
A Reference Architecture for Enabling Interoperability and Data Sovereignty in the Agricultural Data Space

Abstract
:1. Introduction
How to enable interoperability and data sovereignty in the ADS?
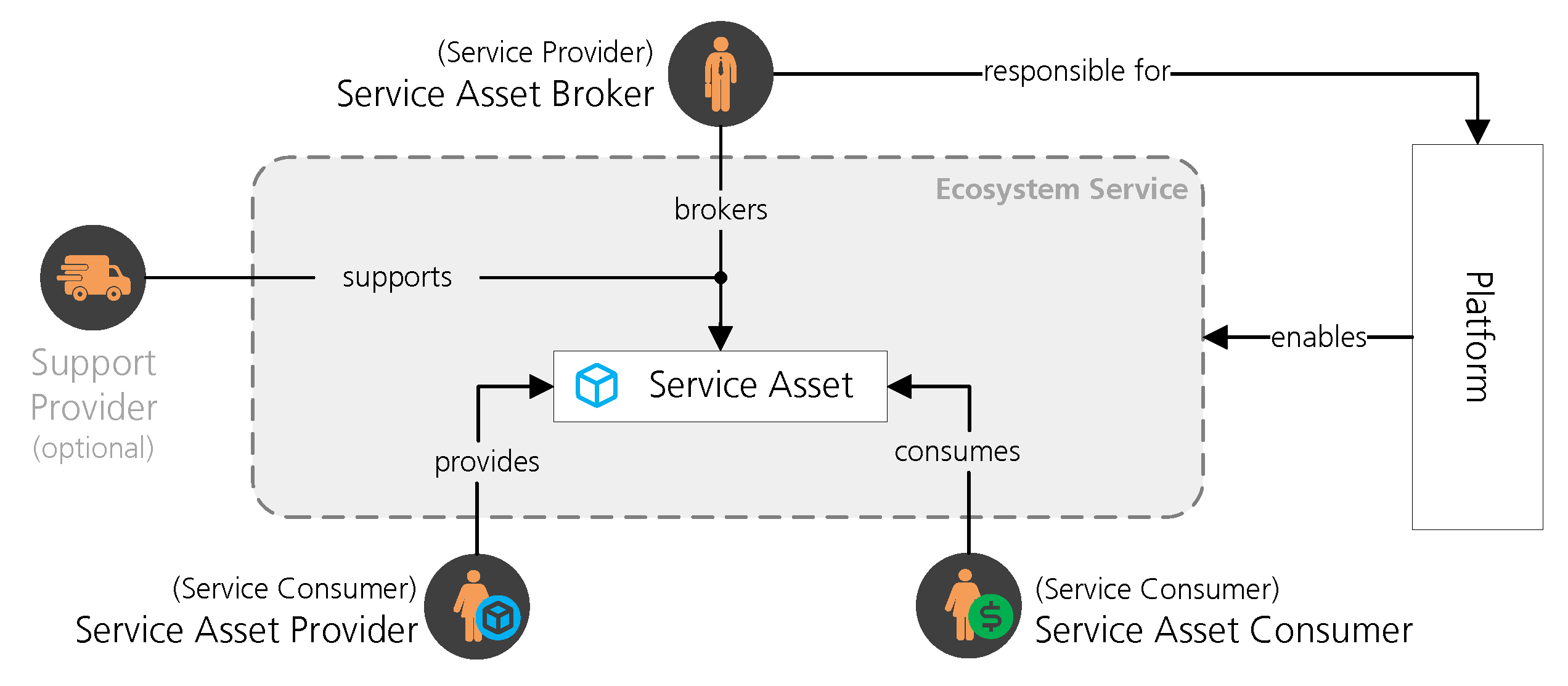
2. Background
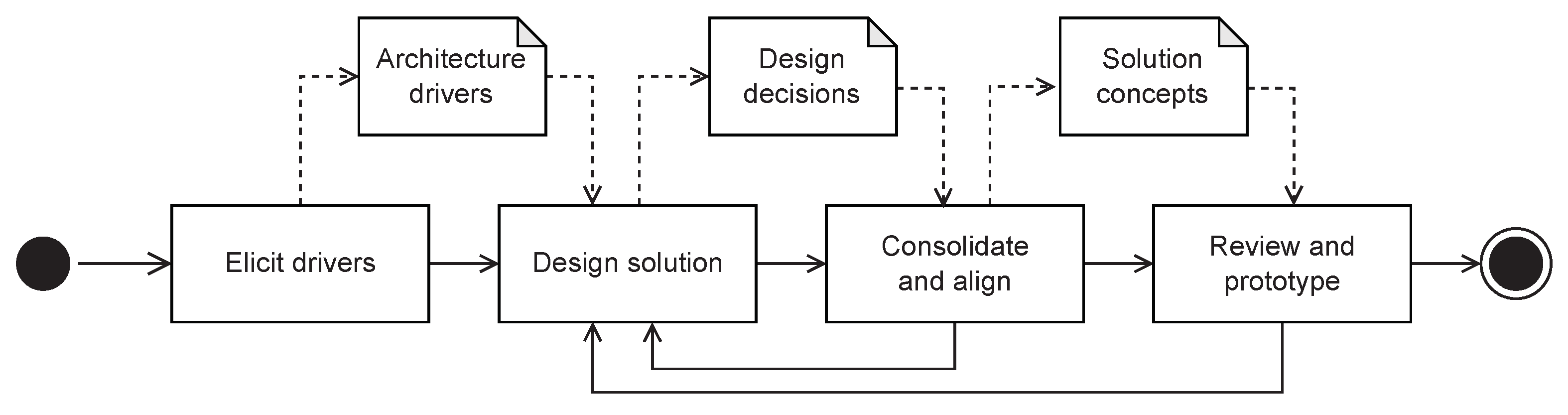
3. Method
To elaborate a reference architecture for a platform in order to improve interoperability and data sovereignty from the point of view of the data owner in the context of the ADS.
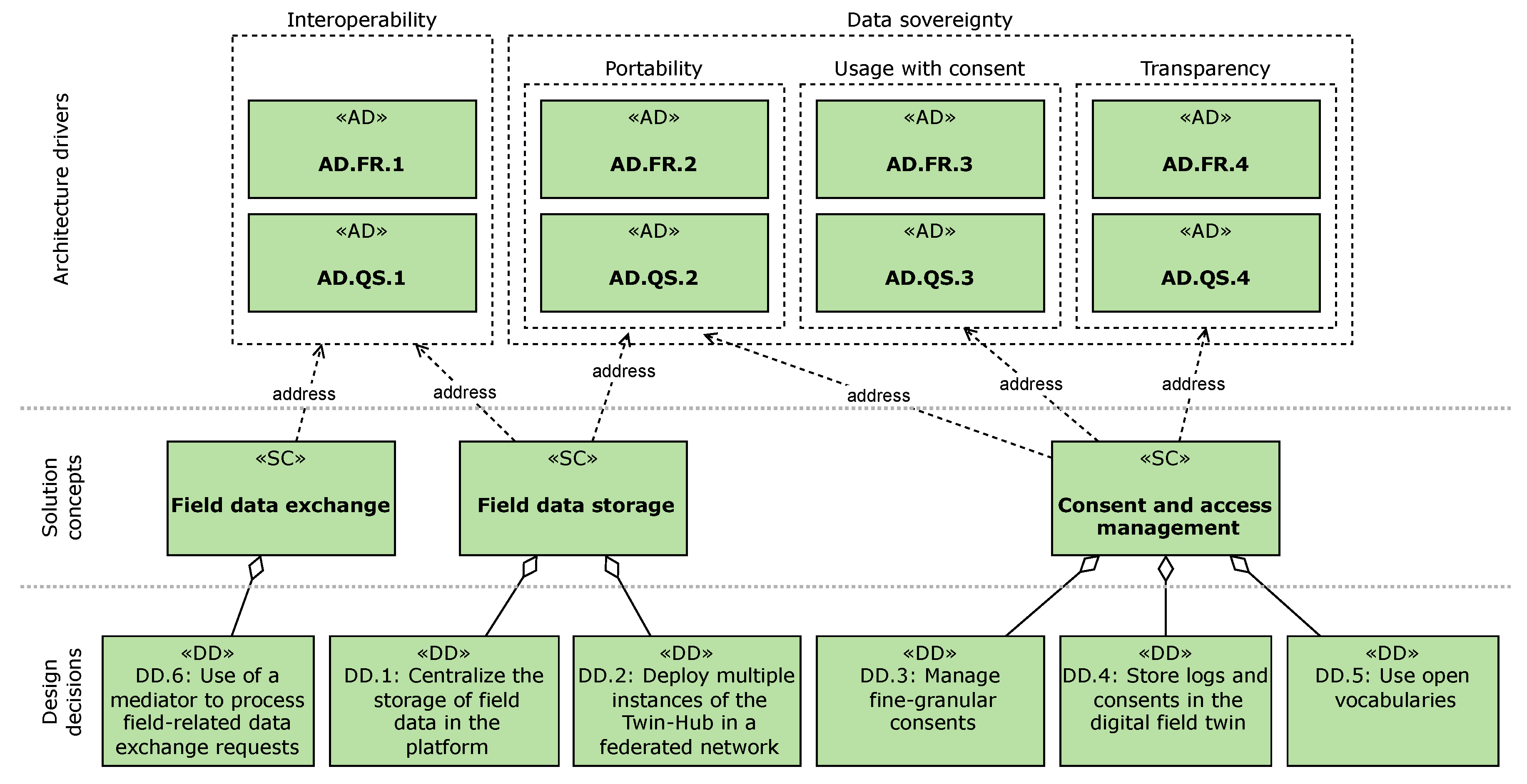
4. Architecture Drivers
4.1. Interoperability
- AD.FR.1:
- The platform should provide farmers with the ability to switch from one service provider to another without any impact on the interoperability of their field data.
- AD.QS.1:
- Consider that a service provider operates the service , which is already established in the market. In order to provide its service, needs one-time access to read certain field data, which in turn are managed by the farmer through their FMIS. is already capable of getting field data from farmers who use the leading FMISs on the market; however, a new FMIS now enters the market and gains popularity among farmers. One of the early adopters of the new FMIS wants to use . Assuming that all accesses have already been granted, should be able to retrieve the required field data from the farmer who uses the new FMIS without the need for any design-time modification.
4.2. Data Sovereignty
4.2.1. Concerning Data Portability
- AD.FR.2:
- The platform shall provide the farmer with the ability to host (store) their field data wherever they want; therefore, their field data should not be locked into any particular service provider.
- AD.QS.2:
- Consider a service that has access to the size and the crop type of a certain field of a farmer. The field data are stored by the farmer in a self-hosted server , which is connected to the Internet. The farmer decides to move their field data to a cloud-based server , which belongs to the infrastructure of a certain cloud-service provider. The farmer does not have to notify (or its corresponding service provider) about the change. After the change, continues to have access to the farmer’s field data as before, without the need to make any design-time modification to the service.
4.2.2. Concerning Data Usage Only with Consent
- AD.FR.3:
- The platform shall provide the farmer with the ability to determine who has access to which field data of which fields, for what purpose, and when.
- AD.QS.3:
- Consider that a fertilization recommendation service needs access to the field boundaries, the current nitrogen level, and the crop type of the field in order to be able to deliver a fertilization recommendation. A farmer plans to use the service, but they have not yet granted access to their field data; therefore, cannot access the farmer’s field data. At a certain point, the farmer grants one-time access to the required data of one particular field for the purpose of receiving the corresponding fertilization recommendation. As a result, can access the required field data once and is allowed to use it with the sole purpose of providing the desired recommendation.
4.2.3. Concerning Transparency about What Happens with the Data
- AD.FR.4:
- The platform shall provide the farmer with the ability to know who has accessed which field data of which field, for what purpose, and when.
- AD.QS.4:
- A farmer has granted many services access to their field data. These grants vary in nature: Some are read-only, others are write-only, yet others are read and write grant accesses. The purpose of the access varies from service to service. At any point in time, the farmer should be able to know which services accessed which of their field data, when, and for which purpose.
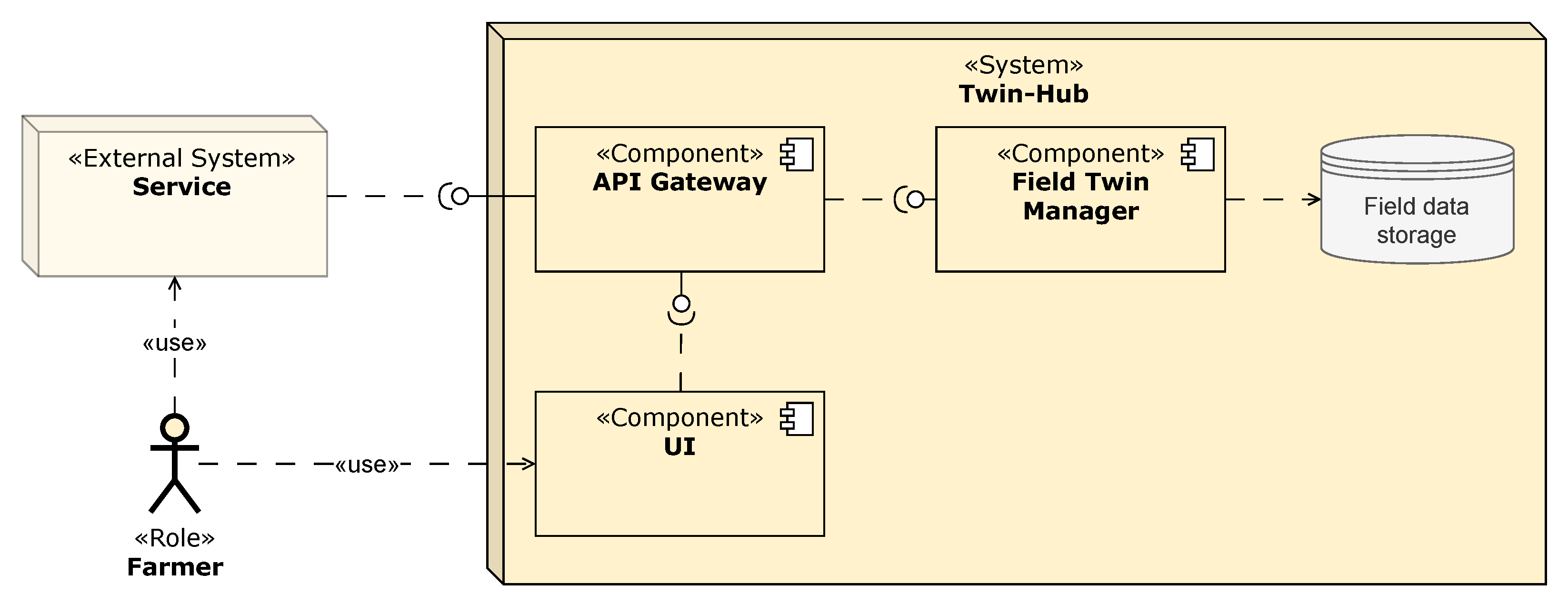
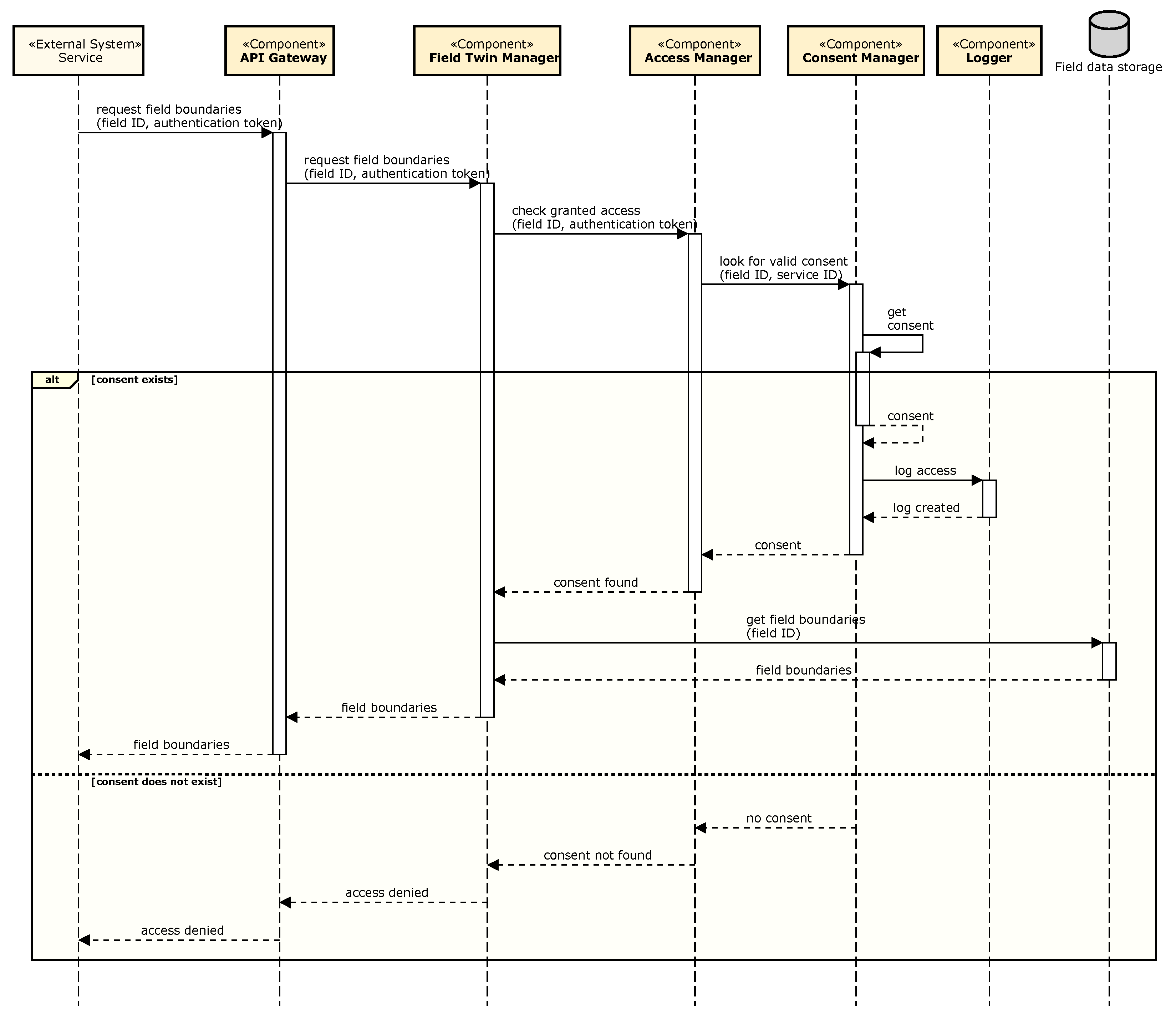
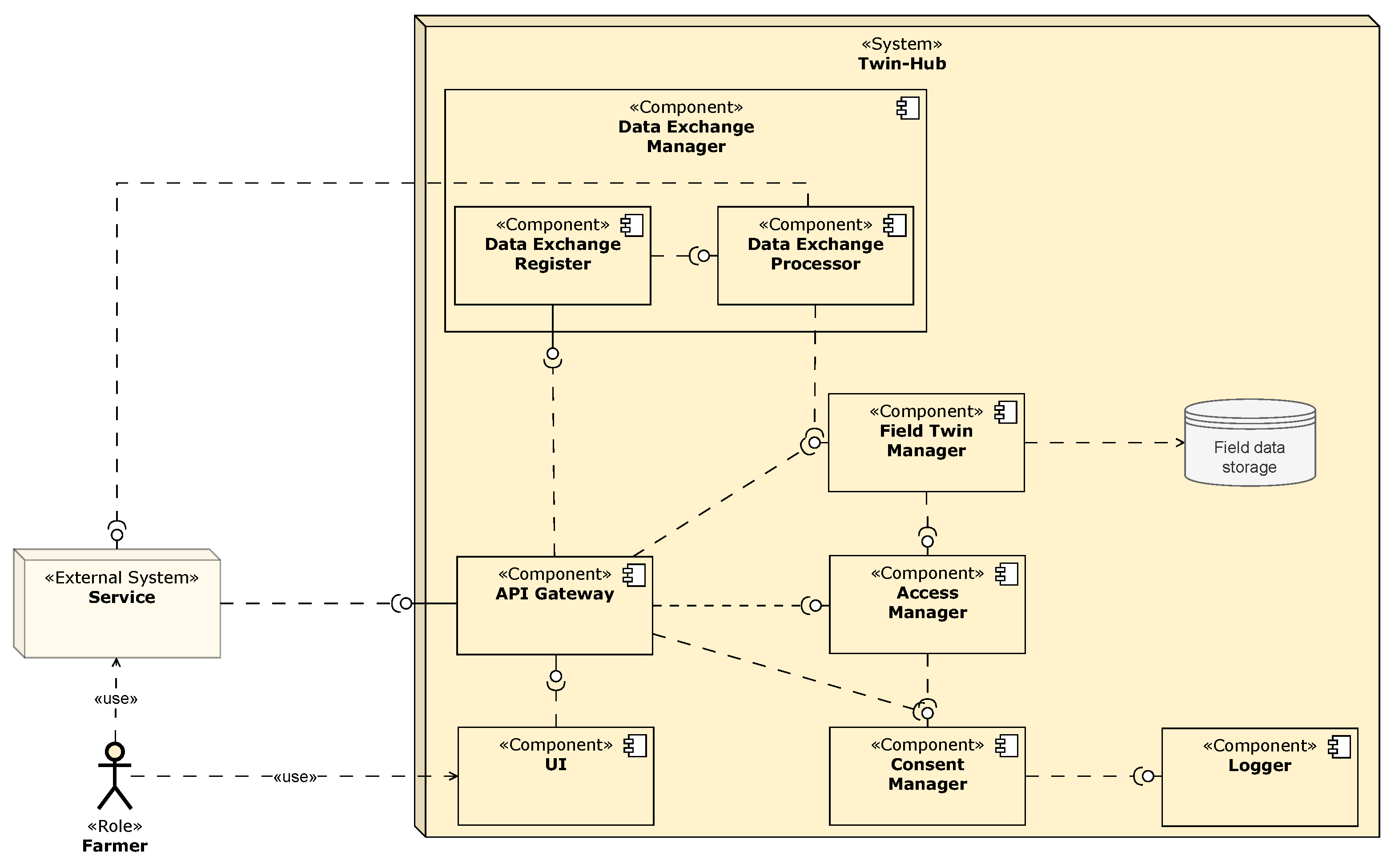
5. The Reference Architecture
- Facilitation of field data exchange (AD.FR.1);
- Storage of field data (AD.FR.2);
- Field data usage consent management (AD.FR.3); and
- Monitoring of field data access (AD.FR.4).
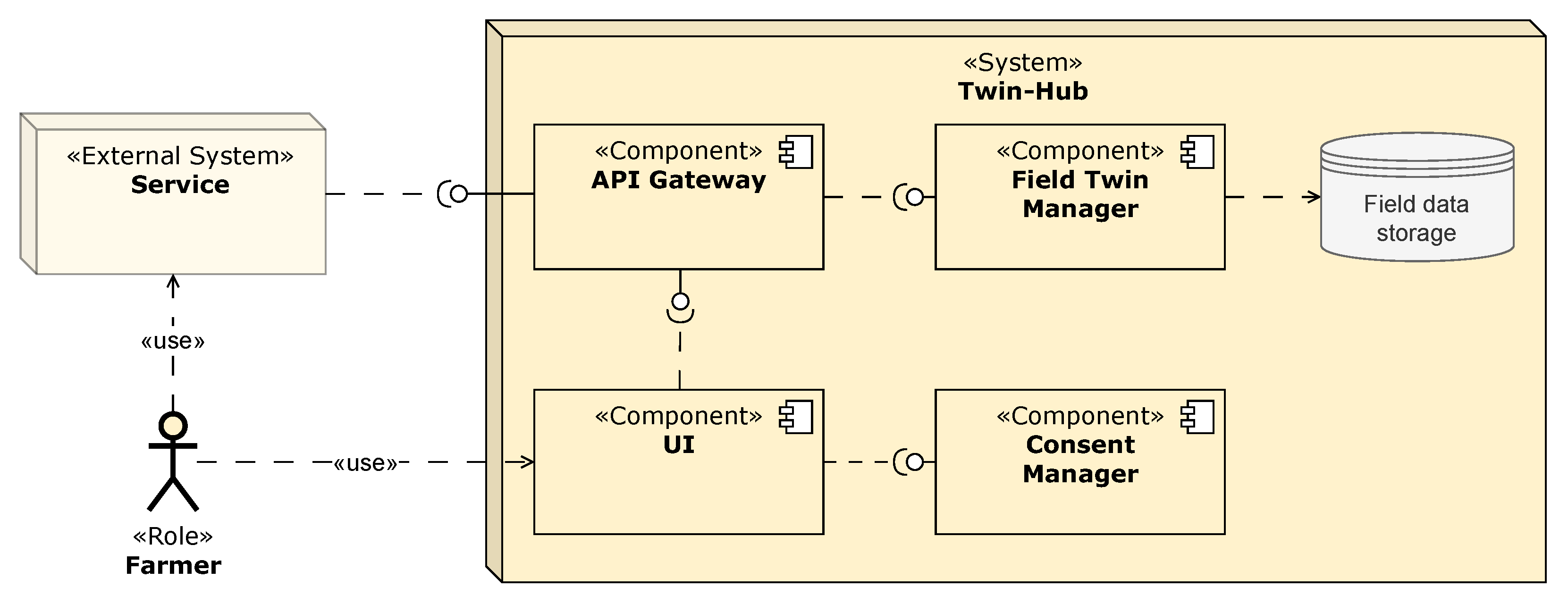
5.1. Solution Concept for Field Data Storage
- Opportunities/pros: Digital field twins represent a single source of truth for field data, making data available in a standardized, up-to-date, and non-redundant way. All services can obtain field data from one place.
- Assumptions: The digital field twins are hosted in an infrastructure that is reachable through the Internet, and both hosts and digital field twins are identified uniquely.
- Risks/cons: In case a digital field twin is unavailable, all services that rely on field data to operate may be impacted.
- Trade-offs: Additional dedicated infrastructure and associated costs for implementation, operation, and maintenance are required to deploy digital twins.
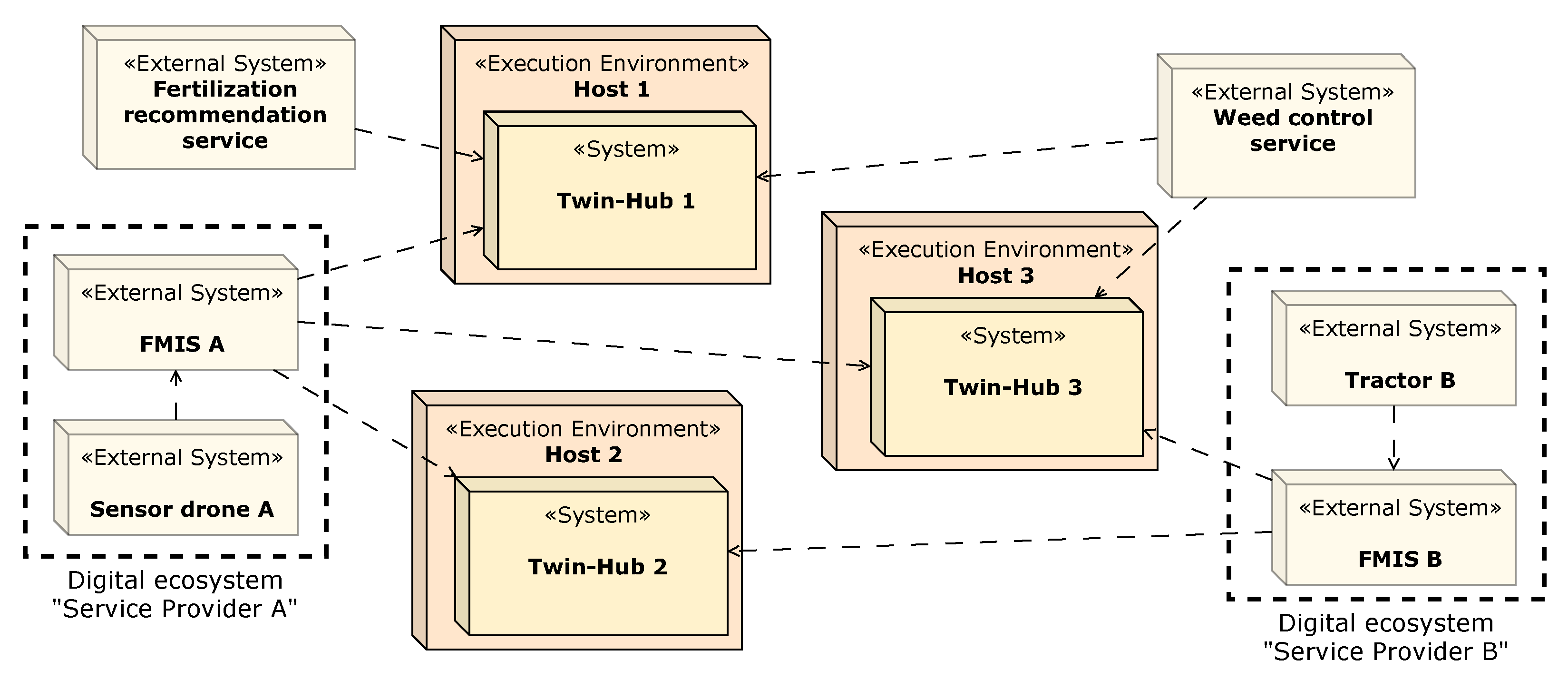
- Opportunities/pros: A federated network of Twin-Hubs increases the chances that the platform will penetrate the market in the current domain ecosystem while giving farmers more choices in terms of data protection policies and operation costs, for example.
- Assumptions: Digital field twins will have universal unique identifiers. Moreover, there will be parties interested in deploying and operating Twin-Hub instances, ensuring that farmers are offered multiple choices.
- Risks/cons: More resources in terms of IT infrastructure are needed in comparison to a centralized approach.
- Trade-offs: The evolution of the platform may increase in complexity due to the need to ensure compatibility among different versions of the platform.
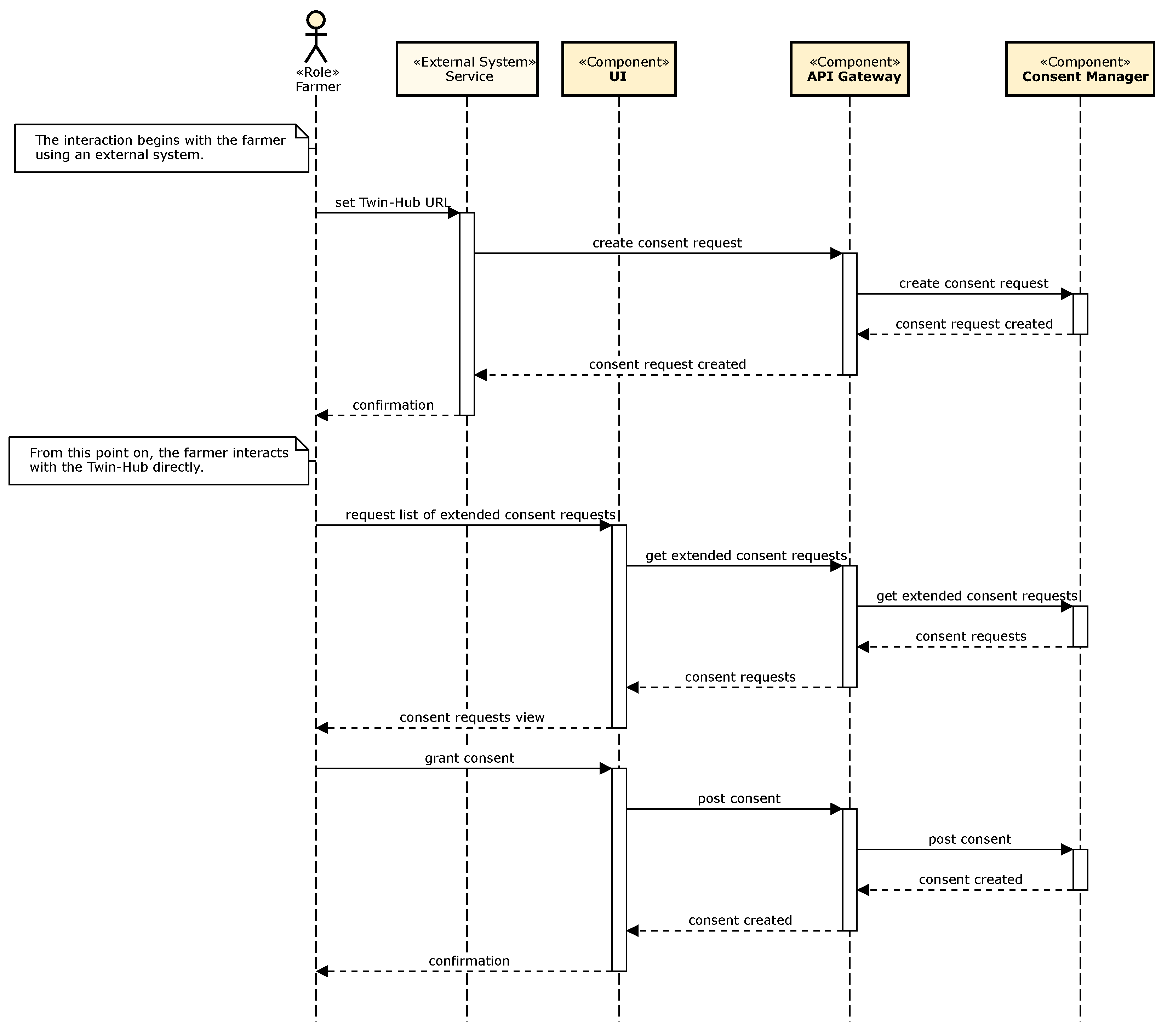
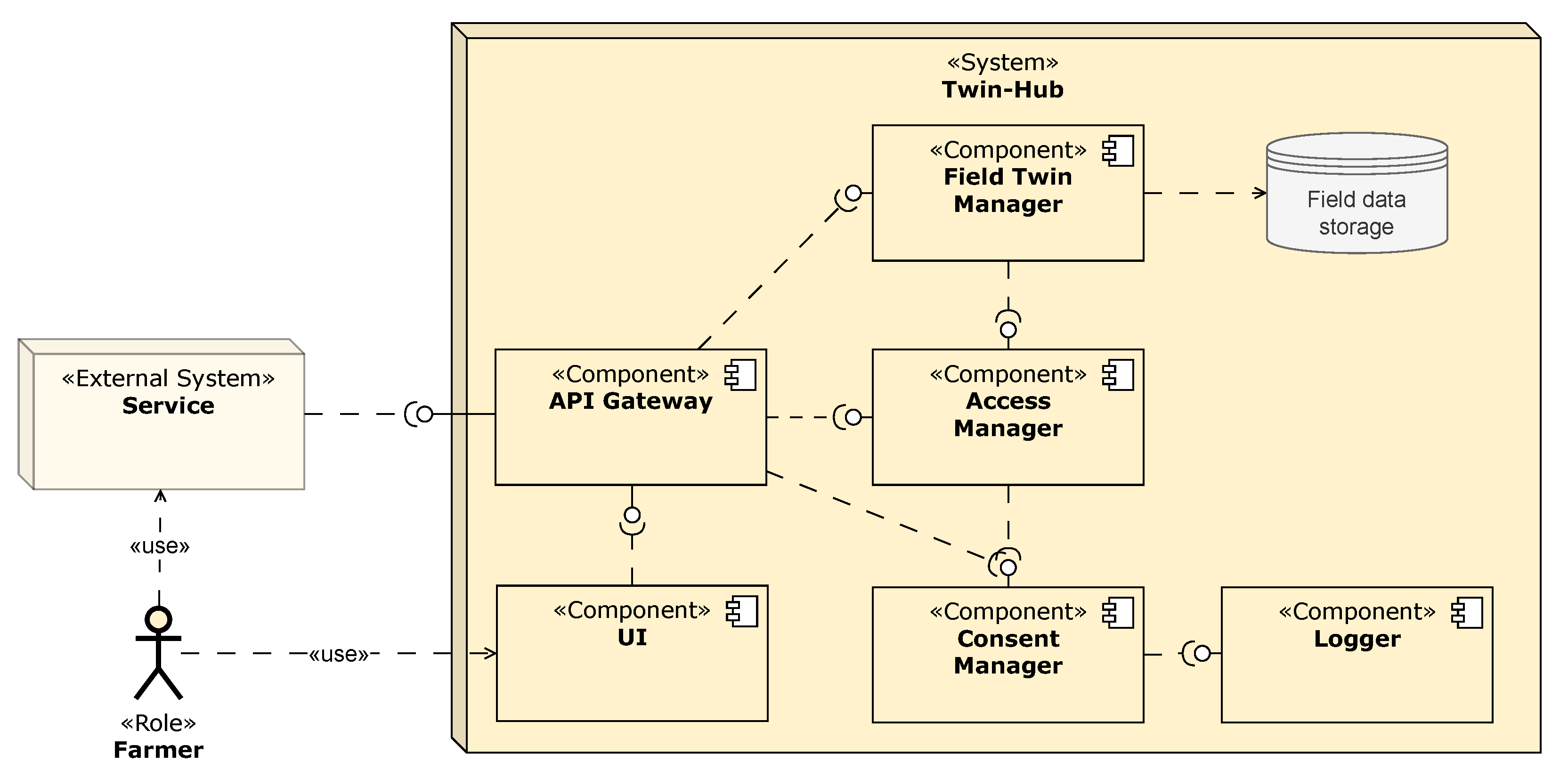
5.2. Solution Concept for Consent and Access Management
- Opportunities/pros: Farmers’ data will be used only as needed—nothing more, nothing less. Service providers can design their solutions to deal with different scenarios—for example, a service could offer the farmer the choice between granting full access to their digital field twins (which would enable more efficiency and/or effectiveness by the service) or minimum access (only the access absolutely required). Fine-granular consent management is also an enabler for transparency about data usage.
- Assumptions: Participants in the domain ecosystem will agree upon open vocabularies about field data.
- Risks/cons: It may be challenging to reach a community consensus in the domain ecosystem about what “fine-granular” means since different services may have different requirements in terms of data granularity. The implication may be to favor a more fine-grained structuring, which would put an additional burden on service providers that do not need such fine-granular data (even though it can raise more opportunities in the ecosystem for parties that build adapters—for more about this, see Section 7).
- Trade-offs: Maintainability of external services (which will need to create fine-granular consent requests).
- Opportunities/pros: Storing logs and consents in the digital field twin improves the portability of the digital field twins. Farmers will be able to export their digital field twins and host them in another Twin-Hub instance of their preference, compromising neither transparency—as information about how the field data have been accessed will come along with the field data—nor consent management—granted field data access will stay valid independent of where the field data are hosted.
- Assumptions: When the farmer decides to move their digital field twins from one Twin-Hub to another instance, the former must keep a reference to the latter so that services that request field data on the former instance can be notified about the new instance and adapt their calls accordingly.
- Risks/cons: In the case of migration of digital field twins, if the former Twin-Hub instance becomes unavailable (due to failure or decommissioning), services will not be able to find the new host automatically. In such scenarios, the farmer will need to reconfigure their services manually.
- Trade-offs: Digital field twins will be inflated with data that do not belong to the real entities (the fields).
- Opportunities/pros: Open vocabularies enable a shared understanding of the meaning of the data. Once the field data has been semantically annotated, field data operations such as consent management and field data exchange can be based on the semantics of the data.
- Assumptions: All field data being exchanged through and stored in digital field twins must be semantically annotated.
- Risks/cons: In some cases, it may be challenging to reconcile the fine granularity of raw data and the high-level nature of semantics.
- Trade-offs: Services must adapt to working semantically, which is not the state of the practice in terms of interoperability in the domain. This means that the ecosystem onboarding effort may increase.
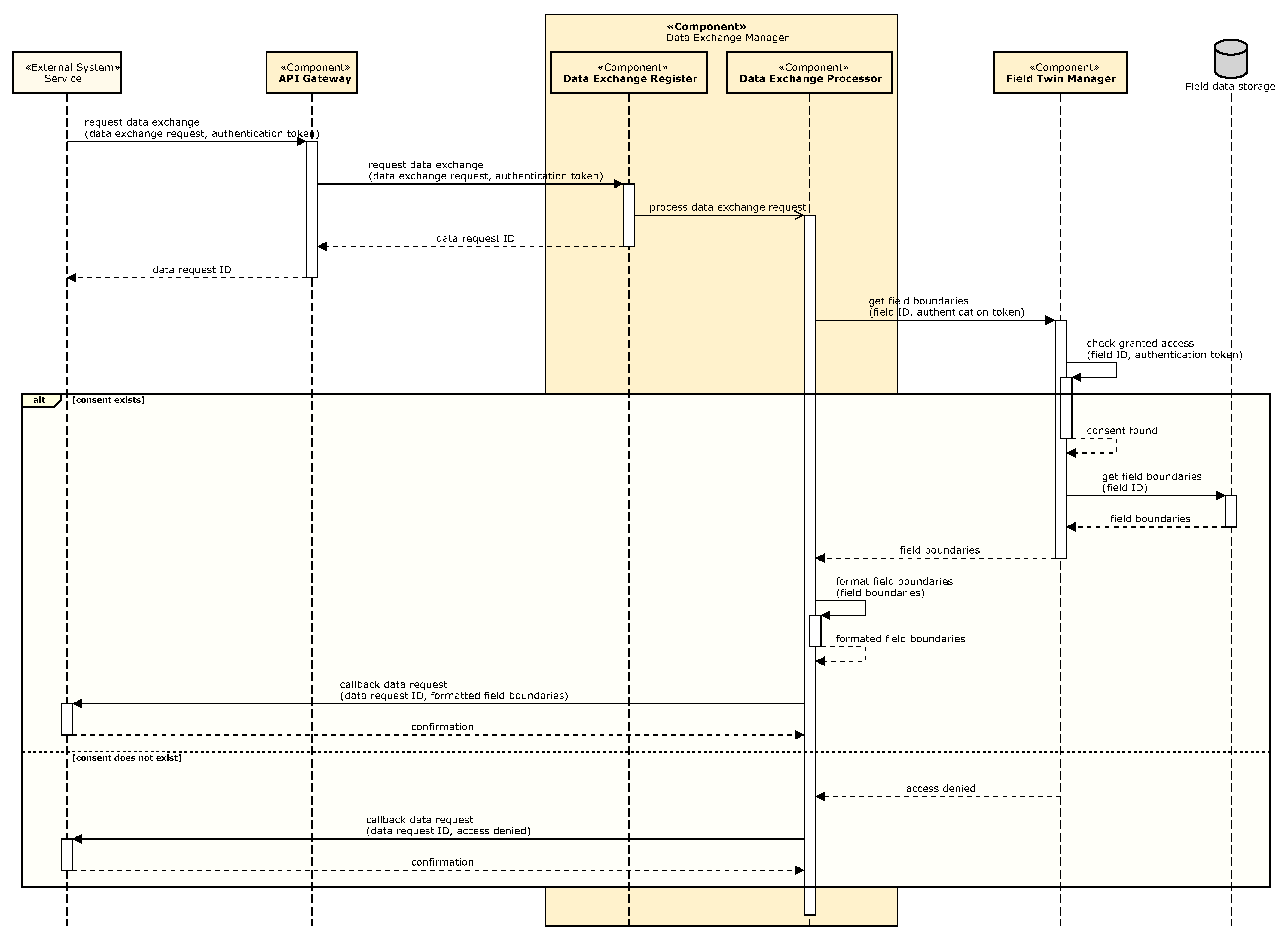
5.3. Solution Concept for Field Data Exchange
- Opportunities/pros: Systems that are interested in field data do not have to comply with any specific interface provided by the digital field twin. New field data can be incorporated into the twin through generic commands.
- Assumptions: All participants agree on the usage of an open shared vocabulary providing the data with semantics.
- Risks/cons: There is a risk that the usage of generic constructs will make the usage of the mediator complex, depending on the data involved.
- Trade-offs: The complexity of the interaction between systems is replaced by the complexity of the mediator itself (as foreseen in [25]). Furthermore, the overhead caused by data transformations and the need for multiple calls to transfer complex data may impact performance.
Prototype
6. Related Work
7. Discussion
7.1. Opportunities and Challenges
7.2. Comparison with Related Work
7.3. Limitations
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| AD | Architecture driver |
| ADS | Agricultural Data Space |
| COGNAC | Research project “Cognitive Agriculture” |
| DD | Design decision |
| DT | Digital twin |
| DS | Data sovereignty |
| FMIS | Farm Management Information System |
| FR | Functional requirements |
| GQM | Goal, Question, Metric |
| ICT | Information and communication technologies |
| ID | Identification |
| IDS | International Data Spaces |
| IOP | Interoperability |
| QS | Quality scenario |
| SC | Solution concept |
| UI | User interface |
References
- Parker, G.G.; Van Alstyne, M.W.; Choudary, S.P. Platform Revolution: How Networked Markets Are Transforming the Economy and How to Make Them Work for You; WW Norton & Company: New York, NY, USA, 2016. [Google Scholar]
- Verdouw, C.; Tekinerdogan, B.; Beulens, A.; Wolfert, S. Digital twins in smart farming. Agric. Syst. 2021, 189, 103046. [Google Scholar] [CrossRef]
- Moshrefzadeh, M.; Machl, T.; Gackstetter, D.; Donaubauer, A.; Kolbe, T.H. Towards a distributed digital twin of the agricultural landscape. JoDLA 2020, 5, 173–186. [Google Scholar]
- Kalmar, R.; Rauch, B.; Dörr, J.; Liggesmeyer, P. Agricultural Data Space. Des. Data Spaces 2022, 279–290. [Google Scholar] [CrossRef]
- Calvet, E.; Falcão, R.; Thom, L.H. Business Process Model for Interoperability Improvement in the Agricultural Domain Using Digital Twins. arXiv 2022, arXiv:2206.08589. [Google Scholar]
- Bartels, N.; Dörr, J.; Fehrmann, J.; Gennen, K.; Groen, E.C.; Härtel, I.; Henningsen, J.; Herlitzius, T.; Jeswein, T.; Kunisch, M.; et al. Machbarkeitsstudie zu Staatlichen Digitalen Datenplattformen fúr Die Landwirtschaft. 2020. Available online: https://www.bmel.de/SharedDocs/Downloads/DE/_Digitalisierung/machbarkeitsstudie-agrardatenplattform.html (accessed on 4 January 2023).
- Jakku, E.; Taylor, B.; Fleming, A.; Mason, C.; Fielke, S.; Sounness, C.; Thorburn, P. “If they don’t tell us what they do with it, why would we trust them?” Trust, transparency and benefit-sharing in Smart Farming. NJAS-Wagening. J. Life Sci. 2019, 90, 100285. [Google Scholar] [CrossRef]
- Wiseman, L.; Sanderson, J.; Zhang, A.; Jakku, E. Farmers and their data: An examination of farmers’ reluctance to share their data through the lens of the laws impacting smart farming. NJAS-Wagening. J. Life Sci. 2019, 90, 100301. [Google Scholar] [CrossRef]
- Falcão, R.; Matar, R.; Rauch, B. Using I4.0 digital twins in agriculture. arXiv 2022, arXiv:2301.09682. [Google Scholar]
- Schor, J.B.; Vallas, S.P. The Sharing Economy: Rhetoric and Reality. Annu. Rev. Sociol. 2021, 47, 369–389. [Google Scholar] [CrossRef]
- Kapoor, K.; Ziaee Bigdeli, A.; Dwivedi, Y.K.; Schroeder, A.; Beltagui, A.; Baines, T. A socio-technical view of platform ecosystems: Systematic review and research agenda. J. Bus. Res. 2021, 128, 94–108. [Google Scholar] [CrossRef]
- Koch, M.; Krohmer, D.; Naab, M.; Rost, D.; Trapp, M. A matter of definition: Criteria for digital ecosystems. Digit. Bus. 2022, 2, 100027. [Google Scholar] [CrossRef]
- Bartels, N.; Wieringa, R.; Koch, M.; Villela, K.; Suzumura, D.; Gordijn, J. Using Tangible Modeling to Create an e3value Conceptual Model for Digital Ecosystems. In The Practice of Enterprise Modeling: 15th IFIP WG 8.1 Working Conference, PoEM 2022, Proceedings, London, UK, 23–25 November 2022; Barn, B.S., Sandkuhl, K., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 134–148. [Google Scholar]
- Basili, V.R.; Rombach, H.D. The TAME project: Towards improvement-oriented software environments. IEEE Trans. Softw. Eng. 1988, 14, 758–773. [Google Scholar] [CrossRef]
- Knodel, J.; Naab, M. Pragmatic Evaluation of Software Architectures; Springer International Publishing: Cham, Switzerland, 2016; Volume 1. [Google Scholar]
- Herlitzius, T.; Schroers, J.O.; Seuring, L.; Striller, B.; Henningsen, J.; Jeswein, T.; Neuschwander, P.; Rauch, B.; Scherr, S.A.; Martini, D.; et al. Betriebliches Datenmanagement und FMIS; Sächsisches Landesamt für Umwelt, Landwirtschaft und Geologie (LfULG): Dresden, Germany, 2022. [Google Scholar]
- IESE, F. Smart Farming—Digitalization Is Revolutionizing Agriculture. 2022. Available online: https://www.iese.fraunhofer.de/en/customers_industries/SmartFarming.html (accessed on 18 November 2022).
- Rozanski, N.; Woods, E. Software Systems Architecture: Working with Stakeholders Using Viewpoints and Perspectives; Addison-Wesley: Boston, MA, USA, 2012. [Google Scholar]
- Bass, L.; Clements, P.; Kazman, R. Software Architecture in Practice; Addison-Wesley Professional: Boston, MA, USA, 2003. [Google Scholar]
- Rost, D.; Naab, M. Softwarearchitekturen Einfacher Designen und Verständlicher Dokumentieren Mit Dem Fraunhofer ADF. 2018. Available online: https://s.fhg.de/architecture-decomposition-framework (accessed on 24 February 2023).
- Pohl, K.; Rupp, C. Requirements Engineering: Fundamentals, Principles, and Techniques, 2nd ed.; Rocky Nook: Santa Barbara, CA, USA, 2015. [Google Scholar]
- OMG. OMG® Unified Modeling Language® (OMG UML®). 2017. Available online: https://www.omg.org/spec/UML/2.5.1/PDF (accessed on 23 February 2023).
- Grieves, M. Digital twin: Manufacturing excellence through virtual factory replication. White Pap. 2014, 1, 1–7. [Google Scholar]
- Pylianidis, C.; Osinga, S.; Athanasiadis, I.N. Introducing digital twins to agriculture. Comput. Electron. Agric. 2021, 184, 105942. [Google Scholar] [CrossRef]
- Gamma, E.; Johnson, R.; Helm, R.; Johnson, R.E.; Vlissides, J. Design Patterns: Elements of Reusable Object-Oriented Software; Addison-Wesley: Boston, MA, USA, 1995. [Google Scholar]
- Roussaki, I.; Doolin, K.; Skarmeta, A.; Routis, G.; Lopez-Morales, J.A.; Claffey, E.; Mora, M.; Martinez, J.A. Building an interoperable space for smart agriculture. Digit. Commun. Netw. 2022, 9, 183–193. [Google Scholar] [CrossRef]
- Budaev, D.; Lada, A.; Simonova, E.; Skobelev, P.; Travin, V.; Yalovenko, O. Conceptual design of smart farming solution for precise agriculture. Manag. App. Complex Syst. 2019, 13, 309–316. [Google Scholar]
- Kruize, J.W.; Wolfert, J.; Scholten, H.; Verdouw, C.; Kassahun, A.; Beulens, A.J. A reference architecture for Farm Software Ecosystems. Comput. Electron. Agric. 2016, 125, 12–28. [Google Scholar] [CrossRef] [Green Version]
- ISO/IEC 25010:2011; Systems and Software Engineering: Systems and Software Quality Requirements and Evaluation (SQuaRE): System and Software Quality Models. Technical Committee ISO/IEC JTC 1, Information technology. Subcommittee SC 7, S.; systems engineering. ISO: Geneva, Switzerland, 2011.
- Roussaki, I.; Vetsikas, I.; Routis, G.; Paraskevopoulos, M.; Poulakidas, T.; Oikonomidis, I.; Skias, D.; Marguglio, A.; Caruso, A.; Skarmeta, A.; et al. D3.3 DEMETER Reference Architecture (Release 2). 2020. Available online: https://h2020-demeter.eu/wp-content/uploads/2022/06/D33_integrated_v23_FINAL.pdf (accessed on 28 February 2023).
- Gurcan, M.N.; Pan, T.; Sharma, A.; Kurc, T.; Oster, S.; Langella, S.; Hastings, S.; Siddiqui, K.M.; Siegel, E.L.; Saltz, J. GridIMAGE: A novel use of grid computing to support interactive human and computer-assisted detection decision support. J. Digit. Imaging 2007, 20, 160–171. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Grujić, N.; Brdar, S.; Osinga, S.; Hofstede, G.J.; Athanasiadis, I.N.; Pljakić, M.; Obrenović, N.; Govedarica, M.; Crnojević, V. Combining Telecom Data with Heterogeneous Data Sources for Traffic and Emission Assessments—An Agent-Based Approach. Isprs Int. J. Geo-Inf. 2022, 11, 366. [Google Scholar] [CrossRef]
- Otto, B.; Jarke, M. Designing a multi-sided data platform: Findings from the International Data Spaces case. Electron. Mark. 2019, 29, 561–580. [Google Scholar] [CrossRef] [Green Version]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aspect | Terms |
|---|---|
| reference architecture and digital ecosystem | “reference architecture” OR “digital eco system” OR “digital ecosystem” OR “data space” |
| agriculture | “agriculture” OR “digital farming” OR “smart farming” |
| Work | Ecosystem Type | Type of Enabling Platform | Interoperability | Data Portability | Data Usage Only with Consent | Transparency |
|---|---|---|---|---|---|---|
| Roussaki et al. [26] | Domain ecosystem | Centralized | Distributed data storage, standardized access (common information model, but extensible) | Indirectly discussed, and from the point of view of service providers: participating services (external to the platform) must be motivated to share their data | Partial: data usage policies are managed by the platform; access control refers to access to the DEMETER-enabled entities, not the data itself. | Not discussed |
| Budaev et al. [27] | Domain ecosystem | Centralized | Not discussed | Not discussed | Not discussed | Not discussed |
| Kruize et al. [28] | Digital ecosystem | Centralized | Distributed data storage, standardization (accepts multiple standards) | Indirectly discussed, and from the point of view of service providers: participants must adhere to standards | Not discussed | Not discussed |
| This work | Domain ecosystem | Distributed (multi-instance) | Two-fold: centralized data storage with standardized access, and generic data exchange mechanism | The data owner—i.e., the farmer—has the autonomy to host their digital field twins wherever they want, and move their digital field twins from one place to another | Partial: solution consists of granular consent management (currently addresses only data access control; data usage control is future work) | Monitoring mechanism included |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Falcão, R.; Matar, R.; Rauch, B.; Elberzhager, F.; Koch, M. A Reference Architecture for Enabling Interoperability and Data Sovereignty in the Agricultural Data Space. Information 2023, 14, 197. https://doi.org/10.3390/info14030197
Falcão R, Matar R, Rauch B, Elberzhager F, Koch M. A Reference Architecture for Enabling Interoperability and Data Sovereignty in the Agricultural Data Space. Information. 2023; 14(3):197. https://doi.org/10.3390/info14030197
Chicago/Turabian StyleFalcão, Rodrigo, Raghad Matar, Bernd Rauch, Frank Elberzhager, and Matthias Koch. 2023. "A Reference Architecture for Enabling Interoperability and Data Sovereignty in the Agricultural Data Space" Information 14, no. 3: 197. https://doi.org/10.3390/info14030197