

Feature Selection Using New Version of V-Shaped Transfer Function for Salp Swarm Algorithm in Sentiment Analysis

Abstract
:1. Introduction
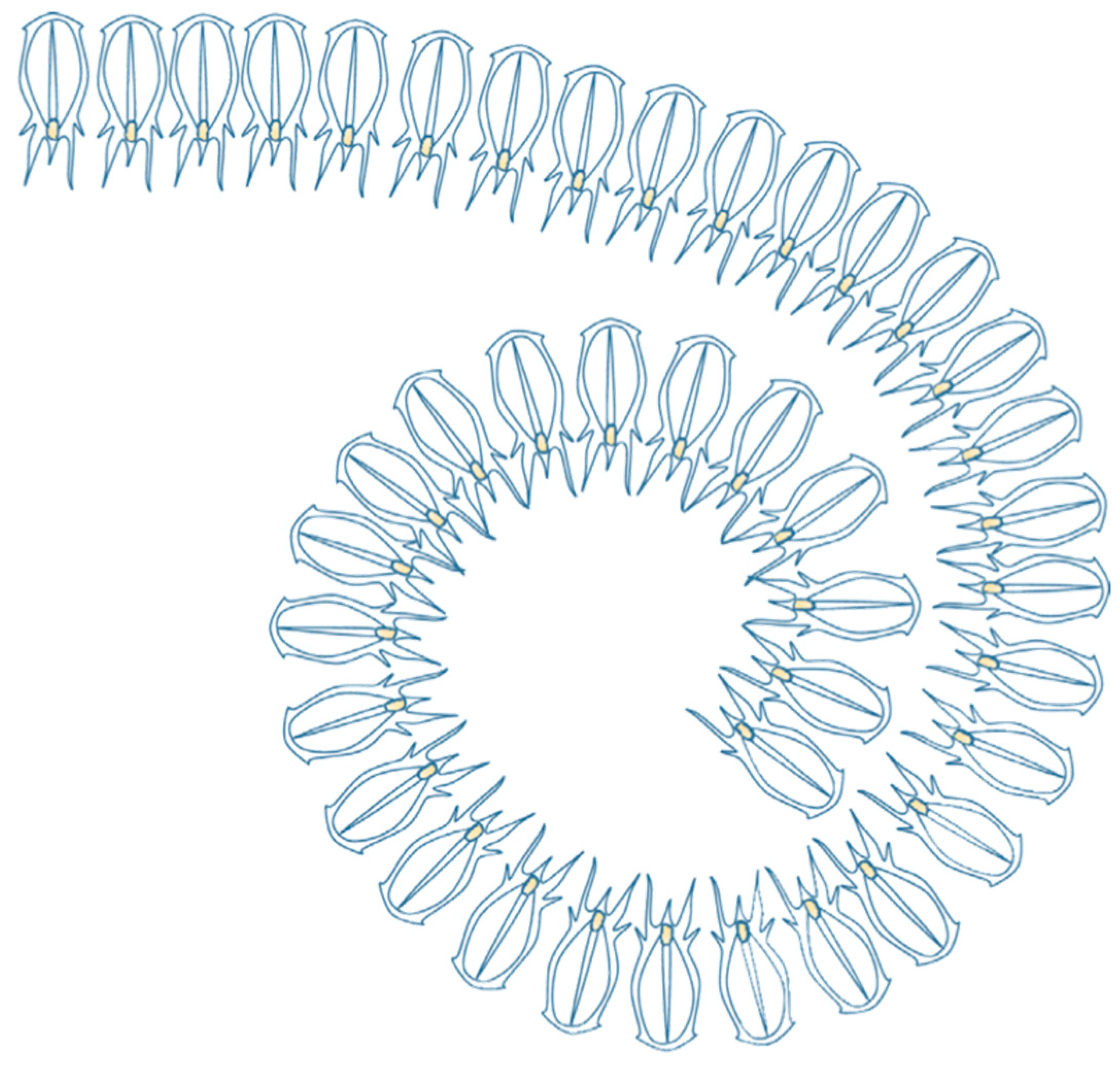
2. Salp Swarm Algorithm (SSA)
| Algorithm 1. Salp Swarm Algorithm |
| Input parameter: Population Size, Number of Iterations, Min Values, Max Values |
| (1) Initialize the salp population (considering ub and lb |
| (2) while (end condition is not satisfied) do |
| (3) calculate the fitness of each search agent (salp) |
| (4) the best search agent |
| (5) update by Equation (3) |
| (6) for each salp () |
| (7) if |
| (8) Update the position of the leading salp by Equation (2) |
| (9) else (10) Update the position of the follower salp by Equation (5) (11) end (12) end |
| (13) Amend the salps based on the upper and lower bounds of variables |
| (14) end |
| (15) return F |
| Output: Global best solution |
3. Materials and Methods
- Text Pre-Processing
- a.
- Tokenization
- b.
- Transform Case
- c.
- Filter Stopword
- d.
- Stopword Removal
- e.
- Generate N-grams
- f.
- Stemming
- 2.
- Data Partition
- 3.
- Salp Swarm Algorithm (SSA) implementation
- 4.
- Develop Classification Models
- 5.
- Model Evaluation
4. Improved of Salp Swarm Algorithm Using Transfer Function (SSA-TF)
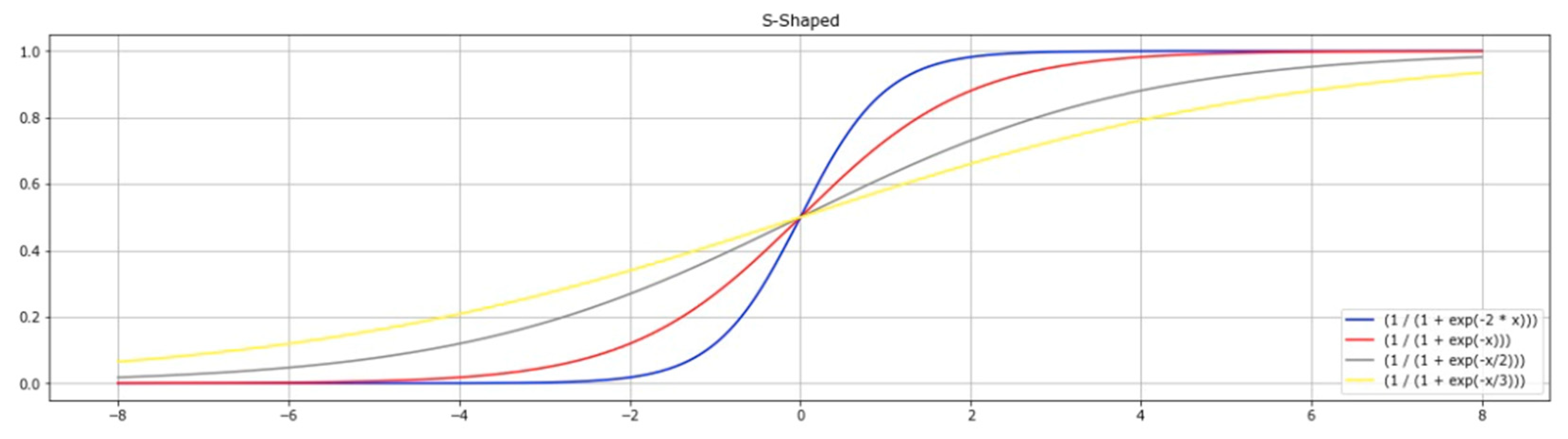
4.1. S-Shaped Transfer Function (S-TF)
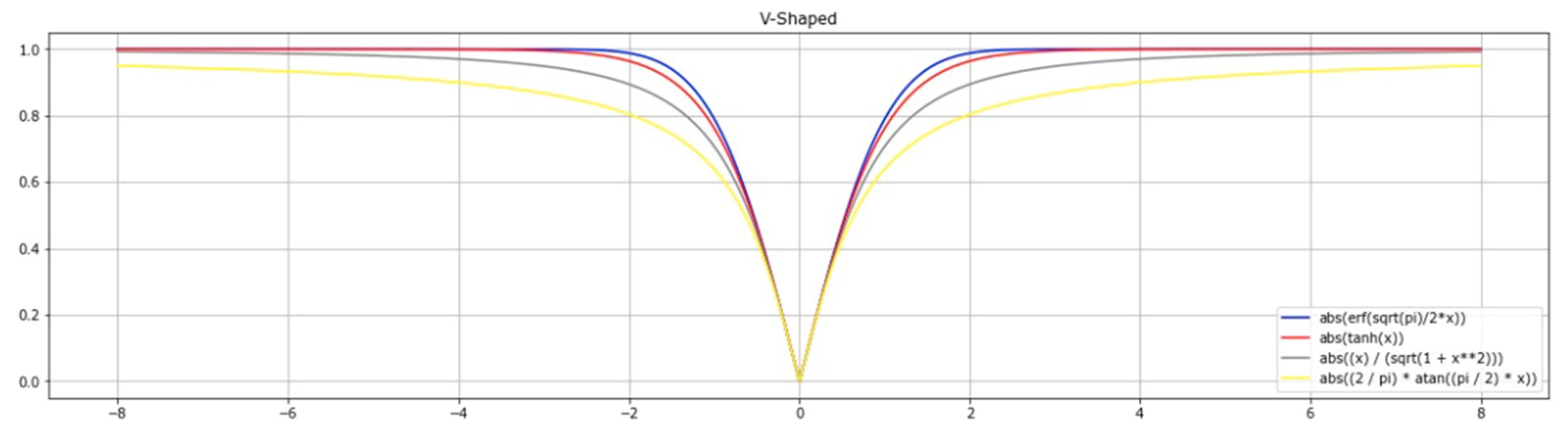
4.2. V-Shaped Transfer Function (V-TF)
4.3. X-Shaped Transfer Function (X1–X2)
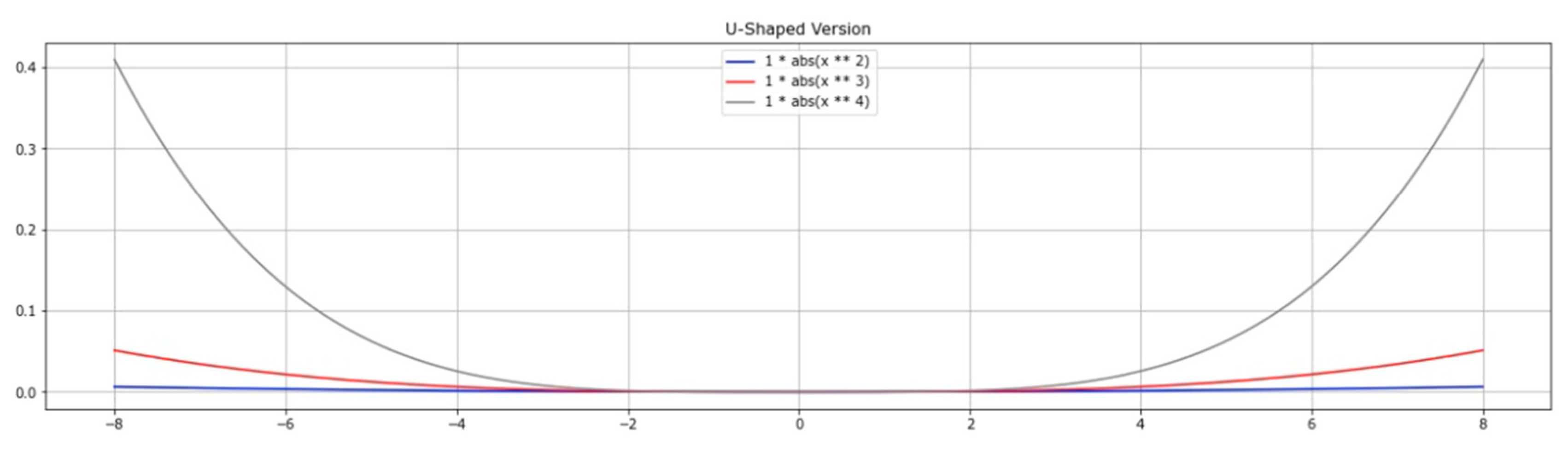
4.4. U-Shaped Transfer Function (U-TF)
4.5. Z-Shaped Transfer Function (Z-TF)
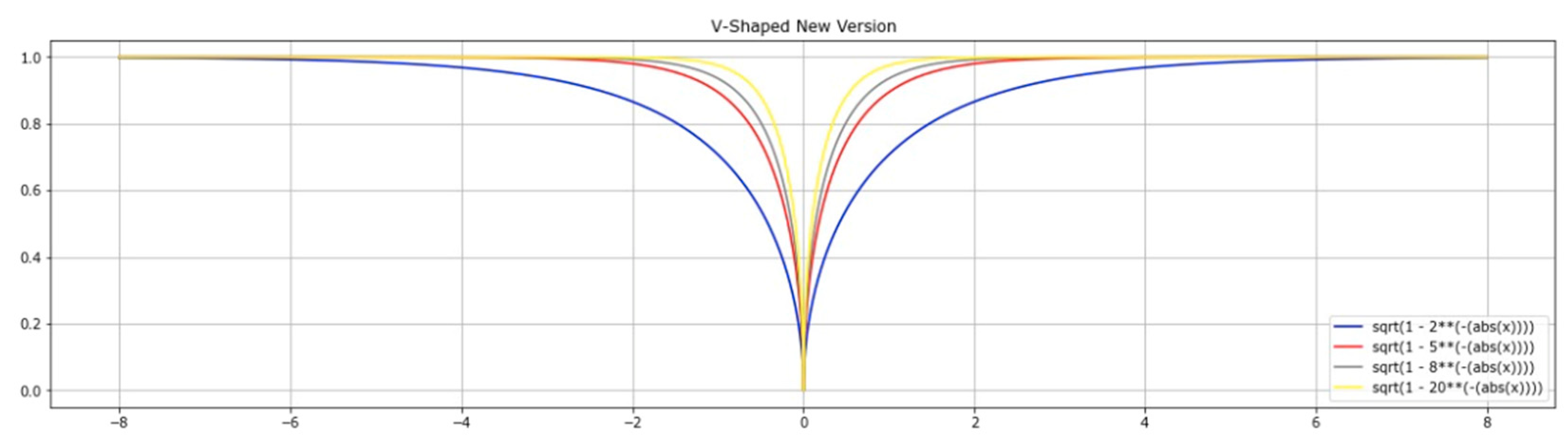
4.6. New Version V-Shaped Transfer Function (New Version V-TF)
| Algorithm 2. Salp Swarm Algorithm-Transfer Function (SSA-TF) |
| Input parameter: Population Size, Number of Iterations, Min Values, Max Values, α dan β for U-TF |
| (1) Initialize the salp population (considering ub and lb |
| (2) initialize the TF type (S-TF using Equations (6)–(9) or the V-TF using Equations (11)–(14) or the X-TF using Equations (16) and (17) or the U-TF using Equations (19)–(21) or the Z-TF using Equations (23)–(26) or the new version V-TF using Equations (28)–(31) |
| (3) while (end condition is not satisfied) do |
| (4) calculate the fitness of each search agent (salp) |
| (5) the best search agent |
| (6) update by Equation (3) |
| (7) for each salp () |
| (8) if |
| (9) based on the probability value of the TF, the SSA will determine the sampling that has the highest information based on Equation (10) for the S-TF type, or Equation (15) for the V-TF type, or Equation (18) for the X-TF type, or Equation (22) for the U-TF type, or Equation (27) for the Z-TF type, or Equation (32) for the V-TF new version type |
| (10) update the position of the leading salp using Equation (2) |
| (11) else (12) update the position of the follower salp using Equation (5) (13) end (14) end |
| (15) amend the salps based on the upper and lower bounds of variables |
| (16) end |
| (17) return F |
| Output: Global best solution |
5. Application of Salp Swarm Algorithm (SSA) Using Transfer Function (SSA-TF) for Feature Selection in Sentiment Analysis
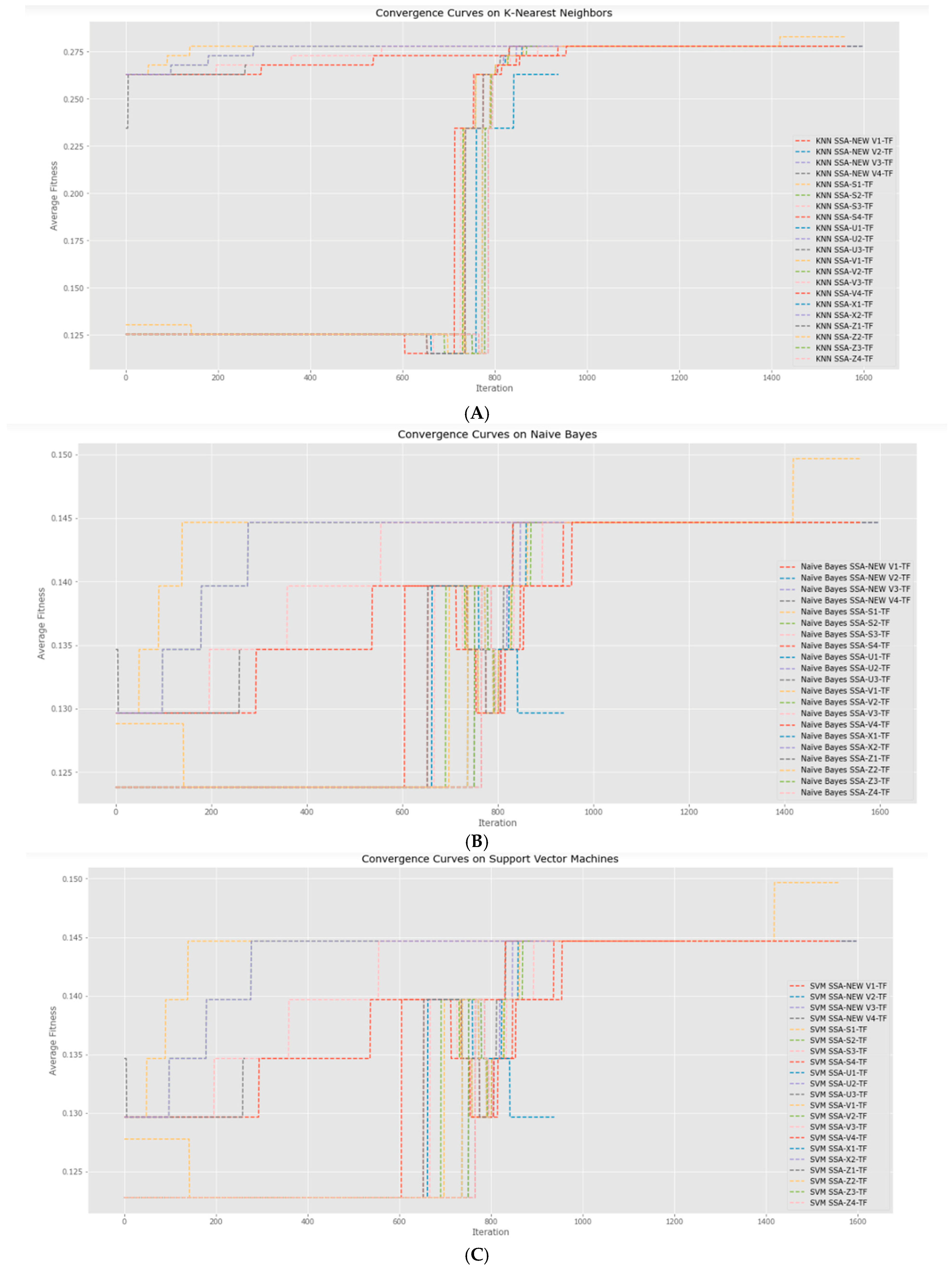
6. Experimental Results of This Study
6.1. Dataset Benchmark
6.2. Experiment Setup
6.3. Comparison Algorithms and Evaluation Metrics
6.4. Statistical Test to Support the Evaluation Metrics Results Obtained
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
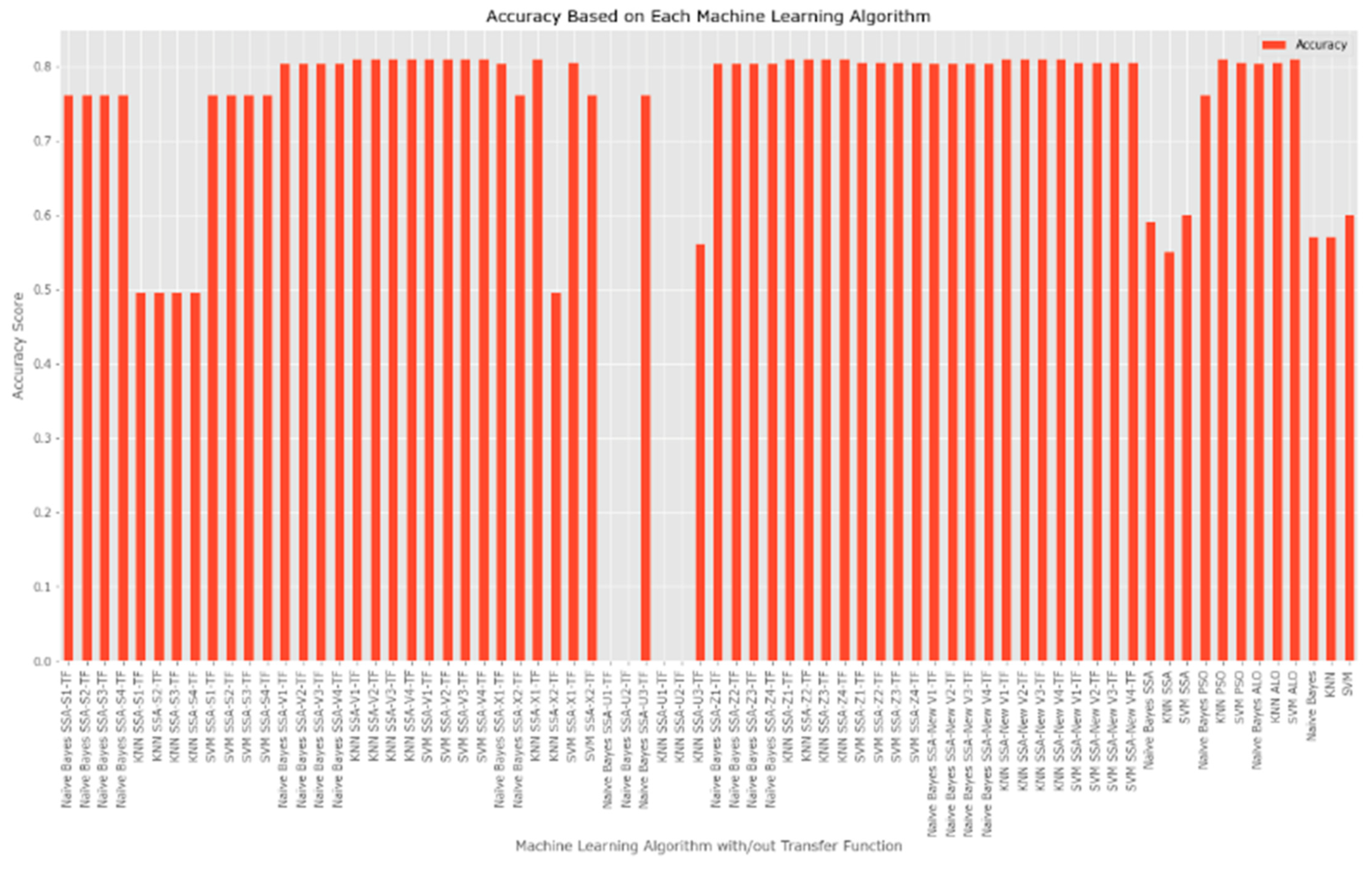
| Algorithm | TF-Family | Accuracy | Precision | Recall | F-1 | Time Processing (ns) | Feature Probability |
|---|---|---|---|---|---|---|---|
| Naive Bayes SSA-S1-TF | S-TF | 0.760679362 | 0.830447267 | 0.757222325 | 0.745670964 | 0.012069225 | 5 |
| Naive Bayes SSA-S2-TF | S-TF | 0.760679362 | 0.830447267 | 0.757222325 | 0.745670964 | 0.012586117 | 5 |
| Naive Bayes SSA-S3-TF | S-TF | 0.760679362 | 0.830447267 | 0.757222325 | 0.745670964 | 0.012335062 | 5 |
| Naive Bayes SSA-S4-TF | S-TF | 0.760679362 | 0.830447267 | 0.757222325 | 0.745670964 | 0.018228531 | 5 |
| KNN SSA-S1-TF | S-TF | 0.494081318 | 0.603785419 | 0.501490565 | 0.335142402 | 0.517837763 | 5 |
| KNN SSA-S2-TF | S-TF | 0.494081318 | 0.603785419 | 0.501490565 | 0.335142402 | 0.623624563 | 5 |
| KNN SSA-S3-TF | S-TF | 0.494081318 | 0.603785419 | 0.501490565 | 0.335142402 | 0.550310850 | 5 |
| KNN SSA-S4-TF | S-TF | 0.494081318 | 0.603785419 | 0.501490565 | 0.335142402 | 0.436069489 | 5 |
| SVM SSA-S1-TF | S-TF | 0.760679362 | 0.830447267 | 0.757222325 | 0.745670964 | 0.310822964 | 5 |
| SVM SSA-S2-TF | S-TF | 0.760679362 | 0.830447267 | 0.757222325 | 0.745670964 | 0.200889826 | 5 |
| SVM SSA-S3-TF | S-TF | 0.760679362 | 0.830447267 | 0.757222325 | 0.745670964 | 0.249196768 | 5 |
| SVM SSA-S4-TF | S-TF | 0.760679362 | 0.830447267 | 0.757222325 | 0.745670964 | 0.303336382 | 5 |
| Naive Bayes SSA-V1-TF | V-TF | 0.802367473 | 0.830447267 | 0.803337636 | 0.801810532 | 0.010612965 | 6 |
| Naive Bayes SSA-V2-TF | V-TF | 0.802367473 | 0.830447267 | 0.803337636 | 0.801810532 | 0.038087845 | 5 |
| Naive Bayes SSA-V3-TF | V-TF | 0.802367473 | 0.830447267 | 0.803337636 | 0.801810532 | 0.010998964 | 5 |
| Naive Bayes SSA-V4-TF | V-TF | 0.802367473 | 0.830447267 | 0.803337636 | 0.801810532 | 0.014706612 | 5 |
| KNN SSA-V1-TF | V-TF | 0.809572826 | 0.840406878 | 0.807548098 | 0.805325383 | 0.523573875 | 6 |
| KNN SSA-V2-TF | V-TF | 0.809572826 | 0.840406878 | 0.807548098 | 0.805325383 | 0.603285313 | 5 |
| KNN SSA-V3-TF | V-TF | 0.809572826 | 0.840406878 | 0.807548098 | 0.805325383 | 0.473382950 | 5 |
| KNN SSA-V4-TF | V-TF | 0.809572826 | 0.840406878 | 0.807548098 | 0.805325383 | 0.487081051 | 5 |
| SVM SSA-V1-TF | V-TF | 0.809572826 | 0.840406878 | 0.807548098 | 0.805325383 | 0.563572645 | 6 |
| SVM SSA-V2-TF | V-TF | 0.809572826 | 0.840406878 | 0.807548098 | 0.805325383 | 0.399179459 | 5 |
| SVM SSA-V3-TF | V-TF | 0.809572826 | 0.840406878 | 0.807548098 | 0.805325383 | 0.642655611 | 5 |
| SVM SSA-V4-TF | V-TF | 0.809572826 | 0.840406878 | 0.807548098 | 0.805325383 | 0.621925592 | 5 |
| Naive Bayes SSA-X1-TF | X-TF | 0.802367473 | 0.830447267 | 0.803337636 | 0.801810532 | 0.007063866 | 5 |
| Naive Bayes SSA-X2-TF | X-TF | 0.760679362 | 0.830447267 | 0.757222325 | 0.745670964 | 0.007018566 | 5 |
| KNN SSA-X1-TF | X-TF | 0.809572826 | 0.840406878 | 0.807548098 | 0.805325383 | 0.476012707 | 5 |
| KNN SSA-X2-TF | X-TF | 0.494081318 | 0.603785419 | 0.501490565 | 0.335142402 | 0.406121969 | 5 |
| SVM SSA-X1-TF | X-TF | 0.804426145 | 0.830447267 | 0.803014936 | 0.802180902 | 0.522874117 | 5 |
| SVM SSA-X2-TF | X-TF | 0.760679362 | 0.830447267 | 0.757222325 | 0.745670964 | 0.243289471 | 5 |
| Naive Bayes SSA-U1-TF | U-TF | 0 | 0 | 0 | 0 | 0 | 0 |
| Naive Bayes SSA-U2-TF | U-TF | 0 | 0 | 0 | 0 | 0 | 0 |
| Naive Bayes SSA-U3-TF | U-TF | 0.760679362 | 0.830447267 | 0.757222325 | 0.745670964 | 0.005551100 | 3 |
| KNN SSA-U1-TF | U-TF | 0 | 0 | 0 | 0 | 0 | 0 |
| KNN SSA-U2-TF | U-TF | 0 | 0 | 0 | 0 | 0 | 0 |
| KNN SSA-U3-TF | U-TF | 0.560988163 | 0.646807540 | 0.566522220 | 0.494644980 | 0.192241669 | 3 |
| SVM SSA-U1-TF | U-TF | 0 | 0 | 0 | 0 | 0 | 0 |
| SVM SSA-U2-TF | U-TF | 0 | 0 | 0 | 0 | 0 | 0 |
| SVM SSA-U3-TF | U-TF | 0.760679362 | 0.830447267 | 0.757222325 | 0.745670964 | 0.118218000 | 3 |
| Naive Bayes SSA-Z1-TF | Z-TF | 0.802367473 | 0.830447267 | 0.803337636 | 0.801810532 | 0.011059284 | 5 |
| Naive Bayes SSA-Z2-TF | Z-TF | 0.802367473 | 0.830447267 | 0.803337636 | 0.801810532 | 0.012661219 | 5 |
| Naive Bayes SSA-Z3-TF | Z-TF | 0.802367473 | 0.830447267 | 0.803337636 | 0.801810532 | 0.012352228 | 5 |
| Naive Bayes SSA-Z4-TF | Z-TF | 0.802367473 | 0.830447267 | 0.803337636 | 0.801810532 | 0.016859770 | 5 |
| KNN SSA-Z1-TF | Z-TF | 0.809572826 | 0.840406878 | 0.807548098 | 0.805325383 | 0.482684851 | 5 |
| KNN SSA-Z2-TF | Z-TF | 0.809572826 | 0.840406878 | 0.807548098 | 0.805325383 | 0.488482714 | 5 |
| KNN SSA-Z3-TF | Z-TF | 0.809572826 | 0.840406878 | 0.807548098 | 0.805325383 | 0.436493635 | 5 |
| KNN SSA-Z4-TF | Z-TF | 0.809572826 | 0.840406878 | 0.807548098 | 0.805325383 | 0.623229980 | 5 |
| SVM SSA-Z1-TF | Z-TF | 0.804426145 | 0.830447267 | 0.803014936 | 0.802180902 | 0.410887957 | 5 |
| SVM SSA-Z2-TF | Z-TF | 0.804426145 | 0.830447267 | 0.803014936 | 0.802180902 | 0.414152384 | 5 |
| SVM SSA-Z3-TF | Z-TF | 0.804426145 | 0.830447267 | 0.803014936 | 0.802180902 | 0.493735790 | 5 |
| SVM SSA-Z4-TF | Z-TF | 0.804426145 | 0.830447267 | 0.803014936 | 0.802180902 | 0.438720942 | 5 |
| Naive Bayes SSA-New V1-TF | New V-TF | 0.802367473 | 0.830447267 | 0.803337636 | 0.801810532 | 0.010612965 | 6 |
| Naive Bayes SSA-New V2-TF | New V-TF | 0.802367473 | 0.830447267 | 0.803337636 | 0.801810532 | 0.038087845 | 5 |
| Naive Bayes SSA-New V3-TF | New V-TF | 0.802367473 | 0.830447267 | 0.803337636 | 0.801810532 | 0.010998964 | 5 |
| Naive Bayes SSA-New V4-TF | New V-TF | 0.802367473 | 0.830447267 | 0.803337636 | 0.801810532 | 0.014706612 | 5 |
| KNN SSA-New V1-TF | New V-TF | 0.809572826 | 0.840406878 | 0.807548098 | 0.805325383 | 0.603285313 | 5 |
| KNN SSA-New V2-TF | New V-TF | 0.809572826 | 0.840406878 | 0.807548098 | 0.805325383 | 0.473382950 | 5 |
| KNN SSA-New V3-TF | New V-TF | 0.809572826 | 0.840406878 | 0.807548098 | 0.805325383 | 0.388332605 | 5 |
| KNN SSA-New V4-TF | New V-TF | 0.809572826 | 0.840406878 | 0.807548098 | 0.805325383 | 0.893996000 | 5 |
| SVM SSA-New V1-TF | New V-TF | 0.804426145 | 0.830447267 | 0.803014936 | 0.802180902 | 0.399179459 | 5 |
| SVM SSA-New V2-TF | New V-TF | 0.804426145 | 0.830447267 | 0.803014936 | 0.802180902 | 0.642655611 | 5 |
| SVM SSA-New V3-TF | New V-TF | 0.804426145 | 0.830447267 | 0.803014936 | 0.802180902 | 0.621925592 | 5 |
| SVM SSA-New V4-TF | New V-TF | 0.804426145 | 0.830447267 | 0.803014936 | 0.802180902 | 0.695250034 | 5 |
| Naive Bayes SSA | - | 0.59 | 0.196667 | 0.333333 | 0.244522 | 1,455,331,000 | 5 |
| KNN SSA | - | 0.55 | 0.343373 | 0.42504 | 0.366227 | 1,879,957,000 | 5 |
| SVM SSA | - | 0.6 | 0.232963 | 0.366667 | 0.279599 | 1,336,488,000 | 5 |
| Naive Bayes PSO | - | 0.760679 | 0.830447 | 0.757222 | 0.745671 | 4,576,292,000 | 5 |
| KNN PSO | - | 0.809573 | 0.807548 | 0.840407 | 0.805325 | 2,187,501,000 | 5 |
| SVM PSO | - | 0.804426 | 0.830447 | 0.803015 | 0.802181 | 5,704,434,000 | 5 |
| Naive Bayes ALO | - | 0.802367 | 0.810447 | 0.807548 | 0.805325 | 1,462,639,000 | 5 |
| KNN ALO | - | 0.804426 | 0.790432 | 0.803015 | 0.802181 | 2,108,248,000 | 5 |
| SVM ALO | - | 0.809573 | 0.820741 | 0.801811 | 0.803338 | 1,229,433,000 | 5 |
| Naive Bayes | - | 0.57 | 0.200741 | 0.333333333 | 0.247703 | 1,283,777,000 | 5 |
| KNN | - | 0.57 | 0.195 | 0.325 | 0.239893 | 1,330,194,000 | 5 |
| SVM | - | 0.6 | 0.232963 | 0.366667 | 0.279599 | 1,141,390,000 | 5 |
Appendix B


References
- W. are S. Hootsuite. Digital 2022 Global Overview Report. 26 January 2022. Available online: https://wearesocial.com/sg/blog/2022/01/digital-2022-another-year-of-bumper-growth/ (accessed on 2 February 2020).
- Arif, M.H.; Li, J.; Iqbal, M.; Liu, K. Sentiment analysis and spam detection in short informal text using learning classifier systems. Soft Comput. 2018, 22, 7281–7291. [Google Scholar] [CrossRef]
- Hangya, V.; Farkas, R. A comparative empirical study on social media sentiment analysis over various genres and languages. Artif. Intell. Rev. 2017, 47, 485–505. [Google Scholar] [CrossRef]
- Agarwal, A.; Toshniwal, D. Application of Lexicon Based Approach in Sentiment Analysis for short Tweets. In Proceedings of the 2018 International Conference on Advances in Computing and Communication Engineering, ICACCE 2018, Paris, France, 22–23 June 2018; pp. 189–193. [Google Scholar] [CrossRef]
- Pandey, A.C.; Rajpoot, D.S. Improving Sentiment Analysis using Hybrid Deep Learning Model. Recent Adv. Comput. Sci. Commun. 2019, 13, 627–640. [Google Scholar] [CrossRef]
- Binsar, F.; Mauritsius, T. Mining of Social Media on Covid-19 Big Data Infodemic in Indonesia. J. Comput. Sci. 2020, 16, 1598–1609. [Google Scholar] [CrossRef]
- Wrycza, S.; Maślankowski, J. Social Media Users’ Opinions on Remote Work during the COVID-19 Pandemic. Thematic and Sentiment Analysis. Inf. Syst. Manag. 2020, 37, 288–297. [Google Scholar] [CrossRef]
- Dhaoui, C.; Webster, C.M.; Tan, L.P. Social media sentiment analysis: Lexicon versus machine learning. J. Consum. Mark. 2017, 34, 480–488. [Google Scholar] [CrossRef]
- Hartmann, J.; Huppertz, J.; Schamp, C.; Heitmann, M. Comparing automated text classification methods. Int. J. Res. Mark. 2019, 36, 20–38. [Google Scholar] [CrossRef]
- Ahmad, S.R.; Bakar, A.A.; Yaakub, M.R. A review of feature selection techniques in sentiment analysis. Intell. Data Anal. 2019, 23, 159–189. [Google Scholar] [CrossRef]
- Deniz, A.; Angin, M.; Angin, P. Evolutionary Multiobjective Feature Selection for Sentiment Analysis. IEEE Access 2021, 9, 142982–142996. [Google Scholar] [CrossRef]
- Nafis, N.S.M.; Awang, S. An Enhanced Hybrid Feature Selection Technique Using Term Frequency-Inverse Document Frequency and Support Vector Machine-Recursive Feature Elimination for Sentiment Classification. IEEE Access 2021, 9, 52177–52192. [Google Scholar] [CrossRef]
- Abdi, A.; Shamsuddin, S.M.; Hasan, S.; Piran, J. Machine learning-based multi-documents sentiment-oriented summarization using linguistic treatment. Expert Syst. Appl. 2018, 109, 66–85. [Google Scholar] [CrossRef]
- Naz, M.; Zafar, K.; Khan, A. Ensemble based classification of sentiments using forest optimization algorithm. Data 2019, 4, 76. [Google Scholar] [CrossRef]
- Hassonah, M.A.; Al-Sayyed, R.; Rodan, A.; Al-Zoubi, A.M.; Aljarah, I.; Faris, H. An efficient hybrid filter and evolutionary wrapper approach for sentiment analysis of various topics on Twitter. Knowl. -Based Syst. 2020, 192, 105353. [Google Scholar] [CrossRef]
- Bahassine, S.; Madani, A.; Al-Sarem, M.; Kissi, M. Feature selection using an improved Chi-square for Arabic text classification. J. King Saud Univ. - Comput. Inf. Sci. 2020, 32, 225–231. [Google Scholar] [CrossRef]
- Tubishat, M.; Ja’Afar, S.; Alswaitti, M.; Mirjalili, S.; Idris, N.; Ismail, M.A.; Omar, M.S. Dynamic Salp swarm algorithm for feature selection. Expert Syst. Appl. 2021, 164, 113873. [Google Scholar] [CrossRef]
- Yang, X.-S. Engineering Optimization an Introduction with Metaheuristic Applications; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2010. [Google Scholar]
- Ahmad, S.R.; Bakar, A.A.; Yaakub, M.R. Ant colony optimization for text feature selection in sentiment analysis. Intell. Data Anal. 2019, 23, 133–158. [Google Scholar] [CrossRef]
- Chen, H.; Jiang, W.; Li, C.; Li, R. A heuristic feature selection approach for text categorization by using chaos optimization and genetic algorithm. Math. Probl. Eng. 2013, 2013, 524017. [Google Scholar] [CrossRef]
- Alghamdi, H.S.; Tang, H.L.; Alshomrani, S. Hybrid ACO and TOFA feature selection approach for text classification. In Proceedings of the 2012 IEEE Congr. EComput. CEC 2012, Brisbane, QLD, Australia, 10–15 June 2012; pp. 10–15. [Google Scholar] [CrossRef]
- Ramasamy, L.K.; Kadry, S.; Lim, S. Selection of optimal hyper-parameter values of support vector machine for sentiment analysis tasks using nature-inspired optimization methods. Bull. Electr. Eng. Inform. 2021, 10, 290–298. [Google Scholar] [CrossRef]
- Aghdam, M.H.; Ghasem-Aghaee, N.; Basiri, M.E. Text feature selection using ant colony optimization. Expert Syst. Appl. 2009, 36, 6843–6853. [Google Scholar] [CrossRef]
- Qiu, C. A novel multi-swarm particle swarm optimization for feature selection. Genet. Program. Evolvable Mach. 2019, 20, 503–529. [Google Scholar] [CrossRef]
- Selvi, V.; Umarani, D.R. Comparative Analysis of Ant Colony and Particle Swarm Optimization Techniques. Int. J. Comput. Appl. 2010, 5, 1–6. [Google Scholar] [CrossRef]
- Zahran, B.M.; Kanaan, G. Text Feature Selection using Particle Swarm Optimization Algorithm. World Appl. Sci. J. Spec. Issue Comput. IT 2009, 7, 69–74. [Google Scholar]
- Tabassum, M. A Genetic Algorithm Analysis Towards Optimization Solutions. Int. J. Digit. Inf. Wirel. Commun. 2014, 4, 124–142. [Google Scholar] [CrossRef]
- Mirjalili, S.; Gandomi, A.H.; Mirjalili, S.Z.; Saremi, S.; Faris, H.; Mirjalili, S.M. Salp Swarm Algorithm: A bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 2017, 114, 163–191. [Google Scholar] [CrossRef]
- Al-Rayes, H.T.; Ibrahim, H.T.; Mazher, W.J.; Ucan, O.N.; Bayat, O. Feature Selection using Salp Swarm Algorithm for Real Biomedical Datasets Recent heuristic optimization algorithms in feature selection View project Feature Selection using Salp Swarm Algorithm for Real Biomedical Datasets. IJCSNS Int. J. Comput. Sci. Netw. Secur. 2017, 17, 13–20. [Google Scholar]
- Alsaleh, A.; Binsaeedan, W. The influence of salp swarm algorithm-based feature selection on network anomaly intrusion detection. IEEE Access 2021, 9, 112466–112477. [Google Scholar] [CrossRef]
- Yan, C.; Suo, Z.; Guan, X.; Luo, H. A novel feature selection method based on salp swarm algorithm. In Proceedings of the 2021 IEEE International Conference on Information Communication and Software Engineering, ICICSE 2021, Chengdu, China, 19–21 March 2021; pp. 126–130. [Google Scholar] [CrossRef]
- Alzaqebah, A.; Smadi, B.; Hammo, B.H. Arabic Sentiment Analysis Based on Salp Swarm Algorithm with S-shaped Transfer Functions. In Proceedings of the 2020 International Conference on Information and Communication Systems ICICS 2020, Irbid, Jordan, 7–9 April 2020; pp. 179–184. [Google Scholar] [CrossRef]
- Mafarja, M.; Eleyan, D.; Abdullah, S.; Mirjalili, S. S-shaped vs. V-shaped transfer functions for ant lion optimization algorithm in feature selection problem. In Proceedings of the ICFNDS ’17: Proceedings of the International Conference on Future Networks and Distributed Systems, Cambridge, UK, 19–20 July 2017. [Google Scholar] [CrossRef]
- Too, J.; Abdullah, A.R.; Saad, N.M. Binary competitive swarm optimizer approaches for feature selection. Computation 2019, 7, 31. [Google Scholar] [CrossRef]
- Ahmed, S.; Ghosh, K.K.; Mirjalili, S.; Sarkar, R. AIEOU: Automata-based improved equilibrium optimizer with U-shaped transfer function for feature selection. Knowl. -Based Syst. 2021, 228, 107283. [Google Scholar] [CrossRef]
- Ghosh, K.K.; Singh, P.K.; Hong, J.; Geem, Z.W.; Sarkar, R. Binary social mimic optimization algorithm with X-shaped transfer function for feature selection. IEEE Access 2020, 8, 97890–97906. [Google Scholar] [CrossRef]
- Mirjalili, S.; Zhang, H.; Mirjalili, S.; Chalup, S.; Noman, N. A Novel U-Shaped Transfer Function for Binary Particle Swarm Optimisation. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2020; Volume 1138, pp. 241–259. [Google Scholar] [CrossRef]
- Faris, H.; Mafarja, M.; Heidari, A.; Aljarah, I.; Al-Zoubi, M.; Mirjalili, S.; Fujita, H. An efficient binary Salp Swarm Algorithm with crossover scheme for feature selection problems. Knowl. -Based Syst. 2018, 154, 43–67. [Google Scholar] [CrossRef]
- Hegazy, A.E.; Makhlouf, M.A.; El-Tawel, G.S. Improved salp swarm algorithm for feature selection. J. King Saud Univ. - Comput. Inf. Sci. 2020, 32, 335–344. [Google Scholar] [CrossRef]
- Ahmed, S.; Mafarja, M.; Faris, H.; Aljarah, I. Feature selection using salp swarm algorithm with chaos. In Proceedings of the ACM International Conference Proceeding Series, Phuket, Thailand, 24–25 March 2018; pp. 65–69. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, J.S. Improved Salp Swarm Algorithm Based on Levy Flight and Sine Cosine Operator. IEEE Access 2020, 8, 99740–99771. [Google Scholar] [CrossRef]
- Abualigah, L.; Shehab, M.; Alshinwan, M.; Alabool, H. Salp swarm algorithm: A comprehensive survey. Neural Comput. Appl. 2020, 32, 11195–11215. [Google Scholar] [CrossRef]
- Kaveh, A.; Talatahari, S. A novel heuristic optimization method: Charged system search. Acta Mech. 2010, 213, 267–289. [Google Scholar] [CrossRef]
- E. Figure. Twitter US Airline Sentiment. Kaggle.com. 2015. Available online: https://www.kaggle.com/datasets/crowdflower/twitter-airline-sentiment (accessed on 31 August 2021).
- Mirjalili, S.; Lewis, A. S-shaped versus V-shaped transfer functions for binary Particle Swarm Optimization. Swarm EComput. 2013, 9, 1–14. [Google Scholar] [CrossRef]
- Mirjalili, S.; Hashim, S.Z.M. BMOA: Binary Magnetic Optimization Algorithm. Int. J. Mach. Learn. Comput. 2012, 2, 204–208. [Google Scholar] [CrossRef]
- Qasim, O.S.; Algamal, Z.Y. Feature selection using different transfer functions for binary bat. Int. J. Math. Eng. Manag. Sci. 2020, 5, 697–706. [Google Scholar] [CrossRef]
- Emary, E.; Zawbaa, H.M.; Hassanien, A.E. Binary grey wolf optimization approaches for feature selection. Neurocomputing 2016, 172, 371–381. [Google Scholar] [CrossRef]
- Mafarja, M.; Aljarah, I.; Faris, H.; Hammouri, A.I.; Al-Zoubi, A.M.; Mirjalili, S. Binary grasshopper optimisation algorithm approaches for feature selection problems. Expert Syst. Appl. 2019, 117, 267–286. [Google Scholar] [CrossRef]
- Ghosh, K.K.; Guha, R.; Bera, S.K.; Kumar, N.; Sarkar, R. S-shaped versus V-shaped transfer functions for binary Manta ray foraging optimization in feature selection problem. Neural Comput. Appl. 2021, 33, 11027–11041. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Yang, X.S. Binary bat algorithm. Neural Comput. Appl. 2014, 25, 663–681. [Google Scholar] [CrossRef]
- Rizk-Allah, R.M.; Hassanien, A.E.; Elhoseny, M.; Gunasekaran, M. A new binary salp swarm algorithm: Development and application for optimization tasks. Neural Comput. Appl. 2019, 31, 1641–1663. [Google Scholar] [CrossRef]
- Guo, S.S.; Wang, J.S.; Wang, J.S.; Guo, M.W. Z-Shaped Transfer Functions for Binary Particle Swarm Optimization Algorithm. Comput. Intell. Neurosci. 2020, 2020, 6502807. [Google Scholar] [CrossRef] [PubMed]
- Aljarah, I.; Mafarja, M.; Heidari, A.A.; Faris, H.; Zhang, Y.; Mirjalili, S. Asynchronous accelerating multi-leader salp chains for feature selection. Appl. Soft Comput. J. 2018, 71, 964–979. [Google Scholar] [CrossRef]
- Ottom, M.A.; Nahar, K.M.O. Social Media Sentiment Analysis: The Hajj Tweets Case Study. J. Comput. Sci. 2021, 17, 265–274. [Google Scholar] [CrossRef]









| Parameter | Value |
|---|---|
| in k-nearest neighbor | 25 |
| Bernoulli, Gaussian and multinomial type in naïve Bayes | Bernoulli |
| Linear, polynomial and RBF type in support vector machine | Linear |
| C in support vector machine | 1 |
| Population size in SSA | 10 |
| Number of iterations in SSA | 10 |
| Min. values in SSA | 5 |
| Max. values in SSA | 50 |
| Population size in PSO | 250 |
| Number of iterations in PSO | 10 |
| Min. values in PSO | 5 |
| Max. values in PSO | 50 |
| (inertia weight) in PSO | 0.9 |
| in PSO | 2 |
| Exponential decay weight in PSO | 0 |
| Verbosity level of the screen output in PSO | True |
| Number of iterations in ALO | 10 |
| Min. values in ALO | 5 |
| Max. values in ALO | 50 |
| Dimension | Number of features |
| in K-fold cross validation | 10 |
| Transfer function | (−8, 8) with different per step 0.01 |
| Max df in TfidfVectorizer | 0.7 |
| Min df in TfidfVectorizer | 0.1 |
| Max features in TfidfVectorizer | 100 |
| N-gram range in TfidfVectorizer | (1, 2) |
| Stopwords in TfidfVectorizer | English |
| t-Statistic | p-Value | Compared Algorithm |
|---|---|---|
| 0.9973 | SSA-S-TF | |
| −2.3452 | 0.01941 | SSA-V-TF |
| 1.3242 | 0.8786 | SSA-X-TF |
| 4.1287 | 0.9955 | SSA-U-TF |
| NA | NA | SSA-Z-TF |
| t-Statistic | p-Value | Compared Algorithm |
|---|---|---|
| 0.9628 | SSA-S-TF | |
| 0.73696 | 0.7617 | SSA-V-TF |
| 1.1743 | 0.8534 | SSA-X-TF |
| 3.6943 | 0.997 | SSA-U-TF |
| 2.3491 | 0.9807 | SSA-Z-TF |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kristiyanti, D.A.; Sitanggang, I.S.; Annisa; Nurdiati, S. Feature Selection Using New Version of V-Shaped Transfer Function for Salp Swarm Algorithm in Sentiment Analysis. Computation 2023, 11, 56. https://doi.org/10.3390/computation11030056
Kristiyanti DA, Sitanggang IS, Annisa, Nurdiati S. Feature Selection Using New Version of V-Shaped Transfer Function for Salp Swarm Algorithm in Sentiment Analysis. Computation. 2023; 11(3):56. https://doi.org/10.3390/computation11030056
Chicago/Turabian StyleKristiyanti, Dinar Ajeng, Imas Sukaesih Sitanggang, Annisa, and Sri Nurdiati. 2023. "Feature Selection Using New Version of V-Shaped Transfer Function for Salp Swarm Algorithm in Sentiment Analysis" Computation 11, no. 3: 56. https://doi.org/10.3390/computation11030056