1. Introduction
Deep neural networks (DNNs) have been widely used in modern artificial intelligence tasks such as image recognition and segmentation. The accuracy improvement in these tasks that is achieved by DNN models such as AlexNet [
1], GoogLeNet [
2], ResNet [
3], ResNeXt [
4], and DenseNet [
5] usually comes at the cost of extremely high computational complexity. These widely used DNN algorithms typically have tens of layers with tens to hundreds of megabytes (MBs) of parameters and require up to several billions of multiply-and-accumulate (MAC) computations even for single inference task, which demands both a large amount of computational hardware resources and considerable storage elements. Unfortunately, on-chip memory and the available computational resources are very limited in mobile and wearable devices (it was reported in [
6] that the capacity of SRAM is typically less than 1 MB), which makes it generally impossible to save the parameters and/or the intermediate results on-chip, even for one layer. It has also been pointed out in [
7] that the data movement is orders of magnitude more energy-consuming than the corresponding MAC computation. More specifically, the relative energy consumption of a 32-bit DRAM access in a 45 nm CMOS process is 6400
, 711
, 206
, 173
, and 128
greater than that of a 32-bit int ADD, a 32-bit float ADD, a 32-bit int MULT, a 32-bit float MULT, and a 32-bit SRAM read operation, respectively, as shown in [
8]. In addition, it has also been reported that the energy consumption of DRAM access can reach up to more than 80% of the total energy consumption in the well-known DNN accelerators, such as DianNao [
9] and Cambricon-X [
10]. Therefore, off-chip memory access has become the performance and energy bottleneck in DNN accelerators [
11,
12], and how to maximize the utilization of the already on-chip data is critical for memory-constrained accelerators.
In the literature, various techniques, such as pruning, compression, data reuse methods, etc., have been developed to reduce off-chip memory accesses for energy-efficient DNN processing. Among them, one of the most promising approaches is to leverage on-chip data reusability, such as with input feature map reuse (
) [
11], partial sum reuse (
) [
13,
14,
15], and weight reuse (
) [
16,
17]. These approaches have shown their advantages; however, they all consider each layer separately. Thus, no matter how large the on-chip memory is, the output feature map (ofmap) of each layer should be written to the off-chip memory and then read back as the input feature map (ifmap) of the next layer. As networks grow deeper, the amount of this shuttling data increases, leading to significant energy consumption. On the other hand, layer fusion [
12] was proposed to maximize the feature map (fmap) reuse in consecutive convolutional layers, and its effectiveness on MobileNet is shown in [
18]. The off-chip memory access of the weights, however, might increase. Moreover, it typically requires large on-chip memory for the storage of cross-layer feature maps, which makes it difficult to deploy it in memory-constrained designs. SuperSlash [
19] adopts the exploration approach of SmartShuttle [
11] and takes the advantage of layer fusion for off-chip DRAM access reduction. However, it only supports
in the first layer and
in the second layer of two fused layers. Moreover, it cannot support grouped convolutional layers. Consequently, the effectiveness of SuperSlash is limited in state-of-the-art neural networks, such as GoogLeNet and ResNeXt.
Although the existing works can effectively reduce the amount of off-chip memory accesses, as neural network models become more diverse for various applications, how to maintain high energy efficiency with limited hardware resources for diverse NN models is still an emerging challenge. To the best of our knowledge, no systematic approach to exploring the opportunity of both single-layer and inter-layer data reuse for minimizing off-chip memory access has yet been studied. Therefore, this paper proposes three inter-layer data reuse methods and a dataflow optimization approach to minimizing the amount of off-chip memory access in memory-constrained accelerators, with the following contributions:
- (1)
A mathematical analysis in terms of required off-chip memory access and on-chip memory capacity for the proposed inter-layer data reuse methods is introduced for modern neural networks. Unlike most of the existing data reuse methods, in which only AlexNet and a VGG-like structure are considered, our analysis can be applied to most of the existing convolutional neural networks, ranging from AlexNet, VGG, ResNet, and DenseNet to ResNeXt, etc.
- (2)
A comprehensive exploration to precisely determine the optimal data reuse strategy from various single-layer and inter-layer-based reuse approaches is proposed for memory-constrained DNN accelerators. Unlike the single-layer-based SmartShuttle and the layer-fusion-based SuperSlash, our method can determine the optimal data flow and the corresponding data reuse strategy along layers; thus, the proposed method can always achieve minimum DRAM access for accelerators with various SRAM capacity.
The rest of this paper is organized as follows.
Section 2 gives the background. The mathematical analysis of the inter-layer data reuse methods is introduced in
Section 3, and the optimal dataflow exploration method is illustrated in
Section 4. The evaluation results are presented in
Section 5. Finally,
Section 6 concludes this paper.
3. Inter-Layer Data Reuse
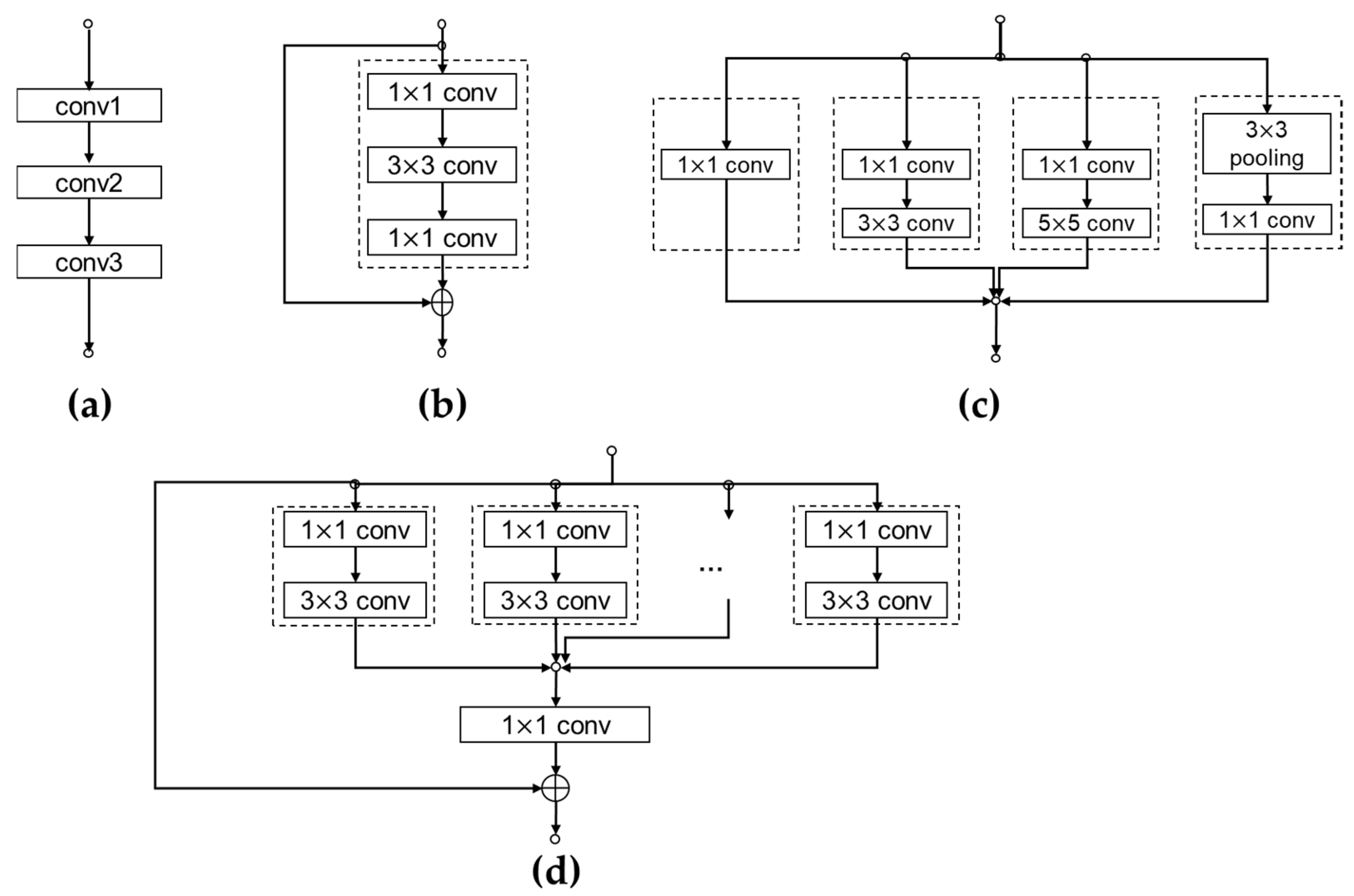
Unlike with single-layer-based data reuse approaches, to improve the efficiency of data reuse across layers we should carefully study the data dependency in the basic module of each network model. Some typical modules in modern networks, such as the normal CONV layers in AlexNet and VGG, the Inception modules in GoogLeNet, and the Bottleneck blocks in ResNet and Network-in-Neuron in ResNext, are shown in
Figure 2, in which, if two or more consecutive layers can be fused together, the corresponding off-chip memory access of the inter-layer feature maps can be eliminated. Moreover, if the input feature maps of the grouped convolutional layers, such as the Inception module and Network-in-Neuron shown in
Figure 2c,d, can be reused, the off-chip memory access can also be reduced. Thus, without loss of generality, grouped convolutional layers, such as those in the Inception module and Network-in-Neuron, are used as the basic module for exploration in our work as it can be easily transformed to other ones, such as the normal CONV layers in VGG and the Bottleneck block in ResNet.
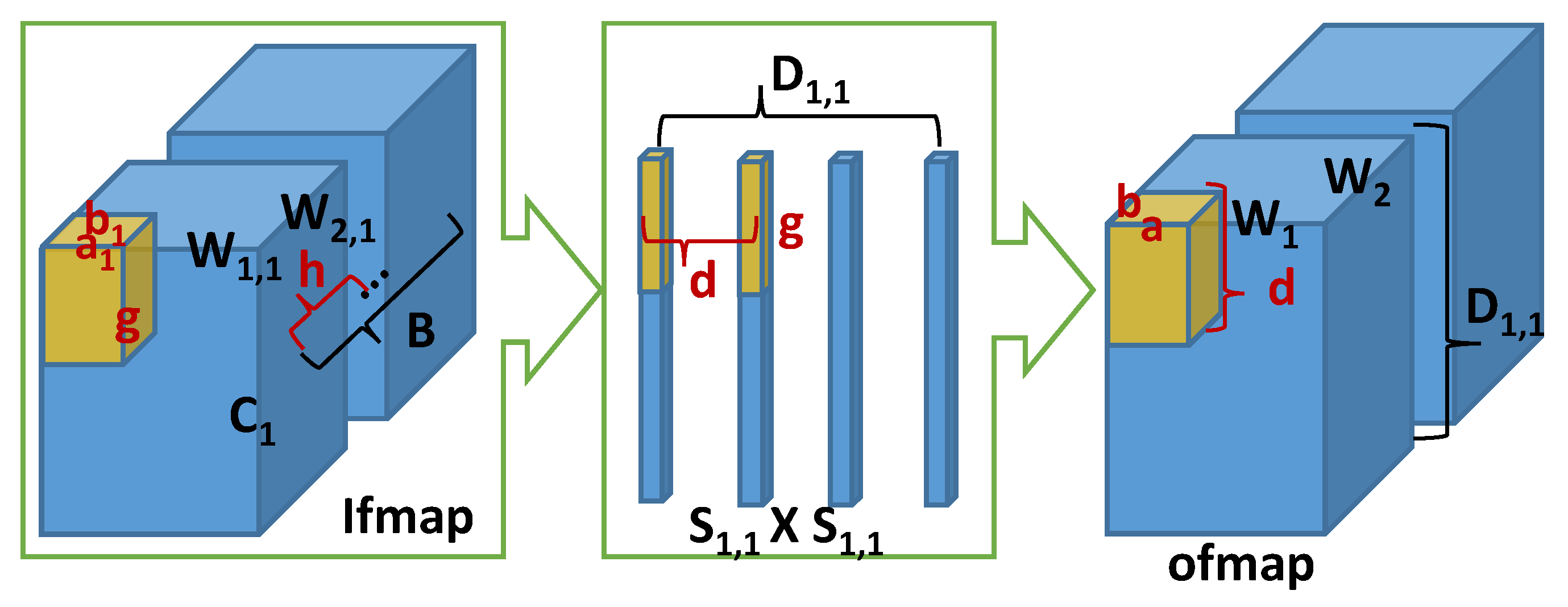
According to the discussion on single-layer-based dataflow, the optimal dataflow problem can be thought of as how to partition ifmaps and weights into small tiles for efficient data reuse so as to minimize the total amount of off-chip memory access with the limited capacity of on-chip memory. As with the single-layer-based dataflow shown in
Figure 1, the dataflow of the fused 2-layer (F2L) is shown in
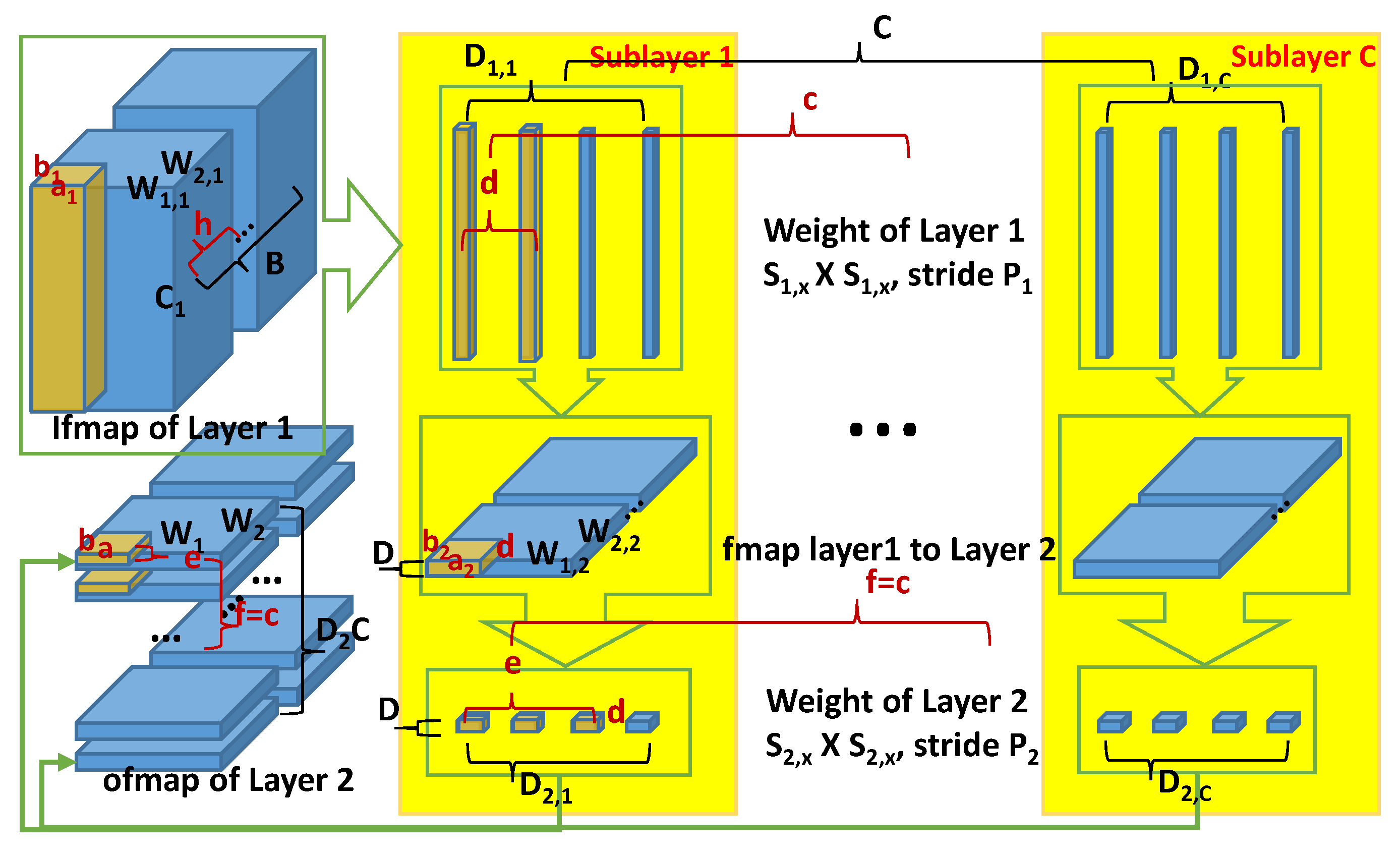
Figure 3, in which there are
sublayers (i.e., Cardinality), and each of them has two layers, indicated as Layer 1 and Layer 2. It is worth noting that although this paper mainly discusses data reuse in two fused CONV layers, the idea of the proposed analysis and exploration can be extended to the cases with more CONV layers being fused together in a similar way and can also be applied to be combined with CONV layers with FC layers and pooling layers.
As shown in
Figure 3, in order to generate the
ofmap values of Layer 2, with the consideration of zero-padding, the required ifmaps of Layer 2 (i.e., the ofmap of Layer 1) need to be
, which is represented as
in the figure, and consequently, the required ifmaps of Layer 1 denoted as
should be
. If these ifmaps can be fetched in an optimal way, the corresponding off-chip memory access of the inter-layer ofmap/ifmap can be eliminated in F2L. Moreover, because all the sublayers have the same ifmap, the ifmap movement can be reduced through exploring the parallelism of the sublayers under the constraint of the on-chip memory capacity. Because the off-chip memory access of the ifmap data of Layer 1 depends on the ratio of the total amount of weights of the layer to the size of the weight tiles, without proper data reuse, each ifmap and each weight need to be read from the off-chip memory
and
times, respectively.
Unlike the existing layer-fusion-based methods [
12,
18], in which only fmap reuse is considered, the proposed strategies for the various data reuse in the fused 2-layer are illustrated in the following. Here, we assume that the ifmap tile of Layer 1 should cover all the
channels, as shown in
Figure 3; thus, the size of an ifmap tile can be expressed as
.
We first introduce the accurate mathematical analysis for ifmap reuse in the fused 2-layer (). The strategy of is to store as many ifmaps of Layer 1 as possible and to ensure that the inter-layer feature maps and all the generated psums can be stored in a global buffer, while the rest of the global buffer can be used to store as many weights as possible to increase the degree of parallelism and speed up the operation.
As with the existing single-layer-based data reuse schemes, also has four stages: (1) the ifmaps and weights of Layer 1 are loaded from the off-chip memory (i.e., DRAM) to an on-chip global buffer; (2) the ifmaps and weights of Layer 1 are transferred to a local buffer, and the convolutional computations are conducted by fully reusing the on-chip ifmaps to generate the ofmap values of Layer 1 (i.e., the ifmap values of Layer 2); (3) the ofmap of Layer 1 is saved on-chip, and the required weights of Layer 2 for the generated ofmaps of Layer 1 are read; and (4) the ofmap values of Layer 2 are generated and written to the off-chip DRAM.
The corresponding pseudo-code of
is shown in
Figure 4a, where
. The pseudo-code of
contains four loops, and the outermost loop shows how the ifmaps are reused in two fused layers; this indicates that each ifmap of Layer 1 needs to be loaded only once, and the ofmaps of Layer 1 (i.e., ifmaps of Layer 2) are kept on-chip for inter-layer feature map reuse.
In , an ifmap tile of Layer 1 with the size of is first read from the DRAM. After transmitting the ifmap tile into the on-chip global buffer, one filter of the jth sublayer in Layer 1, with the size of where , is fetched. With these ifmaps and filters, the corresponding ofmap data of Layer 1 (i.e., the ifmap of Layer 2 with the size of ) can be generated. Then, the corresponding filers of Layer 2 will be read from the DRAM. Because only one channel of the imaps of Layer 2 is on-chip, only one channel in the filter of the jth sublayer in Layer 2 (in size of ) is required to be fetched for the convolutional computations. Consequently, by using the on-chip ifmaps and weights, the corresponding psum of Layer 2 with the size of can be generated and saved on-chip. Then, by reading only one new channel of the next filter of Layer 2 from the DRAM, another psum of Layer 2 can be generated by using the already on-chip ifmaps. Finally, the psums of Layer 2 can be generated in this loop, and the corresponding on-chip buffer should be reserved for the storage of these psums for further accumulation. When the on-chip ifmaps of Layer 2 have been completely reused, they are discarded, and new filters of Layer 1 are fetched for the generation of the new ofmaps of Layer 1. After the corresponding psums of Layer 2 have been fully accumulated, the results are transmitted to the DRAM as the ofmap tile in the jth sublayer. When the on-chip ifmaps of Layer 1 have been fully reused, the next ifmap tile is loaded and the above steps are repeated.
For efficient ifmap reuse in the fused layers, it is desired that both the required ifmap data of Layer 1 and the corresponding psum data of Layer2 should be kept on-chip. Let the ifmap tile of Layer 1 be in the size of
and thus with the consideration of padding
. It is worth noting that here
and
indicate the largest filters in Layer 1 and 2, respectively, which is because the filter size in grouped convolution might be different, as with that in GoogLeNet, as shown in
Figure 2c. As the transaction frequency of the weights depends on the ratio of the on-chip ifmap data to the total ifmap data of Layer 1,
c,
d, and
e can even be set as 1 for the saving of the required on-chip resources for the storage of ifmaps and psums.
Assuming that the number of output channels of a sublayer is
and that
indicates the maximum output channels among all the sublayers, the global buffer must be large enough to store
psums. In addition, it is necessary to store
ifmaps,
inter-layer feature maps (fmaps) from Layer 1 to Layer 2, where
with the consideration of padding, and the maximum weights of a layer in specific channels among all the sublayers. Therefore, the total amount of off-chip DRAM access in
(
) for all the ifmaps/weights/ofmaps is:
and the required on-chip global buffer capacity is:
Similarly, weight reuse in the fused 2-layer () is also possible. However, the capacity of the on-chip memory will affect the dataflow, depending on whether the weights of more than one sublayer can be stored on-chip or not. To store all the weights of more than one sublayer requires a large amount of global buffer capacity, but if it is possible, the ofmap values of Layer 2 can be generated by using only the on-chip data, which can help to save the amount of global buffer used for psum storage. On the other hand, if only a part of the weights of one sublayer are stored on-chip, more on-chip memory is required to store the intermediate psums. As networks become more diverse, we cannot expect to obtain satisfying results by storing all the required weights on-chip, especially for the cases in the fused layers. Therefore, the accurate analysis and formulation of off-chip memory access with given on-chip memory capacity are provided in the following.
Case 1: Weights of more than one sublayer can be stored on-chip ()
The points of this data reuse strategy fall into two folds: to store as many weights as possible in the global buffer and to save as many ifmaps of Layer 1 as possible on-chip. In this case, if the weights of at least one sublayer are completely stored on-chip, the ofmaps can be generated by only using the on-chip data. Although the storage of these weights is required, the total amount of on-chip memory used for the psum storage might be reduced.
The pseudo-code of
is shown in
Figure 4b. There are five loops in
, and the outermost loop shows how the weights of the two fused layers are reused, in which each weight only needs to be fetched once. Initially, the
weights of Layer 1 and the
weights of Layer 2 are fetched from the off-chip memory. After that, the
ifmaps of Layer 1 are also fetched. Because the frequency of the data transaction to read in the ifmaps depends on the on-chip weights and each weight should be read from the off-chip memory only once in weight-reuse-based dataflow, the parameter
can therefore be set as small as 1. However, if
and
are too small,
might be greater than
, which slightly influences the off-chip memory access, and the saved on-chip memory can be used to store more weights for further DRAM access reduction.
In general, the global buffer needs to store
weights of Layer 1 and
weights of Layer 2;
ifmaps of Layer 1; and the
inter-layer fmaps. Therefore, the required amount of off-chip memory access of
can be expressed as
and the required capacity of the on-chip global buffer is
Case 2: Weights of less than one sublayer can be stored on-chip ()
The strategy of
is to store as many weights in the global buffer as possible, while keeping enough storage space for the intermediate generated psums of Layer 2 and storing as many ifmaps of Layer 1 as possible. In this case, because the on-chip global buffer only stores weights of less than one sublayer, it needs to keep sufficiently large global buffer resources to store the corresponding psums to avoid off-chip memory accesses of the psums. The pseudo-code of
is shown in
Figure 4c.
In this case, the global buffer needs to store
weights for Layer 1;
weights for Layer 2; the
ifmaps; the
inter-layer fmaps; the and
psums; therefore, the amount of DRAM accesses and the capacity of the global buffer of
are:
and
The psum reuse in fused 2-layer (
) is to maximize the reuse of psums. Storing the relevant data of the integral sublayers can directly generate ofmaps of Layer 2, which makes it possible not to store additional psums in a global buffer. Therefore, psum reuse is only applied for the case in which weights of more than one sublayer can be stored on-chip. The corresponding pseudo-code of
is shown in
Figure 4d.
In
, the
weights of Layer 1 and the
weights of Layer 2 should be stored in a global buffer; they are read from the off-chip memory
times. The amount of on-chip ifmaps is
, and the same ifmaps of Layer 1 need to be read from the off-chip memory
C times. Therefore, in
, no psums need to communicate with the off-chip memory, while both the weights and the ifmaps need to be read several times. Thus, the tiling size should be carefully selected for off-chip memory access minimization. Generally, the global buffer needs to store
weights for Layer 1;
weights for Layer 2;
ifmaps of Layer 1;
inter-layer fmaps; and
psums. Thus, the required DRAM access (
) and on-chip memory capacity (
) are:
and
4. Optimal Dataflow Exploration for Hybrid Data Reuse
Up till now, the comprehensive mathematical formulation for the inter-layer data reuse approaches have been derived, which makes it possible for us to conduct a design space exploration to determine the optimal inter-layer data reuse strategy with the corresponding tiling parameters for minimizing off-chip memory access while meeting the capacity constraint of on-chip memory. The optimization problem for inter-layer data reuse is formulated as follows:
where
and
represent the minimum off-chip memory access in F2L and the maximum capacity of the global buffer in a specified DNN accelerator, respectively.
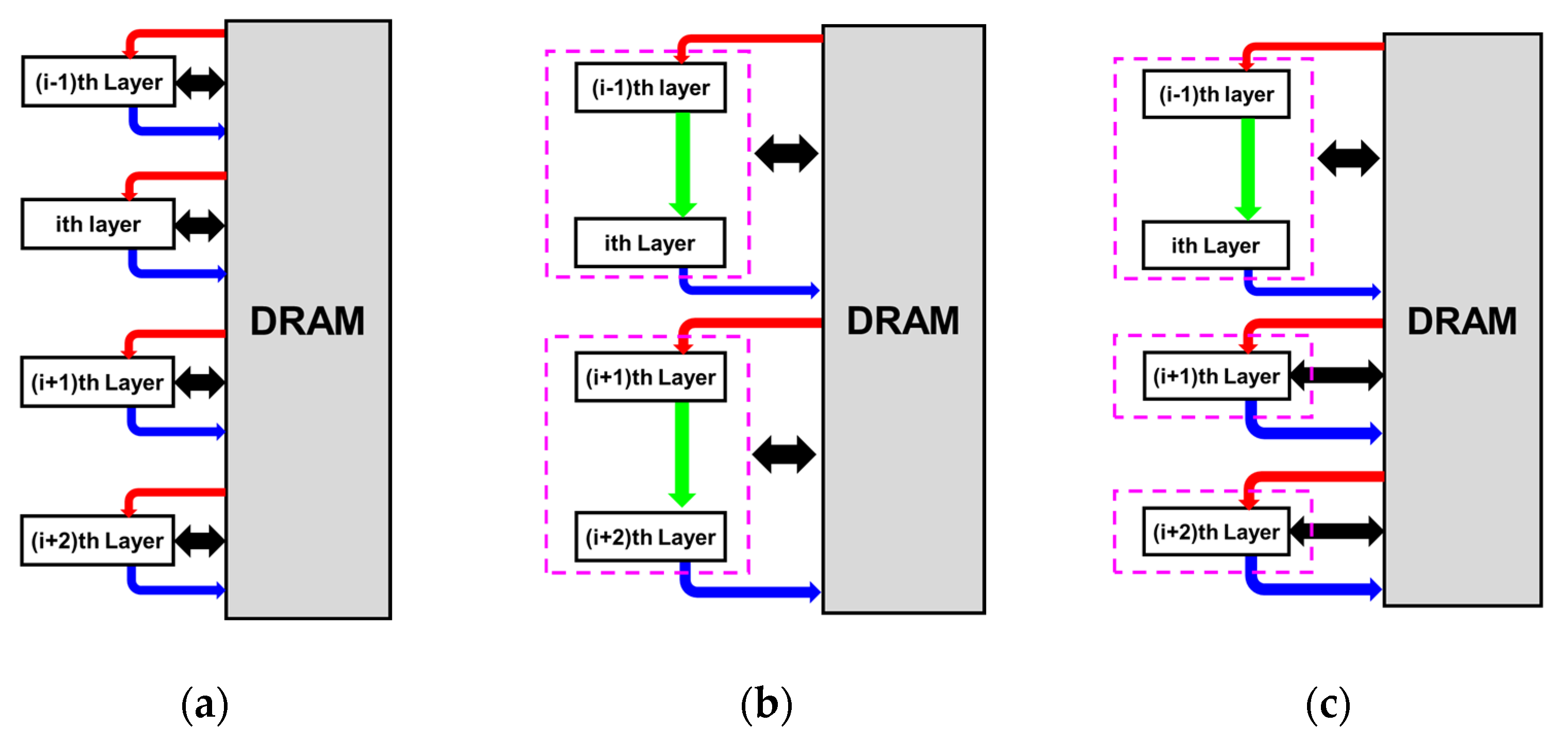
Considering the diversity of neural networks, we extend the exploration space for further optimization, and the improved formulation to determine the optimal data reuse strategy from single-layer-based and inter-layer-based data reuse approaches is given as below, with the concept of this hybrid data reuse approach shown in
Figure 5.
where
and
represent the minimum off-chip memory access required in inter-layer data reuse (i.e., fused 2-layers) and that using the single-layer-based data reuse, respectively. In the exploration of single-layer-based data reuse approaches,
,
, and
are explored layer-by-layer; thus, we can adaptively determine the optimal data reuse strategy for each layer. According to the above formulas, we can determine the optimal data reuse strategy with the corresponding tiling parameters
from single-layer-based and inter-layer-based data reuse approaches for DNN accelerators under the constraint of on-chip storage capacity.
In our work, the optimal data reuse strategy with the corresponding tiling parameters are obtained through the optimal dataflow exploration with a brute force search. In the single-layer-based exploration, in order to minimize the total amount of off-chip memory access, all the possible data reuse strategies with the corresponding tiling sizes will be explored. Because the exploration is conducted with the given constraints, the design space is not large, and the exploration can be finished in seconds. On the other hand, with regard to the inter-layer-based data reuse exploration, it will become much more complex because we need to consider how many, and which, layers can be fused. To reduce the computation complexity, this work only focuses on the exploration of the optimal dataflow of two consecutive convolutional layers. Unlike single-layer-based exploration, inter-layer-based data reuse exploration is conducted in a back-and-forth way; thus, the computation complexity is reduced.
Figure 5 illustrates the concept difference between the single-layer-based dataflow, the layer-fusion approach, and the proposed optimal hybrid approach, from which it is clear that as a more flexible approach, the proposed method promises to outperform the existing methods with less off-chip memory access.
5. Evaluation and Comparison Results
With all the derived formulations as shown above, the proposed optimal dataflow exploration method is built in Python, which takes (i) the layer information of a target neural network and (ii) the memory constraint of a DNN accelerator as inputs. In our work, the exploration is performed in an exhaustive search manner for minimum DRAM accesses. As an output, the optimal dataflow with the corresponding tiling configurations will be generated.
To confirm the effectiveness of the proposed optimal exploration method over the state-of-the-art exploration methods, we run evaluations by using three popular modern networks, DenseNet-121 [
5], ResNeXt-50 [
4], and AlexNet [
1]. It is worth noting that because nonlinear operations, such as ReLU, pooling, and BN, can be performed on-chip, this work only focuses on the exploration of the optimal dataflow of two consecutive convolutional layers.
DenseNet was proposed by Huang et al. in [
5]. The basic module in DenseNet, the DenseLayer in each Dense Block, is similar to the traditional modules, such as those in AlexNet and VGG, except that each layer in DenseNet takes all the outputs of the preceding layers as its input. Thus, the shape parameter
C used in DenseNet is 1. The selection of DenseNet is due to the high classification accuracy and its dense connection between layers.
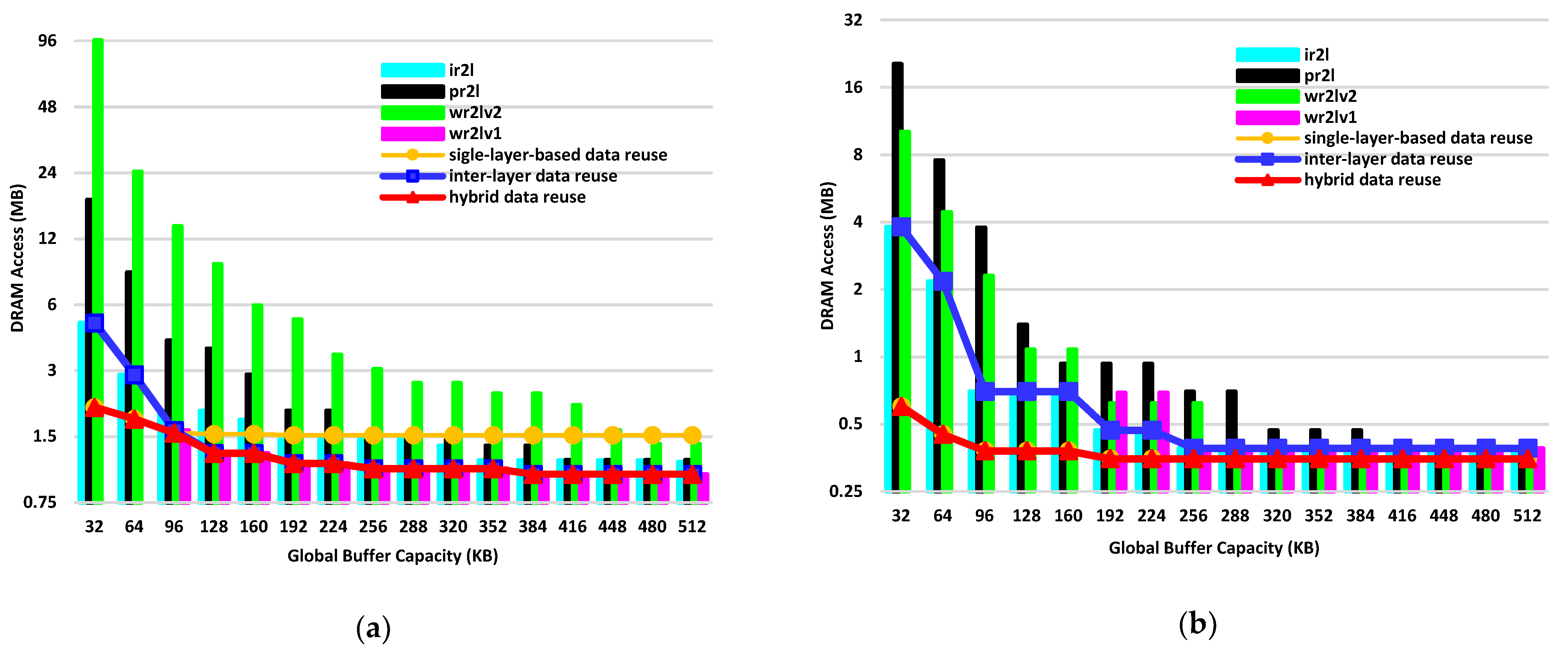
As an example,
Figure 6 shows the exploration results for the 8th DenseLayer in Dense Block (2) and the last DenseLayer in Dense Block (4), both of which contain 1 × 1 and 3 × 3 convolution layers, respectively, with the global buffer capacity ranging from 32 KB to 512 KB.
For the results in
Figure 6a, the ofmap size of Layer 2 (
) is
; the number of input channels of Layer 1 (
) is 336; the number of output channels (
) of Layer 1 (i.e., the input channels of Layer 2) is 128; and the number of output channels (
) of Layer 2 is 32. The filter sizes of Layer 1 and Layer 2 (
and
) are
and
, respectively, and the batch size (
) is 3. For the results of the inter-layer data reuse methods (i.e.,
,
,
, and
), when the size of global buffer is smaller than 64 KB,
achieves the minimized off-chip memory access; while when the size of global buffer is greater than 96 KB,
has the best result. This explains that the proper inter-layer data reuse approach should be adaptively selected under the constraint of the on-chip memory capacity. On the other hand, when compared to the best results of single-layer-based data reuse (i.e.,
,
, and
), it is obvious that single-layer-based data reuse always has less off-chip memory access than the inter-layer data reuse methods when the on-chip memory is small, while the inter-layer data reuse methods have better results if given a large on-chip memory. Due to the variations of the off-chip memory access in modern neural networks, this confirms that we need to select the best approach from the single-layer and inter-layer-based data reuse methods for minimizing off-chip memory access.
Figure 6b shows the results of the last DenseLayer in Dense Block (4) of DenseNet-121, in which
, and
. Unlike the results shown in
Figure 6a, the optimal single-layer-based data reuse method always outperforms the inter-layer-based data reuse methods for the cases when the global buffer capacity ranges from 32 KB to 512 KB. In the case of inter-layer data reuse with two fused layers, for each ofmap value of Layer 2 the required ifmap values of Layer 1 in F2L should be
, which is because the filters in the two consecutive layers are
and
, respectively. On the other hand, in the single-layer-based reuse approaches, the corresponding ifmap size is only
, as the filter size in Layer1 is
. Therefore, even though the single-layer-based reuse approach needs to read and write
fmaps from Layer 1 to Layer 2, the total amount of off-chip memory accesses is smaller than that of the inter-layer-based methods. This example illustrates that, even though the global buffer is sufficiently large, inter-layer-based reuse methods cannot always outperform the single-layer-based reuse approaches. Therefore, it is necessary to perform accurate mathematical analysis on target DNN models to determine the optimized dataflow (single-layer or inter-layer-based data reuse strategy with the corresponding tiling parameters) layer by layer for off-chip memory access minimization in designs with limited on-chip memory capacity.
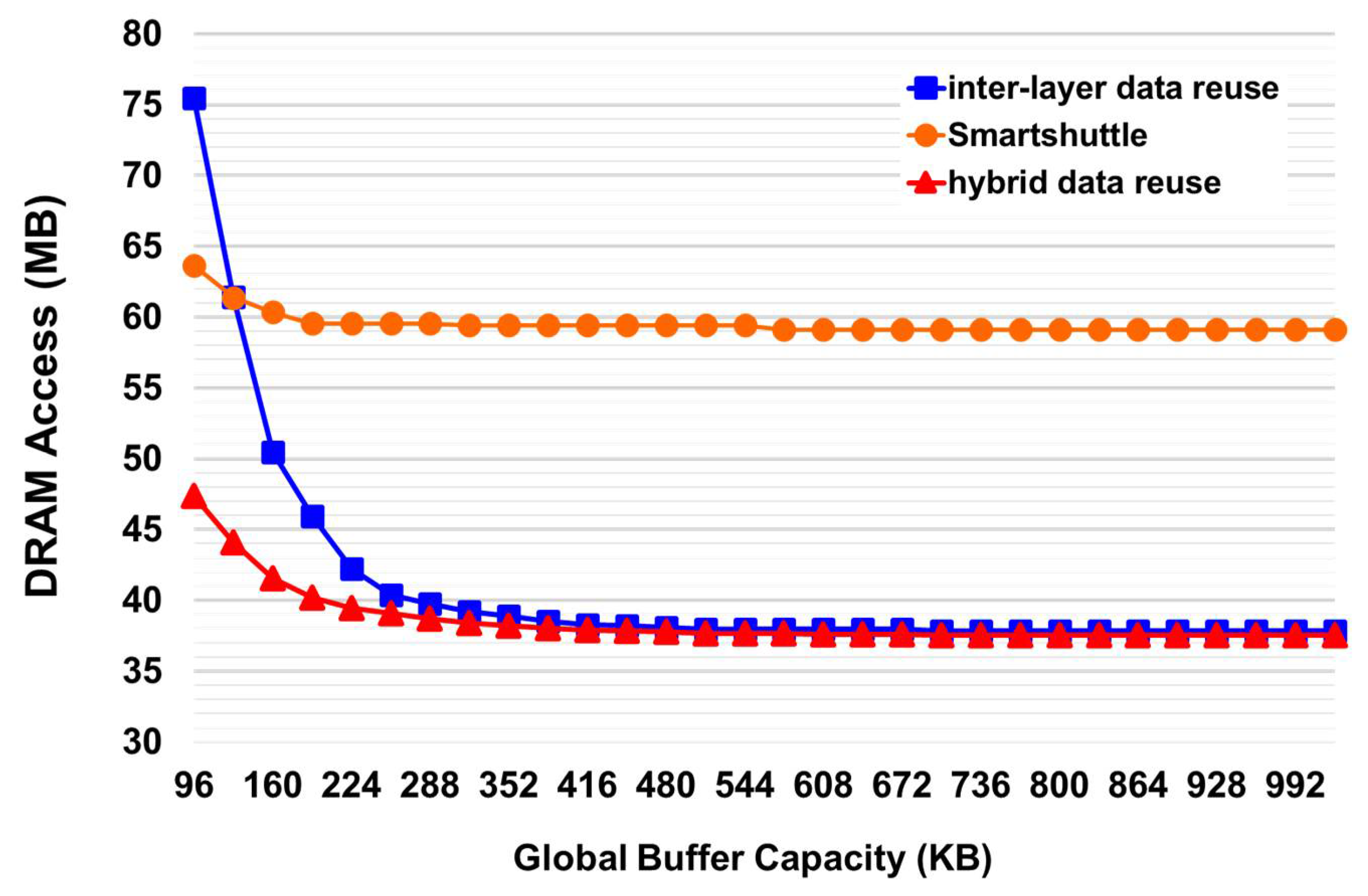
Figure 7 provides the results on the total amount of off-chip memory access of DenseNet-121 with
and
[
4] under the various capacity constraints of the on-chip global buffer. To gain more insights, the results of the existing single-layer-based exploration method, SmartShuttle [
11], are also provided for comparisons. Consistent with the results shown in
Figure 6a, inter-layer reuse with two fused layers outperforms single-layer reuse with SmartShuttle when the capacity of the on-chip memory is larger than 128 KB, while single-layer reuse is suitable for DNN accelerators with small on-chip memory. Moreover, the proposed hybrid data reuse approach outperforms single-layer reuse with SmartShuttle and inter-layer reuse with two fused layers in all the cases, especially in the range that is close to the intersection of the two curves. With a 128 KB on-chip memory, the hybrid data reuse can achieve 24.3% of off-chip memory access reduction when compared to the two methods. For the capacity of on-chip memory ranging from 64 KB to 512 KB, the hybrid data reuse approach can achieve up 32.5% and 48.7% of off-chip memory access reduction when compared to single-layer reuse and inter-layer reuse, respectively. With larger on-chip memory, the benefit of the hybrid reuse over the inter-layer reuse becomes less because most of the off-chip memory access reduction is achieved by inter-layer data reuse, while the case shown in
Figure 6b occupies only a small proportion. With 1 MB on-chip memory, the hybrid reuse requires 0.7% less DRAM access than the inter-layer reuse. It is worth noting that when the capacity of the on-chip memory becomes large enough, the required amount of DRAM accesses would become saturated; however, larger memory requires more power consumption.
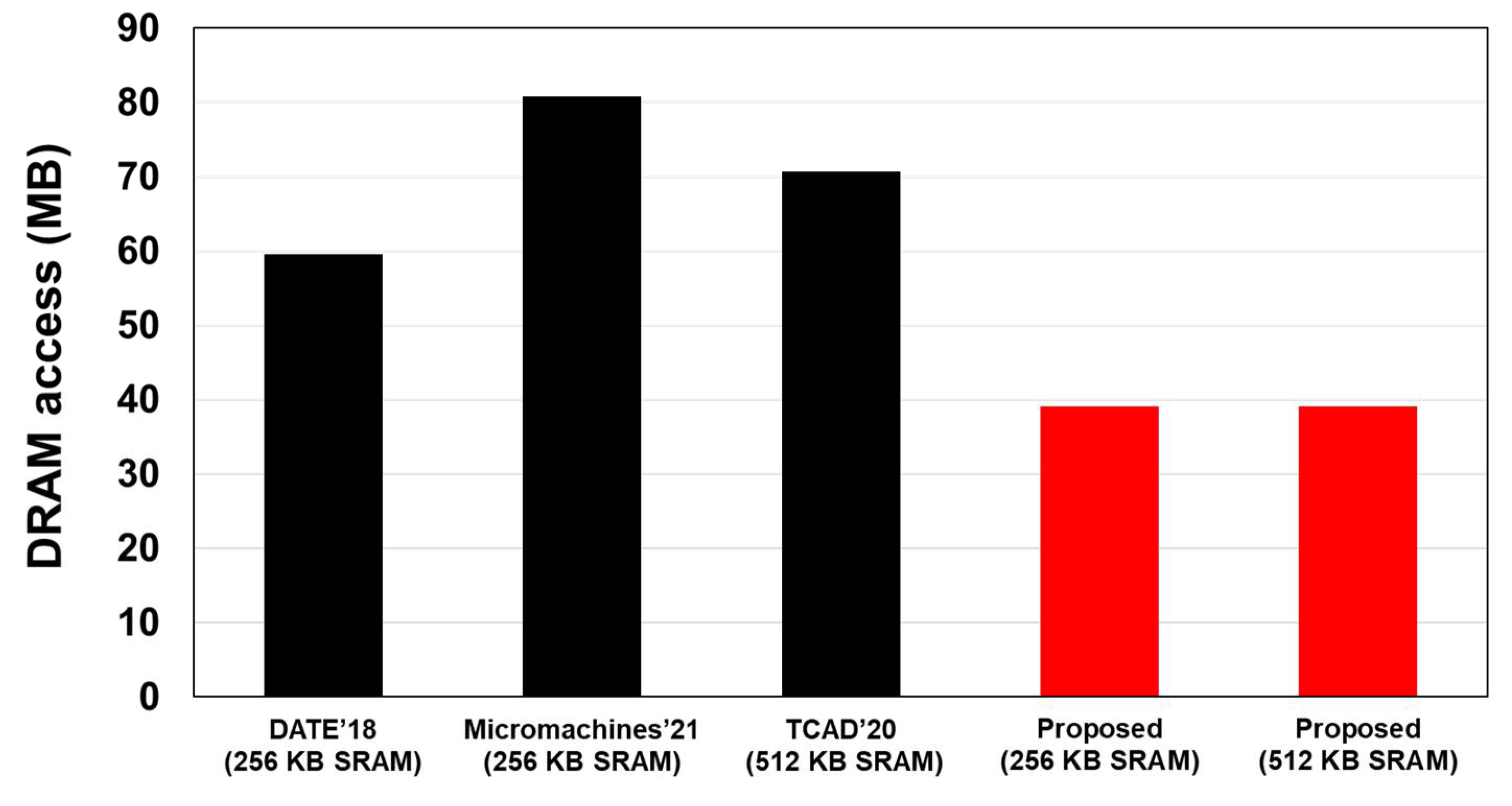
Comparison results with recent works such as [
24,
25] are presented in
Figure 8 together with SmartShuttle [
11]. From the figure, it can be observed that with the same amount of on-chip memory, our method can achieve 46.7% and 51.6% of off-chip memory access reduction when compared to the recent works [
24,
25], respectively.
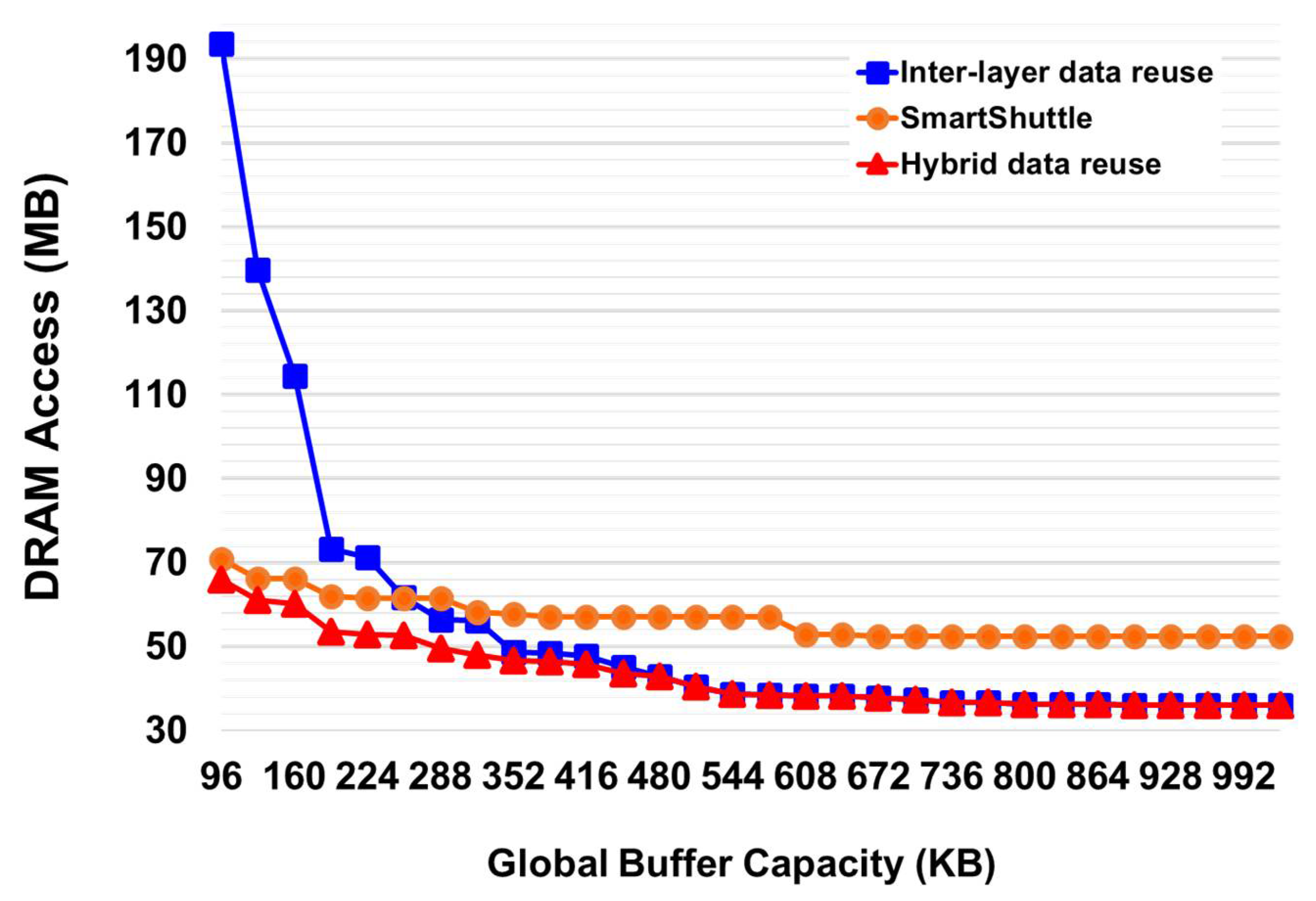
The second result is on ResNeXt-50, a DNN model with 32 sublayers (
) and 50 layers [
4]. ResNeXt is a homogeneous neural network with the Network-in-Neuron shown in
Figure 2d. Unlike DenseNet, there are 32 groups in the grouped convolution in ResNeXt.
The result of ResNeXt is shown in
Figure 9, which is similar to that of DenseNet shown in
Figure 7. For ResNeXt, the intersection point of single-layer reuse with SmartShuttle and inter-layer reuse with two fused layers exists when the capacity of the on-chip memory is 256 KB. When the on-chip memory becomes larger, inter-layer reuse outperforms single-layer reuse, and up to 20.5% of the DRAM access can be reduced. Meanwhile, as with that in DenseNet, the hybrid reuse can always obtain better results than both the single-layer reuse with SmartShuttle and the inter-layer reuse with two fused layers. Although hybrid reuse obtains the same results as inter-layer reuse does when the on-chip memory becomes larger than 480 KB, for the capacity of on-chip memory ranging from 64 KB to 576 KB, the hybrid data reuse approach can achieve up to 20.5% and 66.9% of off-chip memory access reduction when compared to single-layer reuse and inter-layer reuse, respectively.
The third result is on AlexNet [
1], a well-known early neural network that won the ImageNet Challenge in 2012. Unlike DenseNet and ResNeXt shown above, the architecture of AlexNet is irregular; for example, the first CONV layer has a large filter size (11 × 11) with a stride of 4, and the 3 × 3 maximum pooling layers with a stride of 2 are added after the 1st, 2nd, and 5th CONV layers, which makes it difficult for optimal dataflow exploration. Therefore, to evaluate the applicability of the proposed method to diverse neural networks, comparison results with SmartShuttle [
11] and SuperSlash [
19] are given in
Figure 10.
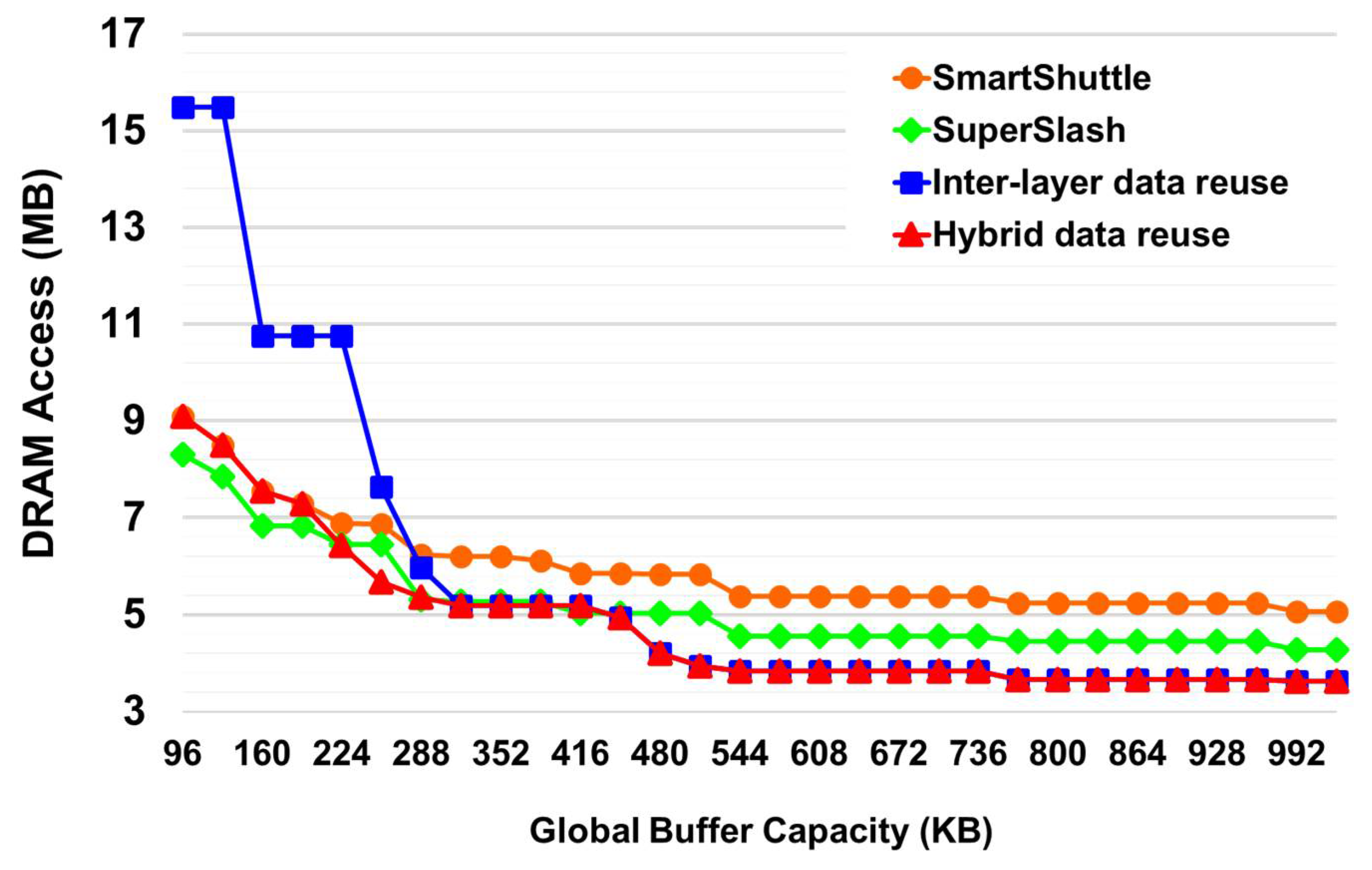
In
Figure 10, SmartShuttle [
11] is used as a baseline for comparison, and all the other methods are normalized to it. SuperSlash [
19] can obtain better results than SmartShuttle in all the cases, while the proposed methods show significant improvements (up to 17.6%) over SuperSlash when the global buffer capacity is greater than 480 KB. It should be mentioned that with a small global buffer such as one in which the size is less than 224 KB, SuperSlash performs better than the proposed method with 0.2–9.5% of DRAM access reduction. This is because the proposed inter-data reuse method needs to store all the channels of the ifmaps of Layer 1 and one full channel of the filters of Layer 2, which results in it having a smaller exploration space than SuperSlash does.
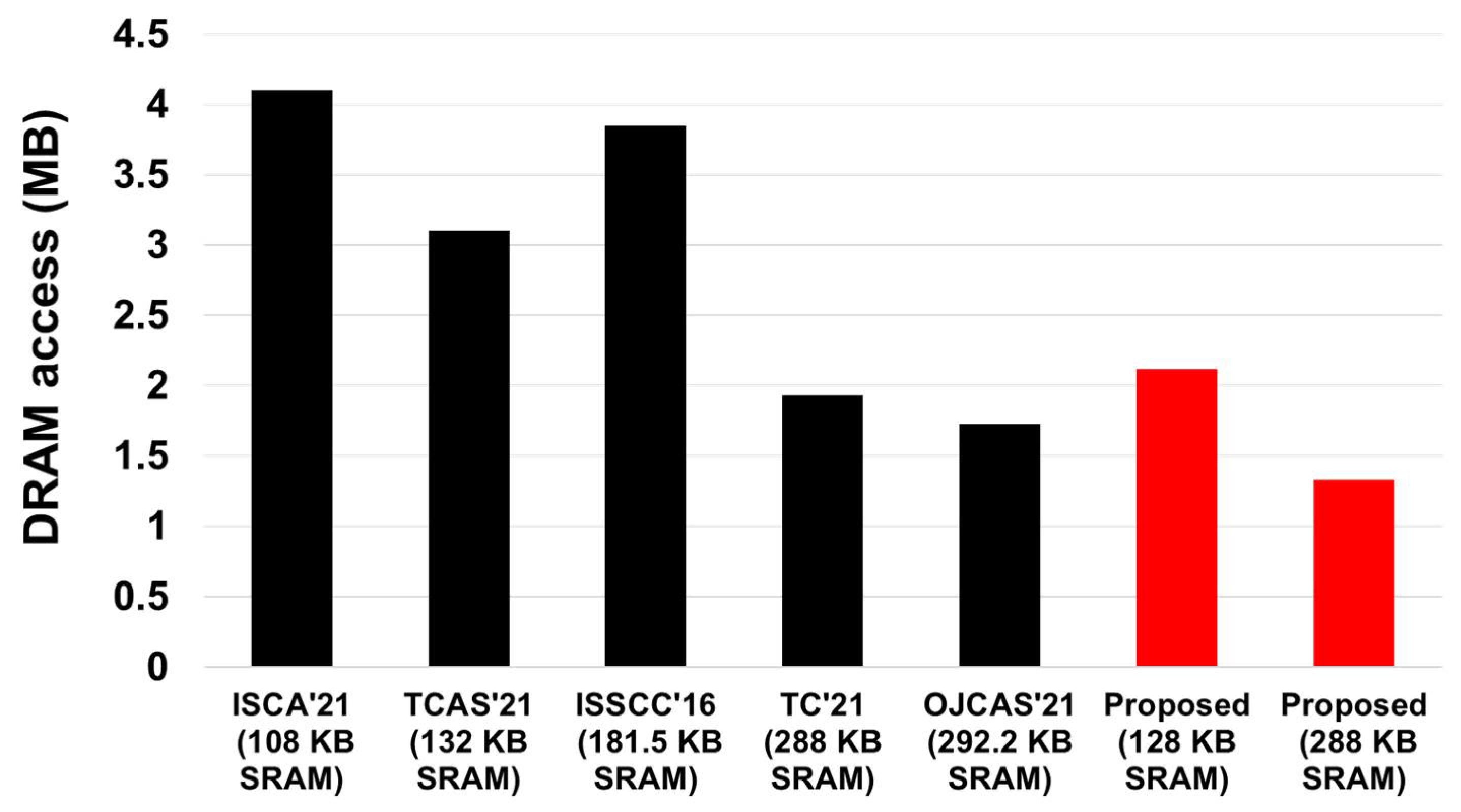
Figure 11 shows the corresponding comparison results for AlexNet with batch size = 1. With 288 KB SRAM, our method can achieve 31.1% and 23.1% of off-chip memory access reduction when compared to the recent works [
22,
23].
The results of the three modern networks show the effectiveness of the proposed hybrid data reuse approach in minimizing off-chip memory access, where hybrid reuse outperforms single-layer reuse and inter-layer reuse in accelerators with larger and smaller on-chip memory, respectively. The existing edge devices supporting TinyML typically contain less than 1 MB SRAM [
6], and the on-chip memory capacity of modern DNN accelerators also ranges from 100 KB to 1 MB. Furthermore, it has been indicated by Han et al. [
8] that a common MCU usually has an SRAM smaller than 512 KB (for example, Cortex M7 STM32H743 (512 KB), STM32F746 (320 KB), and STM32F412 (256 KB)). Therefore, it is expected that these memory-constrained devices will benefit from the proposed hybrid reuse approach for more energy efficient DNN processing.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}