
Disease Detection in Apple Leaves Using Deep Convolutional Neural Network


Abstract
:1. Introduction
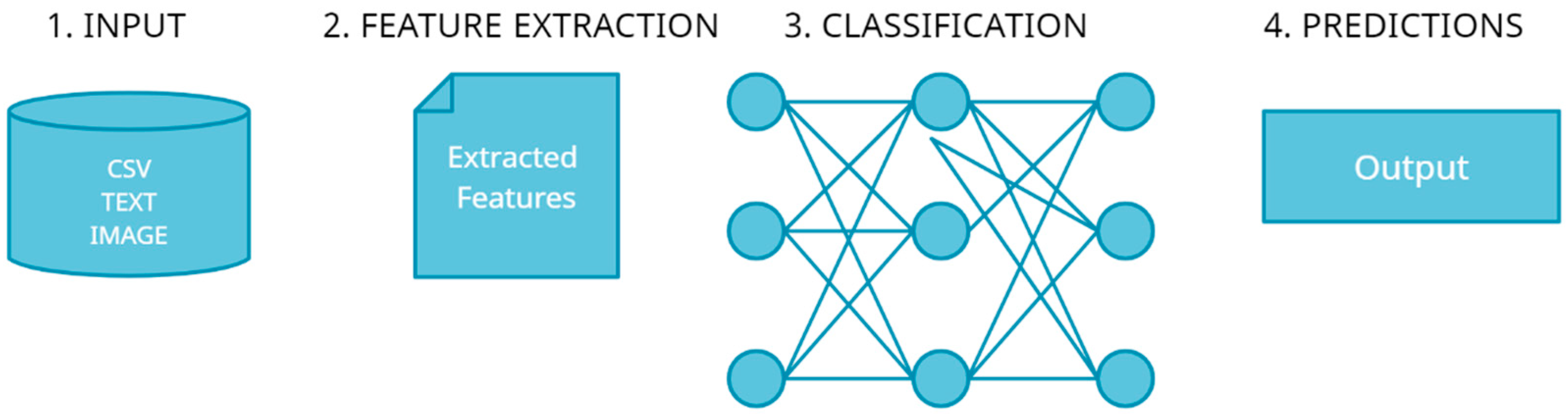
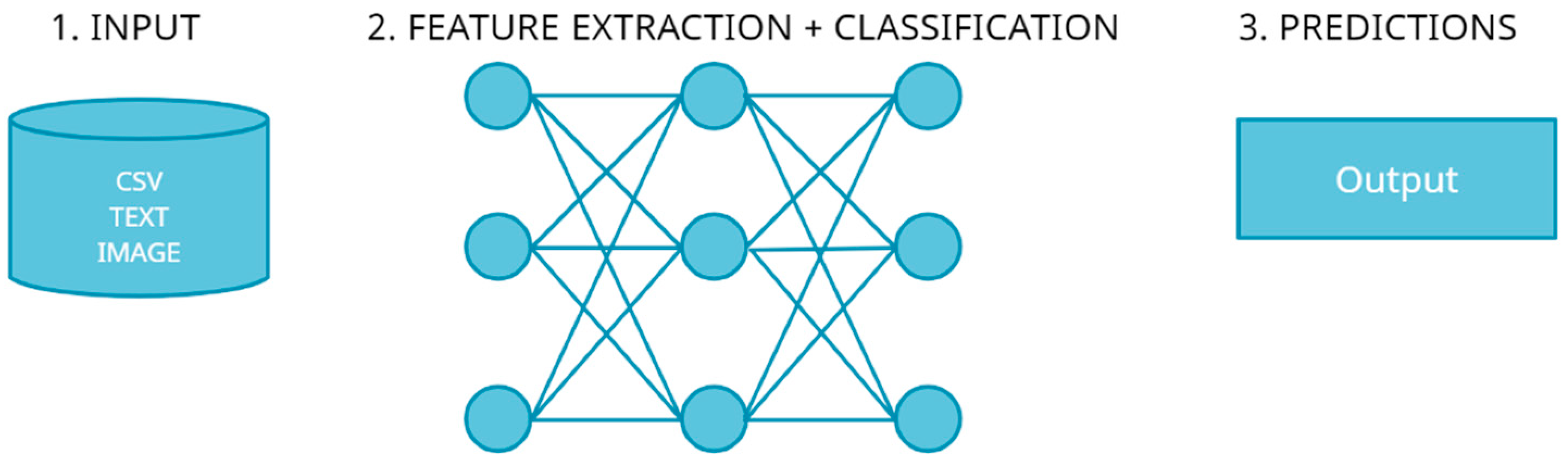
2. Related Works
- Previous models have limitations in utilising the advantage of Image Augmentation techniques properly. Our proposed model uses various Image Augmentation techniques such as Canny Edge Detection, Flipping, Blurring, etc., to enhance our dataset. These techniques can help in building a robust model.
- The performance of many of the previously proposed model were not adequate, especially under challenging cases, e.g., identifying leaves with multiple diseases. In our research, we have used an ensemble of pre-trained deep learning models. The advantage of this is that our proposed model combines the predictions of three models and can perform well under challenging situations.
- We have deployed the proposed model in the form of a web application that serves as an easy-to-use system for I users. The user has to upload the leaf’s image on our web application, and the result is obtained in a couple of seco.
3. Methodology
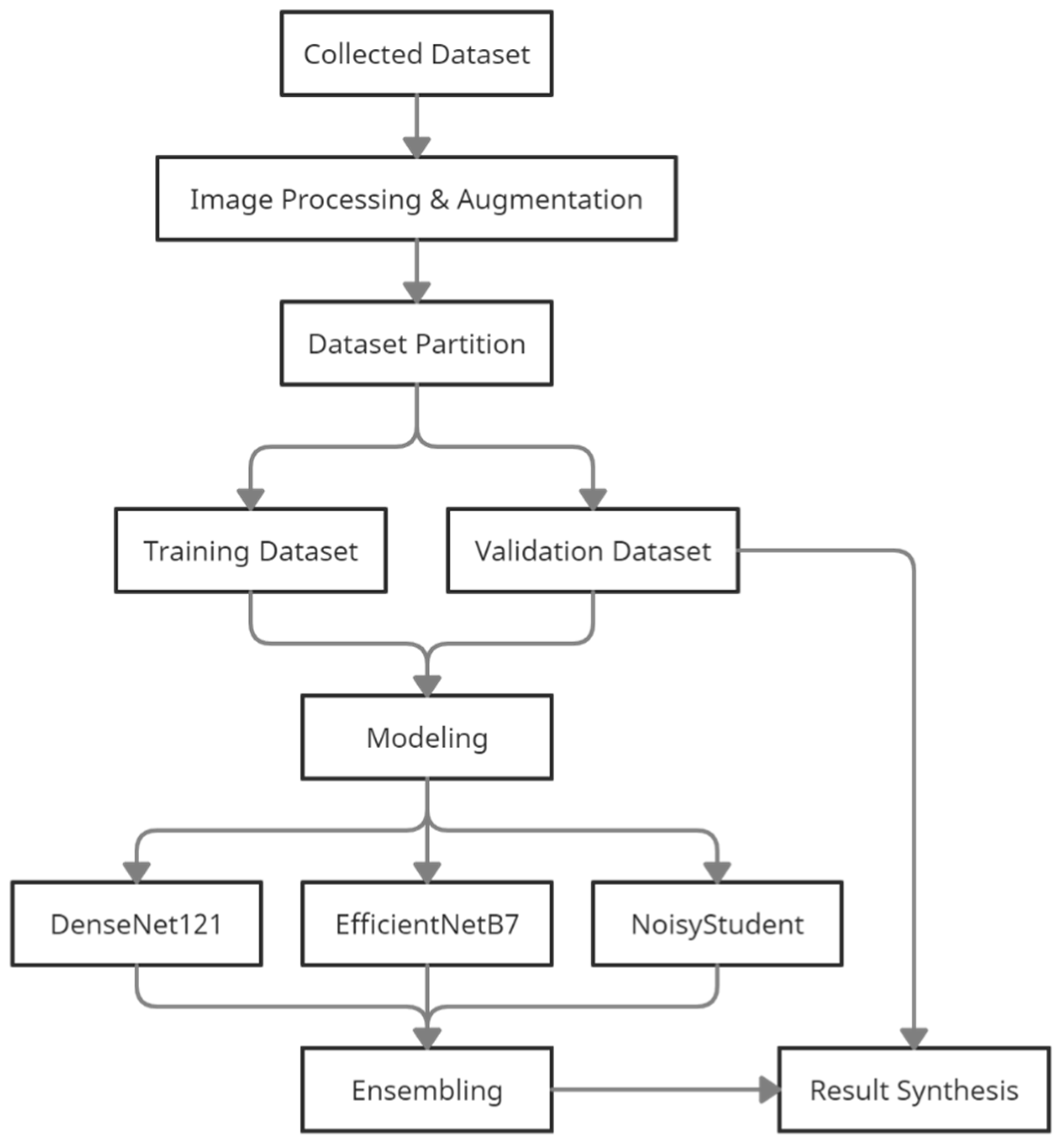
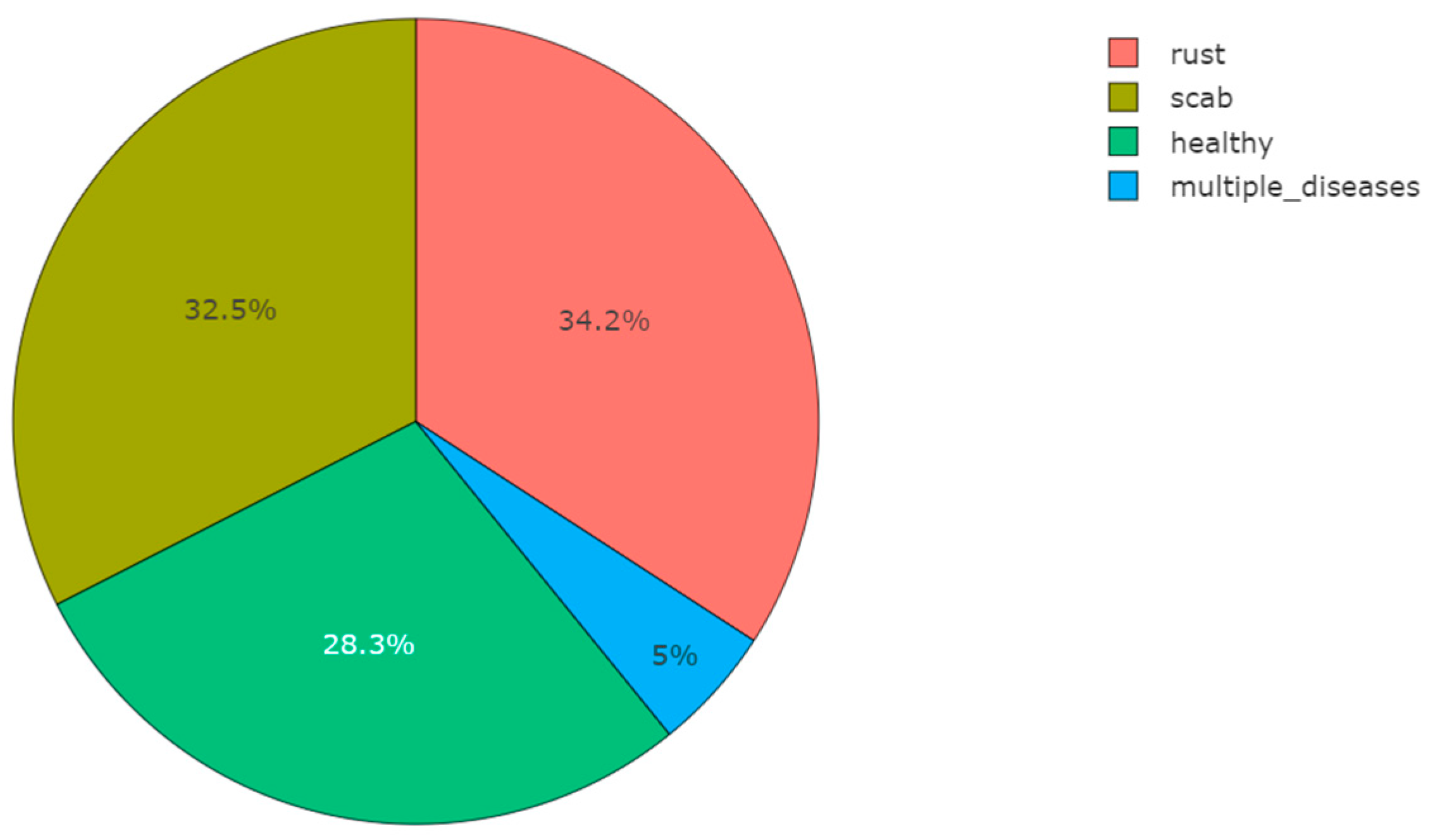
3.1. Dataset Collection
3.1.1. Healthy
3.1.2. Apple Scab
3.1.3. Cedar Apple Rust
3.1.4. Multiple Diseases
3.2. Image Augmentation
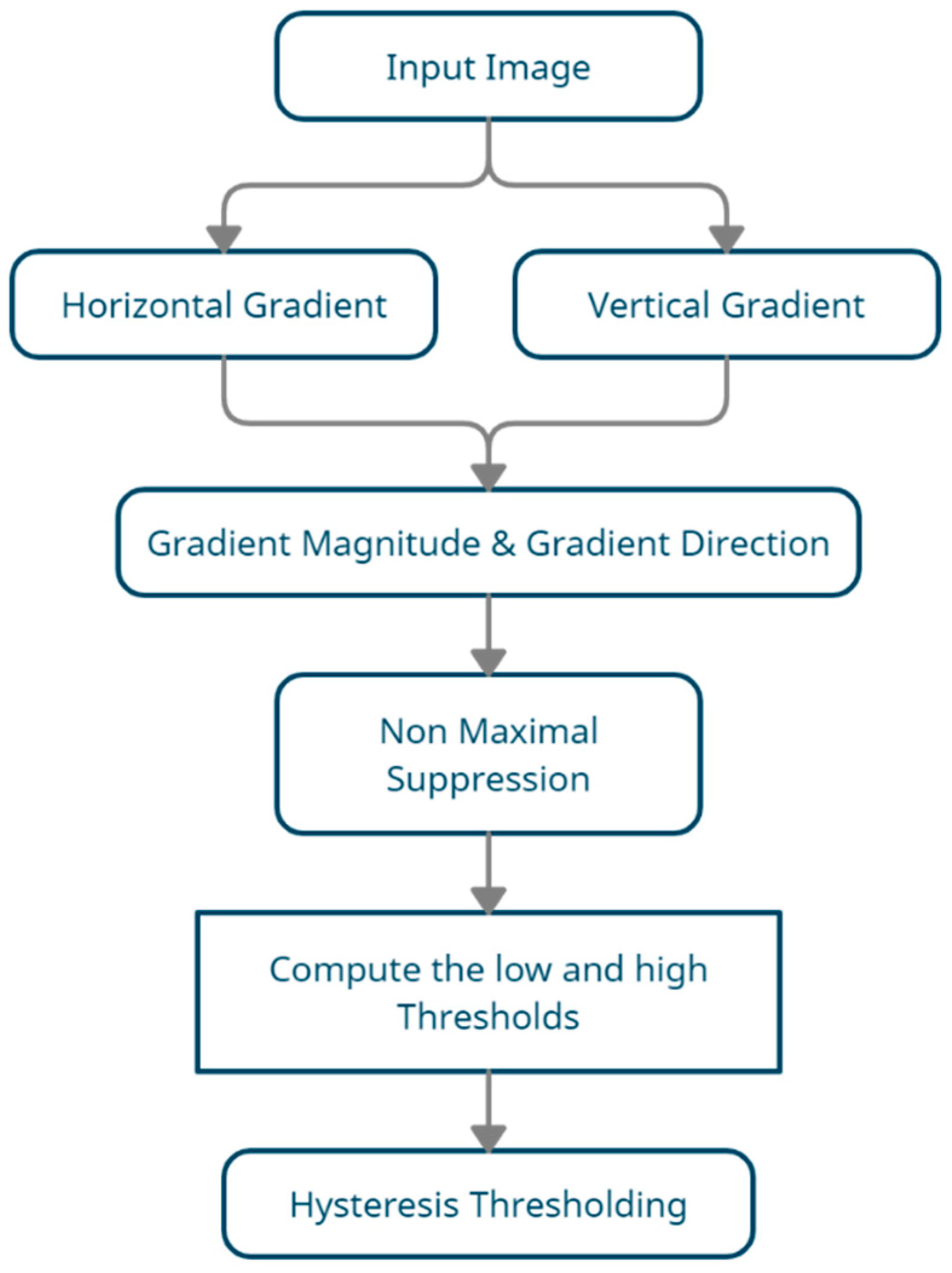
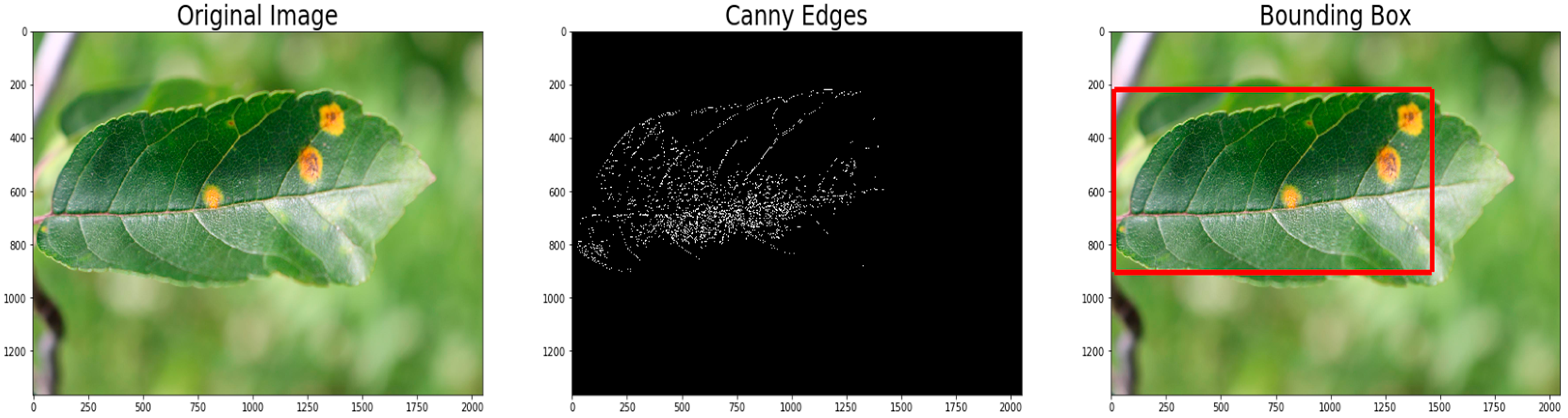
3.2.1. Canny Edge Detection
3.2.2. Flipping
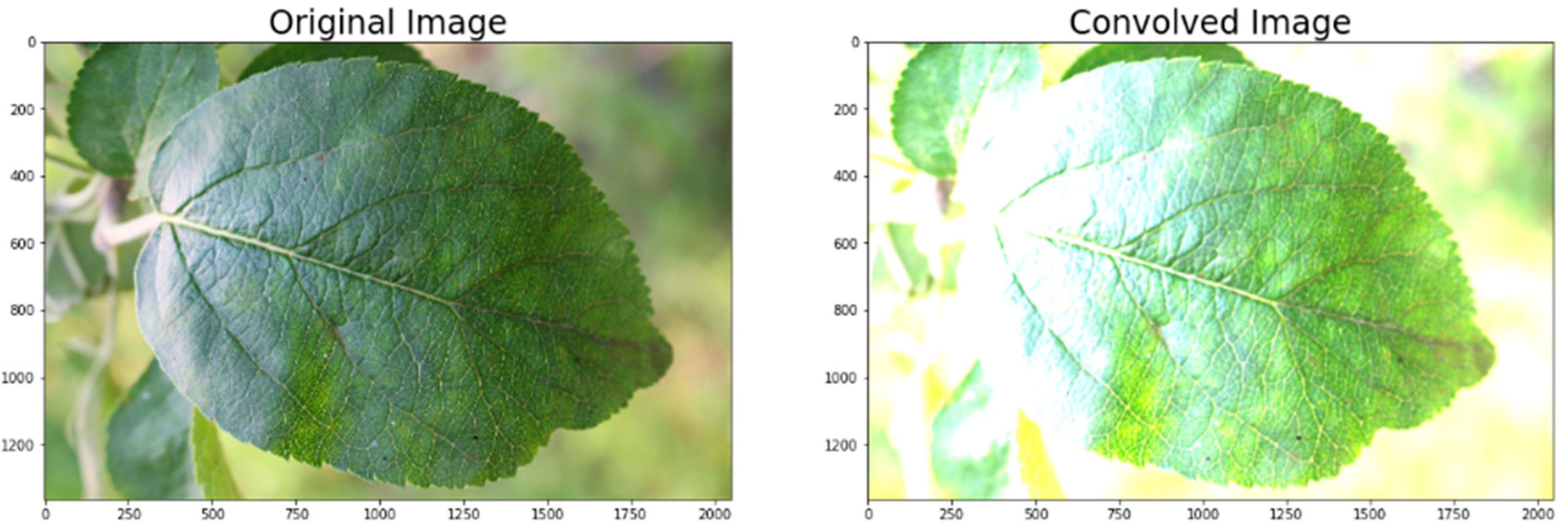
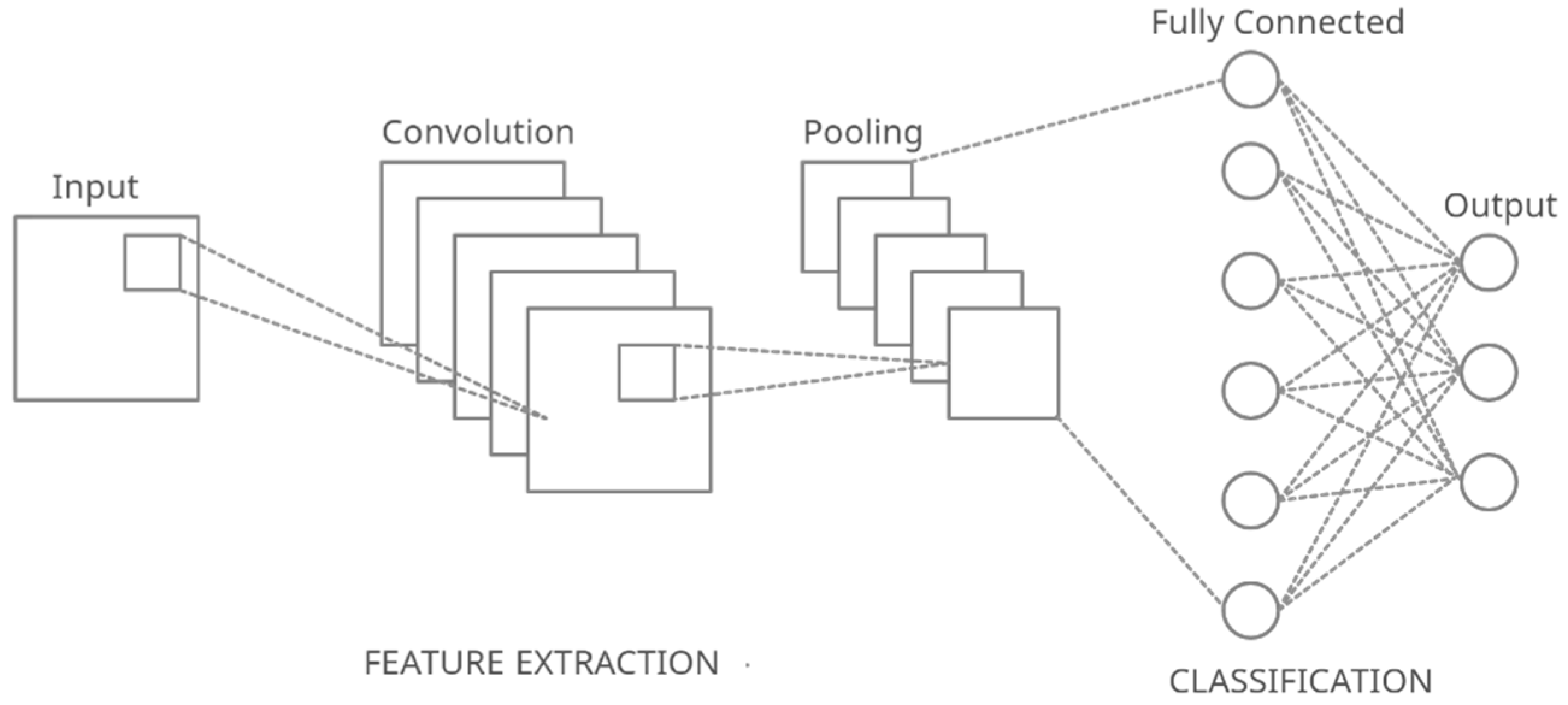
3.2.3. Convolution
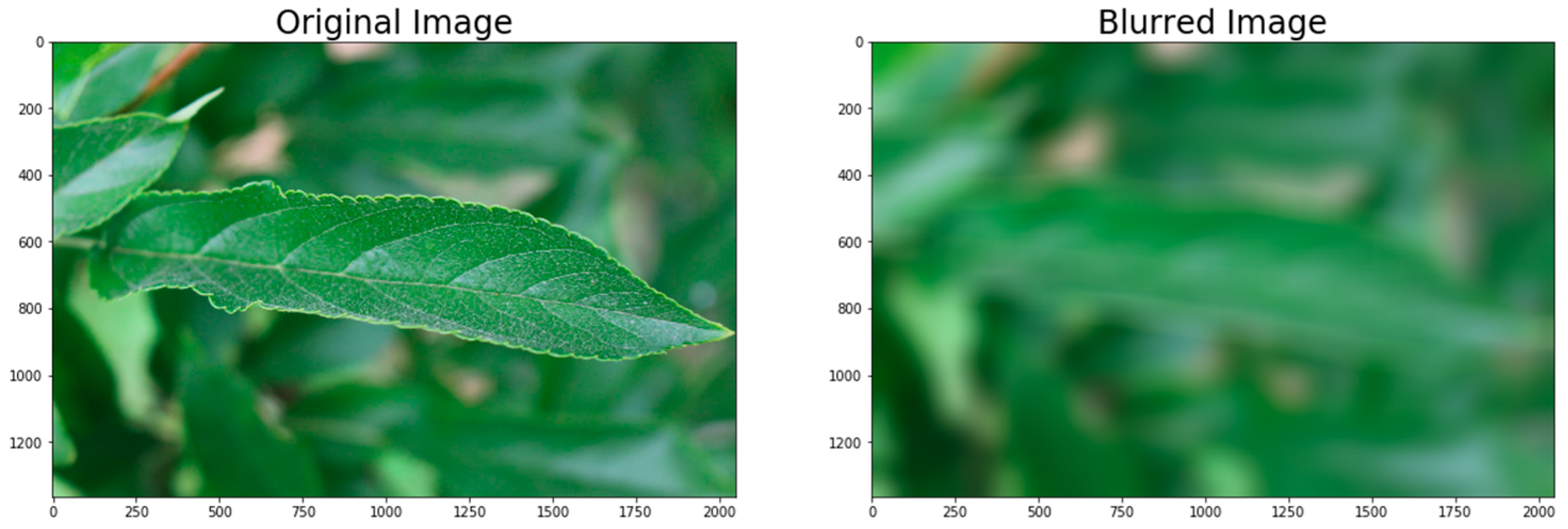
3.2.4. Blurring
3.3. Dataset Partition
3.4. Modeling
3.4.1. Multiclass Classification
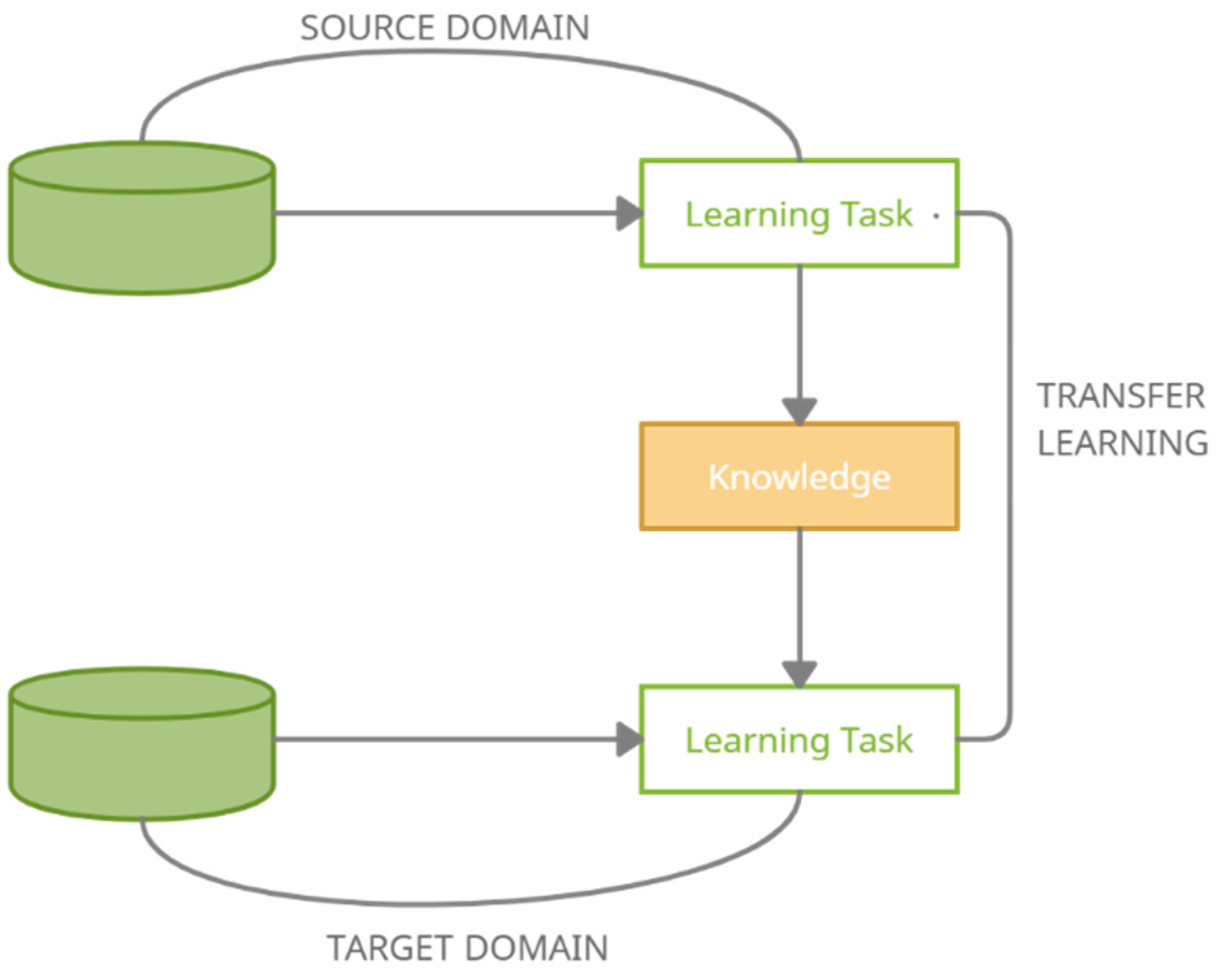
3.4.2. Transfer Learning
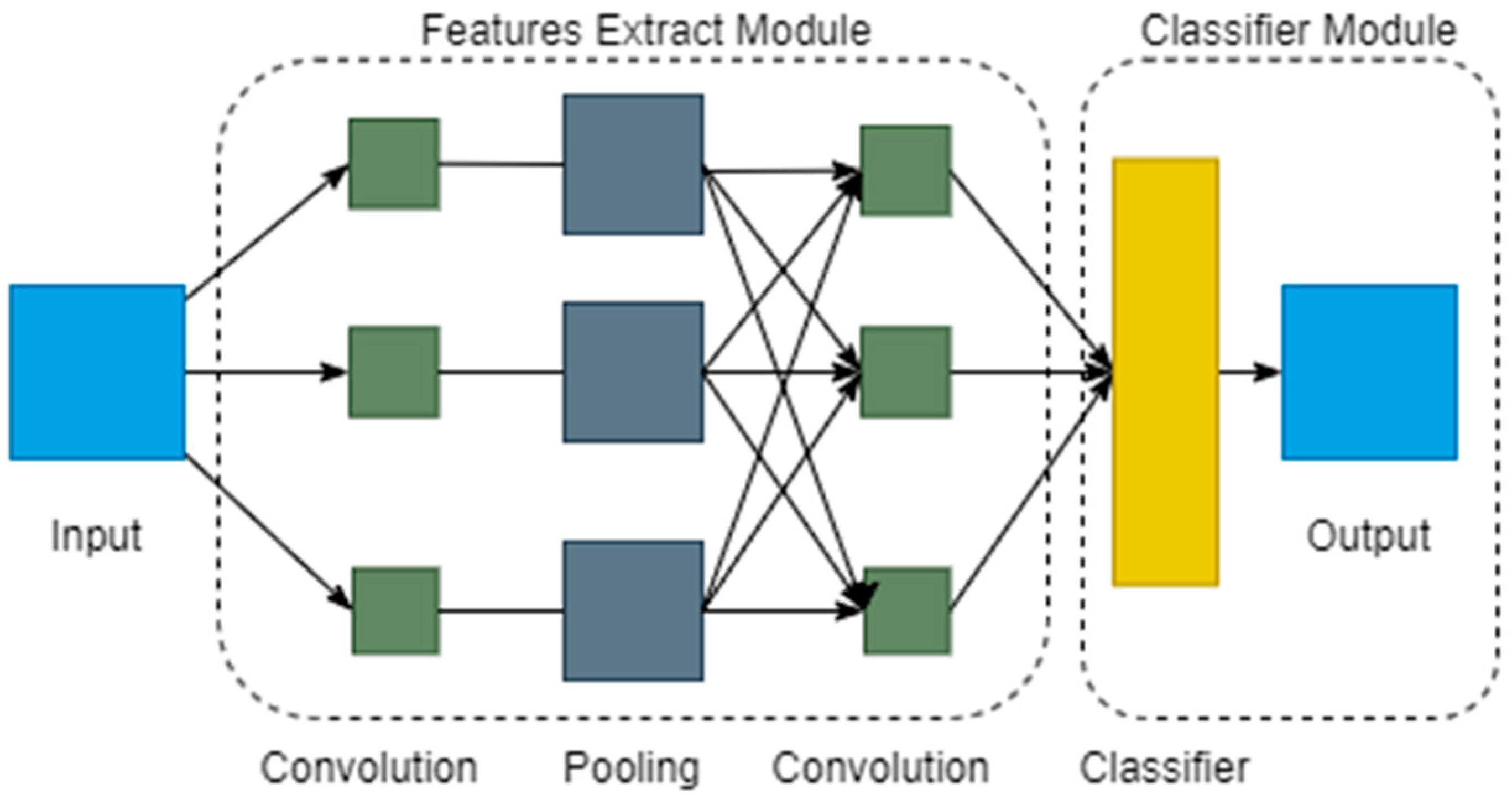
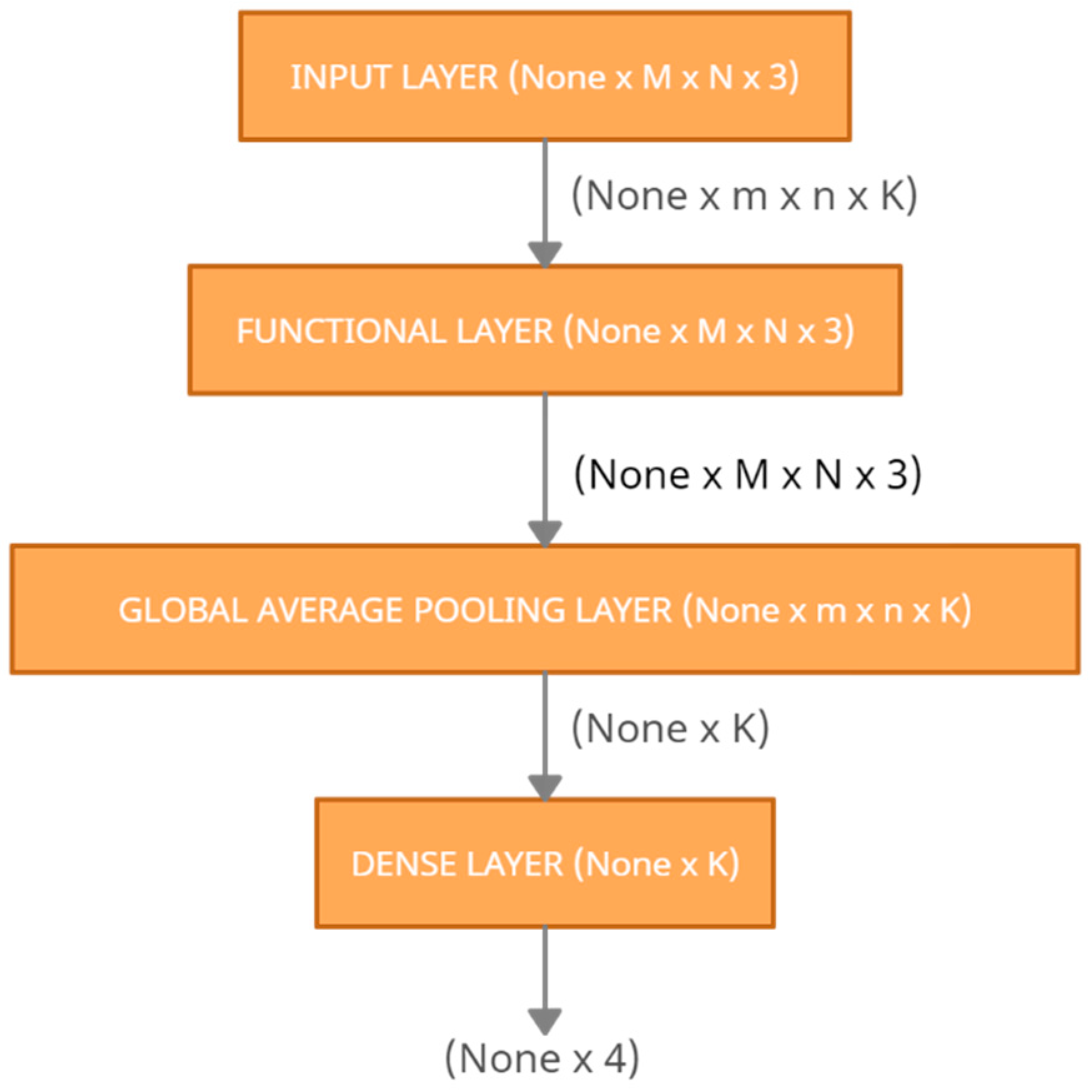
3.4.3. Model Structure
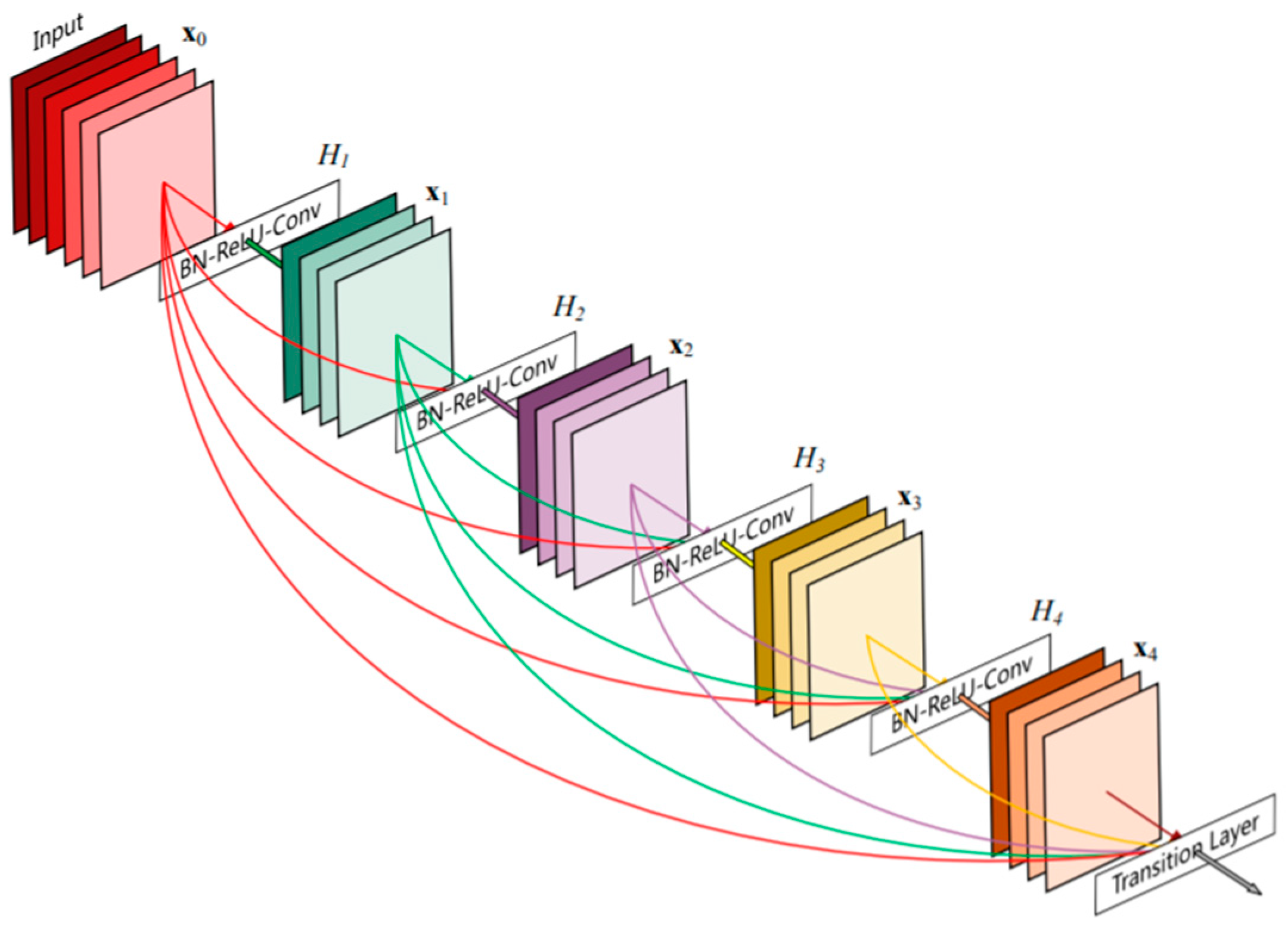
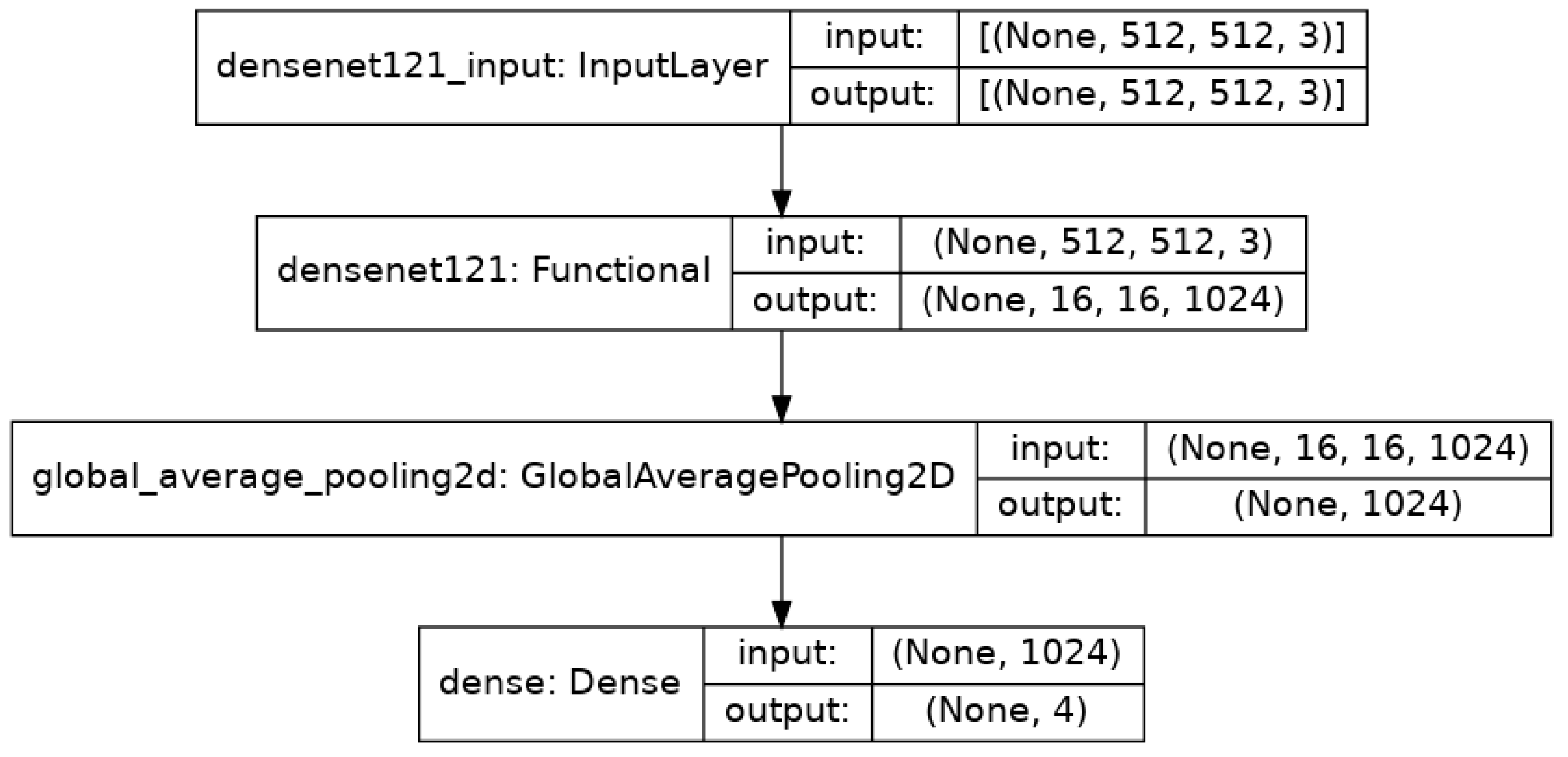
3.4.4. DenseNet121
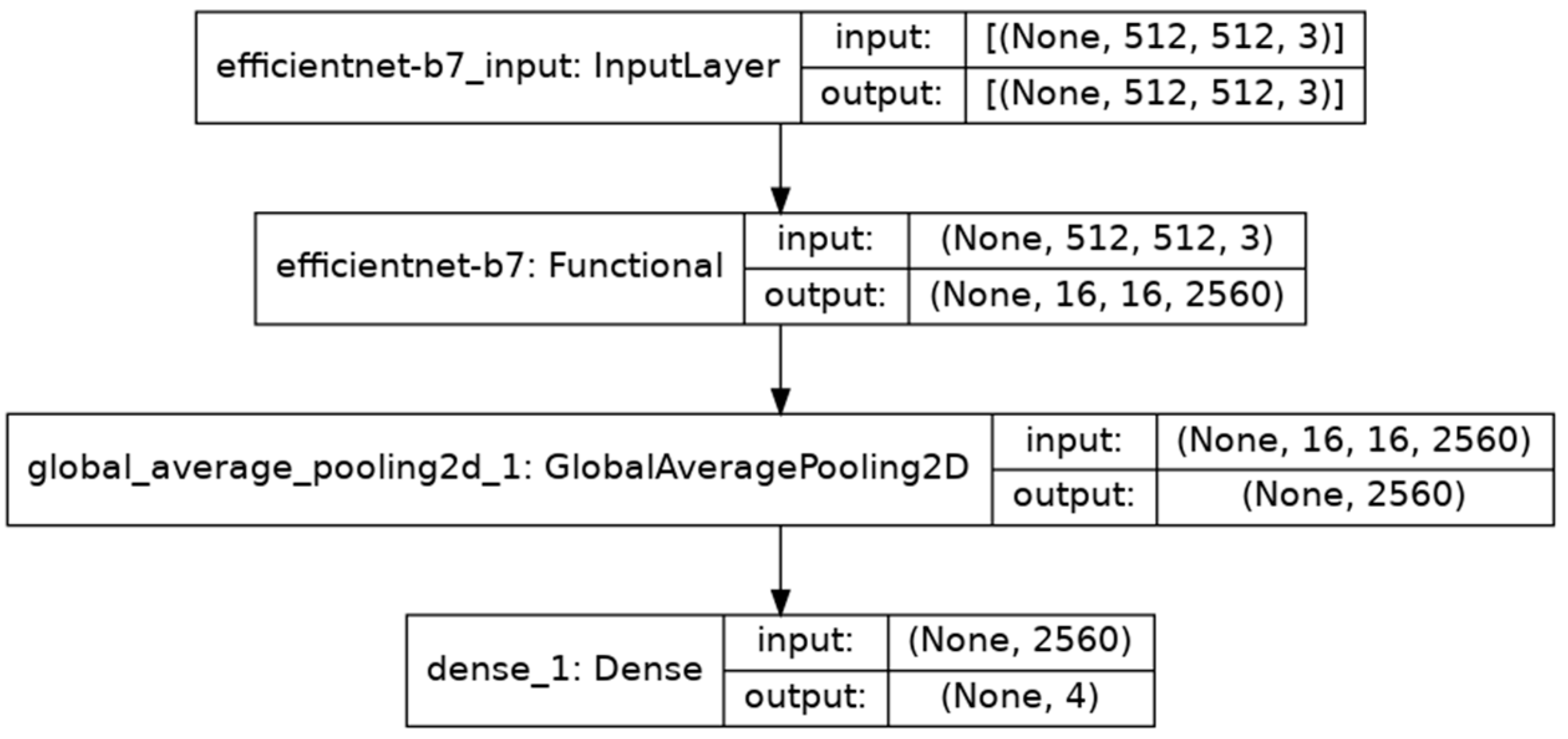
3.4.5. EfficientNet
3.4.6. EfficientNet Noisy Student
3.5. Ensembling
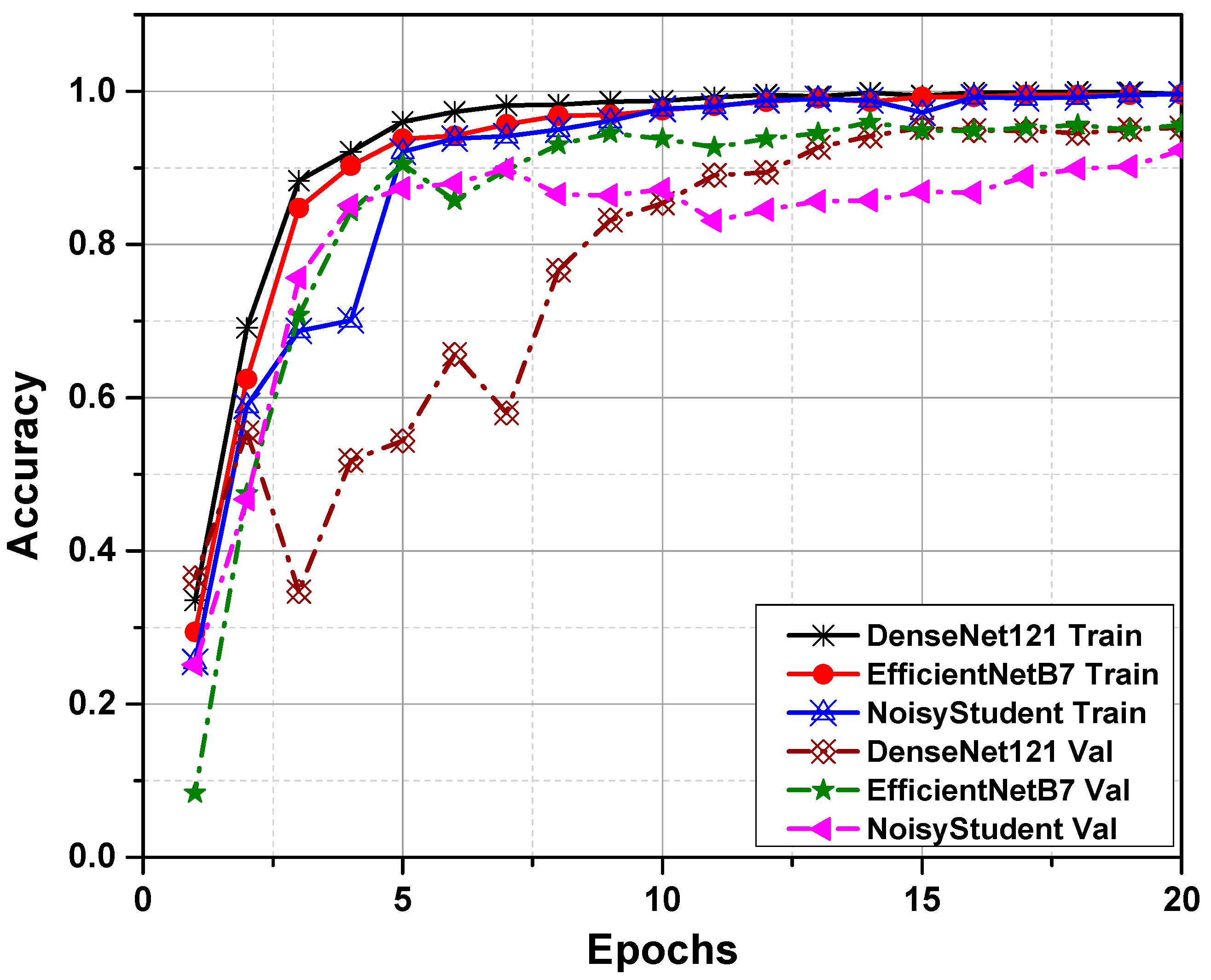
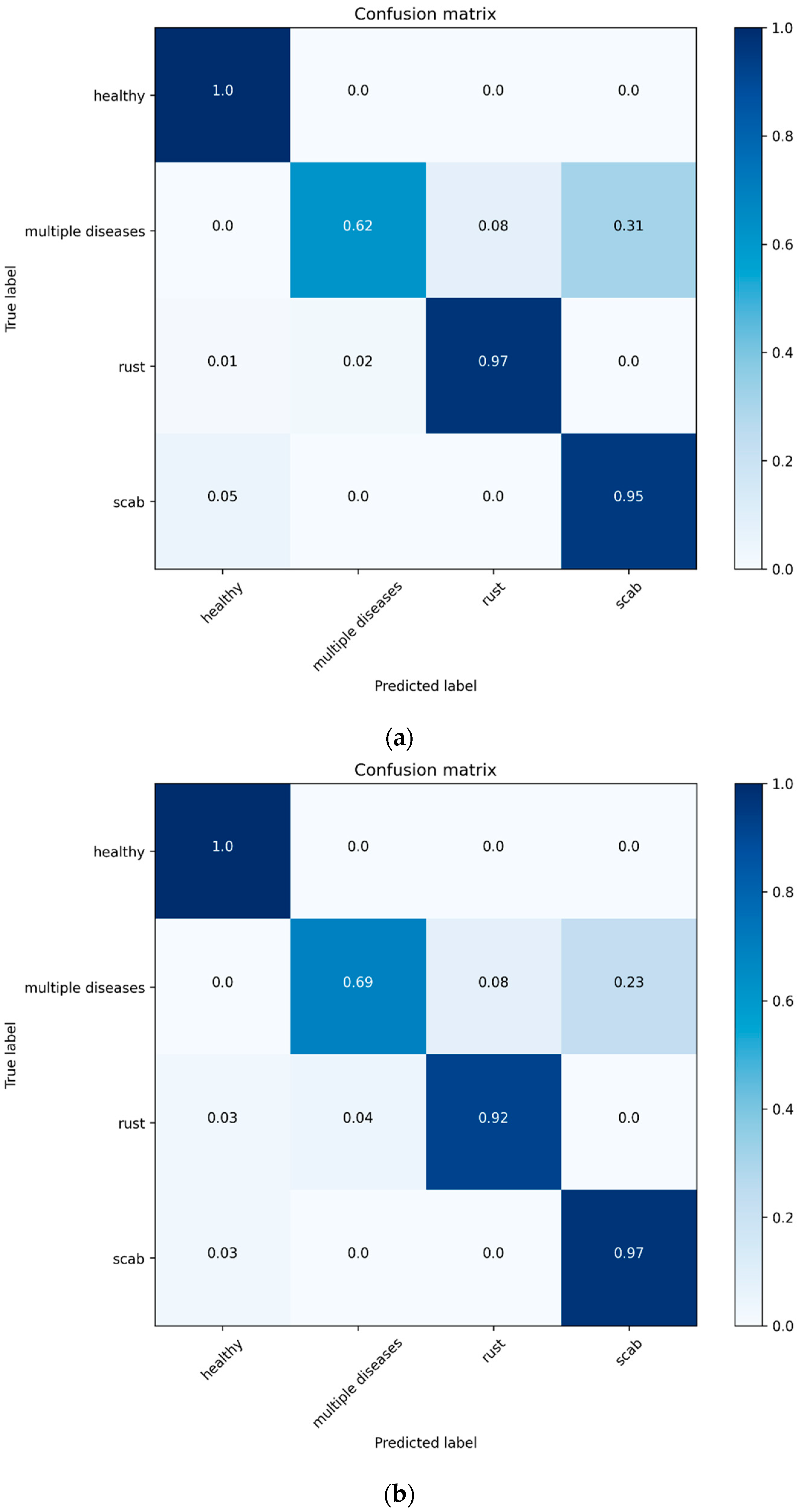
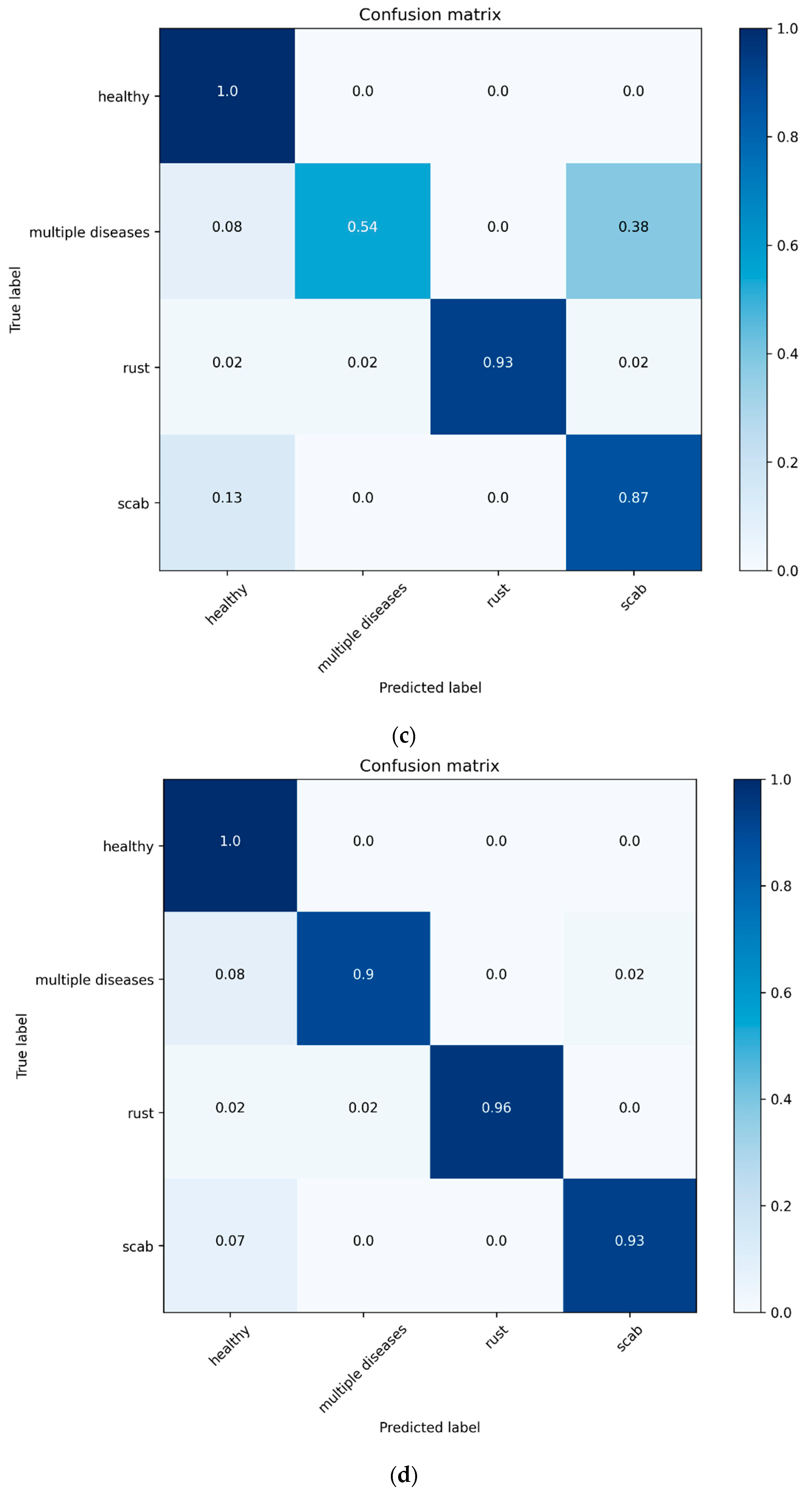
4. Experimental Results and Analyses
4.1. Experimental Setup
4.2. Performance Metrics
4.3. Performance Benchmarking
4.4. Computational Resources
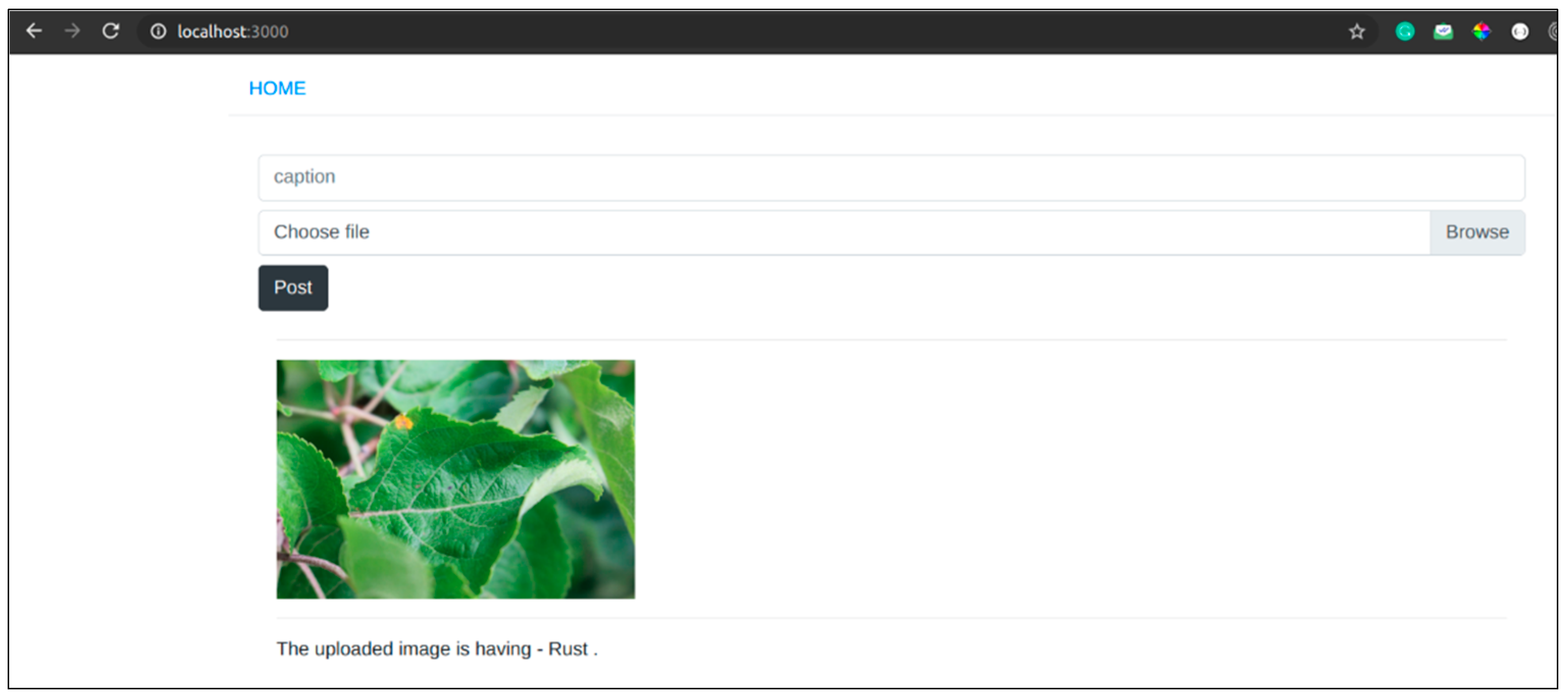
4.5. Model Deployment
4.5.1. Overview
4.5.2. Web Application Work Flow
- User visits our web application and uploads the image of apple leaf. All this takes place at the frontend.
- The image uploaded is then sent to the backend, where it is fed to the CNN model. At the backend, we have stored the weights of our proposed model in the form of an HDF5 file [57]. The model is loaded from this HDF5 file. Before feeding the image to the model, the image is first trimmed into the required shape of 512 × 512.
- The result returned by our model is a NumPy array of size (4,1), which includes the probability of the four classes. The class with the maximum probability is extracted.
- The results are shown to the user at the frontend, and the image is stored in our database to enhance our model.
4.5.3. Technologies Used
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Apple. Wikipedia. 2021. Available online: https://en.wikipedia.org/wiki/Apple (accessed on 22 April 2021).
- Jordan, M.I.; Mitchell, T.M. Machine Learning: Trends, Perspectives, and Prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Badage, A. Crop disease detection using machine learning: Indian agriculture. Int. Res. J. Eng. Technol. 2018, 5, 866–869. [Google Scholar]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Korkut, U.B.; Göktürk, Ö.B.; Yildiz, O. Detection of Plant Diseases by Machine Learning. In Proceedings of the 2018 26th Signal Processing and Communications Applications Conference (SIU), Izmir, Turkey, 2–5 May 2018; pp. 1–4. [Google Scholar]
- Noble, W.S. What Is a Support Vector Machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- Quinlan, J.R. Simplifying Decision Trees. Int. J. Man-Mach. Stud. 1987, 27, 221–234. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.; Li, L. Naive Bayes Classification Algorithm Based on Small Sample Set. In Proceedings of the 2011 IEEE International Conference on Cloud Computing and Intelligence Systems, Beijing, China, 15–17 September 2011; pp. 34–39. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Kumar, E.P.; Sharma, E.P. Artificial neural networks-a study. Int. J. Emerg. Eng. Res. Technol. 2014, 2, 143–148. [Google Scholar]
- Pardede, H.F.; Suryawati, E.; Sustika, R.; Zilvan, V. Unsupervised Convolutional Autoencoder-Based Feature Learning for Automatic Detection of Plant Diseases. In Proceedings of the 2018 International Conference on Computer, Control, Informatics and Its Applications (IC3INA), Tangerang, Indonesia, 1–2 November 2018; pp. 158–162. [Google Scholar]
- Howard, A.G. Some Improvements on Deep Convolutional Neural Network Based Image Classification. arXiv 2013, arXiv:1312.5402. [Google Scholar]
- Boulent, J.; Foucher, S.; Théau, J.; St-Charles, P.-L. Convolutional Neural Networks for the Automatic Identification of Plant Diseases. Front. Plant Sci. 2019, 10, 941. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 24 May 2019; pp. 6105–6114. [Google Scholar]
- Xie, Q.; Luong, M.-T.; Hovy, E.; Le, Q.V. Self-Training With Noisy Student Improves ImageNet Classification. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10684–10695. [Google Scholar]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A Survey on Deep Transfer Learning. In Artificial Neural Networks and Machine Learning-ICANN 2018 Lecture Notes in Computer Science; Kůrková, V., Manolopoulos, Y., Hammer, B., Iliadis, L., Maglogiannis, I., Eds.; Springer: Cham, Germany, 2018; Volume 11141. [Google Scholar] [CrossRef] [Green Version]
- Steel, M.F.J. Model Averaging and Its Use in Economics. J. Econ. Lit. 2020, 58, 644–719. [Google Scholar] [CrossRef]
- Selvaraj, M.G.; Vergara, A.; Ruiz, H.; Safari, N.; Elayabalan, S.; Ocimati, W.; Blomme, G. AI-Powered Banana Diseases and Pest Detection. Plant Methods 2019, 15, 92. [Google Scholar] [CrossRef]
- Early Detection and Classification of Plant Diseases with Support Vector Machines Based on Hyperspectral Reflectance. Comput. Electron. Agric. 2010, 74, 91–99. [CrossRef]
- Sinha, A.; Shekhawat, R.S. Review of Image Processing Approaches for Detecting Plant Diseases. IET Image Process. 2019, 14, 1427–1439. [Google Scholar] [CrossRef]
- Ramesh, S.; Hebbar, R.; Niveditha, M.; Pooja, R.; Shashank, N.; Vinod, P.V. Plant Disease Detection Using Machine Learning. In Proceedings of the 2018 International Conference on Design Innovations for 3Cs Compute Communicate Control (ICDI3C), Bangalore, India, 25–28 April 2018; pp. 41–45. [Google Scholar]
- Yang, X.; Guo, T. Machine Learning in Plant Disease Research. Eur. J. Biomed. Res. 2017, 3, 6–9. [Google Scholar] [CrossRef] [Green Version]
- Mohanty, S.P.; Hughes, D.P.; Salathé, M. Using Deep Learning for Image-Based Plant Disease Detection. Front. Plant Sci. 2016, 7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saleem, M.H.; Potgieter, J.; Arif, K.M. Plant Disease Detection and Classification by Deep Learning. Plants 2019, 8, 468. [Google Scholar] [CrossRef] [Green Version]
- Goncharov, P.; Ososkov, G.; Nechaevskiy, A.; Uzhinskiy, A.; Nestsiarenia, I. Disease Detection on the Plant Leaves by Deep Learning. In Proceedings of the International Conference on Neuroinformatics, Moscow, Russia, 8–12 October 2018; Kryzhanovsky, B., Dunin-Barkowski, W., Redko, V., Tiumentsev, Y., Eds.; Advances in Neural Computation, Machine Learning, and Cognitive Research II. Springer International Publishing: Cham, Germany, 2019; pp. 151–159. [Google Scholar]
- Sun, J.; Yang, Y.; He, X.; Wu, X. Northern Maize Leaf Blight Detection Under Complex Field Environment Based on Deep Learning. IEEE Access 2020, 8, 33679–33688. [Google Scholar] [CrossRef]
- Vine Disease Detection in UAV Multispectral Images Using Optimized Image Registration and Deep Learning Segmentation Approach. Comput. Electron. Agric. 2020, 174, 105446. [CrossRef]
- Identification of Rice Diseases Using Deep Convolutional Neural Networks. Neurocomputing 2017, 267, 378–384. [CrossRef]
- Amara, J.; Bouaziz, B.; Algergawy, A. A Deep Learning-Based Approach for Banana Leaf Diseases Classification. In Datenbanksysteme für Business, Technologie und Web (BTW 2017)-Workshopband; Mitschang, B., Nicklas, D., Leymann, F., Schöning, H., Herschel, M., Teubner, J., Härder, T., Kopp, O., Wieland, M., Eds.; Gesellschaft für Informatik e.V.: Bonn, Germany, 2017; pp. 79–88. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Factors Influencing the Use of Deep Learning for Plant Disease Recognition. Biosyst. Eng. 2018, 172, 84–91. [CrossRef]
- Liu, B.; Zhang, Y.; He, D.; Li, Y. Identification of Apple Leaf Diseases Based on Deep Convolutional Neural Networks. Symmetry 2018, 10, 11. [Google Scholar] [CrossRef] [Green Version]
- Chuanlei, Z.; Shanwen, Z.; Jucheng, Y.; Yancui, S.; Jia, C. Apple Leaf Disease Identification Using Genetic Algorithm and Correlation Based Feature Selection Method. Int. J. Agric. Biol. Eng. 2017, 10, 74–83. [Google Scholar] [CrossRef]
- Dai, B.; Qiu, T.; Ye, K. Foliar Disease Classification. Available online: http://noiselab.ucsd.edu/ECE228/projects/Report/15Report.pdf (accessed on 20 April 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper With Convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Sardoğan, M.; Özen, Y.; Tuncer, A. Detection of Apple Leaf Diseases Using Faster R-CNN. Düzce Üniversitesi Bilim Teknol. Derg. 2020, 8, 1110–1117. [Google Scholar] [CrossRef]
- Jiang, P.; Chen, Y.; Liu, B.; He, D.; Liang, C. Real-Time Detection of Apple Leaf Diseases Using Deep Learning Approach Based on Improved Convolutional Neural Networks. IEEE Access 2019, 7, 59069–59080. [Google Scholar] [CrossRef]
- Jeong, J.; Park, H.; Kwak, N. Enhancement of SSD by Concatenating Feature Maps for Object Detection. arXiv 2017, arXiv:1705.09587. [Google Scholar]
- Plant Pathology 2020-FGVC7. Available online: https://kaggle.com/c/plant-pathology-2020-fgvc7/data/ (accessed on 20 April 2021).
- Perez, L.; Wang, J. The Effectiveness of Data Augmentation in Image Classification Using Deep Learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Glossary-Convolution. Available online: https://homepages.inf.ed.ac.uk/rbf/HIPR2/convolve.htm (accessed on 18 April 2021).
- OpenCV: Smoothing Images. Available online: https://docs.opencv.org/master/d4/d13/tutorial_py_filtering.html (accessed on 18 April 2021).
- Lin, M.; Chen, Q.; Yan, S. Network In Network. arXiv 2014, arXiv:1312.4400. [Google Scholar]
- Nwankpa, C.; Ijomah, W.; Gachagan, A.; Marshall, S. Activation Functions: Comparison of Trends in Practice and Research for Deep Learning. arXiv 2018, arXiv:1811.03378. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Nain, A. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. Available online: https://medium.com/@nainaakash012/efficientnet-rethinking-model-scaling-for-convolutional-neural-networks-92941c5bfb95 (accessed on 25 May 2021).
- Ju, C.; Bibaut, A.; van der Laan, M. The Relative Performance of Ensemble Methods with Deep Convolutional Neural Networks for Image Classification. J. Appl. Stat. 2018, 45, 2800–2818. [Google Scholar] [CrossRef] [PubMed]
- Kaggle: Your Machine Learning and Data Science Community. Available online: https://www.kaggle.com/ (accessed on 20 April 2021).
- Tensor Processing Units (TPUs) Documentation. Available online: https://www.kaggle.com/docs/tpu (accessed on 20 April 2021).
- Tf.Data.Dataset | TensorFlow Core v2.4.1. Available online: https://www.tensorflow.org/api_docs/python/tf/data/Dataset (accessed on 20 April 2021).
- Seaborn: Statistical Data Visualization—Seaborn 0.11.1 Documentation. Available online: https://seaborn.pydata.org/#:~:text=Seaborn%20is%20a%20Python%20data,attractive%20and%20informative%20statistical%20graphics (accessed on 20 April 2021).
- Mishra, A. Metrics to Evaluate Your Machine Learning Algorithm. Available online: https://towardsdatascience.com/metrics-to-evaluate-your-machine-learning-algorithm-f10ba6e38234 (accessed on 18 April 2021).
- Available online: https://github.com/prakhar070/apple-disease-detection (accessed on 20 April 2021).
- The HDF5® Library & File Format. The HDF Group. Available online: https://www.hdfgroup.org/solutions/hdf5/ (accessed on 22 April 2021).




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Split | DenseNet121 | EfficientNetB7 | NoisyStudent | Our Model |
|---|---|---|---|---|
| 0.10 | 0.9398 | 0.9416 | 0.9095 | 0.9344 |
| 0.15 | 0.9526 | 0.9562 | 0.9124 | 0.9625 |
| 0.20 | 0.9511 | 0.9506 | 0.9233 | 0.9499 |
| 0.25 | 0.9414 | 0.9471 | 0.8991 | 0.9211 |
| 0.30 | 0.9232 | 0.9376 | 0.9091 | 0.9301 |
| Split | DenseNet121 | EfficientNetB7 | NoisyStudent | Our Model |
|---|---|---|---|---|
| 0.10 | 0.8432 | 0.8637 | 0.8344 | 0.8555 |
| 0.15 | 0.8637 | 0.8901 | 0.8479 | 0.9091 |
| 0.20 | 0.9496 | 0.8871 | 0.8544 | 0.8963 |
| 0.25 | 0.8598 | 0.8388 | 0.8282 | 0.8446 |
| 0.30 | 0.8876 | 0.8876 | 0.8298 | 0.8991 |
| Split | DenseNet121 | EfficientNetB7 | NoisyStudent | Our Model |
|---|---|---|---|---|
| 0.10 | 0.8442 | 0.8637 | 0.8344 | 0.8518 |
| 0.15 | 0.8637 | 0.8961 | 0.8429 | 0.8977 |
| 0.20 | 0.9496 | 0.8870 | 0.8542 | 0.8951 |
| 0.25 | 0.8221 | 0.8388 | 0.8238 | 0.8331 |
| 0.30 | 0.8806 | 0.8806 | 0.8301 | 0.8881 |
| Split | DenseNet121 | EfficientNetB7 | NoisyStudent | Our Model |
|---|---|---|---|---|
| 0.10 | 0.8442 | 0.8637 | 0.8329 | 0.8497 |
| 0.15 | 0.8637 | 0.8922 | 0.8453 | 0.9098 |
| 0.20 | 0.9496 | 0.8871 | 0.8576 | 0.8732 |
| 0.25 | 0.8560 | 0.8382 | 0.8249 | 0.8490 |
| 0.30 | 0.8839 | 0.8839 | 0.8290 | 0.8987 |
| Model | Accuracy |
|---|---|
| DenseNet | 0.9260 |
| GoogleNet | 0.9530 |
| EfficientNetB7 | 0.9562 |
| ResNet20 | 0.9370 |
| VggNet-16 | 0.9400 |
| Our Model | 0.9625 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bansal, P.; Kumar, R.; Kumar, S. Disease Detection in Apple Leaves Using Deep Convolutional Neural Network. Agriculture 2021, 11, 617. https://doi.org/10.3390/agriculture11070617
Bansal P, Kumar R, Kumar S. Disease Detection in Apple Leaves Using Deep Convolutional Neural Network. Agriculture. 2021; 11(7):617. https://doi.org/10.3390/agriculture11070617
Chicago/Turabian StyleBansal, Prakhar, Rahul Kumar, and Somesh Kumar. 2021. "Disease Detection in Apple Leaves Using Deep Convolutional Neural Network" Agriculture 11, no. 7: 617. https://doi.org/10.3390/agriculture11070617