On Fitting the Lomax Distribution: A Comparison between Minimum Distance Estimators and Other Estimation Techniques


School of Mathematical and Statistical Sciences, North-West University, Potchefstroom 2520, South Africa
*
Author to whom correspondence should be addressed.
Computation 2023, 11(3), 44; https://doi.org/10.3390/computation11030044
Submission received: 27 November 2022
/
Revised: 15 February 2023
/
Accepted: 16 February 2023
/
Published: 23 February 2023
(This article belongs to the Section Computational Engineering)
Abstract
:In this paper, we investigate the performance of a variety of frequentist estimation techniques for the scale and shape parameters of the Lomax distribution. These methods include traditional methods such as the maximum likelihood estimator and the method of moments estimator. A version of the maximum likelihood estimator adjusted for bias is included as well. Furthermore, an alternative moment-based estimation technique, the L-moment estimator, is included, along with three different minimum distance estimators. The finite sample performances of each of these estimators are compared in an extensive Monte Carlo study. We find that no single estimator outperforms its competitors uniformly. We recommend one of the minimum distance estimators for use with smaller samples, while a bias-reduced version of maximum likelihood estimation is recommended for use with larger samples. In addition, the desirable asymptotic properties of traditional maximum likelihood estimators make them appealing for larger samples. We include a practical application demonstrating the use of the described techniques on observed data.
1. Introduction
The Pareto distribution is a heavy-tailed distribution that was originally developed in the 19th century to model the distribution of income among individuals [1]. However, in the years following its introduction it has been extensively modified and changed to produce several variants, referred to as the Type I, II, III, and IV Pareto distributions, as well as the so-called generalised Pareto distribution (GPD). The focus of this paper is on the Pareto Type II distribution, in which the location parameter is zero, which is known as the Lomax distribution. This rather popular distribution was originally introduced to model business failure data [2], and has subsequently been employed as a model in a wide range of settings. This distribution has proven useful in modelling survival times when censoring is present, e.g., in the lifetimes of electric power transformers [3]; as the times are left-truncated and right-censored, when they are modelled it is found that the Lomax distribution provides the best fit among the various distributions considered. As another example, the exponential Lomax and Weibull Lomax are a good fit for right-censored lung cancer survival data [4].
Other scenarios in which the Lomax distribution has been used as a model include wealth distribution [5], the distribution of queueing service times [6], life testing [7], and the sizes of files on a computer server [8], to name only a few.
We can say that a random variable X follows a Lomax distribution with scale parameter and shape parameter if its cumulative distribution function (CDF) is
with a probability density function (PDF) of
In this paper, we investigate different approaches used for estimating the parameters of the Lomax distribution. We draw parallels with the methods used to estimate the parameters of other distributions in order to ascertain how one might go about obtaining reliable estimators. For example, when considering the estimation of the parameters of the GPD, a number of approaches have been studied, such as maximum likelihood estimation (MLE), method of moment estimation (MME), L-moment estimation (LME), and probability-weighted moment estimation (PWME). However, not all approaches are equally viable in all settings. It was noted in [9], for example, that MLE experiences difficulty when estimating the parameters of the GPD under a variety of configurations of the shape and scale parameter values. Similarly, ref. [10] found that the usefulness of MLE is restricted to very large sample sizes; instead, the use of PWME is advocated in case of moderate sample sizes. Several studies similar to the one presented in this paper have been conducted for other distributions; to mention only a few examples, ref. [11] considered improved estimators for the generalised gamma distribution using small samples, whereas [12,13] compared a variety of different estimators for the parameters of the unit-gamma and Weibull distributions, respectively. For the Lomax distribution in particular, studies include [14,15]. These papers are concerned with the estimation of Lomax parameters using diverse traditional methods of estimation, including MLE, MME, and PWME. The results of these methods have been compared to one another and recommendations have been made concerning the use of these more traditional estimation approaches. From previous papers, it is clear that MLE approaches are not particularly reliable when used with moderately large samples. The conclusion from these studies is that though traditional approaches have utility in certain settings, none are generally applicable.
The aim of this paper is twofold. First, we provide an overview of estimation techniques used for the Lomax distribution and compare the performance of various estimators. Second, we focus on the minimum distance estimators (MDEs), which represent an unexplored avenue for estimating the parameters of the Lomax distribution. While a number of these procedures have already been examined in [16] for the GPD, focusing on the Lomax distribution can provide specific insight into the usefulness of these methods for this particular distribution. In addition, the MDEs we consider here differ substantially from those proposed in [16,17] in that their paper only considered density power divergence measures, whereas we additionally explore distribution function-based methods.
Generally speaking, MDEs measure the difference between an empirical estimate of the probability density or distribution function and the theoretical function [18]. The use of minimum distance estimation measures has been advocated by a number of authors, including [19,20,21], when modelling data containing extreme values, as these estimators have good robustness qualities.
This paper studies the general case in which both the scale () and shape () parameters of the Lomax distribution are unknown. We start by considering the myriad different traditional estimation methods proposed for related distributions, including the L-moment estimator, the MLE, and the MME. We then proceed to propose the use of MDEs in the hope that these may represent competitive alternatives to the more traditional estimators. Although we do not consider any Bayesian estimators in this study, we refer interested readers to [22] and the very recent paper by [23], where Bayesian estimators for the Lomax distribution are discussed and compared, as well as to [24], where Bayesian estimation of the two-parameter gamma distribution is discussed. The performance of the estimators are compared to one another through a comprehensive numerical study involving Monte Carlo simulations in which the finite sample variance, relative bias, and mean squared error (MSE) of each estimator are approximated. In addition, an omnibus measure allowing the MSE of the estimation of both and to be gauged simultaneously is employed in the simulation study.
The remainder of this article is organised as follows. In Section 2, the different parameter estimation methods are introduced and discussed. Next, the Monte Carlo study is presented in Section 3, including a detailed discussion of the simulation results. In Section 4, we apply the different estimators to a real world example. Finally, in Section 5, we conclude the paper by making a number of general observations regarding the estimators and provide recommendations concerning their use.
2. Estimation of Parameters
In this section, we discuss the parameter estimation methods used to estimate the shape and scale parameters of the Lomax distribution. Included here are traditional methods of parameter estimation as well as methods based on optimising a variety of distance measures. In addition to the performance of the MDEs, we provide an overview of the performance of a wide variety of competing estimators. This facilitates recommendations regarding the choice of estimator to be used in various settings. Theoretical details relevant to the estimation of the parameters are provided in each case.
For the remainder of the section, we assume that we have data which are independently and identically distributed (i.i.d.) from the Lomax distribution with parameters and . The order statistics based on this sample are denoted using .
2.1. Method of Moment Estimators (MMES)
MME is one of the most widely used estimation techniques. It has been used to investigate key aspects of probability distributions, such as central tendency, spread, skewness, and kurtosis. However, for the Lomax distribution, due to the fact that with shape parameter only moments lower than are finite, this approach is often not ideal for the parameters of the Lomax distribution. It is ultimately presented here and in the Monte Carlo in Section 3.1 in order to illustrate its functionality for a range of values of .
To derive the MMEs for the Lomax distribution, we can note that the theoretical raw moment of the distribution is
The first and second theoretical raw moments are then provided by
From (1), we can express and as
By simply substituting and with their sample estimators in (2), the MMEs of these parameters are obtained:
where .
2.2. L-Moment Estimators (LMEs)
L-moments provide an alternative way to describe the shapes of probability distributions, and are defined as the expected values of linear combinations of order statistics. They were proposed in [25] as robust alternatives to classical moments. The method of L-moments has advantages over classical moments, including unbiasedness, robustness to the presence of outliers in the data, and lower sensitivity to sampling variability, especially when the data of interest are heavy-tailed, as is the case in our context. If the mean of the distribution exists, it follows that all of the L-moments exist and uniquely define the distribution [25]. The population L-moment is provided by
where r is the integer order of the L-moment and is the expectation of the order statistic of a sample of size r. The sample L-moment is provided by
Therefore, the expressions of the first two sample L-moments are
where is the sample mean.
Similar to the method of moments, the L-moments can be used to obtain parameter estimates by equating the theoretical L-moments of the distribution to the corresponding L-moments of a sample. Therefore, the L-moment estimators of the parameters of the Lomax distribution are provided by
see [15]. L-moments can be a good starting point for the iterative numerical procedure needed to obtain maximum likelihood estimates [26].
2.3. Maximum Likelihood Estimators (MLEs)
Maximum likelihood estimation is one of the most popular methods for estimating the unknown parameters of probability distributions. The popularity of MLE can be attributable to its desirable asymptotic properties, such as unbiasedness and consistency. However, for small sample sizes, these properties may not hold true, resulting in biased MLEs.
In this section, we first use the MLEs to estimate the unknown parameters; then, in the section that follows, we consider a bias-adjusted approach which reduces the bias of the MLEs to order ; see [14].
2.3.1. MLE of the Lomax Distribution
The MLEs for the Lomax distribution are obtained by maximising the log-likelihood function:
Differentiating the log-likelihood with respect to and , respectively, yields the equations
Unfortunately, we cannot obtain closed-form solutions for both estimators using (4) and (5); thus, numerical procedures are required for optimisation purposes. To simplify the optimisation problem, the expressions can be reduced to the optimisation of a single parameter using the concentrated likelihood estimation approach (the approach followed in [29] using their flomax function). This is accomplished by first noting that when setting (4) to zero and solving, we obtain the MLE expressed in terms of :
2.3.2. MLEs of the Lomax Distribution Adjusted for Bias (MLE.b)
For small sample sizes, the MLEs sometimes perform poorly. In order to solve this problem, [14] proposed the use of second-order bias-adjusted versions of the MLEs. To obtain these estimators, the bias of the MLE is first approximated and then subtracted from the MLE to produce the bias-corrected estimate.
Let K be the Fisher information matrix for the Lomax distribution, as provided in [14]. Furthermore, it can be shown that
The bias is obtained in [14] as
where is an operator that, when applied to a matrix, produces a single column vector of dimension by piling up the column vectors below one another; here, the matrix A is provided by
The bias-adjusted estimators proposed in [14] are then obtained by subtracting an estimator of this approximated bias from the original MLEs:
where
The bias-adjusted estimators in (7) have simple closed-form expressions, making them computationally appealing.
Remark 2.
Note that a robust alternative to maximum likelihood for parameter estimation of univariate continuous distributions is the maximum product of spacings estimator (MPSE) proposed by [31,32]. As this approach essentially employs a discretised analogue of the log-likelihood, maximisation yields similar results to the MLE, and for this reason is omitted from our simulations.
2.4. Minimum Distance Estimators (MDEs) Based on Distribution Functions
MDEs are estimators that minimise (for example) some distance measure between the theoretical CDF and the empirical distribution function (EDF) of the observed sample data. Note that we define the EDF as
where is the indicator function and n is the sample size. The main idea is to determine how close the theoretical CDF is to the EDF; the distance between two probability distributions captures the difference in information between them. Minimum distance estimation was first subjected to in-depth study in a series of papers discussed in [33], and has subsequently been considered a good method for deriving efficient and robust estimators in [19,34,35] as well as in [20], among others.
Several minimum distance estimation methods have been proposed, including those derived from empirical distribution functions, such as Cramér–von Mises, and those derived from entropy, such as Kullback–Liebler divergence. We discuss these estimators in two separate sections; the first is based on distance measures between distribution functions, while the second considers distances between density functions. Below, we consider the Cramér–von Mises (CvM) and squared difference (SD) statistics.
In Section 3, we calculate these MDEs using the optim function in R; specifically we use the “BFGS” optimisation method (see [36,37,38,39]). This is a quasi-Newton method reliant on gradients to perform optimisation. We use the LMEs as initial values, as they are available in closed-form and generally perform well compared to other estimators.
2.4.1. A Cramér–Von Mises Distance Measure (MDE.CvM)
The Cramér–von Mises (CvM) statistic is based on the squared integral difference between the EDF and the theoretical distribution. It has the form
We can define the CvM distance measure used to estimate the parameters of the Lomax distribution using the MDE approach as follows:
where and are the CDF and PDF of the Lomax distribution with scale parameter and shape parameter , respectively. This distance measure permits a simple calculable form provided by
Finally, the resulting estimators for and can be expressed simply as the values of those parameters that minimise this distance measure:
2.4.2. A ‘Squared Difference’ Distance Estimator (MDE.SD)
An alternative to the Cramér–von Mises distance measure is the much simpler ‘squared difference’ measure. This distance measure focuses only on the squared difference between the quantities and F, and has the following general expression:
Now, using the Lomax distribution function , the distance measure can be defined as
where, upon simplification, we obtain the following tractable calculation form:
Therefore, the estimators obtained by minimising this ‘squared difference’ distance measure can be expressed as
2.5. Minimum Distance Estimators (MDEs) Based on Density Functions (-Divergence Distance Measures)
The estimators discussed below are similar to those discussed in Section 2.4, the principal difference being that the distance to be minimised is between density functions instead of distribution functions. The resulting estimators are often referred to as -divergence distance measures, and represent a broad class of distance measures that describe the distance between two densities f and g, defined as
where X is a random variable from a distribution function with density f and is a convex function such that and In (8), we set to be the Lomax density function, , and set to be some empirical estimator for the density, , to obtain the following distance measure to be minimised in order to estimate the parameters and :
The required parameters estimates are
In this setting, we estimate the density using the kernel density estimator , defined as
where is the kernel function chosen to be the standard normal density function and h is the bandwidth, chosen using Silverman’s rule-of-thumb (, where and denote the sample quartiles and s denotes the sample standard deviation [40]). The practical implementation of the kernel density estimator is executed using the density function in R [30].
Different choices of the function lead to different forms of the distance measure described above. Here, we consider three choices of resulting in the Kullback–Leibler (KL) divergence, chi-square () divergence, and total variation (TV) distance. These choices are described below.
2.5.1. Kullback–Liebler -Divergence Distance Measure (MDE.KL)
The Kullback–Liebler -divergence distance measure can be obtained by setting
The resulting distance measure is
and we denote the estimator by [17]; note that this Kullback–Liebler form simply represents a robust extension of MLE. This approach is followed in [16], where a general class of density power divergent estimators are employed to estimate the parameters of the GPD.
2.5.2. Chi-Squared -Divergence Distance Measure (MDE.)
Setting yields the chi-square -divergence distance measure, denoted as
and we can express the resulting estimator as
2.5.3. Total Variation -Divergence Distance Measure (MDE.TV)
When specifying , we obtain the total variation -divergence distance measure, provided by
and we can designate the resulting estimator by .
3. Finite Sample Results
Below, we consider the Monte Carlo settings before turning our attention to the results.
3.1. Monte Carlo Simulation Settings
In order to compare the performance of the various estimators to one another, a comprehensive Monte Carlo simulation study was conducted. The simulation study sets out to approximate several distributional properties of the estimators, including the expected value, variance, mean squared error (MSE), and relative bias (RB), which we define to be the calculated bias divided by the true parameter value. Using these various approximations, it is possible to compare the estimators to one another in a sensible manner.
The Monte Carlo simulation was conducted by simulating samples of size from the Lomax distribution using a variety of parameter settings. For the parameter, the values used included , whereas for the parameter we used . We considered only values of exceeding 1, as the mean of the distribution is infinite if ; see (1). Furthermore, the value of is included in order to consider the case in which variance exists.
For each randomly generated sample, the parameters were estimated and collected to ultimately obtain the approximations of the distributional properties mentioned. All calculations were performed using R v4.2.2 [30].
In addition to calculating the MSE for each parameter separately, a combined MSE yielding a single value was calculated as follows: for every pair of estimates, define
then calculate as the measure of the total mean squared error (TMSE) of the estimation technique.
Table 1, Table 2, Table 3 and Table 4 present the Monte Carlo approximations of the expected value, variance, RB, and MSE for all estimators of and as well as the TMSE described above for sample sizes and 50. The remaining tables for samples sizes , 200, and 500 are presented in the Appendix A Table A1, Table A2, Table A3, Table A4, Table A5 and Table A6.
The main entries in Table 1, Table 2, Table 3 and Table 4 and Table A1, Table A2, Table A3, Table A4, Table A5 and Table A6 represent the unadjusted calculation of these quantities; however, due to issues with a small number of aberrant samples in the simulation, the optimisation produced extreme values for the estimators in these cases. Therefore, in order to better understand the behaviour of the estimators, a ‘trimmed’ version of each of these quantities is provided in parentheses. These were obtained by first removing the largest 1% of the estimator values produced in the simulation and then calculating the various metrics. The effect of this trimming is most pronounced for smaller samples.
Furthermore, each of the columns in the tables have a single value printed in bold that highlights which of the estimators perform ‘best’. Mean values in bold font indicate that the estimated values are closest to the true parameter value on average, whereas for variance, RB, MSE and TMSE bold indicates that these values are the smallest among the estimators considered.
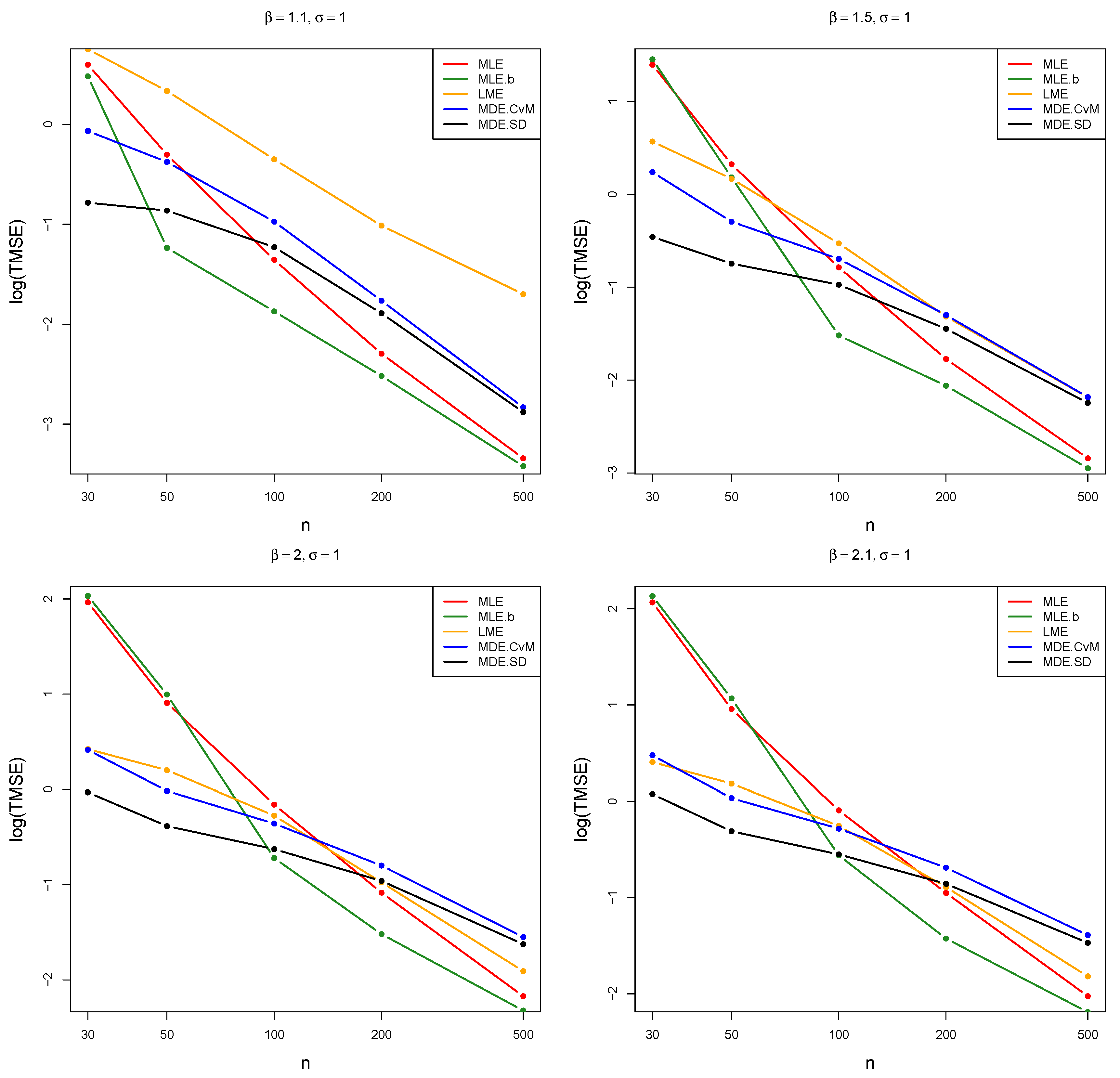
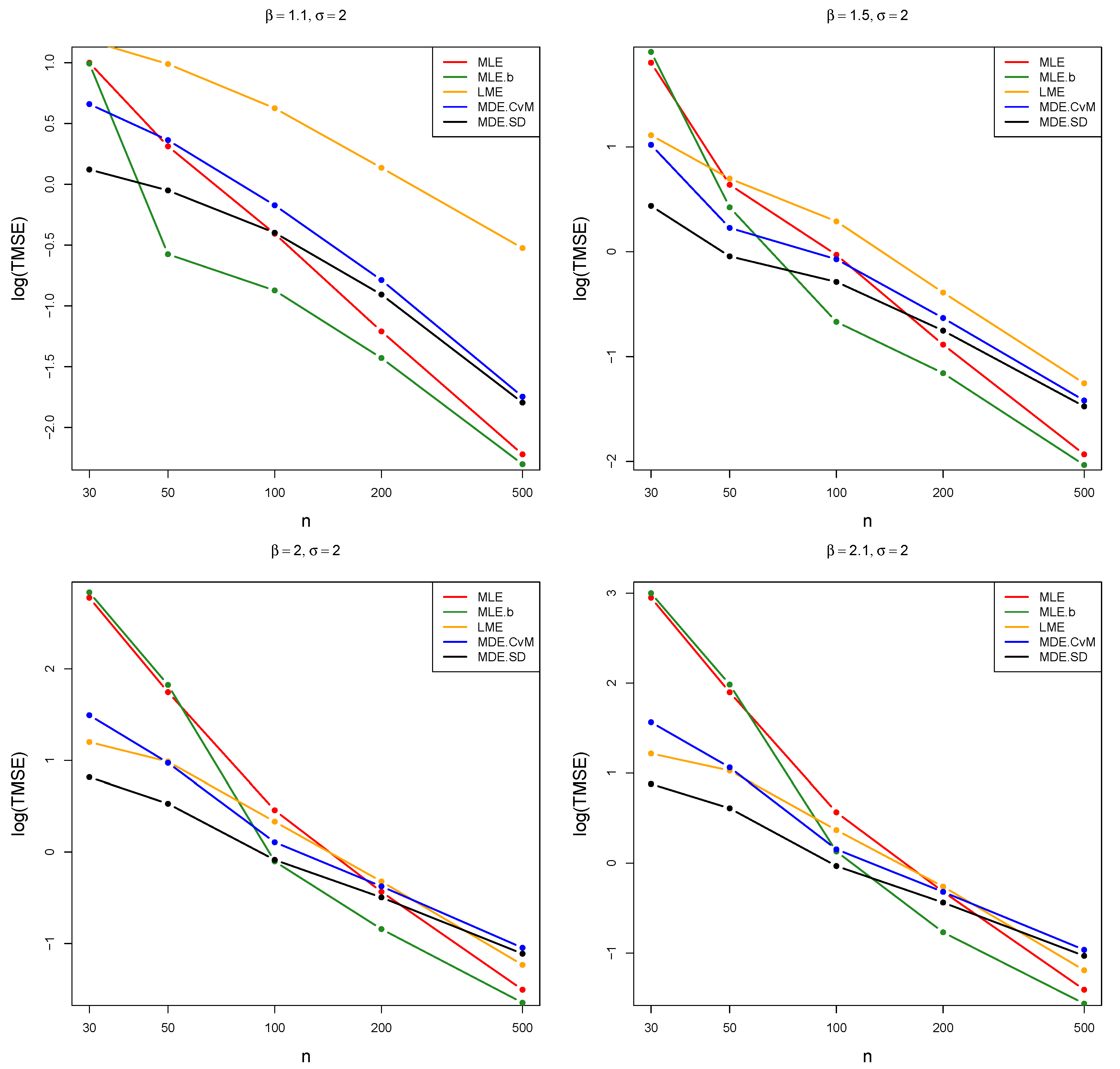
Figure 1 and Figure 2 show the logarithm of the TMSE as a function of sample size. We choose to use a logarithmic scale, as this increases the separation between the lines on the graph, which makes the figures easier to interpret.
Remark 3.
The reason for setting the number of Monte Carlo simulations to the relatively high number of 150,000 was due to the extreme sampling variation observed with the MLE and MLE.b estimators. This variability was exacerbated whenever using a particularly small sample size combined with a β value close to 2; therefore, we thought it best to make the number of simulations as large as possible in order to mitigate this issue. The variability is likely due to numerical issues related to the small sample sizes; note, however, that as the sample increases to and above this artefact disappears almost entirely. In addition, when considering the trimmed version of the measures calculated for each estimator in the simulation it is apparent that the sampling variability exhibited by these estimators is damped, which we feel is a more accurate reflection of the true value of these measures.
3.2. Results
To obtain a better understanding of the performance of the estimators considered in this study, we present a brief discussion of the simulation results presented in Table 1, Table 2, Table 3 and Table 4 and Table A1, Table A2, Table A3, Table A4, Table A5 and Table A6. We compare the trimmed versions of the variance, RB, and MSE performance of the estimators to one another in various parameter settings in the Monte Carlo study.
We start by first noting that the RB, variance, and MSE of each of the estimation methods improve when the sample size increases. The most notable improvements in overall MSE as the sample size increases from 30 to 500 are in the MLE, MDE.TV, and MME; however, as we mention later, the MME method should likely not be considered for estimation even for large samples. Interestingly, we find that the methods that perform well for smaller sample sizes do not always perform well for larger samples when compared to the competing methods. In particular, when the sample size is small ( or ), it can be seen that in the majority of cases MDE.SD, MDE.CvM, and LME have the smallest variance, RB, and MSE values. Note that this small sample behaviour of the variance and MSE measures holds for all but the parameter. However, when considering the case in which the sample size is small and the parameter is specified to be small, there are instances where the MDE.CvM exhibits comparatively larger bias than MDE.SD, LME, and even MLE.b. Thus, it is clear that the underlying parameter values play a role in the relative performance of the various estimation techniques considered. Finally, when considering the RB for the various estimators, we note that MDE.SD most frequently gives rise to negative RB values for small samples. Based on the generally positive RB values associated with the remaining estimators, it seems that these other estimators tend to overestimate the true parameter value in these cases. This behaviour of MDE.SD (and indeed all other MDE-type estimators that we considered) is difficult to explain, as their distributional properties depend on the parameters and do not permit simple closed-form expressions.
Note that while MDE.KL, MDE.SD, and LME are relatively good estimators (in an MSE sense) when the sample size is large ( or ), the MLE method now has the best performance among all methods considered in this setting.
Next, we consider the behaviour of the estimators as the parameter settings of the Monte Carlo change from one value to the next. As increases from 1.1 to 2, the values of the approximated variance, RB, and MSE of the estimators for both and have the tendency to increase as well. However, these values then immediately start to decrease again when is strictly larger than 2.
When the value of increases from 1 to 2, the simulation approximation of the variance of the estimators of generally increases for all of the different estimation methods. The same is not necessarily true for the estimation of , where we find that there are instances in which the approximated variance of the estimator of (using a given estimation method) decreases when the true increases from 1 to 2, and increases in others.
When comparing the class of estimators based on minimum distance measures to the remaining methods, it can be readily seen that the MDE.SD and MDE.CvM estimators are the best performers in terms of the MSE for small to moderate samples. While LME is an excellent competitor, the MLE and MLE.b estimators perform relatively poorly in terms of the MSE in these cases. However, for larger sample sizes, the MLE and MLE.b clearly outperform the entire MDE class of estimators. Interestingly, the LME remains competitive here too, though it is almost never found to have the best MSE performance.
The performances of the estimators within the class of MDE methods differ wildly from one another. We have already noted that the MDE.SD and MDE.CvM methods generally have good MSE performance for small to moderate samples sizes; however, within this class we find that the MDE.TV and MDE. are among the worst performances. The MDE.KL method is something of a mixed bag; certain parameter settings yield good MSE performance, while others yield extremely poor MSE performance. Generally, however, we can state that the MDE.KL method is a better performer than MDE.TV and MDE., although this does not place this estimator near the top performers among the estimation methods considered.
The overall worst performing estimator is MME, regardless of which value of or is considered. While this estimator improves with an increase in sample size, it nonetheless has the worst performance when compared to all other estimation methods.
In Figure 1 and Figure 2, the logarithm of the trimmed TMSE measure is plotted against the samples sizes in order to produce a more intuitive representation of the behaviour of a selection of estimators over varying sample sizes. The estimators MLE, MLE.b, LME, MDE.CvM, and MDE.SD are selected for inclusion in these figures, as according to the tables these estimators generally perform well (the TMSE and trimmed TMSE values of the remaining estimators can be found in the tables). It can be seen that, as expected, the trimmed TMSE measure’s value generally decreases as the sample size increases. Note, however, that the trimmed TMSE indicates that the MLE and MLE.b estimators are erratic for small samples (see for example the graphs associated with in Figure 1 and Figure 2). Furthermore, it is apparent that while the MLE and MLE.b estimators have among the worst trimmed TMSE performance for small sample sizes, this trend is reversed when the sample size increases. Conversely, it clear that the MDE.CvM and MDE.SD estimators perform well in terms of TMSE for smaller sample sizes, in many cases being outperformed only when the sample size increases to and higher. It should be noted that while the performance of LME is comparable to the performance of MDE.CvM for choices of larger than 2, it performs poorly for smaller values. Furthermore, these numerical results indicate that the relative performance of the estimators depends to a certain degree on the specific parameter values considered.
4. Practical Applications
We now apply the various Lomax parameter estimation techniques to a practical data set, namely, the airborne communication transceiver data shown in Table 5, originally discussed in [41], and previously analysed in [22].
The dataset contains 46 observed repair times (measured in hours) of airborne communication transceiver equipment recorded during active operation. Assuming a Lomax distribution for these data, we use each of the estimation techniques to obtain the parameter estimates of the distribution. The resulting parameter estimates, along with 95% parametric bootstrap confidence intervals using bootstrap replications, are shown in Table 6. Note that for each estimation method the parametric bootstrap samples used in these intervals are constructed by first estimating the parameters and then generating samples from a Lomax distribution with the estimators as the parameters [42]. The output in Table 6 indicates that the estimated parameter values are all reasonably close to one another, with the exception of MDE.CvM, MDE., MDE.TV, and MME. The discrepancies observed for these four estimators relative to the other estimators considered is perhaps unsurprising in light of the irregular performance of these estimators observed in the Monte Carlo study presented earlier.
The code for this example can be found here: https://tinyurl.com/LomaxPracticalCode (accessed on 26 November 2023).
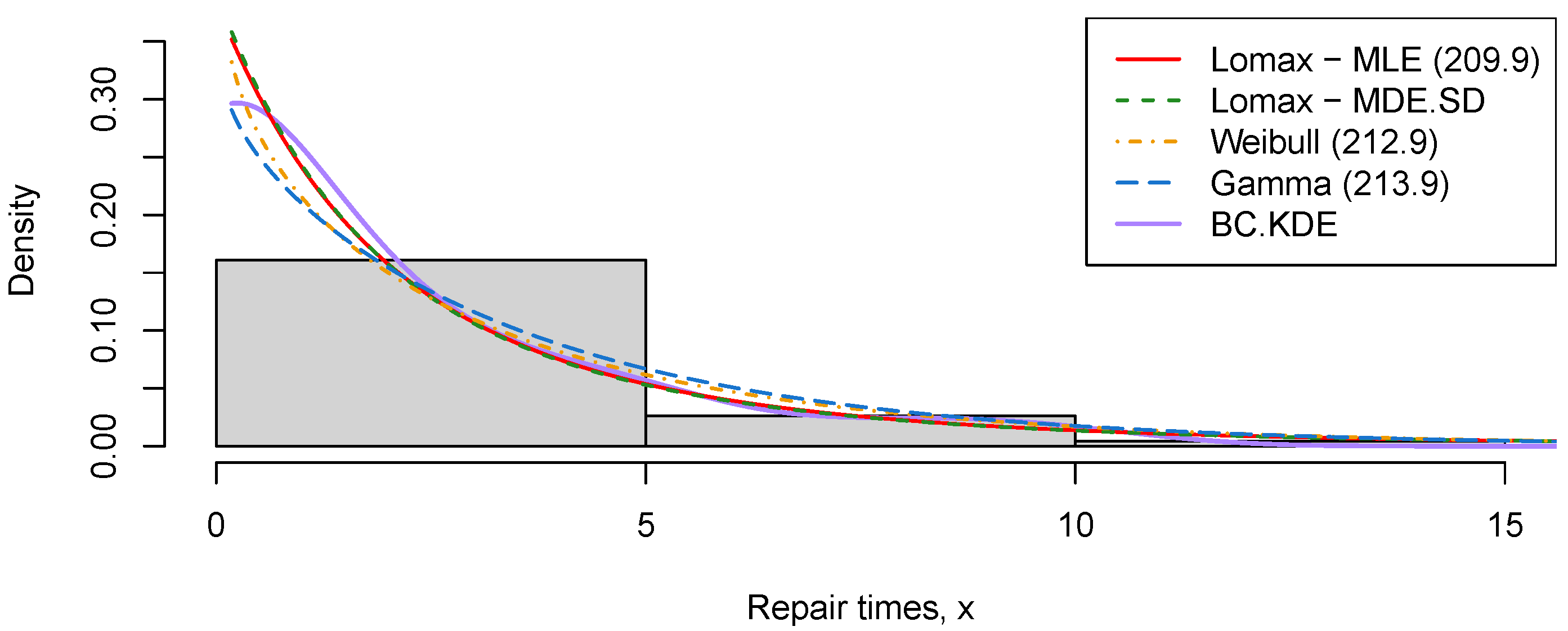
Figure 3 shows the boundary-corrected kernel density estimator (BC.KDE) of the data (obtained using the bckden suite of functions in R’s evmix package [43]) overlaid on a simple histogram. Two separate Lomax density functions are added to the plot using two different methods of parameter estimation, namely, MLE and MDE.SD, the latter being chosen because this method performed well for smaller sample sizes. In addition, the fitted two-parameter Weibull and gamma densities are added to the plot in order to facilitate comparison between the Lomax density and other theoretical densities containing two parameters. The parameters from both of these theoretical densities are estimated via maximum likelihood. Visual inspection of the graph indicates that the Lomax densities can be considered good candidate models, as they most closely match the empirical estimate of the density of these data, whereas the gamma distribution exhibits the greatest deviation from the others.
The Akaike information criterion (AIC) is calculated for each of the three distinct distributions by employing the maximum likelihood estimators, with the results presented in Table 7. From Table 7, it can be seen that the Lomax distribution has the lowest AIC value, closely followed by the AIC of the Weibull and gamma distributions, which supports the conclusions made above.
5. Conclusions
In this study, different parameter estimation methods for the two parameters of the Lomax distribution have been explored and discussed. We have reviewed L-moment estimators, maximum likelihood estimators (with and without a bias adjustment), method of moments estimators, and three different minimum distance estimators. The specific goals of the study were to provide an overview of the different estimation methods as well as to determine whether the minimum distance estimators are feasible estimation alternatives for this distribution when compared to traditional methods of estimation such as maximum likelihood. In an attempt to ascertain the properties of these estimators, all of the methods were compared to one another in a comprehensive Monte Carlo simulation while assuming different parametric values for small to large samples. Unsurprisingly, this study showed that while the MLEs perform well in large samples, they yield severely biased answers in small samples. The bias correction outlined in [14], however, noticeably reduces the bias of the MLE estimates for moderate to large sample sizes.
The traditional MME is found to be a universally poor performer in terms of MSE for all settings of the and parameters and the given sample sizes. Our simulation showed that LME is stable under different parameter settings, including varying values of , , and sample size. Thus, while this estimator is almost never found to have the best performance in either small or large sample settings, it can be considered a ‘safe’ option for estimating of the parameters of the Lomax distribution.
Finally, several estimation methods based on distance measures were investigated, and were found to produce varied results. These methods all attempt to estimate the parameters of the Lomax distribution by considering different measures of distance measures that need to be minimised. The studied measures considered include the Cramér–von Mises (CvM), squared difference, and several phi-divergence measures (including the Kullback–Leibler (KL) divergence, total variation (TV) distance, and chi-square divergence). The results of the simulation study established that, for this class of MDE methods, the MDE.SD and MDE.CvM methods have the best overall MSE performance for small to moderate samples sizes; we would recommend either of these methods for the estimation of the Lomax parameters and when sample sizes are smaller than 100. However, within this MDE class we find two of the worst performing methods, namely, the MDE.TV and MDE. methods. The MDE.KL method produces reasonably good MSE performance for the moderate to large sample sizes, however, as with MLE, the quality of the estimator fluctuates tremendously for smaller samples.
These results show that while no single estimator has the best overall performance, we can identify the distance-based measure, that is, MDE.SD, as generally having the best MSE performance for small sample sizes ( and ), whereas MLE.b is found to be the better choice for moderate and large sample sizes (, and ) for almost all of the and values considered here.
The related literature contains finds competing views about the usefulness of MDEs and MLEs. In the case of multivariate data (specifically estimators for the parameters of a copula), [44] advocates for the use of MDEs because MLEs have the disadvantage that of requiring the density of the copula, whereas MDEs only require its empirical distribution estimate. However, in an extensive overview paper comparing MDEs and MLEs for parameter estimation of copulas, [45] found that MLEs have a lower computational cost while producing lower estimation biases. Naturally, the other main advantages of the traditional MLEs are the ease with which asymptotic standard errors can be obtained, the fact that they have asymptotically normal distributions, and, consequently, that confidence intervals for the parameter being estimated are easy to obtain. In contrast, the standard errors of the other estimators considered in this paper require either complex analytical derivations (possibly with no tractable forms) or require the use of resampling methods.
Finally, we note that another important application of the Lomax distribution, not mentioned yet in this paper, is found in autoregressive conditional duration (ACD) models, which model high frequency financial data; in this context, the duration between market events are of great interest. Without discussing the details of the model, we briefly describe the role of the Lomax distribution in ACD models here; for an in-depth exposition of ACD models, see [46,47]. We only note that the error terms of the ACD model are historically assumed to be exponential or Weibull distributed; see, for example, [48]. However, in [49,50], it is found that these choices do not adequately describe the characteristics of the observed data. In [51], the authors advocate the use of infinite mixtures of exponential distributions to model the distribution of the error term, finding that this choice improves the fit of the model. If the scale parameter of this mixing exponential distribution follows an inverse Gaussian distribution, then the resulting distribution of the error term is Lomax. It is therefore important for the efficient implementation of these ACD models that we are able to accurately estimate the parameters of this distribution. Another important avenue for future research can be found in goodness-of-fit tests for the Lomax and related distributions, as these tests check the assumptions underlying the ACD models.
Author Contributions
Conceptualization, T.N., J.A., L.S. and J.V.; Methodology, T.N., J.A., L.S. and J.V.; Writing—original draft, T.N., J.A., L.S. and J.V.; Writing—review and editing, T.N., J.A., L.S. and J.V. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Not applicable.
Acknowledgments
The work of J.S. Allison, L. Santana and IJH Visagie are based on research supported by the National Research Foundation (NRF). Any opinion, finding and conclusion or recommendation expressed in this material is that of the authors and the NRF does not accept any liability in this regard.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Additional Tables
Table A1, Table A2, Table A3, Table A4, Table A5 and Table A6 report the results of the Monte Carlo experiments for sample sizes , , and . Each table shows the empirical expected value, variance, RB, MSE, and TMSE for the various estimators considered, as in the body of the paper.

{kind=link}
{kind=link}
{kind=link}
Table A1.
Comparison of different estimation methods for different values of ( and ).
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
Note: Main entries correspond to the untrimmed values; the 1% trimmed values are provided in parentheses.
Table A2.
Comparison of different estimation methods for different values of ( and ).
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
Note: Main entries correspond to the untrimmed values; the 1% trimmed values are provided in parentheses.
Table A3.
Comparison of different estimation methods for different values of ( and ).
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
Note: Main entries correspond to the untrimmed values; the 1% trimmed values are provided in parentheses.
Table A4.
Comparison of different estimation methods for different values of ( and ).
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
Note: Main entries correspond to the untrimmed values; the 1% trimmed values are provided in parentheses.
Table A5.
Comparison of different estimation methods for different values of ( and ).
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
Note: Main entries correspond to the untrimmed values; the 1% trimmed values are provided in parentheses.
Table A6.
Comparison of different estimation methods for different values of ( and ).
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
Note: Main entries correspond to the untrimmed values; the 1% trimmed values are provided in parentheses.
References
- Pareto, V. The new theories of economics. J. Political Econ. 1897, 4, 485–502. [Google Scholar] [CrossRef]
- Lomax, K. Business failures: Another example of the analysis of failure data. J. Am. Stat. Assoc. 1954, 49, 847–852. [Google Scholar] [CrossRef]
- Mitra, D.; Kundu, D.; Balakrishnan, N. Likelihood analysis and stochastic EM algorithm for left truncated right censored data and associated model selection from the Lehmann family of life distributions. Jpn. J. Stat. Data Sci. 2021, 4, 1019–1043. [Google Scholar] [CrossRef]
- Abujarad, M.H.A.; Khan, A.A. JMASM 57: Bayesian Survival Analysis of Lomax Family Models with Stan (R). J. Mod. Appl. Stat. Methods 2021, 19, 12. [Google Scholar] [CrossRef]
- Atkinson, A.B.; Harrison, A.J. Distribution of Personal Wealth in Britain; Cambridge University Press: Cambridge, UK, 1978. [Google Scholar]
- Harris, C.M. The Pareto distribution as a queue service discipline. Oper. Res. 1968, 2, 307–308. [Google Scholar] [CrossRef]
- Hassan, A.; Al-Ghamdi, A. Optimum step-stress accelerated life testing for Lomax distribution. J. Appl. Sci. Res. 2009, 12, 2153–2164. [Google Scholar]
- Holland, O.; Golaup, A.; Aghvami, A.H. Traffic characteristics of aggregated module downloads for mobile terminal reconfiguration. IEE Proc. 2006, 135, 683–690. [Google Scholar] [CrossRef]
- Hosking, J.R.M.; Wallis, J.R. Parameter and quantile estimation for the generalized Pareto distribution. Technometrics 1987, 29, 339–349. [Google Scholar] [CrossRef]
- de Zea Bermudez, P.; Kotz, S. Parameter estimation of the generalized Pareto distribution—Part I. J. Stat. Plan. Inference 2010, 140, 1353–1373. [Google Scholar] [CrossRef]
- Ramos, P.L.; Nascimento, D.C.; Ferreira, P.H.; Weber, K.T.; Santos, T.E.G.; Louzada, F. Modelling traumatic brain injury lifetime data: Improved estimators for the generalised gamma distribution under small samples. PLoS ONE 2019, 14, e0221332. [Google Scholar] [CrossRef] [Green Version]
- Teimouri, M.; Hoseini, S.M.; Nadarajah, S. Comparison of estimation methods for the Weibull distribution. Statistics 2013, 47, 93–109. [Google Scholar] [CrossRef]
- Dey, S.; Menezes, F.B.; Mazucheli, J. Comparison of estimation methods for unit-gamma distribution. J. Data Sci. 2019, 17, 768–801. [Google Scholar] [CrossRef]
- Giles, D.E.; Feng, H.; Godwin, R.T. On the bias of the maximum likelihood estimator for the two-parameter Lomax distribution. Commun. Stat. Methods 2013, 42, 1934–1950. [Google Scholar] [CrossRef] [Green Version]
- Shakeel, M.; Rehmat, N.; Haq, M.A. Comparison of the robust parameters estimation methods for the two-parameters Lomax distribution. Cogent Math. 2017, 4, 3–5. [Google Scholar] [CrossRef]
- Juaŕez, S.F.; Schucany, W.R. Robust and efficient estimation for the generalized Pareto distribution. Extremes 2004, 7, 237–251. [Google Scholar] [CrossRef]
- Basu, A.; Harris, I.R.; Hjort, N.L.; Jones, M.C. Robust and efficient estimation by minimising a density power divergence. Biometrika 1998, 85, 549–559. [Google Scholar] [CrossRef] [Green Version]
- Basu, A.; Shioya, H.; Park, C. Statistical Inference: The Minimum Distance Approach; Chapman and Hall: Boca Raton, FL, USA, 2011. [Google Scholar]
- Boos, D. Minimum distance estimators for location and goodness of fit. J. Am. Stat. Assoc. 1981, 76, 663–670. [Google Scholar] [CrossRef]
- Parr, W.C.; Schucany, W.R. Minimum distance and robust estimation. J. Am. Stat. Assoc. 1980, 75, 616–624. [Google Scholar] [CrossRef]
- Parr, W.C.; De Wet, T. On minimum Cramer-von Mises-norm parameter estimation. Commun. Stat. Methods 1981, 10, 1149–1166. [Google Scholar] [CrossRef]
- Ferreira, P.H.; Ramos, R.; Ramos, P.L.; Gonzales, J.F.B.; Tomazella, V.L.D.; Ehlers, R.S.; Silva, E.B.; Louzada, F. Objective Bayesian analysis for the Lomax distribution. Stat. Probab. Lett. 2020, 159, 108677. [Google Scholar] [CrossRef] [Green Version]
- He, D.; Sun, D.; Zhu, Q. Bayesian analysis for the Lomax model using noninformative priors. Stat. Theory Relat. Fields 2022, 1–8. [Google Scholar] [CrossRef]
- Son, Y.S.; Oh, M. Bayesian estimation of the two-parameter gamma distribution. Commun. Stat. Comput. 2006, 35, 285–293. [Google Scholar] [CrossRef]
- Hosking, J.R.M. L-moments: Analysis and estimation of distributions using linear combinations of order statistic. J. R. Stat. Soc. 1990, 52, 105–124. [Google Scholar] [CrossRef]
- Hosking, J.R.M. Maximum-likelihood estimation of the parameters of the generalized extreme-value distribution. J. R. Stat. Society. Ser. C Appl. Stat. 1985, 34, 301–310. [Google Scholar]
- Greenwood, J.A.; Landwehr, J.M.; Matalas, N.C.; Wallis, J.R. Probability weighted moments:Definition and relation to parameters of several distributions expressable in inverse form. Water Resour. Res. 1979, 52, 105–124. [Google Scholar]
- Asquith, W. Univariate Distributional Analysis with L-moment Statistics Using R; Create Space Independent Platform: Scotts Valley, CA, USA, 2011. [Google Scholar]
- Deville, Y. Renext: Renewal Method for Extreme Values Extrapolation, R package version 3.1-0; Institut de Radioprotection et de Sûreté Nucléaire: Fontenay-aux-Roses, France, 2016. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Cheng, R.; Amin, N. Maximum product of spacings estimation with application to the lognormal distribution. Math. Rep. 1979, 1, 79. [Google Scholar]
- Ranneby, B. The maximum spacing method. An estimation method related to the maximum likelihood method. Scand. J. Stat. 1984, 11, 92–112. [Google Scholar]
- Wolfowitz, J. Estimation by the minimum distance method. Ann. Inst. Stat. Math. 1953, 5, 9–23. [Google Scholar]
- Beran, R.J. Minimum Pareto distance estimates for parameter models. Ann. Stat. 1977, 5, 445–463. [Google Scholar] [CrossRef]
- Beran, R.J. An efficient and robust adaptive estimator of location. Ann. Stat. 1978, 6, 292–313. [Google Scholar]
- Broyden, C.G. The convergence of a class of double-rank minimization algorithms. J. Inst. Math. Its Appl. 1970, 6, 76–90. [Google Scholar] [CrossRef] [Green Version]
- Fletcher, R. A New Approach to Variable Metric Algorithms. Comput. J. 1970, 13, 317–322. [Google Scholar] [CrossRef] [Green Version]
- Goldfarb, D. A Family of Variable Metric Updates Derived by Variational Means. Math. Comput. 1970, 24, 23–26. [Google Scholar] [CrossRef]
- Shanno, D.F. Conditioning of quasi-Newton methods for function minimization. Math. Comput. 1970, 24, 647–656. [Google Scholar] [CrossRef]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Chapman & Hall, Inc.: London, UK, 1986. [Google Scholar]
- Von Alven, W.H. Reliability Engineering; Prentice Hall: Hoboken, NJ, USA, 1964. [Google Scholar]
- Efron, B.; Tibshirani, R.J. An Introduction to the Bootstrap; Chapman & Hall, Inc.: New York, NY, USA, 1993. [Google Scholar]
- Hu, Y.; Scarrott, C. evmix: An R package for Extreme Value Mixture Modeling, Threshold Estimation and Boundary Corrected Kernel Density Estimation. J. Stat. Softw. 2018, 84, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Liebscher, E.; Taubert, F.; Hetzer, J. Modelling multivariate data using product copulas and minimum distance estimators: An exemplary application to ecological traits. Environ. Ecol. Stat. 2022, 29, 1–24. [Google Scholar] [CrossRef]
- Weiss, G. Copula parameter estimation by maximum-likelihood and minimum-distance estimator: A simulation study. Comput. Stat. 2011, 26, 31–54. [Google Scholar] [CrossRef]
- Engle, R.F.; Russell, J.R. Autoregressive conditional duration: A new model for irregularly spaced transaction data. Econometrica 1998, 66, 1127–1162. [Google Scholar] [CrossRef] [Green Version]
- Thas, O. Comparing Distributions; Springer: New York, NY, USA, 2010. [Google Scholar]
- Meintanis, S.G.; Milosevic, B.; Obradovic, M. Goodness-of-fit tests in conditional duration models. Stat. Pap. 2020, 61, 123–140. [Google Scholar] [CrossRef]
- Bauwens, L.; Giot, P. Econometric Modelling of Stock Market Intraday Activity; Kluver Academic Publisher: Boston, MA, USA, 2001. [Google Scholar]
- Bauwens, L.; Giot, P.; Grammig, J.; Veredas, D. A comparison of financial duration models via density forecasts. Int. J. Forecast. 2005, 20, 589–609. [Google Scholar] [CrossRef]
- De Luga, G.; Gallo, G.M. Mixture processes for financial intradaily durations. Stud. Nonlinear Dyn. Econom. 2004, 8. [Google Scholar] [CrossRef]
Figure 1.
Plots of the log of the trimmed TMSE measure against sample size for five different estimation techniques when .
Figure 1.
Plots of the log of the trimmed TMSE measure against sample size for five different estimation techniques when .

Figure 2.
Plots of the log of the trimmed TMSE measure against sample size for five different estimation techniques when .
Figure 2.
Plots of the log of the trimmed TMSE measure against sample size for five different estimation techniques when .

Figure 3.
The kernel density estimate and fitted density functions based on the airborne communication transceiver repair time data (AIC values for the MLE estimated distributions provided in parentheses in the legend).
Figure 3.
The kernel density estimate and fitted density functions based on the airborne communication transceiver repair time data (AIC values for the MLE estimated distributions provided in parentheses in the legend).

Table 1.
Comparison of different estimation methods for different values of ( and ).
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
Note: Main entries correspond to the untrimmed values; the 1% trimmed values are provided in parentheses.
Table 2.
Comparison of different estimation methods for different values of ( and ).
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
Note: Main entries correspond to the untrimmed values; the 1% trimmed values are provided in parentheses.
Table 3.
Comparison of different estimation methods for different values of ( and ).
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
Note: Main entries correspond to the untrimmed values; the 1% trimmed values are provided in parentheses.
Table 4.
Comparison of different estimation methods for different values of ( and ).
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
| Method | Mean | Var | RB | MSE | Mean | Var | RB | MSE | TMSE | |||||||||
| MLE | ||||||||||||||||||
| MLE.b | ||||||||||||||||||
| LME | ||||||||||||||||||
| MDE.CvM | ||||||||||||||||||
| MDE.SD | ||||||||||||||||||
| MDE. | ||||||||||||||||||
| MDE.TV | ||||||||||||||||||
| MDE.KL | ||||||||||||||||||
| MME | ||||||||||||||||||
Note: Main entries correspond to the untrimmed values; the 1% trimmed values are provided in parentheses.
Table 5.
Repair times for the airborne communication transceiver dataset.
| 0.2 | 0.3 | 0.5 | 0.5 | 0.5 | 0.5 | 0.6 | 0.6 | 0.7 | 0.7 | 0.7 | 0.8 |
| 0.8 | 1.0 | 1.0 | 1.0 | 1.0 | 1.1 | 1.3 | 1.5 | 1.5 | 1.5 | 1.5 | 2.0 |
| 2.0 | 2.2 | 2.5 | 2.7 | 3.0 | 3.0 | 3.3 | 3.3 | 4.0 | 4.0 | 4.5 | 4.7 |
| 5.0 | 5.4 | 5.4 | 7.0 | 7.5 | 8.8 | 9.0 | 10.3 | 22.0 | 24.5 |
Table 6.
Estimated parameters for the airborne communication transceiver dataset (with a 95% percentile bootstrap confidence interval).
Table 6.
Estimated parameters for the airborne communication transceiver dataset (with a 95% percentile bootstrap confidence interval).
| Estimation Technique | ||||
|---|---|---|---|---|
| MLE | ||||
| MLE.b | ||||
| LME | ||||
| MDE.CvM | ||||
| MDE.SD | ||||
| MDE. | ||||
| MDE.TV | ||||
| MDE.KL | ||||
| MME |
Table 7.
The AIC values for the fitted distributions of the airborne communications transceiver data.
Table 7.
The AIC values for the fitted distributions of the airborne communications transceiver data.
| Weibull | Gamma | Lomax |
|---|---|---|
| 212.9 | 213.9 | 209.9 |
* The AIC value reported for the Lomax distribution employs the MLE.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Nombebe, T.; Allison, J.; Santana, L.; Visagie, J. On Fitting the Lomax Distribution: A Comparison between Minimum Distance Estimators and Other Estimation Techniques. Computation 2023, 11, 44. https://doi.org/10.3390/computation11030044
AMA Style
Nombebe T, Allison J, Santana L, Visagie J. On Fitting the Lomax Distribution: A Comparison between Minimum Distance Estimators and Other Estimation Techniques. Computation. 2023; 11(3):44. https://doi.org/10.3390/computation11030044
Chicago/Turabian StyleNombebe, Thobeka, James Allison, Leonard Santana, and Jaco Visagie. 2023. "On Fitting the Lomax Distribution: A Comparison between Minimum Distance Estimators and Other Estimation Techniques" Computation 11, no. 3: 44. https://doi.org/10.3390/computation11030044
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.