
Improved Boundary Support Vector Clustering with Self-Adaption Support


Abstract
:1. Introduction
- (1)
- A movable edge selection (MES) method with self-adaption support is proposed. It collects local data samples from the boundaries of clusters divided by the k-means++, removes the fake edge patterns, and shrinks the remaining edges for requisite connectivity and fewer outliers. Due to the divide-and-conquer strategy, the achieved efficiency improvement enables MES to efficiently handle large-scale data analyses and supply informative and reasonable edges.
- (2)
- For an appropriate kernel width q, a flexible parameter selection (FPS) strategy is presented in the direct model construction without a penalty factor C. Rather than the traditional search strategy, FPS automatically adjusts q in a smaller range with a clearer target, i.e., the iterative directions drawn by the model is close to the actual data pattern. More importantly, no complete clustering procedure is required by each adjustment of q.
- (3)
- Benefiting from the divide-and-conquer strategy and the convex decomposition-based labeling strategy [12], IBSVC can easily adjust the discovered clusters by considering the neighborhood relationship of convex hulls even though there is no prior knowledge of the cluster number.
2. Preliminaries
2.1. Classical SVC
2.1.1. Estimation of a Trained Support Function
2.1.2. Cluster Assignments
2.2. Boundary SVC
3. The Proposed IBSVC
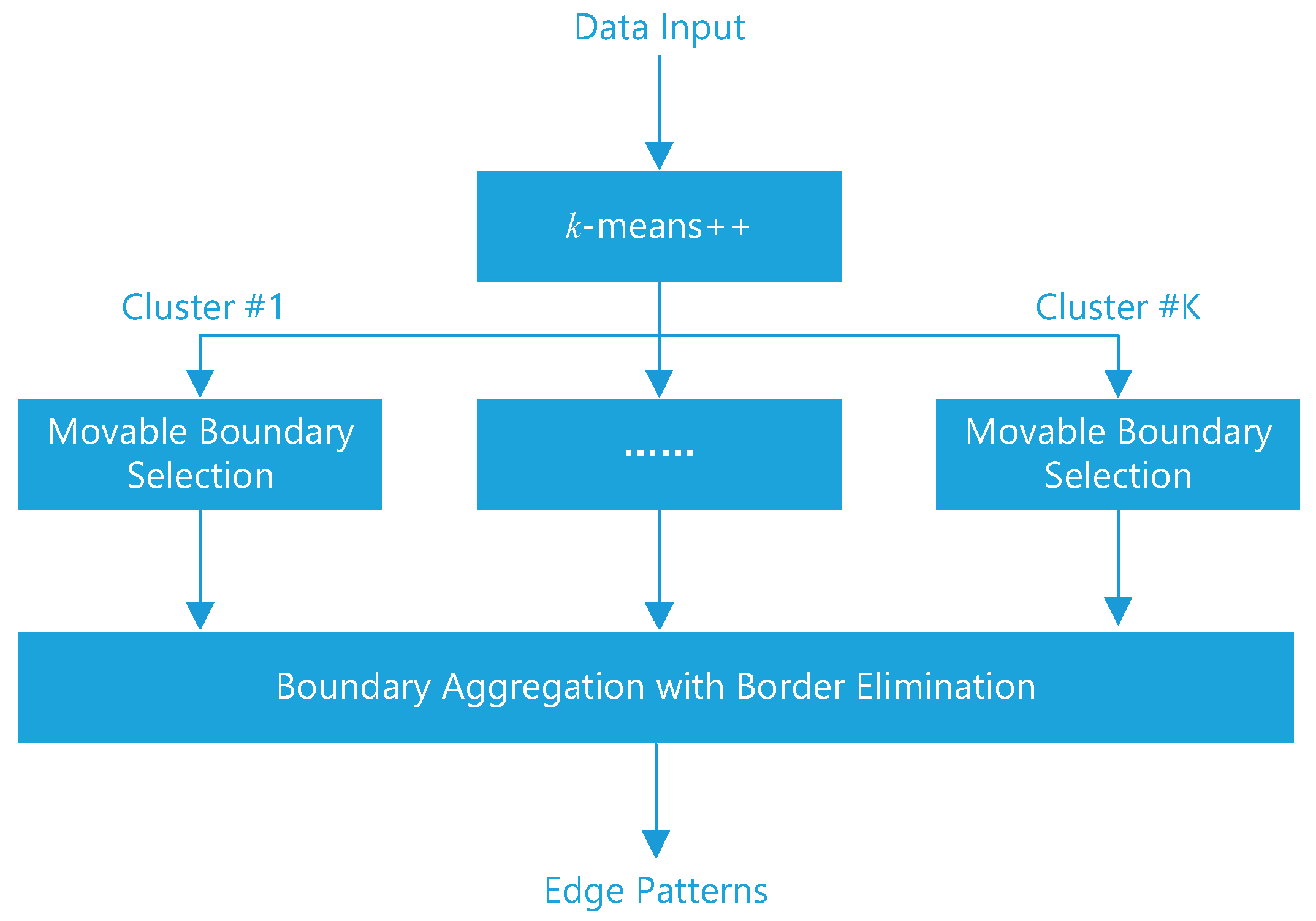
3.1. Movable Edge Selection
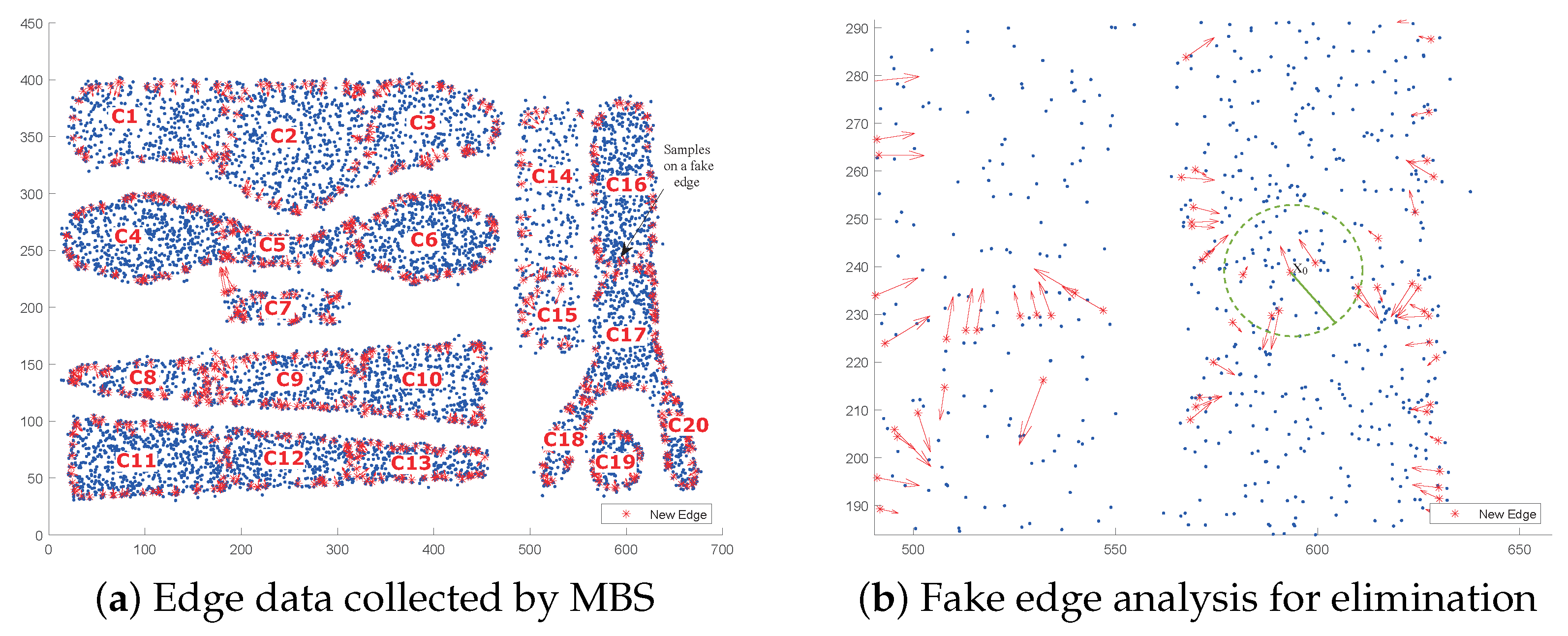
3.1.1. Movable Boundary Selection
| Algorithm 1 Movable Boundary Selection |
| Require: Dataset , thresholds , integer Ensure: Original edges and normal vectors ; New edges and normal vectors
|
3.1.2. Boundary Aggregation with Border Elimination
| Algorithm 2 Boundary Aggregation with Border Elimination |
| Require: Local original edges and normal vectors ; Local new edges and normal vectors , and Ensure: Global edges with their normal vectors
|
3.2. Improved Hypersphere Construction
3.3. Improved Solver for Dual Problem
| Algorithm 3 iSolver for the Dual Problem (11) |
| Require: Global edges , normal vectors , and Ensure: Coefficient vector |
3.4. Flexible Parameter Selection of Q
3.5. The Framework of IBSVC
| Algorithm 4 Description of IBSVC |
| Require: Dataset , integers , and thresholds Ensure: Clustering labels for all the data samples
|
4. Performance Analysis
4.1. Complexity Analysis
4.2. Datasets and Experimental Settings
- (1)
- Check whether the MES correctly and efficiently obtains informative edges for data description.
- (2)
- Find out how the initialization strategy affects the number of iterations required by the iSolver and whether the effect can be maintained if we limit the iteration number to a small one, such as with the BSVC.
- (3)
- Make several comparisons between the FPS and the traditional strategy to collect evidence corresponding to its efficiency and usability. The former is about the run-time, while the latter is closely related to the gap between the discovered kernel width q and the ideal value.
- (4)
- Perform a comprehensive analysis of the IBSVC based on its comparison with the state-of-the-art variants of the SVC listed in Table 1, which adopt a method similar to clustering.
- (5)
- Compare IBSVC with the typical k-means++ [22] to verify the cost–performance ratio since k-means++ is well-known for its efficiency.
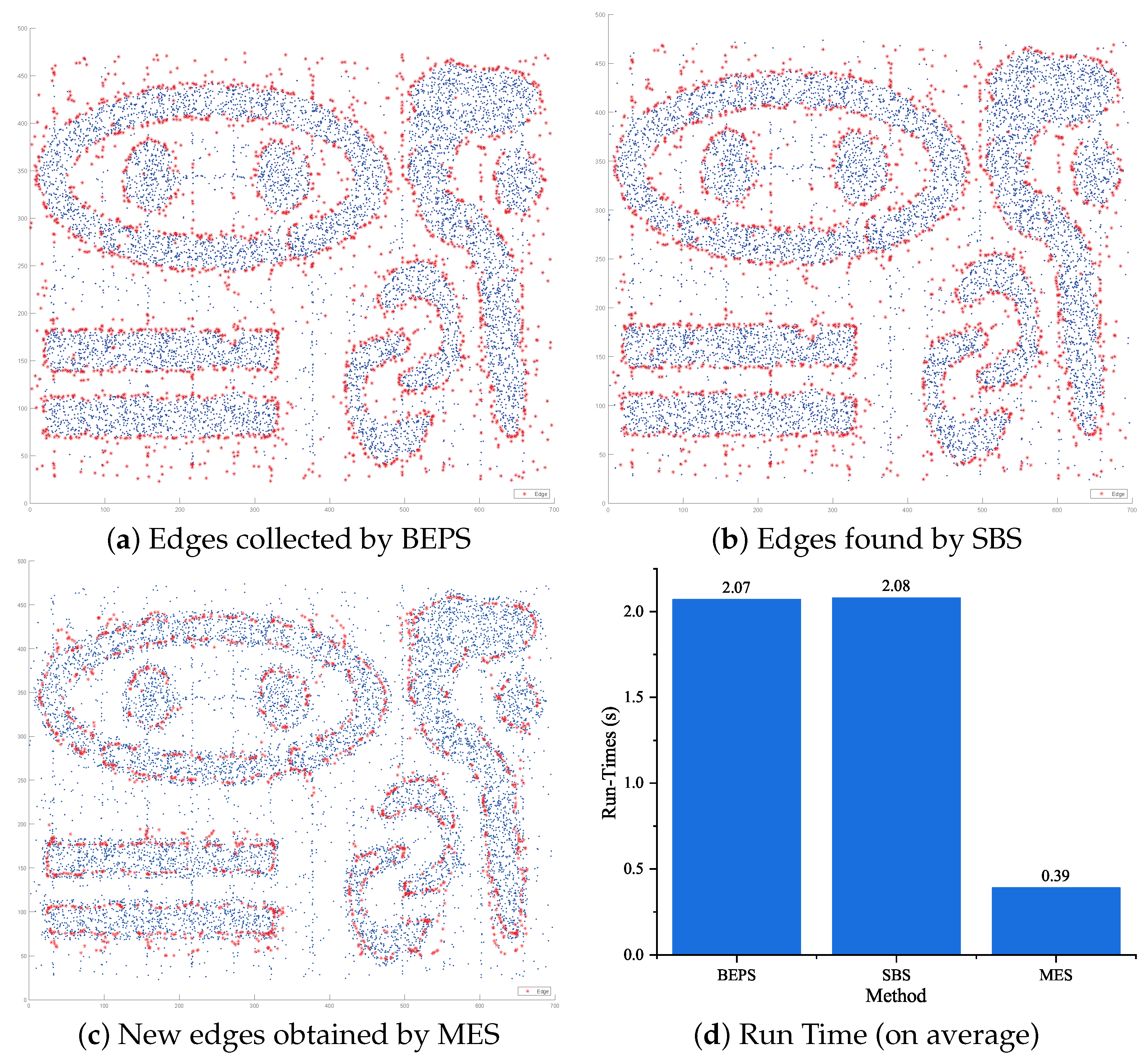
4.3. Performance of MES for Informative Edges
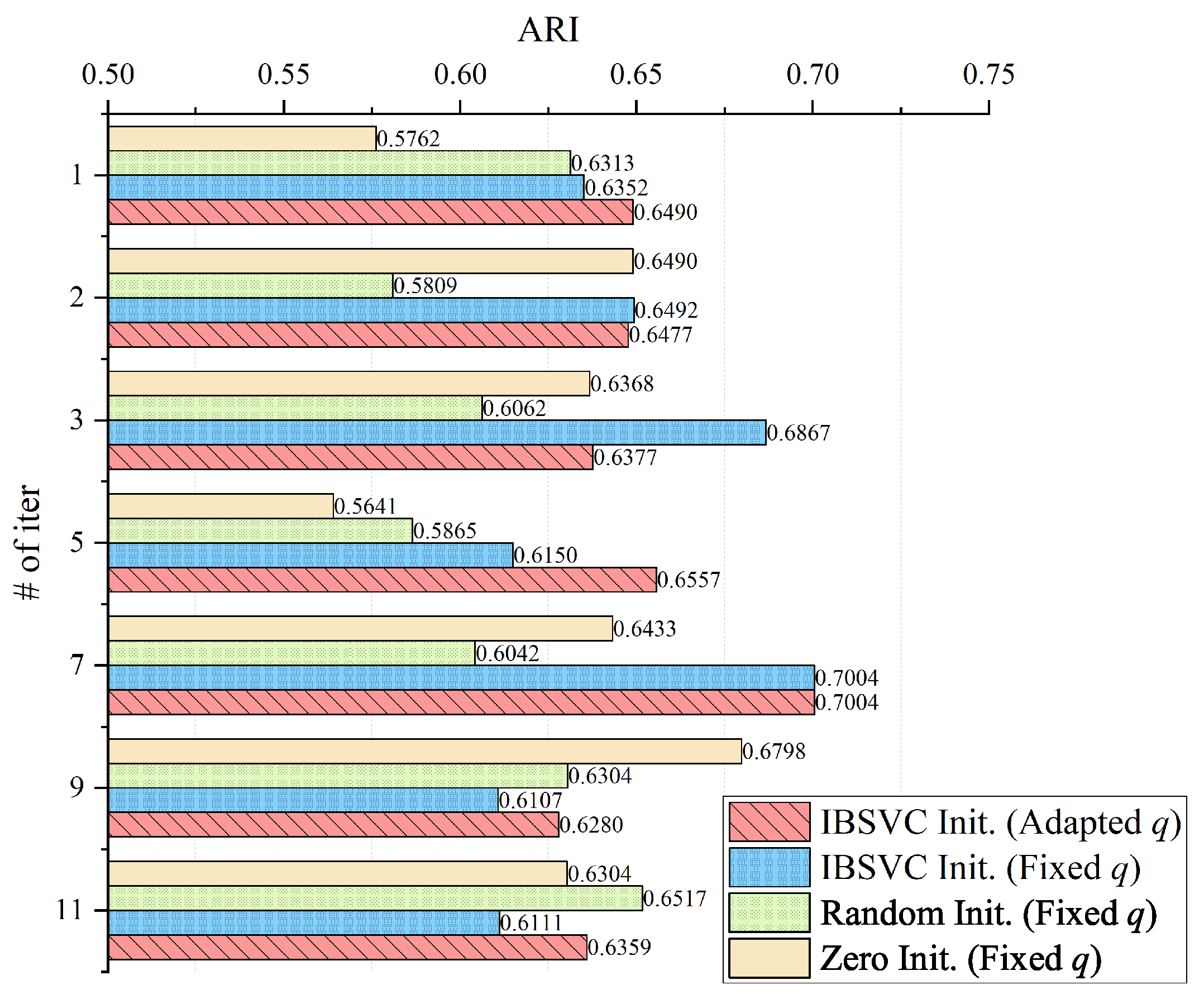
4.4. Validity Analysis of the Coefficient Vector Initialization Strategy
4.5. Adaptivity Analysis of FPS for Usable Kernel Width Q
4.6. Performance Contrast with the State-of-the-Art Methods
- (1)
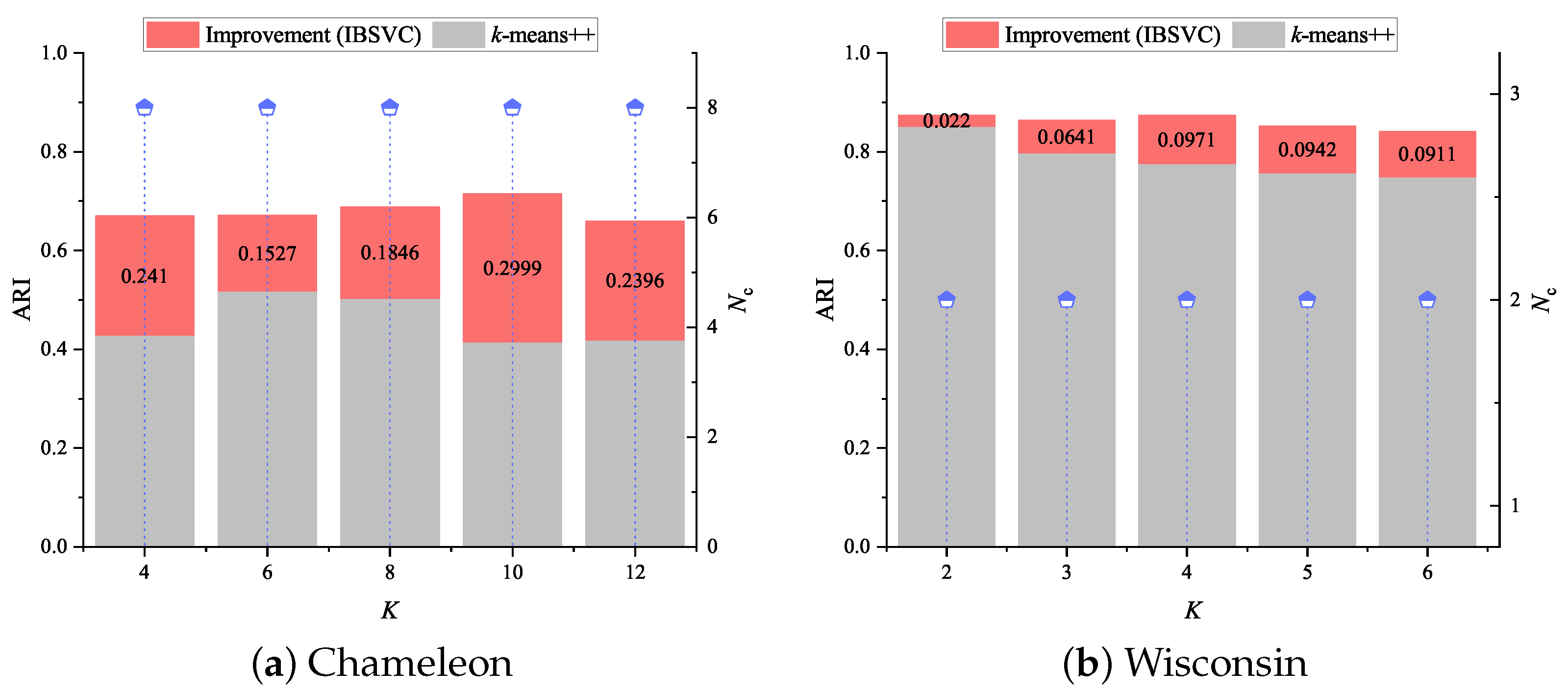
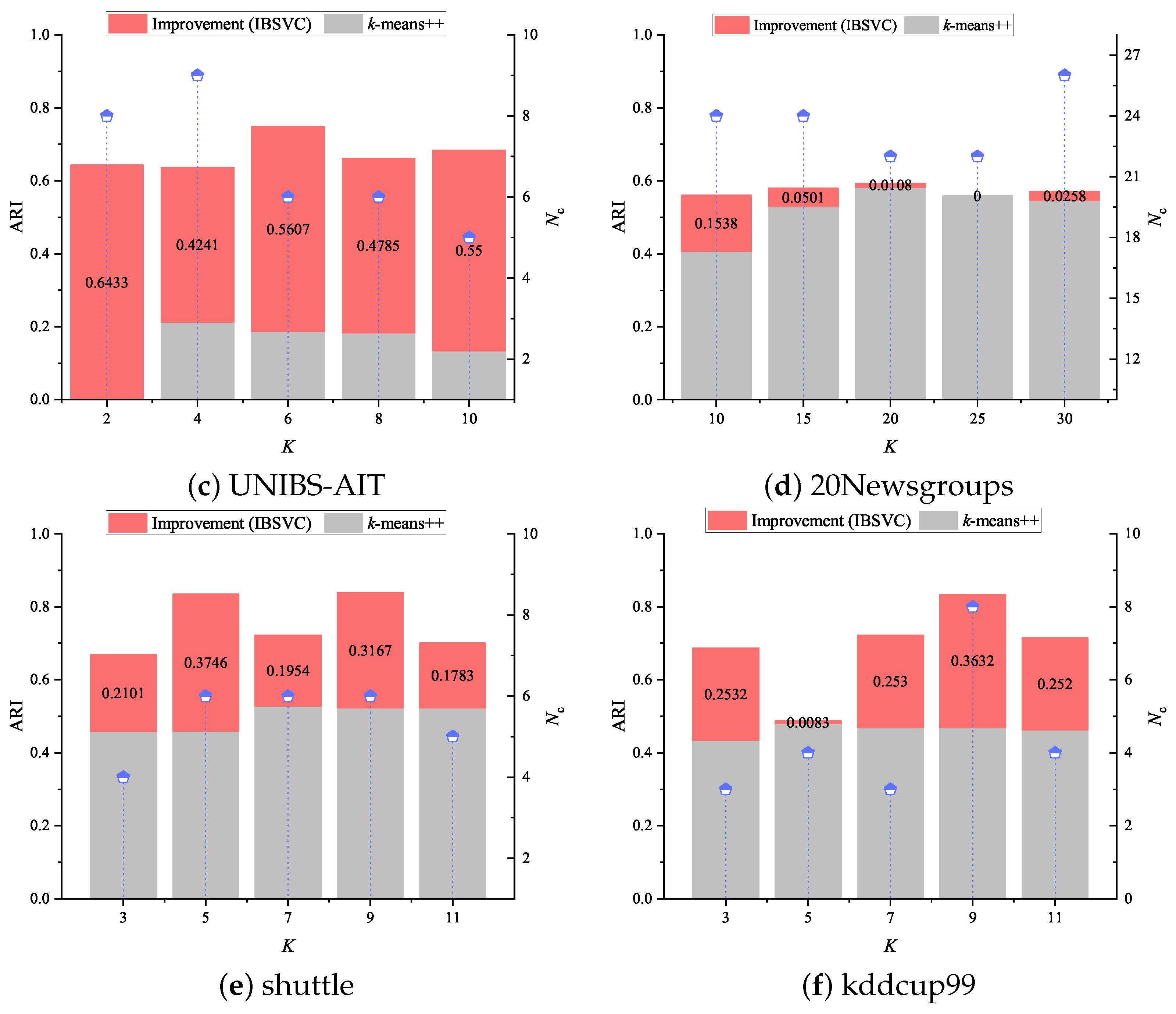
- In terms of accuracy, both IBSVC and IBSVC outperform the others on kddcup99 while achieving an equivalent level of sub-optimal results on most of the other data sets. For further verification, we also present the results of the pair comparisons in Table 5, following the work of Garcia and Herrera [33]. Here, IBSVC is the control method, and the results of Table 3 are taken into account. A nonparametric statistical test, namely the Friedman test, was employed to obtain the average ranks and the unadjusted p values. By introducing an adjustment method, namely the Bergmann–Hommel procedure, the adjusted p value denoted by and corresponding to each comparison was obtained. IBSVC reached the best performance in terms of the average ranking, while IBSVC’s performance was close to FRSVC and is comparable with that of RSVC-EO and BSVC. Unlike the other methods that adopt the manually discovered optimal parameters, IBSVC utilizes FPS to find the kernel width q in the training phase. Therefore, there is a self-adaptive adjustment of q for each evaluation due to subtle changes in edge patterns. Since the Bergmann–Hommel procedure rejects those hypotheses with p values , together with run-time costs, we further confirm that IBSVC and IBSVC can achieve a comparable accuracy using the state-of-the-art methods with the optimal parameters and achieve better performance on relatively large data sets with clearer shapes.
- (2)
- In terms of efficiency, IBSVC has significant advantages over the other methods, except for VCC. When we integrated NMMRS into the training phase, IBSVC showed its advantage in efficiency without affecting the accuracy. For instance, IBSVC reached better accuracies and was 13.58 and 113.53 times faster than VCC on shuttle and kddcup99, respectively. This suggests that the k-means++ indeed contributes to the improvement in efficiency, while its drawbacks are effectively controlled by MES. Thanks to the sampling strategy, the absolute proportion of data samples can be directly labeled according to their distances from the cluster prototypes (lines 11–13 of Algorithm 4). If we do not consider the labeling strategy, FSSVC and BSVC take much more time to collect global edges, while FRSVC and RSVC-EO consume too much time in collecting SVs from the entire data through their solvers. Without an appropriate noise elimination strategy integrated, a process similar to that in lines 7–9 of Algorithm 4 is also time-consuming. Therefore, FSVC, FSSVC, and FRSVC cannot complete the cluster analysis in 10,000 s.
- (3)
- Without sufficient prior knowledge, the discovered cluster number is a critical indicator that shows whether a method can capture data distribution accurately. Generally, if fake edge patterns cannot be eliminated appropriately, the discovered is frequently greater than the ground truth. Meanwhile, if the noise data samples (or outliers) are not removed correctly, many more cluster prototypes (e.g., convex hulls in IBSVC) will be assumed to be connected, which reduces . Apparently, IBSVC, FRSVC, BSVC, and RSVC-EO often obtain an decision, which is close or equivalent to the real number given in Table 2.
4.7. Finding Improvement Evidence over K-Means++
5. Related Works
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, H.; Ping, Y. Recent Advances in Support Vector Clustering: Theory and Applications. Int. J. Pattern Recogn. Artif. Intell. 2015, 29, 1550002. [Google Scholar] [CrossRef]
- Jin, T.; Gao, X. Overcoming The Error of Optical Power Measurement Caused by The Curvature Radius. Opt. Express 2022, 30, 17115–17129. [Google Scholar] [CrossRef]
- Arslan, G.; Madran, U.; Soyoğlu, D. An Algebraic Approach to Clustering and Classification with Support Vector Machines. Mathematics 2022, 10, 128. [Google Scholar] [CrossRef]
- Guo, C.; Li, F. An Improved Algorithm for Support Vector Clustering based on Maximum Entropy Principle and Kernel Matrix. Expert Syst. Appl. 2011, 38, 8138–8143. [Google Scholar] [CrossRef]
- Jung, K.H.; Lee, D.; Lee, J. Fast support-based clustering method for large-scale problems. Pattern Recogn. 2010, 43, 1975–1983. [Google Scholar] [CrossRef]
- Kim, K.; Son, Y.; Lee, J. Voronoi Cell-Based Clustering Using a Kernel Support. IEEE Trans. Knowl. Data Eng. 2015, 27, 1146–1156. [Google Scholar] [CrossRef]
- Ping, Y.; Chang, Y.; Zhou, Y.; Tian, Y.; Yang, Y.; Zhang, Z. Fast and Scalable Support Vector Clustering for Large-scale Data Analysis. Knowl. Inf. Syst. 2015, 43, 281–310. [Google Scholar] [CrossRef]
- Ping, Y.; Hao, B.; Li, H.; Lai, Y.; Guo, C.; Ma, H.; Wang, B.; Hei, X. Efficient Training Support Vector Clustering with Appropriate Boundary Information. IEEE Access 2019, 7, 146964–146978. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, J.; Xie, X.; Yang, S.; Pang, W.; Huang, L.; Zhang, S.; Zhao, S. Minimum Distribution Support Vector Clustering. Entropy 2021, 23, 1473. [Google Scholar] [CrossRef]
- Li, C.; Wang, N.; Li, W.; Li, Y.; Zhang, J. Regrouping and Echelon Utilization of Retired Lithium-ion Batteries based on A Novel Support Vector Clustering Approach. IEEE Trans. Transp. Electrif. 2022, 1–11. [Google Scholar] [CrossRef]
- Lee, S.H. Gaussian Kernel width Selection and Fast Cluster Labeling for Support Vector Clustering. Ph.D. Thesis, University of Massachusetts Lowell, Lowell, MA, USA, 2005. [Google Scholar]
- Ping, Y.; Tian, Y.; Guo, C.; Wang, B.; Yang, Y. FRSVC: Towards Making Support Vector Clustering Consume Less. Pattern Recogn. 2017, 69, 286–298. [Google Scholar] [CrossRef]
- Ben-Hur, A.; Horn, D.; Siegelmann, H.T.; Vapnik, V.N. Support Vector Clustering. J. Mach. Learn. Res. 2001, 2, 125–137. [Google Scholar] [CrossRef]
- Ting, K.M.; Wells, J.R.; Zhu, Y. Point-Set Kernel Clustering. IEEE Trans. Knowl. Data Eng. 2022, 41–51. [Google Scholar] [CrossRef]
- Li, Y.H.; Maguire, L. Selecting Critical Patterns Based on Local Geometrical and Statistical Information. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1189–1201. [Google Scholar]
- Karypis, G.; Han, E.H.; Kumar, V. Chameleon: A Hierarchical Clustering Algorithm Using Dynamic Modeling. Computer 1999, 32, 68–75. [Google Scholar] [CrossRef]
- Ping, Y.; Zhou, Y.; Yang, Y. A Novel Scheme for Accelerating Support Vector Clustering. Comput. Inform. 2012, 31, 1001–1026. [Google Scholar]
- Lee, J.; Lee, D. Dynamic Characterization of Cluster Structures for Robust and Inductive Support Vector Clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1869–1874. [Google Scholar] [PubMed]
- Lee, J.; Lee, D. An Improved Cluster Labeling Method for Support Vector Clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 461–464. [Google Scholar]
- Ping, Y.; Hao, B.; Hei, X.; Wu, J.; Wang, B. Maximized Privacy-Preserving Outsourcing on Support Vector Clustering. Electronics 2020, 9, 178. [Google Scholar] [CrossRef]
- Ping, Y.; Tian, Y.; Zhou, Y.; Yang, Y. Convex Decomposition Based Cluster Labeling Method for Support Vector Clustering. J. Comput. Sci. Technol. 2012, 27, 428–442. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. k-means++: The Advantages of Careful Seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms (SODA ’07), New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Frank, A.; Asuncion, A. UCI Machine Learning Repository. 2010. Available online: http://archive.ics.uci.edu/ml (accessed on 1 June 2022).
- Lang, K. NewsWeeder: Learning to filter netnews. In Proceedings of the 12th International Conference on Machine Learning, (ICML’95), Tahoe City, CA, USA, 9–12 July 1995; pp. 331–339. [Google Scholar]
- Ping, Y.; Zhou, Y.; Xue, C.; Yang, Y. Efficient representation of text with multiple perspectives. J. China Univ. Posts Telecommun. 2012, 19, 101–111. [Google Scholar] [CrossRef]
- UNIBS. The UNIBS Anonymized 2009 Internet Traces. 18 March 2010. Available online: http://www.ing.unibs.it/ntw/tools/traces (accessed on 1 June 2022).
- Peng, J.; Zhou, Y.; Wang, C.; Yang, Y.; Ping, Y. Early TCP Traffic Classification. J. Appl. Sci. Electron. Inf. Eng. 2011, 29, 73–77. [Google Scholar]
- Guo, C.; Zhou, Y.; Ping, Y.; Zhang, Z.; Liu, G.; Yang, Y. A Distance Sum-based Hybrid Method for Intrusion Detection. Appl. Intell. 2014, 40, 178–188. [Google Scholar] [CrossRef]
- UCI Lab. KDD Cup 1999 Intrusion Detection Dataset. 28 October 1999. Available online: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html (accessed on 1 June 2022).
- Xu, R.; Wunsch, D.C. Clustering. In Clustering; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Lee, S.H.; Daniels, K.M. Cone Cluster Labeling for Support Vector Clustering. In Proceedings of the 6th SIAM International Conference on Data Mining, Bethesda, MD, USA, 20–22 April 2006; pp. 484–488. [Google Scholar]
- Rathore, P.; Ghafoori, Z.; Bezdek, J.C.; Palaniswami, M.; Leckie, C. Approximating Dunn’s Cluster Validity Indices for Partitions of Big Data. IEEE Trans. Cybern. 2019, 49, 1629–1641. [Google Scholar] [CrossRef]
- Garcia, S.; Herrera, F. An Extension on “Statistical Comparisons of Classifiers over Multiple Data Sets” for all Pairwise Comparisons. J. Mach. Learn. Res. 2008, 9, 2677–2694. [Google Scholar]
- Lee, D.; Lee, J. Dynamic Dissimilarity Measure for Support-based Clustering. IEEE Trans. Knowl. Data Eng. 2010, 22, 900–905. [Google Scholar] [CrossRef]
- Wang, C.D.; Lai, J.H. Position Regularized Support Vector Domain Description. Pattern Recogn. 2013, 46, 875–884. [Google Scholar] [CrossRef]
- Lee, D.; Jung, K.H.; Lee, J. Constructing Sparse Kernel Machines Using Attractors. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 20, 721–729. [Google Scholar]
- Chiang, J.H.; Hao, P.Y. A New Kernel-based Fuzzy Clustering Approach: Support Vector Clustering with Cell Growing. IEEE Trans. Fuzzy Syst. 2003, 11, 518–527. [Google Scholar] [CrossRef]
- Gonitz, N.; Lima, L.A.; Muller, K.R.; Kloft, M.; Nakajima, S. Support Vector Data Descriptions and k-Means Clustering: One Class? IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 3994–4006. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Method | SVC Training | Labeling |
|---|---|---|---|
| 1 | FSVC | ||
| 2 | VCC | Mode I: | |
| Mode II: | |||
| 3 | FSSVC | or | |
| 4 | FRSVC | ||
| 5 | RSVC-EO | ||
| 6 | BSVC | ||
| 7 | IBSVC | ||
| 8 | k-means++ | ||
| Data Sets | Data Set Description | ||
|---|---|---|---|
| Size | Dims | # of Classes | |
| wisconsin | 683 | 9 | 2 |
| Chameleon | 7670 | 2 | 8 |
| UNIBS-AIT | 9209 | 4 | 4 |
| 20Newsgroups | 13,998 | 20 | 20 |
| shuttle | 43,500 | 9 | 7 |
| kddcup99 | 494,021 | 9 | 5 |
| Methods | Run Time (s) | ARI | Iteration Control? | |
|---|---|---|---|---|
| CCL | 5289.71 | 0.5004 | 30 | No ([31]) |
| FSVC | 1582.19 | 0.5319 | 9 | No ([5]) |
| VCC | 85.32 | 0.4820 | 9 | No ([6]) |
| FSSVC | 123.73 | 0.5894 | 23 | No ([7]) |
| FRSVC | 631.61 | 0.7060 | 14 | No ( [12]) |
| BSVC | 102.65 | 0.5808 | 12 | # of iter = 10 [8] |
| RSVC-EO | 81.13 | 0.5898 | 10 | # of iter = 3 [20] |
| IBSVC | 0.57 | 0.7004 | 8 | No iteration |
| Method | Wisconsion | UNIBS-AIT | 20Newsgroups | Shuttle | kddcup99 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ARI | Time(s.) | ARI | Time(s.) | ARI | Time(s.) | ARI | Time(s.) | ARI | Time(s.) | ||||||
| CCL | 0.9076 | 0.21 | 2 | — | — | — | — | — | — | — | — | — | — | — | — |
| FSVC | 0.6687 | 2.02 | 153 | 0.8367 | 426.15 | 4 | — | — | — | 0.58 [5] | — | — | — | — | — |
| VCC | 0.8543 | 2.60 | 2 | 0.7455 | 7.94 | 5 | 0.4858 | 14.62 | 27 | 0.6096 | 11.41 | 14 | 0.7955 | 175.96 | 9 |
| FSSVC | 0.9248 | 0.71 | 6 | 0.8815 | 3.23 | 4 | 0.3628 | 17.92 | 105 | 0.6857 | 86.81 | 33 | — | — | — |
| FRSVC | 0.8798 | 0.66 | 2 | 0.8678 | 37.60 | 4 | 0.4927 | 145.81 | 26 | 0.8050 | 380.91 | 13 | — | — | — |
| BSVC | 0.8963 | 0.88 | 2 | 0.8565 | 8.61 | 4 | 0.4752 | 21.05 | 23 | 0.8843 | 108.55 | 7 | 0.8677 | 6191.20 | 8 |
| RSVC-EO | 0.8632 | 0.35 | 2 | 0.8807 | 9.24 | 4 | 0.6084 | 32.13 | 26 | 0.7337 | 343.46 | 9 | 0.7621 | 9489.38 | 5 |
| IBSVC | 0.8739 | 0.31 | 2 | 0.7482 | 2.82 | 5 | 0.5796 | 4.23 | 24 | 0.6929 | 19.89 | 8 | 0.9120 | 5500.93 | 12 |
| IBSVC | 0.8395 | 0.84 | 6 | 0.8862 | 1.55 | 4 | |||||||||
| Methods | Average Ranks | Unadjusted p | |
|---|---|---|---|
| Control Method: IBSVC, Average Rank = 3.5000 | |||
| FSVC | 7.5000 | 0.0114 | 0.0913 |
| CCL | 7.3333 | 0.0153 | 0.1073 |
| VCC | 6.8333 | 0.0350 | 0.2101 |
| FSSVC | 4.5833 | 0.4932 | 2.4662 |
| BSVC | 3.8333 | 0.8330 | 3.3321 |
| RSVC-EO | 3.8333 | 0.8330 | 3.3321 |
| IBSVC | 3.8333 | 0.8330 | 3.3321 |
| FRSVC | 3.7500 | 0.8743 | 3.3321 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Ping, Y.; Hao, B.; Guo, C.; Liu, Y. Improved Boundary Support Vector Clustering with Self-Adaption Support. Electronics 2022, 11, 1854. https://doi.org/10.3390/electronics11121854
Li H, Ping Y, Hao B, Guo C, Liu Y. Improved Boundary Support Vector Clustering with Self-Adaption Support. Electronics. 2022; 11(12):1854. https://doi.org/10.3390/electronics11121854
Chicago/Turabian StyleLi, Huina, Yuan Ping, Bin Hao, Chun Guo, and Yujian Liu. 2022. "Improved Boundary Support Vector Clustering with Self-Adaption Support" Electronics 11, no. 12: 1854. https://doi.org/10.3390/electronics11121854