
Evaluating the Quality of Machine Learning Explanations: A Survey on Methods and Metrics



Abstract
:1. Introduction
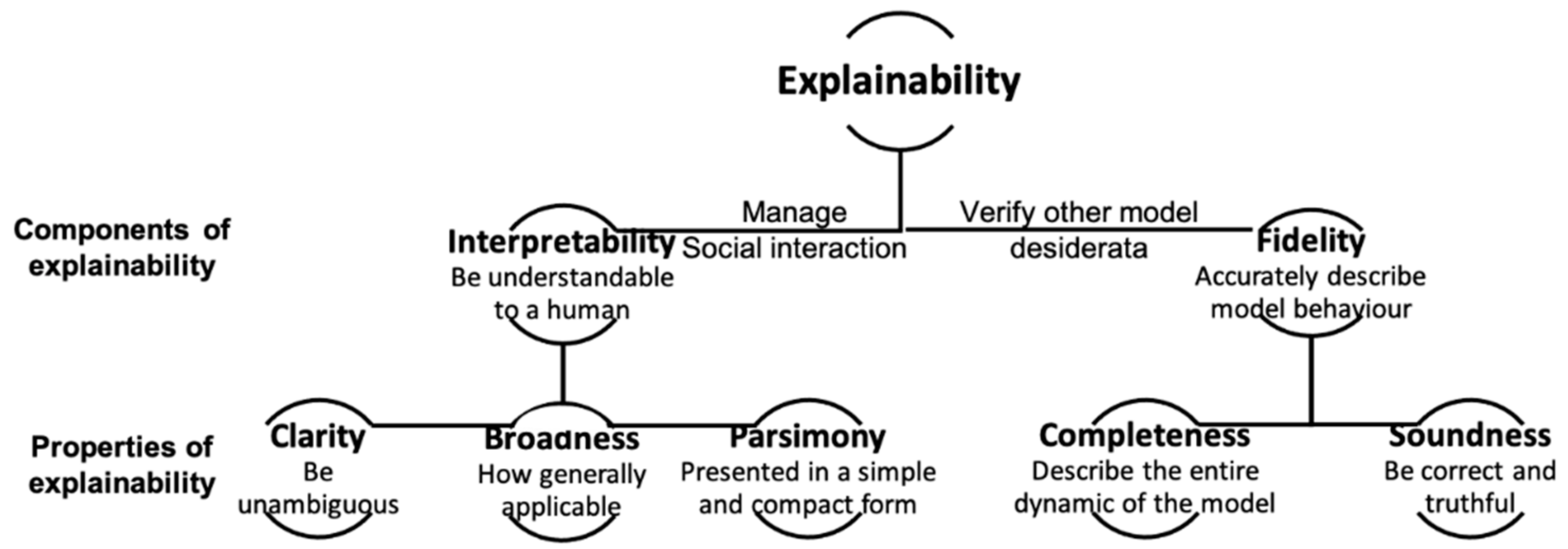
- We identify properties of explainability by reviewing definitions of explainability from recent papers. The identified properties of explainability are used as objectives that evaluation metrics should achieve;
- A systematic analysis on the human-centred explanation evaluations and quantitative objective explanation evaluations are performed to learn the current status of ML explanation evaluations;
- The gaps and future research directions on the evaluation of ML explanations are identified.
2. Definitions
3. Machine Learning Explanation Approaches
3.1. Taxonomy of Explanation Approaches
- Saliency methods [static -> model -> local -> post-hoc -> feature]: This category of explanation methods highlights different parts in the data to understand classification tasks. This category belongs to local post-hoc explanation methods, which use static and feature-based explanations. Local Interpretable Model-Agnostic Explanations (LIME) [33] and SHapley Additive exPlanations (SHAP) [34] fall under the umbrella of this category of explanations.
- Neural network visualisation methods [static -> model -> global -> post-hoc -> visualise]: This category of explanation methods is mainly used for neural network explanations and visualizes intermediate representations/layers of a neural network. It allows us to inspect a high level of features of a model with visualisations to understand the model. Therefore, this category belongs to the global post-hoc and static explanation methods. For example, Nguyen et al. [35] introduced multifaceted feature visualisations to explain neural networks.
- Feature relevance methods [static -> model -> global -> post-hoc -> feature]: This category of explanation methods studies the input features’ relevance to and global effects on the target/output values. This category belongs to the static global and post-hoc explanation methods through visualisations for explanations. The Partial Dependence Plot [36] showing the marginal effect that one or two features have on the predicted outcome belongs to this category.
- Knowledge distillation methods [static -> model -> global -> post-hoc -> surrogate]: Machine learning models, such as deep learning models, are usually black boxes to users and difficult to understand. Knowledge distillation methods learn a simpler model, such as a linear model, to simulate a complex model and explain it. This category of explanations is considered as global post-hoc explanations with surrogate models. For example, Hinton et al. [39] explained an ensemble of models, such as neural networks with a single model effectively.
- High-level feature learning methods [static -> data -> feature]: This category of explanations learns a high level of interpretable features using approaches such as Variational AutoEncoder (VAE) or Generative Adversarial Network (GAN) for explanations. For example, Chen et al. [40] described a GAN-based approach to learn interpretable representations. This kind of explanation is under the data followed by a feature category.
- Methods that provide rationales [static -> model -> local -> self]: This category of explanations generates explanations derived from input data, which could be considered as local self-explanations. For example, Hendricks et al. [41] proposed a visual explanation generation approach, which describes visual content in a specific image instance and constrains information to explain why an image instance belongs to a specific class.
- Restricted neural network architectures [static -> model -> global -> direct]: This category of explanations applies certain restrictions on the neural network architecture to make it interpretable. It falls under the global direct explanation category. For example, Zhang et al. [42] proposed to modify a traditional Convolutional Neural Network (CNN) into an explainable CNN by allowing clear knowledge representations (e.g., a specific object part) in high cov-layers of the CNN.
- Rationale explanation. This type of explanation is about the “why” of an ML decision and provides reasons that led to a decision, and is delivered in an accessible and understandable way, especially for lay users. If the ML decision was not what users expected, this type of explanation allows users to assess whether they believe the reasoning of the decision is flawed. While, if so, the explanation supports them to formulate reasonable arguments for why they think this is the case.
- Responsibility explanation. This type of explanation concerns “who” is involved in the development, management, and implementation of an ML system, and “who” to contact for a human review of a decision. This type of explanation helps by directing the individual to the person or team responsible for a decision. It also makes accountability traceable.
- Data explanation. This type of explanation focuses on what the data is and how it has been used in a particular decision, as well as what data and how it has been used to train and test the ML model. This type of explanation can help users understand the influence of data on decisions.
- Fairness explanation. This type of explanation provides steps taken across the design and implementation of an ML system to ensure that the decisions it assists are generally unbiased, and whether or not an individual has been treated equitably. This type of explanation is key to increasing individuals’ confidence in an Artificial Intelligence (AI) system. It can foster meaningful trust by explaining to an individual how bias and discrimination in decisions are avoided.
- Safety and performance explanation. This type of explanation deals with steps taken across the design and implementation of an ML system to maximise the accuracy, reliability, security, and robustness of its decisions and behaviours. This type of explanation helps to assure individuals that an ML system is safe and reliable by explanation to test and monitor the accuracy, reliability, security, and robustness of the ML model.
- Impact explanation. This type of explanation concerns the impact that the use of an ML system and its decisions has or may have on an individual and on a wider society. This type of explanation gives individuals some power and control over their involvement in ML-assisted decisions. By understanding the possible consequences of the decision, an individual can better assess his/her participation in the process and how the outcomes of the decision may affect them. Therefore, this type of explanation is often suited to delivery before an ML-assisted decision is made.
- Statistical uncertainty and inferences. Not only the machine learning model itself, but also its explanations, are computed from data and, hence, are subject to uncertainty. However, many ML explanation methods, such as featuring importance-based approaches, provide explanations without quantifying the uncertainty of the explanation.
- Causal explanation. Ideally, an ML model should reflect the true causal relations of its underlying phenomena, in order to enable causal explanation. However, most statistical learning procedures reflect correlation structures between features instead of its true, inherent, causal structure that is the true goal of explanation.
- Evaluation of explainability. This challenge is caused because the ground truth explanation is not known, and any straightforward way is not available to quantify how interpretable a model is or how correct an explanation is.
- Feature dependence. Feature dependence introduces problems with attribution and extrapolation. Extrapolation and correlated features can cause misleading explanations.
3.2. Visualisation Approaches
4. Evaluation of ML Explanations
4.1. The Goal of Evaluation of ML Explanations
- To compare available explanation methods and find preferred explanations from the comparison. The challenge is that there is no ground truth when evaluating post-hoc explanations, as the real inner workings of the model is not known [60].
- To assess if explainability is achieved in an application. The focus of the assessment lies in determining if the provided explainability achieves the defined objective [61].
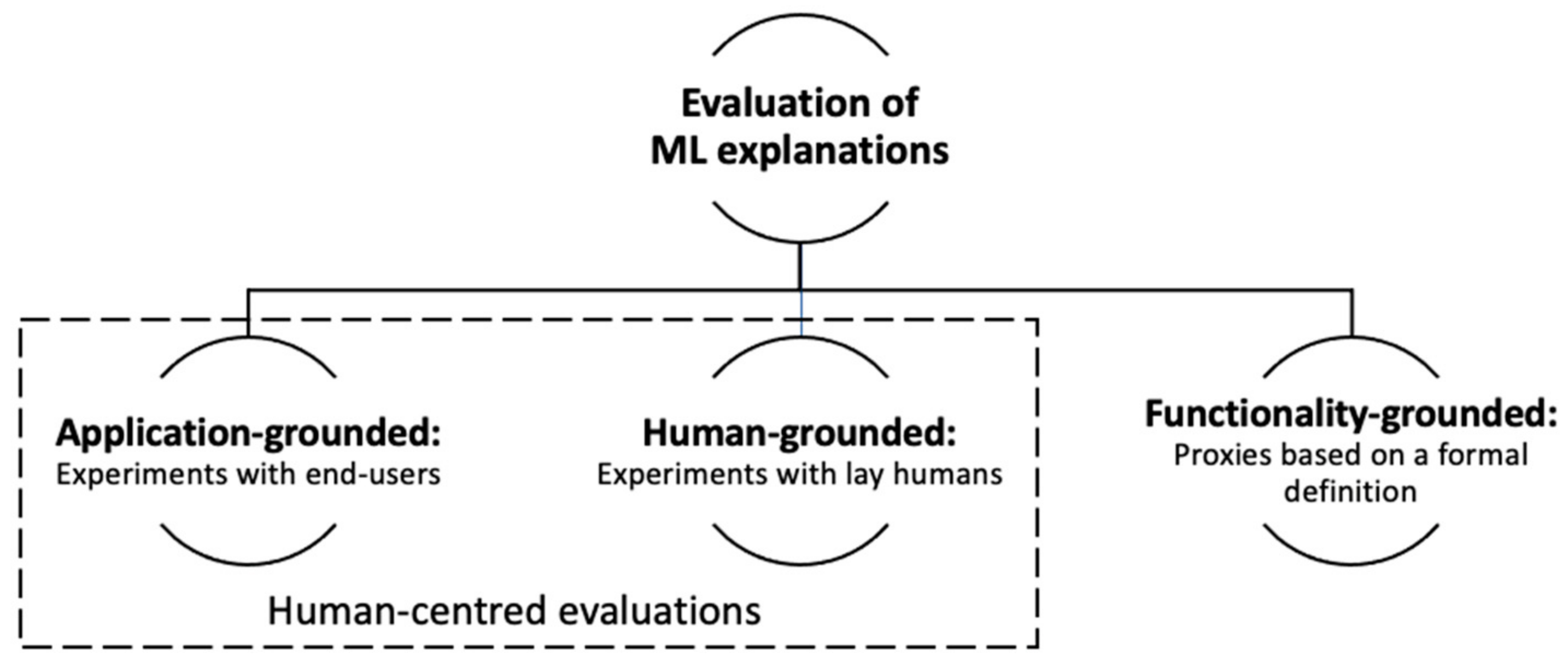
4.2. Taxonomy of Evaluation of ML Explanations
- Application-grounded evaluation (experiments with end-users). This kind of evaluation requires conducting end-user experiments using the explanation within a real-world application. It directly tests the objective that the system is built for in a real-world application, and, thus, performance with respect to that objective gives strong evidence of the success of explanations. An important baseline for this is how well explanations assist in humans trying to complete tasks, such as decision-making tasks.
- Human-grounded evaluation (experiments with lay humans). It refers to conducting simpler human–subject experiments that maintain the essence of the target application. Compared with the application-grounded evaluation, the experiments in this kind of evaluation are not carried out with the domain experts but with lay humans, allowing a big subject pool and less expenses for the evaluation. Ideally, this evaluation approach will depend only on the quality of the explanation, regardless of the types of explanations and the accuracy of the associated prediction.
- Functionality-grounded evaluation (proxies based on a formal definition of interpretability). This kind of evaluation does not require human experiments. In this type of evaluation, some formal definition of interpretability serves as a proxy to evaluate the explanation quality, e.g., the depth of a decision tree.
5. Application-Grounded and Human-Grounded Evaluations
- Global vs. local explanation. Global explanation means explaining why patterns are present in general, while local explanation implies knowing the reasons for a specific decision (such as why a particular prediction was made).
- Area and severity of incompleteness. This relates to incompletely specified inputs, constraints, domains, internal model structure, costs, or even the need to understand the training algorithm. The types of explanations needed may vary depending on whether the source of concern is due to different incompleteness. The severity of the incompleteness may also affect explanation needs.
- Time constraints. This refers to the time that the user can afford to spend to understand the explanation. Different applications may have different times end-users can spend on the explanation. Such constraints may affect approaches and effectiveness of explanations.
- Nature of user expertise. This is related to how experienced the user is in the task. The nature of user expertise will affect the level of sophistication of explanation, the organisation of explanation information, and others. For example, domain-users, machine learning researchers, and layman users have different background knowledge and communication styles.
- Studies using proxy tasks to evaluate how well users are able to simulate the model’s decisions [6,70,71] or decision boundaries [72]. In such studies, participants are specifically instructed to pay attention to the ML to evaluate human’s mental model of the ML system with the system’s predictions and explanations, but do not necessarily evaluate how well users are able to perform real decision-making tasks with the ML system.
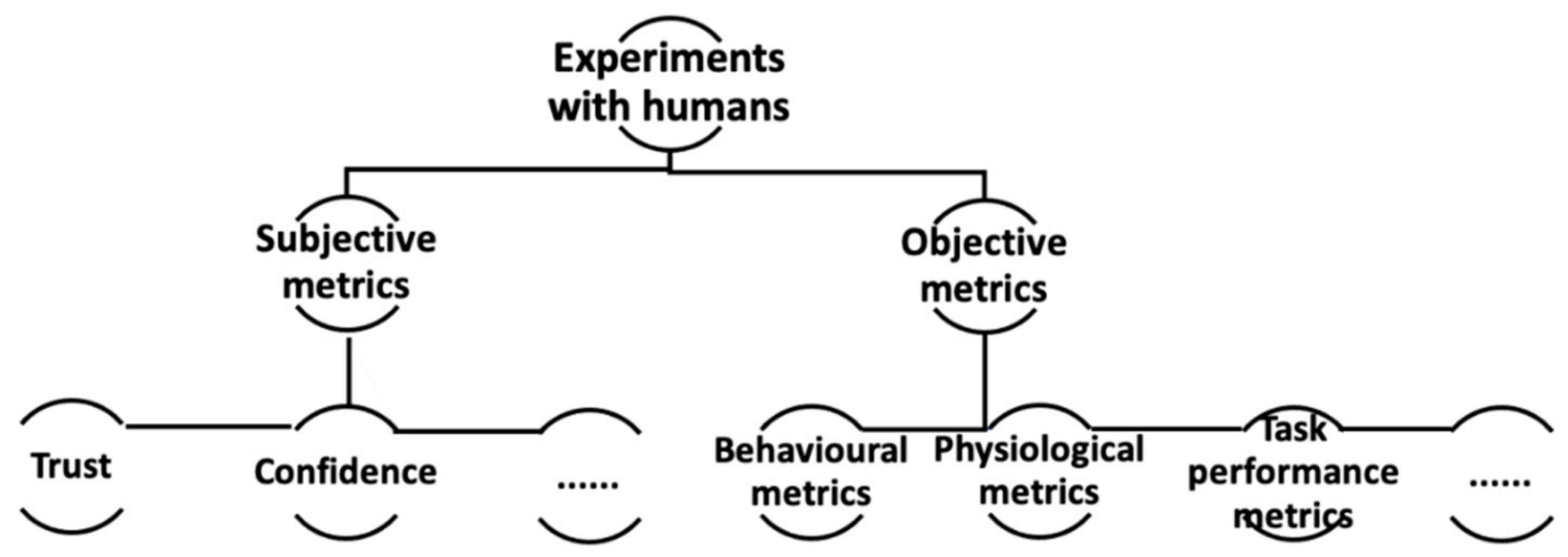
- Subjective metrics. Subjective questionnaires are designed for users on tasks and explanations, and are asked during or after task time to obtain user’s subjective responses on tasks and explanations. Examples of subjective metrics are user trust, confidence, and preference (see Figure 4), which have been largely embraced as the focal point for the evaluation of explainable systems [33,64,65,73]. For example, Hoffman et al. [74] presented metrics for explainable systems that are grounded in the subjective evaluation of a system (e.g., user trust, satisfaction, and understanding). Zhou, et al. [65,75] investigated factors such as uncertainty and correlation that affect user confidence in ML-informed decision-making. Zhou et al. [64] found that the explanation of influence of training data points significantly affected user trust in ML-informed decision-making. Yu et al. [76] investigated the trust dynamics corresponding to ML performance changes. Holzinger et al. [77] developed a scale named System Causability Scale to quickly determine whether and to what extent an explanation or an explanation process itself is suitable for the intended purpose.
- Objective metrics. This refers to objective information on tasks or humans before, after, or during the task time. Examples include human metrics, such as physiological and behaviour indicators of humans, during ML-informed decision-making, or task-related metrics, such as task time length and task performance [37] (see Figure 4). For example, Zhou et al. [37] found that physiological signals such as Galvanic Skin Response (GSR) and Blood Volume Pulse (BVP) showed significant differences with the explanation presentation influencing training data points [38] on ML predictions, and these physiological responses can be used as indicators of user trust to assess the quality of ML explanations. Based on approaches that quantify response times in user studies as well as agreement between human labels and model predictions [63,72], Schmidt and Biessmann [78] proposed that faster and more accurate decisions indicate intuitive understanding of explanations. A trust metric was then derived based on these explainability metrics.
6. Functionality-Grounded Evaluation Metrics
- Model-based explanations. It refers to explanations that use a model to explain original task models. In this category, either the task model itself (e.g., decision tree) is used as an explanation or more interpretable models are generated to explain the task model.
- Example-based explanations. This kind of method explains the task model by selecting instances from the training/testing dataset or creating new instances. For example, selecting instances that are well predicted or not well predicted by the model as explanations, or creating counterfactual examples as explanations.
6.1. Explainability Properties
6.2. Quantitative Metrics for Model-Based Explanations
6.3. Quantitative Metrics for Attribution-Based Explanations
6.4. Quantitative Metrics for Example-Based Explanations
7. Discussion
7.1. Human-Centred Evaluations
7.2. Functionality-Grounded Evaluations
7.3. Comparison of Explanations
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Taddeo, M.; Floridi, L. How AI Can Be a Force for Good. Science 2018, 361, 751–752. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, J.; Chen, F. AI in the public interest. In Closer to the Machine: Technical, Social, and Legal Aspects of AI; Bertram, C., Gibson, A., Nugent, A., Eds.; Office of the Victorian Information Commissioner: Melbourne, Australia, 2019. [Google Scholar]
- Zhou, J.; Chen, F. (Eds.) Human and Machine Learning: Visible, Explainable, Trustworthy and Transparent; Human–Computer Interaction Series; Springer: Berlin/Heidelberg, Germany, 2018; ISBN 978-3-319-90402-3. [Google Scholar]
- Lee, B.; Kim, N.; Kim, E.-S.; Jang, K.; Kang, M.; Lim, J.-H.; Cho, J.; Lee, Y. An Artificial Intelligence Approach to Predict Gross Primary Productivity in the Forests of South Korea Using Satellite Remote Sensing Data. Forests 2020, 11, 1000. [Google Scholar] [CrossRef]
- Liu, M.; Liu, J.; Chen, Y.; Wang, M.; Chen, H.; Zheng, Q. AHNG: Representation Learning on Attributed Heterogeneous Network. Inform. Fusion 2019, 50, 221–230. [Google Scholar] [CrossRef]
- Zhou, J.; Khawaja, M.A.; Li, Z.; Sun, J.; Wang, Y.; Chen, F. Making Machine Learning Useable by Revealing Internal States Update—A Transparent Approach. Int. J. Comput. Sci. Eng. 2016, 13, 378–389. [Google Scholar] [CrossRef]
- Castelvecchi, D. Can We Open the Black Box of AI? Nat. News 2016, 538, 20. [Google Scholar] [CrossRef] [Green Version]
- Schneeberger, D.; Stöger, K.; Holzinger, A. The European Legal Framework for Medical AI. In Proceedings of the Machine Learning and Knowledge Extraction, Dublin, Ireland, 25–28 August 2020; pp. 209–226. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards A Rigorous Science of Interpretable Machine Learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Arya, V.; Bellamy, R.K.E.; Chen, P.-Y.; Dhurandhar, A.; Hind, M.; Hoffman, S.C.; Houde, S.; Liao, Q.V.; Luss, R.; Mojsilović, A.; et al. One Explanation Does Not Fit All: A Toolkit and Taxonomy of AI Explainability Techniques. arXiv 2019, arXiv:1909.03012. [Google Scholar]
- Holzinger, K.; Mak, K.; Kieseberg, P.; Holzinger, A. Can We Trust Machine Learning Results? Artificial Intelligence in Safety-Critical Decision Support. ERCIM News 2018, 112, 42–43. [Google Scholar]
- Gunning, D.; Aha, D. DARPA’s Explainable Artificial Intelligence (XAI) Program. AIMag 2019, 40, 44–58. [Google Scholar] [CrossRef]
- Hagras, H. Toward Human-Understandable, Explainable AI. Computer 2018, 51, 28–36. [Google Scholar] [CrossRef]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A Survey of Methods for Explaining Black Box Models. ACM Comput. Surv. (CSUR) 2018, 51, 1–42. [Google Scholar] [CrossRef] [Green Version]
- Holzinger, A. From Machine Learning to Explainable AI. In Proceedings of the 2018 World Symposium on Digital Intelligence for Systems and Machines (DISA), Kosice, Slovakia, 23–25 August 2018; pp. 55–66. [Google Scholar]
- Goebel, R.; Chander, A.; Holzinger, K.; Lecue, F.; Akata, Z.; Stumpf, S.; Kieseberg, P.; Holzinger, A. Explainable AI: The New 42? In Proceedings of the Machine Learning and Knowledge Extraction, Hamburg, Germany, 27–30 August 2018; pp. 295–303. [Google Scholar]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine Learning Interpretability: A Survey on Methods and Metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef] [Green Version]
- Lage, I.; Doshi-Velez, F. Human-in-the-Loop Learning of Interpretable and Intuitive Representations. In Proceedings of the ICML Workshop on Human Interpretability in Machine Learning, Vienna, Austria, 17 July 2020. [Google Scholar]
- Holzinger, A. Interactive Machine Learning for Health Informatics: When Do We Need the Human-in-the-Loop? Brain Inf. 2016, 3, 119–131. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Keim, D.A.; Mansmann, F.; Schneidewind, J.; Thomas, J.; Ziegler, H. Visual Analytics: Scope and Challenges. In Visual Data Mining: Theory, Techniques and Tools for Visual Analytics; Simoff, S.J., Böhlen, M.H., Mazeika, A., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2008; pp. 76–90. ISBN 978-3-540-71080-6. [Google Scholar]
- Rüping, S. Learning Interpretable Models. Ph.D. Thesis, University of Dortmund, Dortmund, Germany, 2006. [Google Scholar]
- Rudin, S. Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef] [Green Version]
- Markus, A.F.; Kors, J.A.; Rijnbeek, P.R. The Role of Explainability in Creating Trustworthy Artificial Intelligence for Health Care: A Comprehensive Survey of the Terminology, Design Choices, and Evaluation Strategies. arXiv 2020, arXiv:2007.15911. [Google Scholar]
- Pearl, J. Causality: Models, Reasoning, and Inference, 2nd ed.; Cambridge University Press: Cambridge, UK, 2009; ISBN 978-0-521-89560-6. [Google Scholar]
- Holzinger, A.; Langs, G.; Denk, H.; Zatloukal, K.; Müller, H. Causability and Explainability of Artificial Intelligence in Medicine. WIREs Data Min. Knowl. Discov. 2019, 9, e1312. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stickel, C.; Ebner, M.; Holzinger, A. The XAOS Metric—Understanding Visual Complexity as Measure of Usability. In Proceedings of the HCI in Work and Learning, Life and Leisure; Leitner, G., Hitz, M., Holzinger, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 278–290. [Google Scholar]
- Miller, T. Explanation in Artificial Intelligence: Insights from the Social Sciences. Artif. Intell. 2019, 267, 1–38. [Google Scholar] [CrossRef]
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining Explanations: An Overview of Interpretability of Machine Learning. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–4 October 2018; pp. 80–89. [Google Scholar]
- Lombrozo, T. Explanatory Preferences Shape Learning and Inference. Trends Cognit. Sci. 2016, 20, 748–759. [Google Scholar] [CrossRef]
- Verma, S.; Dickerson, J.; Hines, K. Counterfactual Explanations for Machine Learning: A Review. arXiv 2020, arXiv:2010.10596. [Google Scholar]
- Mi, J.-X.; Li, A.-D.; Zhou, L.-F. Review Study of Interpretation Methods for Future Interpretable Machine Learning. IEEE Access 2020, 8, 191969–191985. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. Proceeding of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the Advances in Neural Information Processing Systems (NIPS2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 4765–4774. [Google Scholar]
- Nguyen, A.; Yosinski, J.; Clune, J. Multifaceted Feature Visualization: Uncovering the Different Types of Features Learned By Each Neuron in Deep Neural Networks. arXiv 2016, arXiv:1602.03616. [Google Scholar]
- Molnar, C. Interpretable Machine Learning. Available online: https://originalstatic.aminer.cn/misc/pdf/Molnar-interpretable-machine-learning_compressed.pdf (accessed on 21 February 2019).
- Zhou, J.; Hu, H.; Li, Z.; Yu, K.; Chen, F. Physiological Indicators for User Trust in Machine Learning with Influence Enhanced Fact-Checking. In International Cross-Domain Conference for Machine Learning and Knowledge Extraction; Holzinger, A., Kieseberg, P., Tjoa, A.M., Weippl, E., Eds.; Springer: Cham, Switzerland, 2019; pp. 94–113. [Google Scholar]
- Koh, P.W.; Liang, P. Understanding Black-Box Predictions via Influence Functions. In Proceedings of the ICML 2017, Sydney, Australia, 9 July 2017. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. arXiv 2016, arXiv:1606.03657. [Google Scholar]
- Hendricks, L.A.; Akata, Z.; Rohrbach, M.; Donahue, J.; Schiele, B.; Darrell, T. Generating Visual Explanations. arXiv 2016, arXiv:1603.08507. [Google Scholar]
- Zhang, Q.; Wu, Y.N.; Zhu, S. Interpretable Convolutional Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8827–8836. [Google Scholar]
- Explaining Decisions Made with AI: Draft Guidance for Consultation—Part 1: The Basics of Explaining AI; ICO & The Alan Turing Institute: Wilmslow/Cheshire, UK, 2019; p. 19.
- Webb, M.E.; Fluck, A.; Magenheim, J.; Malyn-Smith, J.; Waters, J.; Deschênes, M.; Zagami, J. Machine Learning for Human Learners: Opportunities, Issues, Tensions and Threats. Educ. Tech. Res. Dev. 2020. [Google Scholar] [CrossRef]
- Zhou, J.; Chen, F.; Berry, A.; Reed, M.; Zhang, S.; Savage, S. A Survey on Ethical Principles of AI and Implementations. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (IEEE SSCI), Canberra, Australia, 1–4 December 2020. [Google Scholar]
- Molnar, C.; Casalicchio, G.; Bischl, B. Interpretable Machine Learning—A Brief History, State-of-the-Art and Challenges. arXiv 2020, arXiv:2010.09337. [Google Scholar]
- Becker, B.; Kohavi, R.; Sommerfield, D. Visualizing the Simple Bayesian Classifier. In Information Visualization in Data Mining and Knowledge Discovery; Morgan Kaufmann Publishers Inc: San Francisco, CA, USA, 2001; pp. 237–249. [Google Scholar]
- Caragea, D.; Cook, D.; Honavar, V.G. Gaining Insights into Support Vector Machine Pattern Classifiers Using Projection-Based Tour Methods. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001; pp. 251–256. [Google Scholar]
- Erra, U.; Frola, B.; Scarano, V. An Interactive Bio-Inspired Approach to Clustering and Visualizing Datasets. In Proceedings of the 15th International Conference on Information Visualisation 2011, London, UK, 13–15 July 2011; pp. 440–447. [Google Scholar]
- Paiva, J.G.; Florian, L.; Pedrini, H.; Telles, G.; Minghim, R. Improved Similarity Trees and Their Application to Visual Data Classification. IEEE Trans. Vis. Comput. Graph. 2011, 17, 2459–2468. [Google Scholar] [CrossRef] [PubMed]
- Guo, Z.; Ward, M.O.; Rundensteiner, E.A. Nugget Browser: Visual Subgroup Mining and Statistical Significance Discovery in Multivariate Datasets. In Proceedings of the 2011 15th International Conference on Information Visualisation, London, UK, 13–15 July 2011; IEEE Computer Society: Washington, DC, USA, 2011; pp. 267–275. [Google Scholar]
- Talbot, J.; Lee, B.; Kapoor, A.; Tan, D.S. EnsembleMatrix: Interactive Visualization to Support Machine Learning with Multiple Classifiers. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Boston, MA, USA, 4–9 April 2009; pp. 1283–1292. [Google Scholar]
- Amershi, S.; Chickering, M.; Drucker, S.M.; Lee, B.; Simard, P.; Suh, J. ModelTracker: Redesigning Performance Analysis Tools for Machine Learning. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015; pp. 337–346. [Google Scholar]
- Chen, D.; Bellamy, R.K.E.; Malkin, P.K.; Erickson, T. Diagnostic Visualization for Non-Expert Machine Learning Practitioners: A Design Study. In Proceedings of the 2016 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC), Cambridge, UK, 4–8 September 2016; pp. 87–95. [Google Scholar]
- Neto, M.P.; Paulovich, F.V. Explainable Matrix—Visualization for Global and Local Interpretability of Random Forest Classification Ensembles. IEEE Trans. Vis. Comput. Graph. 2020. [Google Scholar] [CrossRef] [PubMed]
- Chan, G.Y.-Y.; Bertini, E.; Nonato, L.G.; Barr, B.; Silva, C.T. Melody: Generating and Visualizing Machine Learning Model Summary to Understand Data and Classifiers Together. arXiv 2020, arXiv:2007.10614. [Google Scholar]
- Zhou, J.; Huang, W.; Chen, F. A Radial Visualisation for Model Comparison and Feature Identification. In Proceedings of the IEEE PacificVis 2020, Tianjin, China, 14–17 April 2020. [Google Scholar]
- Gomez, O.; Holter, S.; Yuan, J.; Bertini, E. ViCE: Visual Counterfactual Explanations for Machine Learning Models. In Proceedings of the 25th International Conference on Intelligent User Interfaces, Cagliari, Italy, 17 March 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 531–535. [Google Scholar]
- Wongsuphasawat, K.; Smilkov, D.; Wexler, J.; Wilson, J.; Mané, D.; Fritz, D.; Krishnan, D.; Viégas, F.B.; Wattenberg, M. Visualizing Dataflow Graphs of Deep Learning Models in TensorFlow. IEEE Trans. Vis. Comput. Graph. 2018, 24, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Samek, W.; Montavon, G.; Vedaldi, A.; Hansen, L.K.; Müller, K.-R. (Eds.) Explainable AI: Interpreting, Explaining and Visualizing Deep Learning; Lecture Notes in Artificial Intelligence, Lect.Notes ComputerState-of-the-Art Surveys; Springer: Berlin/Heidelberg, Germany, 2019; ISBN 978-3-030-28953-9. [Google Scholar]
- Lipton, Z.C. The Mythos of Model Interpretability: In Machine Learning, the Concept of Interpretability Is Both Important and Slippery. Queue 2018, 16, 31–57. [Google Scholar] [CrossRef]
- Holland Michel, A. The Black Box, Unlocked: Predictability and Understand-Ability in Military AI; United Nations Institute for Disarmament Research: Geneva, Switzerland, 2020. [Google Scholar]
- Huysmans, J.; Dejaeger, K.; Mues, C.; Vanthienen, J.; Baesens, B. An Empirical Evaluation of the Comprehensibility of Decision Table, Tree and Rule Based Predictive Models. Decis. Support Syst. 2011, 51, 141–154. [Google Scholar] [CrossRef]
- Zhou, J.; Li, Z.; Hu, H.; Yu, K.; Chen, F.; Li, Z.; Wang, Y. Effects of Influence on User Trust in Predictive Decision Making. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, Scotland, UK, 4–9 May 2019; pp. 1–6. [Google Scholar]
- Zhou, J.; Arshad, S.Z.; Yu, K.; Chen, F. Correlation for User Confidence in Predictive Decision Making. In Proceedings of the 28th Australian Conference on Computer-Human Interaction, OzCHI 2016, Launceston, TAS, Australia, 29 November–2 December 2016. [Google Scholar]
- Poursabzi-Sangdeh, F.; Goldstein, D.G.; Hofman, J.M.; Vaughan, J.W.; Wallach, H. Manipulating and Measuring Model Interpretability. arXiv 2019, arXiv:1802.07810. [Google Scholar]
- Zhou, J.; Sun, J.; Chen, F.; Wang, Y.; Taib, R.; Khawaji, A.; Li, Z. Measurable Decision Making with GSR and Pupillary Analysis for Intelligent User Interface. ACM Trans. Comput.-Hum. Interact. 2015, 21, 33. [Google Scholar] [CrossRef]
- Bansal, G.; Nushi, B.; Kamar, E.; Lasecki, W.; Weld, D.S.; Horvitz, E. Beyond Accuracy: The Role of Mental Models in Human-AI Team Performance. In Proceedings of the AAAI Conference on Human Computationand Crowdsourcing, Stevenson, WA, USA, 28–30 October 2019; p. 10. [Google Scholar]
- Yu, K.; Berkovsky, S.; Taib, R.; Conway, D.; Zhou, J.; Chen, F. User Trust Dynamics: An Investigation Driven by Differences in System Performance. In Proceedings of the IUI 2017, Limassol, Cyprus, 13–16 March 2017. [Google Scholar]
- Lage, I.; Chen, E.; He, J.; Narayanan, M.; Kim, B.; Gershman, S.J.; Doshi-Velez, F. Human Evaluation of Models Built for Interpretability. In Proceedings of the AAAI Conference on Human Computation and Crowdsourcing, Skamania Lodge, WA, USA, 28 October 2019; Volume 7, pp. 59–67. [Google Scholar]
- Chang, J.; Boyd-Graber, J.; Gerrish, S.; Wang, C.; Blei, D.M. Reading Tea Leaves: How Humans Interpret Topic Models. In Proceedings of the 22nd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 7 2009; Curran Associates Inc.: Red Hook, NY, USA, 2009; pp. 288–296. [Google Scholar]
- Lakkaraju, H.; Bach, S.H.; Leskovec, J. Interpretable Decision Sets: A Joint Framework for Description and Prediction. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1675–1684. [Google Scholar]
- Weitz, K.; Schiller, D.; Schlagowski, R.; Huber, T.; André, E. “Do You Trust Me?”: Increasing User-Trust by Integrating Virtual Agents in Explainable AI Interaction Design. In Proceedings of the 19th ACM International Conference on Intelligent Virtual Agents, Paris, France, 2–5 July 2019; pp. 7–9. [Google Scholar]
- Hoffman, R.R.; Mueller, S.T.; Klein, G.; Litman, J. Metrics for Explainable AI: Challenges and Prospects. arXiv 2019, arXiv:1812.04608. [Google Scholar]
- Zhou, J.; Bridon, C.; Chen, F.; Khawaji, A.; Wang, Y. Be Informed and Be Involved: Effects of Uncertainty and Correlation on User’s Confidence in Decision Making. In Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems (CHI2015) Works-in-Progress, Seoul, Korea, 18–23 April 2015. [Google Scholar]
- Yu, K.; Berkovsky, S.; Conway, D.; Taib, R.; Zhou, J.; Chen, F. Do I Trust a Machine? Differences in User Trust Based on System Performance. In Human and Machine Learning: Visible, Explainable, Trustworthy and Transparent; Zhou, J., Chen, F., Eds.; Human–Computer Interaction Series; Springer International Publishing: Cham, Switzerland, 2018; pp. 245–264. ISBN 978-3-319-90403-0. [Google Scholar]
- Holzinger, A.; Carrington, A.; Müller, H. Measuring the Quality of Explanations: The System Causability Scale (SCS). KI-Künstl. Intell. 2020, 34, 193–198. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schmidt, P.; Biessmann, F. Quantifying Interpretability and Trust in Machine Learning Systems. In Proceedings of the AAAI-19 Workshop on Network Interpretability for Deep Learning, Honolulu, HI, USA, 27 January–2 February 2019; p. 8. [Google Scholar]
- Yang, M.; Kim, B. Benchmarking Attribution Methods with Relative Feature Importance. arXiv 2019, arXiv:1907.097011907. [Google Scholar]
- Nguyen, A.; Martínez, M.R. On Quantitative Aspects of Model Interpretability. arXiv 2020, arXiv:2007.07584. [Google Scholar]
- Slack, D.; Friedler, S.A.; Scheidegger, C.; Roy, C.D. Assessing the Local Interpretability of Machine Learning Models. arXiv 2019, arXiv:1902.03501. [Google Scholar]
- Lakkaraju, H.; Kamar, E.; Caruana, R.; Leskovec, J. Interpretable & Explorable Approximations of Black Box Models. arXiv 2017, arXiv:1707.01154. [Google Scholar]
- Ylikoski, P.; Kuorikoski, J. Dissecting Explanatory Power. Philos. Stud. 2010, 148, 201–219. [Google Scholar] [CrossRef]
- Yeh, C.-K.; Hsieh, C.-Y.; Suggala, A.; Inouye, D.I.; Ravikumar, P.K. On the (In)Fidelity and Sensitivity of Explanations. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; pp. 10967–10978. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic Attribution for Deep Networks. In Proceedings of the 34th International Conference on Machine Learning—Volume 70, Sydney, NSW, Australia, 6–11 August 2017; pp. 3319–3328. [Google Scholar]
- Hooker, S.; Erhan, D.; Kindermans, P.-J.; Kim, B. A Benchmark for Interpretability Methods in Deep Neural Networks. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; p. 12. [Google Scholar]
- Montavon, G.; Samek, W.; Müller, K.-R. Methods for Interpreting and Understanding Deep Neural Networks. Dig. Signal Process. 2018, 73, 1–15. [Google Scholar] [CrossRef]
- Ancona, M.; Ceolini, E.; Öztireli, C.; Gross, M. Towards Better Understanding of Gradient-Based Attribution Methods for Deep Neural Networks. Available online: https://openreview.net/pdf?id=Sy21R9JAW (accessed on 7 March 2018).
- Molnar, C.; Casalicchio, G.; Bischl, B. Quantifying Model Complexity via Functional Decomposition for Better Post-hoc Interpretability. In Machine Learning and Knowledge Discovery in Databases; Cellier, P., Driessens, K., Eds.; Communications in Computer and Information Science; Springer International Publishing: Cham, Switzerland, 2020; Volume 1167, pp. 193–204. ISBN 978-3-030-43822-7. [Google Scholar]
- Alvarez-Melis, D.; Jaakkola, T.S. Towards Robust Interpretability with Self-Explaining Neural Networks. arXiv 2018, arXiv:1806.07538. [Google Scholar]
- Guidotti, R.; Monreale, A.; Matwin, S.; Pedreschi, D. Black Box Explanation by Learning Image Exemplars in the Latent Feature Space. arXiv 2020, arXiv:2002.03746. [Google Scholar]
- Buçinca, Z.; Lin, P.; Gajos, K.Z.; Glassman, E.L. Proxy Tasks and Subjective Measures Can Be Misleading in Evaluating Explainable AI Systems. In Proceedings of the 25th International Conference on Intelligent User Interfaces, Cagliari, Italy, 17 March 2020; pp. 454–464. [Google Scholar]
- Zhou, J.; Arshad, S.Z.; Luo, S.; Chen, F. Effects of Uncertainty and Cognitive Load on User Trust in Predictive Decision Making. In Proceedings of the INTERACT 2017, Mumbai, India, 25–29 September 2017. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Explanation Types from Reference [43] | Explanation Categories from Reference [10] |
|---|---|
| Rationale explanation | Methods that provide rationales |
| Saliency methods | |
| Neural network visualisation methods | |
| Knowledge distillation methods | |
| Restricted neural network architecture | |
| Data explanation | Feature relevance methods |
| Exemplar methods | |
| High-level feature learning methods | |
| Safety and performance explanation | Restricted neural network architecture |
| Explanation Types | Quantitative Metrics | Properties of Explainability | ||||
|---|---|---|---|---|---|---|
| Interpretability | Fidelity | |||||
| Clarity | Broadness | Parsimony/ Simplicity | Completeness | Soundness | ||
| Model-based explanations | Model size [14,46] | ✓ | ||||
| Runtime operation counts [81] | ✓ | |||||
| Interaction strength [23,46] | ✓ | |||||
| Main effect complexity [46] | ✓ | |||||
| Level of (dis)agreement [82] | ✓ | ✓ | ||||
| Attribution- based explanations | Monotonicity [80] | ✓ | ||||
| Non-sensitivity [80,83], Sensitivity [84,85] | ✓ | |||||
| Effective complexity [80] | ✓ | ✓ | ||||
| Remove and retrain [86] | ✓ | |||||
| Recall of important features [33] | ✓ | |||||
| Implementation invariance [85] | ✓ | |||||
| Selectivity [87] | ✓ | |||||
| Continuity [87] | ✓ | |||||
| Sensitivity-n [88] | ✓ | |||||
| Mutual information [80] | ✓ | ✓ | ✓ | |||
| Example-based explanations | Non-representativeness [80] | ✓ | ✓ | |||
| Diversity [80] | ✓ | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, J.; Gandomi, A.H.; Chen, F.; Holzinger, A. Evaluating the Quality of Machine Learning Explanations: A Survey on Methods and Metrics. Electronics 2021, 10, 593. https://doi.org/10.3390/electronics10050593
Zhou J, Gandomi AH, Chen F, Holzinger A. Evaluating the Quality of Machine Learning Explanations: A Survey on Methods and Metrics. Electronics. 2021; 10(5):593. https://doi.org/10.3390/electronics10050593
Chicago/Turabian StyleZhou, Jianlong, Amir H. Gandomi, Fang Chen, and Andreas Holzinger. 2021. "Evaluating the Quality of Machine Learning Explanations: A Survey on Methods and Metrics" Electronics 10, no. 5: 593. https://doi.org/10.3390/electronics10050593