1. Introduction
Customer retention is a problem that many organizations have to deal with, in the context of which dropout prediction provides insights to identify customers that could churn. Dropout represents the decision of a customer to end their relationship with an organization [
1], which creates two outcomes: Dropout or non-dropout. The case where dropout is developed has two main scenarios [
2,
3]: (1) Contractual settings, where customers pay a monthly fee and the customer informs the end of the relationship; and (2) non-contractual settings, where the organization has to extrapolate whether the customer is still active or not. In the contractual setting, the customer must choose whether they will dropout or not; for example, if they renew a contract or not [
4]. This means that, in contractual settings, the customer dropout represents an explicit ending of a relationship that is more penalizing than that in non-contractual settings [
5], which has implications for the profitability of organizations, increasing marketing costs and reducing sales [
6].
The advantages of developing retention strategies have been supported in the concept that the costs of customer retention are lower than those associated with customer acquisition [
7,
8], where a reduction of dropout by 5% could realize almost a duplication of profits [
9]. To address this problem, the use of the customer databases could be explored, which is considered the most valuable asset that most organizations possess [
10]. The development of a customer retention strategy could be supported through the identification of customers may dropout [
11]; for example, using churn prediction models to detect customers with high propensity to dropout [
12].
The anticipation of the dropout allows for the development of countermeasures to reduce customer churn. Several studies have addressed the problem related to customer retention in trying to improve the profitability [
13,
14,
15]; in particular, organizations have been addressing this problem by shifting their target from capturing new customers to preserving existing ones [
14], considering that investments in retention strategies are more profitable than acquiring new customers [
13].
Machine learning allows for the extraction of patterns from data, learning from a model using a set of descriptive features and a target feature based on a set of historical examples [
16]. The approaches normally employed address the problem by use of a dependent variable representing dropout or non-dropout, without considering the dynamic perspective that the dropout risk changes over time [
11]. A static perspective determines the dropout risk at a specific moment in time, but does not consider changes over time. Survival models have been proposed in an attempt to resolve this limitation [
17], capturing the temporal dimension of customer dropout to predict when the dropout will occur, as well as the use of censured data, which allows for consideration of existing information about customers that have not churned yet [
18].
There are several challenges related to the timing of the dropout, such as considering the behavior of the customer as static and not considering the dynamic behavior of the customer, in terms of the intent to dropout [
11]. The importance of understanding when dropout will occur and the risk related to the temporal perspective of the problem seems to be an element that should be addressed. However, few studies have considered this aspect [
18,
19,
20,
21]. Van den Poel and Larivière [
20] have used a Cox proportional hazards model to investigate customer attrition in an European financial services company. Baesens et al. [
21] have explored the use of a neural network-based survival model to anticipate the timing when customers will default or pay off loans early. Burez and Vandenpoel [
19] have proposed two different processes to predict customer dropout, instead of using only one, including commercial and financial churn, and suggested that financial churn (customer stops paying the invoices) is easier to predict than commercial churn (customers not renewing their subscription). Perianez et al. [
18] have investigated the use of survival trees and forests to improve prediction accuracy compared to traditional methods, such Cox regression, in mobile social game subscriptions.
Survival analysis, which originates from biomedical statistics, is especially well-suited to studying the timing of events in longitudinal data [
22]. Survival analysis consists of a class of statistical methods modelling the occurrence and timing of an event, such as the customer dropout. Survival analysis allows us to examine not only if an event occurred, but also how long it took to occur. The primary value of survival analysis in our context, however, is comparing the dropout probability for individuals classified through theoretically relevant variables. The survival methods have enjoyed increasing popularity in several disciplines, ranging from medicine to economics [
22].
Random Survival Forests do not make the proportional hazards assumption [
23], and have the flexibility to model survival curves of dissimilar shapes for contrasting groups of subjects. Random Survival Forest is an extension of Random Forest, allowing for efficient non-parametric analysis of time–event data [
24]. These characteristics allow us to surpass the Cox Regression limitation of the proportional hazard assumption, which requires us to exclude variables that do not fulfill the model assumptions. It has also been shown, by Breiman [
24], that ensemble learning can be further improved by injecting randomization into the base learning process (i.e., the use of Random Forests).
Previous researchers have also proposed the integration of several algorithms to improve the performance in the prediction of dropout, such as the use of clustering methods combined with churn prediction [
25,
26,
27], where the customers are grouped on clusters to improve the prediction performance within each cluster. Clustering methods use unsupervised algorithms to group elements with similar characteristics. Such unsupervised methods have been widely used, employing approaches such Hierarchical Clustering [
28],
k-Means [
27], or Random Forest Clustering [
24]. Vijaya and Sivasankar [
27], following this concept, have suggested the adoption of hybrid models combining more than one classier, in order to increase the performance, compared to the use of single classifiers. Jafari-Marandi et al. [
29] have also explored an approach combining clustering methods in parallel with a classification approach.
Although there have been several studies addressing whether a given customer will dropout or not, there is a lack of research regarding the prediction of when customer will dropout. To address this lack of research, survival analysis can be utilized, which allows for prediction of when the customer will dropout, providing an opportunity to explore the duration of the relation of the customer with the organization and its influence on the churn prediction. Additionally, we assess whether survival analysis combined with the clustering could improve the prediction performance.
In this study, we investigate whether a hybrid approach using clustering and random survival forests, which have never been used to predict membership based on data, can improve the prediction performance compared to a random survival model without the use of clusters. The performance is evaluated by comparing the average discrepancies in the customer status (dropout/non-dropout) in both approaches.
The remainder of this paper is organized as follows: In the next sections, we detail survival analysis, and survival trees. Next, we describe our research methodology. The
Section 7 provides the outcomes, addressing our research goal, providing evaluation metrics, and comparing the performance using clusters or without clusters. Finally, the discussion and conclusion are provided.
3. Survival Analysis
Survival analysis focuses on the analysis of the time remaining until an event of interest occurs, and explores its relationships with different factors. The main advantage is related to the concept of censoring, indicating those observations that are not completely related to the event of interest (e.g., customers that have not dropped out yet), which are incorporated into the analysis. This means that there are customers that are still active, for whom we do not know whether the event of dropout has occurred; we call this censorship. Survival models take censoring into account and incorporate this uncertainty—instead of predicting the time of event such in regression models, survival models allow for prediction of probability of an event happening at a particular time.
The time of dropout is represented by T, which is a non-negative random variable, indicating the time period of the event occurring for a randomly selected individual from the population, representing the probability of an event to occurring each time period, given that it has not already occurred in a previous time period; this is known as the discrete-time hazard function [
22]. The survival function represents the probability of an individual surviving after time
t, S(
t) =
P(
T >
t),
t ≥ 0, with the properties S(0) = 1 and S(
∞) = 0. The distribution function is represented by F, defined as F(
t) =
P(
T ≤ 0), for
t ≥ 0. The function of probability density represented by
f where:
where
represents the probability of an event occurring at time
t. We represent the distribution evolution of the dropout probability with time using the hazard function, represented as:
The determination of the survival curves is based on the following elements: (1) The total value of observations removed during the time period (e.g., days, months, or years), either by dropout or by censorship; (2) observations composing the sample of the study; and (3) customers who have not yet dropped out at any given time. The survival probability until the time period
i, (
) is calculated as:
where
is the number of individuals that survived at the beginning of the period and
the number of individuals who left during the period. The survival time estimate is also made considering the month in which it is found (estimated). Cox regression allows us to test difference between survival times. The advantage of using survival analysis is that it further allows us to detect whether the risk of an event differs systematically across different people, using specific predictors. The coefficients in the Cox regression are related to the hazard, where a positive value represents a worse prognosis and, in contrast, a negative denotes a better prognosis. The advantage of survival analysis is that it allows us to include information of covariates that were censored up to the censoring event.
The Cox PH model assumes the covariates to be time-independent; for example, gender and age do not change over time when retrieved [
32]. As the Cox model requires the hazards in both groups to be proportional, researchers are often asked to “test” whether the hazards are proportional [
33]. Considering this, we explored another approach that allowed us to develop the analysis without proportional hazard assumptions; namely, survival trees.
4. Survival Trees
Survival trees are methods based on Random Forest models [
24]. A Random Survival Forest is an ensemble method for analysis of right-censored data [
34], using randomization to improve the performance. Random survival forests follow this framework [
34]:
Draw B random samples of the same size from the original data set with replacement. The samples that are not drawn are said to be out-of-bag (OOB). Grow a survival tree on each of the b = 1, …, B samples.
At each node, select a random subset of predictor variables and find the best predictor and splitting value that provide two subsets (the daughter nodes) which maximizes the difference in the objective function.
Repeat step 2 recursively on each daughter node until a stopping criterion is met.
Calculate a cumulative hazard function (CHF) for each tree and average over all CHF for the B trees to obtain the ensemble CHF.
Compute the prediction error for the ensemble CHF using only the OOB data.
In each node, a predictor
x is selected from a randomly selected predicted variables and split value
c (one unique value of
x). Each sample
i if assigned to the daughter right node if
, or the left node if
. Then, the log-rank is calculated, as follows:
where
j: Daughter node, ;
: Number of events at time in daughter node j;
: Number of elements that had the event or are in risk at time in daughter node j;
: Number of events at time , such that ;
: Number of elements that experienced an event or are at risk at , such that .
We loop every
x and
c until we find
that satisfies
for every
x and
c. The model performance is assessed using the concordance probability (C-index), and Brier Score (BS) [
35]. The feature importance is determined by calculating the difference between the true class labels and noised data [
24].
The BS is used to evaluate the predicted accuracy of the survival function at a given time
t. It represents the average square distance between the survival status and the predicted survival probability, where a value of 0 is the best possible outcome.
The model should have a Brier score below , considering that, if , , then .
5. Methodology
To achieve our research goals, to simplify the analysis, the survival probabilities are first presented as a survival curve to provide an overall perspective of dropout over time; the representation of the survival probabilities indicates the time where the events are observed [
36]. Then, the machine learning survival model was created, following the approach of Ishwaran et al. [
34] and using PySurvival [
37]. The model performance was determined according to the Brier Score (BS) and Mean Absolute Error (MAE), considering that, due to the censoring of data, standard evaluation metrics such as root mean square error are not suitable [
35] in the testing set. The model performance predicted and actual customer dropout are presented as a time-series with the performance indicators Root Mean Square Errors, Median Absolute Error and Mean Absolute Error [
37]. The training and testing sets were created using the scikit-learn package with the holdout method (85/25) [
38]. The feature importance was determined by calculating the differences between the true class label and noised data [
24].
The hybrid model was developed through the identification of an optimal number of clusters. The calculation of the optimal number of clusters was developed based on the Bayesian Information Criterion (BIC), where the model with the lowest score was selected as the best model [
39]; however, Scrucca et al. [
40] have suggested using the higher BIC score, which we followed. In addition, we used visualization to increase the interpretability of the number of clusters, which was provided using the elbow method. Next,
k-Means was used to partition the observations into the identified number of clusters.
5.1. Model Performance Evaluation
The BS measures the average discrepancy between the status (dropout/non-dropout) and the estimated probabilities at a given time. The Integrated Brier Score (IBS) was used to calculate the performance for all available times (i.e., from
to
) as:
This represents the average square distance between the survival status and the predicted survival probability, where a value of 0 is the best possible outcome.
The Mean Absolute Error (MAE) is a measure of error between observed values and predicted ones, where
and
are the predicted and the true values, respectively:
The IBS and MAE were also calculated for each cluster, in order to conduct a performance comparison against the model without clusters. Additionally, validation tests were performed to compare the accuracy of the hybrid approach against that of the random survival model without clusters. To that end, a paired Mann–Whitney was conducted to estimate whether the prediction ability was significant, with a confidence interval of 95%.
5.2. Model Operacionalization
The survival analysis was conducted using the Lifelines package [
41] (See
Appendix A for software versioning). Dropout was considered a binary value, where one represents churn and zero represents no churn. Dropout happens when a member does not make a payment.
The random survival forest was developed using the PySurvival package [
37]. PySurvival is an open-source python package for Survival Analysis modeling. The model was built with 75% of the data for training and 25% for testing.
Using the mclust package [
40], the number of clusters was calculated by choosing a varying number of components and identifying the structure of the covariance matrix, based on modelling with a multivariate normal distribution for each component constituting the data set [
42].
The hybrid approach was developed as follows:
Identify the optimal number of clusters using the mclust package of Scrucca et al. [
40].
Fit the model using the identified number of clusters.
For each element, estimate the cluster membership.
For each cluster, follow the framework proposed by Ishwaran et al. [
34] to calculate the random survival model.
6. Data Set
In this study, the data of 5209 Portuguese health club customers were analyzed (mean age = 27.88, SD = 11.80 years). The data were collected using the e@sport software (Cedis, Portugal) between 2014 and 2017. The information retrieved included: Age of the participants (in years), Sex (0, female; 1, male), non-attendance days before dropout, total amount billed, average number of visits per week, total number of visits, weekly contracted accesses, number of registration renewals, number of customer referrals, registration month, customer enrollment duration, and status (dropout/non-dropout). A dropout event is considered to occur when a customer communicates their intention to terminate the contract, or have not paid the monthly fee for 60 days.
Table 1 shows the summary statistics of the data. The average age was 27.9 ± 11.8, and the entries were 29 ± 41.2 with an inscription period of 9 ± 8.2 months.
Figure 1 shows the distribution of the dropout, considering the number of months of membership (where 0 denotes non-dropout and 1 denotes dropout).
7. Results
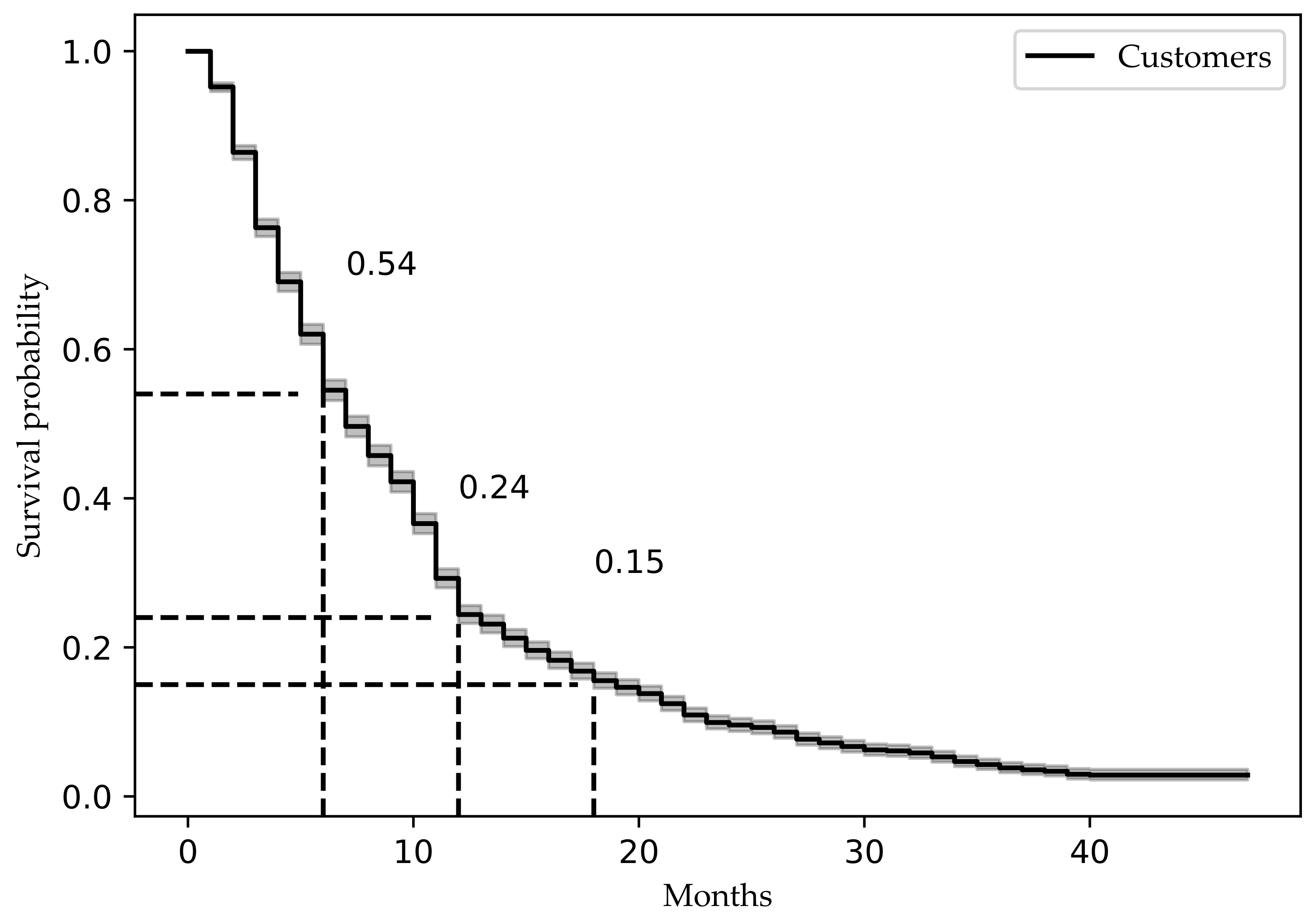
Table 2 provides the data regarding the survival time of the customers during the first couple of months. The results indicate that the customers have a survival probability of 24.44% at 12 months (column
; likelihood probability) with a median survival time of 10 months (column estimated_survival). The survival probability at 6 months was 54.5%, representing a risk of dropout of 45.5% with an estimated survival of 6 months.
Figure 2 shows the overall Kaplan–Meier survival curve, considering the number of months of membership (
x axis) against survival probability (
y axis). The customer dropout is very high in the first 12 months, ranging from a survival probability of 54% after the first 6 months to 24.44% after 12 months.
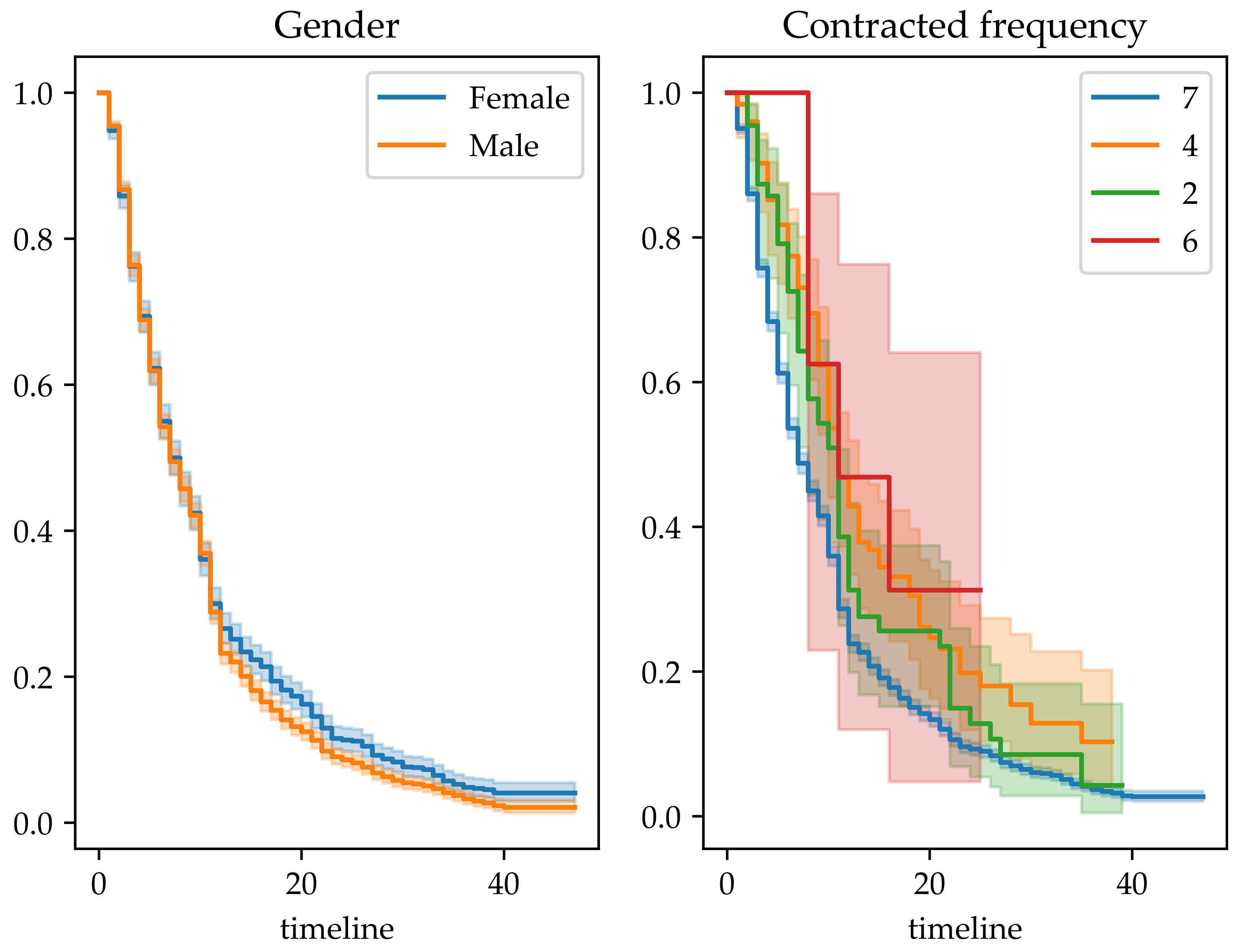
The survival considering other cohorts is represented in
Figure 3; in particular survival by gender and survival by contracted frequency. The survival by gender was very similar; however, that by contracted access frequency indicated that customers with a contracted access frequency of 6 and 4 times a week have higher survival probabilities, compared to the lower survival of customers with contracted access frequencies of 7 and 2 times a week. Survival curves can explore tendencies related to survival, in order to extract actionable knowledge, giving a perspective regarding the probability to survival within a given period of time.
The proportional hazard assumptions failed in the following variables: Age (p < 0.01), cfreq (p < 0.01), dayswfreq (p < 0.01), tbilled (p < 0.01), freeuse (p < 0.01), and nentries (p < 0.01). Therefore, it was not possible to calculate the effect of the cohorts, in terms of the survival time, using the Cox regression.
7.1. Survival Trees
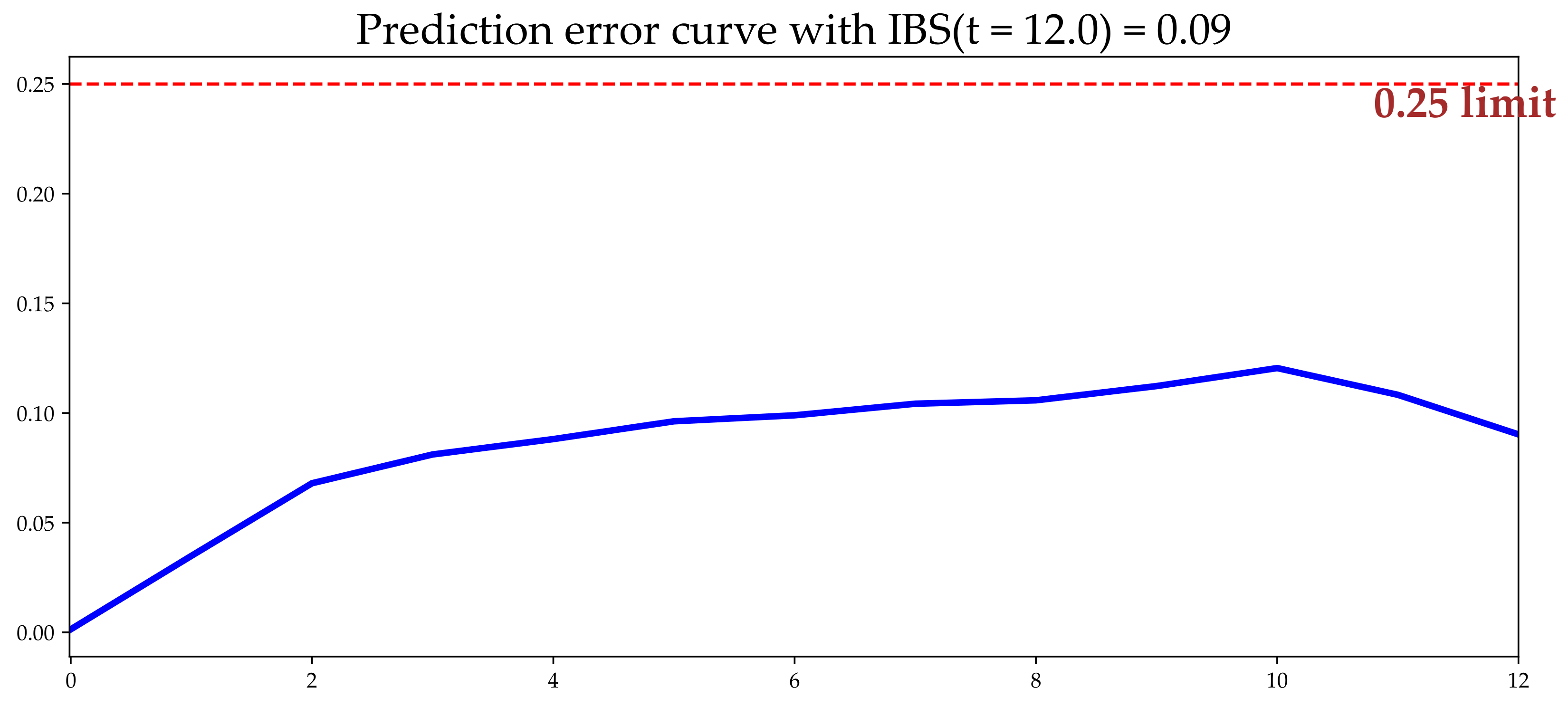
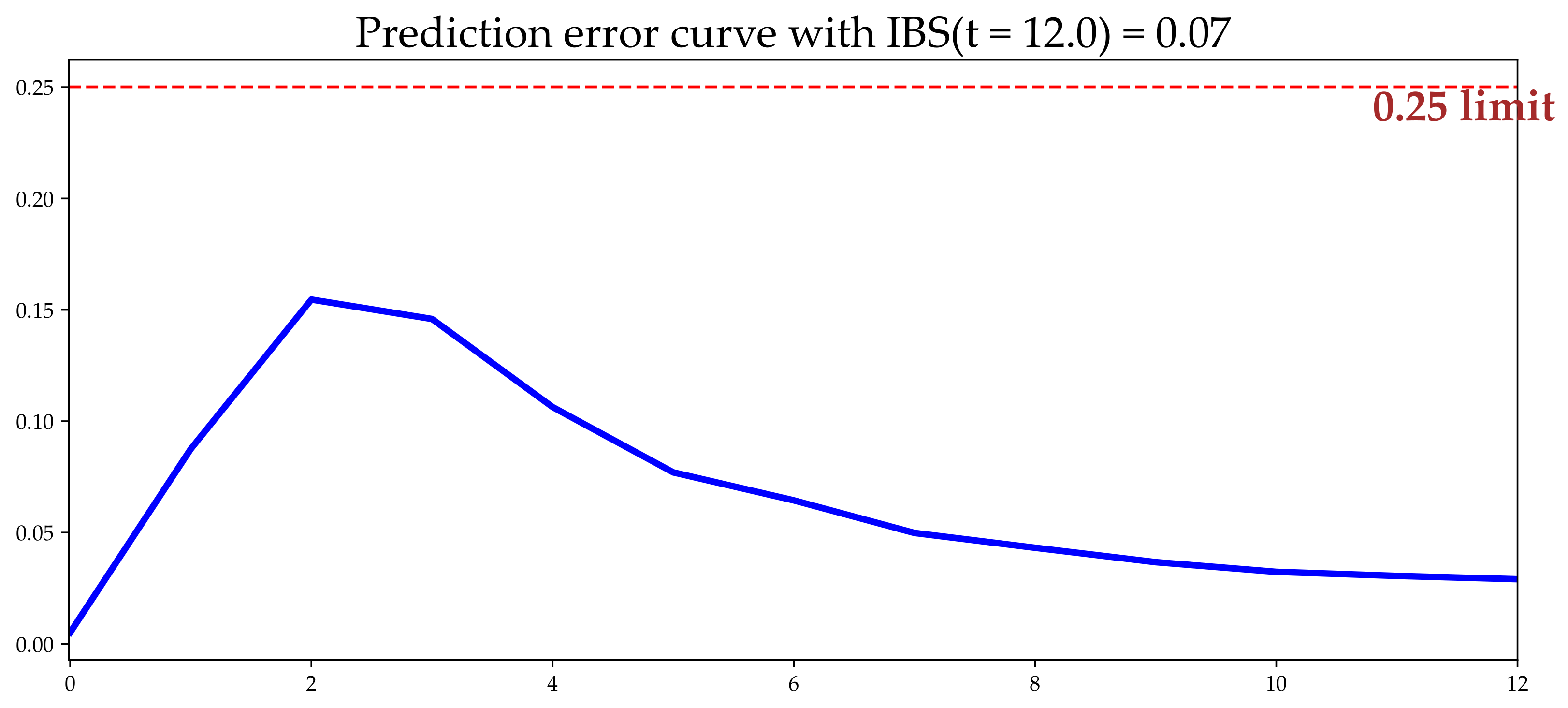
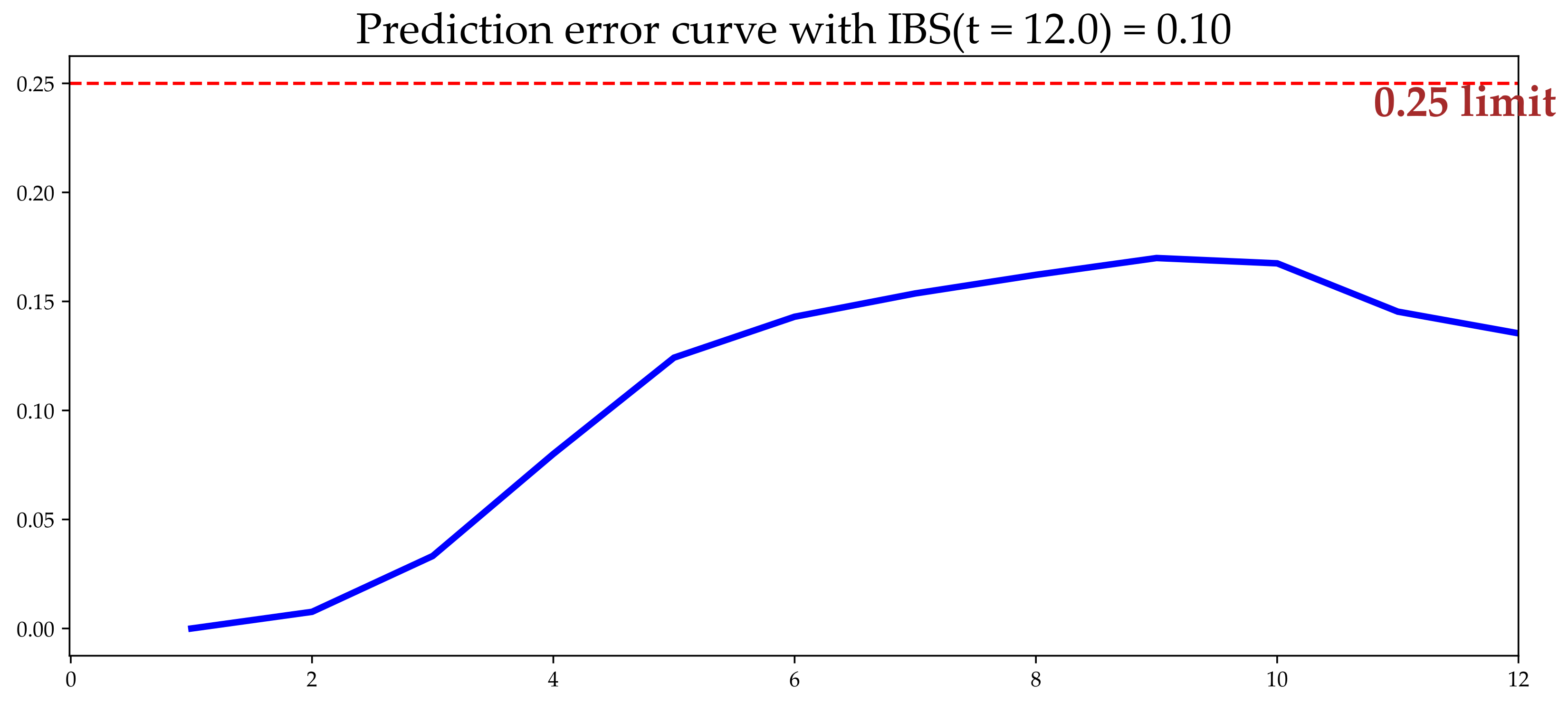
To evaluate the performance of the random survival forest in predicting the survival time, considering the effect of the cohorts, we calculated the concordance probability (C-index), IBS, and Mean Absolute Error (MAE). The IBS presented an accuracy along the 12 months of 0.08 (
Figure 4).
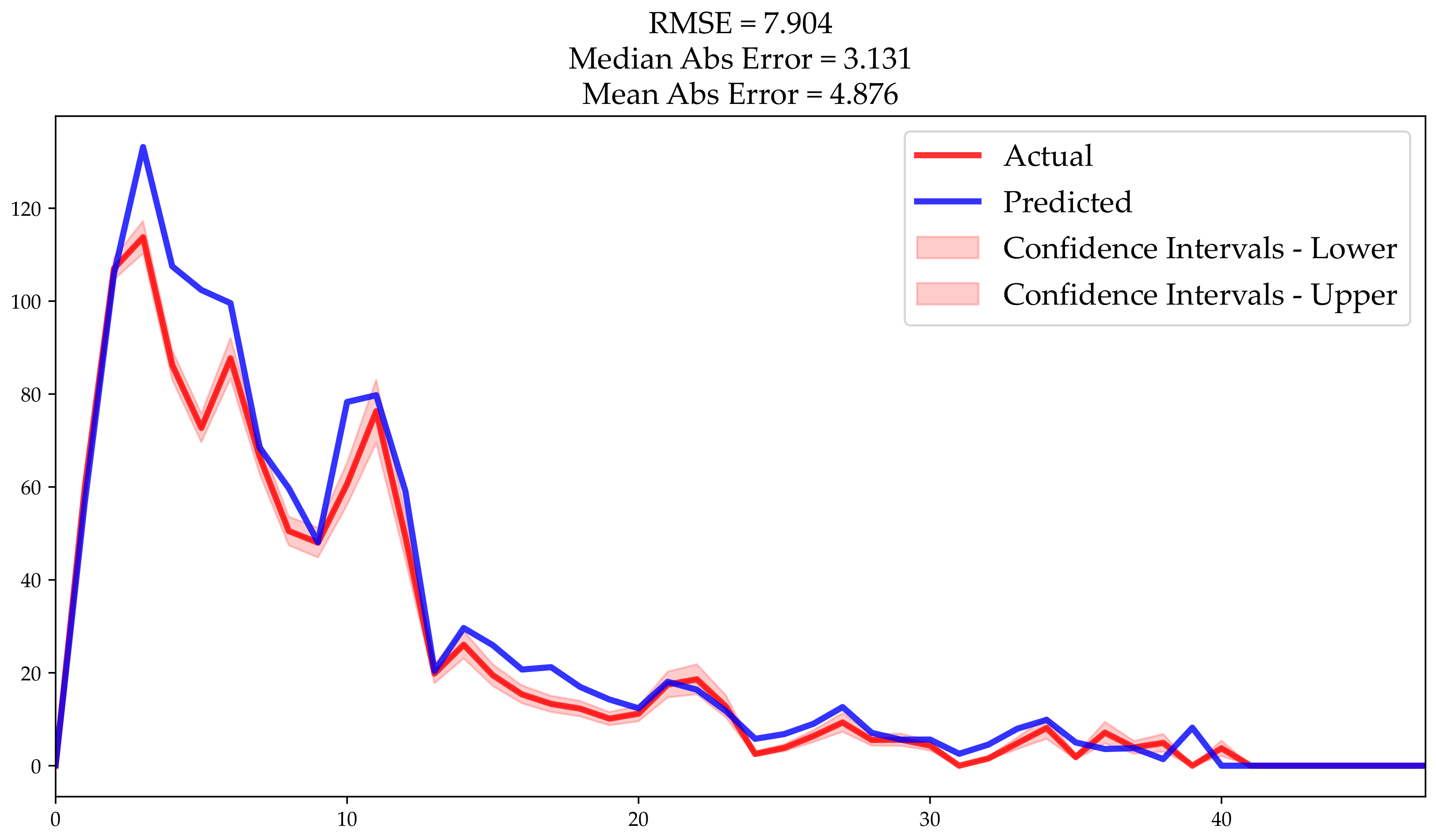
Figure 5 presents the actual and predicted customers that dropped out during the 40 months, showing an average absolute error of 7.2 customers.
Table 3 shows the feature importance, calculated according to Breiman [
24], with the percent increase in misclassification rate, as compared to the out-of-bag rate (with all variables intact). Out-of-bag is a bootstrap aggregating method (i.e., sub-sampling with replacement to create training samples for the model to learn from), where two independent sets are created. One set, the bootstrap sample (in-the-bag), is obtained by sampling with replacement from the from the original data set; meanwhile, the out-of-bag is the difference between the original data set and the bootstrap data set. The most important variable was
, followed by
and
. The least relevant features where
,
, and
.
The prediction was very similar to the actual value. The model accuracy was very high, with a root mean square error of 8. The mean absolute error mean was 4.88 customers, and the median absolute error was 3.13 customers.
7.2. Survival Tree-Based Model with Clusters
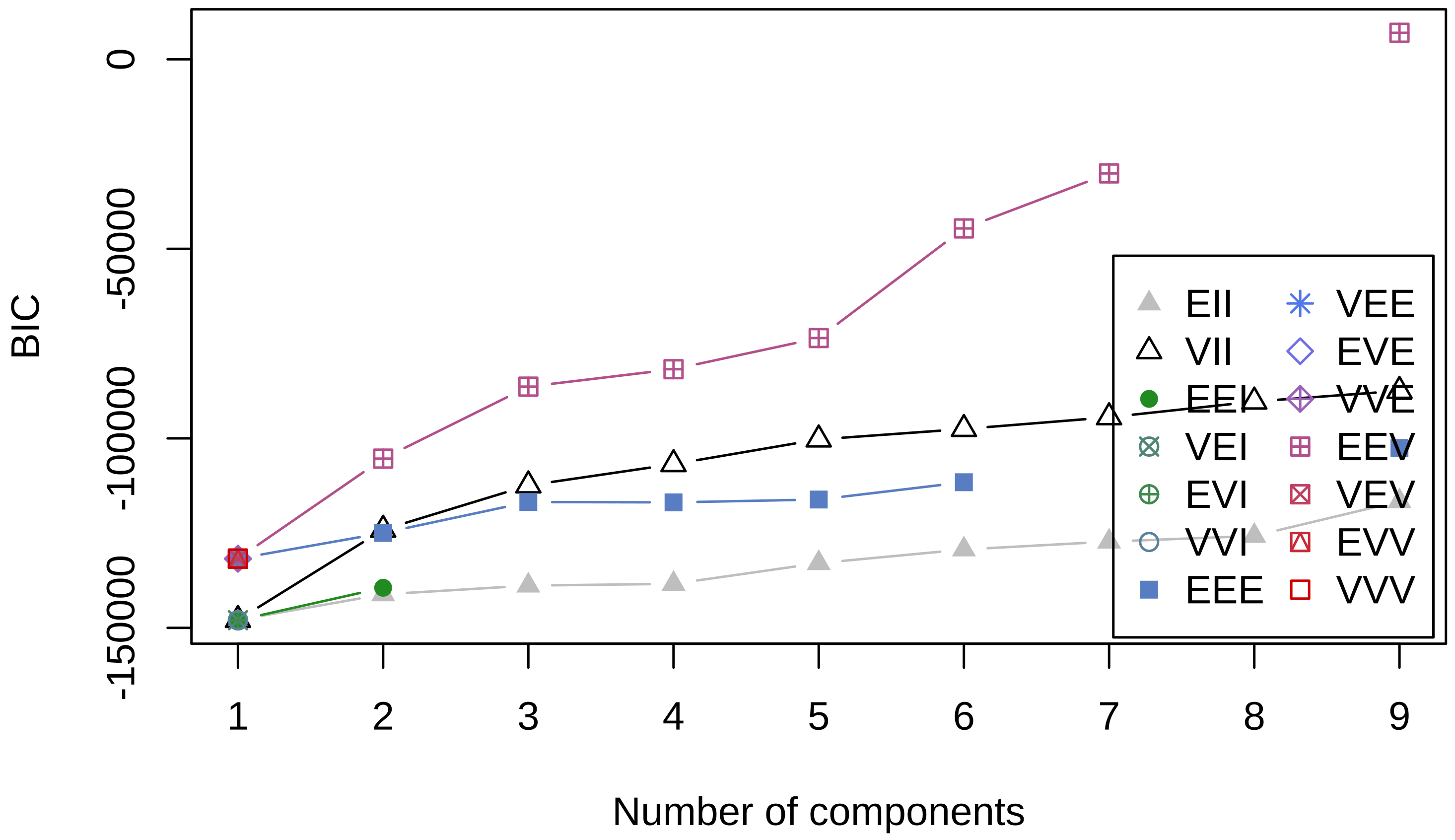
In our approach, we have created clusters and applied the survival trees within each cluster. The determination of the clusters using the BIC criterion and the EEV model was as follows: 9 clusters, 6990.94; 7 clusters, −30,105.59; and 6 clusters, −44,616.29.
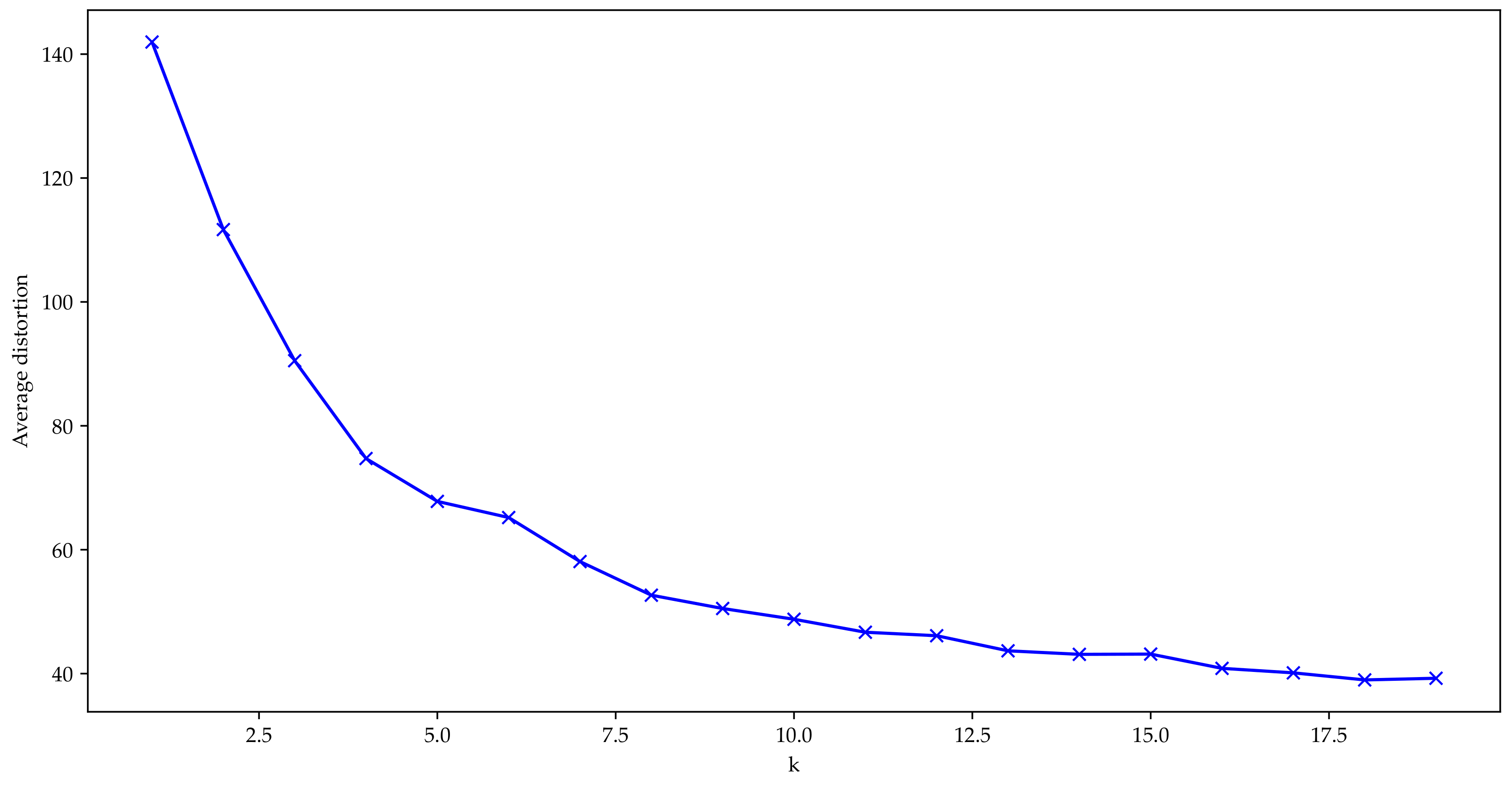
Figure 6 shows the determination of the number of clusters using the BIC. The elbow analysis, presented in
Figure 7, shows that the curve flattened after 8 clusters. Therefore, nine clusters was considered the optimal number of clusters, which was used to partition the customers. The higher prediction performance is represented in the three bigger clusters, considering the number of elements cluster 0 (
n = 1955), cluster 4 (
n = 729), and cluster 8 (
n = 1020).
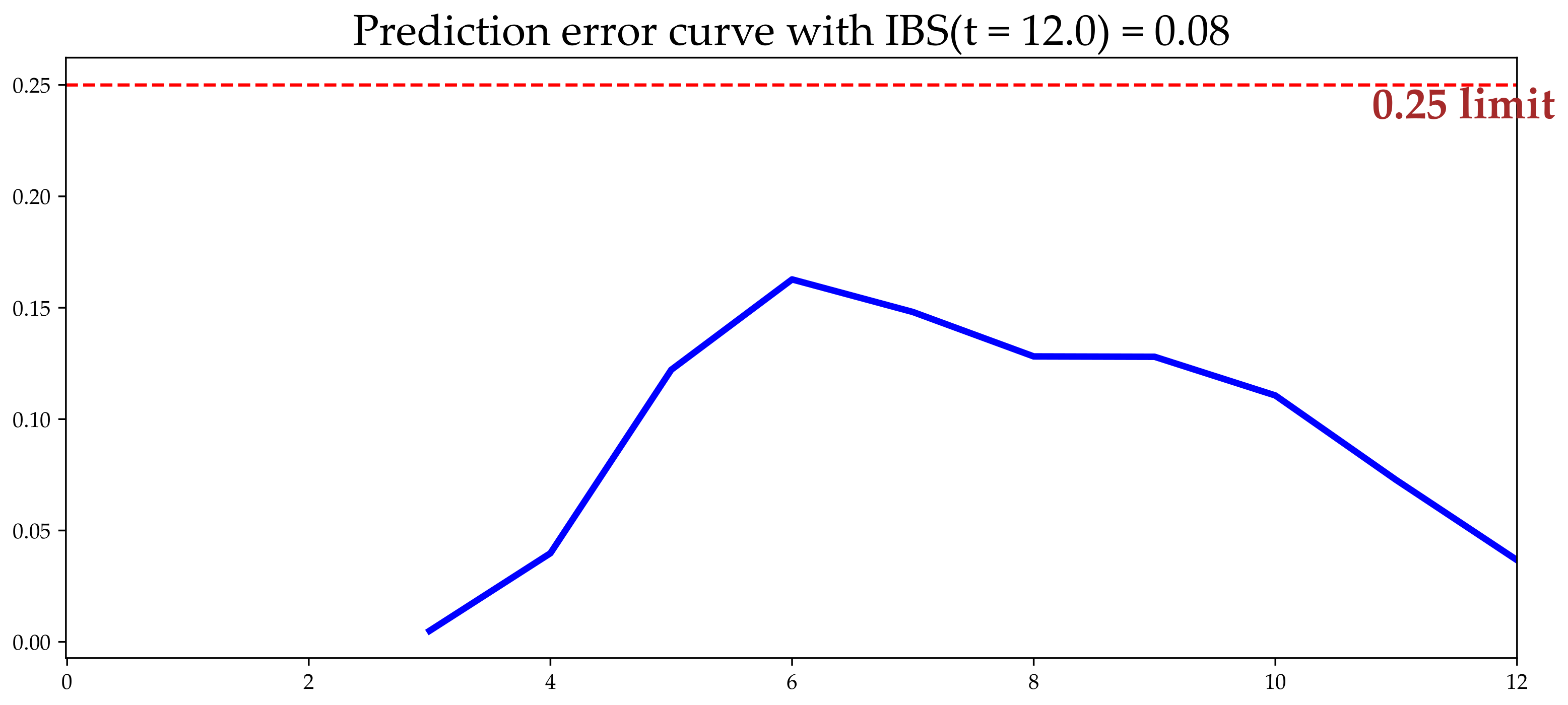
The prediction performance analysis (IBS score) in clusters 0, 4, and 9, yielded accuracies of 0.07 (
Figure 8), 0.078 (
Figure 9), and 0.105 (
Figure 10), respectively. The cluster 0 actual versus predicted model had a mean absolute error of 4.9 customers, median absolute error of 0.864, and the Root Mean Square Error of 8.96 (
Figure 11). The feature importance in the survival model with cluster 0 (
Table 4) identified the three most relevant features to predict survival as
,
, and
, while the features with lower relevance were
,
, and
.
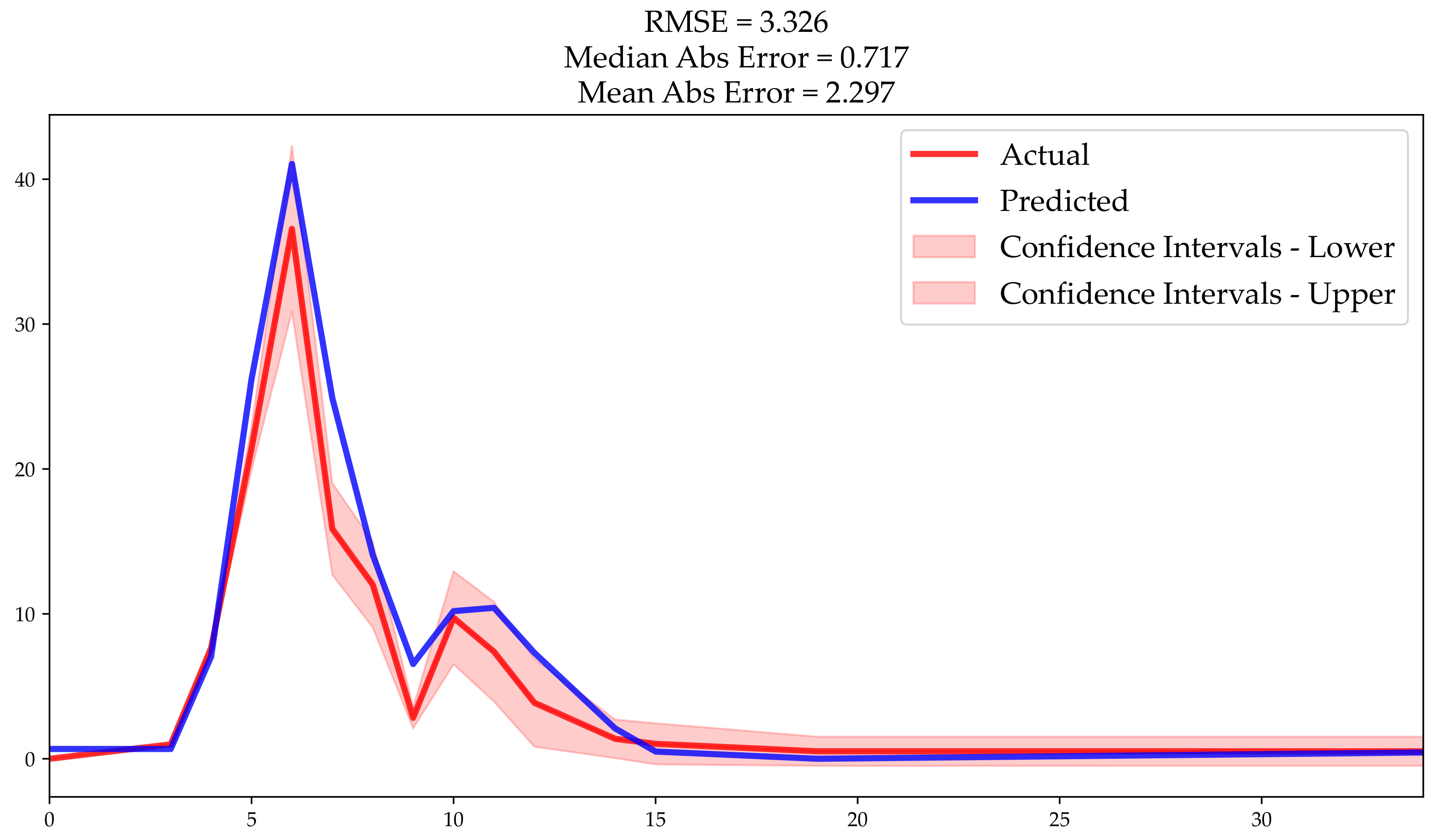
The cluster 4 actual versus predicted model presented a mean absolute error of 2.29 customers, median absolute error of 0.717, and Root Mean Square Error of 3.32 (
Figure 12). The feature importance in the survival model with cluster 4 (
Table 5) identified the three most relevant features to predict survival as
,
, and
, while the least relevant were
,
, and
.
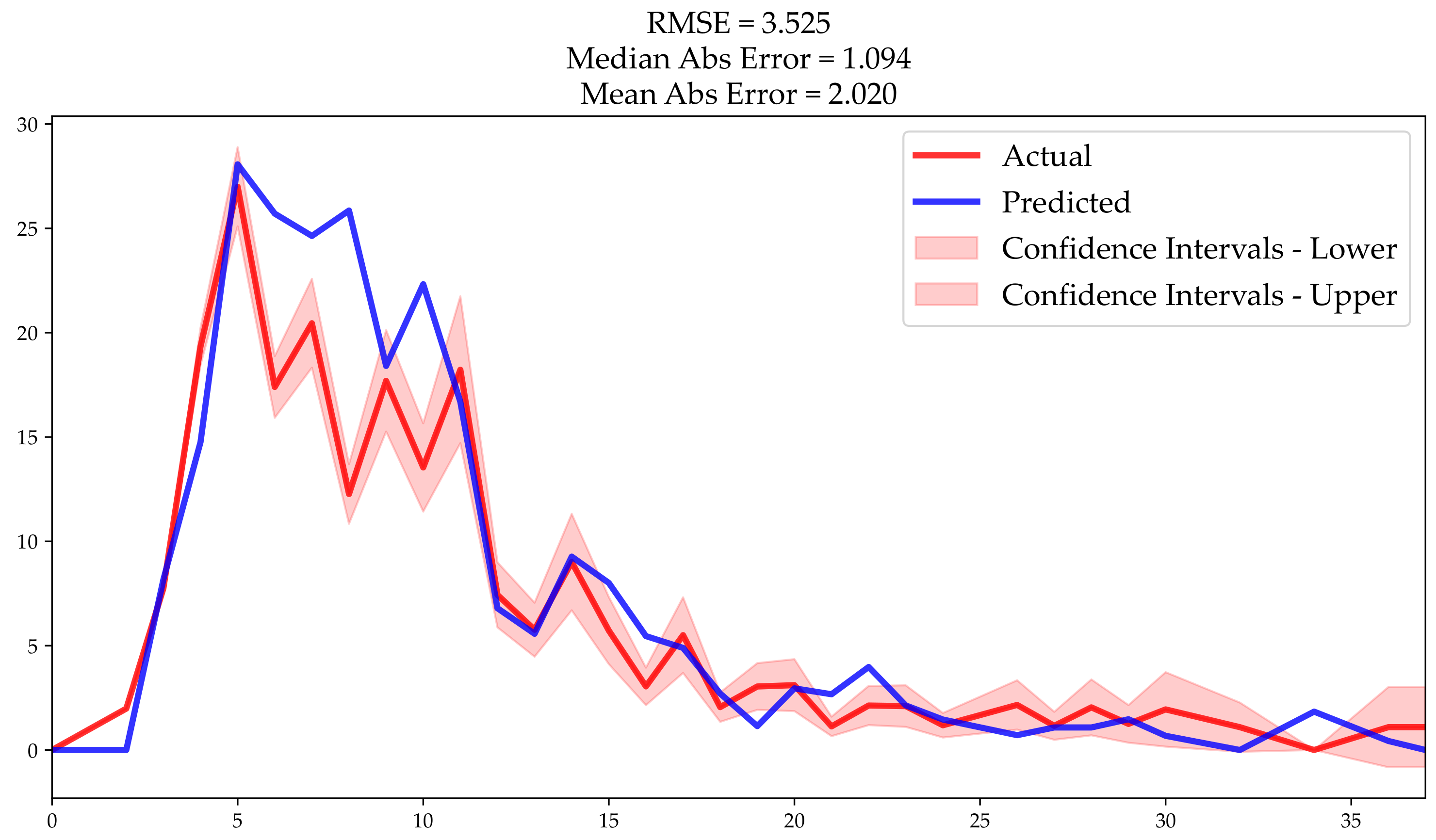
Finally, cluster 8 actual versus predicted model presented a mean absolute error of 2.02 customers, median absolute error was 1.09, and Root Mean Square Error of 3.52 (
Figure 13). The feature importance in the survival model with cluster 8 (
Table 6) identified the three most relevant features to predict survival as
,
, and
, while the least relevant were
,
, and
.
Model Comparison
Table 7 shows the performance of both approaches; that is, with and without clusters. The RMSE, mean, and median in the clustered approach was lower than that when not using clusters to predict the survival time until dropout. The metrics, comparing the actual values in each cluster against the model without clusters, were as follows: median 1.68 ± 1.34 vs. 4.8 w/o clusters; mean 1.348 ± 0.831 vs. 3.13 w/o clusters, RMSE 2.80 ± 2.69 vs. 7.9 w/o clusters, and IBS 0.051 ± 0.036 vs. 0.089 w/o clusters. On average, the results outperform the model without clusters even if we consider plus one standard deviation in all the indicators.
Overall, the performance was improved through clustering. The performance is also better using mean and median.
The model without clusters presented a RMSE of 7.904, the mean absolute error mean was customers, the median absolute error was 4.876, and the IBS was 0.089. One cluster in the model using clusters had worse performance (cluster 0), with a RMSE 9.181, mean absolute error of 0.893, and median absolute error 4.766. The cluster with the best performance (cluster 5) had a RMSE of 0.312, mean absolute error of 0, and median absolute error 0.127. The overall performance of the model was improved when using clusters, with the non-clustering IBS of 0.089 only being surpassed by cluster 8, with an IBS of 0.105.
Comparing the prediction accuracy in each cluster using the Brier Score, the median Brier score without clusters was 0.356, while those for clusters 0, 1, 2, 3, 4, 5, 6, 7, and 8, were 0.022, 0.114, 0.041, 0.056, 0.022, 0.072, 0.133, 0.137, and 0.049, respectively. The results of applying the Mann–Whitney test between clusters and without clusters were as follows: cluster 0 (U = 530, n1 = 19, n2 = 29, p < 0.05); cluster 1 (U = 400, n1 = 19, n2 = 25, p < 0.05); cluster 2 (U = 374, n1 = 19, n2 = 21, p < 0.05); cluster 3 (U = 721, n1 = 19, n2 = 42, p < 0.05); cluster 4 (U = 415, n1 = 19, n2 = 23, p < 0.05); cluster 5 (U = 220, n1 = 19, n2 = 13, p < 0.05); cluster 6 (U = 276, n1 = 19, n2 = 19, p < 0.05); cluster 7 (U = 597, n1 = 19, n2 = 39, p < 0.05); and cluster 8 (U = 663, n1 = 19, n2 = 38, p < 0.05). The prediction was statistically significant, when comparing the prediction accuracy of the survival model using clusters against that without clusters; namely, the median value was lower using clusters.
8. Discussion
In this study, we evaluated the performance of random survival forests using membership data of customers of a health club. A survival model was created to determine the duration of the relationship. This approach provides an additional view to identify when the customer dropout will occur, allowing for the development of retention strategies, considering the timings of the events. More than 70% of the customers were predicted to dropout in the first 12 months, which is very high, and has not been identified in other studies. Burez and Vandenpoel [
19], in a study of pay TV users, have found that one out of three customers leave the company before one year, and half the customers leave within two years.
The accuracy calculated using the actual and predicted customers who dropped out during the 40 months showed a mean absolute error of 7.5 customers. Using the hybrid model, the mean absolute errors were 1.56, 6.52, and 1.56 customers in clusters 1,2, and 3, respectively. The features , and represented more than 66% of the importance predicting the survival model without clusters. Accordingly, in the hybrid approach, the most relevant features were , , and , representing 67% of the importance in the cluster 1; in Cluster 2, , , and represented 70% in prediction importance; and, in Cluster 3, , , and representing 69% in the prediction importance.
The use of clustering in supporting customer segmentation to improve the performance of machine learning techniques is not new. Jafari-Marandi et al. [
29] have also explored the use of clusters to improve the prediction accuracy. However, this approach combined with the use of survival models, to the best of our knowledge, has not been previously attempted or reported.
The better performance of the hybrid model in predicting when customers will dropout, using existing data, supports the development of management counter-measures to reduce dropout. The duration of the relationship between the customer and the organization is an important aspect, allowing us to understand that the decision of the customer to dropout changes over time, which implies that existing models predicting customer dropout may be only correct at a specific point in time, after which their decision may change [
11].
The time perspective allows us to identify the period in which retention actions should be developed; therefore, the prediction should be as accurate as possible. However, customers who are about to churn but cannot be retained should be excluded from the countermeasures to avoid dropout, considering that targeting them may constitute a waste of scarce resources [
15]. Addressing only the performance of predictive models considering only accuracy seems to be a reduced perspective, considering that customers with a higher risk of churning may not be the best targets for the development of retention strategies. Further research should be conducted exploring this perspective, thus providing further insight into the return on investment in the development of countermeasures. A business context, or the clarification of business objectives underlying the prediction of customer dropout, should be developed, in order to clarify which objectives should be achieved before the employment of machine learning algorithms.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}