
Design and Implementation of 3-D Measurement Method for Container Handling Target

Abstract
:1. Introduction
- (1)
- Directly detect the three-dimensional attitude of the target in RGB images, such as YOLO-6D [13], Pose-RCNN [14], DOPE [15] and other algorithms. The key is to find the center of the target in the RGB image, and then return to the centroid of the target in the camera coordinate system, to realize the pose detection of the target. Although the attitude detection of the target can be performed directly, the algorithm is usually too complicated and the real-time performance is relatively poor, so it must rely on high-performance computers.
- (2)
- Define multiple target attitudes in advance as annotation information, and transform the attitude estimation problem into a classification problem. This method is often used for attitude detection of non-cooperative targets [16,17]. For example, Sharma et al. [18], at Stanford University, proposed a non-cooperative target attitude estimation method, based on convolutional neural network. However, the actual application of the target attitude changes was diverse and could not be directly applied.
- (3)
- The deep learning network is combined with traditional image processing methods to solve the target attitude by establishing a model [19,20]. This method can not only detect targets well in environments with poor lighting and weather conditions, but also greatly reduces the complexity of the model, so that it can meet the requirements of real-time detection in embedded computing devices with low performance and limited working space. Our team used the above methods to identify and measure the truck wheel target [21] and the top hole of the container corner [22] in the early stage, but could only complete the measurement in a single direction, and could not measure the attitude of the container in three dimensions with the methods.
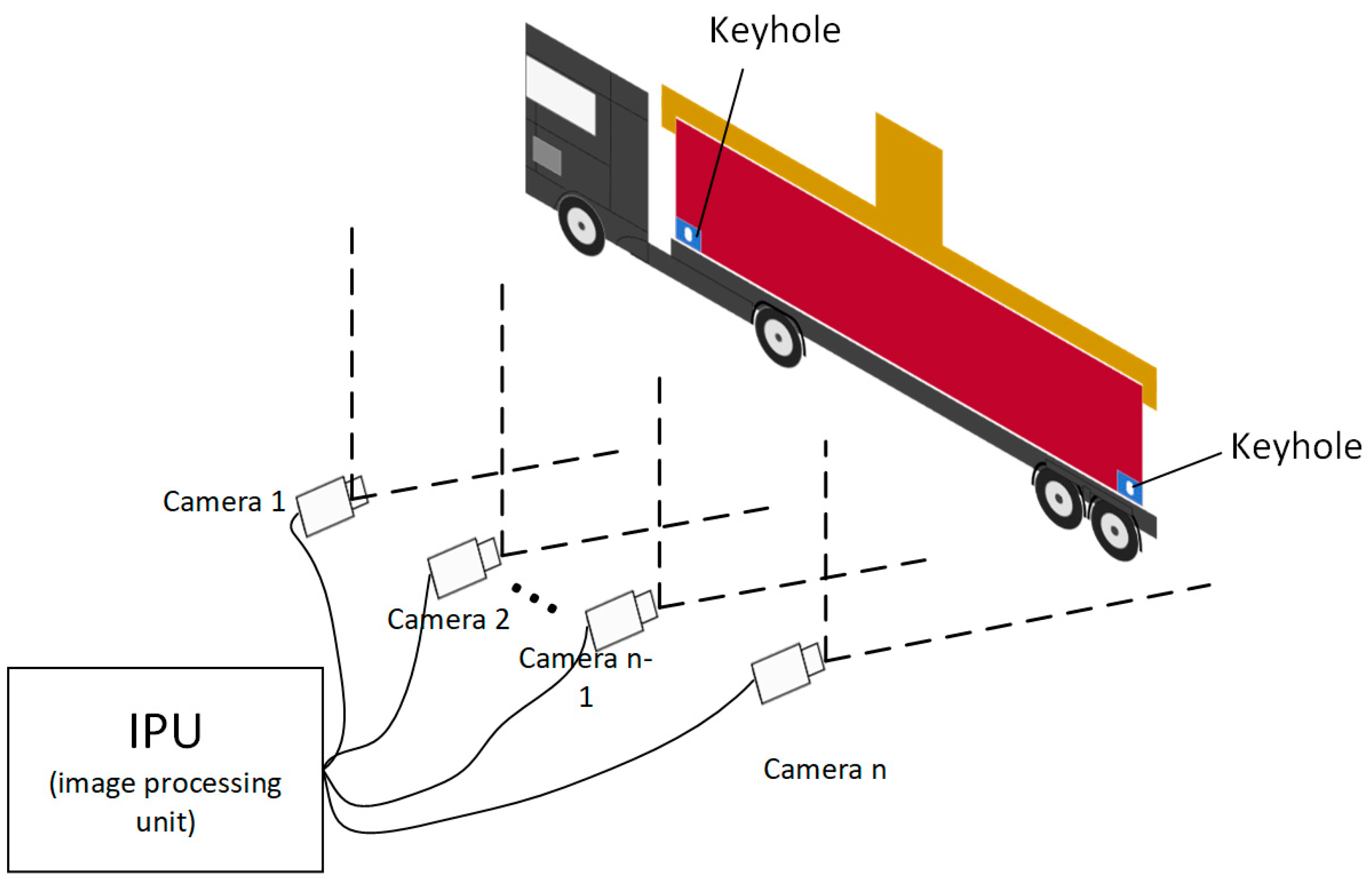
2. Vision-Based Measurement System
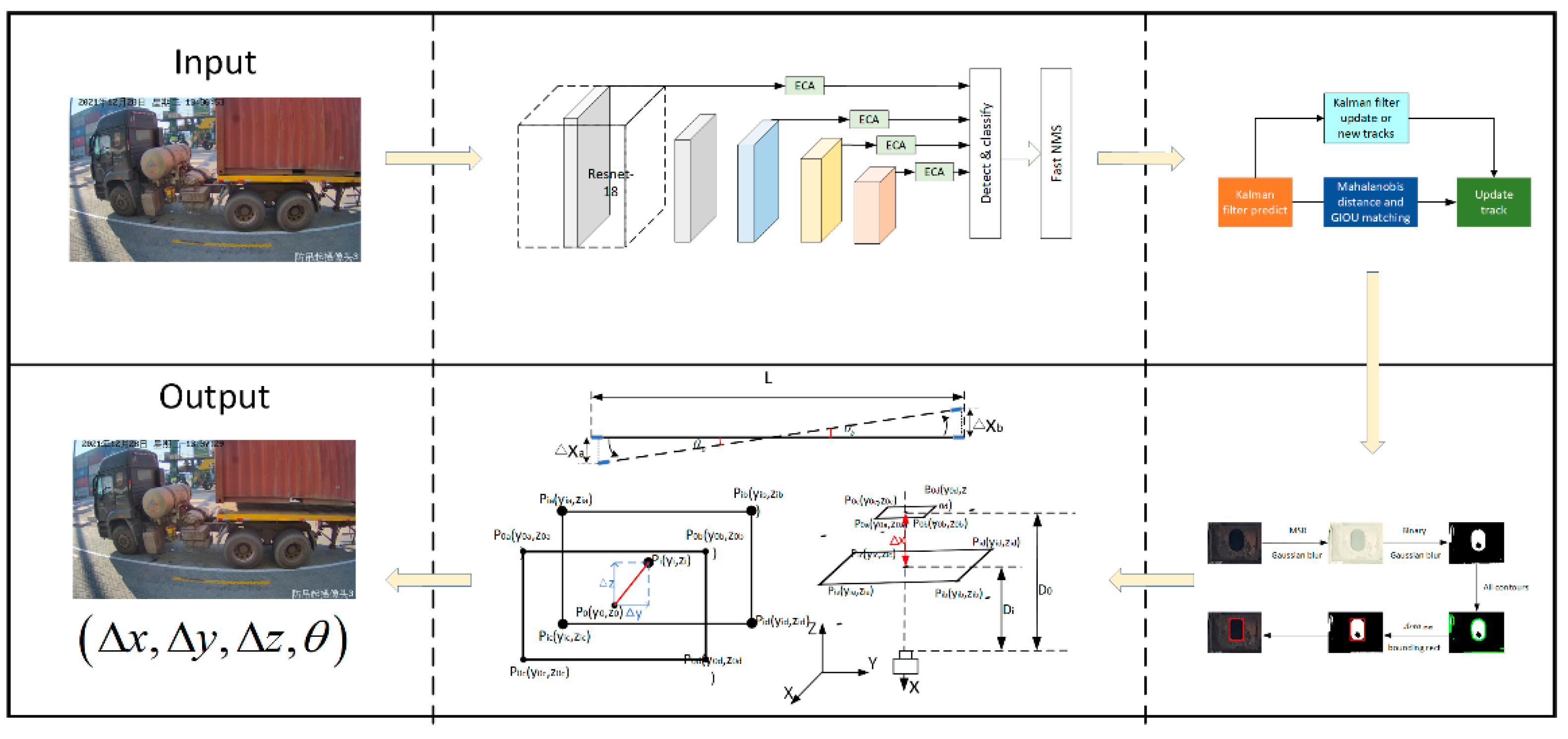
3. Visual Measurement Algorithm
3.1. Detection-Based Tracking Algorithm
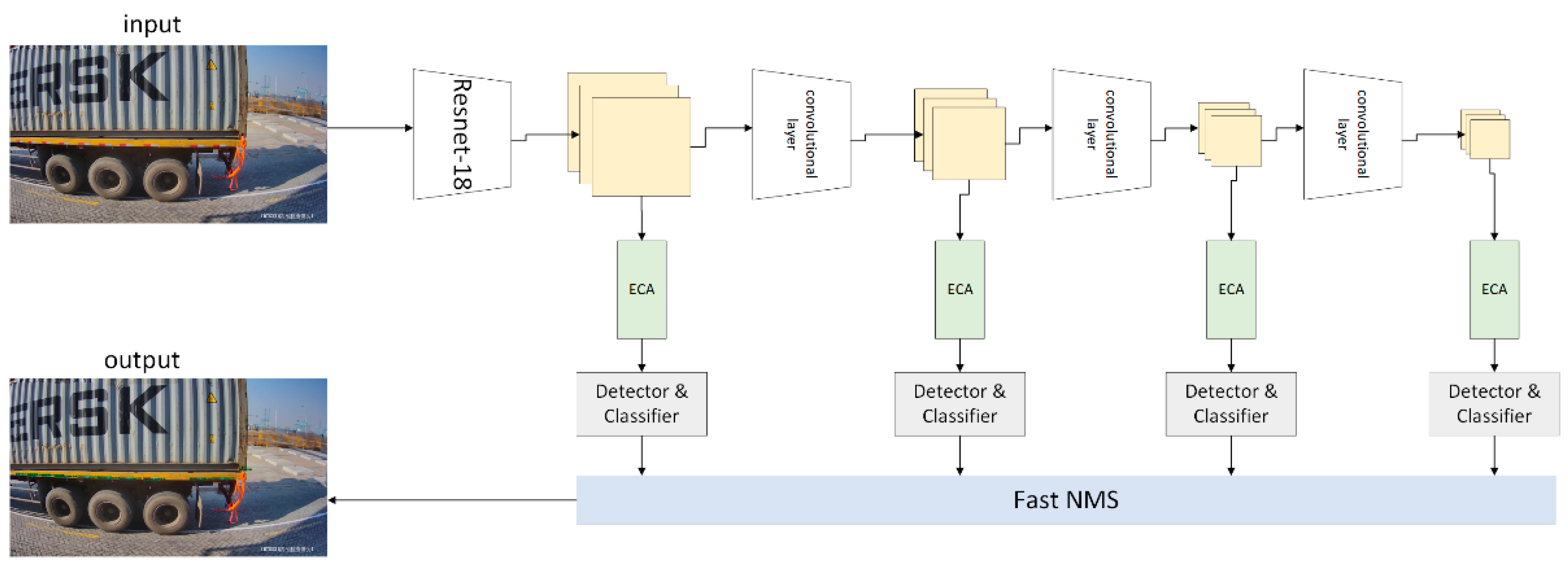
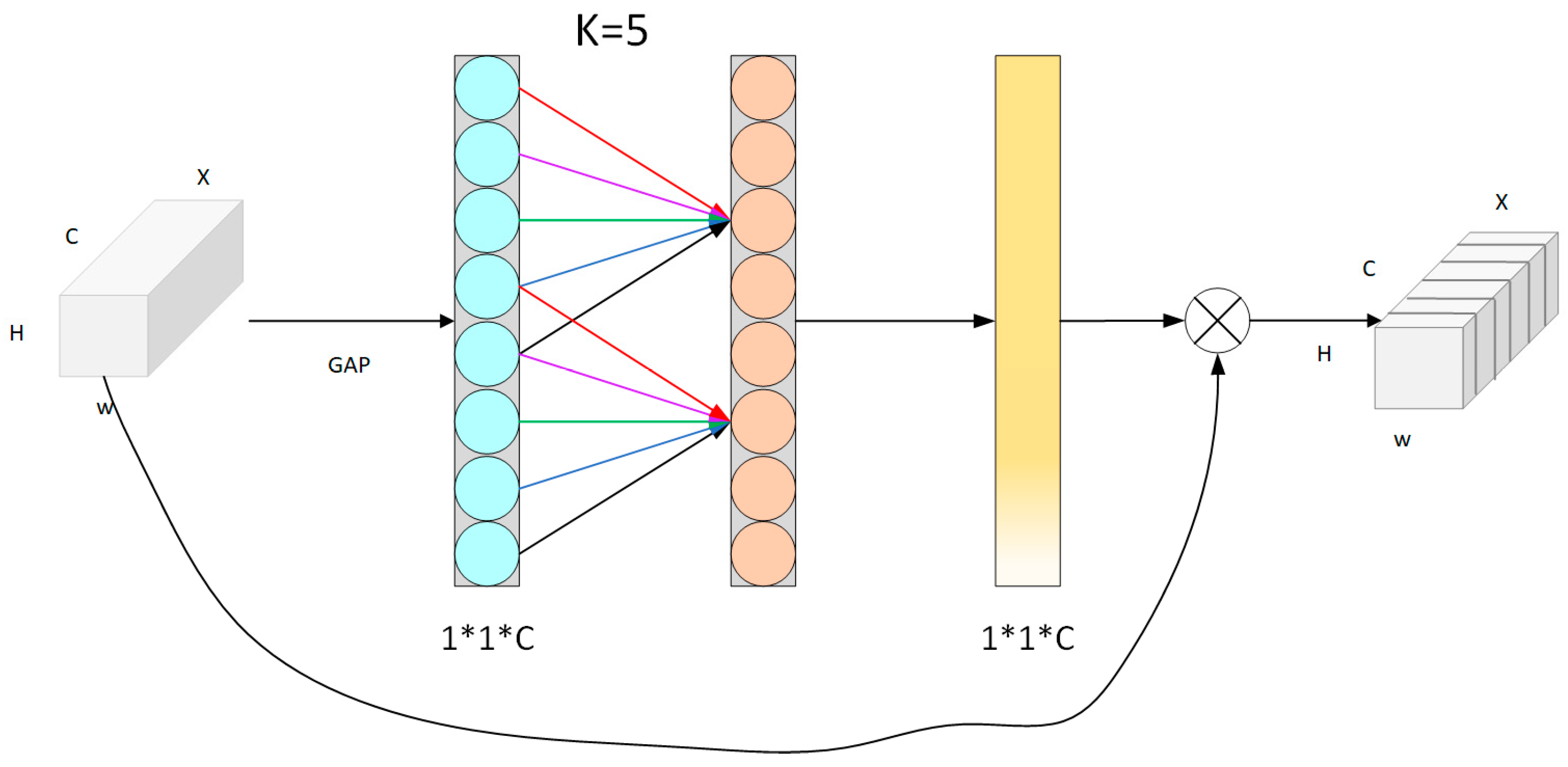
3.1.1. Target Detection Algorithm
3.1.2. Tracking Algorithm
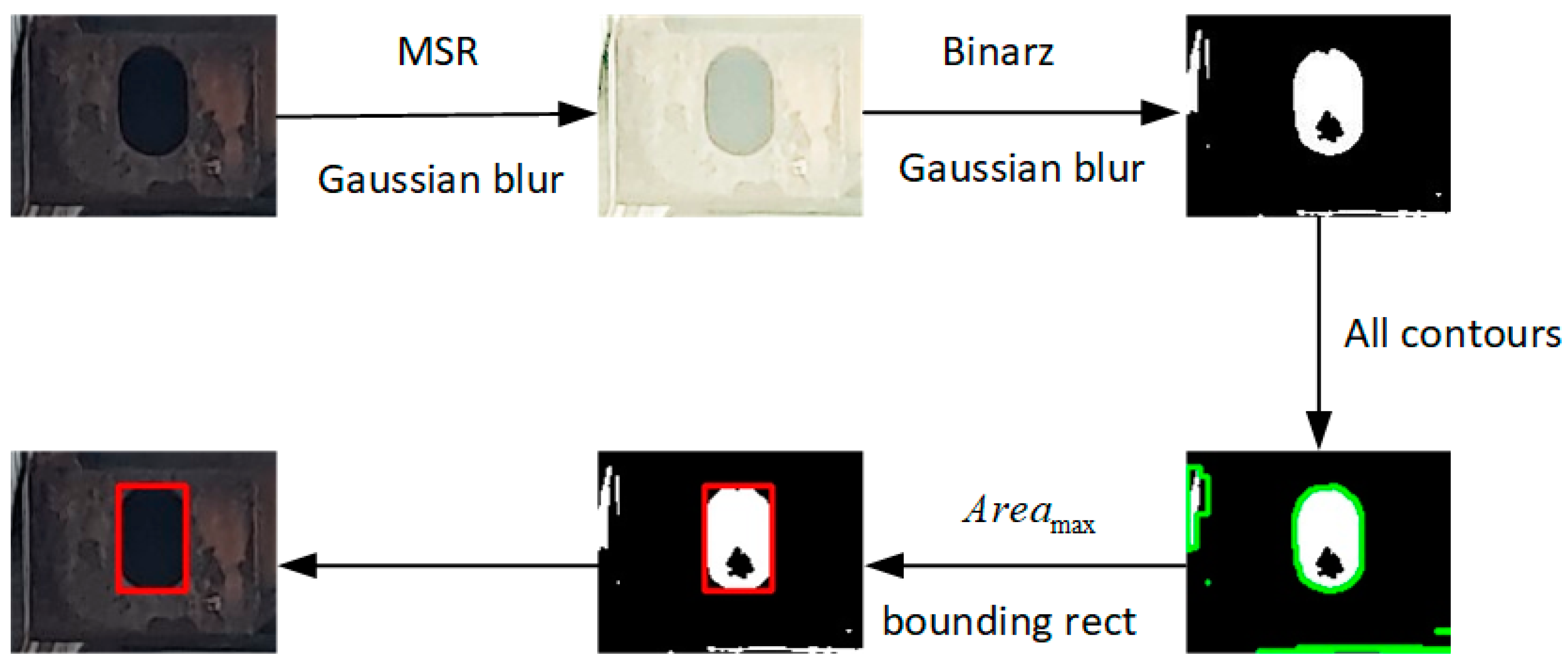
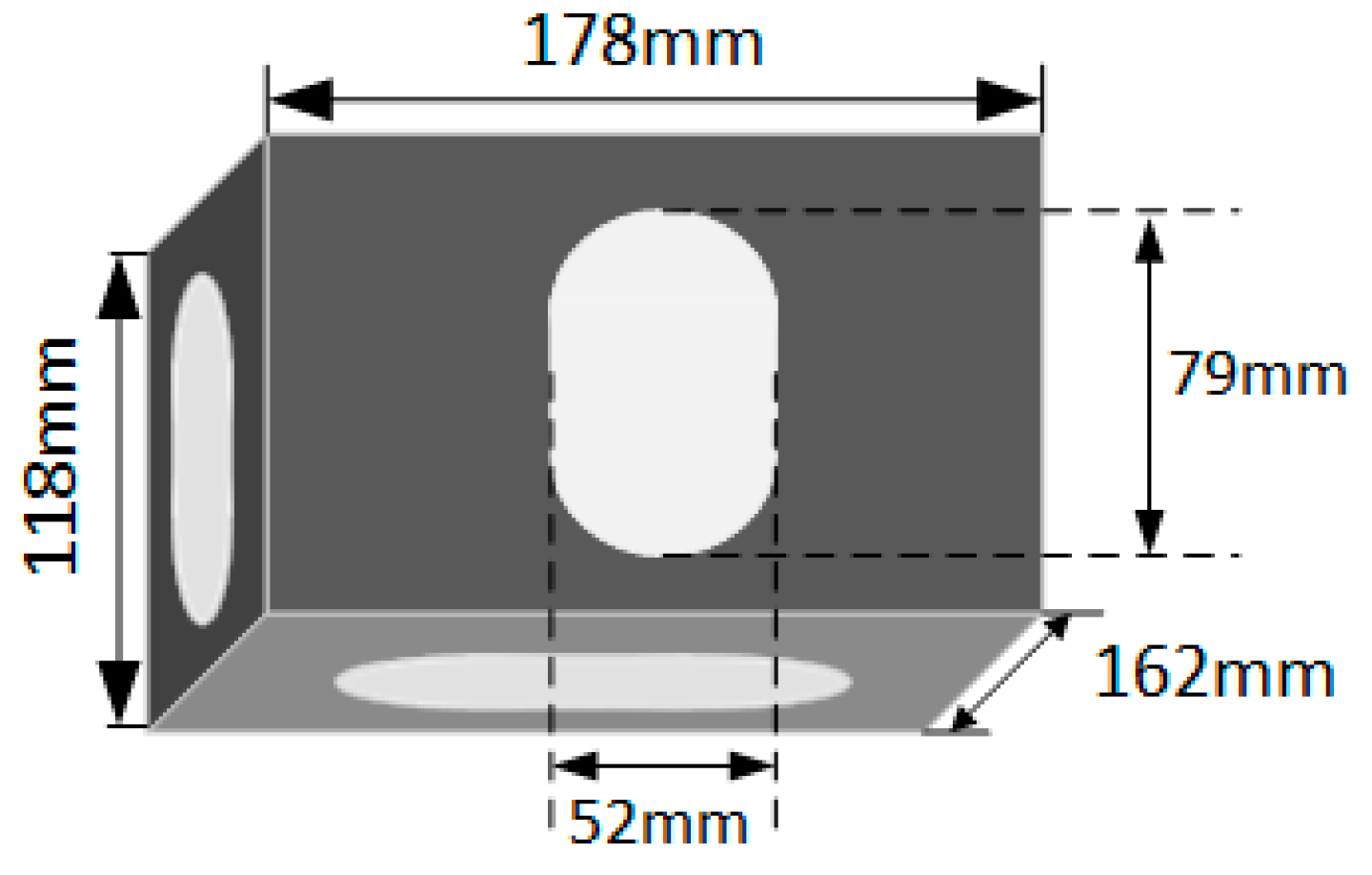
3.2. Target Secondary Positioning Algorithm
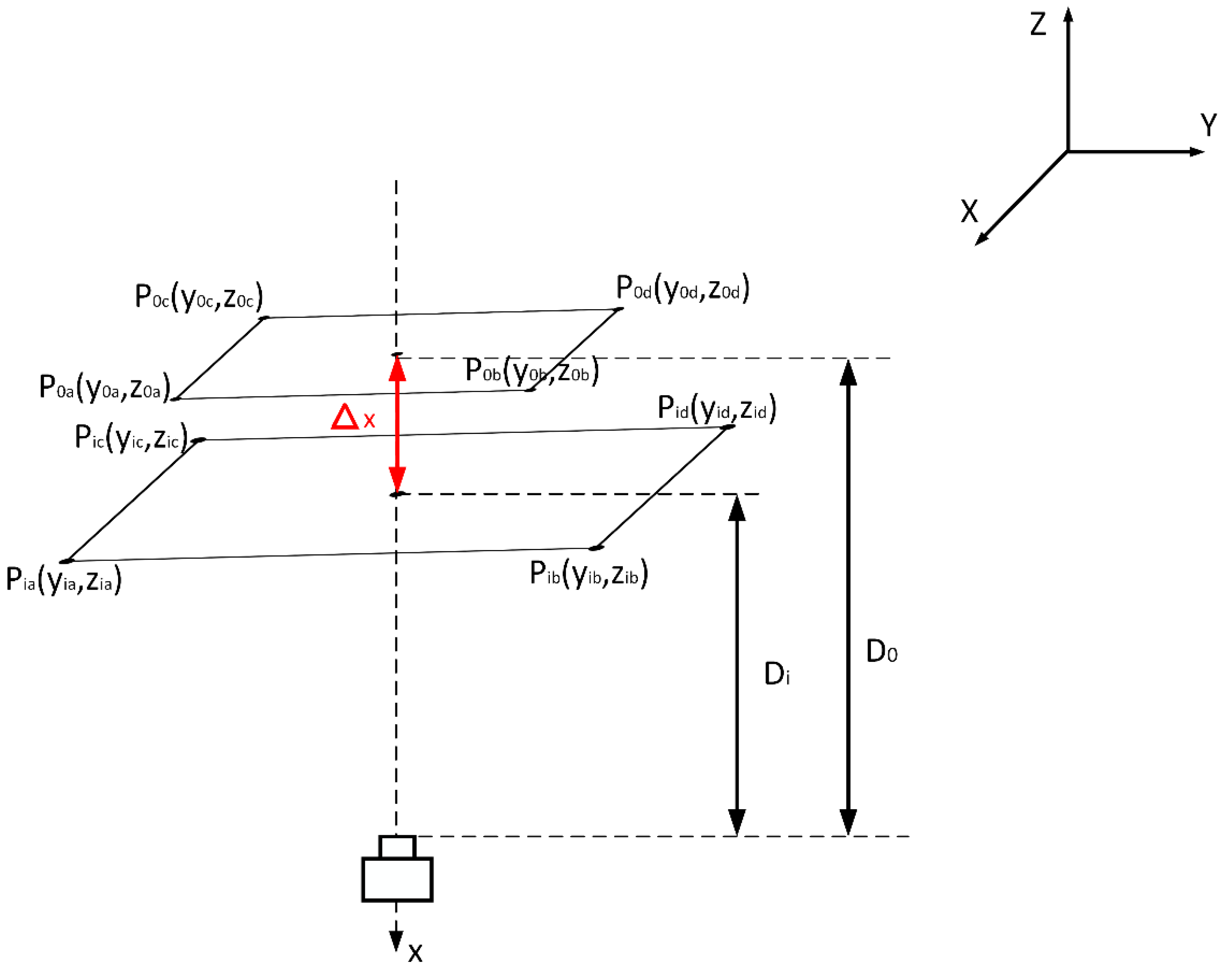
3.3. Three Dimensional Measurement Algorithm
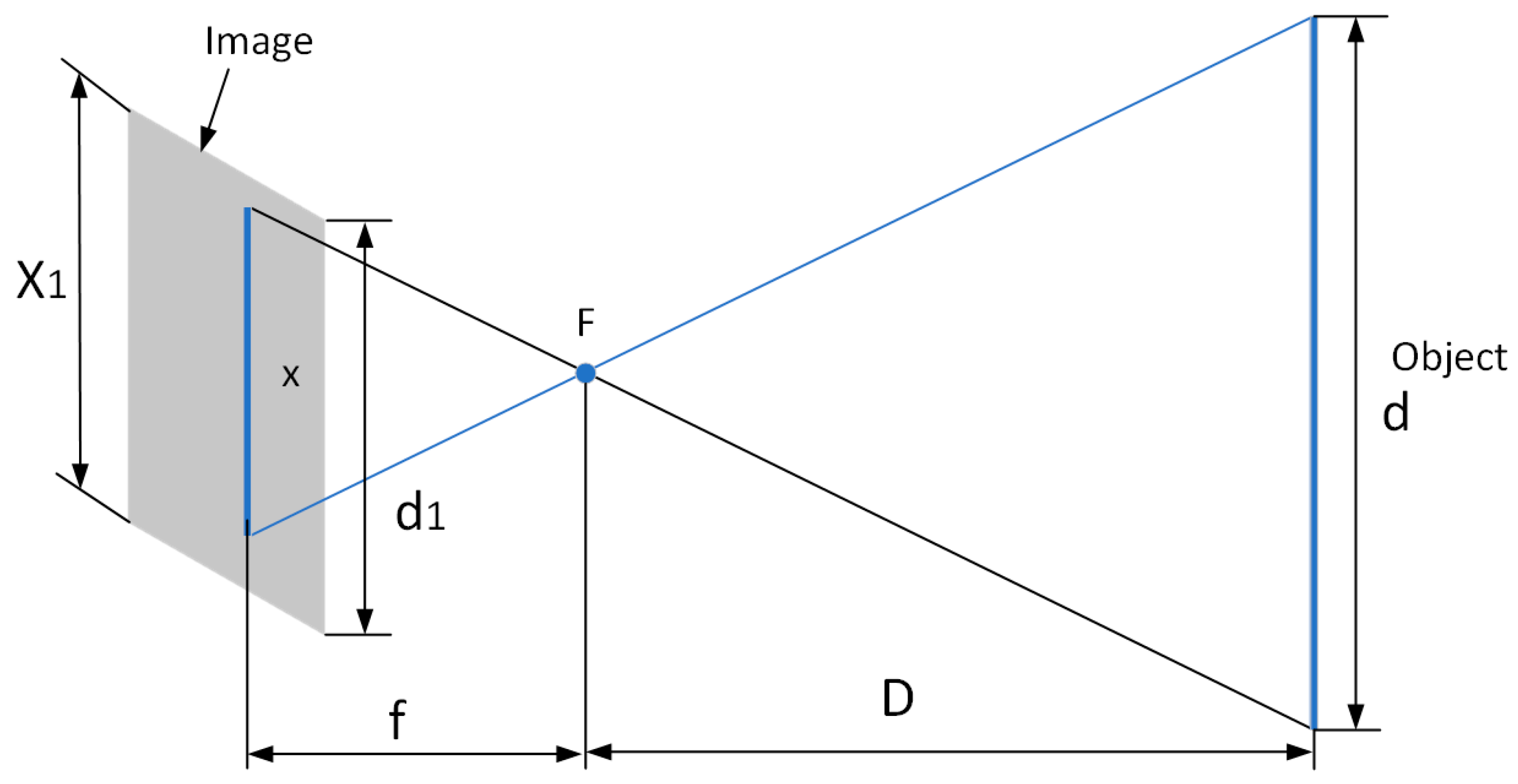
3.3.1. Convert Pixel Distance to Actual Distance
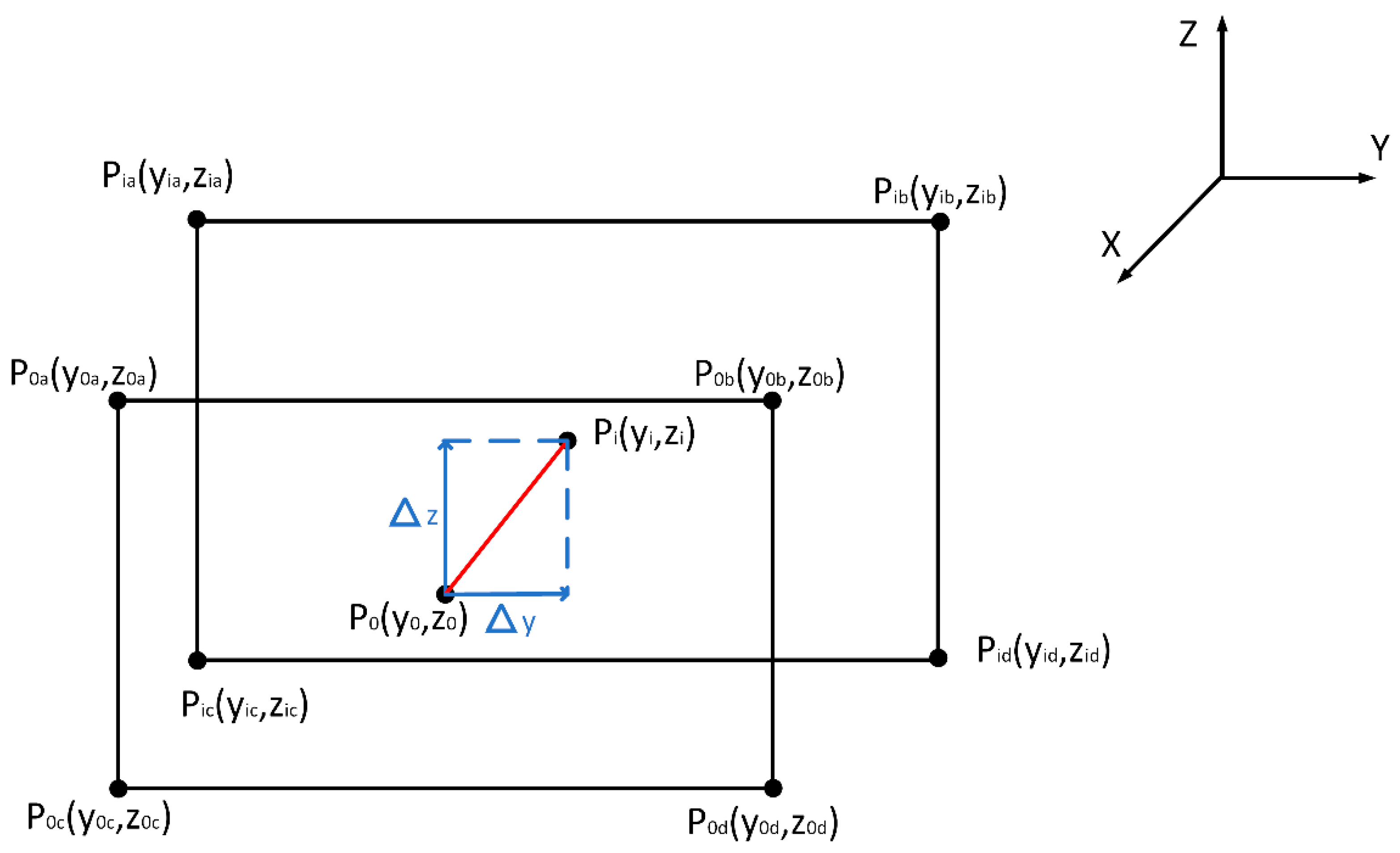
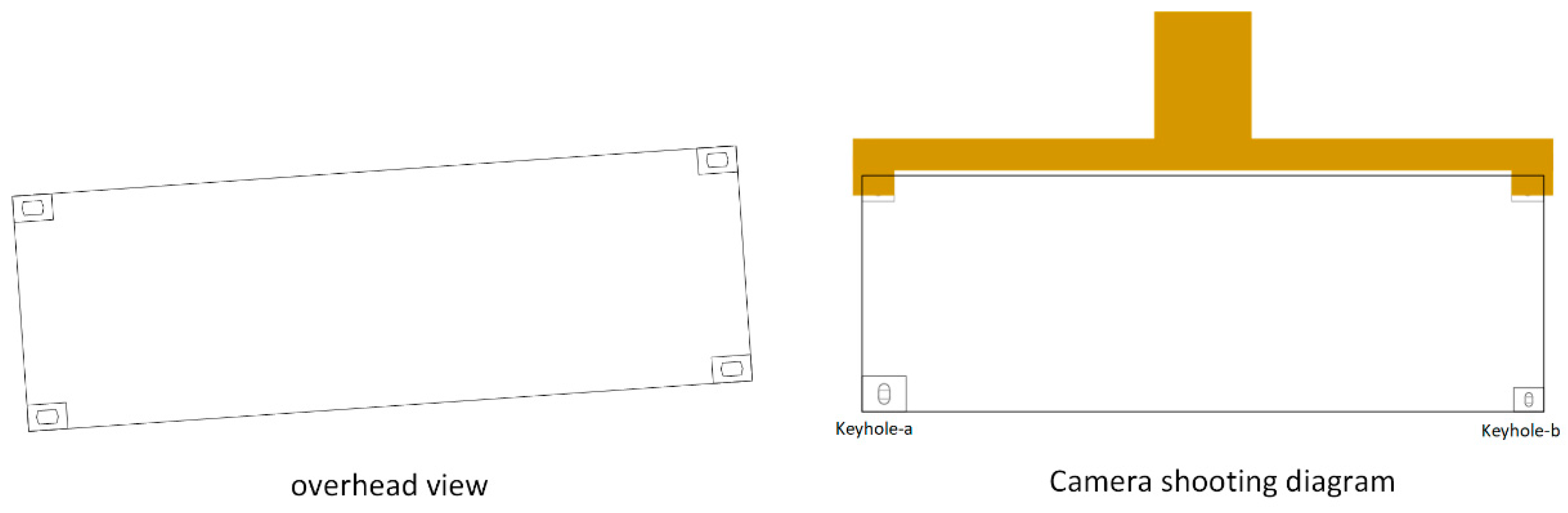
3.3.2. Keyhole Offset Distance
3.3.3. Keyhole Offset Angle
4. Experiment
4.1. Experimental Platform
4.2. Experimental Data
4.3. Experimental Results and Analysis
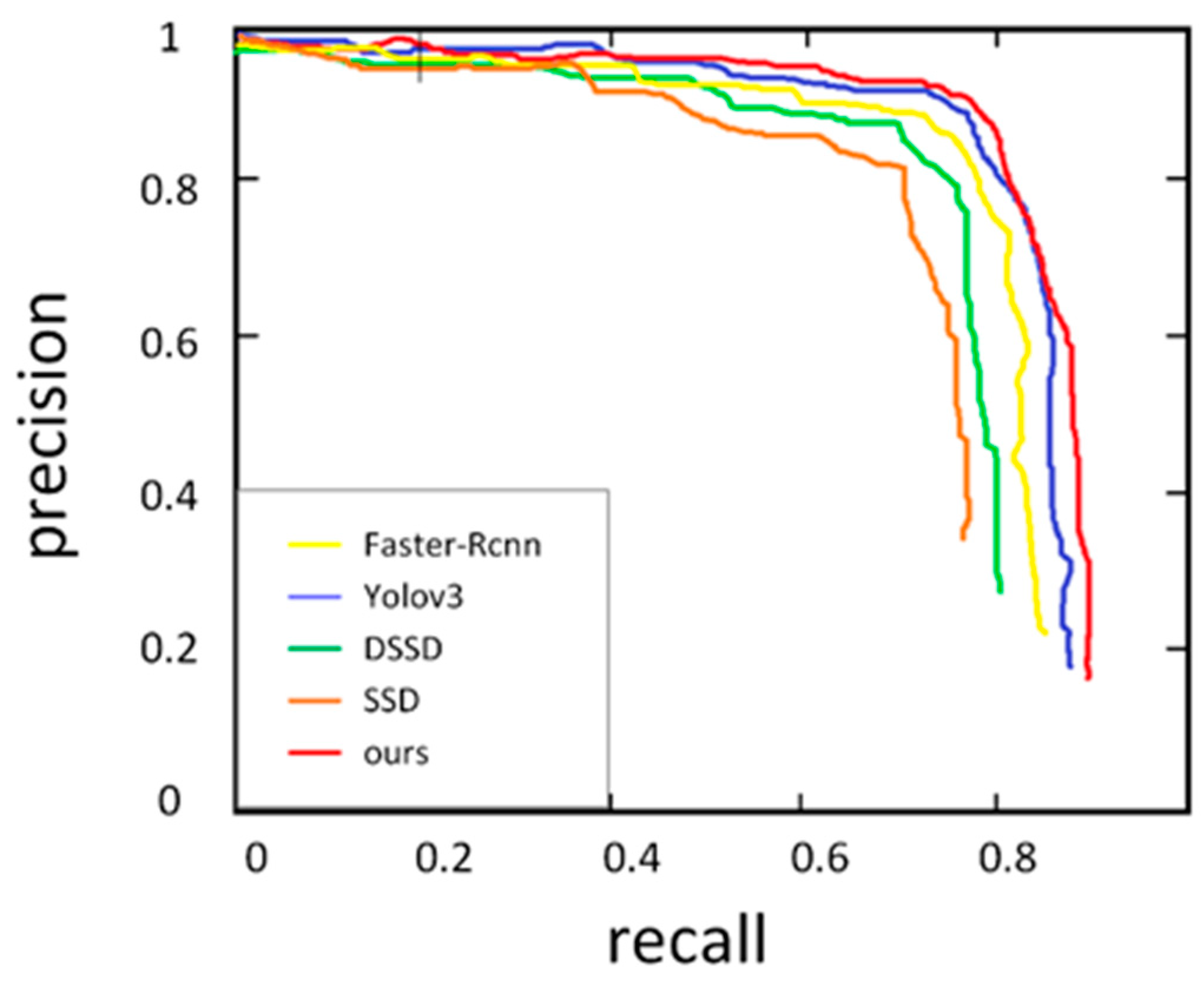
4.3.1. Target Detection Experiment
4.3.2. Target Tracking Experiment
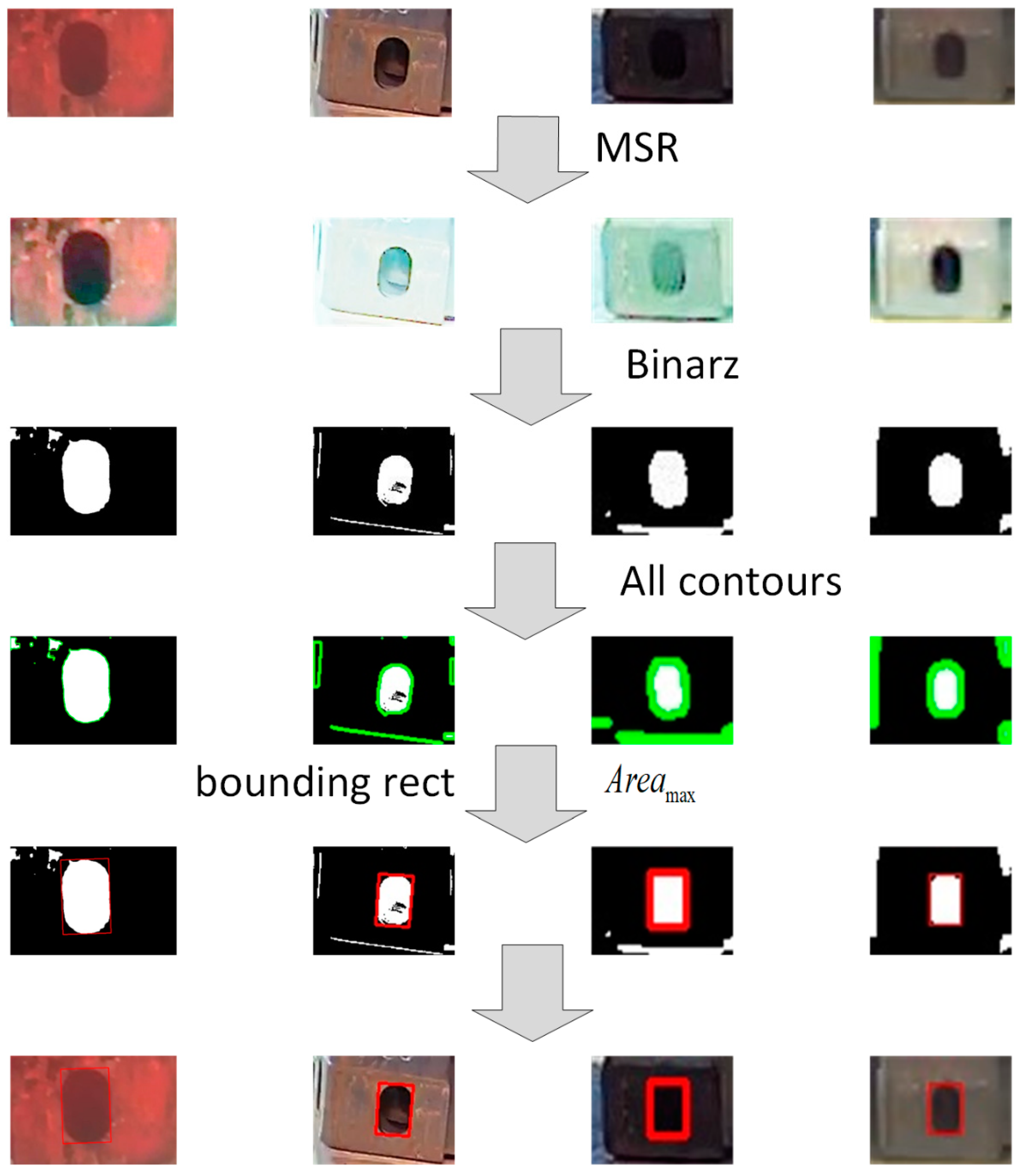
4.3.3. Secondary Positioning Experiment
4.3.4. Three-Dimensional Measurement Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mi, C.; Huang, Y.; Fu, C.; Zhang, Z.; Postolache, O. Vision-Based Measurement: Actualities and Developing Trends in Automated Container Terminals. IEEE Instrum. Meas. Mag. 2021, 24, 65–76. [Google Scholar] [CrossRef]
- Schwalbe, E.; Maas, H.G.; Seidel, F. 3D building model generation from airborne laser scanner data using 2D GIS data and or-thogonal point cloud projections. In Proceedings of the ISPRS WG III/3, III/4, V/3 Workshop “Laser Scanning 2005”, Enschede, The Netherlands, 12–14 September 2005; IEEE: Piscataway, NJ, USA, 2005. [Google Scholar]
- Miao, Y.; Li, C.; Li, Z.; Yang, Y.; Yu, X. A novel algorithm of ship structure modeling and target identification based on point cloud for automation in bulk cargo terminals. Meas. Control. 2021, 54, 155–163. [Google Scholar] [CrossRef]
- Yang, J.; Man, J.; Xi, M.; Gao, X.; Lu, W.; Meng, Q. Precise Measurement of Position and Attitude Based on Convolutional Neural Network and Visual Correspondence Relationship. IEEE Trans. Neural Networks Learn. Syst. 2020, 31, 2030–2041. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.; Zhang, Y.; Xu, D.; Miao, W. A Deformation Measurement Algorithm Based on Adaptive Variable Parameter Multiple Model for Large Ships. IEEE Trans. Instrum. Meas. 2021, 70, 1–10. [Google Scholar] [CrossRef]
- Yin, Z.; Cai, Y.; Ren, Y.; Wang, W.; Chen, X. A High Precision Attitude Measurement Method for Spacecraft Based on Magnetically Suspended Rotor Tilt Modulation. IEEE Sens. J. 2020, 20, 14882–14891. [Google Scholar] [CrossRef]
- Wang, K.; Liu, Y.; Li, L. Vision-Based Tracking Control of Underactuated Water Surface Robots Without Direct Position Measurement. IEEE Trans. Control Syst. Technol. 2015, 23, 2391–2399. [Google Scholar] [CrossRef]
- Xia, C.; Weng, C.-Y.; Zhang, Y.; Chen, I.-M. Vision-Based Measurement and Prediction of Object Trajectory for Robotic Manipulation in Dynamic and Uncertain Scenarios. IEEE Trans. Instrum. Meas. 2020, 69, 8939–8952. [Google Scholar] [CrossRef]
- Yoon, H.-J.; Hwang, Y.-C.; Cha, E.-Y. Real-time container position estimation method using stereo vision for container auto-landing system. In Proceedings of the ICCAS, Gyeonggi-do, Republic of Korea, 27–30 October 2010; pp. 872–876. [Google Scholar] [CrossRef]
- Ulrich, I.; Nourbakhsh, I.R. Appearance-Based Obstacle Detection with Monocular Color Vision. AAAI/IAAI 2000, 866–871. [Google Scholar]
- Shen, Y.; Lin, W.; Wang, Z.; Li, J.; Sun, X.; Wu, X.; Wang, S.; Huang, F. Rapid Detection of Camouflaged Artificial Target Based on Polarization Imaging and Deep Learning. IEEE Photon J. 2021, 13, 7800309. [Google Scholar] [CrossRef]
- Liu, M.; Zhu, Q.; Yin, Y.; Fan, Y.; Su, Z.; Zhang, S. Damage Detection Method of Mining Conveyor Belt Based on Deep Learning. IEEE Sens. J. 2022, 22, 10870–10879. [Google Scholar] [CrossRef]
- Tekin, B.; Tekin, B.; Sinha, S.N.; Sinha, S.N.; Fua, P.; Fua, P. Real-Time Seamless Single Shot 6D Object Pose Prediction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 292–301. [Google Scholar] [CrossRef] [Green Version]
- Braun, M.; Rao, Q.; Wang, Y.; Flohr, F. Pose-RCNN: Joint object detection and pose estimation using 3D object proposals. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 1546–1551. [Google Scholar] [CrossRef]
- Weinzaepfel, P.; Brégier, R.; Combaluzier, H.; Leroy, V.; Rogez, G. DOPE: Dis-tillation Of Part Experts for whole-body 3D pose estimation in the wild. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Zhang, L.; Wu, D.-M.; Ren, Y. Pose Measurement for Non-Cooperative Target Based on Visual Information. IEEE Access 2019, 7, 106179–106194. [Google Scholar] [CrossRef]
- Long, C.; Bai, Z.; Zhi, S.; Qiu, C.; Wang, Y.; Hu, Q. A Pose Measurement Method of Non-cooperative Target Based on Monocular Vision. In Proceedings of the 33rd Chinese Control and Decision Conference (CCDC), Kunming, China, 22–24 May 2021; pp. 3110–3115. [Google Scholar] [CrossRef]
- Sharma, S.; Beierle, C.; D’Amico, S. Pose estimation for non-cooperative spacecraft rendezvous using convolutional neural networks. In Proceedings of the 2018 IEEE Aerospace Conference, Big Sky, MT, USA, 3–10 March 2018; pp. 1–12. [Google Scholar] [CrossRef] [Green Version]
- Shamsafar, F.; Ebrahimnezhad, H. Uniting holistic and part-based attitudes for accurate and robust deep human pose estimation. J. Ambient Intell. Humaniz. Comput. 2021, 12, 2339–2353. [Google Scholar] [CrossRef]
- Yang, J.; Xi, M.; Jiang, B.; Man, J.; Meng, Q.; Li, B. FADN: Fully Connected Attitude Detection Network Based on Industrial Video. IEEE Trans. Ind. Inform. 2020, 17, 2011–2020. [Google Scholar] [CrossRef]
- Huang, Q.; Huang, Y.; Zhang, Z.; Zhang, Y.; Mi, W.; Mi, C. Truck-Lifting Prevention System Based on Vision Tracking for Container-Lifting Operation. J. Adv. Transp. 2021, 2021, 1–9. [Google Scholar] [CrossRef]
- Zhang, Y.; Huang, Y.; Zhang, Z.; Postolache, O.; Mi, C. A vision-based container position measuring system for ARMG. Meas. Control 2022, 1–10. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multi-box detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 July 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar] [CrossRef]
- Zotin, A. Fast Algorithm of Image Enhancement based on Multi-Scale Retinex. Procedia Comput. Sci. 2018, 131, 6–14. [Google Scholar] [CrossRef]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. In Proceedings of the 2017 IEEE/CVF Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | Input | AP/% | FPS | |
|---|---|---|---|---|
| SSD | VGG-16 | 300*300 | 71.86 | 36 |
| DSSD | Resnet-101 | 320*320 | 73.46 | 17 |
| Faster-RCNN | Resnet-50 | 600*600 | 81.95 | 7.8 |
| Yolov3 | Darknet-53 | 416*416 | 87.54 | 31.4 |
| ours | Resnet-18 | 300*300 | 94.75 | 30.7 |
| X-Error (cm) | Y-Error (cm) | Z-Error (cm) | (°) | |
|---|---|---|---|---|
| First | 4.75 | 1.88 | 1.43 | 0.45 |
| Second | 4.72 | 1.72 | 1.47 | 0.41 |
| Third | 4.26 | 1.68 | 1.17 | 0.46 |
| Fourth | 4.63 | 1.75 | 1.58 | 0.45 |
| Fifth | 4.81 | 1.92 | 1.27 | 0.37 |
| Sixth | 4.18 | 1.75 | 1.32 | 0.46 |
| Seventh | 4.72 | 1.68 | 1.54 | 0.35 |
| Eighth | 4.38 | 1.95 | 1.04 | 0.53 |
| Nineth | 4.09 | 1.73 | 1.45 | 0.38 |
| Tenth | 4.31 | 1.83 | 1.41 | 0.37 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mi, C.; Huang, S.; Zhang, Y.; Zhang, Z.; Postolache, O. Design and Implementation of 3-D Measurement Method for Container Handling Target. J. Mar. Sci. Eng. 2022, 10, 1961. https://doi.org/10.3390/jmse10121961
Mi C, Huang S, Zhang Y, Zhang Z, Postolache O. Design and Implementation of 3-D Measurement Method for Container Handling Target. Journal of Marine Science and Engineering. 2022; 10(12):1961. https://doi.org/10.3390/jmse10121961
Chicago/Turabian StyleMi, Chao, Shifeng Huang, Yujie Zhang, Zhiwei Zhang, and Octavian Postolache. 2022. "Design and Implementation of 3-D Measurement Method for Container Handling Target" Journal of Marine Science and Engineering 10, no. 12: 1961. https://doi.org/10.3390/jmse10121961