3.1. Input Selection for the Proposed ANN Model
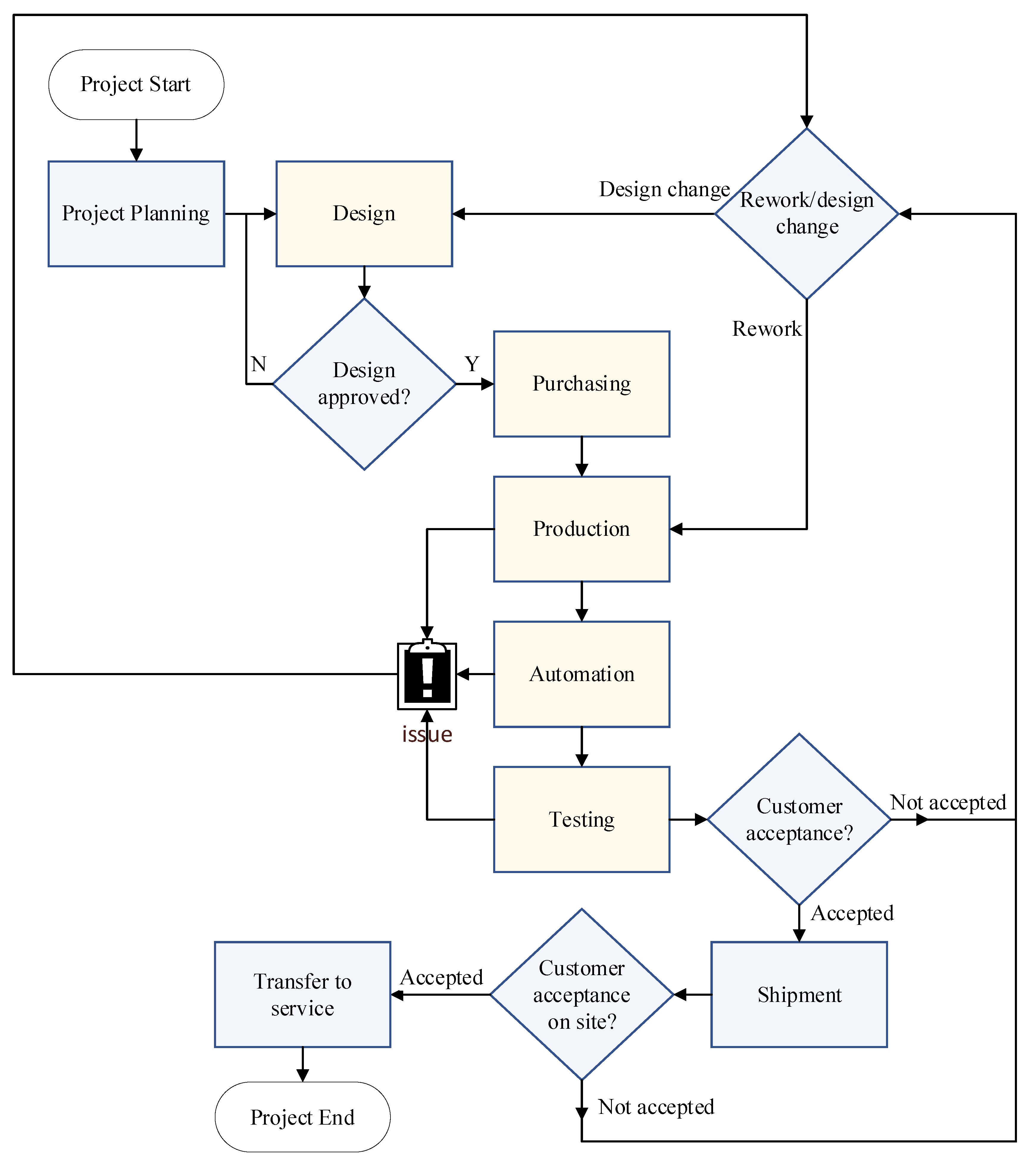
In this study, the ANN model was constructed using data collected from a company that designs and manufactures customized machines for the semiconductor industry. These machines are developed by considering the customer-specific product and process requirements to execute the process of customer products automatically. Machine development projects within this company mainly consist of four main phases: design, purchasing, production, automation, and testing, as shown in
Figure 1. The project starts with the design phase, where the mechanical, electronic, and micro-optic components and subassemblies of the machine are designed according to the customers’ requirements. After the design is reviewed and approved by the customer, the machine’s bill of material is transferred to the purchasing team. Next, the process continues searching and selecting suppliers to purchase the necessary components and parts. As necessary components are delivered, according to the production plan, the assembly of the machine starts. The machine’s mechanic, electronic, and micro-optic components are assembled considering the drawings and an integration plan. Finally, equipment that works with the machine is integrated and tested, and the machine is prepared for automation.
Then, automation starts, and the process is developed to produce customer products automatically using the machine. The general software system, which has already been developed to control machines, is integrated into the machine, and the process steps are defined to control the necessary subassemblies and equipment integrated into the machine, in other words, to automate the production process of customer products. This phase is crucial since each customer has a specific product and process. In most cases, the customer production process is manual, and the product is manufactured for R&D purposes. During machine automation, effective communication is necessary to reconstruct the customer’s production process according to the machine’s capabilities. In some cases, the process is well-known for the company and has been previously developed for another customer. Therefore, the necessary effort is relatively less than needed to develop a new process. In conclusion, the necessary effort to develop a process and automate a machine can vary from machine to machine.
Effort drivers and categories were defined through brainstorming sessions with experts within the company and considering the studies mentioned in the literature review. First, eleven factors were selected, as listed below:
Hardware complexity;
Process complexity;
Customer type;
Customer product novelty;
Customer process novelty;
System configuration novelty;
Machine function;
Machine main system size;
Machine housing size;
Machine line type;
Outsource usage for production.
Hardware complexity defines how complex the machine’s hardware design is. To evaluate this factor, two categories were used: low and high. Specific statements describing the attributes of the machine’s motion, vision, and data acquisition systems were defined for these two categories but are not explicitly presented here for security reasons. Process complexity defines the complexity level of the process of customer products and is categorized as low and high. Customer products can require more than one different process in a machine. Additionally, some processes can be more challenging due to the maturity level of the technology used and the company’s familiarity with the process. Therefore, some statements were identified for the low and high factor levels to prevent subjective assessment considering the above situations.
The factors regarding the customer type, product, and process novelty define how the company is familiar with this customer, product, and process. Customer type can be new or old. If the customer has already bought at least one machine before, the customer type is assessed as old. Two factors regarding customer product and process novelty have a three-point scale: no change, upgraded, and new. The level of “no change” defines the situation in which the customer has already previously purchased the same type of machine for the same customer product and process, so there is no significant change in the customer product or process. In the category of “upgraded”, the same type of machine is produced for upgraded customer products and processes. Although additional effort is needed due to the process changes for the automation phase, it is expected to be less than in the case of new products and processes. Since the company has experienced such machines and a process has been previously developed, the process can be developed for a new machine with minor adjustments. The last option, “new”, is when a customer is new, and the company has not previously experienced such products and processes with this customer. The factor of system configuration novelty is the novelty level of the sub-systems that comprise the entire system. This input is also on a three-point scale: no change, upgraded, and new.
The factor regarding machine function provides information about the machine’s primary function. It describes the process that the machine mainly executes and has five categories. The “machine main system size” factor includes six categories that define the complexity of the main sub-assembly that conducts the machine’s primary function, the number of subassemblies, and the components used. The housing size is the factor that defines the size of the exterior case of a machine that protects the internal mechanism. This factor is assessed in six categories: no housing, extra-small, small, medium, large, and extra-large. Most R&D-purpose machines are built without housing. An extra-small housing is usually chosen if a machine executes only one simple function including a few small subassemblies. A machine housing is considered as small when it is of below-average size. Medium-sized housing is used in machines that execute more than one function. If a machine is highly customized and performs more than one function, it includes many subassemblies. A larger size than average is needed for housing these kinds of machines. If a machine includes several big-sized subassemblies, the housing will be significantly larger than the average size.
The “machine line type” factor identifies the line type in terms of the production volume the machine will be used in, and has three categories: entry, standalone, and in-line. If the machine is produced for a low-volume production environment and produces a low-complexity product, the machine type is entry-level. In the standalone category, the machine can execute its primary function independently. If the machine is integrated within a line of several machines, it is described as an in-line machine. The last input is outsourcing usage for machine production and categorized as outsource used or in-house production.
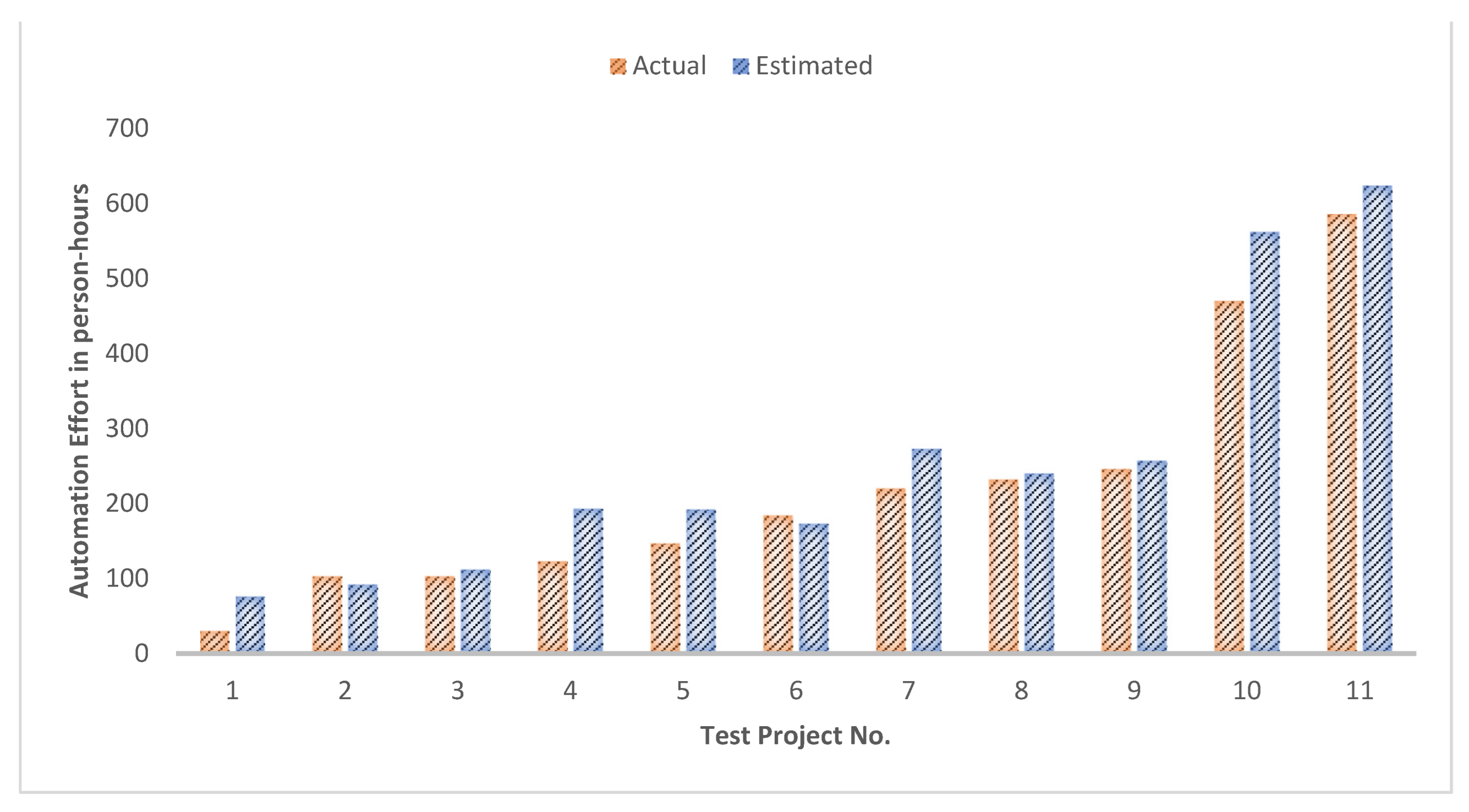
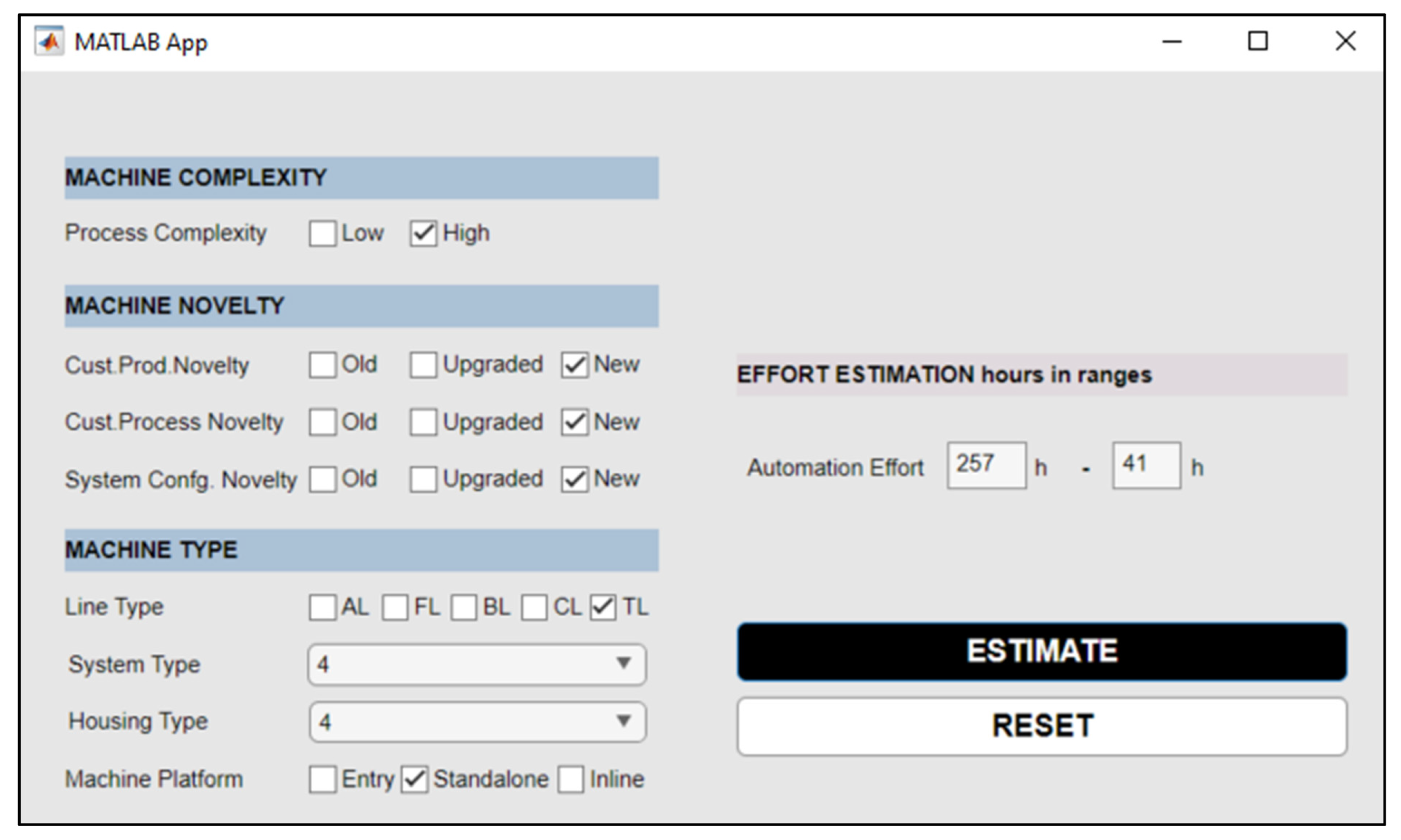
Automation effort is the output of the model. The automation effort value includes all of the efforts necessary to automate a machine. Person-hours were used to evaluate the automation effort value. This value was obtained from a database containing the company personnel’s time spent on projects. Then, revisions were made with the assistance of the company experts in the case of an error.
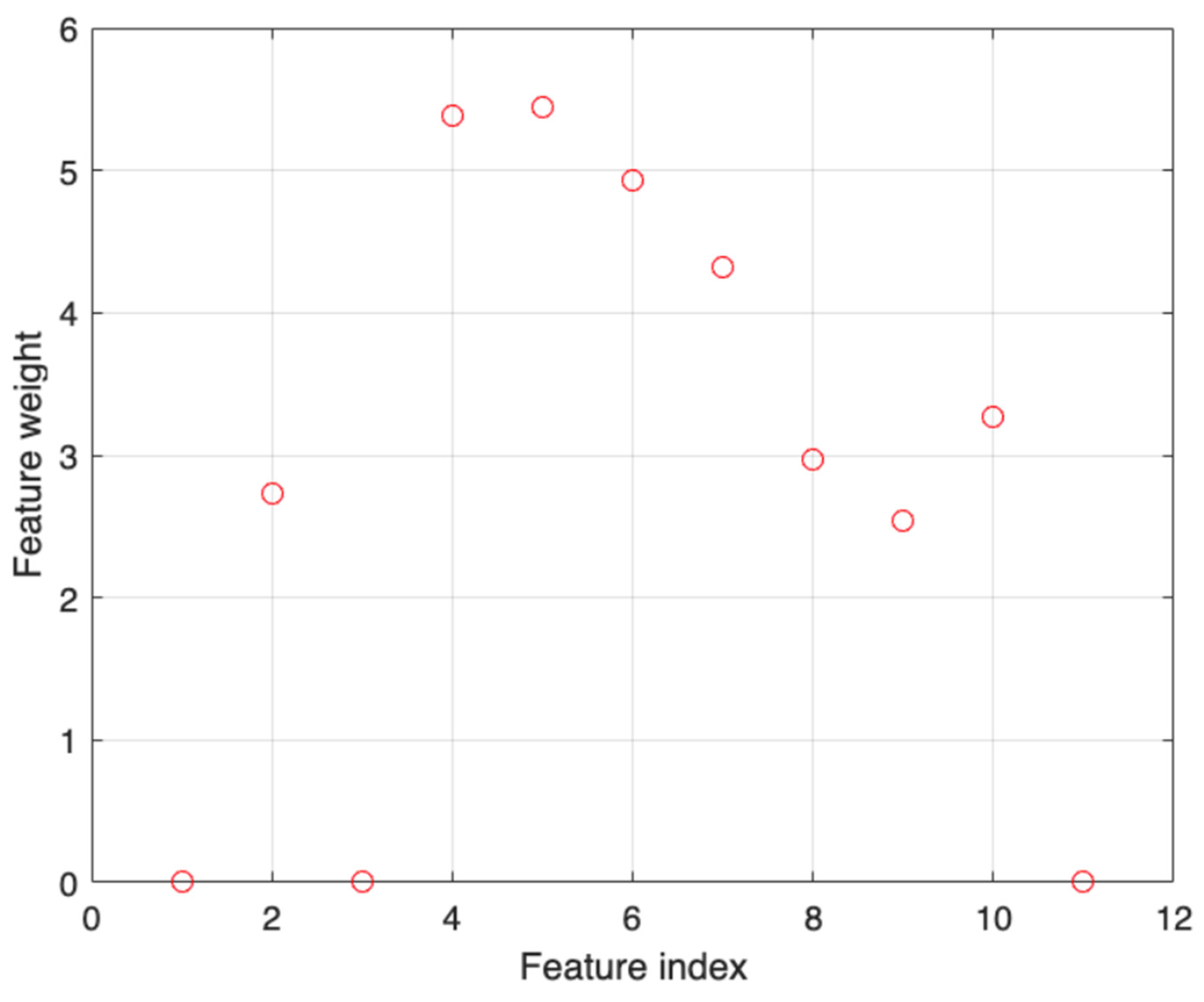
The data for the eleven effort drivers described above as well as the automation effort were collected from 101 completed projects. To maximize the prediction accuracy, neighborhood component analysis (NCA) was applied for feature selection. This nonparametric feature selection technique selects the best subsets of features by assigning weights to each feature. Based on the weights, the features with low weights can be removed from the input dataset. Instead of transforming the data into a different feature space as in principal component analysis (PCA), NCA assigns a weight to each feature. Similarly, individual features can be analyzed for relevance. While retaining features having significant weights, the rest can be eliminated. This technique was used by Goyal and Bhatia [
27] to select features for a MLP-based model to estimate the software project effort. The eleven features listed above were used as predictors and automation efforts as a response. MATLAB was used for the implementation of the method. As shown in
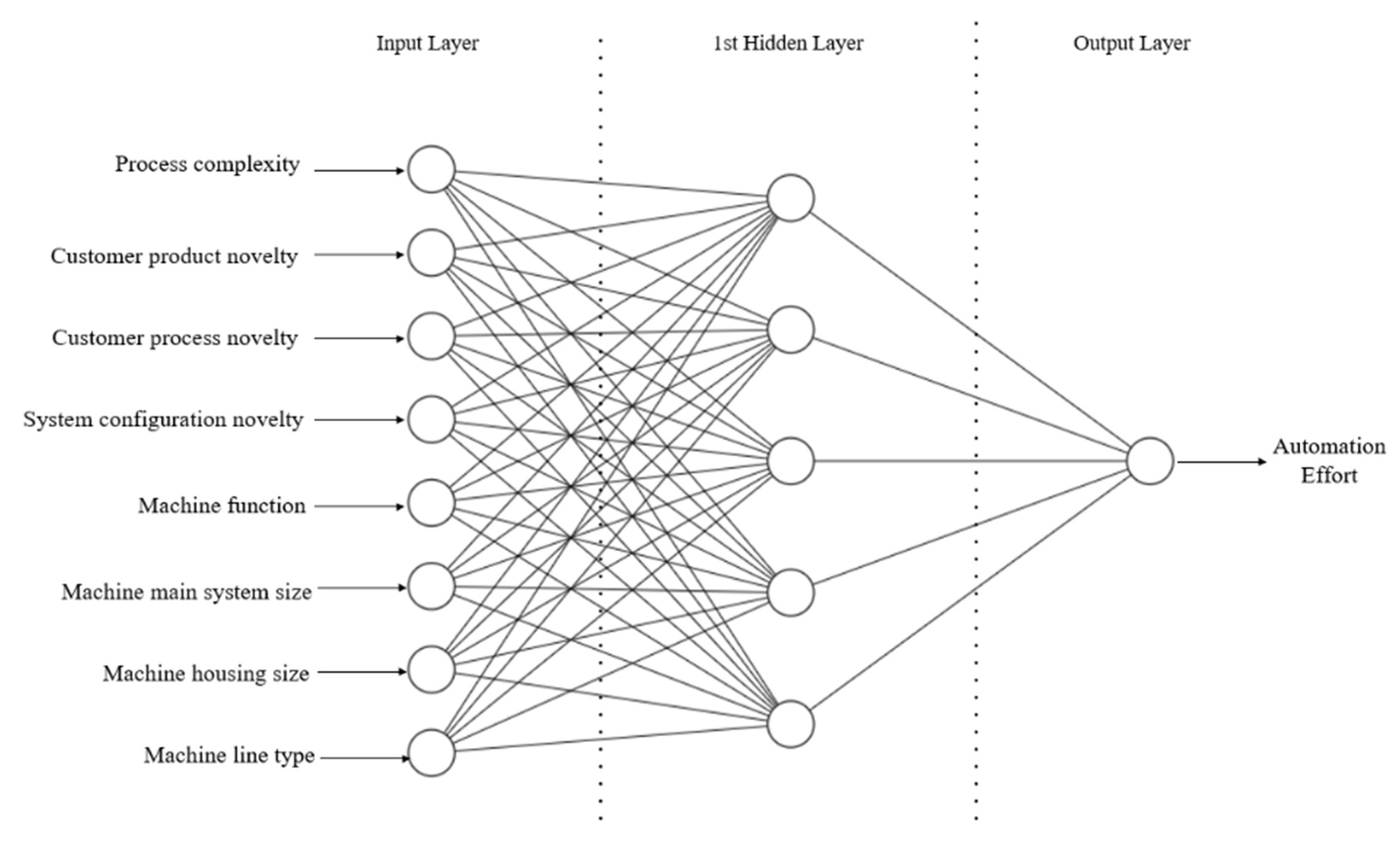
Figure 2, features 1, 3, and 11 have zero weights. These features, hardware complexity, customer type, and outsource usage were eliminated from the dataset. The remaining features with significant weights were selected for the automation effort estimation. As a result, only eight out of 11 features were used in the ANN model. The inputs and output defined for the ANN model are shown in
Table 1.
3.2. Hyperparameter Optimization of the Proposed ANN
One of the most widely used architectures in the field of effort estimation, FFNN, was used in this study. In the effort estimation area, gradient descent-based learning algorithms have been used to train an ANN [
17,
21,
22]. However, there are some drawbacks. GD-based algorithms require the selection of hyperparameters such learning rate and momentum, which significantly affect the ANN performance. In addition, they require matrix calculations and have slow convergence due to gradient calculations. Levenberg–Marquardt is another learning algorithm to overcome the drawbacks of GD related to storage requirements. Since the LM algorithm does not require complex matrix calculations, learning rate, or momentum selection and has a higher convergence, it was chosen for this study. The LM method is also the most effective method for t FFNN structures.
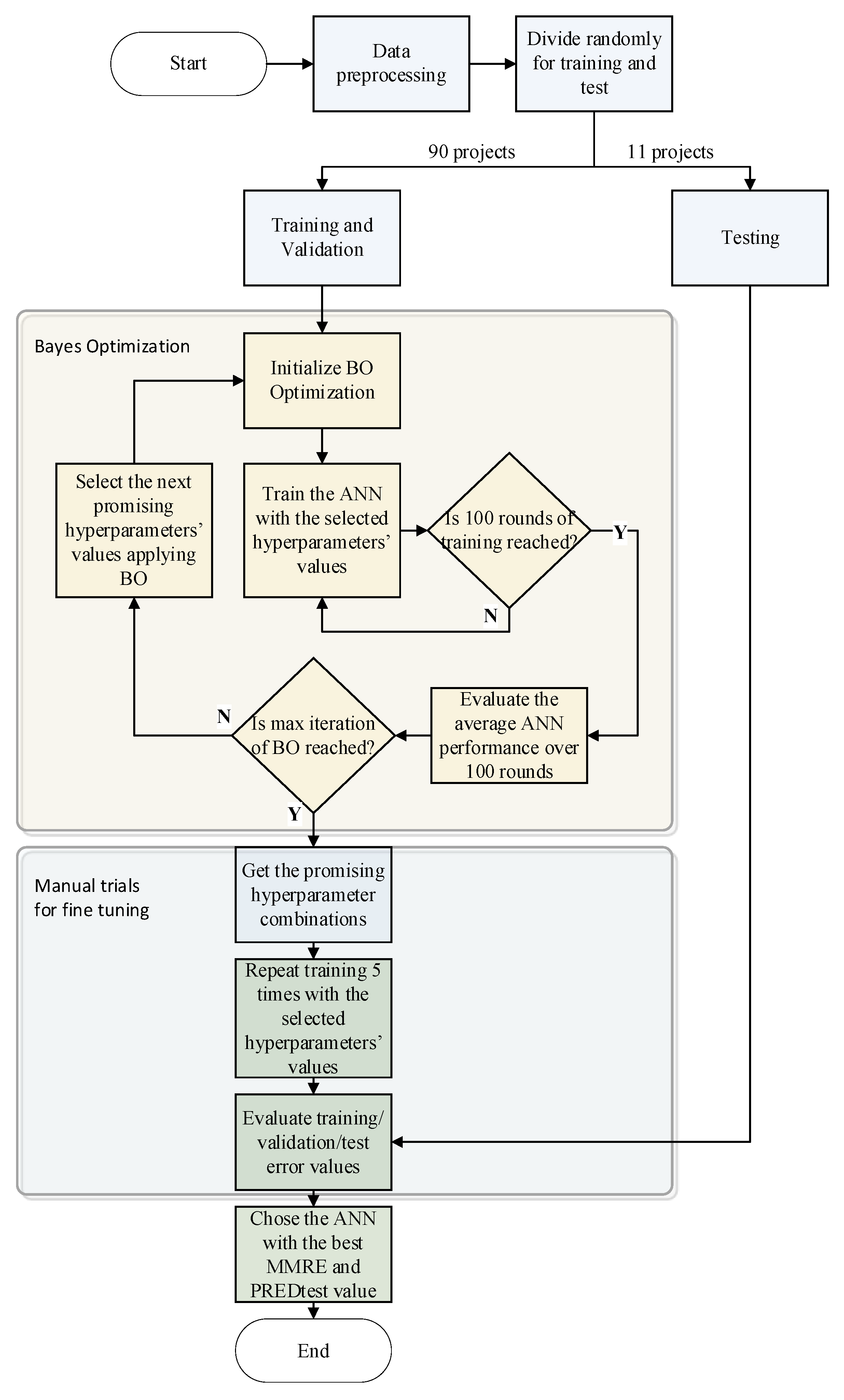
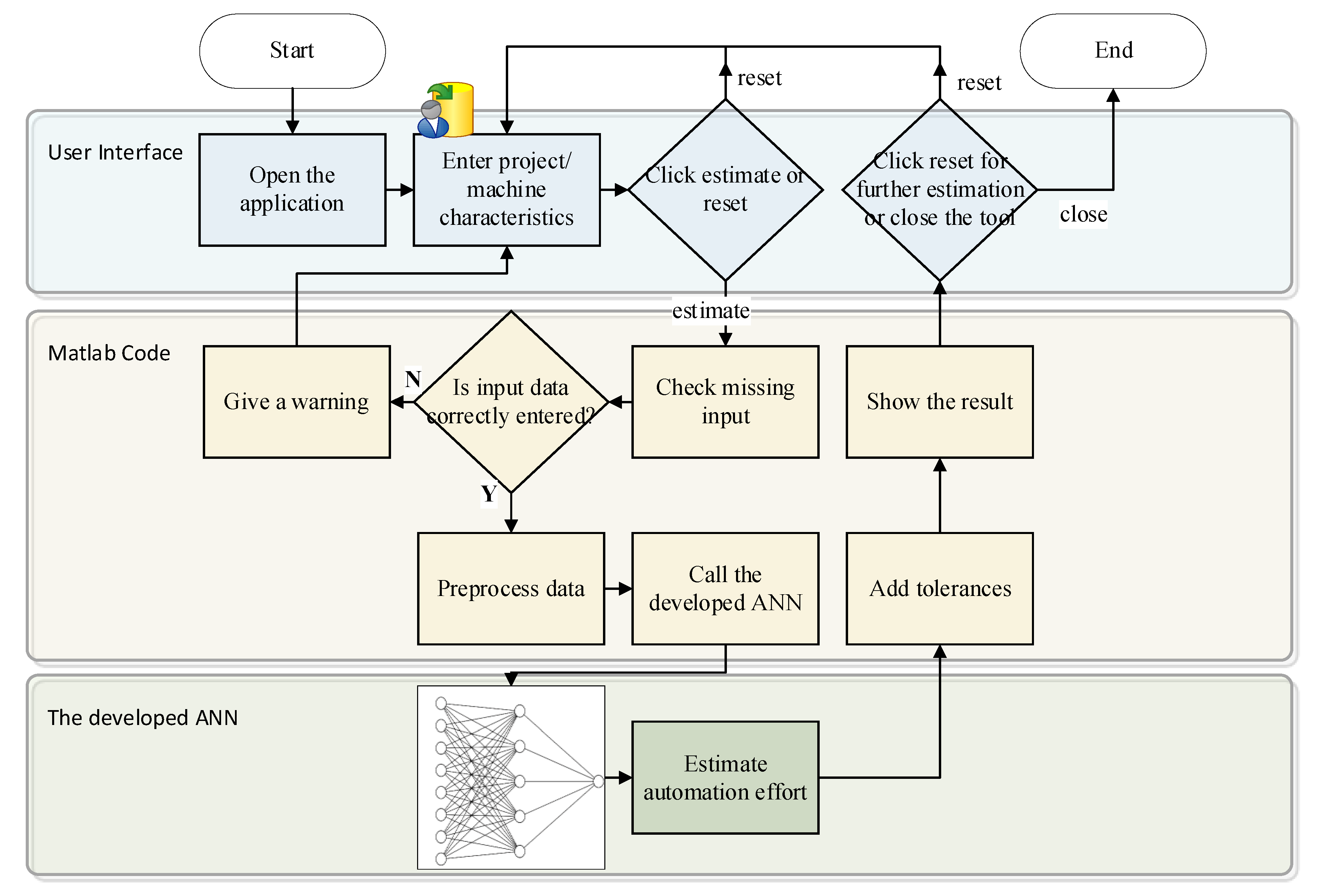
Most studies have reported that the FFNN structure outperforms other prediction models in software effort estimation. However, hyperparameter tuning is crucial to network performance. Any minor hyperparameter adjustment can significantly affect the prediction accuracy. For this purpose, one of the intelligent optimization methods, BO, was used to tune the hyperparameters. The procedure including BO for developing the network was programmed using MATLAB and is illustrated in
Figure 3.
A min–max normalization was applied first to reduce the bias of the higher values. Normalization was applied to all of the input variables to make them all the same scale even though they were categorical. Additionally, a log transformation was applied to the output data to reduce skewness and make it more normal. After data preparation, the dataset containing 101 machine development projects was randomly divided into two parts: the training and test sets. The test data containing 11 projects were not shown to the ANN during training and was used only for testing purposes to understand the ANN performance on different datasets.
Next, model architecture development steps continued with the training data. The hyperparameters selected for optimization were the number of hidden neurons, activation functions in the hidden layers and the output layer, as shown in
Table 2. In the effort estimation area, many studies have reached the best ANN structure with one hidden layer [
8,
9,
19,
22,
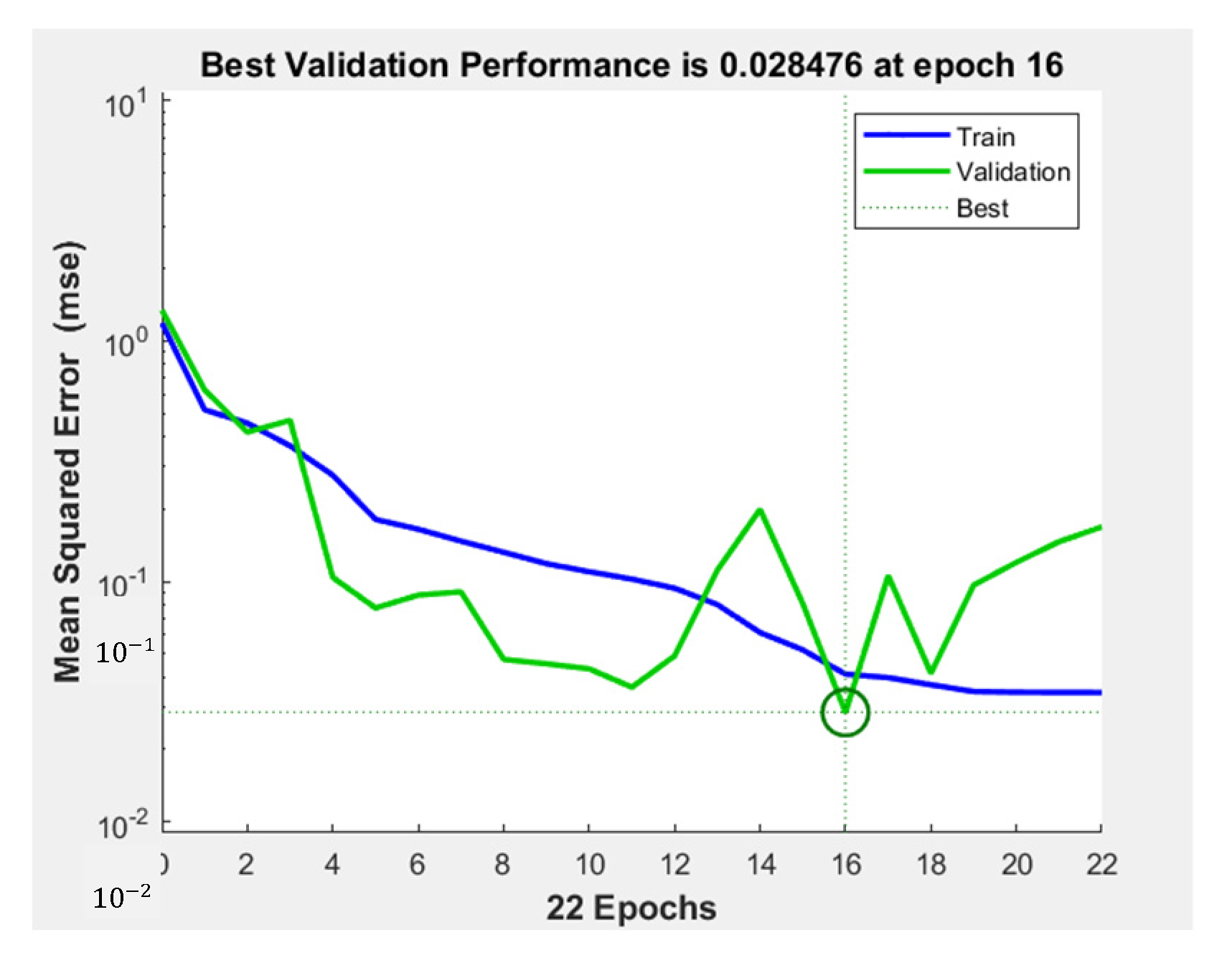
29]. Thus, one hidden layer was used for this study. For the first hidden layer, the number of hidden neurons was set to between two and eight. The possible values for activation functions for the hidden and output layers were chosen as tansig, logsig, and purelin. The division ratio of the data that decides the percentage of projects used in the training and validation dataset was set as 90–10%. Validation performance is one of the crucial points to determine how well the training process is and when it is to be terminated. This training process is to be terminated when generalization stops to prevent overfitting, which means that the model obtained good results for training but not for validation. Therefore, the stopping criteria were chosen as the max validation failure, which means that the MSEval is higher than the MSEval-best in the last six times.
The BO procedure begins with the selection of the initial hyperparameter values. After setting the hyperparameters, the network is initialized with randomly selected initial weights and training and validation dataset combinations. Training with the selected hyperparameters was repeated 100 times, and the average validation error was calculated to determine the validation performance of the network on the different datasets. At each training round, samples for training and validation were randomly selected. This technique is known in the literature as repeated random subsampling validation (Monte Carlo cross-validation), which splits the dataset randomly into training and validation datasets and averages the results over the splits. Repeating the training and validation rounds 100 times helps a model to produce more repeatable results and increases the prediction robustness by repeating this process with different randomly chosen initial weights and a combination of training and validation datasets.
The evaluation method of mean squared errors (MSE) was chosen to assess the ANN performance. MSE can be calculated as per the following equation:
After 100 rounds of training, the average MSE value was calculated, as per the following equation:
The calculated average performance value was taken as an objective function of BO. Therefore, BO aims to find the best hyperparameter values that minimize this objective function.
After determining the average validation performance value over 100 rounds, BO builds a probability model of the unknown objective function using the observed objective function values. This prior probability model of the objective function is known as a surrogate model. Due to its simplicity and ease of optimization, the Gaussian process is most commonly used as a surrogate model. It provides a probabilistic representation of the objective function’s uncertainty at any given data point by building a multivariate Gaussian distribution from the historical data. The BO algorithm finds the next data point, the following promising hyperparameter value that performs best on the surrogate model. BO uses the acquisition function to find the next promising point on the surrogate model. The mostly used acquisition function is expected improvement. BO chooses the next data point that gives the max expected amount of improvement in the objective function. BO then obtains the objective function value by training ANN with the selected hyperparameters. Then, it updates GP prior distribution (surrogate model) with the new data to produce a posterior. This posterior will become the prior in the next step. This procedure is repeated until the stopping criteria of BO, 30 iterations.
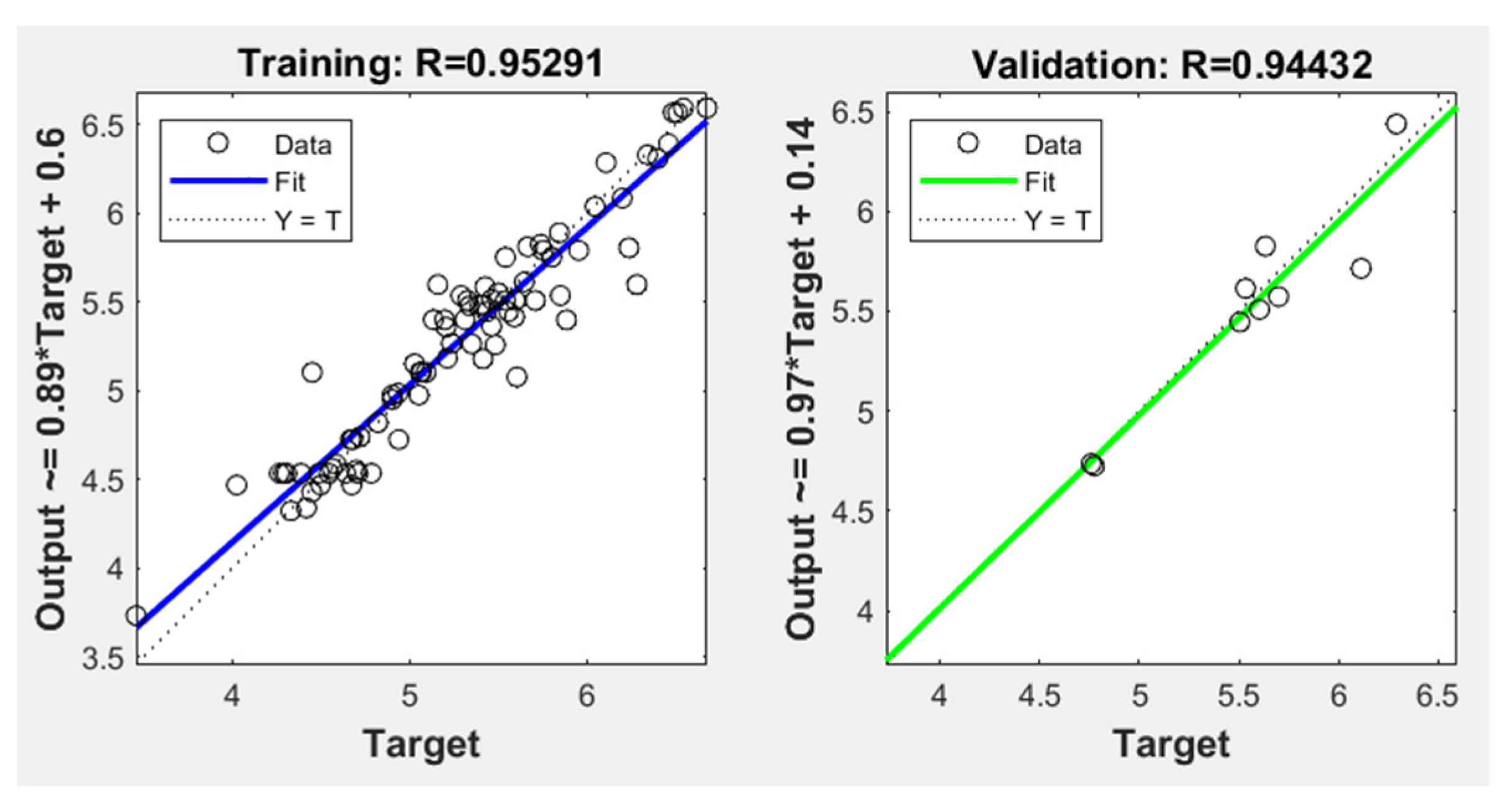
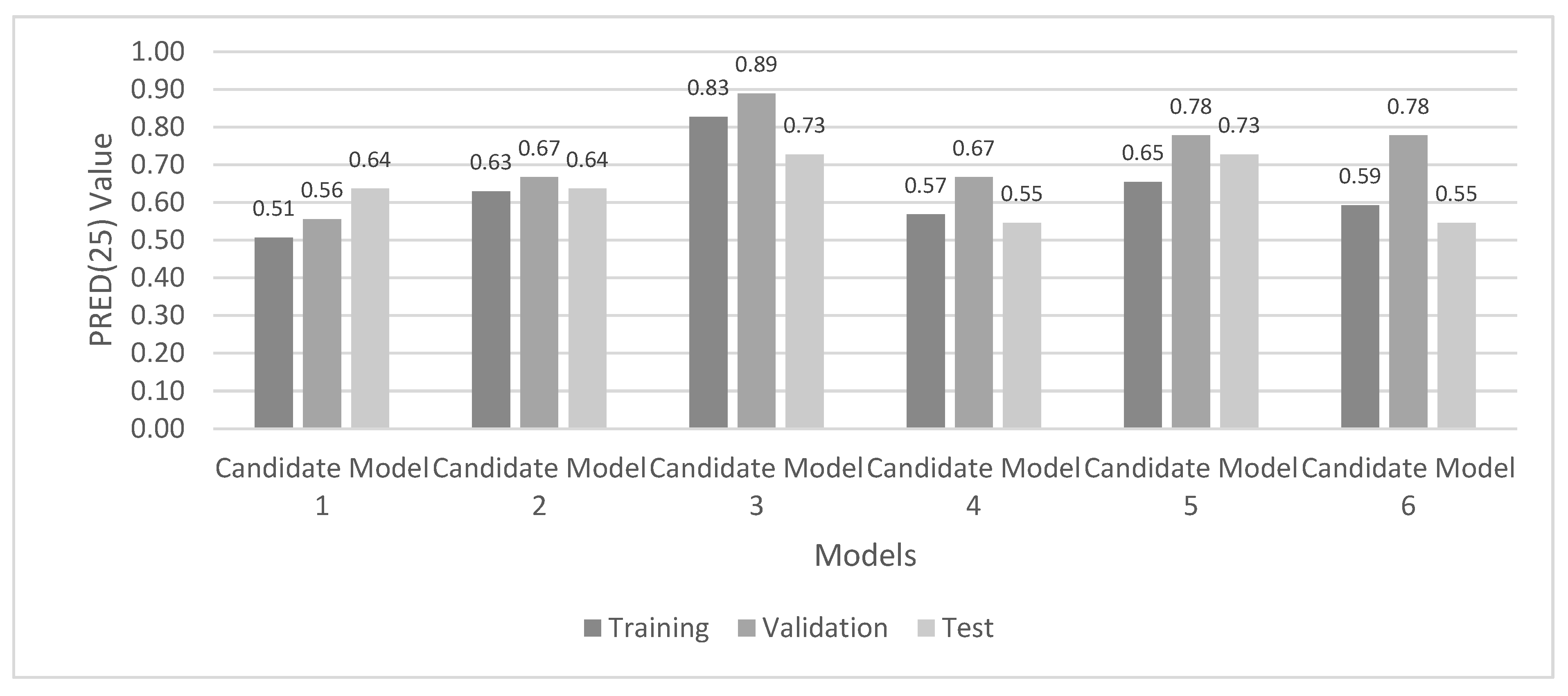
According to the results of the BO, the optimal hyperparameter values and a number of hyperparameter combinations that produce promising results were selected. For each combination, training was repeated five times. For each round, the ANN test performance was calculated over a test dataset containing 11 projects.
The mean magnitude of relative errors (MMRE) and prediction accuracy (PRED) were used to evaluate the ANN performance. Several methods exist to evaluate the performance of ANNs and determine how well they match the desired output. In the effort estimation area, MMRE and
are commonly used methods for calculating model performance. MMRE is the mean of the magnitude of relative errors (MRE), which is calculated for each observation
, expressed by the following equation:
MMRE is achieved by aggregating the MRE over multiple observations
as in the following equation:
By using MRE values,
can be calculated as the average of the MREs (or MERs) that are less than or equal to
[
7], as shown in the equation below:
Model accuracy is directly proportional to
and inversely proportional to MMER or MMRE [
7].
represents the percentage of project effort estimates that are within
of the actual [
8]. In many studies, the value of x is taken as 25 [
11,
22,
31]. A model with the prediction accuracy of MMRE
and PRED(25)
75% are considered sufficient for software effort prediction [
9].
Before calculating MMRE and PRED(25) for each training experiment, the output values were transformed to original values from the logarithmic. After calculating the ANN test performance over the test data for each training experiment, the network with the best MMRE and PRED(25) values was selected.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}