
IoT Device Identification Using Unsupervised Machine Learning

Abstract
:1. Introduction
2. Related Work
3. Unsupervised Machine-Learning-Assisted Approach for IoT Device Identification
3.1. Pre-Processing
3.2. Feature Selection
3.3. Clustering
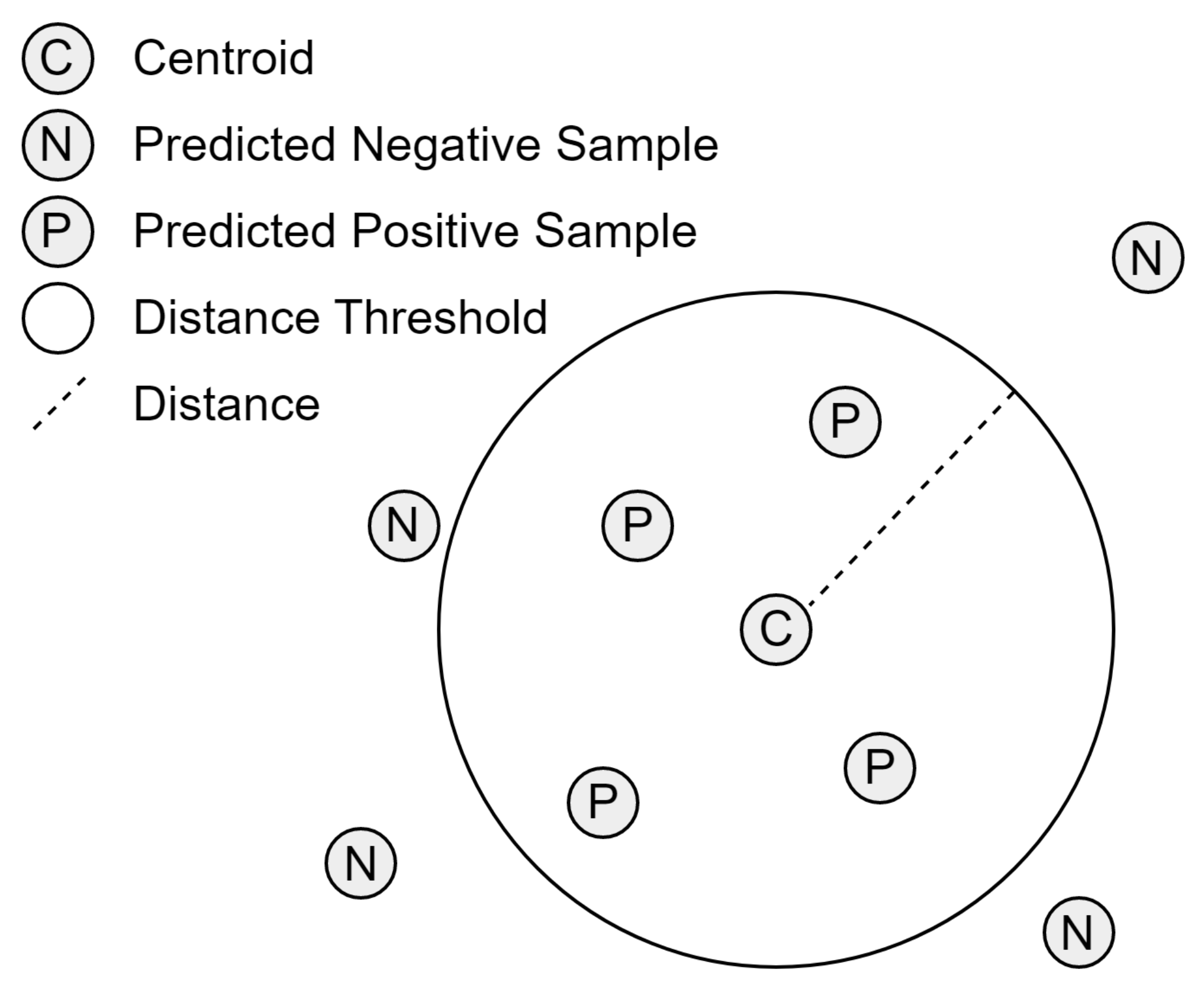
3.4. Threshold Creation
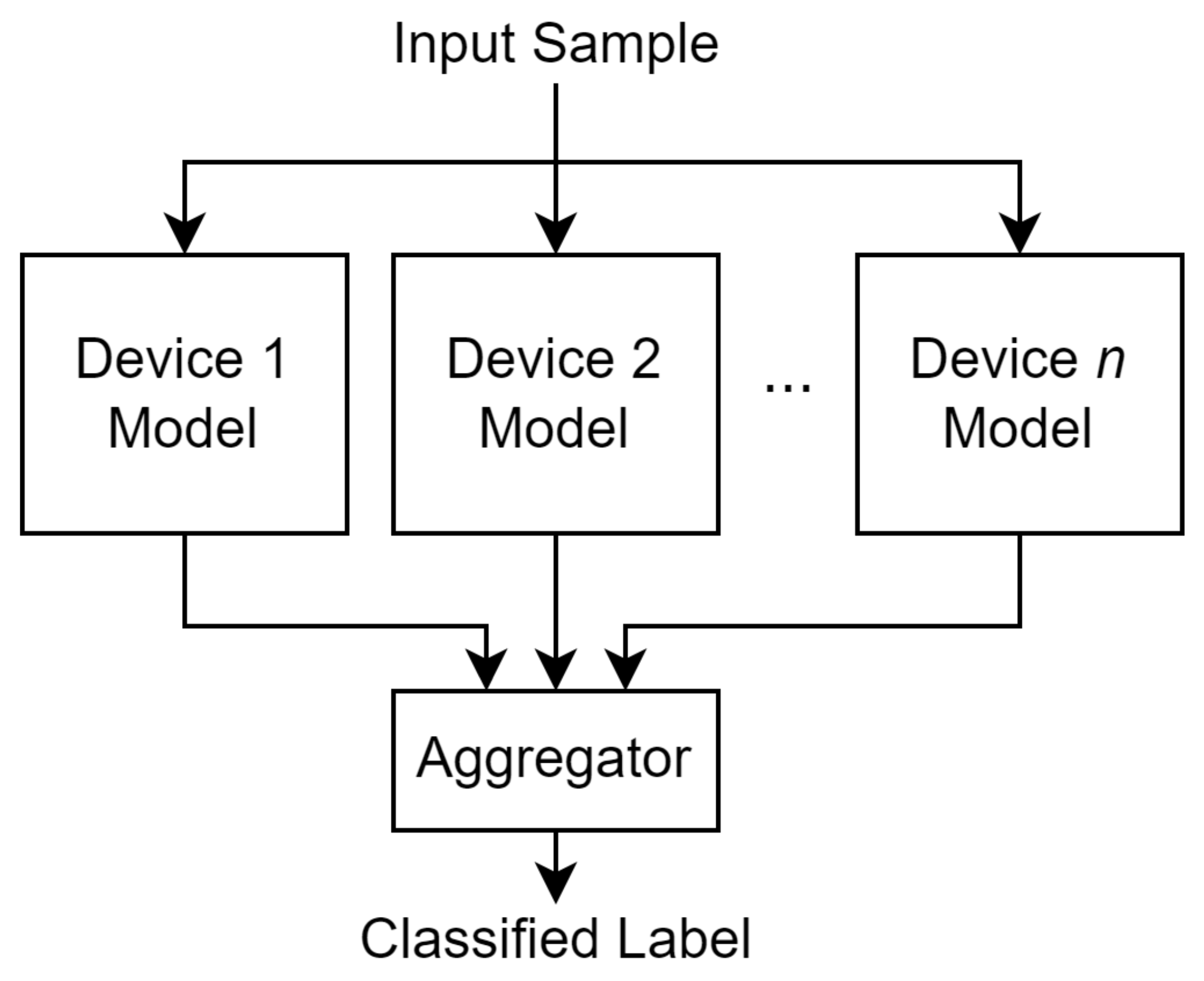
3.5. Predicting
3.6. Testing Dataset
3.7. Feature Extraction
4. Results and Discussions
4.1. Feature Selection
4.2. Clustering
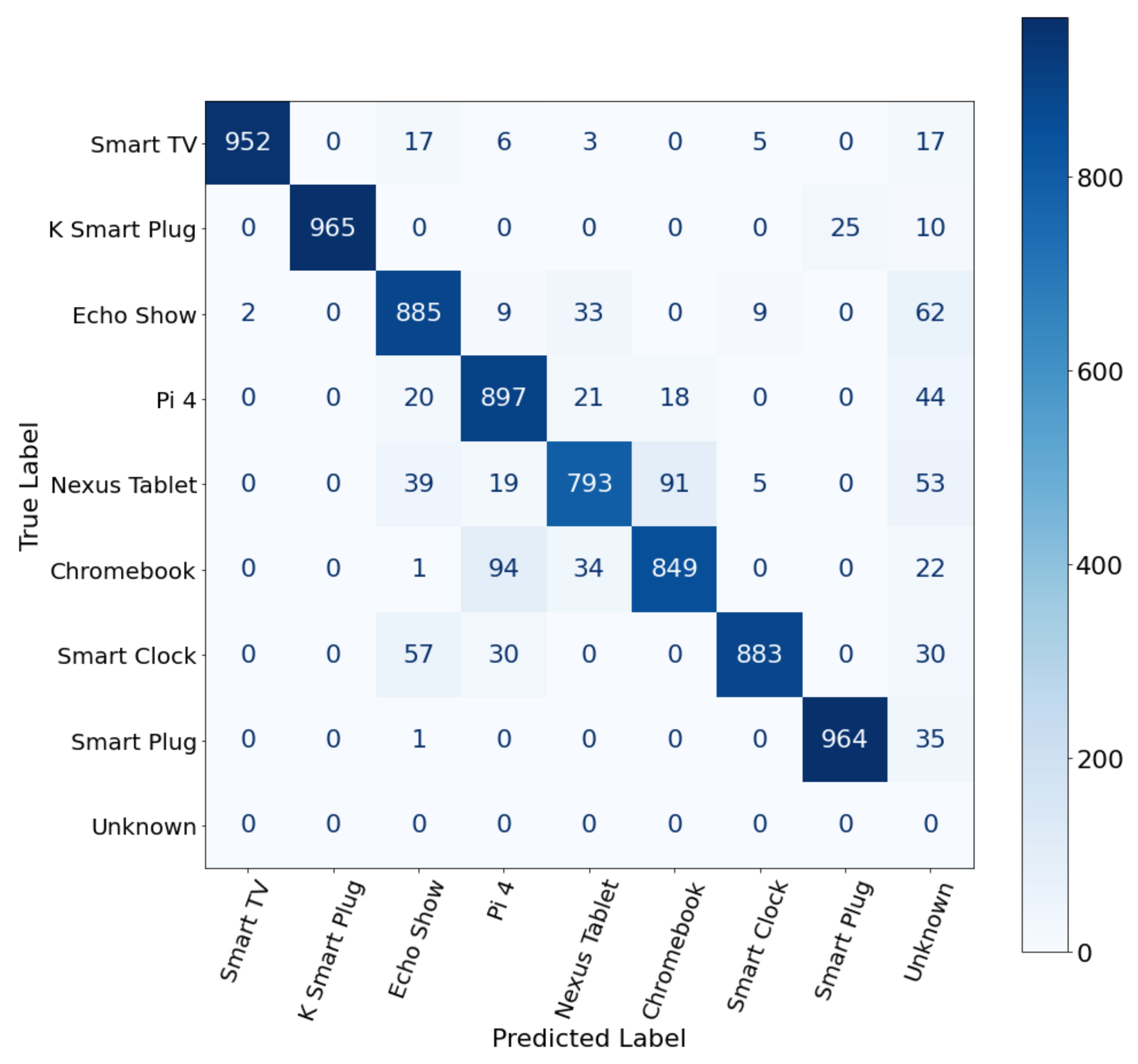
4.3. Device Identification
4.4. Unsupervised ML vs. Supervised ML
5. Conclusions and Outlook
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Al-Fuqaha, A.; Guizani, M.; Mohammadi, M.; Aledhari, M.; Ayyash, M. Internet of things: A survey on enabling technologies, protocols, and applications. IEEE Commun. Surv. Tutor. 2015, 17, 2347–2376. [Google Scholar] [CrossRef]
- Bhattarai, S.; Wang, Y. End-to-End Trust and Security for Internet of Things Applications. Computer 2018, 51, 20–27. [Google Scholar] [CrossRef]
- Muthusamy Ragothaman, K.N.; Wang, Y. A Systematic Mapping Study of Access Control in the Internet of Things. In Proceedings of the 54th Hawaii International Conference on System Sciences, Kauai, HI, USA, 5–8 January 2021; pp. 7090–7099. Available online: http://hdl.handle.net/10125/71474 (accessed on 25 February 2023).
- Pal, S.; Hitchens, M.; Varadharajan, V. Modeling Identity for the Internet of Things: Survey, Classification and Trends. In Proceedings of the 12th International Conference on Sensing Technology (ICST), Limerick, Ireland, 4–6 December 2018; pp. 45–51. [Google Scholar] [CrossRef]
- Koo, J.; Kim, Y.G. Interoperability of device identification in heterogeneous IoT platforms. In Proceedings of the 2017 13th International Computer Engineering Conference (ICENCO), Cairo, Egypt, 27–28 December 2017; pp. 26–29. [Google Scholar] [CrossRef]
- Ning, H.; Zhen, Z.; Shi, F.; Daneshmand, M. A Survey of Identity Modeling and Identity Addressing in Internet of Things. IEEE Internet Things J. 2020, 7, 4697–4710. [Google Scholar] [CrossRef]
- Jøsang, A.; Fabre, J.; Hay, B.; Dalziel, J.; Pope, S. Trust requirements in identity management. In Proceedings of the Australasian Workshop on Grid Computing and e-Research-Volume 44; Australian Computer Society, Inc.: Darlinghurst, NSW, Australia, 2005; pp. 99–108. [Google Scholar]
- Alpár, G.; Batina, L.; Batten, L.; Moonsamy, V.; Krasnova, A.; Guellier, A.; Natgunanathan, I. New directions in IoT privacy using attribute-based authentication. In Proceedings of the ACM International Conference on Computing Frontiers, Como, Italy, 16–19 May 2016; pp. 461–466. [Google Scholar]
- Cameron, K. The laws of identity. Microsoft Corp. 2005, 12, 8–11. [Google Scholar]
- Meidan, Y.; Bohadana, M.; Shabtai, A.; Guarnizo, J.D.; Ochoa, M.; Tippenhauer, N.O.; Elovici, Y. ProfilIoT: A Machine Learning Approach for IoT Device Identification Based on Network Traffic Analysis. In Proceedings of the Symposium on Applied Computing, Marrakech, Morocco, 4–6 April 2017; pp. 506–509. [Google Scholar]
- Wang, Y.; Rimal, B.P.; Elder, M.; Maldonado, S.I.C.; Chen, H.; Koball, C.; Ragothaman, K. IoT Device Identification Using Supervised Machine Learning. In Proceedings of the 2022 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 7–9 January 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Sivanathan, A.; Gharakheili, H.H.; Sivaraman, V. Inferring IoT Device Types from Network Behavior Using Unsupervised Clustering. In Proceedings of the 2019 IEEE 44th Conference on Local Computer Networks (LCN), Osnabrueck, Germany, 14–17 October 2019; pp. 230–233. [Google Scholar]
- Marchal, S.; Miettinen, M.; Nguyen, T.D.; Sadeghi, A.-R.; Asokan, N. AuDI: Toward Autonomous IoT Device-Type Identification Using Periodic Communication. IEEE J. Sel. Areas Commun. 2019, 37, 1402–1412. [Google Scholar] [CrossRef]
- Bhatia, R.; Benno, S.; Esteban, J.; Lakshman, T.V.; Grogan, J. Unsupervised Machine Learning for Network-Centric Anomaly Detection in IoT. In Proceedings of the 3rd ACM CoNEXT Workshop on Big Data, Machine Learning and Artificial Intelligence for Data Communication Networks, Orlando, FL, USA, 9 December 2019; pp. 42–48. [Google Scholar]
- Zhang, S.; Wang, Z.; Yang, J.; Bai, D.; Li, F.; Li, Z.; Wu, J.; Liu, X. Unsupervised IoT Fingerprinting Method via Variational Auto-encoder and K-means. In Proceedings of the ICC 2021—IEEE International Conference on Communications, Montreal, QC, Canada, 14–23 June 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Sikeridis, D.; Rimal, B.P.; Papapanagiotou, I.; Devetsikiotis, M. Unsupervised Crowd-Assisted Learning Enabling Location-Aware Facilities. IEEE Internet Things J. 2018, 5, 4699–4713. [Google Scholar] [CrossRef]
- Liu, X.; Abdelhakim, M.; Krishnamurthy, P.; Tipper, D. Identifying Malicious Nodes in Multihop IoT Networks Using Diversity and Unsupervised Learning. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, J.; Li, J.; Niu, S.; Song, H. Machine Learning for the Detection and Identification of Internet of Things Devices: A Survey. IEEE Internet Things J. 2022, 9, 298–320. [Google Scholar] [CrossRef]
- Safi, M.; Dadkhah, S.; Shoeleh, F.; Mahdikhani, H.; Molyneaux, H.; Ghorbani, A.A. A Survey on IoT Profiling, Fingerprinting, and Identification. ACM Trans. Internet Things 2022, 3, 1–39. [Google Scholar] [CrossRef]
- Meidan, Y.; Bohadana, M.; Shabtai, A.; Ochoa, M.; Tippenhauer, N.O.; Guarnizo, J.D.; Elovici, Y. Detection of unauthorized IoT devices using machine learning techniques. arXiv 2017, arXiv:1709.04647. [Google Scholar]
- Aksoy, A.; Gunes, M.H. Automated IoT Device Identification using Network Traffic. In Proceedings of the IEEE ICC, Shanghai, China, 20–24 May 2019; pp. 1–7. [Google Scholar]
- Hamad, S.A.; Zhang, W.E.; Sheng, Q.Z.; Nepal, S. IoT Device Identification via Network-Flow Based Fingerprinting and Learning. In Proceedings of the 18th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/13th IEEE International Conference on Big Data Science and Engineering (TrustCom/BigDataSE), Rotorua, New Zealand, 5–8 August 2019; pp. 103–111. [Google Scholar]
- Bekerman, D.; Shapira, B.; Rokach, L.; Bar, A. Unknown malware detection using network traffic classification. In Proceedings of the 2015 IEEE Conference on Communications and Network Security (CNS), Florence, Italy, 28–30 September 2015; pp. 134–142. [Google Scholar] [CrossRef]
- Kassambara, A. Practical Guide to Cluster Analysis in R: Unsupervised Machine Learning. 2017, Volume 1. Available online: http://www.sthda.com/english/ (accessed on 25 February 2023).
- Jolliffe, I.T. Principal Component Analysis for Special Types of Data; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN revisited, revisited: Why and how you should (still) use DBSCAN. ACM Trans. Database Syst. 2017, 42, 1–21. [Google Scholar] [CrossRef]
- RaspAP. RaspAP: Simple Wireless AP Setup & Management for Debian-Based Devices. Available online: https://github.com/RaspAP (accessed on 25 February 2023).
- Lashkari, A.H.; Draper-Gil, G.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of tor traffic using time based features. In Proceedings of the ICISSP, Porto, Portugal, 19–21 February 2017; pp. 253–262. [Google Scholar]
- Draper-Gil, G.; Lashkari, A.H.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of encrypted and vpn traffic using time-related. In Proceedings of the 2nd International Conference Information Systems Security and Privacy, Rome, Italy, 19–21 February 2016; pp. 407–414. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device | Dataset |
|---|---|
| Amazon Echo Show | 47,804 |
| Lenovo Chromebook | 9307 |
| Google Nexus Tablet | 9388 |
| K Smart Plug * | 79,160 |
| Raspberry Pi * | 19,481 |
| ZMI Smart Clock | 7185 |
| Amazon Smart Plug | 5227 |
| Samsung Smart TV | 94,976 |
| Device | Number of Clusters |
|---|---|
| Amazon Echo Show | 400 |
| Lenovo Chromebook | 100 |
| Google Nexus Tablet | 300 |
| K Smart Plug | 60 |
| Raspberry Pi | 300 |
| ZMI Smart Clock | 70 |
| Amazon Smart Plug | 70 |
| Samsung Smart TV | 100 |
| Metric | DBSCAN | 1% Dropoff |
|---|---|---|
| Macro Precision | 0.821 | 0.828 |
| Macro Recall | 0.777 | 0.799 |
| Macro F1 Score | 0.797 | 0.813 |
| Device | Supervised ML | Unsupervised ML |
|---|---|---|
| Amazon Echo Show | 92.4% | 88.5% |
| Lenovo Chromebook | 87.5% | 84.9% |
| Google Nexus Tablet | 100.0% | 79.3% |
| K Smart Plug | 91.0% | 96.5% |
| Raspberry Pi | 97.5% | 89.7% |
| ZMI Smart Clock | 98.8% | 88.3% |
| Amazon Smart Plug | 90.4% | 96.4% |
| Samsung Smart TV | 99.1% | 95.2% |
| Device | Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|---|
| Amazon Echo Show | 0.87 | 0.89 | 0.88 | 88.5% |
| Lenovo Chromebook | 0.89 | 0.85 | 0.87 | 84.9% |
| Google Nexus Tablet | 0.90 | 0.79 | 0.84 | 79.3% |
| K Smart Plug | 1.00 | 0.96 | 0.98 | 96.5% |
| Raspberry Pi | 0.85 | 0.90 | 0.87 | 89.7% |
| ZMI Smart Clock | 0.98 | 0.88 | 0.93 | 88.3% |
| Amazon Smart Plug | 0.97 | 0.96 | 0.97 | 96.4% |
| Samsung Smart TV | 1.00 | 0.95 | 0.97 | 95.2% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koball, C.; Rimal, B.P.; Wang, Y.; Salmen, T.; Ford, C. IoT Device Identification Using Unsupervised Machine Learning. Information 2023, 14, 320. https://doi.org/10.3390/info14060320
Koball C, Rimal BP, Wang Y, Salmen T, Ford C. IoT Device Identification Using Unsupervised Machine Learning. Information. 2023; 14(6):320. https://doi.org/10.3390/info14060320
Chicago/Turabian StyleKoball, Carson, Bhaskar P. Rimal, Yong Wang, Tyler Salmen, and Connor Ford. 2023. "IoT Device Identification Using Unsupervised Machine Learning" Information 14, no. 6: 320. https://doi.org/10.3390/info14060320