
A Novel Deep-Learning-Based Enhanced Texture Transformer Network for Reference Image Super-Resolution
 , and
, and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Single-Image Super-Resolution
2.2. Super-Resolution of Reference Images
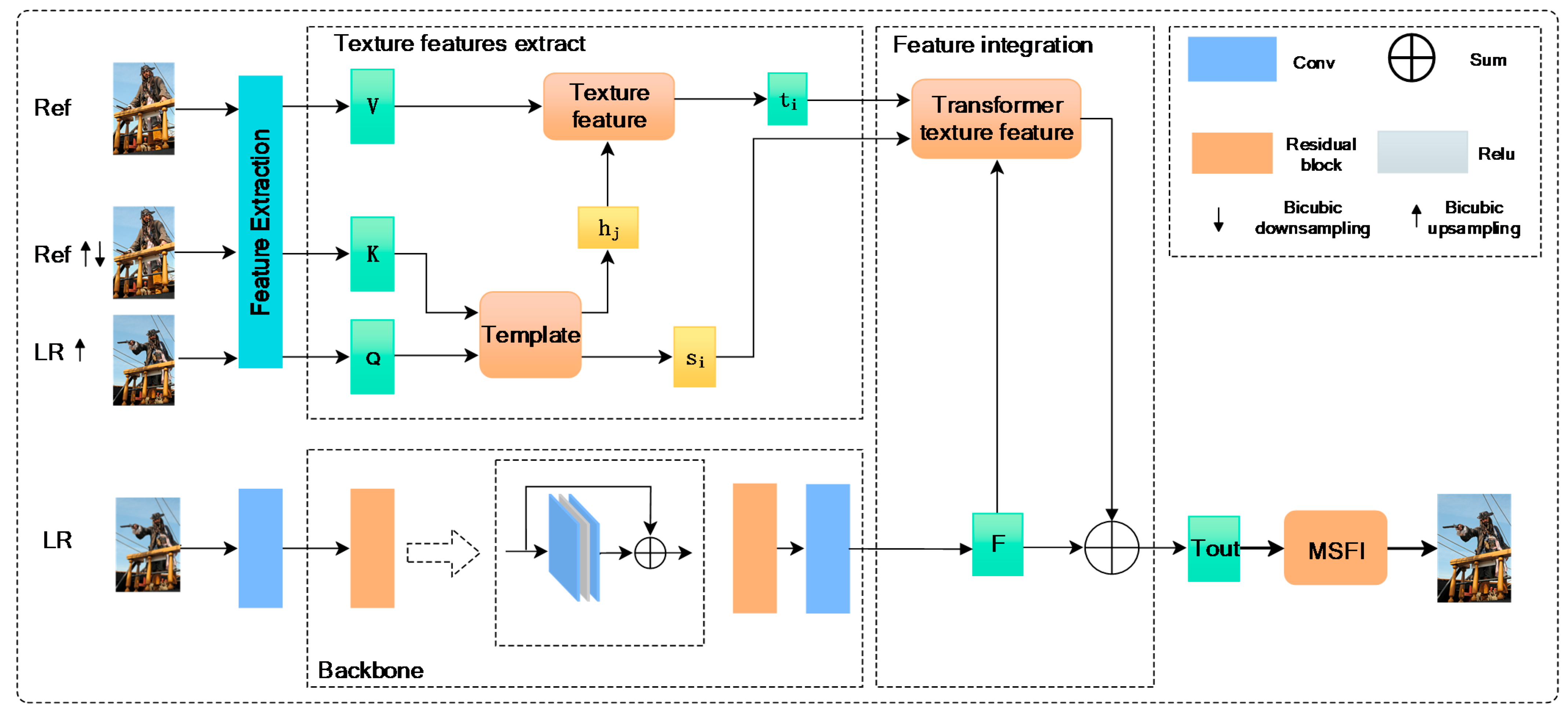
3. The Proposed ETTN
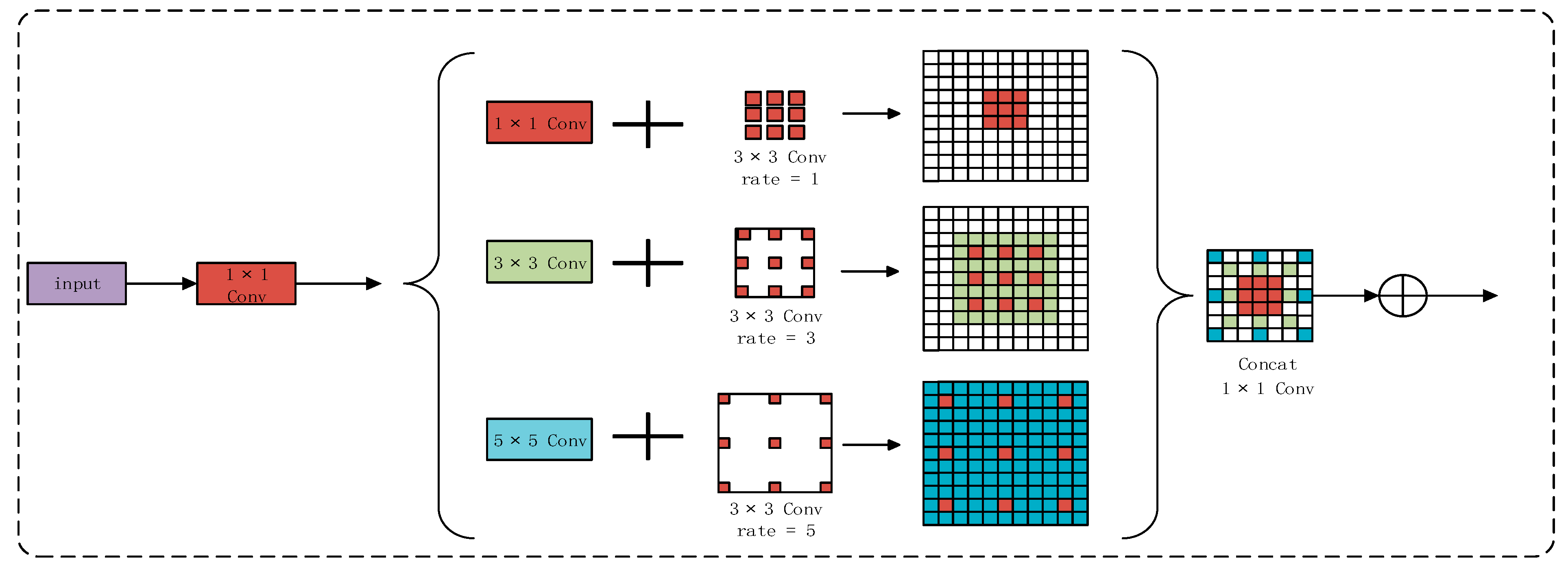
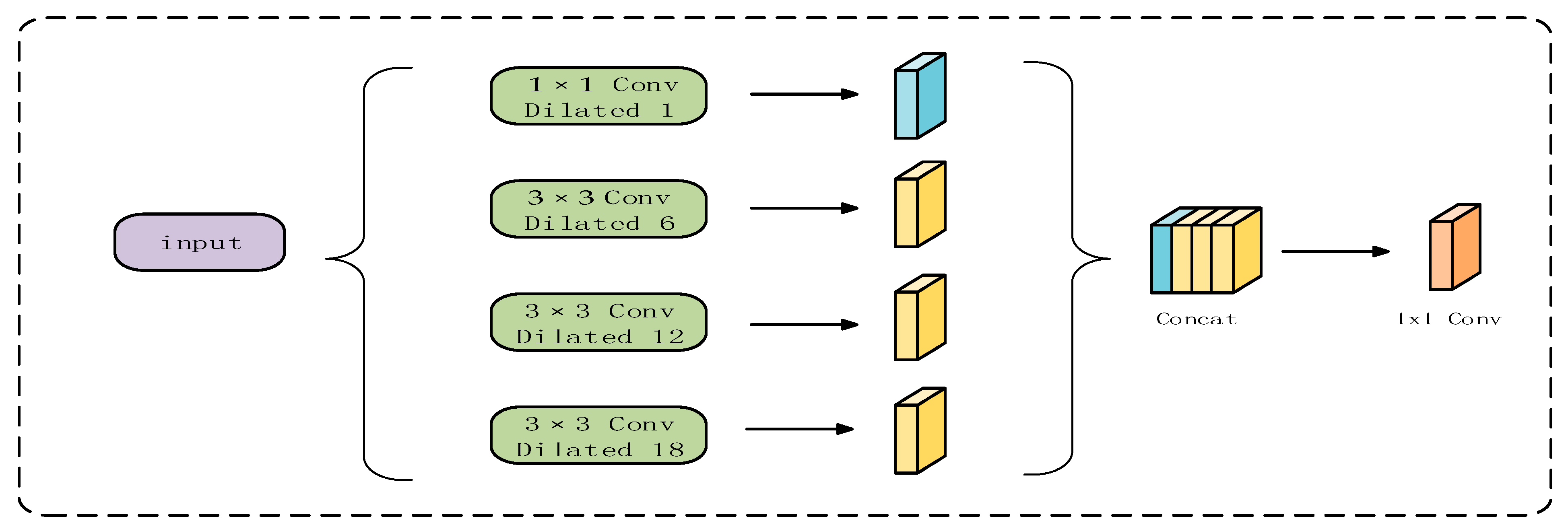
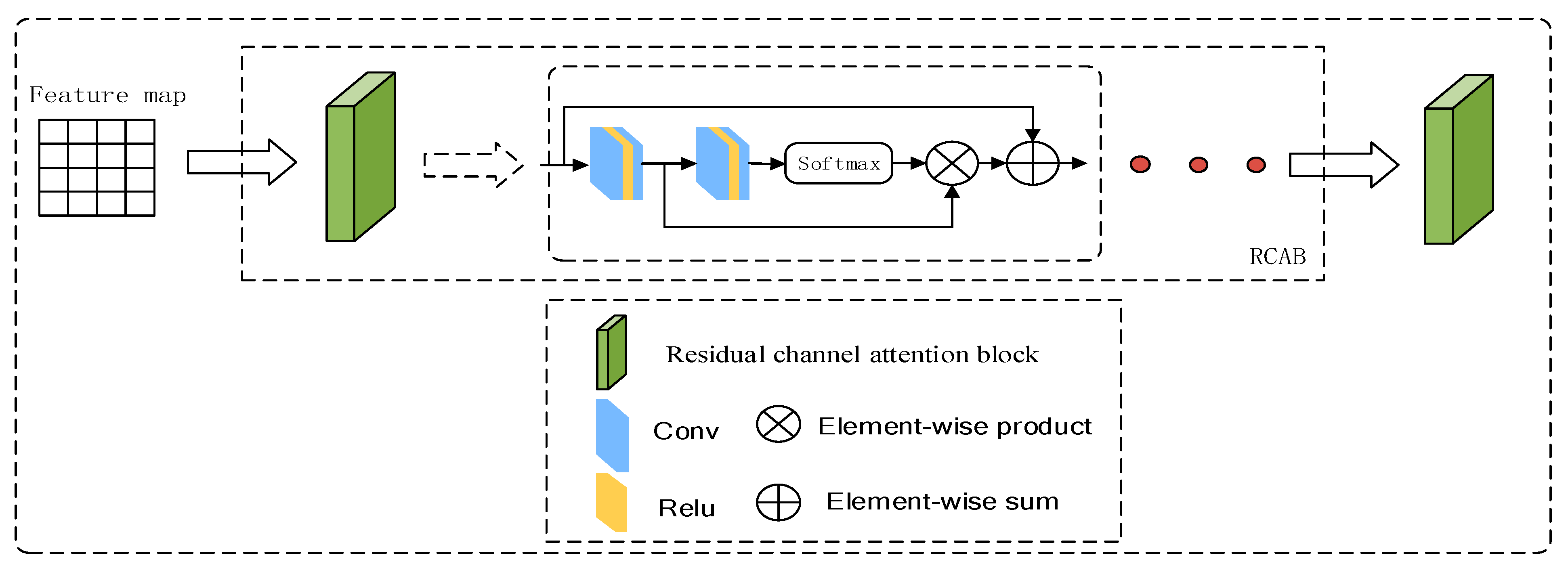
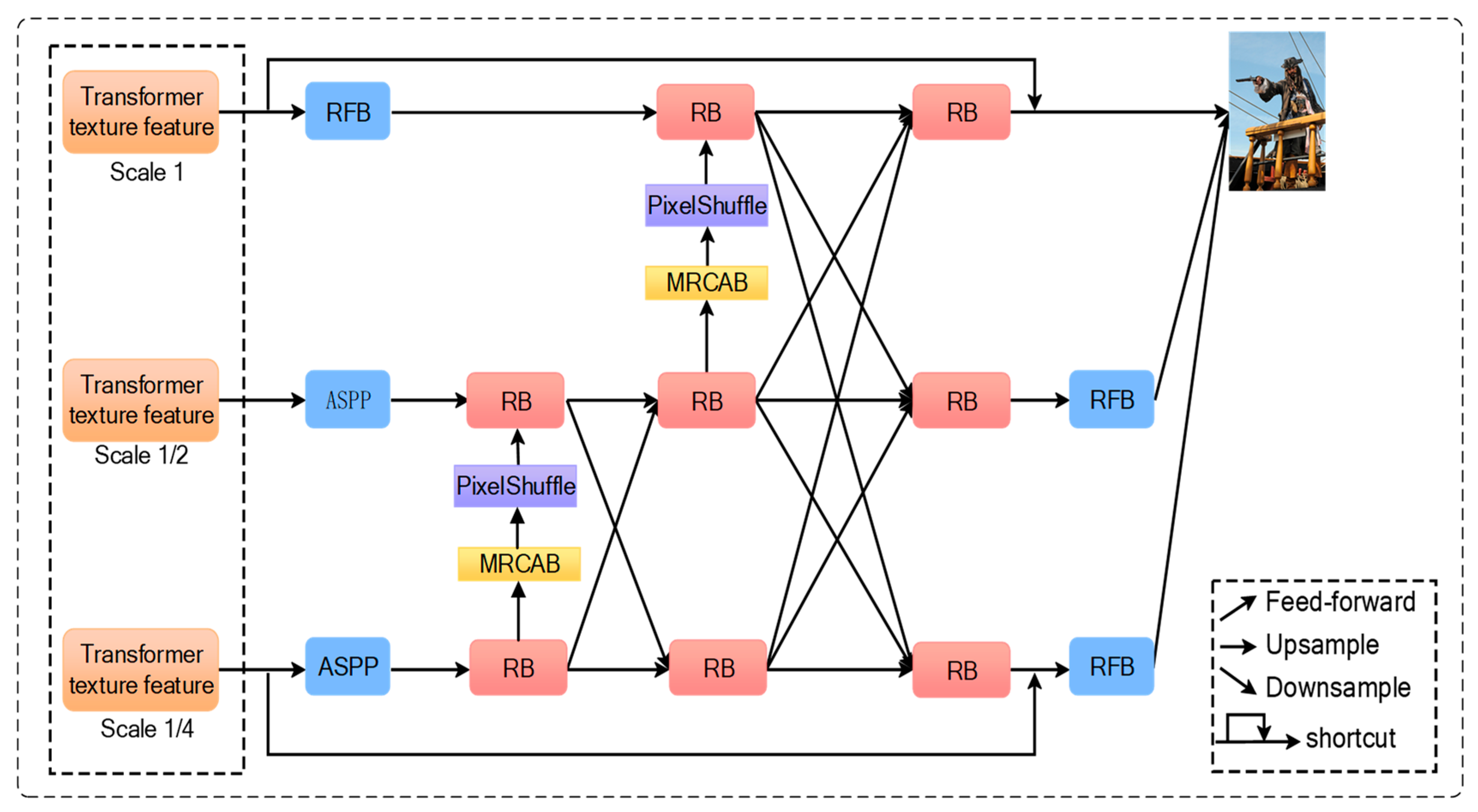
3.1. The Enhanced Texture Transformer Network
3.2. Multi-Scale Feature Integration
3.3. Objective Function and Evaluation Metrics
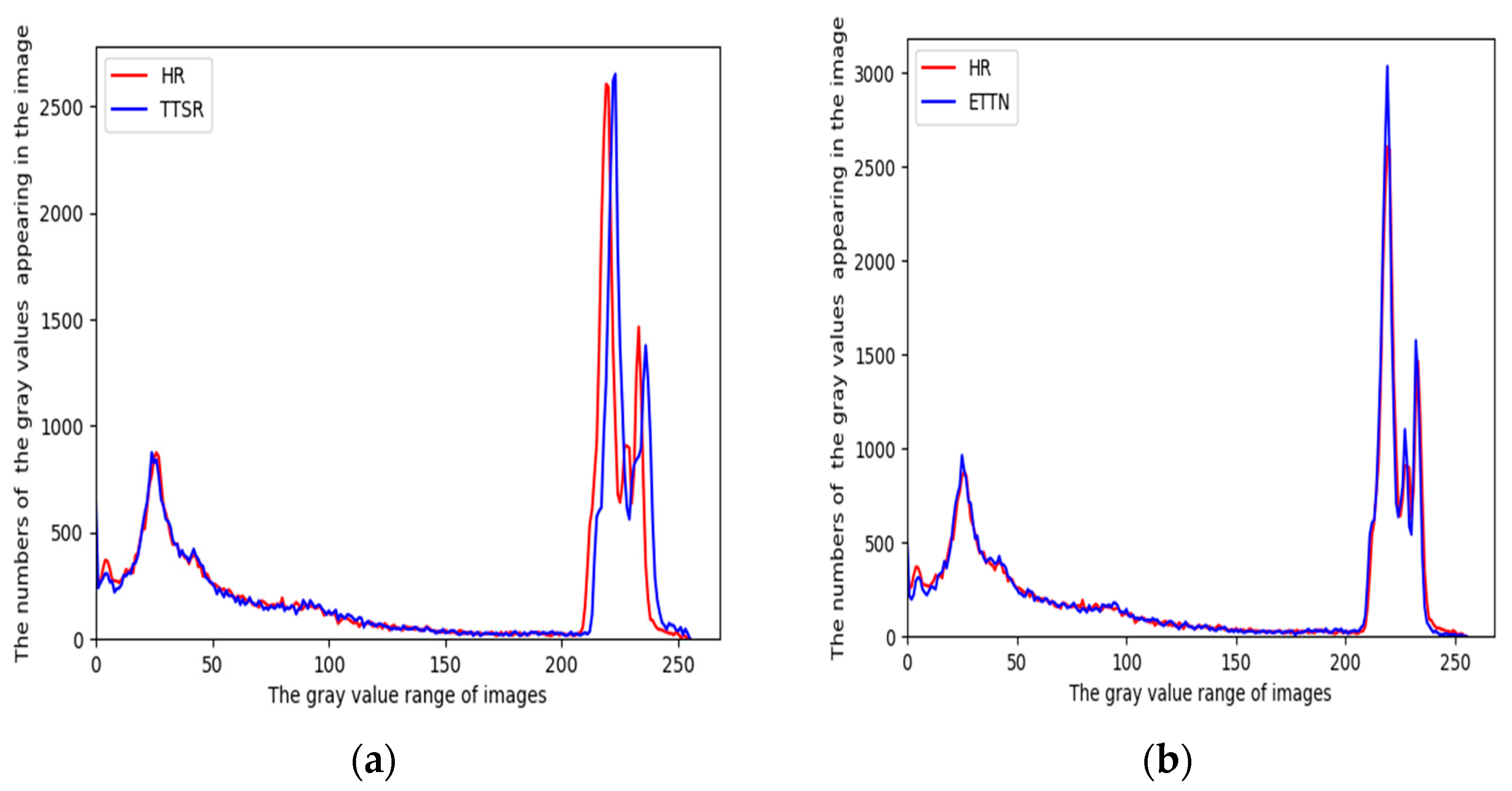
3.4. Histogram Analysis
4. Experiments
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
4.3. Comparison of Super-Resolution
4.4. Ablation Study
4.5. Quantitative Evaluation
4.6. Qualitative Evaluation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, Q.; Song, H.; Yu, J.; Kim, K. Current development and applications of super-resolution ultrasound imaging. Sensors 2021, 21, 2417. [Google Scholar] [CrossRef] [PubMed]
- Dong, X.; Xi, Z.; Sun, X.; Gao, L. Transferred multi-perception attention networks for remote sensing image super-resolution. Remote Sens. 2019, 11, 2857. [Google Scholar] [CrossRef]
- Shermeyer, J.; Van Etten, A. The effects of super-resolution on object detection performance in satellite imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 1432–1441. [Google Scholar]
- Wu, K.; Qiang, Y.; Song, K.; Ren, X.; Yang, W.; Zhang, W.; Hussain, A.; Cui, Y. Image synthesis in contrast MRI based on super resolution reconstruction with multi-refinement cycle-consistent generative adversarial networks. J. Intell. Manuf. 2020, 31, 1215–1228. [Google Scholar] [CrossRef]
- Yang, J.; Wright, J.; Huang, T.; Ma, Y. Image super-resolution as sparse representation of raw image patches. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. (PAMI) 2015, 38, 295–307. Available online: https://arxiv.org/abs/1501.00092 (accessed on 19 September 2022). [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer vision and Pattern Recognition, Las Vegas, NV, USA, 26 June 2016; pp. 1637–1645. [Google Scholar]
- Freedman, G.; Fattal, R. Image and video upscaling from local self-examples. ACM Trans. Graph. (TOG) 2012, 30, 1–11. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Processing Syst. 2014, 27. [Google Scholar] [CrossRef]
- Lai, W.-S.; Huang, J.-B.; Ahuja, N.; Yang, M.-H. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA; 2017; pp. 624–632. [Google Scholar]
- Zhang, Z.; Song, Y.; Qi, H. Age progression/regression by conditional adversarial autoencoder. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 21–30 October 2017; pp. 5810–5818. [Google Scholar]
- Lai, W.-S.; Huang, J.-B.; Ahuja, N.; Yang, M.-H. Fast and accurate image super-resolution with deep laplacian pyramid networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2599–2613. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the IEEE European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Zheng, H.; Ji, M.; Wang, H.; Liu, Y.; Fang, L. Crossnet: An end-to-end reference-based super resolution network using cross-scale warping. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 88–104. [Google Scholar]
- Yang, F.; Yang, H.; Fu, J.; Lu, H.; Guo, B. Learning texture transformer network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 19–24 June 2020; pp. 5791–5800. [Google Scholar]
- Zhang, Z.; Wang, Z.; Lin, Z.; Qi, H. Image super-resolution by neural texture transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7982–7991. [Google Scholar]
- Yao, C.; Zhang, S.; Yang, M.; Liu, M.; Qi, J. Depth super-resolution by texture-depth transformer. In Proceedings of the International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Yue, H.; Sun, X.; Yang, J.; Wu, F. Landmark image super-resolution by retrieving web images. IEEE Trans. Image Process. 2013, 22, 4865–4878. [Google Scholar]
- Meng, Z.; Zhang, J.; Li, X.; Zhang, L. Lightweight Image Super-Resolution Based on Local Interaction of Multi-Scale Features and Global Fusion. Mathematics 2022, 10, 1096. [Google Scholar] [CrossRef]
- Wu, W.; Xu, W.; Zheng, B.; Huang, A.; Yan, C. Learning Local Distribution for Extremely Efficient Single-Image Super-Resolution. Electronics 2022, 11, 1348. [Google Scholar] [CrossRef]
- Yun, J.-S.; Yoo, S.-B. Single image super-resolution with arbitrary magnification based on high-frequency attention network. Mathematics 2022, 10, 275. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, D.; Yang, J.; Han, W.; Huang, T. Deep networks for image super-resolution with sparse prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Santiago, Chile, 7–13 December 2015; pp. 370–378. [Google Scholar]
- Xie, C.; Liu, Y.; Zeng, W.; Lu, X. An improved method for single image super-resolution based on deep learning. Signal Image Video Processing 2019, 13, 557–565. [Google Scholar] [CrossRef]
- Zhu, M.; Luo, W. Closed-Loop Residual Attention Network for Single Image Super-Resolution. Electronics 2022, 11, 1112. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1646–1654. [Google Scholar]
- Liu, A.; Li, S.; Chang, Y. Image super-resolution using progressive residual multi-dilated aggregation network. Signal Image Video Processing 2022, 16, 1271–1279. [Google Scholar] [CrossRef]
- Xu, T.; Zhang, P.; Huang, Q.; Zhang, H.; Gan, Z.; Huang, X.; He, X.A. Fine-grained text to image generation with attentional generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA,, 18–23 June 2018. [Google Scholar]
- Sajjadi, M.S.; Scholkopf, B.; Hirsch, M. Enhancenet: Single image super-resolution through automated texture synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4491–4500. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Chudasama, V.; Upla, K. RSRGAN: Computationally efficient real-world single image super-resolution using generative adversarial network. Mach. Vis. Appl. 2021, 32, 3. [Google Scholar] [CrossRef]
- Lin, R.; Xiao, N. Dual Projection Fusion for Reference-Based Image Super-Resolution. Sensor 2022, 22, 4119. [Google Scholar] [CrossRef]
- Liu, X.; Li, J.; Duan, T.; Li, J.; Wang, Y. DSMA: Reference-Based Image Super-Resolution Method Based on Dual-View Supervised Learning and Multi-Attention Mechanism. IEEE Access 2022, 10, 54649–54659. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbia, IN, USA, 23–28 June 2014. [Google Scholar]
- Lu, L.; Li, W.; Tao, X.; Lu, J.; Jia, J. MASA-SR: Matching acceleration and spatial adaptation for reference-based image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6368–6377. [Google Scholar]
- Georgescu, M.-I.; Ionescu, R.T.; Miron, A.-I.; Savencu, O.; Ristea, N.-C.; Verga, N.; Khan, F.S. Multimodal Multi-Head Convolutional Attention with Various Kernel Sizes for Medical Image Super-Resolution. arXiv 2022, preprint. arXiv:2204.04218. [Google Scholar]
- Shang, T.; Dai, Q.; Zhu, S.; Yang, T.; Guo, Y. Perceptual extreme super-resolution network with receptive field block. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 440–441. [Google Scholar]
- Liu, H.; Cao, F.; Wen, C.; Zhang, Q. Lightweight multi-scale residual networks with attention for image super-resolution. Knowl. Based Syst. 2020, 203, 106103. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Lin, R.; Xiao, N. Residual Channel Attention Connection Network for Reference-based Image Super-resolution. In Proceedings of the 2021 8th International Conference on Information, Cybernetics, and Computational Social Systems (ICCSS), Beijing, China, 10–12 December 2021; pp. 307–313. [Google Scholar]
- Duan, C.; Xiao, N. Parallax-based spatial and channel attention for stereo image super-resolution. IEEE Access 2019, 7, 183672–183679. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, K.; Li, K.; Fu, Y. Mr image super-resolution with squeeze and excitation reasoning attention network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13425–13434. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Huang, J.-B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Sun, L.; Hays, J. Super-resolution from internet-scale scene matching. In Proceedings of the IEEE International Conference on Computational Photography (ICCP), Seattle, WA, USA, 28–29 April 2012; pp. 1–12. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1874–1883. [Google Scholar]
- Cheng, M.; Yongming, R.; Yean, C.; Ce, C.; Lu, J. Structure-Preserving Super Resolution with Gradient Guidance. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 19–24 June 2020; pp. 7769–7778. [Google Scholar]
- Schulter, S.; Leistner, C.; Bischof, H. Fast and accurate image upscaling with super-resolution forests. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3791–3799. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CUFED im006 | Bhattacharyya Distance | Chi-Square Distance | Urban100 im008 | Bhattacharyya Distance | Chi-Square Distance |
|---|---|---|---|---|---|
| SRNTT | 0.219 | 95,860 | SRNTT | 0.231 | 231,325 |
| TTSR | 0.187 | 96,554 | TTSR | 0.171 | 393,684 |
| Ours | 0.108 | 13,646 | Ours | 0.142 | 196,324 |
| Level | L1 | L2 | L3 | L4 | L5 | LR |
|---|---|---|---|---|---|---|
| TTSR | 25.53/0.765 | 25.30/0.760 | 25.17/0.750 | 25.17/0.750 | 25.23/0.751 | 25.31/0.756 |
| Ours | 25.68/0.768 | 25.44/0.758 | 25.34/0.756 | 25.31/0.755 | 25.31/0.754 | 25.46/0.761 |
| Method | ASPP | RFB | RCAB | Param(M) | PSNR/SSIM |
|---|---|---|---|---|---|
| Base + ASPP | √ | 7.01 | 25.30/0.749 | ||
| Base + ASPP + RFB | √ | √ | 7.10 | 25.50/0.761 | |
| Base + ASPP + MRCAB(4/8) + RFB | √ | √ | √ | 7.56 (8.22) | 25.60/0.767 (25.65/0.768) |
| Algorithm | CUFED5 [19] | Sun80 [48] | Urban100 [47] |
|---|---|---|---|
| ESRGAN [32] | 21.90/0.633/0.00646 | 24.18/0.651/0.00382 | 20.91/0.620/0.00810 |
| RSRGAN [34] | 22.31/0.635/0.00587 | 25.60/0.667/0.00275 | 21.47/0.624/0.00712 |
| SelfEx [47] | 23.22/0.680/0.00476 | 27.03/0.756/0.00198 | 24.67/0.749/0.00341 |
| Bicubic | 24.18/0.648/0.00382 | 27.26/0.739/0.00188 | 23.14/0.674/0.00485 |
| ENet [49] | 24.24/0.695/0.00377 | 26.24/0.702/0.00237 | 23.63/0.711/0.00433 |
| SPSR [50] | 24.39/0.714/0.00364 | 27.94/0.744/0.00160 | 24.29/0.729/0.00372 |
| SRGAN [10] | 24.40/0.695/0.00363 | 26.76/0.729/0.00211 | 23.63/0.711/0.00433 |
| Landmark [21] | 24.91/0.718/0.00323 | 27.68/0.776/0.00170 | — |
| MASA [38] | 24.92/0.729/0.00322 | 27.12/0.708/0.00194 | 23.78/0.712/0.00419 |
| SRCNN [6] | 25.33/0.745/0.00293 | 28.26/0.781/0.00149 | 24.41/0.738/0.00362 |
| DPSR [35] | 25.23/0.808/0.00281 | 28.42/0.762/0.00144 | 24.35/0.734/0.00367 |
| SCN [51] | 25.45/0.743/0.00285 | 27.93/0.786/0.00161 | 24.52/0.741/0.00535 |
| TTSR [18] | 25.53/0.765/0.00280 | 28.59/0.774/0.00138 | 24.62/0.747/0.00345 |
| SRNTT [19] | 25.61/0.764/0.00275 | 27.59/0.756/0.00174 | 25.09/0.774/0.00310 |
| DSMA [36] | 25.61/0.758/0.00275 | - | 24.55/0.733/0.00354 |
| Ours | 25.67/0.769/0.00271 | 28.80/0.786/0.00131 | 25.09/0.768/0.00310 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; Li, H.; Liang, Z.; Zhang, Y.; Yan, Y.; Zhong, R.Y.; Peng, S. A Novel Deep-Learning-Based Enhanced Texture Transformer Network for Reference Image Super-Resolution. Electronics 2022, 11, 3038. https://doi.org/10.3390/electronics11193038
Liu C, Li H, Liang Z, Zhang Y, Yan Y, Zhong RY, Peng S. A Novel Deep-Learning-Based Enhanced Texture Transformer Network for Reference Image Super-Resolution. Electronics. 2022; 11(19):3038. https://doi.org/10.3390/electronics11193038
Chicago/Turabian StyleLiu, Changhong, Hongyin Li, Zhongwei Liang, Yongjun Zhang, Yier Yan, Ray Y. Zhong, and Shaohu Peng. 2022. "A Novel Deep-Learning-Based Enhanced Texture Transformer Network for Reference Image Super-Resolution" Electronics 11, no. 19: 3038. https://doi.org/10.3390/electronics11193038