1. Introduction
Nowadays, people turn their eyes to the ocean because of the shortage of land resources. This has greatly promoted the study and exploration of the ocean, and the development of underwater resources. In order to perform relevant underwater tasks, some devices with visual sensors, such as underwater robots, have become the preferred tools and play an important role in underwater exploration. However, due to the diversity and complexity of the underwater environment, the directly captured visual information is usually mixed with a lot of noise, which makes it difficult to carry out object detection, sample capture, and other visual tasks. It has greatly hindered the process of ocean exploitation. Therefore, underwater image enhancement technology becomes particularly important.
Due to the degradation of underwater light and the different absorption rates of various colors of light by water, the underwater image always appears blue or green. At the same time, the underwater image is noisy to a certain extent because of the scattering effect of suspended particles on the light. Additionally, it gets more complicated as the depth, light, and suspended objects change in the water. Directly captured underwater images are always blurry and appear blue or green, such as in
Figure 1. In order to obtain high-quality images in water, underwater image enhancement technology comes into being and plays an important role. With this technique, we can obtain clear and high-quality underwater images, as shown in
Figure 1.
Many underwater image enhancement methods have been proposed in the past few years. They can be roughly divided into two categories according to whether they are based on deep learning technology. The first kind is the physical model-based method, which is mainly based on the physical model of underwater imaging, they achieve enhancement by eliminating the scattering effect of light and color correction in the imaging process, such as white balance adjustment [
1], histogram equalization [
2], and fusion technology [
3]. However, these physical model-based algorithms usually use simplified underwater imaging models, which are inaccurate since they assume many parameters and cannot reflect the complexity of real underwater environments. With the changes in the water area, water depth, illumination, magazines, and other factors, the underwater imaging process becomes more complex, and it is difficult for such algorithms to achieve good generalization results. On the other hand, this kind of method generally needs a long time to obtain the enhanced image and cannot achieve the real-time visual enhancement task.
The second is deep learning-based methods. In recent years, with the improvement of hardware performance, artificial intelligence has ushered in a new wave. Deep learning [
4] as its sub-branch also has produced a technological explosion, especially in computer vision and image processing tasks [
5,
6]. Those deep learning-based methods mainly use a large number of paired or unpaired underwater image datasets for training, such as the references [
7,
8,
9,
10,
11]. However, most of these methods are trained on synthetic underwater image datasets, and the generalization of those methods in the real underwater environment is not very good. Additionally, some of these methods need to pre-process the dataset, so it is impossible to train end-to-end and achieve real-time image enhancement.
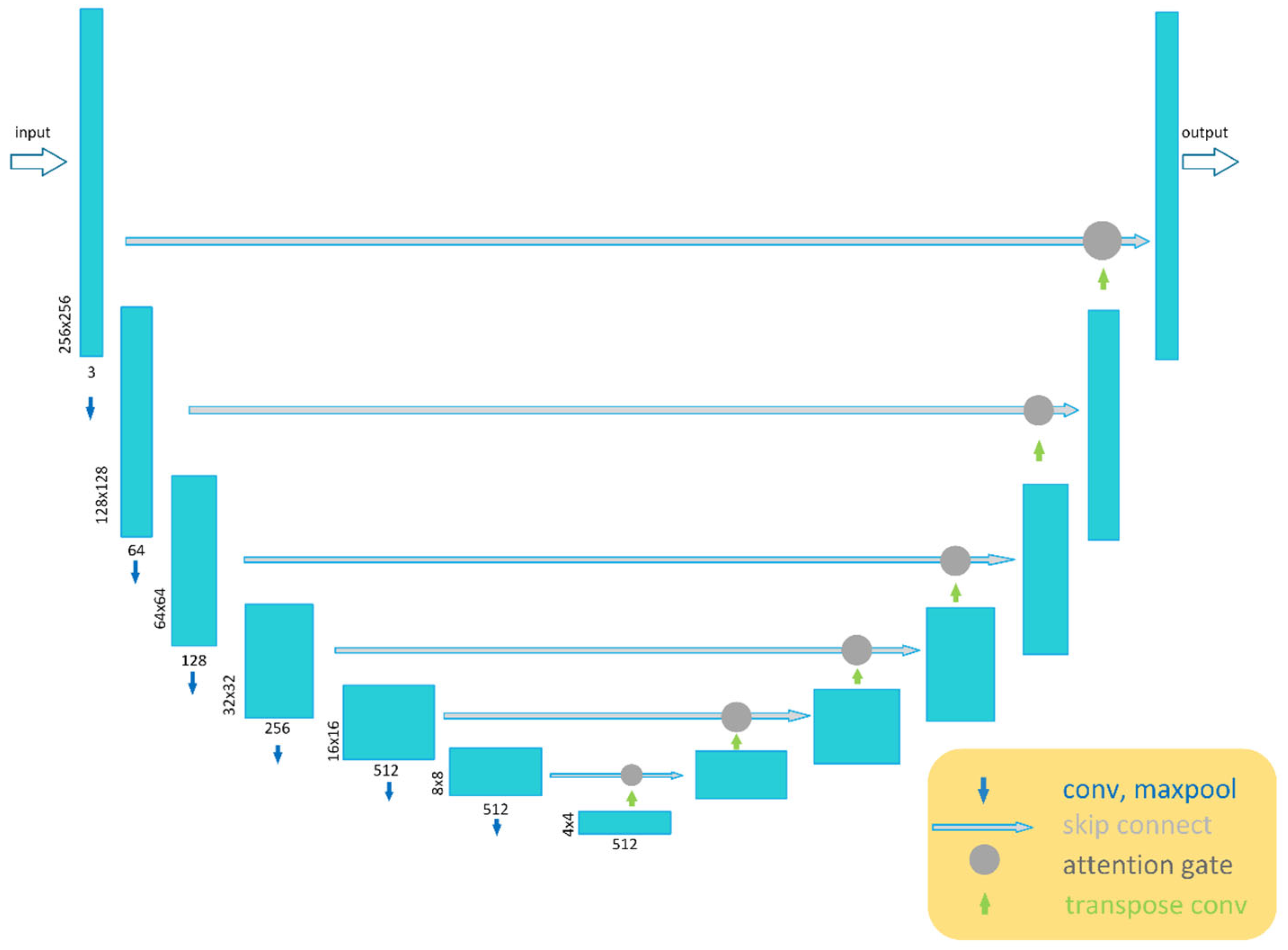
To tackle these issues, a novel generative adversarial network (GAN) based on the attention-gate (AG) mechanism [
12] is proposed in this paper. Our proposed model can be trained end-to-end using public real-world underwater image datasets. The AG mechanism screens the important feature information from the original feature map and eliminates the irrelevant noise, allowing only the filtered feature information to be merged through the skip connection. Moreover, the AG mechanism filters the activation operation of neurons during both forward and backward propagation, thereby enabling the efficient update of model parameters at a shallow level. To improve generalization performance, we combine three different loss functions to obtain a new objective function, which is used to train our model with a real-world underwater image dataset. Our proposed model, which incorporates the AG mechanism and the new objective function, achieves impressive performance in real-world underwater environments. The contributions of this paper can be summarized as follows:
We propose a generative adversarial network (GAN) for enhancing underwater images based on the attention-gate (AG) mechanism. The AG is integrated into the standard U-Net architecture to screen important feature information;
We formulate a new objective function and train our model end-to-end on a real-world underwater image dataset. Experiments demonstrate that our model outperforms several state-of-the-art methods in both qualitative and quantitative evaluations.
4. Experimental Results and Analysis
In this section, we will introduce the details of the experiments, including data sets, experimental environment, experimental methods and experimental results. Additionally, we analyze and explain the experimental results.
4.1. Datasets
We use the Underwater Image Enhancement Benchmark (UIEB) dataset proposed by Li et al. [
7] to train and test our model. The UIEB dataset includes 950 real-world underwater images, 890 of which have corresponding reference images. The original images of the dataset were captured from different real-world underwater environments. For the reference images, 12 different enhancement methods were used to generate candidate images, and then multiple volunteers voted for each pair of enhanced images, and the image with the highest number of votes was used as the corresponding reference image. We divided the 890 images into 3 parts: 710 images as the training set, 90 images as validation sets, and 90 images as test sets.
4.2. Experimental Environment
In order to evaluate our model objectively and effectively, we conducted qualitative and quantitative comparison experiments with several of the most advanced methods. They include Fusion based [
3], Statistical based [
23], UGAN [
8] and FUnIE [
9]. We use the source codes provided by the authors, or according to the description of the original papers, or refer to open-source resources to build the models. All the methods used in the experiment adopted the same testing and training process and were carried out in the following environment, AMD Ryzen 7 5800H CPU, NVIDIA GeForce RTX 3060 Laptop 6GB GPU, and 16GB DDR4 RAM.
4.3. Evaluations
In this part, we conducted both qualitative and quantitative experiments. The qualitative experiment served as a supplement to express subjective evaluation results. Additionally, the quantitative experiment served as the main indicator to show the objective evaluation results.
4.3.1. Subjective Evaluation
We selected images of different underwater environments from 90 test images and tested them using the above methods. The used real-world underwater images have diverse tones, light, and contrast. The comparison results with competitive methods are shown in
Figure 3. A first glance at the results may give the impression that the comparison of Fusion [
3] is stronger and better. However, after careful observation, it will be found that Fusion only has an obvious comparison with the pictures with relatively regular noise distribution, such as
Figure 3d. However, in another picture in
Figure 3, you can see that the effect is minimal. The reason why is that the physical model approach used in Fusion is not always valid. Similarly, the images enhanced by Statistics [
23] are not natural, and the color is too bright. The disadvantage of UGAN [
8] and FUnIE [
9] is that they do not have good fitting and generalization ability for the real-world underwater image dataset, which makes their test results obviously inadequate. In contrast, our results show good generalization ability on all the test set, and the comparison with the other images shows that our results are more realistic in color and more accurate in detail reduction.
In addition, we performed a comparative experiment using the DEA-Net algorithm for image dehazing, which was accepted at CVPR2023 [
24]. The pre-training weights provided by the authors were used to test the algorithm, and the results of the experiment on the UIEB dataset are presented in
Figure 4. While some images showed a denoising effect, the overall performance of the algorithm was not as good as our method, and we use two underwater image quality evaluation metrics, UCIQE and UIQM, to evaluate the DEA-Net test results, as detailed in
Section 4.3.2.
4.3.2. Objective Evaluation
Objective evaluation is mainly divided into two categories: one is full reference, which requires a comparison between the original image and the corresponding reference image; the other is non-reference, which only needs an enhanced image to be evaluated. All test data in the following table are averaged on the test set. We mark the best performer in red, the second best in blue, and the reference result in black.
We chose Peak Signal to Noise Ratio (PSNR) and Structural Similarity (SSIM) as full-reference image quality evaluation indicators. PSNR is an image quality evaluation index based on the error between corresponding pixels calculated by MSE. The larger the value is, the smaller the image distortion. For images I and K, it can be formulated as follows:
SSIM is another image quality evaluation index, which measures image similarity from brightness, contrast, and structure. When SSIM calculates the difference between two images at each position, it does not take a pixel from each of the two images at that position but takes a pixel from each region. The higher the SSIM value is, the closer the reference image is to the original image in structure, and SSIM ≤ 1. It is defined as below:
Table 1 shows the evaluation results of different methods. All the results are computed in the YCrCb color space, using methods provided by Python’s third-party library scikit-image, as can be seen from the table. In PSNR, our method achieved the best result, even beyond the reference. Additionally, in SSIM, our method achieved the second best but was very close to the best one. Across the board, our method achieved the best results.
We chose underwater color image quality evaluation (UCIQE) [
25] and underwater image quality measure (UIQM) [
26,
27] as non-reference image quality evaluation indicators. UCIQE evaluates underwater image quality by color density, saturation, and contrast. The result is shown in
Table 2.
UIQM is a comprehensive underwater image evaluation index, which is the weighted sum of the underwater image colorfulness measure (UICM), underwater image sharpness measure (UISM), and underwater image contrast measure (UIConM). Its formula is as follows:
According to the original paper, we set the parameters as follows: c1 = 0.0282, c2 = 0.2953, and c3 = 3.5753. Results are shown in
Table 3. We found that our method achieved the best results on UCIQE and UICM and the second best on UISM and UIQM. Of all the results, three exceeded the reference. So, our method also achieved the best results overall.
4.3.3. Ablation Experiments
In the above, we proposed a novel method: training the model by weighting and summing multiple loss functions. In order to verify the effectiveness of the method, we will use different loss functions to compare the ablation experiments below. In the case of keeping other parameters and modules unchanged, only a single loss function is used to train the model. We will analyze the training results using both subjective evaluation (as shown in
Figure 5 and
Figure 6) and objective evaluation (as shown in
Table 4,
Table 5 and
Table 6).
From the above experimental results, it is not difficult to see that the combination of multiple loss functions proposed by us is better than a single loss function, whether it is subjective evaluation or objective evaluation. In terms of objective evaluation, the result of a single loss function still has some noise, but the image generated by our development is more accurate and complete. In terms of objective evaluation, it can be seen intuitively that among all seven indicators, we achieved the five best results.
4.3.4. Generalizability Verification
In this section, we will validate the generalization capability of our method on the EUVP [
9] dataset.
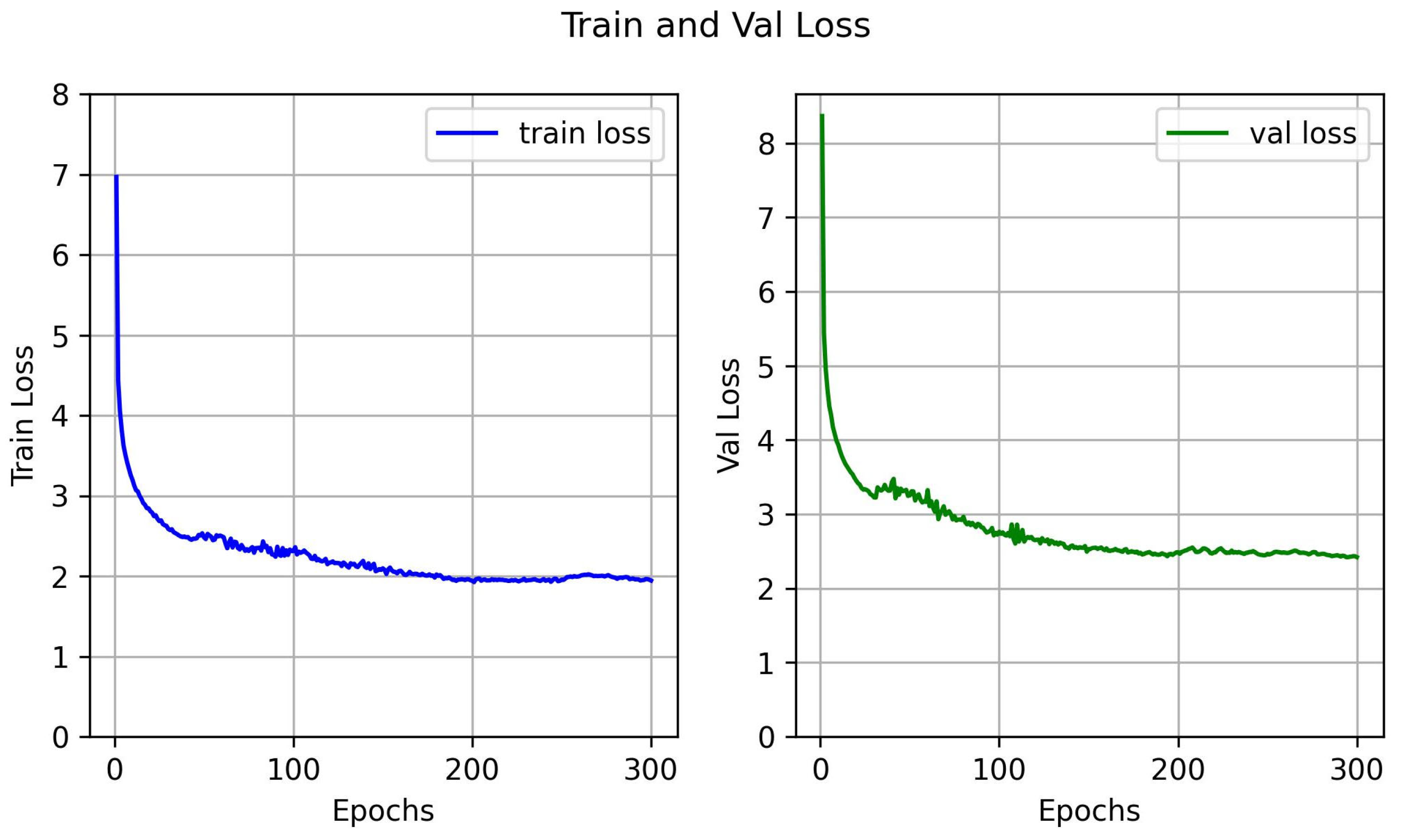
EUVP’s test set contains 515 paired real-world underwater images. We will use the AttU-GAN model trained on the UIEB dataset and other compared methods to test on the EUVP test set to verify the generalization of our method. Additionally, the training loss of our model on the UIEB dataset is shown in
Figure 7; our model has a good fitting ability. The test results in EUVP are shown in
Figure 8. From the figures, we can see that our method still has excellent enhancement results on unfamiliar data sets, which proves that our method has a strong generalization ability.
5. Conclusions
We present a general and effective model for underwater image enhancement in this paper. Our model filters the noise in the images and effectively retains the important feature information during the reconstruction process to generate high-quality enhanced images. We construct a new multi-loss function weighted objective function and train our model on a real-world underwater image dataset, UIEB, and validate the effectiveness and generalization of our method on two different datasets, UIEB and EUVP. The comparison experiments show that our method outperforms all the compared methods, the ablation experiments show that the loss function proposed in this paper outperforms a single loss function, and finally, the generalization of our method is verified by testing it on different datasets. In our future work, we will focus on improving the performance of the network to make it faster, lighter, and stronger.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}