
Research on Underwater Image Restoration Technology Based on Multi-Domain Translation

Abstract
:1. Introduction
2. Proposed Method
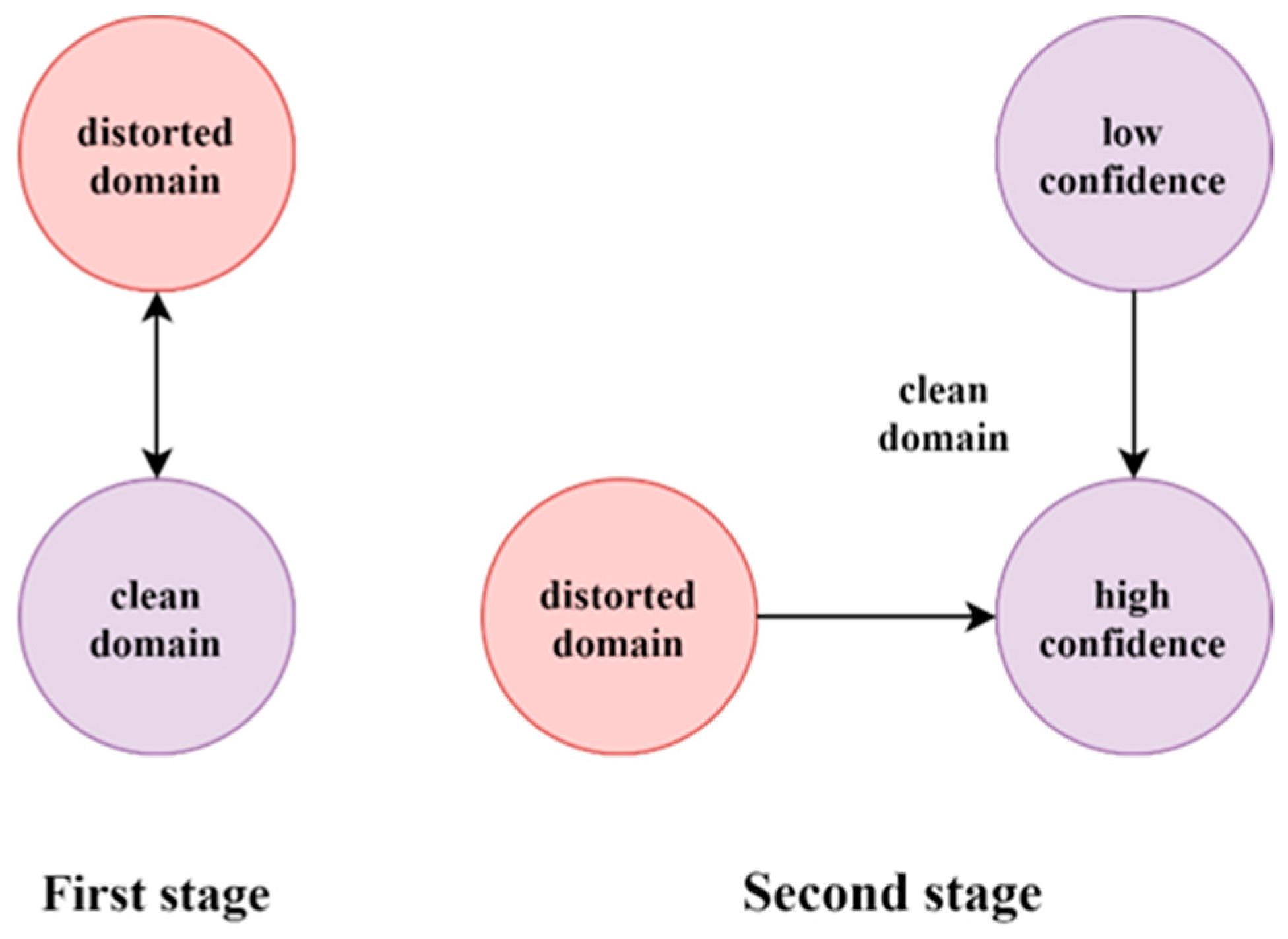
2.1. Confidence Estimation Improvement Method
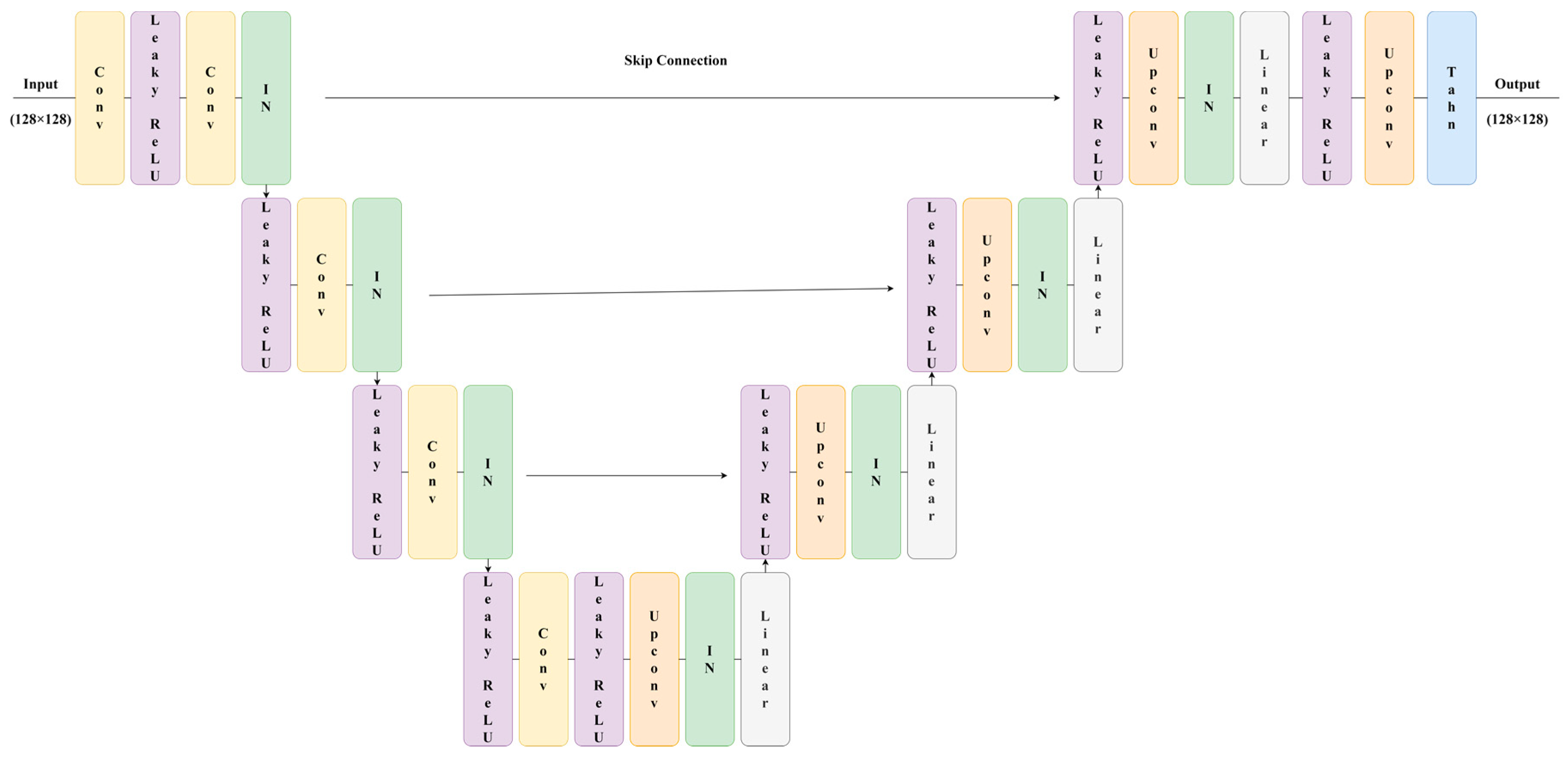
2.2. Underwater Image Restoration Network
2.2.1. Generator Network
2.2.2. Discriminator Network
2.2.3. Loss
3. Experimental Results
3.1. Confidence Improvement Experiment
3.1.1. Training Details
3.1.2. Evaluation Metrics
3.2. Underwater Image Restoration Experiment
3.2.1. Training Details
3.2.2. Evaluation Metrics
3.3. Division Experiment of Underwater Image Restoration
3.3.1. Quantitative Evaluation
3.3.2. Qualitative Evaluation
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- McGlamery, B.L. A computer model for underwater camera systems. Int. Soc. Opt. Photonics 1980, 208, 221–231. [Google Scholar]
- Jaffe, J.S. Computer modeling and the design of optimal underwater imaging systems. IEEE J. Ocean. Eng. 1990, 15, 101–111. [Google Scholar] [CrossRef]
- Zhou, J.; Wei, X.; Shi, J.; Chu, W.; Lin, Y. Underwater image enhancement via two-level wavelet decomposition maximum brightness color restoration and edge refinement histogram stretching. Opt. Express 2022, 30, 17290–17306. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [CrossRef] [PubMed]
- Liang, Z.; Ding, X.; Wang, Y.; Yan, X.; Fu, X. GUDCP: Generalization of Underwater Dark Channel Prior for Underwater Image Restoration. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4879–4884. [Google Scholar] [CrossRef]
- Zhou, Y.; Wu, Q.; Yan, K.; Feng, L.; Xiang, W. Underwater image restoration using color-line model. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 907–911. [Google Scholar] [CrossRef]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast underwater image enhancement for improved visual perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Tong, L.; Zhou, F.; Jiang, Z.; Li, Z.; Lv, J.; Dong, J.; Zhou, H. A Benchmark dataset for both underwater image enhancement and underwater object detection. arXiv 2020, arXiv:2006.15789. [Google Scholar] [CrossRef]
- Hou, G.; Zhao, X.; Pan, Z.; Yang, H.; Tan, L.; Li, J. Benchmarking underwater image enhancement and restoration, and beyond. IEEE Access 2020, 8, 122078–122091. [Google Scholar] [CrossRef]
- WaterGAN: Unsupervised generative network to enable real-time color correction of monocular underwater images. IEEE Robot. Autom. Lett. 2017, 3, 387–394. [CrossRef] [Green Version]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar] [CrossRef]
- Fabbri, C.; Islam, M.J.; Sattar, J. Enhancing underwater imagery using generative adversarial networks. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 7159–7165. [Google Scholar] [CrossRef] [Green Version]
- Islam, M.J.; Luo, P.; Sattar, J. Simultaneous enhancement and super-resolution of underwater imagery for improved visual perception. arXiv 2020, arXiv:2002.01155. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 2019, 29, 4376–4389. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hong, L.; Wang, X.; Xiao, Z.; Zhang, G.; Liu, J. WSUIE: Weakly supervised underwater image enhancement for improved visual perception. IEEE Robot. Autom. Lett. 2021, 6, 8237–8244. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar] [CrossRef] [Green Version]
- Moon, J.; Kim, J.; Shin, Y.; Hwang, S. Confidence-aware learning for deep neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 7034–7044. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar] [CrossRef]
- Li, C.; Guo, J.; Guo, C. Emerging from water: Underwater image color correction based on weakly supervised color transfer. IEEE Signal Process. Lett. 2018, 25, 323–327. [Google Scholar] [CrossRef] [Green Version]
- Liu, P.; Wang, G.; Qi, H.; Zhang, C.; Zheng, H.; Yu, Z. Underwater image enhancement with a deep residual framework. IEEE Access 2019, 7, 94614–94629. [Google Scholar] [CrossRef]
- Park, J.; Han, D.K.; Ko, H. Adaptive weighted multi-discriminator CycleGAN for underwater image enhancement. J. Mar. Sci. Eng. 2019, 7, 200. [Google Scholar] [CrossRef] [Green Version]
- Maniyath, S.R.; Vijayakumar, K.; Singh, L.; Sharma, S.K.; Olabiyisi, T. Learning-based approach to underwater image dehazing using CycleGAN. Arab. J. Geosci. 2021, 14, 1908. [Google Scholar] [CrossRef]
- Wang, P.; Chen, H.; Xu, W.; Jin, S. Underwater image restoration based on the perceptually optimized generative adversarial network. J. Electron. Imaging 2020, 29, 033020. [Google Scholar] [CrossRef]
- Zhai, L.; Wang, Y.; Cui, S.; Zhou, Y. Enhancing Underwater Image Using Degradation Adaptive Adversarial Network. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 4093–4097. [Google Scholar] [CrossRef]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8789–8797. [Google Scholar] [CrossRef]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Conference on Medical image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance normalization: The missing ingredient for fast stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar] [CrossRef]
- Odena, A.; Olah, C.; Shlens, J. Conditional image synthesis with auxiliary classifier gans. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 2642–2651. [Google Scholar] [CrossRef]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral normalization for generative adversarial networks. arXiv 2018, arXiv:1802.05957. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Geifman, Y.; Uziel, G.; El-Yaniv, R. Bias-reduced uncertainty estimation for deep neural classifiers. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar] [CrossRef]
- Naeini, M.P.; Cooper, G.; Hauskrecht, M. Obtaining well calibrated probabilities using bayesian binning. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar] [CrossRef]
- Lakshminarayanan, B.; Pritzel, A.; Blundell, C. Simple and scalable predictive uncertainty estimation using deep ensembles. Adv. Neural Inf. Process. Syst. 2017, 30, 6402–6413. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report TR-2009; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading Digits in Natural Images with Unsupervised Feature Learning. In Proceedings of the NIPS Workshop on Deep Learning and Unsupervised Feature Learning, Granada, Spain, 12–17 December 2011; Available online: https://storage.googleapis.com/pub-tools-public-publication-data/pdf/37648.pdf (accessed on 5 January 2023).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Panetta, K.; Gao, C.; Agaian, S. Human-visual-system-inspired underwater image quality measures. IEEE J. Ocean. Eng. 2015, 41, 541–551. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Accuracy (↑) | AURC (↓) | EAURC (↓) | AUPR (↑) | FPR (↓) | ECE (↓) | NLL (↓) | Brier (↓) |
|---|---|---|---|---|---|---|---|---|
| Baseline [17] | 93.82 | 9.17 | 7.22 | 44.11 | 41.1 | 4.77 | 3.43 | 10.67 |
| Moon [17] | 94.06 | 6.1 | 4.3 | 46.37 | 39.06 | 1.2 | 1.84 | 8.83 |
| Proposed | 94.06 | 5.84 | 4.03 | 47.43 | 38.72 | 0.96 | 1.8 | 8.77 |
| Method | Accuracy (↑) | AURC (↓) | EAURC (↓) | AUPR (↑) | FPR (↓) | ECE (↓) | NLL (↓) | Brier (↓) |
|---|---|---|---|---|---|---|---|---|
| Baseline [17] | 98.58 | 1.67 | 1.67 | 26.7 | 33.33 | 1.24 | 0.96 | 2.53 |
| Moon [17] | 97.95 | 1.4 | 1.19 | 36.59 | 23.08 | 1.48 | 0.76 | 3.32 |
| Proposed | 98.58 | 0.91 | 0.81 | 21.1 | 22.22 | 1.09 | 0.56 | 2.66 |
| Model Dataset | Method | Accuracy (↑) | AURC (↓) | EAURC (↓) | AUPR (↑) | FPR (↓) | ECE (↓) | NLL (↓) | Brier (↓) |
|---|---|---|---|---|---|---|---|---|---|
| DenseNet-121 CIFAR-10 | Baseline [17] | 88.76 ± 0.44 | 20.21 ± 2.12 | 13.61 ± 0.46 | 49.08 ± 2.41 | 56.58 ± 2.39 | 7.86 ± 0.19 | 5.71 ± 0.09 | 18.81 ± 1.04 |
| Moon [17] | 89.17 ± 0.19 | 18.62 ± 2.4 | 12.52 ± 1.24 | 49.13 ± 2.38 | 54.57 ± 5.10 | 3.21 ± 0.09 | 3.59 ± 0.03 | 16.15 ± 0.48 | |
| Proposed | 89.22 ± 0.1 | 18.25 ± 0.85 | 12.22 ± 0.34 | 49.96 ± 0.82 | 53.39 ± 2.48 | 2.99 ± 0.04 | 3.54 ± 0.01 | 15.99 ± 0.21 | |
| DenseNet-121 CIFAR-100 | Baseline [17] | 60.49 ± 0.79 | 158.38 ± 54.42 | 67.33 ± 8.87 | 74.51 ± 0.37 | 67.46 ± 0.35 | 18.59 ± 0.13 | 18.67 ± 0.23 | 57.23 ± 1.22 |
| Moon [17] | 62.63 ± 0.34 | 141.51 ± 15.41 | 60.87 ± 1.62 | 74.29 ± 0.56 | 65.78 ± 3.25 | 14.36 ± 0.02 | 15.95 ± 0.08 | 52.39 ± 0.6 | |
| Proposed | 62.6 ± 0.52 | 140.53 ± 18.34 | 59.75 ± 2.29 | 74.43 ± 0.32 | 66.21 ± 0.77 | 14.54 ± 0.33 | 15.85 ± 0.1 | 52.32 ± 0.82 | |
| DenseNet-121 SVHN | Baseline [17] | 95.45 ± 0.03 | 8.85 ± 2.5 | 7.8 ± 2.5 | 40.47 ± 5.13 | 37.54 ± 6.7 | 3 ± 0.02 | 2.45 ± 0.01 | 7.7 ± 0.08 |
| Moon [17] | 95.83 ± 0.01 | 5.53 ± 0.04 | 4.65 ± 0.05 | 45.07 ± 4.14 | 31.91 ± 4.64 | 0.65 ± 0.003 | 1.64 ± 0.001 | 6.43 ± 0.02 | |
| Proposed | 95.99 ± 0.03 | 5.29 ± 0.02 | 4.47 ± 0.02 | 43.87 ± 3.76 | 31.29 ± 3.64 | 0.63 ± 0.001 | 1.59 ± 0.003 | 6.20 ± 0.04 |
| Model | Random Seed | Accuracy | AURC | EAURC | AUPR | FPR | ECE | NLL | Brier |
|---|---|---|---|---|---|---|---|---|---|
| Moon [17] | 100 | 94.49 | 7.42 | 5.87 | 33.71 | 48.57 | 2.61 | 1.69 | 8.66 |
| 101 | 94.33 | 7.85 | 6.21 | 32.63 | 61.11 | 3.03 | 1.84 | 9.13 | |
| 102 | 94.96 | 8.16 | 6.87 | 37.9 | 40.62 | 2.47 | 1.76 | 7.64 | |
| 103 | 94.02 | 7.79 | 5.97 | 39.09 | 50 | 3.28 | 1.84 | 9.21 | |
| 104 | 91.34 | 15.2 | 11.34 | 51.14 | 50.91 | 4.76 | 2.8 | 12.44 | |
| Average Value | 93.83 | 9.28 | 7.25 | 38.89 | 50.24 | 3.23 | 1.99 | 9.42 | |
| 93.76 | 8.37 | 6.26 | 39.82 | 46.58 | 3.38 | 1.79 | 9.24 | ||
| Proposed | 100 | 96.06 | 4.5 | 3.72 | 27.57 | 48 | 2.32 | 1.2 | 6.67 |
| 101 | 94.49 | 10.32 | 8.77 | 38.42 | 51.43 | 2.8 | 1.88 | 8.73 | |
| 102 | 92.28 | 7.92 | 4.87 | 57 | 30.61 | 4.56 | 1.9 | 10.01 | |
| 103 | 94.17 | 7.6 | 5.87 | 33.6 | 43.24 | 2.84 | 1.7 | 8.68 | |
| 104 | 91.81 | 11.5 | 8.05 | 42.52 | 59.62 | 4.37 | 2.27 | 12.11 | |
| Input UIQM 2.57 ± 0.55 | Not Inversion | 3.22 ± 0.33 | |||
| Label Inversed | 50th | 60th | 70th | 80th | |
| 3.24 ± 0.34 | 3.24 ± 0.32 | 3.24 ± 0.31 | 3.26 ± 0.4 | ||
| Original Image | Not Reverse | DCP | 80th |
|---|---|---|---|
 |  |  |  |
 |  |  |  |
 |  |  |  |
 |  |  |  |
 |  |  |  |
| Original image |  |  |  |
| Restored image |  |  |  |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xue, T.; Zhang, T.; Zhang, J. Research on Underwater Image Restoration Technology Based on Multi-Domain Translation. J. Mar. Sci. Eng. 2023, 11, 674. https://doi.org/10.3390/jmse11030674
Xue T, Zhang T, Zhang J. Research on Underwater Image Restoration Technology Based on Multi-Domain Translation. Journal of Marine Science and Engineering. 2023; 11(3):674. https://doi.org/10.3390/jmse11030674
Chicago/Turabian StyleXue, Teng, Tianchi Zhang, and Jing Zhang. 2023. "Research on Underwater Image Restoration Technology Based on Multi-Domain Translation" Journal of Marine Science and Engineering 11, no. 3: 674. https://doi.org/10.3390/jmse11030674