

Sufficient Networks for Computing Support of Graph Patterns

Department of Software Engineering, Shamoon College of Engineering, Beer Sheva 84417, Israel
Information 2023, 14(3), 143; https://doi.org/10.3390/info14030143
Submission received: 26 January 2023
/
Revised: 15 February 2023
/
Accepted: 19 February 2023
/
Published: 21 February 2023
(This article belongs to the Topic Data Science and Knowledge Discovery)
Abstract
:Graph mining is the process of extracting and analyzing patterns from graph data. Graphs are a data structure that consists of a set of nodes and a set of edges that connect these nodes. Graphs are often used to represent real-world entities and the relationships between them. In a graph database, the importance of a pattern (also known as support) must be quantified using a counting function called a support measure. This function must adhere to several constraints, such as antimonotonicity that forbids a pattern to have support bigger than its sub-patterns. These constraints make the tasks of defining and computing support measures highly non-trivial and computationally expensive. In this paper, I use the previously discovered relationship between support measures in graph databases and flows in networks of subgraph appearances to simplify the process of computing support measures. I show that the network of pattern instances may be successfully pruned to contain just particular kinds of patterns and prove that any legitimate computing support measures in graph databases can adopt this strategy. When the suggested method is utilized, experimental evaluation demonstrates that network size reduction is significant.
1. Introduction
Graph mining is used in a variety of fields and applications. In social network analysis, graph mining techniques are often used to analyze social media networks to understand the relationships between users and identify key influencers [1]. Graphs can be used to represent financial transactions for the task of fraud detection, and graph mining algorithms can be used to identify suspicious patterns that may indicate fraudulent activity [2,3]. In recommendation systems, graphs are used to represent the relationships between users and items (e.g., products, articles), and graph mining algorithms can be used to recommend items to users based on their relationships with other users and items [4,5]. Graphs can also be used to represent networks of interconnected systems (e.g., transportation networks, communication networks), and graph mining algorithms can be used to understand the structure and function of these networks [6]. In bioinformatics, graphs are used to represent biological networks (e.g., protein–protein interaction networks, gene regulatory networks), and graph mining algorithms can be used to understand the relationships between the elements in these networks [7,8]. In Natural Language Processing (NLP), graphs are used extensively to represent relationships between words and concepts in natural language texts, and graph mining algorithms can be used to understand the meaning and context of the text [9,10].
Graphs are also used to describe various modern technologies such as wireless sensor networks, neural networks, the Internet of Things (IOT), Global System For Mobile Communication (GSM) networks, landscape connectivity and conservation planning, image and signal processing, subway systems analysis, robotics, and more [11,12,13].
A frequent graph pattern is a subgraph (i.e., a subset of vertices and edges) that appears frequently in a given graph database. Frequent graph patterns are often used to discover interesting and meaningful patterns in graph data that may not be apparent when looking at the graph as a whole.
The task of finding all frequent graph patterns in a database is called graph mining.This task has been applied successfully to several challenging real-world problems, such as library recommendations [14], social network analysis [15], aerial scene classification [16], software requirements analysis [17], molecular database processing [18], and drug discovery [19].
The frequency of a graph pattern is typically defined as the number of times it appears in the transactional dataset, and a threshold is set to determine which patterns are considered frequent. The problem of counting patterns is more difficult for single-graph datasets. In a large unlabeled graph, for instance, a single node is regarded as a frequent pattern because the number of times it appears is equal to the graph order. However, larger patterns will often have intersecting appearances, and the number of them may increase exponentially with the size of the dataset. To handle this issue, one typically first defines a notion of support, which is a measure of how frequently the pattern occurs in the graph. The support of a pattern must represent the total number of subgraphs in the graph that are isomorphic to the pattern.
Once the support of a pattern has been defined, one can use algorithms to search for patterns with high support. These algorithms typically involve searching the space of all possible subgraphs in the graph and counting the support of each pattern. This issue makes graph mining algorithms computationally challenging because the search space of all possible subgraphs is exponential in the size of a database graph. If a database is a single large dense graph, this issue becomes even more serious. Graph density is defined as the ratio between the number of edges present in a graph and the maximum number of edges that the graph can contain. Common examples of dense graphs are complete graphs or expander graphs [20]. In practice, the transitive closure of a social network graph (i.e., a friend of a friend) is a dense graph.
The support measure is required to successfully manage the graph mining task. Graph databases present a problem, as opposed to transactional databases, where a support measure typically calls for counting and perhaps even standardization. This issue is caused by the highly non-trivial way that graph patterns might contain additional patterns as subgraphs. This is crucial in single-graph databases, which are the focus of this paper.
Several intuitive properties must be fulfilled by every support measure—an absent pattern should have measure zero, independent (e.g., non-intersecting) patterns should be counted separately, and the measure must be anti-monotonic, meaning that support of a pattern cannot increase when a pattern grows. Several support measures for graphs that uphold all of the above properties have been proposed over the years [21,22,23,24,25,26]. In [27] it was established that all proper support measures for graph databases can be viewed as flows in the network of pattern instances for all graph patterns.
However, computing support of a graph pattern usually requires finding all instances (e.g., isomorphic copies) of that pattern in the database graph and examining their connections, which is a computationally challenging task. Several general methods have been suggested to tackle this challenge. Ya et al. [28] present the distributed graph mining framework G-thinker for graph mining workloads that require a large amount of computing power. Graph summarization techniques that produce compact data representations can also be used for this purpose [29]. Paper [30] investigated how maximal subgraphs with all of the vertex degrees at least k might be used to improve the efficiency of graph mining. Symmetry-breaking techniques that solve computing duplication in graph mining systems have also been proposed in [31,32]. When the number of possible subgraphs is large, the MapReduce architecture was used in [33] to parallelize the production of such subgraphs. To manage database graphs that are too huge to fit into memory, paper [34] employed graph partitioning and optimization techniques; this approach guarantees that there are no false negatives in the search for frequent subgraphs. The authors of [35] studied what chip architecture works best for parallel graph mining.
In this paper, I examine networks constructed from graph pattern instances. I use the connection between support measures and flows in these instance networks established earlier in [27] to describe when a smaller sub-network can be used to compute valid support measures, thus decreasing the computational effort. By utilizing a unique sub-network of the instance network, called the intersection network, I present an effective approach that computes support measures directly from the database graph. This method is particularly helpful when a user wants to determine whether a particular graph pattern is statistically significant or not. Due to the difficulty of the computational process, one would not want to find all frequent patterns in this situation. Instead, the end user can discover the solution by using a much smaller intersecting network. This situation can be used in code analysis and the biomedical field, where a graph pattern represents a code sample or a molecular structure.
Section 2 contains formal definitions of graphs, patterns, support measures, and instance networks, and describes the connection between measures and flows. Section 3 introduces the concept of sufficiency and describes how the instance network can be pruned to facilitate the computation of support measures. Section 4 studies a specific type of pruned instance networks, called intersection networks, and shows that they possess the sufficiency property. The experimental evaluation is presented in Section 5, and the limitations and expansions of the suggested approach are covered in Section 6. Section 7 summarizes the results of this paper.
2. Definitions
2.1. Graphs and Networks
Let be a simple undirected graph (no multiple edges, no loops) with a node set and an edge set . An undirected edge between nodes u and v is denoted by . Nodes u and v are said to be adjacent, and the edge is said to be incident to nodes u and v. The number of a graph’s nodes is called its order and is denoted by . I use the following relations between graphs:
- Graphs and are isomorphic, denoted by , if there exists a bijection such that if and only if ;
- A graph is called a subgraph of a graph if and , written as ;
- A graph H is a proper subgraph of a graph G if it is a subgraph of G but it is not equal to G, denoted by ;
- A subgraph isomorphism from a graph H to a graph G exists if H is isomorphic to a subgraph of G, denoted by ;
- If a graph H is isomorphic to a proper subgraph of a graph G, we denote it by .
This paper relies heavily on the concept of graph connectivity:
- A graph G is disconnected if there exists a partition of its nodes such that there are no edges with one end in and another in , and it is connected otherwise;
- A node subset U is a node-cut (or cut) if removal of U and edges incident to the nodes in U results in a disconnected graph;
- A node-cut of minimal size is called a minimal node-cut or simply a min-cut.
A network (sometimes called a flow network) is defined as a tuple , where is a directed graph, and are nodes in it that are called the source and the sink, respectively. Function is called the edge capacity function. A flow f in a network N is a weight function that satisfies the edge capacity constraint for every edge , and the flow preservation constraint for all nodes . The following definitions and notations are used for flows:
- The size of a flow is the total weight of paths exiting the source or entering the sink;
- A flow of maximal size is called a maximal flow (or max-flow);
- A flow is called integer if it assumes an integer value on all edges—such a flow is a collection of paths with one end in the source and another in the sink; for a path P its segment bounded by nodes is denoted by ;
- An integer flow is node-disjoint if its paths have no common nodes except for the source and the sink.
For node-disjoint integer flows with one source and one sink the following Menger’s theorem is used:
Theorem 1
([36]). The size of a maximal node-disjoint flow is equal to the size of a minimal node-cut separating source and sink.
2.2. Patterns and Support Measures
Let us observe graphs p and G. Graph call p is called a graph pattern, or simply a pattern, in a graph database/dataset G. A subgraph of G that is isomorphic to p is called an instance of p in G. A set of all instances of pattern p in G is denoted by . Note that a pattern does not have to be a connected graph. Two instances of a pattern are called disjoint if their node sets do not intersect. An instance is called a sub-instance of an instance if .
Intuitively, a support measure ’counts’ the instances of a pattern while preserving properties that align with properties of support measures in transactional databases.
Next, let us define a notion of valid support measures that are used by graph mining algorithms. A valid support measure M should return zero for a pattern p if there are no instances of p in the database, and n if there are n disjoint instances of p in the database. The value of a valid support measure can not exceed the total number of pattern instances in the database, and it should have the property of anti-monotonicity stating that for every pair of patterns such that .
The task of graph mining deals can be re-defined as the task of finding all patterns p in the database having for some valid support measure M and a user-defined support value .
2.3. Properties of Valid Support Measures
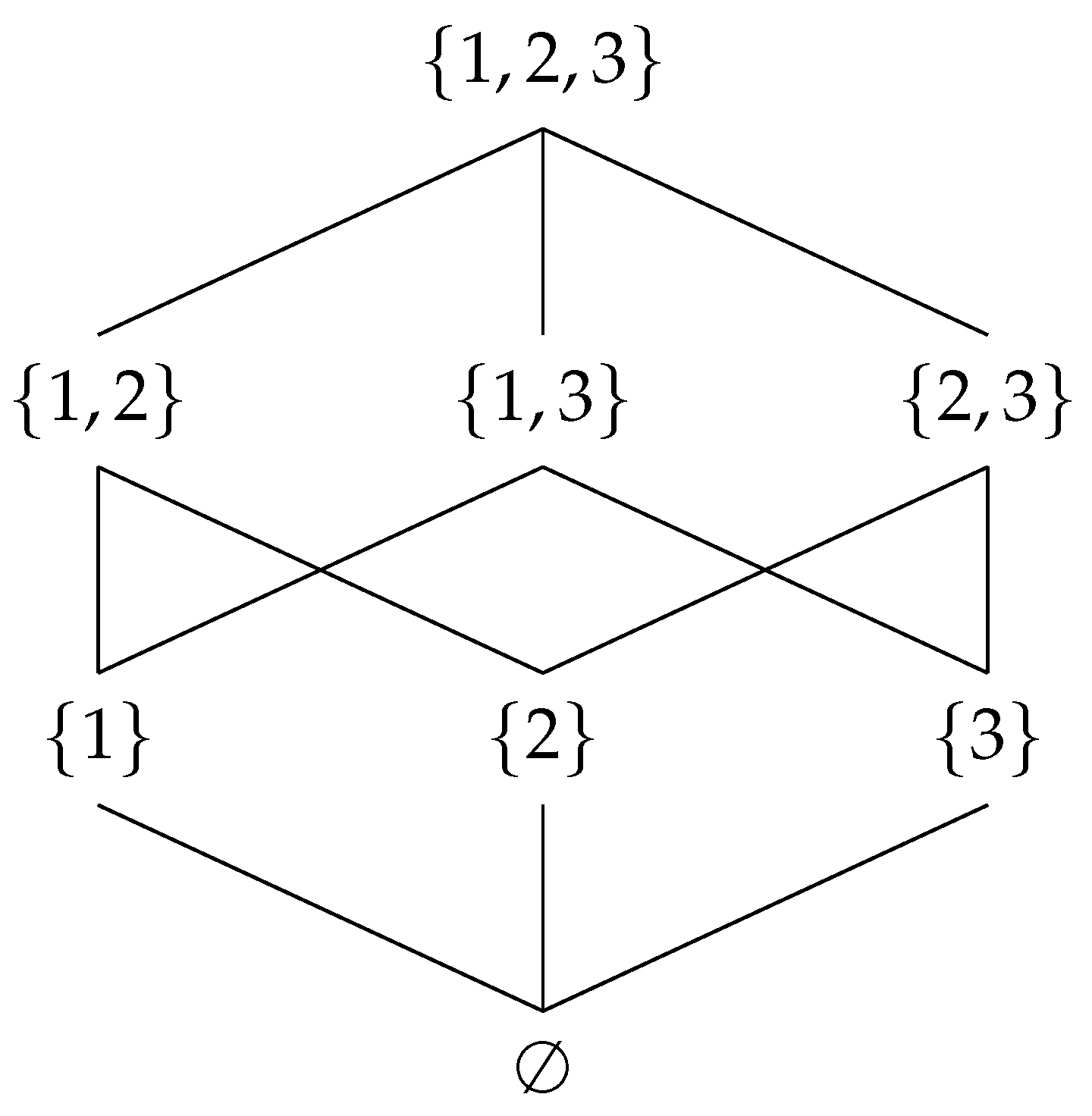
A Hasse diagram is a graphical representation of a finite partially ordered set, in which each element is represented by a node and each relationship between elements is represented by an edge connecting the vertices. The nodes are arranged in a hierarchy, with the elements that are related by a partial order being placed on a single line. The edges of the diagram are directed, pointing from the element that is lower in the partial order to the element that is higher in the partial order. A Hasse diagram example for a power set of a set is shown in Figure 1. The partial order in this instance is the subset–superset relation.
Using this concept, I define a flow network for a single-graph database that is called an instance network as follows:
- The nodes of this network are instances of all the patterns in G, including the empty instance ⊥ and G itself.
- The empty instance is the bottom element of the diagram, and G is the top element.
- The edges of the network are defined by the Hasse diagram of the partially ordered set implied by the subgraph relation on pattern instances.
- All edge weights are set to 1.
- The empty instance ⊥ is considered to be a subgraph of all the nodes in V.
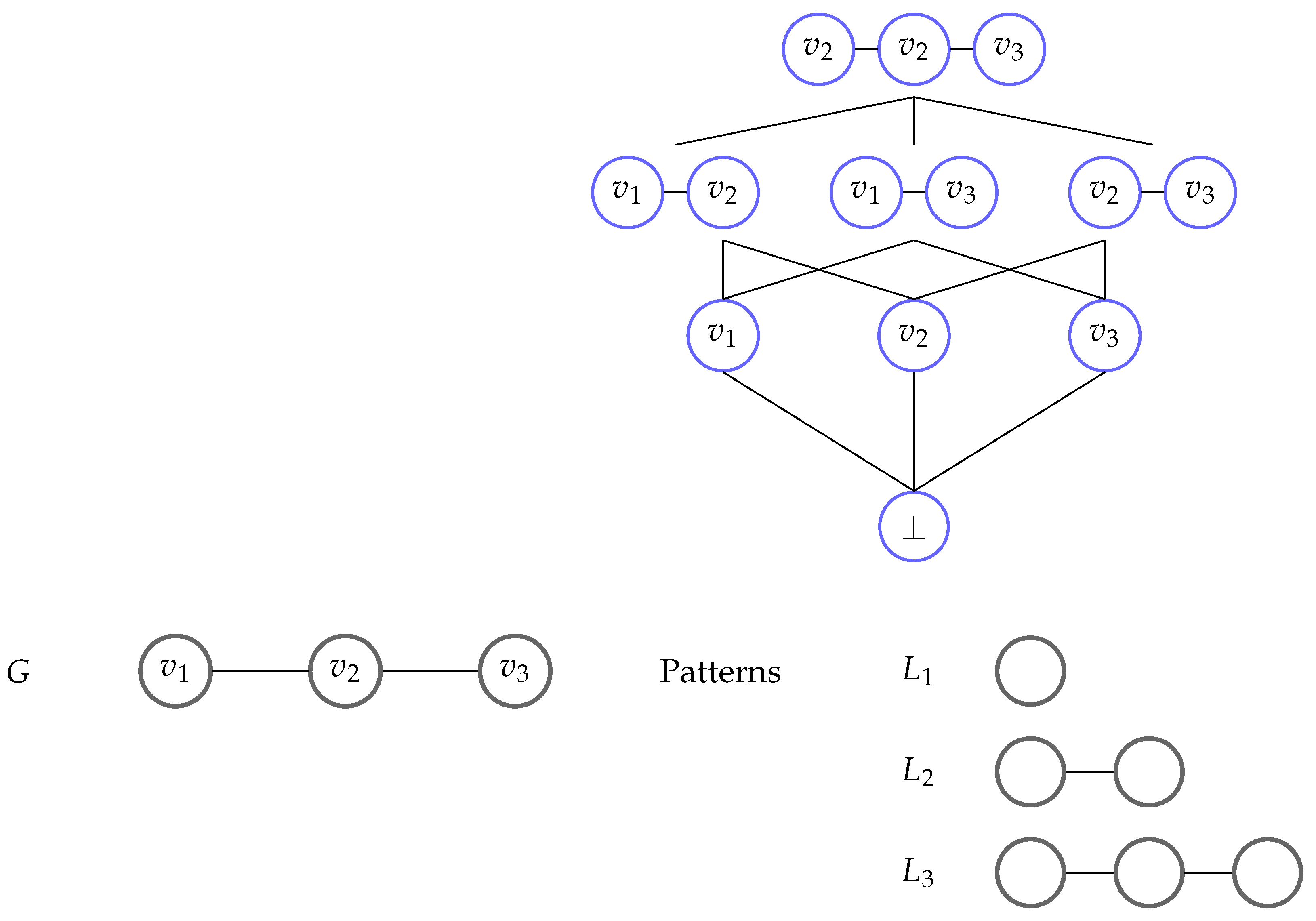
Example 1.
Figure 2 shows the instance network of a database graph G, which is an unlabeled path of length 2. It has three patterns, , , and , that are unlabeled paths of length 1, 2, and 3, respectively. has three instances in G that are single nodes, has three different instances, and has one instance.
For a pattern, p, denotes the instance network defined on instances of p and its sub-patterns only.
In this paper, I rely on the following theorem proven in my previous work.
Theorem 2
([27]). Let M be a valid support measure, G be a database graph, and p a pattern in G. Then, there exists a node-disjoint flow in so that .
Given the connection between flows and support measures, I define a separate category for measures that correspond to max-flows in the following definition.
Definition 1.
A valid support measure M is maximal for pattern p in database G if the size of a max-flow in instance network is . A valid support measure M is maximal if it is maximal for all patterns p.
Note that any valid support measure can be extended to a maximal one by taking its corresponding flow in the instance network and extending it to a max-flow.
Additionally, I prove here some basic properties of maximal node-disjoint flows that will be used later.
Property 1.
Let p be a pattern, and its corresponding instance network of a database graph G. Let C be a node min-cut in , and be a -flow saturating (i.e., traversing all the nodes of) cut C. Then, no two paths of intersect in a node different from ⊥ and G.
Proof.
Assume the contrary and let two paths , have a common node x. Let p and q be the nodes of C traversed by P and Q, respectively. Then, is a node cut in that is saturated by of size . This contradicts the assumption about C being a min-cut by Menger’s theorem. □
Property 2.
Let p be a pattern, and its corresponding instance network. Let C be a node min-cut in , and be a node-disjoint -flow saturating (i.e., traversing all the nodes of) C. Let path traverse a node and a node y lie on a segment of P. Then, is a node min-cut in as well.
Proof.
Note that node set is saturated by the paths of that do not intersect by Property 1, and its size is identical to the size of C. □
3. Sufficient Instance Networks
For frequent graph patterns or those with support measures bigger than a user-defined parameter S, one is interested in computing valid graph measures when mining graphs, meaning that one must determine whether is bigger than S for a given measure M. Theorem 2 states that for any valid measure M, a flow corresponding to exists in the instance network N, allowing one to compute M using this network. However, when there are numerous patterns and instances and the database graph is dense, the size of a network N might be rather huge.
In this section, I demonstrate how N can be replaced by smaller instance network sub-networks. When using a certain graph mining algorithm, the obvious reason to seek a smaller network is to reduce the computation time of a reliable support measure. These algorithms have a propensity to iteratively construct graph patterns, but the precise sequence in which they appear varies from method to algorithm (e.g., [37,38,39,40,41]). The process of graph mining does not require a central element. Patterns are usually generated and tested for frequency in a bottom–up fashion, from smaller patterns to larger ones.
3.1. Definition
First, notation is provided below.
Definition 2.
Let be a sub-network of the instance network defined on instances of some patterns in G. Let M be a valid support measure. Then, denotes the value of the measure M for pattern p computed from the network .
Super patterns of p are not necessary to compute the value of by Theorem 2 if M is a valid support measure. As a result, we can declare the following right away.
Property 3.
Let p be a pattern and let include the instances of p and its sub-patterns only. Then, .
Following Property 3, I can introduce an extension of this concept.
Definition 3.
Let be a sub-network of the instance network . is called sufficient if for every valid support measure M, every pattern p, and every user-defined support threshold holds
Definition 4.
A sub-network is called sufficient for pattern p if Equation (1) holds for p.
Note that sufficiency is transitive because pruning a sufficient network with a filter according to Equation (1) preserves it.
3.2. Examples of Insufficient Sub-Networks
I list several counterexamples of sufficiency below to demonstrate that the notion of sufficiency is not straightforward. They serve to demonstrate that naive recommendations for adequate sub-network architecture are ineffective.
Counterexample 1.
Graphs are said to cover graph g if the union of instances give us precisely the node and edge sets of g. Let p be a connected pattern in G. Sub-network , which contains instances of patterns covering p, is not sufficient.
Proof.
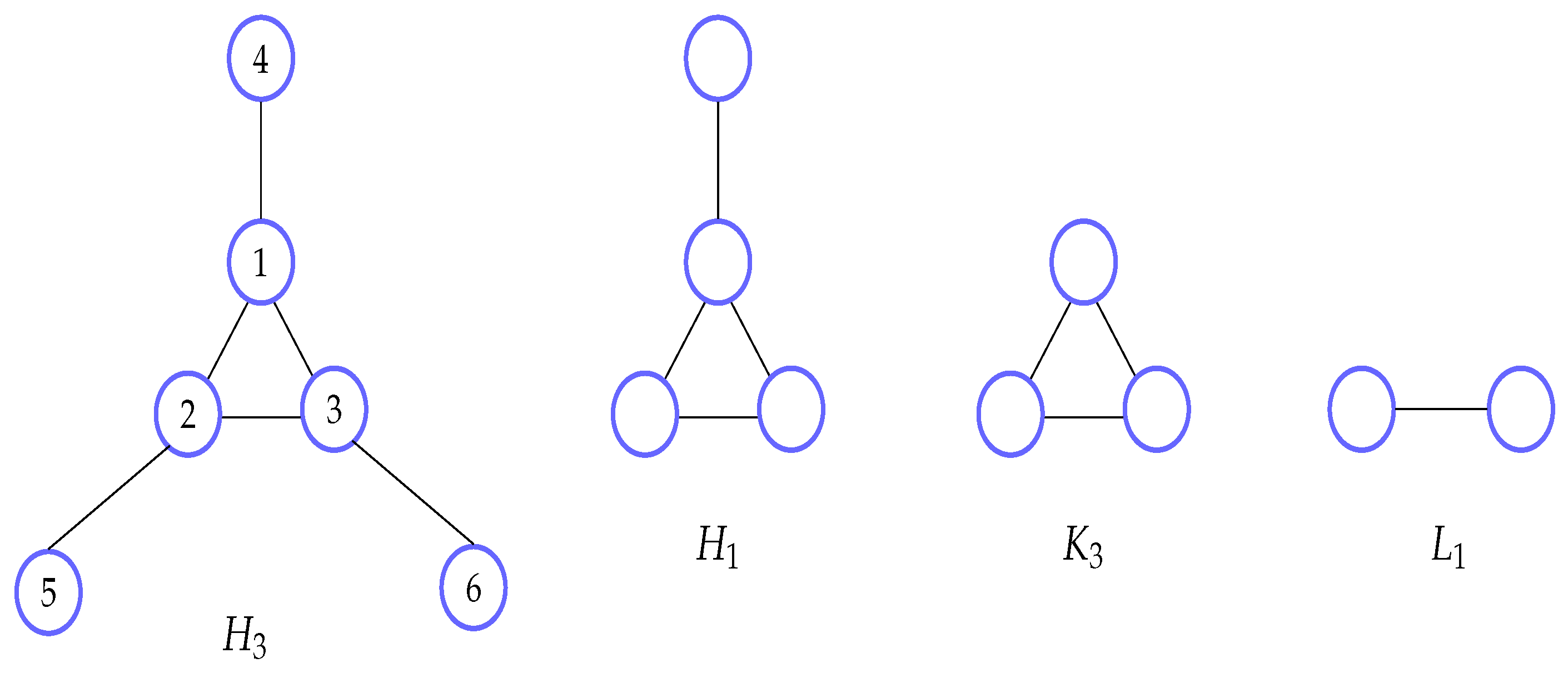
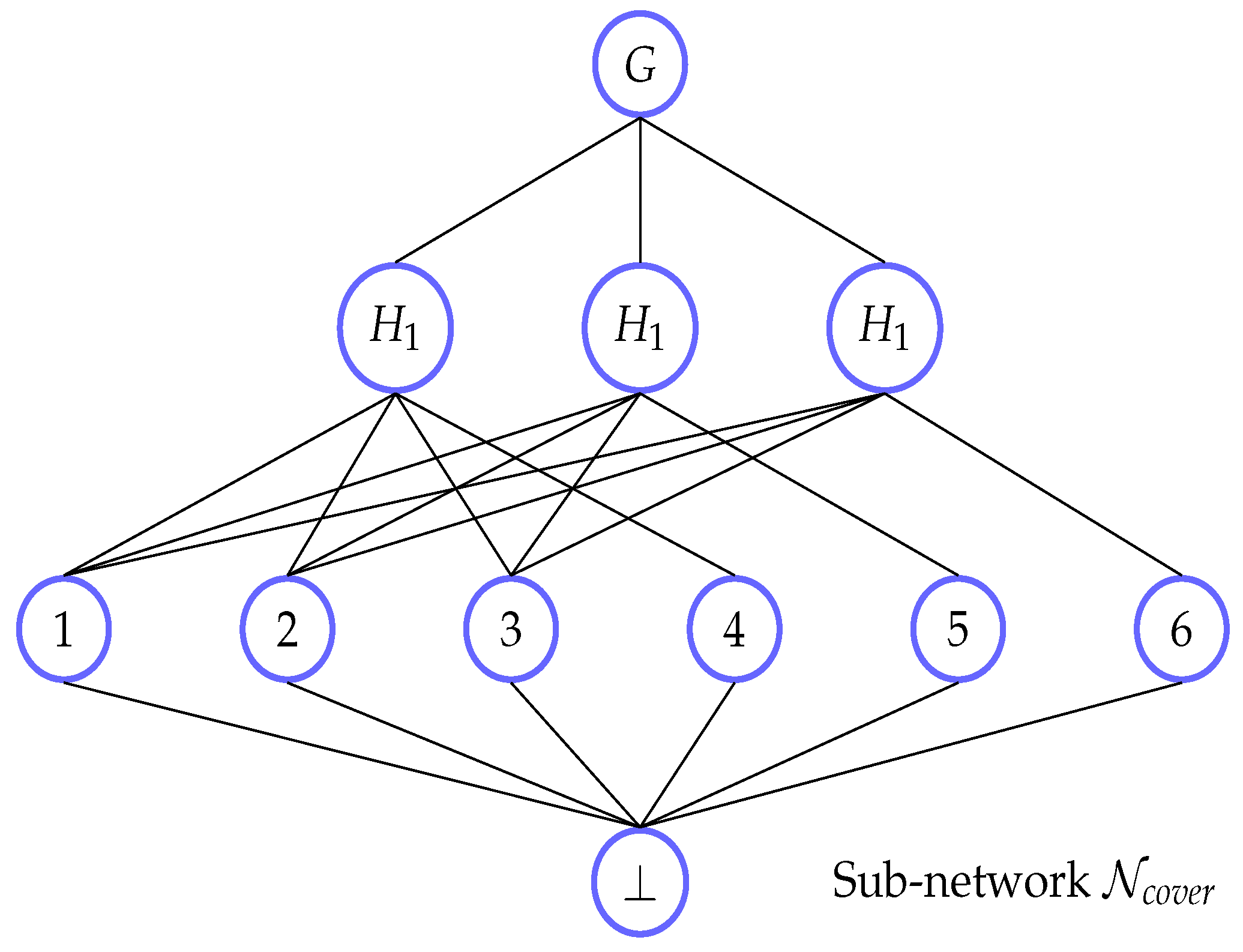
Observe an unlabeled pattern (for the ‘three horns’) depicted in Figure 3. In a setting where , a subpattern (a single edge) of covers all other patterns, including and . Let M be any maximal valid support measure. Clearly, because has only one instance in G and therefore the size of a node min-cut in is 1. Then, because is a subgraph of and M is anti-monotonic.
Let us define a sub-network to contain the instances of edge only (this network is shown in Figure 4). This network does not contain a node cut of size 1 separating G and ⊥, and thus by Menger’s theorem a max-flow corresponding to has a size bigger than 1. □
Because is still the bounding factor when computing any maximal valid measure for , the same issue as in Counterexample 1 arises if one uses larger patterns encompassing , such as paths of length 2.
It may seem that covering p with patterns similar to will provide a solution, but the next claim shows that is not true.
Counterexample 2.
Let p be a connected pattern in G and let be a sub-network limited to instances of complete graphs of size no more than c. Then, is not sufficient.
Proof.
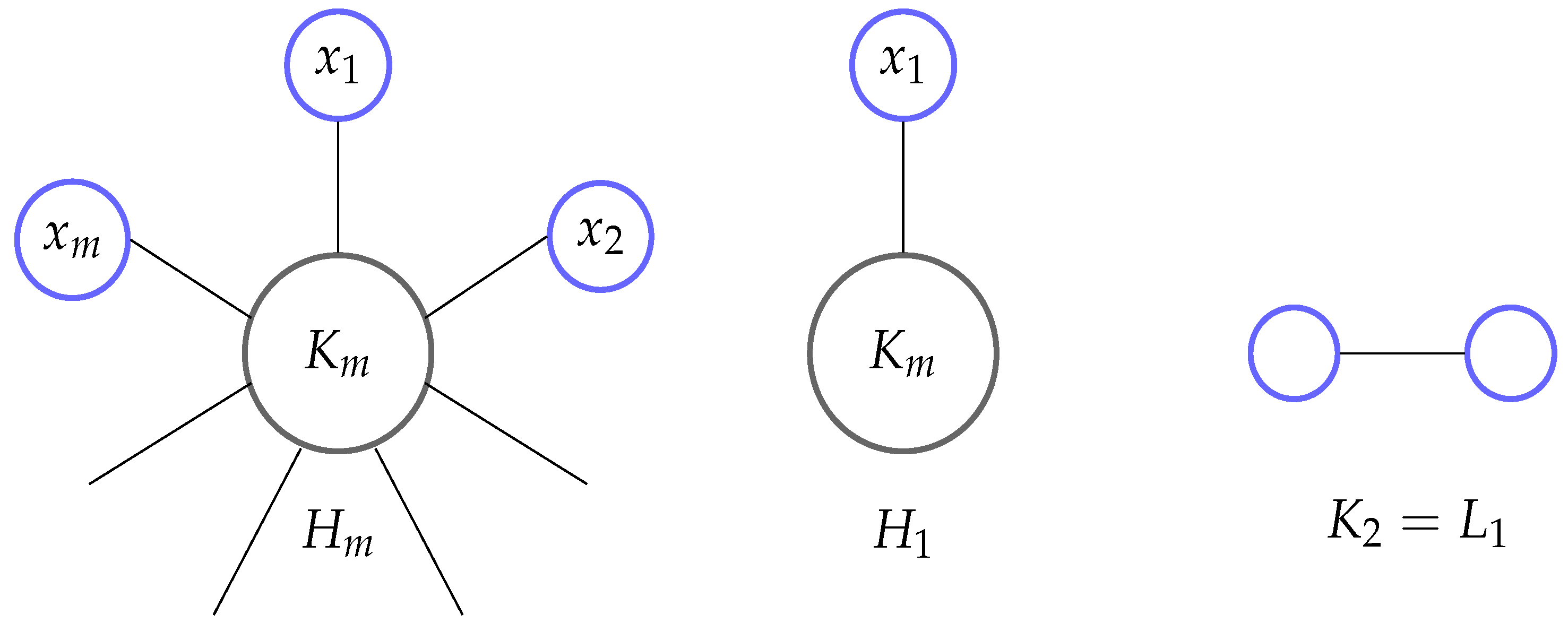
Observe a maximal valid measure M. Let (for ‘m horns’) be a pattern consisting of a complete graph , , and nodes of degree 1, each connected to a different node of (see Figure 5). A pattern consists of a complete graph and one degree 1 node connected to it.
Clearly, instances of all complete graphs cover both and in the data graph. However, itself has only one instance in the database graph that is not contained in .
Then, because there are at least two instances of graphs that are the largest subgraphs of represented in and thus the size of a node min-cut is at least 2. In the original network, however, . Therefore, is not sufficient. □
Even if a limit on the order of complete subgraphs is waived, sufficiency remains out of reach.
Counterexample 3.
Let denote a simple path with edges. Let p be a connected pattern in G and let be the sub-network that contains instances of complete graphs of any order. Then, is not sufficient for .
Proof.
Because , the only complete subgraphs with instances in G are and . A pattern contains more than two disjoint copies of because . Then, contains no node cut of size 1, meaning that for any maximal valid supports measure M. It contradicts (1) because there is only one instance of in the database and for support values , sufficiency requires that . □
3.3. Sufficient Networks
In this section, I prove sufficiency for several types of instance networks. Our first theorem addresses connected patterns. It is worth noting that most modern graph mining algorithms focus on connected patterns only.
Theorem 3.
Let be the sub-network of containing the instances of connected patterns only. Then, is sufficient for all connected patterns.
Proof.
Let p be a connected pattern in G and let M be a valid support measure.
Suppose first that and M is maximal. Then, there exists no node-disjoint flow of size S in , implying the existence of a node min-cut C in of size .
Case 1: C contains instances of connected patterns only. Then, C is a cut in as well. This cut prevents the existence of flows of a size larger than in , meaning that by Theorem 2.
Case 2: C contains at least one instance of a disconnected pattern. Let be a maximal edge-disjoint flow in that saturates C, and let be a path that traverses a disconnected instance . Because P traverses a single instance of p that is connected by definition, we can replace x by in C by Property 2. Thus, one can assume that C contains connected instances only and we have the previous case.
Suppose now that . Let be a maximal flow in that saturates a node min-cut C. Then, by Theorem 2. Observe a path . If all instances traversed by P are connected, this path exists in as well. Otherwise, P contains at least one disconnected instance. Let denote the segment of P whose start x and end y are connected instances, and the inner nodes are disconnected instances. Because x is a subgraph of y, there exists a path in such that all are connected instances. For example, one can take to be a union of x and a spanning tree of y and then add edges until one obtains y. Replace the segment in path P with a new segment and obtain a new path . Flow has the same size as and is therefore a maximal flow in that saturates C. Then, by Property 2, its paths do not intersect. Thus, one can always select the paths of to contain connected instances only, meaning that this flow of size at least S exists in . Then, as well, as required. □
The theorem below and its corollaries describe additional classes of patterns of sufficient networks.
Theorem 4.
Let be a class of graph patterns closed under inclusion, meaning that subgraph isomorphism implies that either or q is a single node. Then, the sub-network limited to instances of patterns in is sufficient for all the patterns in . Moreover, the value of a valid support measure in this network is identical to the original.
Proof.
Let p be a connected pattern in G and let M be a valid support measure. By Theorem 2 there exists a flow f of size in . Any path traverses instances of sub-patterns of p that are contained in because is closed under inclusion. Therefore, the flow f exists in the network too, meaning that .
Similarly, let P be a path of a flow g in and let be an edge of P. If this edge does not exist in , then contains a path Q from x to y because x is a subgraph of y. However, is closed under inclusion, and any instance traversed by Q lies in , meaning that it is present in network as well. But then Q exists in and thus an edge cannot exist there because the network is a Hasse diagram. Therefore . Therefore, we have and thus sufficiency holds. □
Corollary 1.
Any class of graphs with forbidden minors satisfies Theorem 4. This includes planar graphs and graphs of bounded treewidth.
Corollary 2.
Trees satisfy the condition of Theorem 4.
Proof.
By Theorem 3 and transitivity of sufficiency, we can limit the network to connected subgraphs of trees, which are trees as well. □
Because any valid support measure M is anti-monotonic, implies that for any . Therefore, frequent patterns are closed under inclusion and the following can be deduced.
Corollary 3.
Let the network contain only the instances of frequent patterns. Then, is sufficient.
Joining Theorem 3 and Corollary 3 together and using a transitivity of sufficiency, the following corollary arises.
Corollary 4.
Let be the sub-network containing only the instances of frequent connected patterns. Then, is sufficient for any connected pattern p.
4. Intersection Networks
In this section, I describe instance networks that can be utilized to compute a valid support measure for a given pattern directly from the database graph.
Let G be a database graph, p a pattern in that graph, and the instance network corresponding to G. Let be the instances of p in G. Observe a set of patterns contained in intersections of these instances:
Definition 5.
The intersection network is the sub-network of that contains ⊥, the database graph G, the instances of p, the instances of all the patterns in the set , and the instances of their sub-patterns.
This network is far smaller than as a whole.
Sufficiency
Next, I prove the sufficiency of intersection networks.
Theorem 5.
Network is sufficient for p.
Proof.
Let p be a connected pattern in G, M be a valid support measure and S be a support boundary. By Theorem 2 there exists a flow f of size in .
Assume first that . If has no flow of size or bigger, then it contains a node min-cut C of size . The cut C contains instances of sub-patterns of p that lie in . But then C is a cut for a network for some subpattern q of p such that . Because M is valid and thus anti-monotonic, and by Theorem 2 there exists a flow of size in , which is a contradiction to C being a node-cut in .
Assume now that and M is maximal, meaning that a node cut C of size exists in .
- Case 1: if C contains nodes, instances of p and instances of patterns in , it exists in network as well and then as well because there is no flow of size S or bigger in .
- Case 2: otherwise, C contains instances of patterns . Then, every instance of in C is a subgraph of a different instance of p, denoted by . If this is not the case then lies in an intersection of two instances of p and we have contrary to our assumption. Let us replace in C every such instance by the instance of p and have case 1.
□
Next, observe an even smaller network that contains only inclusion-maximal intersections of instances of p. Define the set to be a subset of where if and only if there exists a pair of instances such that .
Definition 6.
The intersection network is the sub-network of that contains ⊥, the database graph G, the instances of p, and the instances of all the patterns in the set of inclusion-maximal patterns .
Corollary 6.
Network is sufficient for p.
Proof.
Let p be a connected pattern in G, M be a valid support measure and S be a support boundary. By Theorem 2 there exists a flow f of size in .
The case of is identical to Theorem 5. If and M is maximal, then a node cut C of size exists in . If C is a cut in as well, meaning that C is a subset of , then by Menger’s theorem. Otherwise, C contains instances . If these instances are not contained in either, we have the case identical to Theorem 5. Otherwise, let . Let P be a path of max-flow in that saturates C and traverses . Then, P traverses an instance by the definition of . Replace by in C and do so for all non-maximal instances in C; it is possible because the paths of are node-disjoint. Then, we have the previous case. □
Maximal intersection networks are minimal in the sense that in general, omitting even one maximal intersection pattern results in an insufficient instance network. As an illustration, if one looks at database graph and sees pattern , the only maximal intersection pattern for its instances is (shown in Figure 5). The single node-cut in the instance network with a size of 1 is eliminated when this pattern is skipped, and a maximal valid support measure for this pattern will then have a value of ≥2.
Next, I offer a method for computing a reliable support metric for a graph pattern using maximal intersection networks. Using Corollary 6, this approach uses only the instances of p to reconstruct the necessary portion of the instance network. Therefore, one just needs to look at the sub-network of these patterns and their sub-patterns for a pattern p. The top–down construction used in this method is described in Algorithm 1.
| Algorithm 1 Computing maximal support measures from |
|
5. Experimental Evaluation
5.1. Graph Types and Objectives of Experiments
The testing was conducted on synthetic graphs of three types: Erdős–Rényi graphs (with default density 0.5), complete graphs (denoted by ), and balanced complete bipartite graphs (denoted by ). Density of an undirected graph is measured as
Queries in all cases were random Erdős–Rényi graphs of orders 10 to 20; even sizes only were used for complete bipartite graphs. Experiments evaluated sizes of several instance network types: (1) the complete network , (2) the network containing connected patterns only, and (3) the intersection network . The purpose of experimental assessment was multifold:
- To study whether or not using instead of decreases the network size;
- To evaluate the effect of graph density on network size when using ;
- To study how the use of an intersection network for a specific pattern affects the network size.
5.2. Software and Hardware Setup
5.3. Evaluation Results
Table 1 shows the sizes of full instance networks and that were generated for the three types of graphs. Graph sizes vary from 10 to 20 nodes. In the final column, the ratio of instance network sizes is displayed. Since the ratios are tiny and the number of instances rises quickly, they are shown in exponential form. As can be seen, the ratio decreases as graph size increases. This growth is more noticeable for denser graphs, such as complete graphs.
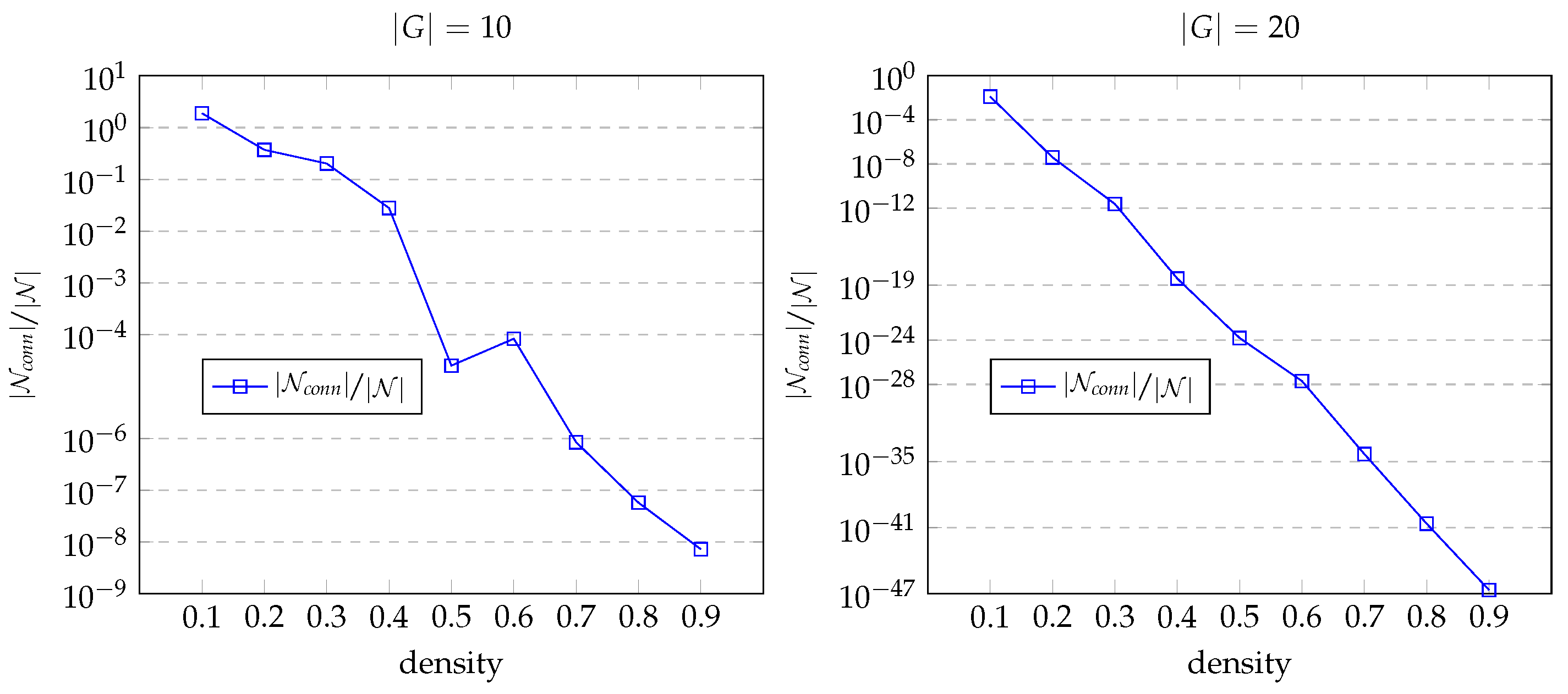
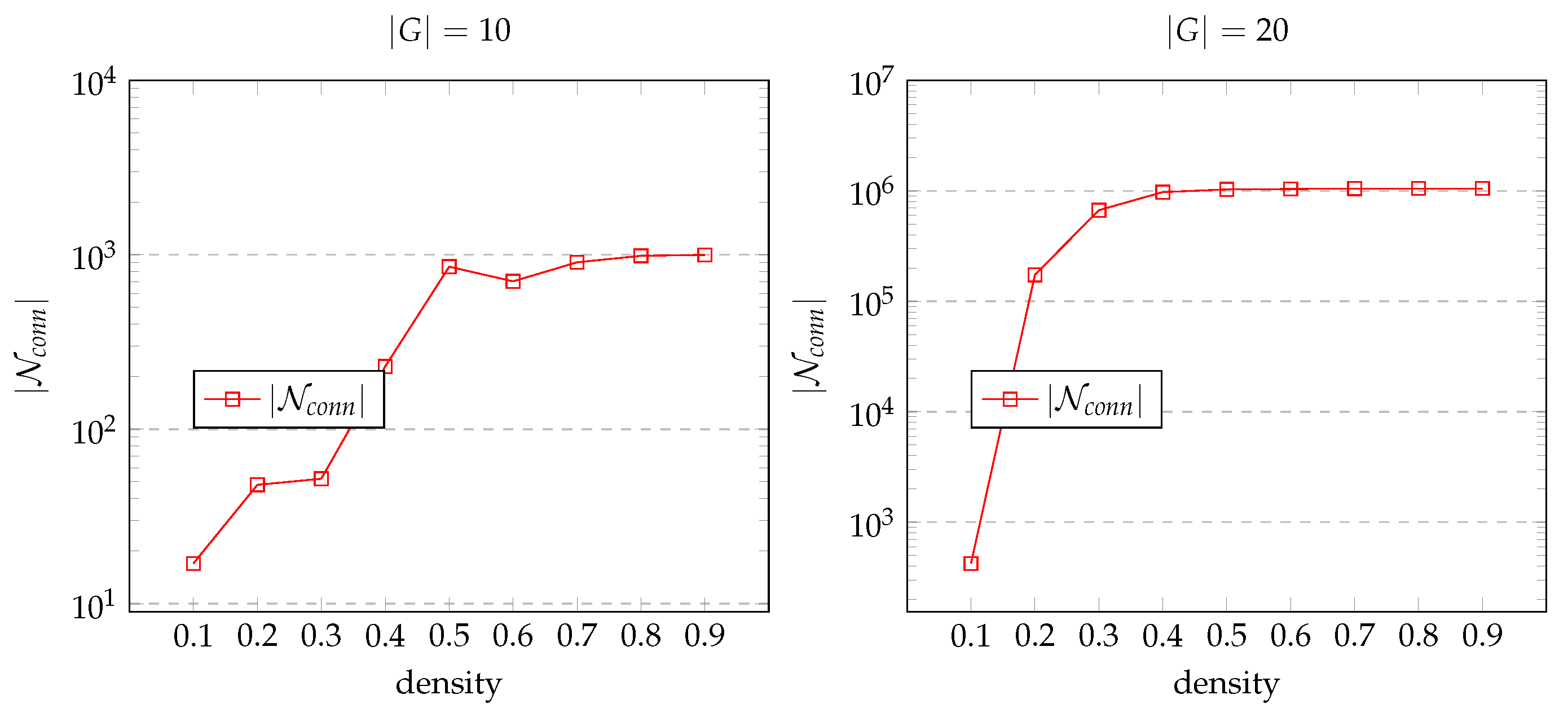
Charts in Figure 6 show how the ratio of sizes and varies. For Erdős–Rényi random graphs of various densities, the charts in Figure 7 show dependency of size on graph density for graphs of size 10 and 20. The finding unmistakably demonstrates that as the database graph becomes denser, employing the instance network offers more significant benefits.
Table 2 shows how the size of instance network changes with the growth of . Both database graph G and patterns p are Erdős–Rényi unlabeled random graphs. For and larger, the search becomes infeasible in our experimental setting.
The size comparison for the full instance network and intersection network for various sizes of a pattern p is shown in Table 3. Patterns p and database graph G are both Erdős–Rényi unlabeled random graphs. Due to the necessity of including all of the nodes in G, G itself, and the empty node ⊥, it should be noted that the minimum size of any instance network in this scenario is . The ratio of instance network sizes is displayed in the last column.
Table 4 shows size comparison for the full instance network and intersection network for labeled graphs. The size of a pattern is fixed (). Both the database graph and patterns are Erdős–Rényi random graphs with randomly assigned node labels, with the number of labels being in the range . The ratio of instance network sizes is shown in the last column. One can see that all network sizes decrease as the number of labels increases, but the sizes of intersection networks are still significantly smaller.
6. Extensions and Limitations
The approach presented in this paper can be extended to the following types of graphs.
- Directed graphs.In this case, patterns and their instances are directed graphs as well, and the instance network is defined in the same way as for the undirected graphs. Therefore, Theorem 2 holds for directed graphs as well, and all the results in this paper apply to them.
- Edge and node labeled graphs.Node and edge labels affect how instances of graph patterns are found in the database graphs because subgraph isomorphism has to take label matching into account. However, the rest of the results are not affected. Table 4 shows some experimental evaluations I performed for this type of graph.
- Multi-graphs and graphs with integer edge weights.An integer edge weight w is equivalent to replacing that edge with w edges between its incident nodes. In both cases, the subgraph isomorphism test for pattern instances is affected, because of the number of edges between a pair of nodes taken into account. The rest of the results hold for these graph types.
- Graphs with real edge weights.This case is equivalent to the previous one.
The main limitation of the presented approach is that it does not address extensions of subgraph isomorphism, such as graph homomorphism, and less-than-or-equal edge matching for a real edge-weighted graph. For example, a graph can be considered a subgraph of , and they cannot be reduced to multigraphs. In this case, Theorem 2 needs to be extended, and the instance network (in the form it is currently defined) is not suitable for representing support measures.
7. Conclusions
In this paper, I demonstrate how instance network sub-networks can be used to compute valid support measures for graph patterns. This concept has been incorporated into several graph mining methods, but because it is frequently entangled with the techniques themselves, each algorithm and each supporting measure must have its proof. Before the connection between flows and support measures was established in Theorem 2 in my prior work, it was impossible to verify these types of broad statements. This relationship means that a proving effort only needs to be made once, and this is the main result of this paper.
I demonstrate that smaller networks restricted to connected patterns, patterns with forbidden minors, or pattern intersections can be employed in place of larger networks when computing the support measure of a pattern. Additionally, I carried out an experimental evaluation that demonstrates unequivocally how important it is for graphs of different sizes, types, and labels to reduce the size of the instance network.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Barbier, G.; Liu, H. Data mining in social media. In Social Network Data Analytics; Springer: Berlin/Heidelberg, Germany, 2011; pp. 327–352. [Google Scholar]
- Kurshan, E.; Shen, H. Graph computing for financial crime and fraud detection: Trends, challenges and outlook. Int. J. Semant. Comput. 2020, 14, 565–589. [Google Scholar] [CrossRef]
- Pourhabibi, T.; Ong, K.L.; Kam, B.H.; Boo, Y.L. Fraud detection: A systematic literature review of graph-based anomaly detection approaches. Decis. Support Syst. 2020, 133, 113303. [Google Scholar] [CrossRef]
- Kutty, S.; Nayak, R.; Chen, L. A people-to-people matching system using graph mining techniques. World Wide Web 2014, 17, 311–349. [Google Scholar] [CrossRef]
- Ebrahimi, F.; Asemi, A.; Nezarat, A.; Ko, A. Developing a mathematical model of the co-author recommender system using graph mining techniques and big data applications. J. Big Data 2021, 8, 1–15. [Google Scholar] [CrossRef]
- Shin, Y.; Yoon, Y. Incorporating dynamicity of transportation network with multi-weight traffic graph convolutional network for traffic forecasting. IEEE Trans. Intell. Transp. Syst. 2020, 23, 2082–2092. [Google Scholar] [CrossRef]
- Ay, F.; Gülsoy, G.; Kahveci, T. Mining Biological Networks for Similar Patterns. In Data Mining: Foundations and Intelligent Paradigms; Springer: Berlin/Heidelberg, Germany, 2012; pp. 63–99. [Google Scholar]
- Durmaz, A.; Henderson, T.A.; Bebek, G. Frequent Subgraph Mining of Functional Interaction Patterns Across Multiple Cancers. In Proceedings of the BIOCOMPUTING 2021: Proceedings of the Pacific Symposium, Fairmont Orchid, HI, USA, 5–7 January 2020; pp. 261–272. [Google Scholar]
- Mihalcea, R.; Tarau, P. Textrank: Bringing order into text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; pp. 404–411. [Google Scholar]
- Jiang, C.; Coenen, F.; Sanderson, R.; Zito, M. Text classification using graph mining-based feature extraction. In Research and Development in Intelligent Systems XXVI; Springer: Berlin/Heidelberg, Germany, 2010; pp. 21–34. [Google Scholar]
- Liu, J.B.; Raza, Z.; Javaid, M. Zagreb connection numbers for cellular neural networks. Discret. Dyn. Nat. Soc. 2020, 2020, 8038304. [Google Scholar] [CrossRef]
- Majeed, A.; Rauf, I. Graph theory: A comprehensive survey about graph theory applications in computer science and social networks. Inventions 2020, 5, 10. [Google Scholar] [CrossRef] [Green Version]
- Kenyeres, M.; Kenyeres, J. Distributed Mechanism for Detecting Average Consensus with Maximum-Degree Weights in Bipartite Regular Graphs. Mathematics 2021, 9, 3020. [Google Scholar] [CrossRef]
- Krasanakis, E.; Symeonidis, A. Fast library recommendation in software dependency graphs with symmetric partially absorbing random walks. Future Internet 2022, 14, 124. [Google Scholar] [CrossRef]
- Jalali, M.; Tsotsalas, M.; Wöll, C. MOFSocialNet: Exploiting Metal-Organic Framework Relationships via Social Network Analysis. Nanomaterials 2022, 12, 704. [Google Scholar] [CrossRef]
- Li, P.; Chen, P.; Zhang, D. Cross-modal feature representation learning and label graph mining in a residual multi-attentional CNN-LSTM network for multi-label aerial scene classification. Remote Sens. 2022, 14, 2424. [Google Scholar] [CrossRef]
- Singh, M. Using natural language processing and graph mining to explore inter-related requirements in software artefacts. ACM Sigsoft Softw. Eng. Notes 2022, 44, 37–42. [Google Scholar] [CrossRef]
- Nijssen, S.; Kok, J.N. Frequent graph mining and its application to molecular databases. In Proceedings of the 2004 IEEE International Conference on Systems, Man and Cybernetics (IEEE Cat. No. 04CH37583), The Hague, The Netherlands, 10–13 October 2004; Volume 5, pp. 4571–4577. [Google Scholar]
- Takigawa, I.; Mamitsuka, H. Graph mining: Procedure, application to drug discovery and recent advances. Drug Discov. Today 2013, 18, 50–57. [Google Scholar] [CrossRef]
- Hoory, S.; Linial, N.; Wigderson, A. Expander graphs and their applications. Bull. Am. Math. Soc. 2006, 43, 439–561. [Google Scholar] [CrossRef]
- Vanetik, N.; Shimony, S.E.; Gudes, E. Support measures for graph data. Data Min. Knowl. Discov. 2006, 13, 243–260. [Google Scholar] [CrossRef]
- Bringmann, B.; Nijssen, S. What is frequent in a single graph? In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Osaka, Japan, 20–23 May 2008; pp. 858–863. [Google Scholar]
- Fiedler, M.; Borgelt, C. Subgraph support in a single large graph. In Proceedings of the Seventh IEEE International Conference on Data Mining Workshops (ICDMW 2007), Omaha, NE, USA, 28–31 October 2007; pp. 399–404. [Google Scholar]
- Wang, Y.; Guo, Z.C.; Ramon, J. Learning from networked examples. In Proceedings of the International Conference on Algorithmic Learning Theory, Kyoto, Japan, 15–17 October 2017; pp. 641–666. [Google Scholar]
- Meng, J.; Tu, Y.c. Flexible and Feasible Support Measures for Mining Frequent Patterns in Large Labeled Graphs. In Proceedings of the 2017 ACM International Conference on Management of Data, Chicago, IL, USA, 14–19 May 2017; pp. 391–402. [Google Scholar]
- Meng, J.; Tu, Y.C.; Pitaksirianan, N. A New Polynomial-time Support Measure for Counting Frequent Patterns in Graphs. In Proceedings of the 31st International Conference on Scientific and Statistical Database Management, Santa Cruz, CA, USA, 23–25 July 2019; pp. 214–217. [Google Scholar]
- Vanetik, N. Graph support measures and flows. Soc. Netw. Anal. Min. 2022, 12, 1–9. [Google Scholar]
- Yan, D.; Chen, H.; Cheng, J.; Özsu, M.T.; Zhang, Q.; Lui, J. G-thinker: Big graph mining made easier and faster. arXiv 2017, arXiv:1709.03110. [Google Scholar]
- Koutra, D. The power of summarization in graph mining and learning: Smaller data, faster methods, more interpretability. Proc. VLDB Endow. 2021, 14, 3416. [Google Scholar] [CrossRef]
- Shin, K.; Eliassi-Rad, T.; Faloutsos, C. Corescope: Graph mining using k-core analysis—patterns, anomalies and algorithms. In Proceedings of the 2016 IEEE 16th international conference on data mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 469–478. [Google Scholar]
- Mawhirter, D.; Reinehr, S.; Holmes, C.; Liu, T.; Wu, B. Graphzero: Breaking symmetry for efficient graph mining. arXiv 2019, arXiv:1911.12877. [Google Scholar]
- Rao, G.; Chen, J.; Yik, J.; Qian, X. Intersectx: An efficient accelerator for graph mining. arXiv 2020, arXiv:2012.10848. [Google Scholar]
- Teixeira, C.H.; Fonseca, A.J.; Serafini, M.; Siganos, G.; Zaki, M.J.; Aboulnaga, A. Arabesque: A system for distributed graph mining. In Proceedings of the 25th Symposium on Operating Systems Principles, Monterey, CA, USA, 4–7 October 2015; pp. 425–440. [Google Scholar]
- Talukder, N.; Zaki, M.J. A distributed approach for graph mining in massive networks. Data Min. Knowl. Discov. 2016, 30, 1024–1052. [Google Scholar] [CrossRef]
- Buehrer, G.; Parthasarathy, S.; Chen, Y.K. Adaptive parallel graph mining for CMP architectures. In Proceedings of the Sixth International Conference on Data Mining (ICDM’06), Hong Kong, China, 18–22 December 2006; pp. 97–106. [Google Scholar]
- Menger, K. Zur allgemeinen kurventheorie. Fundam. Math. 1927, 10, 96–115. [Google Scholar] [CrossRef]
- Huan, J.; Wang, W.; Prins, J.; Yang, J. Spin: Mining maximal frequent subgraphs from graph databases. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 581–586. [Google Scholar]
- Li, X.L.; Foo, C.S.; Tan, S.H.; Ng, S.K. Interaction graph mining for protein complexes using local clique merging. Genome Inform. 2005, 16, 260–269. [Google Scholar] [PubMed]
- Falkowski, T.; Barth, A.; Spiliopoulou, M. Studying community dynamics with an incremental graph mining algorithm. AMCIS 2008 Proc. 2008, 29. [Google Scholar]
- Kuramochi, M.; Karypis, G. An efficient algorithm for discovering frequent subgraphs. IEEE Trans. Knowl. Data Eng. 2004, 16, 1038–1051. [Google Scholar] [CrossRef]
- Yan, X.; Han, J. gSpan: Graph-based substructure pattern mining. In Proceedings of the 2002 IEEE International Conference on Data Mining, Maebashi City, Japan, 9–12 December 2002; pp. 721–724. [Google Scholar]
- Bisong, E. Building Machine Learning and Deep Learning Models on Google Cloud Platform: A Comprehensive Guide for Beginners; Apress: New York, NY, USA, 2019. [Google Scholar]
- Hagberg, A.; Swart, P.; S Chult, D. Exploring Network Structure, Dynamics, and Function Using NetworkX; Technical Report; Los Alamos National Lab. (LANL): Los Alamos, NM, USA, 2008. [Google Scholar]
Figure 1.
Instance network as a Hasse diagram.

Figure 2.
Insufficient sub-network of in Counterexample 1.

Figure 3.
Counterexample graphs for the cover assumption.

Figure 4.
Insufficient sub-network of in Counterexample 1.

Figure 5.
Patterns for Counterexample 2.

Figure 6.
Ratio and graph density.

Figure 7.
Size of and graph density.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Instance network size comparison for and .
| Graph | Nodes | Edges | Ratio | ||
|---|---|---|---|---|---|
| Erdős–Rényi | 10 | 20 | 576 | ||
| Erdős–Rényi | 11 | 26 | 1496 | ||
| Erdős–Rényi | 12 | 30 | 3066 | ||
| Erdős–Rényi | 13 | 34 | 6265 | ||
| Erdős–Rényi | 14 | 41 | 13,561 | ||
| Erdős–Rényi | 15 | 56 | 30,517 | ||
| Erdős–Rényi | 16 | 55 | 57,956 | ||
| Erdős–Rényi | 17 | 68 | 121,646 | ||
| Erdős–Rényi | 18 | 74 | 247,486 | ||
| Erdős–Rényi | 19 | 85 | 497,709 | ||
| Erdős–Rényi | 20 | 102 | 1,031,828 | ||
| 10 | 45 | 1023 | |||
| 11 | 55 | 2047 | |||
| 12 | 66 | 4095 | |||
| 13 | 78 | 8191 | |||
| 14 | 91 | 16,383 | |||
| 15 | 105 | 32,767 | |||
| 16 | 120 | 65,535 | |||
| 17 | 136 | 131,071 | |||
| 18 | 153 | 262,143 | |||
| 19 | 171 | 524,287 | |||
| 20 | 190 | 1,048,575 | |||
| 10 | 25 | 971 | |||
| 12 | 36 | 3981 | |||
| 14 | 49 | 16,143 | |||
| 16 | 64 | 65,041 | |||
| 18 | 81 | 261,139 | |||
| 20 | 100 | 1,046,549 |
Table 2.
Sizes of for patterns p on Erdős–Rényi graphs.
| # of Graph | # of Graph | # of Pattern | # of Pattern | Size of | # of Pattern |
|---|---|---|---|---|---|
| Nodes | Edges | Nodes | Edges | Instances | |
| 25 | 141 | 5 | 6 | 2752 | |
| 25 | 141 | 6 | 4 | 3032 | |
| 25 | 141 | 7 | 9 | 1693 | |
| 25 | 141 | 8 | 16 | 136 | |
| 25 | 141 | 9 | 23 | 1 | |
| 25 | 141 | 10 | 17 | 2 | |
| 25 | 141 | 11 | 26 | 0 | |
| 25 | 141 | 12 | 32 | 0 | |
| 25 | 141 | 13 | 38 | 0 | |
| 25 | 141 | 14 | 45 | 0 | |
| 30 | 225 | 5 | 6 | 9141 | |
| 30 | 225 | 6 | 8 | 13,144 | |
| 30 | 225 | 7 | 11 | 1339 | |
| 30 | 225 | 8 | 14 | 933 | |
| 30 | 225 | 9 | 18 | 85 | |
| 30 | 225 | 10 | 26 | 1 | |
| 30 | 225 | 11 | 28 | 0 | |
| 30 | 225 | 12 | 32 | 0 | |
| 30 | 225 | 13 | 43 | 0 | |
| 30 | 225 | 14 | 50 | 0 |
Table 3.
Comparison of and for Erdős–Rényi graphs.
| # of Graph | # of Graph | # of Pattern | # of Pattern | Size of | Size of | Ratio |
|---|---|---|---|---|---|---|
| Nodes | Edges | Nodes | Edges | |||
| 25 | 150 | 5 | 7 | 3139 | ||
| 25 | 150 | 6 | 6 | 3648 | ||
| 25 | 150 | 7 | 13 | 1297 | ||
| 25 | 150 | 8 | 16 | 181 | ||
| 25 | 150 | 9 | 15 | 44 | ||
| 25 | 150 | 10 | 25 | 27 | ||
| 25 | 150 | 11 | 28 | 27 | ||
| 25 | 150 | 12 | 33 | 27 | ||
| 25 | 150 | 13 | 42 | 27 | ||
| 25 | 150 | 14 | 56 | 27 | ||
| 30 | 224 | 5 | 2 | 1542 | ||
| 30 | 224 | 6 | 8 | 7135 | ||
| 30 | 224 | 7 | 9 | 2223 | ||
| 30 | 224 | 8 | 11 | 320 | ||
| 30 | 224 | 9 | 23 | 137 | ||
| 30 | 224 | 10 | 19 | 32 | ||
| 30 | 224 | 11 | 21 | 32 | ||
| 30 | 224 | 12 | 38 | 32 | ||
| 30 | 224 | 13 | 32 | 32 | ||
| 30 | 224 | 14 | 50 | 32 |
Table 4.
Comparison of and for Erdős–Rényi graphs with different number of labels and .
| # of | # of Graph | # of Graph | # of Pattern | # of Pattern | Size of | Size of | Ratio |
|---|---|---|---|---|---|---|---|
| Labels | Nodes | Edges | Nodes | Edges | |||
| 1 | 25 | 149 | 5 | 3 | 1644 | ||
| 2 | 25 | 157 | 5 | 6 | 277 | ||
| 3 | 25 | 140 | 5 | 3 | 53 | ||
| 4 | 25 | 148 | 5 | 6 | 38 | ||
| 5 | 25 | 149 | 5 | 8 | 27 | ||
| 1 | 30 | 217 | 5 | 5 | 8380 | ||
| 2 | 30 | 217 | 5 | 2 | 56 | ||
| 3 | 30 | 224 | 5 | 5 | 40 | ||
| 4 | 30 | 230 | 5 | 4 | 36 | ||
| 5 | 30 | 234 | 5 | 6 | 32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Vanetik, N. Sufficient Networks for Computing Support of Graph Patterns. Information 2023, 14, 143. https://doi.org/10.3390/info14030143
AMA Style
Vanetik N. Sufficient Networks for Computing Support of Graph Patterns. Information. 2023; 14(3):143. https://doi.org/10.3390/info14030143
Chicago/Turabian StyleVanetik, Natalia. 2023. "Sufficient Networks for Computing Support of Graph Patterns" Information 14, no. 3: 143. https://doi.org/10.3390/info14030143
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.