
Fast Fallback Watermark Detection Using Perceptual Hashes





Abstract
:1. Introduction
- This is the first work that uses perceptual hashes to improve the performance of forensic watermarking methods.
- This work demonstrates that using perceptual hashes of secondary watermarks still allows for robust fallback detection.
- By calculating the perceptual hashes prior to detection, the fallback method is sped up with a factor between approximately 26,000 and 92,000, and does not require access to the watermarked videos during detection.
2. State of the Art
2.1. Forensic Watermarking
2.2. Fallback Detection Using Secondary Watermark
2.3. Perceptual Hashes
3. Materials and Methods
3.1. Perceptual Hash of Secondary Watermark
3.2. Fast Fallback Detection Using Perceptual Hashes
3.3. Theoretical Complexity Analysis
4. Results
4.1. Experimental Setup
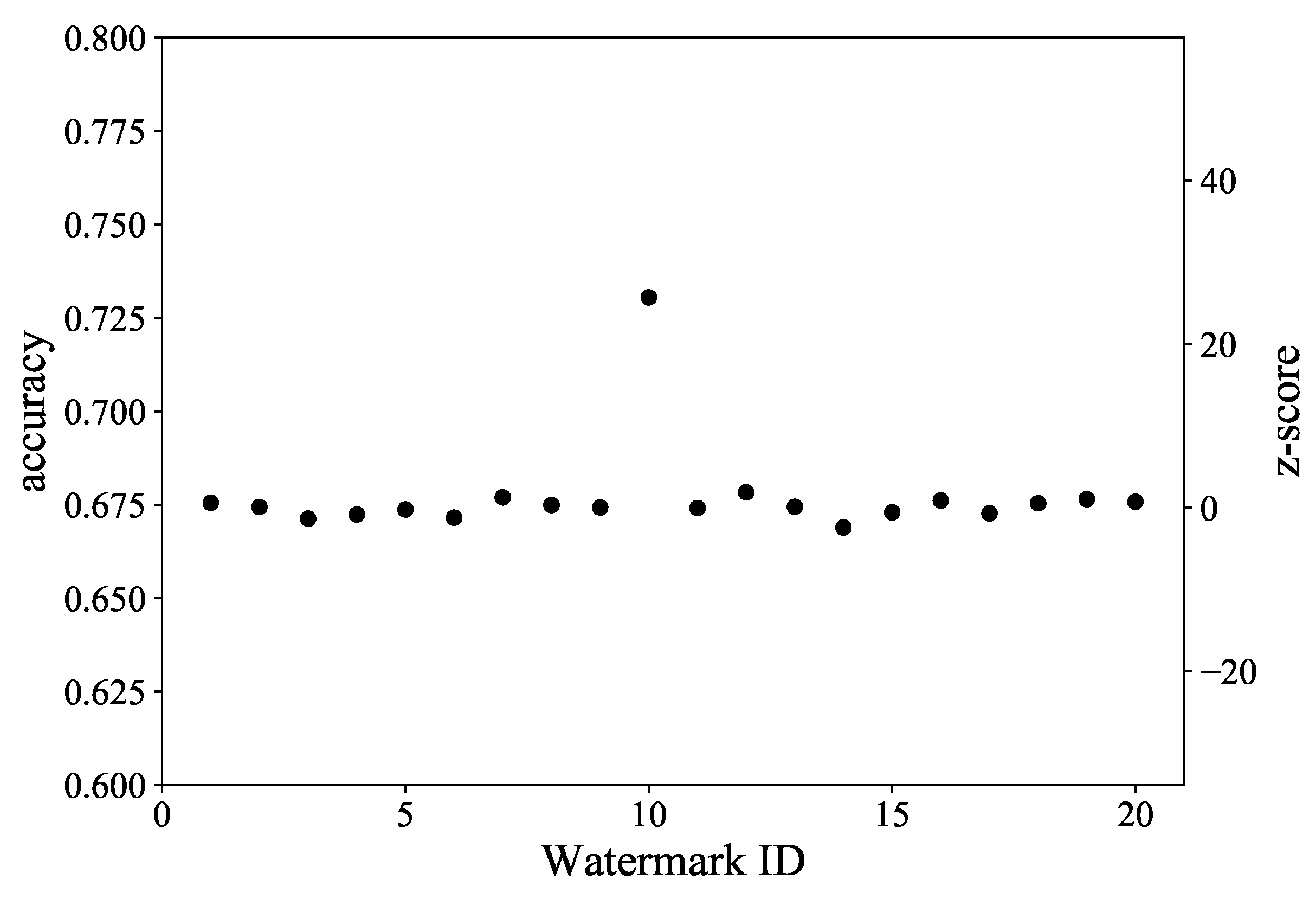
4.2. Perceptibility
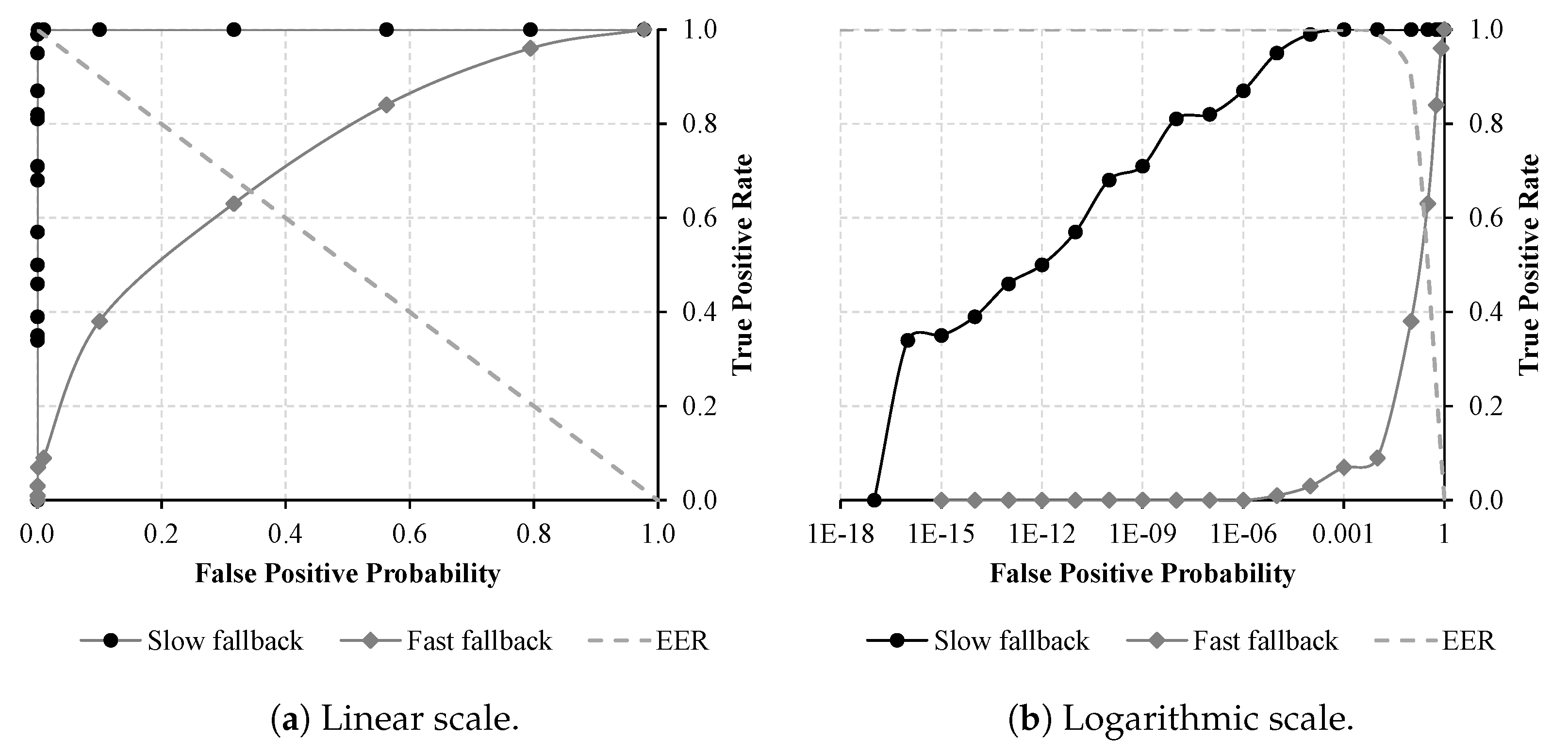
4.3. Robustness
4.4. Time Measurements
5. Limitations
6. Practical Example
7. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Asikuzzaman, M.; Pickering, M.R. An Overview of Digital Video Watermarking. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 2131–2153. [Google Scholar] [CrossRef]
- Bianchi, T.; Piva, A. Secure Watermarking for Multimedia Content Protection: A Review of its Benefits and Open Issues. IEEE Signal Process. Mag. 2013, 30, 87–96. [Google Scholar] [CrossRef]
- Langelaar, G.C.; Setyawan, I.; Lagendijk, R.L. Watermarking digital image and video data. A state-of-the-art overview. IEEE Signal Process. Mag. 2000, 17, 20–46. [Google Scholar] [CrossRef] [Green Version]
- Mareen, H.; Courteaux, M.; De Praeter, J.; Asikuzzaman, M.; Van Wallendael, G.; Pickering, M.R.; Lambert, P. Camcording-resistant Forensic Watermarking Fallback System using Secondary Watermark Signal. IEEE Trans. Circuits Syst. Video Technol. 2020. [Google Scholar] [CrossRef]
- Cox, I.J.; Kilian, J.; Leighton, F.T.; Shamoon, T. Secure spread spectrum watermarking for multimedia. IEEE Trans. Image Process. 1997, 6, 1673–1687. [Google Scholar] [CrossRef]
- Ali, M.; Ahn, C.W.; Pant, M.; Kumar, S.; Singh, M.K.; Saini, D. An Optimized Digital Watermarking Scheme Based on Invariant DC Coefficients in Spatial Domain. Electronics 2020, 9, 1428. [Google Scholar] [CrossRef]
- Byun, S.; Son, H.; Lee, S. Fast and Robust Watermarking Method Based on DCT Specific Location. IEEE Access 2019, 7, 100706–100718. [Google Scholar] [CrossRef]
- Kalarikkal Pullayikodi, S.; Tarhuni, N.; Ahmed, A.; Shiginah, F.B. Computationally Efficient Robust Color Image Watermarking Using Fast Walsh Hadamard Transform. J. Imaging 2017, 3, 46. [Google Scholar] [CrossRef] [Green Version]
- Ali, M.; Ahn, C.W.; Siarry, P. Differential evolution algorithm for the selection of optimal scaling factors in image watermarking. Eng. Appl. Artif. Intell. 2014, 31, 15–26. [Google Scholar] [CrossRef]
- Asikuzzaman, M.; Alam, M.J.; Lambert, A.J.; Pickering, M.R. Imperceptible and Robust Blind Video Watermarking Using Chrominance Embedding: A Set of Approaches in the DT CWT Domain. IEEE Trans. Inf. Forensics Secur. 2014, 9, 1502–1517. [Google Scholar] [CrossRef]
- Liu, J.; Rao, Y.; Huang, Y. Complex Wavelet-Based Image Watermarking with the Human Visual Saliency Model. Electronics 2019, 8, 1462. [Google Scholar] [CrossRef] [Green Version]
- Tan, Y.; Qin, J.; Xiang, X.; Ma, W.; Pan, W.; Xiong, N.N. A Robust Watermarking Scheme in YCbCr Color Space Based on Channel Coding. IEEE Access 2019, 7, 25026–25036. [Google Scholar] [CrossRef]
- Mareen, H.; De Praeter, J.; Van Wallendael, G.; Lambert, P. A Scalable Architecture for Uncompressed-Domain Watermarked Videos. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1432–1444. [Google Scholar] [CrossRef]
- Jarnikov, D.; Hietbrink, E.; Arana, M.; Doumene, J.M. A watermarking system for adaptive streaming. In Proceedings of the 2014 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 10–13 January 2014; pp. 375–377. [Google Scholar] [CrossRef]
- Kim, K.S.; Lee, H.Y.; Im, D.H.; Lee, H.K. Practical, Real-Time, and Robust Watermarking on the Spatial Domain for High-Definition Video Contents. IEICE Trans. Inf. Syst. 2008, E91-D, 1359–1368. [Google Scholar] [CrossRef]
- Piva, A.; Bianchi, T.; Rosa, A.D. Secure Client-Side ST-DM Watermark Embedding. IEEE Trans. Inf. Forensics Secur. 2010, 5, 13–26. [Google Scholar] [CrossRef]
- Noorkami, M.; Mersereau, R.M. A Framework for Robust Watermarking of H.264-Encoded Video With Controllable Detection Performance. IEEE Trans. Inf. Forensics Secur. 2007, 2, 14–23. [Google Scholar] [CrossRef]
- Jang, B.J.; Lee, S.H.; Lee, Y.S.; Kwon, K.R. Biological Viral Infection Watermarking Architecture of MPEG/H.264/AVC/HEVC. Electronics 2019, 8, 889. [Google Scholar] [CrossRef] [Green Version]
- Mareen, H.; Courteaux, M.; De Praeter, J.; Asikuzzaman, M.; Van Wallendael, G.; Lambert, P. Rate-Distortion-Preserving Forensic Watermarking Using Quantization Parameter Variation. IEEE Access 2020, 8, 63700–63709. [Google Scholar] [CrossRef]
- Buhari, A.M.; Ling, H.C.; Baskaran, V.M.; Wong, K. Fast watermarking scheme for real-time spatial scalable video coding. Signal Process. Image Commun. 2016, 47, 86–95. [Google Scholar] [CrossRef]
- Meerwald, P.; Uhl, A. Robust Watermarking of H.264/SVC-encoded Video: Quality and Resolution Scalability. In International Workshop on Digital Watermarking; IWDW’10; Springer: Berlin/Heidelberg, Germay, 2011; pp. 159–169. [Google Scholar] [CrossRef] [Green Version]
- Mareen, H.; Van Wallendael, G.; Lambert, P. Implementation-Free Forensic Watermarking for Adaptive Streaming with A/B Watermarking. In Proceedings of the International Conference Information Communication Technology (ICICT) 2021, London, UK, 25–26 February 2021. [Google Scholar]
- Lee, M.J.; Im, D.H.; Lee, H.Y.; Kim, K.S.; Lee, H.K. Real-Time Video Watermarking System on the Compressed Domain for High-Definition Video Contents: Practical Issues. Digit. Signal Process. 2012, 22, 190–198. [Google Scholar] [CrossRef]
- Stütz, T.; Autrusseau, F.; Uhl, A. Non-Blind Structure-Preserving Substitution Watermarking of H.264/CAVLC Inter-Frames. IEEE Trans. Multimed. 2014, 16, 1337–1349. [Google Scholar] [CrossRef] [Green Version]
- Ma, X.; Li, Z.; Tu, H.; Zhang, B. A Data Hiding Algorithm for H.264/AVC Video Streams Without Intra-Frame Distortion Drift. IEEE Trans. Circuits Syst. Video Technol. 2010, 20, 1320–1330. [Google Scholar] [CrossRef]
- Chen, W.; Shahid, Z.; Stütz, T.; Autrusseau, F.; Le Callet, P. Robust drift-free bit-rate preserving H.264 watermarking. Multimed. Syst. 2014, 20, 179–193. [Google Scholar] [CrossRef] [Green Version]
- Pham Van, L.; De Praeter, J.; Van Wallendael, G.; De Cock, J.; Van de Walle, R. Out-of-the-loop information hiding for HEVC video. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3610–3614. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Wang, C.; Zhou, X. An Intra-Drift-Free Robust Watermarking Algorithm in High Efficiency Video Coding Compressed Domain. IEEE Access 2019, 7, 132991–133007. [Google Scholar] [CrossRef]
- Cox, I.; Miller, M.; Bloom, J.; Fridrich, J.; Kalker, T. Digital Watermarking and Steganography, 2nd ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2008. [Google Scholar]
- Liu, X.; Liang, J.; Wang, Z.Y.; Tsai, Y.T.; Lin, C.C.; Chen, C.C. Content-Based Image Copy Detection Using Convolutional Neural Network. Electronics 2020, 9, 29. [Google Scholar] [CrossRef]
- Du, L.; Ho, A.T.; Cong, R. Perceptual hashing for image authentication: A survey. Signal Process. Image Commun. 2020, 81, 115713. [Google Scholar] [CrossRef]
- Zhou, Z.; Yang, C.N.; Chen, B.; Sun, X.; Liu, Q.; QM, J. Effective and efficient image copy detection with resistance to arbitrary rotation. IEICE Trans. Inf. Syst. 2016, 99, 1531–1540. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Wang, M.; Cao, Y.; Su, Y. CNN Feature-Based Image Copy Detection with Contextual Hash Embedding. Mathematics 2020, 8, 1172. [Google Scholar] [CrossRef]
- Coskun, B.; Sankur, B.; Memon, N. Spatio–Temporal Transform Based Video Hashing. IEEE Trans. Multimed. 2006, 8, 1190–1208. [Google Scholar] [CrossRef]
- Law-To, J.; Chen, L.; Joly, A.; Laptev, I.; Buisson, O.; Gouet-Brunet, V.; Boujemaa, N.; Stentiford, F. Video copy detection: A comparative study. In Proceedings of the 6th ACM International Conference on Image and Video Retrieval, Amsterdam, The Netherlands, 9–11 July 2007; pp. 371–378. [Google Scholar]
- Esmaeili, M.M.; Fatourechi, M.; Ward, R.K. A Robust and Fast Video Copy Detection System Using Content-Based Fingerprinting. IEEE Trans. Inf. Forensics Secur. 2011, 6, 213–226. [Google Scholar] [CrossRef]
- Lee, S.; Yoo, C.D. Robust video fingerprinting for content-based video identification. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 983–988. [Google Scholar] [CrossRef] [Green Version]
- Guzman-Zavaleta, Z.J.; Feregrino-Uribe, C.; Morales-Sandoval, M.; Menendez-Ortiz, A. A robust and low-cost video fingerprint extraction method for copy detection. Multimed. Tools Appl. 2017, 76, 24143–24163. [Google Scholar] [CrossRef]
- Joolee, J.B.; Uddin, M.A.; Khan, J.; Kim, T.; Lee, Y.K. A Novel Lightweight Approach for Video Retrieval on Mobile Augmented Reality Environment. Appl. Sci. 2018, 8, 1860. [Google Scholar] [CrossRef] [Green Version]
- Jiang, D.; Kim, J. Video Searching and Fingerprint Detection by Using the Image Query and PlaceNet-Based Shot Boundary Detection Method. Appl. Sci. 2018, 8, 1735. [Google Scholar] [CrossRef] [Green Version]
- Hampapur, A.; Hyun, K.; Bolle, R.M. Comparison of sequence matching techniques for video copy detection. In Storage and Retrieval for Media Databases 2002; International Society for Optics and Photonics: San Jose, CA, USA, 2001; Volume 4676, pp. 194–201. [Google Scholar]
- Bossen, F. Common Test Conditions and Software Reference Configurations; Technical Report JCTVC-L1100, ITU-T Joint Collaborative Team on Video Coding (JCT-VC); Joint Video Experts Team (JVET): San Diego, CA, USA, 2013. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Average PSNRY (dB) | ||
|---|---|---|
| Unwatermarked | Watermarked | |
| 22 | 40.78 | 40.76 |
| 27 | 38.42 | 38.42 |
| 32 | 35.86 | 35.87 |
| 37 | 33.29 | 33.26 |
| False-Negative Rate * (%) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 22 | 27 | 32 | 37 | 42 | 47 | 22 | 27 | 32 | 37 | 42 | 47 | ||
| DTCWT [10] | Slow Fallback [4] | ||||||||||||
| 22 | 100 | 100 | 100 | 100 | 100 | 100 | 0 | 0 | 0 | 0 | 0 | 13 | |
| 27 | 100 | 100 | 100 | 100 | 100 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 32 | 100 | 100 | 100 | 100 | 100 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 37 | 100 | 100 | 100 | 100 | 100 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | |
| False-Negative Rate * (%) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 22 | 27 | 32 | 37 | 42 | 47 | 22 | 27 | 32 | 37 | 42 | 47 | ||
| (570 B) | (2508 B) | ||||||||||||
| 22 | 0 | 40 | 99 | 100 | 100 | 100 | 0 | 0 | 60 | 100 | 100 | 100 | |
| 27 | 0 | 0 | 40 | 99 | 99 | 100 | 0 | 0 | 0 | 60 | 100 | 100 | |
| 32 | 0 | 0 | 0 | 30 | 99 | 100 | 0 | 0 | 0 | 0 | 58 | 98 | |
| 37 | 0 | 0 | 0 | 0 | 37 | 95 | 0 | 0 | 0 | 0 | 0 | 42 | |
| (1140 B) | (5016 B) | ||||||||||||
| 22 | 0 | 17 | 97 | 100 | 100 | 100 | 0 | 0 | 51 | 100 | 99 | 100 | |
| 27 | 0 | 0 | 13 | 92 | 100 | 100 | 0 | 0 | 0 | 39 | 100 | 100 | |
| 32 | 0 | 0 | 0 | 18 | 93 | 100 | 0 | 0 | 0 | 0 | 70 | 99 | |
| 37 | 0 | 0 | 0 | 0 | 23 | 92 | 0 | 0 | 0 | 0 | 0 | 26 | |
| (4560 B) | (20,026 B) | ||||||||||||
| 22 | 0 | 0 | 34 | 94 | 100 | 100 | 0 | 0 | 0 | 68 | 100 | 100 | |
| 27 | 0 | 0 | 0 | 36 | 98 | 100 | 0 | 0 | 0 | 0 | 74 | 99 | |
| 32 | 0 | 0 | 0 | 0 | 42 | 97 | 0 | 0 | 0 | 0 | 0 | 63 | |
| 37 | 0 | 0 | 0 | 0 | 0 | 25 | 0 | 0 | 0 | 0 | 0 | 1 | |
| False-Negative Rate * (%) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 22 | 27 | 32 | 37 | 42 | 47 | 22 | 27 | 32 | 37 | 42 | 47 | ||
| (22,800 B) | (100,130 B) | ||||||||||||
| 22 | 0 | 0 | 0 | 30 | 100 | 100 | 0 | 0 | 0 | 0 | 90 | 90 | |
| 27 | 0 | 0 | 0 | 0 | 35 | 100 | 0 | 0 | 0 | 0 | 0 | 65 | |
| 32 | 0 | 0 | 0 | 0 | 0 | 50 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 37 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Time (ms) | ||||||||
|---|---|---|---|---|---|---|---|---|
| Perceptual Hashing | Accuracy Calculation | |||||||
| b | 0 | 2 | 4 | 0 | 2 | 4 | ||
| 16 | 204 | 233 | 429 | 0.15 | 0.16 | 0.25 | ||
| 8 | 591 | 760 | 1612 | 0.21 | 0.25 | 0.53 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mareen, H.; Van Kets, N.; Lambert, P.; Van Wallendael, G. Fast Fallback Watermark Detection Using Perceptual Hashes. Electronics 2021, 10, 1155. https://doi.org/10.3390/electronics10101155
Mareen H, Van Kets N, Lambert P, Van Wallendael G. Fast Fallback Watermark Detection Using Perceptual Hashes. Electronics. 2021; 10(10):1155. https://doi.org/10.3390/electronics10101155
Chicago/Turabian StyleMareen, Hannes, Niels Van Kets, Peter Lambert, and Glenn Van Wallendael. 2021. "Fast Fallback Watermark Detection Using Perceptual Hashes" Electronics 10, no. 10: 1155. https://doi.org/10.3390/electronics10101155