
Identifying Field Crop Diseases Using Transformer-Embedded Convolutional Neural Network

Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
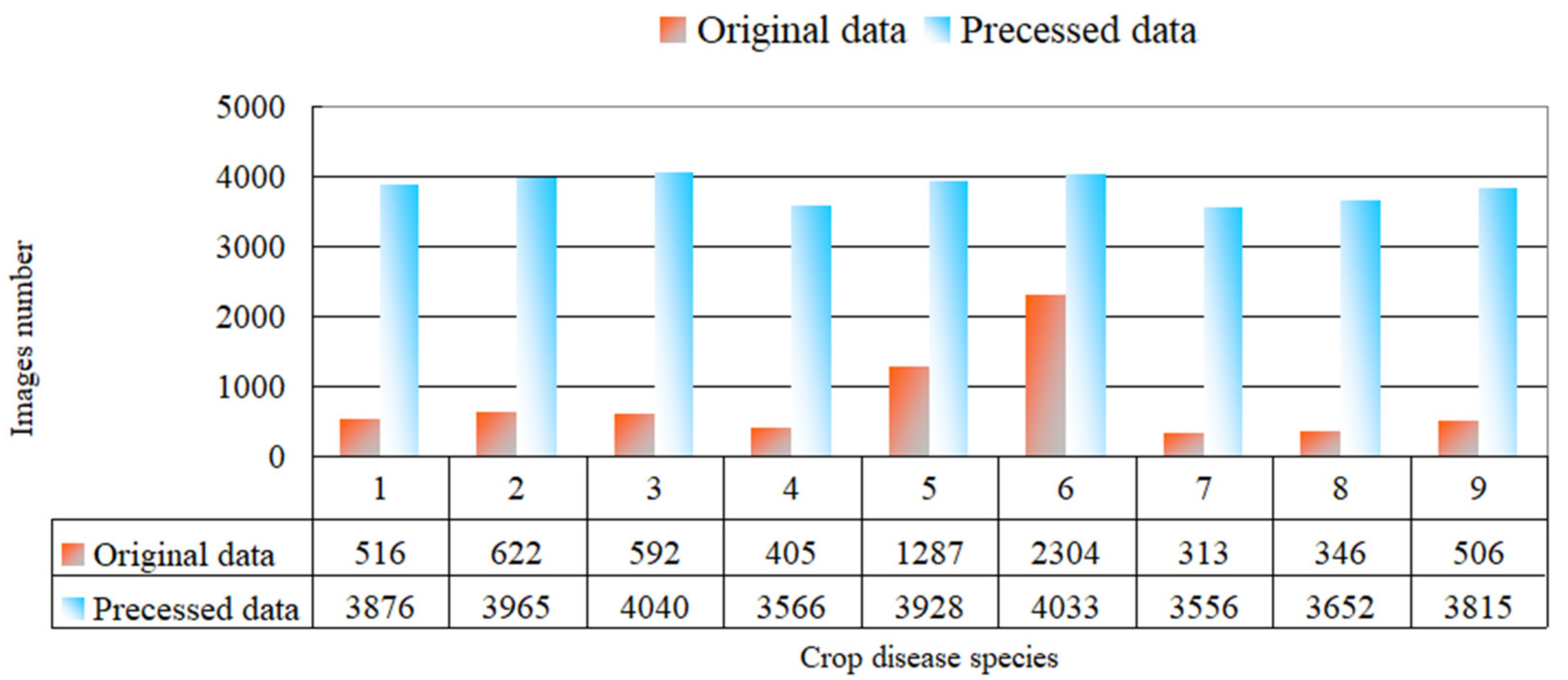
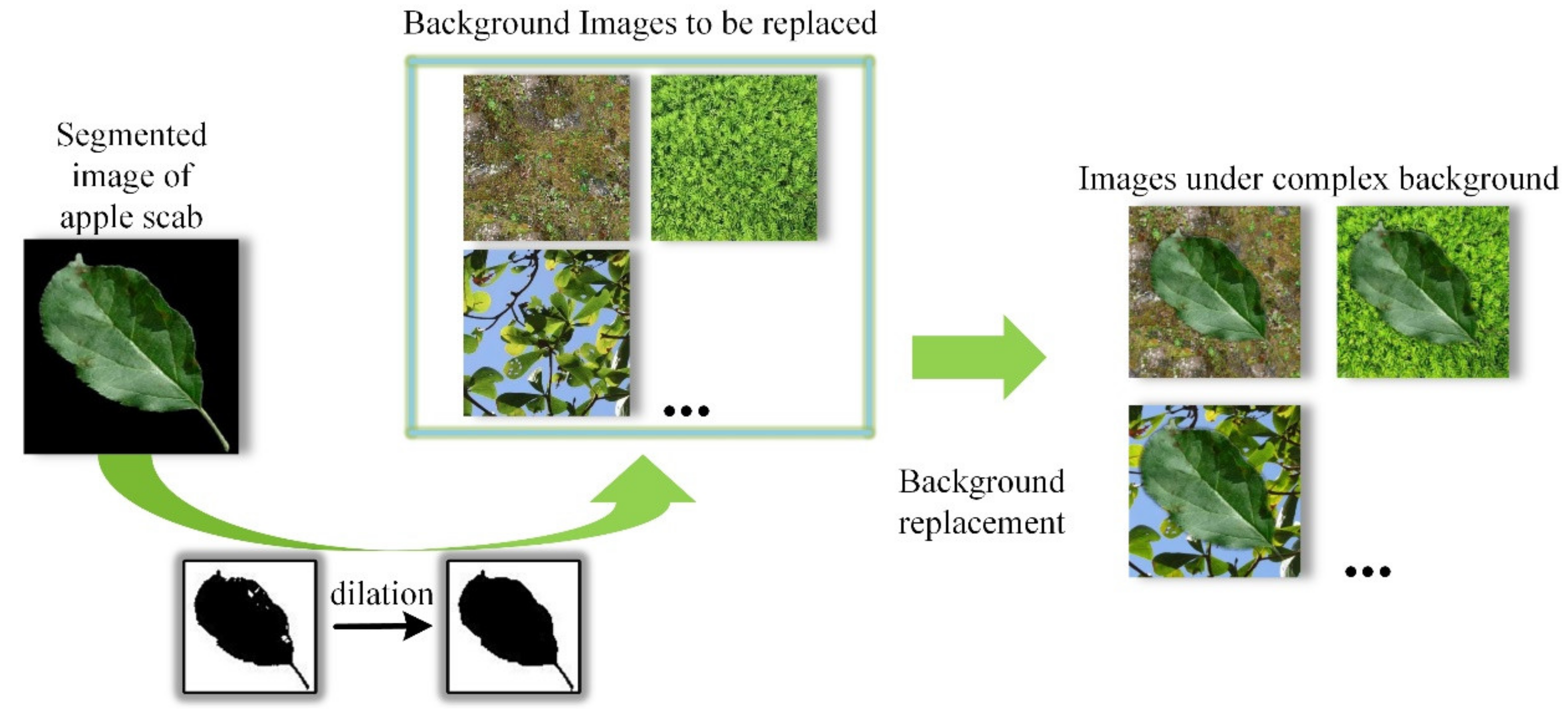
3.1. Datasets Acquisition and Preprocessing
3.2. MobileNet-V2
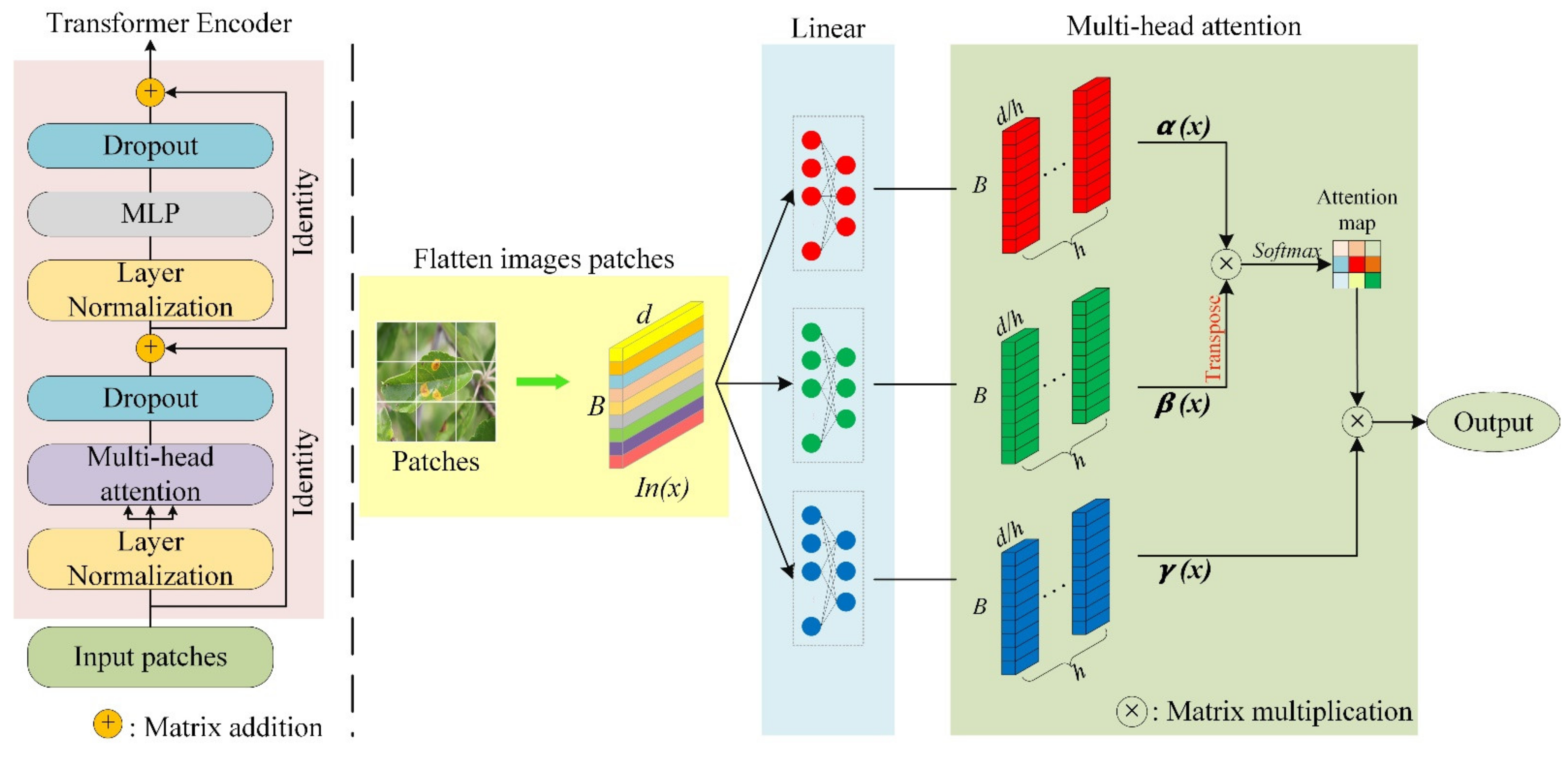
3.3. Transformer Encoder
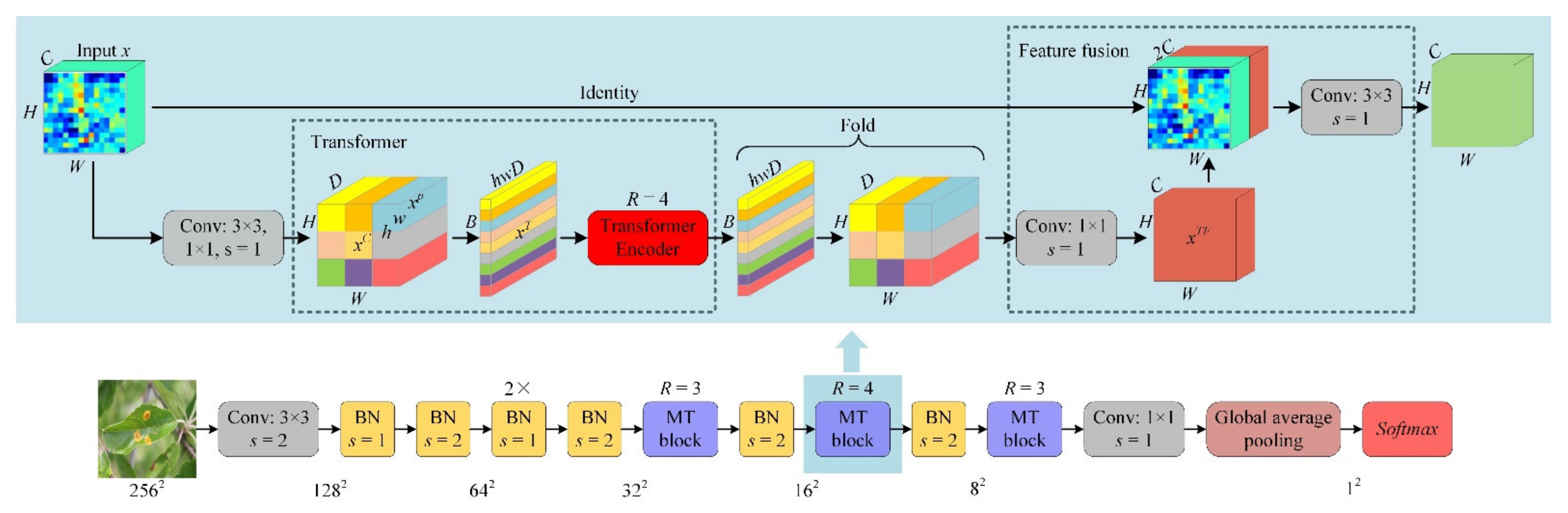
3.4. Proposed Hybrid Model
3.5. Improved Loss Function
3.6. Experiments Setup
3.7. Evaluation Index
4. Results and Discussion
4.1. Results of Different Models on Plant Village
4.2. Ablation Study on Dataset1
4.3. Comparisons with Results from Other Paper
4.4. Generalization on Dataset2
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gu, Y.H.; Yin, H.; Jin, D.; Zheng, R.; Yoo, S.J. Improved multi-plant disease recognition method using deep convolutional neural networks in six diseases of apples and pears. Agriculture 2022, 12, 300. [Google Scholar] [CrossRef]
- Wagle, S.A.; Harikrishnan, R.; Ali, S.H.M.; Faseehuddin, M. Classification of plant leaves using new compact convolutional neural network models. Plants 2022, 11, 24. [Google Scholar] [CrossRef] [PubMed]
- Nasirahmadi, A.; Wilczek, U.; Hensel, O. Sugar beet damage detection during harvesting using different convolutional neural network models. Agriculture 2021, 11, 1111. [Google Scholar] [CrossRef]
- Sun, J.; He, X.F.; Tan, W.J.; Wu, X.H.; Lu, H. Recognition of crop seedling and weed recognition based on dilated convolution and global pooling in CNN. Trans. Chin. Soc. Agric. Eng. 2018, 34, 159–165. [Google Scholar] [CrossRef]
- Machado, B.B.; Orue, J.P.M.; Arruda, M.S.; Santos, C.V.; Sarath, D.S.; Goncalves, W.N. Bioleaf: A professional mobile application to measure foliar damage caused by insect herbivory. Comput. Electron. Agric. 2016, 129, 44–55. [Google Scholar] [CrossRef] [Green Version]
- Xu, P.; Tan, Q.; Zhang, Y.; Zha, X.; Yang, S.; Yang, R. Research on maize seed classification and recognition based on machine vision and deep learning. Agriculture 2022, 12, 232. [Google Scholar] [CrossRef]
- Sun, J.; He, X.; Ge, X.; Wu, X.; Shen, J.; Song, Y. Detection of key organs in tomato based on deep migration learning in a complex background. Agriculture 2018, 8, 196. [Google Scholar] [CrossRef] [Green Version]
- Luo, H.; Dai, S.; Li, M.; Liu, E.P.; Zheng, Q.; Hu, Y.; Yi, X.P. Comparison of machine learning algorithms for mapping mango plantations based on Gaofen-1 imagery. J. Integr. Agric. 2020, 19, 2815–2828. [Google Scholar] [CrossRef]
- Ashwinkumar, S.; Rajagopal, S.; Manimaran, V.; Jegajothi, B. Automated plant leaf disease detection and classification using optimal MobileNet based convolutional neural networks. Mater. Today Proc. 2021, 51, 480–487. [Google Scholar] [CrossRef]
- Kamal, K.C.; Yin, Z.; Wu, M.; Wu, Z.L. Depthwise separable convolution architectures for plant disease classification. Comput. Electron. Agric. 2019, 165, 104948. [Google Scholar] [CrossRef]
- Ji, M.; Zhang, L.; Wu, Q. Automatic grape leaf diseases identification via united model based on multiple convolutional neural networks. Inf. Process. Agric. 2020, 7, 418–426. [Google Scholar] [CrossRef]
- Sun, J.; Tan, W.; Mao, H.P.; Wu, X.H.; Chen, Y.; Wang, L. Recognition of multiple plant leaf diseases based on improved convolutional neural network. Trans. Chin. Soc. Agric. Eng. 2017, 33, 209–215. [Google Scholar] [CrossRef]
- Too, E.C.; Li, Y.J.; Njuki, S.; Liu, Y.C. A comparative study of fine-tuning deep learning models for plant disease identification. Comput. Electron. Agric. 2019, 161, 272–279. [Google Scholar] [CrossRef]
- Zhao, L.X.; Hou, F.D.; Lu, L.Z.; Zhu, H.C.; Ding, X.L. Image recognition of cotton leaf diseases and pests based on transfer learning. Trans. Chin. Soc. Agric. Eng. 2020, 36, 184–191. [Google Scholar] [CrossRef]
- Mohameth, F.; Chen, B.C.; Kane, A.S. Plant disease detection with deep learning and feature extraction using plant village. J. Computer. Commun. 2020, 8, 10–22. [Google Scholar] [CrossRef]
- Mohanty, S.P.; Hughes, D.P.; Salathe, M. Using deep learning for image-based plant disease detection. Front. Plant. Sci. 2016, 7, 159–167. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.P.; Chen, J.; Li, K.X.; Li, J.Y.; Liu, H. Identification of multiple plant leaf diseases using neural architecture search. Trans. Chin. Soc. Agric. Eng. 2020, 36, 166–173. [Google Scholar] [CrossRef]
- Gao, R.; Wang, R.; Feng, L.; Li, Q.; Wu, H.R. Dual-branch, efficient, channel attention-based crop disease identification. Comput. Electron. Agric. 2021, 190, 106410. [Google Scholar] [CrossRef]
- Zhou, J.; Li, J.X.; Wang, C.S.; Wu, H.R.; Zhao, C.J.; Teng, G.F. Crop disease identification and interpretation method based on multimodal deep learning. Comput. Electron. Agric. 2021, 189, 106408. [Google Scholar] [CrossRef]
- Picon, A.; Seitz, M.; Alvarez, G.A.; Mohnke, P.; Ortiz, B.A.; Echazarra, J. Crop conditional convolutional neural networks for massive multi-crop plant disease classification over cell phone acquired images taken on real field conditions. Comput. Electron. Agric. 2019, 167, 105093. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, D.; Suzauddola, M.; Zeb, A. Identifying crop diseases using attention embedded MobileNet-V2 model. Appl. Soft Comput. 2021, 113, 107901. [Google Scholar] [CrossRef]
- Wang, C.S.; Zhou, J.; Wu, H.R.; Teng, G.F.; Zhao, C.J.; Li, J.X. Identification of vegetable leaf diseases based on improved multi-scale ResNet. Trans. Chin. Soc. Agric. Eng. 2020, 36, 209–217. [Google Scholar] [CrossRef]
- Tang, Z.; Yang, J.L.; Li, Z.; Qi, F. Grape disease image classification based on lightweight convolution neural networks and channelwise attention. Comput. Electron. Agric. 2020, 178, 105735. [Google Scholar] [CrossRef]
- Machado, B.B.; Spadon, G.; Arruda, M.S.; Gon, W.N. A smartphone application to measure the quality of pest control spraying machines via image analysis. In Proceedings of the 33rd Annual ACM Symposium on Applied Computing, Pau, France, 9–13 April 2018; pp. 956–963. [Google Scholar] [CrossRef] [Green Version]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Spadon, G.; Hong, S.; Brandoli, B.; Matwin, S.; Rodrigues, J.F., Jr.; Sun, J. Pay attention to evolution: Time series forecasting with deep graph-evolution learning. arXiv 2008, arXiv:2008.12833v3. [Google Scholar] [CrossRef]
- Hossain, S.; Deb, K.; Dhar, P.; Koshiba, T. Plant leaf disease recognition using depth-wise separable convolution-based models. Symmetry 2021, 13, 511. [Google Scholar] [CrossRef]
- Dataset1. Available online: https://www.kaggle.com (accessed on 20 October 2021).
- Wagle, S.A.; Harikrishnan, R. A deep learning-based approach in classification and validation of tomato leaf disease. Trait. Signal 2021, 38, 699–709. [Google Scholar] [CrossRef]
- Wagle, S.A.; Harikrishnan, R.; Sampe, J.; Mohammad, F.; Md Ali, S.H. Effect of data augmentation in the classification and validation of tomato plant disease with deep learning methods. Trait. Signal 2021, 38, 1657–1670. [Google Scholar] [CrossRef]
- Bruno, B.; Gabriel, S.; Travis, E.; Patrick, H.; Andre, C. Dropleaf: A precision farming smartphone tool for real-time quantification of pesticide application coverage. Comput. Electron. Agric. 2021, 180, 105906. [Google Scholar] [CrossRef]
- Castro, A.D.; Madalozzo, G.A.; Trentin, N.; Costa, R.; Rieder, R. Berryip embedded: An embedded vision system for strawberry crop. Comput. Electron. Agric. 2020, 173, 105354. [Google Scholar] [CrossRef]
- Yadav, S.; Sengar, N.; Singh, A.; Singh, A.; Dutta, M.K. Identification of disease using deep learning and evaluation of bacteriosis in peach leaf. Ecol. Inform. 2021, 61, 101247. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR2018), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems (NIPS2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Yu, Q. A discriminative feature learning approach for deep face recognition. In Proceedings of the European Conference on Computer Vision (ECCV2016), Amsterdam, The Netherlands, 11–14 October 2016; pp. 499–515. [Google Scholar] [CrossRef]
- Luo, Y.Q.; Sun, J.; Shen, J.F.; Wu, X.H.; Wang, L.; Zhu, W.D. Apple leaf disease recognition and sub-class categorization based on improved multi-scale feature fusion network. IEEE Access 2021, 9, 95517–95527. [Google Scholar] [CrossRef]
- Sun, J.; Zhu, W.D.; Luo, Y.Q. Recognizing the diseases of crop leaves in fields using improved Mobilenet-V2. Trans. Chin. Soc. Agric. Eng. 2021, 37, 161–169. [Google Scholar] [CrossRef]
- Liu, Y.; Gao, G.Q. Identification of multiple leaf diseases using improved SqueezeNet model. Trans. Chin. Soc. Agric. Eng. 2021, 37, 187–195. [Google Scholar] [CrossRef]
- Yadav, D.; Akanksha; Yadav, A.K. A novel convolutional neural network-based model for recognition and classification of apple leaf diseases. Trait. Signal 2020, 37, 1093–1101. [Google Scholar] [CrossRef]
- Ramcharan, A.; McCloskey, P.; Baranowski, K.; Mbilinyi, N.; Mrisho, L. A mobile-based deep learning model for cassava disease diagnosis. Front. Plant Sci. 2019, 10, 272. [Google Scholar] [CrossRef] [Green Version]
- Sambasivam, G.; Opiyo, G.D. A predictive machine learning application in agriculture: Cassava disease detection and classification with imbalanced dataset using convolutional neural networks. Egypt. Inform. J. 2021, 22, 27–34. [Google Scholar] [CrossRef]
- Caldeira, R.F.; Santiago, W.E.; Teruel, B. Identification of cotton leaf lesions using deep learning techniques. Sensors 2021, 21, 3169. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref No. | Model | Data Situation | Background | Accuracy | Challenges/Future Scope |
|---|---|---|---|---|---|
| [9] | MobileNet | Five tomato diseases in Plant Village | Simple | 98.50% | The background of tomato disease is simple, and the images need a lot of complex preprocessing. |
| [10] | MobileNet | Plant Village | Simple | 98.34% | The improved model has low recognition accuracy in the face of diseases in complex environment. |
| [11] | Inception-V3 and ResNet-50 | Four grape diseases in Plant Village | Simple | 98.57% | The background is simple, and the correlation between disease characteristics is not considered. |
| [17] | NAS | Plant Village | Simple | 95.40% | The improved model performs poorly on datasets with unbalanced quantity and requires a certain amount of operation time. |
| [18] | ResNet-18 | Self-collected cucumber diseases | Complex | 98.54% | The improved model ignores the relationship between cucumber disease characteristics and only pays attention to the separability between classes. |
| [20] | ResNet-50 | Self-collected diseases | Complex | 98.00% | The local limitations of the features extracted by CNN are not considered, which is not conducive to the early detection of the disease. |
| [21] | MobileNet-V2 | Self-collected diseases | Complex | 99.13% | The influence of unbalanced sample size on experimental results is not considered. |
| [22] | ResNet-18 | Self-collected diseases | Complex | 93.05% | The recognition accuracy is not high in complex background. Furthermore, the parameters of the model are large, and the image processing rate is not discussed. |
| [23] | ShuffleNet | Four grape diseases | Complex | 99.14% | The influence of unbalanced data volume on experimental results is not considered, and how to expand intra class differences is not analyzed. |
| Parameters | Values |
|---|---|
| Classes on Dataset1 | 9 |
| Classes on Dataset2 | 3 |
| Image size | 256 × 256 |
| Batch size | 32 |
| Epochs | 150 |
| Learning rate (LR) | 0.001 |
| LR decay index | 80% |
| Dropout | 0.2 |
| Optimizer | Adam |
| Default (0.9, 0.999) |
| Paper | Backone | Transfer Learning | Image Number | Accuracy (%) | ||
|---|---|---|---|---|---|---|
| Color | Gray | Segmented | ||||
| Mohameth et al. [15] | VGG16 | √ | 54,306 | 97.82 | - | - |
| Mohanty et al. [16] | AlexNet | √ | 54,306 | 99.27 | 97.26 | 98.91 |
| Huang et al. [17] | NasNet | √ | 54,306 | 98.96 | 99.01 | 95.40 |
| @Mohameth et al. [15] | VGG16 | √ | 54,306 | 98.14 | 97.64 | 98.31 |
| @Mohanty et al. [16] | AlexNet | √ | 54,306 | 99.36 | 97.91 | 98.92 |
| @Huang et al. [17] | NasNet | √ | 54,306 | 99.15 | 98.96 | 98.66 |
| This paper | MV2 | √ | 54,306 | 99.62 | 99.08 | 99.22 |
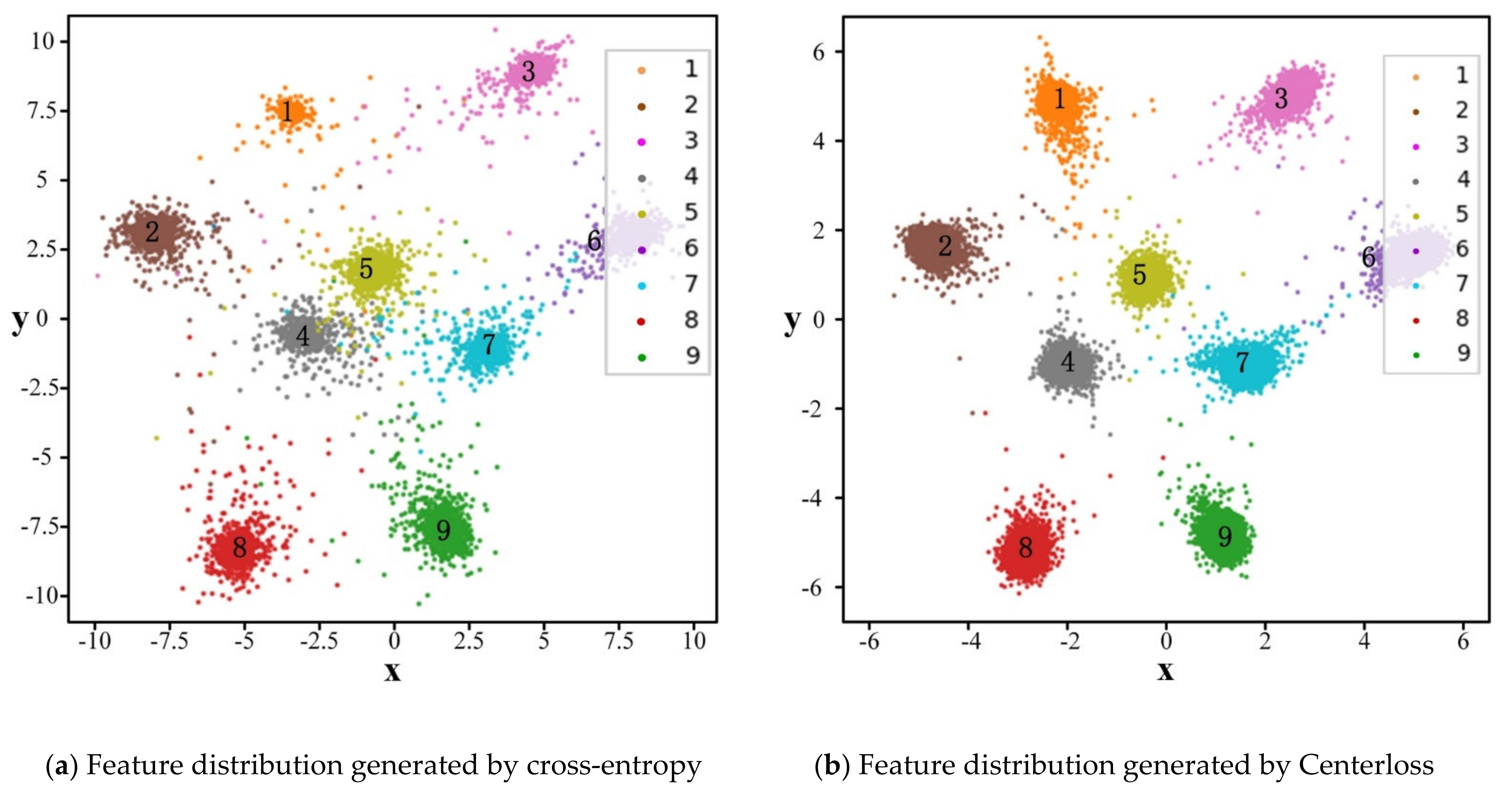
| Plan | TL | Centerloss | Transformer | Balanced Accuracy (%) | Micro_ Sensitivity (%) | Micro_ Precision (%) | Micro_ F1 (%) | Param (M) |
|---|---|---|---|---|---|---|---|---|
| 0 | √ | - | - | 91.94 | 91.64 | 91.37 | 91.50 | 2.24 |
| 1 | √ | √ | - | 93.59 | 93.49 | 93.48 | 93.49 | 2.24 |
| 2 | √ | - | √ | 94.82 | 95.16 | 95.20 | 95.18 | 5.00 |
| 3 | √ | √ | √ | 96.58 | 96.97 | 96.76 | 96.86 | 5.00 |
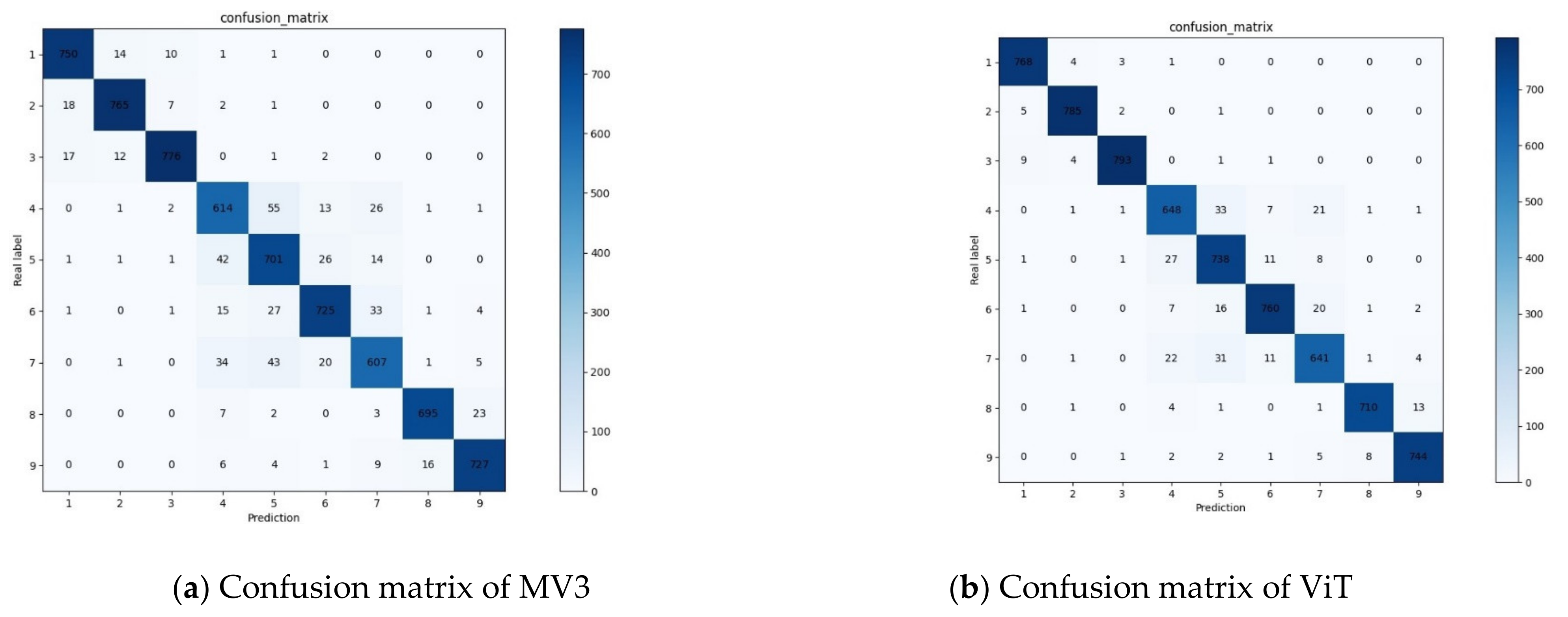
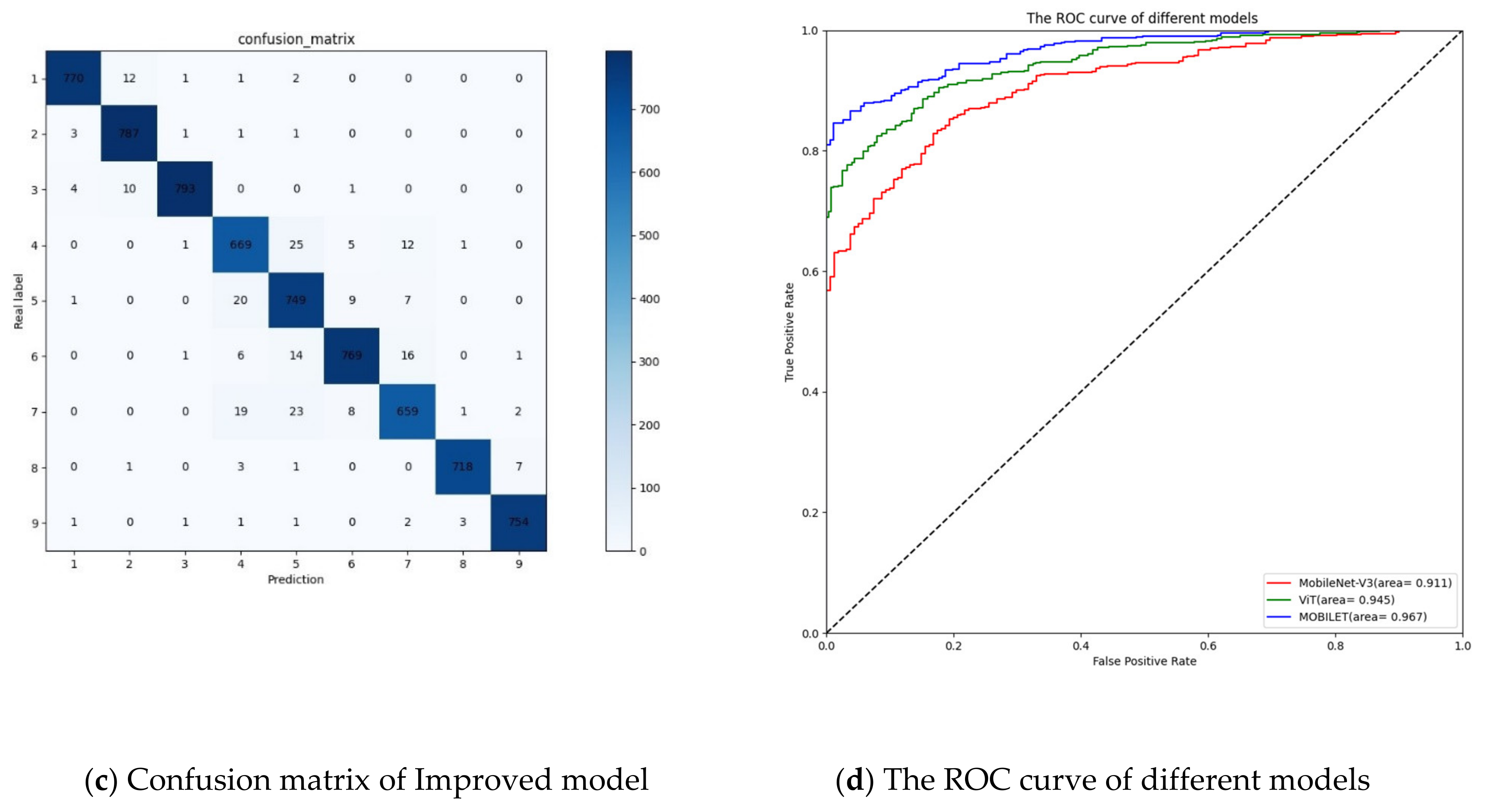
| Crop Name | Disease Situation | Accuracy (%) | ||
|---|---|---|---|---|
| MV3 | ViT | MOBILET | ||
| Apple | Healthy | 96.79 | 99.02 | 99.37 |
| Rust | 96.50 | 99.03 | 99.21 | |
| Scab | 96.08 | 98.11 | 98.90 | |
| Cassava | Bacterial blight | 86.12 | 90.89 | 93.76 |
| Brown streak | 89.28 | 93.96 | 95.33 | |
| Mosaic virus | 85.37 | 90.17 | 92.66 | |
| Healthy | 89.83 | 94.15 | 95.30 | |
| Cotton | Boll blight | 95.13 | 97.28 | 98.34 |
| Healthy | 95.27 | 97.51 | 98.77 | |
| Weighed accuracy (%) | 92.31 | 95.60 | 96.87 | |
| Param quantity (M) | 4.38 | 103.03 | 5.00 | |
| Recognition speed per image (ms) | 4.24 | 8.77 | 4.93 | |
| Paper | Year | Backone | Dataset | Number of Categories | Accuracy (%) |
|---|---|---|---|---|---|
| Zhao et al. [14] | 2020 | VGG-19 | Cotton | 6 | 97.16 |
| Luo et al. [37] | 2021 | ResNet-50 | Apple | 6 | 94.99 |
| Sun et al. [38] | 2021 | MobileNet-V2 | Cassava | 5 | 92.20 |
| Liu et al. [39] | 2021 | SqueezeNet | Apple | 4 | 98.13 |
| Yadav et al. [40] | 2020 | AlexNet | Apple | 4 | 98.00 |
| Ramcharan et al. [41] | 2019 | MobileNet | Cassava | 3 | 83.90 |
| Sambasivam et al. [42] | 2021 | Private model | Cassava | 4 | 93.00 |
| Caldeira et al. [43] | 2021 | GoogleNet | Cotton | 3 | 86.60 |
| ResNet-50 | Cotton | 3 | 89.20 | ||
| This paper | 2022 | MobileNet-V2 + Transformer | Cotton | 2 | 98.56 |
| Apple | 3 | 99.16 | |||
| Cassava | 4 | 94.26 |
| Model | Accuracy in Simple Background (%) | Accuracy with Background Replacement (%) | ||||
|---|---|---|---|---|---|---|
| Apple Scab | Cassava Brown Streak | Cotton Boll Blight | Apple Scab | CASSAVA Brown Streak | Cotton Boll Blight | |
| MV3 | 95.14 | 93.33 | 95.97 | 92.22 | 91.11 | 93.47 |
| ViT | 97.22 | 93.89 | 97.64 | 93.89 | 91.53 | 94.72 |
| MOBILET | 98.33 | 95.42 | 98.89 | 95.97 | 94.03 | 96.39 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, W.; Sun, J.; Wang, S.; Shen, J.; Yang, K.; Zhou, X. Identifying Field Crop Diseases Using Transformer-Embedded Convolutional Neural Network. Agriculture 2022, 12, 1083. https://doi.org/10.3390/agriculture12081083
Zhu W, Sun J, Wang S, Shen J, Yang K, Zhou X. Identifying Field Crop Diseases Using Transformer-Embedded Convolutional Neural Network. Agriculture. 2022; 12(8):1083. https://doi.org/10.3390/agriculture12081083
Chicago/Turabian StyleZhu, Weidong, Jun Sun, Simin Wang, Jifeng Shen, Kaifeng Yang, and Xin Zhou. 2022. "Identifying Field Crop Diseases Using Transformer-Embedded Convolutional Neural Network" Agriculture 12, no. 8: 1083. https://doi.org/10.3390/agriculture12081083