
Data-Driven Channel Pruning towards Local Binary Convolution Inverse Bottleneck Network Based on Squeeze-and-Excitation Optimization Weights



Abstract
:1. Introduction
2. Related Work
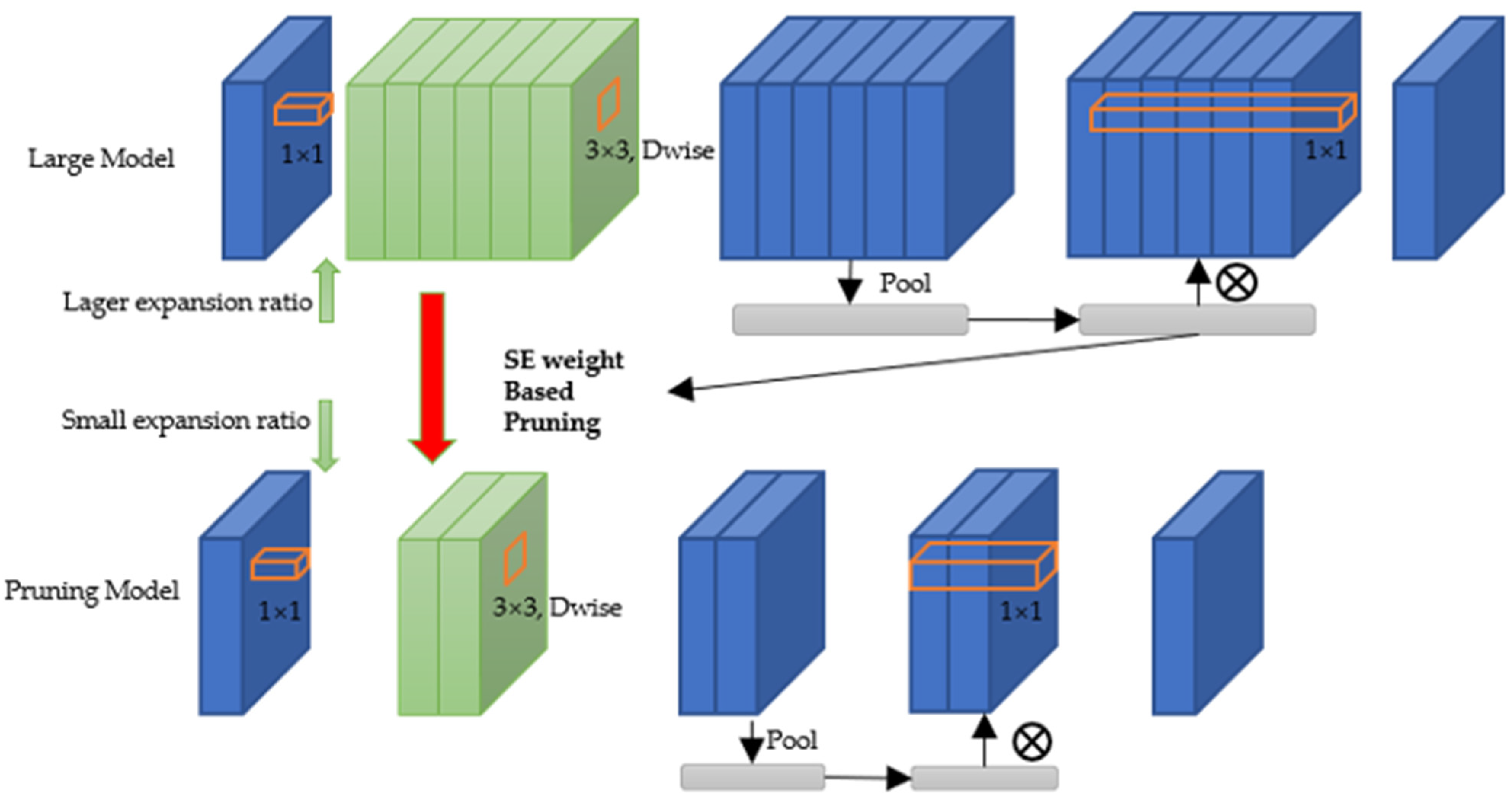
3. Model Pruning Based on SE Optimization Weight
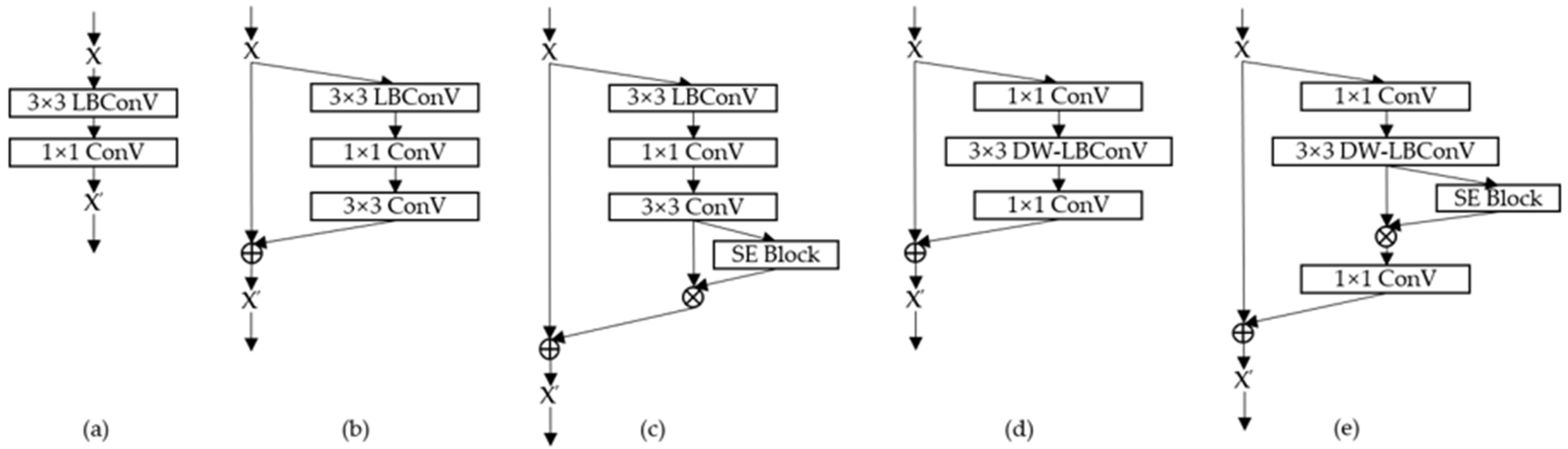
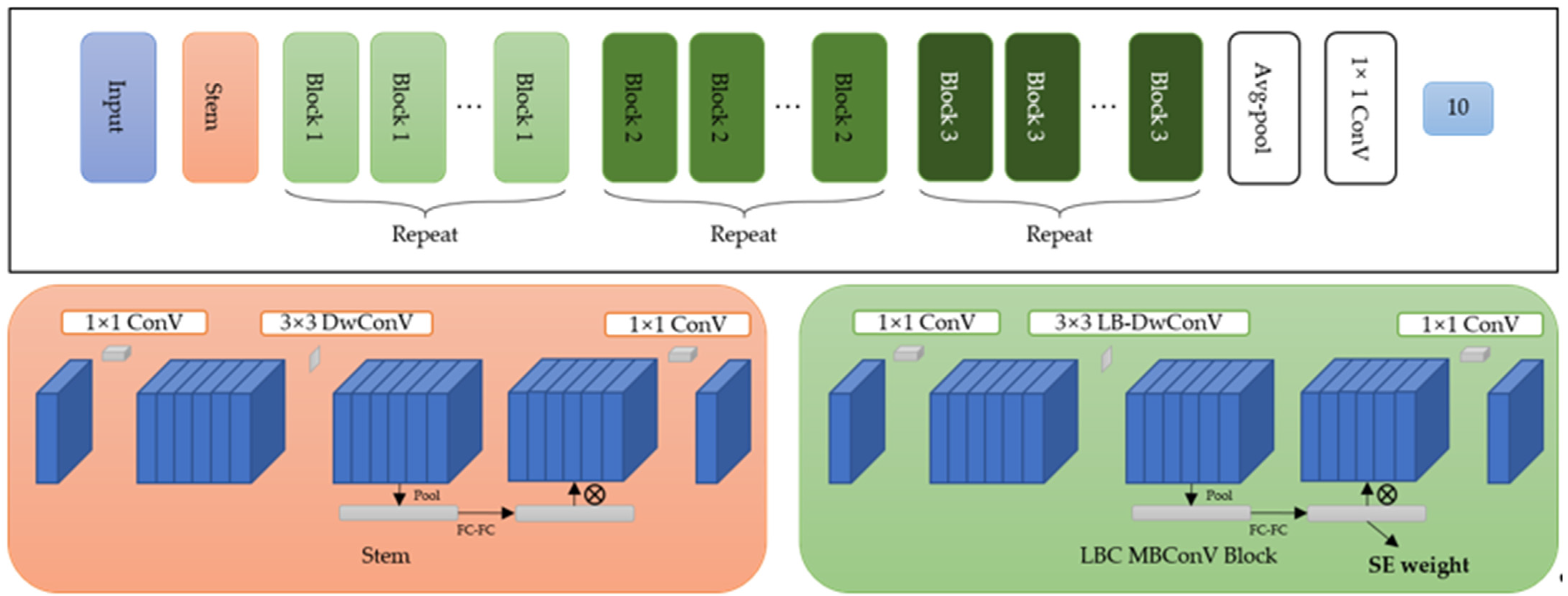
3.1. Depthwise LBC Layer and LB Mobile Inverted Bottleneck Block
3.2. Baseline LB-MBNet Model
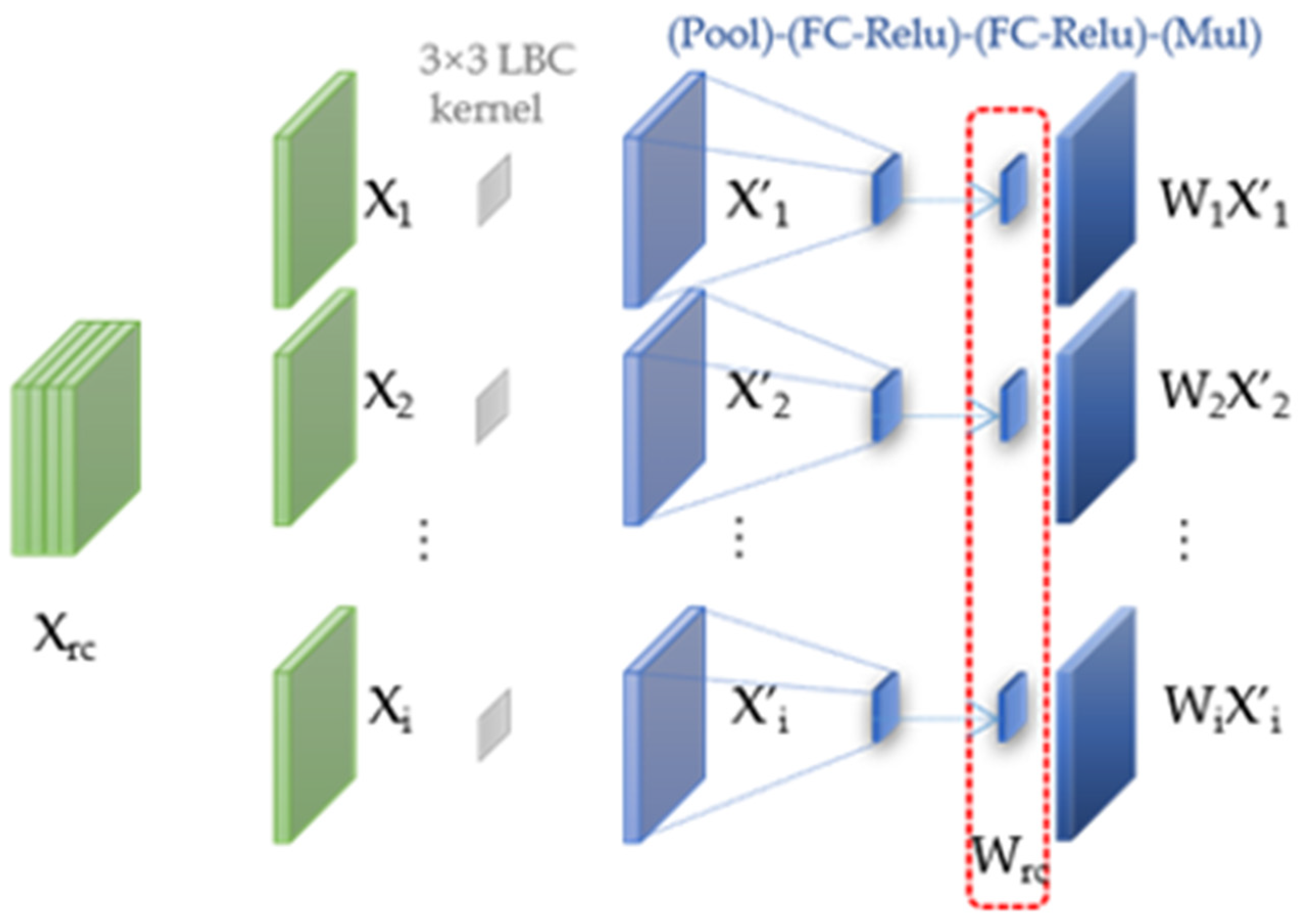
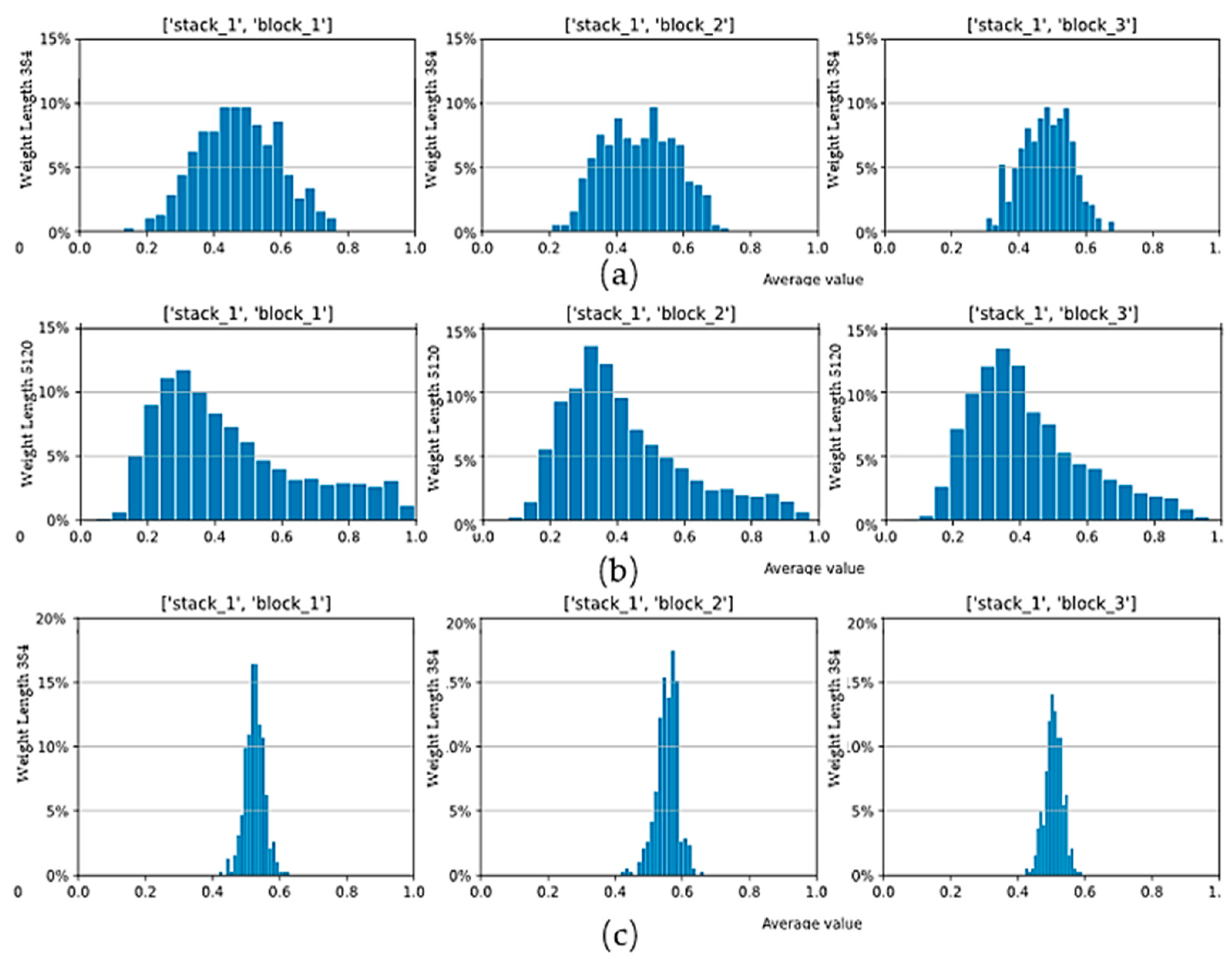
3.3. Model Pruning Based on SE Optimization Weight
4. Experiment
4.1. Experiment Settings
4.2. Experimental Result
4.3. Comparison with State-of-the-Art
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhuang, Z.; Tan, M.; Zhuang, B.; Liu, J.; Guo, Y.; Wu, Q.; Huang, J.; Zhu, J. Discrimination-aware channel pruning for deep neural networks. arXiv 2018, arXiv:1810.11809. [Google Scholar]
- Ding, X.; Ding, G.; Guo, Y.; Han, J. Centripetal sgd for pruning very deep convolutional networks with complicated structure. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4943–4953. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Denton, E.; Zaremba, W.; Bruna, J.; LeCun, Y.; Fergus, R. Exploiting linear structure within convolutional networks for efficient evaluation. arXiv 2014, arXiv:1404.0736. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Wu, J.; Leng, C.; Wang, Y.; Hu, Q.; Cheng, J. Quantized convolutional neural networks for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4820–4828. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning. ICML, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Cao, X.; Li, T.; Li, H.; Xia, S.; Ren, F.; Sun, Y.; Xu, X. A robust parameter-free thresholding method for image segmentation. IEEE Access 2018, 7, 3448–3458. [Google Scholar] [CrossRef]
- Jaderberg, M.; Vedaldi, A.; Zisserman, A. Speeding up convolutional neural networks with low rank expansions. arXiv 2014, arXiv:1405.3866. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2704–2713. [Google Scholar]
- Krishnamoorthi, R. Quantizing deep convolutional networks for efficient inference: A whitepaper. arXiv 2018, arXiv:1806.08342. [Google Scholar]
- LeCun, Y.; Denker, J.S.; Solla, S.A.; Howard, R.E.; Jackel, L.D. Optimal brain damage. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 27–30 November 1989; Volume 2, pp. 598–605. [Google Scholar]
- Hassibi, B.; Stork, D.G. Second Order Derivatives for Network Pruning: Optimal Brain Surgeon; Morgan Kaufmann: Denver, CO, USA, 1993; pp. 164–171. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- Zhu, M.; Gupta, S. To prune, or not to prune: Exploring the efficacy of pruning for model compression. arXiv 2017, arXiv:1710.01878. [Google Scholar]
- Luo, J.H.; Wu, J.; Lin, W. Thinet: A filter level pruning method for deep neural network compression. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 5058–5066. [Google Scholar]
- Carreira-Perpinán, M.A.; Idelbayev, Y. “learning-compression” algorithms for neural net pruning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8532–8541. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W.J. Learning both weights and connections for efficient neural networks. arXiv 2015, arXiv:1506.02626. [Google Scholar]
- Louizos, C.; Welling, M.; Kingma, D.P. Learning Sparse Neural Networks through L0 Regularization. arXiv 2017, arXiv:1712.01312. [Google Scholar]
- Huang, Z.; Wang, N. Data-driven sparse structure selection for deep neural networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 304–320. [Google Scholar]
- Chin, T.W.; Zhang, C.; Marculescu, D. Layer-compensated pruning for resource-constrained convolutional neural networks. arXiv 2018, arXiv:1810.00518. [Google Scholar]
- Han, S.; Liu, X.; Mao, H.; Pu, J.; Pedram, A.; Horowitz, M.A.; Dally, W.J. EIE: Efficient inference engine on compressed deep neural network. ACM Sigarch Comput. Archit. News 2016, 44, 243–254. [Google Scholar] [CrossRef]
- Liu, Z.; Sun, M.; Zhou, T.; Huang, G.; Darrell, T. Rethinking the value of network pruning. arXiv 2018, arXiv:1810.05270. [Google Scholar]
- Elsken, T.; Metzen, J.H.; Hutter, F. Neural architecture search: A survey. J. Mach. Learn. Res. 2019, 20, 1–21. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef] [Green Version]
- Corbetta, M.; Shulman, G.L. Control of goal-directed and stimulus-driven attention in the brain. Nat. Rev. Neurosci. 2002, 3, 201–215. [Google Scholar] [CrossRef] [PubMed]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. arXiv 2015, arXiv:1506.02025. [Google Scholar]
- Bhowmik, P.; Pantho, M.J.H.; Bobda, C. HARP: Hierarchical Attention Oriented Region-Based Processing for High-Performance Computation in Vision Sensor. Sensors 2021, 21, 1757. [Google Scholar] [CrossRef] [PubMed]
- Bhowmik, P.; Pantho, M.J.H.; Bobda, C. Bio-inspired smart vision sensor: Toward a reconfigurable hardware modeling of the hierarchical processing in the brain. J. Real-Time Image Process. 2020, 18, 157–174. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Liu, W.; Wu, G.; Ren, F.; Kang, X. DFF-ResNet: An insect pest recognition model based on residual networks. Big Data Min. Anal. 2020, 3, 300–310. [Google Scholar] [CrossRef]
- Juefei-Xu, F.; Naresh Boddeti, V.; Savvides, M. Local binary convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 19–28. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Harwood, D. Performance evaluation of texture measures with classification based on Kullback discrimination of distributions. In Proceedings of the 12th International Conference on Pattern Recognition, Jerusalem, Israel, 9–13 October 1994; Volume 1, pp. 582–585. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Citeseer: University Park, PA, USA, 2009. [Google Scholar]
- Rakhuba, M.; Oseledets, I.; Lempitsky, V.; Lebedev, V.; Ganin, Y. Speeding-up convolutional neural networks using fine-tuned cp-decomposition. arXiv 2018, arXiv:1412.6553. [Google Scholar]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized neural networks: Training deep neural networks with weights and activations constrained to+ 1 or-1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. Xnor-net: Imagenet classification using binary convolutional neural networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, October 2016; pp. 525–542. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. Fitnets: Hints for thin deep nets. arXiv 2014, arXiv:1412.6550. [Google Scholar]
- Molchanov, D.; Ashukha, A.; Vetrov, D. Variational dropout sparsifies deep neural networks. In Proceedings of the International Conference on Machine Learning, ICML, Sydney, Australia, 6–11 August 2017; pp. 2498–2507. [Google Scholar]
- He, Y.; Zhang, X.; Sun, J. Channel pruning for accelerating very deep neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 1389–1397. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, Hawaii, USA, 21–26 July 2017; pp. 2736–2744. [Google Scholar]
- Hu, M.; Qian, F.; Guo, D.; Wang, X.; He, L.; Ren, F. ETA-rPPGNet: Effective Time-Domain Attention Network for Remote Heart Rate Measurement. IEEE Trans. Instrum. Meas. 2021, 70, 1–12. [Google Scholar]
- Zhang, G.; Huang, X.; Li, S.Z.; Wang, Y.; Wu, X. Boosting local binary pattern (LBP)-based face recognition. In Chinese Conference on Biometric Recognition; Springer: Berlin/Heidelberg, Germany, December 2004; pp. 179–186. [Google Scholar]
- Hu, M.; Yang, C.; Zheng, Y.; Wang, X.; He, L.; Ren, F. Facial Expression Recognition Based on Fusion Features of Center-Symmetric Local Signal Magnitude Pattern. IEEE Access 2019, 7, 118435–118445. [Google Scholar] [CrossRef]
- Nanni, L.; Lumini, A.; Brahnam, S. Survey on LBP based texture descriptors for image classification. Expert Syst. Appl. 2012, 39, 3634–3641. [Google Scholar] [CrossRef]
- Courbariaux, M.; Bengio, Y.; David, J.P. Binaryconnect: Training deep neural networks with binary weights during propagations. arXiv 2015, arXiv:1511.00363. [Google Scholar]
- Sifre, L.; Mallat, S. Rigid-motion scattering for texture classification. arXiv 2014, arXiv:1403.1687. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Kumawat, S.; Verma, M.; Raman, S. LBVCNN: Local binary volume convolutional neural network for facial expression recognition from image sequences. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, October 2016; pp. 630–645. [Google Scholar]
- Yu, R.; Li, A.; Chen, C.F.; Lai, J.H.; Morariu, V.I.; Han, X.; Gao, M.; Lin, C.Y.; Davis, L.S. Nisp: Pruning networks using neuron importance score propagation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9194–9203. [Google Scholar]
- He, Y.; Lin, J.; Liu, Z.; Wang, H.; Li, L.J.; Han, S. Amc: Automl for model compression and acceleration on mobile devices. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 784–800. [Google Scholar]
- You, Z.; Yan, K.; Ye, J.; Ma, M.; Wang, P. Gate decorator: Global filter pruning method for accelerating deep convolutional neural networks. arXiv 2019, arXiv:1909.08174. [Google Scholar]
- Yu, J.; Huang, T. Autoslim: Towards one-shot architecture search for channel numbers. arXiv 2019, arXiv:1903.11728. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stack | Operator | Resolution | Channel | Repeat Num | Expansion Ratio |
|---|---|---|---|---|---|
| Stem | Conv3 × 3 | 32 × 32 | 32 | 1 | - |
| 0 | LB-MBConv, k3 × 3 | 32 × 32 | 16 | 1 | 1 |
| 1 | LB-MBConv, k3 × 3 | 32 × 32 | 64 | 6 (3) | 6 |
| 2 | LB-MBConv, k3 × 3 | 16 × 16 | 128 | 6 (3) | 6 |
| 3 | LB-MBConv, k3 × 3 | 8 × 8 | 256 | 6 (3) | 6 |
| Top | Conv1 × 1 and Pooling and FC | 4 × 4 | 512 | 1 | - |
| Model Name | Accuracy Rate (%) | Trainable Params | FLOPs (108) | Ratio to r6 Model |
|---|---|---|---|---|
| LB-MBNet-59-r6 | 92.47 | 7.11 M | 4.57 | 1× |
| LB-MBNet-59-r10 | 93.65 | 11.75 M | 7.57 | 1.7× |
| LB-MBNet-59-r18 | 93.81 | 21.03 M | 13.6 | 3.0× |
| LB-MBNet-59-r30 | 94.40 | 34.96 M | 22.5 | 4.9× |
| LB-MBNet-59-r60 | 95.05 | 69.78 M | 45.0 | 9.8× |
| LB-MBNet-59-r80 | 96.06 | 92.99 M | 59.9 | 13.1× |
| LB-MBNet-32-r6 | 92.88 | 3.19 M | 2.16 | 1× |
| LB-MBNet-32-r80 | 95.63 | 40.84 M | 27.7 | 12.8× |
| Model Name | Accuracy Rate (%) | Trainable Params | FLOPs (108) | Ratio to r6 Model |
|---|---|---|---|---|
| LB-MBNet-59-r80 | 96.06 | 92.99 M | 59.9 | 13.1× |
| Re-LB-MBNet-59-r40 | 96.15 | 46.57 M | 30.0 | 6.6× |
| Re-LB-MBNet-59-r20 | 95.76 | 23.36 M | 15.0 | 3.3× |
| Re-LB-MBNet-59-r18 | 95.58 | 21.03 M | 13.6 | 3.0× |
| Re-LB-MBNet-59-r10 | 95.65 | 11.75 M | 7.57 | 1.7× |
| Re-LB-MBNet-59-r6 | 95.24 | 7.11 M | 4.57 | 1× |
| Re-LB-MBNet-59-r3 | 93.97 | 3.63 M | 2.33 | 0.5× |
| LB-MBNet-32-r80 | 95.63 | 40.84 M | 27.7 | 12.8× |
| Re-LB-MBNet-32-r6 | 94.90 | 3.19 M | 2.16 | 1× |
| Methods | Accuracy Rate (%) | Params (M) | Params Pruned (%) | FLOPs (108) | FLOPs Pruned (%) |
|---|---|---|---|---|---|
| ResNetV2-56 1 [63] | 93.01 | 0.597 | - | 1.71 | - |
| Li et al. [20] | 93.03 | 0.516 | 13.7 | 1.24 | 27.6 |
| NISP [64] | 92.98 | 0.343 | 42.6 | 0.96 | 43.6 |
| DCP-A [64] | 93.02 | 0.177 | 70.3 | 0.90 | 47.1 |
| CP [51] | 92.01 | 0.597 | 0 | 0.86 | 50.0 |
| AMC [65] | 92.11 | 0.597 | 0 | 0.86 | 50.0 |
| C-SGD [31] | 93.24 | 0.597 | 0 | 0.67 | 60.8 |
| GBN-40 [66] | 93.34 | 0.278 | 53.5 | 0.68 | 60.1 |
| ResNetV2-164 1 [63] | 94.58 | 1.73 | - | 4.97 | - |
| L1-Sparse [52] | 94.92 | 1.44 | 16.8 | 3.81 | 23.3 |
| ResNetV2-1001 [63] | 95.08 | 10.48 | - | 30.3 | - |
| MobileNetV2 1 [43] | 91.93 | 2.2 | - | 0.88 | - |
| AutoSlim [67] | 93.20 | 1.5 | 31.8 | 0.88 | 0 |
| MobileNetV3 [50] | 92.97 | 1.52 | - | 0.35 | - |
| LB-MBNet-59-r6 1 | 92.35 | 7.11 | - | 4.57 | - |
| Re-LB-MBNet-59-r6 | 95.24 | 7.11 | 0 | 4.57 | 0 |
| Re-LB-MBNet-59-r3 | 93.97 | 3.63 | 48.9 | 2.33 | 49 |
| LB-MBNet-32-r6 1 | 92.88 | 3.19 | - | 2.16 | - |
| Re-LB-MBNet-32-r6 | 94.90 | 3.19 | 0 | 2.16 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, D.; Ren, F. Data-Driven Channel Pruning towards Local Binary Convolution Inverse Bottleneck Network Based on Squeeze-and-Excitation Optimization Weights. Electronics 2021, 10, 1329. https://doi.org/10.3390/electronics10111329
Feng D, Ren F. Data-Driven Channel Pruning towards Local Binary Convolution Inverse Bottleneck Network Based on Squeeze-and-Excitation Optimization Weights. Electronics. 2021; 10(11):1329. https://doi.org/10.3390/electronics10111329
Chicago/Turabian StyleFeng, Duo, and Fuji Ren. 2021. "Data-Driven Channel Pruning towards Local Binary Convolution Inverse Bottleneck Network Based on Squeeze-and-Excitation Optimization Weights" Electronics 10, no. 11: 1329. https://doi.org/10.3390/electronics10111329