1. Introduction
As global economic activities become more interconnected, the density of maritime traffic flows is increasing, especially in inshore navigation and in fishing areas. Clearly, this situation increases the risk of collisions between vessels. Ship collisions often result in significant casualties and economic damage. At present, the officer on watch (OOW) can obtain navigational data on surrounding vessels through navigation aids, such as radar and automatic identification systems (AIS). However, contrary to expectations, misinterpretation or omission of information by the pilot can sometimes lead to incorrect decisions or untimely action. Surveys show that approximately 94.7% of ship-to-ship collisions in the last 43 years have been caused by human error on the part of the crew, and at least 56% of collisions are caused by violations of the International Regulations for Collision Avoidance at Sea (COLREGs) established by the International Maritime Organization (IMO) [
1,
2]. Therefore, the development of autonomous collision avoidance systems that comply with navigation rules is one of the most effective ways to reduce the human factor and the incidence of collisions by improving the intelligence of ships.
In recent years, with the continuous improvement of the theory of unmanned control technology and the gradual development of perception systems, unmanned vessels have started to gradually replace human operators in performing tasks. Unmanned surface vehicles (USVs), as small unmanned offshore platforms, have a wide range of applications in both military and civilian fields, such as port patrol, coast guard, environmental monitoring, seaway mapping, etc. [
3]. Maritime autonomous surface ship (MASS) is considered to be an important development field in maritime transportation systems. Both USV and MASS should develop autonomous navigation systems. Moreover, the key technology of autonomous navigation systems is the autonomous collision avoidance technology to ensure safety of navigation. The development of unmanned ships is in its infancy, which means that in the long term future, there will be a coexistence of manned and unmanned ships. In order to adapt to this situation, the developed automatic collision avoidance system should be in line with the current collision avoidance rules and human habits, although the COLREGs may be modified because of MASS operation [
4].
The problem with autonomous collision avoidance on ships is one of decision optimization that has long been of interest to scholars. Before the rapid development of machine learning, scholars proposed many deterministic and heuristic algorithms, such as fuzzy control, the artificial potential field method (APF), the velocity obstacle method (VO), the A*-based global path planning collision avoidance algorithm, Dijkstra path planning, GA (genetic algorithm)-based collision avoidance algorithm, etc. [
5,
6,
7,
8,
9,
10,
11,
12]. However, these algorithms have their limitation; for example, the APF algorithm cannot be applied in complex and uncertain navigation environment, and the algorithm itself has the defect of easily falling into local minima. The A* algorithm relies on a grid map and is very effective for avoiding static obstacles but is not suitable for dynamic environments, with the generated paths needing to be smoothed. Due to the problems of model-dependent accuracy, grid maps and computational complexity of traditional algorithms, artificial intelligence techniques have been applied to ship collision avoidance decision making in recent years with the rapid development of machine learning, especially deep reinforcement learning tools. Reinforcement learning (RL) is an important branch of artificial intelligence in which learning takes place through interaction with the environment. It is a goal-oriented form of learning where the learner is not told what behavior to execute but instead learns from the consequences of their actions. The ship collision avoidance decision problem is a typical Markov decision process (MDP), so reinforcement learning can be used to solve this problem. Deep reinforcement learning (DRL) has the unique advantage that it does not rely on model building but on state transition information gathered through interaction with the environment, bypassing complex issues, such as system modelling, and using the ability of deep neural networks (DNNs) to fit non-linear systems to achieve sequential decisions. The agent is allowed to learn offline, which means that real human collision avoidance experience can be learned so that agents make decisions that are more like human behavior. The agent makes collision avoidance decisions like human behavior by learning real human collision avoidance experience by offline learning. Therefore, a collision avoidance algorithm based on an improved deep Q network (DQN) is proposed in this paper. This method can produce collision avoidance actions that comply with COLREGs and are similar to human maneuvering.
2. Literature Review
The issue of ship automatic collision avoidance has, so far, attracted the attention of many researchers, and relevant theories and technologies are constantly being updated and developed. Numerous collision avoidance algorithms can be broadly classified into two categories: traditional methods based on modelling the environment (model-based) and deep reinforcement learning algorithms that are model-free.
In the field of traditional model-based algorithms, the A* algorithm generates the optimal path by minimizing the path cost. Liu et al. [
8] proposed an improved A* algorithm that takes into account collision avoidance rules and ship maneuverability to automatically generate optimal paths that combine economy and safety. Yogang et al. [
9] used a constrained A* method for global path planning with the simultaneous inclusion of static obstacles, dynamic obstacles and currents of different intensities and also investigated the effect of wind currents on optimal waypoints in selected environments. Ship collision avoidance is an uncertain system of interaction between humans, the ship and the marine environment, with time-varying, non-linear characteristics, so some scholars apply fuzzy set to the field of ship collision avoidance. Namgung et al. [
13] developed a collision risk assessment system based on fuzzy logic, which calculates the CRI (collision risk index) to determine the optimal time and distance to take collision avoidance action. Some scholars also use model predictive control (MPC) to avoid collisions. Xie et al. [
14] proposed an MPC method combined with improved Q-learning beetle swarm search (IQ-BSAS) and neural networks. This algorithm achieves collision avoidance by using neural networks to approximate the inverse model of MPC decisions. Multi-objective evolutionary algorithms (MOEAs) are a class of global probabilistic optimization search methods that mimic biological evolutionary mechanisms to make multiple objectives as optimal as possible for a given region at the same time. Li et al. [
15] used the improved non-dominated sorting genetic algorithm II (NSGA-II) and ship domain model to optimize the ship collision avoidance strategy by balancing the safety and economy of ship collision avoidance actions. Zhou Kang et al. [
16] proposed a method to reduce fuel consumption during collision avoidance, but their simulation results show that the model outputs a large rudder angle for small changes of course, which is a clear departure from sailing practice. Ni et al. [
10] used multiple genetic algorithms and linear expansion algorithms for planning collision avoidance trajectories. Liu et al. [
17] adopted a hybrid optimization algorithm combining an improved bacterial foraging algorithm and a particle swarm optimization algorithm to optimize the ship’s collision avoidance path and generated the optimal collision avoidance steering angle. The path planning of the artificial potential field (APF) method is a virtual force method proposed by Khatib. Its basic idea is to design an abstract gravitational field. The target point produces “gravity” on the ship, the obstacle ship produces “repulsion” and, finally, by seeking the resultant force, to control the trajectory of the ship’s movement. The paths planned by the potential field method are generally smooth and safe, but this method has the problem of local optimum. Li et al. [
18] used the APF to improve the action space and reward function of the DQN algorithm, solved the problem of sparse reward function in the reinforcement learning algorithm and realized the path planning of autonomous collision avoidance. Hongguang Lyu and Yong Yin [
5] proposed a path-oriented hybrid artificial potential field method (PGHAPF) that has the potential to integrate potential field models into ECDIS for path planning and is extremely feasible for practical engineering applications. The VO algorithm proposed by Fiorini and Shiller [
19] could resolve conflicts with multiple moving obstacles, and this algorithm collects all the velocities that result in collisions and presents a set of collision-free velocities, which facilitates a machine search for the best option. Huang et al. [
7] applied the generalized velocity obstacle (GVO) method to the field of multi-ship collision avoidance, and the simulation results show that the algorithm can take fewer necessary actions. Shaobo et al. [
6] developed an autonomous navigation system based on an improved VO algorithm combined with a finite state machine (FSM), introducing a multi-level optimization decision model considering ship maneuverability, COLREGs and other constraints. A case study was carried out on ECDIS, the results of which show the robustness of this system under various sea conditions.
Model-free RL algorithms are well adapted to complex systems and have self-learning capabilities that discover optimal strategies from unknown environments through trial-and-error interactions, thus providing an effective way to deal with extremely complex systems. There are two main branches of DRL. One is the method of learning the optimal action value function, such as deep Q networks (DQNs), which combine value-based Q-learning with neural networks, using neural networks to approximate the action value of all possible behavior in each state, effectively solving the problem that Q-Learning can only make decisions in an environment with a limited number of states. The other is the DRL algorithm, which is based on policy gradients, such as DDPG, which can handle continuous action spaces. These methods are often used in the field of ship collision avoidance to control the rudder angle of a ship. Both types of algorithms have been widely used in the field of ship collision avoidance. Shen et al. [
20] proposed an intelligent collision avoidance algorithm based on DQN, which applies the ship domain and predicts area of danger to describe the area of obstruction, uses 12 distance detection lines to detect the distance to the area of obstruction and uses the distance at five consecutive moments as the input to the DQN. Numerical simulations were carried out in conjunction with a ship model, and, finally, pool experiments are conducted using three scaled models of ships with different maneuverability to verify the possibility of intelligent collision avoidance in more complex waters. Zhao and Roh [
21] proposed an actor–critic (AC) algorithm for ship collision avoidance. This algorithm divides the target ship area into four regions based on COLREGs, solving the problem of fixing the input dimension of the neural network when the number of target ships varies. This method considers only the nearest ship in the divided region and does not consider all ships and static obstacles. Sawada et al. [
22] proposed a collision avoidance method based on proximal policy optimization (PPO). This method improves obstacle zone by target (OZT), uses grid sensor to quantize OZTs and uses A convolutional neural network (CNN) and long-short-term memory network (LSTM) to control the rudder angle in the continuous action space. This method is only suitable for open waters. When the number of obstructions and target ships is increased, the number and area of OZTs increase, which may cause the action taken to fail to change the observed state of the agent. Jiahui Shi [
23] first mined successful collision avoidance cases in Tianjin port AIS big data and used a double GRU-RNN network for learning, which provides a new solution for massive AIS data in a practical application. Chen et al. [
24] proposed a collision avoidance method based on Q-learning for path planning, which allowed the ship to sail independently along the appropriate path or navigation strategy without human intervention. Compared with the traditional path planning method, the effect of this algorithm is closer to that of human operation. Xu et al. [
25] proposed a COLREGs intelligent collision avoidance (CICA) algorithm, employing DNN to automatically extract the observation state characteristics and proposing a new method to track the current network weight to update the target network weight, which improves the stability of learning the optimal strategy. Compared with other updating strategies, their training convergence time was significantly reduced. Finally, the simulation results were compared with VO and APF algorithms, and the results were obviously better than those of the other two algorithms. Woo and Kim [
26] proposed a USV collision avoidance algorithm based on improved DQN, which represented the encounter situation of ships with a grid map and used the visual recognition capabilities of DNN to realize the perception of the encounter situation of ships and collision avoidance decision making. A VO algorithm was used to plan the collision avoidance path. In contrast to previous decisions, this network only decides whether to take collision avoidance action or continue to follow the route. If an action should be taken, steering to port or starboard is decided by the DQN, and the steering angle is generated by the VO algorithm. However, this approach is a departure from the basic idea of reinforcement learning.
The above studies were conducted from the perspective of safety and compliance with collision avoidance rules and did not considered whether collision avoidance decisions are consistent with human maneuvering habits, with trajectories that are difficult to track, frequent steering and the use of large rudder angles (close to full rudder) to shift very small courses. Moreover, a ship’s collision avoidance usually consists of four parts: environment perception, taking collision avoidance action, keeping course and speed, and returning to the planned route. Usually, a complete collision avoidance process will take ten minutes or more, and the stage of keeping course and speed, as well as returning to the planned route, takes up most of the time, whereas taking collision avoidance action is a relatively short step. The decision to take action is the core part of collision avoidance. In most cases, it takes a few actions to make the collision risk disappear. Therefore, using a reinforcement learning algorithm for the entire collision avoidance process increases the length of the state transition chain, which leads to an increase in the complexity of the algorithm and, consequently, to learning difficulties. In addition, the RL algorithm relies heavily on the input of the observation state, which directly affects the learning ability of the agent. In previous studies, ship kinematic parameters, distance and bearing have usually been used as inputs, but raw, unprocessed data are difficult to learn and often require a deeper and wider network structure to process. At the same time, the number of target ships and the number of static obstacles may result in different dimensions of the observed states.
Motivated by all of the above, we designed a novel method for collision avoidance based on DRL. In this paper, we proposed a new strategy that uses dynamic information about obstructions and target vessels to predict hazardous areas for collisions and quantified the areas as observation states of the agent to fix the input dimension and cluster similar collision avoidance scenarios. The DRL algorithm is applied only to the collision avoidance decision-making phase so that the number of state transitions in the collision avoidance process can be reduced to optimize the learning process while using prioritized experience replay to accelerate the learning process. In addition, the reward function is designed to take into account the COLREGs and human maneuvering habits so that the agent can take collision avoidance actions, effectively comply with the collision avoidance rules and more closely mimic human behavior. Finally, a simulation of collision avoidance in a crowded water environment with multiple vessel encounters was carried out.
To summarize the above, the contributions of this paper are concluded as follows:
A novel automatic collision avoidance strategy is proposed. The strategy applies the DRL navigation algorithm only in the collision avoidance decision-making phase, which reduces the number of state transitions in the Markov decision process and thus optimizes the learning process. The convergence rate is also optimized by using an improved DQN.
Based on the perception information, hazardous areas are predicted and quantified as input to the DRL algorithm, which serves to fix the dimensionality of the observation state of the agent and to cluster similar ship collision avoidance scenarios.
When designing the reward function for DRL, COLREGs and human experience are taken into account so that the decisions made by the agent more closely resemble human operation.
Nineteen single-ship encounter scenarios (non-close-quarters situations) were created based on the ship encounter situations classified by the COLREGs. These scenarios were arranged and combined to serve as the training set for the agent. The Imazu problem, a set of more difficult encounter situations different from the training scenarios, was also used as a test set to verify the effectiveness of the method in close-quarters situations in crowded waters.
The remainder of this paper is organized as follows:
Section 3 introduces reinforcement learning.
Section 4 describes the details of the algorithm design and includes the design of the observation state, action space and reward function, as well as the arrangement of training scenarios. In
Section 5, we carry out validation and a case study.
Section 6 is the conclusion and prospect.
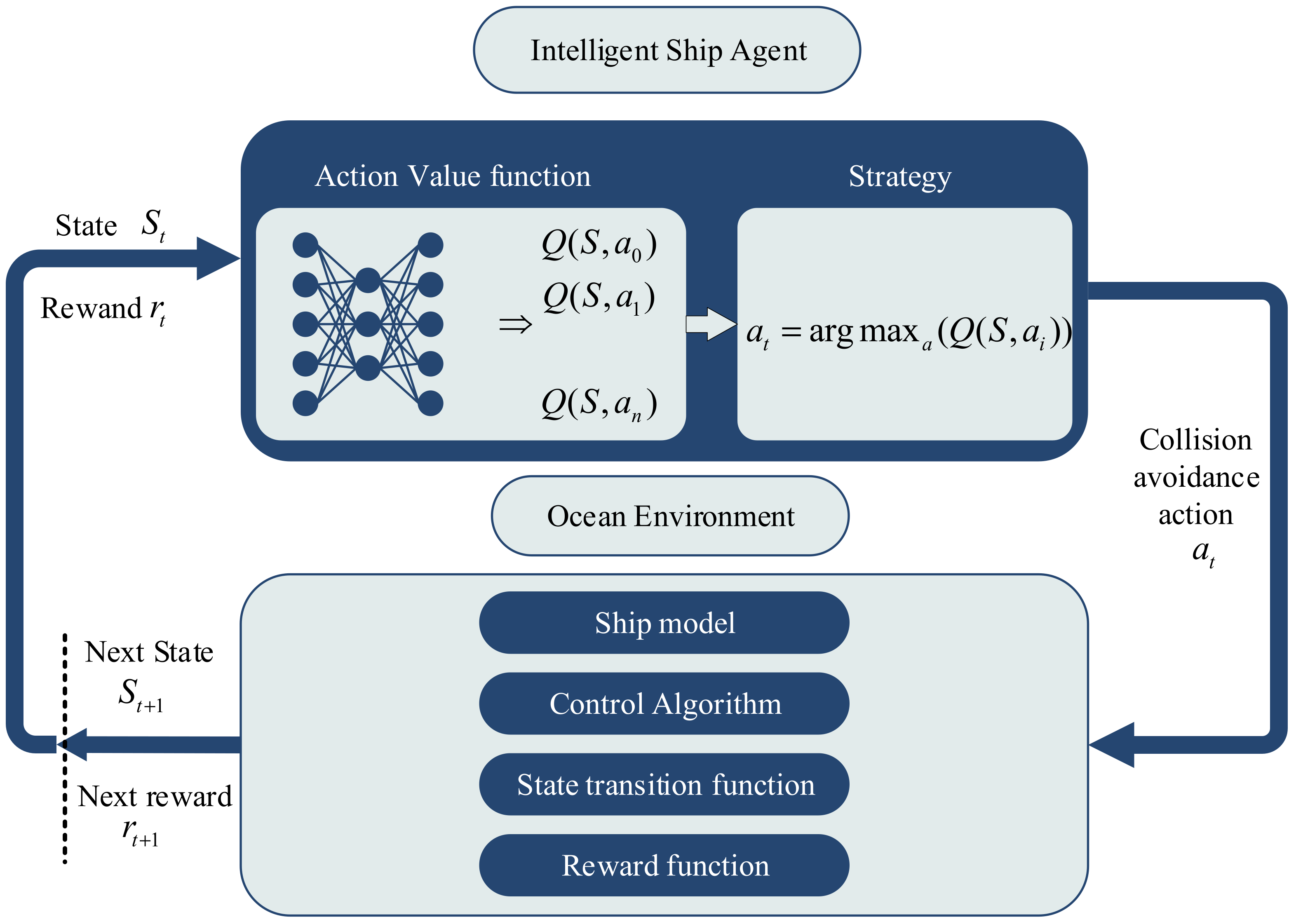
4. RL Algorithm Design
In this section, we will discuss the design of observation state space, action space, neural network model, reward function and training scenarios in the RL algorithm.
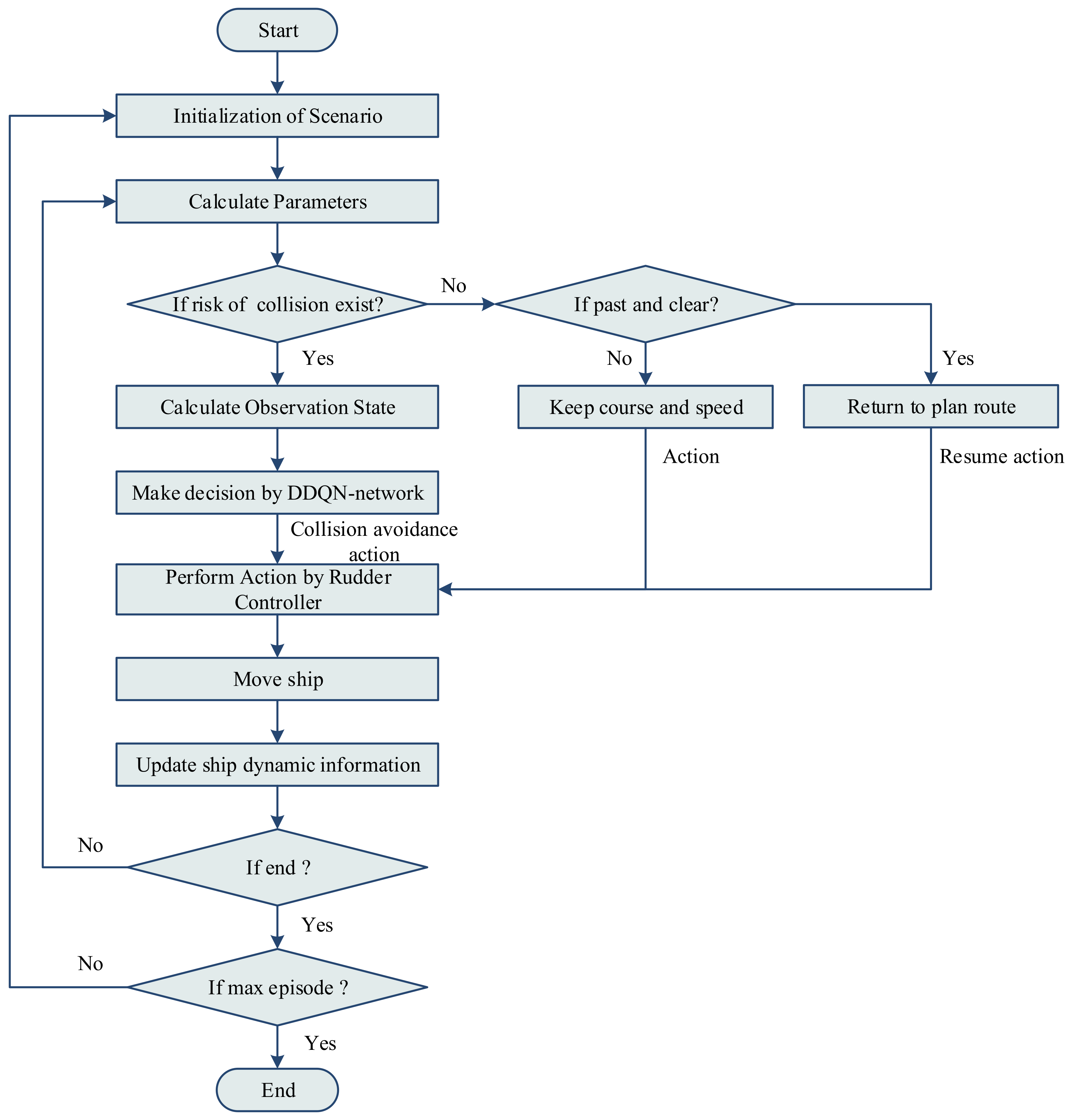
Figure 2 shows the flow chart of the algorithm. At the beginning of each episode, the scenario is first initialized and randomly selected from the scenario set. Then, distance of the closest point of approach (DCPA), time to the closest point of approach (TCPA), range, bearing and other parameters are calculated. If there is a risk of collision, the observation state will be input to the RL algorithm to generate a collision avoidance decision; if there is no danger of collision, the ship will be judged as to whether it has passed and cleared the target ship, and if not, the ship will continue to sail in the same course and at the same speed; if it has passed and cleared the target vessel, the ship will take an action to return to the planned route. The resulting action is fed to the rudder controller, which updates the ship’s dynamic information in conjunction with the motion model. Then, the algorithm judges judge whether the end condition is satisfied: when the distances between the agent ship and target ships are less than the threshold (collision occurs) or the distance to the waypoint is less than the threshold and there is no risk of collision (collision avoidance success), end the round; otherwise continue to execute the cycle. Training ends when the training rounds reach the maximum.
4.1. Observation State
RL algorithms rely heavily on the input of the observed state, and it can even be argued that the observed state directly influences the learning ability of the agent. In previous studies, environmental states, such as ship kinematic parameters, distance and bearing, have been used as inputs, but raw, unprocessed data are difficult to learn and often require a deeper and wider network structure to process. In this paper, we use an approach that quantifies the predicted hazardous areas where future collisions are likely to occur by the dynamic information received from external sensors about obstacles and target ships as the observation states of the DNN. This approach clusters several similar collision avoidance scenarios.
In past research, researchers have usually used the predict area of danger (PAD) model to predict the areas where ships may collide in the future. Junji Fukuto and Hayama Imazu proposed obstacle zone by target (OZT), a method based on risk evaluation circle, to predict the danger zone of collision between ships [
29].
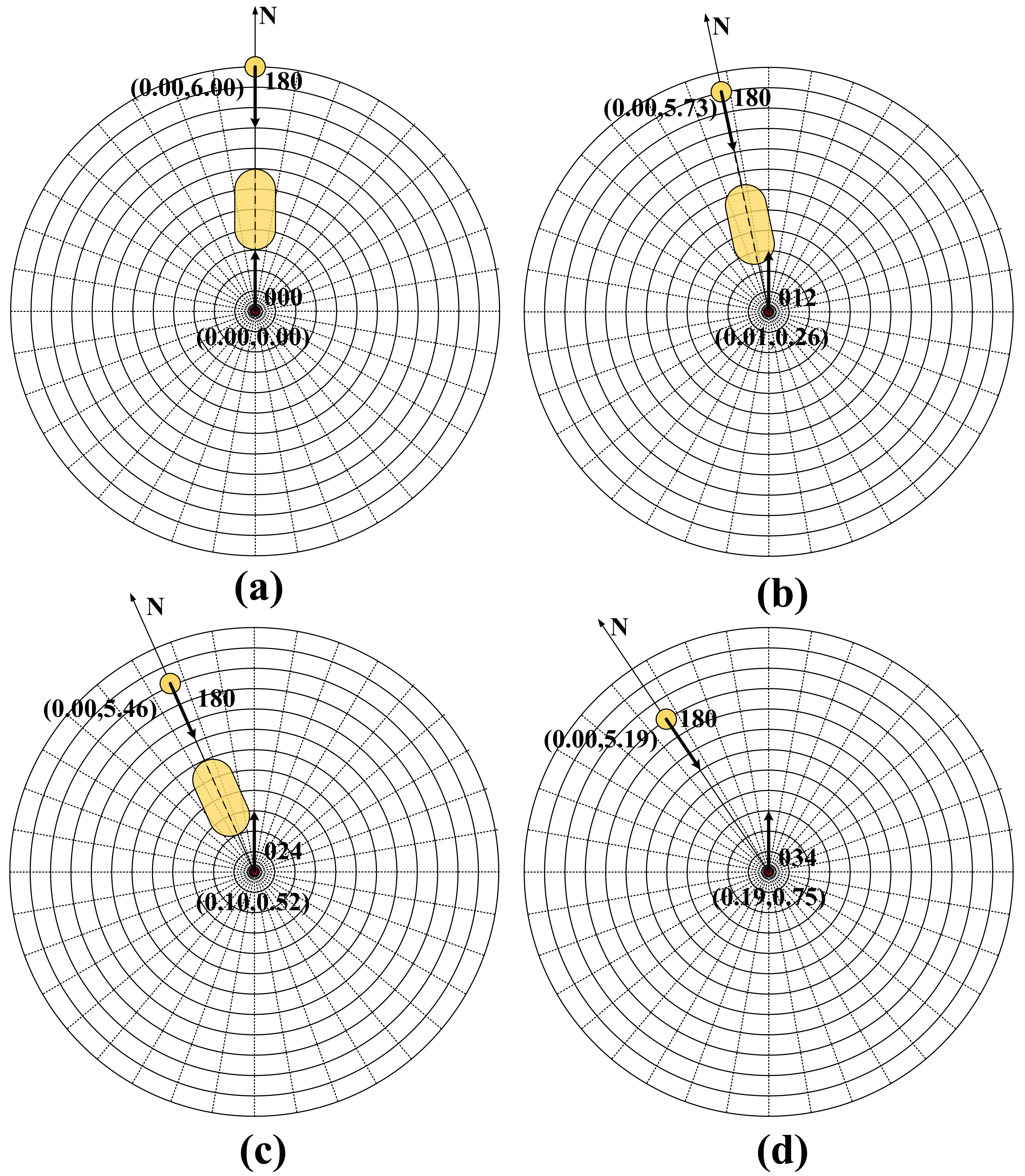
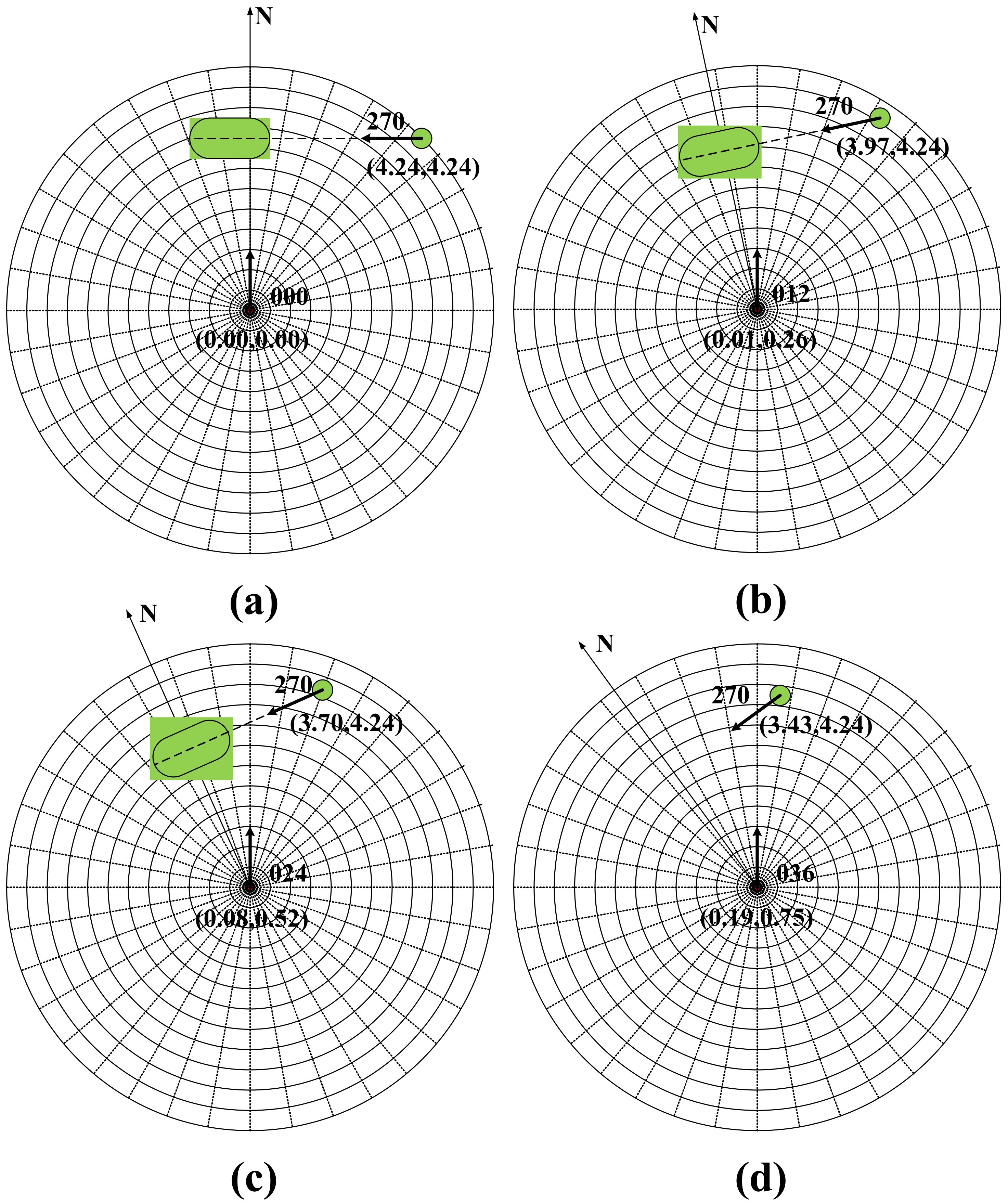
Figure 3a shows the PAD, and
Figure 3b shows the OZT; however, neither the OZT nor the PAD takes into account the actual course of the ship. Based on the OZT and PAD, we simplify the prediction of dangerous areas, take the actual course of the agent ship into account and filter the ships without risk of collision, which can avoid the redundancy of plotting.
Normally, the navigation status of ships involves course and speed, so the position of collision is usually near the closest point of approach (CPA) of the two ships. Therefore, the dangerous area shall be a circular area; the center of area is the CPA of the target ship, and the radius is the safety passing distance (SPD). It is the ordinary practice of seamen and good seamanship for seafarers to avoid crossing the bow of the other vessel when the two vessels meet. Thus, a longer distance should be reserved when crossing the other ship’s bow to avoid invading the others ship domain. Thus, the predicted hazardous area shall be extended for bow crossing distance along the heading direction of the target ship. The agent ship shall avoid entering this area, as shown in
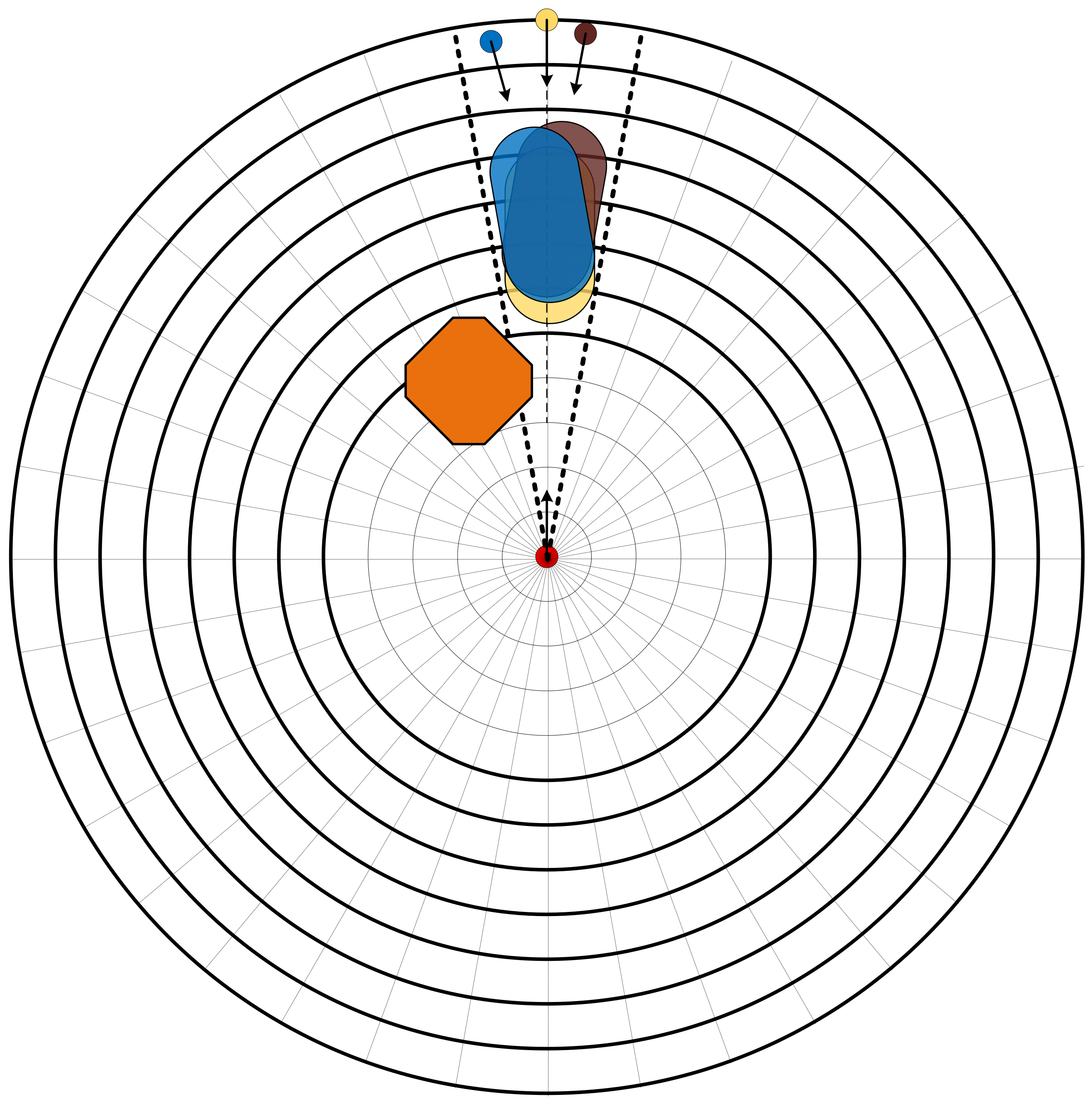
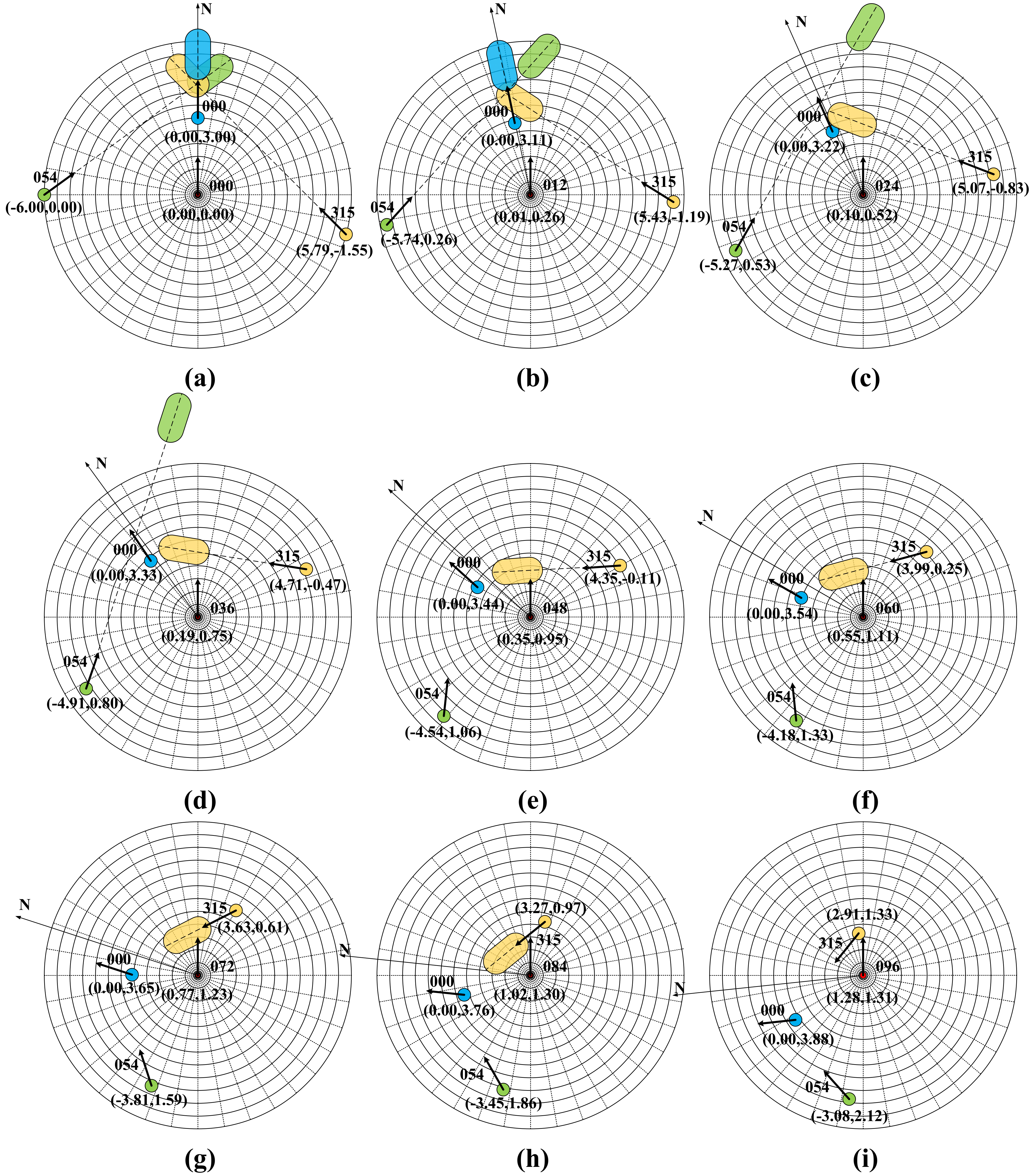
Figure 3c. As the input of the neural network can only be a vector of fixed dimensionality, the algorithm should have the ability to process multiple ships at the same time. Therefore, in order to deal with this problem, we use the grid method to vectorize the predicted hazardous area to ensure that the observation vector can maintain the same dimension, regardless of the number of target ships. As shown in
Figure 4, we adopt a concentric circle grid processing centered on the agent ship and extending outwards in all directions at fixed radius intervals and angular intervals. Take the ship’s course as the starting point and clockwise as the positive direction to set the position. When the predicted hazardous area overlaps with the grid map, the component of the observation vector is set to 1; otherwise, it is set to 0. After repeated attempts, the distance and angle interval of 0.5 NM and 10 degrees, respectively, are taken as the best values (
Table 1). Therefore, the design input dimension of the algorithm is 1 × 433, with the 433rd component indicating that the collision risk area falls outside 6NM. This method can cluster similar scenes and also be used to display static obstructions. As shown in
Figure 4, the red circle represents the agent ship, and the yellow, blue and brown circles and capsule-shaped areas represent the target ship and the predicted hazardous area, respectively. The orange polygons represent static obstructions.
Figure 4 simulates a situation where the agent ship and three target ships meet at the same time. According to the COLREGs, the agent ship and the three target ships all constitute a pair head-on situation. Through this observation method, it can be found that the observation states between the agent ship and the three target ships are the same, which means that the agent can identify these three meeting situations as one, narrowing the observation state space.
4.2. Action Space
4.2.1. COLREGs
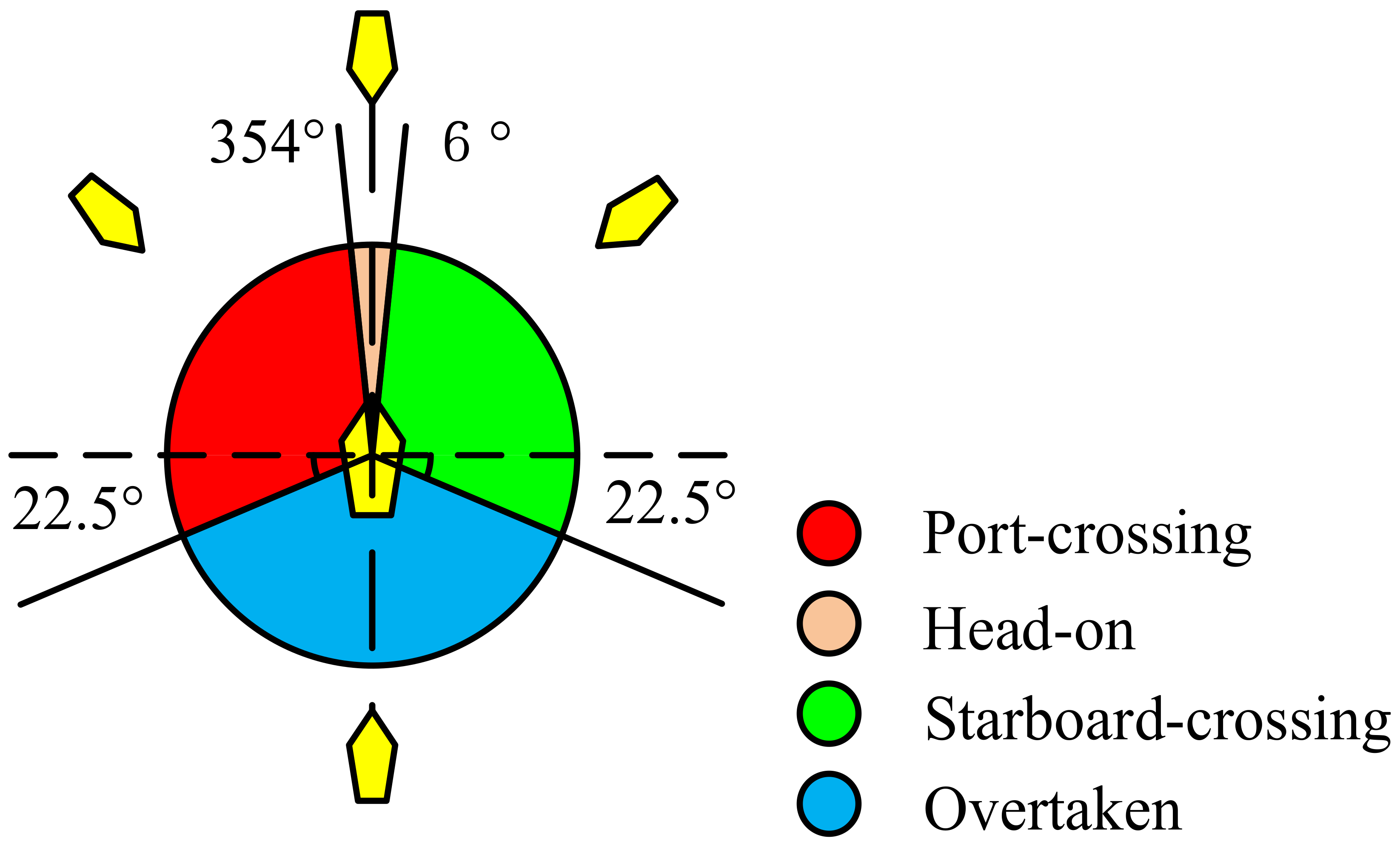
The importance of collision avoidance in navigational watch is recognized by the maritime community, as it often results in huge losses of life, cargo and ships, as well as serious pollution of the water environment. Furthermore, ship collisions often account for the largest proportion of maritime accidents. Many of the requirements of the International Convention on Standards of Training, Certification and Watchkeeping for Seafarers (STCW) for the officer’s navigational watch responsibility relate to collision avoidance at sea. In October 1972, the maritime departments of governments of various countries signed and adopted the 1972 Convention on the International Regulations for Preventing Collisions at Sea. After six amendments, the 1972 Convention on the International Regulations for Preventing Collisions at Sea became the current rules for preventing collisions. The rules clearly specify the applicable ships, waters and collision avoidance actions to be taken. The environment involved in a ship’s autonomous collision avoidance system is mainly defined in Part B (steering and sailing rules). Rule 13 (overtaking), rule 14 (head-on situations) and rule 15 (crossing situations) stipulate the judgment of encounter situations between ships, the division of collision avoidance responsibilities and the collision avoidance actions to be taken. A vessel is deemed to be overtaking when coming up to another vessel from a direction more than 22.5 degrees abaft her beam. In the case of an overtaking situation, the giving-way vessel shall turn starboard or port to avoid other ships. When two vessels are meeting on reciprocal or near reciprocal courses so as to involve risk of collision, such a situation is deemed a head-on situation. In case of head-on situations, each ship shall alter her course to starboard so that each shall pass on the port side of the other. When two vessels are crossing so as to involve risk of collision, the vessel with the other on her own starboard side is the give-way vessel. In the crossing situation, the give-way vessel shall keep out of the way and alter her course to starboard to pass through the stern of the other ship if the circumstances of the case admit. In
Figure 5, the red area represents the port crossing situation with other ships, the green area represents the starboard crossing situation, the pink area represents the head-on situation and the blue area represents the overtaking situation in which the agent ship is the overtaken vessel.
Figure 6 shows the actions to be taken by each ship according to the COLREGs.
4.2.2. Action Space Design
The ship collision avoidance process usually consists of four stages:
Environmental perception: detect the target ship; determine the encounter situation, whether there is a risk of collision and the time required to take collision avoidance action.
Take collision avoidance action: the give-way vessel shall take corresponding actions to keep clear other ships in accordance with COLREGs.
Keep course and speed: the give-way vessel shall drive in a straight line at a constant speed along the collision avoidance course until finally past and clear.
Return to the planned route: the ship shall return to the original planned route after finally past and clear.
In a complete collision avoidance process, the time occupied by keeping course, the speed stage and returning to the planned route is much longer than that required to take collision avoidance action, but the decision making is the key part of ship collision avoidance. Therefore, the application of an RL algorithm in the whole collision avoidance process will increase the complexity of the algorithm and cause the problem of difficult convergence of the model. In this paper, the collision avoidance algorithm is only used to take collision avoidance actions, which greatly improves the efficiency and robustness of the algorithm.
In the process of collision avoidance, the collision avoidance actions that can be taken by the OOW include steering course and changing speed. Due to the high inertia of the vessel, it is difficult to change speed, and the steering action is easily detected by the target vessel. The OOW therefore usually takes steering avoidance measures. In navigation practice, there are usually two kinds of decisions made by the pilot: one is to control the rudder angle, which turns the rudder or turns back at the appropriate position through empirical judgment to steer the ship to avoid collision; the other is to control the course of the ship an adjust the course to the appropriate course through a series of steering orders. As the first method depends on the maneuvering characteristics of ships, different ships adopt different rudder angles for collision avoidance under the same encounter, but the optimal steering angle is the same. Therefore, we take the second collision avoidance method as the action space, that is, a series of discrete steering orders to change course.
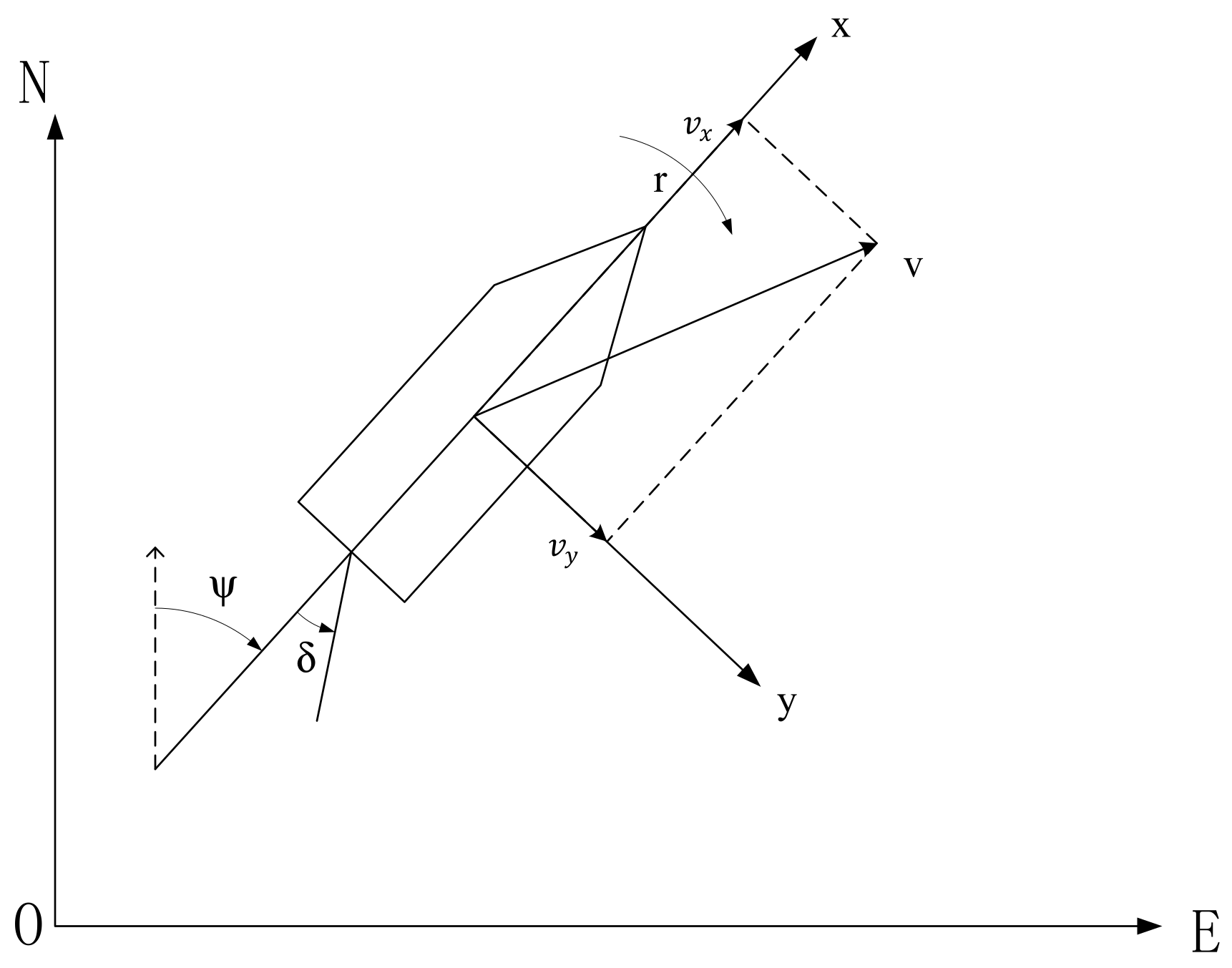
Usually, the six degrees of freedom (DOF) model is used to describe the motion of the ship, but in the field of ship collision avoidance the, 3 DOF model is usually used to describe ship motion. The coordinate system of the 3DOF model is shown in
Figure 7. In
Figure 7,
and
are the transverse component and longitudinal component of velocity, respectively;
and
are speed and head turning angular speed, respectively;
is the course of the ship, and
is the rudder angle. To simulate maneuverability of the ship, we use the Nomoto equation [
30] to calculate the ship motion, as expressed in Equation (1). In addition, the rudder angle is calculated by the PD controller (Equation (2)):
where
is the course of the ship;
is the target course of the ship;
is the yow rate;
and
are the index parameters of ship maneuverability in clam water;
and
are the real rudder angle and command rudder angle, respectively;
is the time constant of the steering gear; and
and
are the controller gain coefficient and the controller differential coefficient, respectively.
According to the above contents and Rule 8 of the COLREGs, if there is sufficient sea-room, alterations of course alone may be the most effective action to avoid a close-quarters situation. The action space of the algorithm is discrete course change angle, the port steering is negative, and the starboard steering is positive, with an interval of
from
to
. The calculation formula of a ship’s course is as follows in Equations (3) and (4):
where
is the course of the ship at the last sampling time, and
is the collision avoidance action.
4.3. Reward Function Design
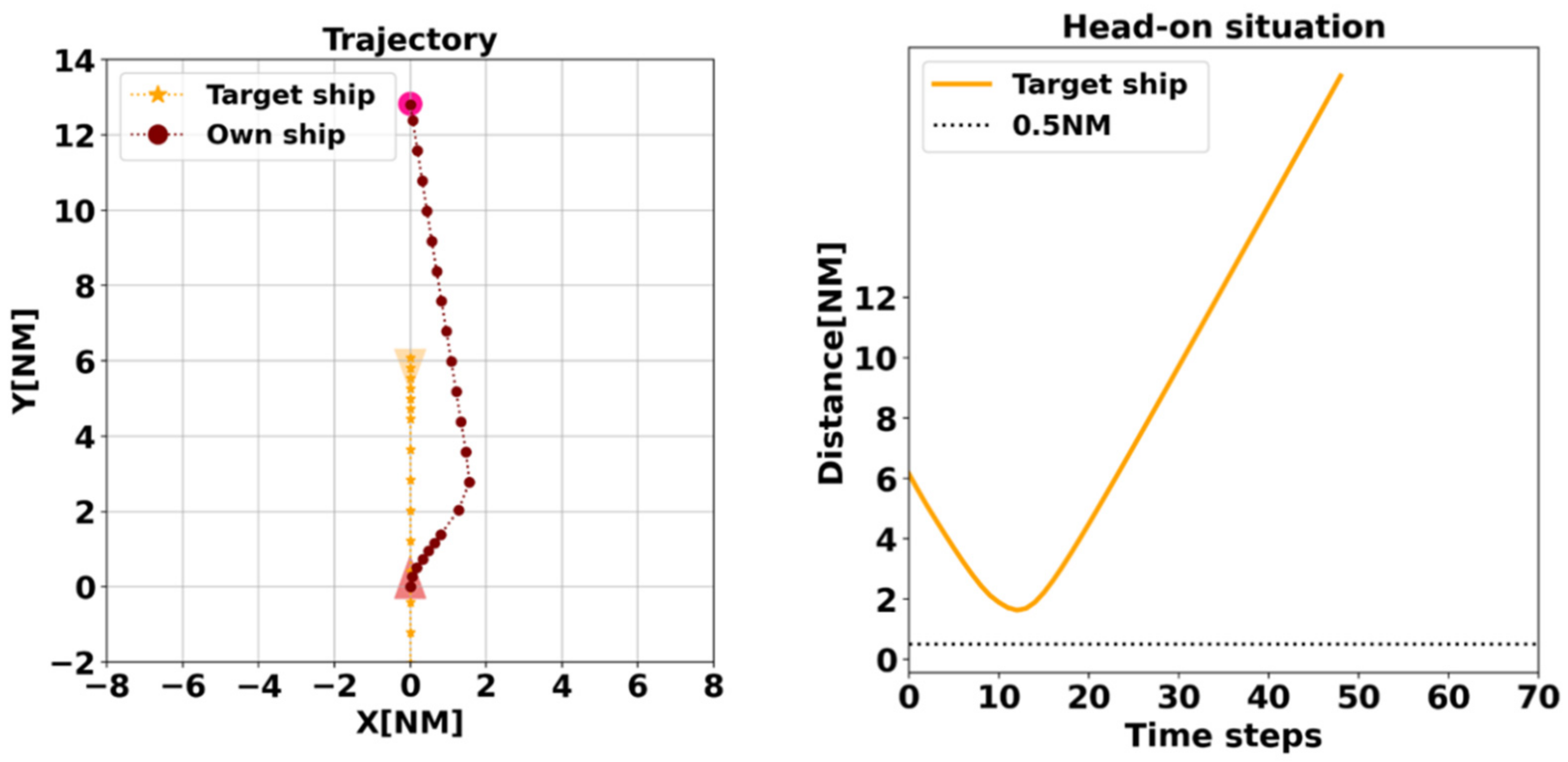
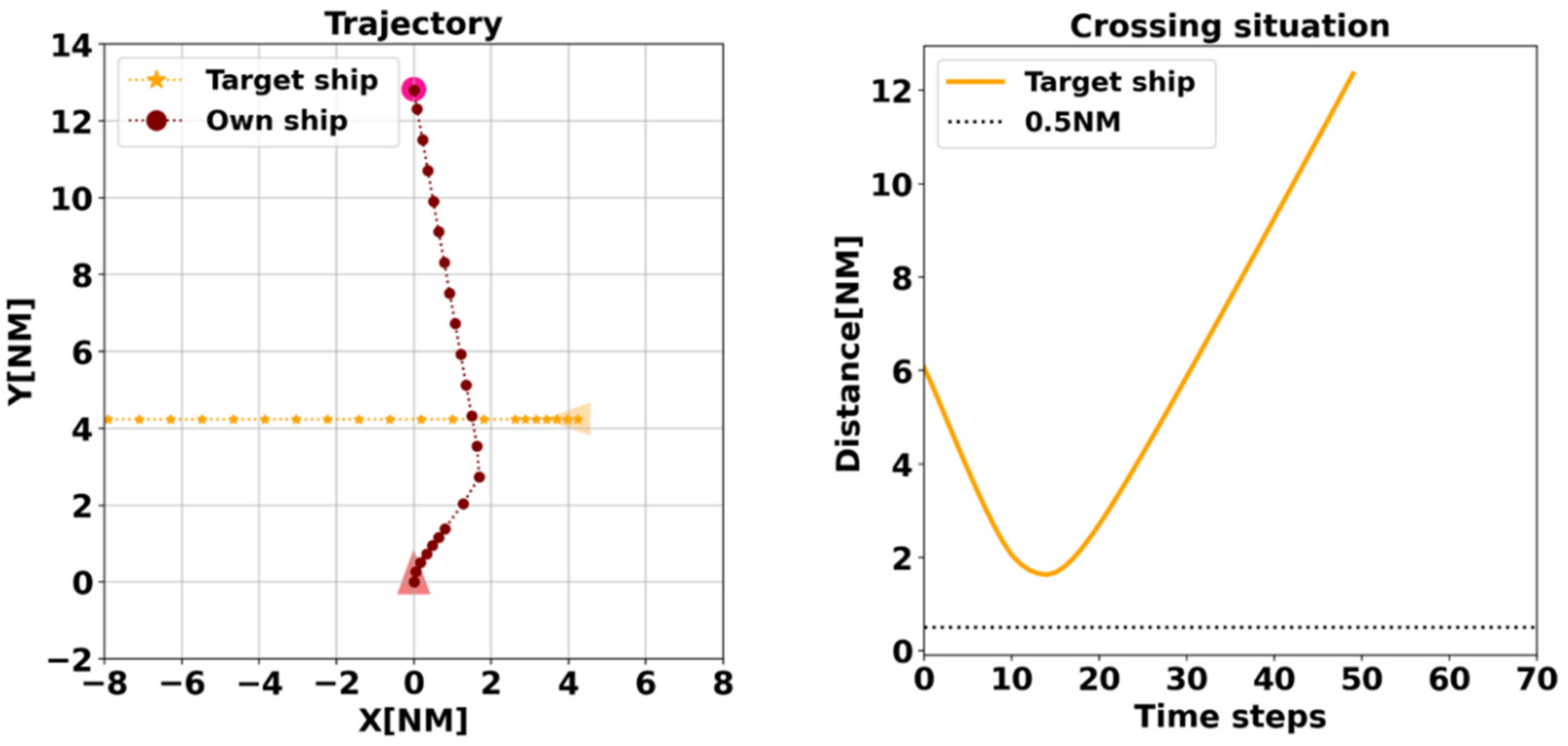
The reward function is the core part of RL and directly affects the learning of the agent. In designing the reward function, we incorporated the COLREGs and expert experience to make the decisions made by the agent more like the results of human operation. Both rule 8 and rule 16 of the COLREGs stipulate collision avoidance actions. The action of the give-way vessel should be positive, made in ample time and with due regard to the observance of good seamanship. According to the recommendation of experts and scholars, collision avoidance usually starts when two ships are 5–8 NM apart. DCPA should be no less than 1 NM when 10,000-ton ships meet in daytime in good visibility, 1.5 NM in night or windy weather and greater than 2 NM in open waters in poor visibility.
In this paper:
When TCPA is less than 0, it is considered that there is no risk of collision (ROC);
When the distance from the target ship is greater than 2 NM and DCPA is less than 1.5 NM, there is considered to be a collision hazard;
When the distance is less than 2 NM and more than 1 NM and DCPA is less than 0.5 NM, a collision hazard exists.
When the distance is less than 1 NM and more than 0.5 NM and if DCPA is less than 0.3 NM, ROC exists.
Collision avoidance is considered to have failed when the distance between the two ships is less than 0.3 NM.
In the overtaking situation, when the distance between the two ships is less than 2 NM and the agent ship is a stand-on ship, the agent ship should take collision avoidance action alone to avoid immediate danger. In a crossing situation, where the distance from target ship is less than 4 NM, the ship should also act alone in order to reserve sufficient distance and time.
The reward function designed in this paper has four components, with a positive reward when the agent successfully avoids the target ship or static obstruction, i.e., when there is no ROC with any target ships (the observation state at the next moment is zero vector). This part of the reward takes the COLREGs and good seamanship into account. When the distance between the agent ship and any of the target ships is less than 0.3 NM, a collision is considered to have occurred, and a larger negative reward is given. When the ship moves into the predicted collision hazardous area, the agent will receive a smaller negative reward. In other cases, the reward is 0.
Five factors are considered when designing the reward for successful collision avoidance, namely the number of steering decisions, the amount of the cumulative steering angle, the deviation distance, the DCPA when clear of the other vessel and compliance with the COLREGs. Rule 8 states that, “Collision avoidance actions shall, be sufficient to allow easy observation by other vessels, as well as avoiding a series of minor changes to course speed”. Therefore, intelligences should minimize the number of turns during collision avoidance and, in particular, should avoid swinging the bow from side to side. According to expert recommendations, the range of steering to avoid collisions should be at least 30 degrees. The effect of the avoidance action should be to clear the ship as much as possible, so the DCPA between the two ships should be as large as possible. In order to meet the practical requirements, the ship should avoid collisions with as few unnecessary detours as possible to save fuel and time costs. Therefore, taking into account the requirements of the above rules and the actual situation, the reward function used in this algorithm is specified as follows.
where
is the number of collision avoidance actions,
is the course change angle and
is the deviation distance. It is assumed that both the agent ship and target ships maintain course and speed, and the deviation distance is calculated by estimating the position of the agent ship when the requirements of returning to the planned route are met. In this paper, the requirements for pass and clear are that the agent ship is sailing along the resumed course without a renewed risk of collision with another ship. In particular, it should be noted that the course to be used for the calculation of the pass and clear should not be the current course of the agent ship but the resumed course towards the planned waypoint.
is the number of target ships, and
is the part of rule reward. If the action complies with the COLREGs,
is +2; otherwise
is −2,
is the state at the next sample moment and
is the distance from the target ship.
is the weight of each part of reward, where
,
,
,
.
4.4. Scenario Set
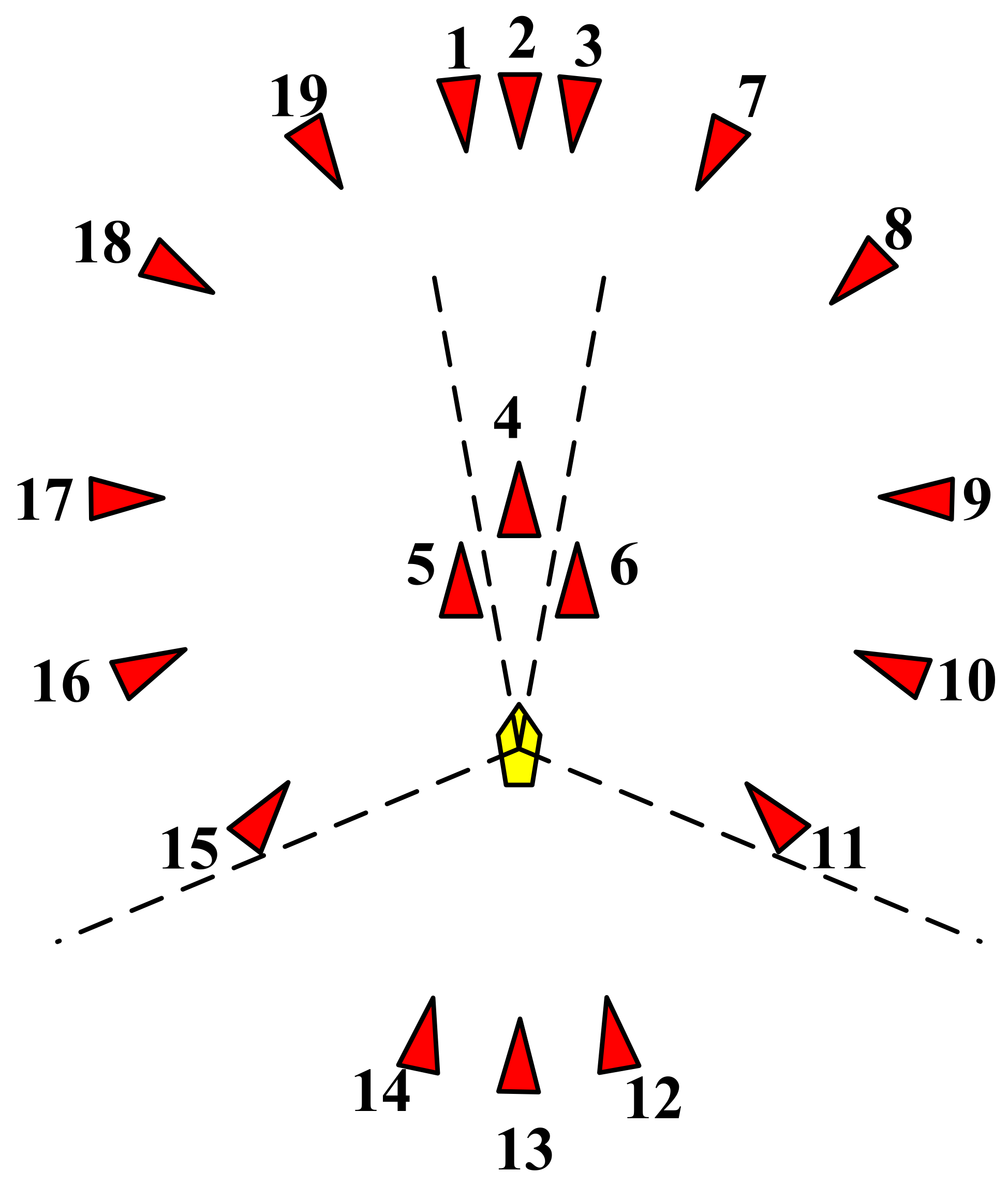
In this paper, encounter situations are divided into six types: head-on situation, port crossing situation, starboard crossing situation, overtaking situation, overtaken situation and other situations. As shown in the
Figure 8, 1 to 3 are head-on situations, 4 to 6 are overtaking situations, 7 to 11 are starboard crossing situations, 12 to 14 are overtaken situations and 15 to 19 are port crossing situations. When setting up the scenarios, the initial ship position, course and speed of each scenario are within a random range to ensure that the DCPAs with target ships are small enough. When designing the initial positions of target ships, they are 6NM away from the agent ship, which is in line with the ordinary practice of seafarers, whereby the OOW usually takes collision avoidance action when the target ship is 5–8 nautical miles away from the agent ship. In addition, the training set contains all the ship encounter situations described in the COLREGs and clusters the scenarios with similar initial observation states. The details of scenarios are shown in
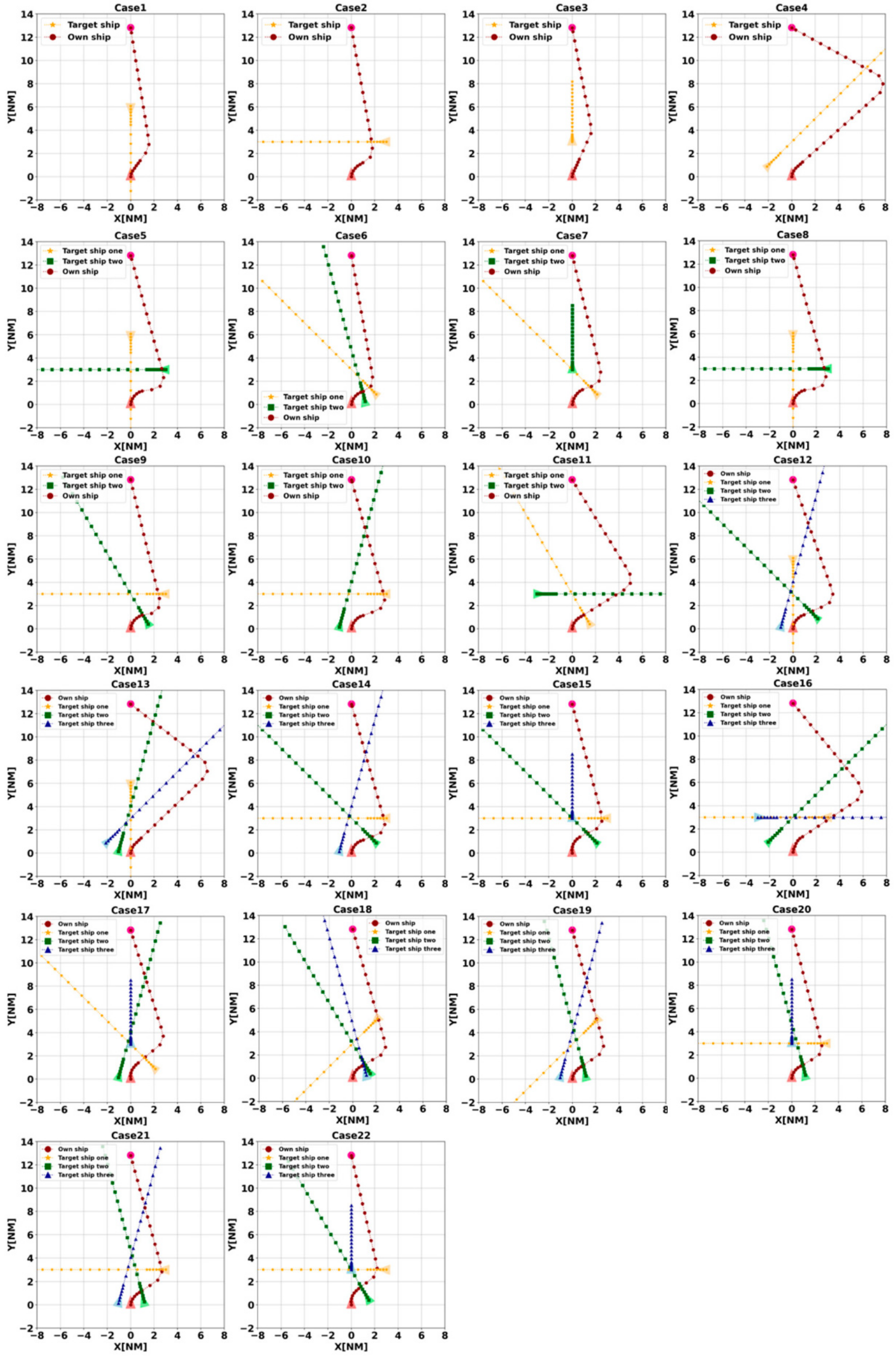
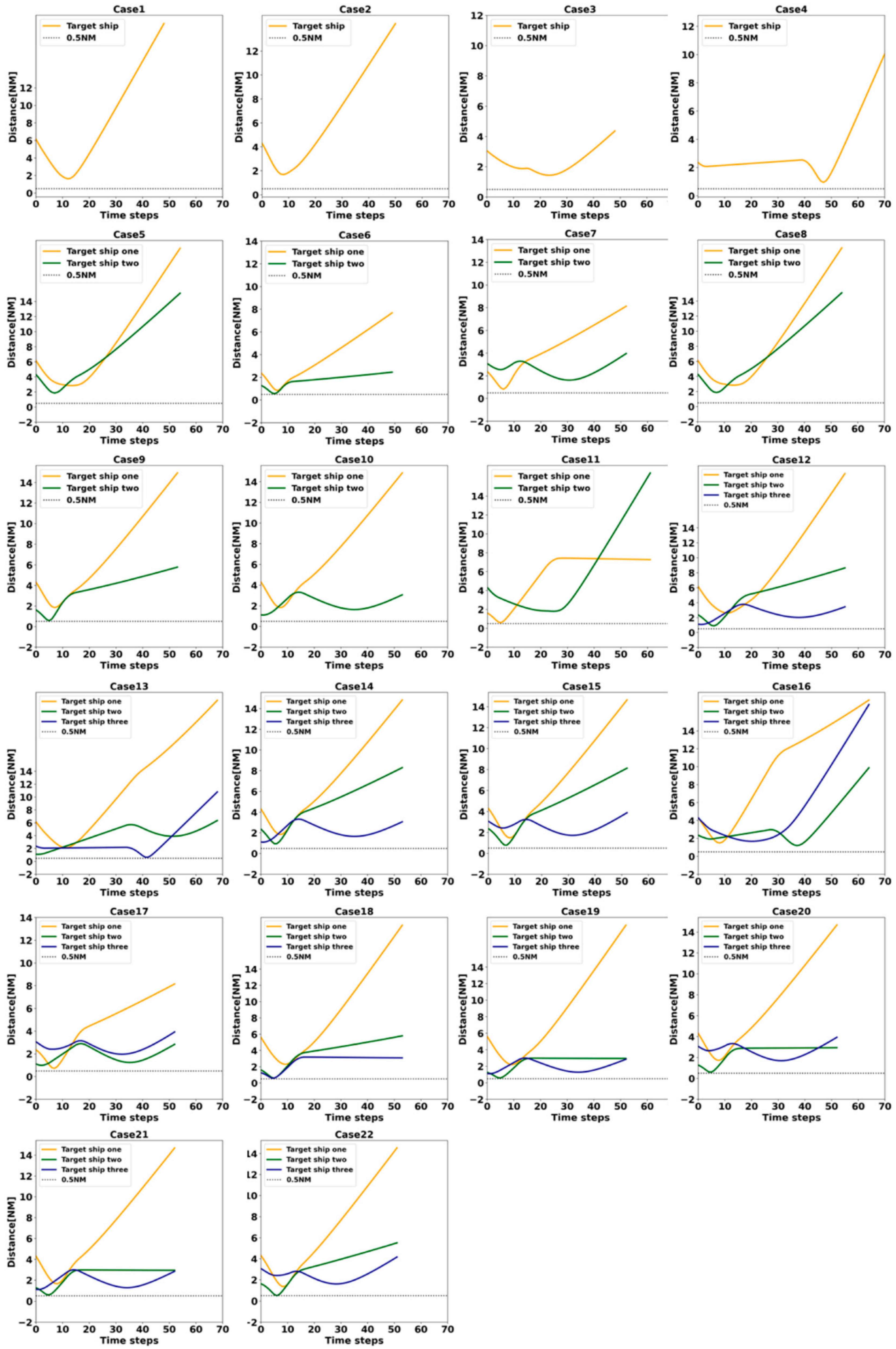
Table 2. The ship’s position is set at (0,0), course is 000 and the destination waypoint is set at (0,13). During training, 19 encounter scenarios are combined through arrangement, combination and random selection, including both simple, single-ship encounter situations and complex, multi-ship encounter situations.
4.5. DDQN with PER
V. Mnih et al. [
28,
31] proposed a deep Q network based on experience replay in 2013 and proposed the concept of target network in 2015, marking the birth of DQN. DQN is a mainstream and widely used deep reinforcement learning algorithm. In fact, once it was launched, it has a great impact on the field of reinforcement learning. When playing any Atari game, it can reach or even surpass the human level, only using the game screen as input. However, DQN often overestimates Q values with maximization deviation due to the maximum operator and bootstrap. To solve this problem, the Deepmind team published a paper in 2015 proposing DDQN, which is solved by setting two independent Q networks and training each network independently [
32]. One Q function is used to select actions, and the other Q function is used to evaluate actions. With experience replay, an agent transitions from one state,
, to the next state,
, by executing a given action,
, in the interaction with the environment and gets a reward,
. The transition information
is stored in an experience pool, and the algorithm learns from the experience pool. In DQN architecture, experience replay is used to ensure that the updates are uncorrelated. However, random or uniform sampling of transition information from playback memory is not the best approach. Instead, transition information can be selected and sampled according to priority. In the training process, the transition information with large temporal difference error (TD error), which is given higher priority, is sampled, which is conducive to the rapid and effective learning of the network [
33].
In this paper, we use DDQN with a prioritized experience replay algorithm. During model training, this algorithm adopts two sets of neural networks with the same structure but different parameters, as well as temporary freezing correlation technology, to effectively solve the overestimation problem of natural DQN and uses prioritized experience replay (PER) [
33] to reduce the amount of experience required for learning. The minibatch in the training set is given priority weight, which reduces the number of iterations in the training process and the training time of the model. The model is shown in
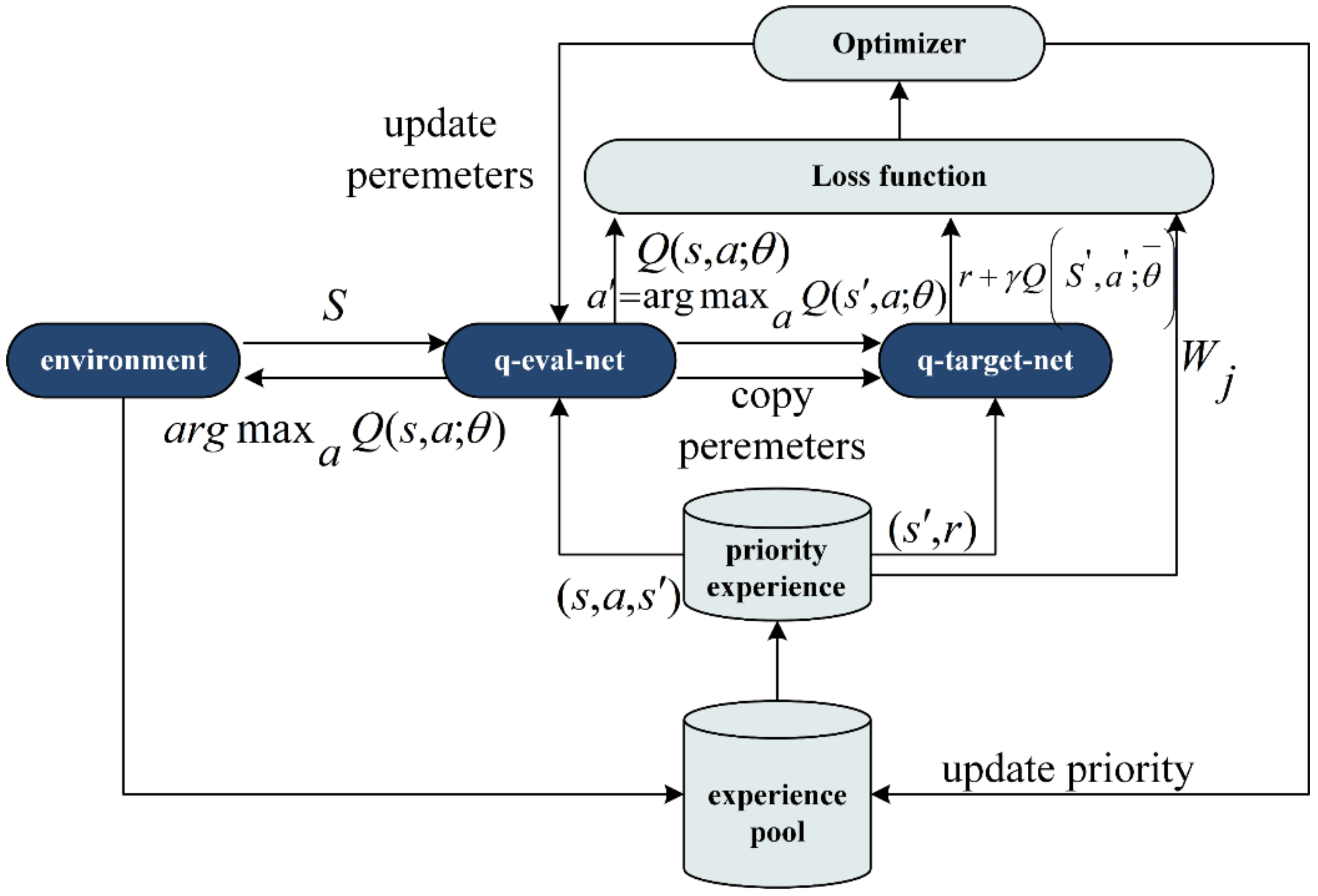
Figure 9.
Where is the parameter of q-eval-net, is the parameter of q-target-net, is the next action and is the reward decay index.
First, the agent observes the environment state and selects the action through q-eval-net and returns it to the environment. Then, the environment returns the reward and the next state to the agent. The agent updates the state and stores in the experience pool. Then comes the learning process: the agent first extracts the prioritized experience from the pool and returns to the next action that can get the maximum reward in the next state by q-eval-net. Then, the next action and next state are input into q-target-net to obtain q-target. Then, the state is input into q-eval-net to get the q-eval of action and calculate the error between q-eval and q-target. The gradient descent method is used to update the parameters. Finally, the priority of experience is updated in the experience pool. After a fixed episode interval, the parameters of q-eval-net are copied to q-target-net.
The priority of experience and the probability of its selection are as follows:
where
is the priority of experience;
is the TD error of experience;
is a hyperparameter, which is a minimal number to prevent the experience with TD equal to 0 from being selected;
is the probability of sampling experience being selected;
is the hyperparameter that controls the preference of sampling in uniform sampling and greedy sampling; and
. When
is 0, the sampling is uniform; when it is 1, the sampling is greedy.
By defining priority and probability, we use Sumtree to select the experience that should be preferentially selected. Sumtree is a tree structure. Each leaf stores the priority, , of each experience. Each branch node has only two forks. The value of the node is the sum of two forks. The top of Sumtree is the sum of all . The batch size is , the range, [0,], is divided into ranges and then random numbers are generated in each interval and selected according to the corresponding strategies (van Hasselt et al., 2015).
With the use of prioritized experience replay, the distribution of samples is changed, which may cause the model to converge to different values. We use importance sampling, which ensures that each sample has a different probability of being selected and that they have the same effect on gradient descent. The importance sampling weight,
, is introduced into the loss function:
where
is the weight of the experience in the memory pool,
is the weight of the experience in the minibatch,
is the memory size,
is a hyperparameter used to offset the effect of prioritized experience replay on convergence results and
. When
, the effect of prior experience is completely offset. Considering the priority of samples, the loss function is:
We used Pytorch to build the neural network, Tkinter to realize the visual display and Matplotlib to draw figures. The network consists of five layers. The first layer is the input layer, with 433 nodes using the LeakyRelu activation function. Three hidden layers, 512 nodes in the first hidden layer, 256 nodes in the second hidden layer and 128 nodes in the third hidden layer, use the Relu activation function. There are 13 nodes in the output layer using the Softmax activation function. See for details of hyperparameters in
Table 3.
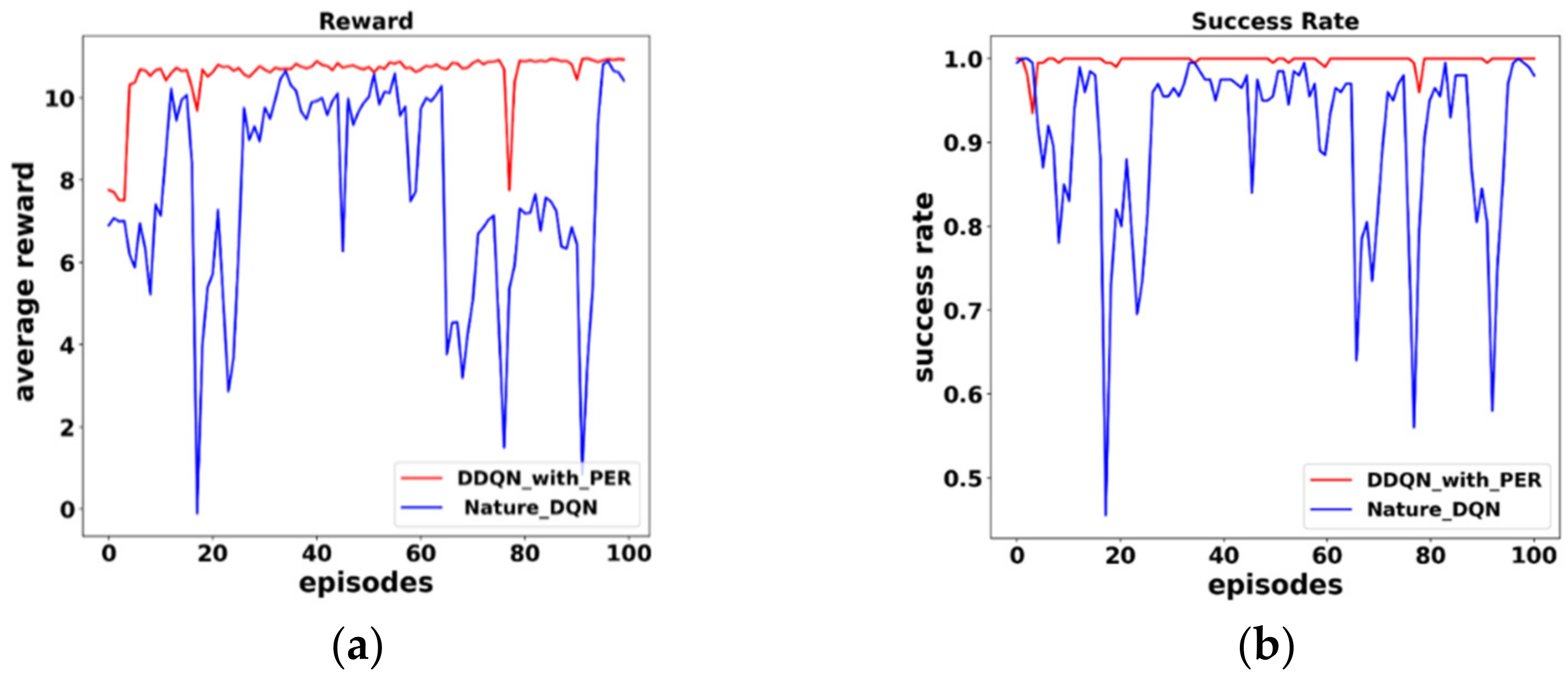
Before training, we compare the performance of DDQN with the PER algorithm with that of Nature DQN. Both algorithms adopt the same hyperparameters and the same single-ship encounter scenario (scenario 2 mentioned above), and a total of 20,000 episodes are trained; the
initial value is 0.9, and every 1000 episodes, ε increases by 0.05. The q-eval-net parameters are copied to q-target-net every 200 episodes. The network is deemed to have converged when rewards received by the agent are almost unchanged and the agent has sailed without collision.
Figure 10a shows the average reward obtained by the agent every 200 episodes; the red line represents DDQN with PER, and the blue line represents Nature DQN.
Figure 10b shows the success rate of agent collision avoidance. The results show that compared with Nature DQN, DDQN with PER can converge rapidly and obtain greater rewards by learning the experience with larger TD error. In terms of success rate, DDQN achieves a success rate of about 99% after a few episodes.
6. Conclusions and Future Work
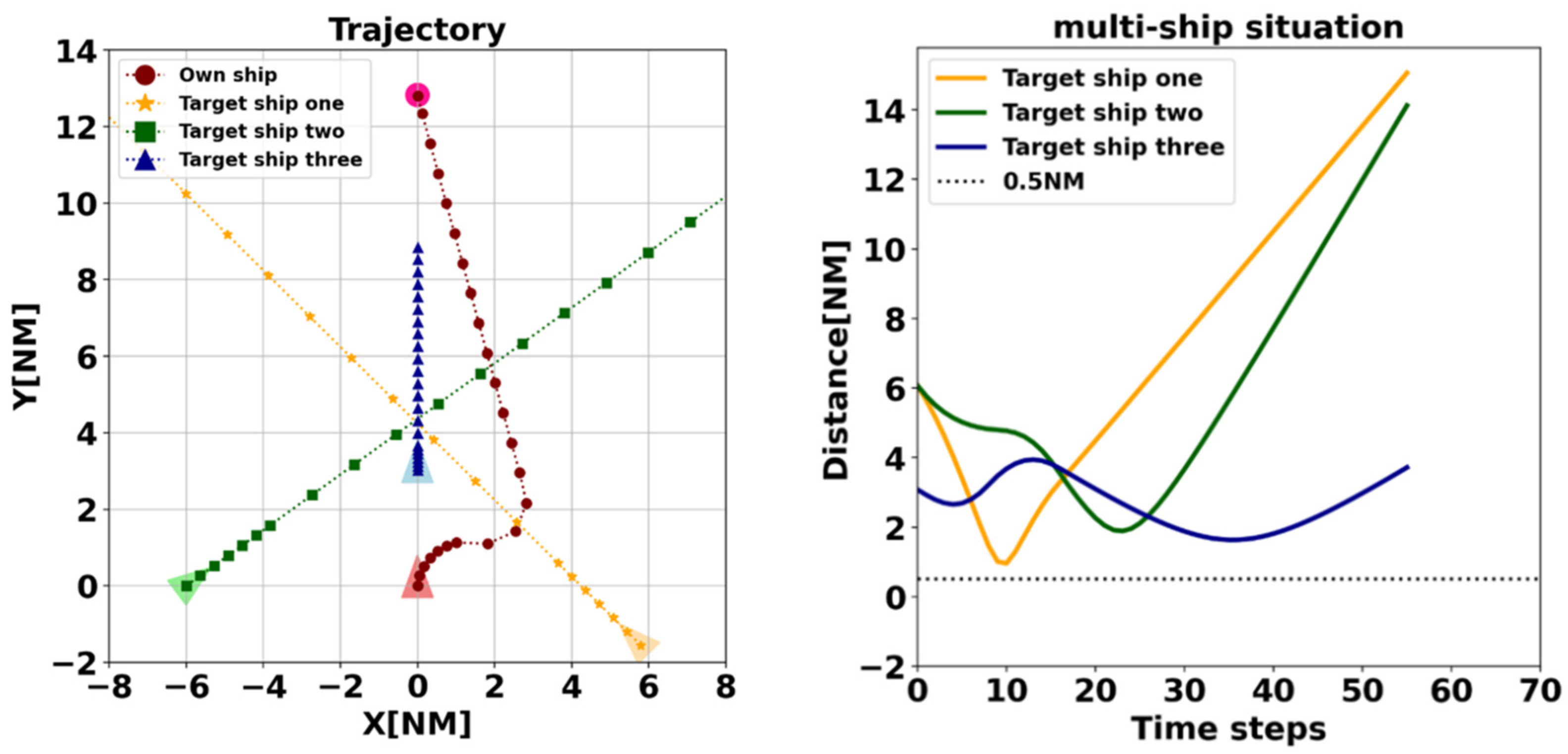
In this paper, a multi-ship automatic collision avoidance method based on DDQN architecture is proposed. We vectorize the predicted hazardous areas as the observation states of the agent so that similar ship encounter scenarios can be clustered and the model can cope with any number of target ships. In order to achieve decision-making of the agent close to that of the human level, we designed a reward function based on the COLREGs and human experience, taking into account the five main factors considered by the OOW in a real collision avoidance situation. To speed up the learning process, DDQN with Prioritized experience replay is used to improve natural DQN. Before training the model, we compare the performance of the traditional DQN with the improved DQN using the same scenario and the same neural network model parameters, and the results show a significant improvement in the learning ability of the agent. Finally, 19 single-vessel collision avoidance scenarios are constructed based on the encounter situations classified by the COLREGs, which are arranged and combined as the training set of the agent. The Imazu problem is used to validate the effectiveness of the collision avoidance algorithm in close-quarters situations. The test results show that the algorithm can cope with multi-vessel encounter situations in crowded open water, even in close-quarters situations. The decisions made by the agent are in line with the COLREGs and close to human-level.
There are shortcomings of this study. For example, in case 4 of the Imazu problem, in a realistic situation at sea, sometimes the OOW may take a greater angle to the right than the agent’s decision to avoid and, after sailing for a sufficient distance, would turn sharply to the left to pass the stern of the target ship to markedly reduce the deviation distance and time. The application of DRL in the field of ship collision avoidance is still in the exploratory stage, and there is still a gap between DRL and realistic collision avoidance at sea. In future research, we will build on this algorithm to design ship navigation, collision avoidance and control algorithms for restricted waters. In realistic multi-vessel collision avoidance scenarios at sea, collision avoidance actions are coordinated through communication, so we will try to use the multi-agent deep reinforcement learning (MADRL) distributed coordination method to implement multi-vessel collision avoidance.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}