
Fundamental Research Challenges for Distributed Computing Continuum Systems
 , , ,
, , ,  and
and 
{kind=link}
Abstract
:1. Introduction
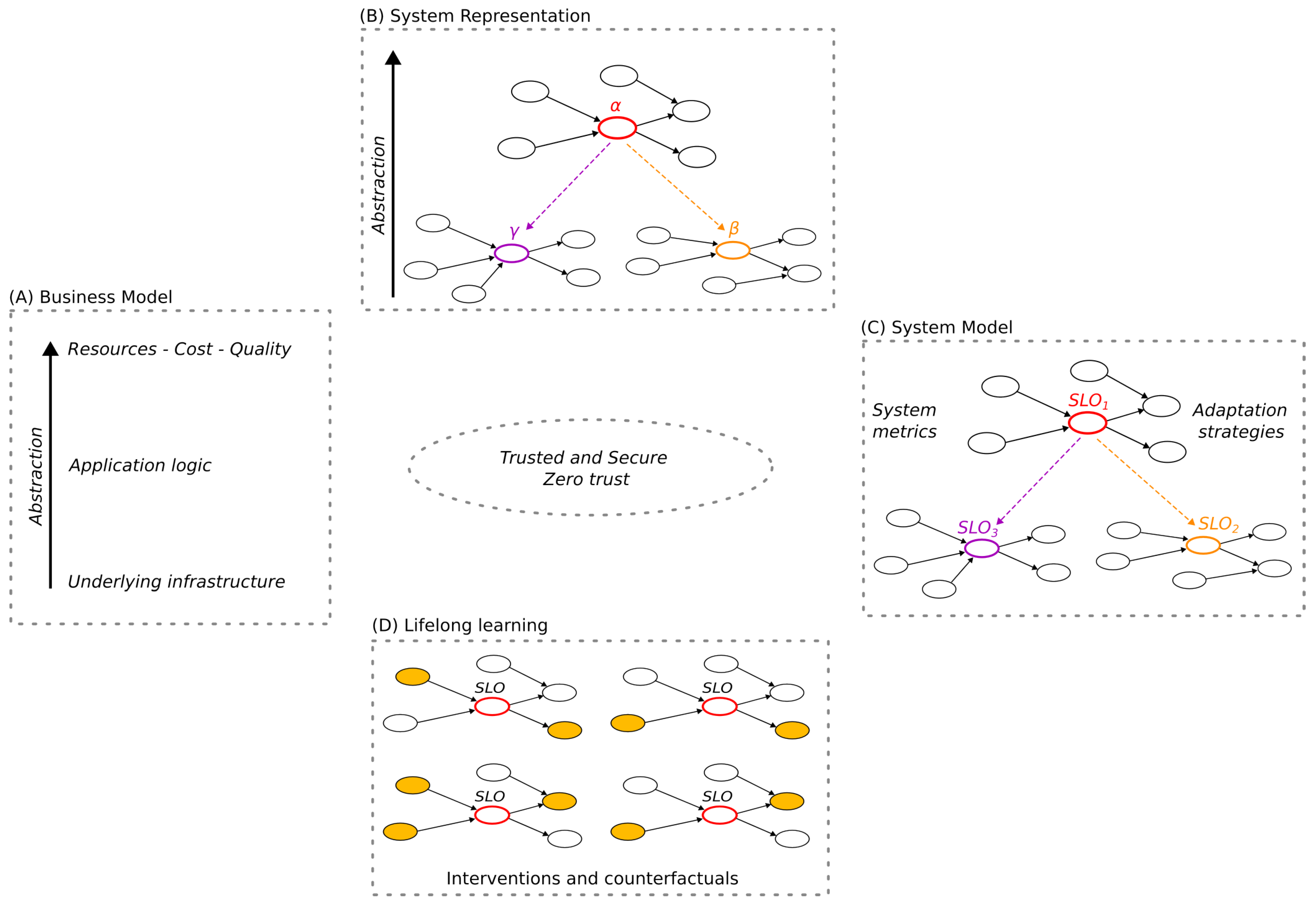
2. Vision
2.1. Representation
Markov Blanket
2.2. Model
2.2.1. DeepSLOs
2.2.2. Causal Inference
2.3. Lifelong Learning Framework
Free Energy Principle and Active Inference
2.4. Business Model
2.4.1. Resources, Quality, and Cost
2.4.2. Security through Zero Trust
3. Discussion
3.1. Techniques Discussion
3.2. Holistic Perspective
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Beckman, P.; Dongarra, J.; Ferrier, N.; Fox, G.; Moore, T.; Reed, D.; Beck, M. Harnessing the computing continuum for programming our world. In Fog Computing; Zomaya, A., Abbas, A., Khan, S., Eds.; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2020; pp. 215–230. [Google Scholar] [CrossRef]
- Morichetta, A.; Casamayor Pujol, V.; Dustdar, S. A roadmap on learning and reasoning for distributed computing continuum ecosystems. In Proceedings of the IEEE International Conference on Edge Computing (EDGE), Chicago, IL, USA, 5–10 September 2021; Institute of Electrical and Electronics Engineers: New York, NY, USA, 2021; pp. 25–31. [Google Scholar] [CrossRef]
- Costa, B.; Bachiega, J., Jr.; de Carvalho, L.R.; Araujo, A.P. Orchestration in Fog Computing: A Comprehensive Survey. ACM Comput. Surv. (CSUR) 2022, 55, 1–34. [Google Scholar] [CrossRef]
- Dustdar, S.; Casamayor Pujol, V.; Donta, P.K. On distributed computing continuum systems. IEEE Trans. Knowl. Data Eng. 2023, 35, 4092–4105. [Google Scholar] [CrossRef]
- Yu, S.; Chen, X.; Zhou, Z.; Gong, X.; Wu, D. When Deep Reinforcement Learning Meets Federated Learning: Intelligent Multitimescale Resource Management for Multiaccess Edge Computing in 5G Ultradense Network. IEEE Internet Things J. 2021, 8, 2238–2251. [Google Scholar] [CrossRef]
- Xia, X.; Chen, F.; He, Q.; Grundy, J.C.; Abdelrazek, M.; Jin, H. Cost-Effective App Data Distribution in Edge Computing. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 31–44. [Google Scholar] [CrossRef]
- Ullah, A.; Dagdeviren, H.; Ariyattu, R.C.; DesLauriers, J.; Kiss, T.; Bowden, J. MiCADO-Edge: Towards an Application-level Orchestrator for the Cloud-to-Edge Computing Continuum. J. Grid Comput. 2021, 19, 47. [Google Scholar] [CrossRef]
- Hastbacka, D.; Halme, J.; Barna, L.; Hoikka, H.; Pettinen, H.; Larranaga, M.; Bjorkbom, M.; Mesia, H.; Jaatinen, A.; Elo, M. Dynamic Edge and Cloud Service Integration for Industrial IoT and Production Monitoring Applications of Industrial Cyber-Physical Systems. IEEE Trans. Ind. Inform. 2022, 18, 498–508. [Google Scholar] [CrossRef]
- Pusztai, T.; Nastic, S.; Morichetta, A.; Casamayor Pujol, V.; Dustdar, S.; Ding, X.; Vij, D.; Xiong, Y. A Novel Middleware for Efficiently Implementing Complex Cloud-Native SLOs. In Proceedings of the 2021 IEEE 14th International Conference on Cloud Computing (CLOUD), Chicago, IL, USA, 5–10 September 2021. [Google Scholar]
- Gheibi, O.; Weyns, D. Lifelong self-adaptation: Self-adaptation meets lifelong machine learning. In Proceedings of the SEAMS’22—17th Symposium on Software Engineering for Adaptive and Self-Managing Systems, Pittsburgh, PA, USA, 22–24 May 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 1–12. [Google Scholar] [CrossRef]
- Kirchhoff, M.; Parr, T.; Palacios, E.; Friston, K.; Kiverstein, J. The Markov blankets of life: Autonomy, active inference and the free energy principle. J. R. Soc. Interface 2018, 15, 20170792. [Google Scholar] [CrossRef]
- Pearl, J. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1988. [Google Scholar]
- Forti, S.; Bisicchia, G.; Brogi, A. Declarative continuous reasoning in the cloud-IoT continuum. J. Log. Comput. 2022, 32, 206–232. [Google Scholar] [CrossRef]
- Rihan, M.; Elwekeil, M.; Yang, Y.; Huang, L.; Xu, C.; Selim, M.M. Deep-VFog: When Artificial Intelligence Meets Fog Computing in V2X. IEEE Syst. J. 2021, 15, 3492–3505. [Google Scholar] [CrossRef]
- Esfahani, N.; Malek, S. Uncertainty in self-adaptive software systems. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2013; Volume 7475 LNCS, pp. 214–238. ISBN 9783642358128. [Google Scholar] [CrossRef]
- Pearl, J.; Mackenzie, D. The Book of Why: The New Science of Cause and Effect, 1st ed.; Basic Books, Inc.: New York, NY, USA, 2018. [Google Scholar]
- Casamayor Pujol, V.; Raith, P.; Dustdar, S. Towards a new paradigm for managing computing continuum applications. In Proceedings of the IEEE 3rd International Conference on Cognitive Machine Intelligence, CogMI 2021, Virtual, 13–15 December 2021; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2021; pp. 180–188. [Google Scholar] [CrossRef]
- Friston, K.; Kilner, J.; Harrison, L. A free energy principle for the brain. J. Physiol. Paris 2006, 100, 70–87. [Google Scholar] [CrossRef] [Green Version]
- Palacios, E.R.; Razi, A.; Parr, T.; Kirchhoff, M.; Friston, K. On Markov blankets and hierarchical self-organisation. J. Theor. Biol. 2020, 486, 110089. [Google Scholar] [CrossRef]
- Smith, R.; Friston, K.J.; Whyte, C.J. A step-by-step tutorial on active inference and its application to empirical data. J. Math. Psychol. 2022, 107, 102632. [Google Scholar] [CrossRef]
- Dustdar, S.; Guo, Y.; Satzger, B.; Truong, H.L. Principles of elastic processes. IEEE Internet Comput. 2011, 15, 66–71. [Google Scholar] [CrossRef]
- Nastic, S.; Morichetta, A.; Pusztai, T.; Dustdar, S.; Ding, X.; Vij, D.; Xiong, Y. SLOC: Service level objectives for next generation cloud computing. IEEE Internet Comput. 2020, 24, 39–50. [Google Scholar] [CrossRef]
- Stafford, V. Zero trust architecture. NIST Spec. Publ. 2020, 800, 207. [Google Scholar]
- Truong, H.L.; Dustdar, S.; Leymann, F. Towards the Realization of Multi-dimensional Elasticity for Distributed Cloud Systems. Procedia Comput. Sci. 2016, 97, 14–23. [Google Scholar] [CrossRef] [Green Version]
- Rose, S.; Borchert, O.; Mitchell, S.; Connelly, S. Zero Trust Architecture; Technical Report; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2020. [Google Scholar]
- LiWang, M.; Gao, Z.; Hosseinalipour, S.; Dai, H. Multi-Task Offloading over Vehicular Clouds under Graph-based Representation. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Virtual, 7–11 June 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Zhao, Z.; Verma, G.; Rao, C.; Swami, A.; Segarra, S. Distributed scheduling using graph neural networks. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing—Proceedings, Toronto, ON, Canada, 6–11 June 2021; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2021; pp. 4720–4724. [Google Scholar] [CrossRef]
- Yu, Z.; Hu, J.; Min, G.; Wang, Z.; Miao, W.; Li, S. Privacy-Preserving Federated Deep Learning for Cooperative Hierarchical Caching in Fog Computing. IEEE Internet Things J. 2022, 9, 22246–22255. [Google Scholar] [CrossRef]
- Zhang, K.; Cao, J.; Zhang, Y. Adaptive Digital Twin and Multi-agent Deep Reinforcement Learning for Vehicular Edge Computing and Networks. IEEE Trans. Ind. Inform. 2022, 18, 1405–1413. [Google Scholar] [CrossRef]
- Sheng, S.; Chen, P.; Chen, Z.; Wu, L.; Yao, Y. Deep Reinforcement Learning-Based Task Scheduling in IoT Edge Computing. Sensors 2021, 21, 1666. [Google Scholar] [CrossRef]
- Xia, X.; Chen, F.; He, Q.; Cui, G.; Grundy, J.C.; Abdelrazek, M.; Xu, X.; Jin, H. Data, User and Power Allocations for Caching in Multi-Access Edge Computing. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 1144–1155. [Google Scholar] [CrossRef]
- Tadakamalla, V.; Menasce, D. Autonomic Elasticity Control for Multi-server Queues under Generic Workload Surges in Cloud Environments. IEEE Trans. Cloud Comput. 2020, 10, 984–995. [Google Scholar] [CrossRef]
- Guo, S.; Wu, D.; Zhang, H.; Yuan, D. Queueing Network Model and Average Delay Analysis for Mobile Edge Computing. In Proceedings of the 2018 International Conference on Computing, Networking and Communications, ICNC 2018, Maui, HI, USA, 5–8 March 2018; pp. 172–176. [Google Scholar] [CrossRef]
- Villari, M.; Fazio, M.; Dustdar, S.; Rana, O.; Ranjan, R. Osmotic Computing: A New Paradigm for Edge/Cloud Integration. IEEE Cloud Comput. 2016, 3, 76–83. [Google Scholar] [CrossRef] [Green Version]
- Gamal, I.; Abdel-Galil, H.; Ghalwash, A. Osmotic Message-Oriented Middleware for Internet of Things. Computers 2022, 11, 56. [Google Scholar] [CrossRef]
- Camara, J.; Muccini, H.; Vaidhyanathan, K. Quantitative verification-aided machine learning: A tandem approach for architecting self-adaptive IoT systems. In Proceedings of the IEEE 17th International Conference on Software Architecture, ICSA 2020, Salvador, Brazil, 16–20 March 2020; pp. 11–22. [Google Scholar] [CrossRef]
- Thrun, S. Lifelong Learning Algorithms. In Learning to Learn; Thrun, S., Pratt, L., Eds.; Springer US: Boston, MA, USA, 1998; pp. 181–209. [Google Scholar] [CrossRef]
- Yang, F.; Yang, C.; Liu, H.; Sun, F. Evaluations of the Gap between Supervised and Reinforcement Lifelong Learning on Robotic Manipulation Tasks. In Proceedings of the 5th Conference on Robot Learning. PMLR, London, UK, 8–11 November 2022; pp. 547–556. [Google Scholar]
- Febrinanto, F.G.; Xia, F.; Moore, K.; Thapa, C.; Aggarwal, C. Graph Lifelong Learning: A Survey. IEEE Comput. Intell. Mag. 2023, 18, 32–51. [Google Scholar] [CrossRef]
- Aguilera, M.; Millidge, B.; Tschantz, A.; Buckley, C.L. How particular is the physics of the free energy principle? Phys. Life Rev. 2021, 40, 24–50. [Google Scholar] [CrossRef]
- Raja, V.; Valluri, D.; Baggs, E.; Chemero, A.; Anderson, M.L. The Markov blanket trick: On the scope of the free energy principle and active inference. Phys. Life Rev. 2021, 39, 49–72. [Google Scholar] [CrossRef] [PubMed]
- Da Costa, L.; Parr, T.; Sajid, N.; Veselic, S.; Neacsu, V.; Friston, K. Active inference on discrete state-spaces: A synthesis. J. Math. Psychol. 2020, 99, 102447. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Casamayor Pujol, V.; Morichetta, A.; Murturi, I.; Kumar Donta, P.; Dustdar, S. Fundamental Research Challenges for Distributed Computing Continuum Systems. Information 2023, 14, 198. https://doi.org/10.3390/info14030198
Casamayor Pujol V, Morichetta A, Murturi I, Kumar Donta P, Dustdar S. Fundamental Research Challenges for Distributed Computing Continuum Systems. Information. 2023; 14(3):198. https://doi.org/10.3390/info14030198
Chicago/Turabian StyleCasamayor Pujol, Victor, Andrea Morichetta, Ilir Murturi, Praveen Kumar Donta, and Schahram Dustdar. 2023. "Fundamental Research Challenges for Distributed Computing Continuum Systems" Information 14, no. 3: 198. https://doi.org/10.3390/info14030198