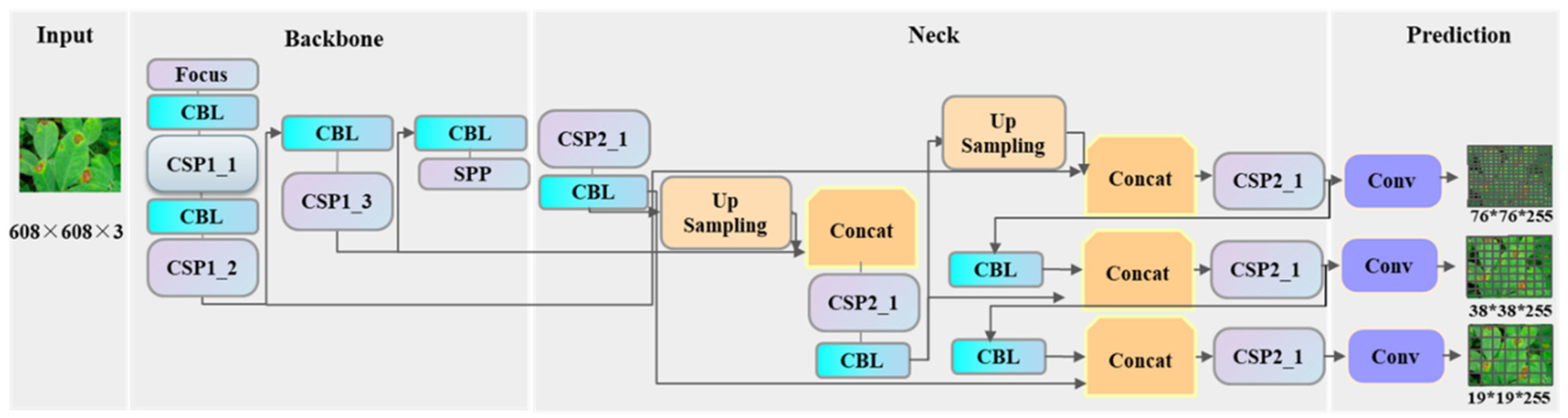
3.3.2. Model Improvement
The YOLO algorithm has been researched in the recognition and classification of fruits [
45,
49] and marine organisms [
50,
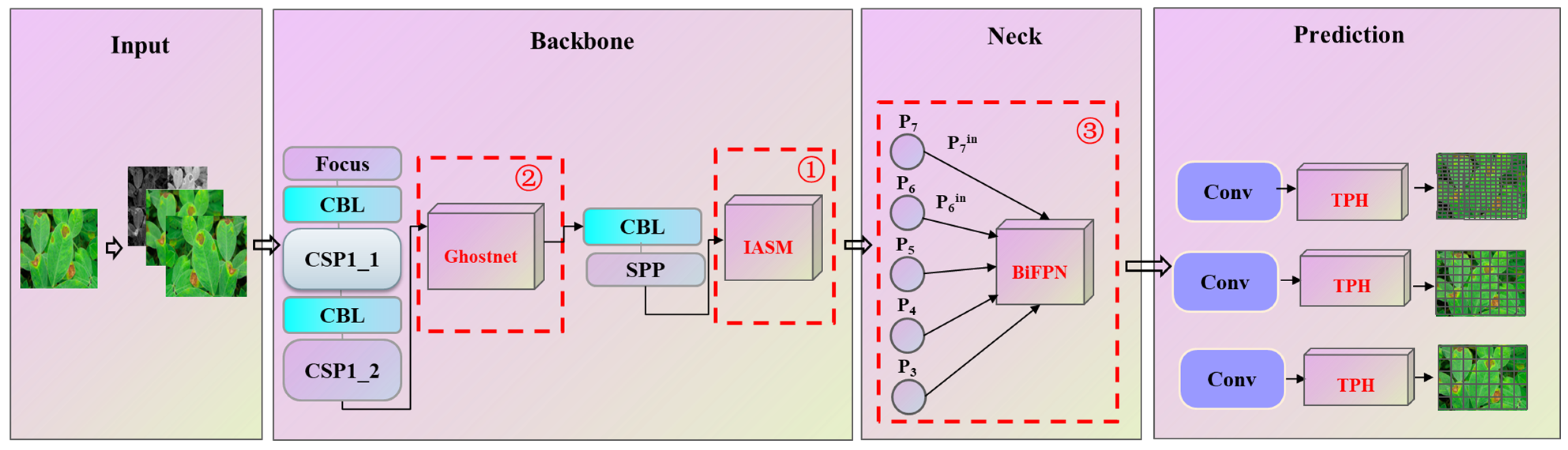
51], but, due to the significant differences in the characteristics of different detection targets, the model needs to be improved and optimized to meet the detection and classification requirements. In view of the complex and diverse plant species and disease species in the disease detection task, the dataset background is complex and diverse, and the images are greatly affected by the shooting environment. However, the existing model has the limitation of too large a number of parameters and lack of attention to key areas. In order to improve the efficiency and accuracy of plant disease detection, identification, and classification, this study proposes an optimized plant disease detection and classification algorithm. The specific optimization work is as follows: (1) the improved attention submodule (IASM) is proposed to improve the accuracy and efficiency of the model; (2) the Ghostnet structure is introduced to reduce the amount of calculation, and the weighted frame is used to fuse WBF for postprocessing to realize the lightweight of the model; (3) the original FPN + PANet structure is replaced with the BiFPN structure, and Fast normalized fusion is used for weighted feature fusion to improve operation speed.
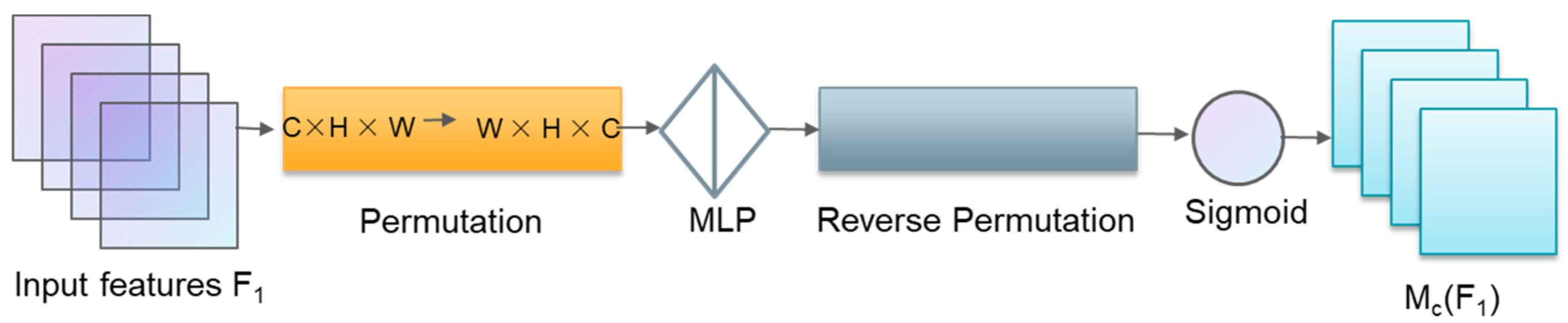
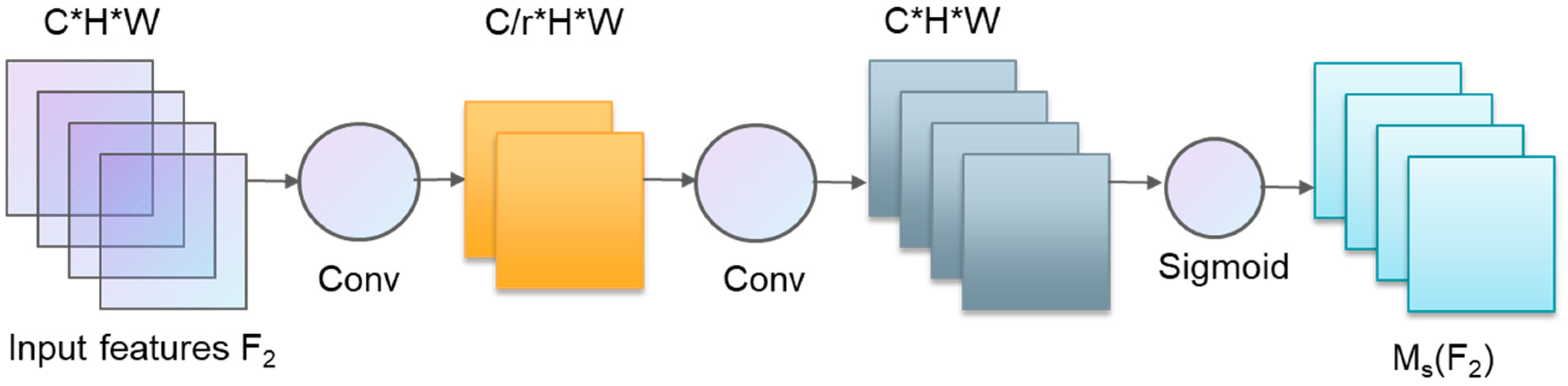
Just as when seeing an image for the first time, the brain pays general attention to the big picture of the image. The YOLOv5 model detects sub-regions of the entire image and lacks attention to key areas. If it is set in advance to find an object in the image (such as a dog), the brain will quickly scan the image, and, according to the previous impression of the dog, it will assign higher attention to similar parts of the image and focus on it. The process is the subconscious ability of the brain to find key areas. Researchers use this as the basis for model training and propose the Attention Mechanism. In order to improve the model’s attention to the key areas of plant disease images, this paper proposes the Improved Attention Submodule (IASM), which acquires the target area that needs to be focused on by scanning the image globally and gives the area greater weight to obtain more details. At present, the most widely used attention mechanisms are mainly channeled attention, spatial attention, branch attention, and multi-class mixing mechanisms. Among them, channel attention uses a three-dimensional arrangement to save three-dimensional information and uses a multi-layer perceptron (MLP) to amplify the channel-space dependence, which can adaptively calibrate the channel weights. Spatial Attention first performs global average or maximum pooling on the channel, and then obtains attention from the spatial level. The structure is shown in
Figure 4 and
Figure 5, respectively.
The improved attention submodule preserves and fuses information by combining channel attention and spatial attention mechanisms, assuming the intermediate feature
as the output. The useful information (such as simple edges and shapes) is captured by each feature layer to obtain a more complex semantic representation of the input, expecting the network to pay more attention to the essential parts. Therefore, to enhance the discrimination of shallow semantic information, this study introduces the improved attention submodule for network optimization based on considering the 3D interaction, and adopts the structure of ResBlock + CBAM to optimize the model. Combined with the function of channel attention and spatial attention to pay attention to the key objects and key areas of the image, the operation speed of key target areas is enhanced, and the parallel and serial performance comparisons of channel attention and spatial attention are carried out, respectively. The results show that the optimization effect of the model is the best by adopting parallel and spatial attention followed by channel attention. The structure optimized in this paper is shown in
Figure 6.
The main process is to obtain the intermediate feature
by performing the convolution operation and the average and maximum pooling operations on the inputs, and then use the activation function to calculate the output channel attention
Mc, which is multiplied by the MLP to obtain the channel attention. Force distribution map
F’, illustrates the importance of channels in the feature map. The channel attention map
F’ is averaged, max pooled, and convolutional to obtain the spatial attention
Ms,
Ms, and
F’, which are multiplied to obtain the spatial attention map
F”, and the channel attention map is related to the spatial attention map. This is multiplied and added to the original input to obtain the final output. The calculation process of channel attention mainly includes attention distribution and weighted average. The attention distribution is to calculate the attention distribution of all input information and input the task-related information into the network to save computing resources, introduce the query vector q, and calculate the attention distribution
through the scoring function
, namely:
where the attention distribution
represents the degree of attention to the
i-th input vector when performing the detection task.
Weighted distribution
is a process of useful weighting information and the weighted average of all input attention. The calculation process is as follows:
where the attention distribution
represents the degree of attention to the
i-th input vector when performing the classification task; and
represents the weight assigned to the
i-th input vector.
To accurately locate the position of disease and improve the characterization ability of the detection and classification model, an improved process of weight fusion applicable to plant disease classification is proposed based on the introduction of the improved attention submodule and the idea of feature rescaling and fusion in the SENet module. The module structure is shown in
Figure 7. The input vectors are subjected to maximum global pooling and average pooling operations, and then added after the operations of fully connected layer 1 (FC_1), modified linear unit, and fully connected layer 2 (FC_2). After the result is cross-multiplied with the original input, the result is obtained and output to the next layer. In the process of maximum pooling, first, the maximum possible value of each candidate box is calculated and used as the main influencing factor of the result. Then, the IOU of the candidate frame corresponding to the maximum possible value is calculated, which is the basis for measuring the accuracy of the prediction model.
The attention mechanism is used to generate the weights of different connections dynamically. Assuming that the input sequence is , and the output sequence is , three sets of vector sequences can be obtained by linear transformation:
where
,
, and
are the query vector sequence, the key vector sequence, and the value vector sequence, respectively. The above formulas represent the learnable parameter matrix, respectively, and the output vector
can be obtained by Equation (9):
where
, represent the positions of the output and input vector sequences, respectively; and
represents the connection weight, which is dynamically generated by an optimized global attention mechanism.
- 2.
Ghostnet
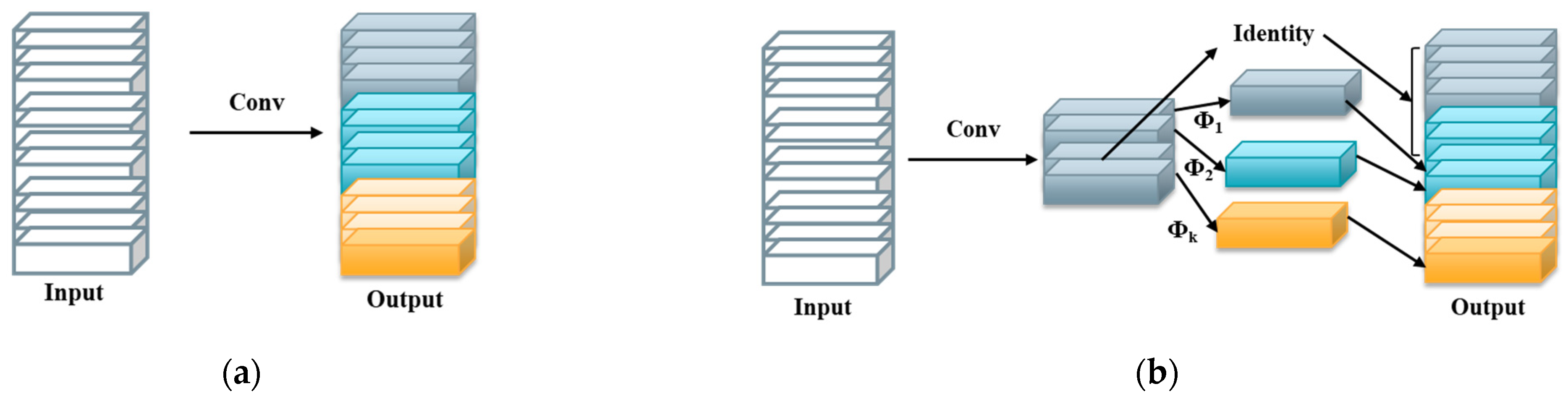
Since the feature map layer in the plant disease image dataset selected in this study contains more redundant information, the size of the model is also increased when the validity of the input data is increased. To reduce the calculation amount of the model and further improve the operation speed of the model, this study proposes to combine Ghostnet to reduce the weight of the network, and use a low-cost calculation method to obtain redundant feature map layer information. The convolution operation is divided into two steps: small-scale convolution and channel-by-channel convolution. Small-scale convolution realizes the degree of parameter optimization by customizing the number of convolution kernels. Channel-by-channel convolution combines original convolution with simple linear transformation to get more features. Ghostnet adopts identity and linear transformation at the same time, and realizes the lightweight of the model based on maintaining the original features. The model structure is shown in
Figure 8.
The calculation process of conventional convolution is as in Equation (10); the input data
pass through the convolution kernel
, and, finally, obtains the output
. The calculation amount reaches
, and the number is huge.
The Ghostnet model obtains a part of the output
by customizing the number of convolution kernels
, while the rest of the s-dimensional feature output
is generated by a linear calculation, which greatly simplifies the calculation.
where
is the linear transformation function for generating the
j-th feature map of
.
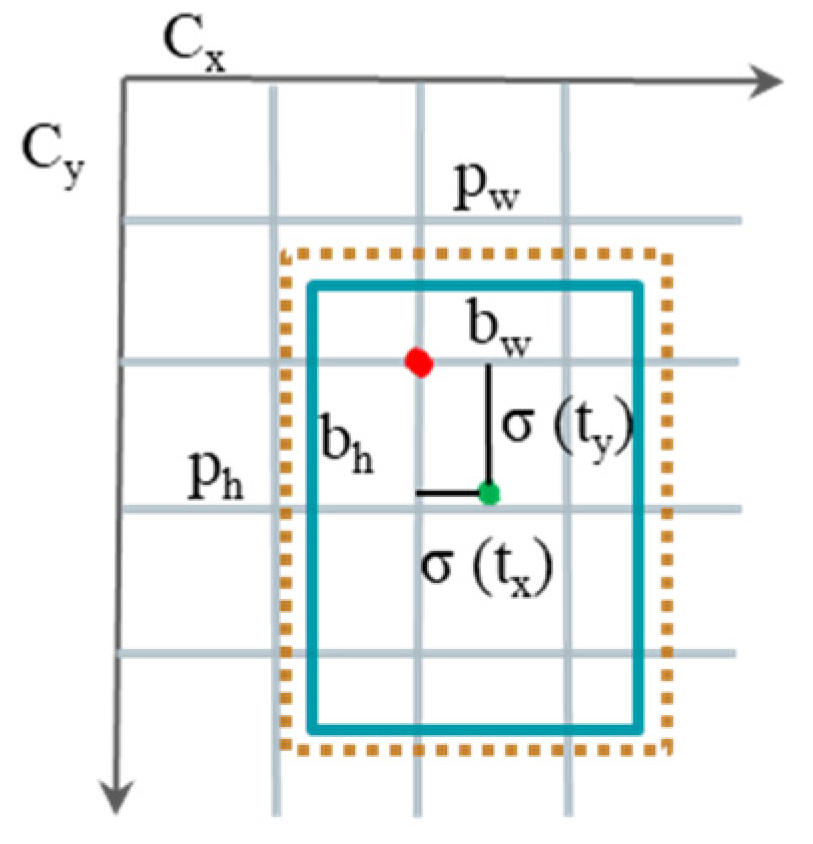
Some plant disease images contain multiple target types, that is, an image often contains multiple target boxes, which are likely to overlap and misjudgment occurs. Therefore, it is necessary to optimize the output process of the bounding box of the model. The non-maximum suppression method NMS (non-maximum) of the original model simply divides the pros and cons of the prediction box by deleting operations. In this study, by adding the bounding box fusion algorithm weighted boxes fusion (WBF) to the original model, the boundaries are sorted according to the confidence score and Equation (13) is used to calculate the co-ordinates and confidence score of the target box, which are determined by the new confidence score. Weights are used for co-ordinate weighting. This is equivalent to giving high-confidence target boxes a higher priority for the output, and so on. Assuming that the original model predicts two close target frames: A:
, B:
, where
represent the co-ordinates of the upper left corner and the lower right corner of the target frame, respectively, and
is the confidence score of the target frame, then the target frame C
is finally obtained through the fusion of A and B. The calculation process is as follows:
Through this improved method, the confidence score of the target frame is used as a weight to determine the contribution of the original frame to the fusion frame, so that the position and size of the fusion frame are closer to the frame with high confidence, ensuring the accuracy of positioning and classification.
- 3.
The Bidirectional Feature Pyramid Network
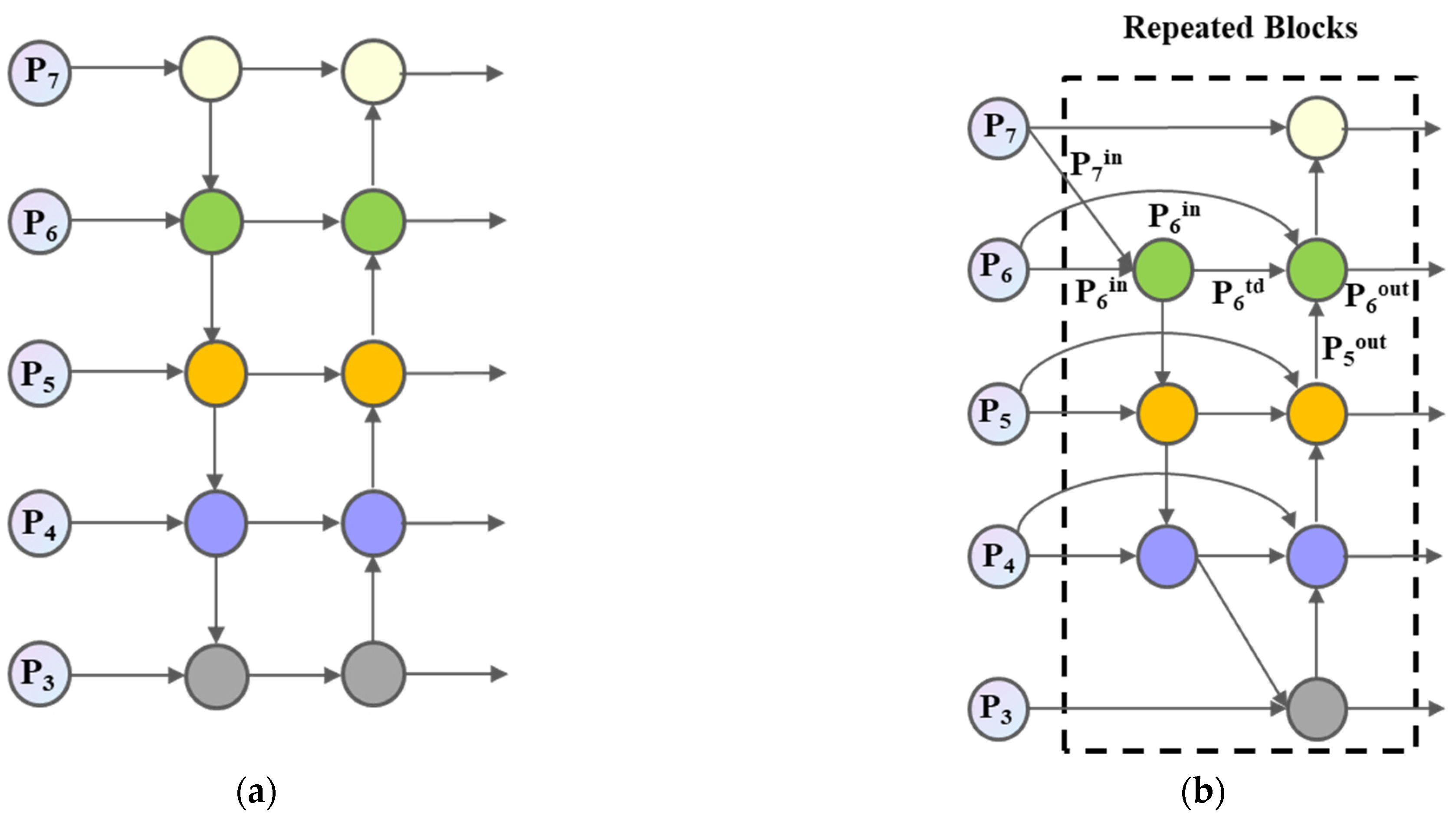
The neck layer of the YOLOv5 network adopts the FPN + PANet structure for feature aggregation. Due to the one-way structure of FPN, PANet adds a bottom-up inter-layer transmission path, which improves the connection between high-level semantic information and bottom-level location information. It is beneficial to the classification and localization of the target, but it consumes extra time due to the establishment of one more path. The repeated weighted bidirectional feature pyramid network (BiFPN) ignores nodes with only one input edge, that is, the network believes that if a node has only one input edge, the node’s contribution to the feature network is small.
However, since different input features have different resolutions, different scale feature layers have different contributions. Therefore, this paper uses the BiFPN structure to replace the original FPN + PANet structure, and the improved network structure is shown in
Figure 9. In addition, by setting the learning parameters to ensure the consistency of the input layer size, according to the importance of different feature layers, additional weights are added to each feature layer, and fast normalized fusion (Fast normalized fusion) is used to carry out feature layer weighted features. The fusion process is as follows:
where
is the up-sampling or down-sampling operation.
denotes the weight parameter that determines the significance of additional features.
After the above improvements, the improved optimized lightweight YOLOv5 network model of this study is finally proposed. The specific structure is shown in
Figure 10.
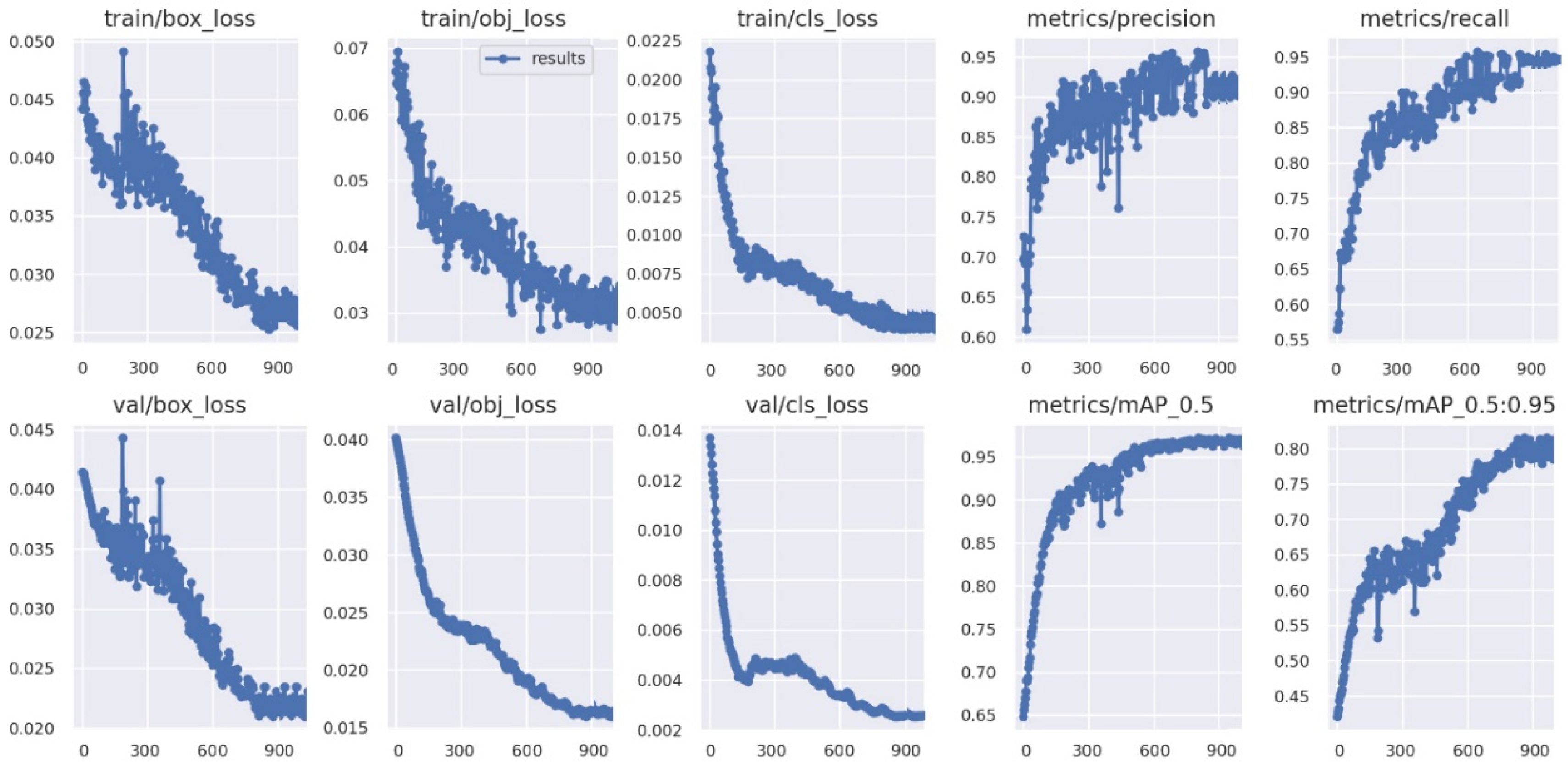
3.3.3. Performance Indicators
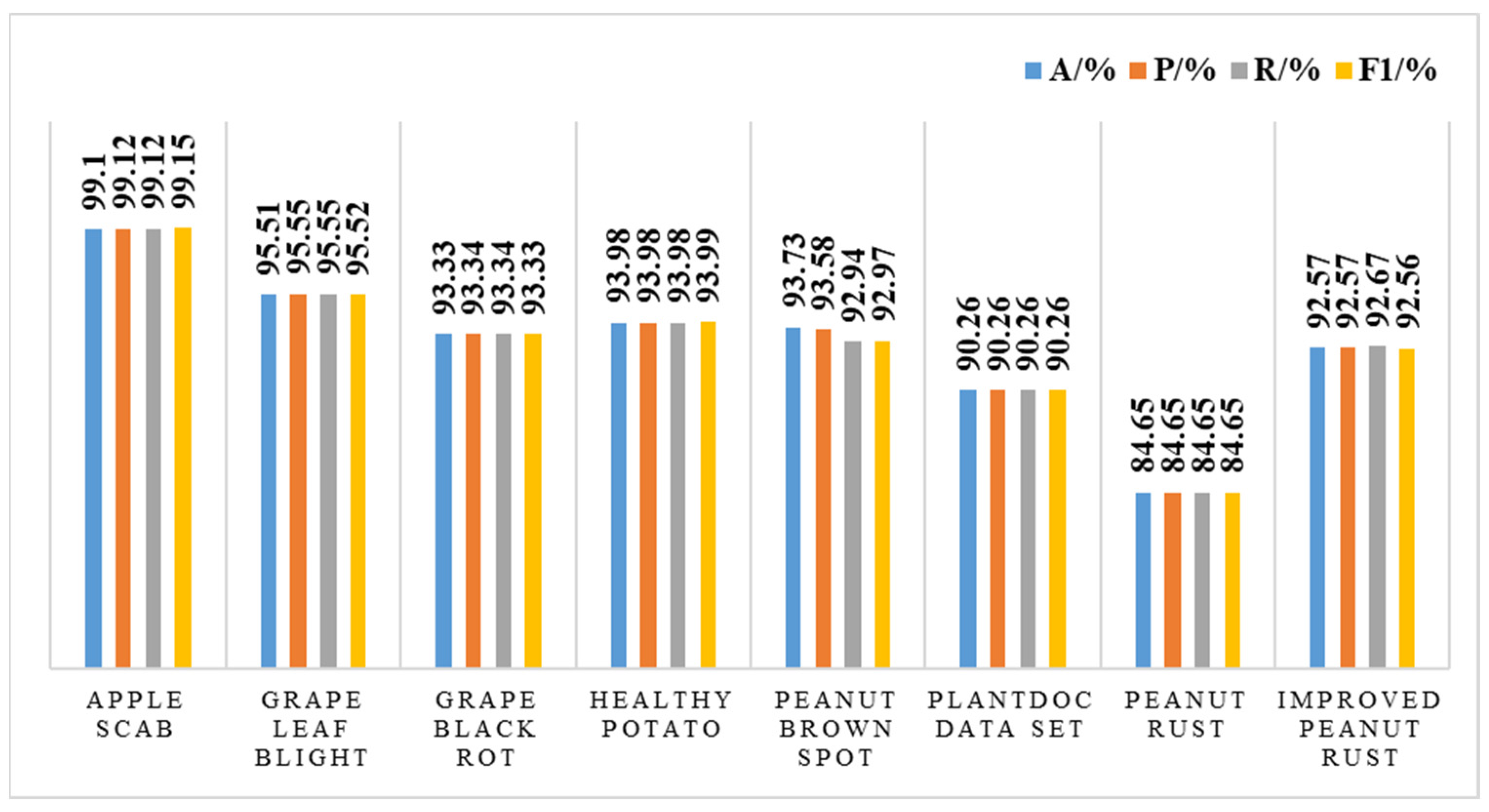
The speed and accuracy of the object detection algorithm are the main indicators to measure the algorithm’s performance. Therefore, this paper evaluated the performance of the improved algorithm by comparing the performance indicators, such as accuracy rate, recall rate, operation time, and loss function.
The classification results are given by the algorithm usually include four cases:
T and
F, respectively, indicating that the model prediction is true or false.
P and
N indicate that the instance is predicted to be a positive or negative class. The combination of the prediction categories constitutes all the prediction results, and the performance of the model can be evaluated according to the ratio between the different prediction results.
where Accuracy (
A) refers to the ratio of correct targets to the total number of targets. Precision (
P) refers to the ratio of the number of correct objects detected to the number of correct objects in the sample. Recall (
R) refers to the ratio of the number of correct objects detected to the number of objects in the sample. Therefore, in optimizing the algorithm, it is necessary to balance the relationship between
A,
P, and
R. To comprehensively evaluate the algorithm’s performance, the
F1 value is introduced. The
F1 value is the weighted harmonic average of
P and
R. The test method is more effective when the
F1 value is high.
- 2.
Loss function
The YOLOv5 model uses the mean square error between the output image vector and the real image vector as a loss function, including confidence loss, classification loss, and localization box. The weighted addition of the three parts obtains the overall loss, and the attention to the relevant loss can be adjusted by assigning weights.
The confidence loss (
) includes the confidence prediction with the object and the confident prediction of the box without an object in the box, which is defined as follows:
The classification loss (
) determines whether there is an object center in the
i-th grid, which is defined as follows:
The localization loss (
) includes the center point co-ordinate
error and the width and height co-ordinate
error of the target frame and the prediction frame, which are defined as follows:
In summary, the loss function is defined as follows:
where
represents judging whether the j-th box in the i-th grid is responsible for this object.
is the grid number.
is the number of prediction boxes in the grid and
is the prediction confidence.
is the true value of confidence.
is the diagonal distance between the predicted box and the ground-truth box.
is the probability of being predicted to be the true category
.





















{kind=link}
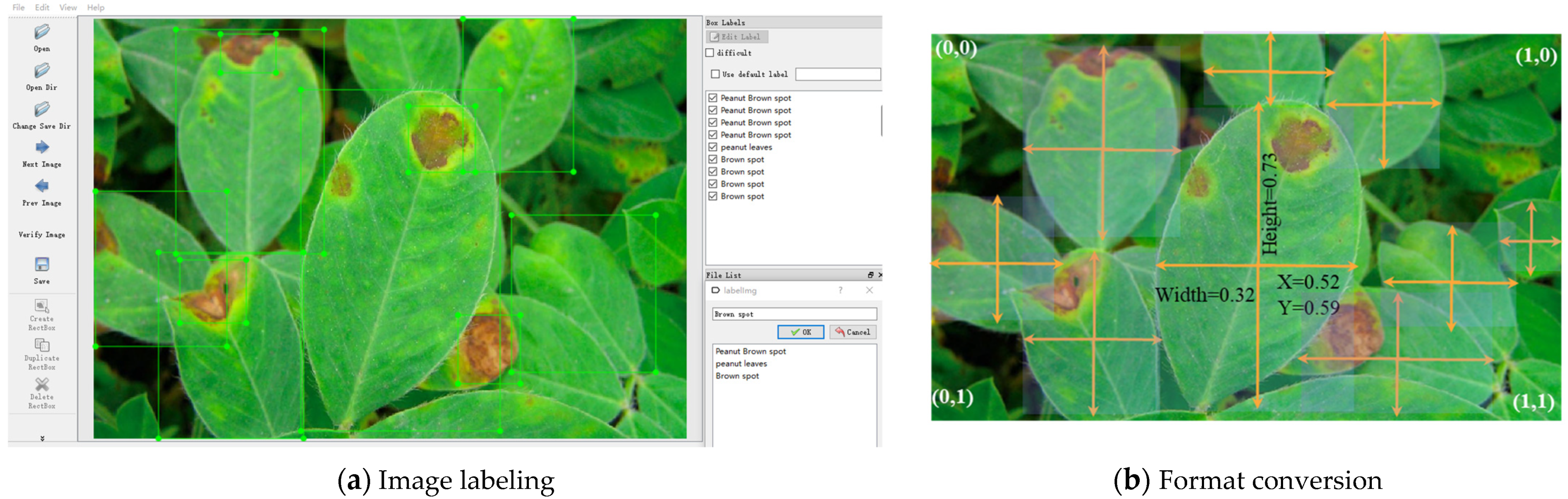{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}