1. Introduction
Rapid advancement in technology has led to an exponential growth in the number of resources available on a single chip leading to the Many-Core Network-on-Chip (MCNoC) era. With this development, thousands of reduced-sized transistors can be integrated to improve chip performance. Unfortunately, transistor size reduction has led to thermal issues such as high-power density, high chip temperature, and permanent faults caused by leakage power and enforces the dark-silicon phenomenon. The dark-silicon is a phenomenon where more than 30% of chips are predicted to be “dark” or “dumso” at 8 nm [
1], limiting full utilization of the abundant of nodes available for maximum performance. Permanent faults cause chip damage and increase the Mean Time To Failure (MTTF) of MCNoCs therefore efficient techniques are required. To prevent chip damage, many-core/multi-core chips have to operate under a fixed budget technique such as Thermal Design Power (TDP) or a fixed per-core power budget such as Thermal Safe Power (TSP) which can also lead to thermal violations [
2,
3,
4,
5].
In these power budgeting techniques, Dynamic Thermal Management (DTM) techniques such as Task Migration (TM), Dynamic Voltage Frequency Scaling (DVFS), Task Migration (TM), Power Gating (PG), and Near-Threshold Computing (NTC) are used to control the frequency of the chip and to migrate applications or tasks. TDP can be optimistic or pessimistic when implemented causing unnecessary triggering of DTM techniques. TSP is more favoured in recent many-core blueprints because it considers the position of active and dark nodes. Unfortunately, these techniques present challenges. DVFS reduces the temperature of the chip by reducing the frequency which in turn reduces the performance of the chip. On the other hand, TM [
6,
7] migrates tasks from active nodes to dumso nodes to improve the chip temperature performance. Consequently, in the dark-silicon era, different placements of dark nodes can lead to different thermal profiles of the many-core system.
Unfortunately, this incurs a performance overhead because of memory data transfer and high wake-up latency. Refs. [
8,
9,
10] proposed a fixed wake-threshold but this may not apply to a many-core system with stochastic applications. Another widely used technique concerns the number of dark nodes allocated to a specific application. Active nodes can function at higher frequencies when placed near dumso nodes. However, this must be done strategically or there would be insufficient nodes available for the mapping of new applications which can cause delays and performance degradation. Another thing to consider when mapping an application is which node to migrate to. Mapping nodes non-contiguously can lead to communication latency between tasks that require inter-communication.
Other existing literature [
11,
12,
13,
14,
15] adopts the option of reducing power consumption in Network-on-Chip (NoC). NoC consists of a router and links. The routers contain components such as the arbiter, crossbars, input and output ports, and routers. These components consume about 64% of the NoC’s leakage power. Particularly, this is the case for the buffers and the crossbars in the routers since they are identified as the most consuming components in the NoC [
16,
17].
One technique is the employment of bufferless routers. Ref. [
18] propose a heterogeneous NoC architecture comprised of buffered and bufferless routers that reduce the power consumption by 42% in comparison to a buffered router. Unfortunately, this can lead to network congestion. The bufferless router consists of only one local output port for ejection, which can cause several flits to compete for that output port.
Another technique is to reduce power consumption in the cache. Due to their size, LLCs have reportedly been identified to consume the majority of cache leakage power. Several methods have been put up to increase power efficiency. However, these methods can be divided into two groups: cache performance and hybrid designs. The hybrid designs employ Spin-transfer torque magnetic random-access memory (STT-RAM) and static random access memory (SRAM) [
19,
20,
21]. As an alternative, idle parts of the cache are disabled using power-gating techniques when there is little workload. However, turning off inactive portions of a cache may result in performance costs that increase the amount of power being used.
In [
22], less frequently used banks are switched off and their requests are sent to neighbouring requests to ensure that power-gating techniques do not contribute a substantial threat to the performance. Moreover, several design aspects can be employed to improve the dark area on the chips. To address the aforementioned problems, we propose the following novel contributions:
A dynamic mapping approach to improve the ageing of many-core nodes. The proposed framework is built on our previous contribution ABENA [
23];
The proposed architecture migrates tasks between two nodes depending on the MTTF after an epoch and also during an epoch;
DVFS and Task Migration are used to reduce the frequency to maintain the temperature of nodes under the temperature constraint.
The paper is organized as follows:
Section 2 briefly discusses related work.
Section 3 presents the problem statement and in
Section 4, the experimental results are presented.
Section 5 presents the summary and finally,
Section 6 concludes the paper and discusses future work.
2. Related Work
Considering the issues surrounding dark silicon, existing work addresses this problem from architectural heterogeneity, on-chip components such as the NoC, Cache, and Core, and Application Mapping techniques. Unfortunately, many existing works do not consider the dark-silicon constraints or process variations and the impact of the ageing of nodes. High temperature accelerates ageing mechanisms such as Electromigration (EM), Negative Bias Temperature Instability (NBTI), time-dependent dielectric breakdown (TDDB), etc. [
24,
25], leading to a shorter life span for nodes. The lifetime reliability of a node can be reduced by more than 50% by a 10% increase in temperature. Additionally, according to [
26], process variation causes nodes to age faster and slower, which affects the lifetime of the chip.
The following work [
27,
28,
29,
30] tackles the thermal constraints by employing DVFS. However, DFVS alone cannot improve the power and ageing performance of a chip. Ageing depends on several factors such as supply voltage, frequency, stress time, and process variation. Isci et al. [
30] introduced a dark-silicon framework that utilises DVFS and dumso node placement to improve the reliability and performance of the chip. Unfortunately, the proposed framework is not scalable for large networks. Additionally, they employ TDP which can be either too pessimistic or optimistic. On the other hand, refs. [
31,
32,
33] propose online decision-making approaches to overcome the stochastic nature of applications. Unfortunately, due to the large uncertainty of program execution, performance can be degraded.
Haghbayan et al. [
34] proposed the Reliability-aware Mapping framework for dark-silicon applications but it does not consider process variation. Alternatively, Rathore et al. [
35] proposed the Longevity Framework (LF) to improve the lifetime of nodes. The longevity framework considers process variation in the decision-making of assigning applications to cores. The proposed methodology groups several cores into blocks and then forms a cluster around several blocks. Each cluster consists of dark nodes. Gnad et al. [
36] also proposed a Hayat, a dark-silicon framework for ageing deceleration and balancing. They consider process variation in their architecture.
Similarly, Ofori-Attah et al. [
23] proposed ABENA. In ABENA, applications are mapped to Nodes with high MTTF after every epoch. In ABENA, NANA is used to form clusters between two nodes. This is to ensure that there is at least one dumso node next to an active node. In the Longevity framework [
35], the position of dark nodes is not strategically positioned and controlled. Additionally, they do not consider task migration during an Epoch.
Alternatively, Mohammed et al. proposed dynamic thermal-aware performance optimization (DTaPO), an algorithm that migrates tasks from active nodes to dark nodes. Similarly to ABENA, in DTaPO, dark nodes are not completely power-gated. When the tasks are migrated from the active node, they enter into a low-power state and retain the L2 cache content. This is to allow the new active nodes to access the new dark nodes for information reducing access to the main memory. Clusters are formed between nodes that share the same Last Level Cache (LLC). Similar to ABENA and the Longevity framework, DVFS is used to reduce power consumption. Unfortunately, DTaPo does not consider the MTTF of nodes in its implementation and does not consider periodic workloads.
Wen et al. [
37] proposed a dynamic task migration scheme that employs three migration modes. The migration modes are selected based on application characteristics. The first mode is Square Swap Migration where an application is mapped to half of a region. When a hotspot is detected, the entire application is migrated to the next half of the region. The second mode is confined local coolest migration, where an individual task is migrated to a dark core in the same region. The third migration is confined neighbour migration, where a task can be migrated to its neighbouring core which can either be a dark core or an active core if it is below the temperature threshold. Unfortunately, the proposed approach does not consider process variation and ageing. Compared to existing dark-silicon patterning approaches, the proposed scheme considers several factors: process variation, ageing, and the allocation of dark nodes to a specific region.
3. System Model and Problem Formulation
3.1. Many-Core Platform Model
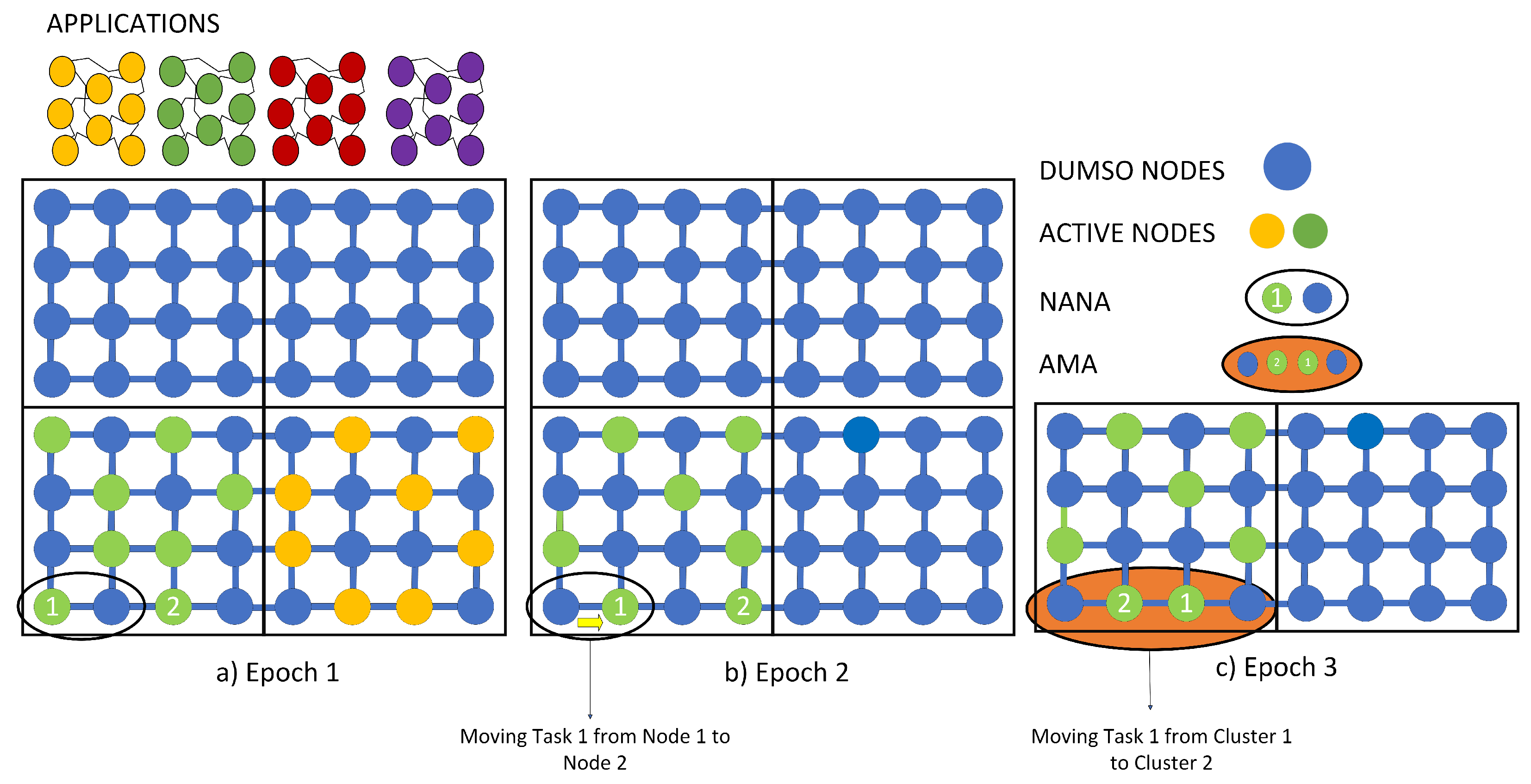
The many-core system is an grid of MCA tiles. In the proposed framework, clusters are formed by specifying the number of nodes available and the type of mesh required. Additionally, the number of nodes allocated to each application is dependent on the application with the highest number. This is to ensure that clusters are formed of equal sizes. For example, in a system with 64 nodes where the application with the largest number of tasks is 8, 4 clusters of 16 will be formed. By doubling the nodes in that cluster, we ensure that in the cluster there are 8 active nodes and 8 dumso nodes. This is because ABENA employs the 50% dumso rule for dark silicon.
Each cluster is allocated a module to monitor the temperature and lifetime of nodes and to utilise DTM techniques to the nodes accordingly. Each module then returns the average temperature and lifetime of its cluster to a centralised resource manager. Based on the information collected, applications are assigned to the right cluster. Additionally, each node has per-core DVFS capability. Each tile consists of a core, a memory (private L1 and L2 caches), and NoC. Unlike [
35], the dark nodes enter into a low-power state to allow the active nodes to access the L2 cache contents. Each node has a coordinate of
. The temperature and MTTF of each node are sent to a global manager. Applications are allocated by a resource manager.
3.2. Problem Statement
It is important to understand the difference between MTTF and ageing. MTTF is a value generated under existing conditions. Therefore, the MTTF depends on several factors: temperature and the number of active and dumso nodes. Additionally, it also depends on the current applications being executed. Different applications have different characteristics which can change the MTTF of a node. Furthermore, the tasks from a particular application can also have an impact on the MTTF of every single node.
On the other hand, the ageing of a system is measured over a period of time. Exiting work compares the temperature of nodes after an epoch and assigns applications after an Epoch. As a result of the stochastic nature of applications, the MTTF during an epoch can change.
3.3. ABENA 2.0 Overview
At any given time, a total n of applications arrive at the system. Each application consists of several T threads. The objective is to map application tasks to nodes whilst satisfying the thermal constraints and performance. ABENA has two different modes.
ABENA 2.0 inherits the majority of the algorithm structures from ABENA 1.0 with an additional clustering feature. In ABENA 2.0 clustering is formed in two different ways. The clustering can be performed by specifying the type of mesh required or by forming clusters based on the LLC that the nodes share as depicted by [
7]. Similar to ABENA 1.0, the first cluster to map the first application is chosen by calculating the
of all the clusters. Then, the cluster with the highest
is chosen. This process is repeated until the last step. If two clusters return the same
, the
C with the lowest
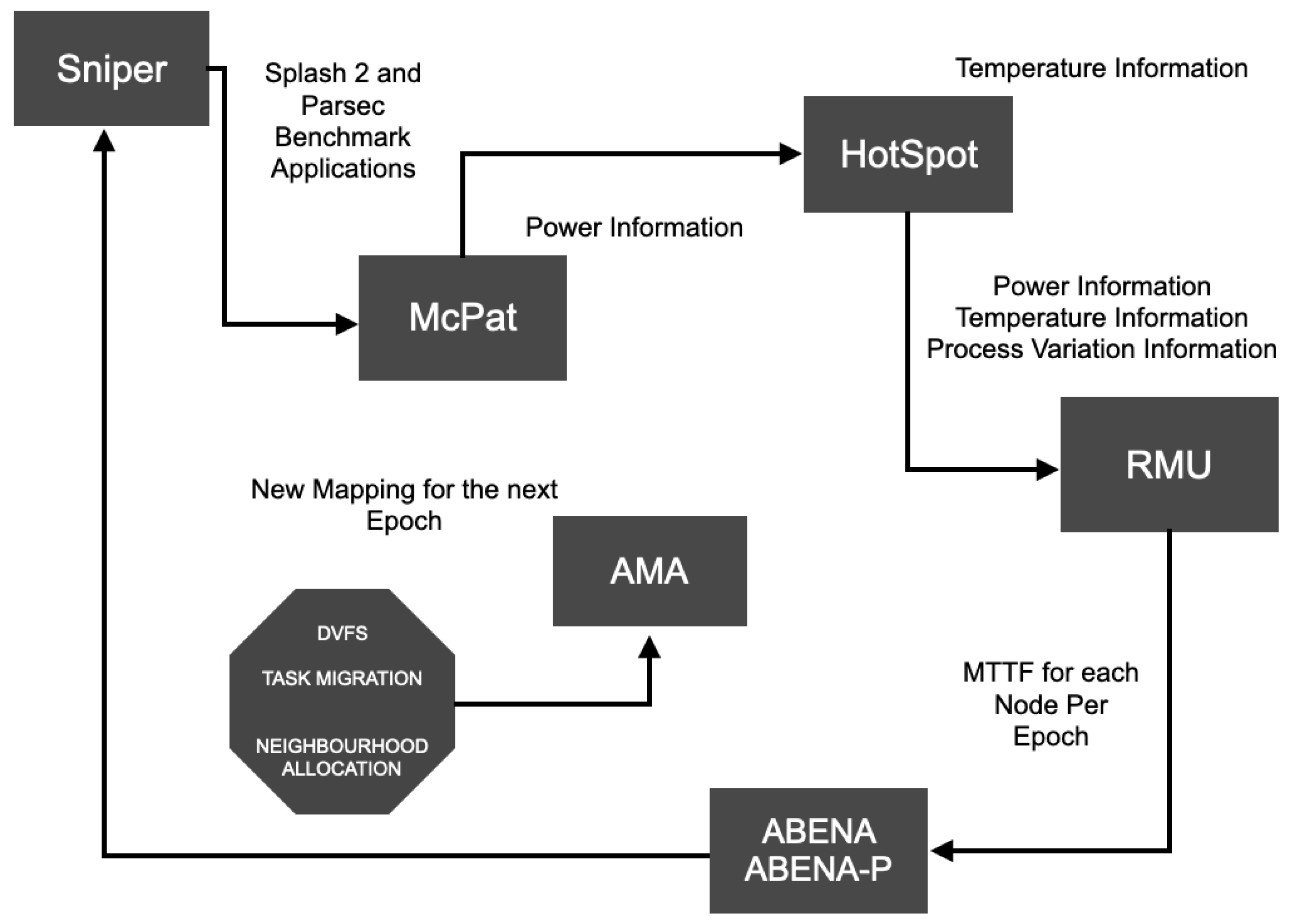
T is chosen. ABENA 2.0 also inherits Neighbour-Temperature-Aware Node-Allocation (NANA) to form mini clusters between two neighbouring nodes. NANA compares the MTTF of the two neighbouring nodes and maps the task to the nodes that return the highest MTTF. DVFS is then used to reduce the voltage frequency by 10%. This 10% is not a special number. This number is chosen because increasing and decreasing the VF by 1% does not have a significant impact on the temperature. Algorithm 1 depicts ABENA 2.0.
| Algorithm 1: ABENA Periodic [23] |
![Jlpea 13 00036 i001]() |
In [
4], the execution of blackscholes shows how threads are executed. In Phase 1, only the parent threads are executed. In Phase 2, the slave threads are executed and in Phase 3, the master threads are executed. By using this analysis, they proposed the Transient-Temperature Based Safe Power Budgeting (TSP) to fully exploit TSP budgeting. We derived the motivation from [
4]. Based on these conclusions, we propose An Ageing Task Migration Aware for High-Performance Computing(AMA) to improve ABENA 2.0.
6. Conclusions
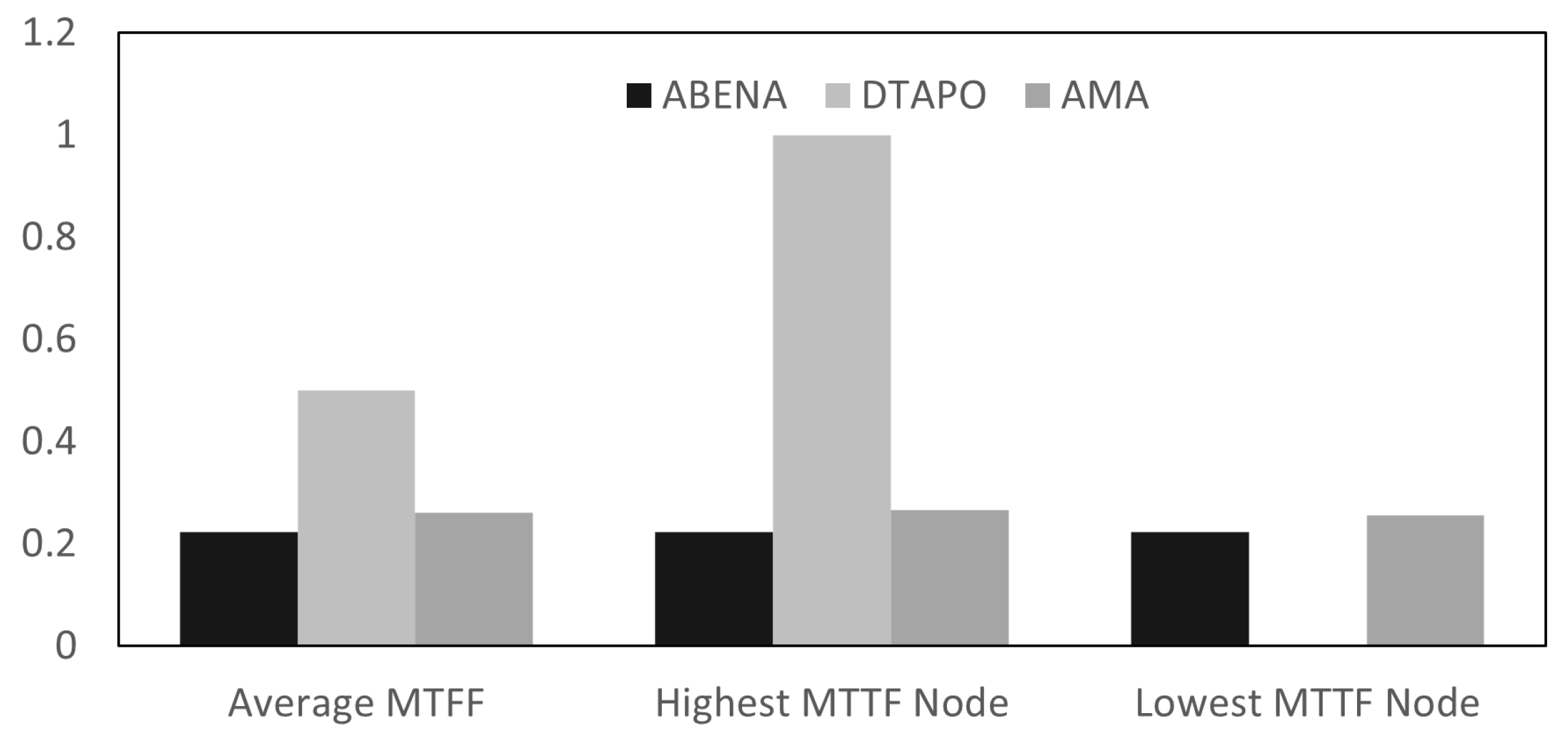
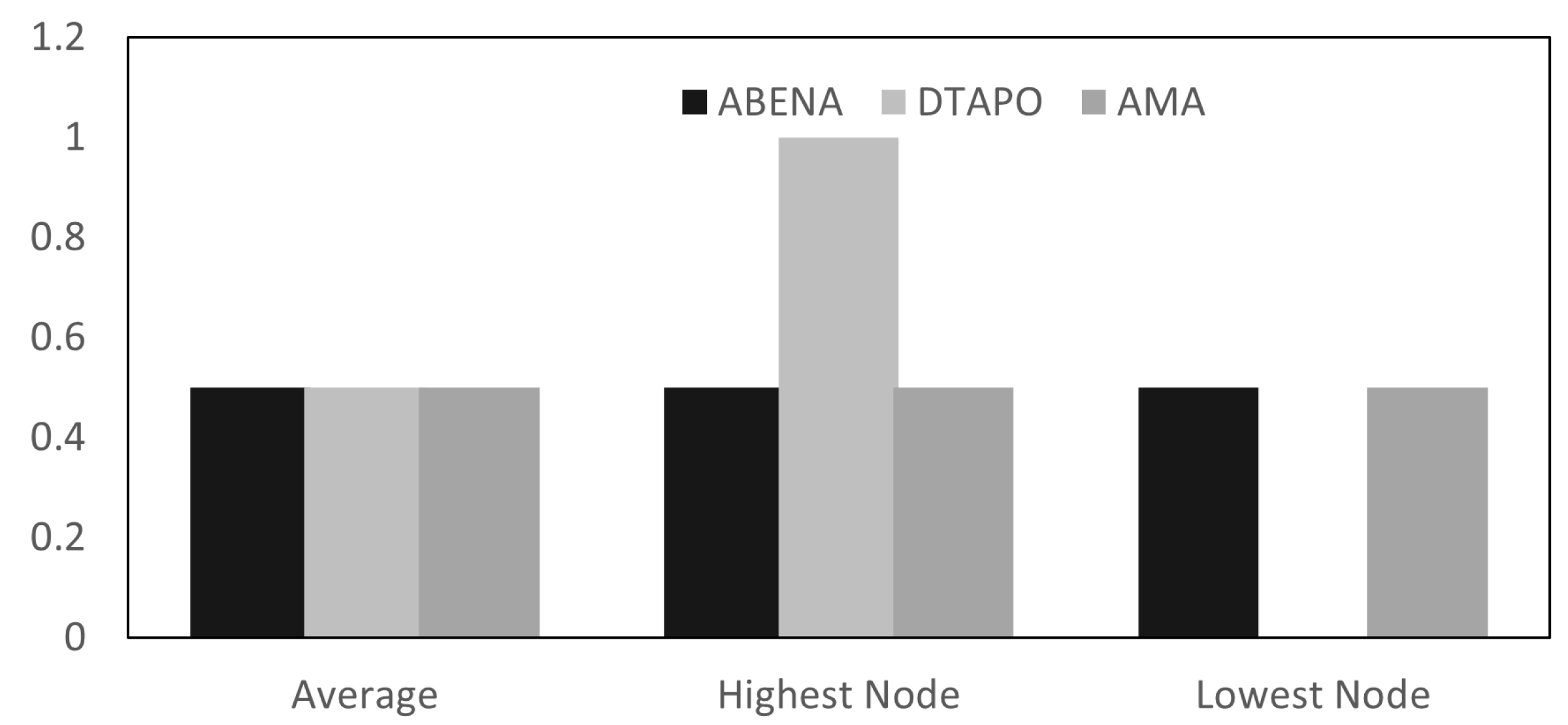
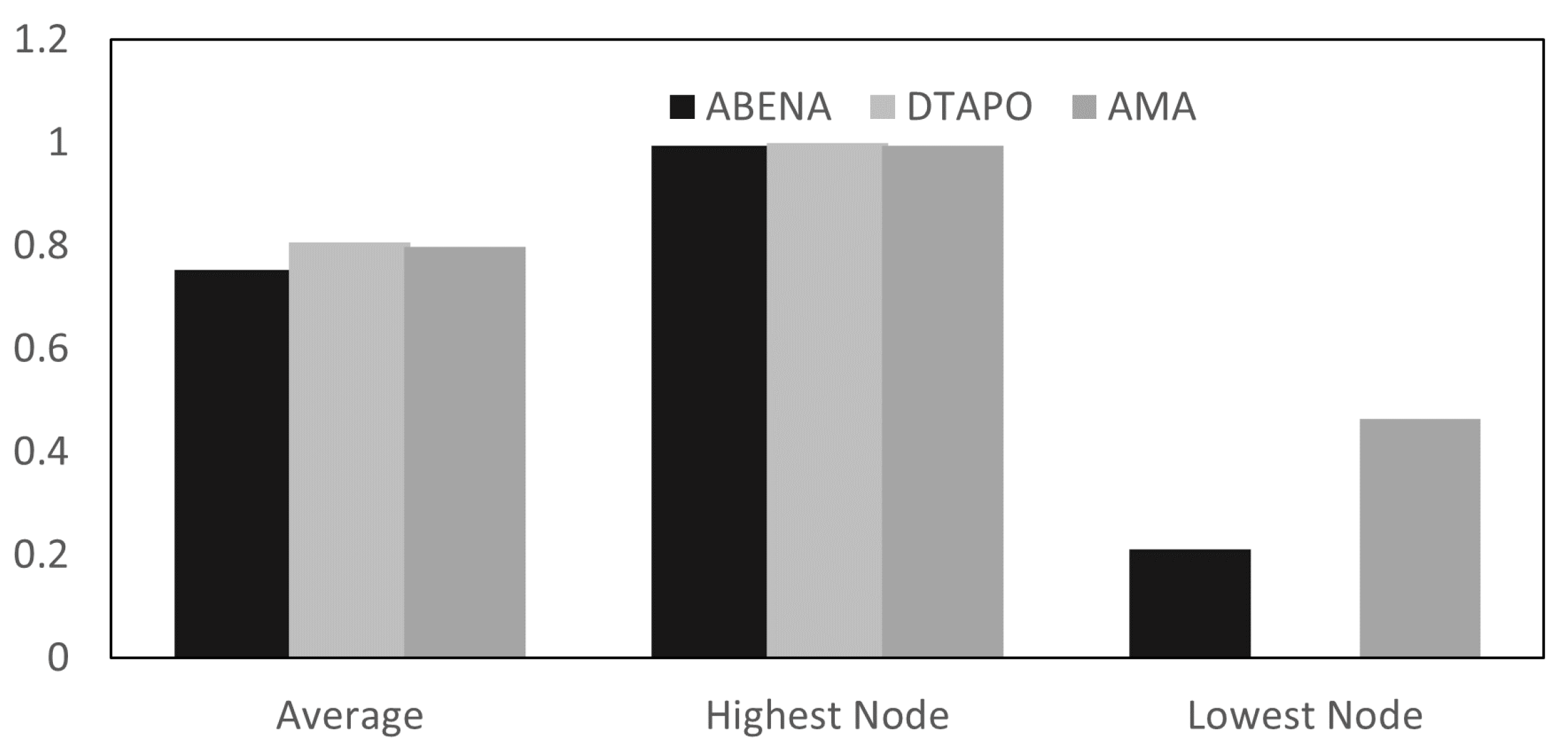
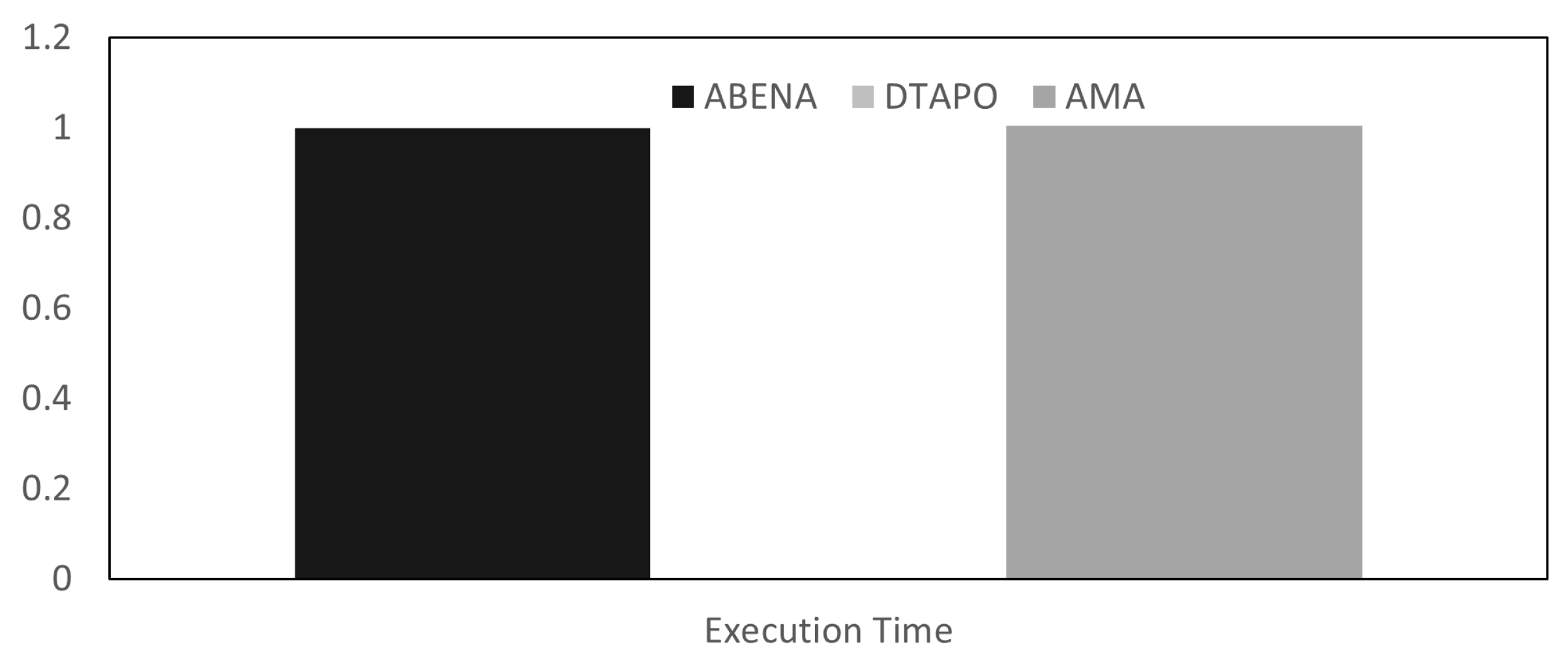
In this paper, we presented AMA, an Ageing Task Migration Aware for High-Performance Computing algorithm to improve the lifetime of nodes, temperature, and utilisation. Simulation results show that the proposed algorithm outperforms the existing technique. AMA maps tasks with high utilisation amongst nodes to avoid placing the burden on just a few specific nodes. Additionally, this improves the lifetime of the nodes when the nodes do not exceed the temperature cap. Moreover, the proposed framework outperforms DTaPO by more than 20% in MTFF. AMA also outperforms in terms of utilisation by more than 30%. Although this seems very insignificant, for a periodic workload system where applications are executed (10–20 epochs), the lifetime of each node is extended compared to other techniques. In future work, we plan to improve the MTTF of each node and also improve the execution time of AMA. Currently, DTaPO executes applications quicker than AMA.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}