1. Introduction
The ‘Kyoho’ (
Vitis labruscana) grape is mainly a fresh fruit, and there is no post-ripening period after picking; so, it is very important to obtain information about the fruit’s maturity and ripening time to select the best picking period for the high quality of ‘Kyoho’ grapes after picking [
1]. The traditional method of judging the maturity of the ‘Kyoho’ grape bunch mainly relies on manual destructive detection, such as tasting or checking for skin color changes, by the fruit farmer. However, this method has disadvantages: it is highly subjective and inefficient, and there is a limited professional ability to judge the maturity of ‘Kyoho’ grape bunch [
2]. In order to maintain the quality of the grapes, vineyards need to be carefully managed so that the quantity and quality of the grapes are well balanced and maximum vineyard profitability is achieved. This vineyard management can be difficult as workers should closely monitor the quantity and quality of bunches throughout the growing season to avoid the overripening of large amounts of fruit [
3]. At the same time, the decrease in the agricultural labor force and the increase in costs have presented significant challenges to wine grape growers and managers [
4]. In addition, the overripe ‘Kyoho’ grape is prone to becoming rotten fruit; it is easily damaged by birds and does not respond well to transportation and storage [
5]. Therefore, it is necessary to explore a fast, accurate, and non-destructive prediction method for ‘Kyoho’ grape bunch maturity to assist farmers in the rational distribution of labor and to reduce the waste of human resources; this would not only help to improve the commodity rate of ‘Kyoho’ grapes, it would also provide a research basis for robot picking. As a result, to improve the commercial rate of grape clusters it is important to know how to quickly and accurately judge the ripeness of grape clusters.
In recent years, with the progress and rapid development of image processing, more and more methods of deep learning have been applied to agricultural production. This also plays an important role in object detection and instance segmentation. The deep learning method was used to detect the maturity of the ‘Kyoho’ grape bunch in the natural environment [
6]. Compared with the traditional taste or chemical methods, it not only did not damage the fruit growth condition, it also improved the detection rate. However, in the natural growing environment of ‘Kyoho’ grapes, a series of problems need to be solved with regard to bunch detection and recognition, such as different light levels, different angles, and the difficult identification of leaf occlusion.
The traditional method of judging grape ripeness has been studied by scholars since the early 1980s. As early as 1980, Lee and Boume used the puncture method to detect the hardness and sugar content of grapes to judge their maturity [
7], but the puncture method is a destructive test and is not suitable for the detection of grape maturity. In 2003, Herrera et al. used a portable near-infrared spectrometer combined with a contact probe to detect the total soluble solid content of post-harvest Chardonnay and Cabernet Sauvignon to judge the grape maturity [
8]. In 2010, Ghozlen et al. used optical sensors to determine the maturity of grape panicles in the field by detecting the anthocyanin content of grape kernels [
9]. In 2011, Bramley et al. installed a sensor on a harvester to detect the grape bunch maturity in the vineyard [
10]. However, this method can only detect one bunch of grapes at a time, which is inefficient, and the price of optical sensors is very high; thus, they cannot be popularized.
With the continuous development of image processing, some scholars have combined the maturity of fruits with images. In 2012, Rodriguez-Pulido et al. carried out histogram threshold processing on CIELAB and HIS color space with an image analysis method and realized the rapid judgment of the ripeness of multiple grapes at the same time [
9]. However, this study was carried out in the positive laboratory and did not consider many of the interference factors existing in the complex field environment. In 2014, Rahman and Hellicar used image processing and computational intelligence methods to roughly divide the field grape bunch into two types of ripe and unripe grapes according to the brown characteristics of ripe grapes [
11]. In 2016, Pothen and Nuske developed an image analysis algorithm to classify grape panes into four levels and used a texture feature description combined with a random forest algorithm to realize the recognition of grape panes [
12]. In 2018, Luo et al. used a
K-means algorithm to realize the identification of ripe grape bunches in the field [
13]. In 2015, Liu et al. used a support vector machine (SVM) algorithm to identify grape bunches in the natural environment, and the accuracy rate was 88.0% [
14]. In 2018, Perez-Zavala et al. [
15] used the same method and achieved an accuracy of 88.61%. The above studies used shallow machine learning algorithms to identify grape bunches, with low accuracy and relatively cumbersome feature extraction processes.
Since deep learning was proposed, there has been continuous experimentation and research by scholars. In recent years, the convolutional neural network (CNN) has been gradually applied to classification, object detection, and background segmentation. For example, Aggarwal et al. presented a stacked ensemble-based deep learning classification model based on Human Protein Atlas images [
16]. Gulzar et al. constructed a fruit image classification model based on MobileNetV2 with a deep transfer learning technique [
17]. Hamid et al. established a seed classification model with a deep learning convolutional neural network of MobileNetV2 [
18]. Some scholars have used the Faster R-CNN network to detect different fruits (melon, avocado, mango [
19], orange, apple, etc.) by using RGB and NIR images and their combinations. Grimm et al. used the full convolutional neural network (FCN) with VGG-Net 16 as the backbone to segment and detect many organs, including grape berries; the accuracy of the berry detection was 86.60%, and the
F1 value was 87.60% [
20]. Fu et al. proposed that the background in an apple image should be removed by depth feature first, and Faster R-CNN was used for apple detection, with an average detection accuracy of 89.3% [
21]. Parvathi et al. used ResNet50 as the backbone network of Faster R-CNN to detect coconut maturity, and the accuracy rate reached 89.4% [
22]. A supervised learning method was used to train FCN for plant leaf detection, and the pixel accuracy reached 91%. In 2020, Wan et al. took into account the characteristics of fruit images in natural light and the hanging state of fruit; they optimized the convolution layer and pooling layer of the Faster R-CNN model [
23] and achieved high accuracy in the apple, mango, and citrus datasets. In 2020, Mai et al. [
24] proposed a Faster R-CNN model with classifier fusion. In the region candidate stage, three different levels of features were used to train three classifiers for object classification; the stage was composed of a simple convolutional layer, and a new loss function with a classifier correlation coefficient was introduced to train the region candidate network. It improved the reliability of the Faster R-CNN network in small target fruit detection. In 2022, Lei et al. proposed a new backbone network ResNet50-FPN-ED to improve the mask region convolutional neural network (Mask RCNN) instance segmentation in order to improve detection and segmentation performance in complex environments, such as the cluster shape changes, leaf shadows, tree trunk occlusion, and grape overlap [
25]. However, the average accuracy of the proposed model in object detection and instance segmentation reached 60.1% and 59.5%, respectively. In 2022, Wei et al. proposed a two-stage instance segmentation method based on an optimized Mask RCNN to solve the various difficulties of intelligent grape picking in a complex orchard environment [
26]. It not only accelerates the speed of the model but also greatly improves the accuracy of the model and meets the storage resource requirements of the mobile robot. The mean average precision (
mAP) and mean average recall (
mAR) of the optimized Mask RCNN are 76.3% and 81.1%, respectively.
Due to the influence of the complex natural environment background, the research work on the feature extraction and target detection of ‘Kyoho’ grape bunch maturity is facing great challenges. Color is one of the most important characteristics for determining fruit ripeness. The color of an item is determined by the light reflected from it; these changes serve as a foundation for image processing and analysis [
27]. In this paper, grape panicle images are taken as the research object, and the ripeness of the ‘Kyoho’ grape panicle is divided into four grades, from maturity level 1 to maturity level 4, according to the color of the fruit skin, so as to judge the best picking time and the expected picking time of this grape bunch. This paper deeply analyzes the Mask RCNN [
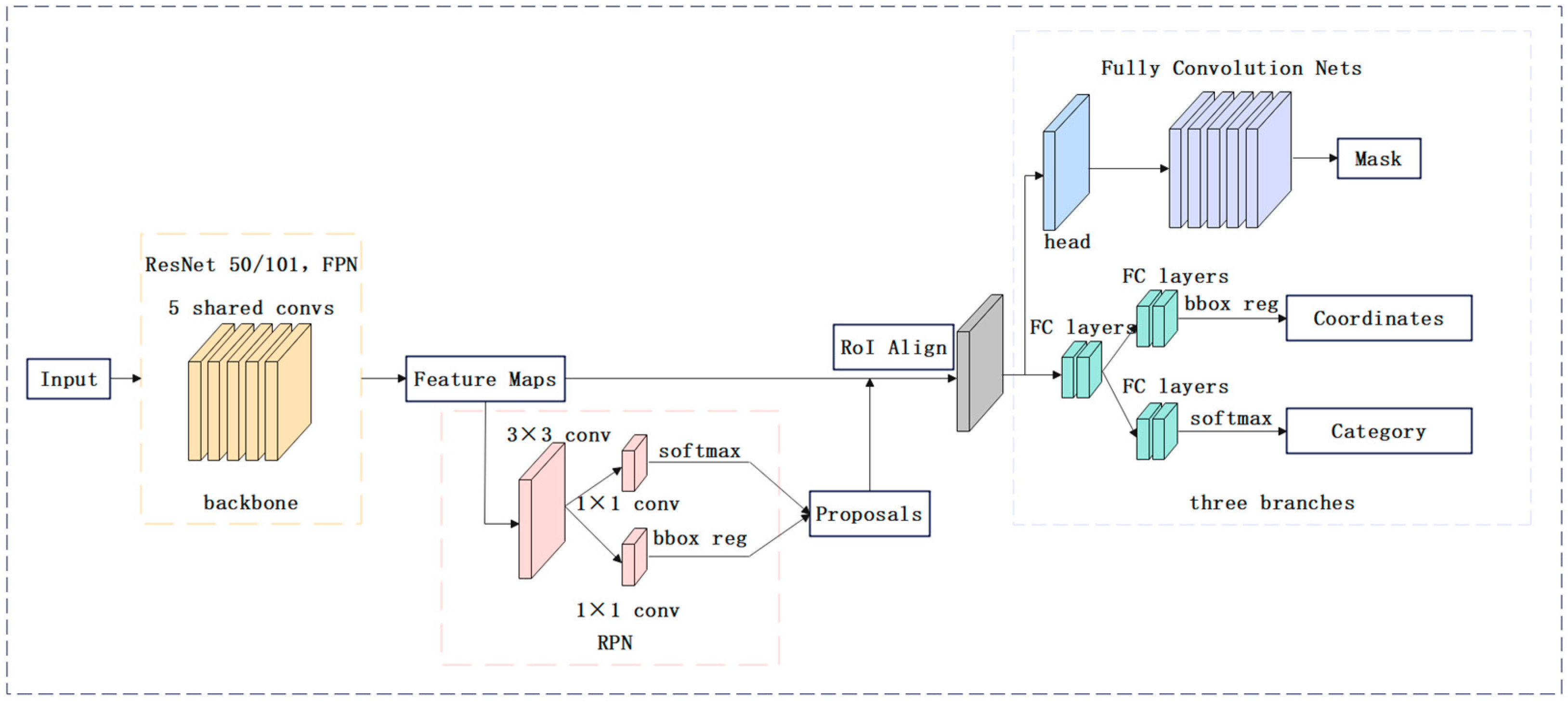
28] network and its development prospect based on the mmdetection framework; it optimizes and improves the existing algorithm by analyzing the current algorithm and proposes an optimization method combined with the Mask RCNN algorithm. The optimized algorithm results are obtained by a comparison with the existing Mask RCNN algorithm. The experimental results show that the proposed method improves the accuracy of its maturity detection and segmentation. Because the Mask RCNN algorithm has good instance segmentation performance, it solves the problem of the difficultly that exists in detecting grape bunches under occlusion or overlap. At the same time, the experiment can be applied to the intelligent picking of agricultural products and other fields, which solves the problem of the large use of manpower in the traditional picking process, saves human resources to a large extent, and is a qualitative breakthrough in computer-aided agriculture.
The goal of this research is to investigate a model that can not only accurately segment the grape bunch but can also evaluate the maturity of the grape bunch. In this study, a Mask RCNN-based algorithm is improved by the addition of an attention mechanism module to establish a grape bunch segmentation and maturity level detection model. We first collected a dataset of grape bunches in different stages of maturity from different angles and backgrounds in natural environments. Then, an improved grape bunch segmentation and maturity evaluation model was proposed by combining a Mask RCNN network and an attention mechanism. The model has practical significance in that it helps in the maturity judgment of the ‘Kyoho’ grape in order for artificial intelligence to pick grapes. In addition, the model can judge the maturity level of the ‘Kyoho’ grape and provide a basis for a further evaluation of the time required for grape ripening, avoiding the wasteful situation of picking too early or too late.
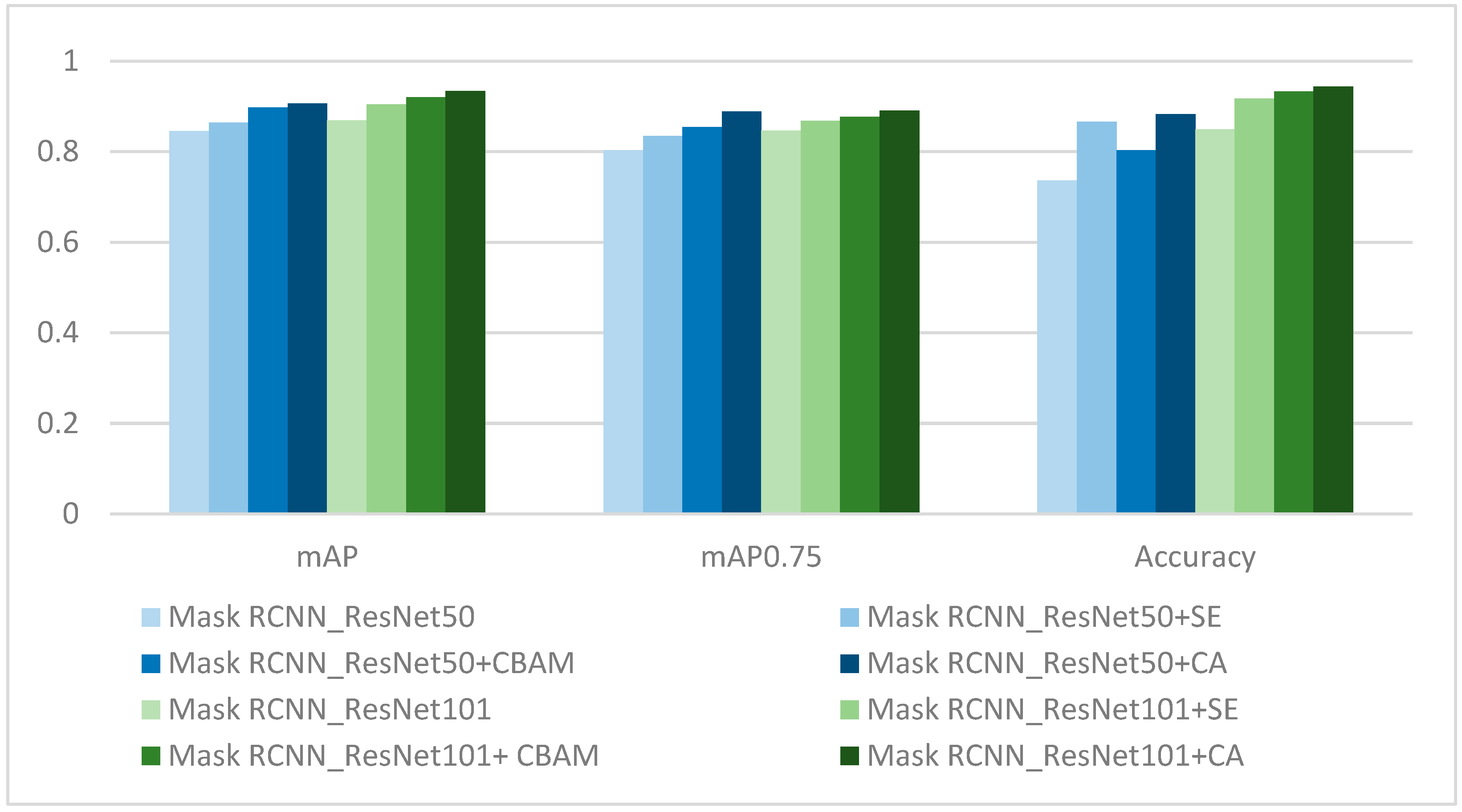
The main contributions of this work include the following. First, we collected one dataset, including grape bunches of four different maturity levels, collected from different views and backgrounds in the real word of the vineyard. Second, we designed an improved segmentation and classification model by combining Mask RCNN and an attention mechanism of coordinated attention, which has higher precision for the segmentation of the grape bunch and the evaluation of the grape maturity level. The mean average precision (
mAP),
mAP0.75 and the average accuracy of the model reached 0.934, 0.891, and 0.944. In the process of this model design, we compared the performances of different models established with YoloV3 [
29], Solov2 [
30], Yolact [
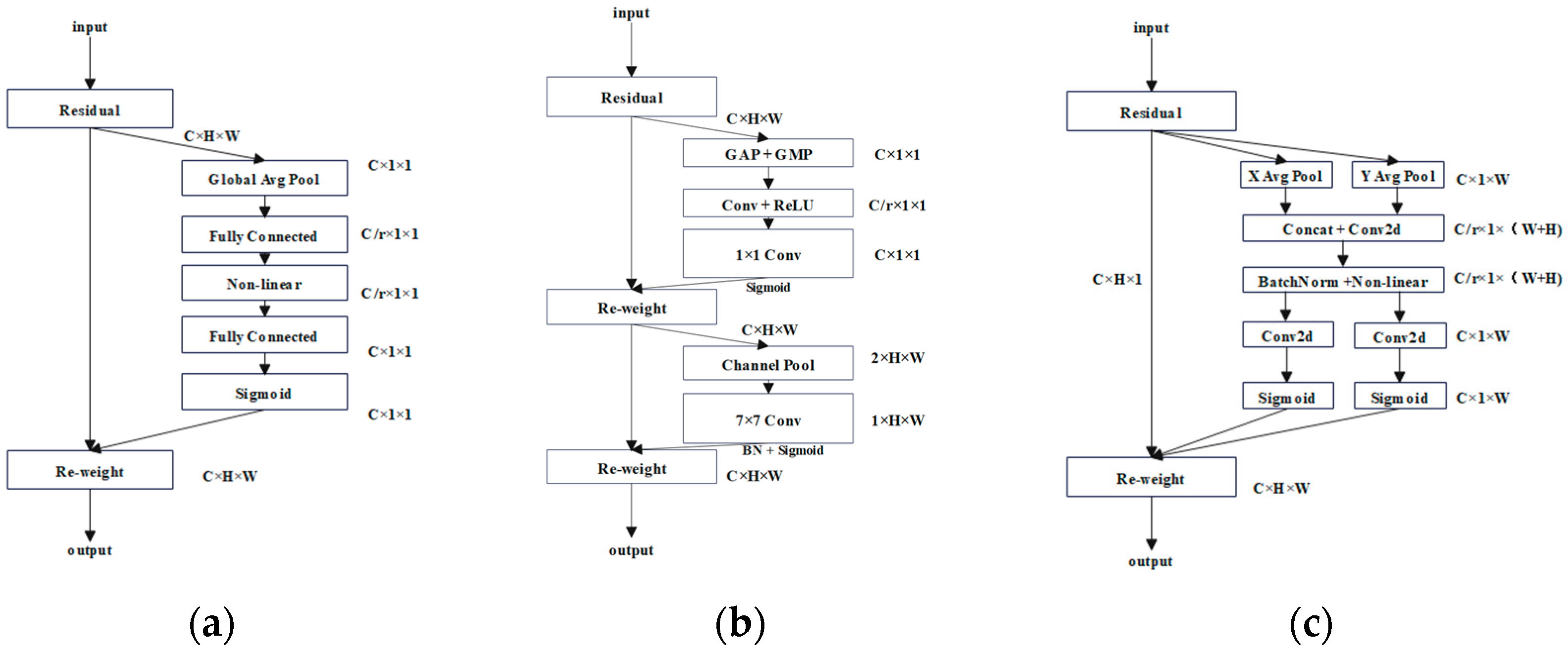
31], and Mask RCNN to select the backbone network. Then, three different attention mechanism modules, including squeeze-and-excitation attention (SE) [
32], the convolutional block attention module (CBAM) [
33], and coordinate attention (CA) [
34], were introduced to the backbone network of the Mask RCNN, respectively. In addition, the performances of models constructed with a combination of different network layers of ResNet50- and ResNet101-based [
35] attention mechanism modules were compared. The experimental results showed that the segmentation and classification ability of this model was higher than those of the above models. Finally, feature visualization was analyzed.
4. Discussion
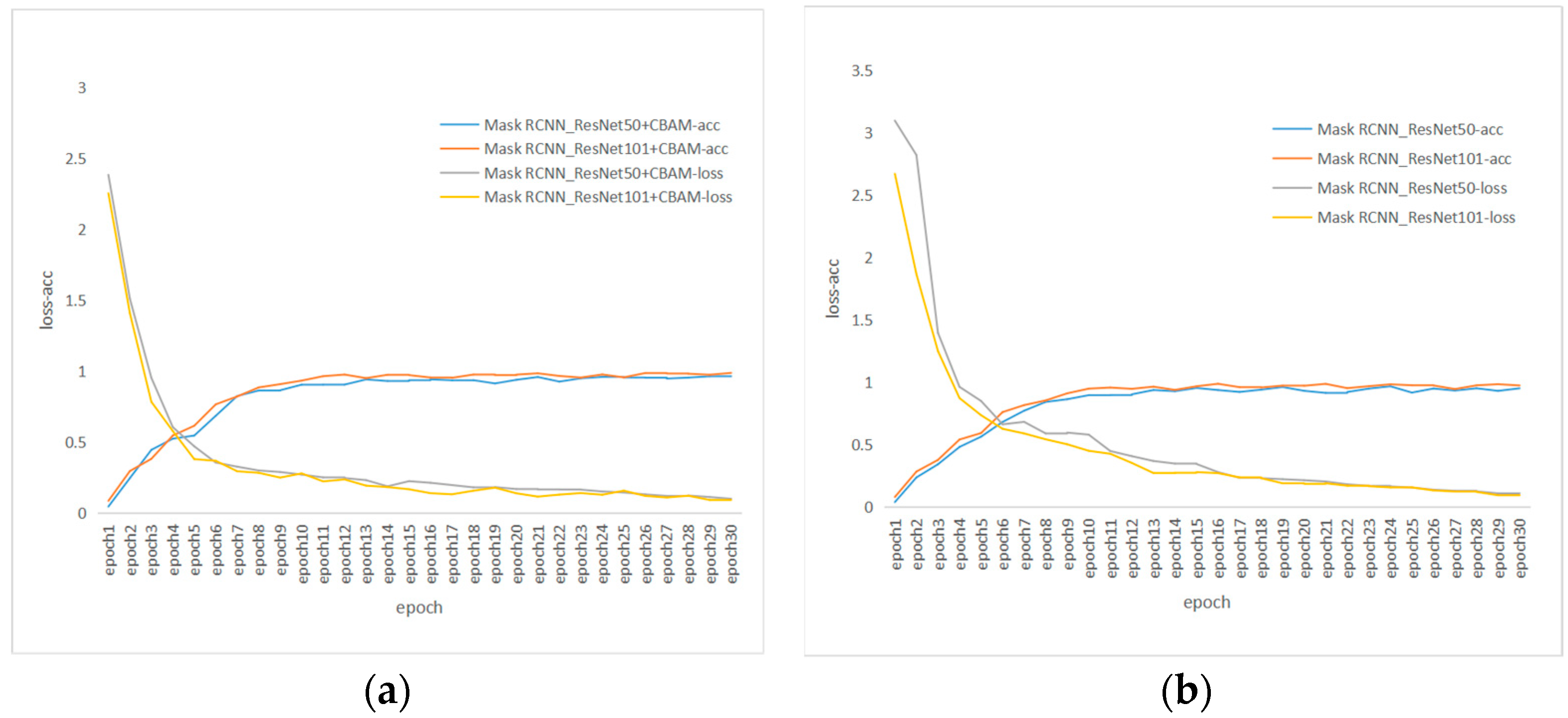
In this paper, the attention module was introduced into the backbone network of Mask RCNN to segment and identify the maturity of the “Kyoho” grape bunch. The performance of the model established by the combining of Mask RCNN_ResNet101 and coordinate attention was significantly higher than that of the other models.
First, the comparison of the established models with the other common networks of Solov2, Yolov3, and Yolact showed that the Mask RCNN can not only better detect the grape bunch but can also better segment the grape bunch by adding mask branches. At the same time, to solve the problem related to the fact that the feature map could not be accurately aligned with the original pixels, Mask RCNN used ROI to align the pixels, meeting the accuracy requirements of the image segmentation.
Second, ResNet101 and ResNet50 were used as the backbone networks to combine the different attention mechanism modules, respectively. Compared with the deep network, with the depth of the network layer the sensitivity field was larger; the features covered by the pixel blocks of the same size were richer; the image features extracted were more advanced; and the detection performance was significantly improved. On the same algorithm basis, the results of this paper further proved that the models established with the ResNet101-based methods were more accurate than the ResNet50-based methods.
Third, after the introduction of the attention mechanism module to the Mask RCNN, the module enhanced the attention of the ‘Kyoho’ grape bunch extraction; selected the focus position; generated more distinguishable feature representation; and made the model focus on the specific part of the input data, thus improving the ability and accuracy of the model in grape bunch extraction.
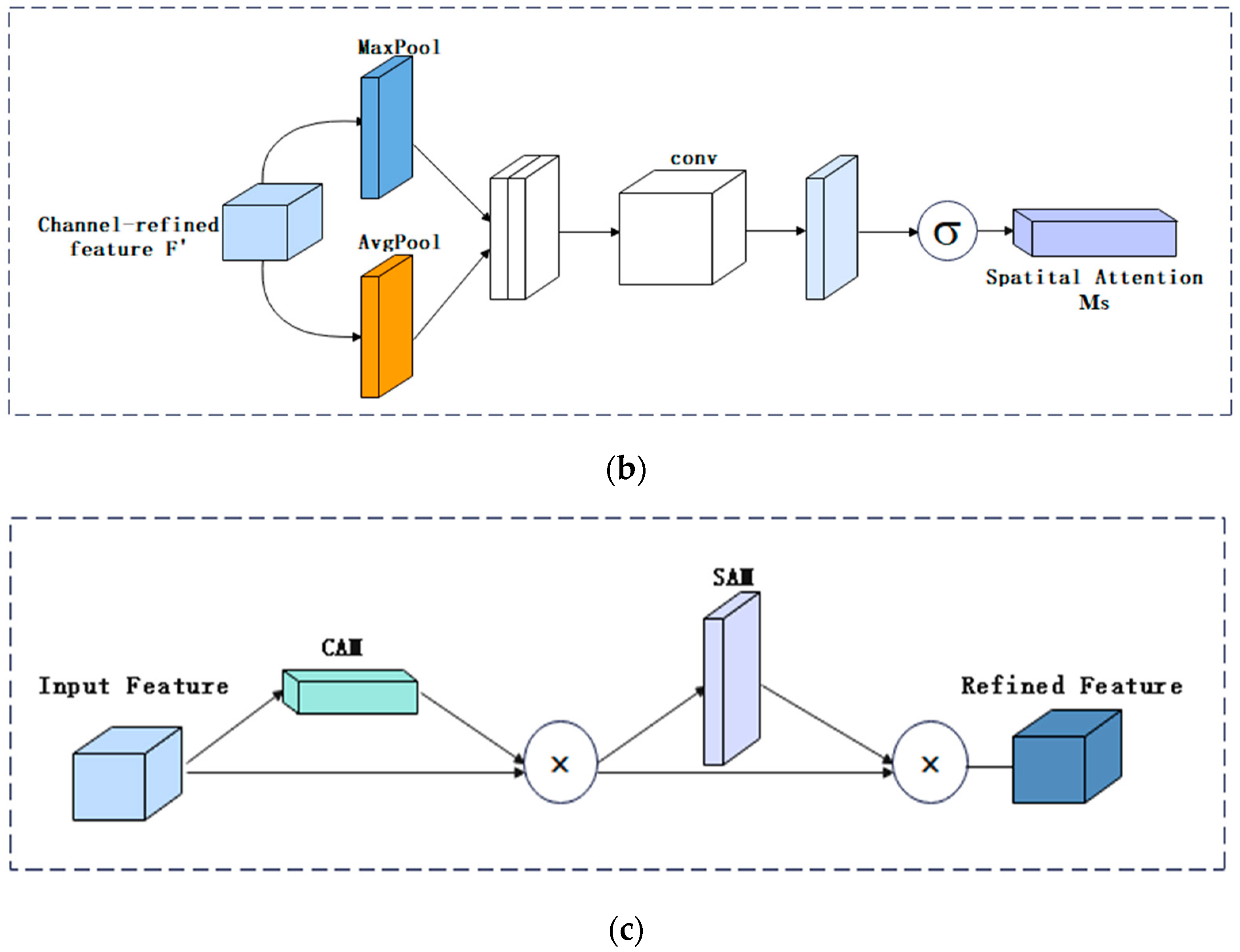
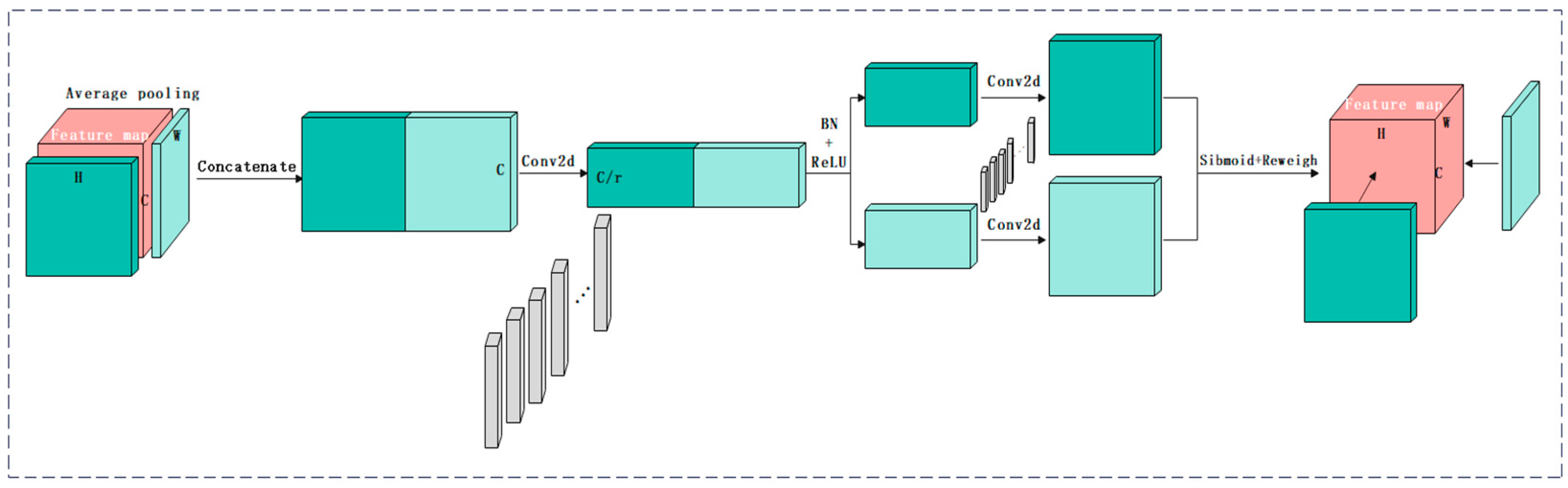
Fourth, the comparison of the three attention mechanisms shows that SE only focused on constructing the interdependence between channels, ignoring the spatial features. CBAM introduced the large-scale convolution kernel to extract the spatial features and took the maximum value and the average value of the multiple channels at each position as the weighting coefficients. Therefore, this weighting only considered the local range of information. CA carried out maximum pooling in the horizontal and vertical directions, and then transformed it to encode the spatial information. The spatial information was fused by means of weighted channels. The experiment shows that combining Mask RCNN and the attention mechanism module of CA can improve the performance of the grape maturity level detection model.
Fifth, the results of the image of the grape bunch acquired in different views, including the elevation image, flat image, backlight image, and downlight image, as well as the block image, showed that the model established by combining mask RCNN ResNet and the attention mechanisms could adapt to different complex backgrounds, improving the detection accuracy of the maturity level of the grape bunch.
The research of this paper is helpful in detecting the maturity level of the ‘Kyoho’ grape. At the same time, image processing was introduced into agriculture to provide help for the intelligent picking of ‘Kyoho’ grape. The estimated picking time of ‘Kyoho’ grapes can be deduced according to the maturity level of the grape bunch combined with the grape growth cycle, effectively avoiding the phenomenon of overripening or inaccurate picking time in the growth process of ‘Kyoho’ grapes. However, in the process of testing, it was found that there were still some errors in the segmentation of the edge of the grape bunch case. At the same time, the dataset used in this paper was small, and the data with regard to a complicated background should be collected later for an experimental supplement, which needs to be improved through subsequent experimental research.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}