

Intelligent Identification and Order-Sensitive Correction Method of Outliers from Multi-Data Source Based on Historical Data Mining
Abstract
:1. Introduction
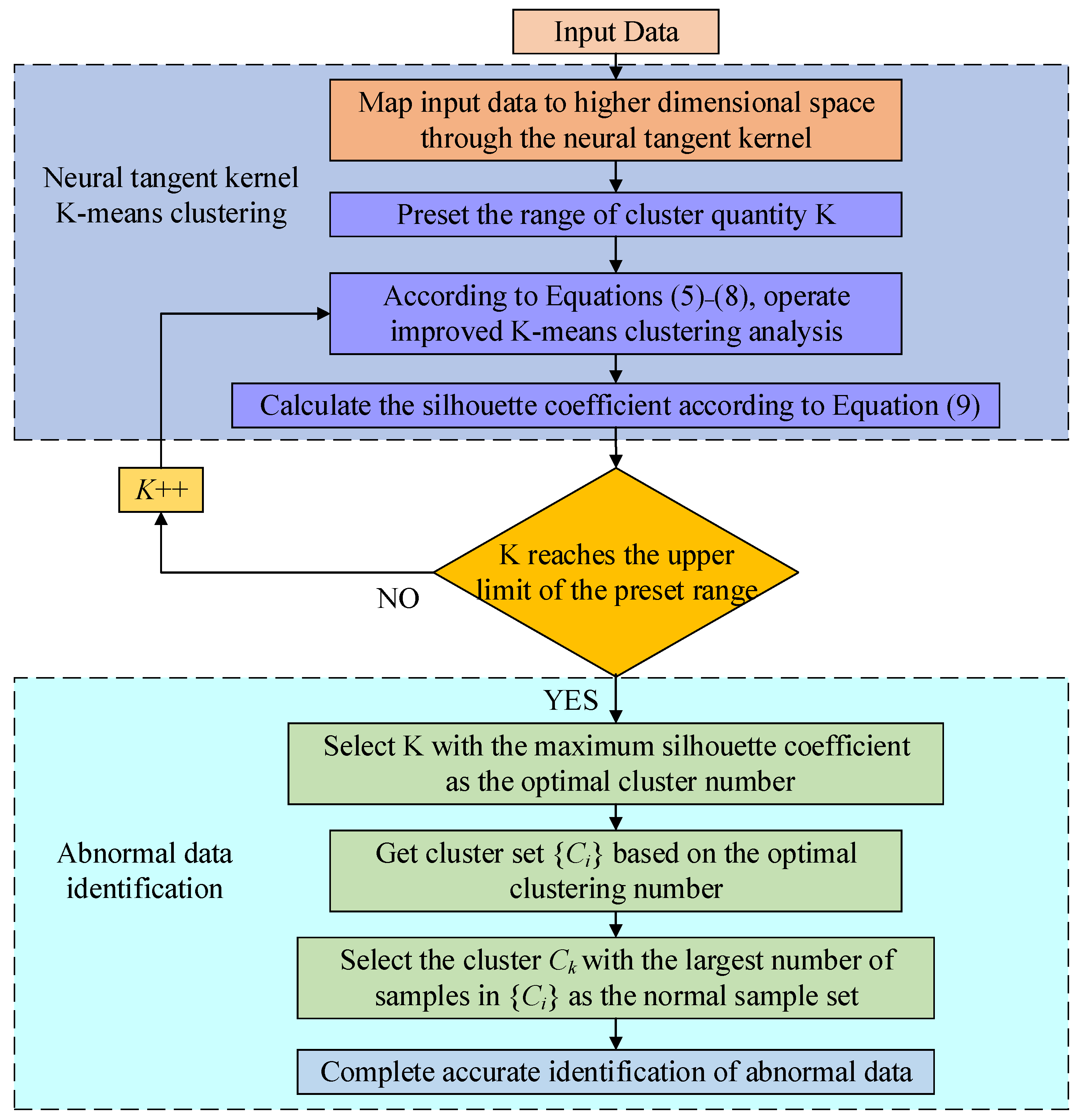
2. Intelligent Identification of Outliers from Single-Source Data based on Neural Tangent Kernels K-Means Clustering
2.1. A Brief Introduction of Kernel K-Means Clustering
2.2. Neural Tangent Kernel K-Means Clustering Algorithm
2.2.1. Neural Tangent Kernel
2.2.2. Decision of Initial Cluster Centers
2.2.3. Update Method of Cluster Centers
2.2.4. Objective Function of Clustering Algorithm
2.2.5. Determination of Optimal Cluster Number
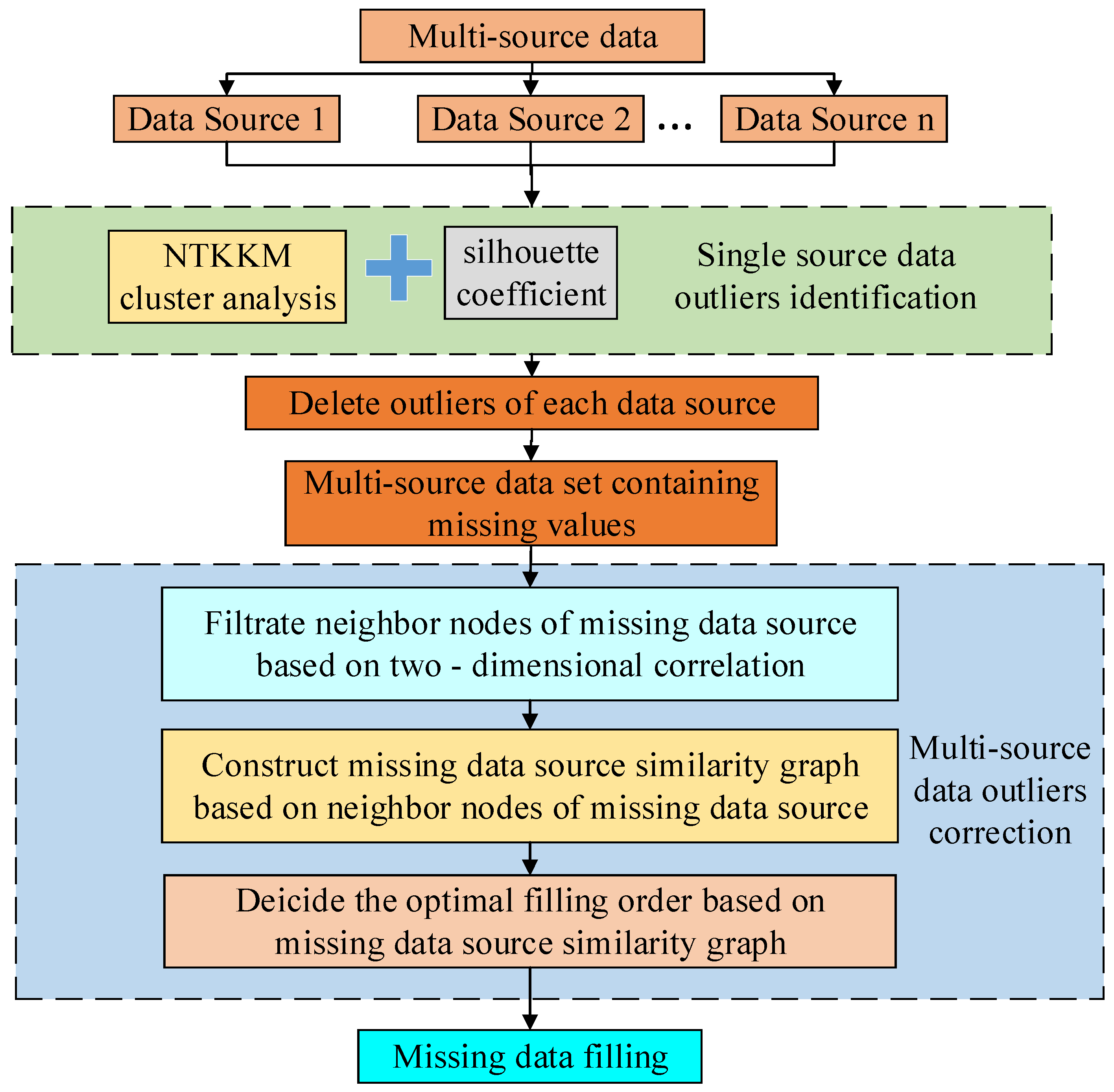
3. Order-Sensitive Correction Strategies of Outlier from Multi-Source Data
3.1. Filtering Neighbor of Missing Data Source Based on Bi-Dimensional Correlation
3.2. Decision of Optimal Filling Order and Data Filling Based on Missing Data Source Similarity Graph
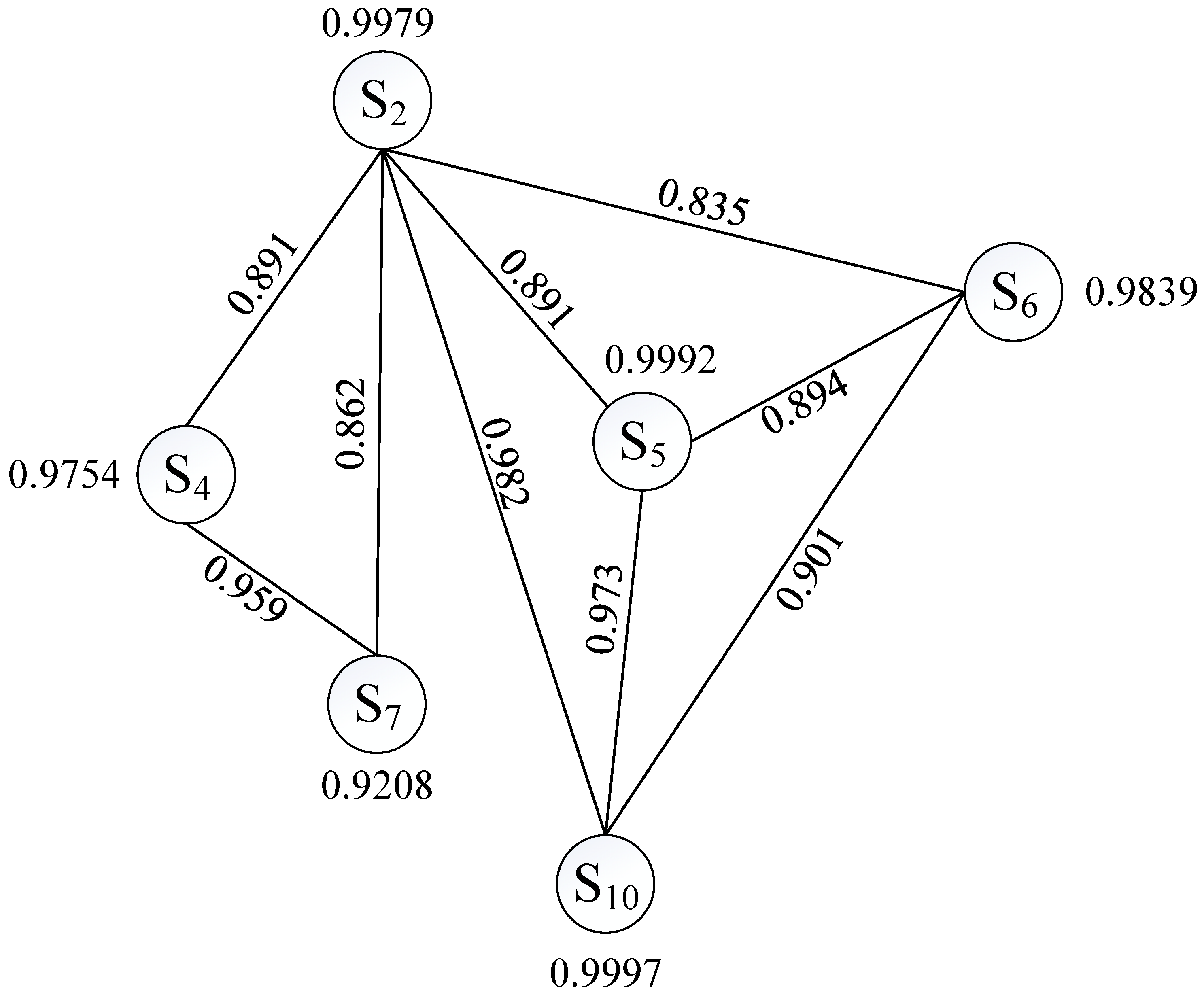
3.2.1. Construction of MISSING data Source Similarity Graph Based on Similarity Analysis
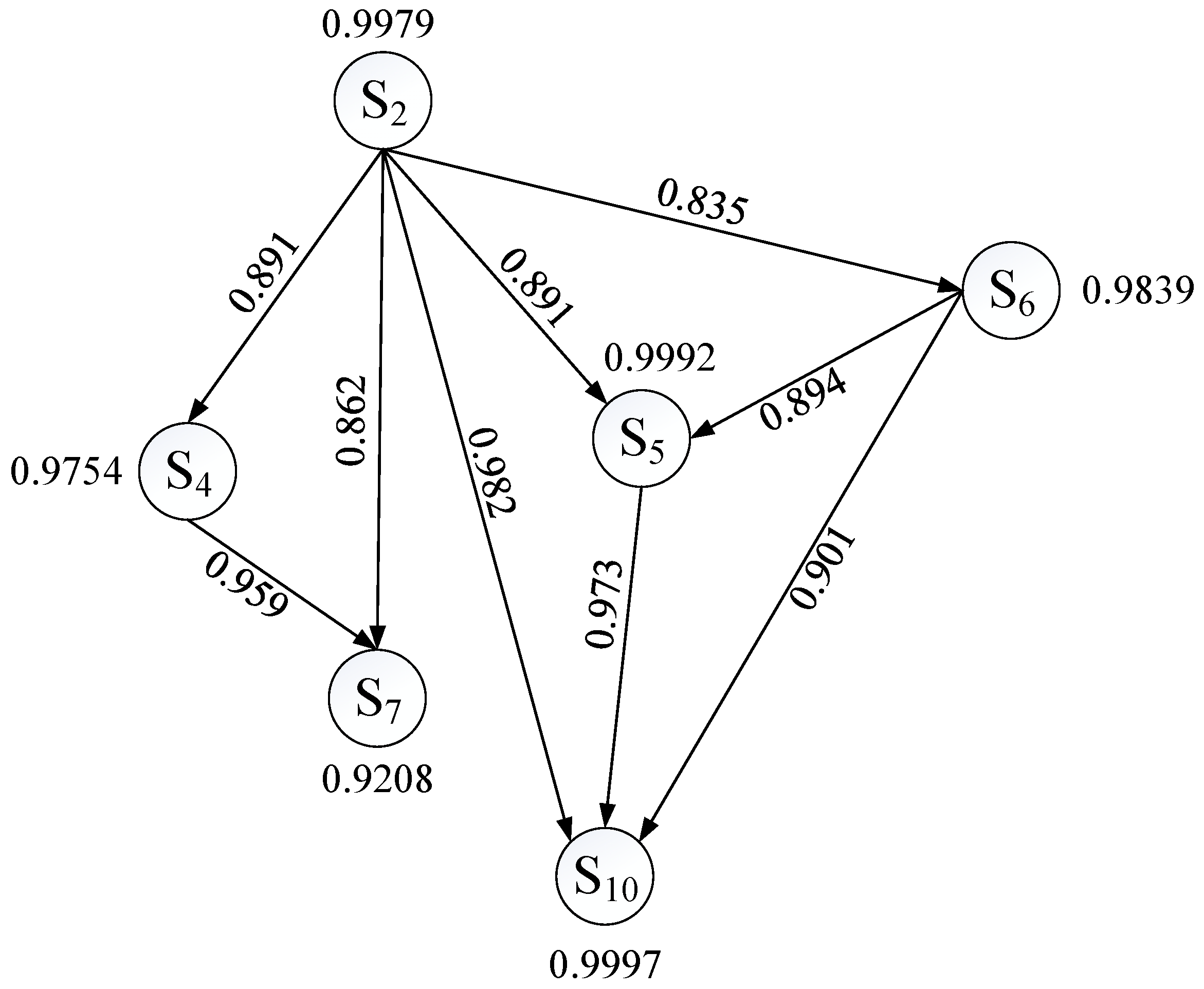
3.2.2. Decision of Optimal Filling Order Based on Missing Data Source Similarity Graph
3.2.3. Data Filling Method Based on Missing Data Source Similarity Graph
4. Case Experiment and Analysis
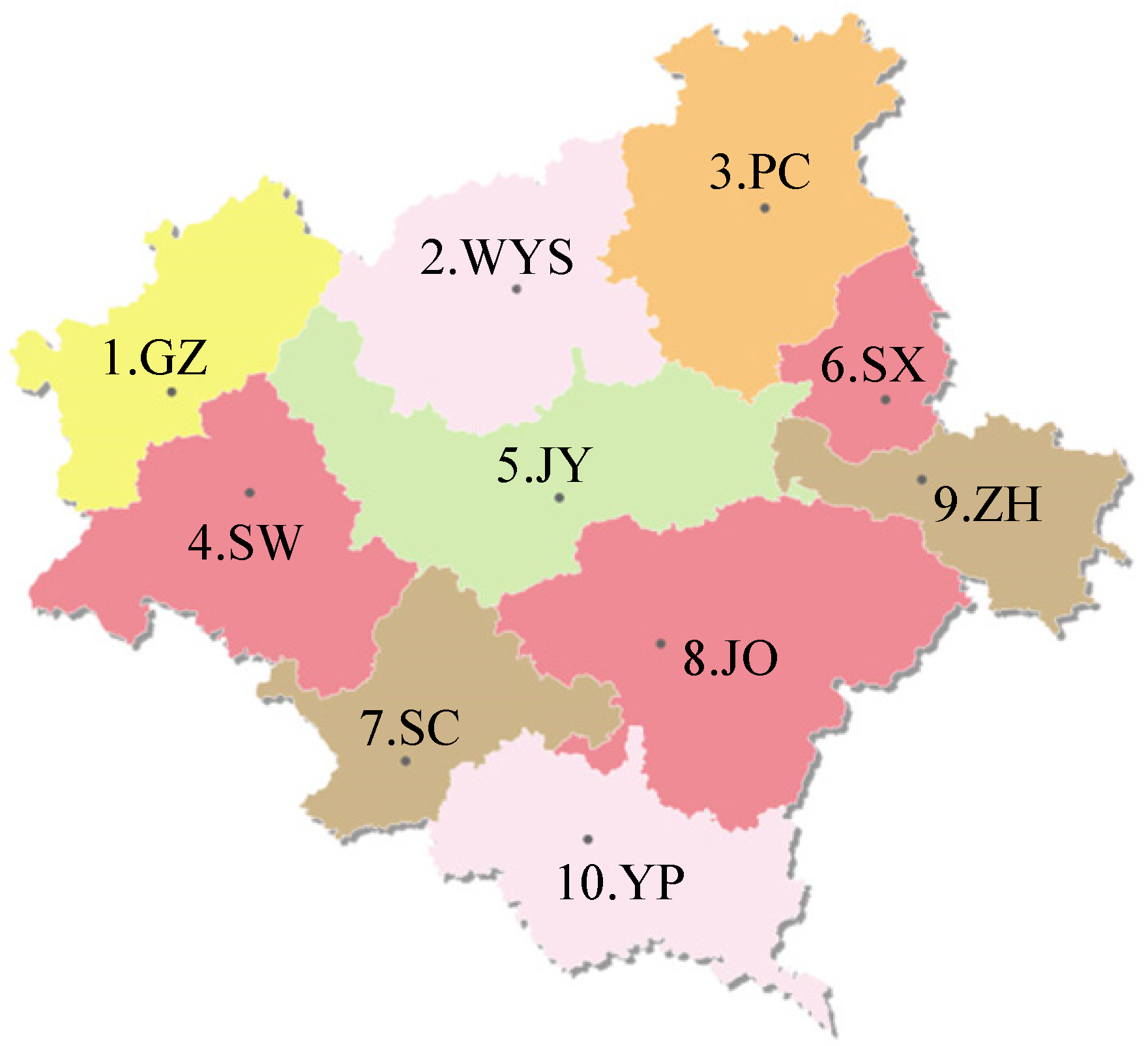
4.1. Case Background Introduction
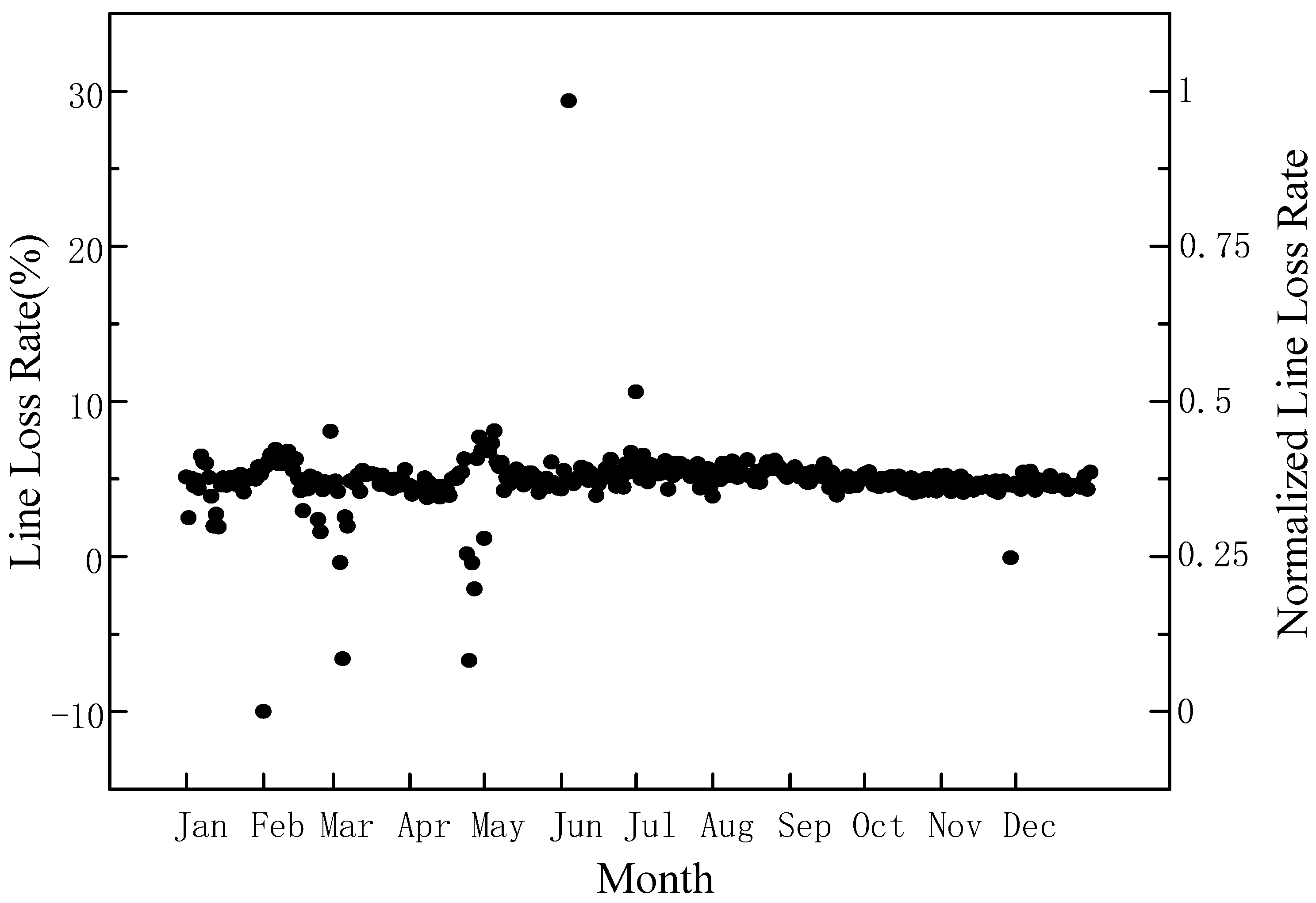
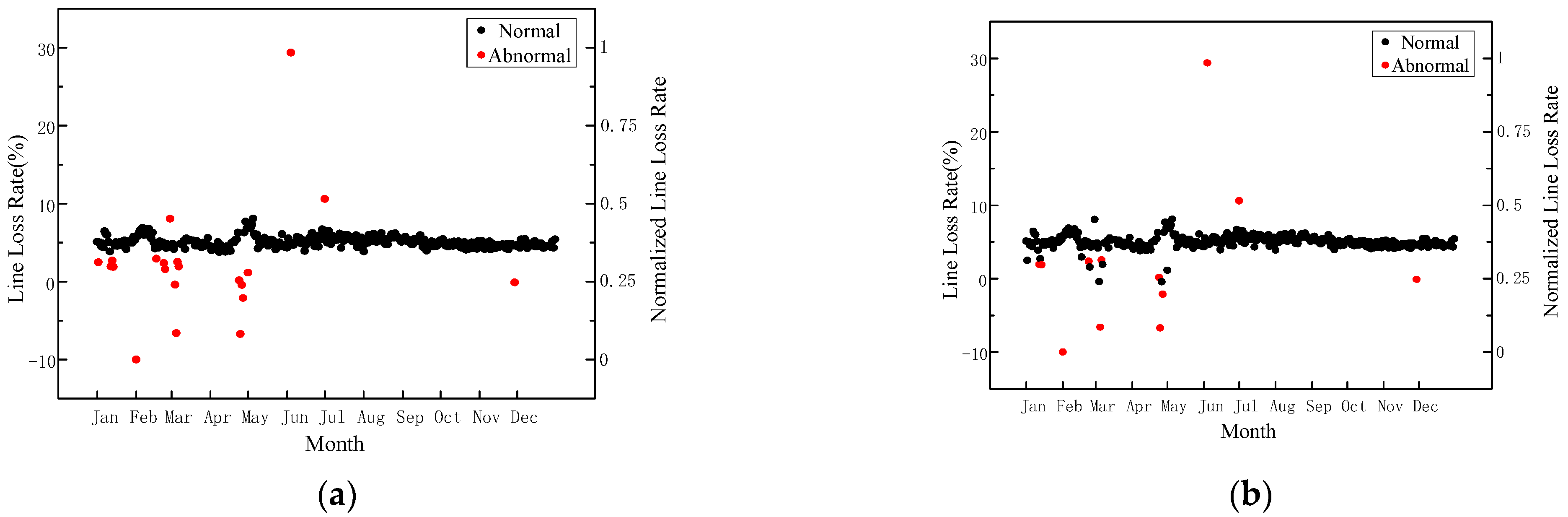
4.2. Outliers Identification Analysis of Single-Source Data Based on Neural Tangent Kernel K-Means Clustering
4.3. Missing Data Source Neighbor Node Filtering and Similarity Graph Construction Analysis
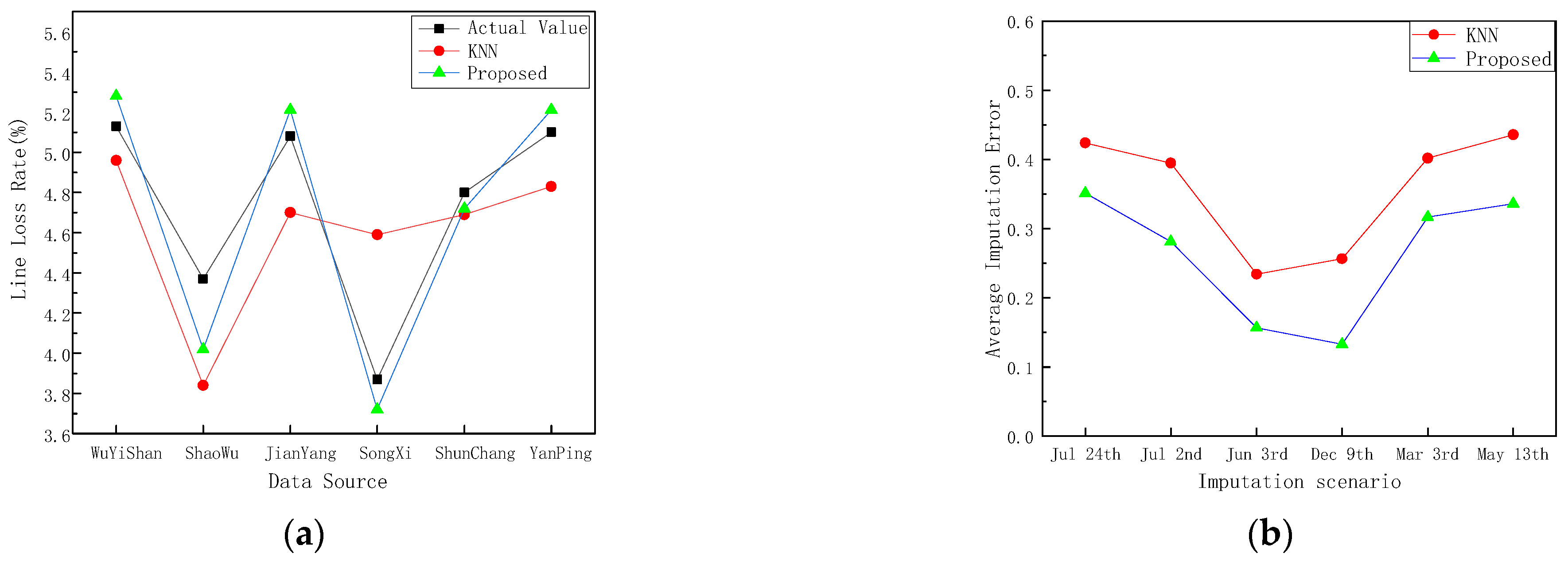
4.4. Optimal Filling Order Decision and Filling Effect Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, N. Methodolgical Progress Note: Handling Missing Data in Clinical Research. J. Hosp. Med. 2020, 14, 237–239. [Google Scholar] [CrossRef] [PubMed]
- Gomila, R.; Clark, C.S. Missing data in experiment-s: Challenges and solutions. Psychol. Methods 2020, 2, 66–71. [Google Scholar] [CrossRef] [PubMed]
- Wang, R.; Ji, W.; Liu, M.; Wang, X.; Weng, J.; Deng, S.; Gao, S.; Yuan, C. Review on mining data from multiple data sources. Pattern Recognit. Lett. 2018, 109, 120–128. [Google Scholar] [CrossRef]
- Mahmud, M.S.; Huang, J.Z.; Salloum, S.; Emara, T.Z.; Sadatdiynov, K. A survey of data partitioning and sampling methods to support big data analysis. Big Data Min. Anal. 2020, 3, 85–101. [Google Scholar] [CrossRef]
- Markovsky, I. A Missing Data Approach to Data-Driven Filtering and Control. IEEE Trans. Autom. Control. 2017, 62, 1972–1978. [Google Scholar] [CrossRef]
- Chuan, S.; Yueyi, C.; Cheng, C. Imputation of missing data from offshore wind farms using spatio-temporal correlation and feature correlation. Energy 2021, 229, 92–104. [Google Scholar] [CrossRef]
- Shao, N.; Chen, Y. Abnormal Data Detection and Identification Method of Distribution Internet of Things Monitoring Terminal Based on Spatiotemporal Correlation. Energies 2022, 15, 2151. [Google Scholar] [CrossRef]
- Ma, Y.; Zhao, X.; Zhang, C.; Zhang, J.; Qin, X. Outlier detection from multiple data sources. Inf. Sci. 2021, 580, 819–837. [Google Scholar] [CrossRef]
- Chang, X.; Qiu, Y.; Su, S.; Yang, D. Data Cleaning Based on Stacked Denoising Autoencoders and Multi-Sensor Collaborations. Comput. Mater. Contin. 2020, 63, 691–703. [Google Scholar]
- Kermorvant, C.; Liquet, B.; Litt, G.; Jones, J.B.; Mengersen, K.; Peterson, E.E.; Hyndman, R.J.; Leigh, C. Reconstructing Missing and Anomalous Data Collected from High-Frequency In-Situ Sensors in Fresh Waters. Int. J. Environ. Res. Public Health 2021, 18, 12803. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Wang, L.; Huang, C. A Fast Abnormal Data Cleaning Algorithm for Performance Evaluation of Wind Turbine. IEEE Trans. Instrum. Meas. 2021, 70, 5006512. [Google Scholar] [CrossRef]
- Gondeau, A.; Aouabed, Z.; Hijri, M.; Peres-Neto, P.R.; Makarenkov, V. Object Weighting: A New Clustering Approach to Deal with Outliers and Cluster Overlap in Computational Biology. IEEE/ACM Trans. Comput. Biol. Bioinform. 2021, 18, 633–643. [Google Scholar] [CrossRef] [PubMed]
- Huang, D.; Wang, C.-D.; Peng, H.; Lai, J.; Kwoh, C.-K. Enhanced Ensemble Clustering via Fast Propagation of Cluster-Wise Similarities. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 508–520. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, X.; Chen, X.; Zhang, A. The Kernel Conjugate Gradient Algorithms. IEEE Trans. Signal Process. 2018, 66, 4377–4387. [Google Scholar] [CrossRef]
- Yao, Y.; Li, Y.; Jiang, B.; Chen, H. Multiple Kernel k-Means Clustering by Selecting Representative Kernels. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4983–4996. [Google Scholar] [CrossRef] [PubMed]
- Lu, J.; Lu, Y.; Wang, R.; Nie, F.; Li, X. Multiple Kernel K-Means Clustering with Simultaneous Spectral Rotation. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2022, Singapore, 23–27 May 2022; pp. 4143–4147. [Google Scholar] [CrossRef]
- Nguyen, T.V.; Wong, R.K.W.; Hegde, C. Benefits of Jointly Training Autoencoders: An Improved Neural Tangent Kernel Analysis. IEEE Trans. Inf. Theory 2021, 67, 4669–4692. [Google Scholar] [CrossRef]
- Alemohammad, S.; Babaei, H.; Balestriero, R.; Cheung, M.Y.; Humayun, A.I.; LeJeune, D.; Liu, N.; Luzi, L.; Tan, J.; Wang, Z.; et al. Wearing A Mask: Compressed Representations of Variable-Length Sequences Using Recurrent Neural Tangent Kernels. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2021, Toronto, ON, Canada, 6–11 June 2021; pp. 2950–2954. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| K | NTKKM | K-Means |
|---|---|---|
| 2 | 0.441 | 0.402 |
| 3 | 0.502 | 0.395 |
| 4 | 0.425 | 0.432 |
| 5 | 0.404 | 0.312 |
| 6 | 0.371 | 0.291 |
| Date | GZ | WYS | PC | SW | JY | SX | … |
|---|---|---|---|---|---|---|---|
| 24 July | √ | × | √ | × | × | × | … |
| 2 July | × | √ | × | √ | √ | × | … |
| 3 June | √ | √ | × | √ | √ | √ | … |
| 9 December | × | × | √ | √ | √ | √ | … |
| 3 March | √ | √ | × | × | × | × | … |
| 13 May | √ | × | √ | √ | × | √ | … |
| … | … | … | … | … | … | … | … |
| Data Source Number | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 0.897 | — | 0.894 | 0.891 | 0.92 | 0.835 | 0.862 | 0.889 | 0.881 | 0.982 |
| 4 | 0.995 | 0.891 | 0.992 | — | 0.755 | 0.694 | 0.959 | 0.977 | 0.800 | 0.541 |
| 5 | 0.761 | 0.92 | 0.759 | 0.755 | — | 0.894 | 0.735 | 0.757 | 0.977 | 0.973 |
| 6 | 0.794 | 0.835 | 0.697 | 0.694 | 0.894 | — | 0.698 | 0.696 | 0.838 | 0.901 |
| 7 | 0.953 | 0.862 | 0.956 | 0.959 | 0.735 | 0.698 | — | 0.958 | 0.698 | 0.727 |
| 10 | 0.973 | 0.982 | 0.889 | 0.541 | 0.973 | 0.901 | 0.727 | 0.803 | 0.749 | — |
| Data Source Number | Neighboring Data Sources |
|---|---|
| 2 | 1, 3, 4, 5, 6, 7, 8, 9, 10 |
| 4 | 1, 2, 3, 7, 8, 9 |
| 5 | 2, 6, 9, 10 |
| 6 | 2, 5, 9, 10 |
| 7 | 1, 2, 3, 4, 8 |
| 10 | 1, 2, 3, 5, 6, 8 |
| Imputation Order Sequence | Confidence | Average Filling Error |
|---|---|---|
| (2, 4, 5, 6, 7, 10) | 0.5875 | 0.2326 |
| (4, 2, 5, 6, 7, 10) | 0.6349 | 0.1875 |
| (2, 4, 6, 5, 7, 10) | 0.6320 | 0.1898 |
| (2, 4, 7, 5, 6, 10) | 0.6001 | 0.2103 |
| … | … |
| Imputation Scenario and Amounts of Abnormal Data Source | KNN | Proposed Method |
|---|---|---|
| Jul 24th (6) | 0.4238 | 0.3510 |
| Jul 2nd (4) | 0.3944 | 0.2813 |
| Jun 3rd (2) | 0.2341 | 0.1566 |
| Dec 9th (2) | 0.2563 | 0.1329 |
| Mar 3rd (5) | 0.4017 | 0.3163 |
| May 13th (5) | 0.4356 | 0.3358 |
| … | … | … |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, G.; Zhu, Z.; Yang, L.; Huang, W.; Zhang, Y.; Lin, G.; Zhang, S. Intelligent Identification and Order-Sensitive Correction Method of Outliers from Multi-Data Source Based on Historical Data Mining. Electronics 2022, 11, 2819. https://doi.org/10.3390/electronics11182819
Chen G, Zhu Z, Yang L, Huang W, Zhang Y, Lin G, Zhang S. Intelligent Identification and Order-Sensitive Correction Method of Outliers from Multi-Data Source Based on Historical Data Mining. Electronics. 2022; 11(18):2819. https://doi.org/10.3390/electronics11182819
Chicago/Turabian StyleChen, Guangyu, Zhengyang Zhu, Li Yang, Wenhao Huang, Yuzhuo Zhang, Gang Lin, and Shengjie Zhang. 2022. "Intelligent Identification and Order-Sensitive Correction Method of Outliers from Multi-Data Source Based on Historical Data Mining" Electronics 11, no. 18: 2819. https://doi.org/10.3390/electronics11182819