
A Hybrid Method for Performance Degradation Probability Prediction of Proton Exchange Membrane Fuel Cell

Abstract
:1. Introduction
- (1)
- With consideration of the uncertainties in the degradation process, a Wiener process model is established to describe the overall degradation trend of PEMFC and multiple kinds of variability sources are adequately considered in the model.
- (2)
- To overcome the disadvantage of LSTM in parallel processing, a degradation prediction model is established by transformer, which is used to predict the degradation trend and capture the local fluctuation information.
- (3)
- The MC-dropout is added in transformer network to quantify the uncertainty of the prediction results in order to provide more effective decision support for practical engineering applications.
2. Degradation Modeling of PEMFC
3. State of Health Estimation and Parameter Estimation
| Algorithm 1 The procedures of the UKF algorithm |
1. Initialization (k = 0): , 2. Time update: , 3. Sigma points and weights calculation: (1) ; ; where , is the ith column of the square root of the matrix . (2) ; ; , where is the scaling parameter, and the other parameters are generally set to = 3 4. Measurement update |
4. Method of Degradation Prediction
4.1. Problem Description
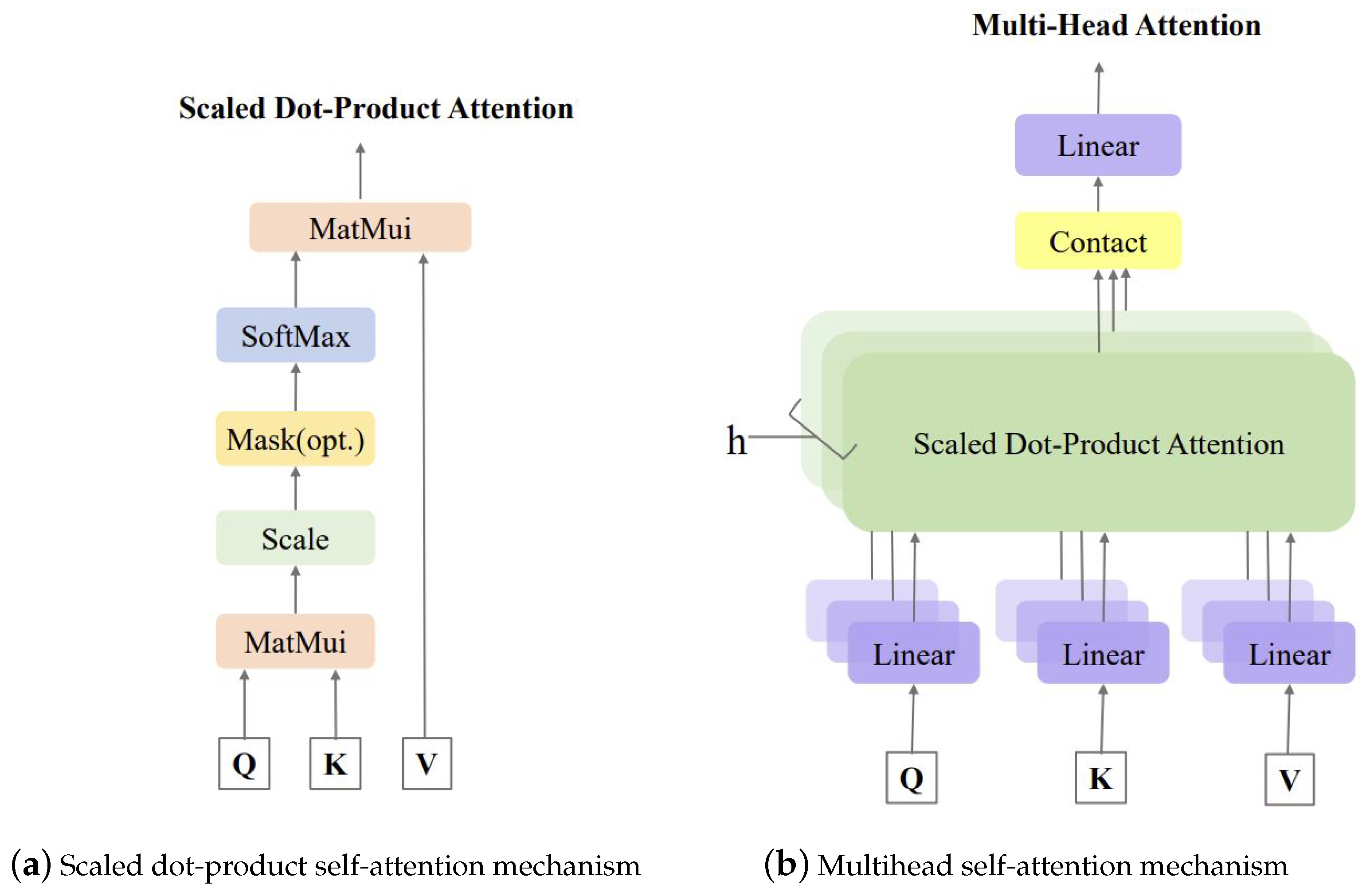
4.2. The Transformer Structure
4.2.1. Data Input
4.2.2. Encoder
4.2.3. Decoder
4.2.4. Output
4.3. The Method of MC-Dropout
4.4. The Hybrid Prediction Method for Performance Degradation
5. Experimental Study
5.1. Experimental Dataset
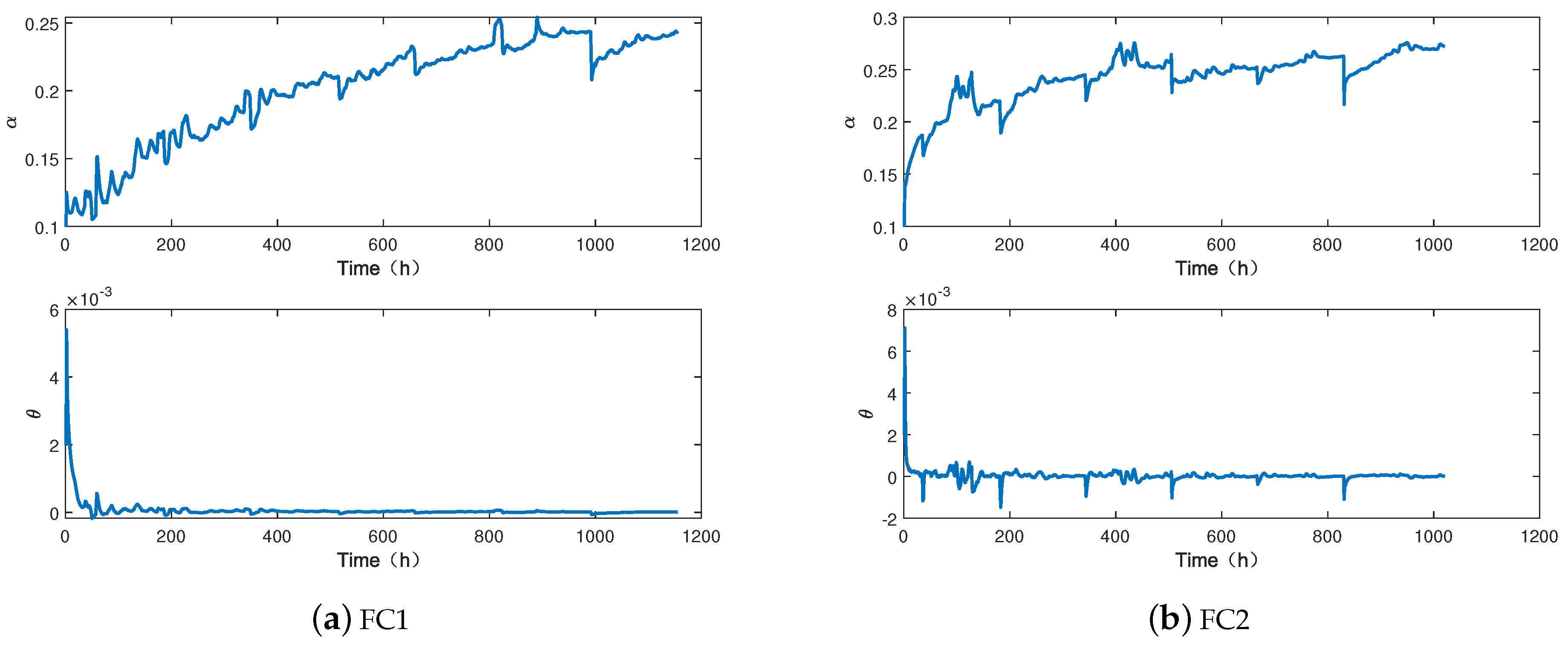
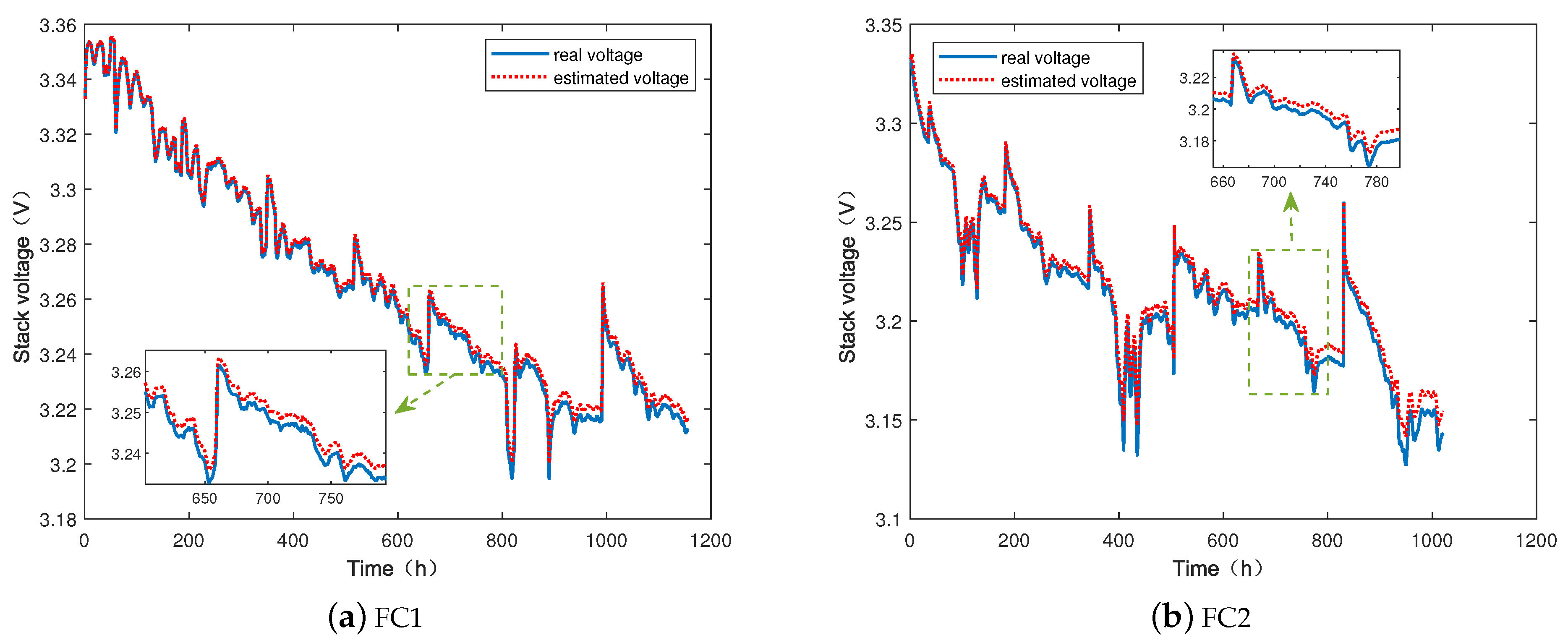
5.2. State Estimation
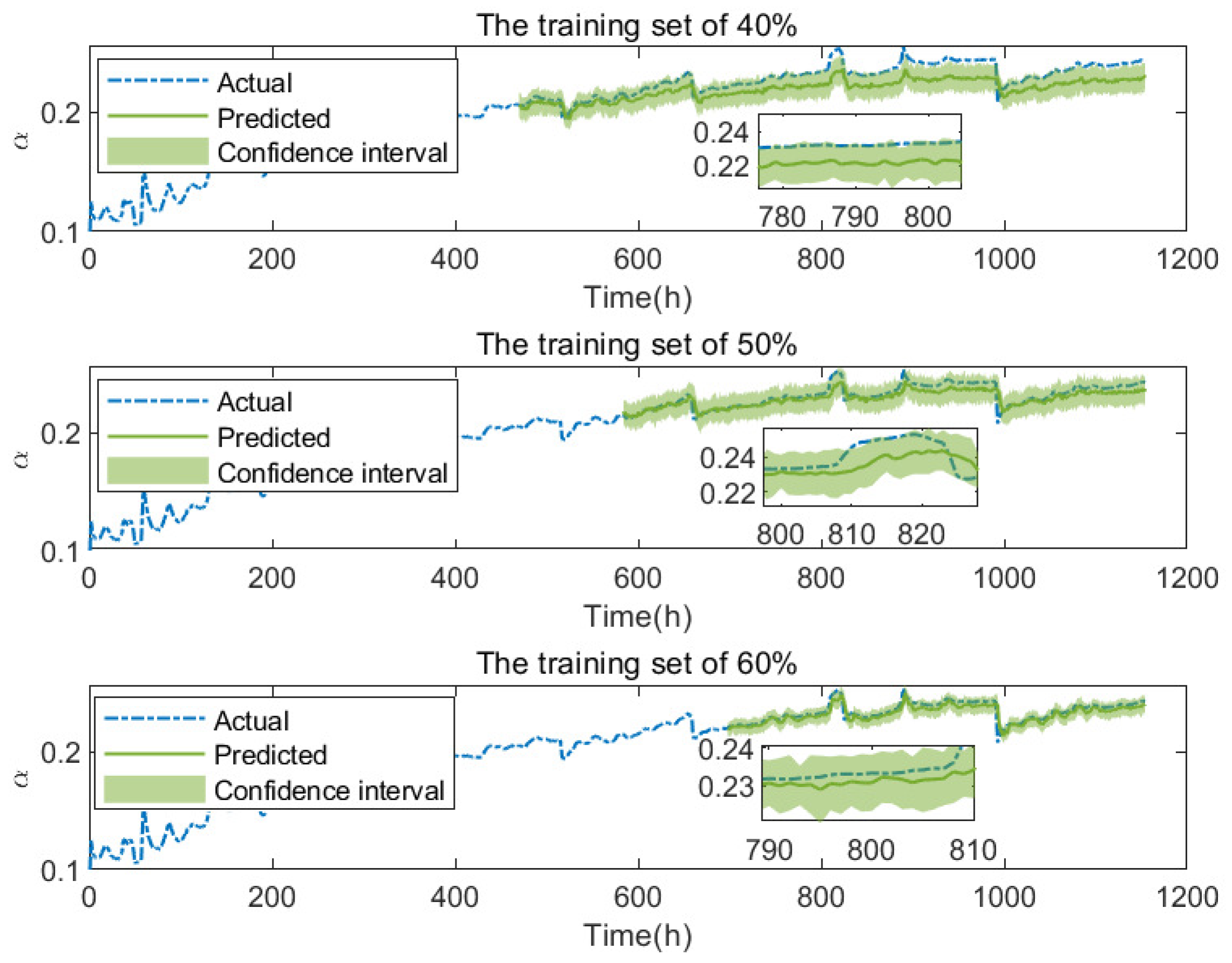
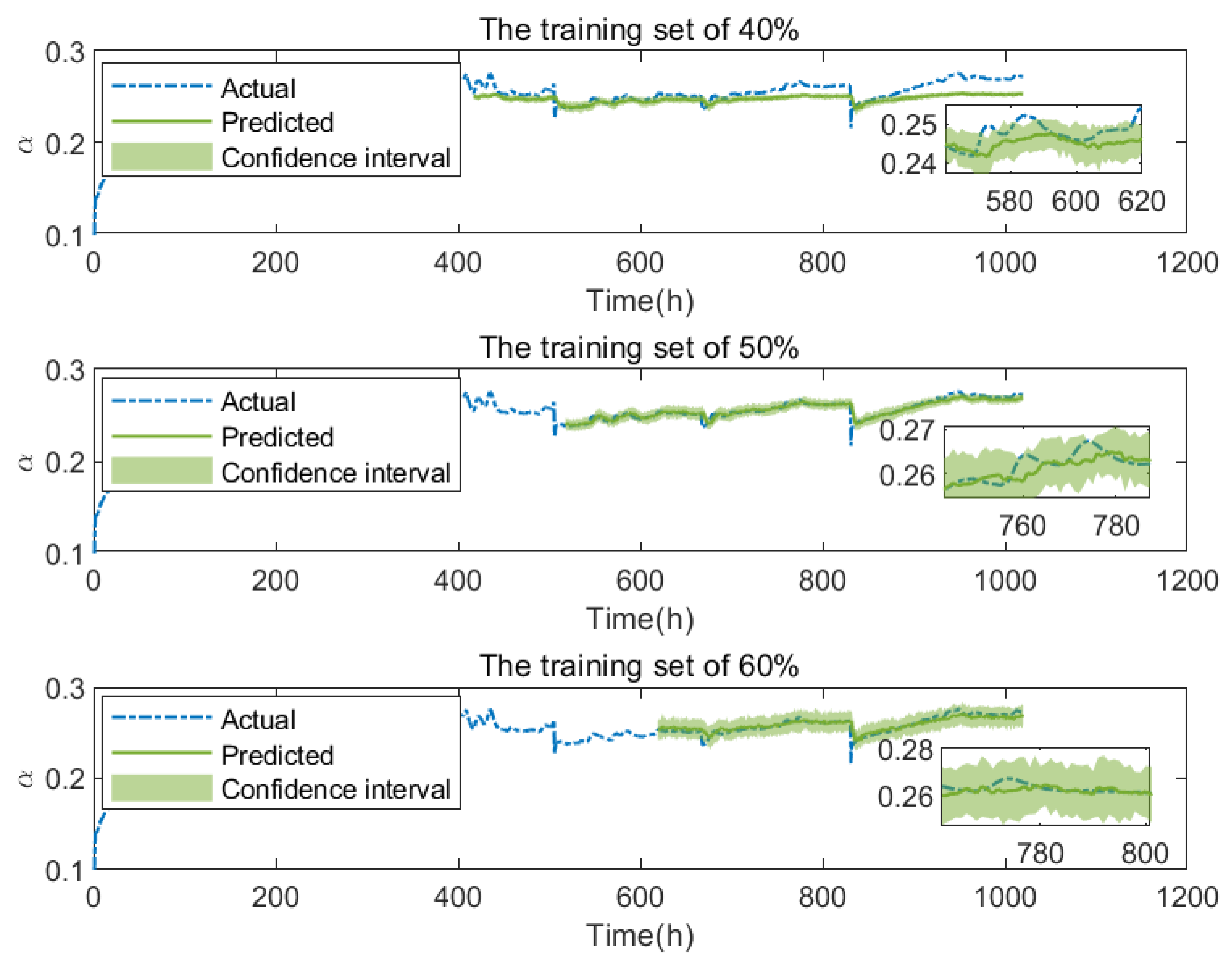
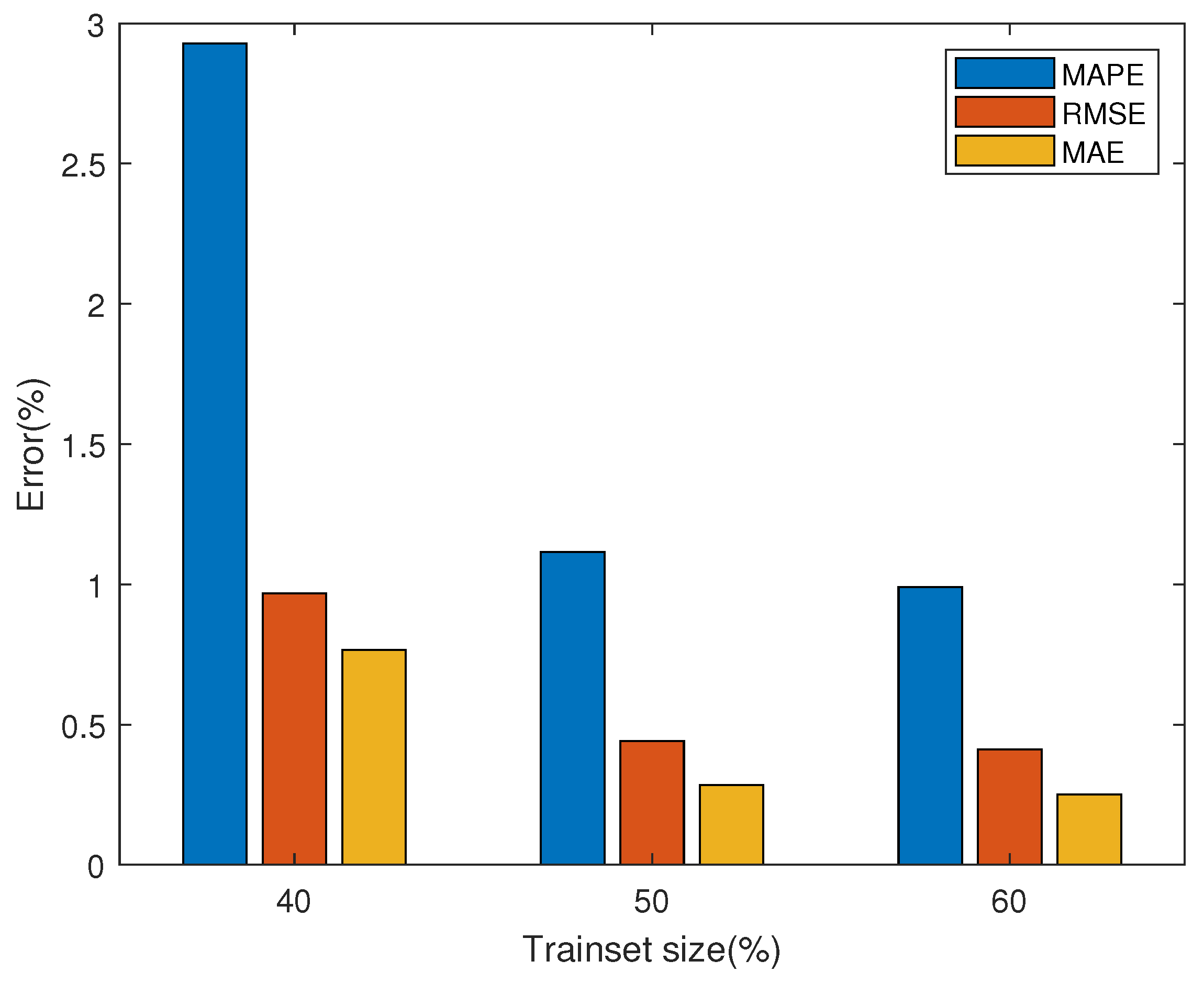
5.3. Performance Degradation Prediction Results
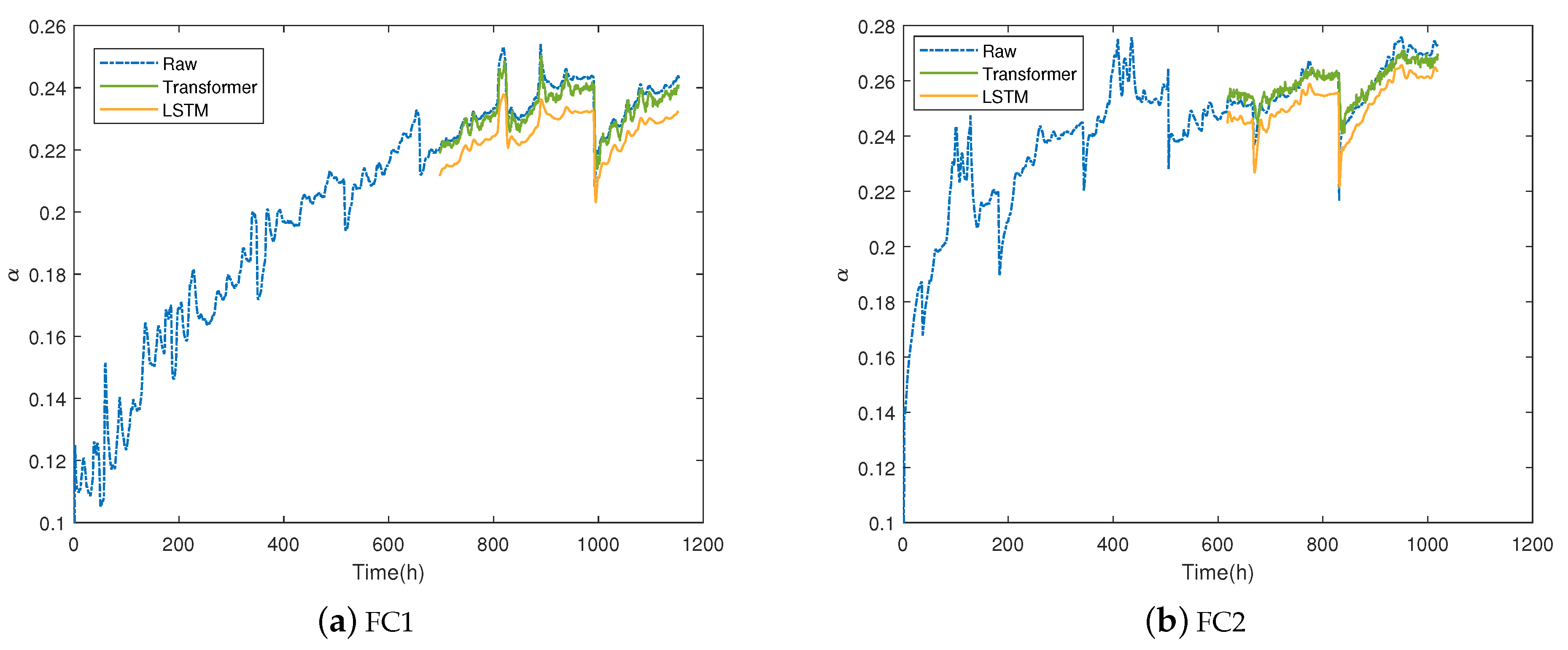
5.4. Verification with LSTM
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, S.; Zhang, G.; Fan, L.; Gao, J.H.; Pei, F.L. Scenario-oriented stacks allocation optimization for multi-stack fuel cell systems. Appl. Energy 2022, 308, 118328. [Google Scholar] [CrossRef]
- Hua, Z.G.; Zheng, Z.X.; Pahon, E.; Pera, M.C.; Gao, F. Remaining useful life prediction of PEMFC systems under dynamic operating conditions. Energy Convers. Manag. 2021, 231, 113825. [Google Scholar] [CrossRef]
- Wang, F.K.; Huang, C.Y.; Mamo, T.; Cheng, X.B. Ensemble model for the degradation prediction of proton exchange membrane fuel cell stacks. Qual. Reliab. Eng. Int. 2021, 37, 34–46. [Google Scholar] [CrossRef]
- Li, Q.; Yang, W.Y.; Yin, L.Z.; Chen, W.R. Real-time implementation of maximum net power strategy based on sliding mode variable structure control for proton-exchange membrane fuel cell system. IEEE Trans. Transp. Electrif. 2020, 6, 288–297. [Google Scholar] [CrossRef]
- Manohar, M.; Kim, D. Advantageous of hybrid fuel cell operation under self-humidification for energy efficient bipolar membrane. Acs Sustain. Chem. Eng. 2019, 7, 16493–16500. [Google Scholar] [CrossRef]
- Hua, Z.G.; Zheng, Z.X.; Pera, M.C.; Gao, F. Remaining useful life prediction of PEMFC systems based on the multi-input echo state network. Appl. Energy 2020, 265, 114791. [Google Scholar] [CrossRef]
- Zhou, D.M.; Wu, Y.M.; Gao, F.; Breaz, E.; Ravey, A.; Miraoui, A. Degradation prediction of PEM fuel cell stack based on multiphysical aging model with particle filter approach. IEEE Trans. Ind. Appl. 2017, 53, 4041–4052. [Google Scholar] [CrossRef]
- Chen, K.; Laghrouche, S.; Djerdir, A. Fuel cell health prognosis using Unscented Kalman Filter: Postal fuel cell electric vehicles case study. Int. J. Hydrogen Energy 2019, 44, 1930–1939. [Google Scholar] [CrossRef]
- Wu, Y.M.; Breaz, E.; Gao, F.; Miraoui, A. A modified relevance vector machine for PEM fuel-cell stack aging prediction. IEEE Trans. Ind. Appl. 2016, 52, 2573–2581. [Google Scholar] [CrossRef]
- Wu, Y.M.; Breaz, E.; Gao, F.; Paire, D.; Miraoui, A. Nonlinear performance degradation prediction of proton exchange membrane fuel cells using relevance vector machine. IEEE Trans. Energy Convers. 2016, 31, 1570–1582. [Google Scholar] [CrossRef]
- Hua, Z.G.; Zheng, Z.X.; Pera, M.C.; Gao, F. Data-driven prognostics for PEMFC systems by different echo state network prediction structures. In Proceedings of the 2020 IEEE Transportation Electrification Conference & Expo (ITEC), Chicago, IL, USA, 23–26 June 2020. [Google Scholar]
- Mezzi, R.; Yousfi-Steiner, N.; Pera, M.C.; Hissel, D.; Larger, L. An echo state network for fuel cell lifetime prediction under a dynamic micro-cogeneration load profile. Appl. Energy 2021, 283, 116297. [Google Scholar] [CrossRef]
- Zhang, X.X.; Yu, Z.X.; Chen, W.R. Life prediction based on D-S ELM for PEMFC. Energies 2019, 12, 3752. [Google Scholar] [CrossRef] [Green Version]
- Chen, K.; Laghrouche, S.; Djerdir, A. Degradation model of proton exchange membrane fuel cell based on a novel hybrid method. Appl. Energy 2019, 252, 113439. [Google Scholar] [CrossRef]
- Peng, Y.L.; Chen, T.; Xiao, F.; Zhang, S.J. Remaining useful lifetime prediction methods of proton exchange membrane fuel cell based on convolutional neural network-long short-term memory and convolutional neural network-bidirectional long short-term memory. Fuel Cells 2022, 23, 75–87. [Google Scholar] [CrossRef]
- Ma, R.; Yang, T.; Breaz, E.; Li, Z.; Briois, P.; Gao, F. Data-driven proton exchange membrane fuel cell degradation predication through deep learning method. Appl. Energy 2018, 231, 102–115. [Google Scholar] [CrossRef]
- Ma, R.; Breaz, E.; Liu, C.; Bai, H.; Briois, P.; Gao, F. Data-driven prognostics for pem fuel cell degradation by long short-term memory network. In Proceedings of the 2018 IEEE Transportation and Electrification Conference and Expo(ITEC), Long Beach, CA, USA, 13–15 June 2018. [Google Scholar]
- Liu, J.W.; Li, Q.; Chen, W.R.; Yan, Y.; Qiu, Y.B.; Gao, T.Q. Remaining useful life prediction of PEMFC based on long short-term memory recurrent neural networks. Int. J. Hydrogen Energy 2019, 44, 5470–5480. [Google Scholar] [CrossRef]
- Zhang, R.F.; Chen, T.; Xiao, F.; Luo, J.L. Bi-directional gated recurrent unit recurrent neural networks for failure prognosis of proton exchange membrane fuel cells. Int. J. Hydrogen Energy 2022, 47, 33027–33038. [Google Scholar] [CrossRef]
- Cheng, Y.J.; Zerhouni, N.; Lu, C. A hybrid remaining useful life prognostic method for proton exchange membrane fuel cell. Int. J. Hydrogen Energy 2018, 43, 12314–12327. [Google Scholar] [CrossRef]
- Liu, H.; Chen, J.; Hissel, D.; Su, H. Remaining useful life estimation for proton exchange membrane fuel cells using a hybrid method. Appl. Energy 2019, 237, 910–919. [Google Scholar] [CrossRef]
- Xie, R.Y.; Ma, R.; Pu, S.C.; Xu, L.C.; Zhao, D.D.; Huangfu, Y.G. Prognostic for fuel cell based on particle filter and recurrent neural network fusion structure. Energy AI 2020, 2, 100017. [Google Scholar] [CrossRef]
- Ma, R.; Xie, R.Y.; Xu, L.C.; Huangfu, Y.G.; Li, Y.R. A hybrid prognostic method for PEMFC with aging parameter prediction. IEEE Trans. Transp. Electrif. 2021, 7, 2318–2331. [Google Scholar] [CrossRef]
- Xia, Z.T.; Wang, Y.N.; Ma, L.H.; Zhu, Y.; Li, Y.J.; Tao, J.L.; Tian, G.Z. A hybrid prognostic method for proton-exchange- membrane fuel cell with decomposition forecasting framework based on AEKF and LSTM. Sensors 2023, 23, 166. [Google Scholar] [CrossRef] [PubMed]
- Ashish, V.; Noam, S.; Niki, P.; Jakob, U.; Llion, J.; Aidan, N.G.; Lukasz, K.; Illia, P. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Wei, M.; Gu, H.R.; Ye, M.; Wang, Q.; Xu, X.X.; Wu, C.G. Remaining useful life prediction of lithium-ion batteries based on Monte Carlo Dropout and gated recurrent unit. Energy Rep. 2021, 7, 2862–2871. [Google Scholar] [CrossRef]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Larminie, J.; Dicks, A. Fuel Cell Systems Explained, 2nd ed.; John Wiley and Sons: Chichester, UK, 2003. [Google Scholar]
- Pan, R.; Yang, D.; Wang, Y.J.; Chen, Z.H. Performance degradation prediction of proton exchange membrane fuel cell using a hybrid prognostic approach. Int. J. Hydrogen Energy 2020, 45, 30994–31008. [Google Scholar] [CrossRef]
- Jha, M.S.; Bressel, M.; Ould-Bouamama, B.; Dauphin-Tanguy, G. Particle filter based hybrid prognostics of proton exchange membrane fuel cell in bond graph framework. Comput. Chem. Eng. 2016, 95, 216–230. [Google Scholar] [CrossRef]
- Bressel, M.; Hilairet, M.; Hissel, D.; Bouamama, B.O. Extended Kalman Filter for prognostic of Proton Exchange Membrane Fuel Cell. Appl. Energy 2016, 164, 220–227. [Google Scholar] [CrossRef]
- Julier, S.J.; Uhlmann, J.K.; Durrant-Whyte, H.F. A new approach for filtering nonlinear systems. In Proceedings of the 1995 American Control Conference—ACC’95, Seattle, WA, USA, 21–23 June 1955. [Google Scholar]
- Zhang, J.S.; Jiang, Y.C.; Li, X.; Huo, M.Y.; Luo, H.; Yin, S. An adaptive remaining useful life prediction approach for single battery with unlabeled small sample data and parameter uncertainty. Reliab. Eng. Syst. Saf. 2022, 222, 108357. [Google Scholar] [CrossRef]
- FCLAB Research. IEEE PHM 2014 Data Challenge. 2014. Available online: http://eng.fclab.fr/ieeephm-2014-data-challenge/ (accessed on 16 May 2014).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters Setting | Value |
|---|---|
| Window length | 10 |
| Batch size | 50 |
| Epochs | 50 |
| Dropout | 0.1 |
| Multi-Head | 10 |
| Learning rate | 0.001 |
| Training Set | MAPE (%) | RMSE (%) | MAE (%) |
|---|---|---|---|
| 40% | 4.0261 | 1.0416 | 0.9380 |
| 50% | 1.5429 | 0.4826 | 0.3630 |
| 60% | 1.2410 | 0.3845 | 0.2923 |
| Training Set | MAPE (%) | RMSE (%) | MAE (%) |
|---|---|---|---|
| 40% | 2.9276 | 0.9675 | 0.7665 |
| 50% | 1.1153 | 0.4408 | 0.2851 |
| 60% | 0.9896 | 0.4117 | 0.2515 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Y.; Zhang, L.; Jiang, Y.; Peng, K.; Jin, Z. A Hybrid Method for Performance Degradation Probability Prediction of Proton Exchange Membrane Fuel Cell. Membranes 2023, 13, 426. https://doi.org/10.3390/membranes13040426
Hu Y, Zhang L, Jiang Y, Peng K, Jin Z. A Hybrid Method for Performance Degradation Probability Prediction of Proton Exchange Membrane Fuel Cell. Membranes. 2023; 13(4):426. https://doi.org/10.3390/membranes13040426
Chicago/Turabian StyleHu, Yanyan, Li Zhang, Yunpeng Jiang, Kaixiang Peng, and Zengwang Jin. 2023. "A Hybrid Method for Performance Degradation Probability Prediction of Proton Exchange Membrane Fuel Cell" Membranes 13, no. 4: 426. https://doi.org/10.3390/membranes13040426