
Marine Adaptive Sampling Scheme Design for Mobile Platforms under Different Scenarios


Abstract
:1. Introduction
2. Adaptive Observation System
2.1. Numerical Simulation and Data Assimilation Method
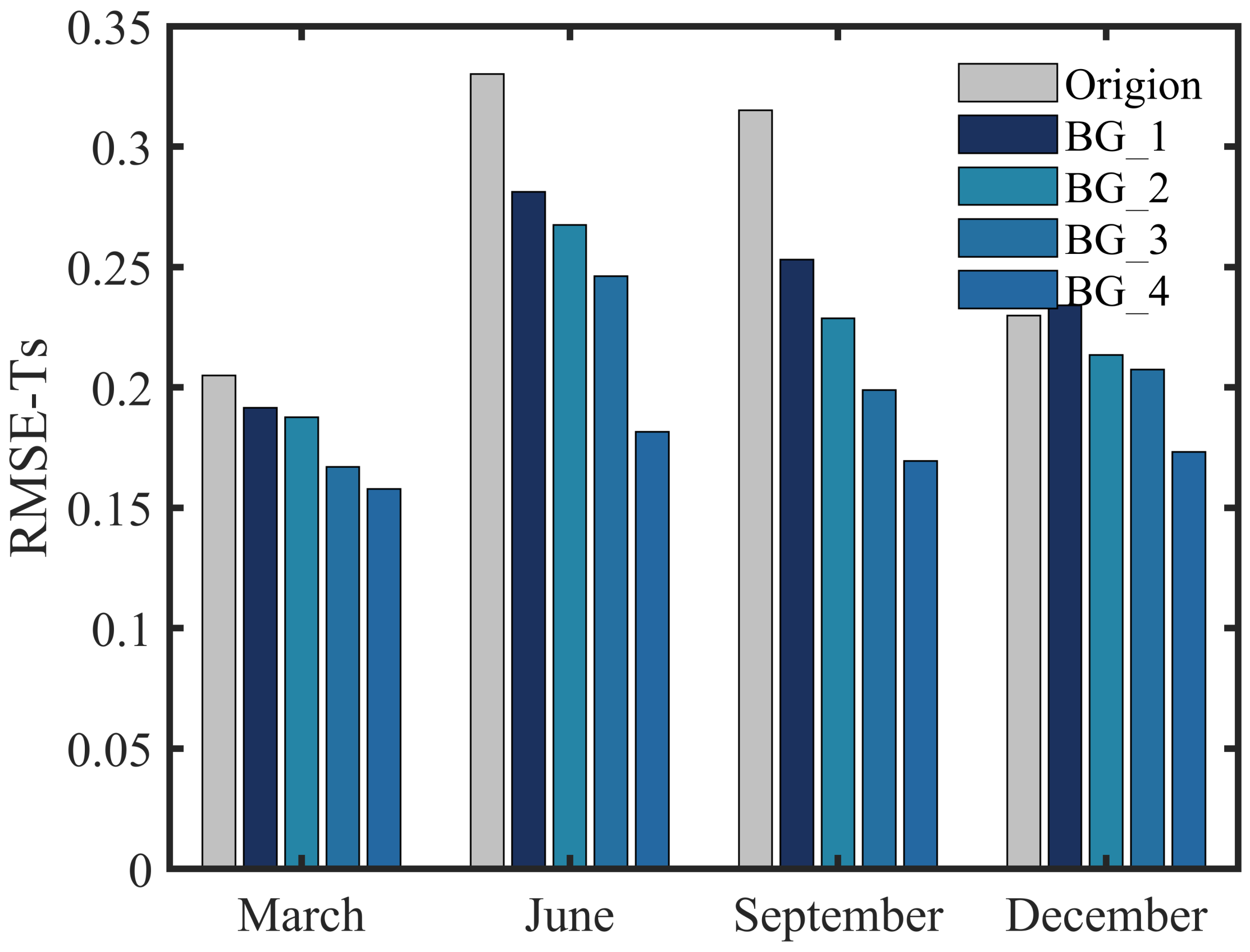
2.2. Constructing and Testing Method for Background
2.3. Optimization Framework and Algorithm
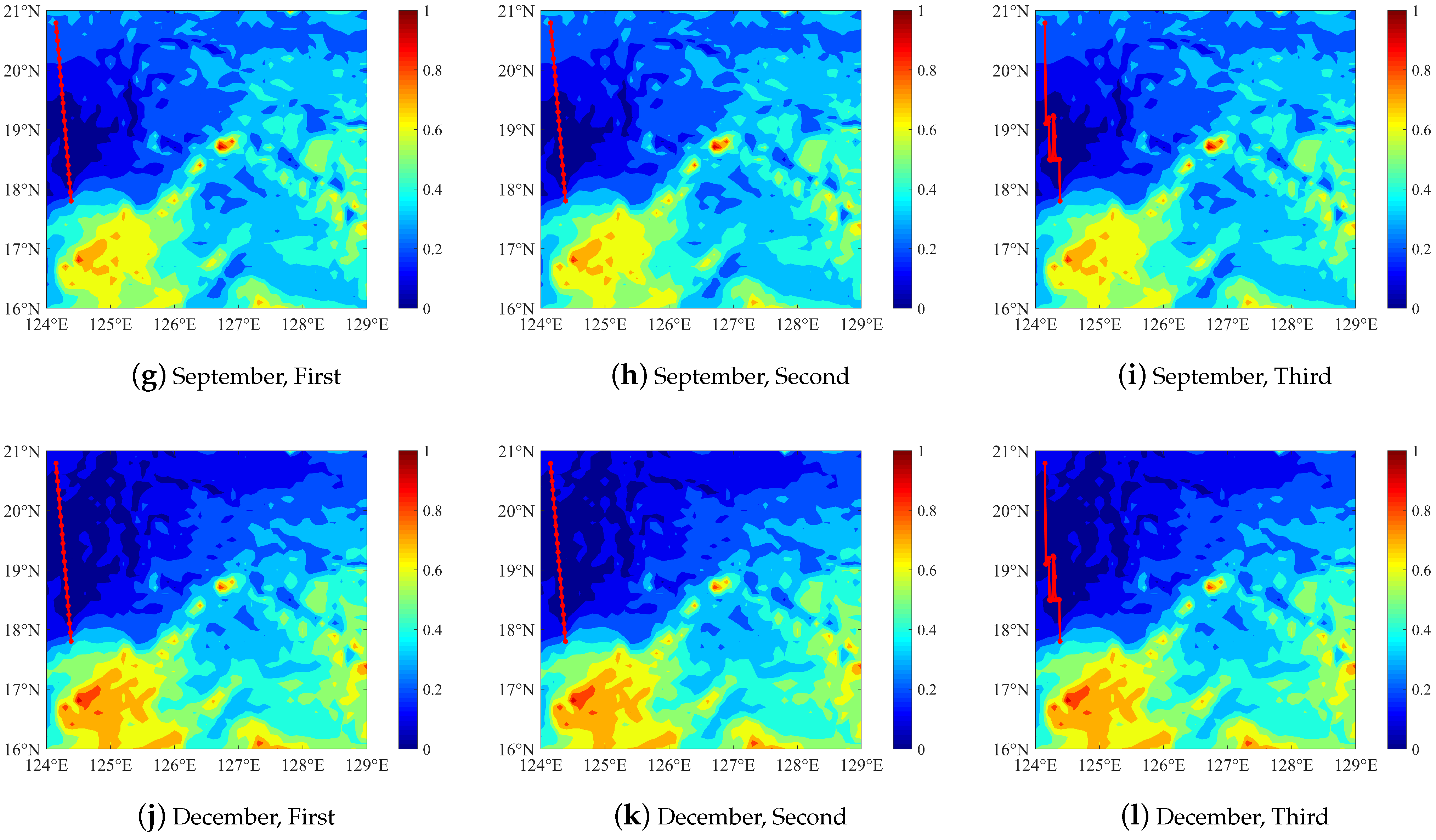
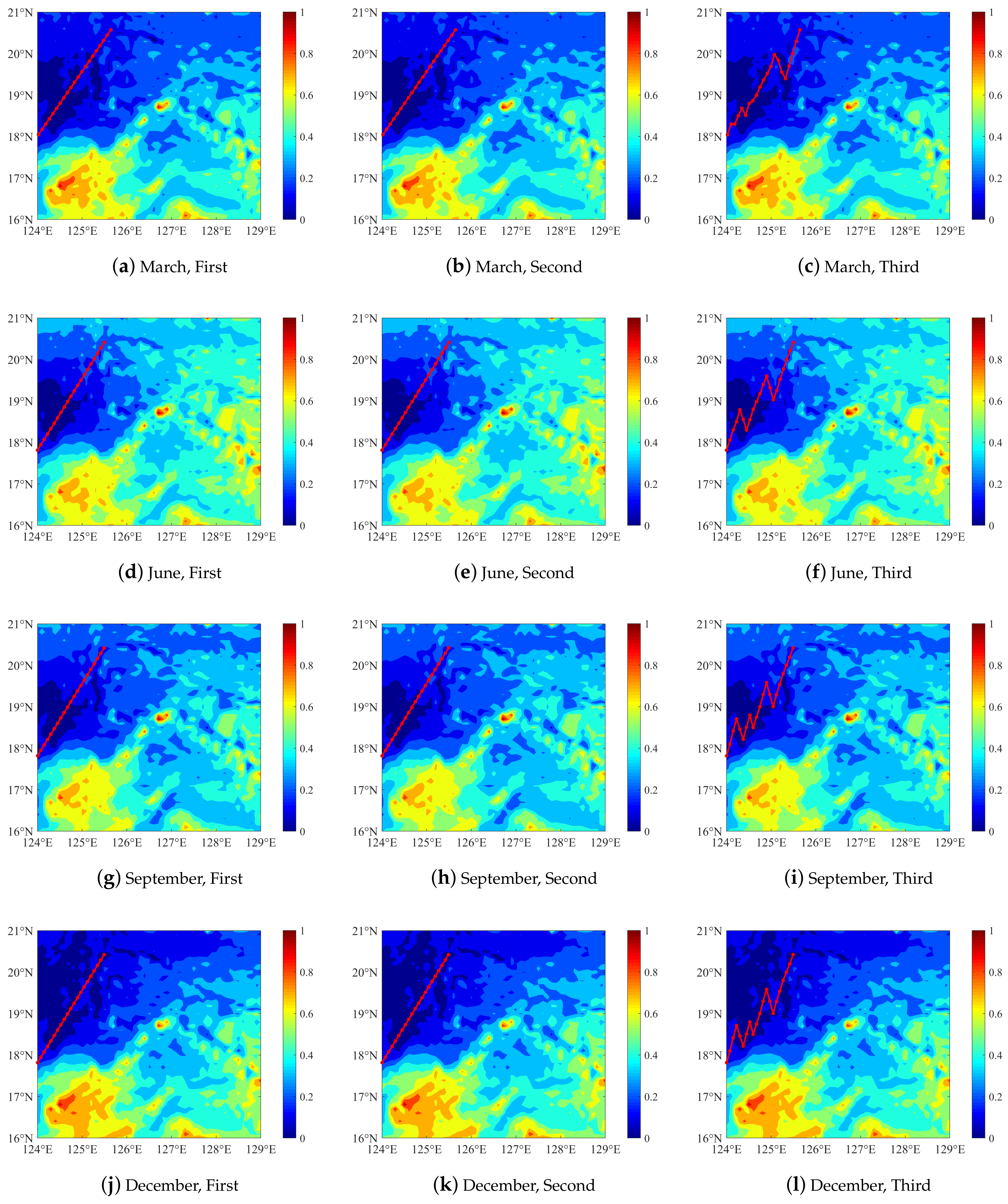
3. Scheme Design for a Single Platform
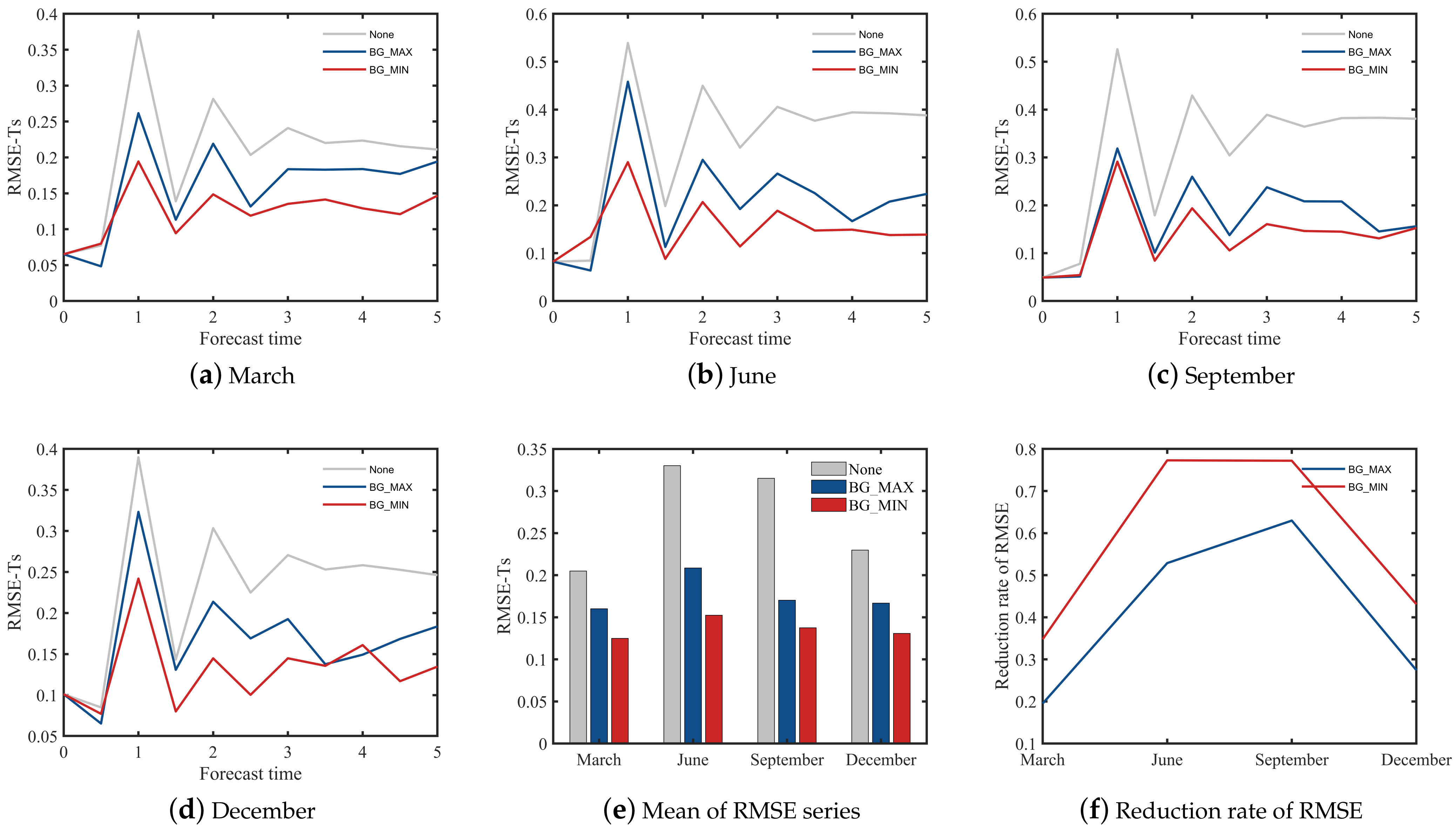
3.1. Validation of the Background Field
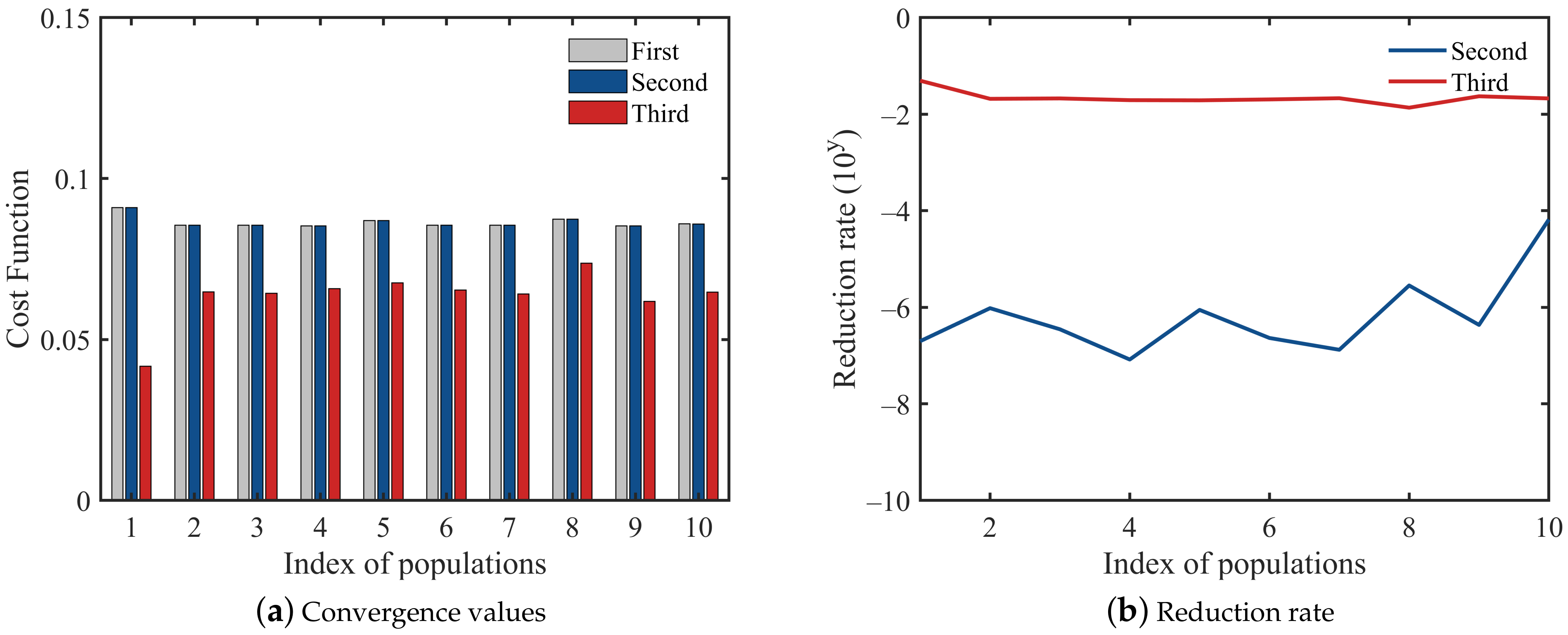
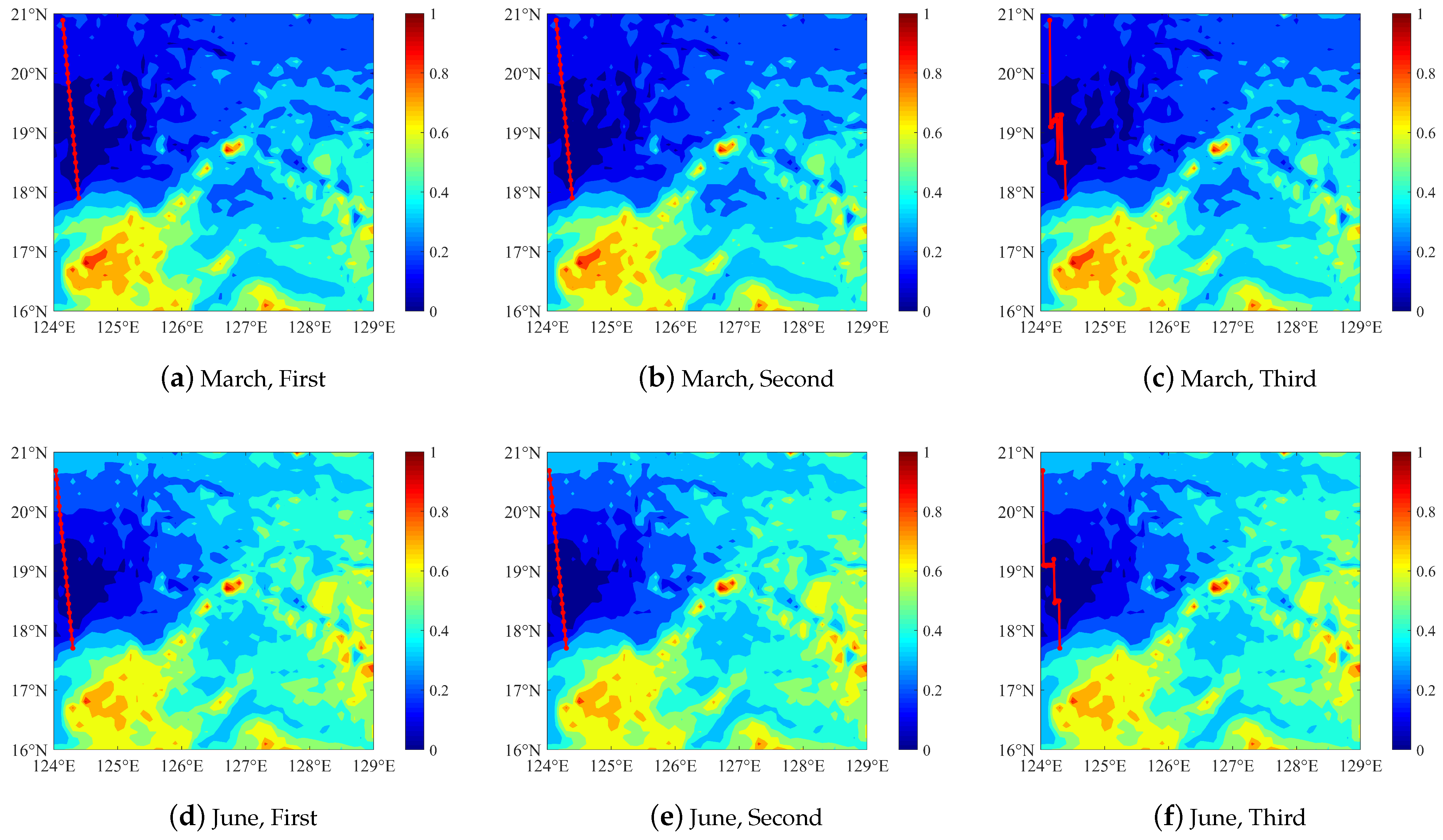
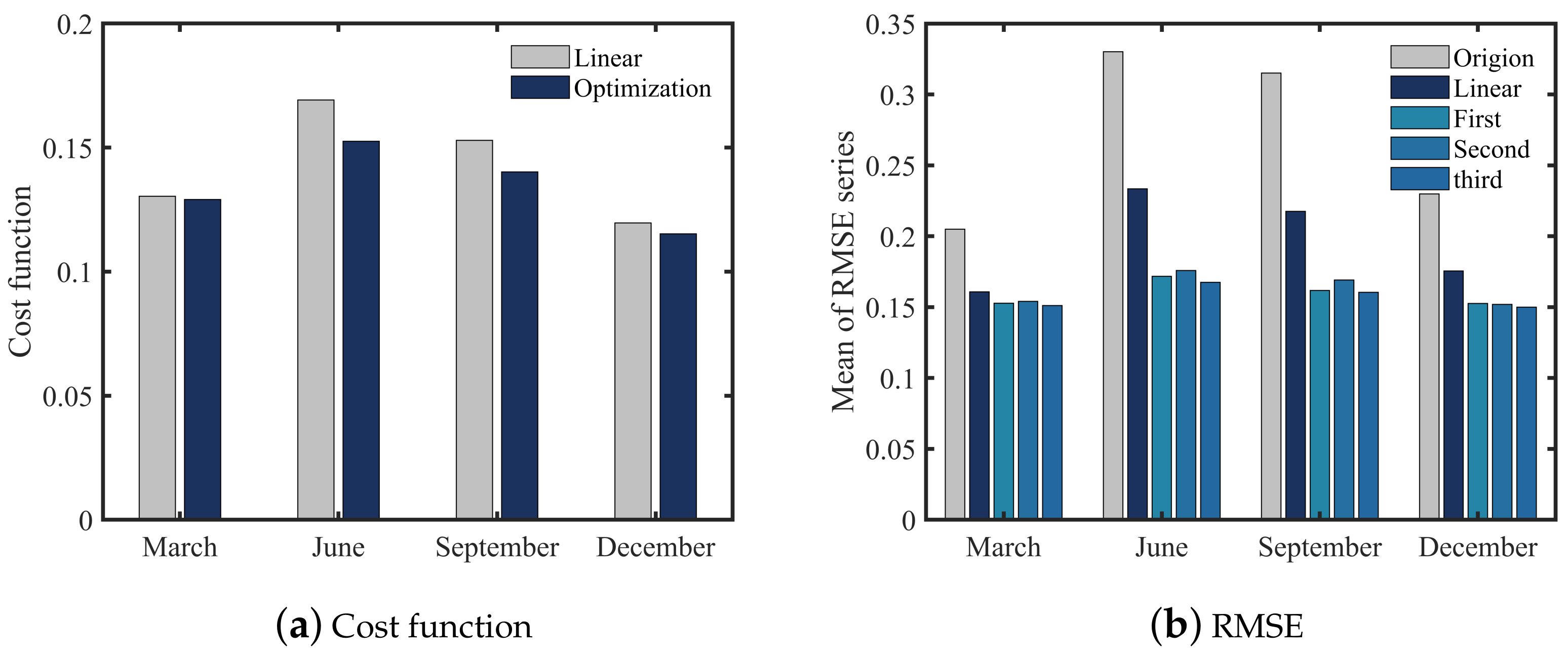
3.2. Three-Level Optimization under the Simple Cost Function
3.3. Improved Cost Function
3.4. Three-Level Optimization under the Improved Cost Function
4. Validation and Application of Design Methods
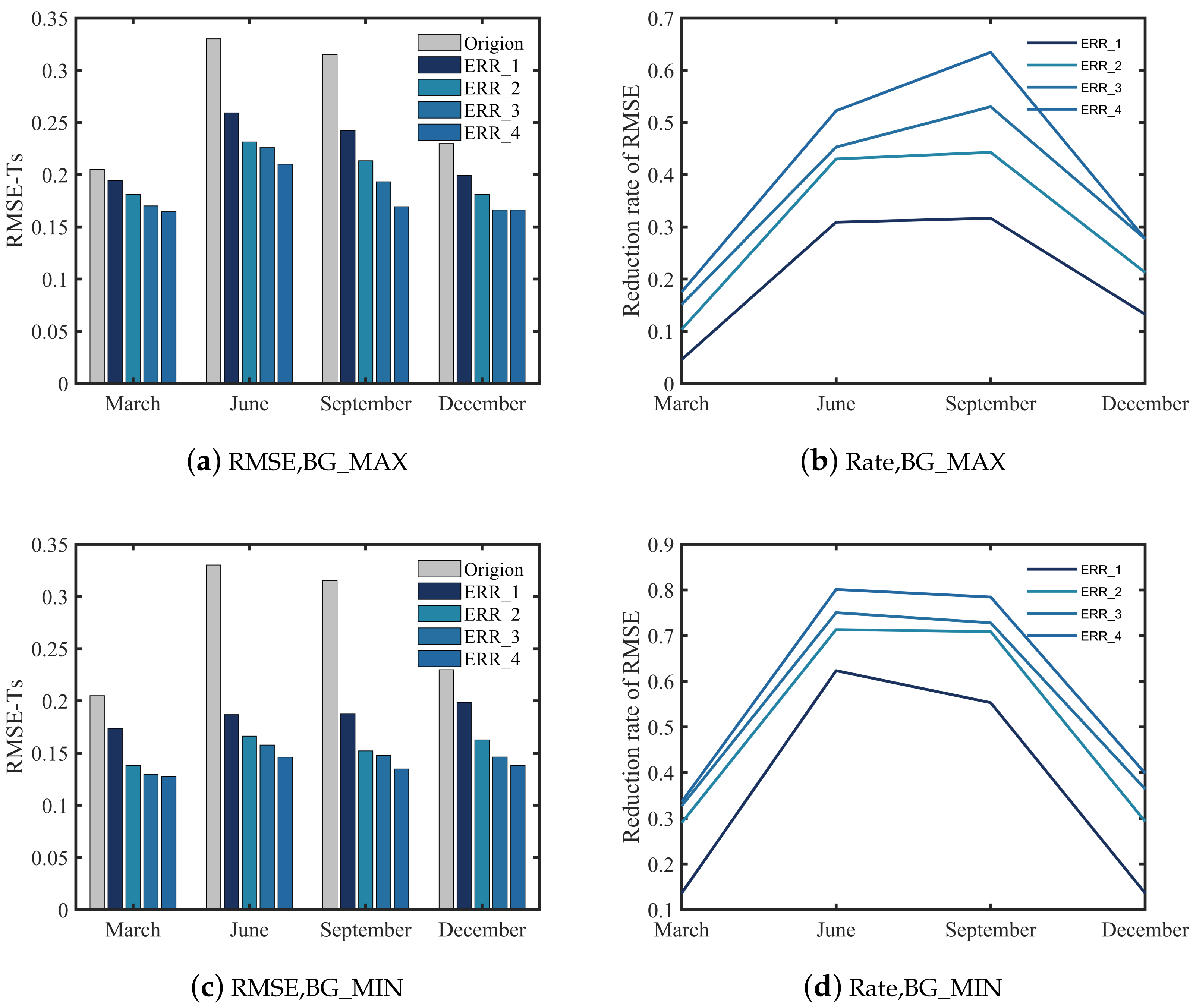
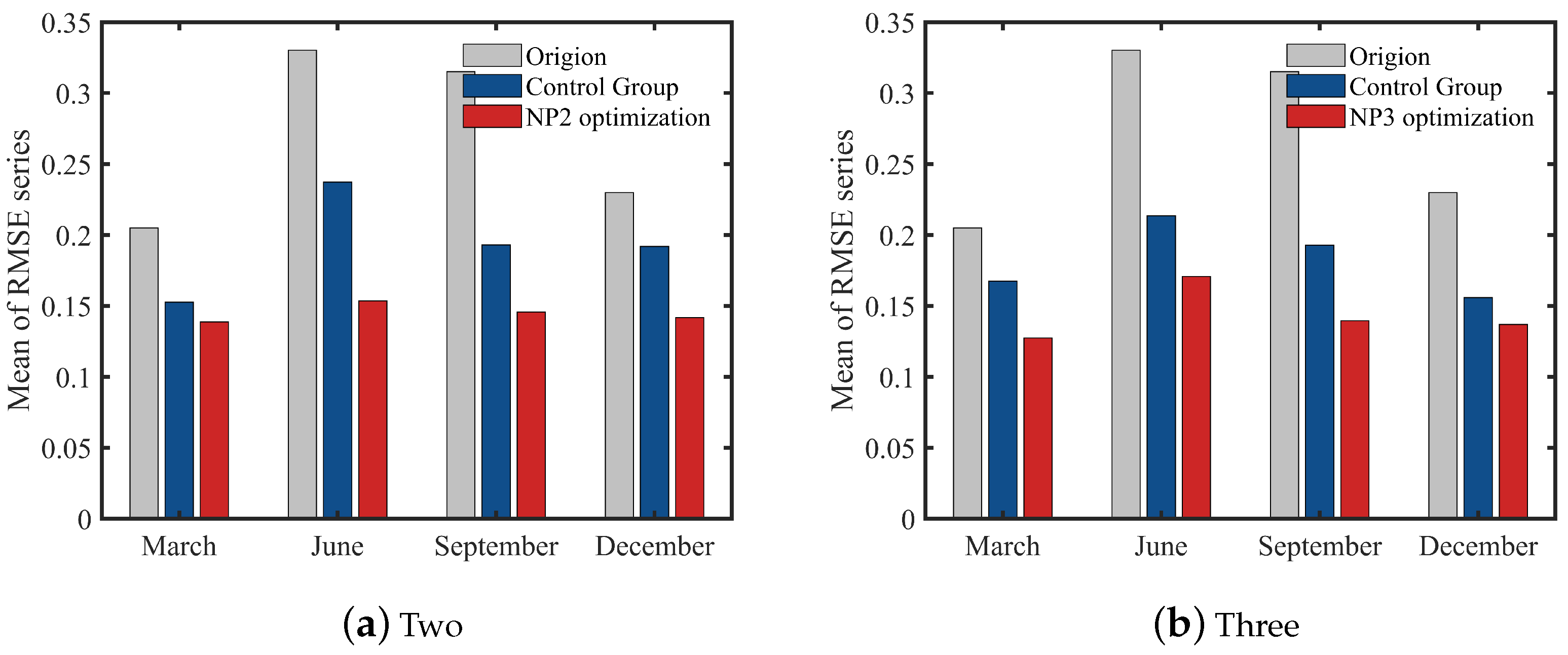
4.1. Verification of Single Platform Scheme
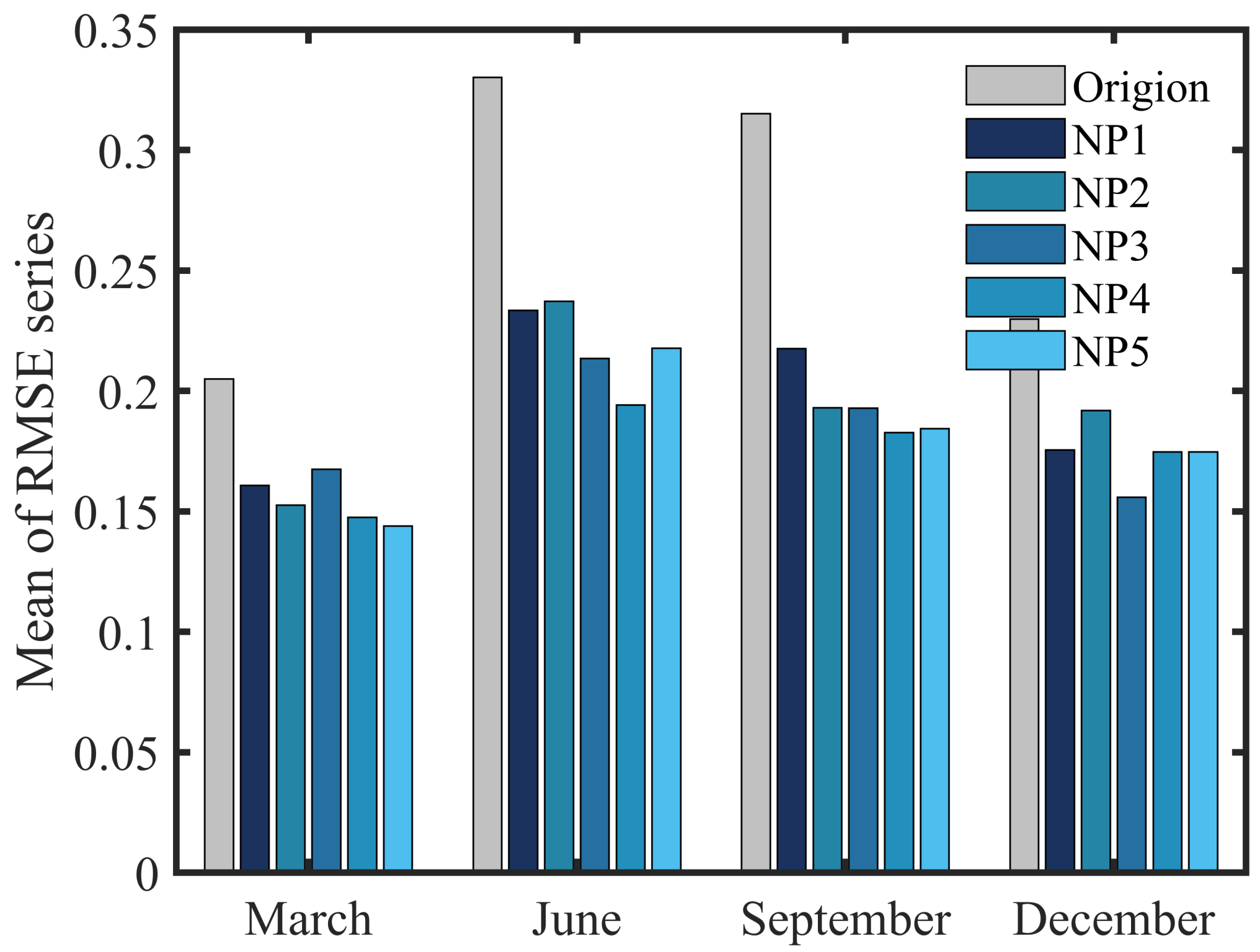
4.2. Application of Design Method in Multi-Platform Observation
5. Summary and Discussions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AUV | Autonomous Underwater Vehicle |
| BBPSO | Bare-bone Particle Swarm Optimization |
| CNOP | Conditional Nonlinear Optimal Perturbation |
| EAKF | Ensemble Adjustment Kalman Filter |
| GREB | Globally Resolved Energy Balance |
| ICCM | Intermediate Coupled Circulation Model |
| PSO | Particle Swarm Optimization |
| ROMS | Regional Ocean Model System |
| RMSE | Root Mean Square Error |
References
- Liu, Y.; Wang, M.; Su, Z.; Luo, J.; Xie, S.; Peng, Y.; Pu, H.; Xie, J.; Zhou, R. Multi-AUVs Cooperative Target Search Based on Autonomous Cooperative Search Learning Algorithm. J. Mar. Sci. Eng. 2020, 8, 843. [Google Scholar] [CrossRef]
- Li, X.; Xu, X.; Yan, L.; Zhao, H.; Zhang, T. Energy-Efficient Data Collection Using Autonomous Underwater Glider: A Reinforcement Learning Formulation. Sensors 2020, 20, 3758. [Google Scholar] [CrossRef] [PubMed]
- Feng, H.; Yu, J.; Huang, Y.; Qiao, J.; Wang, Z.; Xie, Z.; Liu, K. Adaptive coverage sampling of thermocline with an autonomous underwater vehicle. Ocean. Eng. 2021, 233, 109151. [Google Scholar] [CrossRef]
- Hu, Y.; Wang, D.; Li, J.; Wang, Y.; Shen, H. Adaptive Environmental Sampling for Underwater Vehicles Based on Ant Colony Optimization Algorithm. In Proceedings of the Global Oceans 2020: Singapore—US Gulf Coast, Virtual, 5–30 October 2020; IEEE: Biloxi, MS, USA, 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Klonaris, G.; Van Eeden, F.; Verbeurgt, J.; Troch, P.; Constales, D.; Poppe, H.; De Wulf, A. ROMS Based Hydrodynamic Modelling Focusing on the Belgian Part of the Southern North Sea. J. Mar. Sci. Eng. 2021, 9, 58. [Google Scholar] [CrossRef]
- Badriana, M.R.; Lee, H.S. Multimodel Ensemble Projections of Wave Climate in the Western North Pacific Using CMIP6 Marine Surface Winds. J. Mar. Sci. Eng. 2021, 9, 835. [Google Scholar] [CrossRef]
- Heaney, K.D.; Lermusiaux, P.F.J.; Duda, T.F.; Haley, P.J. Validation of genetic algorithm-based optimal sampling for ocean data assimilation. Ocean. Dyn. 2016, 66, 1209–1229. [Google Scholar] [CrossRef] [Green Version]
- Heaney, K.D.; Gawarkiewicz, G.; Duda, T.F.; Lermusiaux, P.F.J. Nonlinear optimization of autonomous undersea vehicle sampling strategies for oceanographic data-assimilation. J. Field Robot. 2007, 24, 437–448. [Google Scholar] [CrossRef] [Green Version]
- Ma, K.; Liu, L.; Heidarsson, H.K.; Sukhatme, G.S. Data-driven learning and planning for environmental sampling. J. Field Robot. 2018, 35, 643–661. [Google Scholar] [CrossRef] [Green Version]
- Xiong, C.; Lu, D.; Zeng, Z.; Lian, L.; Yu, C. Path Planning of Multiple Unmanned Marine Vehicles for Adaptive Ocean Sampling Using Elite Group-Based Evolutionary Algorithms. J. Intell. Robot. Syst. 2020, 99, 875–889. [Google Scholar] [CrossRef]
- Zhang, L.; Mou, J.; Chen, P.; Li, M. Path Planning for Autonomous Ships: A Hybrid Approach Based on Improved APF and Modified VO Methods. J. Mar. Sci. Eng. 2021, 9, 761. [Google Scholar] [CrossRef]
- Zhang, Z.; Wu, D.; Gu, J.; Li, F. A Path-Planning Strategy for Unmanned Surface Vehicles Based on an Adaptive Hybrid Dynamic Stepsize and Target Attractive Force-RRT Algorithm. J. Mar. Sci. Eng. 2019, 7, 132. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Ran, X.; Zhang, G.; Xu, H.; Wang, X. AUV 3D Path Planning Based on the Improved Hierarchical Deep Q Network. J. Mar. Sci. Eng. 2020, 8, 145. [Google Scholar] [CrossRef] [Green Version]
- Alvarez, A.; Mourre, B. Optimum Sampling Designs for a Glider–Mooring Observing Network. J. Atmos. Ocean. Technol. 2012, 29, 601–612. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Lei, Y.; Gao, F.; Zhao, M. Optimal Configuration Method of Sampling Points Based on Variability of Sea Surface Temperature. Adv. Meteorol. 2017, 2017, 5638289. [Google Scholar] [CrossRef] [Green Version]
- Mu, M.; Duan, W.S.; Wang, B. Conditional nonlinear optimal perturbation and its applications. Nonlinear Process. Geophys. 2003, 10, 493–501. [Google Scholar] [CrossRef]
- Zhao, S.; Li, W.; Cao, J. A User-Adaptive Algorithm for Activity Recognition Based on K-Means Clustering, Local Outlier Factor, and Multivariate Gaussian Distribution. Sensors 2018, 18, 1850. [Google Scholar] [CrossRef] [Green Version]
- Anbalagan, B.; Karnam Anantha, S.; Arjunan, S.; Balasubramanian, V.; Murugesan, M. A Non-Invasive IR Sensor Technique to Differentiate Parkinson’s Disease from Other Neurological Disorders Using Autonomic Dysfunction as Diagnostic Criterion. Sensors 2021, 22, 266. [Google Scholar] [CrossRef]
- Eberhart, R.; Kennedy, J. A new optimizer using particle swarm theory. In Proceedings of the MHS’95—Sixth International Symposium on Micro Machine and Human Science, Nagoya, Japan, 4–6 October 1995; IEEE: Nagoya, Japan, 1995; pp. 39–43. [Google Scholar] [CrossRef]
- Kennedy, J. Bare bones particle swarms. In Proceedings of the 2003 IEEE Swarm Intelligence Symposium SIS’03 (Cat. No.03EX706), Indianapolis, IN, USA, 26 April 2003; IEEE: Indianapolis, IN, USA, 2003; pp. 80–87. [Google Scholar] [CrossRef]
- Shang, W.; Xue, W.; Li, Y.; Wu, X.; Xu, Y. An Improved Underwater Electric Field-Based Target Localization Combining Subspace Scanning Algorithm And Meta-EP PSO Algorithm. J. Mar. Sci. Eng. 2020, 8, 232. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Q.; Feng, B.W.; Liu, Z.Y.; Chang, H.C. Application of Improved Particle Swarm Optimisation Algorithm in Hull form Optimisation. J. Mar. Sci. Eng. 2021, 9, 955. [Google Scholar] [CrossRef]
- Yong, Z.; Yuan, L.; Qian, Z.; Sun, X. Multi-objective optimization of building energy performance using a particle swarm optimizer with less control parameters. J. Build. Eng. 2020, 32, 101505. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, S.; Liu, Z.; Wu, X.; Han, G. Parameter Optimization in an Intermediate Coupled Climate Model with Biased Physics. J. Clim. 2015, 28, 1227–1247. [Google Scholar] [CrossRef]
- Anderson, J.L. An Ensemble Adjustment Kalman Filter for Data Assimilation. Mon. Weather Rev. 2001, 129, 2884–2903. [Google Scholar] [CrossRef] [Green Version]
- Dommenget, D.; Flöter, J. Conceptual understanding of climate change with a globally resolved energy balance model. Clim. Dyn. 2011, 37, 2143–2165. [Google Scholar] [CrossRef]
- Wu, X.; Zhang, S.; Liu, Z.; Rosati, A.; Delworth, T.L.; Liu, Y. Impact of Geographic-Dependent Parameter Optimization on Climate Estimation and Prediction: Simulation with an Intermediate Coupled Model. Mon. Weather Rev. 2012, 140, 3956–3971. [Google Scholar] [CrossRef]
- Thompson, S.L.; Warren, S.G. Parameterization of Outgoing Infrared Radiation Derived from Detailed Radiative Calculations. J. Atmos. Sci. 1982, 39, 2667–2680. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.; Deng, X.; Zhang, S.; Liu, Z.; Liu, C. Sensitivity determined simultaneous estimation of multiple parameters in coupled models: Part I—Based on single model component sensitivities. Clim. Dyn. 2019, 53, 5349–5373. [Google Scholar] [CrossRef]
- Zhang, S.; Harrison, M.J.; Rosati, A.; Wittenberg, A. System Design and Evaluation of Coupled Ensemble Data Assimilation for Global Oceanic Climate Studies. Mon. Weather Rev. 2007, 135, 3541–3564. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S. A Study of Impacts of Coupled Model Initial Shocks and State–Parameter Optimization on Climate Predictions Using a Simple Pycnocline Prediction Model. J. Clim. 2011, 24, 6210–6226. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Liu, Z.; Rosati, A.; Delworth, T. A study of enhancive parameter correction with coupled data assimilation for climate estimation and prediction using a simple coupled model. Tellus A Dyn. Meteorol. Oceanogr. 2012, 64, 10963. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.; Li, W.; Han, G.; Zhang, L.; Shao, C.; Sun, C.; Xuan, L. An Adaptive Compensatory Approach of the Fixed Localization in the EnKF. Mon. Weather Rev. 2015, 143, 4714–4735. [Google Scholar] [CrossRef]
- Gaspari, G.; Cohn, S.E. Construction of correlation functions in two and three dimensions. Q. J. R. Meteorol. Soc. 1999, 125, 723–757. [Google Scholar] [CrossRef]
- Pan, F.; Hu, X.; Eberhart, R.; Chen, Y. An analysis of Bare Bones Particle Swarm. In Proceedings of the 2008 IEEE Swarm Intelligence Symposium, St. Louis, MO, USA, 21–23 September 2008; IEEE: St. Louis, MO, USA, 2008; pp. 1–5. [Google Scholar] [CrossRef]
- Shi, Y.; Eberhart, R.C. Parameter selection in particle swarm optimization. In Evolutionary Programming VII; Lecture Notes in Computer Science Series; Goos, G., Hartmanis, J., van Leeuwen, J., Porto, V.W., Saravanan, N., Waagen, D., Eiben, A.E., Eds.; Springer: Berlin/Heidelberg, Germany, 1998; Volume 1447, pp. 591–600. [Google Scholar] [CrossRef]
- Zhang, E.; Wu, Y.; Chen, Q. A practical approach for solving multi-objective reliability redundancy allocation problems using extended bare-bones particle swarm optimization. Reliab. Eng. Syst. Saf. 2014, 127, 65–76. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Components | Equations |
|---|---|
| atmospheric | potential vorticity conservation equation |
| atmospheric temperature equation | |
| ocean | ocean surface temperature equation |
| subsurface temperature equation | |
| oceanic stream function equation | |
| land | land temperature equation |
| Freedom | Cases |
|---|---|
| High | The distribution point and recovery point of the mobile platform are both determined by the users. |
| Medium | Only one of the distribution points and recovery points of the mobile platform are determined by the users. |
| Low | The distribution point and recovery point of the mobile platform are known. |
| Months | Category | Centers |
|---|---|---|
| March | BG_1 | 0.664387 |
| BG_2 | 0.426747 | |
| BG_3 | 0.266542 | |
| BG_4 | 0.126797 | |
| June | BG_1 | 0.667943 |
| BG_2 | 0.477465 | |
| BG_3 | 0.343627 | |
| BG_4 | 0.150293 | |
| September | BG_1 | 0.624139 |
| BG_2 | 0.432476 | |
| BG_3 | 0.293865 | |
| BG_4 | 0.114702 | |
| December | Var_1 | 0.711194 |
| BG_2 | 0.478621 | |
| BG_3 | 0.298754 | |
| BG_4 | 0.117448 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Zhao, H.; Liu, Y.; Deng, X. Marine Adaptive Sampling Scheme Design for Mobile Platforms under Different Scenarios. J. Mar. Sci. Eng. 2022, 10, 664. https://doi.org/10.3390/jmse10050664
Zhao Y, Zhao H, Liu Y, Deng X. Marine Adaptive Sampling Scheme Design for Mobile Platforms under Different Scenarios. Journal of Marine Science and Engineering. 2022; 10(5):664. https://doi.org/10.3390/jmse10050664
Chicago/Turabian StyleZhao, Yuxin, Hengde Zhao, Yanlong Liu, and Xiong Deng. 2022. "Marine Adaptive Sampling Scheme Design for Mobile Platforms under Different Scenarios" Journal of Marine Science and Engineering 10, no. 5: 664. https://doi.org/10.3390/jmse10050664