1. Introduction
Today’s livestock industry faces important challenges in terms of monitoring, control, economics, etc. Recognizing animals’ behaviors plays an important role in addressing most of these challenges, since animals’ different activities in modern intensive housing systems can dramatically influence the required management systems [
1,
2]. For an effective management of such systems, the monitoring task should be performed continuously during the daytime. Such an intensive monitoring task is no longer feasible to perform manually by humans, as it is tedious, time-consuming, and also no longer cost-effective. Therefore, a sort of automation is crucial for monitoring systems of today’s livestock production, as well as moving towards precision livestock farming [
3,
4,
5,
6,
7,
8].
There are several reasons supporting the need for development of automatic activity recognition models for hen housing systems, most notably: (i) A significant source of fine dust emissions comes from the agricultural industry. Animal matters, such as feces, hairs, and feathers, are among important contributors in this regard [
9,
10,
11,
12,
13]. An effective recognition model could detect high-intensity activities of the hens, and proper control policies on illumination, feeding, humidity, and other possible inputs can be implemented accordingly; (ii) Detecting and preventing abnormal behaviors of hens could decrease the rate of injuries among them, since intrusive precautions such as beak trimming are being or have been banned in most developed countries [
14,
15]. It could also lead to the early detection of animal illnesses, when the behaviors of an individual hen or a flock are monitored day-to-day.
Generally, two different approaches can be taken to perceive different behaviors of hens. Remote sensing through computer vision is one option that provides rich data from the scene. For example, a deep convolutional neural network is trained in [
16] to detect and segment hens with the goal to assess the plumage condition. A vision-based posture analysis is developed in [
17] to detect sick broilers and give early warnings. Although getting closer to being operational in low intensive environments, it is truly difficult to use it for tracking individual hens in today’s loose housing systems [
18]. The visual similarities between hens, the large domain of movements provided in these new housing systems, and occlusion incidences that could happen quite frequently hinder the effective application of this solution. Moreover, recognition of the moderate- and high-intensity activities, accomplished in a short period of time, requires high-frequency data sampling, which is not affordably available through vision sensing. Nevertheless, there are good opportunities for the study of flock behaviors using long-shot imagery, which is not the focus of the present work.
The other option, which is more suited for capturing the behavior of individual subjects, is to make use of wearable sensors that can be safely attached to a target limb of hens. Inertial measurement unit (IMU) modules are commonly used for motion capturing in various domains including human and animal activity recognition [
19,
20,
21]. Whereas, other local positioning systems, such as the RFID technology that could help in positioning tagged subjects within a covered area by antenna receivers, have not received similar attention mostly due to their expensive and time-consuming setups (see [
22] for a recent review). The use of IMU sensors for motion capturing and activity recognition has seen a breakthrough after the emergence of MEMS-based modules, which are low-cost, lightweight, easy-to-log, and low-power devices. The attachment of such sensors on animals such as hens does not introduce significant restrictions, and the subject can hopefully behave seamlessly [
23]. IMU can provide data about the translational and angular movements of the subject in 3D, which can then be analyzed to infer high-level information about the type of activities being performed [
19,
21].
Real-time sensor-based hen activity recognition models dealing with the time-series IMU signals typically make use of machine learning technology. Machine learning provides a framework for large datasets to extract hidden features and patterns of signals that are otherwise impossible to be identified by manual or physics-based analyses [
24]. A heavy preprocessing practice is required before machine learning-based classifiers can digest the time-series sensory data. Generally, this is accomplished by handcrafting a limited number of features, typically of a statistical flavor, then extracting these features from the segmented raw data, and finally allowing machine learning techniques to learn the correlations between these features and the output.
Based on the intensity of behaviors, Kozak et al. [
25] identified three super classes a typical hen can perform: low-, medium-, and high-intensity activities. Accordingly, in [
26] we presented a machine learning framework for recognizing these classes using 9-axis IMU modules worn by different hen subjects. A custom dataset was established for this study, and each data sample was manually labeled with the aid of the video streams recorded for this purpose. From the segments of raw data, skewness, kurtosis, mean, standard deviation, variance, minimum, maximum, entropy, energy, and covariance were manually calculated as representative features, and a number of standard machine learning techniques including support vector machine (SVM), and Bagged Trees were trained while the influences of different parameters and settings were thoroughly analyzed. The best predictor model, namely the Bagged Trees, achieved 89% accuracy for the classification.
In a binary classification task, Hepworth et al. [
27] showed that applying a SVM model to routinely collected bird farm management data enables the prediction of sickness status with a superior accuracy of up to 99.5%. The activity recognition of hens in a non-cage maintenance system was studied in [
28], where wireless accelerometers were installed on the subjects for real-time activity monitoring. The entropy and mean were extracted from the segments of recorded data, and several machine learning models including the Decision Tree and Radial Basis Function were employed to classify the static (sit/sleep), dynamic (walk/run), and resource (feed/drink) activities of the subjects. Accelerometers were also examined in classifying cow behaviors into three classes: standing, walking, and lying down [
29]. If further research supports behavioral monitoring to identify animal health status, accelerometers could be used for larger populations of animals at risk for diseases [
29].
Apart from the reviewed literature that focused on the training of classical machine learning algorithms using handcrafted features of data, a recent body of literature has studied the autonomous feature learning capabilities of Deep Learning (DL) technology. This paradigm has received particular attention in the field of human activity recognition (see [
30] for a recent review). The efficacy of the methods in this scheme has further been enhanced by the rapid advancements in the hardware (i.e., lightweight sensors for large data acquisition, and powerful processors for deep networks training), and software (advanced framework for optimization and parallel computations). Motivated by the outstanding performance of DL models in image classification and object detection, a number of studies have investigated the possibility of encoding IMU signals into a form of images that can readily be recognized by the well-known DL-based models [
19,
21,
31,
32,
33,
34]. This encoding technique is sometimes referred to as the
signal imaging.
The primary objective of the present study is to adopt the signal imaging and deep feature learning techniques to the problem of individual hen activity recognition. We would like to explore to what extent the introduced methodology can improve the results obtained by taking a traditional machine learning approach in our earlier study [
26]. As a second objective, this study benchmarks the influence of different setups, parameters, and properties pertaining to the data collection and preprocessing, model architecture, and model training process. The results of this benchmark could aid further studies in examining different possibilities through remote/wearable sensing to move from individual hen analysis to a large-scale practical implementation being useful in optimally managing the future’s livestock systems.
The reset of this paper is organized as follows. In
Section 2, we start by presenting the pipeline of the work, followed by the description of the dataset establishment. Next, the sophisticated data preprocessing presented in this paper is carefully detailed, and deep learning recognition architectures and the training process are described.
Section 3 is devoted to the presentation of results and discussion. Here, the proposed model is investigated in terms of efficacy, robustness, and generalizability. Finally, the paper is concluded in
Section 4.


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
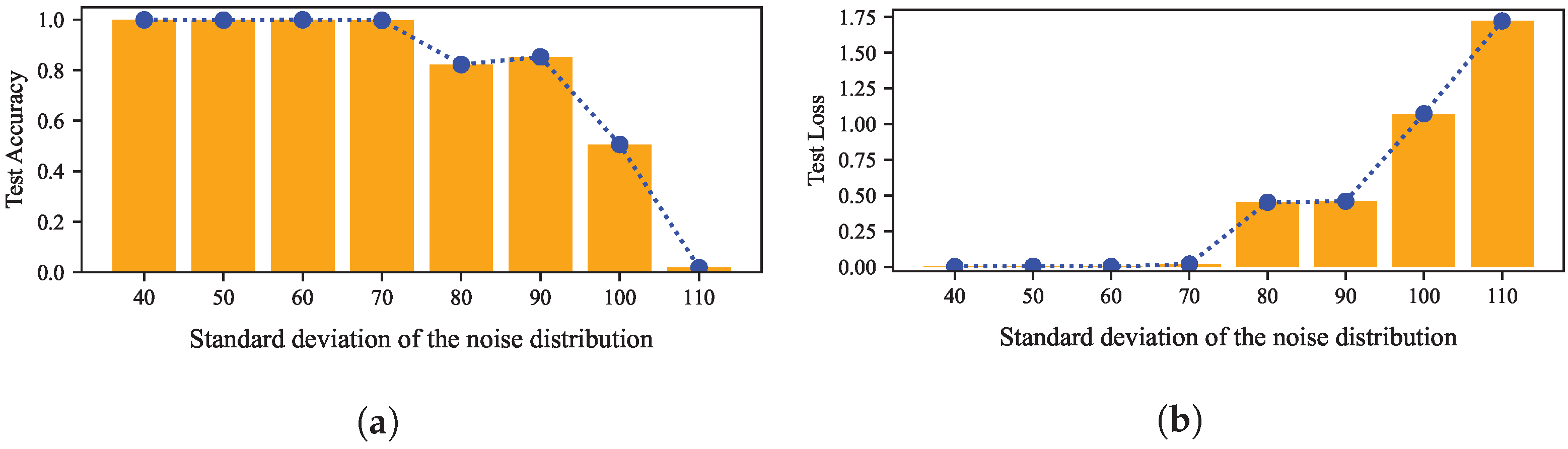{kind=link}
{kind=link}
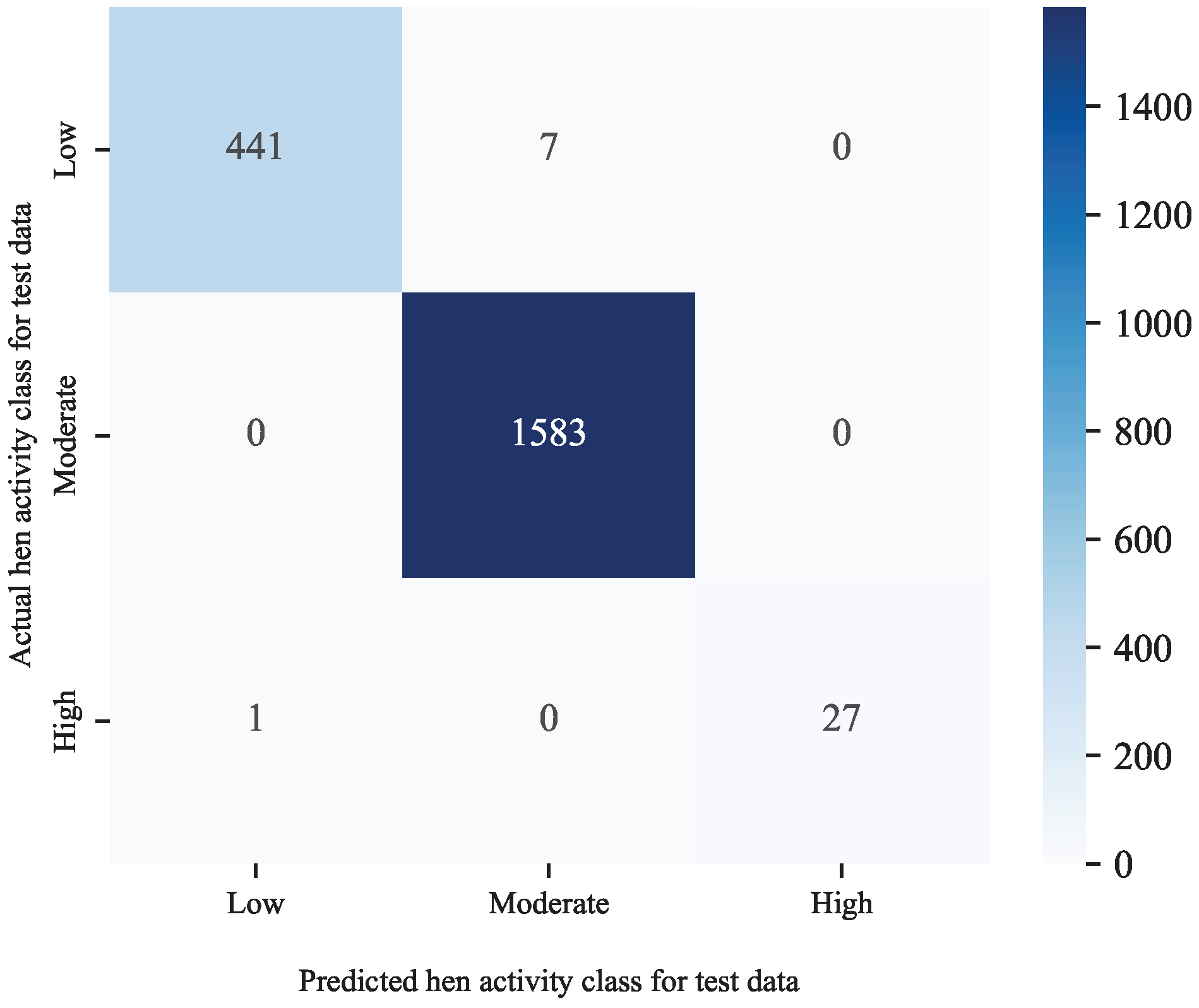{kind=link}
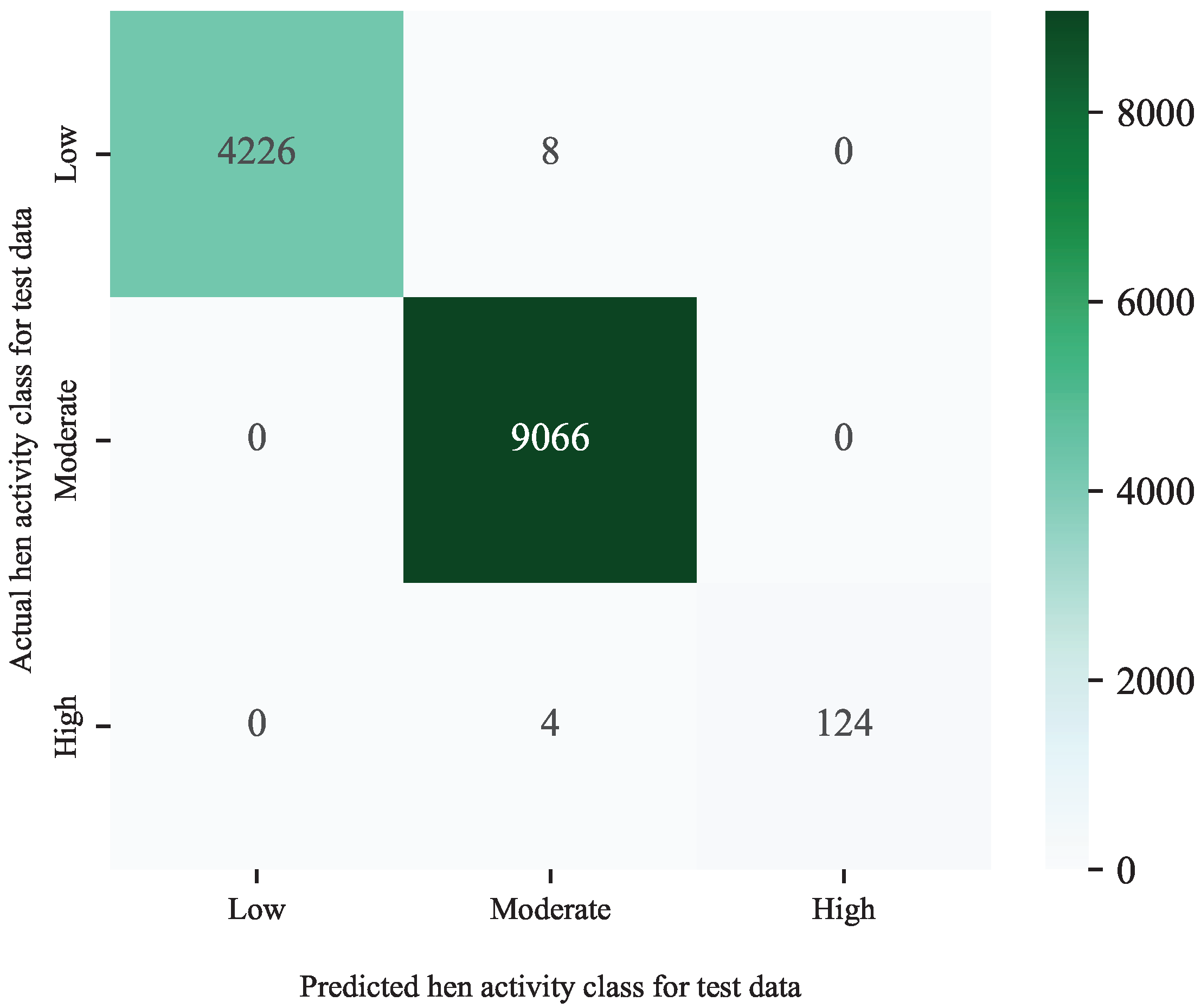{kind=link}