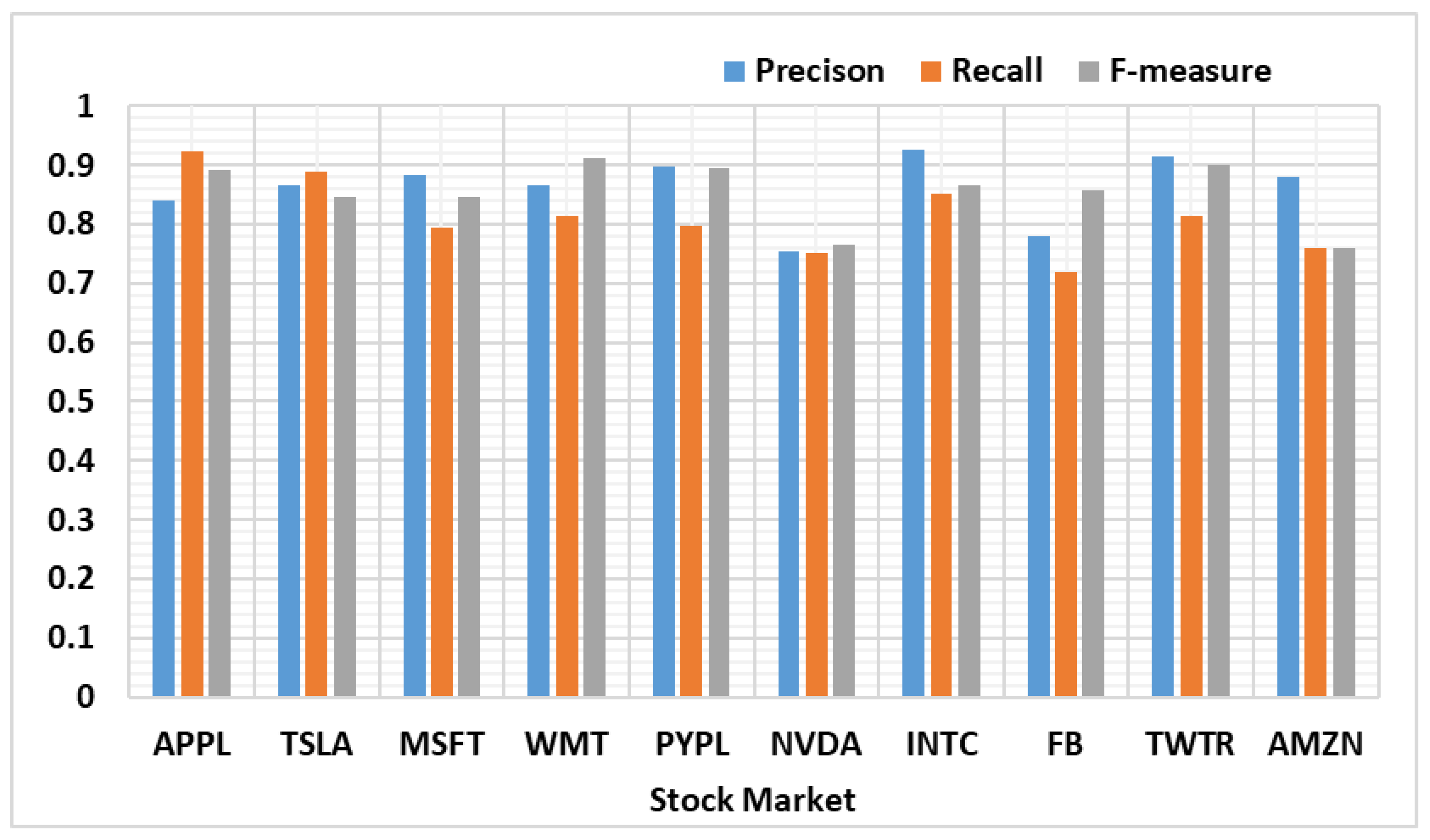
4.2.4. Classifiers’ Performance Evaluation
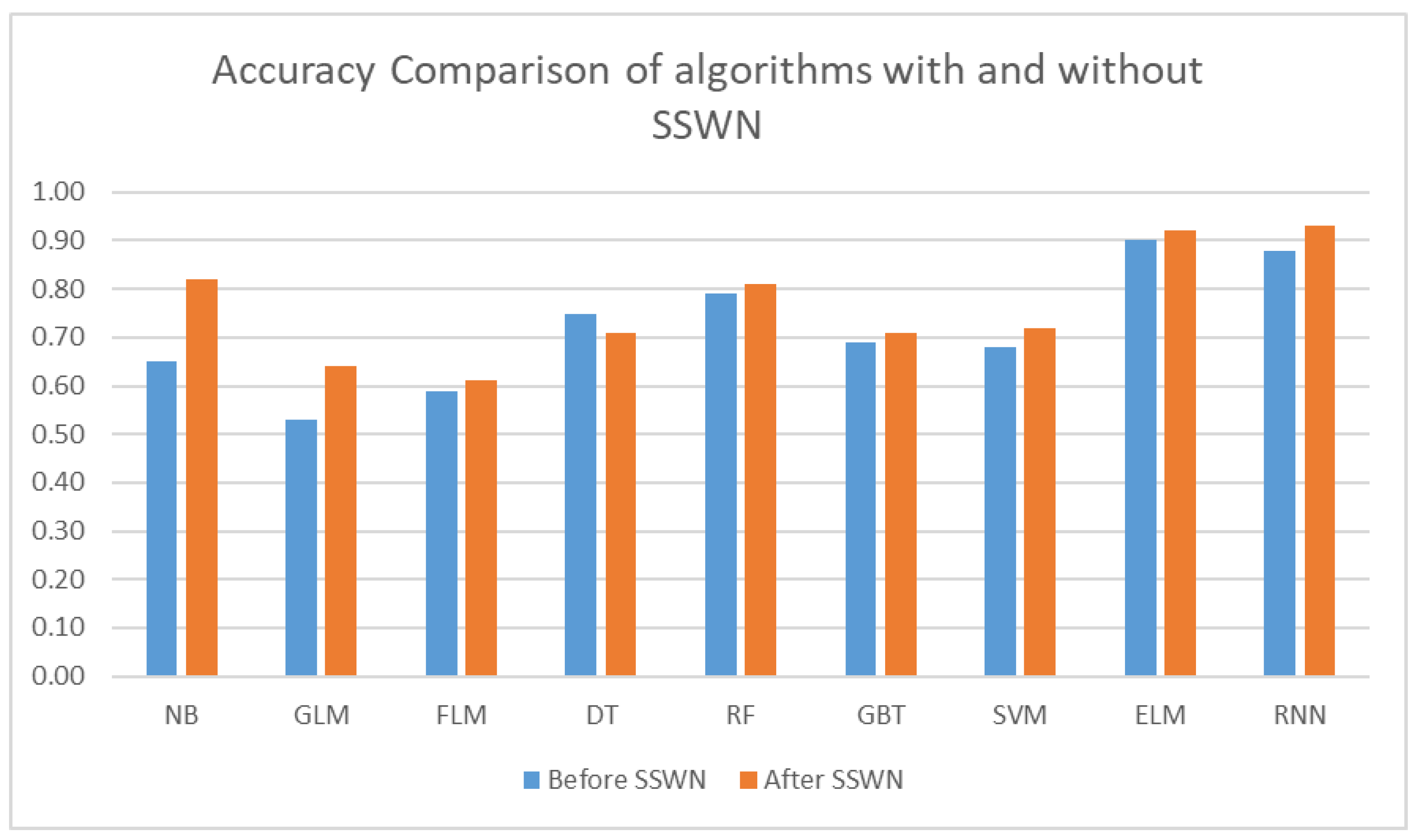
4.2.5. Performance of Algorithms before and after SSWN
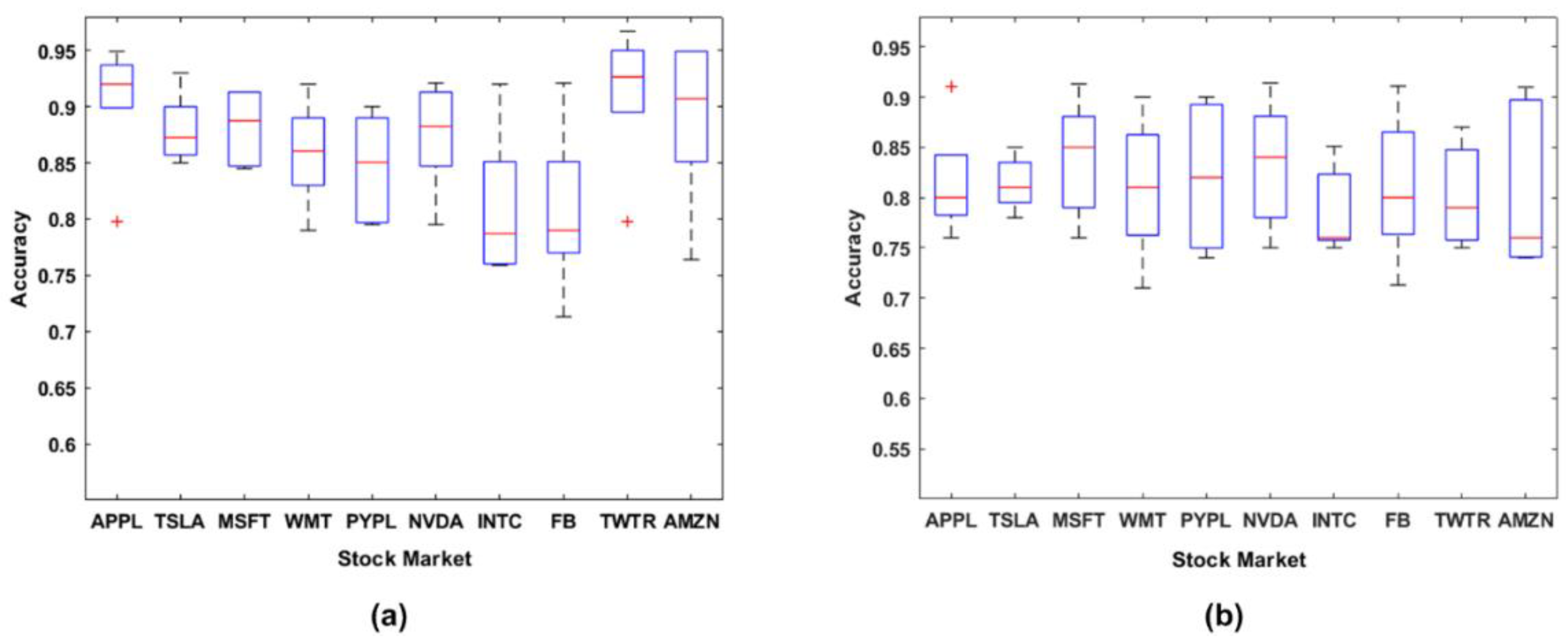
4.3. Performance of Algorithms on Both Datasets
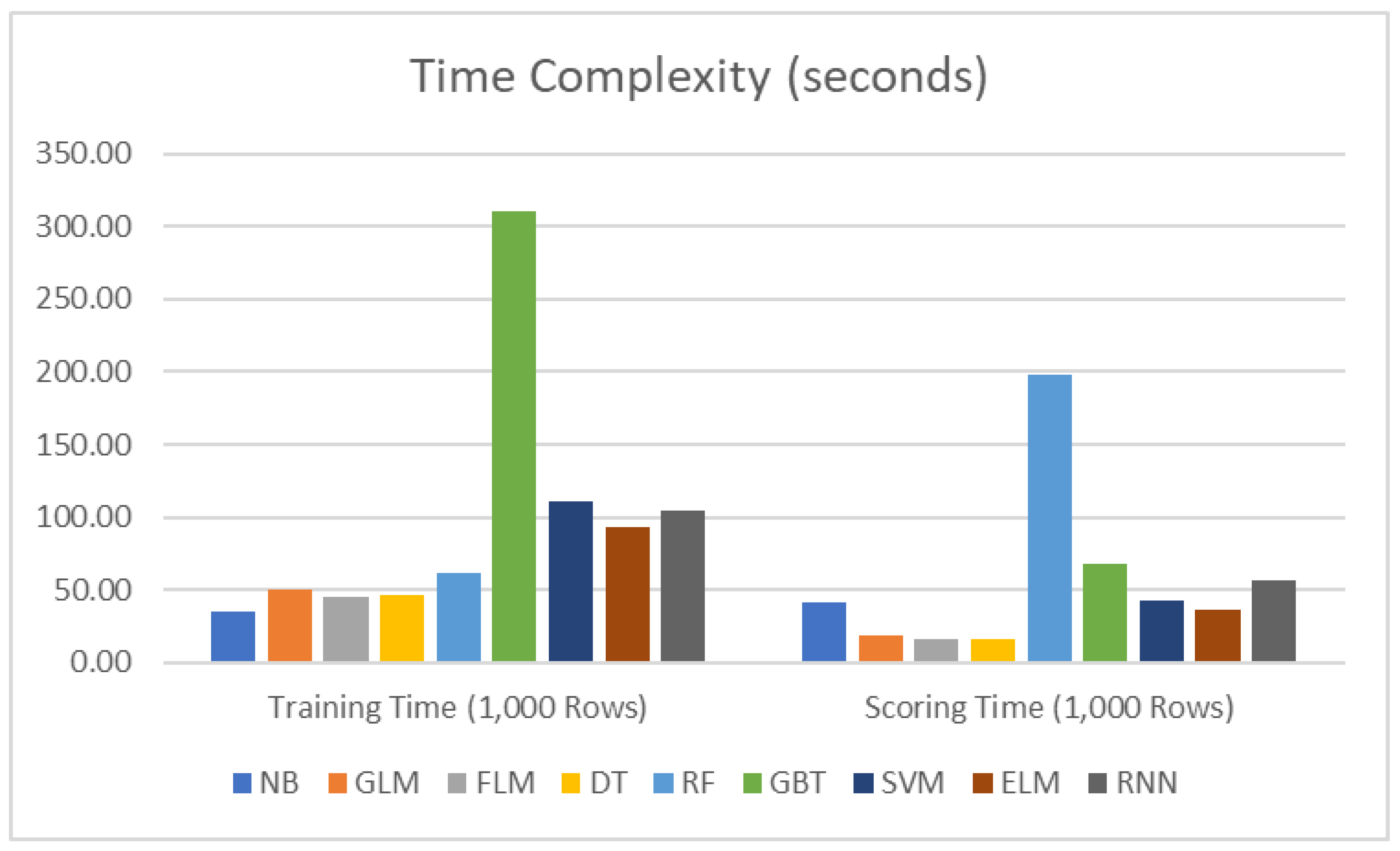
4.4. Time Complexity
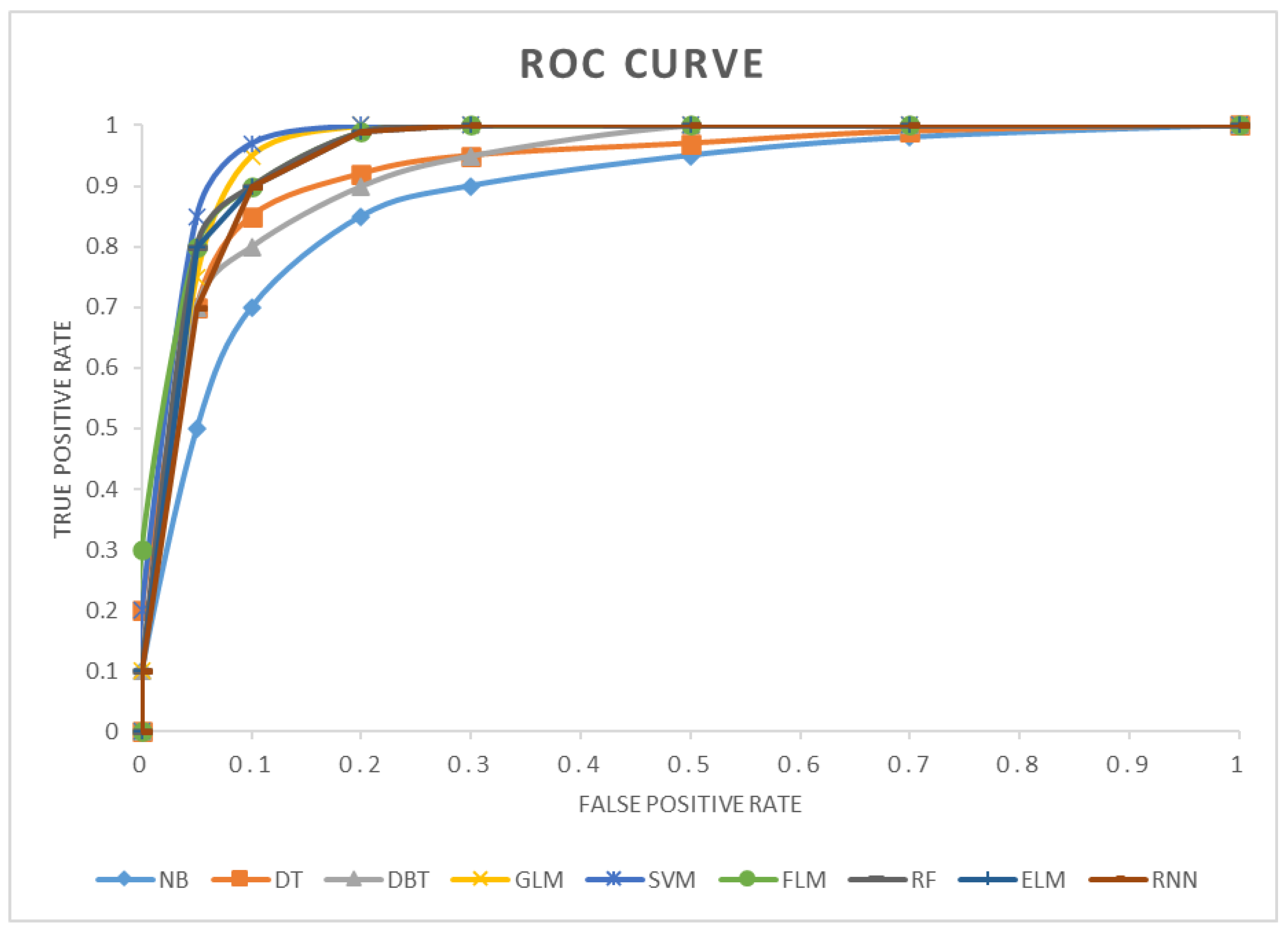
4.5. Classification Performance of the Selected Algorithms
4.6. Comparison with State-of-the-Art Techniques
4.7. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Li, X.; Wu, P.; Wang, W. Incorporating stock prices and news sentiments for stock market prediction: A case of Hong Kong. Inf. Process. Manag. 2020, 57, 102212. [Google Scholar] [CrossRef]
- Roy, S.S.; Mittal, D.; Basu, A.; Abraham, A. Stock market forecasting using LASSO linear regression model. In Afro-European Conference for Industrial Advancement; Springer: Cham, Switzerland, 2015; pp. 371–381. [Google Scholar]
- Ruan, Y.; Durresi, A.; Alfantoukh, L. Using Twitter trust network for stock market analysis. Knowledge-Based Syst. 2018, 145, 207–218. [Google Scholar] [CrossRef] [Green Version]
- Oliveira, N.; Cortez, P.; Areal, N. The impact of microblogging data for stock market prediction: Using Twitter to predict returns, volatility, trading volume and survey sentiment indices. Expert Syst. Appl. 2017, 73, 125–144. [Google Scholar] [CrossRef] [Green Version]
- Bose, A.; Hsu, C.-H.; Roy, S.S.; Lee, K.C.; Mohammadi-Ivatloo, B.; Abimannan, S. Forecasting stock price by hybrid model of cascading Multivariate Adaptive Regression Splines and Deep Neural Network. Comput. Electr. Eng. 2021, 95, 107405. [Google Scholar] [CrossRef]
- Gite, S.; Khatavkar, H.; Kotecha, K.; Srivastava, S.; Maheshwari, P.; Pandey, N. Explainable stock prices prediction from financial news articles using sentiment analysis. PeerJ Comput. Sci. 2021, 7, e340. [Google Scholar] [CrossRef]
- Patel, J.; Shah, S.; Thakkar, P.; Kotecha, K. Predicting stock market index using fusion of machine learning techniques. Expert Syst. Appl. 2015, 42, 2162–2172. [Google Scholar] [CrossRef]
- Patel, J.; Shah, S.; Thakkar, P.; Kotecha, K. Predicting stock and stock price index movement using Trend Deterministic Data Preparation and machine learning techniques. Expert Syst. Appl. 2015, 42, 259–268. [Google Scholar] [CrossRef]
- Derakhshan, A.; Beigy, H. Sentiment analysis on stock social media for stock price movement prediction. Eng. Appl. Artif. Intell. 2019, 85, 569–578. [Google Scholar] [CrossRef]
- Pai, P.-F.; Liu, C.-H. Predicting Vehicle Sales by Sentiment Analysis of Twitter Data and Stock Market Values. IEEE Access 2018, 6, 57655–57662. [Google Scholar] [CrossRef]
- Panday, H.; Vijayarajan, V.; Mahendran, A.; Krishnamoorthy, A.; Prasath, V. Stock Prediction using Sentiment analysis and Long Short Term Memory. Eur. J. Mol. Clin. Med. 2020, 7, 5060–5069. [Google Scholar]
- Shi, Y.; Zheng, Y.; Guo, K.; Ren, X. Stock movement prediction with sentiment analysis based on deep learning networks. Concurr. Comput. Pr. Exp. 2020, 33, e6076. [Google Scholar] [CrossRef]
- Kelotra, A.; Pandey, P. Stock market prediction using optimized deep-convlstm model. Big Data 2020, 8, 5–24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bouktif, S.; Fiaz, A.; Awad, M. Augmented Textual Features-Based Stock Market Prediction. IEEE Access 2020, 8, 40269–40282. [Google Scholar] [CrossRef]
- Ren, R.; Wu, D.D.; Liu, T. Forecasting Stock Market Movement Direction Using Sentiment Analysis and Support Vector Machine. IEEE Syst. J. 2018, 13, 760–770. [Google Scholar] [CrossRef]
- Deveikyte, J.; Geman, H.; Piccari, C.; Provetti, A. A sentiment analysis approach to the prediction of market volatility. arXiv 2020, arXiv:2012.05906. [Google Scholar]
- Mudinas, A.; Zhang, D.; Levene, M. Market trend prediction using sentiment analysis: Lessons learned and paths forward. arXiv 2019, arXiv:1903.05440. [Google Scholar]
- Pimprikar, R.; Ramachadran, S.; Senthilkumar, K. Use of machine learning algorithms and twitter sentiment analysis for stock market prediction. Int. J. Pure Appl. Math. 2017, 115, 521–526. [Google Scholar]
- Kilimci, Z.H. Financial sentiment analysis with Deep Ensemble Models (DEMs) for stock market prediction. J. Fac. Eng. Archit. Gazi Univ. 2020, 35, 635–650. [Google Scholar]
- AlKubaisi, G.A.A.; Kamaruddin, S.S.; Husni, H. Stock Market Classification Model Using Sentiment Analysis on Twitter Based on Hybrid Naive Bayes Classifiers. Comput. Inf. Sci. 2017, 11, 52–64. [Google Scholar] [CrossRef] [Green Version]
- Al-mashhadani, M.I.; Hussein, K.M.; Khudir, E.T. Sentiment analysis using optimized feature sets in different facebook/twitter dataset domains using big data. Iraqi J. Comput. Sci. Math. 2022, 3, 64–70. [Google Scholar] [CrossRef]
- Zhang, G.; Xu, L.; Xue, Y. Model and forecast stock market behavior integrating investor sentiment analysis and transaction data. Clust. Comput. 2017, 20, 789–803. [Google Scholar] [CrossRef]
- Xu, Q.; Chang, V.; Hsu, C.-H. Event Study and Principal Component Analysis Based on Sentiment Analysis—A Combined Methodology to Study the Stock Market with an Empirical Study. Inf. Syst. Front. 2020, 22, 1021–1037. [Google Scholar] [CrossRef]
- Wu, J.-L.; Huang, M.-T.; Yang, C.-S.; Liu, K.-H. Sentiment analysis of stock markets using a novel dimensional valence–arousal approach. Soft Comput. 2021, 25, 4433–4450. [Google Scholar] [CrossRef]
- Qian, F.; Gong, C.; Sharma, K.; Liu, Y. Neural User Response Generator: Fake News Detection with Collective User Intelligence. IJCAI 2018, 18, 3834–3840. [Google Scholar]
- Munk, M.; Pilkova, A.; Benko, L.; Blazekova, P.; Svec, P. Web usage analysis of Pillar 3 disclosed information by deposit customers in turbulent times. Expert Syst. Appl. 2021, 185, 115503. [Google Scholar] [CrossRef]
- Khan, W.; Malik, U.; Ghazanfar, M.A.; Azam, M.A.; Alyoubi, K.H.; Alfakeeh, A.S. Predicting stock market trends using machine learning algorithms via public sentiment and political situation analysis. Soft Comput. 2020, 24, 11019–11043. [Google Scholar] [CrossRef]
- Agrawal, A.; Hamling, T. Sentiment Analysis of Tweets to Gain Insights into the 2016 US Election. Columbia Undergrad. Sci. J. 2021, 11. [Google Scholar] [CrossRef]
- Ding, X.; Liu, B.; Yu, P.S. A holistic lexicon-based approach to opinion mining. In Proceedings of the 2008 International Conference on Web Search and Data Mining, Palo Alto, CA, USA, 11–12 February 2008; pp. 231–240. [Google Scholar]
- Singh, T.; Nayyar, A.; Solanki, A. Multilingual opinion mining movie recommendation system using RNN. In Proceedings of First International Conference on Computing, Communications, and Cyber-Security (IC4S 2019); Springer: Singapore, 2020; pp. 589–605. [Google Scholar]
- Cambria, E.; Speer, R.; Havasi, C.; Hussain, A. Senticnet: A publicly available semantic resource for opinion mining. In Commonsense Knowledge: Papers from the AAAI Fall Symposium; AAAI Press: Menlo Park, CA, USA, 2010. [Google Scholar]
- Aung, K.Z.; Myo, N.N. Sentiment analysis of students’ comment using lexicon based approach. In Proceedings of the 2017 IEEE/ACIS 16th International Conference on Computer and Information Science (ICIS), Wuhan, China, 24–26 May 2017; pp. 149–154. [Google Scholar]
- Taboada, M.; Brooke, J.; Tofiloski, M.; Voll, K.; Stede, M. Lexicon-based methods for sentiment analysis. Comput. Linguist. 2011, 37, 267–307. [Google Scholar] [CrossRef]
- de Smedt, T.; Daelemans, W. “Vreselijk mooi!” (terribly beautiful): A Subjectivity Lexicon for Dutch Adjectives. In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC’12); European Language Resources Association (ELRA): Luxembourg, 2012; pp. 3568–3572. [Google Scholar]
- Bravo-Marquez, F.; Frank, E.; Pfahringer, B. Building a Twitter opinion lexicon from automatically-annotated tweets. Knowledge-Based Syst. 2016, 108, 65–78. [Google Scholar] [CrossRef] [Green Version]
- Rao, D.; Ravichandran, D. Semi-supervised polarity lexicon induction. In Proceedings of the 12th Conference of the European Chapter of the ACL (EACL 2009), Athens, Greece, 30 March–3 April 2009; pp. 675–682. [Google Scholar]
- de Albornoz, J.C.; Plaza, L.; Gervás, P. SentiSense: An easily scalable concept-based affective lexicon for sentiment analysis. In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC’12); European Language Resources Association (ELRA): Luxembourg, 2012; pp. 3562–3567. [Google Scholar]
- Cerini, S.; Compagnoni, V.; Demontis, A.; Formentelli, M.; Gandini, C. Micro-WNOp. Language Resources and Linguistic Theory; Franco Angeli: Milan, Italy, 2007; p. 200. [Google Scholar]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Strapparava, C.; Valitutti, A. Wordnet affect: An affective extension of wordnet. In Proceedings of the Fourth International Conference on Language Resources and Evaluation (LREC’04); European Language Resources Association (ELRA): Luxembourg, 2004; Volume 4, p. 40. [Google Scholar]
- Esuli, A.; Sebastiani, F. Sentiwordnet: A publicly available lexical resource for opinion mining. In Proceedings of the Fifth International Conference on Language Resources and Evaluation (LREC’06); European Language Resources Association (ELRA): Luxembourg, 2006. [Google Scholar]
- Schuster, M.; Nakajima, K. Japanese and korean voice search. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 5149–5152. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural machine translation of rare words with subword units. arXiv 2015, arXiv:1508.07909. [Google Scholar]
- Lewis, D.D.; Ringuette, M. A comparison of two learning algorithms for text categorization. In Third Annual Symposium on Document Analysis and Information Retrieval; University of Nevada: Reno, NV, USA, 1994; Volume 33, pp. 81–93. [Google Scholar]
- Ding, S.; Zhao, H.; Zhang, Y.; Xu, X.; Nie, R. Extreme learning machine: Algorithm, theory and applications. Artif. Intell. Rev. 2015, 44, 103–115. [Google Scholar] [CrossRef]
- Bodapati, S.; Bandarupally, H.; Shaw, R.N.; Ghosh, A. Comparison and analysis of RNN-LSTMs and CNNs for social reviews classification. In Advances in Applications of Data-Driven Computing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 49–59. [Google Scholar]
- Wei, D.; Wang, B.; Lin, G.; Liu, D.; Dong, Z.; Liu, H.; Liu, Y. Research on Unstructured Text Data Mining and Fault Classification Based on RNN-LSTM with Malfunction Inspection Report. Energies 2017, 10, 406. [Google Scholar] [CrossRef] [Green Version]
- Williams, G.; Baxter, R.; He, H.; Hawkins, S.; Gu, L. A comparative study of RNN for outlier detection in data mining. In Proceedings of the 2002 IEEE International Conference on Data Mining, Maebashi City, Japan, 9–12 December 2002; pp. 709–712. [Google Scholar]
- Khan, F.H.; Qamar, U.; Bashir, S. A semi-supervised approach to sentiment analysis using revised sentiment strength based on SentiWordNet. Knowl. Inf. Syst. 2017, 51, 851–872. [Google Scholar] [CrossRef]
- Zhao, H.; Sun, M.; Deng, W.; Yang, X. A New Feature Extraction Method Based on EEMD and Multi-Scale Fuzzy Entropy for Motor Bearing. Entropy 2016, 19, 14. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, T.H.; Shirai, K.; Velcin, J. Sentiment analysis on social media for stock movement prediction. Expert Syst. Appl. 2015, 42, 9603–9611. [Google Scholar] [CrossRef]
- Bing, L.; Chan, K.C.; Ou, C. Public sentiment analysis in Twitter data for prediction of a company’s stock price movements. In Proceedings of the 2014 IEEE 11th International Conference on e-Business Engineering, Guangzhou, China, 5–7 November 2014; pp. 232–239. [Google Scholar]
- Nti, I.K.; Adekoya, A.F.; Weyori, B.A. Predicting Stock Market Price Movement Using Sentiment Analysis: Evidence From Ghana. Appl. Comput. Syst. 2020, 25, 33–42. [Google Scholar] [CrossRef]
- Khan, W.; Ghazanfar, M.A.; Azam, M.A.; Karami, A.; Alyoubi, K.H.; Alfakeeh, A.S. Stock market prediction using machine learning classifiers and social media, news. J. Ambient Intell. Humaniz. Comput. 2020, 13, 3433–3456. [Google Scholar] [CrossRef]
- Kordonis, J.; Symeonidis, S.; Arampatzis, A. Stock price forecasting via sentiment analysis on Twitter. In Proceedings of the 20th Pan-Hellenic Conference on Informatics, Patras, Greece, 10–12 November 2016; pp. 1–6. [Google Scholar]
- Jing, N.; Wu, Z.; Wang, H. A hybrid model integrating deep learning with investor sentiment analysis for stock price prediction. Expert Syst. Appl. 2021, 178, 115019. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resource | Total Features | Score Range | POS | ||
|---|---|---|---|---|---|
| Synsets | Words | Min | Max | ||
| SenticNet [31] | 15,143 | N/A | −1 | 1 | ✕ |
| AFINN [32] | 2477 | N/A | −5 | 5 | ✕ |
| SO-CAL [33] | 6306 | N/A | −5 | 5 | ✕ |
| Subjectivity Lexicon [34] | 8221 | N/A | N/A | N/A | ✕ |
| Opinion Lexicon [35] | 6786 | N/A | N/A | N/A | ✕ |
| General Inquirer [36] | 11,789 | N/A | N/A | N/A | ✕ |
| SentiSense [37] | 2190 | 5496 | N/A | N/A | ✔ |
| Micro-WNOp [38] | 1105 | 1960 | 0 | 1 | ✔ |
| WordNet [39] | 117,659 | 155,287 | N/A | N/A | ✔ |
| WordNet-Affect [40] | 2874 | 4787 | N/A | N/A | ✔ |
| SentiWordNet [41] | 117,659 | 155,287 | 0 | 1 | ✔ |
| POS | ID | Pos Score | Neg Score | Synset Terms |
|---|---|---|---|---|
| a | 2098 | 0 | 0.75 | unable#1 |
| n | 37006 | 0.625 | 0 | masterpiece#2 |
| r | 5453 | 0.375 | 0 | unabashedly#1 |
| v | 18813 | 0.375 | 0 | waken#1 wake_up#1 wake#5 rouse#4 awaken#1 arouse#5 |
| Presence of a Term t | Absence of a Term t | |
|---|---|---|
| Prescence of a class c | A | C |
| Absence of a class c | B | D |
| POS | ID | Pos | Neg | Synset Terms |
|---|---|---|---|---|
| A | 2772347 | 0.125 | 0.625 | volatility#4 |
| N | 2772317 | 0.375 | 0.125 | blue_chip_stocks#1 blue_chip_stock#1 |
| V | 2772344 | 0.125 | 0.625 | short_selling#2 short_sale#2 short_sell#2 |
| A | 2772348 | 0.375 | 0.125 | volume#7 |
| N | 2772336 | 0 | 0 | open#1 |
| V | 2772314 | 0.125 | 0 | average_down#1 |
| 2772453 | 0.425 | 0.125 | bull#1 | |
| bullish# | ||||
| A | 2772494 | 0.125 | 0.625 | bear#1 |
| bearish#2 | ||||
| N | 2772458 | 0.625 | 0.125 | Breakout |
| N | 2772455 | 0.125 | 0 | Cap |
| N | 2772457 | 0.125 | 0.125 | Floor |
| A | 2772501 | 0.425 | 0.785 | greed#1 |
| greedy#2 | ||||
| A | 2772450 | 0.125 | 0.625 | Fear |
| A | 2772660 | P | Gain | |
| A | 2772561 | 0 | 0.625 | Loss |
| A | 2772462 | 0.125 | 0.625 | late_entry#1 |
| later_entry#2 | ||||
| A | 2772470 | 0.425 | 0.125 | early_entry |
| N | 2772468 | 0.625 | 0.125 | morning_star |
| N | 2772465 | 0.125 | 0.625 | evening_star |
| N | 2772483 | 0.125 | 0.375 | raising_index_rate |
| N | 2772481 | 0.375 | 0.125 | falling_index_rate |
| A | 2772463 | 0.625 | 0 | green#1 |
| green_chips#2 | ||||
| A | 2772610 | 0.625 | 0.125 | blue#1 |
| blue_chips#2 | ||||
| A | 2772623 | 0 | 0.425 | red#1 |
| red_chips#2 | ||||
| A | 2772612 | 0.425 | 0.125 | low_risk |
| A | 2772503 | 0.125 | 0.625 | high_risk |
| V | 2772473 | 0.125 | 0.625 | buyer_exhaust |
| V | 2772474 | 0.425 | 0 | seller_exhaust |
| Column | Description |
|---|---|
| target | Tweet polarity (negative = 0, neutral = 2, and positive = 4) |
| ids | Tweet IDs (e.g., 2088) |
| date | The time the tweet was published. (e.g., Sun May 17 22:57:44 UTC 2008) |
| flag | The query. NO_QUERY flag means there is no query. |
| user | ID of the user who posted this tweet. (e.g., the TwitterFellow) |
| text | Body of the tweet. (e.g., The shares of #AAPL have been stable for a week). |
| Stock Market | Symbol | Number of Tweets (Before Preprocessing) | Number of Tweets (After Preprocessing) | |||||
|---|---|---|---|---|---|---|---|---|
| Positive | Negative | Neutral | Total | Positive | Negative | Total | ||
| Apple | APPL | 14,400 | 10,500 | 5940 | 30,840 | 12,384 | 9135 | 21,519 |
| Tesla | TSLA | 40,050 | 31,290 | 80,916 | 152,256 | 33,642 | 27,222 | 60,864 |
| Microsoft | MSFT | 26,100 | 20,730 | 21,963 | 68,793 | 22,446 | 17,828 | 40,274 |
| Walmart | WMT | 13,200 | 11,400 | 17,222 | 41,822 | 11,220 | 9918 | 21,138 |
| PayPal | PYPL | 10,500 | 5670 | 30,182 | 46,352 | 9030 | 4820 | 13,850 |
| Nvidia | NVDA | 6150 | 4800 | 31,140 | 42,090 | 5351 | 3984 | 9335 |
| Intel | INTC | 3900 | 3360 | 31,750 | 39,010 | 3315 | 2789 | 6104 |
| FB | 15,150 | 10,500 | 28,912 | 54,562 | 13,181 | 8820 | 22,001 | |
| TWTR | 10,650 | 10,350 | 28,170 | 49,170 | 9053 | 9005 | 18,057 | |
| Amazon | AMZN | 6630 | 6300 | 23,247 | 36,177 | 5636 | 5418 | 11,054 |
| GrandTotal | 146,730 | 114,900 | 299,442 | 561,072 | 125,256 | 98,938 | 224,194 | |
| No. | Algorithm | Abbreviation | Optimal Parameter Set |
|---|---|---|---|
| 1 | Naive Bayes | NB | N/A |
| 2 | Generalized Linear Model | GLM | kernel = rbf, C: 0.6 |
| 3 | Fast Large Margin | FLM | Solver = L2, C = 0.5, epsilon = 0.25, class_weights = 1, use_bias = false |
| 4 | Decision Tree | DT | criterion:’entropy’, splitter = ’best’, max_depth = 8, min_samples_split = 2, min_samples_leaf = 1, min_weight_fraction_leaf = 0.5, presort = ’true’ |
| 5 | Random Forest | RF | n_jobs = −1, min_samples_leaf: 2, n_estimators: 25, random_state: 125, criterion: gini, min_samples_split: 4 |
| 6 | Gradient Boosted Trees | GBT | min_samples_split = 2500, min_samples_leaf = 50, max_depth = 8, max_features = ‘sqrt’, subsample = 0.8, random_state = 8 |
| 7 | Support Vector Machine | SVM | kernel = ‘rbf’, C = 10, gamma = auto, |
| 8 | Extreme Learning Machine | ELM | hidden_layers = 20, weights = [−1, 1], activation_function = ’sigmoid’ |
| 9 | Recurrent Neural Network | RNN | init = ‘glorot_uniform’, inner_init = ‘orthogonal’, activation = ‘tanh’, w_regularizer = none, u_regularizer = none, b_regularizer = none, dropout_w = 0.1, dropout_u = 0.02 |
| Model | Accuracy | Precision | Recall | F-Measure |
|---|---|---|---|---|
| NB | 0.82 | 0.65 | 0.75 | 0.66 |
| GLM | 0.64 | 0.53 | 0.71 | 0.60 |
| FLM | 0.61 | 0.59 | 0.95 | 0.50 |
| DT | 0.71 | 0.75 | 0.66 | 0.53 |
| RF | 0.69 | 0.79 | 0.30 | 0.10 |
| GBT | 0.71 | 0.69 | 0.20 | 0.27 |
| SVM | 0.61 | 0.68 | 0.20 | 0.29 |
| ELM | 0.81 | 0.80 | 0.77 | 0.82 |
| RNN | 0.86 | 0.86 | 0.81 | 0.85 |
| Model | Accuracy | Precision | Recall | F-Measure |
|---|---|---|---|---|
| NB | 0.81 | 0.67 | 0.72 | 0.64 |
| GLM | 0.67 | 0.56 | 0.75 | 0.63 |
| FLM | 0.64 | 0.62 | 0.79 | 0.53 |
| DT | 0.69 | 0.71 | 0.69 | 0.57 |
| RF | 0.72 | 0.83 | 0.32 | 0.11 |
| GBT | 0.75 | 0.72 | 0.21 | 0.28 |
| SVM | 0.64 | 0.71 | 0.21 | 0.31 |
| ELM | 0.85 | 0.84 | 0.81 | 0.86 |
| RNN | 0.89 | 0.90 | 0.85 | 0.89 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Albahli, S.; Irtaza, A.; Nazir, T.; Mehmood, A.; Alkhalifah, A.; Albattah, W. A Machine Learning Method for Prediction of Stock Market Using Real-Time Twitter Data. Electronics 2022, 11, 3414. https://doi.org/10.3390/electronics11203414
Albahli S, Irtaza A, Nazir T, Mehmood A, Alkhalifah A, Albattah W. A Machine Learning Method for Prediction of Stock Market Using Real-Time Twitter Data. Electronics. 2022; 11(20):3414. https://doi.org/10.3390/electronics11203414
Chicago/Turabian StyleAlbahli, Saleh, Aun Irtaza, Tahira Nazir, Awais Mehmood, Ali Alkhalifah, and Waleed Albattah. 2022. "A Machine Learning Method for Prediction of Stock Market Using Real-Time Twitter Data" Electronics 11, no. 20: 3414. https://doi.org/10.3390/electronics11203414