
Deep Time-Series Clustering: A Review


Abstract
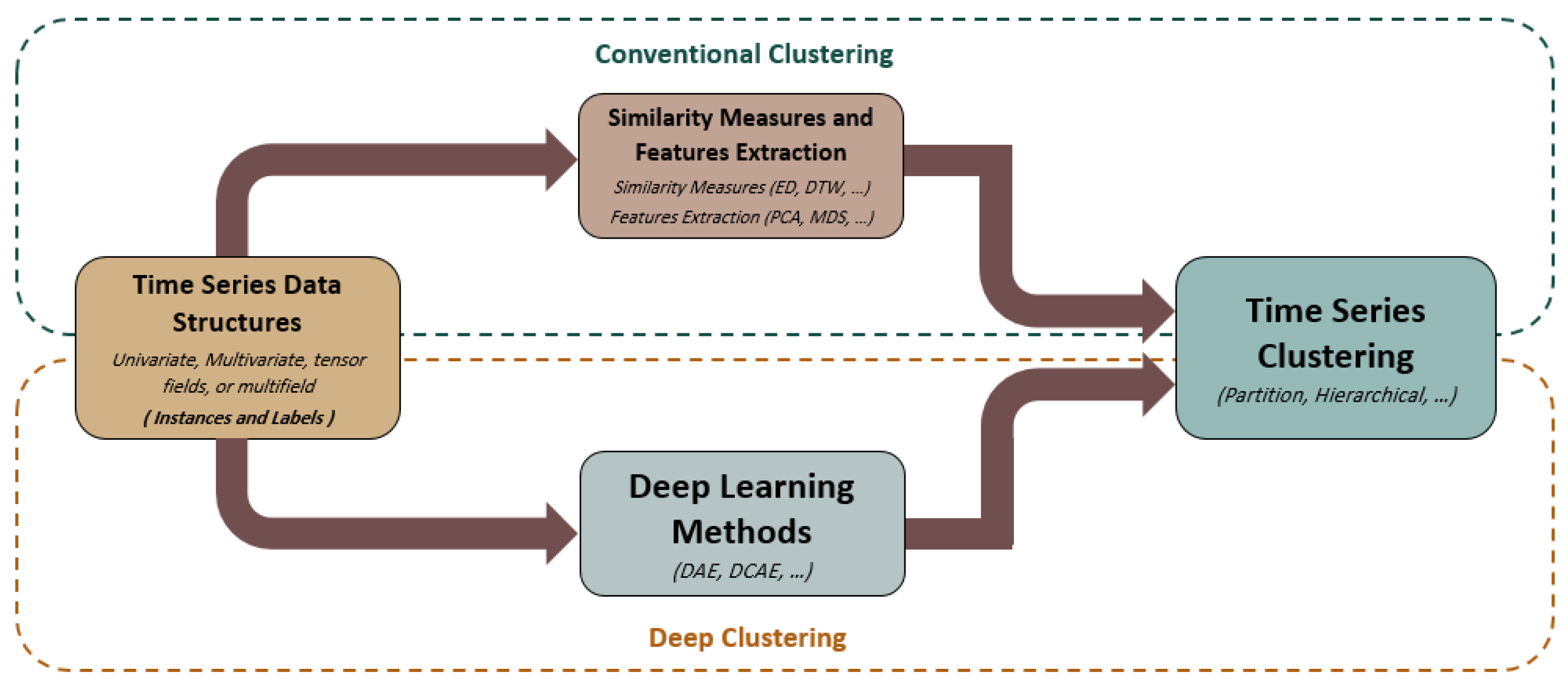
:1. Introduction
2. Methodology
2.1. Review Search Methodology
2.2. Review Scope
2.3. Review Structure
3. Time-Series Data Types
3.1. Univariate
3.2. Multivariate
3.3. Tensor Fields
3.3.1. Time-Series of Graph and Network
3.3.2. Time-Series of Spatial Positions of Moving Objects
3.3.3. Time-Series of Spatial Configurations and Distributions
3.4. Multifield
4. Conventional Time-Series Analysis
4.1. Similarity Measures and Feature Extraction
4.1.1. Raw Data Similarity
4.1.2. Features Extraction
4.2. Conventional Clustering Algorithms
4.2.1. Partitioning Methods
4.2.2. Hierarchical Methods
4.2.3. Model Based Methods
4.2.4. Density-Based Methods
5. Deep Clustering Method Applied to Biological Time-Series Data: A Case Study
5.1. Network Architectures for ICBD
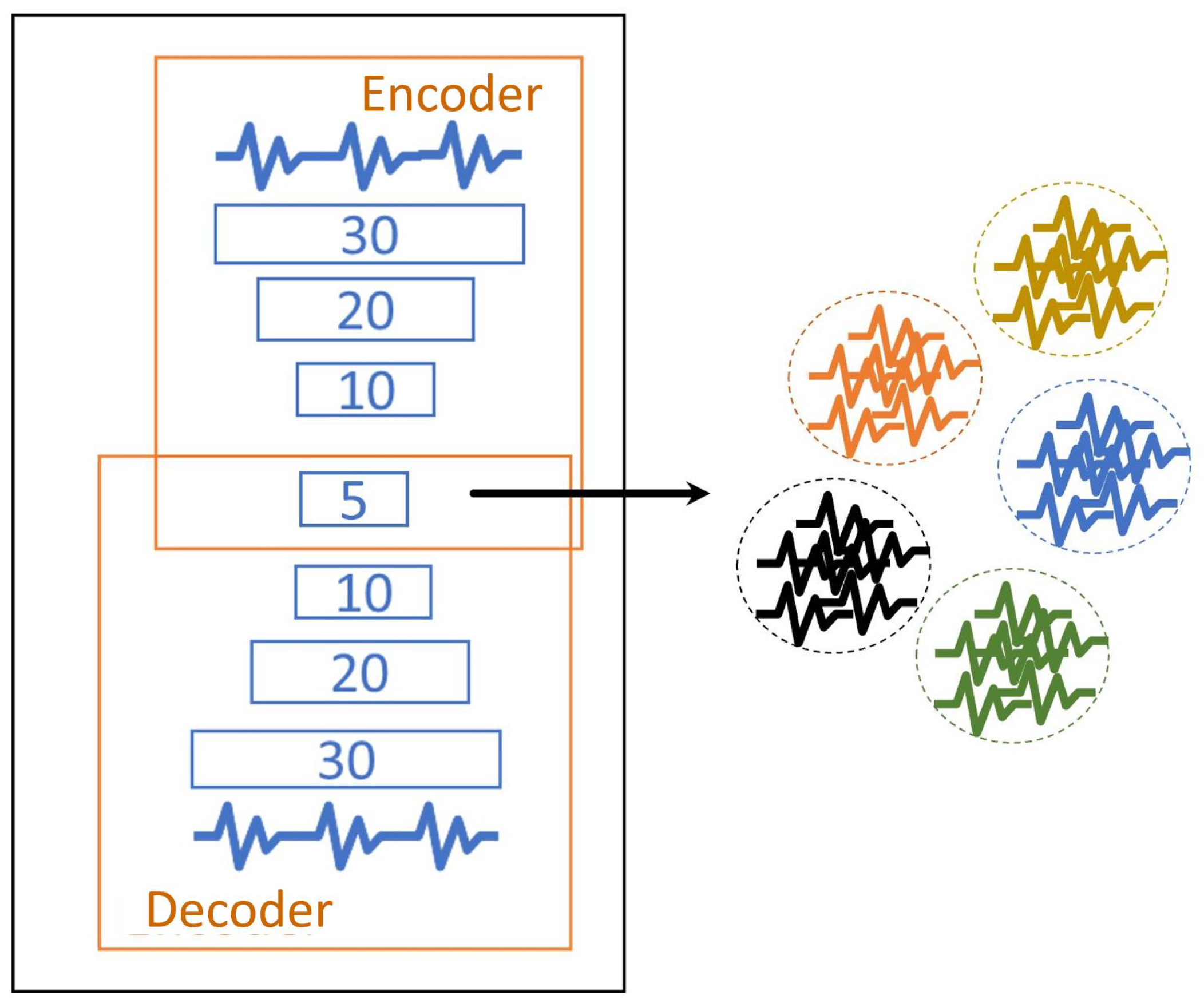
5.1.1. Deep Auto-Encoder (DAE)
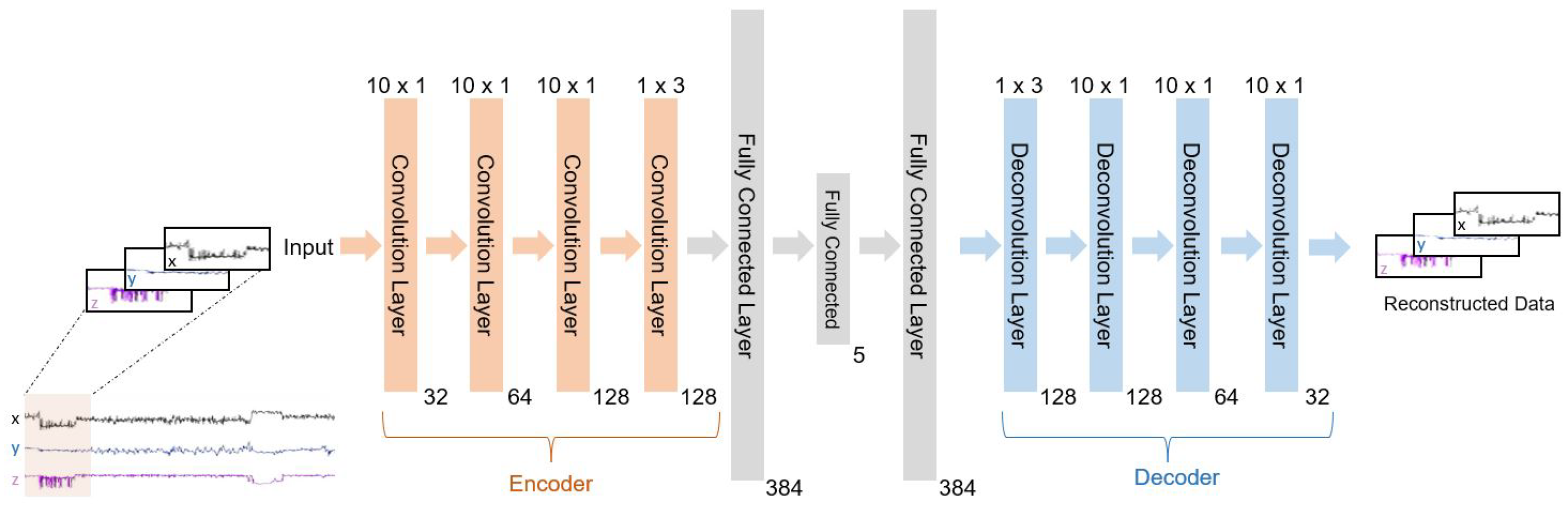
5.1.2. 1D-Convolutional Layer for Deep Convolutional Auto-Encoder (1D-DCAE)
5.2. Imperial Cormorant Birds Dataset (ICBD) and Pre-Processing
5.2.1. Feature Scaling
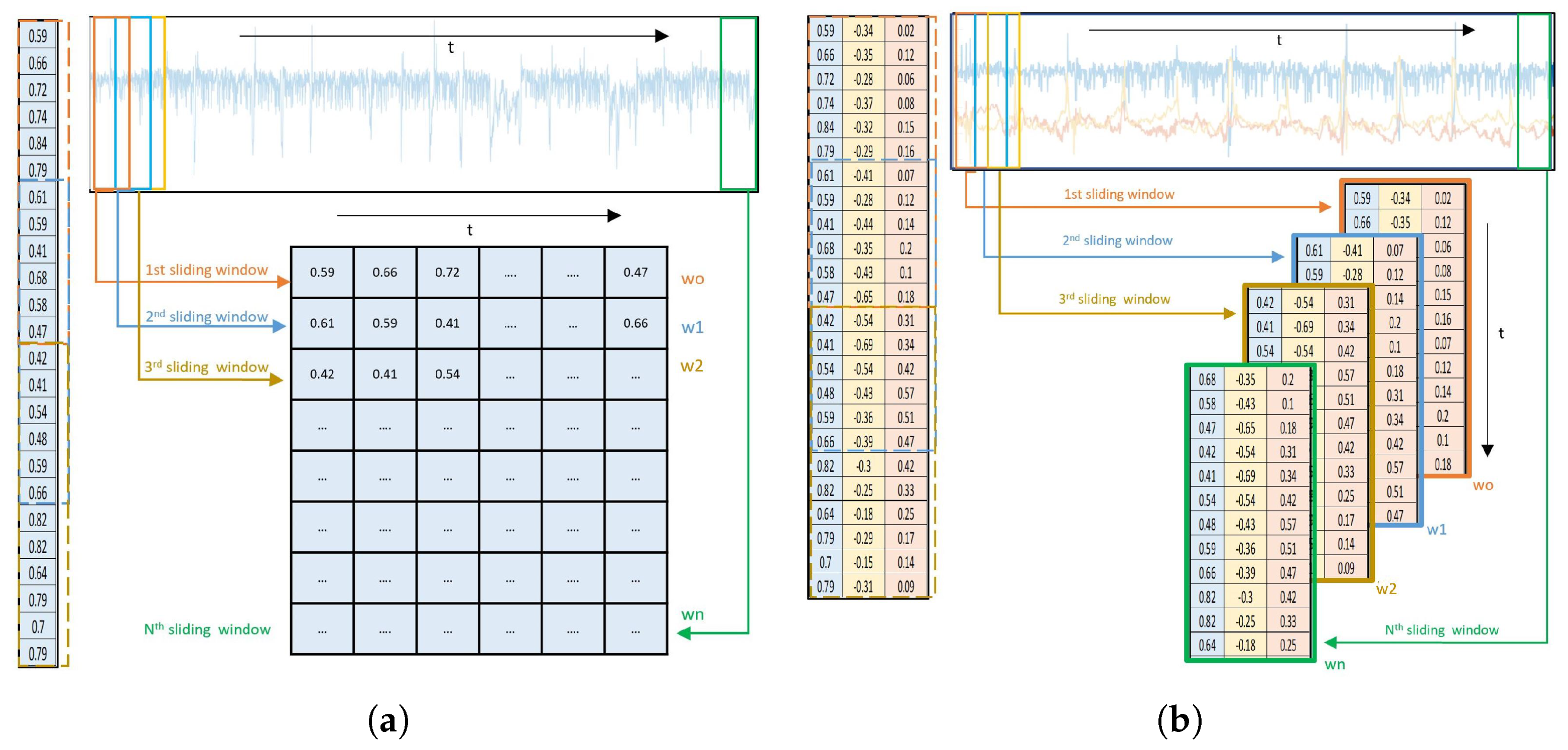
5.2.2. Sliding Window Approach
5.3. Experiment and Discussion
5.3.1. Experiments Setup
5.3.2. Experimental Results
Evaluation Metrics
- Accuracy (ACC): Clustering accuracy is a widely used measurement to evaluate clustering results. It is computed using obtained clustering results and ground truth labels by using the following form [179,180]:where n is the number of samples, denotes ground truth labels, is obtained clusters, is a function that equals one if and zero otherwise, and is the permutation function that maps obtained cluster labels into their corresponding ground truth labels.
- Normalized Mutual Information (NMI): The NMI is another metric used to measure clustering quality. It is defined between two random variables as [181]:where X denotes ground truth labels, Y is the obtained cluster, is the mutual information between X and Y, and and denote the utilized entropy, which normalize the value of mutual information into [0, 1] range.
Baseline Methods, Results and Analysis
6. State-of-the-Art and Outlook
6.1. Different Network Architectures
6.2. Different Clustering Methods
6.3. Deep Learning Heuristics
6.4. DTSC Applications
6.5. DTSC Benchmarks
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Aigner, W.; Miksch, S.; Schumann, H.; Tominski, C. Visualization of Time-Oriented Data; Springer Publishing Company: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Alqahtani, A.; Xie, X.; Deng, J.; Jones, M. A Deep Convolutional Auto-Encoder with Embedded Clustering. In Proceedings of the IEEE International Conference on Image Processing, Athens, Greece, 7–10 October 2018; pp. 4058–4062. [Google Scholar]
- Hotz, I.; Peikert, R. Definition of a Multifield. In Scientific Visualization: Uncertainty, Multifield, Biomedical, and Scalable Visualization; Hansen, C.D., Chen, M., Johnson, C.R., Kaufman, A.E., Hagen, H., Eds.; Springer: London, UK, 2014; pp. 105–109. [Google Scholar]
- Zheng, Y.; Liu, Q.; Chen, E.; Ge, Y.; Zhao, J.L. Time series classification using multi-channels deep convolutional neural networks. In Proceedings of the International Conference on Web-Age Information Management, Macau, China, 16–18 June 2014; pp. 298–310. [Google Scholar]
- Lughofer, E.; Sayed-Mouchaweh, M. Predictive Maintenance in Dynamic Systems: Advanced Methods, Decision Support Tools and Real-World Applications; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Lughofer, E.; Zavoianu, A.C.; Pollak, R.; Pratama, M.; Meyer-Heye, P.; Zörrer, H.; Eitzinger, C.; Radauer, T. Autonomous supervision and optimization of product quality in a multi-stage manufacturing process based on self-adaptive prediction models. J. Process Control 2019, 76, 27–45. [Google Scholar] [CrossRef]
- Battke, F.; Symons, S.; Nieselt, K. Mayday-integrative analytics for expression data. BMC Bioinform. 2010, 11, 121. [Google Scholar] [CrossRef] [Green Version]
- Jeong, D.H.; Darvish, A.; Najarian, K.; Yang, J.; Ribarsky, W. Interactive visual analysis of time-series microarray data. Vis. Comput. 2008, 24, 1053–1066. [Google Scholar] [CrossRef]
- Vogogias, A.; Kennedy, J.; Archambault, D. Hierarchical Clustering with Multiple-Height Branch-Cut Applied to Short Time-Series Gene Expression Data. In Proceedings of the EuroVis Posters, Groningen, The Netherlands, 6–10 June 2016. [Google Scholar]
- Cho, M.; Kim, B.; Bae, H.J.; Seo, J. Stroscope: Multi-scale visualization of irregularly measured time-series data. IEEE Trans. Vis. Comput. Graph. 2014, 20, 808–821. [Google Scholar] [CrossRef] [PubMed]
- Chang, R.; Ghoniem, M.; Kosara, R.; Ribarsky, W.; Yang, J.; Suma, E.; Ziemkiewicz, C.; Kern, D.; Sudjianto, A. Wirevis: Visualization of categorical, time-varying data from financial transactions. In Proceedings of the IEEE Symposium on Visual Analytics Science and Technology, Sacramento, CA, USA, 30 October–1 November 2007; pp. 155–162. [Google Scholar]
- Xie, C.; Chen, W.; Huang, X.; Hu, Y.; Barlowe, S.; Yang, J. VAET: A visual analytics approach for e-transactions time-series. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1743–1752. [Google Scholar] [CrossRef] [Green Version]
- Turkay, C.; Kaya, E.; Balcisoy, S.; Hauser, H. Designing progressive and interactive analytics processes for high-dimensional data analysis. IEEE Trans. Vis. Comput. Graph. 2017, 23, 131–140. [Google Scholar] [CrossRef]
- Lei, S.T.; Zhang, K. A visual analytics system for financial time-series data. In Proceedings of the International Symposium on Visual Information Communication, Beijing, China, 28–29 September 2010; pp. 1–9. [Google Scholar]
- Ziegler, H.; Jenny, M.; Gruse, T.; Keim, D.A. Visual market sector analysis for financial time series data. In Proceedings of the IEEE Symposium on Visual Analytics Science and Technology, Salt Lake City, UT, USA, 24–29 October 2010; pp. 83–90. [Google Scholar]
- Schreck, T.; Bernard, J.; Von Landesberger, T.; Kohlhammer, J. Visual cluster analysis of trajectory data with interactive kohonen maps. Inf. Vis. 2009, 8, 14–29. [Google Scholar] [CrossRef] [Green Version]
- Schreck, T.; Tekušová, T.; Kohlhammer, J.; Fellner, D. Trajectory-based visual analysis of large financial time series data. ACM SIGKDD Explor. Newsl. 2007, 9, 30–37. [Google Scholar] [CrossRef] [Green Version]
- Perer, A.; Sun, J. MatrixFlow: Temporal network visual analytics to track symptom evolution during disease progression. In Proceedings of the AMIA Annual Symposium, Chicago, IL, USA, 3–7 November 2012; Volume 2012, pp. 716–725. [Google Scholar]
- Guo, S.; Xu, K.; Zhao, R.; Gotz, D.; Zha, H.; Cao, N. EventThread: Visual Summarization and Stage Analysis of Event Sequence Data. IEEE Trans. Vis. Comput. Graph. 2018, 24, 56–65. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, T.; Chen, Z.; Luo, Q.; Qu, H. Stac: Enhancing stacked graphs for time series analysis. In Proceedings of the IEEE Pacific Visualization Symposium, Taipei, Taiwan, 19–22 April 2016; pp. 234–238. [Google Scholar]
- Wilkinson, L. Visualizing Big Data Outliers through Distributed Aggregation. IEEE Trans. Vis. Comput. Graph. 2017, 24, 256–266. [Google Scholar] [CrossRef] [PubMed]
- Meidiana, A.; Hong, S.H. MultiStory: Visual analytics of dynamic multi-relational networks. In Proceedings of the IEEE Pacific Visualization Symposium, Hangzhou, China, 14–17 April 2015; pp. 75–79. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Hadlak, S.; Schumann, H.; Cap, C.H.; Wollenberg, T. Supporting the visual analysis of dynamic networks by clustering associated temporal attributes. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2267–2276. [Google Scholar] [CrossRef] [PubMed]
- Steiger, M.; Bernard, J.; Mittelstadt, S.; Lucke-Tieke, H.; Keim, D.; May, T.; Kohlhammer, J. Visual Analysis of Time-Series Similarities for Anomaly Detection in Sensor Networks. Comput. Graph. Forum 2014, 33, 401–410. [Google Scholar] [CrossRef]
- van den Elzen, S.; Holten, D.; Blaas, J.; van Wijk, J.J. Reducing snapshots to points: A visual analytics approach to dynamic network exploration. IEEE Trans. Vis. Comput. Graph. 2016, 22, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Zhou, F.; Huang, W.; Zhao, Y.; Shi, Y.; Liang, X.; Fan, X. Entvis: A visual analytic tool for entropy-based network traffic anomaly detection. IEEE Comput. Graph. Appl. 2015, 35, 42–50. [Google Scholar] [CrossRef]
- Fujiwara, T.; Li, J.K.; Mubarak, M.; Ross, C.; Carothers, C.D.; Ross, R.B.; Ma, K.L. A visual analytics system for optimizing the performance of large-scale networks in supercomputing systems. Vis. Inform. 2018, 2, 98–110. [Google Scholar] [CrossRef]
- Cao, N.; Shi, C.; Lin, S.; Lu, J.; Lin, Y.R.; Lin, C.Y. TargetVue: Visual analysis of anomalous user behaviors in online communication systems. IEEE Trans. Vis. Comput. Graph. 2016, 22, 280–289. [Google Scholar] [CrossRef]
- Hao, M.C.; Marwah, M.; Janetzko, H.; Keim, D.i.A.; Dayal, U.; Sharma, R.; Patnaik, D.; Ramakrish-nan, N. Visual analysis of frequent patterns in large time series. In Proceedings of the IEEE Symposium on Visual Analytics Science and Technology, Salt Lake City, UT, USA, 24–29 October 2010; pp. 227–228. [Google Scholar]
- Muelder, C.; Zhu, B.; Chen, W.; Zhang, H.; Ma, K.L. Visual analysis of cloud computing performance using behavioral lines. IEEE Trans. Vis. Comput. Graph. 2016, 22, 1694–1704. [Google Scholar] [CrossRef] [PubMed]
- Sharma, G.; Shroff, G.; Pandey, A.; Singh, B.; Sehgal, G.; Paneri, K.; Agarwal, P. Multi-sensor visual analytics supported by machine-learning models. In Proceedings of the International Conference on Data Mining Workshop, Atlantic City, NJ, USA, 14–17 November 2015; pp. 668–674. [Google Scholar]
- Shi, L.; Liao, Q.; He, Y.; Li, R.; Striegel, A.; Su, Z. SAVE: Sensor anomaly visualization engine. In Proceedings of the IEEE Conference on Visual Analytics Science and Technology, Providence, RI, USA, 23–28 October 2011; pp. 201–210. [Google Scholar]
- Arbesser, C.; Spechtenhauser, F.; Mühlbacher, T.; Piringer, H. Visplause: Visual data quality assessment of many time series using plausibility checks. IEEE Trans. Vis. Comput. Graph. 2017, 23, 641–650. [Google Scholar] [CrossRef]
- Chen, Y.; Xu, P.; Ren, L. Sequence Synopsis: Optimize Visual Summary of Temporal Event Data. IEEE Trans. Vis. Comput. Graph. 2018, 24, 45–55. [Google Scholar] [CrossRef]
- Andrienko, G.; Andrienko, N.; Wrobel, S. Visual analytics tools for analysis of movement data. ACM SIGKDD Explor. Newsl. 2007, 9, 38–46. [Google Scholar] [CrossRef]
- Andrienko, G.; Andrienko, N. Spatio-temporal aggregation for visual analysis of movements. In Proceedings of the IEEE Symposium on Visual Analytics Science and Technology, Columbus, OH, USA, 19–24 October 2008; pp. 51–58. [Google Scholar]
- Andrienko, G.; Andrienko, N.; Hurter, C.; Rinzivillo, S.; Wrobel, S. From movement tracks through events to places: Extracting and characterizing significant places from mobility data. In Proceedings of the IEEE Conference on Visual Analytics Science and Technology, Providence, RI, USA, 23–28 October 2011; pp. 161–170. [Google Scholar]
- Andrienko, G.; Andrienko, N.; Hurter, C.; Rinzivillo, S.; Wrobel, S. Scalable Analysis of Movement Data for Extracting and Exploring Significant Places. IEEE Trans. Vis. Comput. Graph. 2013, 19, 1078–1094. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lu, M.; Wang, Z.; Yuan, X. Trajrank: Exploring travel behaviour on a route by trajectory ranking. In Proceedings of the IEEE Pacific Visualization Symposium, Hangzhou, China, 14–17 April 2015; pp. 311–318. [Google Scholar]
- Andrienko, G.; Andrienko, N.; Rinzivillo, S.; Nanni, M.; Pedreschi, D.; Giannotti, F. Interactive visual clustering of large collections of trajectories. In Proceedings of the IEEE Symposium on Visual Analytics Science and Technology, Atlantic City, NJ, USA, 11–16 October 2009; pp. 3–10. [Google Scholar]
- Riveiro, M.; Lebram, M.; Elmer, M. Anomaly detection for road traffic: A visual analytics framework. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2260–2270. [Google Scholar] [CrossRef]
- Kalamaras, I.; Zamichos, A.; Salamanis, A.; Drosou, A.; Kehagias, D.D.; Margaritis, G.; Papadopoulos, S.; Tzovaras, D. An interactive visual analytics platform for smart intelligent transportation systems management. IEEE Trans. Intell. Transp. Syst. 2018, 19, 487–496. [Google Scholar] [CrossRef]
- Andrienko, G.; Andrienko, N.; Mladenov, M.; Mock, M.; Pölitz, C. Identifying place histories from activity traces with an eye to parameter impact. IEEE Trans. Vis. Comput. Graph. 2012, 18, 675–688. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Andrienko, G.L.; Andrienko, N.V.; Fuchs, G.; Raimond, A.M.O.; Symanzik, J.; Ziemlicki, C. Extracting Semantics of Individual Places from Movement Data by Analyzing Temporal Patterns of Visits. In Proceedings of the ACM SIGSPATIAL International Workshop on Computational Models of Place, Orlando, FL, USA, 5 November 2013; pp. 9–15. [Google Scholar]
- Chae, J.; Wang, G.; Ahlbrand, B.; Gorantla, M.B.; Zhang, J.; Chen, S.; Xu, H.; Zhao, J.; Hatton, W.; Malik, A.; et al. Visual analytics of heterogeneous data for criminal event analysis VAST challenge 2015: Grand challenge. In Proceedings of the IEEE Conference on Visual Analytics Science and Technology, Chicago, IL, USA, 25–30 October 2015; pp. 149–150. [Google Scholar]
- Pu, J.; Liu, S.; Xu, P.; Qu, H.; Ni, L.M. MViewer: Mobile phone spatiotemporal data viewer. Front. Comput. Sci. 2014, 8, 298–315. [Google Scholar] [CrossRef]
- Shen, Z.; Ma, K.L. Mobivis: A visualization system for exploring mobile data. In Proceedings of the IEEE Pacific Visualization Symposium, Kyoto, Japan, 5–7 March 2008; pp. 175–182. [Google Scholar]
- Zhao, J.; Wang, G.; Chae, J.; Xu, H.; Chen, S.; Hatton, W.; Towers, S.; Gorantla, M.B.; Ahlbrand, B.; Zhang, J.; et al. ParkAnalyzer: Characterizing the movement patterns of visitors VAST 2015 Mini-Challenge 1. In Proceedings of the IEEE Conference on Visual Analytics Science and Technology, Chicago, IL, USA, 25–30 October 2015; pp. 179–180. [Google Scholar]
- von Landesberger, T.; Brodkorb, F.; Roskosch, P.; Andrienko, N.; Andrienko, G.; Kerren, A. Mobilitygraphs: Visual analysis of mass mobility dynamics via spatio-temporal graphs and clustering. IEEE Trans. Vis. Comput. Graph. 2016, 22, 11–20. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Biswas, A.; Lin, G.; Liu, X.; Shen, H.W. Visualization of time-varying weather ensembles across multiple resolutions. IEEE Trans. Vis. Comput. Graph. 2017, 23, 841–850. [Google Scholar] [CrossRef] [PubMed]
- Senaratne, H.; Mueller, M.; Behrisch, M.; Lalanne, F.; Bustos-Jiménez, J.; Schneidewind, J.; Keim, D.; Schreck, T. Urban Mobility Analysis With Mobile Network Data: A Visual Analytics Approach. IEEE Trans. Intell. Transp. Syst. 2018, 19, 1537–1546. [Google Scholar] [CrossRef] [Green Version]
- Stopar, L.; Skraba, P.; Grobelnik, M.; Mladenic, D. StreamStory: Exploring Multivariate Time Series on Multiple Scales. IEEE Trans. Vis. Comput. Graph. 2018, 25, 1788–1802. [Google Scholar] [CrossRef]
- Gao, L.; Campbell, H.A.; Bidder, O.R.; Hunter, J. A Web-based semantic tagging and activity recognition system for species’ accelerometry data. Ecol. Inform. 2013, 13, 47–56. [Google Scholar] [CrossRef]
- Walker, J.S.; Jones, M.W.; Laramee, R.S.; Bidder, O.R.; Williams, H.J.; Scott, R.; Shepard, E.L.; Wilson, R.P. TimeClassifier: A visual analytic system for the classification of multi-dimensional time series data. Vis. Comput. 2015, 31, 1067–1078. [Google Scholar] [CrossRef] [Green Version]
- Bernard, J.; Wilhelm, N.; Scherer, M.; May, T.; Schreck, T. TimeSeriesPaths: Projection-based explorative analysis of multivariate time series data. J. WSCG 2012, 2, 97–106. [Google Scholar]
- Kincaid, R.; Lam, H. Line graph explorer: Scalable display of line graphs using focus+ context. In Proceedings of the Conference on Advanced Visual Interfaces, Venezia, Italy, 23–26 May 2006; pp. 404–411. [Google Scholar]
- Li, J.; Xiao, Z.; Zhao, H.Q.; Meng, Z.P.; Zhang, K. Visual analytics of smogs in China. J. Vis. 2016, 19, 461–474. [Google Scholar] [CrossRef]
- Li, J.; Zhang, K.; Meng, Z.P. Vismate: Interactive visual analysis of station-based observation data on climate changes. In Proceedings of the Conference Visual Analytics Science and Technology, Paris, France, 25–31 October 2014; pp. 133–142. [Google Scholar]
- Martin, S.; Quach, T.T. Interactive visualization of multivariate time series data. In Proceedings of the International Conference on Augmented Cognition, Toronto, ON, Canada, 17–22 July 2016; pp. 322–332. [Google Scholar]
- Shu, Q.; Guo, H.; Liang, J.; Che, L.; Liu, J.; Yuan, X. EnsembleGraph: Interactive visual analysis of spatiotemporal behaviors in ensemble simulation data. In Proceedings of the IEEE Pacific Visualization Symposium, Taipei, Taiwan, 19–22 April 2016; pp. 56–63. [Google Scholar]
- Wu, W.; Zheng, Y.; Qu, H.; Chen, W.; Gröller, E.; Ni, L.M. Boundaryseer: Visual analysis of 2d boundary changes. In Proceedings of the IEEE Conference on Visual Analytics Science and Technology, Paris, France, 25–31 October 2014; pp. 143–152. [Google Scholar]
- Bernard, J.; Wilhelm, N.; Krüger, B.; May, T.; Schreck, T.; Kohlhammer, J. Motionexplorer: Exploratory search in human motion capture data based on hierarchical aggregation. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2257–2266. [Google Scholar] [CrossRef] [Green Version]
- Blascheck, T.; John, M.; Kurzhals, K.; Koch, S.; Ertl, T. Va 2: A visual analytics approach for evaluating visual analytics applications. IEEE Trans. Vis. Comput. Graph. 2016, 22, 61–70. [Google Scholar] [CrossRef]
- Purwantiningsih, O.; Sallaberry, A.; Andary, S.; Seilles, A.; Aze, J. Visual analysis of body movement in serious games for healthcare. In Proceedings of the IEEE Pacific Visualization Symposium, Taipei, Taiwan, 19–22 April 2016; pp. 229–233. [Google Scholar]
- Kim, J.G.; Snodgrass, M.; Pietrowicz, M.; Karahalios, K. Visual Analysis of Relationships between Behavioral and Physiological Sensor Data. In Proceedings of the International Conference on Healthcare Informatics, Dallas, TX, USA, 21–23 October 2015; pp. 170–179. [Google Scholar]
- Turkay, C.; Parulek, J.; Reuter, N.; Hauser, H. Interactive visual analysis of temporal cluster structures. Comput. Graph. Forum 2011, 30, 711–720. [Google Scholar] [CrossRef]
- Soriano-Vargas, A.; Vani, B.C.; Shimabukuro, M.H.; Monico, J.F.; Oliveira, M.C.F.; Hamann, B. Visual analytics of time-varying multivariate ionospheric scintillation data. Comput. Graph. 2017, 68, 96–107. [Google Scholar] [CrossRef] [Green Version]
- Trajcevski, G.; Gunopulos, D.; Aggarwal, C.C.; Reddy, C. Time-series data clustering. In Data Clustering: Algorithms and Applications; Chapman and Hall/CRC: Boca Raton, FL, USA, 2013; pp. 357–375. [Google Scholar]
- Xing, Z.; Pei, J.; Keogh, E. A brief survey on sequence classification. ACM SIGKDD Explor. Newsl. 2010, 12, 40–48. [Google Scholar] [CrossRef]
- Sorzano, C.O.S.; Vargas, J.; Montano, A.P. A survey of dimensionality reduction techniques. arXiv 2014, arXiv:1403.2877. [Google Scholar]
- Liao, T.W. Clustering of time series data—A survey. Pattern Recognit. 2005, 38, 1857–1874. [Google Scholar] [CrossRef]
- Fulcher, B.D.; Jones, N.S. Highly comparative feature-based time-series classification. IEEE Trans. Knowl. Data Eng. 2014, 26, 3026–3037. [Google Scholar] [CrossRef] [Green Version]
- Aghabozorgi, S.; Shirkhorshidi, A.S.; Wah, T.Y. Time-series clustering—A decade review. Inf. Syst. 2015, 53, 16–38. [Google Scholar] [CrossRef]
- Tucci, M.; Raugi, M. Analysis of spectral clustering algorithms for linear and nonlinear time series. In Proceedings of the International Conference on Intelligent Systems Design and Applications, Córdoba, Spain, 22–24 November 2011; pp. 925–930. [Google Scholar]
- Batóg, J.; Batóg, B. Synchronization of Business Cycles in the EU: Time Series Clustering. WSEAS Trans. Bus. Econ. 2019, 16, 298–305. [Google Scholar]
- Petitjean, F.; Ketterlin, A.; Gançarski, P. A global averaging method for dynamic time warping, with applications to clustering. Pattern Recognit. 2011, 44, 678–693. [Google Scholar] [CrossRef]
- Yang, J.; Leskovec, J. Patterns of temporal variation in online media. In Proceedings of the ACM International Conference on Web Search and Data Mining, Hong Kong, China, 9–12 February 2011; pp. 177–186. [Google Scholar]
- Paparrizos, J.; Gravano, L. k-shape: Efficient and accurate clustering of time series. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Melbourne, Australia, 31 May–4 June 2015; pp. 1855–1870. [Google Scholar]
- Ferreira, L.N.; Zhao, L. Time series clustering via community detection in networks. Inf. Sci. 2016, 326, 227–242. [Google Scholar] [CrossRef] [Green Version]
- Guo, C.; Jia, H.; Zhang, N. Time series clustering based on ICA for stock data analysis. In Proceedings of the International Conference on Wireless Communications, Networking and Mobile Computing, Avignon, France, 12–14 October 2008; pp. 1–4. [Google Scholar]
- Zakaria, J.; Mueen, A.; Keogh, E. Clustering time series using unsupervised-shapelets. In Proceedings of the International Conference on Data Mining, Brussels, Belgium, 10–13 December 2012; pp. 785–794. [Google Scholar]
- Theodor, P. Time Series Analysis for Assessing and Forecasting of Road Traffic Accidents -Case Studies. WSEAS Trans. Math. 2020, 19, 177–185. [Google Scholar]
- Shi, L.; Du, L.; Shen, Y.D. Robust spectral learning for unsupervised feature selection. In Proceedings of the International Conference on Data Mining, Shenzhen, China, 14–17 December 2014; pp. 977–982. [Google Scholar]
- Qian, M.; Zhai, C. Robust unsupervised feature selection. In Proceedings of the International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 1621–1627. [Google Scholar]
- Li, Z.; Yang, Y.; Liu, J.; Zhou, X.; Lu, H. Unsupervised feature selection using nonnegative spectral analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; pp. 1026–1032. [Google Scholar]
- Yang, Y.; Shen, H.T.; Ma, Z.; Huang, Z.; Zhou, X. L2,1-norm regularized discriminative feature selection for unsupervised learning. In Proceedings of the International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011; pp. 1589–1594. [Google Scholar]
- Ma, Q.; Li, S.; Shen, L.; Wang, J.; Wei, J.; Yu, Z.; Cottrell, G. End-to-End Incomplete Time-Series Modeling From Linear Memory of Latent Variables. IEEE Trans. Cybern. 2020, 50, 4908–4920. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lei, H.; Xia, Y.; Qin, X. Estimation of semivarying coefficient time series models with ARMA errors. Ann. Stat. 2016, 44, 1618–1660. [Google Scholar] [CrossRef]
- Cai, Z.; Fan, J.; Yao, Q. Functional-Coefficient Regression Models for Nonlinear Time Series. J. Am. Stat. Assoc. 1999, 95, 941–956. [Google Scholar] [CrossRef]
- Tjostheim, D.; Auestad, B. Nonparametric Identification of Nonlinear Time Series: Projections. J. Am. Stat. Assoc. 1994, 89, 1398–1409. [Google Scholar]
- Wang, X.; Mueen, A.; Ding, H.; Trajcevski, G.; Scheuermann, P.; Keogh, E. Experimental comparison of representation methods and distance measures for time series data. Data Min. Knowl. Discov. 2013, 26, 275–309. [Google Scholar] [CrossRef] [Green Version]
- Tornai, K.; Kovács, L.; Oláh, A.; Drenyovszki, R.; Pintér, I.; Tisza, D.; Levendovszky, J. Classification for consumption data in smart grid based on forecasting time series. Electr. Power Syst. Res. 2016, 141, 191–201. [Google Scholar] [CrossRef]
- Yahyaoui, H.; Al-Mutairi, A. A feature-based trust sequence classification algorithm. Inf. Sci. 2016, 328, 455–484. [Google Scholar] [CrossRef]
- Wei, L.; Keogh, E. Semi-supervised time series classification. In Proceedings of the International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 748–753. [Google Scholar]
- Ye, J.; Xiao, C.; Esteves, R.M.; Rong, C. Time Series Similarity Evaluation Based on Spearman’s Correlation Coefficients and Distance Measures. In Proceedings of the International Conference on Cloud Computing and Big Data in Asia, Huangshan, China, 17–19 June 2015; pp. 319–331. [Google Scholar]
- Buono, P.; Aris, A.; Plaisant, C.; Khella, A.; Shneiderman, B. Interactive pattern search in time series. Electron. Imaging 2005, 5669, 175–186. [Google Scholar]
- Yu, D.; Yu, X.; Hu, Q.; Liu, J.; Wu, A. Dynamic time warping constraint learning for large margin nearest neighbor classification. Inf. Sci. 2011, 181, 2787–2796. [Google Scholar] [CrossRef]
- Zhao, J.; Itti, L. shapeDTW: Shape Dynamic Time Warping. Pattern Recognit. 2018, 74, 171–184. [Google Scholar] [CrossRef] [Green Version]
- Ratanamahatana, C.A.; Keogh, E. Making time-series classification more accurate using learned constraints. In Proceedings of the SIAM International Conference on Data Mining, Lake Buena Vista, FL, USA, 22–24 April 2004; pp. 11–22. [Google Scholar]
- Mueen, A.; Keogh, E. Extracting Optimal Performance from Dynamic Time Warping. In Proceedings of the International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 2129–2130. [Google Scholar]
- Kotas, M.; Leski, J.M.; Moroń, T. Dynamic time warping based on modified alignment costs for evoked potentials averaging. In Man–Machine Interactions 4; Springer: Cham, Switzerland, 2016; pp. 305–314. [Google Scholar]
- Faloutsos, C.; Ranganathan, M.; Manolopoulos, Y. Fast Subsequence Matching in Time-Series Databases; ACM: New York, NY, USA, 1994; Volume 23. [Google Scholar]
- Berndt, D.J.; Clifford, J. Using Dynamic Time Warping to Find Patterns in Time Series. In Proceedings of the Workshop on Knowledge Discovery in Databases, Seattle, WA, USA, July 1994; pp. 359–370. [Google Scholar]
- Keogh, E.; Ratanamahatana, C.A. Exact indexing of dynamic time warping. Knowl. Inf. Syst. 2005, 7, 358–386. [Google Scholar] [CrossRef]
- Vlachos, M.; Kollios, G.; Gunopulos, D. Discovering similar multidimensional trajectories. In Proceedings of the International Conference on Data Engineering, San Jose, CA, USA, 26 February–1 March 2002; pp. 673–684. [Google Scholar]
- Smith, S. Digital Signal Processing: A practical Guide for Engineers and Scientists; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Kaya, H.; Gündüz-Öğüdücü, Ş. A distance based time series classification framework. Inf. Syst. 2015, 51, 27–42. [Google Scholar] [CrossRef]
- Yang, K.; Shahabi, C. A PCA-based similarity measure for multivariate time series. In Proceedings of the ACM International Workshop on Multimedia Databases, Washington, DC, USA, 13 November 2004; pp. 65–74. [Google Scholar]
- Singhal, A.; Seborg, D.E. Clustering multivariate time-series data. J. Chemom. 2005, 19, 427–438. [Google Scholar] [CrossRef]
- Yang, K.; Shahabi, C. On the stationarity of multivariate time series for correlation-based data analysis. In Proceedings of the International Conference on Data Mining, Houston, TX, USA, 27–30 November 2005; p. 4. [Google Scholar]
- Lesch, R.H.; Caillé, Y.; Lowe, D. Component analysis in financial time series. In Proceedings of the Conference on Computational Intelligence for Financial Engineering, New York, NY, USA, 27 April 1999; pp. 183–190. [Google Scholar]
- Lin, T.; Guo, F.; Wu, Y.; Zhu, B.; Zhang, F.; Qu, H.; Chen, W. TieVis: Visual analytics of evolution of interpersonal ties. In Proceedings of the International Conference on Technologies for E-Learning and Digital Entertainment, Hangzhou, China, 14–16 April 2016; pp. 412–424. [Google Scholar]
- Dong, G.; Pei, J. Sequence Data Mining; Springer: Berlin/Heidelberg, Germany, 2007; Volume 33. [Google Scholar]
- Fu, T.c. A review on time series data mining. Eng. Appl. Artif. Intell. 2011, 24, 164–181. [Google Scholar] [CrossRef]
- Agrawal, R.; Faloutsos, C.; Swami, A. Efficient similarity search in sequence databases. In Proceedings of the International Conference on Foundations of Data Organization and Algorithms, Chicago, IL, USA, 13–15 October 1993; pp. 69–84. [Google Scholar]
- Rafiei, D.; Mendelzon, A.O. Querying time series data based on similarity. IEEE Trans. Knowl. Data Eng. 2000, 12, 675–693. [Google Scholar] [CrossRef]
- Janacek, G.J.; Bagnall, A.J.; Powell, M. A likelihood ratio distance measure for the similarity between the fourier transform of time series. In Proceedings of the Pacific Asia Conference on Knowledge Discovery and Data Mining, Hanoi, Vietnam, 18–20 May 2005; pp. 737–743. [Google Scholar]
- Popivanov, I.; Miller, R.J. Similarity search over time-series data using wavelets. In Proceedings of the International Conference on Data Engineering, San Jose, CA, USA, 26 February–1 March 2002; pp. 212–221. [Google Scholar]
- Chan, K.P.; Fu, A.W.C. Efficient time series matching by wavelets. In Proceedings of the International Conference on Data Engineering, Sydney, Australia, 23–26 March 1999; pp. 126–133. [Google Scholar]
- Aggarwal, C.C. On effective classification of strings with wavelets. In Proceedings of the International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; pp. 163–172. [Google Scholar]
- Li, D.; Bissyande, T.F.D.A.; Klein, J.; Le Traon, Y. Time Series Classification with Discrete Wavelet Transformed Data: Insights from an Empirical Study. In Proceedings of the International Conference on Software Engineering and Knowledge Engineering, Redwood City, CA, USA, 1–3 July 2016; pp. 1361–1377. [Google Scholar]
- Ye, L.; Keogh, E. Time series shapelets: A new primitive for data mining. In Proceedings of the International Conference on Knowledge discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 947–956. [Google Scholar]
- Xing, Z.; Pei, J.; Philip, S.Y.; Wang, K. Extracting Interpretable Features for Early Classification on Time Series. In Proceedings of the SIAM International Conference on Data Mining, Mesa, AZ, USA, 28–30 April 2011; Volume 11, pp. 247–258. [Google Scholar]
- Ali, M.; Alqahtani, A.; Jones, M.W.; Xie, X. Clustering and Classification for Time Series Data in Visual Analytics: A Survey. IEEE Access 2019, 7, 181314–181338. [Google Scholar] [CrossRef]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Berkeley, CA, USA, 1967; pp. 281–297. [Google Scholar]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 344. [Google Scholar]
- Dunn, J.C. A Fuzzy Relative of the ISODATA Process and Its Use in Detecting Compact Well-Separated Clusters; Taylor & Francis: Tokyo, Japan, 1973. [Google Scholar]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms; Book Series: Advanced Applications in Pattern Recognition; Springer: New York, NY, USA; Philadelphia, PA, USA, 1981. [Google Scholar]
- Krishnapuram, R.; Joshi, A.; Nasraoui, O.; Yi, L.y. Low-complexity fuzzy relational clustering algorithms for web mining. IEEE Trans. Fuzzy Syst. 2001, 9, 595–607. [Google Scholar] [CrossRef] [Green Version]
- Goutte, C.; Toft, P.; Rostrup, E.; Nielsen, F.A.; Hansen, L.K. On clustering fMRI time series. NeuroImage 1999, 9, 298–310. [Google Scholar] [CrossRef] [Green Version]
- Niennattrakul, V.; Ratanamahatana, C.A. On clustering multimedia time series data using k-means and dynamic time warping. In Proceedings of the International Conference on Multimedia and Ubiquitous Engineering, Seoul, Korea, 26–28 April 2007; pp. 733–738. [Google Scholar]
- Meesrikamolkul, W.; Niennattrakul, V.; Ratanamahatana, C.A. Shape-based clustering for time series data. In Proceedings of the Pacific Asia Conference on Knowledge Discovery and Data Mining, Kuala Lumpur, Malaysia, 29 May–1 June 2012; pp. 530–541. [Google Scholar]
- Hautamaki, V.; Nykanen, P.; Franti, P. Time-series clustering by approximate prototypes. In Proceedings of the International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Kalpakis, K.; Gada, D.; Puttagunta, V. Distance measures for effective clustering of ARIMA time-series. In Proceedings of the International Conference on Data Mining, San Jose, CA, USA, 29 November–2 December 2001; pp. 273–280. [Google Scholar]
- Möller-Levet, C.S.; Klawonn, F.; Cho, K.H.; Wolkenhauer, O. Fuzzy clustering of short time-series and unevenly distributed sam-pling points. In Proceedings of the International Symposium on Intelligent Data Analysis, Berlin, Germany, 28–30 August 2003; pp. 330–340. [Google Scholar]
- Golay, X.; Kollias, S.; Stoll, G.; Meier, D.E.; Valavanis, A.; Boesiger, P. A new correlation-based fuzzy logic clustering algorithm for FMRI. Magn. Reson. Med. 1998, 40, 249–260. [Google Scholar] [CrossRef]
- D’Urso, P.; Cappelli, C.; Lallo, D.D.; Massari, R. Clustering of financial time series. Phys. A Stat. Mech. Its Appl. 2013, 392, 2114–2129. [Google Scholar] [CrossRef]
- Das, S.; Abraham, A.; Konar, A. Automatic clustering using an improved differential evolution algorithm. IEEE Trans. Syst. Man, Cybern.-Part A Syst. Hum. 2008, 38, 218–237. [Google Scholar] [CrossRef]
- Van Wijk, J.J.; Van Selow, E.R. Cluster and calendar based visualization of time series data. In Proceedings of the IEEE Symposium on Information Visualization, San Francisco, CA, USA, 24–29 October 1999; pp. 4–9. [Google Scholar]
- Simonsen, M.; Mailund, T.; Pedersen, C.N.S. Rapid Neighbour-Joining. In Proceedings of the International Workshop on Algorithms in Bioinformatics, Karlsruhe, Germany, 15–19 September 2008; pp. 113–122. [Google Scholar]
- Alkhushayni, S.; Choi, T.; Alzaleq, D. Data analysis using representation theory and clustering algorithms. WSEAS Trans. Comput. 2020, 19, 310–320. [Google Scholar] [CrossRef]
- Kohonen, T. The self-organizing map. Proc. IEEE 1990, 78, 1464–1480. [Google Scholar] [CrossRef]
- Sacha, D.; Kraus, M.; Bernard, J.; Behrisch, M.; Schreck, T.; Asano, Y.; Keim, D.A. Somflow: Guided exploratory cluster analysis with self-organizing maps and analytic provenance. IEEE Trans. Vis. Comput. Graph. 2018, 24, 120–130. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Varstal, M.; Millán, J.D.R.; Heikkonen, J. A recurrent self-organizing map for temporal sequence processing. In Proceedings of the International Conference on Artificial Neural Networks, Lausanne, Switzerland, 8–10 October 1997; pp. 421–426. [Google Scholar]
- Voegtlin, T. Recursive self-organizing maps. Neural Netw. 2002, 15, 979–991. [Google Scholar] [CrossRef]
- Yin, H. The self-organizing maps: Background, theories, extensions and applications. In Computational Intelligence: A Compendium; Springer: Berlin/Heidelberg, Germany, 2008; pp. 715–762. [Google Scholar]
- Fu, T.c.; Chung, F.l.; Ng, V.; Luk, R. Pattern discovery from stock time series using self-organizing maps. In Proceedings of the Workshop on Temporal Data Mining, Lyon, France, 12 September 2000; pp. 26–29. [Google Scholar]
- Wang, X.; Smith, K.A.; Hyndman, R.; Alahakoon, D. A scalable method for time series clustering. Res. Pap. 2004. Available online: https://robjhyndman.com/papers/wang.pdf (accessed on 27 November 2021).
- Cui, Z.; Chen, W.; Chen, Y. Multi-Scale Convolutional Neural Networks for Time Series Classification. arXiv 2016, arXiv:1603.06995. [Google Scholar]
- Antunes, C.; Oliveira, A. Temporal data mining: An overview. In Proceedings of the KDD Workshop on Temporal Data Mining, San Francisco, CA, USA, 26–29 August 2001; pp. 26–29. [Google Scholar]
- Tian, F.; Gao, B.; Cui, Q.; Chen, E.; Liu, T.Y. Learning Deep Representations for Graph Clustering. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; pp. 1293–1299. [Google Scholar]
- Huang, P.; Huang, Y.; Wang, W.; Wang, L. Deep embedding network for clustering. In Proceedings of the International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 1532–1537. [Google Scholar]
- Song, C.; Liu, F.; Huang, Y.; Wang, L.; Tan, T. Auto-encoder based data clustering. In Proceedings of the Iberoamerican Congress on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2013; pp. 117–124. [Google Scholar]
- Xie, J.; Girshick, R.; Farhadi, A. Unsupervised deep embedding for clustering analysis. In Proceedings of the International Conference on Machine Learning, NewYork, NY, USA, 19–24 June 2016; pp. 478–487. [Google Scholar]
- Li, F.; Qiao, H.; Zhang, B.; Xi, X. Discriminatively Boosted Image Clustering with Fully Convolutional Auto-Encoders. Pattern Recognit. 2018, 83, 161–173. [Google Scholar] [CrossRef] [Green Version]
- Guo, X.; Liu, X.; Zhu, E.; Yin, J. Deep Clustering with Convolutional Autoencoders. In Proceedings of the International Conference on Neural Information Processing, Guangzhou, China, 14–18 November 2017; pp. 373–382. [Google Scholar]
- Alqahtani, A.; Xie, X.; Deng, J.; Jones, M.W. Learning discriminatory deep clustering models. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, Salerno, Italy, 3–5 September 2019; pp. 224–233. [Google Scholar]
- Wilson, R.; Quintana, F.; Gómez-Laich, A. Accelerometry Data for an Imperial Cormorant. 2021. Available online: https://zenodo.org/record/5500402#.Yag4krEzbIU (accessed on 27 November 2021). [CrossRef]
- Shepard, E.; Wilson, R.; Quintana, F.; Laich, A.G.; Liebsch, N.; Albareda, D.; Halsey, L.; Gleiss, A.; Morgan, D.; Myers, A.; et al. Identification of animal movement patterns using tri-axial accelerometry. Endanger. Species Res. 2008, 10, 47–60. [Google Scholar] [CrossRef] [Green Version]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 27 November 2021).
- Zeiler, M.D.; Taylor, G.W.; Fergus, R. Adaptive deconvolutional networks for mid and high level feature learning. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2018–2025. [Google Scholar]
- Zeiler, M.D.; Krishnan, D.; Taylor, G.W.; Fergus, R. Deconvolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2528–2535. [Google Scholar]
- Masci, J.; Meier, U.; Ciresan, D.; Schmidhuber, J. Stacked convolutional auto-encoders for hierarchical feature extraction. In Proceedings of the International Conference on Artificial Neural Networks, Espoo, Finland, 14–17 June 2011; pp. 52–59. [Google Scholar]
- Li, Z.; Zhou, D.; Wan, L.; Li, J.; Mou, W. Heartbeat classification using deep residual convolutional neural network from 2-lead electrocardiogram. J. Electrocardiol. 2020, 58, 105–112. [Google Scholar] [CrossRef] [PubMed]
- Gandhi, S.; Oates, T.; Mohsenin, T.; Hairston, D. Denoising time series data using asymmetric generative adversarial networks. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2018; pp. 285–296. [Google Scholar]
- Zheng, Y.; Liu, Q.; Chen, E.; Ge, Y.; Zhao, J.L. Exploiting multi-channels deep convolutional neural networks for multivariate time series classification. Front. Comput. Sci. 2016, 10, 96–112. [Google Scholar] [CrossRef]
- Walker, J.S.; Jones, M.W.; Laramee, R.S.; Holton, M.D.; Shepard, E.L.; Williams, H.J.; Scantlebury, D.M.; Nikki, J.M.; Magowan, E.A.; Maguire, I.E.; et al. Prying into the intimate secrets of animal lives; software beyond hardware for comprehensive annotation in ‘Daily Diary’tags. Mov. Ecol. 2015, 3, 29. [Google Scholar] [CrossRef] [Green Version]
- Bidder, O.; Walker, J.; Jones, M.; Holton, M.; Urge, P.; Scantlebury, D.; Marks, N.; Magowan, E.; Maguire, I.; Wilson, R. Step by step: Reconstruction of terrestrial animal movement paths by dead-reckoning. Mov. Ecol. 2015, 3, 23. [Google Scholar] [CrossRef] [Green Version]
- Wilson, R.P.; Shepard, E.; Liebsch, N. Prying into the intimate details of animal lives: Use of a daily diary on animals. Endanger. Species Res. 2008, 4, 123–137. [Google Scholar] [CrossRef] [Green Version]
- Fagan, W.F.; Lewis, M.A.; Auger-Méthé, M.; Avgar, T.; Benhamou, S.; Breed, G.; LaDage, L.; Schlägel, U.E.; Tang, W.W.; Papastamatiou, Y.P.; et al. Spatial memory and animal movement. Ecol. Lett. 2013, 16, 1316–1329. [Google Scholar] [CrossRef]
- Bidder, O.R.; Qasem, L.A.; Wilson, R.P. On higher ground: How well can dynamic body acceleration determine speed in variable terrain? PLoS ONE 2012, 7, e50556. [Google Scholar] [CrossRef] [Green Version]
- Aksoy, S.; Haralick, R.M. Feature normalization and likelihood-based similarity measures for image retrieval. Pattern Recognit. Lett. 2001, 22, 563–582. [Google Scholar] [CrossRef] [Green Version]
- Yang, C.; Liu, J.; Zeng, Y.; Xie, G. Real-time condition monitoring and fault detection of components based on machine-learning reconstruction model. Renew. Energy 2019, 133, 433–441. [Google Scholar] [CrossRef]
- LeCun, Y.A.; Bottou, L.; Orr, G.B.; Müller, K.R. Efficient backprop. In Proceedings of the Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 9–48. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Vedaldi, A.; Lenc, K. MatConvNet: Convolutional Neural Networks for MATLAB. In Proceedings of the ACM Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 689–692. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Wu, M.; Schölkopf, B. A local learning approach for clustering. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; pp. 1529–1536. [Google Scholar]
- Chen, W.Y.; Song, Y.; Bai, H.; Lin, C.J.; Chang, E.Y. Parallel Spectral Clustering in Distributed Systems. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 568–586. [Google Scholar] [CrossRef] [PubMed]
- Strehl, A.; Ghosh, J. Cluster ensembles—A knowledge reuse framework for combining multiple partitions. J. Mach. Learn. Res. 2002, 3, 583–617. [Google Scholar]
- Thinsungnoen, T.; Kerdprasop, K.; Kerdprasop, N. Deep Autoencoder Networks Optimized with Genetic Algorithms for Efficient ECG Clustering. Int. J. Mach. Learn. Comput. 2018, 8, 112–116. [Google Scholar] [CrossRef]
- Sun, M.; Wang, Y.; Teng, F.; Ye, Y.; Strbac, G.; Kang, C. Clustering-Based Residential Baseline Estimation: A Probabilistic Perspective. IEEE Trans. Smart Grid 2019, 10, 6014–6028. [Google Scholar] [CrossRef]
- de Jong, J.; Emon, M.A.; Wu, P.; Karki, R.; Sood, M.; Godard, P.; Ahmad, A.; Vrooman, H.A.; Hofmann-Apitius, M.; Frohlich, H. Deep learning for clustering of multivariate clinical patient trajectories with missing values. GigaScience 2019, 8, giz134. [Google Scholar] [CrossRef] [PubMed]
- Asadi, R.; Regan, A. Spatio-temporal clustering of traffic data with deep embedded clustering. In Proceedings of the ACM SIGSPATIAL International Workshop on Prediction of Human Mobility, Chicago, IL, USA, 5 November 2019; pp. 45–52. [Google Scholar]
- Madiraju, N.S.; Sadat, S.; Fisher, D.; Karimabadi, H. Deep Temporal Clustering: Fully Unsupervised Learning of Time-Domain Features. arXiv 2018, arXiv:1802.01059. [Google Scholar]
- Wachowiak, M.P.; Moggridge, J.J.; Wachowiak-Smolikova, R. Deep Embedded Clustering for Data-Driven ECG Exploration Using Continuous Wavelet Transforms. In Proceedings of the International Conference on Information and Digital Technologies, Zilina, Slovakia, 25–27 June 2019; pp. 551–556. [Google Scholar]
- Wolf, P.; Chin, A.; Baker, B. Unsupervised Data-Driven Automotive Diagnostics with Improved Deep Temporal Clustering. In Proceedings of the Vehicular Technology Conference, Honolulu, HI, USA, 22–25 September 2019; pp. 1–6. [Google Scholar]
- Zhang, G.; Singer, A.R.; Vlahopoulos, N. Temporal clustering network for self-diagnosing faults from vibration measurements. arXiv 2020, arXiv:2006.09505. [Google Scholar]
- Richard, G.; Grossin, B.; Germaine, G.; Hebrail, G.; de Moliner, A. Autoencoder-based time series clustering with energy applications. arXiv 2020, arXiv:2002.03624. [Google Scholar]
- Mousavi, S.M.; Zhu, W.; Ellsworth, W.; Beroza, G. Unsupervised clustering of seismic signals using deep convolutional autoencoders. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1693–1697. [Google Scholar] [CrossRef]
- Ryu, S.; Choi, H.; Lee, H.; Kim, H.; Wong, V.S. Residential Load Profile Clustering via Deep Convolutional Autoencoder. In Proceedings of the IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids, Aalborg, Denmark, 29–31 October 2018; pp. 1–6. [Google Scholar]
- Liu, C.; Liu, C.; Liu, F.; Hu, J. Clustering Analysis of Urban Fabric Detection Based on Mobile Traffic Data. Phys. Conf. Ser. 2020, 1453, 012158. [Google Scholar] [CrossRef]
- Ali, M.; Borgo, R.; Jones, M.W. Concurrent Time-Series Selections Using Deep Learning and Dimension Reduction. Knowl.-Based Syst. 2021, 233, 107507. [Google Scholar] [CrossRef]
- Ienco, D.; Interdonato, R. Deep Multivariate Time Series Embedding Clustering via Attentive-Gated Autoencoder. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Singapore, 11–14 May 2020; pp. 318–329. [Google Scholar]
- Yue, M.; Li, Y.; Yang, H.; Ahuja, R.; Chiang, Y.Y.; Shahabi, C. DETECT: Deep Trajectory Clustering for Mobility-Behavior Analysis. In Proceedings of the International Conference on Big Data, Los Angeles, CA, USA, 9–12 December 2019; pp. 988–997. [Google Scholar]
- Lee, C.; Schaar, M.V.D. Temporal Phenotyping using Deep Predictive Clustering of Disease Progression. In Proceedings of the International Conference on Machine learning, Virtual Event, 13–18 July 2020; pp. 5767–5777. [Google Scholar]
- Luxem, K.; Fuhrmann, F.; Kursch, J.; Remy, S.; Bauer, P. Identifying Behavioral Structure from Deep Variational Embeddings of Animal Motion. bioRxiv 2020. [Google Scholar] [CrossRef]
- Abedin, A.; Motlagh, F.; Shi, Q.; Rezatofighi, H.; Ranasinghe, D. Towards Deep Clustering of Human Activities from Wearables. In Proceedings of the International Symposium on Wearable Computers, Virtual Event, 12–17 September 2020; pp. 1–6. [Google Scholar]
- Ma, Q.; Zheng, J.; Li, S.; Cottrell, G. Learning Representations for Time Series Clustering. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 13 December 2019. [Google Scholar]
- Khan, N.; Ahmed, M.; Roy, N. Temporal Clustering Based Thermal Condition Monitoring in Building. Sustain. Comput. Inform. Syst. 2020, 29, 100441. [Google Scholar] [CrossRef]
- Han, L.; Zheng, K.; Zhao, L.; Wang, X.; Shen, X. Short-Term Traffic Prediction Based on DeepCluster in Large-Scale Road Networks. IEEE Trans. Veh. Technol. 2019, 68, 12301–12313. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Greff, K.; Srivastava, R.K.; Koutnik, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cho, K.; Van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Logeswaran, L.; Lee, H. An efficient framework for learning sentence representations. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Kiros, R.; Zhu, Y.; Salakhutdinov, R.R.; Zemel, R.; Urtasun, R.; Torralba, A.; Fidler, S. Skip-thought vectors. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 3294–3302. [Google Scholar]
- Gan, Z.; Pu, Y.; Henao, R.; Li, C.; He, X.; Carin, L. Learning Generic Sentence Representations Using Convolutional Neural Networks. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 2390–2400. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Mukherjee, S.; Asnani, H.; Lin, E.; Kannan, S. Clustergan: Latent space clustering in generative adversarial networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HA, USA, 27 January–1 February 2019; Volume 33, pp. 4610–4617. [Google Scholar]
- Smith, K.E.; Smith, A.O. Conditional GAN for timeseries generation. arXiv 2020, arXiv:2006.16477. [Google Scholar]
- Ouahabi, A.; Taleb-Ahmed, A. Deep learning for real-time semantic segmentation: Application in ultrasound imaging. Pattern Recognit. Lett. 2021, 144, 27–34. [Google Scholar] [CrossRef]
- Cuturi, M.; Blondel, M. Soft-dtw: A differentiable loss function for time-series. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 894–903. [Google Scholar]
- Sakoe, H.; Chiba, S. Dynamic programming algorithm optimization for spoken word recognition. IEEE Trans. Acoust. Speech Signal Process. 1978, 26, 43–49. [Google Scholar] [CrossRef] [Green Version]
- Weber, R.A.S.; Eyal, M.; Skafte, N.; Shriki, O.; Freifeld, O. Diffeomorphic temporal alignment nets. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 13 December 2019; pp. 6574–6585. [Google Scholar]
- Edwards, M.; Deng, J.; Xie, X. From pose to activity: Surveying datasets and introducing CONVERSE. Comput. Vis. Image Underst. 2016, 144, 73–105. [Google Scholar] [CrossRef] [Green Version]
- Alqahtani, A.; Xie, X.; Jones, M.W. Literature Review of Deep Network Compression. Informatics 2021, 8, 77. [Google Scholar] [CrossRef]
- Alqahtani, A.; Xie, X.; Jones, M.W.; Essa, E. Pruning CNN filters via quantifying the importance of deep visual representations. Comput. Vis. Image Underst. 2021, 208, 103220. [Google Scholar] [CrossRef]
- Alqahtani, A.; Xie, X.; Essa, E.; Jones, M.W. Neuron-based Network Pruning Based on Majority Voting. In Proceedings of the International Conference on Pattern Recognition, Milano, Italy, 22–24 February 2020; pp. 3090–3097. [Google Scholar]
- Dau, H.A.; Bagnall, A.; Kamgar, K.; Yeh, C.C.M.; Zhu, Y.; Gharghabi, S.; Ratanamahatana, C.A.; Keogh, E. The UCR time series archive. J. Autom. Sin. 2019, 6, 1293–1305. [Google Scholar] [CrossRef]
- Javed, A.; Lee, B.S.; Rizzo, D.M. A Benchmark Study on Time Series Clustering. Mach. Learn. Appl. 2020, 1, 100001. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Separated Clustering | Embedded Clustering |
|---|---|---|
| DAE | Tian et al. [152], Huang et al. [153] | Song et al. [154], Xie et al. [155] |
| DCAE | Li et al. [156], Guo et al. [157] | Alqahtani et al. [2,158] |
| ACC | MNI | |
|---|---|---|
| k-means | 37.44 | 19.73 |
| DAE with embedded clustering | 78.67 | 53.63 |
| DCAE with embedded clustering | 94.36 | 79.40 |
| Categories | DTSC Methods | Year | Architecture | Loss | Clustering Methods | Data Type & Applications |
|---|---|---|---|---|---|---|
| Multi-step | DAN-ECG [182] | 2018 | DAE | RL | Hierarchical | ECG |
| RLPC-DCAE [192] | 2018 | DCAE | RL | k-means | Load Forecasting | |
| DEC-ECG [187] | 2019 | DCAE | RL | GMM | ECG | |
| CSS-DCAE [191] | 2019 | DCAE | RL | k-means | Seismology | |
| STTP-DC [202] | 2019 | CNN | Multi | k-means | Traffic Analysis | |
| AE-TSC [190] | 2020 | DCAE | RL | Kmedoids | Energy (Demand Response) | |
| CA-MTD [193] | 2020 | DCAE | RL | k-means | Urban Detection | |
| TCN-SDF [189] | 2020 | 1D-DCAE | RL | k-means | Operating Machinery | |
| DM-TSEC [195] | 2020 | RNN-AE | RL | k-means | ECG | |
| IBS-DC [198] | 2020 | RNN-AE | RL | k-means | Animal Motion | |
| DPC-DP [197] | 2020 | RNN-AE | Multi | k-means | Disease Progression | |
| Joint | DTC [186] | 2018 | 1D-DCAE | RL | k-means | UCR Archive datasets |
| DL-CMCPT [184] | 2019 | DAE | RL | GMM | Disease Progression | |
| C-RBE [183] | 2019 | DAE | RL | k-means | Energy (Demand Response) | |
| STC-TD [185] | 2019 | DAE | RL | k-means | Traffic Analysis | |
| IDTC [188] | 2019 | DCAE | RL | k-means | Automotive Diagnostic | |
| DETECT [196] | 2019 | RNN-AE | RL | k-means | Mobility Analysis | |
| LR-TSC [200] | 2019 | S2S-AE | RL | k-means | ECG | |
| TC-TCM [201] | 2020 | RNN-AE, DCAE | RL | k-means | Thermal Condition Monitoring | |
| DC-HA [199] | 2020 | RNN-AE | RL | k-means | Human Activities |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alqahtani, A.; Ali, M.; Xie, X.; Jones, M.W. Deep Time-Series Clustering: A Review. Electronics 2021, 10, 3001. https://doi.org/10.3390/electronics10233001
Alqahtani A, Ali M, Xie X, Jones MW. Deep Time-Series Clustering: A Review. Electronics. 2021; 10(23):3001. https://doi.org/10.3390/electronics10233001
Chicago/Turabian StyleAlqahtani, Ali, Mohammed Ali, Xianghua Xie, and Mark W. Jones. 2021. "Deep Time-Series Clustering: A Review" Electronics 10, no. 23: 3001. https://doi.org/10.3390/electronics10233001