
Deep-Learning Temporal Predictor via Bidirectional Self-Attentive Encoder–Decoder Framework for IOT-Based Environmental Sensing in Intelligent Greenhouse

 ,
,  ,
,
Abstract
:1. Introduction
2. Related Works
2.1. Microclimate Mechanistic Modeling
2.2. Data-Driven Analytic Modeling
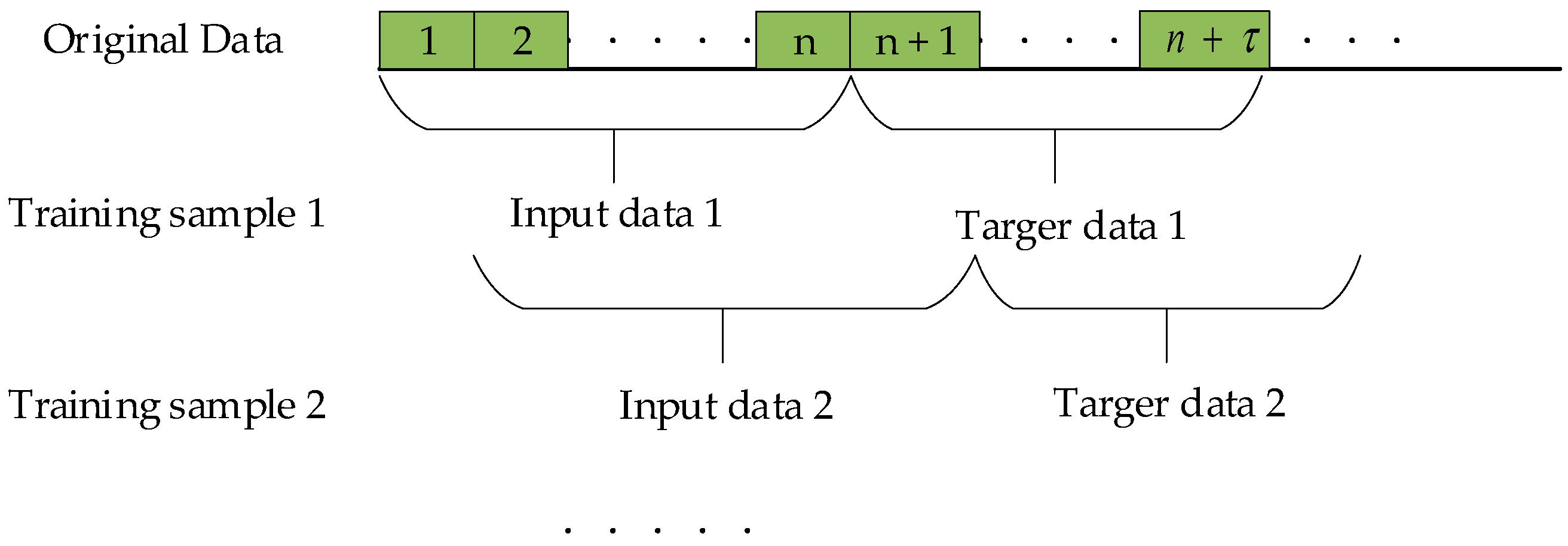
3. Materials and Methods
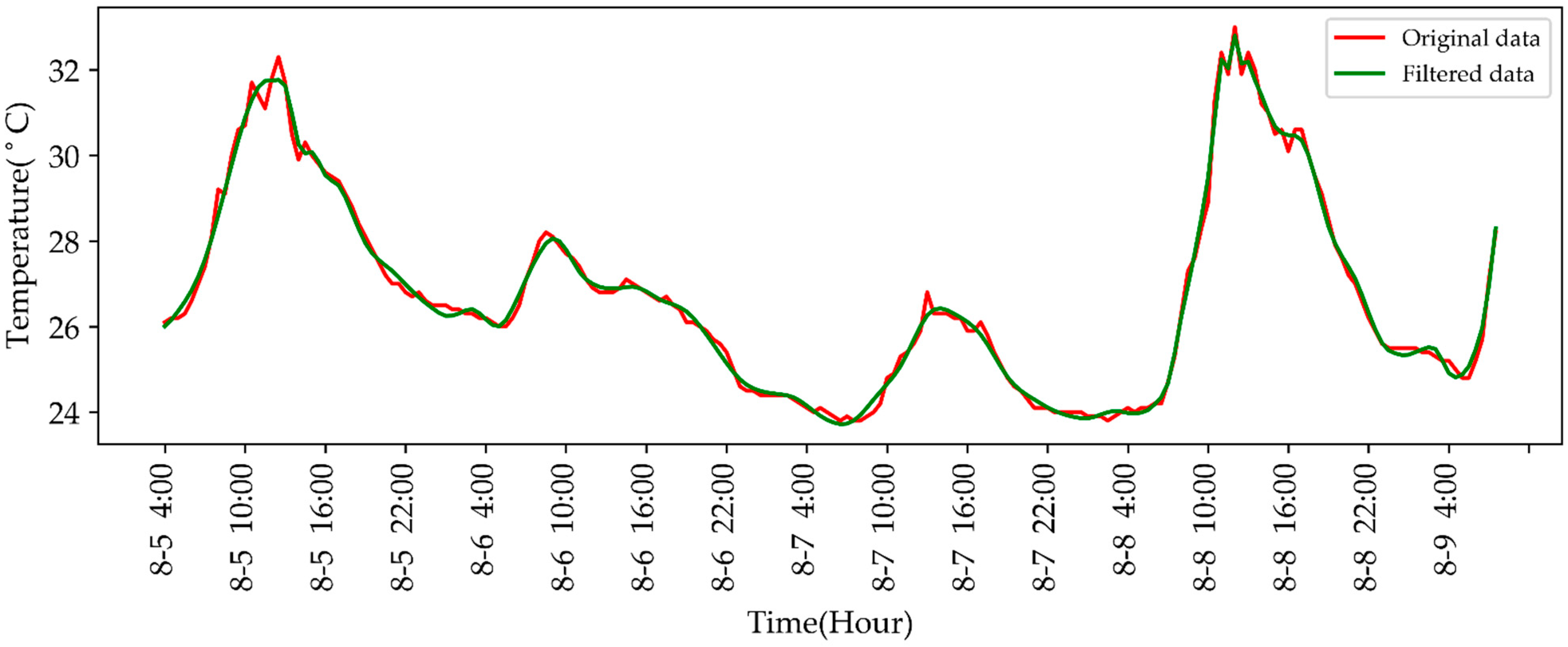
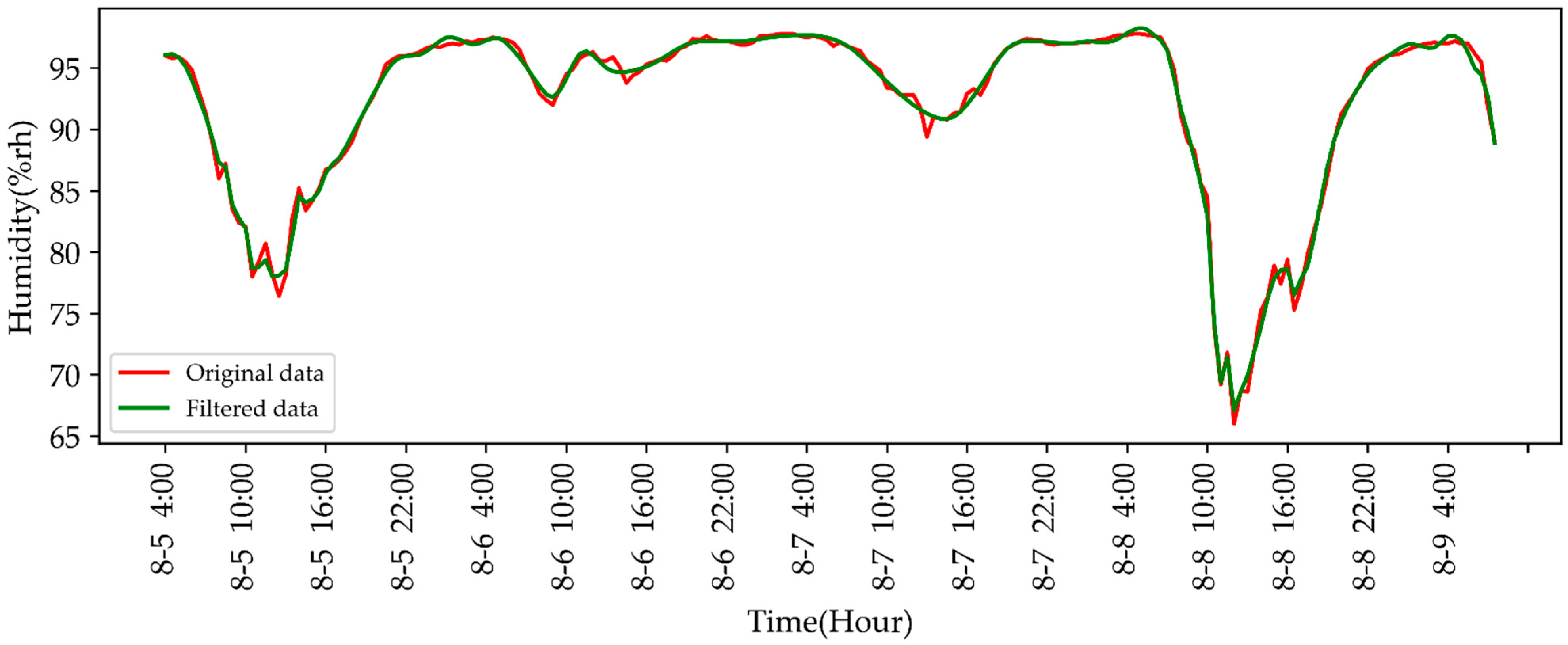
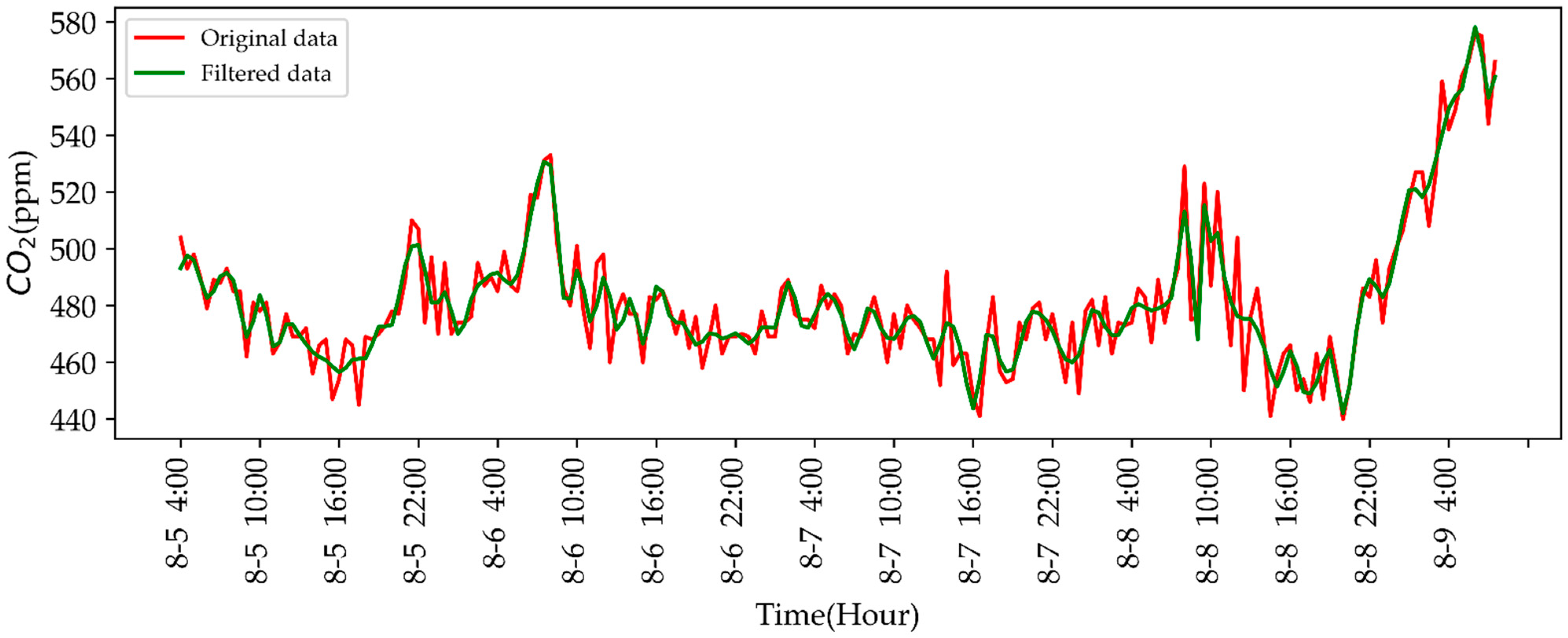
3.1. Wavelet Threshold Denoising
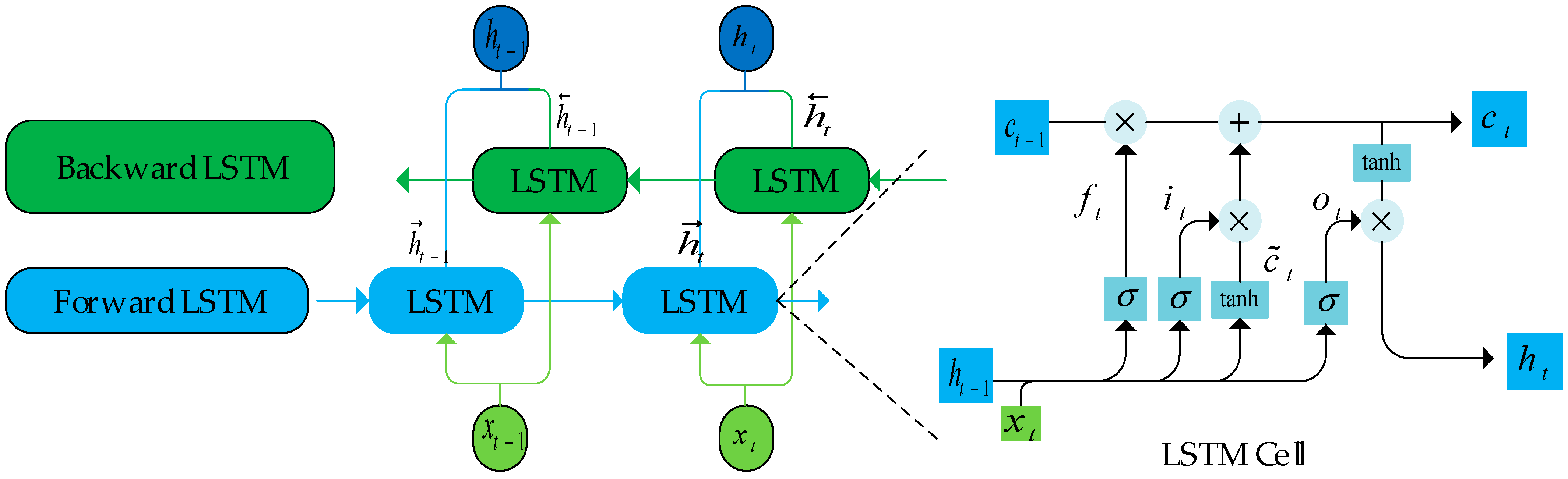
3.2. Bidirectional LSTM Unit
3.3. Multi-Head Self-Attention Mechanism
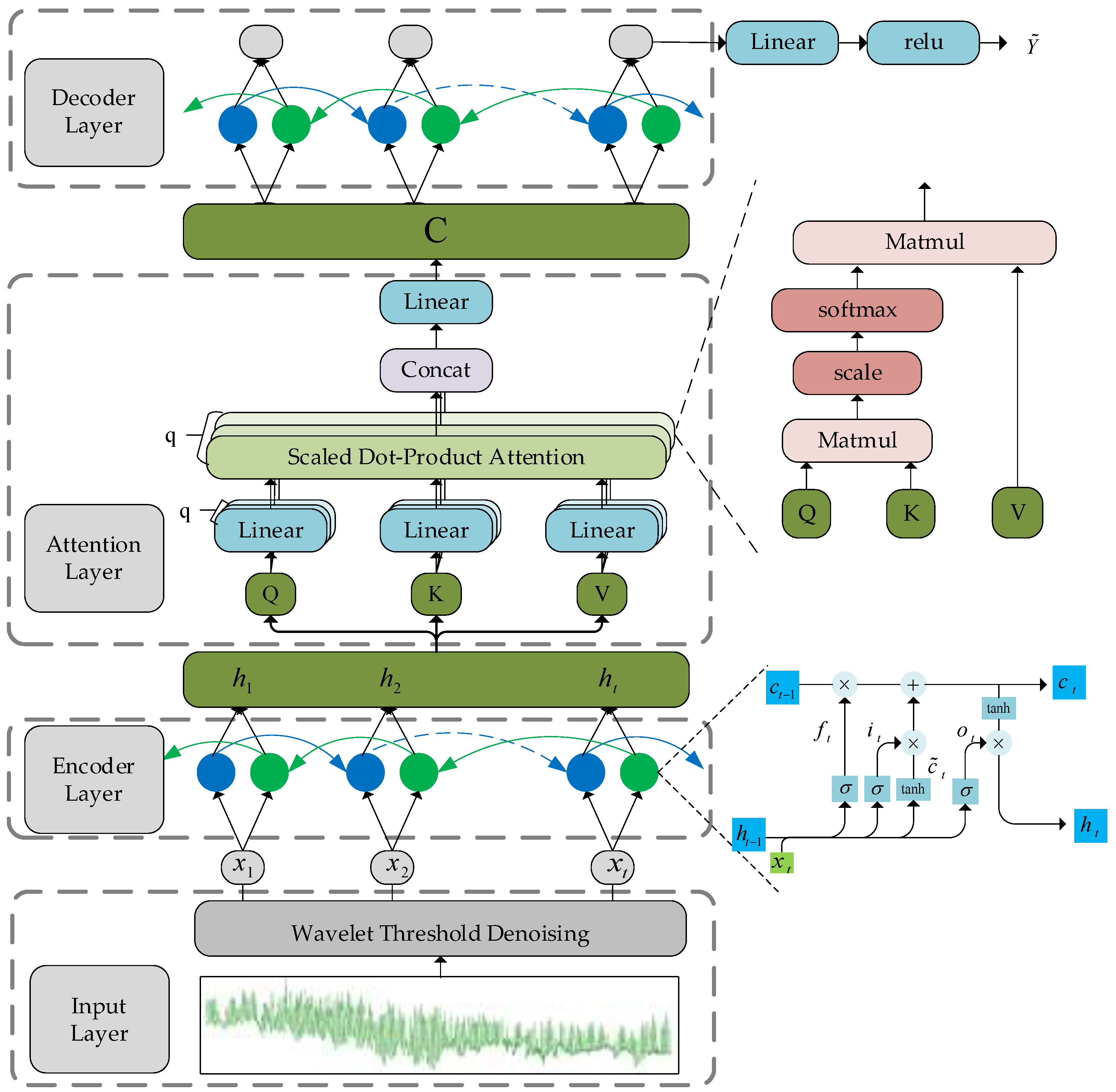
3.4. Bidirectional Self-Attentive Encoding-Decoding Framework
4. Results and Discussion
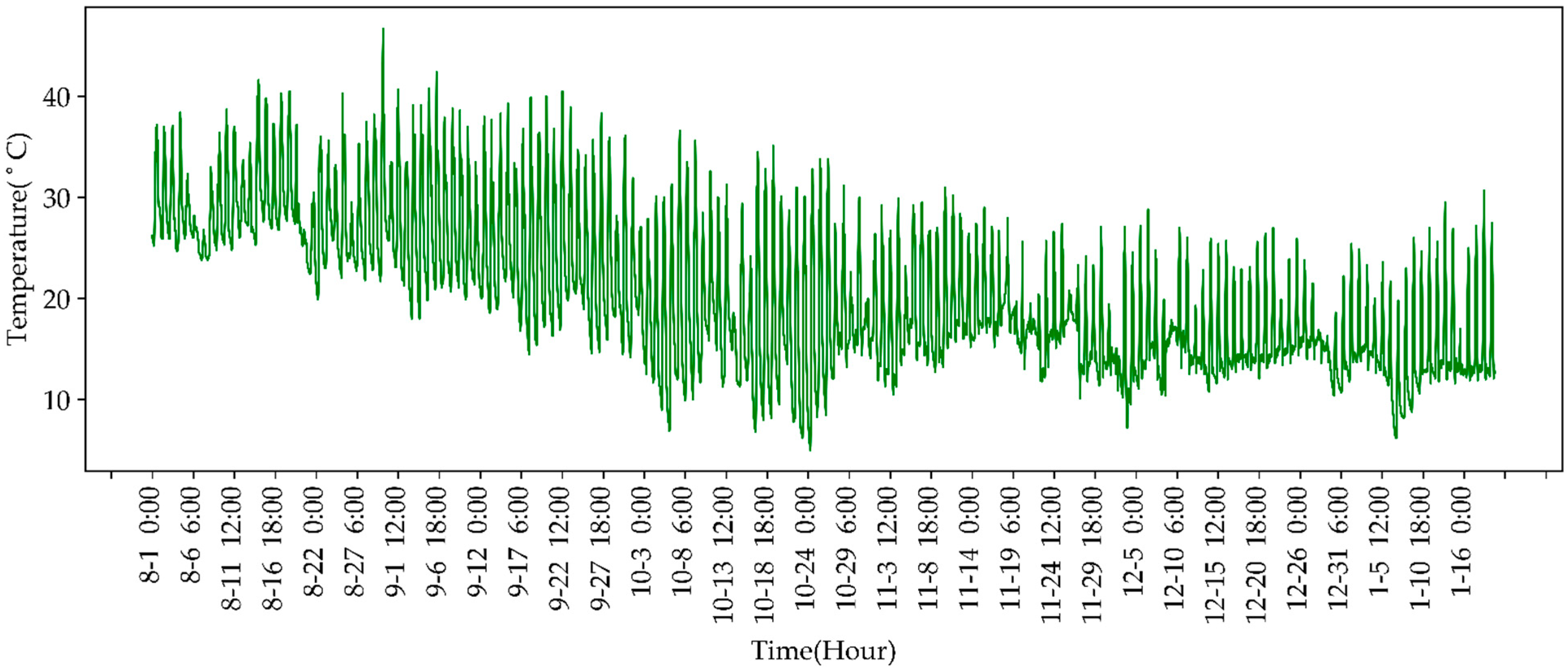
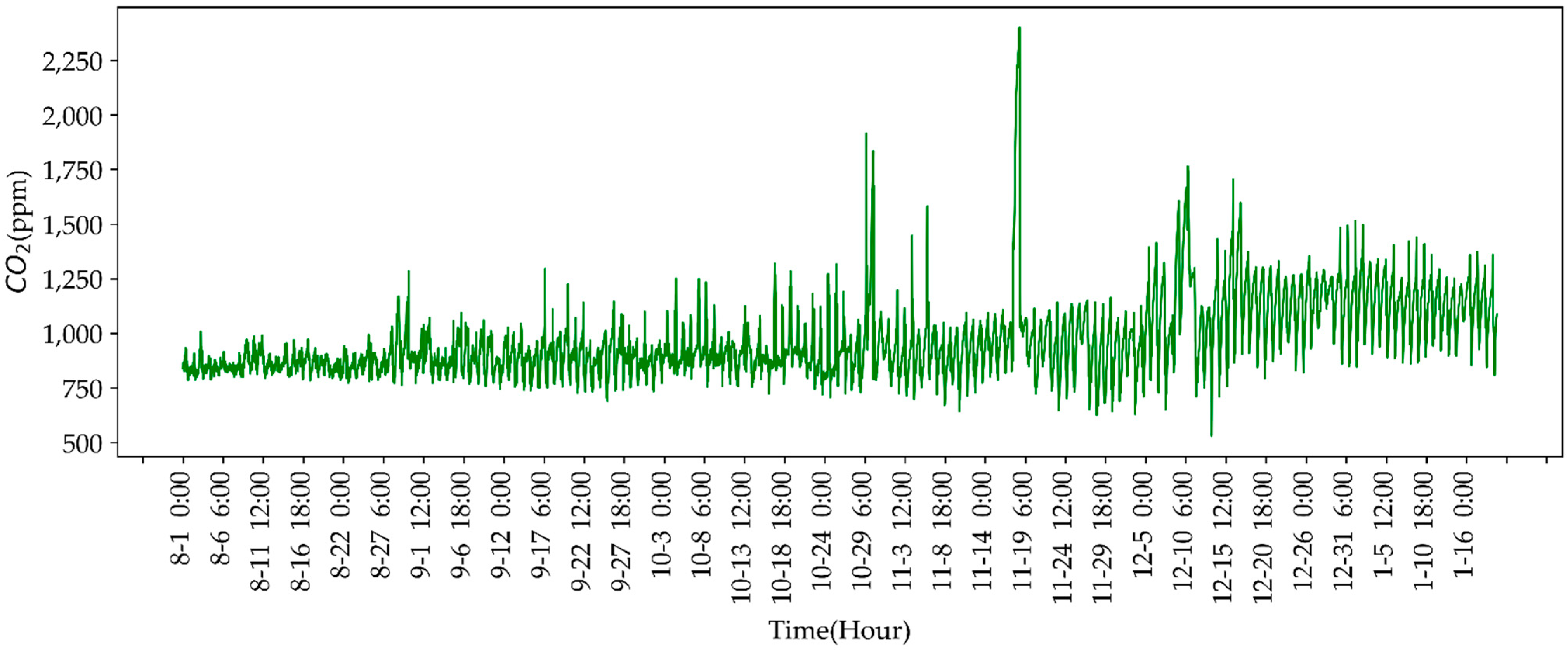
4.1. Experimental Datasets
4.2. Evaluation Metrics
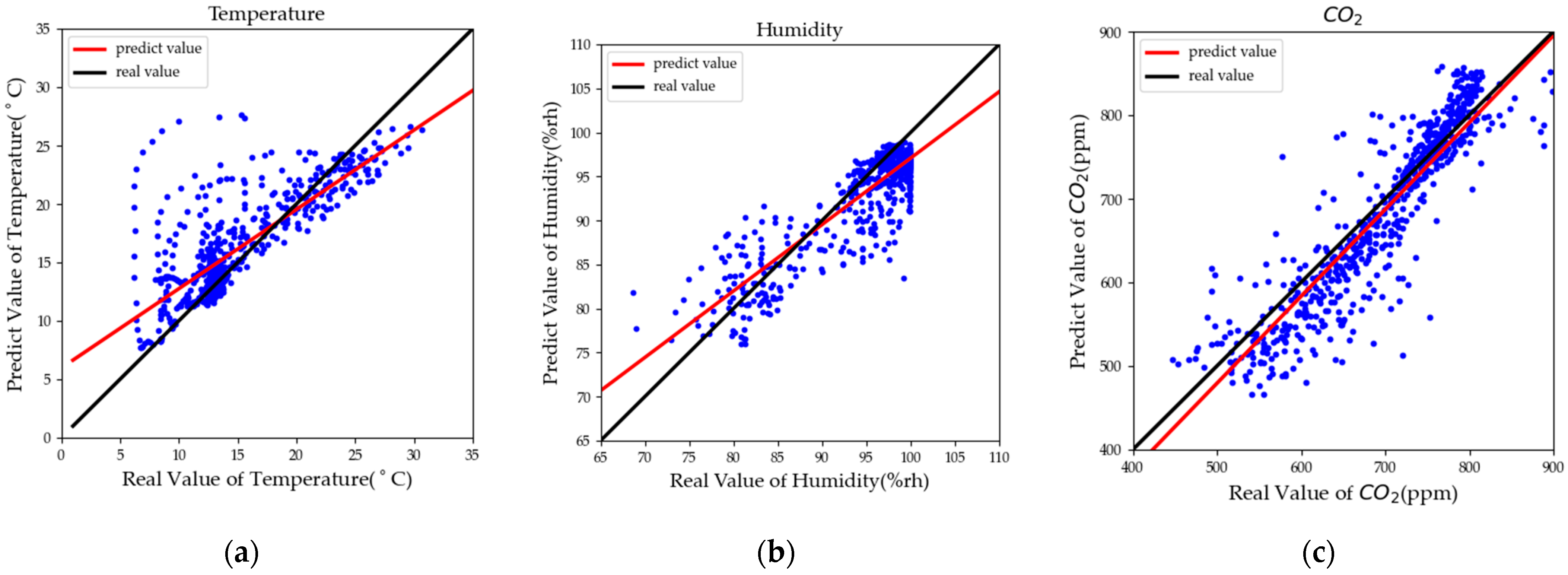
4.3. Comparative Experiments
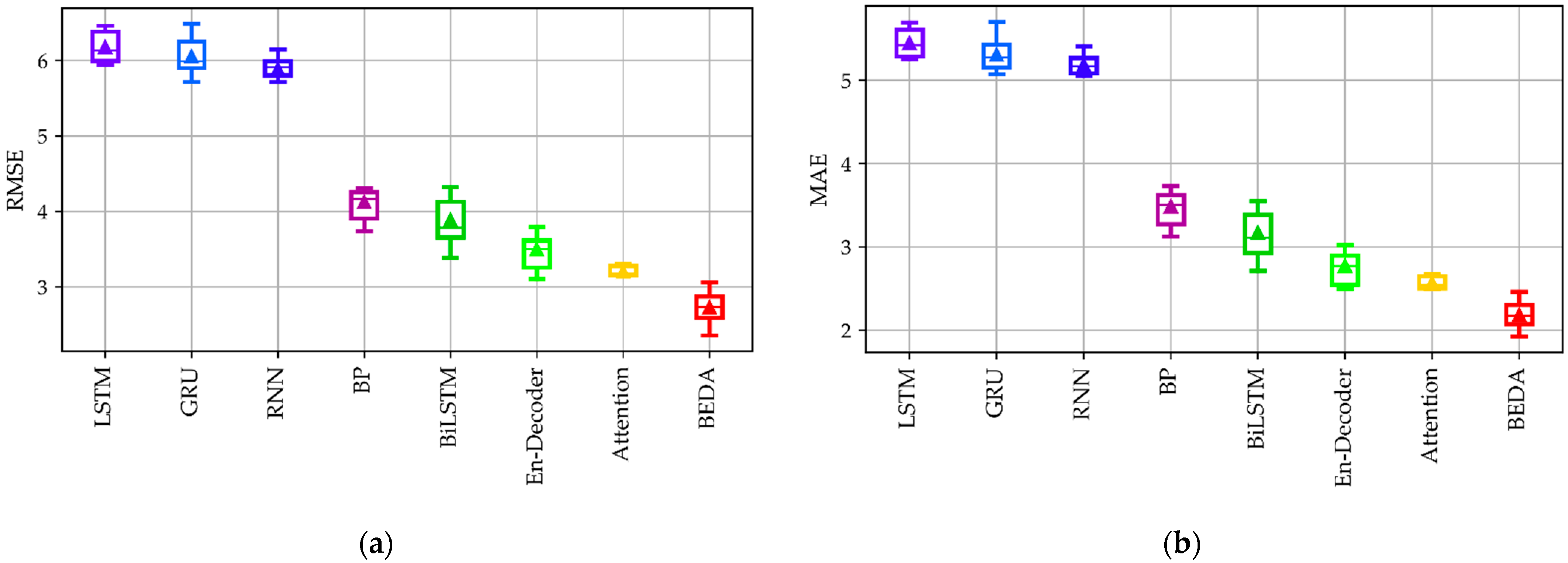
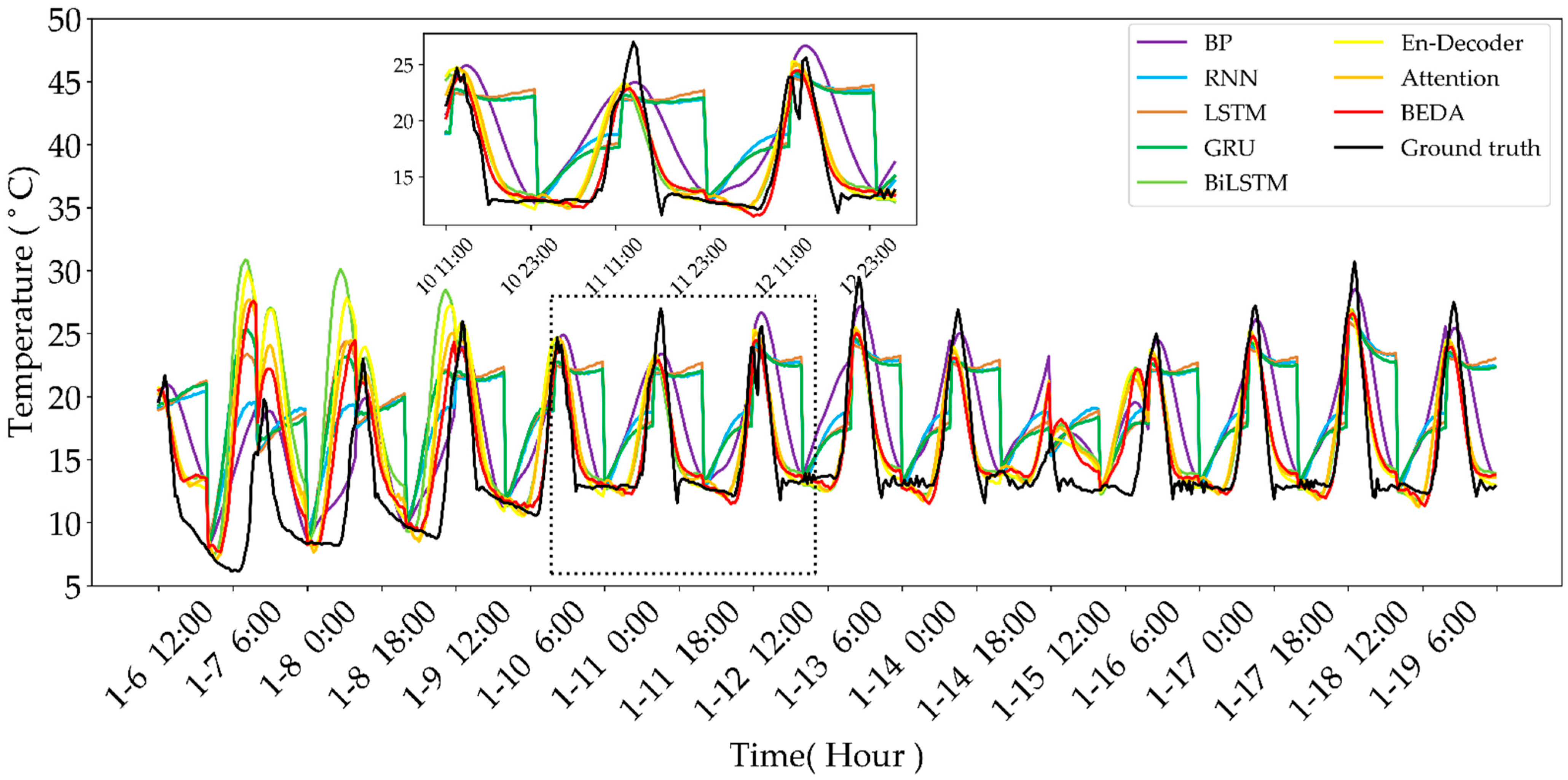
4.3.1. Temperature-Predicting Results
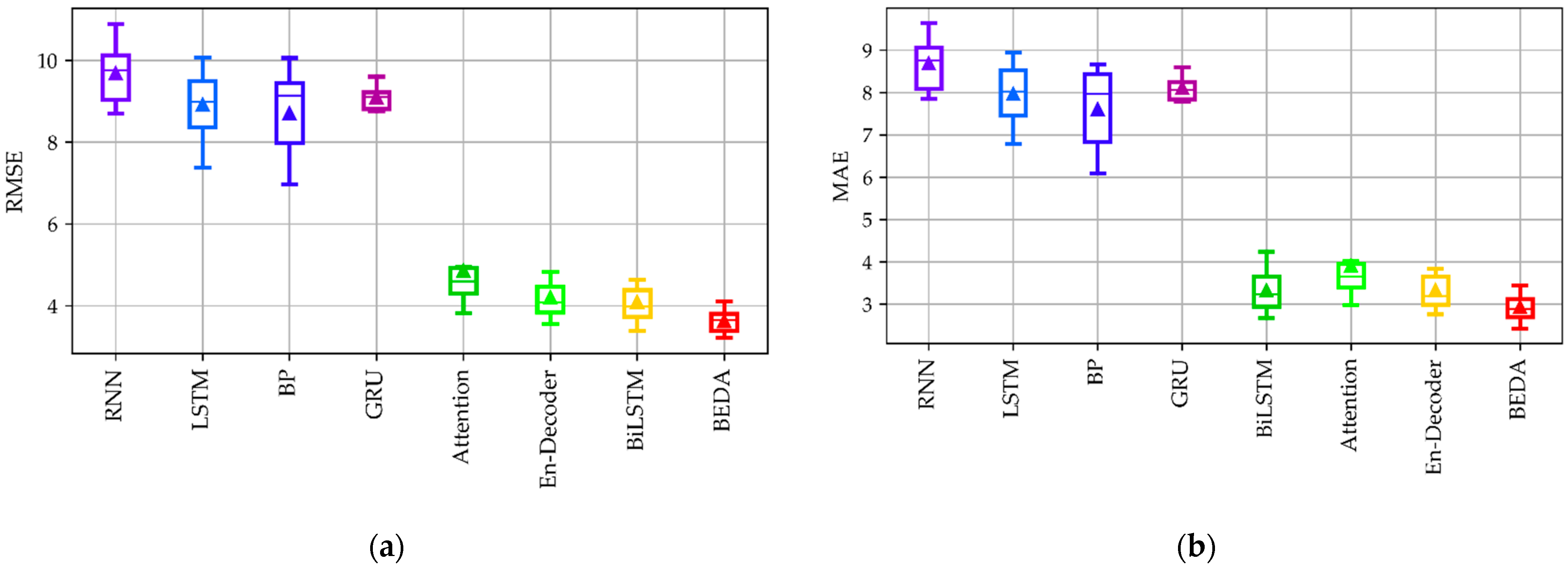
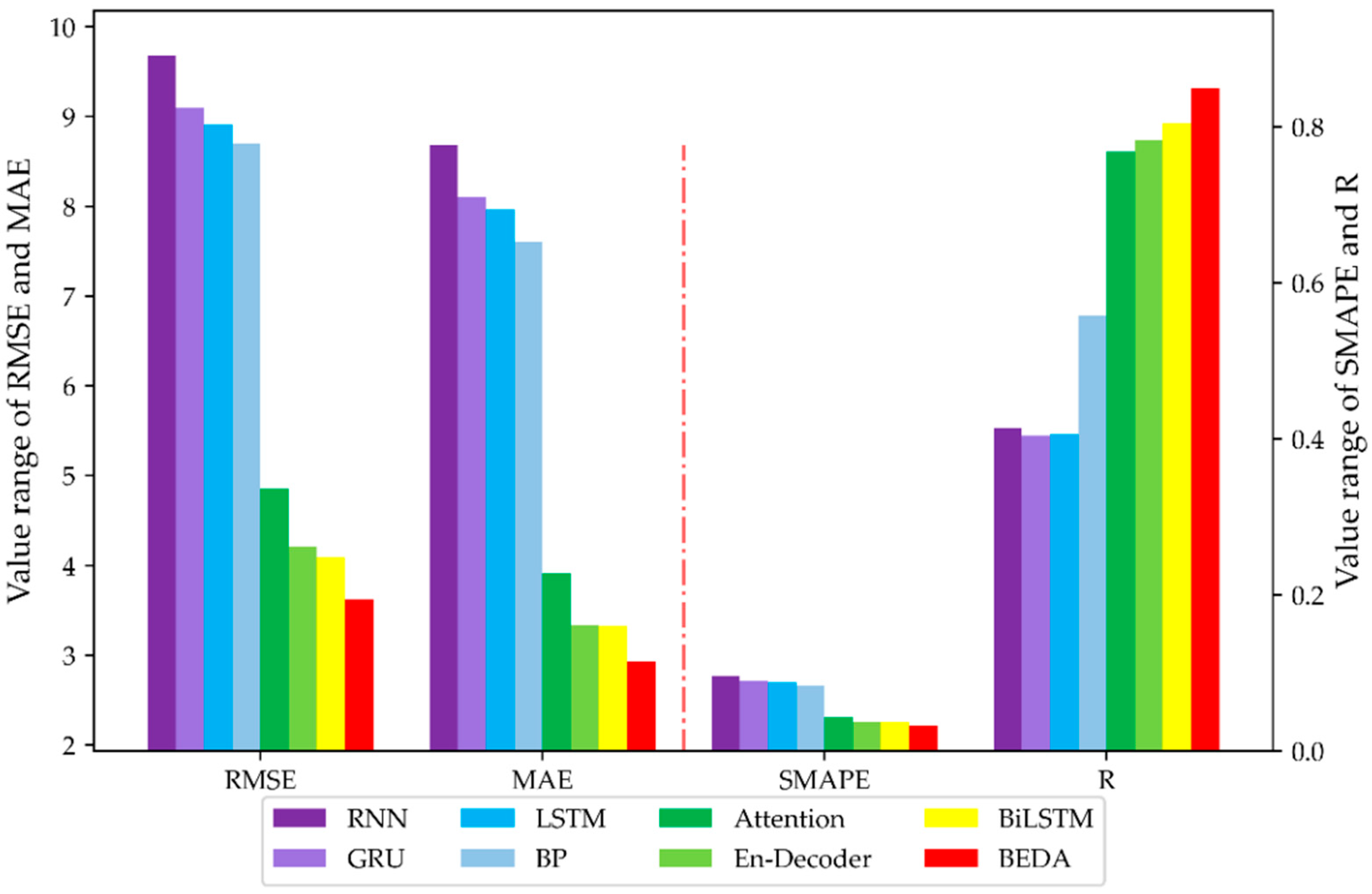
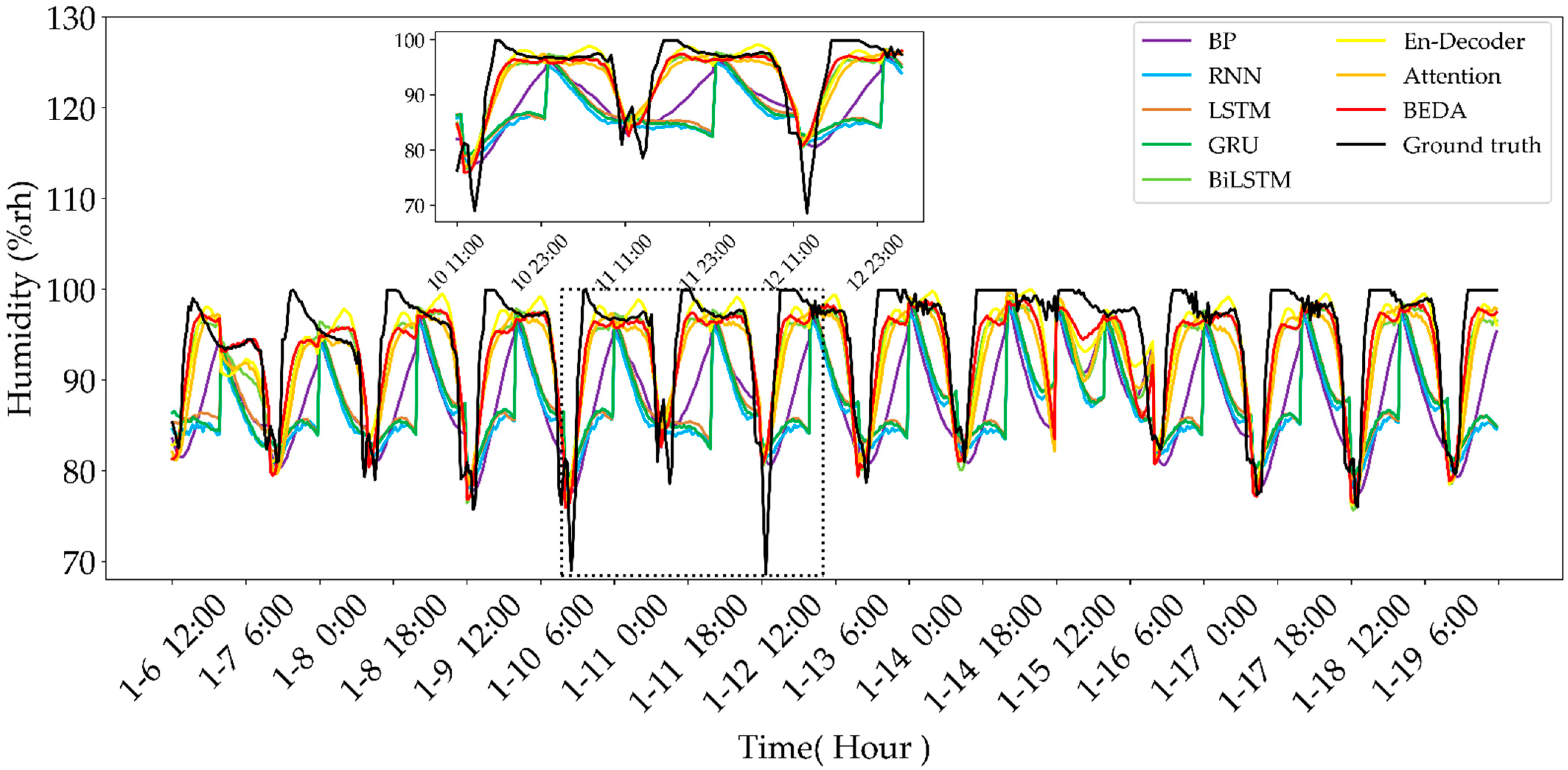
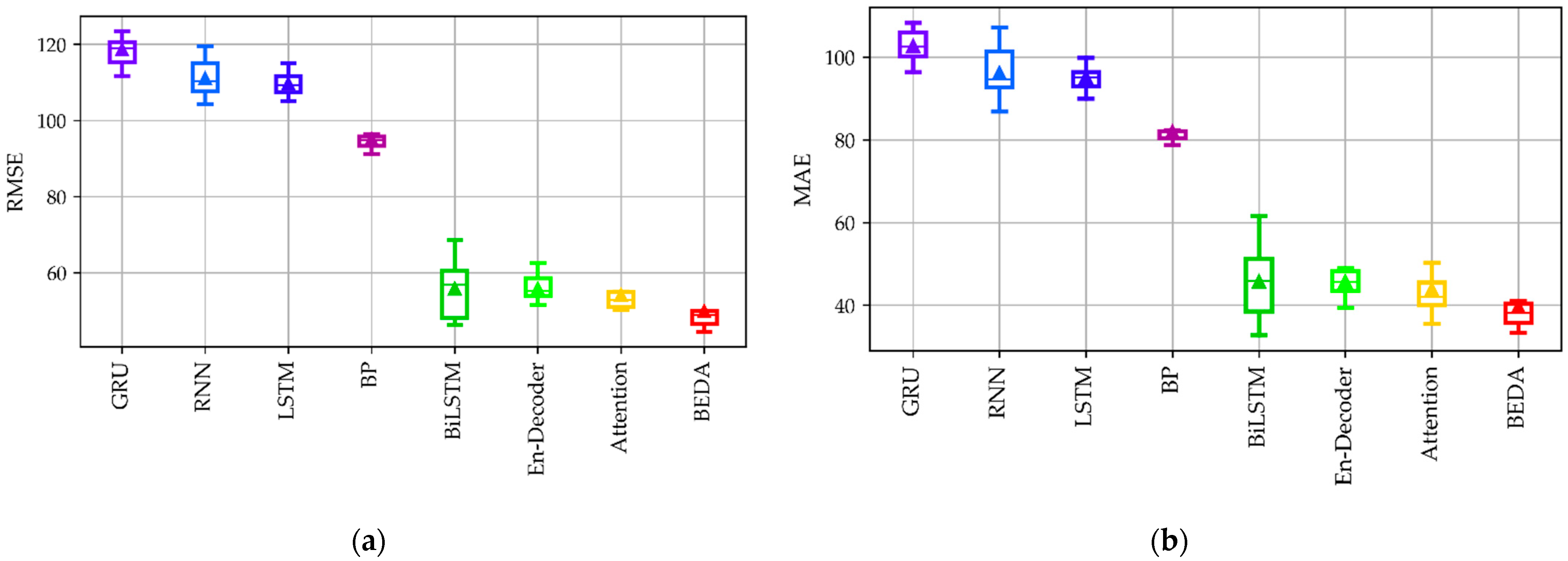
4.3.2. Humidity-Predicting Results
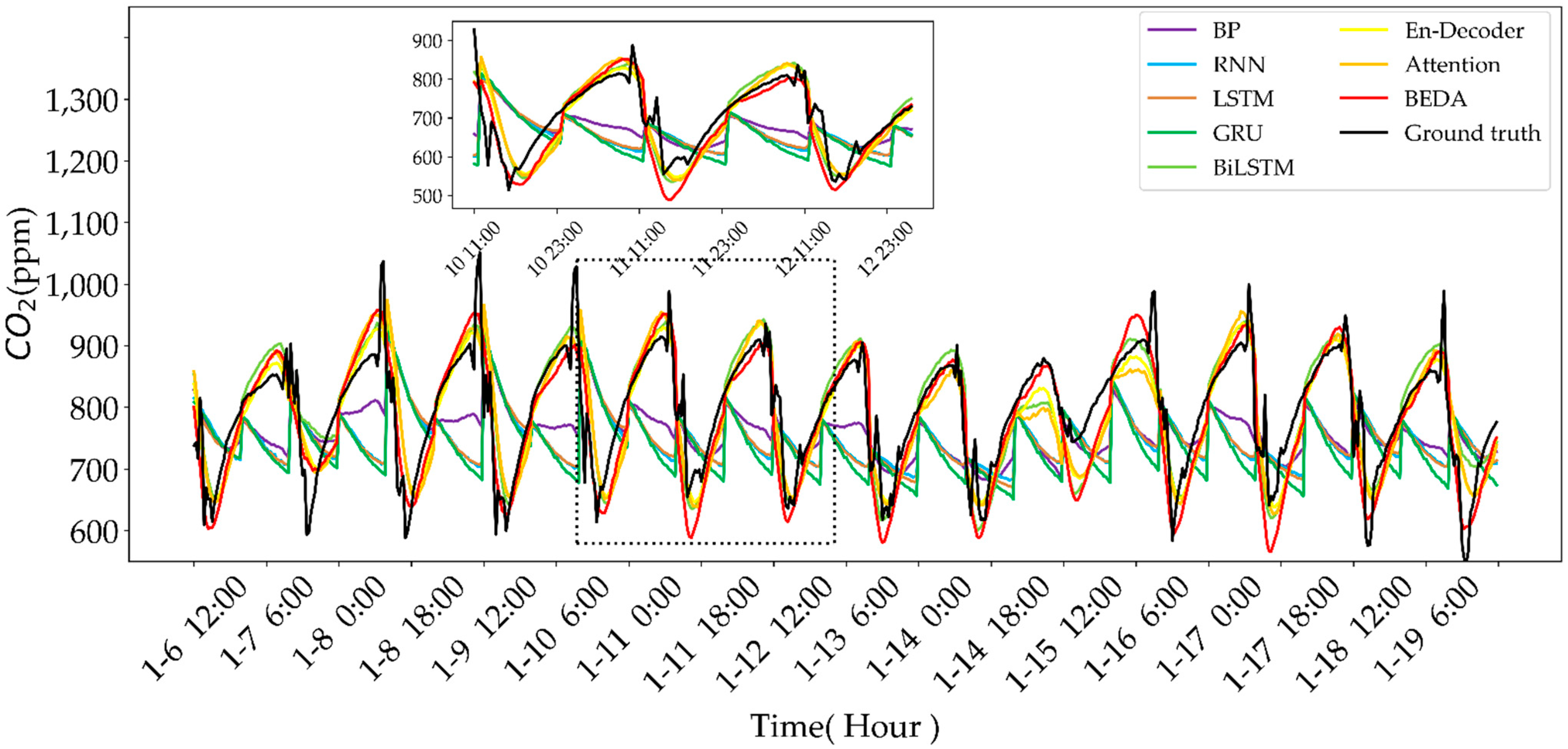
4.3.3. CO2 Concentration-Predicting Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kksal, O.; Tekinerdogan, B. Architecture design approach for IoT-based farm management information systems. Precis. Agric. 2019, 20, 926–958. [Google Scholar] [CrossRef] [Green Version]
- Eli-Chukwu, N.; Ogwugwam, E.C. Applications of artificial intelligence in agriculture: A review. Eng. Technol. Appl. Sci. Res. 2019, 9, 4377–4383. [Google Scholar] [CrossRef]
- Jirapond, M.; Nathaphon, B.; Siriwan, K.; Narongsak, L.; Apirat, W.; Pichetwut, N. IoT and agriculture data analysis for smart farm. Comput. Electron. Agric. 2019, 156, 467–474. [Google Scholar]
- Zhang, C.; Liu, Z. Application of big data technology in agricultural internet of things. Int. J. Distrib. Sens. Netw. 2019, 15, 155014771988161. [Google Scholar] [CrossRef]
- Dananjayan, S. A survey on the 5G network and its impact on agriculture: Challenges and opportunities. Comput. Electron. Agric. 2020, 180, 105895. [Google Scholar]
- Mta, C.; Aehb, C. Integrating blockchain and the internet of things in precision agriculture: Analysis, opportunities, and challenges. Comput. Electron. Agric. 2020, 178, 105476. [Google Scholar]
- Jin, X.B.; Yang, N.X.; Wang, X.Y.; Bai, Y.T.; Kong, J.L. Hybrid deep learning predictor for smart agriculture sensing based on empirical mode decomposition and gated recurrent unit group model. Sensors 2020, 20, 1334. [Google Scholar] [CrossRef] [Green Version]
- Xu, L.; Xiong, W.L.; Alsaedi, A.; Hayat, T. Hierarchical parameter estimation for the frequency response based on the dynamical window data. Int. J. Control Autom. Syst. 2018, 16, 1756–1764. [Google Scholar] [CrossRef]
- Sun, Q. Ecological agriculture development and spatial and temporal characteristics of carbon emissions of land use. Appl. Ecol. Environ. Res. 2019, 17, 17. [Google Scholar] [CrossRef]
- Kolasa-Więcek, A. Use of Artificial neural networks in predicting direct nitrous oxide emissions from agricultural soils. Ecol. Chem. Eng. 2013, 20, 419–428. [Google Scholar] [CrossRef]
- Ayele, T.W.; Mehta, R. Real time temperature prediction using IoT. In Proceedings of the 2nd IEEE International Conference on Inventive Communication and Computational Technologies, Coimbatore, India, 20–21 April 2018; pp. 1114–1117. [Google Scholar]
- Ding, F.; Zhang, X.; Xu, L. The innovation algorithms for multivariable state-space models. Int. J. Adapt. Control Signal Process. 2019, 33, 1601–1608. [Google Scholar] [CrossRef]
- Ding, F.; Ma, H.; Pan, J.; Yang, E. Hierarchical gradient- and least squares-based iterative algorithms for input nonlinear output-error systems using the key term separation. J. Frankl. Inst. 2021, 358, 5113–5135. [Google Scholar] [CrossRef]
- Ding, F.; Chen, H.; Xu, L.; Dai, J.; Li, Q.; Hayat, T. A hierarchical least squares identification algorithm for Hammerstein nonlinear systems using the key term separation. J. Frankl. Inst. 2018, 355, 3737–3752. [Google Scholar] [CrossRef]
- Xu, L.; Song, G. A recursive parameter estimation algorithm for modeling signals with multi-frequencies. Circuits Syst. Signal Process. 2020, 39, 4198–4224. [Google Scholar] [CrossRef]
- Li, M.; Liu, X. Maximum likelihood hierarchical least squares-based iterative identification for dual-rate stochastic systems. Int. J. Adapt. Control Signal Process. 2021, 35, 240–261. [Google Scholar] [CrossRef]
- Li, M.; Liu, X. Iterative parameter estimation methods for dual-rate sampled-data bilinear systems by means of the data filtering technique. IET Control Theory Appl. 2021, 15, 1230–1245. [Google Scholar] [CrossRef]
- Ding, F. Coupled-least-squares identification for multivariable systems. IET Control Theory Appl. 2013, 7, 68–79. [Google Scholar] [CrossRef]
- Ding, F.; Xu, L.; Meng, D.D. Gradient estimation algorithms for the parameter identification of bilinear systems using the auxiliary model. J. Comput. Appl. Math. 2020, 369, 112575. [Google Scholar] [CrossRef]
- Pan, J.; Jiang, X.; Wan, X.; Ding, W. A filtering based multi-innovation extended stochastic gradient algorithm for multivariable control systems. Int. J. Control Autom. Syst. 2017, 15, 1189–1197. [Google Scholar] [CrossRef]
- Pan, J.; Ma, H.; Zhang, X.; Liu, Q.Y. Recursive coupled projection algorithms for multivariable output-error-like systems with coloured noises. IET Signal Process. 2020, 14, 455–466. [Google Scholar] [CrossRef]
- Ding, F.; Liu, X.; Chu, J. Gradient-based and least-squares-based iterative algorithms for Hammerstein systems using the hierarchical identification principle. IET Control Theory Appl. 2013, 7, 176–184. [Google Scholar] [CrossRef]
- Ding, F. Decomposition based fast least squares algorithm for output error systems. Signal Process. 2013, 93, 1235–1242. [Google Scholar] [CrossRef]
- Ding, F. Hierarchical multi-innovation stochastic gradient algorithm for Hammerstein nonlinear system modeling. Appl. Math. Model. 2013, 37, 1694–1704. [Google Scholar] [CrossRef]
- Li, M.; Liu, X. Maximum likelihood least squares based iterative estimation for a class of bilinear systems using the data filtering technique. Int. J. Control Autom. Syst. 2020, 18, 1581–1592. [Google Scholar] [CrossRef]
- Li, M.; Liu, X. The least squares based iterative algorithms for parameter estimation of a bilinear system with autoregressive noise using the data filtering technique. Signal Process. 2018, 147, 23–34. [Google Scholar] [CrossRef]
- Ding, F. Two-stage least squares based iterative estimation algorithm for CARARMA system modeling. Appl. Math. Model. 2013, 37, 4798–4808. [Google Scholar] [CrossRef]
- Ding, F.; Xu, L.; Zhu, Q. Performance analysis of the generalised projection identification for time-varying systems. IET Control Theory Appl. 2016, 10, 2506–2514. [Google Scholar] [CrossRef] [Green Version]
- Beverena, P.J.M.; Bontsemab, J.; Stratenc, G.; Hentena, E.J. Minimal Heating and Cooling in a Modern Rose Greenhouse. Appl. Energy 2015, 137, 97–109. [Google Scholar] [CrossRef]
- Berroug, F.; Lakhal, E.K.; Omari, M.E.; Faraji, M.; Qarnia, H.E. Thermal performance of a greenhouse with a phase change material north wall. Energy Build. 2012, 43, 3027–3035. [Google Scholar] [CrossRef]
- Rasheed, A.; Kwak, C.S.; Na, W.H.; Lee, J.W.; Kim, H.T.; HyunWoo, L. Development of a building energy simulation model for control of multi-span greenhouse microclimate. Agronomy 2020, 10, 1236. [Google Scholar] [CrossRef]
- Yu, H.; Chen, Y.; Hassan, S.G.; Li, D. Prediction of the temperature in a Chinese solar greenhouse based on LSSVM optimized by improved PSO. Comput. Electron. Agric. 2016, 122, 94–102. [Google Scholar] [CrossRef]
- Linker, R.; Seginer, I.; Gutman, P.O. Optimal CO2 control in a greenhouse modeled with neural networks. Comput. Electron. Agric. 1998, 19, 289–310. [Google Scholar] [CrossRef]
- Ferreira, P.M.; FariaE, A.; RuanoA, E. Neural network models in greenhouse air temperature prediction. Neurocomputing 2002, 43, 51–75. [Google Scholar] [CrossRef] [Green Version]
- Fourati, F.; Chtourou, M. A greenhouse control with feed-forward and recurrent neural networks. Simul. Model. Pract. Theory 2007, 15, 1016–1028. [Google Scholar] [CrossRef]
- Zheng, Y.Y.; Kong, J.L.; Jin, X.B.; Wang, X.Y.; Zuo, M. CropDeep: The crop vision dataset for deep-learning-based classification and detection in precision agriculture. Sensors 2019, 19, 1058. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Y.Y.; Kong, J.L.; Jin, X.B.; Wang, X.Y.; Su, T.L.; Wang, J.L. Probability fusion decision framework of multiple deep neural networks for fine-grained visual classification. IEEE Access 2019, 7, 122740–122757. [Google Scholar] [CrossRef]
- Zhen, T.; Kong, J.L.; Yan, L. Hybrid deep-learning framework based on gaussian fusion of multiple spatiotemporal networks for walking gait phase recognition. Complexity 2020, 2020, 1–17. [Google Scholar] [CrossRef]
- Shi, Z.G.; Bai, Y.T.; Jin, X.B.; Wang, X.Y.; Su, T.L.; Kong, J.L. Parallel deep prediction with covariance intersection fusion on non-stationary time series. Knowl. Based Syst. 2021, 211, 106523. [Google Scholar] [CrossRef]
- Jin, X.B.; Yu, X.H.; Su, T.L.; Yang, D.N.; Wang, L. Distributed deep fusion predictor for a multi-sensor system based on causality entropy. Entropy 2021, 23, 219. [Google Scholar] [CrossRef]
- Perez, I.G.; Godoy, A.J.C. Neural networks-based models for greenhouse climate control. In Proceedings of the XXXIX Jornadas de Automática, Badajoz, Spain, 5–7 September 2018; pp. 875–879. [Google Scholar]
- Song, Y.E.; Moon, A.; An, S.Y.; Jung, H. Prediction of smart greenhouse temperature-humidity based on multi-dimensional LSTMs. J. Korean Soc. Precis. Eng. 2019, 36, 239–246. [Google Scholar] [CrossRef]
- Jin, X.B.; Zheng, W.Z.; Kong, J.L.; Wang, X.Y.; Bai, Y.T.; Su, T.L.; Lin, S. Deep-learning forecasting method for electric power load via attention-based encoder-decoder with bayesian optimization. Energies 2021, 14, 1596. [Google Scholar] [CrossRef]
- Shi, P.F.; Fang, X.L.; Ni, J.J.; Zhu, J.X. An Improved attention-based integrated deep neural network for PM2.5 concentration prediction. Appl. Sci. 2021, 11, 4001. [Google Scholar] [CrossRef]
- Luong, M.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Zhao, Z.Y.; Wang, X.Y.; Yao, P.; Bai, Y.T. A health performance evaluation method of multirotors under wind turbulence. Nonlinear Dyn. 2020, 102, 1–15. [Google Scholar] [CrossRef]
- Jin, X.-B.; Zhang, J.-H.; Su, T.-L.; Bai, Y.-T.; Kong, J.-L.; Wang, X.-Y. Modeling and Analysis of Data-Driven Systems through Computational Neuroscience Wavelet-Deep Optimized Model for Nonlinear Multicomponent Data Forecasting. Comput. Intell. Neurosci. 2021, 2021, 1–13. [Google Scholar] [CrossRef]
- Batista, G.; Keogh, E.J.; Tataw, O.M.; De Souza, V.M. CID: An efficient complexity-invariant distance for time series. Data Min. Knowl. Discov. 2014, 28, 634–669. [Google Scholar] [CrossRef]
- Moon, T.; Son, J.E. Knowledge transfer for adapting pre-trained deep neural models to predict different greenhouse environments based on a low quantity of data. Comput. Electron. Agric. 2021, 185, 106136. [Google Scholar] [CrossRef]
- Ding, F. State filtering and parameter estimation for state space systems with scarce measurements. Signal Process. 2014, 104, 369–380. [Google Scholar] [CrossRef]
- Ding, F. Combined state and least squares parameter estimation algorithms for dynamic systems. Appl. Math. Model. 2014, 38, 403–412. [Google Scholar] [CrossRef]
- Liu, Y.; Shi, Y. An efficient hierarchical identification method for general dual-rate sampled-data systems. Automatica 2014, 50, 962–970. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, Q.Y. Recursive identification of bilinear time-delay systems through the redundant rule. J. Frankl. Inst. 2020, 257, 726–747. [Google Scholar] [CrossRef]
- Zhang, X. Recursive parameter estimation and its convergence for bilinear systems. IET Control Theory Appl. 2020, 14, 677–688. [Google Scholar] [CrossRef]
- Ding, F.; Zhan, X.; Alsaedi, A.; Hayat, T. Hierarchical extended least squares estimation approaches for a multi-input multi-output stochastic system with colored noise from observation data. J. Frankl. Inst. 2020, 357, 11094–11110. [Google Scholar] [CrossRef]
- Xu, L.; Sheng, J. Hierarchical multi-innovation generalised extended stochastic gradient methods for multivariable equation-error autoregressive moving average systems. IET Control Theory Appl. 2020, 14, 1276–1286. [Google Scholar] [CrossRef]
- Xu, L.; Sheng, J. Separable multi-innovation stochastic gradient estimation algorithm for the nonlinear dynamic responses of systems. Int. J. Adapt. Control Signal Process. 2020, 34, 937–954. [Google Scholar] [CrossRef]
- Zhang, X.; Hayat, T. Recursive parameter identification of the dynamical models for bilinear state space systems. Nonlinear Dyn. 2017, 89, 2415–2429. [Google Scholar] [CrossRef]
- Zhang, X.; Hayat, T. Combined state and parameter estimation for a bilinear state space system with moving average noise. J. Frankl. Inst. 2018, 355, 3079–3103. [Google Scholar] [CrossRef]
- Zhou, Y. Modeling nonlinear processes using the radial basis function-based state-dependent autoregressive models. IEEE Signal Process. Lett. 2020, 27, 1600–1604. [Google Scholar] [CrossRef]
- Xu, L.; Yang, E. Separable recursive gradient algorithm for dynamical systems based on the impulse response signals. Int. J. Control Autom. Syst. 2020, 18, 3167–3177. [Google Scholar] [CrossRef]
- Ding, F.; Lv, L.; Pan, J.; Wan, X.; Jin, X. Two-stage gradient-based iterative estimation methods for controlled autoregressive systems using the measurement data. Int. J. Control Autom. Syst. 2020, 18, 886–896. [Google Scholar] [CrossRef]
- Pan, J.; Li, W.; Zhang, H. Control algorithms of magnetic suspension systems based on the improved double exponential reaching law of sliding mode control. Int. J. Control Autom. Syst. 2018, 16, 2878–2887. [Google Scholar] [CrossRef]
- Xu, L.; Chen, F.; Hayat, T. Hierarchical recursive signal modeling for multi-frequency signals based on discrete measured data. Int. J. Adapt. Control Signal Process. 2021, 35, 676–693. [Google Scholar] [CrossRef]
- Kong, J.L.; Wang, Z.N.; Jin, X.B.; Wang, X.Y.; Su, T.L.; Wang, J.L. Semi-supervised segmentation framework based on spot-divergence supervoxelization of multi-sensor fusion data for autonomous forest machine applications. Sensors 2018, 18, 3061. [Google Scholar] [CrossRef] [Green Version]
- Kong, J.L.; Wang, H.X.; Wang, X.Y.; Jin, X.B.; Fang, X.; Lin, S. Multi-stream hybrid architecture based on cross-level fusion strategy for fine-grained crop species recognition in precision agriculture. Comput. Electron. Agric. 2021, 182, 106134. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | RMSE | MAE | SMAPE | R | CID |
|---|---|---|---|---|---|
| LSTM | 6.179 | 5.451 | 0.333 | 0.377 | 254.5 |
| GRU | 6.054 | 5.31 | 0.326 | 0.399 | 249 |
| RNN | 5.888 | 5.186 | 0.322 | 0.481 | 228.2 |
| BP | 4.125 | 3.487 | 0.227 | 0.51 | 147.6 |
| BiLSTM | 3.887 | 3.169 | 0.193 | 0.517 | 145.2 |
| Encoder–decoder | 3.498 | 2.773 | 0.174 | 0.646 | 124.1 |
| Attention | 3.202 | 2.567 | 0.166 | 0.706 | 112.5 |
| Proposed BEDA | 2.726 | 2.183 | 0.144 | 0.749 | 97.38 |
| Model | RMSE | MAE | SMAPE | R | CID |
|---|---|---|---|---|---|
| RNN | 9.680 | 8.683 | 0.0954 | 0.412 | 283.7 |
| GRU | 9.092 | 8.106 | 0.0888 | 0.403 | 257.7 |
| LSTM | 8.912 | 7.963 | 0.0872 | 0.406 | 259.5 |
| BP | 8.702 | 7.606 | 0.0834 | 0.557 | 355.1 |
| Attention | 4.851 | 3.90 | 0.0425 | 0.767 | 171.4 |
| Encoder–decoder | 4.201 | 3.335 | 0.0363 | 0.782 | 141.7 |
| BiLSTM | 4.093 | 3.325 | 0.0363 | 0.804 | 147.1 |
| Proposed BEDA | 3.621 | 2.934 | 0.0319 | 0.848 | 127.8 |
| Model | RMSE | MAE | SMAPE | R | CID |
|---|---|---|---|---|---|
| GRU | 118.610 | 102.699 | 0.1526 | 0.1723 | 4046.4 |
| RNN | 111.068 | 96.196 | 0.1420 | 0.1601 | 4773.2 |
| LSTM | 109.683 | 95.131 | 0.1403 | 0.1369 | 5135.1 |
| BP | 95.083 | 81.975 | 0.1201 | 0.1626 | 5432.7 |
| BiLSTM | 55.821 | 45.712 | 0.0683 | 0.8087 | 2576.6 |
| Encoder–decoder | 55.782 | 45.796 | 0.0683 | 0.8125 | 2652.1 |
| Attention | 54.110 | 43.883 | 0.0664 | 0.8405 | 2541.8 |
| Proposed BEDA | 49.817 | 39.640 | 0.0590 | 0.8711 | 2221.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, X.-B.; Zheng, W.-Z.; Kong, J.-L.; Wang, X.-Y.; Zuo, M.; Zhang, Q.-C.; Lin, S. Deep-Learning Temporal Predictor via Bidirectional Self-Attentive Encoder–Decoder Framework for IOT-Based Environmental Sensing in Intelligent Greenhouse. Agriculture 2021, 11, 802. https://doi.org/10.3390/agriculture11080802
Jin X-B, Zheng W-Z, Kong J-L, Wang X-Y, Zuo M, Zhang Q-C, Lin S. Deep-Learning Temporal Predictor via Bidirectional Self-Attentive Encoder–Decoder Framework for IOT-Based Environmental Sensing in Intelligent Greenhouse. Agriculture. 2021; 11(8):802. https://doi.org/10.3390/agriculture11080802
Chicago/Turabian StyleJin, Xue-Bo, Wei-Zhen Zheng, Jian-Lei Kong, Xiao-Yi Wang, Min Zuo, Qing-Chuan Zhang, and Seng Lin. 2021. "Deep-Learning Temporal Predictor via Bidirectional Self-Attentive Encoder–Decoder Framework for IOT-Based Environmental Sensing in Intelligent Greenhouse" Agriculture 11, no. 8: 802. https://doi.org/10.3390/agriculture11080802