1. Introduction
Hepatitis C is a blood-borne virus-related infection triggered by the hepatitis C virus (HCV) that mostly damages the liver. HCV infections are a significant cause of liver diseases, including cirrhosis and hepatocellular carcinoma, making it an important public health concern globally. HCV infections are a prominent cause of liver disease, cirrhosis, and hepatocellular cancer around the globe. As stated by the World Health Organization, 58 million individuals worldwide are infected with hepatitis C at its extreme stages, representing 3% of the global population, and that 1.5 million new cases occur annually. In 2019, almost 290,000 infected patients died from cirrhosis or liver cancer [
1]. A 2018 meta-analysis estimated that HCV antibody prevalence in Egypt was 11.9%, making it the country with the highest HCV prevalence worldwide [
2]. Therefore, HCV is estimated to be a leading public health dilemma worldwide, which must be addressed with solid program interventions.
Currently, hepatitis C can be cured with direct-acting antiviral (DAA). Nevertheless, many patients still have chronic hepatitis C infection and run the danger of experiencing its associated complications, including cirrhosis and liver cancer. Furthermore, obstacles still stand in the way of attaining widespread access to these medications, particularly in low- and middle-income nations where the hepatitis C epidemic is most severe. According to a study by Elgharably et al. [
3], although recent medicines have shown an efficiency rate greater than 90%, access to these new medications is significantly restricted by cost. Additionally, extensive DAA therapy would not eliminate all the issues caused by the HCV pandemic in Egypt. Hepatocellular carcinoma and the sequelae of decompensated cirrhosis continue to place a significant burden on Egyptian society and require sufficient allocation of healthcare resources.
Liver cirrhosis is an advanced stage of liver fibrosis that develops due to the long-term effects of various chronic liver diseases. This condition is characterized by transforming healthy liver tissue into abnormal lesions, accompanied by tissue fibrosis, which can be detected through a medical examination [
4]. In the initial stages of cirrhosis, most patients do not experience noticeable symptoms, and the disease is frequently discovered by accident during routine medical examinations for other conditions [
5]. When a healthy liver experiences ongoing fibrosis and scarring, intrahepatic resistance in the liver increases, and portal hypertension develops, leading to decreased liver function and fatal consequences [
6]. Sepanlou et al. [
4] found that, in 2017, cirrhosis was responsible for over 1.32 million fatalities worldwide, with 33.3% of these deaths occurring among females and 66.7% among males. There was a 1.9% mortality rate from cirrhosis in 1990, which has been increasing ever since, reaching 2.4% in 2017. Furthermore, according to the study, Egypt had the highest age-standardized death rate due to cirrhosis, which has remained consistently high since 1990.
Currently, the most accurate way to diagnose cirrhosis is by liver biopsy. However, this is expensive, invasive, and risky. Less invasive tests, such as transient elastography, have therefore been introduced. Transient elastography is a good predictor of HCV and its stages, offering a sensitivity between 72–84% and a specificity between 82–95%. However, it is not widely available [
6]. As an alternative to imaging techniques, there are several simple and non-invasive clinical laboratory tests, such as the aspartate aminotransferase-to-platelet ratio index (APRI), aspartate aminotransferase (AST)/alanine aminotransferase (ALT) ratio, alkaline phosphatase, the Naples prognostic score, the Lok score, and the fibrosis index. Those tests have proven to help assess cirrhosis or fibrosis. Yet, they suffer from some limitations and can be used only for certain cases [
6,
7,
8]. These limitations include unpredictability, insufficient accuracy, and risk factors for error. Additionally, the development of new biomarkers for fibrosis may be constrained by the inherent sample error associated with the current reference standard [
9]. Furthermore, FibroTest is a tool that has been widely used for assessing liver fibrosis. Nevertheless, FibroTest is a static examination that offers a single score instantly. As a result, it would not be able to record changes in liver fibrosis over time, which might be crucial for tracking the development of the illness and directing treatment choices [
10]. Moreover, due to technical restrictions, FibroTest cannot be used on all patients, including those with ascites, those who are morbidly obese, and/or those with a lot of chest wall fat [
11].
The rise of high computational power, the progresses in machine learning (ML) algorithms and the abundance of available data have established artificial intelligence (AI) as a prominent factor in healthcare. ML models have demonstrated remarkable potential in delivering precise diagnostic assessments, identifying appropriate treatment options, and predicting patient outcomes [
12]. Several studies have therefore used ML models to diagnose patients with different HCV stages. A recent study by [
13] assessed the accuracy of real-time shear wave elastography in identifying liver cirrhosis. The study concluded that this technique reached 92.86% sensitivity, 89.66% specificity, and 91.23% accuracy. However, to the best of our knowledge, no study has focused on developing an ML model to detect the development of cirrhosis in hepatitis C patients. Accordingly, this paper proposes an ML model that detects the presence of cirrhosis in HCV patients to assist medical specialists in recommending timely treatment plans.
Despite the success that ML algorithms have reached in many classification problems, they are still distrusted by end users and people without technical expertise. This is because they have little understanding of how AI models work. To build trust in ML models, researchers have adopted explainable artificial intelligence (XAI) to demonstrate and explain how their models reach a decision [
14,
15]. This study used Shapley additive explanations (SHAP) and local interpretable model-agnostic explanations (LIME) to explain the outcomes of the best-performing model.
The subsequent sections of this paper are structured as follows.
Section 2 comprises a comprehensive literature review.
Section 3 outlines the materials and methods employed, encompassing the dataset, the ML algorithms utilized, the performance metrics utilized to assess the proposed models, and the optimization strategy.
Section 4 elaborates on the study’s findings and the technique used for feature selection.
Section 5 describes the models’ outcomes using XAI techniques. Finally,
Section 6 contains the conclusion and discussion of potential future research avenues.
Contribution
Given the gravity of the consequences associated with cirrhosis in individuals with Hepatitis C, it is imperative to reduce unnecessary medical check-ups and optimize time utilization for both medical professionals and patients. Below is a summary of the study’s contribution:
Compare the performance of ensemble learners in diagnosing cirrhosis in hepatitis C patients;
Apply SFS to minimize the number of features required to form the diagnosis;
Utilize XAI techniques to explain the outcomes of the best-performing model;
Utilize XAI techniques to identify the most significant attributes for diagnosing cirrhosis in hepatitis C patients.
2. Literature Review
Mostafa et al. [
16] used supervised ML algorithms, including an artificial neural network (ANN), a support vector machine (SVM), and an RF, for early diagnosis of hepatitis C. The classifiers were trained using an HCV dataset gathered from the (UCI) ML Repository [
17]. The authors found that RF was the best-performing model, achieving an accuracy of 98.14%. Despite the promising results, the model could not be generalized to replace expert knowledge to determine diagnostic paths since the data include numerous missing values.
Similarly, Oladimeji et al. [
18] proposed ML models automatically classifying hepatitis C using the same UCI dataset. The authors used several classifiers, including decision tree (DT), RF, k-nearest neighbors (KNN), logistic regression (LR), and naive Bayes (NB). After evaluating all five algorithms, the results indicated that RF outperformed other models with a precision-recall curve of 1.00, an F-measure of 0.99, a Matthews correlation coefficient of 0.99, a receiver operating characteristic area under the curve (ROC-AUC) of 0.99, and an accuracy of 98.97%.
Likewise, Safdari et al. [
19] used several classification algorithms to categorize individuals with suspected HCV. Six classification algorithms were used, including SVM, Gaussian naive Bayes (GNB), RF, DT, LR, and KNN, and they were trained using the same UCI dataset. After evaluating the six models according to various measures, the authors found that the RF classifier surpassed the others with an accuracy of 97.29%.
Kaunang [
20] also attempted to predict HCV using ML approaches on the UCI dataset. The five categories in the original dataset were reduced to two: the blood donor and suspect blood donor categories were combined into a non-hepatitis category, while the hepatitis, fibrosis, and cirrhosis categories were combined into a hepatitis category. The ML algorithms used were KNN, SVM, RF, ANN, NB, and LR. The LR approach surpassed the other algorithms with an accuracy of 97.9%. However, this study required additional analysis because of a data imbalance between the two classes.
Similarly, Li et al. [
21] developed an AI-driven model that has the potential to diagnose HCV and detect the disease at an early stage for potential future treatments. By leveraging the UCI dataset, the researchers used a two-stage cascade strategy that combined the RF and LR algorithms. The artificial bee colony algorithm was utilized to establish the ideal threshold needed for filtering and partitioning. The approach was able to predict the probability of HCV incidence across multiple classes, achieving a high level of accuracy 96.19%, precision 96.94%, recall 96.19%, and F1-score 95.92%.
Ghazal et al. [
22] presented an effective and efficient method for assisting healthcare professionals in the early detection of HCV using ML algorithms. A Gaussian SVM model was trained using the Egyptian cohort from the UCI repository [
23]. The dataset contained 1385 patient entries, each with 29 distinct attributes. The model achieved an accuracy of 97.9%.
Butt et al. [
24] proposed an Intelligent Hepatitis C Stage Diagnosis System that uses an ANN to predict the stage of hepatitis C in a patient using the dataset in [
23]. Using 70% of the dataset during training and 30% during validation, the proposed system achieved a precision of 98.89% and 94.44%, respectively.
Mamdouh et al. [
25] aimed to detect HCV among healthcare staff in Egypt. Two experiments were conducted, one with feature selection and the other without. The features were chosen using SFS. Then, four algorithms, namely, RF, NB, KNN, and LR, were trained in each experiment. The dataset used for this study was developed at Menoufia University based on records obtained from the National Liver Institute. The dataset included 12 different attributes of 859 participants. It was found that using only four features, RF reached the highest accuracy of 94.88%. However, the dataset was limited to Egyptian patients working in risky environments. In addition, the size of the dataset and the features included were not enough to generalize the model to newly infected patients.
Barakat et al. [
26] aimed to build an intelligent diagnostic system using ML to predict and assess fibrosis in children affected with chronic hepatitis C. They used a clinical dataset collected from 166 Egyptian children with this condition. The authors used the RF algorithm to predict the type of fibrosis (no fibrosis, mild, or advanced). The system achieved an accuracy of 87.5% and an AUC-ROC of 90.3%. The prediction of mild fibrosis attained an accuracy of 66% and an AUC of 71%. For advanced fibrosis, it achieved an accuracy of 80% and an AUC of 89.4%. However, the dataset had a limited size and suffered from imbalance.
Similarly, Tsvetkov et al. [
27] aimed to develop and test an ML model that detects fibrosis in the liver of individuals with chronic hepatitis C using private data collected from routine clinical examinations. The authors examined data on 1240 patients with chronic hepatitis C, of which 686 were males and 554 were females. A total of 689 patient data were used to develop and test the ML model to obtain the liver fibrosis stage level, and only 9 out of the 28 features were considered. The model attained an accuracy of 80.56%, a sensitivity of 66.67%, and a specificity of 94.44%. Although the study did not employ abnormal or unbalanced samples, did not reject data at random, and tested accuracy with two separate test samples, the ML model still needed external validation.
ML algorithms have had a significant impact in aiding healthcare providers to detect HCV at earlier stages [
16]. Detecting individuals with early cirrhosis is critical for preventing severe complications. There have been a few studies that attempted to distinguish the cirrhosis stage from the fibrosis stage. However, there is room for improving the results obtained by their models and reducing their computational complexity using feature selection techniques. Additionally, the outputs of these ML models are not easily understood by medical professionals. Accordingly, in this study, XAI techniques were used to ensure that specialists can understand the model’s decisions.
3. Materials and Methods
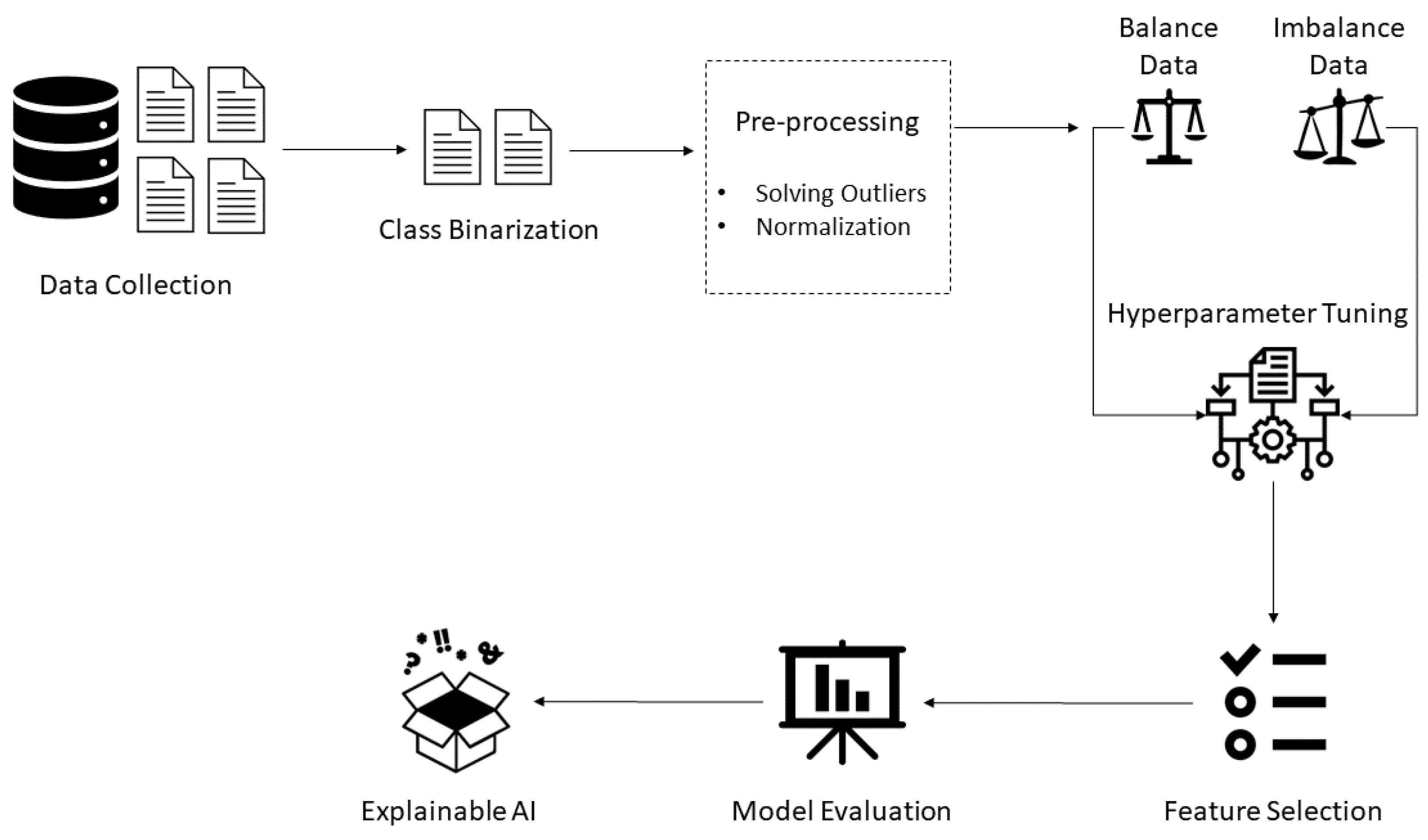
In this study, Python programming language (version 3.9.12) was utilized. First, pre-processing techniques were conducted before building the models. First, binarization focused on predicting only HCV patients with cirrhosis. Consequently, the cirrhosis class was converted to 1 and all other classes were converted to 0. Next, two outliers were identified using a box-plot graphical representation and the interquartile range (IQR) method by comparing the lower bound (first quartile) and upper bound (third quartile) of the data. The values below the first quartile and above the third quartile by 1.5 times the IQR were considered outliers and were removed to improve subsequent analyses or modeling accuracy. Thereafter, the data were normalized using the min-max scaler from the scikit-learn library (version 1.1.1). Due to the conversion of the target class, the data imbalance issue has appeared. Therefore, random oversampling was applied using the imblearn library (version 0.9.1). Subsequently, a stratified k-fold cross-validation approach was used to evaluate four ML algorithms, namely, RF, GBM, XGBoost, and ET, using 10-folds. GridSearchCV from the scikit-learn library was used to tune the algorithms’ hyperparameters, and SFS from the mlxtend (version 0.21.0) library was used for feature selection. After building the models, their performance was evaluated and compared using four metrics: accuracy, precision, recall, and AUC-ROC. Lastly, XAI techniques were used to explain the outputs of the best-performing model.
Figure 1 illustrates the framework of the study.
3.1. Dataset Description and Analysis
The present study is based on the HCV dataset from the UCI ML repository [
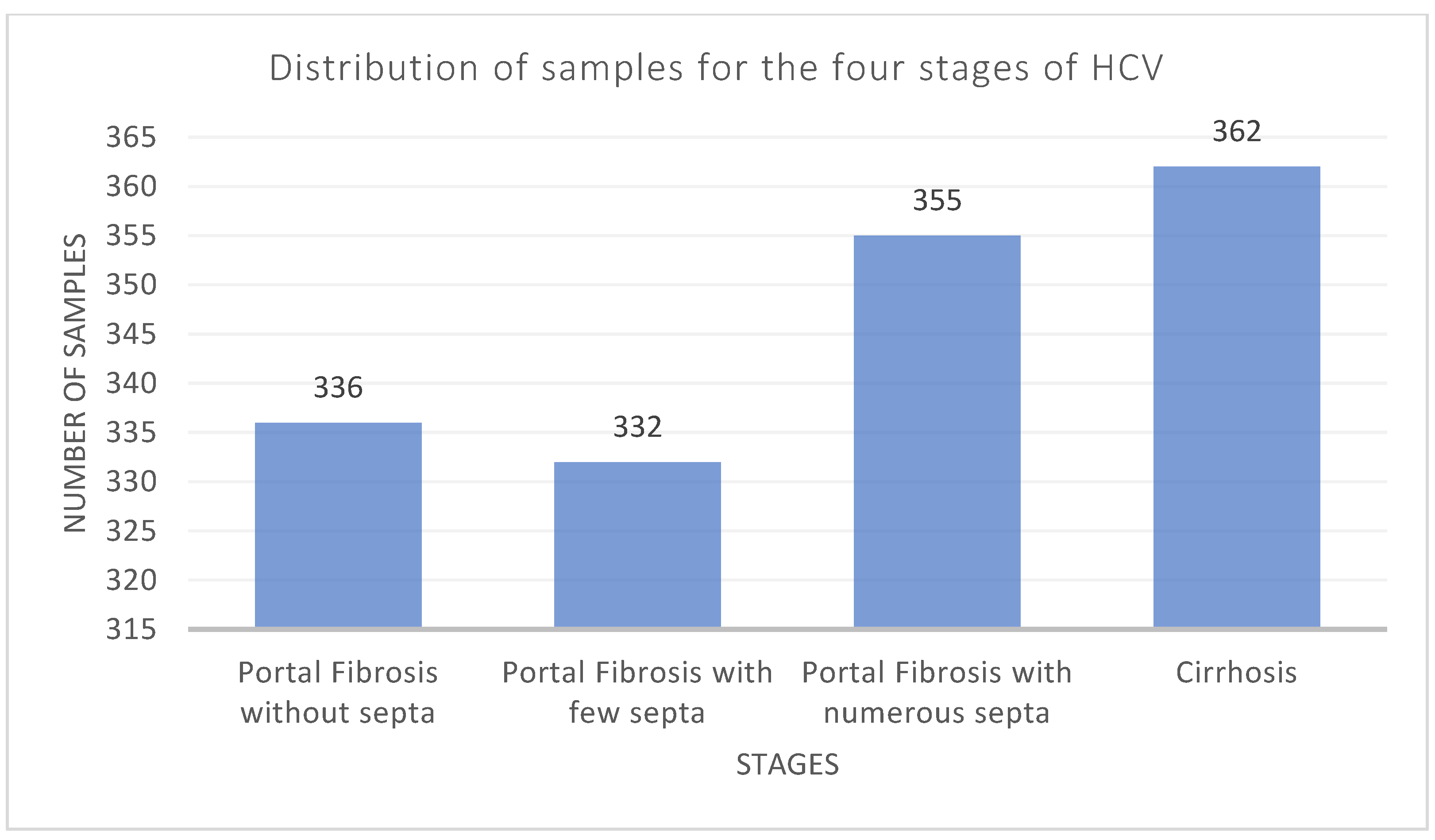
23]. This dataset includes 29 features of 1385 Egyptian patients, including the target class, who had HCV therapy for approximately 18 months. There are four identifiable stages of hepatitis C virus (HCV) included in the dataset: portal fibrosis without septa, portal fibrosis with a small number of septa, portal fibrosis with many septa, and cirrhosis.
Figure 2 shows the sample distribution for each category. More details about the dataset are present in [
23,
28].
Table 1 and
Table 2 outline the statistical analysis of the numerical and categorical attributes. The tables show that the dataset has a nearly equal distribution of cases for each categorical feature, which may guarantee the model’s generalizability utilizing those features. Moreover, some outliers are indicated from the statistical analysis applied to the numerical features, using the IQR method.
To detect the presence of cirrhosis in hepatitis C patients, patients with stages 1, 2, and 3 were considered negative (portal fibrosis), whereas patients with stage 4 were considered positive (cirrhosis). The random oversampling technique was used to balance the data.
Table 3 shows the data before and after outlier removal and random oversampling.
3.2. Description of the Utilized Machine Learning Techniques
Ensemble algorithms involve training multiple models and combining their results. The bagging classifiers combine several independent predictors using weighted averages or majority votes. In contrast, the boosting classifiers are iterative ensemble methods that modify an observation’s weight depending on the most recent classification. If an observation was mistakenly classified, it attempts to enhance the weight of that observation. In this study, two bagging (ET and RF), and two boosting (XGBoost and GBM) techniques were used.
3.2.1. Random Forest
The RF classifier was first introduced by Leo Breiman and Adele Cutler [
29]. It is a supervised ML algorithm used in classification and regression problems. An RF consists of an ensemble of many distinct decision trees running parallel as a committee [
30]. Incorporating such models improves the performance of the RF classifier, making it more effective than models that operate individually [
29]. In classification problems, each decision tree selects a class as an output. The final outcome returned by the RF classifier is produced by taking the highest vote among all trees’ outputs. The majority voting formula is:
where
represents the predicted class and
are the
classification models of the data sample
[
31].
3.2.2. Gradient Boosting Machine
Leo Breiman first introduced GBM in 1998, where adaptive boosting was defined as a gradient descent with a specific loss function. A year later, Jerome Friedman developed GBMs, which generalize boosting algorithms for regression and classification problems [
32]. A common framework for GBM typically involves three fundamental components: an optimized loss function, a weak learner that generates predictions, and an additive model that integrates base learners to decrease the loss function and create a prediction model that is both robust and dependable. Boosting techniques differ from standard ML algorithms because optimization is not included in the function space. However, an optimal function
F(
X) is reached after
iterations [
33],
where
represents a feature increment and
is calculated using
where
is the loss function and
is the negative gradient for the
th iteration.
3.2.3. Extreme Gradient Boosting
XGBoost is an ML classifier that employs a combination of gradient boosting and ensembling methods, and it is built upon decision trees as its base learners [
34]. XGBoost was initially developed in 2016 by Tianqi Chen and Carlos Guestrin as part of a research project at the University of Washington. The boosting strategy employed by XGBoost involves aggregating multiple models to create a group of predictors that work together to enhance the accuracy of predictions, regardless of whether the problem being addressed is related to classification or regression [
34]. The prediction outcome generated by XGBoost is the sum of the scores predicted by the individual decision trees [
35],
where
is the number of trees,
is the score of the
th tree, and
is the set of space functions that include all gradient-boosted trees.
XGBoost tackles the issue of overfitting, which can be a considerable concern for ensemble models, by including additional regularization in its objective function. This regularization element punishes the intricacy of the model, enhancing its ability to generalize and decreasing the possibility of overfitting [
35]. It is given by:
The equation involves the loss function , which quantifies the difference between the target value and the predicted value , and the regularization term , which evaluates the complexity of the model.
3.2.4. Extra Trees
The extra trees (ET) algorithm operates by picking a subset of features at random and then using them to train a decision tree. After that, the tree is pruned to include only the most valuable features for making predictions. ET is a similar algorithm to RF in that it makes a final prediction about which class or category a data point belongs to by using a collection of decision trees. ET differs from RF because it uses the entire original sample rather than sub-sampling and replacing data as RF does. Another distinction is how the nodes are divided. ET chooses random splits, whereas RF always chooses the best possible split. ET and RF are both designed to improve the final output [
36]. Decision trees, RF and ET also differ in performance: the variance is high in decision trees, medium in RF, and low in ET [
37].
3.3. Performance Measures
Four measures assessed classification performance: accuracy, precision, recall, and AUC-ROC. In addition, to assess the performance of the models, a confusion matrix was formed for each model, which evaluates their true positives (TP), false positives (FP), false negatives (FN), and true negatives (TN). TP represents the number of correctly classified patients with cirrhosis-HCV, while FP represents the number of patients incorrectly classified as cirrhosis-HCV. FN is the number of patients incorrectly classified as non-cirrhosis-HCV, and TN is the number of correctly classified non-cirrhosis-HCV patients.
Accuracy is the ratio of accurately classified observations to total observations,
Precision is the ratio of accurately classified positive observations to the total number of positively classified observations,
Recall is the ratio of accurately predicted positive observations in a class to the total number of observations,
3.4. Optimization Strategy
The hyperparameters of an algorithm must be modified in order to generate models that can solve problems optimally. Grid search with stratified 10-fold cross-validation was utilized in this study for this purpose. Grid search is used to define a search space by specifying the hyperparameters and their range of potential values. After defining the hyperparameter grid, the GridsearchCV technique generates every possible combination of the values to identify the optimal set of hyperparameters. To assess the efficacy of each hyperparameter combination, 10-fold cross-validation is conducted to evaluate the performance of the model.
Table 4 highlights the optimal hyperparameters for models using the datasets before and after oversampling.
6. Conclusions and Recommendations
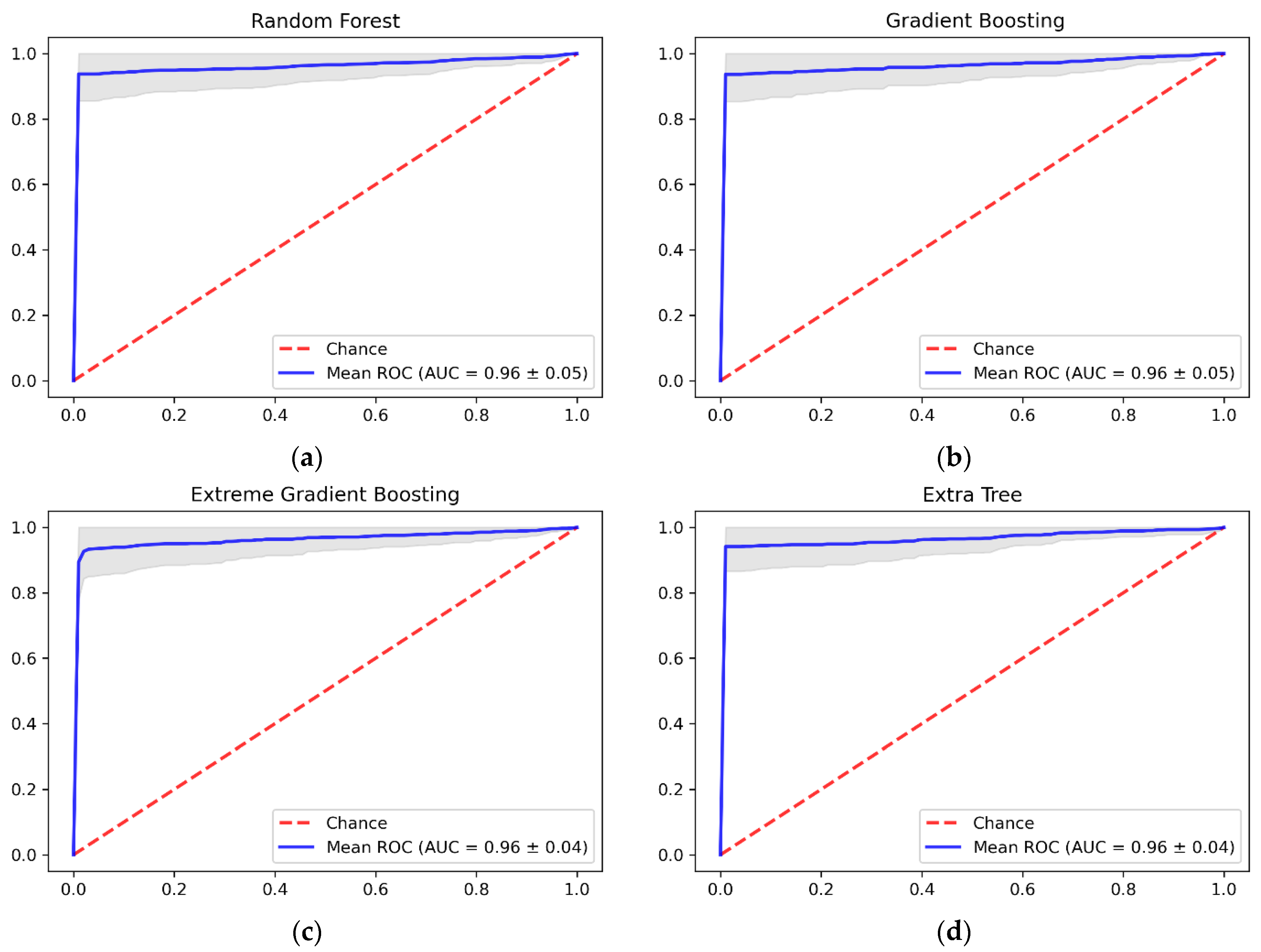
Cirrhosis, caused by extensive liver fibrosis or scarring, is frequently discovered after decompensation when its associated consequences have occurred. The performance of current non-invasive testing for the early detection of advanced liver cirrhosis is poor, with many categories being uncertain. Healthcare professionals can detect the presence of cirrhosis and chronic liver diseases using invasive tests, including liver biopsy. However, ML algorithms can be applied to analyze clinical data to detect the presence of cirrhosis to assist healthcare providers. This study aimed to use ML algorithms to identify cirrhosis in HCV patients. Four algorithms were trained using the Egyptian HCV patient’s dataset from UCI, namely, RF, GBM, XGBoost, and ET. The ET classier outperformed the other algorithms using only 16 out of 29 features, with an accuracy of 96.92%, a recall of 94.00%, a precision of 99.81%, and an AUC-ROC of 96%. Although XGBoost achieved a higher recall value, ET had the highest accuracy value. This would result in less clinical testing, possibly contributing to cost savings.
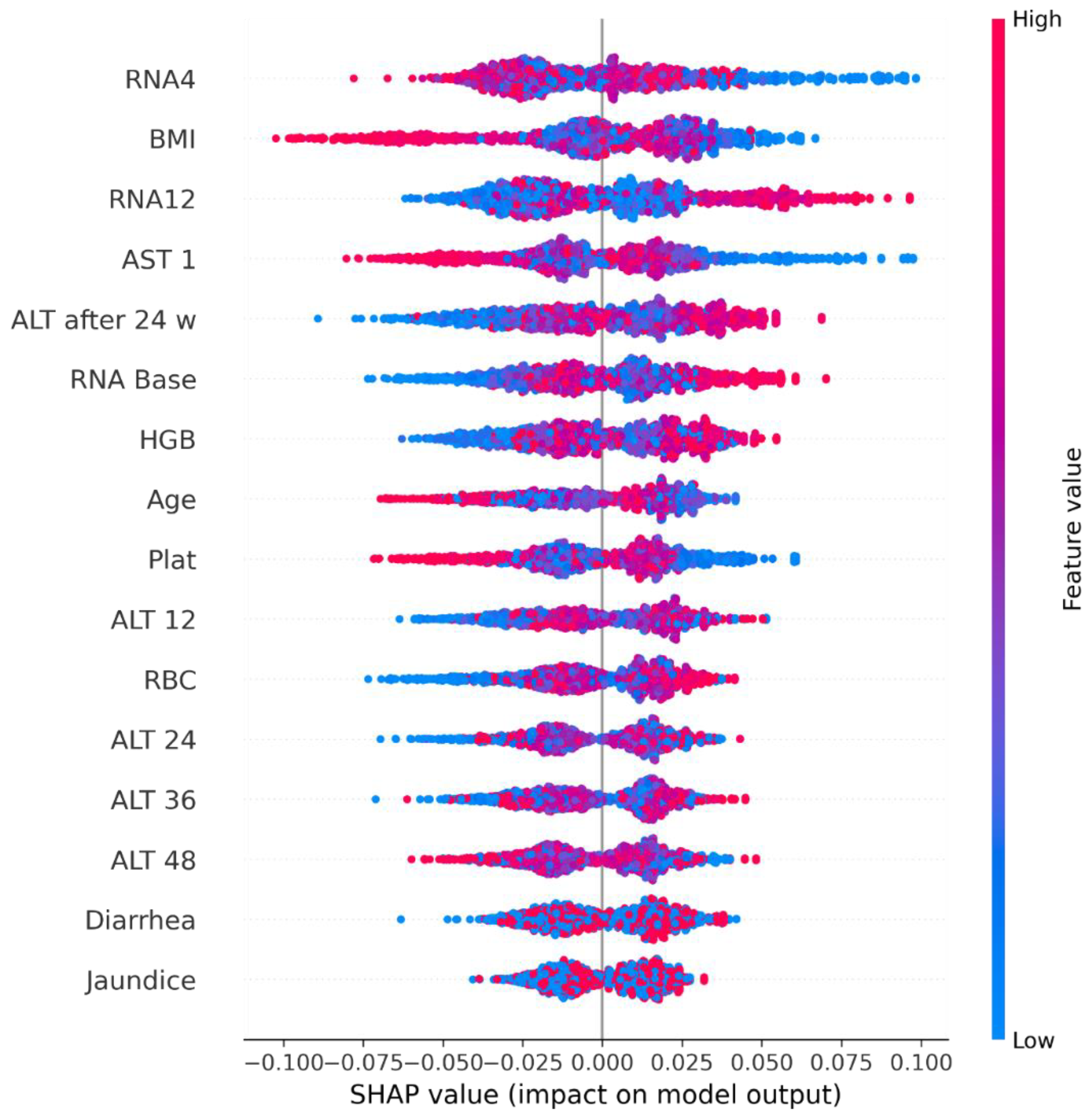
In addition, the use of XAI was implemented in order to guarantee that healthcare experts could comprehend how the algorithm makes decisions and the information utilized to train it. The results of SHAP revealed that the features with the highest importance were RNA 4, BMI, RNA 12, and AST 1. On the other hand, LIME indicated that BMI, RNA Base, ALT 48, RNA 4, and ALT36 contributed to the positive predictions of the model. The results of this study were promising, but more data on patients with cirrhosis are needed to train the model on real data rather than synthetic data. Furthermore, other stages of HCV could be investigated in the future to develop a generalized model that can predict HCV progression earlier.



 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}