
Applying Artificial Intelligence Methods to Detect and Classify Fish Calls from the Northern Gulf of Mexico


Abstract
:1. Introduction
2. Materials and Methods
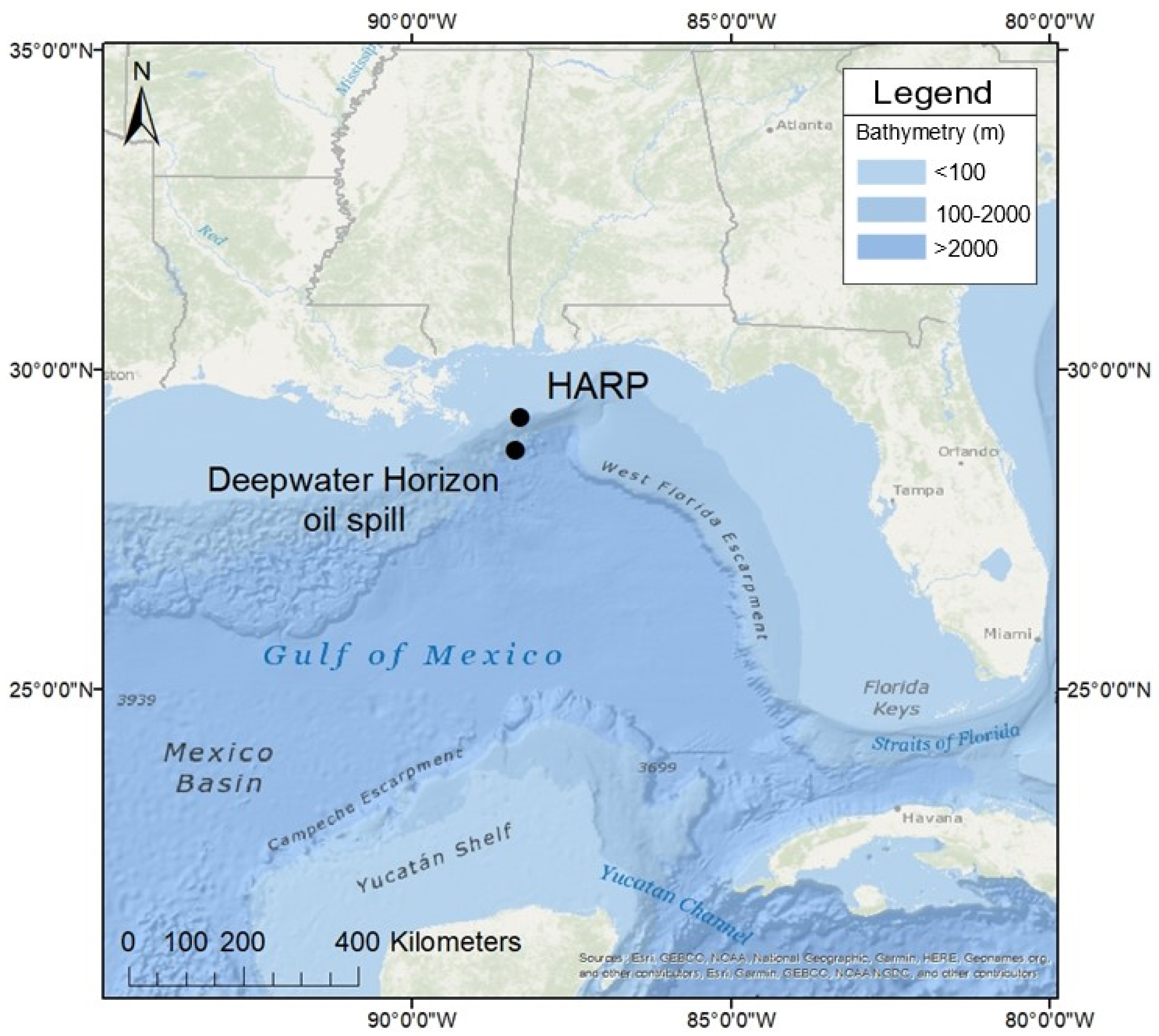
2.1. Data Collection
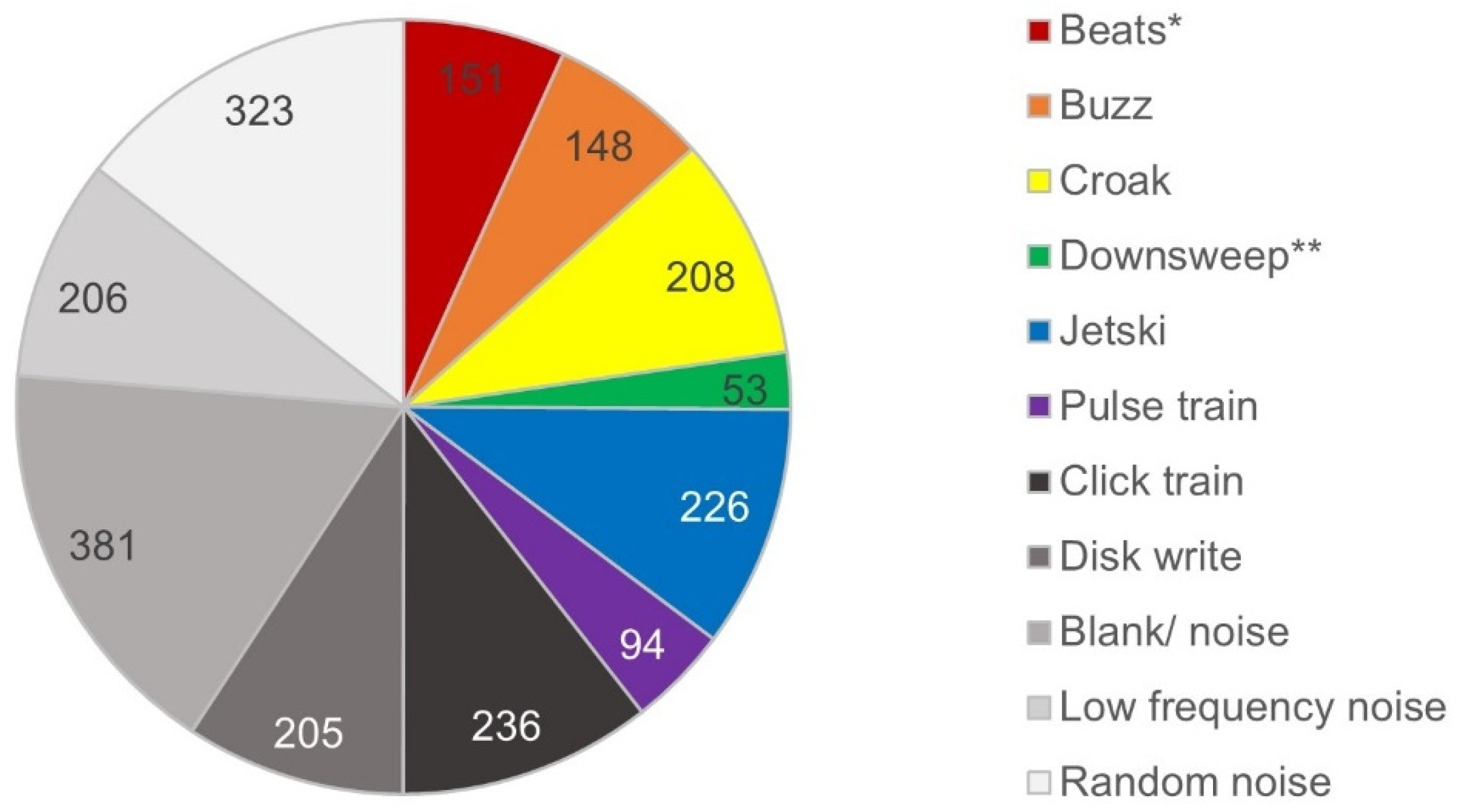
2.2. Train/Test and Evaluation Datasets
2.3. Call Detection: Energy Detector
2.4. Call Classification: ResNet-50 Convolutional Neural Network
3. Results
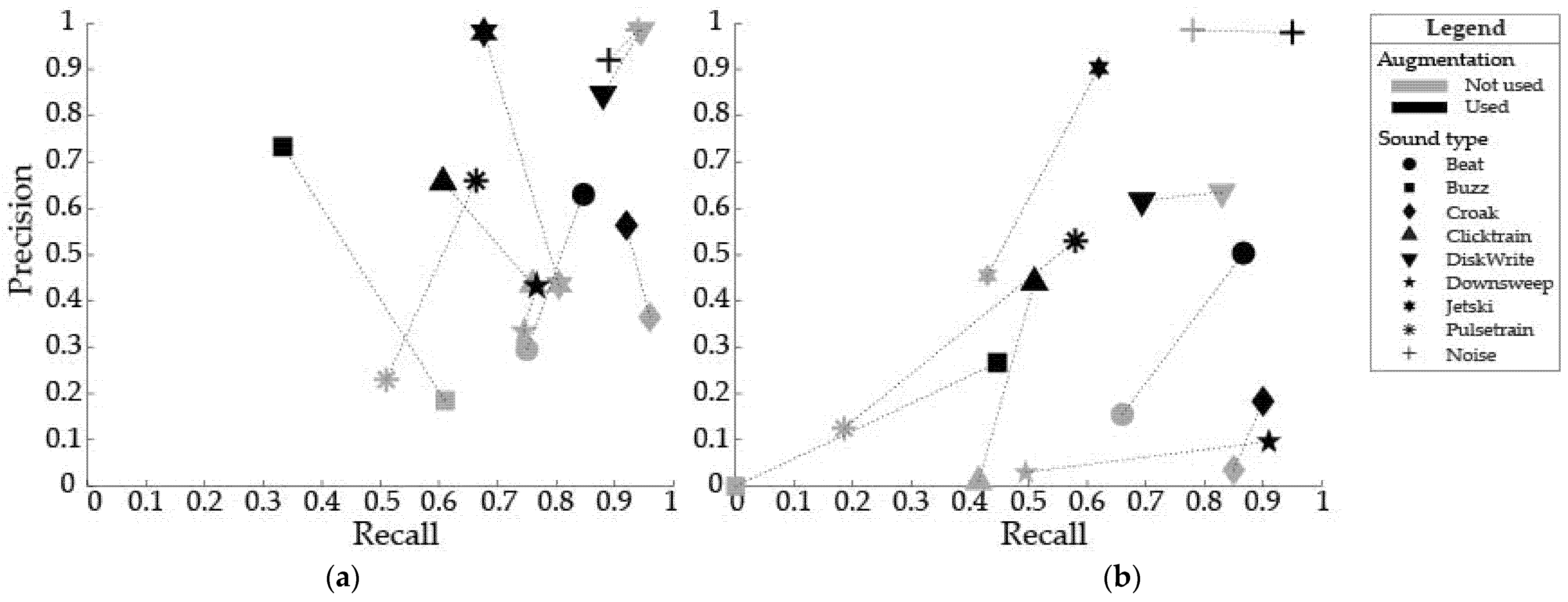
3.1. Energy Detector Performance
3.2. ResNet-50 Classifier Performance
3.3. Analysis Time: Manual vs. Automatic Methods
4. Discussion
4.1. Automatic Energy Detector
4.2. ResNet-50 Classifier
4.3. Considerations for Application of This Approach to Long-Term Datasets
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fine, M.L.; Thorson, R.F. Use of Passive Acoustics for Assessing Behavioral Interactions in Individual Toadfish. Trans. Am. Fish. Soc. 2008, 137, 627–637. [Google Scholar] [CrossRef]
- Blumstein, D.T.; Mennill, D.; Clemins, P.; Girod, L.; Yao, K.; Patricelli, G.; Deppe, J.L.; Krakauer, A.; Clark, C.; Cortopassi, K.A.; et al. Acoustic monitoring in terrestrial environments using microphone arrays: Applications, technological considerations and prospectus. J. Appl. Ecol. 2011, 48, 758–767. [Google Scholar] [CrossRef]
- Wrege, P.H.; Rowland, E.D.; Keen, S.; Shiu, Y. Acoustic monitoring for conservation in tropical forests: Examples from forest elephants. Methods Ecol. Evol. 2017, 8, 1292–1301. [Google Scholar] [CrossRef]
- Linke, S.; Gifford, T.; Desjonquères, C.; Tonolla, D.; Aubin, T.; Barclay, L.; Karaconstantis, C.; Kennard, M.; Rybak, F.; Sueur, J. Freshwater ecoacoustics as a tool for continuous ecosystem monitoring. Front. Ecol. Environ. 2018, 16, 231–238. [Google Scholar] [CrossRef]
- Lammers, M.O.; Brainard, R.E.; Au, W.W.L.; Mooney, T.A.; Wong, K.B. An ecological acoustic recorder (EAR) for long-term monitoring of biological and anthropogenic sounds on coral reefs and other marine habitats. J. Acoust. Soc. Am. 2008, 123, 1720–1728. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dede, A.; Öztürk, A.A.; Akamatsu, T.; Tonay, A.M.; Öztürk, B. Long-term passive acoustic monitoring revealed seasonal and diel patterns of cetacean presence in the Istanbul Strait. J. Mar. Biol. Assoc. United Kingd. 2014, 94, 1195–1202. [Google Scholar] [CrossRef]
- Nelson, D.V.; Garcia, T.S.; Klinck, H. Seasonal and Diel Vocal Behavior of the Northern Red-Legged Frog, Rana aurora. Northwestern Nat. 2017, 98, 33–38. [Google Scholar] [CrossRef]
- Palmer, K.J.; Brookes, K.L.; Davies, I.M.; Edwards, E.; Rendell, L. Habitat use of a coastal delphinid population investigated using passive acoustic monitoring. Aquat. Conserv. Mar. Freshw. Ecosyst. 2019, 29, 254–270. [Google Scholar] [CrossRef] [Green Version]
- Kalan, A.K.; Piel, A.K.; Mundry, R.; Wittig, R.M.; Boesch, C.; Kühl, H.S. Passive acoustic monitoring reveals group ranging and territory use: A case study of wild chimpanzees (Pan troglodytes). Front. Zool. 2016, 13, 34. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Riera, A.; Pilkington, J.; Ford, J.; Stredulinsky, E.; Chapman, N. Passive acoustic monitoring off Vancouver Island reveals extensive use by at-risk Resident killer whale (Orcinus orca) populations. Endanger. Species Res. 2019, 39, 221–234. [Google Scholar] [CrossRef]
- Ricci, S.; Eggleston, D.; Bohnenstiehl, D. Use of passive acoustic monitoring to characterize fish spawning behavior and habitat use within a complex mosaic of estuarine habitats. Bull. Mar. Sci. 2017, 93, 439–453. [Google Scholar] [CrossRef]
- Tricas, T.; Boyle, K. Acoustic behaviors in Hawaiian coral reef fish communities. Mar. Ecol. Prog. Ser. 2014, 511, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Wilson, K.C.; Semmens, B.X.; Pattengill-Semmens, C.V.; McCoy, C. Potential for grouper acoustic competition and parti-tioning at a multispecies spawning site off Little Cayman, Cayman Islands. Mar. Ecol. Prog. Ser. 2020, 634, 127–146. [Google Scholar] [CrossRef] [Green Version]
- Celis-Murillo, A.; Deppe, J.L.; Allen, M.F. Using soundscape recordings to estimate bird species abundance, richness, and composition. J. Field Ornithol. 2009, 80, 64–78. [Google Scholar] [CrossRef]
- Deichmann, J.L.; Hernández-Serna, A.; Delgado C., J.A.; Campos-Cerqueira, M.; Aide, T.M. Soundscape analysis and acoustic monitoring document impacts of natural gas exploration on biodiversity in a tropical forest. Ecol. Indic. 2017, 74, 39–48. [Google Scholar] [CrossRef] [Green Version]
- Frommolt, K.-H. Information obtained from long-term acoustic recordings: Applying bioacoustic techniques for monitoring wetland birds during breeding season. J. Ornithol. 2017, 158, 659–668. [Google Scholar] [CrossRef]
- Širović, A.; Cutter, G.R.; Butler, J.L.; Demer, D.A. Rockfish sounds and their potential use for population monitoring in the Southern California Bight. ICES J. Mar. Sci. 2009, 66, 981–990. [Google Scholar] [CrossRef] [Green Version]
- Piercy, J.; Codling, E.; Hill, A.; Smith, D.; Simpson, S. Habitat quality affects sound production and likely distance of detection on coral reefs. Mar. Ecol. Prog. Ser. 2014, 516, 35–47. [Google Scholar] [CrossRef] [Green Version]
- Butler, J.; Stanley, J.A.; Butler, M.J., IV. Underwater soundscapes in near-shore tropical habitats and the effects of envi-ronmental degradation and habitat restoration. J. Exp. Mar. Biol. Ecol. 2016, 479, 89–96. [Google Scholar] [CrossRef]
- Hildebrand, J.A.; Frasier, K.E.; Baumann-Pickering, S.; Wiggins, S.M.; Merkens, K.P.; Garrison, L.P.; Soldevilla, M.S.; McDonald, M.A. Assessing Seasonality and Density From Passive Acoustic Monitoring of Signals Presumed to be From Pygmy and Dwarf Sperm Whales in the Gulf of Mexico. Front. Mar. Sci. 2019, 6, 66. [Google Scholar] [CrossRef] [Green Version]
- Wiggins, S.M.; Hildebrand, J.A. Long-term monitoring of cetaceans using autonomous acoustic recording packages. In Listening in the Ocean; Springer: Berlin/Heidelberg, Germany, 2016; pp. 35–59. [Google Scholar]
- Pirotta, E.; Brookes, K.L.; Graham, I.M.; Thompson, P.M. Variation in harbour porpoise activity in response to seismic survey noise. Biol. Lett. 2014, 10, 20131090. [Google Scholar] [CrossRef] [Green Version]
- Marcoux, M.; Ferguson, S.H.; Roy, N.; Bedard, J.; Simard, Y. Seasonal marine mammal occurrence detected from passive acoustic monitoring in Scott Inlet, Nunavut, Canada. Polar Biol. 2017, 40, 1127–1138. [Google Scholar] [CrossRef]
- Van Opzeeland, I.; Hillebrand, H. Year-round passive acoustic data reveal spatio-temporal patterns in marine mammal community composition in the Weddell Sea, Antarctica. Mar. Ecol. Prog. Ser. 2020, 638, 191–206. [Google Scholar] [CrossRef] [Green Version]
- Rountree, R.A.; Gilmore, R.G.; Goudey, C.A.; Hawkins, A.D.; Luczkovich, J.J.; Mann, D.A. Listening to fish: Applications of passive acoustics to fisheries science. Fisheries 2006, 31, 433–446. [Google Scholar] [CrossRef]
- Luczkovich, J.J.; Mann, D.A. and Rountree, R.A. Passive acoustics as a tool in fisheries science. Trans. Am. Fish. Soc. 2008, 137, 533–541. [Google Scholar] [CrossRef] [Green Version]
- Slabbekoorn, H.; Bouton, N.; van Opzeeland, I.; Coers, A.; Cate, C.T.; Popper, A.N. A noisy spring: The impact of globally rising underwater sound levels on fish. Trends Ecol. Evol. 2010, 25, 419–427. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fish, M.P.; Mowbray, W.H. Sounds of Western North Atlantic Fishes: A Reference File of Biological Underwater Sounds; Johns Hopkins Press: Baltimore, MD, USA, 1970. [Google Scholar]
- Fine, M.L.; Parmentier, E. Mechanisms of fish sound production. In Sound Communication in Fishes; Ladich, F., Ed.; Springer: Berlin/Heidelberg, Germany, 2015; pp. 77–126. [Google Scholar]
- Amorim, M.C.P. Diversity of sound production in fish. Commun. Fishes 2006, 1, 71–104. [Google Scholar]
- Kasumyan, A.O. Sounds and sound production in fishes. J. Ichthyol. 2008, 48, 981–1030. [Google Scholar] [CrossRef]
- Ladich, F. Agonistic behaviour and significance of sounds in vocalizing fish. Mar. Freshw. Behav. Physiol. 1997, 29, 87–108. [Google Scholar] [CrossRef]
- Mann, D.A.; Lobel, P.S. Passive acoustic detection of sounds produced by the damselfish, Dascyllus albisella (Pomacentridae). Bioacoustics 1995, 6, 199–213. [Google Scholar] [CrossRef]
- Locascio, J.V.; Burton, M.L. A passive acoustic survey of fish sound production at Riley’s Hump within Tortugas South Ecological Reserve; implications regarding spawning and habitat use. Fish. Bull. 2016, 114, 103–116. [Google Scholar] [CrossRef]
- Lowerre-Barbieri, S.K.; Barbieri, L.R.; Flanders, J.R.; Woodward, A.G.; Cotton, C.F.; Knowlton, M.K. Use of Passive Acoustics to Determine Red Drum Spawning in Georgia Waters. Trans. Am. Fish. Soc. 2008, 137, 562–575. [Google Scholar] [CrossRef]
- Pieretti, N.; Martire, M.L.; Farina, A.; Danovaro, R. Marine soundscape as an additional biodiversity monitoring tool: A case study from the Adriatic Sea (Mediterranean Sea). Ecol. Indic. 2017, 83, 13–20. [Google Scholar] [CrossRef]
- Buscaino, G.; Ceraulo, M.; Pieretti, N.; Corrias, V.; Farina, A.; Filiciotto, F.; Maccarrone, V.; Grammauta, R.; Caruso, F.; Giuseppe, A.; et al. Temporal patterns in the soundscape of the shallow waters of a Mediterranean marine protected area. Sci. Rep. 2016, 6, 34230. [Google Scholar] [CrossRef] [Green Version]
- Lindseth, A.V.; Lobel, P.S. Underwater soundscape monitoring and fish bioacoustics: A review. Fishes 2018, 3, 36. [Google Scholar] [CrossRef] [Green Version]
- McCauley, R.D.; Cato, D.H. Patterns of fish calling in a nearshore environment in the Great Barrier Reef. Philos. Trans. R. Soc. Lond. Ser. B Biol. Sci. 2000, 355, 1289–1293. [Google Scholar] [CrossRef] [PubMed]
- Gavrilov, A.N.; McCauley, R.D.; Gedamke, J. Steady inter and intra-annual decrease in the vocalization frequency of Antarctic blue whales. J. Acoust. Soc. Am. 2012, 131, 4476–4480. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Y.-J.; Huang, J.-F.; Gong, N.; Ling, Z.-H.; Hu, Y. Automatic detection and classification of marmoset vocalizations using deep and recurrent neural networks. J. Acoust. Soc. Am. 2018, 144, 478–487. [Google Scholar] [CrossRef]
- Salamon, J.; Bello, J.P.; Farnsworth, A.; Robbins, M.; Keen, S.; Klinck, H.; Kelling, S. Towards the Automatic Classification of Avian Flight Calls for Bioacoustic Monitoring. PLoS ONE 2016, 11, e0166866. [Google Scholar] [CrossRef]
- Mac Aodha, O.; Gibb, R.; Barlow, K.E.; Browning, E.; Firman, M.; Freeman, R.; Harder, B.; Kinsey, L.; Mead, G.R.; Newson, S.E.; et al. Bat detective—Deep learning tools for bat acoustic signal detection. PLoS Comput. Biol. 2018, 14, e1005995. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bittle, M.; Duncan, A. A review of current marine mammal detection and classification algorithms for use in automated passive acoustic monitoring. In Proceedings of the Acoustics, Victor Harbor, Australia, 17–20 November 2013. [Google Scholar]
- Vieira, M.; Pereira, B.P.; Pousão-Ferreira, P.; Fonseca, P.J.; Amorim, M.C.P.; Ferreira, P. Seasonal Variation of Captive Meagre Acoustic Signalling: A Manual and Automatic Recognition Approach. Fishes 2019, 4, 28. [Google Scholar] [CrossRef] [Green Version]
- Ruiz-Blais, S.; Camacho, A.; Rivera-Chavarria, M.R. Sound-based automatic neotropical sciaenid fishes identification: Cynoscion jamaicensis. In Proceedings of the Meetings on Acoustics 167th ASA, Acoustical Society of America, Providence, RI, USA, 5–9 May 2014. [Google Scholar]
- Ricci, S.W.; Bohnenstiehl, D.R.; Eggleston, D.B.; Kellogg, M.L.; Lyon, R.P. Oyster toadfish (Opsanus tau) boatwhistle call detection and patterns within a large-scale oyster restoration site. PLoS ONE 2017, 12, e0182757. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kottege, N.; Kroon, F.; Jurdak, R.; Jones, D. Classification of underwater broadband bio-acoustics using spectro-temporal features. In Proceedings of the Seventh ACM International Conference on Underwater Networks and Systems, Los Angeles, CA, USA, 5–6 November 2012; pp. 1–8. [Google Scholar]
- Chérubin, L.M.; Dalgleish, F.; Ibrahim, A.K.; Schärer-Umpierre, M.; Nemeth, R.S.; Matthews, A.; Appeldoorn, R. Fish Spawning Aggregations Dynamics as Inferred from a Novel, Persistent Presence Robotic Approach. Front. Mar. Sci. 2020, 6, 779. [Google Scholar] [CrossRef]
- Monczak, A.; Ji, Y.; Soueidan, J.; Montie, E.W. Automatic detection, classification, and quantification of sciaenid fish calls in an estuarine soundscape in the Southeast United States. PLoS ONE 2019, 14, e0209914. [Google Scholar] [CrossRef]
- Harakawa, R.; Ogawa, T.; Haseyama, M. and Akamatsu, T. Automatic detection of fish sounds based on multi-stage classi-fication including logistic regression via adaptive feature weighting. J. Acoust. Soc. Am. 2018, 144, 2709–2718. [Google Scholar] [CrossRef]
- Vieira, M.; Fonseca, P.J.; Amorim, M.C.P.; Teixeira, C.J.C. Call recognition and individual identification of fish vocalizations based on automatic speech recognition: An example with the Lusitanian toadfish. J. Acoust. Soc. Am. 2015, 138, 3941–3950. [Google Scholar] [CrossRef]
- Noda, J.J.; Travieso, C.M.; Sánchez-Rodríguez, D. Automatic Taxonomic Classification of Fish Based on Their Acoustic Signals. Appl. Sci. 2016, 6, 443. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-H.; Tsao, Y.; Akamatsu, T. Comparison of passive acoustic soniferous fish monitoring with supervised and unsu-pervised approaches. J. Acoust. Soc. Am. 2018, 143, EL278–EL284. [Google Scholar] [CrossRef]
- Wiggins, S.M.; Hildebrand, J.A. High-frequency Acoustic Recording Package (HARP) for broad-band, long-term marine mammal monitoring. In Proceedings of the 2007 Symposium on Underwater Technology and Workshop on Scientific Use of Submarine Cables and Related Technologies, Tokyo, Japan, 17–20 April 2007; pp. 551–557. [Google Scholar]
- Wiggins, S.M.; Roch, M.A.; Hildebrand, J.A. TRITON software package: Analyzing large passive acoustic monitoring data sets using MATLAB. J. Acoust. Soc. Am. 2010, 128, 2299. [Google Scholar] [CrossRef]
- Wall, C.; Lembke, C.; Mann, D. Shelf-scale mapping of sound production by fishes in the eastern Gulf of Mexico, using autonomous glider technology. Mar. Ecol. Prog. Ser. 2012, 449, 55–64. [Google Scholar] [CrossRef] [Green Version]
- Mellinger, D. Ishmael: 1.0 User’s Guide; Ishmael: Integrated System for Holistic Multi-Channel Acoustic Exploration and Localization; NOAA Technical Memorandum OAR PMEL-120: Newport, OR, USA, 2002; Volume 30, p. 2434.
- Sirović, A. Variability in the performance of the spectrogram correlation detector for North-east Pacific blue whale calls. Bioacoustics 2016, 25, 145–160. [Google Scholar] [CrossRef]
- Caruana, R. Learning many related tasks at the same time with backpropagation. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 28 November–1 December 1994; pp. 657–664. [Google Scholar]
- Bengio, Y. Deep learning of representations for unsupervised and transfer learning. In Proceedings of the ICML Workshop on Unsupervised and Transfer Learning, JMLR 27 Workshop and Conference Proceedings, Bellevue, WA, USA, 2 July 2011; pp. 17–37. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sharma, N.; Jain, V.; Mishra, A. An analysis of convolutional neural networks for image classification. Procedia Comput. Sci. 2018, 132, 377–384. [Google Scholar] [CrossRef]
- Rauf, H.T.; Lali, M.I.U.; Zahoor, S.; Shah, S.Z.H.; Rehman, A.U.; Bukhari, S.A.C. Visual features based automated identi-fication of fish species using deep convolutional neural networks. Comput. Electron. Agric. 2019, 167, 105075. [Google Scholar] [CrossRef]
- Raikar, M.M.; Meena, S.M.; Kuchanur, C.; Girraddi, S.; Benagi, P. Classification and Grading of Okra-ladies finger using Deep Learning. Procedia Comput. Sci. 2020, 171, 2380–2389. [Google Scholar] [CrossRef]
- Bianco, M.J.; Gerstoft, P.; Traer, J.; Ozanich, E.; Roch, M.A.; Gannot, S.; Deledalle, C.-A. Machine learning in acoustics: Theory and applications. J. Acoust. Soc. Am. 2019, 146, 3590–3628. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wall, C.; Simard, P.; Lindemuth, M.; Lembke, C.; Naar, D.; Hu, C.; Barnes, B.B.; Muller-Karger, F.E.; Mann, D. Temporal and spatial mapping of red grouper Epinephelus morio sound production. J. Fish. Biol. 2014, 85, 1470–1488. [Google Scholar] [CrossRef]
- Haver, S.M.; Gedamke, J.; Hatch, L.T.; Dziak, R.P.; Van Parijs, S.; McKenna, M.F.; Barlow, J.; Berchok, C.; DiDonato, E.; Hanson, B.; et al. Monitoring long-term soundscape trends in U.S. Waters: The NOAA/NPS Ocean Noise Reference Station Network. Mar. Policy 2018, 90, 6–13. [Google Scholar] [CrossRef]
- Wiggins, S.M.; Hall, J.M.; Thayre, B.J.; Hildebrand, J.A. Gulf of Mexico low-frequency ocean soundscape impacted by airguns. J. Acoust. Soc. Am. 2016, 140, 176–183. [Google Scholar] [CrossRef] [Green Version]
- Estabrook, B.; Ponirakis, D.; Clark, C.; Rice, A. Widespread spatial and temporal extent of anthropogenic noise across the northeastern Gulf of Mexico shelf ecosystem. Endanger. Species Res. 2016, 30, 267–282. [Google Scholar] [CrossRef] [Green Version]
- Baumgartner, M.F.; Mussoline, S.E. A generalized baleen whale call detection and classification system. J. Acoust. Soc. Am. 2011, 129, 2889–2902. [Google Scholar] [CrossRef] [Green Version]
- Malfante, M.; Mars, J.I.; Mura, M.D.; Gervaise, C. Automatic fish sounds classification. J. Acoust. Soc. Am. 2018, 143, 2834–2846. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural. Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Zhang, L.; Wang, D.; Bao, C.; Wang, Y.; Xu, K. Large-Scale Whale-Call Classification by Transfer Learning on Multi-Scale Waveforms and Time-Frequency Features. Appl. Sci. 2019, 9, 1020. [Google Scholar] [CrossRef] [Green Version]
- Kavzoglu, T. Increasing the accuracy of neural network classification using refined training data. Environ. Model. Softw. 2009, 24, 850–858. [Google Scholar] [CrossRef]
- Nanni, L.; Maguolo, G.; Paci, M. Data augmentation approaches for improving animal audio classification. Ecol. Inform. 2020, 57, 101084. [Google Scholar] [CrossRef] [Green Version]
- Vickers, W.; Milner, B.; Lee, R. Improving the robustness of right whale detection in noisy conditions using denoising autoencoders and augmented training. In Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 91–95. [Google Scholar] [CrossRef]
- Padovese, B.; Frazao, F.; Kirsebom, O.S.; Matwin, S. Data augmentation for the classification of North Atlantic right whales upcalls. J. Acoust. Soc. Am. 2021, 149, 2520–2530. [Google Scholar] [CrossRef]
- Rasmussen, J.H.; Širović, A. Automatic detection and classification of baleen whale social calls using convolutional neural networks. J. Acoust. Soc. Am. 2021, 149, 3635–3644. [Google Scholar] [CrossRef]
- Ibrahim, A.K.; Zhuang, H.; Chérubin, L.M.; Schärer-Umpierre, M.T.; Erdol, N. Automatic classification of grouper species by their sounds using deep neural networks. J. Acoust. Soc. Am. 2018, 144, EL196–EL202. [Google Scholar] [CrossRef] [Green Version]
- Strukova, O.V.; Myasnikov, E.V. The choice of methods for the construction of PCA-based features and the selection of SVM parameters for person identification by gait. J. Phys. Conf. Ser. 2019, 1368, 032001. [Google Scholar] [CrossRef]
- Wyse, L. Audio spectrogram representations for processing with convolutional neural networks. In Proceedings of the First International Workshop on Deep Learning and Music, joint with IJCNN, Anchorage, AK, USA, 17–18 May 2017; pp. 37–41. [Google Scholar]
- Zhang, Q.; Zhang, M.; Chen, T.; Sun, Z.; Ma, Y.; Yu, B. Recent advances in convolutional neural network acceleration. Neurocomputing 2019, 323, 37–51. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Call Type | Average Minimum Frequency (Hz) | Average Maximum Frequency (Hz) | Average Duration (s) | Maximum Duration (s) | Minimum Duration (s) |
|---|---|---|---|---|---|
| Beats | 121 | 274 | 1.8 | 2.5 | 1.1 |
| Buzz | 35 | 343 | 6.2 | 18.0 | 2.2 |
| Croak | NA | NA | 10.5 | 92.8 | 2.6 |
| Downsweep | 310 | 850 | 1.9 | 4.8 | 1.0 |
| Jetski | 214 | 802 | 5.1 | 11.7 | 2.8 |
| Pulse train | 461 | 563 | 23.5 | 101.4 | 4.9 |
| Dataset | Trial # | Overall Classifier Accuracy (%) | Average Overall Accuracy (%) |
|---|---|---|---|
| August 2010 Train/test | 1 | 87.42 | 87.97 |
| 2 | 88.20 | ||
| 3 | 88.29 | ||
| Evaluation | 1 | 93.87 | 93.02 |
| 2 | 93.82 | ||
| 3 | 91.35 |
| Dataset | Beats | Buzz | Croak | Downsweep | Jetski | Pulse Train | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Recall (%) | Precision (%) | Recall (%) | Precision (%) | Recall (%) | Precision (%) | Recall (%) | Precision (%) | Recall (%) | Precision (%) | Recall (%) | Precision (%) | |
| August 2010 Train/test | 84.67 | 63.00 | 33.33 | 73.33 | 92.00 | 56.33 | 76.67 | 43.33 | 67.67 | 98.00 | 66.33 | 66.00 |
| Evaluation | 86.67 | 50.33 | 44.67 | 26.67 | 90.00 | 18.33 | 91.00 | 9.67 | 62.00 | 90.33 | 58.00 | 53.00 |
| Combined (Average) | 85.67 | 56.67 | 39.00 | 50.00 | 91.00 | 37.33 | 83.83 | 26.50 | 64.83 | 94.17 | 62.17 | 59.50 |
| Dataset | Trial # | Total Detection Images | Detection Images Labeled as a Call | # Correctly Classified Images | # Correctly Re-Classified Images |
|---|---|---|---|---|---|
| Aug 2010 Train/test | 1 | 91,387 | 3647 | 1902 (52.2%) | 2617 (71.8%) |
| 2 | 91,387 | 2429 | 1751 (72.1%) | 1759 (72.4%) | |
| 3 | 91,387 | 2811 | 1814 (64.5%) | 2042 (72.6%) | |
| Evaluation | 1 | 128,938 | 3413 | 1538 (45.1%) | 1546 (45.3%) |
| 2 | 128,938 | 4987 | 1605 (32.2%) | 3318 (66.5%) | |
| 3 | 128,938 | 7347 | 1717 (23.4%) | 5352 (45.2%) |
| Dataset | Number of Recording Days | Total Detection Images | Time to Run Detector (hr:min) | Average Time to Run Classifier (hr:min) | Manual Analysis Time (hr:min) |
|---|---|---|---|---|---|
| Aug 2010 Train/Test | 31 | 91,387 | 4:10 | 4:07 | 21:35 |
| Evaluation | 35 | 128,938 | 3:50 | 6:09 | 26:20 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Waddell, E.E.; Rasmussen, J.H.; Širović, A. Applying Artificial Intelligence Methods to Detect and Classify Fish Calls from the Northern Gulf of Mexico. J. Mar. Sci. Eng. 2021, 9, 1128. https://doi.org/10.3390/jmse9101128
Waddell EE, Rasmussen JH, Širović A. Applying Artificial Intelligence Methods to Detect and Classify Fish Calls from the Northern Gulf of Mexico. Journal of Marine Science and Engineering. 2021; 9(10):1128. https://doi.org/10.3390/jmse9101128
Chicago/Turabian StyleWaddell, Emily E., Jeppe H. Rasmussen, and Ana Širović. 2021. "Applying Artificial Intelligence Methods to Detect and Classify Fish Calls from the Northern Gulf of Mexico" Journal of Marine Science and Engineering 9, no. 10: 1128. https://doi.org/10.3390/jmse9101128