
Advancing Logistics 4.0 with the Implementation of a Big Data Warehouse: A Demonstration Case for the Automotive Industry

 , , , , , and
, , , , , and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
3. Proposed Architecture for a Logistics 4.0 Big Data Warehouse
3.1. Logical Architecture
- Sandbox Storage: where the raw data are stored in a distributed file system before any transformation. This component is divided into two layers: Update Layer and Backup Layer. The Update Layer contains the up-to-date data retrieved from the sources, while the Backup Layer contains compressed outdated data to be used in case of necessity;
- BDW Storage: where data are stored in the distributed file system and accessible using the Metastore after being transformed. This component has two layers with the same functionality as the Sandbox Storage layers: (i) a layer that provides updated data, (ii) another layer to provide a backup in case of problems with the new data;
- Machine Learning component: uses raw data from the Sandbox Storage or clean data from the BDW to create predictions, in order to enrich the data and store it in the Sandbox Storage or in the BDW to provide predictive capabilities for the organization. This component can increase the organization’s capabilities to understand and predict changes in their supply chain and be capable of adapting quickly;
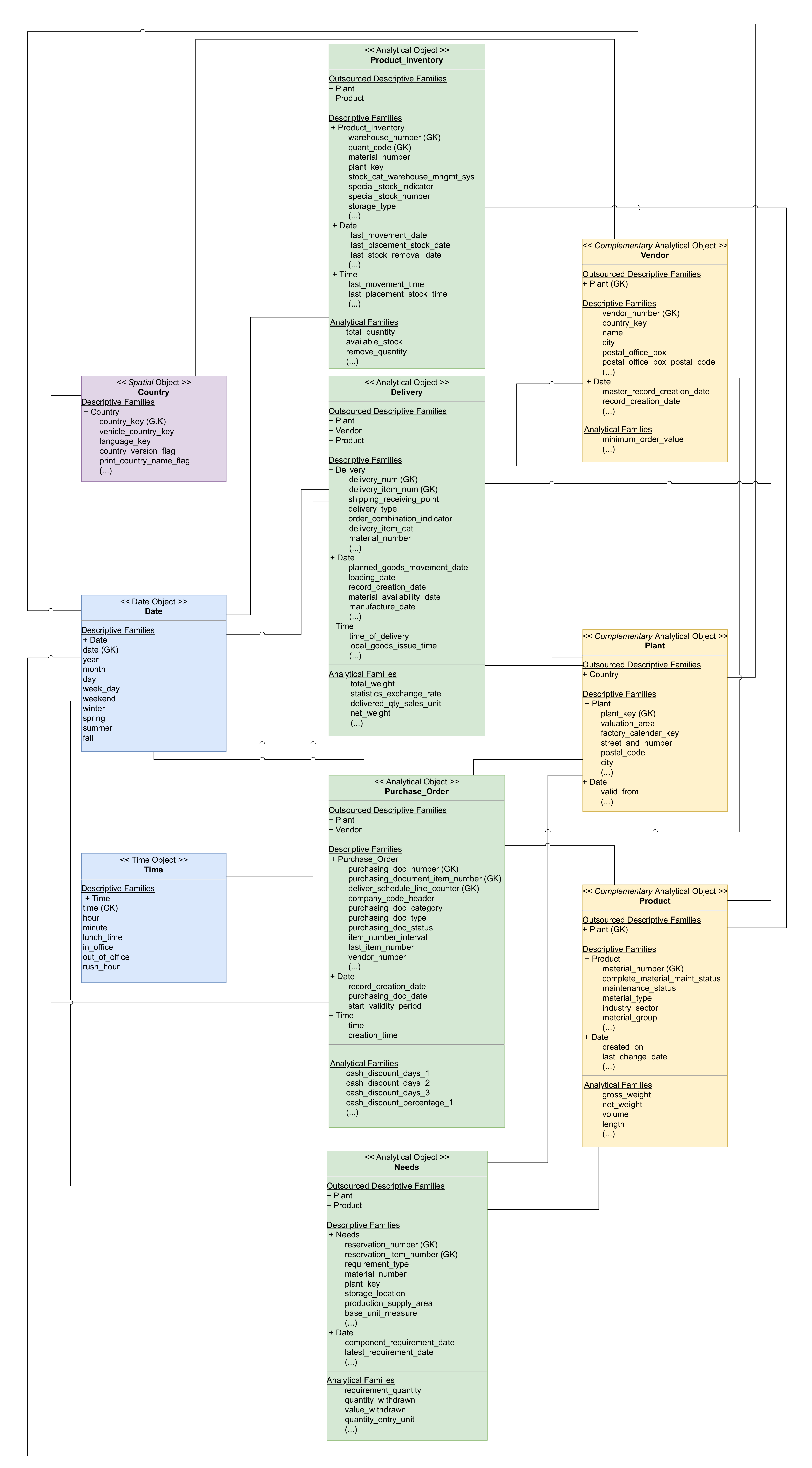
- Metastore: provides an interface to access the stored data. This component is divided into two layers: (i) the data layer where the data are modeled using a data-driven approach; (ii) the application layer where we have the necessary materialized objects or views to answer the needs of specific applications. The existence of these two layers provides some advantages. One of these advantages is the capability of creating several abstractions on top of the data layer, providing a simple and fast way to access the data. In this application layer, each application can have its views or tables (materialized objects), increasing the performance when accessing the data. Moreover, if the organization has different teams working on different applications, if necessary, each team can create the necessary tables or views for their application, providing higher business agility;
- The Coordinator, Resource Management, and Workflows: provide functionalities to manage the Big Data Cluster and the data lifecycle. The Coordinator and Workflow allow the creation of diverse jobs or tasks that can be submitted in the desired order. The Resource Manager distributes the clusters of resources to process the jobs.
3.2. Technological Architecture
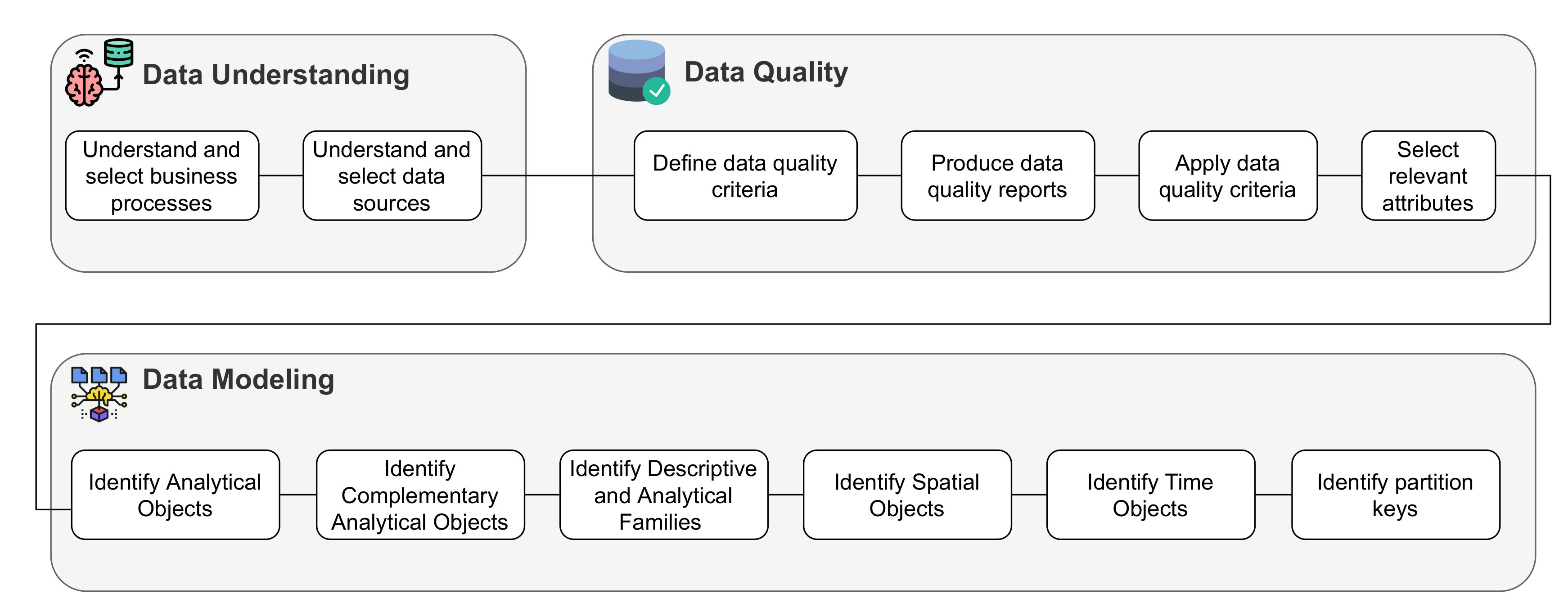
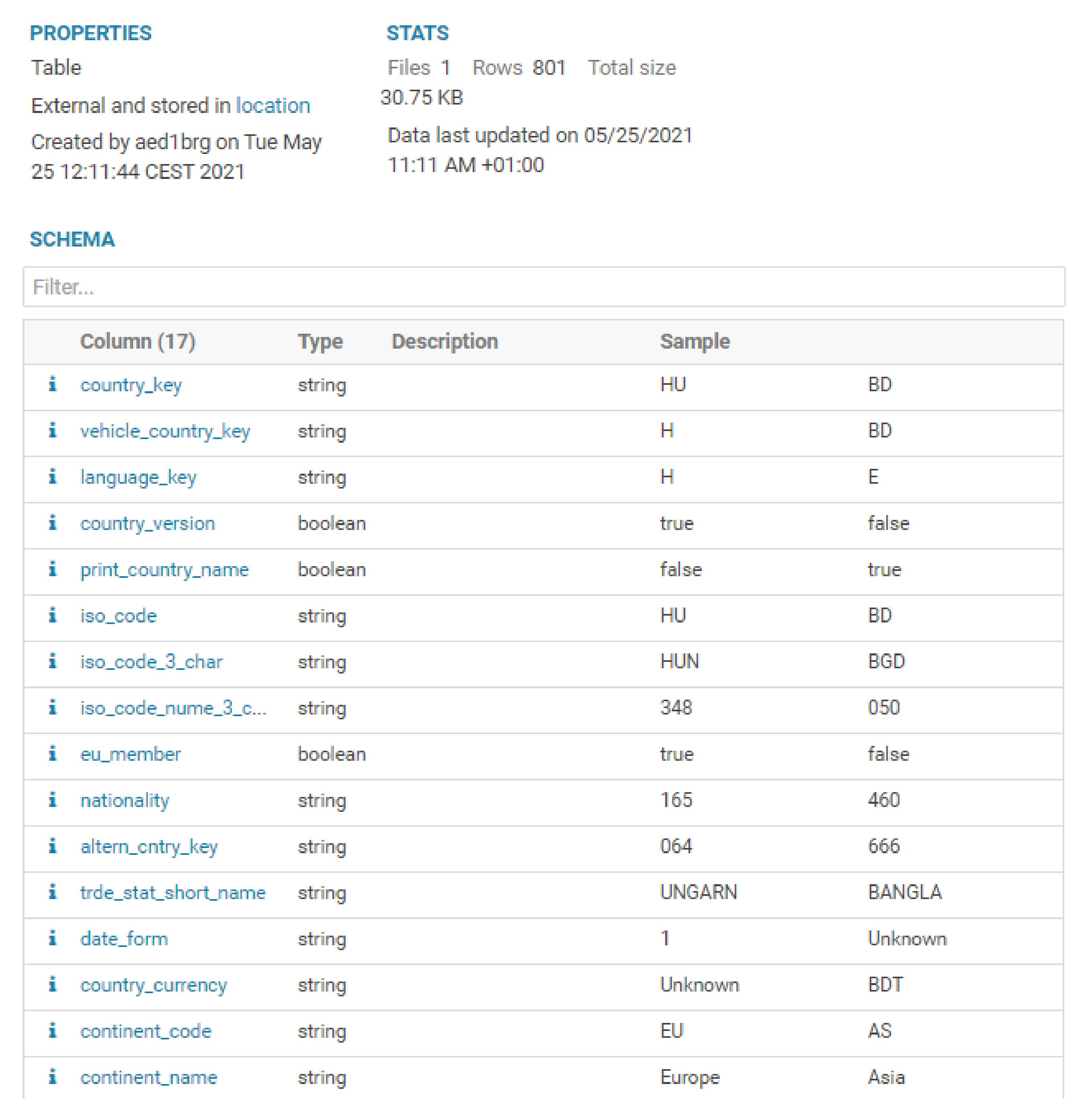
4. Demonstration Case
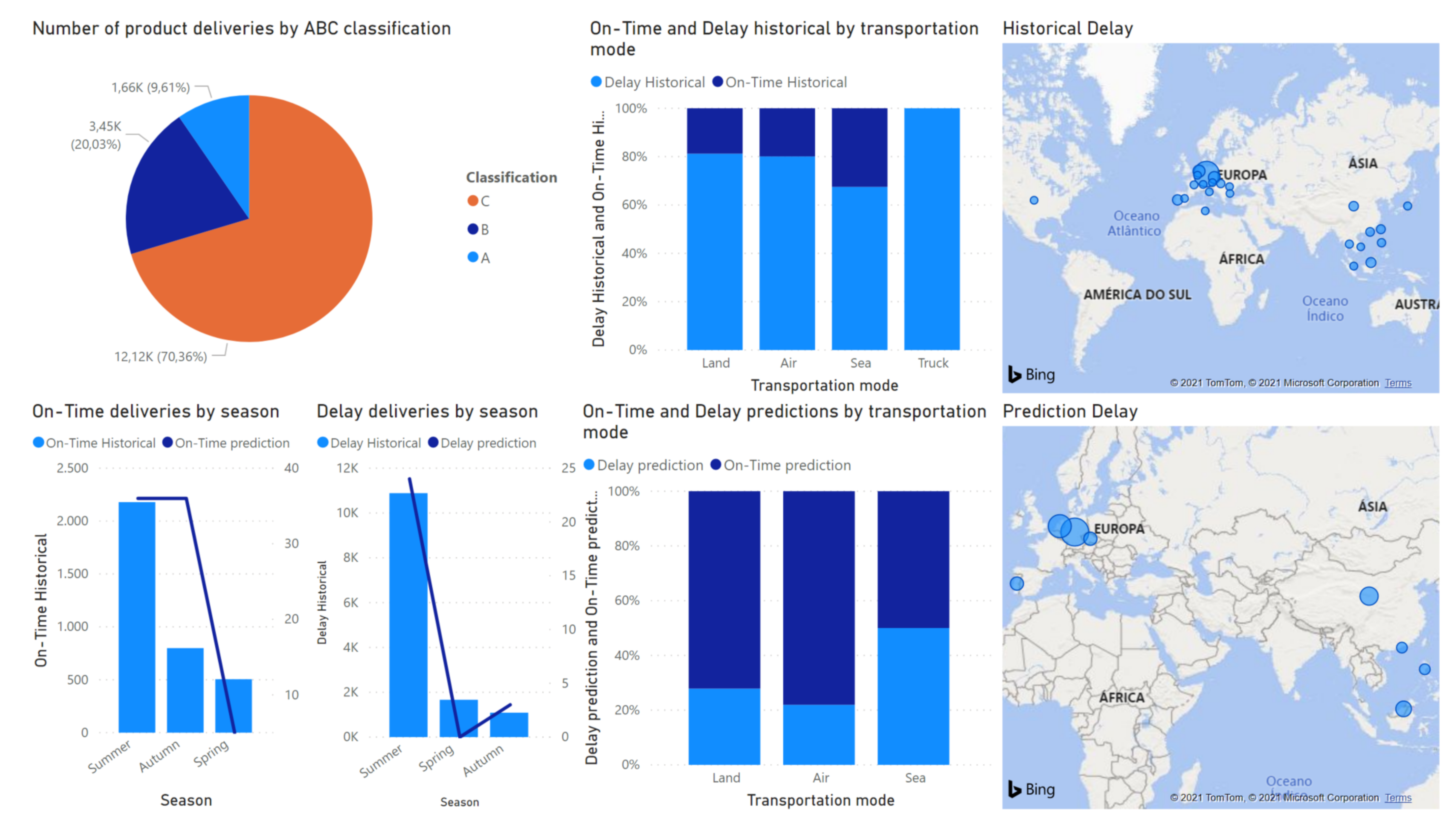
5. Results and Discussion
5.1. Efficacy and Efficiency
5.2. Challenges
- Data and technological challenges:
- Data understanding:Understanding the data that are stored in the transactional database is usually a challenge, made even worse when the organization is a multinational with a considerable dimension. Transactional databases are complex systems, with misleading tables and attribute names. The existing documentation about the data source is usually sparse, not given enough insight into the data. Several logistics concepts need to be known, such as safety stock, safety time, delivery time, and procurement, among others, in order to better understand the data and their relationships;
- Poor or missing raw data:When an organization starts a project that will use the raw data generated by the daily business, it is necessary to identify if the necessary data are being generated and stored in the transactional system and their overall quality. Sometimes, the project goals cannot be achieved due to the lack of data or data quality. In complex ERP systems, it is possible to verify that many attributes are not used by the organization. For example, in logistics, knowing where an order is in transit to its destination can be very useful to predict if it will be on time, or not, and to make decisions about how to avoid stops in the production line;
- Different values in different data sources for the same attribute:Due to the large and complex transactional system, it is fairly common to find the same attribute in different tables, related to the same entity, but with different values. Understanding why this happens and understanding the type of situations that motivate this type of behavior can be difficult;
- Technological infrastructure:An adequate technological infrastructure is essential for a stable project development. In an organization, the technological infrastructure can be based on outdated technology or the technological infrastructure can change during the project lifetime. This will lead to the project’s adaptation to the existing technologies or their evolution as the infrastructure changes;
- Organizational challenges:
- Access to data and to a technological infrastructure:One of the first tasks in projects of this nature is to gain access to data and to the infrastructure that will be used to process and store them. This is a task that needs to be performed at the beginning of the project and where the organizations’ policies can interfere in a negative way. This cannot be an obstacle or take a long time to overcome;
- Understand the business processes:Commonly, large organizations have many and complex business processes, with diverse rules, exceptions, and paths, which can be difficult to understand. Moreover, the documentation about the business processes can be insufficient, creating another obstacle in this type of project. In the logistics area, where daily interactions with the suppliers and their systems exist, where processes are complex in order to achieve better results in the production line, and where concepts such as just-in-time production are being implemented, the documentations has a relevant impact when new projects start to be developed;
- Project team challenges:
- Lack of knowledge of the technologies used:As Big Data is a recent concept, there is a lack of human resources with experience in the technologies used to support this concept. Building a team without any experience in Big Data can lead to several problems in the project. Moreover, when adding specific requirements of a complex area such as logistics, it is more difficult to find multidisciplinary teams with knowledge in both areas;
- Lack of sufficient human resources:To develop such a complex project, the project team needs an adequate number of human resources. The lack of sufficient human resources can cause delays in project development. Teams with a high number of elements can be prejudicial to the project as well, but very small teams lead to a lack of different backgrounds and points of view, which can hinder the project.
5.3. Opportunities
- Data and technological opportunities:
- Improve documentation:Very often, documentation is treated as the least important part of the project. The time and effort put into documentation development are lower than required, leading to poor documentation. With the development of a new project, the poor documentation of the previous one becomes evident. The effort that needs to be made to understand the previous project can be reused to improve the documentation and, therefore, decrease the time and effort needed for the next ones;
- Improve data quality:Data quality is essential to the development of these data-based projects. As we need to perform data quality tasks, this can be used to detect and report data problems that can be fixed in the near future. This can be useful not only for this project, but even for past and future projects.
- Technological infrastructure:A new project that requires new technology can be an excellent driver to improve the technological infrastructure existent in the organization. These changes can include, for example, updating the existent technologies or the implementation of new ones;
- Organizational opportunities:
- Improve internal processes:With the implementation of a new technology, some internal processes will be analyzed and can be improved. Moreover, processes can use the newly available technology to improve their performance;
- Improve business processes’ documentation:Many analytical teams do not know the business processes, and they need to find the right person to ask. Often, if they ask the same question of different persons, they will receive different answers. Properly documenting the business processes can be a key way to improve the business understanding, not only inside the analytical teams, but for the organization in general;
- Project team opportunities:
- Creation of a team specialized in Big Data technologies:Research projects can have a tremendous impact on organizations, not only by the obtained results, but also by the improved capabilities of human resources. In this specific case, the creation of one team specialized in Big Data technologies can boost more projects, more efficiently, and with more efficacy;
- Improve workers’ knowledge in logistics processes:Human resources with more business knowledge can bring their knowledge to other projects and have a positive impact on them. This can be verified not only in new ones, but also in the maintenance and improvement of other ongoing projects;
- Improve workers’ knowledge about data sources:Data analytics projects always depend on the data source. Knowledge about them is essential for a good start and a proper development of the project. It is crucial to have in the project team, at least, one specialized resource in the data sources, helping the development team understand the data.
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tang, C.S.; Veelenturf, L.P. The strategic role of logistics in the industry 4.0 era. Transp. Res. Part E Logist. Transp. Rev. 2019, 129, 1–11. [Google Scholar] [CrossRef]
- Santos, M.Y.; Oliveira e Sá, J.; Andrade, C.; Vale Lima, F.; Costa, E.; Costa, C.; Martinho, B.; Galvão, J. A Big Data system supporting Bosch Braga Industry 4.0 strategy. Int. J. Inf. Manag. 2017, 37, 750–760. [Google Scholar] [CrossRef]
- Winkelhaus, S.; Grosse, E.H. Logistics 4.0: A systematic review towards a new logistics system. Int. J. Prod. Res. 2020, 58, 18–43. [Google Scholar] [CrossRef]
- Ghadge, A.; Kara, M.E.; Moradlou, H.; Goswami, M. The impact of Industry 4.0 implementation on supply chains. J. Manuf. Technol. Manag. 2020, 31. [Google Scholar] [CrossRef]
- Panetto, H.; Iung, B.; Ivanov, D.; Weichhart, G.; Wang, X. Challenges for the cyber-physical manufacturing enterprises of the future. Annu. Rev. Control 2019, 47, 200–213. [Google Scholar] [CrossRef]
- Kostrzewski, M.; Varjan, P.; Gnap, J. Solutions dedicated to internal logistics 4.0. In Sustainable Logistics and Production in Industry 4.0; Springer: Berlin/Heidelberg, Germany, 2020; pp. 243–262. [Google Scholar]
- Oleśków-Szłapka, J.; Stachowiak, A. The Framework of Logistics 4.0 Maturity Model. In Proceedings of the Intelligent Systems in Production Engineering and Maintenance, Wroclaw, Poland, 17–18 September 2018; Burduk, A., Chlebus, E., Nowakowski, T., Tubis, A., Eds.; Springer: Cham, Switzerland, 2019; pp. 771–781. [Google Scholar]
- Strandhagen, J.O.; Vallandingham, L.R.; Fragapane, G.; Strandhagen, J.W.; Stangeland, A.B.H.; Sharma, N. Logistics 4.0 and emerging sustainable business models. Adv. Manuf. 2017, 5, 359–369. [Google Scholar] [CrossRef]
- Yavas, V.; Ozkan-Ozen, Y.D. Logistics centers in the new industrial era: A proposed framework for logistics center 4.0. Transp. Res. Part E Logist. Transp. Rev. 2020, 135, 101864. [Google Scholar] [CrossRef]
- Torbacki, W.; Kijewska, K. Identifying Key Performance Indicators to be used in Logistics 4.0 and Industry 4.0 for the needs of sustainable municipal logistics by means of the DEMATEL method. Transp. Res. Procedia 2019, 39, 534–543. [Google Scholar] [CrossRef]
- Ngo, V.M.; Le-Khac, N.A.; Kechadi, M.T. Designing and Implementing Data Warehouse for Agricultural Big Data. In Proceedings of the Big Data—BigData 2019, San Diego, CA, USA, 25–30 June 2019; Chen, K., Seshadri, S., Zhang, L.J., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 1–17. [Google Scholar]
- Sebaa, A.; Chikh, F.; Nouicer, A.; Tari, A. Medical Big Data Warehouse: Architecture and System Design, a Case Study: Improving Healthcare Resources Distribution. J. Med. Syst. 2018, 42, 59. [Google Scholar] [CrossRef]
- Santoso, L.W.; Yulia. Data Warehouse with Big Data Technology for Higher Education. Procedia Comput. Sci. 2017, 124, 93–99. [Google Scholar] [CrossRef]
- Aftab, U.; Siddiqui, G.F. Big Data Augmentation with Data Warehouse: A Survey. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 2775–2784. [Google Scholar] [CrossRef]
- Costa, C.; Santos, M.Y. Evaluating several design patterns and trends in big data warehousing systems. In Proceedings of the International Conference on Advanced Information Systems Engineering, Tallinn, Estonia, 11–15 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 459–473. [Google Scholar]
- Chevalier, M.; Malki, M.E.; Kopliku, A.; Teste, O.; Tournier, R. Implementing Multidimensional Data Warehouses into NoSQL. In Proceedings of the 17th International Conference on Enterprise Information Systems (ICEIS 2015) Held in Conjunction with ENASE 2015 and GISTAM 2015, Barcelona, Spain, 27–30 April 2015; INSTICC—Institute for Systems and Technologies of Information, Control and Communication: Setubal, Portugal, 2015; pp. 172–183. [Google Scholar]
- Gröger, C.; Schwarz, H.; Mitschang, B. The Deep Data Warehouse: Link-Based Integration and Enrichment of Warehouse Data and Unstructured Content. In Proceedings of the 2014 IEEE 18th International Enterprise Distributed Object Computing Conference, Ulm, Germany, 1–5 September 2014; pp. 210–217. [Google Scholar] [CrossRef]
- Kiran, M.; Murphy, P.; Monga, I.; Dugan, J.; Baveja, S.S. Lambda architecture for cost-effective batch and speed big data processing. In Proceedings of the 2015 IEEE International Conference on Big Data, IEEE Big Data 2015, Santa Clara, CA, USA, 29 October–1 November 2015; pp. 2785–2792. [Google Scholar] [CrossRef] [Green Version]
- NBD-PWG. NIST Big Data Interoperability Framework: Volume 6, Reference Architecture; Technical Report NIST SP 1500-6; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2015. [Google Scholar]
- Santos, M.Y.; Costa, C. Big Data: Concepts, Warehousing, and Analytics. In Big Data: Concepts, Warehousing, and Analytics; River Publishers: Aalborg, Denmark, 2020; pp. 1–284. [Google Scholar]
- Chou, S.; Yang, C.; Jiang, F.; Chang, C. The Implementation of a Data-Accessing Platform Built from Big Data Warehouse of Electric Loads. In Proceedings of the 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC), Tokyo, Japan, 23–27 July 2018; Volume 2, pp. 87–92. [Google Scholar] [CrossRef]
- Santos, M.Y.; Martinho, B.; Costa, C. Modelling and implementing big data warehouses for decision support. J. Manag. Anal. 2017, 4, 111–129. [Google Scholar] [CrossRef]
- Wang, X.; Yang, K.; Liu, T. The Implementation of a Practical Agricultural Big Data System. In Proceedings of the 2019 IEEE 5th International Conference on Computer and Communications (ICCC), Chengdu, China, 6–9 December 2019; pp. 1955–1959. [Google Scholar] [CrossRef]
- Doreswamy; Gad, I.; Manjunatha, B.R. Hybrid data warehouse model for climate big data analysis. In Proceedings of the 2017 International Conference on Circuit, Power and Computing Technologies (ICCPCT), Kollam, India, 20–21 April 2017; pp. 1–9. [Google Scholar] [CrossRef]
- Costa, C.; Santos, M.Y. The SusCity Big Data Warehousing Approach for Smart Cities. In Proceedings of the 21st International Database Engineering, IDEAS 2017, Bristol, UK, 12–14 July 2017; Applications Symposium. Association for Computing Machinery: New York, NY, USA, 2017; pp. 264–273. [Google Scholar] [CrossRef]
- Vieira, A.A.; Dias, L.; Santos, M.Y.; Pereira, G.A.; Oliveira, J. Supply Chain Risk Management: An Interactive Simulation Model in a Big Data Context. Procedia Manuf. 2020, 42, 140–145. [Google Scholar] [CrossRef]
- Shvachko, K.; Kuang, H.; Radia, S.; Chansler, R. The Hadoop Distributed File System. In Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), Incline Village, NV, USA, 3–7 May 2010; pp. 1–10. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. MapReduce: Simplified Data Processing on Large Clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Thusoo, A.; Sarma, J.S.; Jain, N.; Shao, Z.; Chakka, P.; Anthony, S.; Liu, H.; Wyckoff, P.; Murthy, R. Hive: A warehousing solution over a map-reduce framework. Proc. VLDB Endow. 2009, 2, 1626–1629. [Google Scholar] [CrossRef]
- Spark, A. Apache spark. Retrieved Jan. 2018, 17, 2018. [Google Scholar]
- Bittorf, M.; Bobrovytsky, T.; Erickson, C.; Hecht, M.G.D.; Kuff, M.; Leblang, D.K.A.; Robinson, N.; Rus, D.R.S.; Wanderman, J.; Yoder, M.M. Impala: A modern, open-source sql engine for hadoop. In Proceedings of the 7th Biennial Conference on Innovative Data Systems Research, Asilomar, CA, USA, 4–7 January 2015. [Google Scholar]
- L’Heureux, A.; Grolinger, K.; Elyamany, H.F.; Capretz, M.A.M. Machine Learning with Big Data: Challenges and Approaches. IEEE Access 2017, 5, 7776–7797. [Google Scholar] [CrossRef]
- Costa, C.; Andrade, C.; Santos, M.Y. Big Data Warehouses for Smart Industries. In Encyclopedia of Big Data Technologies; Springer International Publishing: Cham, Switzerland, 2018; pp. 1–11. [Google Scholar] [CrossRef]
- Aravinth, S.; Begam, A.H.; Shanmugapriyaa, S.; Sowmya, S.; Arun, E. An efficient HADOOP frameworks SQOOP and ambari for big data processing. Int. J. Innov. Res. Sci. Technol. 2015, 1, 252–255. [Google Scholar]
- Ivanov, T.; Pergolesi, M. The impact of columnar file formats on SQL-on-hadoop engine performance: A study on ORC and Parquet. Concurr. Comput. Pract. Exp. 2020, 32, e5523. [Google Scholar] [CrossRef]
- Baranowski, Z.; Grzybek, M.; Canali, L.; Garcia, D.L.; Surdy, K. Scale out databases for CERN use cases. J. Phys. Conf. Ser. 2015, 664, 042002. [Google Scholar] [CrossRef]
- Armbrust, M.; Xin, R.S.; Lian, C.; Huai, Y.; Liu, D.; Bradley, J.K.; Meng, X.; Kaftan, T.; Franklin, M.J.; Ghodsi, A.; et al. Spark SQL: Relational Data Processing in Spark. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, SIGMOD’15. Melbourne, VIC, Australia, 31 May–4 June 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1383–1394. [Google Scholar] [CrossRef]
- Meng, X.; Bradley, J.; Yavuz, B.; Sparks, E.; Venkataraman, S.; Liu, D.; Freeman, J.; Tsai, D.; Amde, M.; Owen, S.; et al. MLlib: Machine Learning in Apache Spark. J. Mach. Learn. Res. 2016, 17, 1235–1241. [Google Scholar]
- Qin, X.; Chen, Y.; Chen, J.; Li, S.; Liu, J.; Zhang, H. The Performance of SQL-on-Hadoop Systems—An Experimental Study. In Proceedings of the 2017 IEEE International Congress on Big Data (BigData Congress), Honolulu, HI, USA, 25–30 June 2017; pp. 464–471. [Google Scholar] [CrossRef]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Silva, N.; Barros, J.; Santos, M.Y.; Costa, C.; Cortez, P.; Carvalho, M.S.; Gonçalves, J.N.C. Advancing Logistics 4.0 with the Implementation of a Big Data Warehouse: A Demonstration Case for the Automotive Industry. Electronics 2021, 10, 2221. https://doi.org/10.3390/electronics10182221
Silva N, Barros J, Santos MY, Costa C, Cortez P, Carvalho MS, Gonçalves JNC. Advancing Logistics 4.0 with the Implementation of a Big Data Warehouse: A Demonstration Case for the Automotive Industry. Electronics. 2021; 10(18):2221. https://doi.org/10.3390/electronics10182221
Chicago/Turabian StyleSilva, Nuno, Júlio Barros, Maribel Y. Santos, Carlos Costa, Paulo Cortez, M. Sameiro Carvalho, and João N. C. Gonçalves. 2021. "Advancing Logistics 4.0 with the Implementation of a Big Data Warehouse: A Demonstration Case for the Automotive Industry" Electronics 10, no. 18: 2221. https://doi.org/10.3390/electronics10182221