


An Attention-Based Deep Convolutional Neural Network for Brain Tumor and Disorder Classification and Grading in Magnetic Resonance Imaging

Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
3.1. Deep Learning
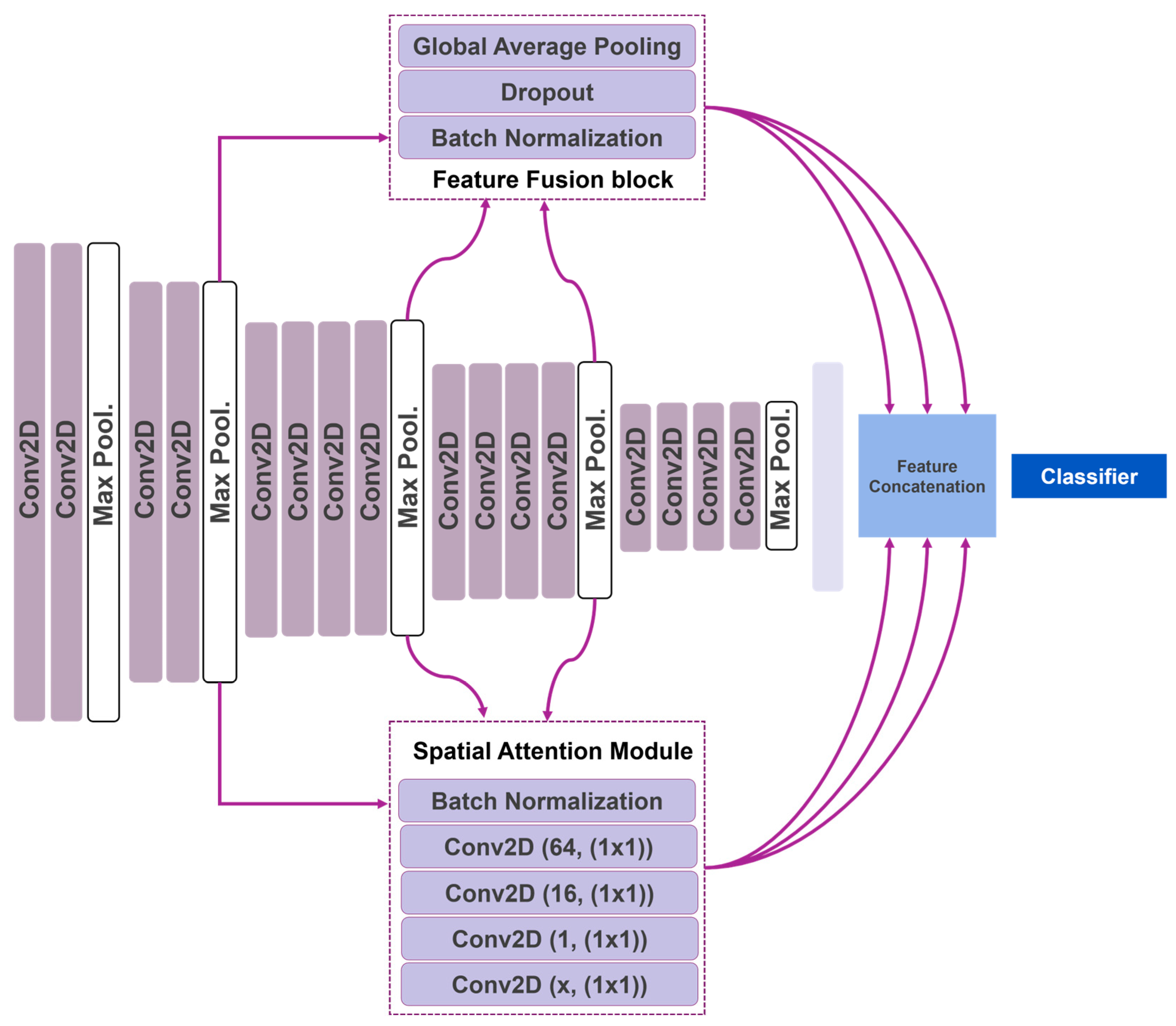
3.2. Attention Feature-Fusion VGG19
3.2.1. Virtual Geometry Group
3.2.2. Feature Fusion Modification
3.2.3. Attention Mechanism
3.3. Datasets of the Study
3.3.1. Brain Tumors Dataset
3.3.2. Brain Disorders Dataset
3.3.3. Dementia Grading Dataset
3.4. Experiment Setup
4. Results
4.1. Brain Tumor Classification
4.2. Brain Disorders Classification
4.3. Dementia Grading
4.4. Comparison with The State-Of-The-Art
4.5. Reproducibility
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Plewes, D.B.; Kucharczyk, W. Physics of MRI: A Primer. J. Magn. Reson. Imaging 2012, 35, 1038–1054. [Google Scholar] [CrossRef]
- Lundervold, A.S.; Lundervold, A. An Overview of Deep Learning in Medical Imaging Focusing on MRI. Z. Med. Phys. 2019, 29, 102–127. [Google Scholar] [CrossRef] [PubMed]
- Turkbey, B.; Haider, M.A. Deep Learning-Based Artificial Intelligence Applications in Prostate MRI: Brief Summary. Br. J. Radiol. BJR 2022, 95, 20210563. [Google Scholar] [CrossRef] [PubMed]
- Noor, M.B.T.; Zenia, N.Z.; Kaiser, M.S.; Mamun, S.A.; Mahmud, M. Application of Deep Learning in Detecting Neurological Disorders from Magnetic Resonance Images: A Survey on the Detection of Alzheimer’s Disease, Parkinson’s Disease and Schizophrenia. Brain Inf. 2020, 7, 11. [Google Scholar] [CrossRef] [PubMed]
- Mostapha, M.; Styner, M. Role of Deep Learning in Infant Brain MRI Analysis. Magn. Reson. Imaging 2019, 64, 171–189. [Google Scholar] [CrossRef]
- Akkus, Z.; Galimzianova, A.; Hoogi, A.; Rubin, D.L.; Erickson, B.J. Deep Learning for Brain MRI Segmentation: State of the Art and Future Directions. J. Digit. Imaging 2017, 30, 449–459. [Google Scholar] [CrossRef] [Green Version]
- Tao, Q.; Lelieveldt, B.P.F.; van der Geest, R.J. Deep Learning for Quantitative Cardiac MRI. Am. J. Roentgenol. 2020, 214, 529–535. [Google Scholar] [CrossRef]
- Schelb, P.; Kohl, S.; Radtke, J.P.; Wiesenfarth, M.; Kickingereder, P.; Bickelhaupt, S.; Kuder, T.A.; Stenzinger, A.; Hohenfellner, M.; Schlemmer, H.-P.; et al. Classification of Cancer at Prostate MRI: Deep Learning versus Clinical PI-RADS Assessment. Radiology 2019, 293, 607–617. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017. [Google Scholar] [CrossRef]
- Le, Q.V.; Ngiam, J.; Coates, A.; Lahiri, A.; Prochnow, B.; Ng, A.Y. On optimization methods for deep learning. In Proceedings of the ICML, Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Sadad, T.; Rehman, A.; Munir, A.; Saba, T.; Tariq, U.; Ayesha, N.; Abbasi, R. Brain tumor detection and multi-classification using advanced deep learning techniques. Microsc. Res. Tech. 2021, 84, 1296–1308. [Google Scholar] [CrossRef]
- Gab Allah, A.M.; Sarhan, A.M.; Elshennawy, N.M. Classification of Brain MRI Tumor Images Based on Deep Learning PGGAN Augmentation. Diagnostics 2021, 11, 2343. [Google Scholar] [CrossRef] [PubMed]
- Rasool, M.; Ismail, N.A.; Boulila, W.; Ammar, A.; Samma, H.; Yafooz, W.M.S.; Emara, A.-H.M. A Hybrid Deep Learning Model for Brain Tumour Classification. Entropy 2022, 24, 799. [Google Scholar] [CrossRef] [PubMed]
- Kang, J.; Ullah, Z.; Gwak, J. MRI-Based Brain Tumor Classification Using Ensemble of Deep Features and Machine Learning Classifiers. Sensors 2021, 21, 2222. [Google Scholar] [CrossRef] [PubMed]
- Sivaranjini, S.; Sujatha, C.M. Deep learning based diagnosis of Parkinson’s disease using convolutional neural network. Multimed. Tools Appl. 2020, 79, 15467–15479. [Google Scholar] [CrossRef]
- Bhan, A.; Kapoor, S.; Gulati, M.; Goyal, A. Early Diagnosis of Parkinson’s Disease in brain MRI using Deep Learning Algorithm. In Proceedings of the 2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 February 2021; IEEE: Tirunelveli, India, 2021; pp. 1467–1470. [Google Scholar]
- Hussain, E.; Hasan, M.; Hassan, S.Z.; Hassan Azmi, T.; Rahman, M.A.; Zavid Parvez, M. Deep Learning Based Binary Classification for Alzheimer’s Disease Detection using Brain MRI Images. In Proceedings of the 2020 15th IEEE Conference on Industrial Electronics and Applications (ICIEA), Kristiansand, Norway, 9–13 November 2020; IEEE: Kristiansand, Norway, 2020; pp. 1115–1120. [Google Scholar]
- Salehi, A.W.; Baglat, P.; Sharma, B.B.; Gupta, G.; Upadhya, A. A CNN Model: Earlier Diagnosis and Classification of Alzheimer Disease using MRI. In Proceedings of the 2020 International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India, 10–12 September 2020; IEEE: Trichy, India, 2020; pp. 156–161. [Google Scholar]
- Alloghani, M.; Al-Jumeily, D.; Mustafina, J.; Hussain, A.; Aljaaf, A.J. A Systematic Review on Supervised and Unsupervised Machine Learning Algorithms for Data Science. In Supervised and Unsupervised Learning for Data Science; Unsupervised and Semi-Supervised Learning; Berry, M.W., Mohamed, A., Yap, B.W., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 3–21. ISBN 978-3-030-22474-5. [Google Scholar]
- Apostolopoulos, I.D.; Papathanasiou, N.D. Classification of lung nodule malignancy in computed tomography imaging utilizing generative adversarial networks and semi-supervised transfer learning. Biocybern. Biomed. Eng. 2021, 41, 1243–1257. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: New York, NY, USA; pp. 248–255. [Google Scholar]
- Huh, M.; Agrawal, P.; Efros, A.A. What makes ImageNet good for transfer learning? arXiv 2016, arXiv:1608.08614. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A Survey of Transfer Learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef] [Green Version]
- Apostolopoulos, I.D.; Pintelas, E.G.; Livieris, I.E.; Apostolopoulos, D.J.; Papathanasiou, N.D.; Pintelas, P.E.; Panayiotakis, G.S. Automatic classification of solitary pulmonary nodules in PET/CT imaging employing transfer learning techniques. Med. Biol. Eng. Comput. 2021, 59, 1299–1310. [Google Scholar] [CrossRef]
- Falkenstetter, S.; Leitner, J.; Brunner, S.M.; Rieder, T.N.; Kofler, B.; Weis, S. Galanin System in Human Glioma and Pituitary Adenoma. Front. Endocrinol. 2020, 11, 155. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Coskun, P.; Wyrembak, J.; Schriner, S.E.; Chen, H.-W.; Marciniack, C.; LaFerla, F.; Wallace, D.C. A Mitochondrial Etiology of Alzheimer and Parkinson Disease. Biochim. Biophys. Acta BBA-Gen. Subj. 2012, 1820, 553–564. [Google Scholar] [CrossRef] [Green Version]
- O’Bryant, S.E.; Lacritz, L.H.; Hall, J.; Waring, S.C.; Chan, W.; Khodr, Z.G.; Massman, P.J.; Hobson, V.; Cullum, C.M. Validation of the New Interpretive Guidelines for the Clinical Dementia Rating Scale Sum of Boxes Score in the National Alzheimer’s Coordinating Center Database. Arch. Neurol. 2010, 67, 746–749. [Google Scholar] [CrossRef] [PubMed]
- Coley, N.; Andrieu, S.; Jaros, M.; Weiner, M.; Cedarbaum, J.; Vellas, B. Suitability of the Clinical Dementia Rating-Sum of Boxes as a Single Primary Endpoint for Alzheimer’s Disease Trials. Alzheimer’s Dement. 2011, 7, 602–610.e2. [Google Scholar] [CrossRef]
- Mohammed, B.A.; Senan, E.M.; Rassem, T.H.; Makbol, N.M.; Alanazi, A.A.; Al-Mekhlafi, Z.G.; Almurayziq, T.S.; Ghaleb, F.A. Multi-Method Analysis of Medical Records and MRI Images for Early Diagnosis of Dementia and Alzheimer’s Disease Based on Deep Learning and Hybrid Methods. Electronics 2021, 10, 2860. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Dataset | Source (s) | Number of Images |
|---|---|---|
| Brain Tumors Dataset | https://www.kaggle.com/datasets/adityakomaravolu/brain-tumor-mri-images (accessed on 24 November 2022). https://www.kaggle.com/datasets/roroyaseen/brain-tumor-data-mri (accessed on 24 November 2022). | 7023 and 19,226. Total 26,249 |
| Brain Disorders Dataset | https://www.kaggle.com/datasets/farjanakabirsamanta/alzheimer-diseases-3-class (accessed on 24 November 2022). | 7756 |
| Dementia Grading Dataset | https://www.kaggle.com/datasets/sachinkumar413/alzheimer-mri-dataset (accessed on 24 November 2022). | 6400 |
| ACC | SEN | SPE | PPV | NPV | FPR | FNR | F1 | AUC | |
|---|---|---|---|---|---|---|---|---|---|
| G | 0.9505 | 0.9676 | 0.9427 | 0.8849 | 0.9846 | 0.0573 | 0.0324 | 0.9244 | 0.9552 |
| M | 0.9304 | 0.9062 | 0.9408 | 0.8675 | 0.9591 | 0.0592 | 0.0938 | 0.8864 | 0.9235 |
| P | 0.9572 | 0.9161 | 0.9758 | 0.9449 | 0.9626 | 0.0242 | 0.0839 | 0.9303 | 0.9460 |
| Control | 0.9795 | 0.9960 | 0.9781 | 0.7895 | 0.9997 | 0.0219 | 0.0040 | 0.8808 | 0.9871 |
| ACC | SEN | SPE | PPV | NPV | FPR | FNR | F1 | AUC | |
|---|---|---|---|---|---|---|---|---|---|
| AD | 0.9409 | 0.9222 | 0.9541 | 0.9339 | 0.9458 | 0.0459 | 0.0778 | 0.9280 | 0.9382 |
| PD | 0.9489 | 0.9860 | 0.9160 | 0.9125 | 0.9866 | 0.0840 | 0.0140 | 0.9479 | 0.9510 |
| Control | 0.9621 | 0.9592 | 0.9625 | 0.7718 | 0.9944 | 0.0375 | 0.0408 | 0.8553 | 0.9608 |
| ACC | SEN | SPE | PPV | NPV | FPR | FNR | F1 | AUC | |
|---|---|---|---|---|---|---|---|---|---|
| Mo | 0.9670 | 0.9531 | 0.9672 | 0.2268 | 0.9995 | 0.0328 | 0.0469 | 0.3664 | 0.9601 |
| Mi | 0.9264 | 0.8281 | 0.9424 | 0.7007 | 0.9712 | 0.0576 | 0.1719 | 0.7591 | 0.8853 |
| VMi | 0.9539 | 0.9362 | 0.9635 | 0.9324 | 0.9656 | 0.0365 | 0.0638 | 0.9343 | 0.9498 |
| Control | 0.9769 | 0.9931 | 0.9606 | 0.9619 | 0.9929 | 0.0394 | 0.0069 | 0.9772 | 0.9769 |
| Brain Tumor | Brain Disorder | Dementia Grading | |
|---|---|---|---|
| Xception | 0.8850 | 0.8925 | 0.8786 |
| VGG16 | 0.8897 | 0.8704 | 0.9088 |
| VGG19 | 0.9108 | 0.8981 | 0.9022 |
| ResNet152 | 0.8600 | 0.8646 | 0.8983 |
| ResNet152V2 | 0.8801 | 0.8613 | 0.8984 |
| InceptionV3 | 0.8713 | 0.8657 | 0.8961 |
| InceptionResNetV2 | 0.8848 | 0.8605 | 0.8872 |
| MobileNet | 0.8689 | 0.8511 | 0.9091 |
| MobileNetV2 | 0.8512 | 0.8312 | 0.9150 |
| DenseNet169 | 0.8732 | 0.8442 | 0.9066 |
| DenseNet201 | 0.8715 | 0.8495 | 0.8891 |
| NASNetMobile | 0.8594 | 0.8695 | 0.9011 |
| EfficientNetB6 | 0.8734 | 0.8726 | 0.8975 |
| EfficientNetB7 | 0.8606 | 0.8717 | 0.8892 |
| EfficientNetV2B3 | 0.8804 | 0.8693 | 0.8814 |
| ConvNeXtLarge | 0.8732 | 0.8463 | 0.9095 |
| ConvNeXtXLarge | 0.8702 | 0.8422 | 0.8898 |
| ATT-FF-VGG19 | 0.9353 | 0.9565 | 0.9497 |
| First Author | Ref. No. | Test Data Size | Classes | Method | ACC | SEN | SPE |
|---|---|---|---|---|---|---|---|
| Sadad | [14] | 612 slices | G-M-P | NASNet | 0.996 | - | - |
| Allah | [15] | 460 slices | G-M-P | VGG19 | G: 0.9854 M: 0.9857 P: 1 | G: 0.9777 M: 0.9804 P: 1 | G: 0.9914 M: 0.9871 P: 1 |
| Rasool | [16] | 692 slices | G-M-P-controls | Google-Net | 0.981 | G: 0.978 M: 0.973 P: 0.989 N: 0.987 | |
| Kang | [17] | 692 slices | DenseNet-169 | 0.9204 | - | - | |
| This study | 26,249 slices | G-M-P-controls | AFF-VGG19 | G: 0.9505 M: 0.9304 P: 0.9572 | G: 9676 M: 0.9062 P: 0.9161 | G: 0.9427 M: 0.9062 P: 0.9758 | |
| Bhan | [19] | 1055 Slices | PD-controls | LeNet-5 | 0.9792 | - | - |
| Sivaranjini | [18] | 36 patients | PD-controls | AlexNet | 0.889 | - | - |
| Hussain | [20] | 11 patients | AD-controls | CNN | 0.9775 | AD: 0.92 C: 1 | - |
| This study | 7756 slices | PD-AD-controls | AFF-VGG19 | PD: 0.9409 AD: 0.9489 | PD: 0.9222 AD: 0.9860 | PD: 0.9541 AD: 0.9160 | |
| Salehi | [21] | 7635 slices | Mi-VMi-controls | CNN | 0.99 | - | - |
| Mohammed | [32] | 6400 slices | Mi-VMi-Mo-controls | AlexNet | 94.8 | 93 | 97.75 |
| This study | 6400 slices | Mi-VMi-Mo-controls | AFF-VGG19 | Mo: 0.967 Mi: 0.9264 VMi: 0.9539 | Mo: 0.9531 Mi: 0.8281 VMi: 0.9362 | Mo: 0.9672 Mi: 0.9424 VMi: 0.9635 |
| Brain Tumor | Brain Disorder | Dementia Grading | |
|---|---|---|---|
| Mean | 0.9355 | 0.9558 | 0.9491 |
| Standard Deviation | 0.002 | 0.002 | 0.001 |
| t-statistic | 0.4 | −1.09 | −1.9 |
| Null Hypothesis | Mean = 0.9355 | Mean = 0.9565 | Mean = 0.9497 |
| Result | At the 0.05 level, the population mean is NOT significantly different from the test mean (0.9353). | At the 0.05 level, the population mean is NOT significantly different from the test mean (0.9565). | At the 0.05 level, the population mean is NOT significantly different from the test mean (0.9497). |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Apostolopoulos, I.D.; Aznaouridis, S.; Tzani, M. An Attention-Based Deep Convolutional Neural Network for Brain Tumor and Disorder Classification and Grading in Magnetic Resonance Imaging. Information 2023, 14, 174. https://doi.org/10.3390/info14030174
Apostolopoulos ID, Aznaouridis S, Tzani M. An Attention-Based Deep Convolutional Neural Network for Brain Tumor and Disorder Classification and Grading in Magnetic Resonance Imaging. Information. 2023; 14(3):174. https://doi.org/10.3390/info14030174
Chicago/Turabian StyleApostolopoulos, Ioannis D., Sokratis Aznaouridis, and Mpesi Tzani. 2023. "An Attention-Based Deep Convolutional Neural Network for Brain Tumor and Disorder Classification and Grading in Magnetic Resonance Imaging" Information 14, no. 3: 174. https://doi.org/10.3390/info14030174