
Predicting Cardiac Arrest in Children with Heart Disease: A Novel Machine Learning Algorithm

Abstract
:1. Introduction
2. Methods
2.1. Study Population
2.2. Study Variables
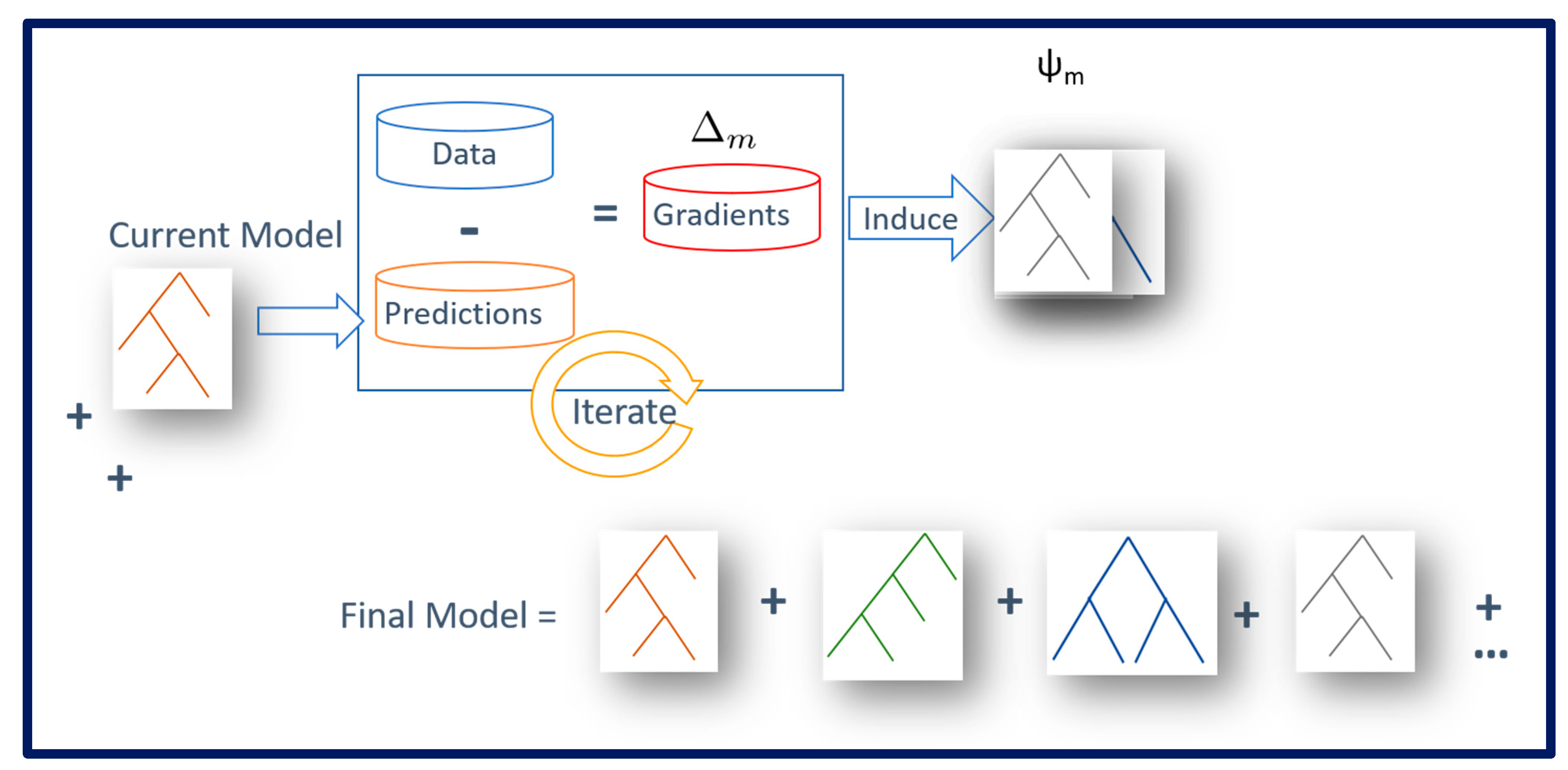
2.3. Study Design
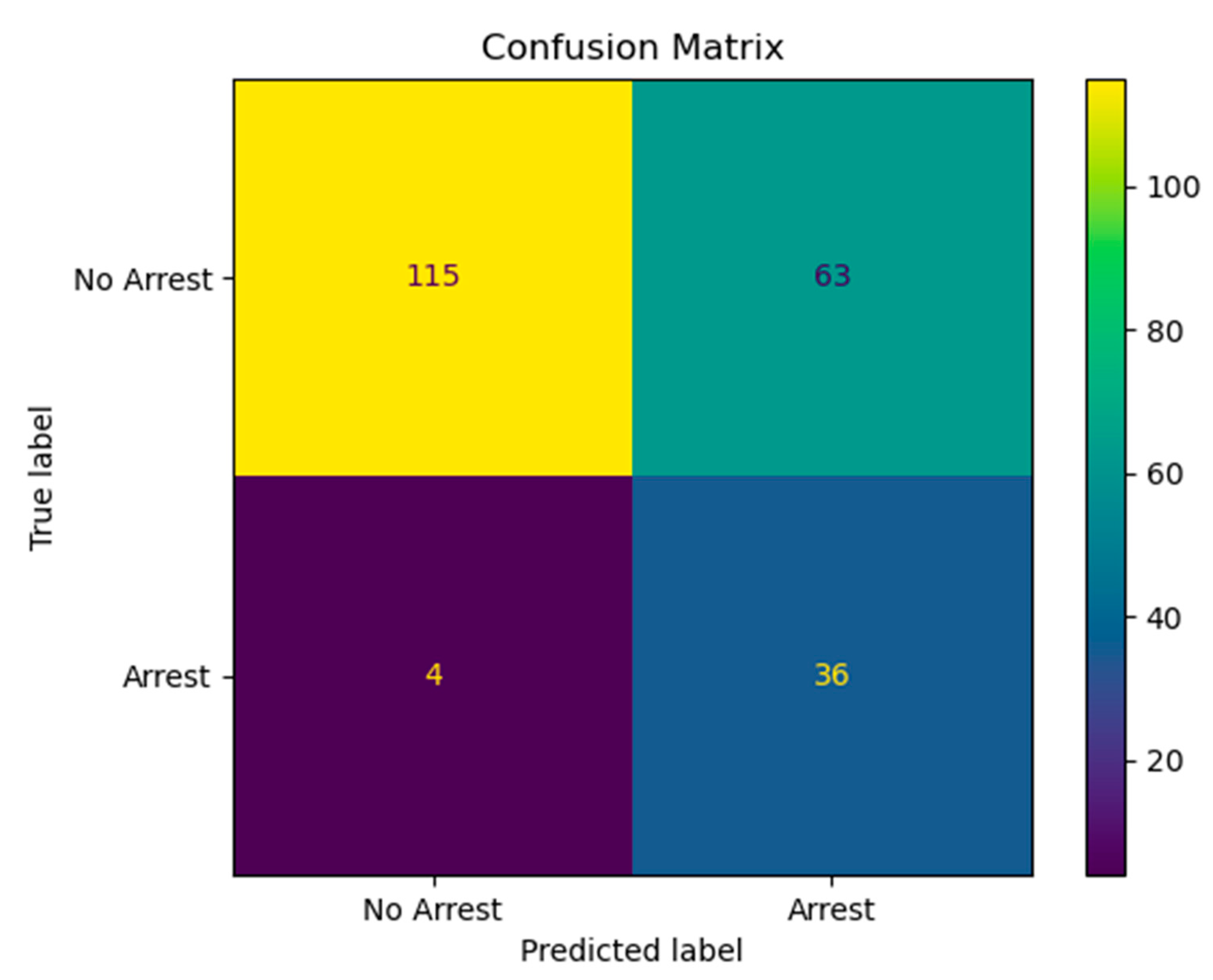
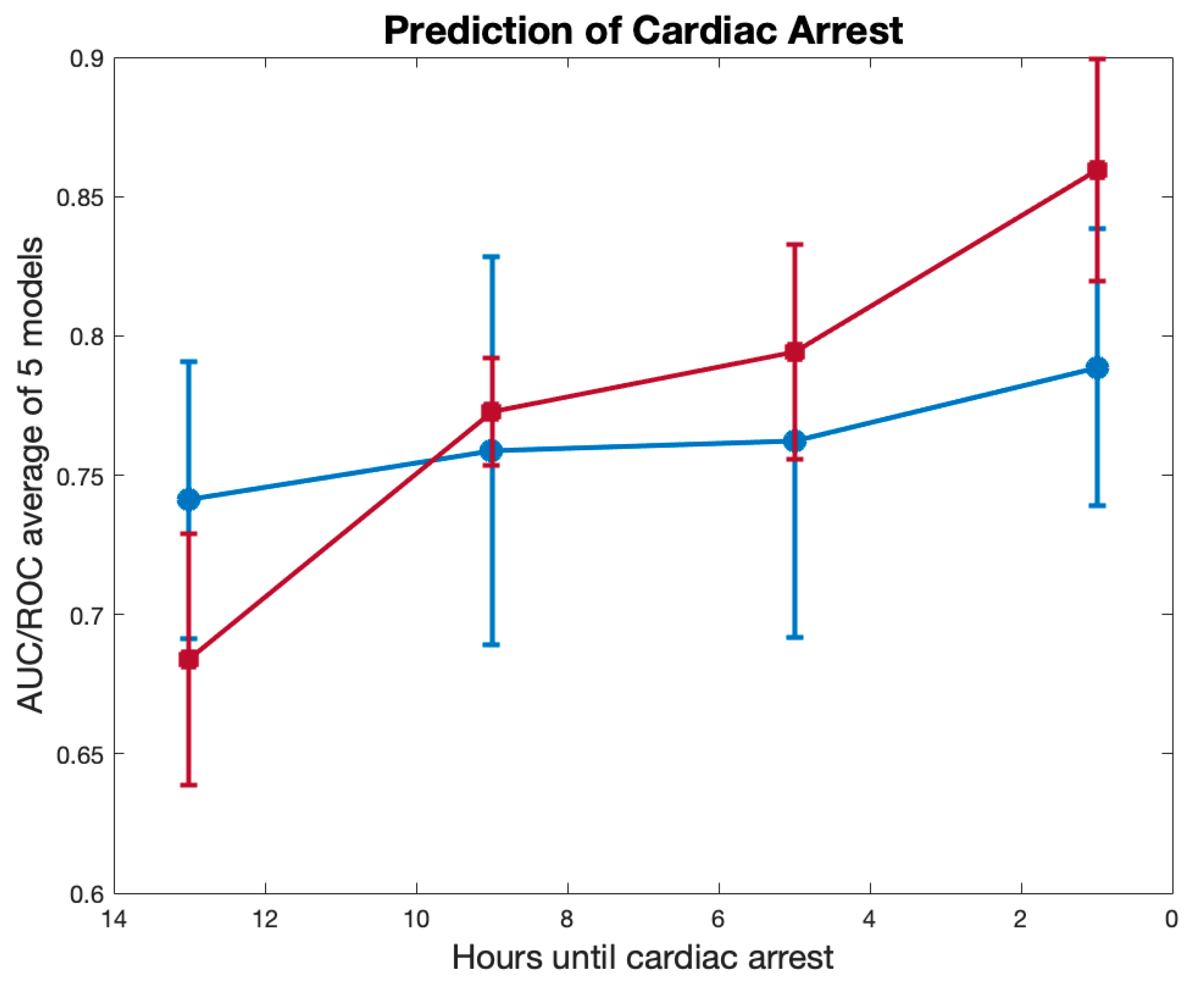
3. Results
3.1. Feature Importance
3.2. Logistic Regression Model
4. Discussion
Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lowry, A.W.; Knudson, J.D.; Cabrera, A.G.; Graves, D.E.; Morales, D.L.; Rossano, J.W. Cardiopulmonary resuscitation in hospitalized children with cardiovascular disease: Estimated prevalence and outcomes from the kids’ inpatient database. Pediatr. Crit. Care Med. 2013, 14, 248–255. [Google Scholar] [CrossRef] [PubMed]
- Alten, J.A.; Klugman, D.; Raymond, T.T.; Cooper, D.S.; Donohue, J.E.; Zhang, W.; Pasquali, S.K.; Gaies, M.G. Epidemiology and Outcomes of Cardiac Arrest in Pediatric Cardiac ICUs. Pediatr. Crit. Care Med. 2017, 18, 935–943. [Google Scholar] [CrossRef]
- Marino, B.S.; Tabbutt, S.; MacLaren, G.; Hazinski, M.F.; Adatia, I.; Atkins, D.L.; Checchia, P.A.; DeCaen, A.; Fink, E.L.; Hoffman, G.M.; et al. Cardiopulmonary Resuscitation in Infants and Children with Cardiac Disease: A Scientific Statement From the American Heart Association. Circulation 2018, 137, e691–e782. [Google Scholar] [CrossRef] [PubMed]
- Yu, P.; Esangbedo, I.; Li, X.; Wolovits, J.; Thiagarajan, R.; Raman, L. Early Changes in Near-Infrared Spectroscopy Are Associated with Cardiac Arrest in Children with Congenital Heart Disease. Front. Pediatr. 2022, 10, 894125. [Google Scholar] [CrossRef] [PubMed]
- Layeghian Javan, S.; Sepehri, M.M.; Aghajani, H. Toward analyzing and synthesizing previous research in early prediction of cardiac arrest using machine learning based on a multi-layered integrative framework. J. Biomed. Inform. 2018, 88, 70–89. [Google Scholar] [CrossRef] [PubMed]
- Matam, B.R.; Duncan, H.; Lowe, D. Machine learning based framework to predict cardiac arrests in a paediatric intensive care unit: Prediction of cardiac arrests. J. Clin. Monit. Comput. 2019, 33, 713–724. [Google Scholar] [CrossRef] [PubMed]
- Kennedy, C.E.; Aoki, N.; Mariscalco, M.; Turley, J.P. Using Time Series Analysis to Predict Cardiac Arrest in a PICU. Pediatr. Crit. Care Med. 2015, 16, e332–e339. [Google Scholar] [CrossRef] [Green Version]
- Rusin, C.G.; Acosta, S.I.; Shekerdemian, L.S.; Vu, E.L.; Bavare, A.C.; Myers, R.B.; Patterson, L.W.; Brady, K.M.; Penny, D.J. Prediction of imminent, severe deterioration of children with parallel circulations using real-time processing of physiologic data. J. Thorac. Cardiovasc. Surg. 2016, 152, 171–177. [Google Scholar] [CrossRef] [Green Version]
- Ruiz, V.M.; Saenz, L.; Lopez-Magallon, A.; Shields, A.; Ogoe, H.A.; Suresh, S.; Munoz, R.; Tsui, F.R. Early prediction of critical events for infants with single-ventricle physiology in critical care using routinely collected data. J. Thorac. Cardiovasc. Surg. 2019, 158, 234–243.e3. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bose, S.N.; Verigan, A.; Hanson, J.; Ahumada, L.M.; Ghazarian, S.R.; Goldenberg, N.A.; Stock, A.; Jacobs, J.P. Early identification of impending cardiac arrest in neonates and infants in the cardiovascular ICU: A statistical modelling approach using physiologic monitoring data-CORRIGENDUM. Cardiol. Young 2019, 29, 1349. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ruiz, V.M.; Goldsmith, M.; Shi, L.; Simpao, A.; Galvaz, J.; Naim, M.; Nadkarni, V.; Gaynor, W.; Tsui, F.R. Early prediction of clinical deterioration using data-driven machine learning modeling of electronic health records. J. Thorac. Cardiovasc. Surg. 2021; in press. [Google Scholar] [CrossRef]
- Raedt, L.D.; Kersting, K.; Natarajan, S.; Poole, D. Statistical relational artificial intelligence: Logic, probability, and computation. Synth. Lect. Artif. Intell. Mach. Learn. 2016, 10, 1–189. [Google Scholar]
- Schwartz, S.M.; Dent, C.L.; Musa, N.L.; Nelson, D.P. Single-ventricle physiology. Crit. Care Clin. 2003, 19, 393–411. [Google Scholar] [CrossRef] [PubMed]
- Natarajan, S.; Khot, T.; Kersting, K.; Gutmann, B.; Shavlik, J. Gradient-based boosting for statistical relational learning: The relational dependency network case. Mach. Learn. 2012, 86, 25–26. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017. [Google Scholar]
- Gaies, M.G.; Jeffries, H.E.; Niebler, R.A.; Pasquali, S.K.; Donohue, J.E.; Yu, S.; Gall, C.; Rice, T.B.; Thiagarajan, R.R. Vasoactive-inotropic score is associated with outcome after infant cardiac surgery: An analysis from the Pediatric Cardiac Critical Care Consortium and Virtual PICU System Registries. Pediatr. Crit. Care Med. 2014, 15, 529–537. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bonanno, F.G. Clinical pathology of the shock syndromes. J. Emerg. Trauma Shock 2011, 4, 233–243. [Google Scholar] [CrossRef] [PubMed]
- Spaeder, M.C.; Klugman, D.; Skurow-Todd, K.; Glass, P.; Jonas, R.A.; Donofrio, M.T. Perioperative Near-Infrared Spectroscopy Monitoring in Neonates with Congenital Heart Disease: Relationship of Cerebral Tissue Oxygenation Index Variability with Neurodevelopmental Outcome. Pediatr. Crit. Care Med. 2017, 18, 213–218. [Google Scholar] [CrossRef] [PubMed]
- Spilka, J.M.; O’Halloran, C.P.; Marino, B.S.; Brady, K.M. Perspective on Cerebral Autoregulation Monitoring in Neonatal Cardiac Surgery Requiring Cardiopulmonary Bypass. Front. Neurol. 2021, 12, 740185. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Groups | AUROC for Hours | |||
|---|---|---|---|---|
| 13 | 9 | 5 | 1 | |
| SpO2, ETCO2, anion gap, base excess, FiO2 | 0.63 ± 0.04 | 0.69 ± 0.03 | 0.75 ± 0.03 | 0.81 ± 0.02 |
| HR, DBP, SpO2 rSO2c | 0.67 ± 0.05 | 0.73 ± 0.06 | 0.80 ± 0.03 | 0.84 ± 0.03 |
| HR, DBP, SpO2 rSO2s | 0.68 ± 0.02 | 0.71 ± 0.01 | 0.78 ± 0.03 | 0.81 ± 0.02 |
| HR, DBP, SpO2, rSO2c, rSO2s | 0.69 ± 0.02 | 0.69 ± 0.03 | 0.79 ± 0.02 | 0.85 ± 0.02 |
| HR, DBP, SpO2, rSO2c, rSO2s, VIS | 0.69 ± 0.05 | 0.72 ± 0.03 | 0.80 ± 0.03 | 0.87 ± 0.02 |
| HR, DBP, SpO2, rSO2c, VIS | 0.66 ± 0.03 | 0.72 ± 0.02 | 0.78 ± 0.01 | 0.87 ± 0.03 |
| HR, DBP, VIS, urine output | 0.71 ± 0.02 | 0.73 ± 0.04 | 0.79 ± 0.03 | 0.84 ± 0.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, P.; Skinner, M.; Esangbedo, I.; Lasa, J.J.; Li, X.; Natarajan, S.; Raman, L. Predicting Cardiac Arrest in Children with Heart Disease: A Novel Machine Learning Algorithm. J. Clin. Med. 2023, 12, 2728. https://doi.org/10.3390/jcm12072728
Yu P, Skinner M, Esangbedo I, Lasa JJ, Li X, Natarajan S, Raman L. Predicting Cardiac Arrest in Children with Heart Disease: A Novel Machine Learning Algorithm. Journal of Clinical Medicine. 2023; 12(7):2728. https://doi.org/10.3390/jcm12072728
Chicago/Turabian StyleYu, Priscilla, Michael Skinner, Ivie Esangbedo, Javier J. Lasa, Xilong Li, Sriraam Natarajan, and Lakshmi Raman. 2023. "Predicting Cardiac Arrest in Children with Heart Disease: A Novel Machine Learning Algorithm" Journal of Clinical Medicine 12, no. 7: 2728. https://doi.org/10.3390/jcm12072728