
Improving Heterogeneous Network Knowledge Transfer Based on the Principle of Generative Adversarial

 ,
,
Abstract
:1. Introduction
2. Related Work
2.1. Feature Matching
2.2. Generative Adversarial Net
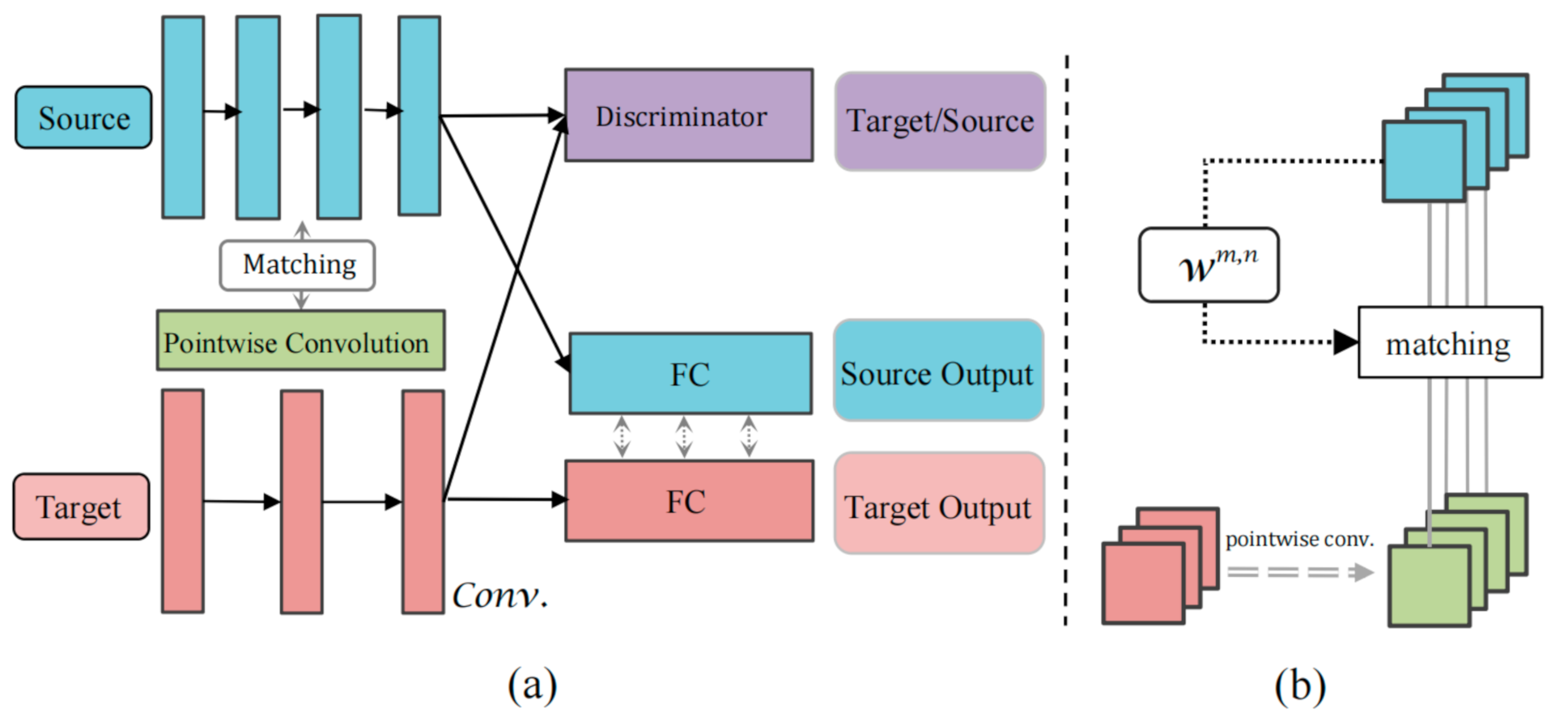
3. Our Approach
3.1. Motivation
3.2. Generative Adversarial Nets
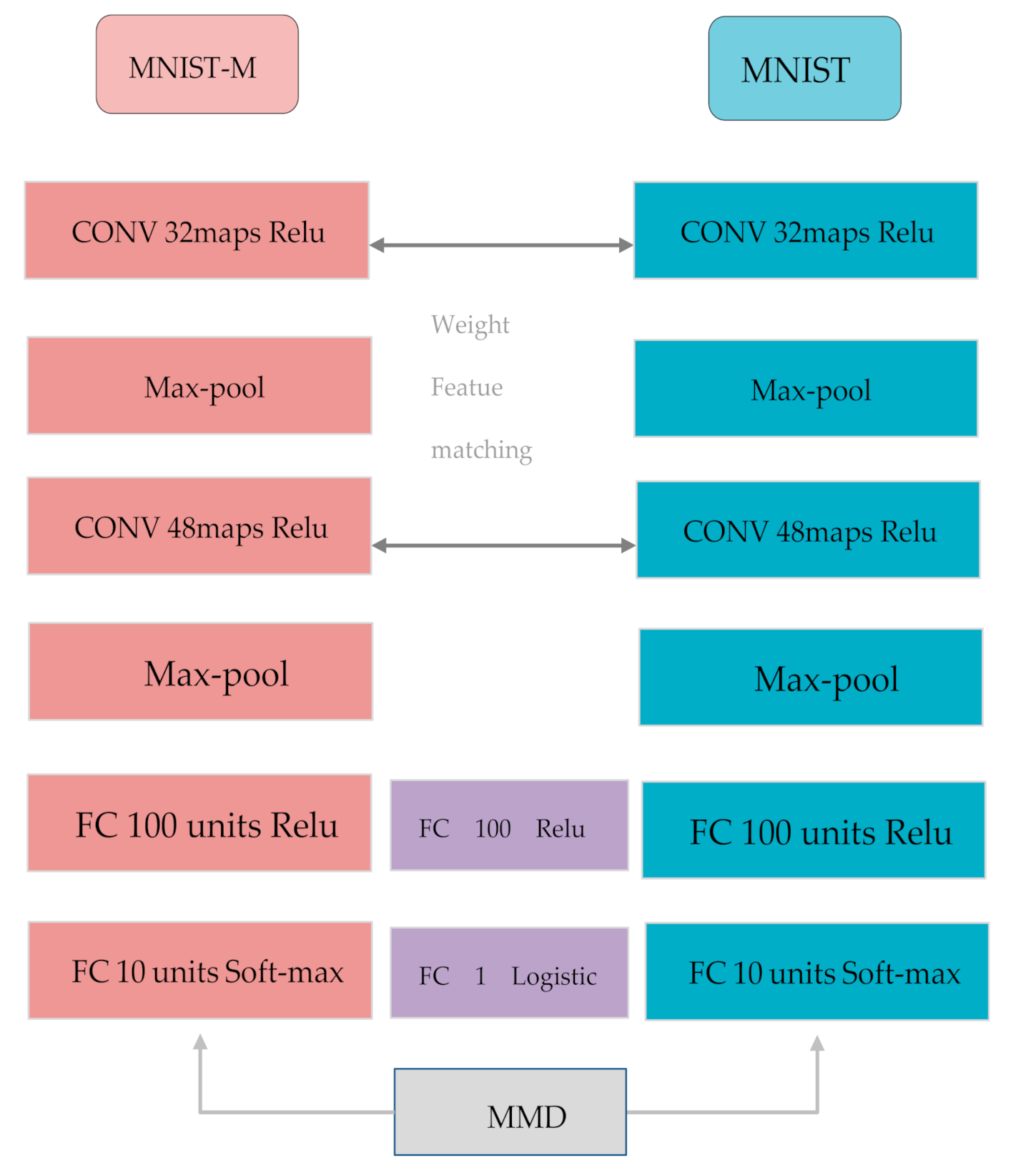
3.3. Weight Feature Matching
3.4. Maximum Mean Discrepancy
3.5. Model Holistic Training
| Algorithm 1 Minibatch stochastic gradient descent training of model. Learning of ,, |
| Input: Dataset |
| Repeat Sample a batch |
| Update to minimize for t0 to T 1 do |
| Update using |
| until done |
4. Experiments
4.1. Setup
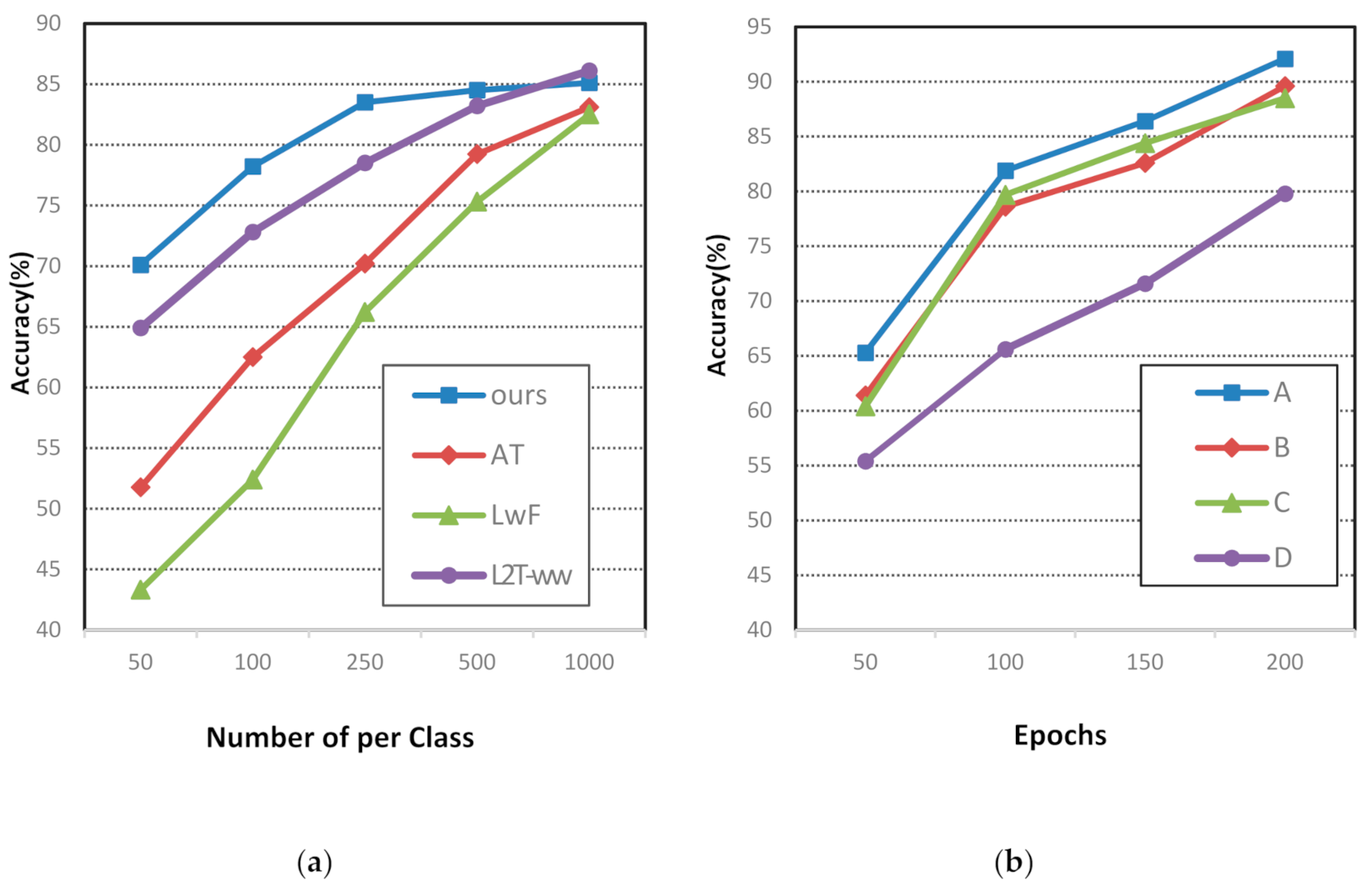
4.2. Results on Different Experiments
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition. In Proceedings of the 31th International Conference on Machine Learning, ICML 2014, Beijing, China, 21–26 June 2014; JMLR.org. 2014; Volume 32, pp. 647–655. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Zhang, N.; Saenko, K.; Darrell, T. Deep Domain Confusion: Maximizing for Domain Invariance. arXiv 2014, arXiv:1412.3474. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M.I. Learning Transferable Features with Deep Adaptation Networks. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6–11 July 2015; Volume 37, pp. 97–105. [Google Scholar]
- Bousmalis, K.; Trigeorgis, G.; Silberman, N.; Krishnan, D.; Erhan, D. Domain Separation Networks. In Proceedings of the Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; pp. 343–351. [Google Scholar]
- Shen, J.; Qu, Y.; Zhang, W.; Yu, Y. Wasserstein Distance Guided Representation Learning for Domain Adaptation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th Innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, LA, USA, 2–7 February 2018; pp. 4058–4065. [Google Scholar]
- Yu, C.; Wang, J.; Chen, Y.; Huang, M. Transfer Learning with Dynamic Adversarial Adaptation Network. In Proceedings of the 2019 IEEE International Conference on Data Mining, ICDM 2019, Beijing, China, 8–11 November 2019; pp. 778–786. [Google Scholar]
- Li, Y.; Peng, X. Learning Domain Adaptive Features with Unlabeled Domain Bridges. arXiv 2019, arXiv:1912.05004. [Google Scholar]
- Ganin, Y.; Lempitsky, V.S. Unsupervised Domain Adaptation by Backpropagation. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6–11 July 2015; Volume 37, pp. 1180–1189. [Google Scholar]
- Jang, Y.; Lee, H.; Hwang, S.J.; Shin, J. Learning What and Where to Transfer. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 3030–3039. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. FitNets: Hints for Thin Deep Nets. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Li, Z.; Hoiem, D. Learning without Forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2935–2947. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zagoruyko, S.; Komodakis, N. Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Srinivas, S.; Fleuret, F. Knowledge Transfer with Jacobian Matching. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 4730–4738. [Google Scholar]
- Xie, D.; Yang, M.; Deng, C.; Liu, W.; Tao, D. Fully-Featured Attribute Transfer. arXiv 2019, arXiv:1902.06258. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.P.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar]
- Cheng, J.L.; Liu, Y.; Tang, X.; Sheng, V.S.; Li, M. DDoS Attack Detection via Multi-Scale Convolutional Neural Network. Comput. Mater. Contin. 2020, 62, 1317–1333. [Google Scholar] [CrossRef]
- Cheng, J.; Cai, C.; Tang, X.; Sheng, V.S.; Guo, W.; Li, M. DDoS Attack Information Fusion Method Based on CNN for Multi-Element Data. Comput. Mater. Contin. 2020, 63, 131–150. [Google Scholar] [CrossRef]
- Yan, B.; Tang, X.; Liu, B.; Wang, J.; Zhou, Y.; Zheng, G.; Zou, Q.; Lu, Y.; Tu, W. An Improved Method for the Fitting and Prediction of the Number of COVID-19 Confirmed Cases Based on LSTM. Comput. Mater. Contin. 2020, 64, 1473–1490. [Google Scholar] [CrossRef]
- Long, M.; Zeng, Y. Detecting Iris Liveness with Batch Normalized Convolutional Neural Network. Comput. Mater. Contin. 2019, 58, 493–504. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, X.; Lu, K.; Su, D. Automatic Arrhythmia Detection Based on Convolutional Neural Networks. Comput. Mater. Contin. 2019, 58, 497–509. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.C.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Borgwardt, K.M.; Gretton, A.; Rasch, M.J.; Kriegel, H.-P.; Schölkopf, B.; Smola, A.J. Integrating Structured Biological Data by Kernel Maximum Mean Discrepancy. In Proceedings of the 14th International Conference on Intelligent Systems for Molecular Biology 2006, Fortaleza, Brazil, 6–10 August 2006; 2006; pp. 49–57. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Coates, A.; Ng, A.Y.; Lee, H. An Analysis of Single-Layer Networks in Unsupervised Feature Learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, AISTATS 2011, Fort Lauderdale, FL, USA, 11–13 April 2011; Volume 15, pp. 215–223. [Google Scholar]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-UCSD Birds-200-2011 Dataset; Technical Report CNS-TR-2011-001; California Institute of Technology: Los Angeles, CA, USA, 2011. [Google Scholar]
- Everingham, M.; Gool, L.V.; Williams, C.K.I.; Winn, J.M.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Tiny-Imagenet. Available online: https://tiny-imagenet.herokuapp.com/ (accessed on 1 February 2014).
- Krizhevsky, A. Convolutional Deep Belief Networks on CIFAR-10. 2012. Available online: http://www.cs.toronto.edu/~kriz/cifar.html(accessed on 8 April 2009).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Arbelaez, P.; Maire, M.; Fowlkes, C.C.; Malik, J. Contour Detection and Hierarchical Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 898–916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Source Task | Tiny ImageNet | |
|---|---|---|
| Target task | CIFAR-100 | STL-10 |
| Scratch | 67.69 ± 0.22 | 67.69 ± 0.22 |
| AT | 69.23 ± 0.09 | 69.23 ± 0.09 |
| LwF | 69.97 ± 0.24 | 69.97 ± 0.24 |
| L2T-ww | 70.96 ± 0.61 | 70.96 ± 0.61 |
| ours | 72.85 ± 0.25 | 70.99 ± 0.88 |
| Source Task | ImageNet | |
|---|---|---|
| Target task | Pascal VOC | CUB 200 |
| AT | 79.22 ± 0.59 | 44.52 ± 0.09 |
| LwF | 79.55 ± 0.64 | 44.56 ± 0.24 |
| L2T-ww | 80.96 ± 0.61 | 46.96 ± 0.67 |
| ours | 83.33 ± 0.64 | 47.11 ± 0.69 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, F.; Cheng, J.; Yang, Y.; Tang, X.; Sheng, V.S.; Huang, C. Improving Heterogeneous Network Knowledge Transfer Based on the Principle of Generative Adversarial. Electronics 2021, 10, 1525. https://doi.org/10.3390/electronics10131525
Lei F, Cheng J, Yang Y, Tang X, Sheng VS, Huang C. Improving Heterogeneous Network Knowledge Transfer Based on the Principle of Generative Adversarial. Electronics. 2021; 10(13):1525. https://doi.org/10.3390/electronics10131525
Chicago/Turabian StyleLei, Feifei, Jieren Cheng, Yue Yang, Xiangyan Tang, Victor S. Sheng, and Chunzao Huang. 2021. "Improving Heterogeneous Network Knowledge Transfer Based on the Principle of Generative Adversarial" Electronics 10, no. 13: 1525. https://doi.org/10.3390/electronics10131525