

METRIC—Multi-Eye to Robot Indoor Calibration Dataset

Abstract
:1. Introduction
- Camera network calibration;
- Robot-world hand-eye calibration.
2. Related Works
2.1. Camera Network Calibration
2.2. Robot-World Hand-Eye Calibration
2.3. Calibration Dataset
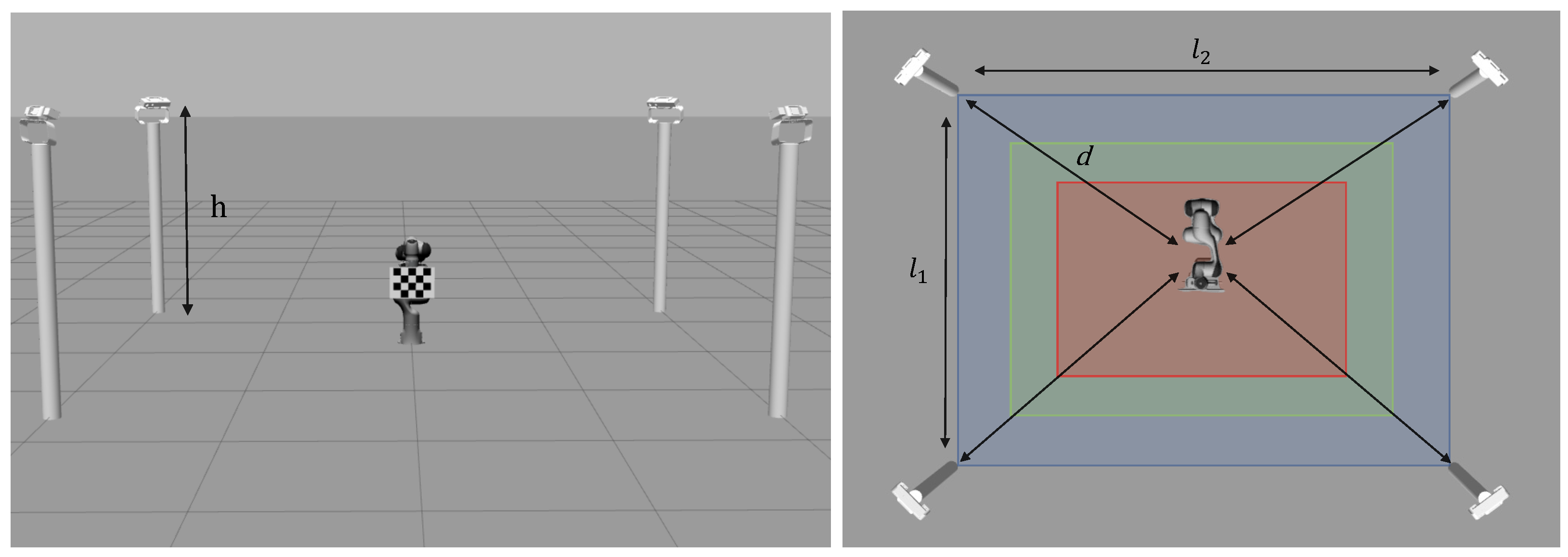
3. Dataset Acquisition
3.1. Synthetic Dataset
3.2. Real Dataset
- Intel RealSense Lidar camera L515 (https://www.intelrealsense.com/lidar-camera-l515/ accessed on 1 May 2023);
- Intel RealSense Depth D455 sensor (https://www.intelrealsense.com/depth-camera-d455/ accessed on 1 May 2023);
- Microsoft Kinect V2 (https://learn.microsoft.com/it-it/windows/apps/design/devices/kinect-for-windows accessed on 1 May 2023).
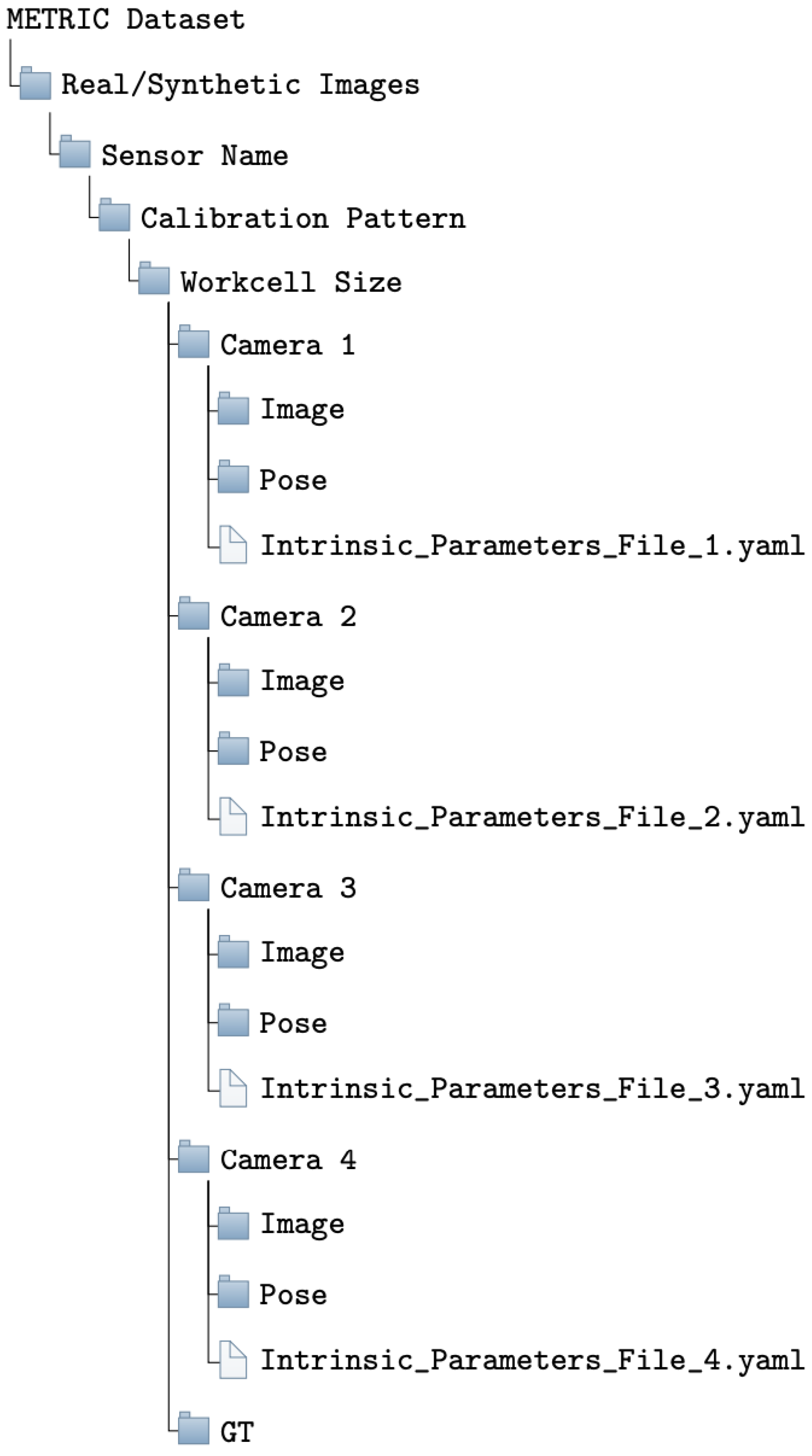
4. Dataset Structure
5. Experiments and Results
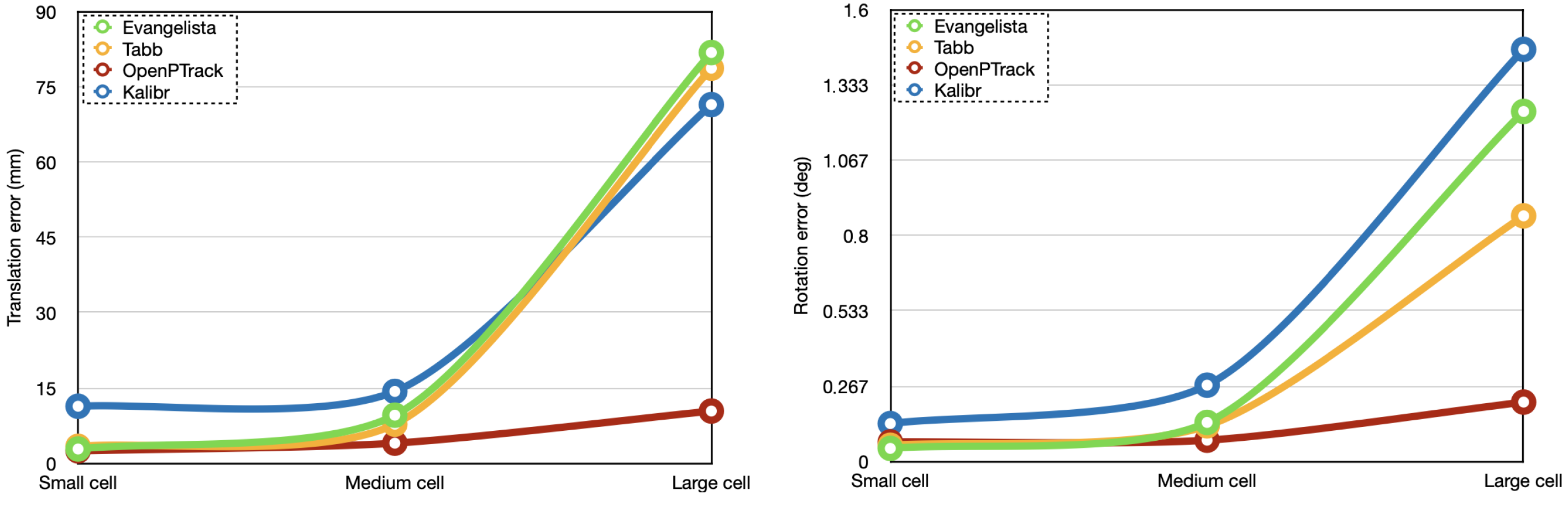
5.1. Camera Network Calibration
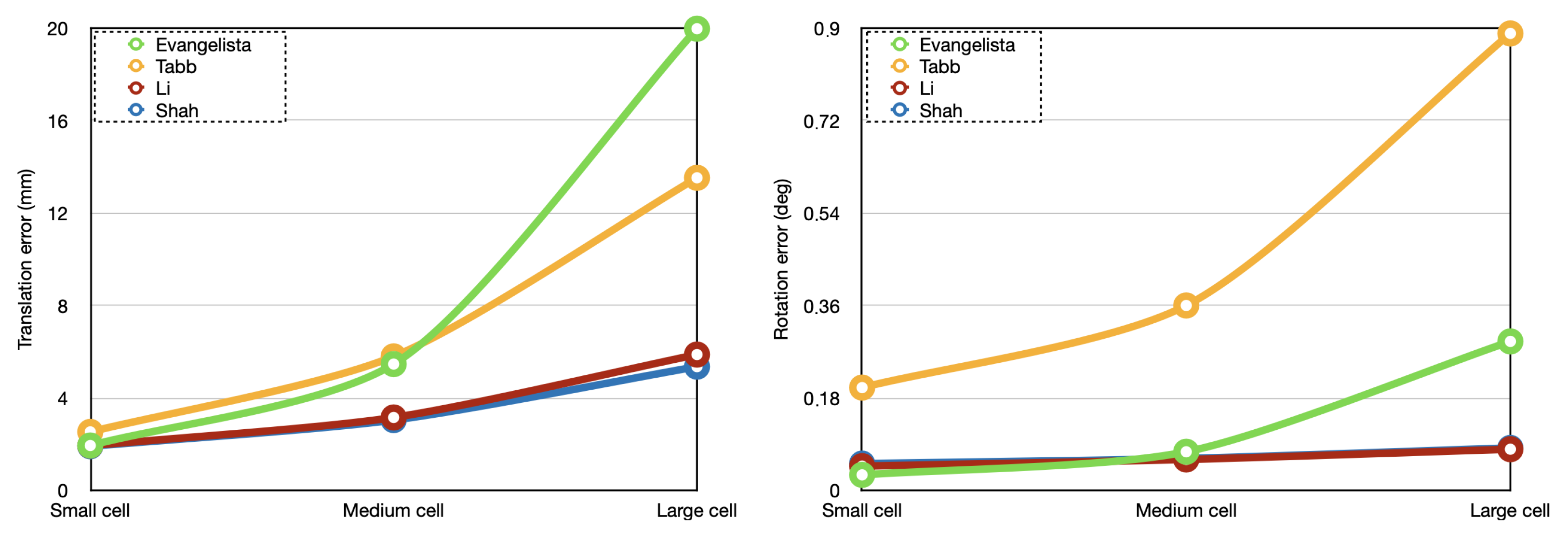
5.2. Robot-World Hand-Eye Calibration
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Translation Error [mm] | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Small | OpenPTrack [13] | 2.69 | 1.96 | 1.75 | 0.93 | 2.56 | 2.02 | 3.79 | 1.81 | 1.76 | 4.13 | 4.20 | 1.72 |
| Kalibr [25] | 12.23 | 13.43 | 12.31 | 10.24 | 12.23 | 9.23 | 9.81 | 8.91 | 9.36 | 12.33 | 12.21 | 13.72 | |
| Evangelista [27] | 2.34 | 3.55 | 3.13 | 2.00 | 1.98 | 3.71 | 3.80 | 2.72 | 2.31 | 3.09 | 4.33 | 0.79 | |
| Tabb RWHE [24] | 3.25 | 2.89 | 4.12 | 3.58 | 3.71 | 4.19 | 2.85 | 3.99 | 2.45 | 3.11 | 2.95 | 3.06 | |
| Medium | OpenPTrack [13] | 3.65 | 3.35 | 2.26 | 1.97 | 2.00 | 4.01 | 4.88 | 3.47 | 3.07 | 6.99 | 7.82 | 4.26 |
| Kalibr [25] | 13.23 | 12.45 | 15.67 | 9.47 | 12.32 | 18.21 | 13.28 | 12.34 | 14.54 | 19.34 | 14.36 | 16.24 | |
| Evangelista [27] | 7.43 | 13.49 | 3.93 | 3.24 | 13.48 | 12.55 | 18.20 | 12.13 | 5.44 | 4.61 | 11.02 | 9.12 | |
| Tabb RWHE [24] | 6.44 | 11.78 | 4.64 | 8.98 | 9.12 | 7.23 | 6.27 | 7.94 | 8.11 | 5.02 | 8.23 | 9.44 | |
| Large | OpenPTrack [13] | 2.51 | 4.34 | 15.16 | 4.86 | 3.73 | 9.93 | 12.74 | 8.57 | 6.39 | 23.12 | 21.95 | 11.29 |
| Kalibr [25] | 47.31 | 44.24 | 38.17 | 42.36 | 32.35 | 59.93 | 72.32 | 68.43 | 96.73 | 124.28 | 121.89 | 110.18 | |
| Evangelista [27] | 116.39 | 112.93 | 123.99 | 77.65 | 31.21 | 60.87 | 75.24 | 32.40 | 59.48 | 125.21 | 85.55 | 81.24 | |
| Tabb RWHE [24] | 52.45 | 68.65 | 76.24 | 112.57 | 79.05 | 83.98 | 49.01 | 84.12 | 73.94 | 81.35 | 95.92 | 87.34 | |
| Rotation Error [deg] | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Small | OpenPTrack [13] | 0.07 | 0.08 | 0.05 | 0.09 | 0.04 | 0.05 | 0.15 | 0.08 | 0.04 | 0.07 | 0.06 | 0.05 |
| Kalibr [25] | 0.13 | 0.11 | 0.13 | 0.12 | 0.18 | 0.09 | 0.15 | 0.13 | 0.12 | 0.13 | 0.17 | 0.15 | |
| Evangelista [27] | 0.05 | 0.03 | 0.05 | 0.04 | 0.06 | 0.06 | 0.04 | 0.03 | 0.04 | 0.06 | 0.05 | 0.05 | |
| Tabb RWHE [24] | 0.05 | 0.06 | 0.05 | 0.04 | 0.05 | 0.05 | 0.05 | 0.06 | 0.07 | 0.07 | 0.08 | 0.08 | |
| Medium | OpenPTrack [13] | 0.06 | 0.04 | 0.11 | 0.06 | 0.05 | 0.07 | 0.05 | 0.09 | 0.12 | 0.06 | 0.11 | 0.08 |
| Kalibr [25] | 0.16 | 0.24 | 0.32 | 0.38 | 0.21 | 0.27 | 0.29 | 0.27 | 0.13 | 0.35 | 0.38 | 0.28 | |
| Evangelista [27] | 0.19 | 0.15 | 0.07 | 0.10 | 0.30 | 0.12 | 0.14 | 0.14 | 0.16 | 0.07 | 0.09 | 0.13 | |
| Tabb RWHE [24] | 0.10 | 0.12 | 0.08 | 0.16 | 0.12 | 0.14 | 0.08 | 0.17 | 0.16 | 0.08 | 0.16 | 0.15 | |
| Large | OpenPTrack [13] | 0.06 | 0.08 | 0.48 | 0.06 | 0.17 | 0.16 | 0.08 | 0.17 | 0.34 | 0.46 | 0.18 | 0.32 |
| Kalibr [25] | 1.40 | 0.58 | 1.32 | 1.67 | 0.98 | 1.62 | 1.21 | 1.98 | 1.32 | 1.87 | 2.13 | 1.45 | |
| Evangelista [27] | 1.12 | 0.98 | 1.23 | 1.32 | 1.29 | 0.32 | 1.12 | 0.48 | 1.92 | 2.87 | 0.69 | 1.65 | |
| Tabb RWHE [24] | 0.98 | 1.14 | 0.65 | 0.88 | 1.17 | 0.45 | 0.54 | 1.12 | 1.67 | 0.56 | 0.78 | 0.58 | |
| Small Workcell—Translation Error [mm] | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Kinect V2 | OpenPTrack [13] | 80.84 | 119.13 | 50.39 | 75.72 | 33.68 | 37.51 | 120.42 | 44.47 | 80.16 | 49.56 | 100.85 | 94.89 |
| Kalibr [25] | 112.93 | 109.24 | 106.54 | 95.57 | 136.36 | 127.44 | 156.32 | 98.73 | 120.57 | 86.36 | 130.43 | 98.39 | |
| Evangelista [27] | 62.18 | 51.44 | 87.99 | 53.34 | 79.58 | 83.81 | 35.06 | 74.74 | 29.56 | 13.14 | 60.53 | 39.50 | |
| Tabb RWHE [24] | 56.78 | 69.89 | 73.62 | 42.48 | 39.38 | 46.52 | 52.38 | 75.23 | 65.47 | 52.49 | 73.42 | 61.08 | |
| Depth D455 | OpenPTrack [13] | 73.52 | 110.11 | 100.53 | 133.05 | 71.95 | 91.40 | 141.13 | 81.15 | 104.53 | 62.55 | 82.15 | 111.99 |
| Kalibr [25] | 75.35 | 147.28 | 192.54 | 95.35 | 56.87 | 89.54 | 129.12 | 76.33 | 112.73 | 71.84 | 125.62 | 134.28 | |
| Evangelista [27] | 85.75 | 54.27 | 67.37 | 89.47 | 73.16 | 73.37 | 57.36 | 66.14 | 14.65 | 23.67 | 52.75 | 44.14 | |
| Tabb RWHE [24] | 59.48 | 65.14 | 69.48 | 89.38 | 53.50 | 59.08 | 74.39 | 69.48 | 54.72 | 89.68 | 92.58 | 39.48 | |
| LiDAR L515 | OpenPTrack [13] | 58.92 | 133.18 | 33.87 | 86.29 | 23.35 | 65.73 | 94.07 | 14.03 | 90.46 | 20.02 | 77.59 | 123.23 |
| Kalibr [25] | 84.62 | 127.83 | 135.38 | 152.14 | 121.27 | 121.32 | 71.35 | 121.46 | 143.73 | 84.67 | 76.75 | 125.34 | |
| Evangelista [27] | 61.11 | 17.19 | 21.01 | 39.76 | 72.08 | 61.55 | 15.43 | 63.41 | 17.95 | 9.86 | 46.26 | 32.79 | |
| Tabb RWHE [24] | 45.68 | 35.68 | 24.74 | 32.48 | 41.55 | 52.53 | 39.48 | 42.68 | 24.62 | 19.58 | 34.53 | 46.38 | |
| Small Workcell—Rotation Error [deg] | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Kinect V2 | OpenPTrack [13] | 0.57 | 0.62 | 0.78 | 1.23 | 1.35 | 0.97 | 1.25 | 1.12 | 0.89 | 1.27 | 1.43 | 0.78 |
| Kalibr [25] | 1.78 | 1.03 | 1.43 | 1.98 | 1.48 | 1.18 | 1.23 | 2.11 | 1.67 | 1.48 | 1.65 | 1.56 | |
| Evangelista [27] | 0.56 | 0.40 | 0.21 | 0.58 | 0.77 | 0.48 | 0.40 | 0.58 | 0.36 | 0.30 | 0.50 | 0.40 | |
| Tabb RWHE [24] | 0.78 | 0.89 | 1.13 | 1.24 | 1.21 | 0.92 | 0.67 | 1.10 | 1.20 | 0.57 | 0.78 | 0.58 | |
| Depth D455 | OpenPTrack [13] | 1.56 | 1.34 | 0.34 | 0.88 | 0.32 | 0.99 | 1.34 | 0.57 | 1.88 | 0.46 | 1.21 | 1.39 |
| Kalibr [25] | 1.98 | 2.89 | 1.92 | 2.76 | 2.43 | 2.12 | 1.98 | 2.34 | 2.76 | 1.89 | 2.06 | 2.88 | |
| Evangelista [27] | 0.45 | 0.24 | 0.22 | 0.44 | 0.53 | 0.63 | 0.21 | 0.87 | 0.44 | 0.37 | 0.69 | 0.40 | |
| Tabb RWHE [24] | 1.21 | 1.56 | 1.76 | 1.32 | 0.97 | 1.56 | 1.09 | 1.57 | 1.72 | 1.09 | 1.45 | 1.36 | |
| LiDAR L515 | OpenPTrack [13] | 1.76 | 1.73 | 0.53 | 1.12 | 0.71 | 1.33 | 1.58 | 0.65 | 2.38 | 0.65 | 1.27 | 2.88 |
| Kalibr [25] | 1.52 | 1.24 | 1.76 | 1.56 | 1.52 | 2.11 | 1.29 | 1.77 | 1.98 | 1.43 | 1.73 | 1.82 | |
| Evangelista [27] | 0.34 | 0.78 | 0.25 | 0.38 | 1.07 | 0.29 | 0.95 | 0.47 | 1.82 | 0.11 | 0.25 | 1.59 | |
| Tabb RWHE [24] | 1.43 | 0.78 | 0.88 | 0.92 | 0.73 | 0.84 | 0.87 | 1.12 | 1.37 | 1.25 | 0.98 | 1.34 | |
| Large Workcell—Translation Error [mm] | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Kinect V2 | OpenPTrack [13] | 138.22 | 178.25 | 91.25 | 180.01 | 65.60 | 27.32 | 250.94 | 77.12 | 105.43 | 75.97 | 232.63 | 184.21 |
| Kalibr [25] | 122.46 | 125.36 | 121.47 | 97.46 | 85.36 | 138.48 | 184.37 | 125.46 | 145.57 | 175.58 | 184.53 | 136.81 | |
| Evangelista [27] | 70.82 | 116.80 | 47.18 | 93.45 | 82.53 | 58.34 | 63.86 | 78.17 | 37.34 | 27.94 | 73.40 | 90.83 | |
| Tabb RWHE [24] | 60.71 | 68.22 | 80.13 | 45.32 | 50.62 | 84.23 | 45.32 | 73.56 | 78.49 | 39.67 | 69.19 | 88.31 | |
| Depth D455 | OpenPTrack [13] | 135.53 | 226.54 | 236.74 | 147.63 | 243.73 | 174.22 | 342.60 | 196.19 | 306.91 | 193.36 | 138.32 | 299.51 |
| Kalibr [25] | − | − | − | − | − | − | − | − | − | − | − | − | |
| Evangelista [27] | 80.03 | 206.39 | 168.55 | 148.34 | 246.65 | 143.02 | 253.20 | 196.19 | 306.91 | 185.06 | 112.24 | 304.51 | |
| Tabb RWHE [24] | 78.82 | 174.53 | 110.34 | 102.43 | 198.42 | 138.32 | 296.22 | 171.24 | 194.36 | 170.42 | 145.81 | 206.35 | |
| LiDAR L515 | OpenPTrack [13] | 158.22 | 153.25 | 72.34 | 157.39 | 78.88 | 45.68 | 198.39 | 98.49 | 88.88 | 69.89 | 187.29 | 163.99 |
| Kalibr [25] | 236.57 | 153.25 | 128.68 | 165.32 | 128.58 | 96.38 | 143.44 | 86.32 | 125.35 | 133.35 | 146.38 | 179.62 | |
| Evangelista [27] | 95.18 | 110.07 | 50.02 | 105.26 | 60.34 | 74.01 | 70.37 | 66.24 | 68.28 | 51.07 | 90.34 | 76.64 | |
| Tabb RWHE [24] | 45.52 | 65.98 | 75.34 | 69.25 | 93.23 | 88.24 | 75.38 | 45.57 | 89.38 | 57.48 | 93.24 | 67.78 | |
| Large Workcell—Rotation Error [deg] | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Kinect V2 | OpenPTrack [13] | 1.98 | 2.23 | 0.83 | 1.53 | 0.79 | 0.83 | 2.09 | 0.74 | 4.21 | 0.97 | 1.73 | 3.29 |
| Kalibr [25] | 3.23 | 3.01 | 2.78 | 2.52 | 3.12 | 2.78 | 2.88 | 2.39 | 3.41 | 2.49 | 1.88 | 3.12 | |
| Evangelista [27] | 0.59 | 0.98 | 0.45 | 0.47 | 0.61 | 0.28 | 0.98 | 0.56 | 1.21 | 0.46 | 0.32 | 1.18 | |
| Tabb RWHE [24] | 2.12 | 0.87 | 2.23 | 2.37 | 2.41 | 2.89 | 1.32 | 1.09 | 1.99 | 1.88 | 1.58 | 1.92 | |
| Depth D455 | OpenPTrack [13] | 3.23 | 1.57 | 3.89 | 1.88 | 3.72 | 2.54 | 4.26 | 1.43 | 2.39 | 3.28 | 1.51 | 3.23 |
| Kalibr [25] | − | − | − | − | − | − | − | − | − | − | − | − | |
| Evangelista [27] | 1.31 | 1.84 | 1.65 | 1.56 | 1.98 | 1.23 | 2.35 | 2.48 | 3.78 | 2.13 | 1.42 | 2.89 | |
| Tabb RWHE [24] | 2.78 | 4.21 | 3.24 | 5.03 | 1.89 | 3.25 | 4.32 | 2.23 | 3.20 | 4.87 | 3.04 | 4.14 | |
| LiDAR L515 | OpenPTrack [13] | 0.74 | 1.23 | 1.26 | 0.73 | 0.81 | 1.99 | 1.56 | 1.83 | 1.45 | 2.19 | 1.33 | 3.01 |
| Kalibr [25] | 3.21 | 3.45 | 2.08 | 1.28 | 2.78 | 2.08 | 3.29 | 1.88 | 2.97 | 1.20 | 3.83 | 2.68 | |
| Evangelista [27] | 0.31 | 0.85 | 0.40 | 0.39 | 1.05 | 0.21 | 0.95 | 0.67 | 1.72 | 0.24 | 0.20 | 1.53 | |
| Tabb RWHE [24] | 1.72 | 1.04 | 0.85 | 1.89 | 1.57 | 2.99 | 1.89 | 1.72 | 1.86 | 0.99 | 2.05 | 1.59 | |
| Translation Error [mm] | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Small | Medium | Large | ||||||||||
| Evangelista [27] | 1.63 | 1.99 | 2.14 | 1.97 | 2.46 | 5.60 | 11.03 | 2.74 | 25.11 | 15.35 | 17.61 | 21.83 |
| Tabb RWHE [24] | 2.42 | 2.60 | 1.70 | 3.37 | 5.25 | 2.85 | 7.21 | 7.85 | 14.89 | 13.78 | 8.90 | 16.54 |
| Li [29] | 2.22 | 2.26 | 2.07 | 1.16 | 2.83 | 4.03 | 2.87 | 2.85 | 4.20 | 12.32 | 3.03 | 3.93 |
| Shah [30] | 2.04 | 2.19 | 2.05 | 1.33 | 2.80 | 3.80 | 2.77 | 2.76 | 3.07 | 10.99 | 3.04 | 4.28 |
| Rotation Error [deg] | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Small | Medium | Large | ||||||||||
| Evangelista [27] | 0.02 | 0.03 | 0.03 | 0.04 | 0.03 | 0.08 | 0.15 | 0.04 | 0.28 | 0.14 | 0.19 | 0.56 |
| Tabb RWHE [24] | 0.23 | 0.28 | 0.13 | 0.16 | 0.54 | 0.49 | 0.31 | 0.11 | 1.56 | 0.59 | 0.44 | 0.98 |
| Li [29] | 0.05 | 0.06 | 0.04 | 0.04 | 0.08 | 0.04 | 0.06 | 0.06 | 0.06 | 0.12 | 0.05 | 0.09 |
| Shah [30] | 0.05 | 0.07 | 0.04 | 0.05 | 0.08 | 0.05 | 0.06 | 0.06 | 0.05 | 0.15 | 0.05 | 0.08 |
| Translation Error [mm] | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Small Workcell | Large Workcell | ||||||||
| Kinect V2 | Evangelista [27] | 29.34 | 76.20 | 38.91 | 26.71 | 82.61 | 86.40 | 60.71 | 79.32 |
| Tabb RWHE [24] | 34.24 | 86.54 | 43.21 | 42.31 | 97.35 | 123.23 | 101.23 | 98.23 | |
| Li [29] | 79.58 | 34.52 | 64.68 | 87.91 | 134.86 | 106.23 | 101.00 | 175.45 | |
| Shah [30] | 30.31 | 31.92 | 14.98 | 31.66 | 46.21 | 45.38 | 59.72 | 68.38 | |
| Depth D455 | Evangelista [27] | 57.97 | 64.43 | 30.19 | 27.98 | 73.82 | 83.18 | 236.55 | 152.01 |
| Tabb RWHE [24] | 69.65 | 93.35 | 46.67 | 46.23 | 129.24 | 102.23 | 182.34 | 198.33 | |
| Li [29] | 39.92 | 47.01 | 70.70 | 46.51 | − | − | − | − | |
| Shah [30] | 12.12 | 23.38 | 22.21 | 37.89 | − | − | − | − | |
| LiDAR L515 | Evangelista [27] | 10.41 | 57.19 | 25.45 | 11.74 | 59.92 | 71.68 | 66.29 | 44.47 |
| Tabb RWHE [24] | 15.23 | 54.35 | 45.34 | 23.46 | 89.34 | 79.33 | 73.22 | 59.43 | |
| Li [29] | 17.74 | 31.69 | 20.36 | 25.01 | 18.13 | 34.60 | 21.52 | 31.30 | |
| Shah [30] | 14.34 | 16.94 | 15.81 | 26.95 | 16.80 | 35.76 | 27.12 | 24.89 | |
| Rotation Error [deg] | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Small Workcell | Large Workcell | ||||||||
| Kinect V2 | Evangelista [27] | 0.50 | 0.82 | 0.37 | 0.57 | 0.93 | 0.54 | 0.40 | 1.21 |
| Tabb RWHE [24] | 0.65 | 0.78 | 0.54 | 0.98 | 0.79 | 0.69 | 0.58 | 0.97 | |
| Li [29] | 1.05 | 0.65 | 0.63 | 0.59 | 1.26 | 0.53 | 0.63 | 0.49 | |
| Shah [30] | 0.85 | 0.67 | 0.73 | 0.75 | 1.03 | 0.43 | 0.69 | 0.79 | |
| Depth D455 | Evangelista [27] | 0.48 | 0.81 | 0.13 | 0.29 | 0.99 | 0.54 | 2.54 | 1.27 |
| Tabb RWHE [24] | 1.23 | 1.65 | 1.59 | 0.99 | 1.57 | 1.43 | 2.14 | 1.83 | |
| Li [29] | 0.12 | 0.87 | 1.43 | 0.47 | − | − | − | − | |
| Shah [30] | 0.25 | 0.78 | 0.31 | 0.83 | − | − | − | − | |
| LiDAR L515 | Evangelista [27] | 0.45 | 0.23 | 0.39 | 0.52 | 0.51 | 0.33 | 0.49 | 0.42 |
| Tabb RWHE [24] | 0.76 | 0.93 | 1.23 | 0.87 | 0.89 | 0.72 | 0.69 | 0.79 | |
| Li [29] | 0.29 | 0.38 | 0.19 | 0.39 | 0.28 | 0.32 | 0.21 | 0.42 | |
| Shah [30] | 0.32 | 0.48 | 0.17 | 0.39 | 0.27 | 0.42 | 0.18 | 0.39 | |
References
- Dong, Z.; Song, J.; Chen, X.; Guo, C.; Hilliges, O. Shape-aware multi-person pose estimation from multi-view images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11158–11168. [Google Scholar]
- Golda, T.; Kalb, T.; Schumann, A.; Beyerer, J. Human pose estimation for real-world crowded scenarios. In Proceedings of the 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Taipei, Taiwan, 18–21 September 2019; pp. 1–8. [Google Scholar]
- Cortés, I.; Beltrán, J.; de la Escalera, A.; García, F. Sianms: Non-maximum suppression with siamese networks for multi-camera 3d object detection. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 933–938. [Google Scholar]
- Quintana, M.; Karaoglu, S.; Alvarez, F.; Menendez, J.M.; Gevers, T. Three-D Wide Faces (3DWF): Facial Landmark Detection and 3D Reconstruction over a New RGB–D Multi-Camera Dataset. Sensors 2019, 19, 1103. [Google Scholar] [CrossRef] [PubMed]
- Terreran, M.; Lamon, E.; Michieletto, S.; Pagello, E. Low-cost scalable people tracking system for human-robot collaboration in industrial environment. Procedia Manuf. 2020, 51, 116–124. [Google Scholar] [CrossRef]
- Zhu, L.; Menon, M.; Santillo, M.; Linkowski, G. Occlusion Handling for Industrial Robots. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October–24 January 2021; pp. 10663–10668. [Google Scholar]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Sturm, P.F.; Maybank, S.J. On plane-based camera calibration: A general algorithm, singularities, applications. In Proceedings of the Proceedings. 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (Cat. No PR00149), Fort Collins, CO, USA, 23–25 June 1999; Volume 1, pp. 432–437. [Google Scholar]
- Tsai, R. A versatile camera calibration technique for high-accuracy 3D machine vision metrology using off-the-shelf TV cameras and lenses. IEEE J. Robot. Autom. 1987, 3, 323–344. [Google Scholar] [CrossRef]
- Garrido-Jurado, S.; Muñoz-Salinas, R.; Madrid-Cuevas, F.J.; Marín-Jiménez, M.J. Automatic generation and detection of highly reliable fiducial markers under occlusion. Pattern Recognit. 2014, 47, 2280–2292. [Google Scholar] [CrossRef]
- Shen, J.; Xu, W.; Luo, Y.; Su, P.C.; Cheung, S.C.S. Extrinsic calibration for wide-baseline RGB-D camera network. In Proceedings of the 2014 IEEE 16th International Workshop on Multimedia Signal Processing (MMSP), Jakarta, Indonesia, 22–24 September 2014; pp. 1–6. [Google Scholar]
- Kim, E.S.; Park, S.Y. Extrinsic calibration of a camera-LIDAR multi sensor system using a planar chessboard. In Proceedings of the 2019 Eleventh International Conference on Ubiquitous and Future Networks (ICUFN), Zagreb, Croatia, 2–5 July 2019; pp. 89–91. [Google Scholar]
- Munaro, M.; Basso, F.; Menegatti, E. OpenPTrack: Open source multi-camera calibration and people tracking for RGB-D camera networks. Robot. Auton. Syst. 2016, 75, 525–538. [Google Scholar] [CrossRef]
- Hödlmoser, M.; Kampel, M. Multiple camera self-calibration and 3D reconstruction using pedestrians. In Proceedings of the Advances in Visual Computing: 6th International Symposium, ISVC 2010, Las Vegas, NV, USA, 29 November–1 December 2010; Proceedings, Part II 6. Springer: Berlin/Heidelberg, Germany, 2010; pp. 1–10. [Google Scholar]
- Le, Q.V.; Ng, A.Y. Joint calibration of multiple sensors. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 10–15 October 2009; pp. 3651–3658. [Google Scholar]
- Zhu, Y.; Wu, Y.; Zhang, Y.; Qu, F. Multi-camera System Calibration of Indoor Mobile Robot Based on SLAM. In Proceedings of the 2021 3rd International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Taiyuan, China, 3–5 December 2021; pp. 240–244. [Google Scholar]
- Kroeger, O.; Huegle, J.; Niebuhr, C.A. An automatic calibration approach for a multi-camera-robot system. In Proceedings of the 2019 24th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Zaragoza, Spain, 10–13 September 2019; pp. 1515–1518. [Google Scholar]
- Mišeikis, J.; Glette, K.; Elle, O.J.; Torresen, J. Automatic Calibration of a Robot Manipulator and Multi 3D Camera System. In Proceedings of the 2016 IEEE/SICE International Symposium on System Integration (SII), Sapporo, Japan, 13–15 December 2016; pp. 735–741. [Google Scholar]
- Sung, H.; Lee, S.; Kim, D. A robot-camera hand/eye self-calibration system using a planar target. In Proceedings of the IEEE ISR 2013, Seoul, Republic of Korea, 24–26 October 2013; pp. 1–4. [Google Scholar]
- Šuligoj, F.; Jerbić, B.; Švaco, M.; Šekoranja, B.; Mihalinec, D.; Vidaković, J. Medical applicability of a low-cost industrial robot arm guided with an optical tracking system. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 3785–3790. [Google Scholar]
- Su, P.C.; Shen, J.; Xu, W.; Cheung, S.C.S.; Luo, Y. A fast and robust extrinsic calibration for RGB-D camera networks. Sensors 2018, 18, 235. [Google Scholar] [CrossRef]
- Tabb, A.; Medeiros, H.; Feldmann, M.J.; Santos, T.T. Calibration of Asynchronous Camera Networks: CALICO. arXiv 2019, arXiv:1903.06811. [Google Scholar]
- Wang, Y.; Jiang, W.; Huang, K.; Schwertfeger, S.; Kneip, L. Accurate Calibration of Multi-Perspective Cameras from a Generalization of the Hand-Eye Constraint. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 1244–1250. [Google Scholar] [CrossRef]
- Tabb, A.; Ahmad Yousef, K.M. Solving the robot-world hand-eye (s) calibration problem with iterative methods. Mach. Vis. Appl. 2017, 28, 569–590. [Google Scholar] [CrossRef]
- Furgale, P.; Rehder, J.; Siegwart, R. Unified temporal and spatial calibration for multi-sensor systems. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 1280–1286. [Google Scholar]
- Caron, G.; Eynard, D. Multiple camera types simultaneous stereo calibration. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 2933–2938. [Google Scholar]
- Evangelista, D.; Allegro, D.; Terreran, M.; Pretto, A.; Ghidoni, S. An Unified Iterative Hand-Eye Calibration Method for Eye-on-Base and Eye-in-Hand Setups. In Proceedings of the 2022 IEEE 27th International Conference on Emerging Technologies and Factory Automation (ETFA), Stuttgart, Germany, 6–9 September 2022; pp. 1–7. [Google Scholar]
- Schweighofer, G.; Pinz, A. Globally Optimal O (n) Solution to the PnP Problem for General Camera Models. In BMVC; BMVA Press: Leeds, UK, 2008; pp. 1–10. [Google Scholar]
- Li, A.; Wang, L.; Wu, D. Simultaneous robot-world and hand-eye calibration using dual-quaternions and Kronecker product. Int. J. Phys. Sci. 2010, 5, 1530–1536. [Google Scholar]
- Shah, M. Solving the robot-world/hand-eye calibration problem using the Kronecker product. J. Mech. Robot. 2013, 5, 031007. [Google Scholar] [CrossRef]
- Hüser, T.; Sheshadri, S.; Dörge, M.; Scherberger, H.; Dann, B. JARVIS-MoCap Monkey Grasping Recordings and Annotations. 2022. Available online: https://doi.org/10.5281/zenodo.6982805 (accessed on 3 March 2023).
- Skaloud, J.; Cucci, D.A.; Joseph Paul, K. Coaxial Octocopter Open Data with Digicam—IGN Calibration 2. 2021. Available online: https://doi.org/10.5281/zenodo.4705424 (accessed on 3 March 2023).
- Koide, K.; Menegatti, E. General hand—Eye calibration based on reprojection error minimization. IEEE Robot. Autom. Lett. 2019, 4, 1021–1028. [Google Scholar] [CrossRef]
- Quigley, M.; Conley, K.; Gerkey, B.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A.Y.; Berger, E. ROS: An open-source Robot Operating System. In Proceedings of the ICRA Workshop on Open Source Software, Kobe, Japan, 12–17 May 2009; Volume 3, p. 5. [Google Scholar]
- Bradski, G. The openCV library. Dr. Dobb’s J. Softw. Tools Prof. Program. 2000, 25, 120–123. [Google Scholar]
- Wang, J.; Olson, E. AprilTag 2: Efficient and robust fiducial detection. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 4193–4198. [Google Scholar]








| Workcell Sizes | Colour | h [m] | d [m] | [m] | [m] |
|---|---|---|---|---|---|
| Small workcell |  | ||||
| Medium workcell |  | ||||
| Large workcell |  |
| Workcell Sizes | h [m] | d [m] | [m] | [m] |
|---|---|---|---|---|
| Small workcell | ||||
| Large workcell |
| Kinect V2 | Depth Camera D455 | LiDAR Camera L515 | |
|---|---|---|---|
| RGB resolution | |||
| RGB FoV () |
| Kinect V2 [pixel] | Depth D455 [pixel] | LiDAR L515 [pixel] | |
|---|---|---|---|
| Camera 1 | |||
| Camera 2 | |||
| Camera 3 | |||
| Camera 4 | |||
| Average |
| Method | Small Cell | Medium Cell | Large Cell | |||
|---|---|---|---|---|---|---|
[mm] | [deg] | [mm] | [deg] | [mm] | [deg] | |
| OpenPTrack [13] | ||||||
| Kalibr [25] | ||||||
| Evangelista [27] | ||||||
| Tabb [24] | ||||||
| Method | Kinect V2 | Depth D455 | LiDAR L515 | |||
|---|---|---|---|---|---|---|
[mm] | [deg] | [mm] | [deg] | [mm] | [deg] | |
| OpenPTrack [13] | ||||||
| Kalibr [25] | ||||||
| Evangelista [27] | ||||||
| Tabb [24] | ||||||
| Method | Kinect V2 | Depth D455 | LiDAR L515 | |||
|---|---|---|---|---|---|---|
[mm] | [deg] | [mm] | [deg] | [mm] | [deg] | |
| OpenPTrack [13] | ||||||
| Kalibr [25] | − | − | ||||
| Evangelista [27] | ||||||
| Tabb [24] | ||||||
| Method | Small Cell | Medium Cell | Large Cell | |||
|---|---|---|---|---|---|---|
[mm] | [deg] | [mm] | [deg] | [mm] | [deg] | |
| Evangelista [27] | ||||||
| Tabb [24] | ||||||
| Li [29] | ||||||
| Shah [30] | ||||||
| Method | Kinect V2 | Depth D455 | LiDAR L515 | |||
|---|---|---|---|---|---|---|
| [mm] | [degree] | [mm] | [degree] | [mm] | [degree] | |
| Evangelista [27] | ||||||
| Tabb [24] | ||||||
| Li [29] | ||||||
| Shah [30] | ||||||
| Method | Kinect V2 | Depth D455 | LiDAR L515 | |||
|---|---|---|---|---|---|---|
| [mm] | [degree] | [mm] | [degree] | [mm] | [degree] | |
| Evangelista [27] | ||||||
| Tabb [24] | ||||||
| Li [29] | − | − | ||||
| Shah [30] | − | − | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Allegro, D.; Terreran, M.; Ghidoni, S. METRIC—Multi-Eye to Robot Indoor Calibration Dataset. Information 2023, 14, 314. https://doi.org/10.3390/info14060314
Allegro D, Terreran M, Ghidoni S. METRIC—Multi-Eye to Robot Indoor Calibration Dataset. Information. 2023; 14(6):314. https://doi.org/10.3390/info14060314
Chicago/Turabian StyleAllegro, Davide, Matteo Terreran, and Stefano Ghidoni. 2023. "METRIC—Multi-Eye to Robot Indoor Calibration Dataset" Information 14, no. 6: 314. https://doi.org/10.3390/info14060314