
Deep Multi-Image Steganography with Private Keys


Abstract
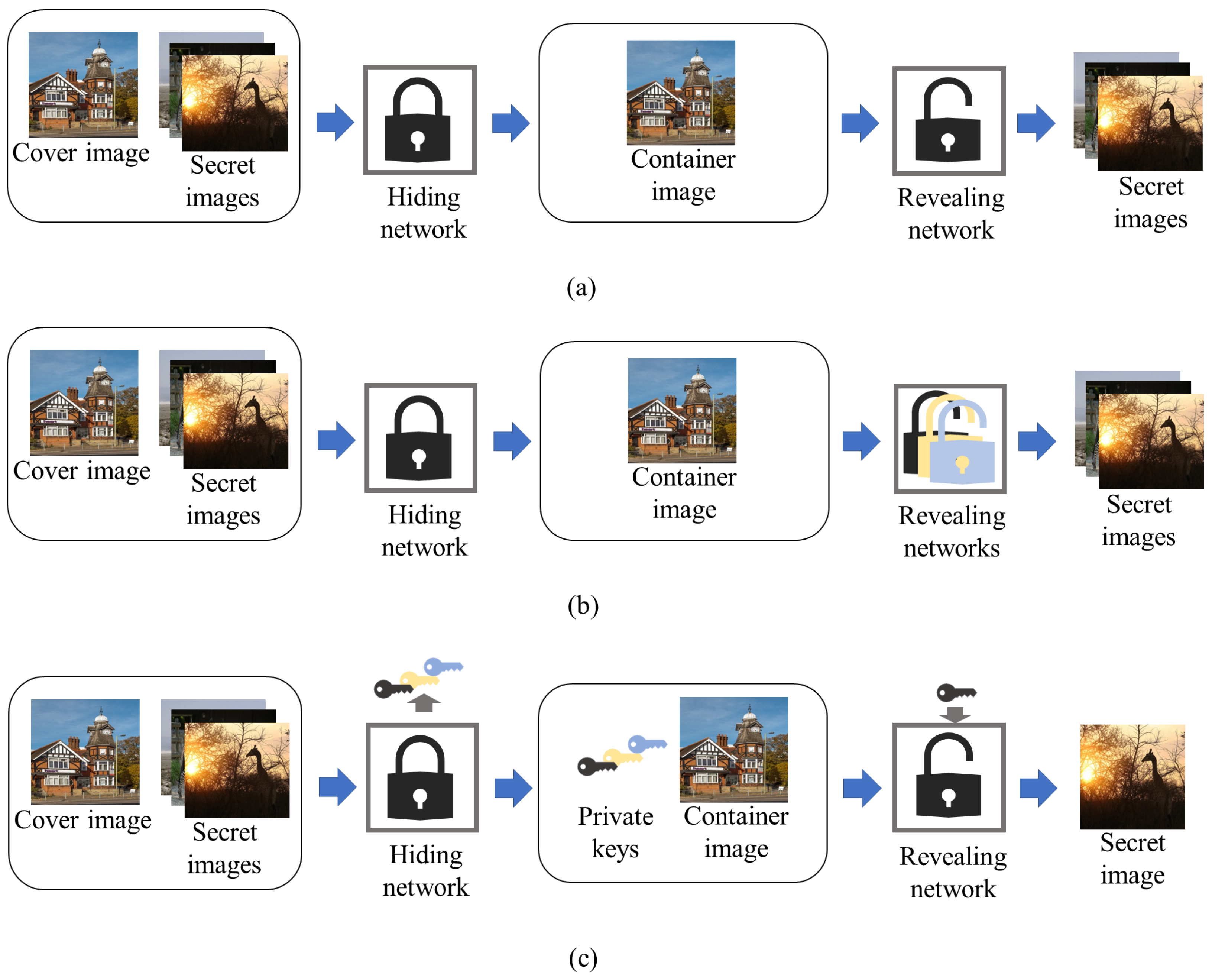
:1. Introduction
2. Related Works
3. Methods
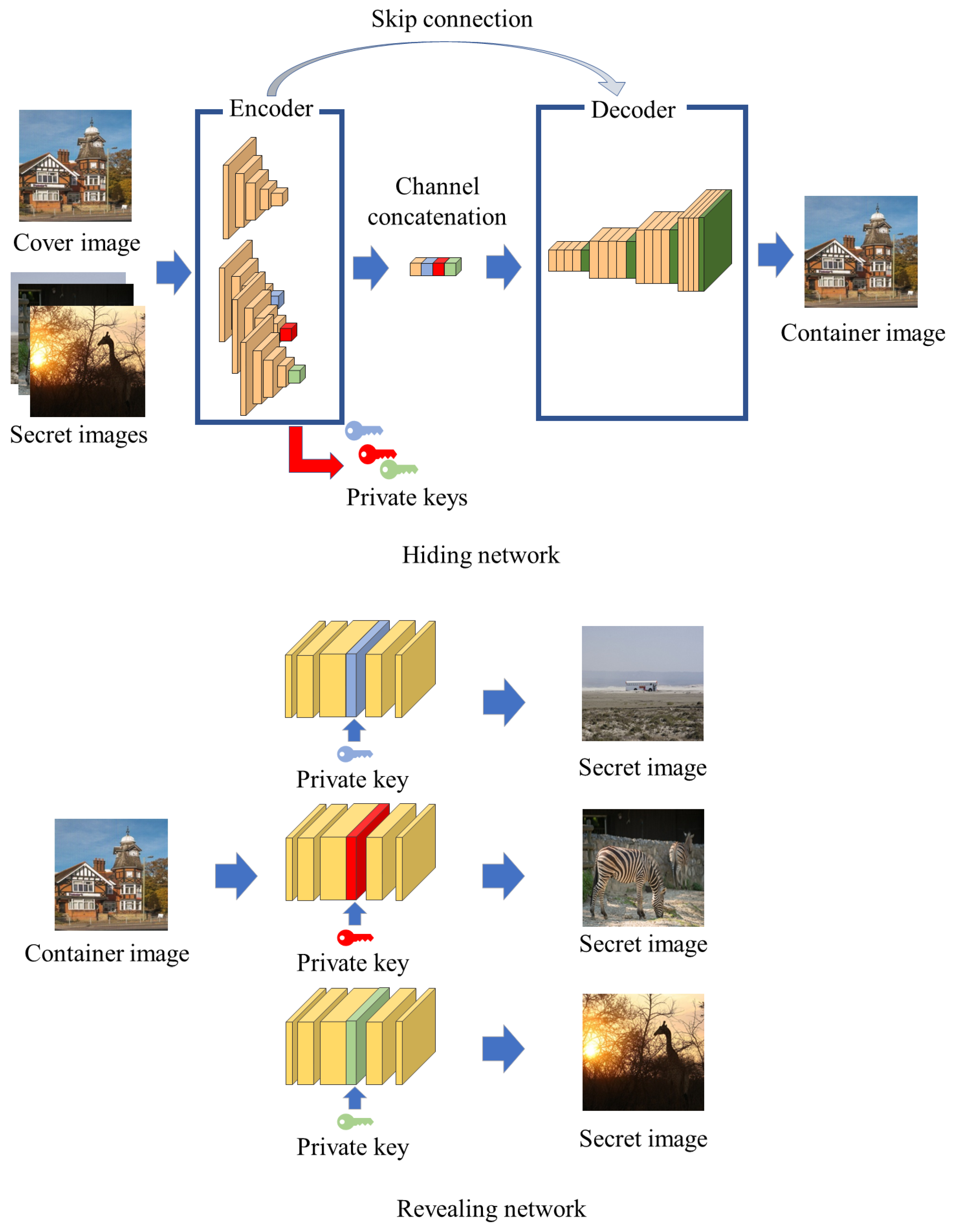
3.1. Hiding Network
3.2. Revealing Network
3.3. Training
4. Experimental Results
4.1. Model Analysis
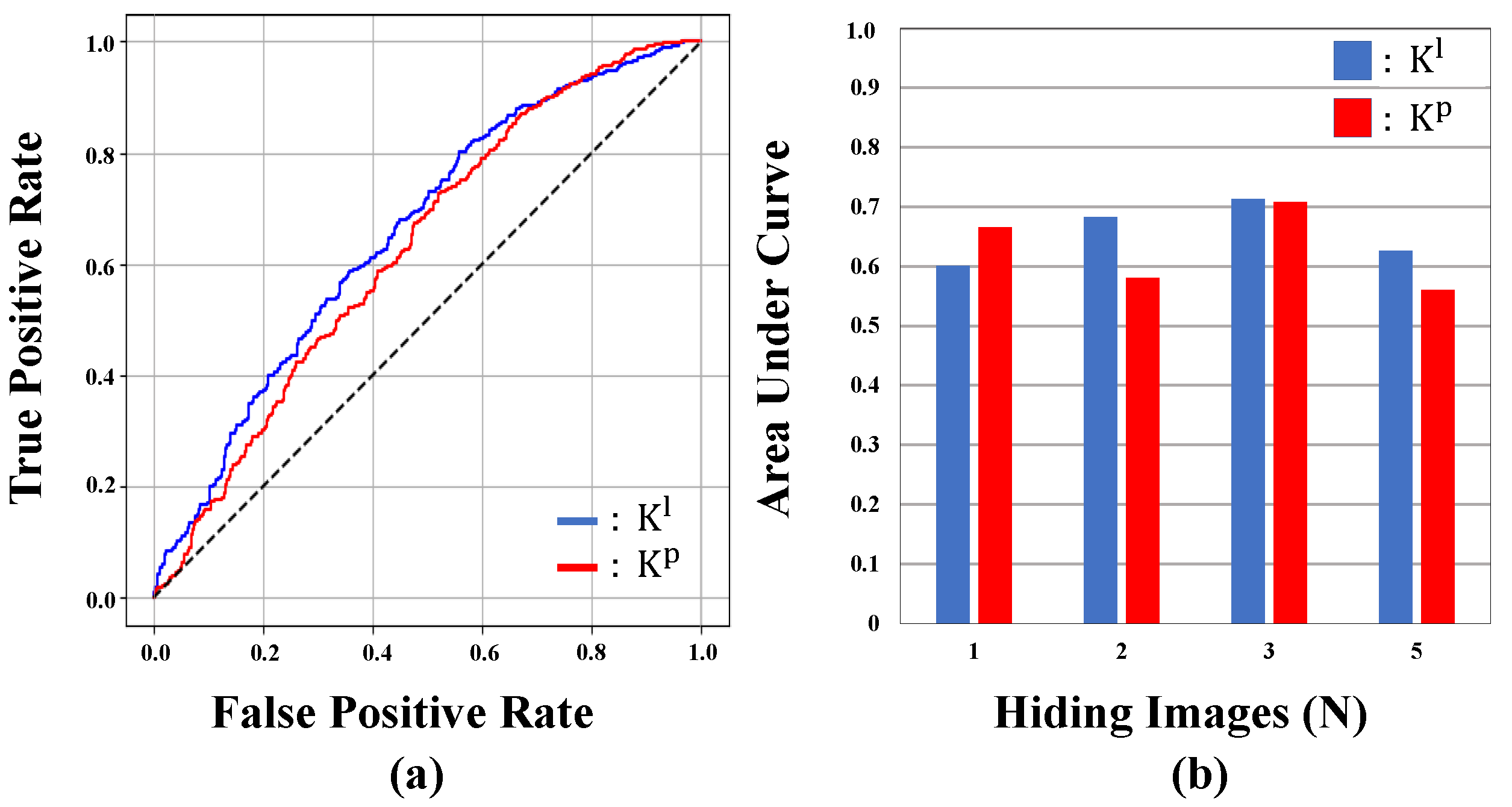
4.2. Robustness to Steganalysis
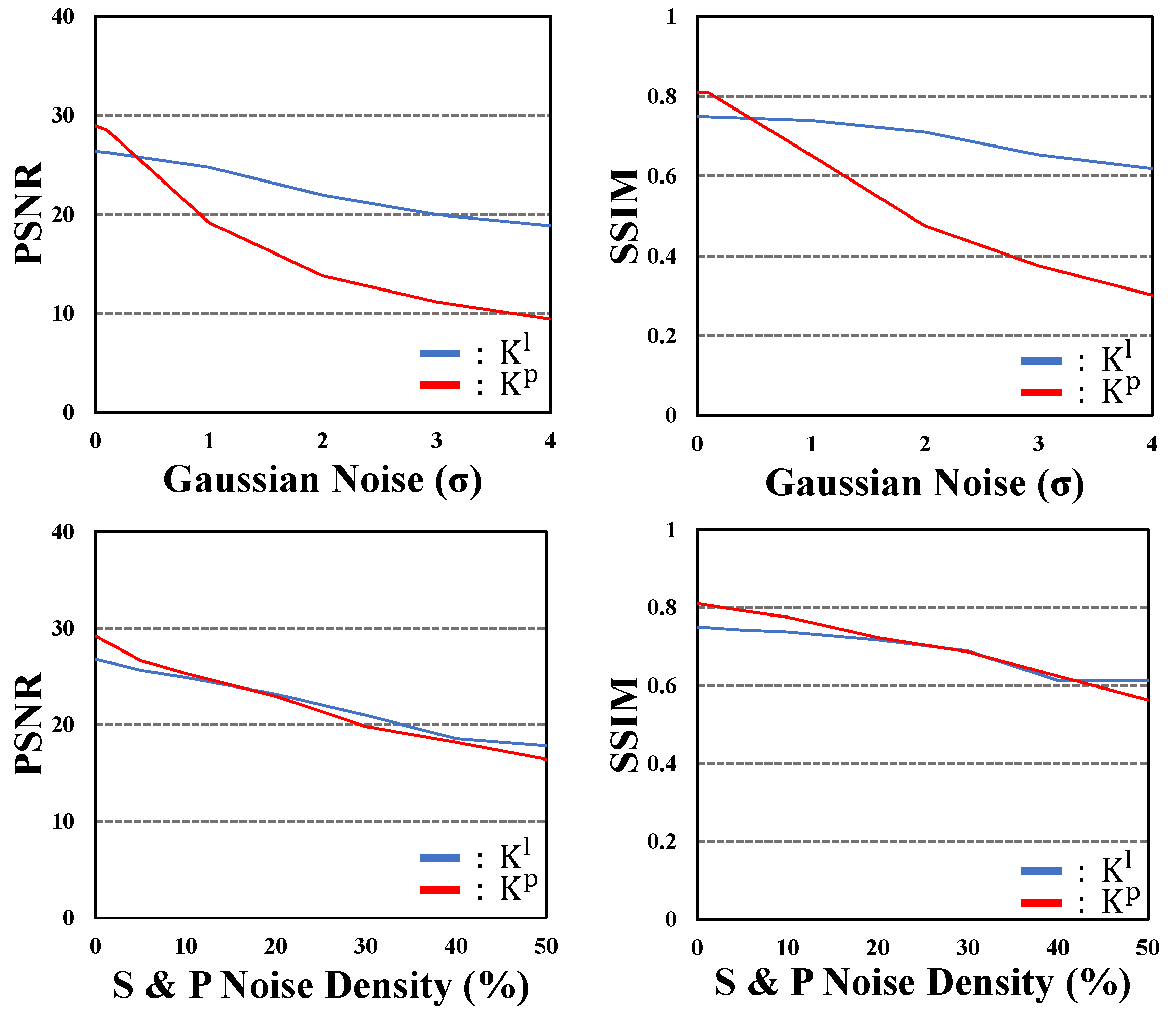
4.3. Effects of Noise
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mielikainen, J. LSB matching revisited. IEEE Signal Process. Lett. 2006, 13, 285–287. [Google Scholar] [CrossRef]
- Wu, D.C.; Tsai, W.H. A steganographic method for images by pixel-value differencing. Pattern Recognit. Lett. 2003, 24, 1613–1626. [Google Scholar] [CrossRef]
- Pevnỳ, T.; Filler, T.; Bas, P. Using high-dimensional image models to perform highly undetectable steganography. In International Workshop on Information Hiding; Springer: Berlin/Heidelberg, Germany, 2010; pp. 161–177. [Google Scholar]
- Holub, V.; Fridrich, J.; Denemark, T. Universal distortion function for steganography in an arbitrary domain. EURASIP J. Inf. Secur. 2014, 2014, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Holub, V.; Fridrich, J. Designing steganographic distortion using directional filters. In Proceedings of the 2012 IEEE International Workshop on Information Forensics and Security (WIFS), Costa Adeje, Spain, 2–5 December 2012; pp. 234–239. [Google Scholar]
- Chen, P.Y.; Lin, H.J. A DWT based approach for image steganography. Int. J. Appl. Sci. Eng. 2006, 4, 275–290. [Google Scholar]
- Kaur, B.; Kaur, A.; Singh, J. Steganographic approach for hiding image in DCT domain. Int. J. Adv. Eng. Technol. 2011, 1, 72. [Google Scholar]
- Baluja, S. Hiding images in plain sight: Deep steganography. In Proceedings of the Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 2066–2076. [Google Scholar]
- Duan, X.; Jia, K.; Li, B.; Guo, D.; Zhang, E.; Qin, C. Reversible image steganography scheme based on a U-Net structure. IEEE Access 2019, 7, 9314–9323. [Google Scholar] [CrossRef]
- Baluja, S. Hiding images within images. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2019, 42, 1685–1697. [Google Scholar] [CrossRef] [PubMed]
- Channalli, S.; Jadhav, A. Steganography an art of hiding data. arXiv 2009, arXiv:0912.2319. [Google Scholar]
- Zhang, X.; Wang, S. Vulnerability of pixel-value differencing steganography to histogram analysis and modification for enhanced security. Pattern Recognit. Lett. 2004, 25, 331–339. [Google Scholar] [CrossRef]
- Goljan, M.; Fridrich, J.; Holotyak, T. New blind steganalysis and its implications. In Security, Steganography, and Watermarking of Multimedia Contents (VIII); International Society for Optics and Photonics: Washington, DC, USA, 2006; Volume 6072, p. 607201. [Google Scholar]
- Pevny, T.; Bas, P.; Fridrich, J. Steganalysis by subtractive pixel adjacency matrix. IEEE Trans. Inf. Forensics Secur. (TIFS) 2010, 5, 215–224. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Springenberg, J.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for Simplicity: The All Convolutional Net. In Proceedings of the International Conference on Learning Representation Workshops (ICLRW), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical evaluation of rectified activations in convolutional network. arXiv 2015, arXiv:1505.00853. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the Int’l Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the Int’l Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representation (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Boehm, B. Stegexpose-A tool for detecting LSB steganography. arXiv 2014, arXiv:1410.6656. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step | Feature-Map (W × H × D) | Output |
|---|---|---|
| 4 × 4 Conv+BN+LeakyReLU 4 × 4 Conv+BN+LeakyReLU 4 × 4 Conv+BN+LeakyReLU 4 × 4 Conv+BN+LeakyReLU 4 × 4 Conv+BN+LeakyReLU 4 × 4 Conv+BN+LeakyReLU 4 × 4 Conv+ReLU | 128 × 128 × 64 64 × 64 × 256 32 × 32 × 512 16 × 16 × 512 8 × 8 × 512 4 × 4 × 512 2 × 2 ×512 | 2 × 2 × 512 |
| 4 × 4 TransConv+BN+LeakyReLU 4 × 4 TransConv+BN+LeakyReLU 4 × 4 TransConv+BN+LeakyReLU 4 × 4 TransConv+BN+LeakyReLU 4 × 4 TransConv+BN+LeakyReLU 4 × 4 TransConv+BN+LeakyReLU TransConv+ReLU | 4 × 4 × 512 8 × 8 × 512 16 × 16 × 512 32 × 32 × 256 64 × 64 × 128 128 × 128 × 64 256 × 256 × 3 | 256 × 256 × 3 |
| Step | Feature-Map (W × H × D) | Output |
|---|---|---|
| 3 × 3 Conv+BN+ReLU 3 × 3 Conv+BN+ReLU 3 × 3 Conv+BN+ReLU 3 × 3 Conv+BN+ReLU 3 × 3 Conv+BN+ReLU 3 × 3 Conv+Sigmoid | 256 × 256 × 64 256 × 256 × 128 256 × 256 × 256 256 × 256 × 128 256 × 256 × 64 256 × 256 × 3 | 256 × 256 × 3 |
| N | C vs. C′ (PSNR/SSIM) | S vs. S′ (PSNR/SSIM) | S vs. S′ with Random Key (PSNR/SSIM) | |||
|---|---|---|---|---|---|---|
| 1 | 34.54/0.9780 | 33.67/0.9707 | 36.55/0.9371 | 34.70/0.9269 | 13.79/0.5399 | 16.48/0.5012 |
| 2 | 33.05/0.9292 | 30.45/0.9103 | 28.31/0.8651 | 26.01/0.8749 | 9.03/0.2923 | 12.09/0.4264 |
| 3 | 30.58/0.9121 | 28.45/0.8748 | 27.70/0.8098 | 24.61/0.7317 | 10.74/0.2213 | 11.41/0.3838 |
| 5 | 28.25/0.8549 | 27.02/0.8434 | 23.25/0.6267 | 20.10/0.5159 | 11.10/0.1984 | 10.66/0.2641 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kweon, H.; Park, J.; Woo, S.; Cho, D. Deep Multi-Image Steganography with Private Keys. Electronics 2021, 10, 1906. https://doi.org/10.3390/electronics10161906
Kweon H, Park J, Woo S, Cho D. Deep Multi-Image Steganography with Private Keys. Electronics. 2021; 10(16):1906. https://doi.org/10.3390/electronics10161906
Chicago/Turabian StyleKweon, Hyeokjoon, Jinsun Park, Sanghyun Woo, and Donghyeon Cho. 2021. "Deep Multi-Image Steganography with Private Keys" Electronics 10, no. 16: 1906. https://doi.org/10.3390/electronics10161906