1. Introduction
Artificial Intelligence (AI) has been used commonly to achieve tasks by mimicking human problem-solving skills, learning from given data, and utilizing the learned skills to process future missions. Artificial neural network (ANN) is a sub-category of AI, which is used to solve applications that are difficult to be reached by the traditional problem-solving algorithm by leveraging approximation theorem. Thanks to the development of VLSI and Moore’s law, the hardware resources make ANN possible to develop and become more complicated and powerful. This intricate, multiple-layered ANN is called deep learning neural network (DNN). DNN utilizes big data as the training source to generate a complex model for individual applications. Convolution neural network (CNN), a kind of DNN that mainly targets image-related processing, has shown its capability as it outperformed human ability regarding image object recognition [
1].
CNN is commonly used by AI frameworks such as TensorFlow and Caffe in data center platforms. The platform typically runs on the central processing unit (CPU) and graphic processing unit (GPU) to train the big data for future inference. The applications utilizing CNN, such as autonomous vehicles, image recognition door locks, wearable devices, robotics, and remote sensing satellites, are seeking to be addressed in the edge scenario. The requirements for edge scenarios are real-time processing, power consumption awareness, and device size limitation. These applications are not suitable to be covered by the general-purpose processor (GPP) and GPU. GPP and GPU are general-purpose designs for sequential works and graphic processing due to their non-size, non-energy, and non-computation efficiency.
Hence, edge-cloud coordination is proposed, which utilizes connections (e.g., the internet) to connect the cloud server and edge sensors to distribute the processing load and balance the system size. In this technique, the sensors collect and transfer the data to the cloud server for inference, which cleverly eliminates the computing load from the edge device. However, edge-cloud coordination technology has its downside for real-time applications. The edge-cloud coordination system, which utilizes the protocol that transfers the collected data back to the cloud server and gets the inference result back for a response, demands an internet connection and cannot run in areas without network coverage. Furthermore, while data privacy and security are an issue to be reckoned with (e.g., applying to face door locker), the edge-cloud coordination system shows the disadvantages. The edge-cloud coordination system might pay the penalty for the real-time computation due to the communication latency, which is not ideal for real-time devices (e.g., surveillance drones).
As a result, edge AI accelerators are proposed to target edge AI devices to meet the unique edge scenario’s requirements. Edge AI systems can be generally divided into two categories, power-size sensitive (PSS) and non-power-size sensitive (NPSS). Non-power-size sensitive edge AI systems include unmanned shops, surveillance systems, etc. These systems acquire power through fixed power supply facilities with a relatively extensive area to locate. Hence, NPSS systems do not urgently care about power consumption and system size but tend to be aware of data privacy. As a result, some NPSS systems also avoid using edge-cloud coordination platforms.
This paper mainly targets PSS edge AI systems, but the proposed design can also be used on NPSS edge AI systems. Edge AI technology has the following advantages to deal with PSS and NPSS systems’ demands. The benefits of the edge AI technology are:
Edge AI can improve the user experience regarding real-time data processing when AI technology is applied near customers.
Edge AI utilizes customized dataflow to pursue the compact size and manages power consumption to meet the mobility and limited power source.
Edge AI can run without internet coverage to offer privacy using local processing.
Furthermore, numerous natural hazards applications have adopted and applied the edge AI system in several hard-to-reach fields, such as space or nuclear power stations. These deployment scenarios are more critical than usual consumer products. It has been seen that the usage of robotics deals with the radiation leakage of nuclear power stations [
2] and remote sensing satellites in space [
3]. Devices that work in these fields should have the self-fault elimination ability to tolerate the radiation since these critical environments can cause a system failure. As a result, edge AI devices targeting hard-to-reach environments should meet the abovementioned requirements and demonstrate fault tolerance to guarantee reliability.
Regarding fault tolerance, a technique called dynamic reconfiguration plays a vital role, and is leveraged in the design to bypass the faulty modules. Overall, the PSS edge AI systems targeting hard-to-reach fields require the following conditions: (I) Size limitation, (II) Power source limitation, (III) Real-time and no internet coverage, and (IV) Fault tolerance. Conditions (I) to (III) are the three key features of edge AI accelerators.
This paper mainly targets designing a competitive convolution engine module for edge AI accelerators to meet conditions (I) to (IV). A convolution engine is an essential module in an edge AI accelerator system and contains control units, convolution engines, memories, etc. In order to provide a convolution engine architecture for a PSS edge AI accelerator to meet the designing trend, we did an investigation [
4], an algorithm pilot study [
5], and a trial study [
6]. The introduction of the three preliminary studies is described in three paragraphs below. The paragraphs clarify what has been done and the contribution of this paper.
The refine content of [
4] added two recent state-of-the-art works, which will be disclosed in
Section 2, design trend of edge AI accelerators. The investigation shows that the low-power ultra-small (LPUS) edge AI accelerators fall into the same scope regarding the three key features, which are said to be hundreds of Giga operation per second (GOPs) ability, with less than 10 mm
2, and below a watt power consumption. This LPUS scope is the scenario for this paper. Several state-of-the-art works [
7,
8,
9] show that an efficient dataflow architecture can reduce an accelerator’s area size and power consumption. Du et al. [
7] use dataflow-aware architecture in the convolution engine to meet the area and power consumption limitation for the PSS edge AI accelerators. Since a convolution engine plays a primary role in an edge accelerator, we decided to design a dataflow-aware oriental architecture. Because the work [
7] stands out in the PSS edge AI scope (LPUS scope) and has been commercialized [
4], this paper uses [
7] as a cross-reference to evaluate the proposed convolution engine architecture within the LPUS scope containing [
7,
8,
10,
11]. The detail of why this work chose [
7] as a ‘targeting reference’ among state-of-the-art works will be refined in the trend of the design chapter.
After a scenario scope and reference target have been set, the following task is the dataflow of the mapping algorithm pilot study [
5], which has shown a competitive result. A convolution engine should be able to process the images or data with different CNN algorithm variables, such as filter size or stride.
After the algorithm has been designed, a preliminary showing the idea of the hardware, the trial study [
6] implements a 48-processing element array of the convolution engine, a smaller scale of a complete size design in this paper without an adder module. The trial study mainly evaluates the reconfiguration bus within the PE array and shows the potential ability to compete with a scale-down PE array of [
7] in terms of power and area size. However, they do not include the adder module, an essential component in a convolution engine, and do not set any clock constraints, which makes the synthesis result different from this paper.
As a result, to give a full size of the convolution engine architecture, this paper completes the full-sized dynamic reconfigurable column streaming-based convolution engine (DycSe) with a reconfigurable adder module. It shows its competitive resource usage and power consumption results with fault tolerance ability on the field programmable gate array (FPGA) tool for prototyping. Due to the fast implementation feature of FPGA in the earlier stage of an application-specific integrated circuit (ASIC) or intelligent property core (IP core) design, FPGA is an excellent platform for structure evaluation. As a result, this paper utilizes FPGA for prototyping our IP core but does not intend to design a pure FPGA-based product. To meet the scope of the PSS edge AI accelerators, we put DycSe and the targeting reference [
7]’s convolution engine architecture on the FPGA synthesis tool Xilinx Vivado for a fair comparison as a cross-reference within the LPUS scope.
The detail of this paper is organized as follows.
Section 2 introduces the design trend of edge AI accelerators and describes why the work [
7] is chosen as a targeting reference in competitive state-of-the-art works.
Section 3 gives essential background knowledge of convolution neural networks.
Section 4 explains the column streaming-based mapping algorithm. The subsections contain convolution computation mapping strategy, mapping strategy comparison, and mapping methods/varieties for flexibility.
Section 5 releases the architecture design, which includes the processing elements, programmable Bus, reconfigurable adder module, and their connections. System verification and experiment results are analyzed in
Section 6. Finally,
Section 7 summarizes the conclusion and gives out future work.
2. Design Trend of Edge AI Accelerators
Several recently released academic/commercial edge AI accelerators, such as [
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22], are proposed to meet the compact size, low-power consumption, and high computation ability for edge devices. According to [
4], LPUS edge AI accelerators should consume power in the order of hundreds of mWs, operate with hundreds of GOPs, and occupy under unit-mm
2 area size. The state-of-the-art edge AI accelerators in this scope are [
7,
8,
10,
11], as shown in
Table 1, which refines from [
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22].
Table 1 introduces the three features: computation ability, power consumption, and the area size of the edge AI accelerators. Although the computation abilities of the accelerators [
9,
22] are under hundreds of GOPs, they contain relatively lower power consumption. As a result, they are worth to be mentioned in the LPUS edge AI accelerator category in a broad sense. Evaluation value
E was introduced by [
4] and can be defined as (1). In (1),
cFixed16 represents the computation ability of an edge AI accelerator with 16 fixed-point precision, and its unit is Giga operation per second (GOPs). On the other hand, the
p and
s represent power consumption in W and area size in mm
2, respectively.
As mentioned, state-of-the-art works [
7,
8,
10,
11] fall in the LPUS consumption scope, and three of them [
7,
8,
9] use the streaming/systolic technique, which shows that streaming/systolic architecture in implementing edge AI accelerators proves its efficiency regarding the three features. Furthermore, Du et al. [
7] have been commercialized and utilized in a face recognition door lock system powered by batteries; this proves that the streaming dataflow technique is competitive for a convolution engine. Inspired by the streaming approach of [
7] and the coarse-grain reconfigurable array design of [
8], DycSe is designed to tolerate a certain degree of permanent faults.
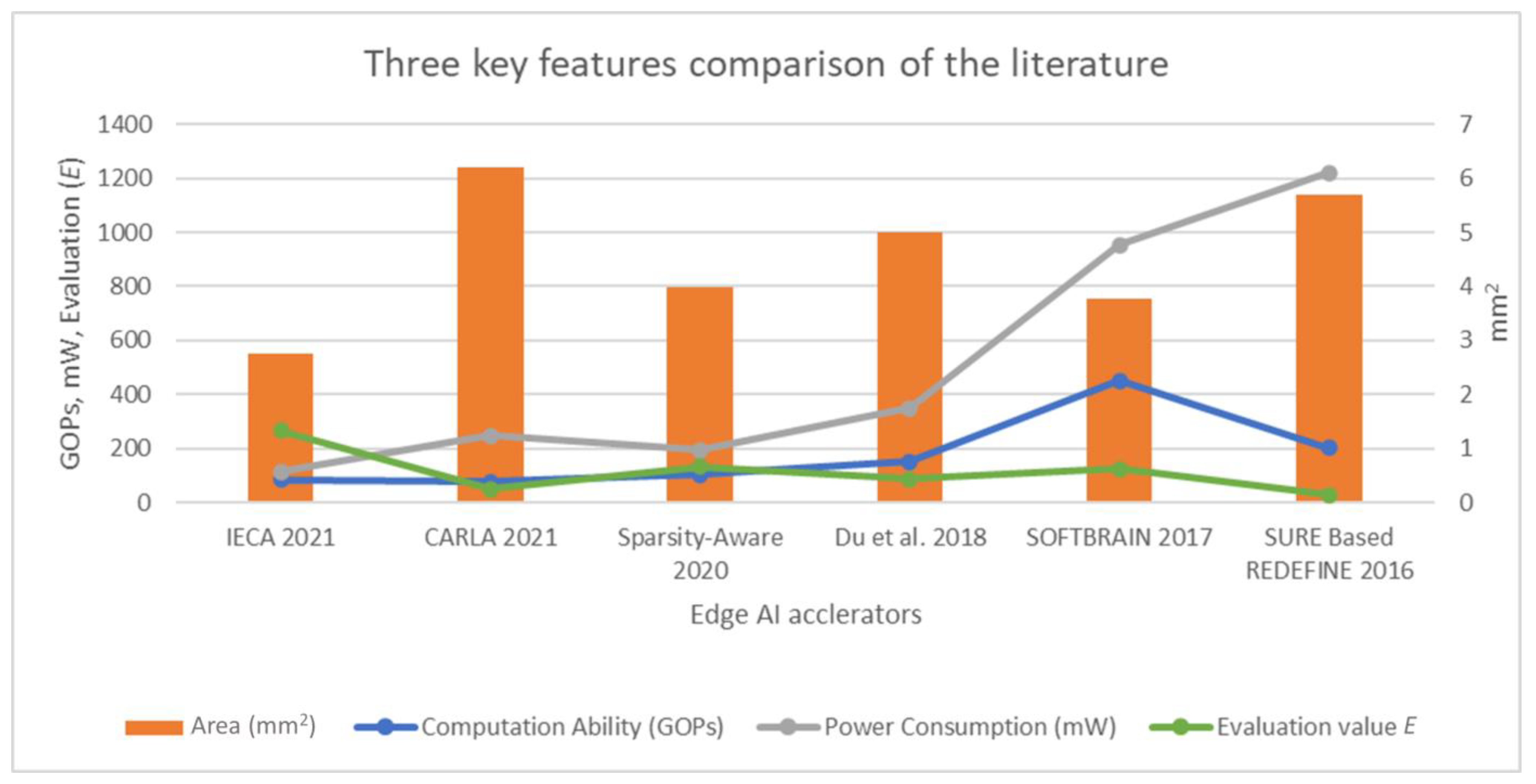
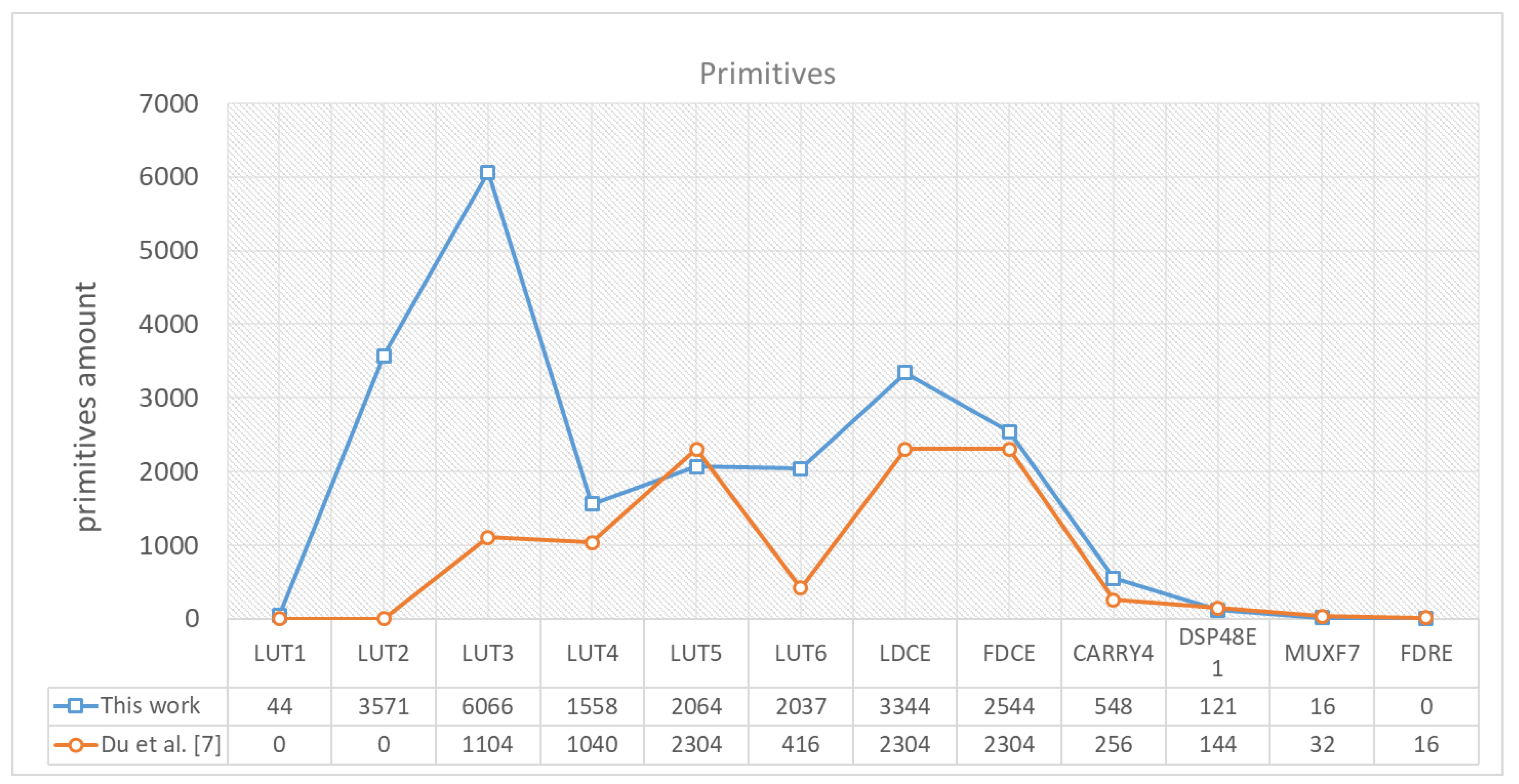
To make the comparison in the specifications of the collected edge AI accelerators falling in the LPUS consumption scope clearer,
Figure 1 illustrates the three key features with the evaluation
E in a line-column chart.
Figure 1 shows that [
8,
10] contain relatively higher power consumption than others, while the design computation of [
9,
22] is relatively lower. Hence, Sparsity-Aware [
11] and Du et al. [
7] are the two edge AI accelerators performing more balance in terms of the three key features within the LPUS scope. Furthermore, we also need to be aware that although Sparsity-Aware [
11] seems to have the best general performance in the scope, its ASIC design technology is also the smallest, making the general performance better beyond just the architecture design. Since the design in this work targets the convolution engine, which is a component in the whole edge AI system, it is hard to release the three key features in the final ASIC encapsulation form of an IP core. Hence, this work uses a cross-reference [
7] to prove that the proposed convolution engine architecture can potentially be integrated into an edge AI accelerator without making the whole system’s performance worse than [
7], which has a similar standard with all the arts [
7,
8,
10,
11] listed in the scope.
3. Convolution Neural Networks Layers
The convolution function is applied in the convolution layer to calculate the inner product of the input features and weight filters. This process can be understood as mapping the input or previous layer’s features to the next layer according to the emphasized features. At the beginning of the convolution computation, the feature detectors (a set of weight filters) generate the output features of a 2D input image. The output features become the following layer’s input features. Each layer can have multiple input feature channels, such as the RGB color channel, so that the convolution features can be realized as 3D data sets. The convolution output data is obtained by computing the inner product of the filter weight and the part of the input feature masked by the filter.
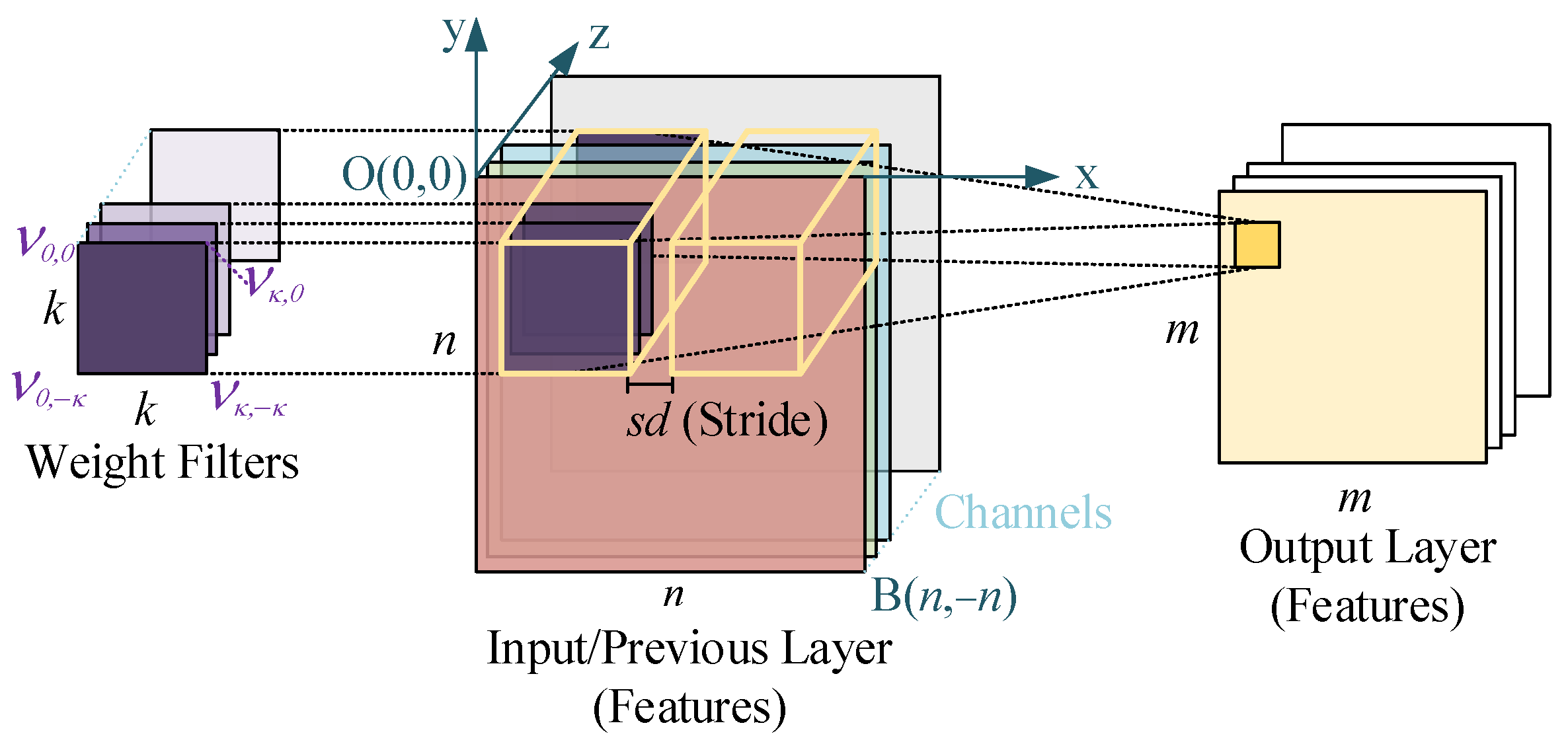
Figure 2 shows an example of a convolution layer. In
Figure 2,
k represents a weight filter’s height and width, known as the kernel size. Variable
n represents the input layer’s height and width, and
m represents the output layer’s height and width. We set a Cartesian coordinate system on the input features to clearly show them. Let
be the origin, and each input feature’s height and width are
n, so point B locates at
. At the beginning of the convolution computation, the weight filter’s point ν
0,0 is located at O(0,0), so ν
0,0 is mapped to
V(α, β), α = β = 0, in the input feature’s coordinate system. Stride
sd means the distance that a weight filter would move from the last location
V(α, β) to its new location
V(α′, β′), which can be realized in
Figure 3. When it comes to the output layer, its height and width are
m, which can be obtained by (2).
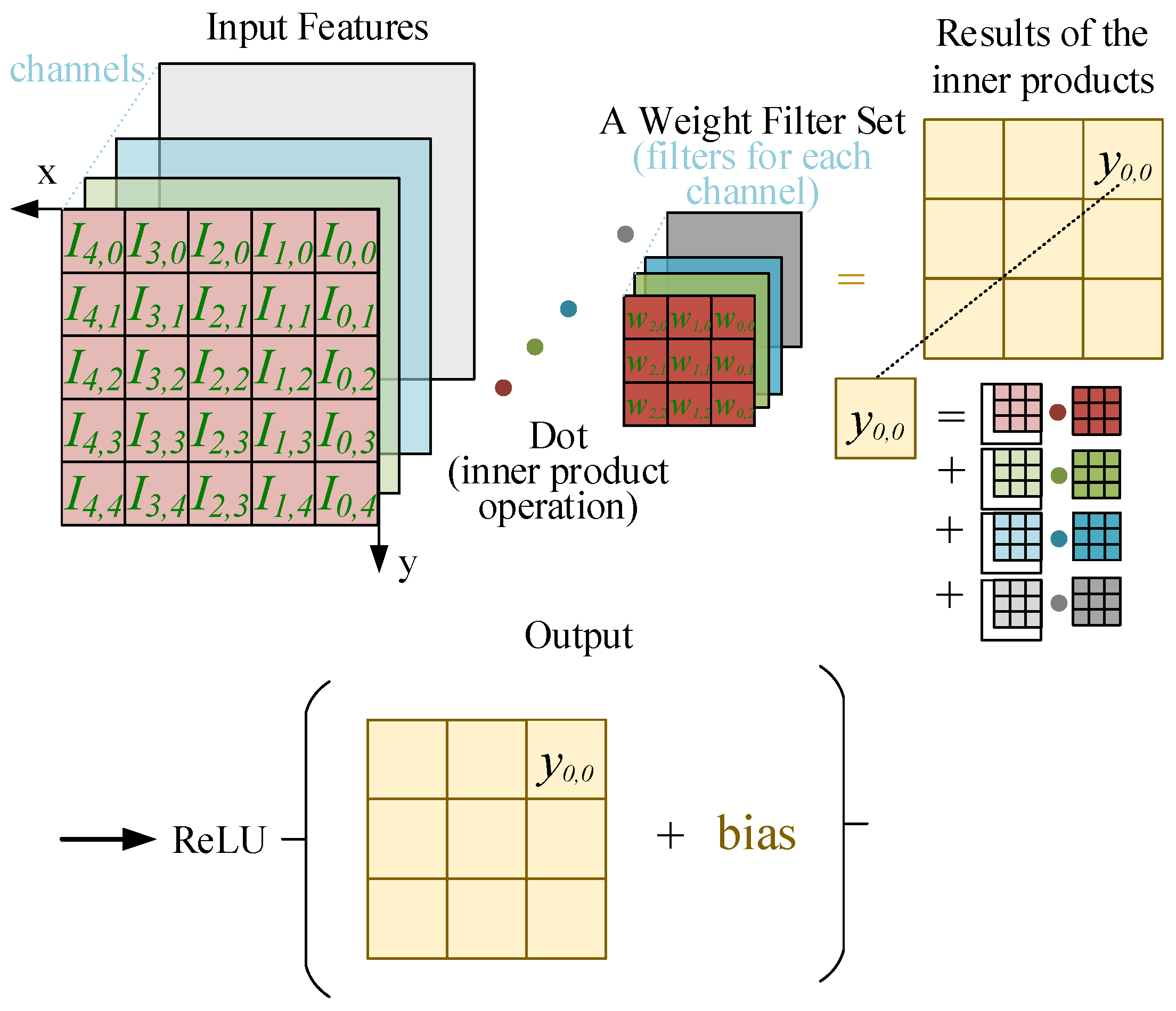
After specifying the variables and their relationships in a convolution layer, we can discuss how a convolution layer can be achieved in computing. The convolution computation of input features and weights obtains an output feature in an output layer.
Figure 4 shows the detail of a convolution computation. In
Figure 4, we flip the
x- and
y-axis (x increases to the west; y increases to the south) compared to
Figure 3, without the loss of generality. The rest of the paper uses the reversed axes system to represent the convolution computation.
Convolution computation can be seen as a filter scanning through an input layer according to the stride size to generate and direct the result to an activation function with an extra bias. The overlapping input feature’s pixel and weights in the weight filter during the scanning should do the inner product, as shown in
Figure 4. Each output feature is obtained by summating the inner products produced by each input feature and weight filter. After the sum is received, an additional bias weight is added to each summed result, followed by applying the final result to an activation function ReLU.
4. Column Streaming-Based Mapping Algorithm
According to our investigation and [
23], several kinds of reconfigurable strategies are used in these state-of-the-art accelerators [
7,
8,
11,
24,
25]. Among these accelerators, the reconfiguration of [
7,
11] is limited to dataflow, while Jiao et al. [
24] and Ryu et al. [
25] target word size type reconfiguration. SOFTBRAIN [
8] utilized a coarse-grained cell array to compute the stream-dataflow DNN. Except for [
7,
11,
24,
25], only SOFTBRAIN [
8] falls into components or module reconfiguration (i.e., structure-wise reconfiguration). Du et al. [
7] and SOFTBRAIN [
8] adopt the competitive streaming architecture, as in
Table 1 and
Figure 1.
Hence, streaming architecture is chosen for DycSe to provide a convolution engine for edge AI accelerators. An edge AI accelerator requires processing AI algorithms (i.e., CNN in this paper). Since CNN algorithm is a general term for different CNN nets, which contain many different convolution layers, a convolution engine in an edge AI accelerator with the ability to adapt arbitrary weight filters is becoming essential. Structure-wise reconfiguration is proposed to offer the ability to process arbitrary weight filter size and the fault tolerance requirement (i.e., condition IV in chapter 1). Structure-wise reconfiguration includes hardware rearrangement through programmable connections, such as muxes or demuxes. Hence, it differs from a dataflow-wise reconfiguration such as the weight filter decomposition technique proposed by [
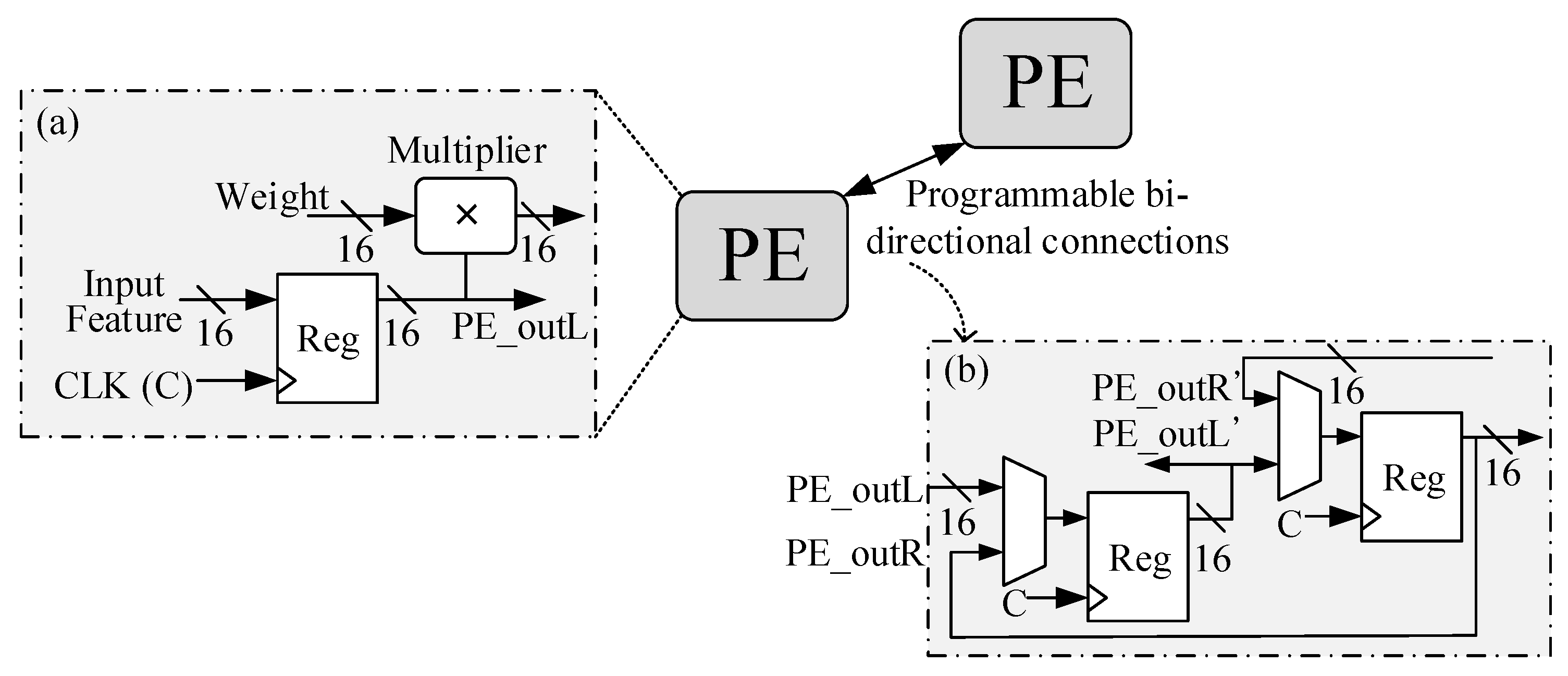
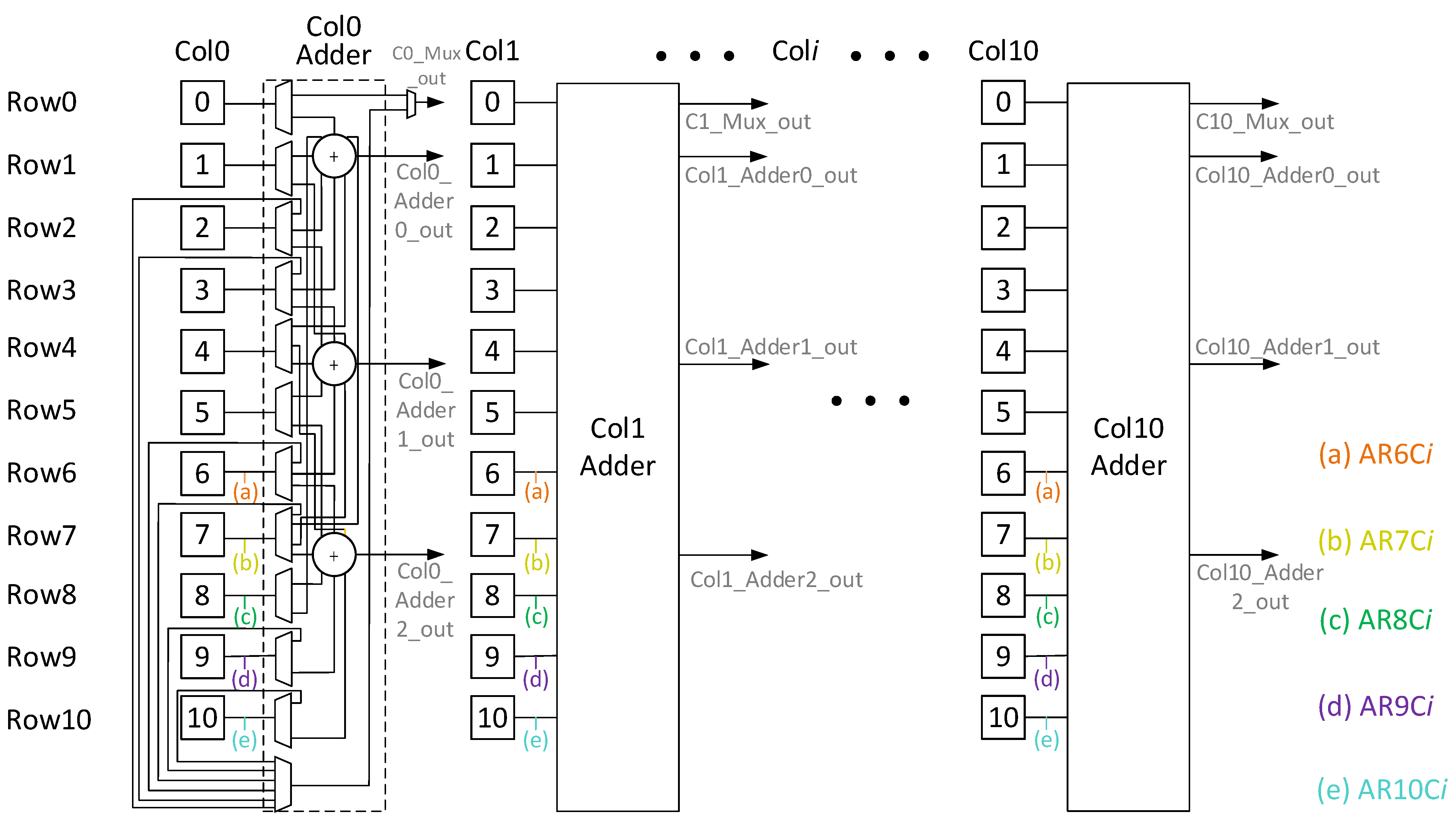
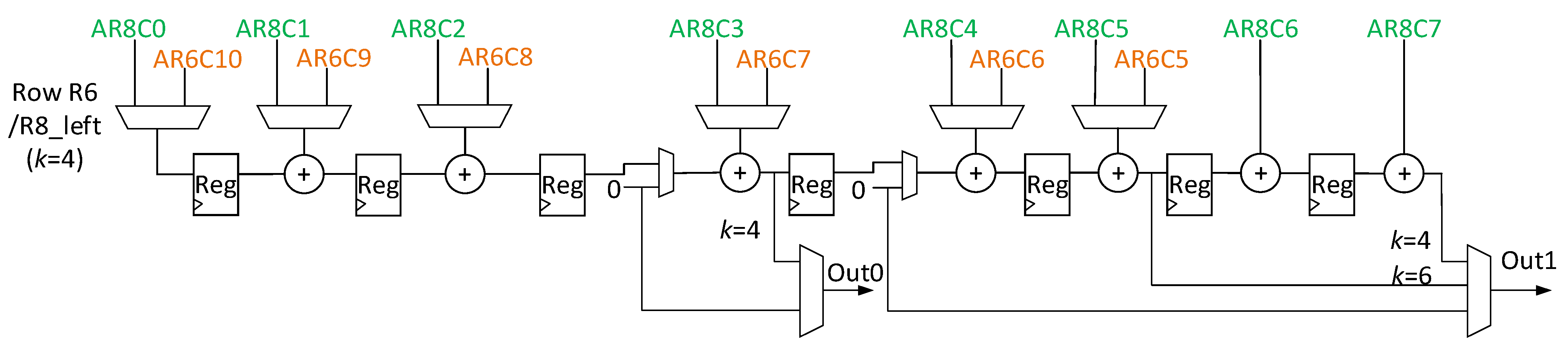
7]. The detail of the structure-wise reconfiguration is described in chapter 5.
Before designing a convolution engine structure, a hardware mapping algorithm should be created first, deciding the structure’s developing flexibility. Hence, a proper mapping algorithm for weight filters and input features to be mapped to the convolution engine architecture is discussed in this chapter.
Section 4.1 introduces the strategy, while
Section 4.2 examines the concept. Finally,
Section 4.3 releases all the mapping varieties categorized by mapping methods, which are represented by the notation
method, equal to 1 or 2.
4.1. Convolution Computation Mapping Strategy
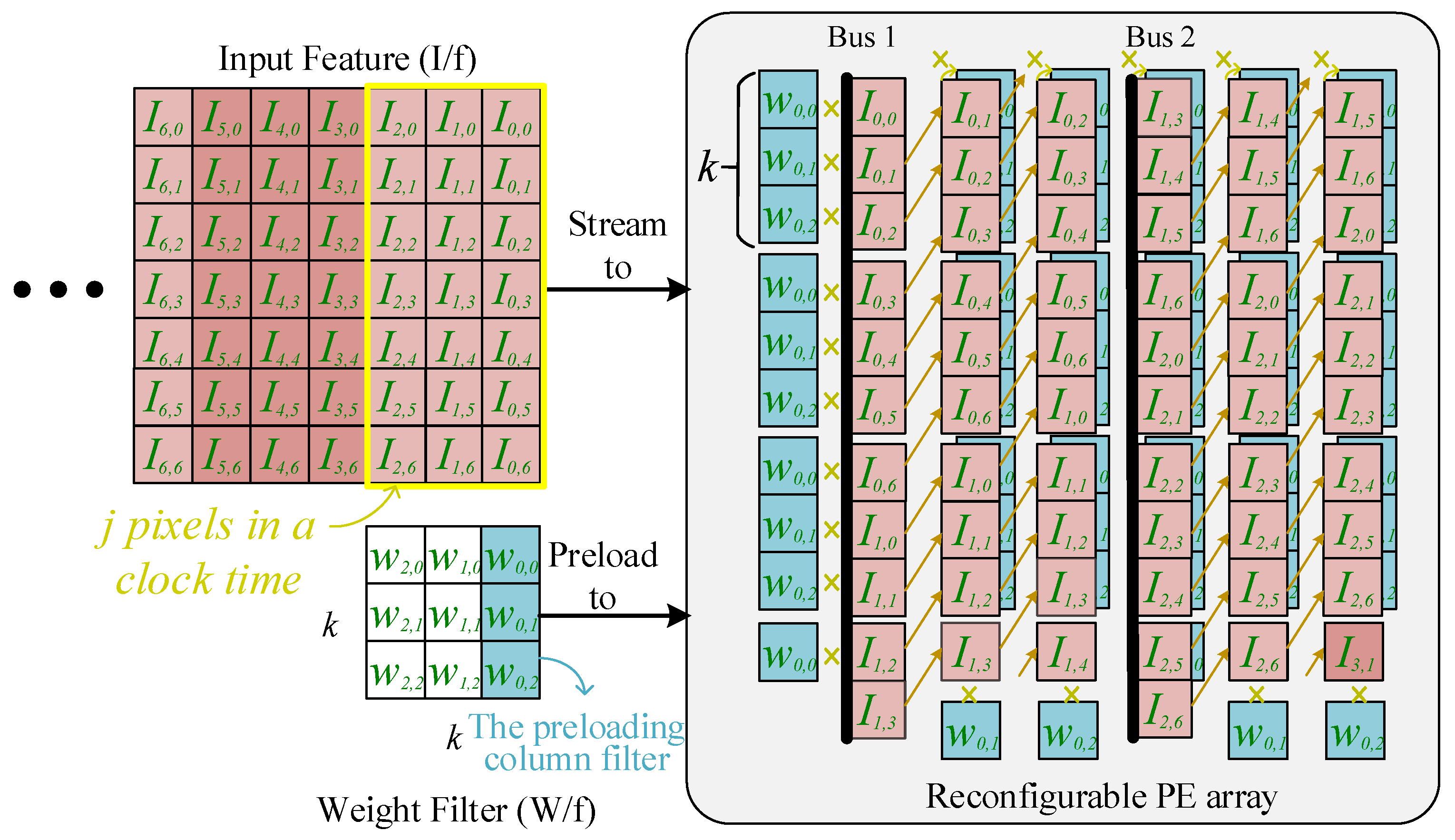
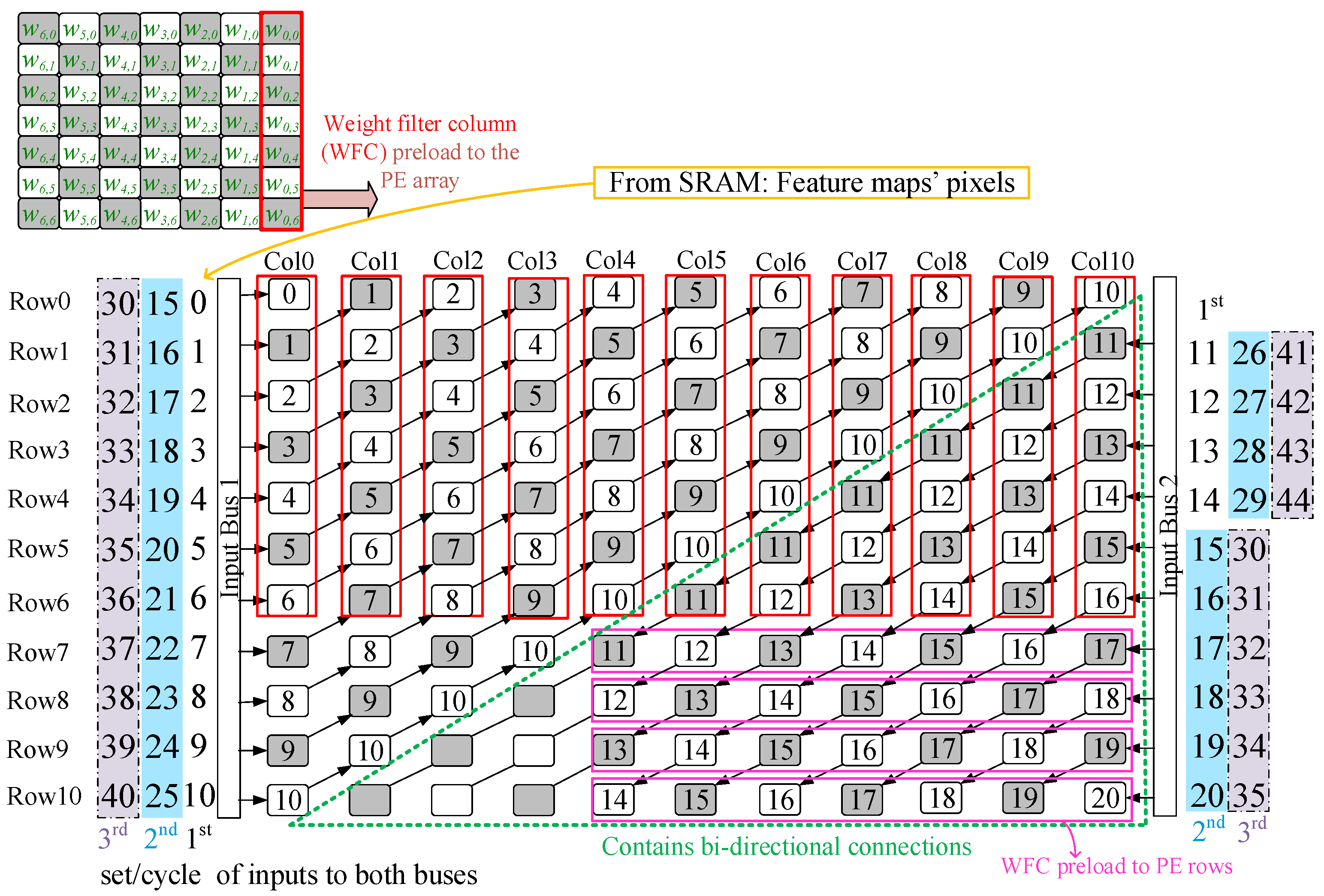
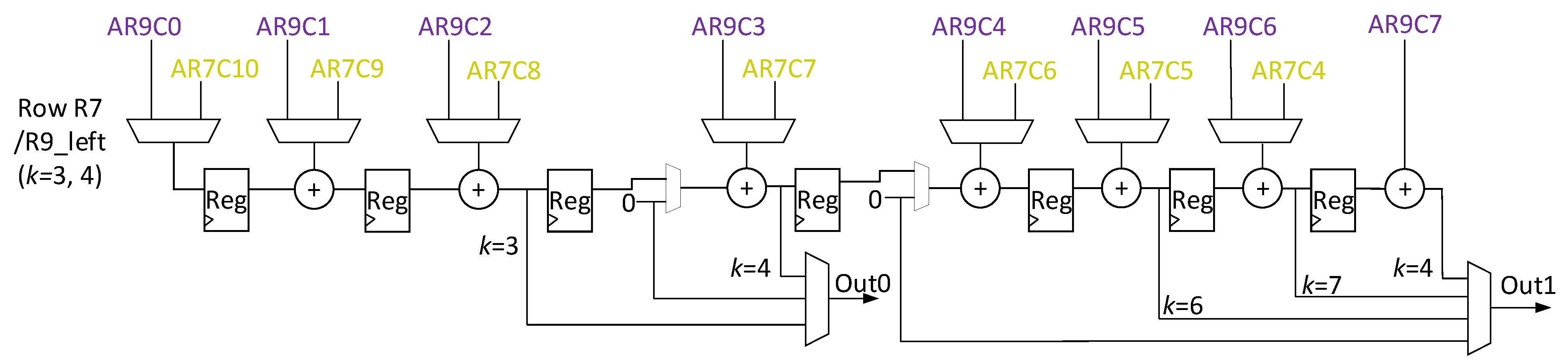
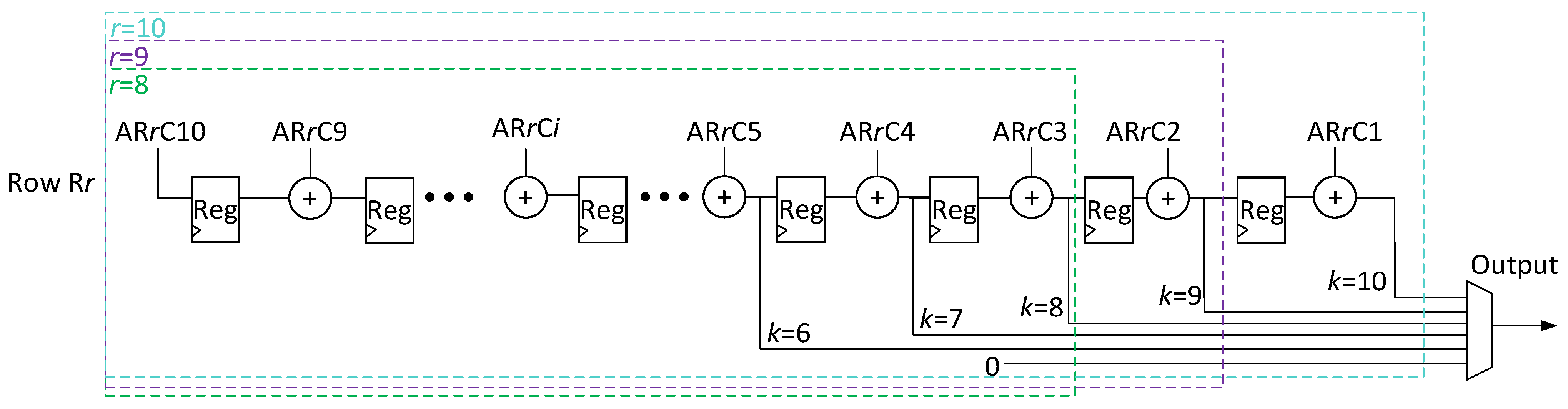
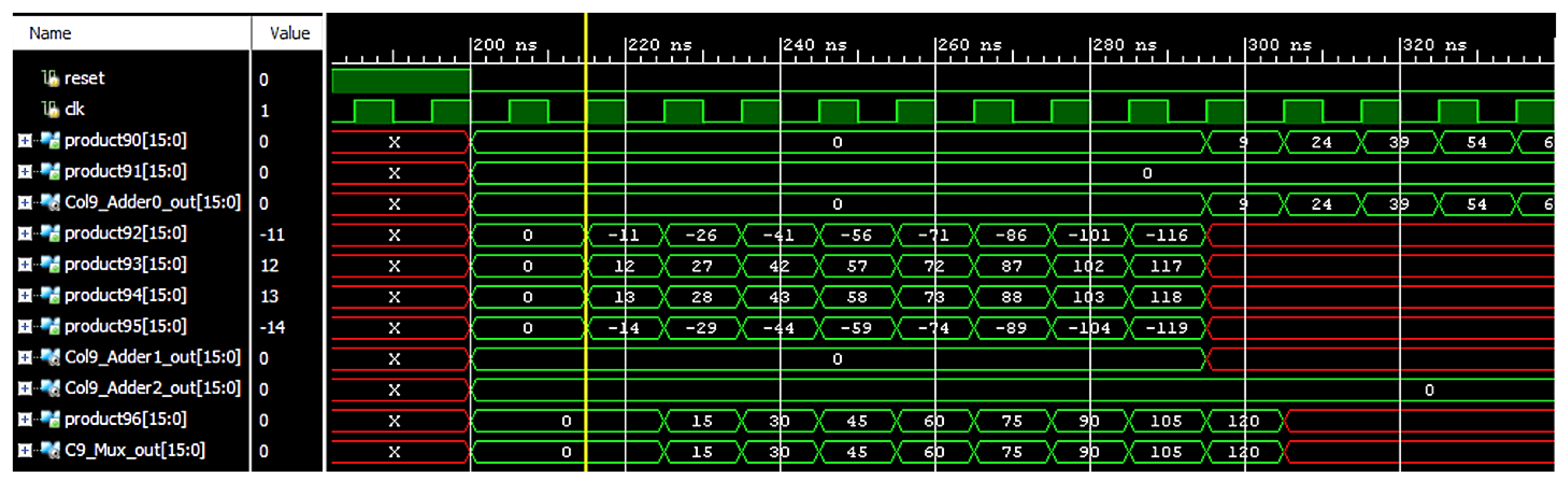
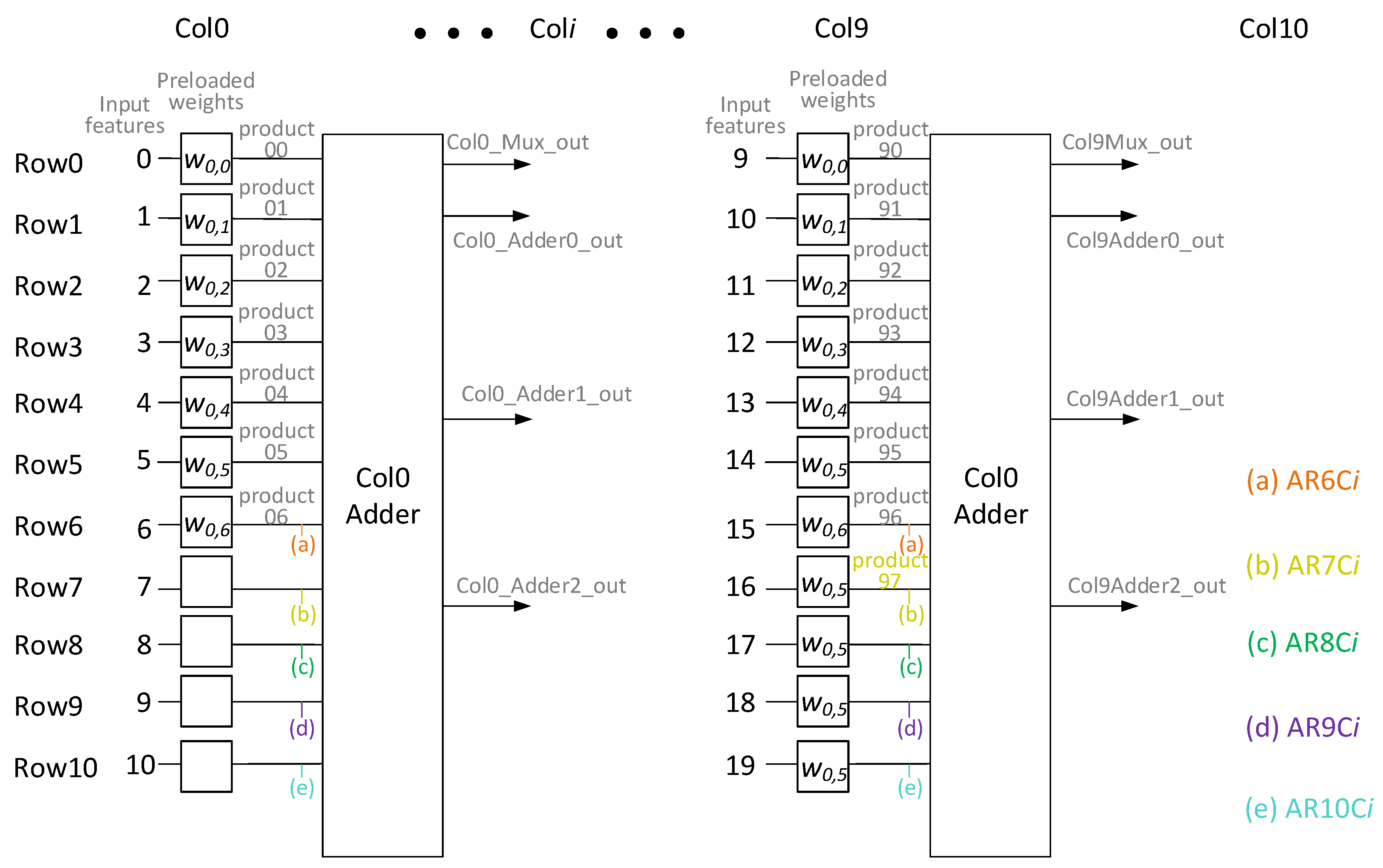
Figure 5 shows DycSe’s data mapping strategy for convolution computation, achieved by the column streaming methods.
Figure 5 is composed of three blocks, input features (I/f), weight filters (W/f), and the PE array (module), where the convolution computation executes; the weight values in the W/f block preload to the PE array in column form. The filter size decides the weight-mapped position and how the PE module is configured.
A
k ×
k-sized W/f is decomposed into
k columns. When
k = 3 in
Figure 5’s case, the first column, {
w0,0,
w0,1,
w0,2} in blue, preloads into the array, and the weight column stays in the PE array until the input feature data finishes the multiplication.
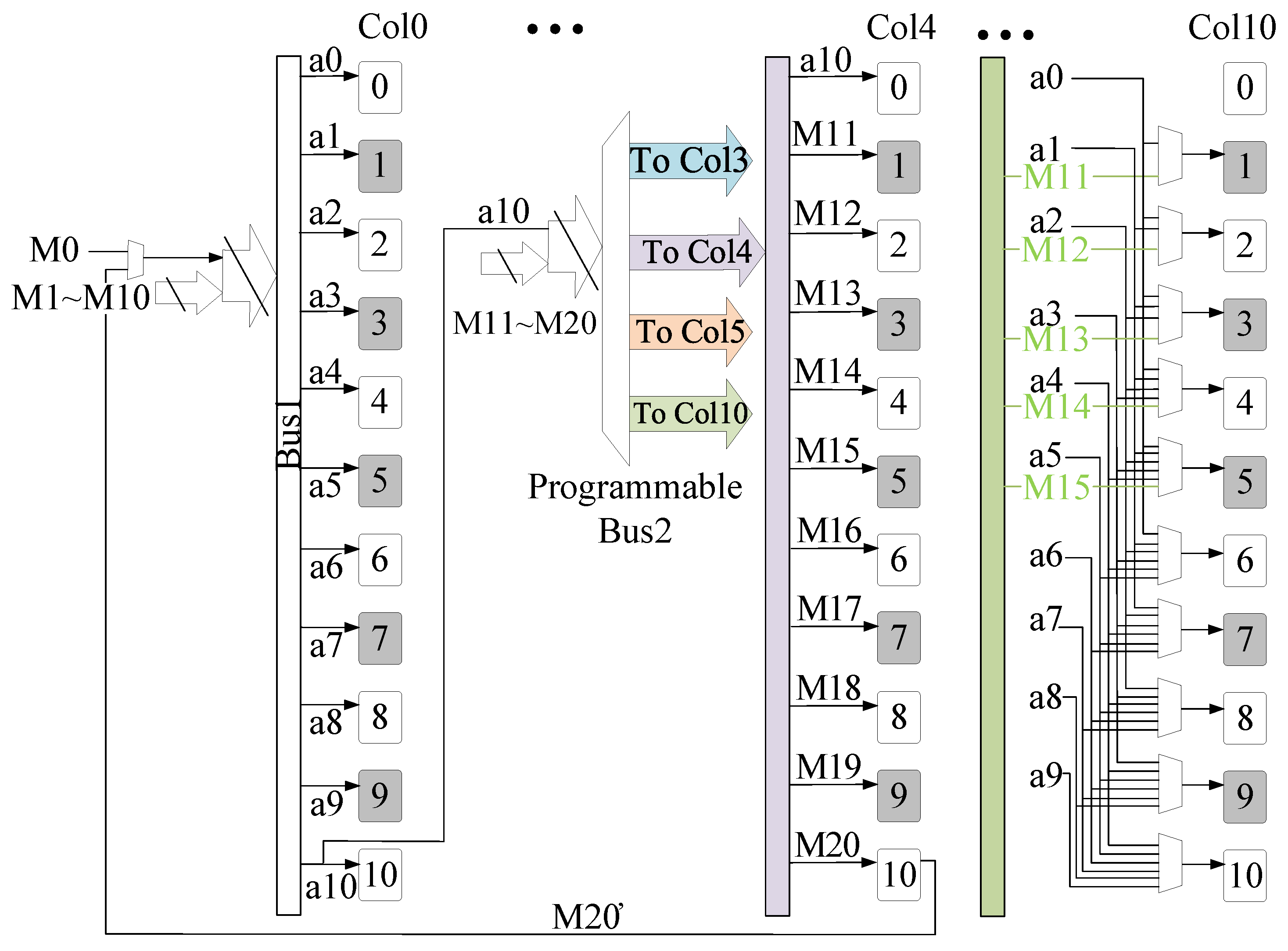
The input feature is decomposed into
j data (pixel) sets, and a data set is steamed into the PE array at each clock cycle. The variable
j is also decided by the mapping method that, according to the PE module reconfiguration, 𝑗 in
Figure 5 is 21. The 21 inputs of data are streamed into the PE array in two subsets, through Bus1 and Bus2. Variable
j can be obtained by using (3). In (3), variable
k represents the kernel size, variable
c represents the streaming data set, and variable
method represents the mapping methods. Variable
AH means PE array heights.
4.2. Mapping Strategy Comparison
For evaluating the column streaming-based convolution engine, we use MATLAB to count the execution cycles needed for DycSe and [
7] to compute a 227 × 227 size feature map in the pilot study [
5]. A 227 × 227 size feature map is the input size of AlexNet, one of the famous CNN.
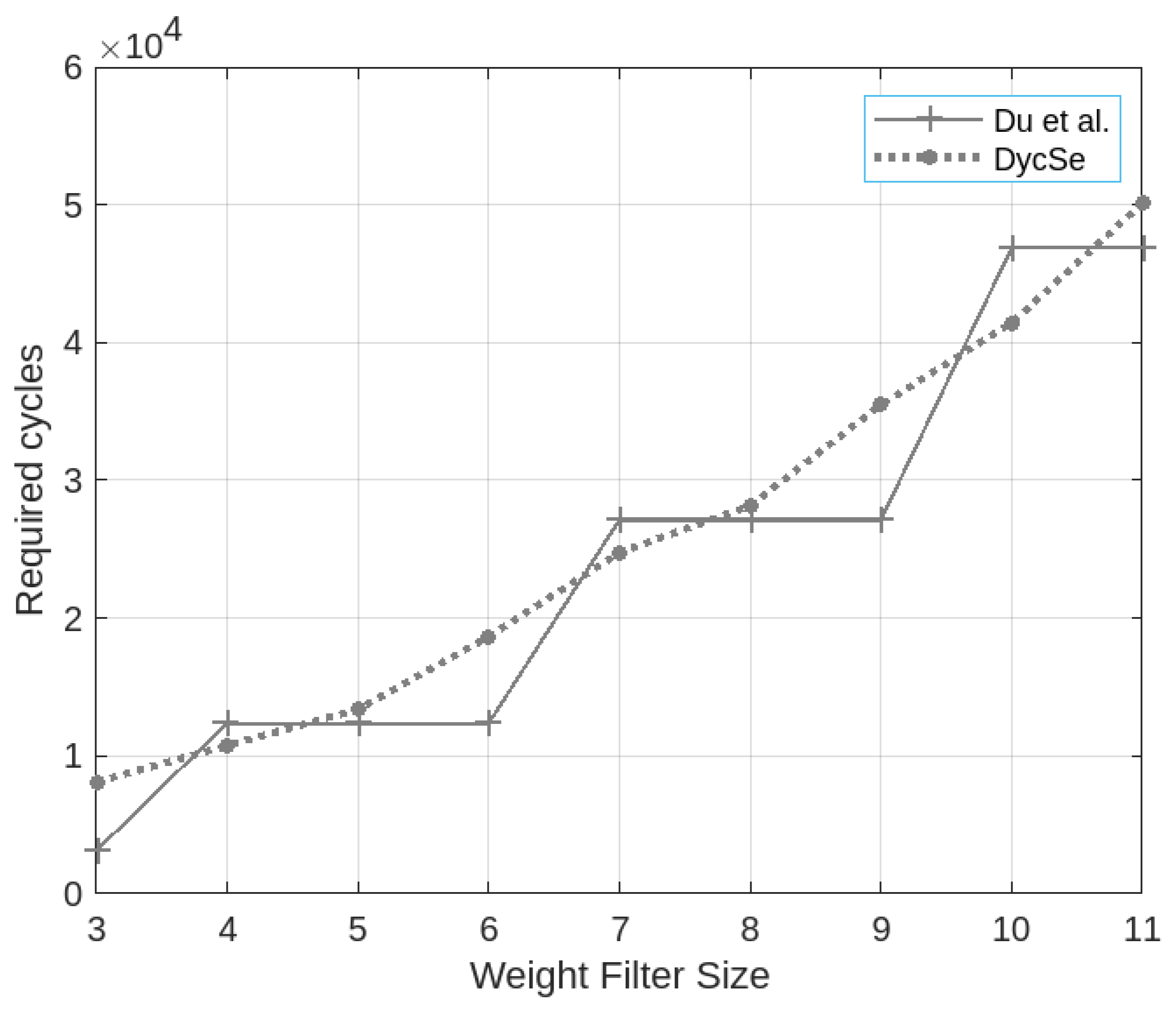
As shown in
Figure 6, the calculation result shows that the proposed convolution engine requires fewer cycles to compute the feature map when the weight filter size is equal to four, seven, and 10. When the weight filter size equals five and eight, the proposed convolution engine shares similar execution cycles. The proposed convolution engine needs more cycles to compute the operations when the weight filter size equals three, six, nine, and 11.
Figure 6 shows that the dash line, indicating the result of the algorithm adopted by DycSe, goes through the solid line Du et al. [
7]. The dash line looks like the regression line of the solid line because the column streaming algorithm [
5] tries to avoid the zero-padding boundary penalty of [
7].
After the LPUS scope has been decided, an efficient convolution engine structure is expected to be proposed by following the LPUS scope’s standard. The dataflow oriental structure is the DycSe’s core design idea, indicating that the input data, such as I/f and W/f, demand an algorithm to be mapped on the hardware. Since Du et al. [
7] share similar performance in the three key features within the LPUS scope accelerators, retaining the data processing cycles not worse than [
7] is the goal, making DycSe stand at the same level as the other architectures in the scope.
The column streaming algorithm [
5] tries to eliminate the zero-padding [
7] to reduce the cycles, which are only for passing through the data but are not used for computing the multiplication under specific filter sizes. The filter sizes require zero-paddings, which do not equal a multiple of three. When zero-padding is used, although the multiplier in the unused PE is turned off to avoid power consumption, the flip-flop in the PE is still working for streaming the data. The result also indicates that the worst penalties happen at the filter size, which equals
, which can be observed in
Figure 6.
4.3. Mapping Methods and Varieties for Flexibility
This section introduces the input feature and weight mapping strategy according to the different mapping varieties. In this section, there are two mapping methods (i.e.,
method = 1 and 2) introduced. Mapping
method = 1 contains several mapping varieties, while
method = 2 only has one. In
Section 4.3.1, we present how the input feature is streamed into the PE array and defines the Bus’s location. According to the input feature’s mapped location in the PE,
Section 4.3.2 introduces the preloaded weight’s mapping destinations.
4.3.1. Input Feature Mapping
Providing different mapping
varieties (
v) for particular-sized filters is the featured function of the proposed convolution engine. The mapping
varieties (
v) of filter size (
k ×
k),
can be found in (4). Each mapping variety is equivalent and can be regarded as each other’s substitution when some PEs fail. The upper bound of
k in a
w ×
h PE array is
h (in this paper,
w = 11,
h = 11), but the array can be flexibly enlarged and customized.
Table 2 lists all the possible mapping varieties and compares them to [
7].
According to the Bus2 location, we define two mapping methods,
method = 1 and 2. When
method = 1, Bus2 can locate at Col
i (
), by default
. Mapping
method = 1 can only be adopted when the filter
. Different from the case,
method = 1, generally for
, the case
method = 2 is also available for
when providing the PE array flexibility and reliability. Bus2 streams data to the rightest column, Col(
w − 1), when in
method = 2. For example,
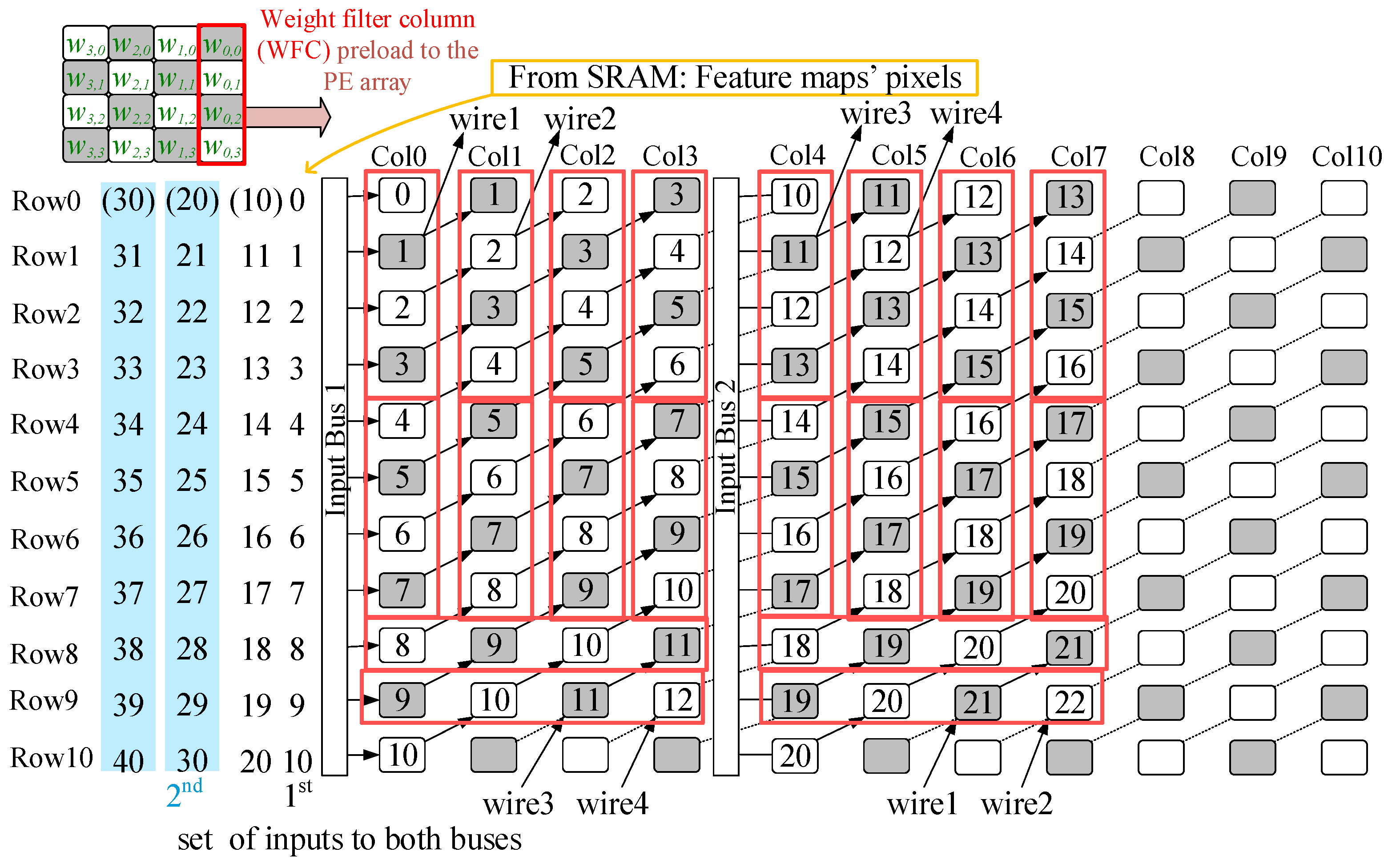
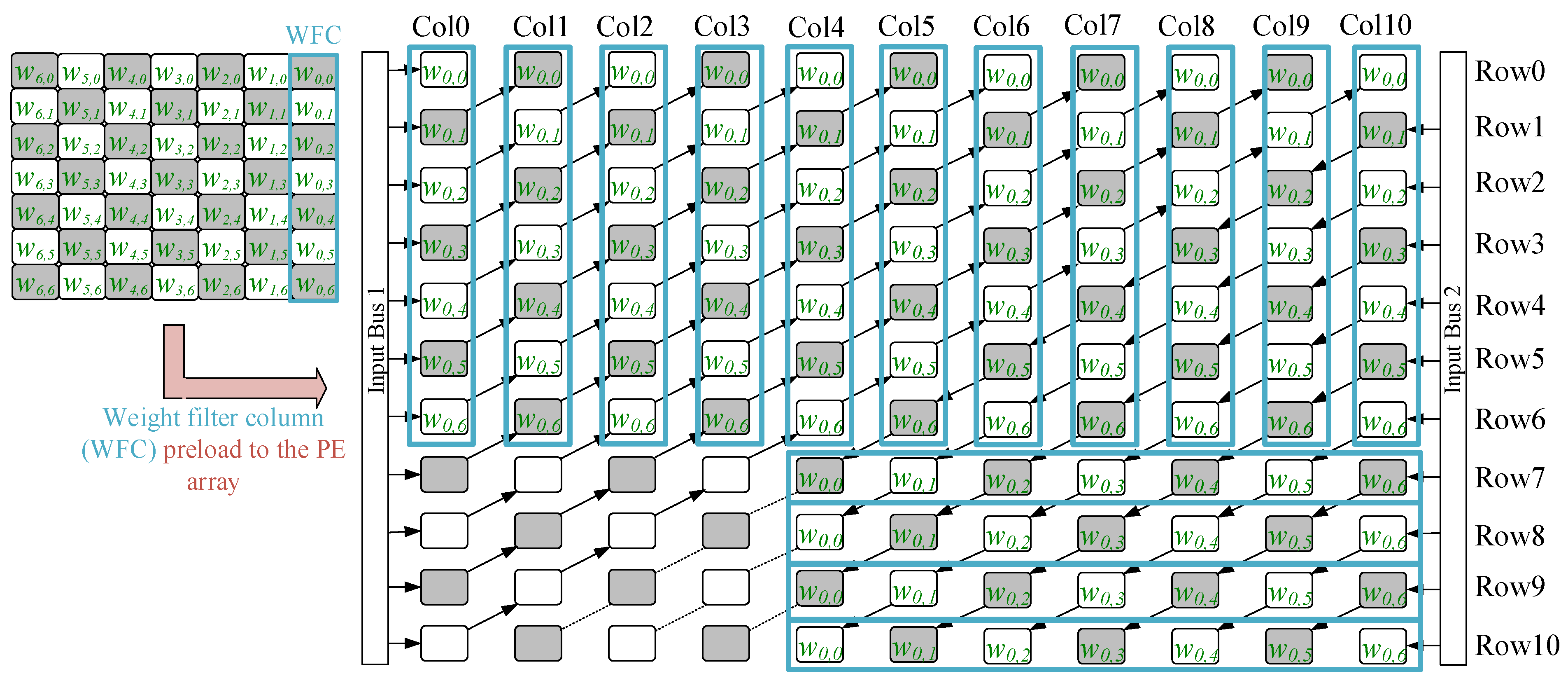
Figure 7 shows a 4 × 4-sized filter
method = 1, and Bus2 streams the data into Col4 (
i = 4). Bus2 can also pour data into Col5 (
i = 5) when a 4 × 4-sized filter uses the other mapping variety with
method = 1. On the other hand,
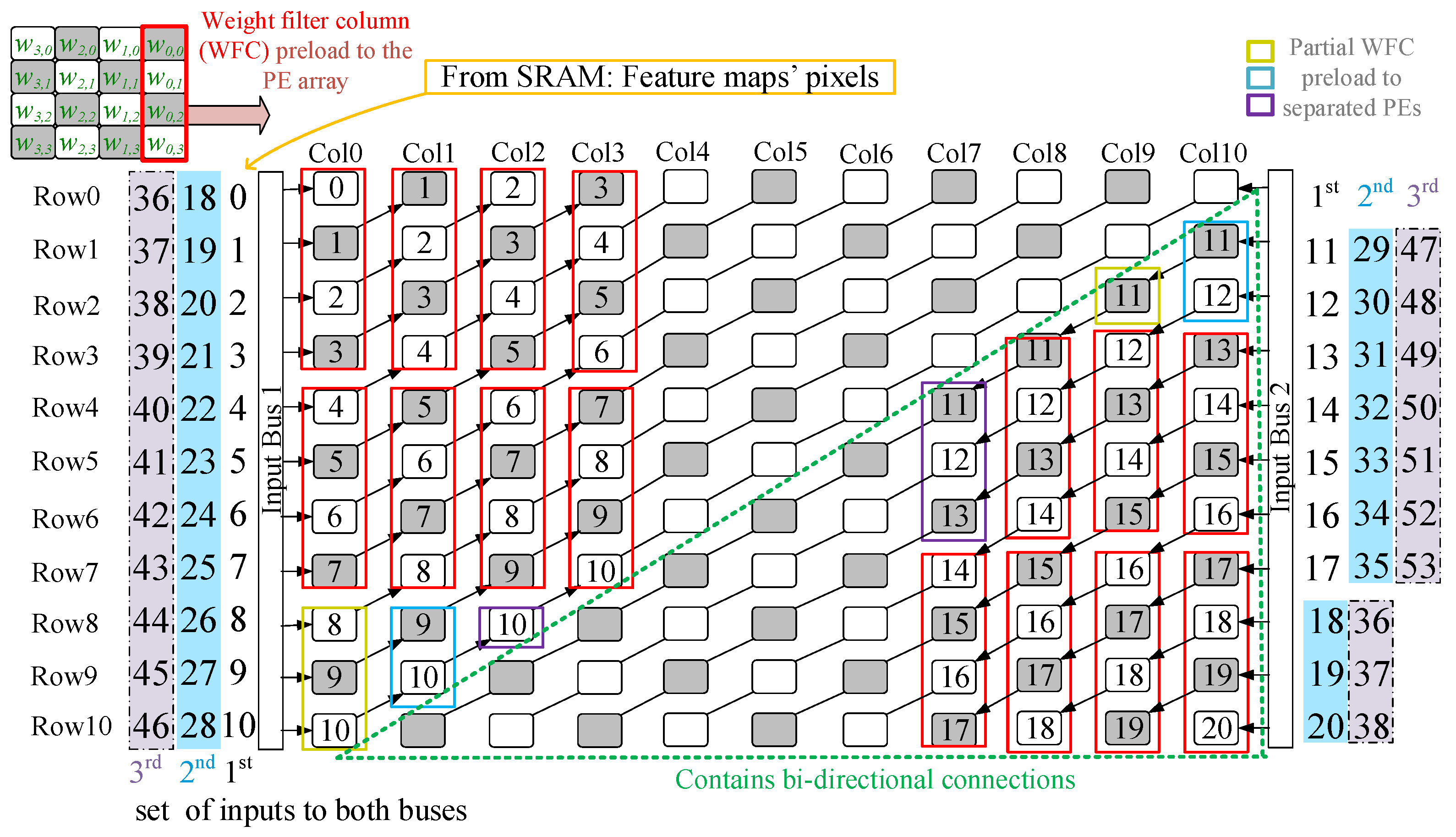
Figure 8 shows a 4 × 4-sized filter
method = 2, and Bus2 streams data into Col10 (
i = 10). The data from Col
i,
i = 10, is streamed to Col
j (0 <
j < 10) cycle by cycle. Overall, there are three mapping varieties (two types when
method = 1 and 1 type when
method = 2) for a 4 × 4-sized filter.
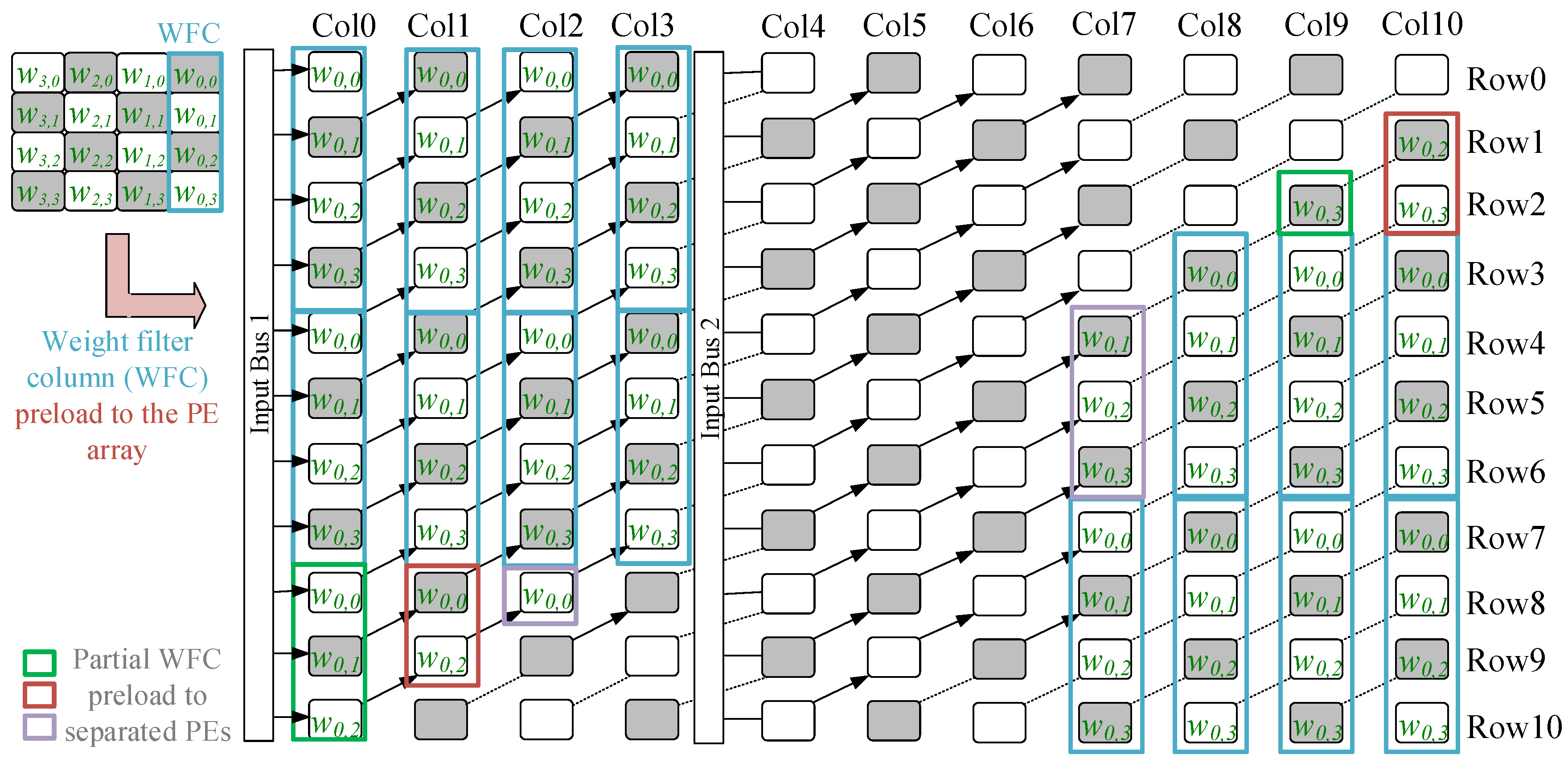
In the
cases, the mapping method is limited to one variety,
method = 2, as shown in (4).
Figure 9 and
Figure 10 show the case a 7 × 7-sized filter case. Since the k in the case is 7 and is bigger than
so that
method = 2 is adopted.
Table 2 concludes the mapping varieties for the filters 3 × 3 to 11 × 11, indicating that one-third of the filters contain at least two mapping methods to provide flexibility. For increasing the flexibility and providing more mapping methods for the filters
, the array can be flexibly enlarged and customized to increase
w and
h.
4.3.2. Weight Mapping
Weight mapping varieties follow the mapping varieties of input features. Bus2 is set to a different position in different mapping varieties to let the input features stream into the PE array. Before streaming, the weights are preloaded to the array according to the required variety. The following examples show the weight mapping location when using the 4 × 4-sized and 7 × 7-sized filters with method = 1 and 2.
Figure 11 and
Figure 12 illustrate the weight filters map to the required location according to the different mapping varieties. Without loss of generality,
Figure 11 uses a 4 × 4-sized filter to show the mapping method,
method = 1 (Col
i = Col4), while
Figure 12 uses a 7 × 7-sized filter to demonstrate the mapping method,
method = 2. In
Figure 11, the 4 × 4-sized filters preload their first column, circled by the blue squire, to the PE array. Hence, the first column {
w0,0,
w0,1,
w0,2,
w0,3} loads to the required positions and waits for streaming input feature data. Then, the multiplication action happens in the circled PEs shown in
Figure 7. On the other hand,
Figure 12 shows the mapping method,
method = 2, using a 7 × 7-sized filter as an example.
Figure 13 shows the other case,
of using mapping method,
method = 2, for the flexible purpose of utilizing a 4 × 4-sized filter as an example.
































{kind=link}
{kind=link}
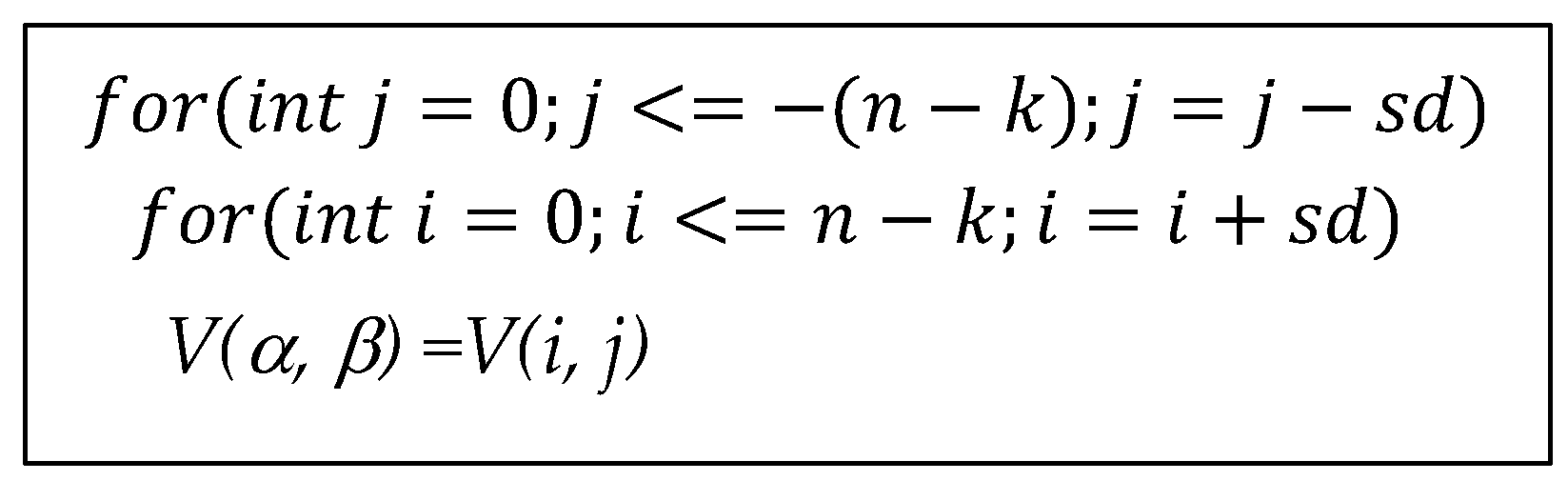{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
