
Multi-Task Learning with Task-Specific Feature Filtering in Low-Data Condition

 , , , , , ,
, , , , , ,
Abstract
:1. Introduction
- We empirically validate the efficacy of multi-task learning in low-data conditions. The model learns the shared knowledge through multi-task learning from multiple datasets, and eventually improves all task performances over single-task models;
- We propose a simple yet effective way to generate task-specific features, with a task-specific feature filtering module. We consistently yet significantly improved the performances of multi-task models with minimal overhead. With the proposed module, small task-specific heads can exploit the task-specific features with minimal computational costs and high performances.
2. Related Works
2.1. Early-Exit Architecture
2.2. Multi-Task Learning
3. Method
3.1. Dataset Integration
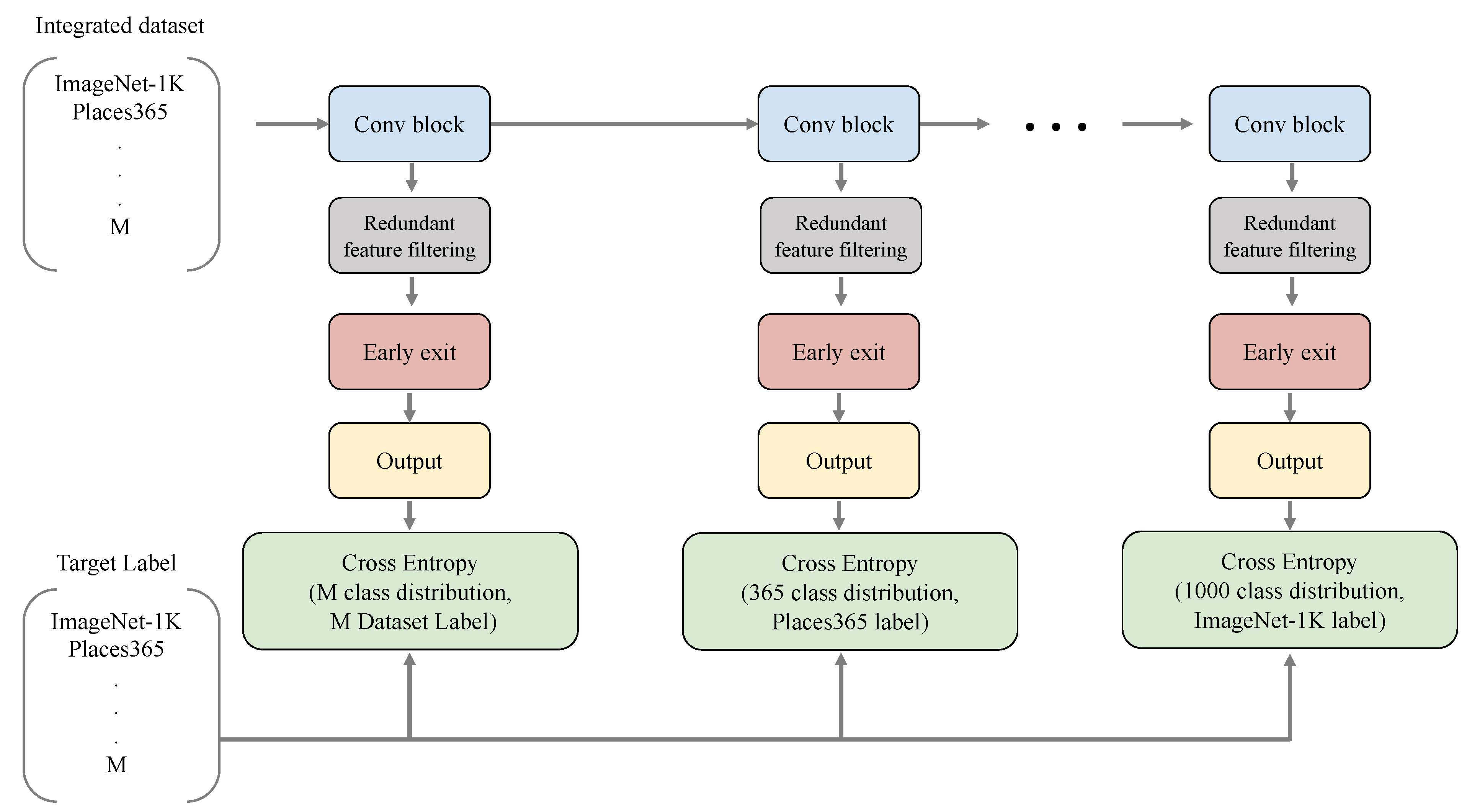
3.2. Multi-Exit Architectures
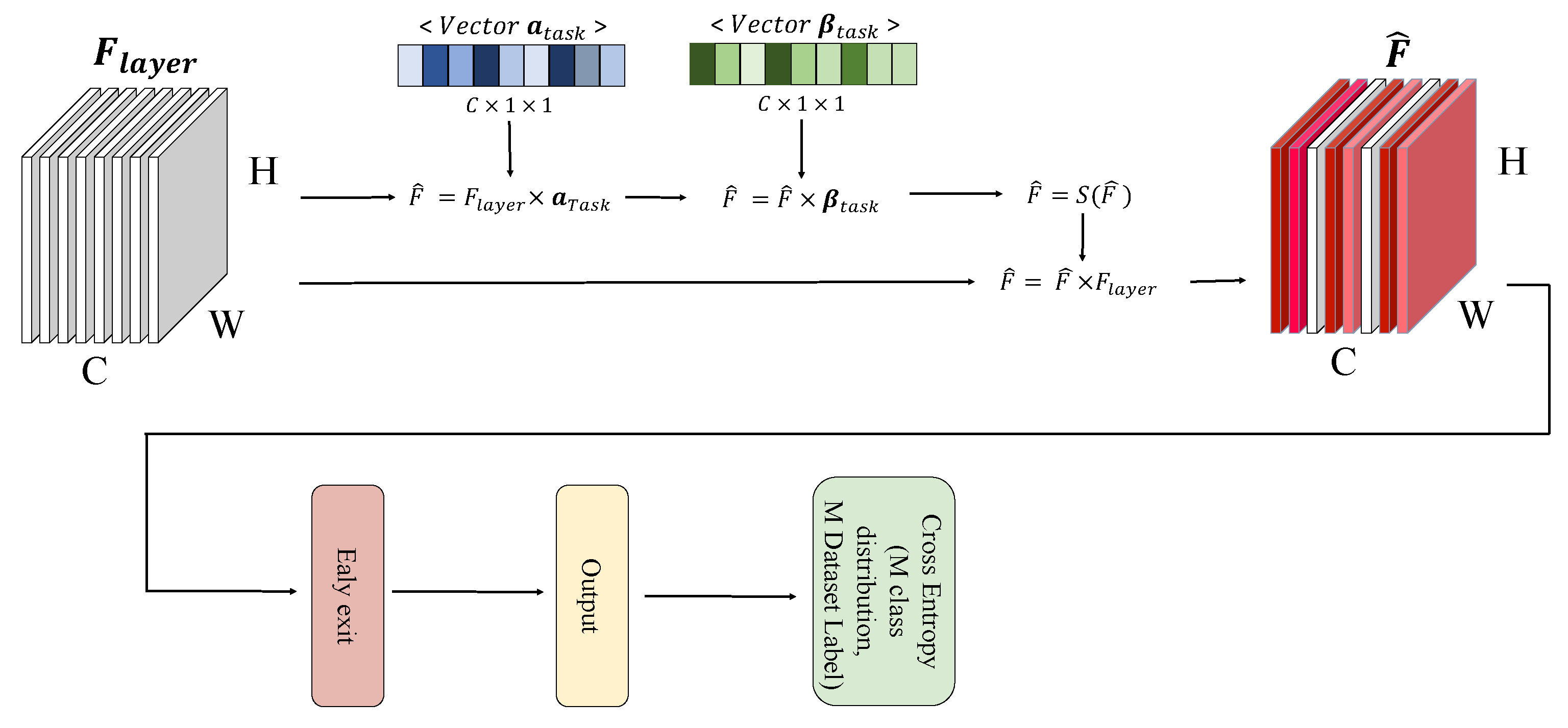
3.3. Task-Specific Feature Filtering
4. Experiments
4.1. Multi Task Learning Details
4.2. Task-Specific Feature Filtering Module Details
4.3. Experiment Result
4.4. Multi-Exit Architecture Search
5. Analysis
5.1. Multi-Exit Architectures with Filter Visualization
5.2. Visualization of the Distribution of Feature Filtering Values
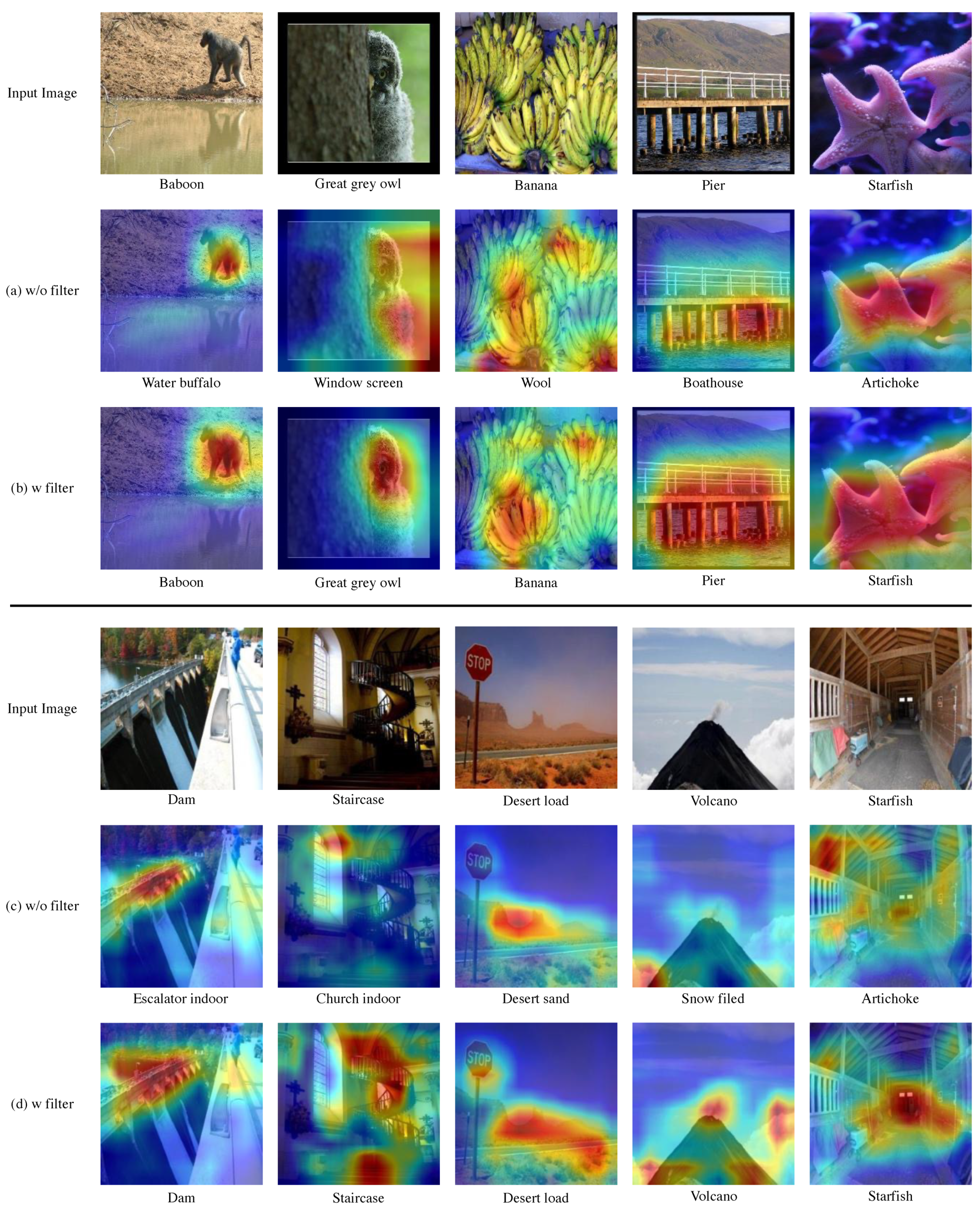
5.3. Redundant Feature Filtering Visualization with Grad-CAM
6. Conclusions
7. Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shao, S.; Li, Z.; Zhang, T.; Peng, C.; Yu, G.; Zhang, X.; Li, J.; Sun, J. Objects365: A Large-Scale, High-Quality Dataset for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8429–8438. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Torralba, A.; Oliva, A. Places: An image database for deep scene understanding. arXiv 2016, arXiv:1610.02055. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016. [Google Scholar]
- Wu, Y.; Mu, G.; Qin, C.; Miao, Q.; Ma, W.; Zhang, X. Semi-supervised hyperspectral image classification via spatial-regulated self-training. Remote Sens. 2020, 12, 159. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wu, Y.; Bai, Z.; Miao, Q.; Ma, W.; Yang, Y.; Gong, M. A classified adversarial network for multi-spectral remote sensing image change detection. Remote Sens. 2020, 12, 2098. [Google Scholar] [CrossRef]
- Hasan, M.K.; Ahsan, M.; Newaz, S.; Lee, G.M.; Abdullah-Al-Mamun. Human face detection techniques: A comprehensive review and future research directions. Electronics 2021, 10, 2354. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Xu, Y.; Zhou, F.; Wang, L.; Peng, W.; Zhang, K. Optimization of Action Recognition Model Based on Multi-Task Learning and Boundary Gradient. Electronics 2021, 10, 2380. [Google Scholar] [CrossRef]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 6299–6308. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. arXiv 2014, arXiv:1406.2199. [Google Scholar]
- Caruana, R. Multitask learning. Machine learning 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Kaiser, L.; Gomez, A.N.; Shazeer, N.M.; Vaswani, A.; Parmar, N.; Jones, L.; Uszkoreit, J. One Model To Learn Them All. arXiv 2017, arXiv:abs/1706.05137. [Google Scholar]
- Li, J.; Zhang, D.; Ma, Y.; Liu, Q. Lane Image Detection Based on Convolution Neural Network Multi-Task Learning. Electronics 2021, 10, 2356. [Google Scholar] [CrossRef]
- Kokkinos, I. UberNet: Training a Universal Convolutional Neural Network for Low-, Mid-, and High-Level Vision Using Diverse Datasets and Limited Memory. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 5454–5463. [Google Scholar]
- Mirowski, P.W.; Pascanu, R.; Viola, F.; Soyer, H.; Ballard, A.; Banino, A.; Denil, M.; Goroshin, R.; Sifre, L.; Kavukcuoglu, K.; et al. Learning to Navigate in Complex Environments. ArXiv 2017, abs/1611.03673. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef] [Green Version]
- Cohn, D.A.; Ghahramani, Z.; Jordan, M.I. Active learning with statistical models. J. Artif. Intell. Res. 1996, 4, 129–145. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Phuong, M.; Lampert, C.H. Distillation-based training for multi-exit architectures. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1355–1364. [Google Scholar]
- Kim, D.; Lin, T.Y.; Angelova, A.; Kweon, I.S.; Kuo, W. Learning Open-World Object Proposals without Learning to Classify. arXiv 2021, arXiv:2108.06753. [Google Scholar]
- Deng, J.; Guo, J.; Zhou, Y.; Yu, J.; Kotsia, I.; Zafeiriou, S. Retinaface: Single-stage dense face localisation in the wild. arXiv 2019, arXiv:1905.00641. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Seo, M.; Lee, J.; Park, J.; Kim, D.; Choi, D.G. Sequential Feature Filtering Classifier. IEEE Access 2021, 9, 97068–97078. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Ma, W.; Zhao, J.; Zhu, H.; Shen, J.; Jiao, L.; Wu, Y.; Hou, B. A Spatial-Channel Collaborative Attention Network for Enhancement of Multiresolution Classification. Remote Sens. 2021, 13, 106. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 770–778. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A.; Jawahar, C. Cats and dogs. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 16–21 June 2012; pp. 3498–3505. [Google Scholar]
- Fei-Fei, L.; Fergus, R.; Perona, P. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. In Proceedings of the 2004 Conference on Computer Vision and Pattern Recognition Workshop, Washington, DC, USA, 27 June–2 July 2004; p. 178. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Kang, D.; Wong, A.; Lee, B.; Kim, J. Real-Time Semantic Segmentation of 3D Point Cloud for Autonomous Driving. Electronics 2021, 10, 1960. [Google Scholar] [CrossRef]
- Garcia-Ortiz, L.B.; Portillo-Portillo, J.; Hernandez-Suarez, A.; Olivares-Mercado, J.; Sanchez-Perez, G.; Toscano-Medina, K.; Perez-Meana, H.; Benitez-Garcia, G. FASSD-Net Model for Person Semantic Segmentation. Electronics 2021, 10, 1393. [Google Scholar] [CrossRef]
- Ouahabi, A.; Taleb-Ahmed, A. Deep learning for real-time semantic segmentation: Application in ultrasound imaging. Pattern Recognit. Lett. 2021, 144, 27–34. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Data | Method | ImageNet ACC (%) | Places365 ACC (%) |
|---|---|---|---|
| 5% ImageNet | STL | 24.173 ± 1.162 | · |
| 5% Places365 | STL | · | 38.063 ± 1.050 |
| 5% Integration | Ours MTL (w/o filtering) | 37.064 (+12.891) | 40.910 (+2.847) |
| 5% Integration | Ours MTL (w filtering) | 40.110 (+15.937) | 42.910 (+4.847) |
| 10% ImageNet | STL | 48.242 ± 0.585 | · |
| 10% Places365 | STL | · | 43.336 ± 1.211 |
| 10% Integration | Ours MTL (w/o filtering) | 51.046 (+2.804) | 47.095 (+3.430) |
| 10% Integration | Ours MTL (w filtering) | 52.656 (+4.414) | 47.29 (+3.625) |
| 20% ImageNet | STL | 59.765 ± 0.391 | · |
| 20% Places365 | STL | · | 48.007 ± 0.375 |
| 20% Integration | Ours MTL (w/o filtering) | 61.890 (+2.125) | 50.300 (+2.293) |
| 20% Integration | Ours MTL (w filtering) | 62.450 (+2.685) | 50.843 (+2.836) |
| Training Data | Method | ImageNet | Integration Dataset |
|---|---|---|---|
| ACC (%) | ACC (%) | ||
| 5% IN | ResNet50 (STL) | 24.173 ± 1.162 | · |
| OP | ResNet50 (STL) | · | 70.460 |
| 5% IN+OP | Ours MTL (w/o filtering) | 32.618 (+8.445) | 76.829 (+6.369) |
| 5% IN+OP | Ours MTL (w filtering) | 37.396 (+13.223) | 85.593 (+15.113) |
| CA | ResNet50 (STL) | · | 74.018 |
| 5% IN+CA | Ours MTL (w/o filtering) | 26.878 (+2.705) | 77.049 (+3.031) |
| 5% IN+CA | Ours MTL (w filtering) | 28.192 (+4.019) | 85.815 (+11.797) |
| Training Data | Method | ImageNet ACC (%) | Places365 ACC (%) |
|---|---|---|---|
| 5% ImageNet | SE (STL) | 26.188 ± 0.867 | · |
| 5% Places365 | SE (STL) | · | 40.545 ± 0.23 |
| 5% Integration | SE (MTL) w/o filtering | 38.810 (+12.622) | 41.632 (+1.092) |
| 5% Integration | SE (MTL) w filtering | 40.201 (+14.013) | 42.117 (+1.572) |
| 5% ImageNet | VGG (STL) | 27.99 ± 1.095 | · |
| 5% Places365 | VGG (STL) | · | 36.84 ± 0.266 |
| 5% Integration | VGG (MTL) w/o filtering | 34.406 (+6.416) | 40.21 (+3.37) |
| 5% Integration | VGG (MTL) w filtering | 35.103 (+7.113) | 41.61 (+4.77) |
| Method | ImageNet ACC (%) | Places365 ACC (%) | MACs | Parameters |
|---|---|---|---|---|
| STL-ImageNet | 48.242 ± 0.585 | · | 4.1114G | 25.557M |
| STL-Places365 | · | 43.336 ± 1.050 | 4.1114G | 25.557M |
| MTL-Layer4 | 50.918 (+2.676) | 45.820 (+2.484) | 4.1123G | 26.305M |
| MTL-Layer3 | 51.046 (+2.804) | 47.095 (+3.759) | 4.1119G | 25.931M |
| MTL-Layer2 | 51.974 (+3.732) | 42.670 (−0.666) | 4.1120G | 25.744M |
| MTL-Layer1 | 49.822 (+1.58) | 34.361 (−8.975) | 4.1123G | 25.651M |
| MTL-Big head | 50.090 (+1.848) | 46.400 (+3.064) | 4.9226G | 41.269M |
| MTL-Layer3 (w filtering) | 52.656 (+4.414) | 47.290 (+3.954) | 4.1120G | 25.931M |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.-w.; Lee, R.; Seo, M.-s.; Park, J.-c.; Noh, H.-c.; Ju, J.-g.; Jang, R.-y.; Lee, G.-w.; Choi, M.-s.; Choi, D.-g. Multi-Task Learning with Task-Specific Feature Filtering in Low-Data Condition. Electronics 2021, 10, 2691. https://doi.org/10.3390/electronics10212691
Lee S-w, Lee R, Seo M-s, Park J-c, Noh H-c, Ju J-g, Jang R-y, Lee G-w, Choi M-s, Choi D-g. Multi-Task Learning with Task-Specific Feature Filtering in Low-Data Condition. Electronics. 2021; 10(21):2691. https://doi.org/10.3390/electronics10212691
Chicago/Turabian StyleLee, Sang-woo, Ryong Lee, Min-seok Seo, Jong-chan Park, Hyeon-cheol Noh, Jin-gi Ju, Rae-young Jang, Gun-woo Lee, Myung-seok Choi, and Dong-geol Choi. 2021. "Multi-Task Learning with Task-Specific Feature Filtering in Low-Data Condition" Electronics 10, no. 21: 2691. https://doi.org/10.3390/electronics10212691