
A Projection Method for the Estimation of Error Covariance Matrices for Variational Data Assimilation in Ocean Modelling


{kind=link}
{kind=link}
{kind=link}
{kind=link}
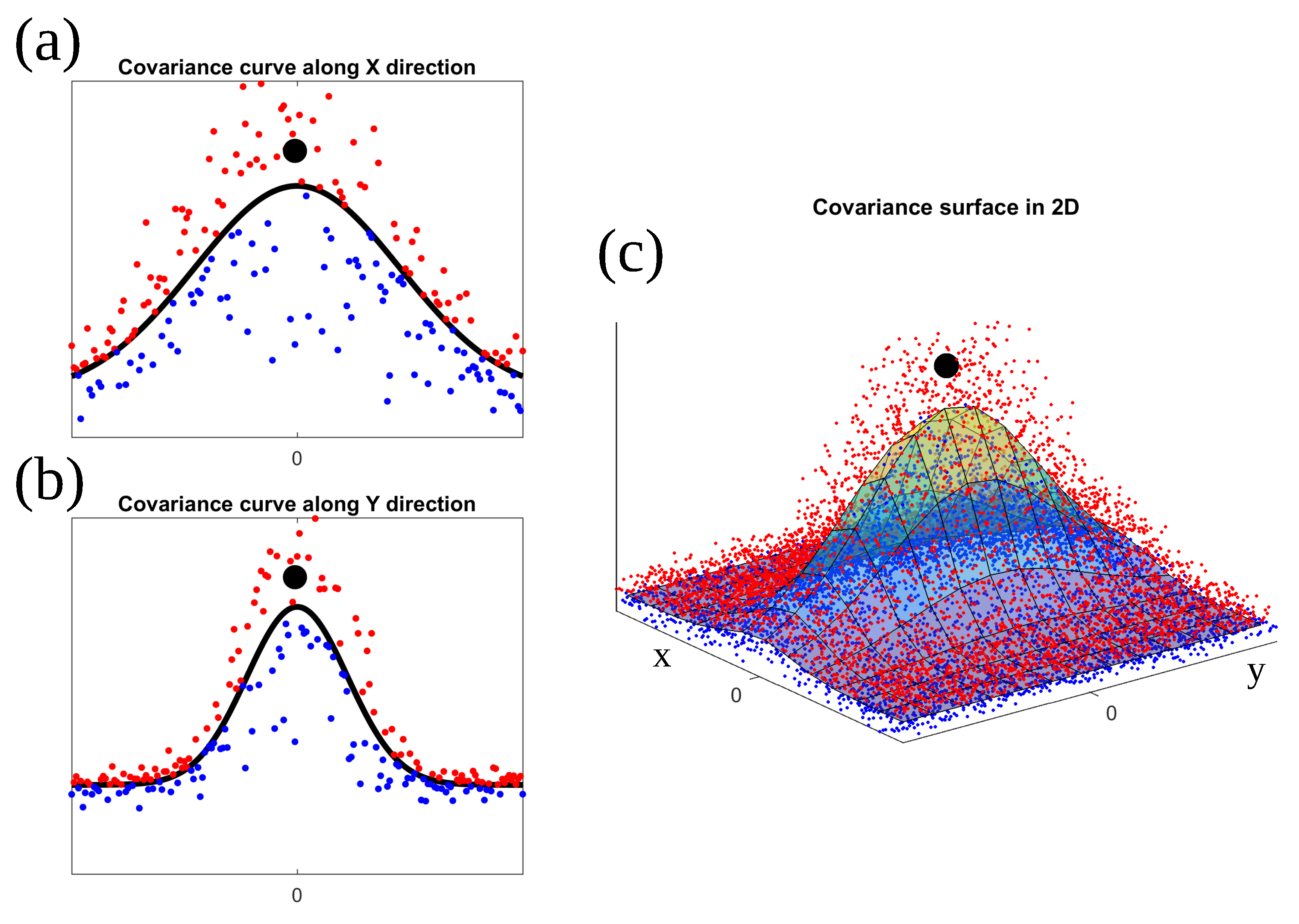
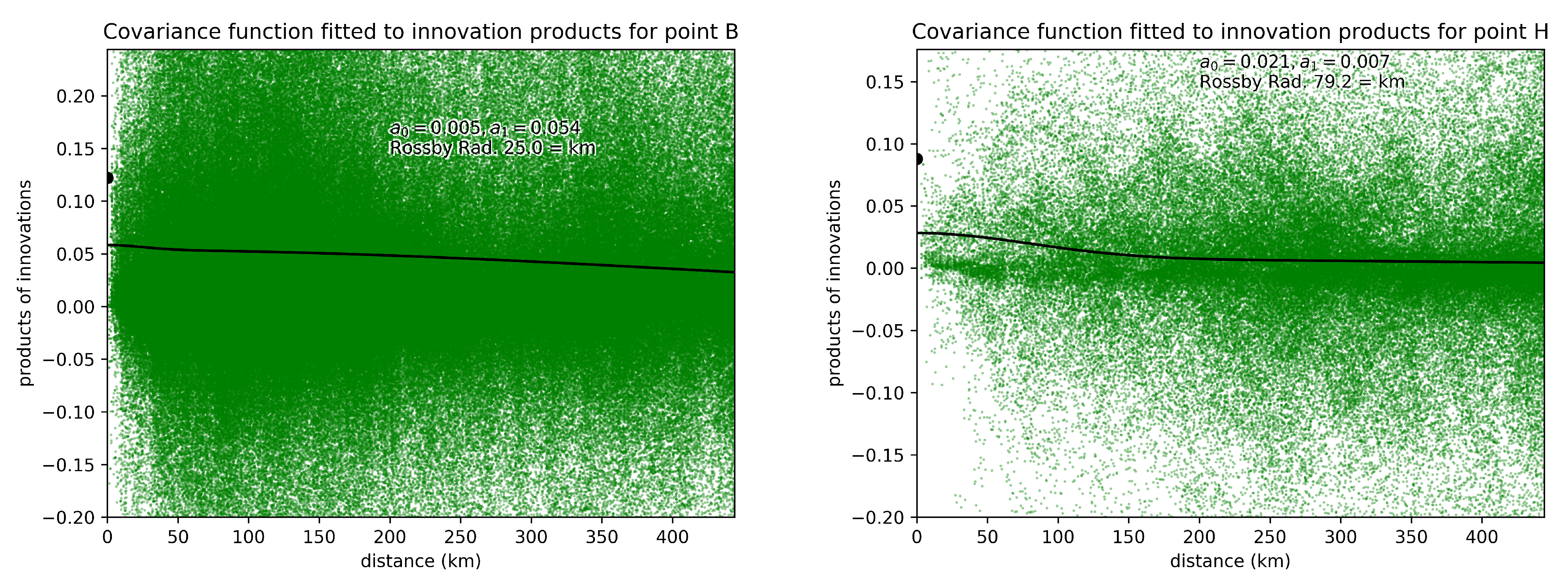{kind=link}
{kind=link}
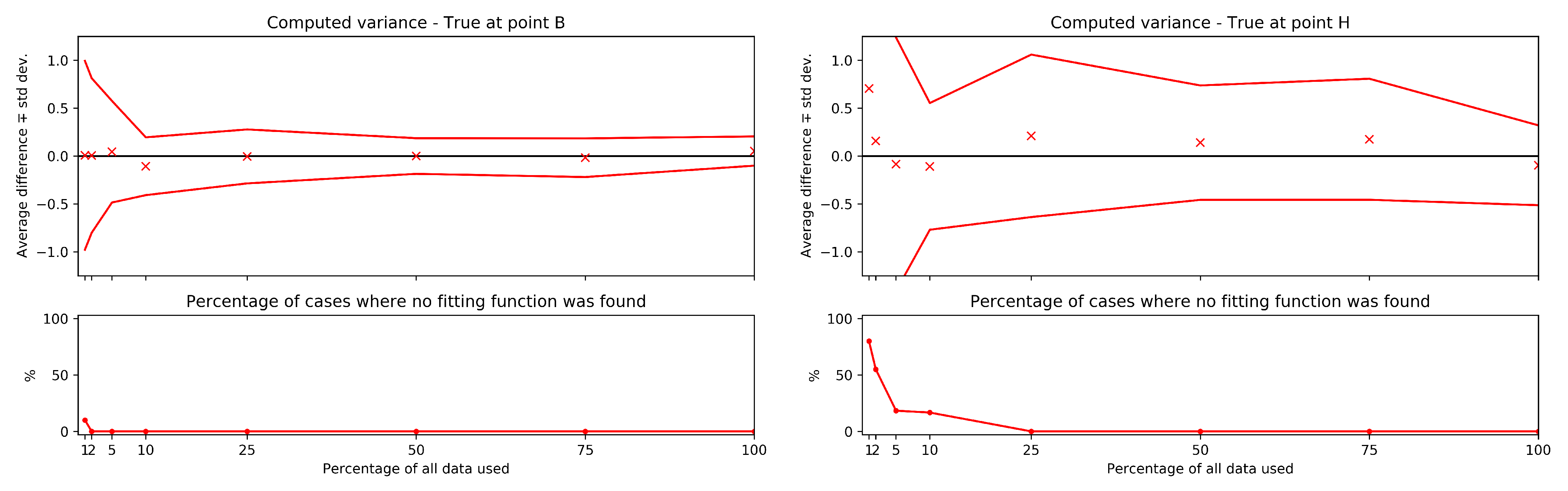
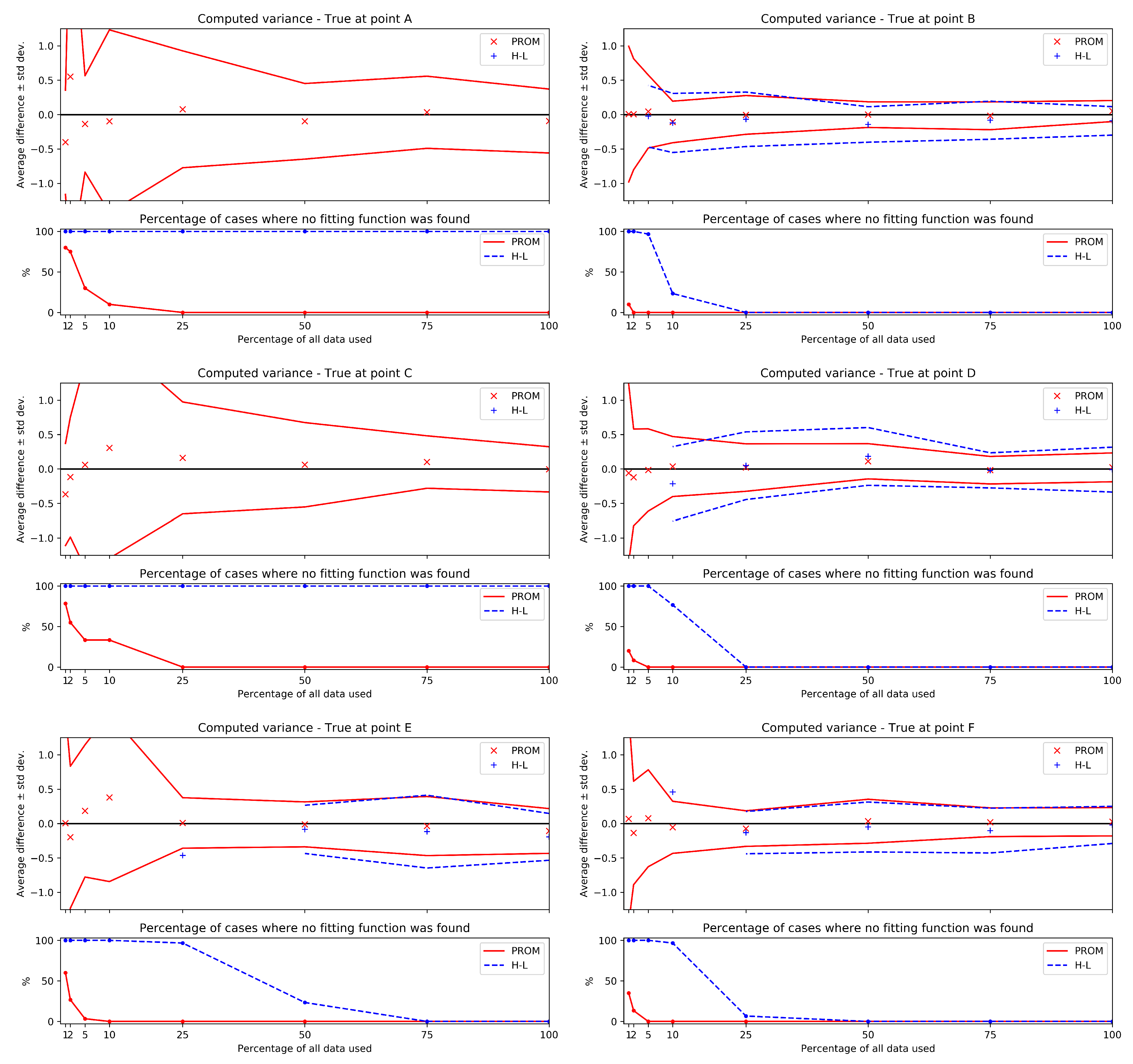{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
2.1. Analysis of Innovations
2.2. Fitting the Covariance Model to Innovations
2.3. Distance between Functions
2.4. Finding the Projection
2.5. Approximating the Inner Product
2.6. Data
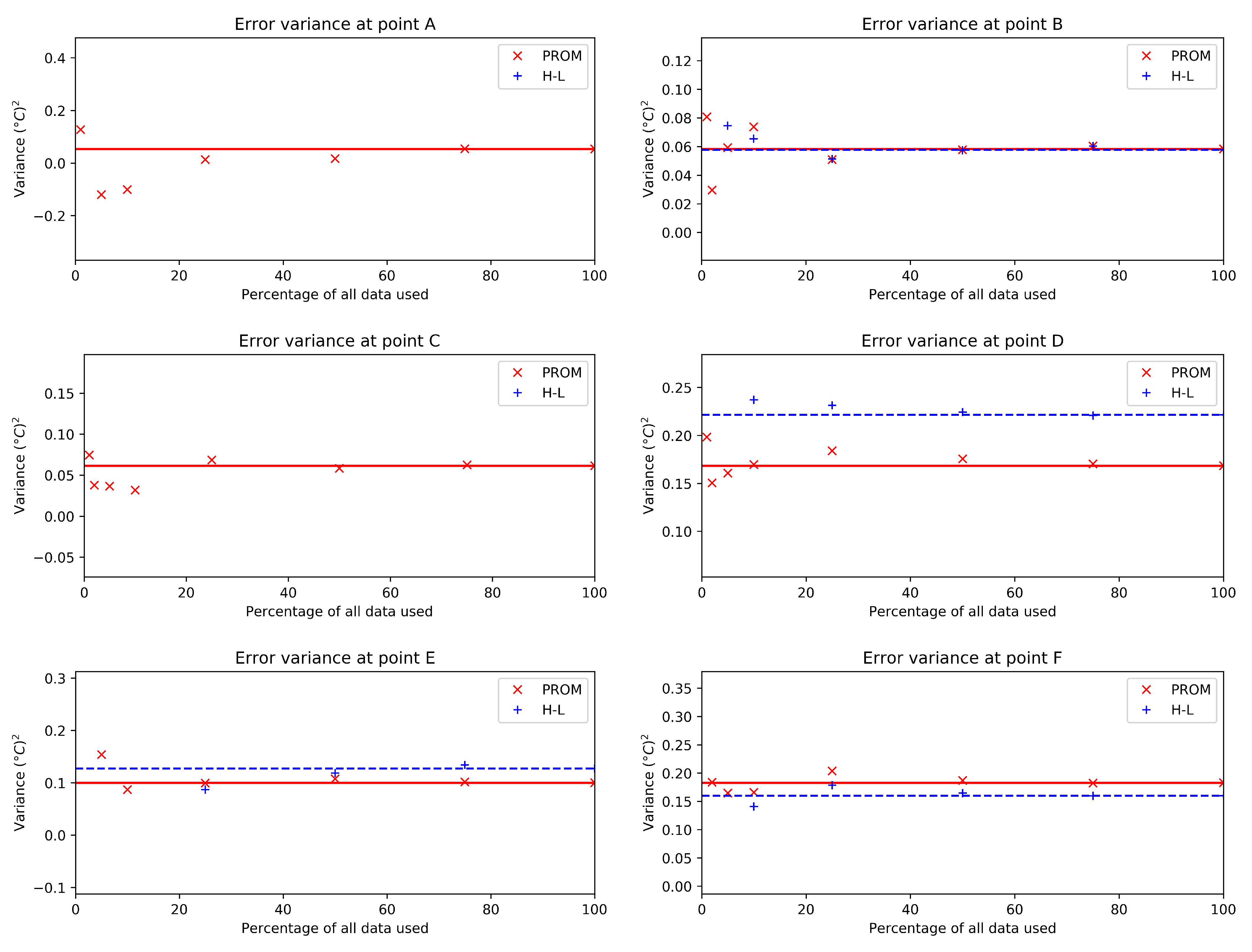
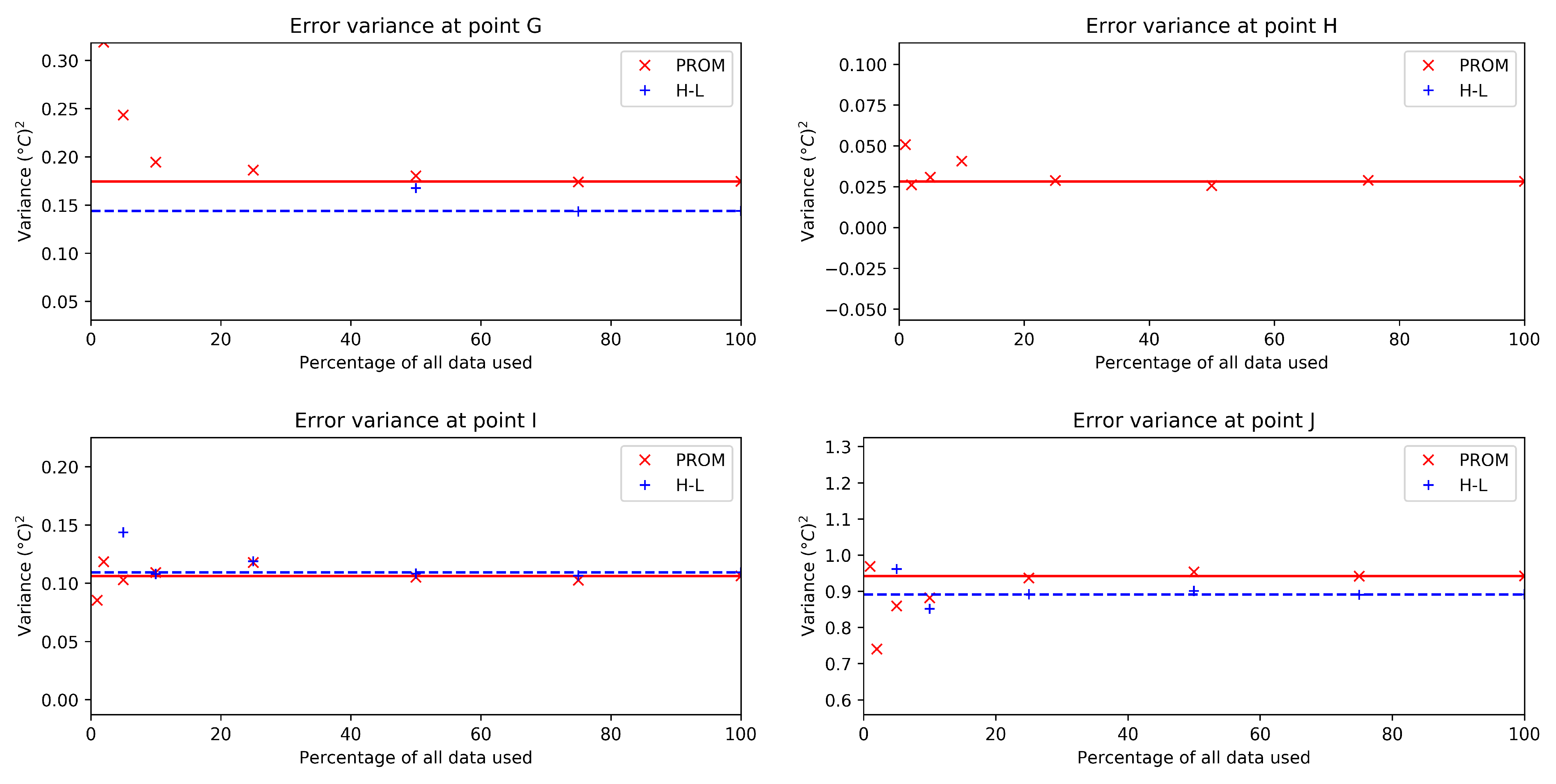
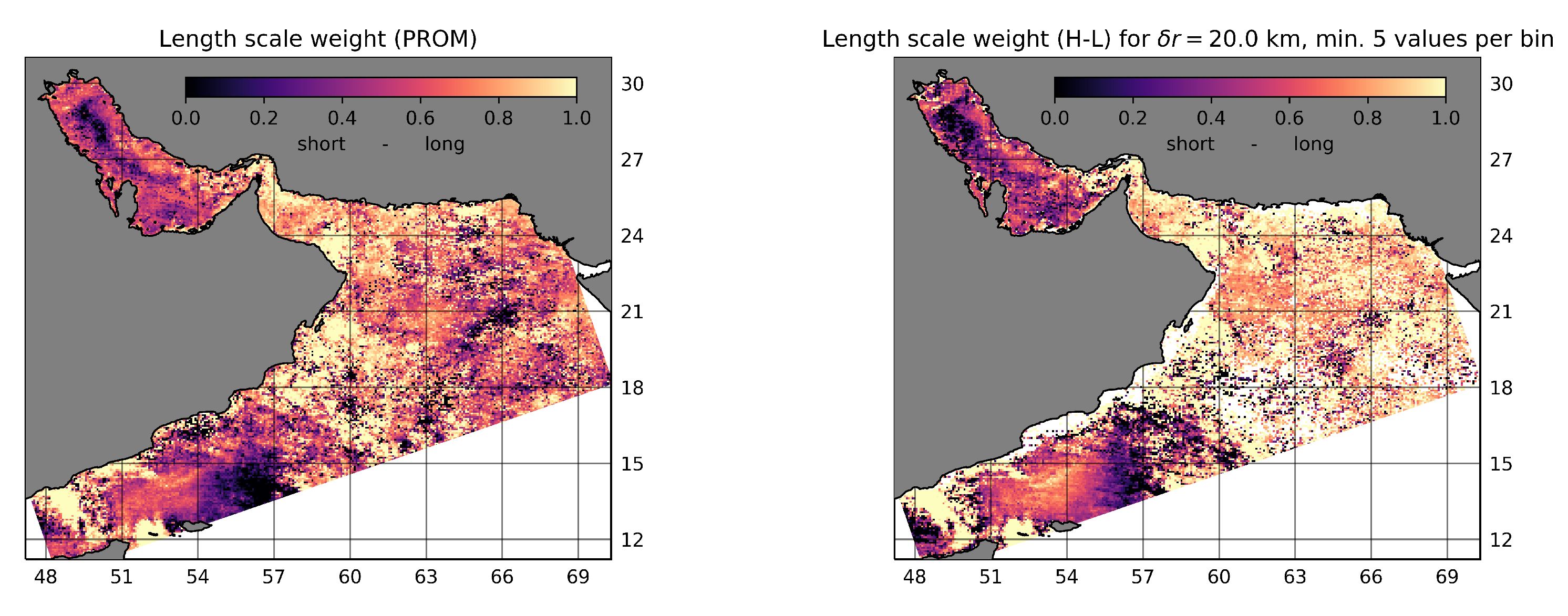
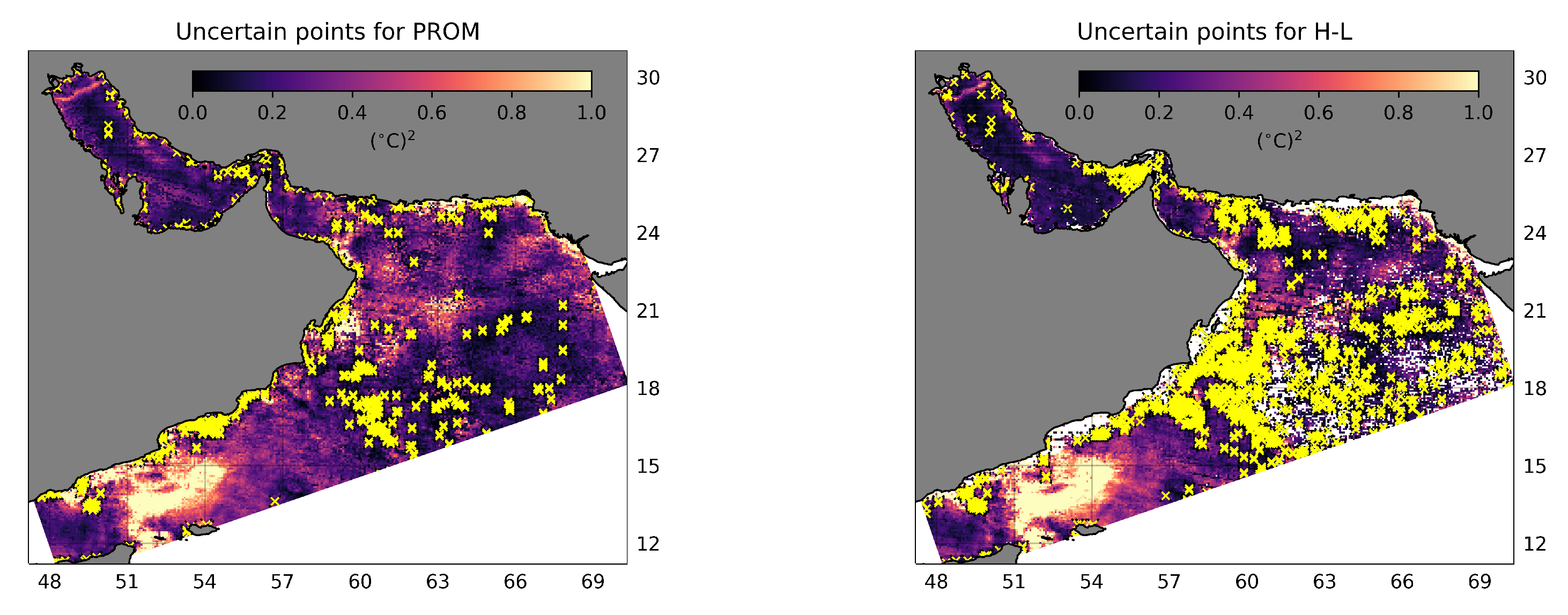
3. Results
3.1. Idealised Case
3.2. Real Case
4. Discussion
4.1. Idealised Case
4.2. Real Case
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Appendix A. Optimisation of the Algorithm
References
- Carrassi, A.; Bocquet, M.; Bertino, L.; Evensen, G. Data assimilation in the geosciences: An overview of methods, issues, and perspectives. Wiley Interdiscip. Rev. Clim. Chang. 2018, 9, e535. [Google Scholar] [CrossRef] [Green Version]
- Lahoz, W.A.; Schneider, P. Data assimilation: Making sense of Earth Observation. Front. Environ. Sci. 2014, 2, 16. [Google Scholar] [CrossRef] [Green Version]
- Bannister, R. A review of operational methods of variational and ensemble-variational data assimilation. Q. J. R. Meteorol. Soc. 2017, 143, 607–633. [Google Scholar] [CrossRef] [Green Version]
- Gandin, L.S. The problem on optimal interpolation. Trudy GGO 1959, 99, 67–75. [Google Scholar]
- Gandin, L.S. Objective analysis of meteorological fields. Translated from the Russian, Jerusalem program for scientific translations. Q. J. R. Meteorol. Soc. Jerus. Isr. 1965, 286, 242. [Google Scholar]
- Lorenc, A.C. Analysis methods for numerical weather prediction. Q. J. R. Meteorol. Soc. 1986, 112, 1177–1194. [Google Scholar] [CrossRef]
- Waters, J.; Lea, D.J.; Martin, M.J.; Mirouze, I.; Weaver, A.; While, J. Implementing a variational data assimilation system in an operational 1/4 degree global ocean model. Q. J. R. Meteorol. Soc. 2015, 141, 333–349. [Google Scholar] [CrossRef]
- Kalnay, E. Atmospheric Modeling, Data Assimilation and Predictability; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Ide, K.; Courtier, P.; Ghil, M.; Lorenc, A.C. Unified notation for data assimilation: Operational, sequential and variational (gtspecial issueltdata assimilation in meteology and oceanography: Theory and practice). J. Meteorol. Soc. Jpn. Ser. II 1997, 75, 181–189. [Google Scholar] [CrossRef] [Green Version]
- Bannister, R.N. A review of forecast error covariance statistics in atmospheric variational data assimilation. I: Characteristics and measurements of forecast error covariances. Q. J. R. Meteorol. Soc. J. Atmos. Sci. Appl. Meteorol. Phys. Oceanogr. 2008, 134, 1951–1970. [Google Scholar] [CrossRef]
- Haben, S.A.; Lawless, A.S.; Nichols, N.K. Conditioning and preconditioning of the variational data assimilation problem. Comput. Fluids 2011, 46, 252–256. [Google Scholar] [CrossRef]
- Bannister, R.N. A review of forecast error covariance statistics in atmospheric variational data assimilation. II: Modelling the forecast error covariance statistics. Q. J. R. Meteorol. Soc. J. Atmos. Sci. Appl. Meteorol. Phys. Oceanogr. 2008, 134, 1971–1996. [Google Scholar] [CrossRef]
- Hollingsworth, A.; Lönnberg, P. The statistical structure of short-range forecast errors as determined from radiosonde data. Part I: The wind field. Tellus A 1986, 38, 111–136. [Google Scholar] [CrossRef] [Green Version]
- Desroziers, G. Observation error specifications. In Advanced Data Assimilation for Geosciences: Lecture Notes of the Les Houches School of Physics: Special Issue, June 2012; OUP: Oxford, UK, 2012; p. 209. [Google Scholar]
- Garand, L.; Heilliette, S.; Buehner, M. Interchannel error correlation associated with AIRS radiance observations: Inference and impact in data assimilation. J. Appl. Meteorol. Climatol. 2007, 46, 714–725. [Google Scholar] [CrossRef]
- Bormann, N.; Bauer, P. Estimates of spatial and interchannel observation-error characteristics for current sounder radiances for numerical weather prediction. I: Methods and application to ATOVS data. Q. J. R. Meteorol. Soc. 2010, 136, 1036–1050. [Google Scholar] [CrossRef]
- Monin, A.S.; Yaglom, A.M. Statistical Fluid Mechanics, Volume II: Mechanics of Turbulence; Dover Publications: Mineola, NY, USA, 2013; Volume 2. [Google Scholar]
- Weaver, A.; Mirouze, I. On the diffusion equation and its application to isotropic and anisotropic correlation modelling in variational assimilation. Q. J. R. Meteorol. Soc. 2013, 139, 242–260. [Google Scholar] [CrossRef]
- Francis, X.; Shapiro, G.; Gonzalez-Ondina, J.M.; Wobus, F.; Maksymczuk, J.; Kenov, I.A.; While, J.; Asif, M. Comparison of skill between high and medium resolution ocean models in the North Indian Ocean. Geophys. Res. Abstr. 2019, 21. Available online: https://meetingorganizer.copernicus.org/EGU2019/EGU2019-5829.pdf (accessed on 8 December 2021).
- Madec, G.; Delecluse, P.; Imbard, M.; Levy, C. OPA 8 Ocean General Circulation Model—Reference Manual; Technical Report, LODYC/IPSL Note 11; Laboratoire d’Océanographie DYnamique et de Climatologie: Paris, France, 1998. [Google Scholar]
- Mogensen, K.; Balmaseda, M.; Weaver, A.; Martin, M.; Vidard, A. NEMOVAR: A variational data assimilation system for the NEMO ocean model. ECMWF Newsl. 2009, 120, 17–22. [Google Scholar]
- Shapiro, G.; Luneva, M.; Pickering, J.; Storkey, D. The effect of various vertical discretization schemes and horizontal diffusion parameterization on the performance of a 3-D ocean model: The Black Sea case study. Ocean. Sci. 2013, 9, 377. [Google Scholar] [CrossRef] [Green Version]
- Weaver, A.; Courtier, P. Correlation modelling on the sphere using a generalized diffusion equation. Q. J. R. Meteorol. Soc. 2001, 127, 1815–1846. [Google Scholar] [CrossRef]
- Lam, S.K.; Pitrou, A.; Seibert, S. Numba: A llvm-based python jit compiler. In Proceedings of the Second Workshop on the LLVM Compiler Infrastructure in HPC, Austin, TX, USA, 15 November 2015; pp. 1–6. [Google Scholar]













Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gonzalez-Ondina, J.M.; Sampson, L.; Shapiro, G.I. A Projection Method for the Estimation of Error Covariance Matrices for Variational Data Assimilation in Ocean Modelling. J. Mar. Sci. Eng. 2021, 9, 1461. https://doi.org/10.3390/jmse9121461
Gonzalez-Ondina JM, Sampson L, Shapiro GI. A Projection Method for the Estimation of Error Covariance Matrices for Variational Data Assimilation in Ocean Modelling. Journal of Marine Science and Engineering. 2021; 9(12):1461. https://doi.org/10.3390/jmse9121461
Chicago/Turabian StyleGonzalez-Ondina, Jose M., Lewis Sampson, and Georgy I. Shapiro. 2021. "A Projection Method for the Estimation of Error Covariance Matrices for Variational Data Assimilation in Ocean Modelling" Journal of Marine Science and Engineering 9, no. 12: 1461. https://doi.org/10.3390/jmse9121461