
Dual Semi-Supervised Learning for Classification of Alzheimer’s Disease and Mild Cognitive Impairment Based on Neuropsychological Data

Abstract
:1. Introduction
- We select some neuropsychological tests by feature selection, which are better predictors of automatic classification and can provide clinical diagnostic references to physicians;
- Propose a novel semi-supervised method that introduces difference regularization in unsupervised loss computation to enhance model perturbations by learning two different feature representations;
- Propose a tri-classification framework for cognitive impairment based on improved SSL and CNN, which identifies AD, MCI, and NC using the most straightforward method (i.e., neuropsychological tests) and fewer labels. Experimental results based on the ADNI dataset indicate that the classifier outperforms other semi-supervised methods in terms of accuracy and stability.
2. Theoretical Backgrounds
2.1. Semi-Supervised Learning
2.1.1. Consistency Regularization
2.1.2. Pseudo-Labeling
2.1.3. Label Propagation
2.2. Contrastive Learning
3. Materials and Methods
3.1. ADNI Database
3.2. Neuropsychological Data
3.3. Method
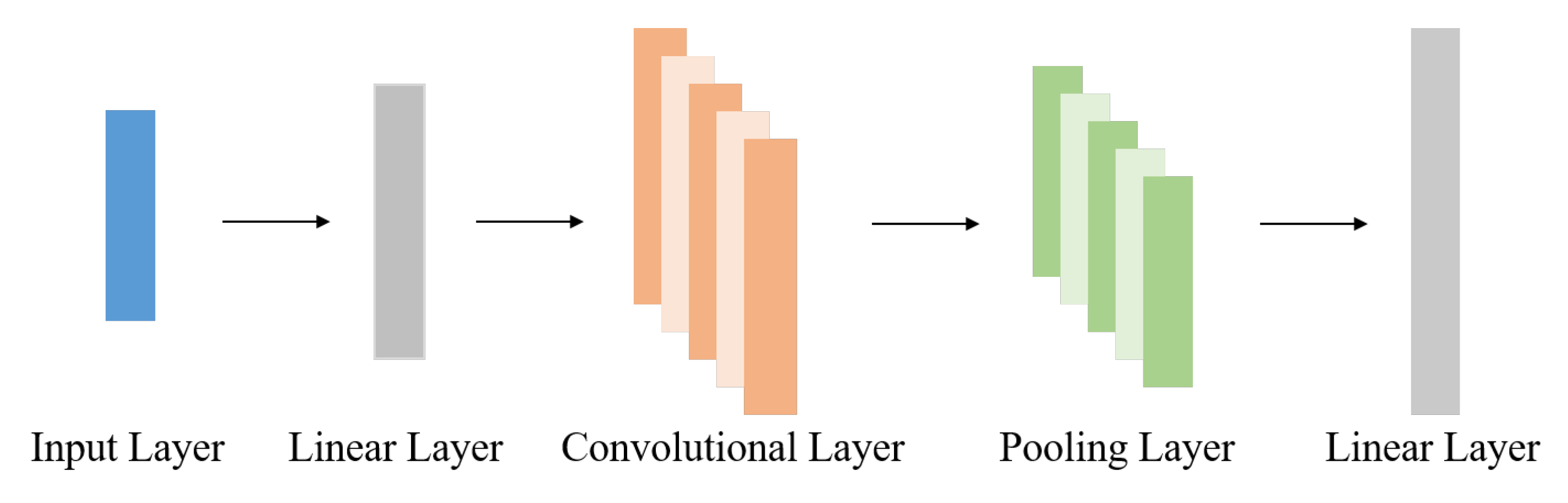
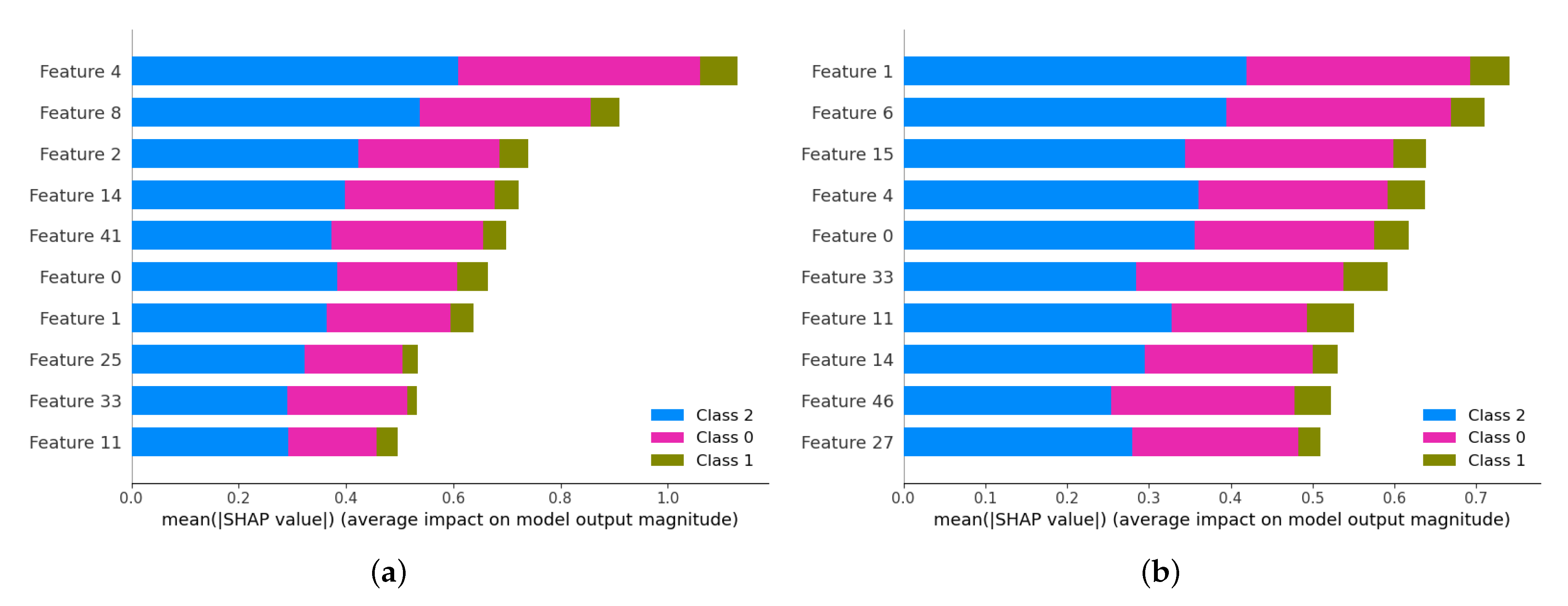
3.3.1. Features Selection
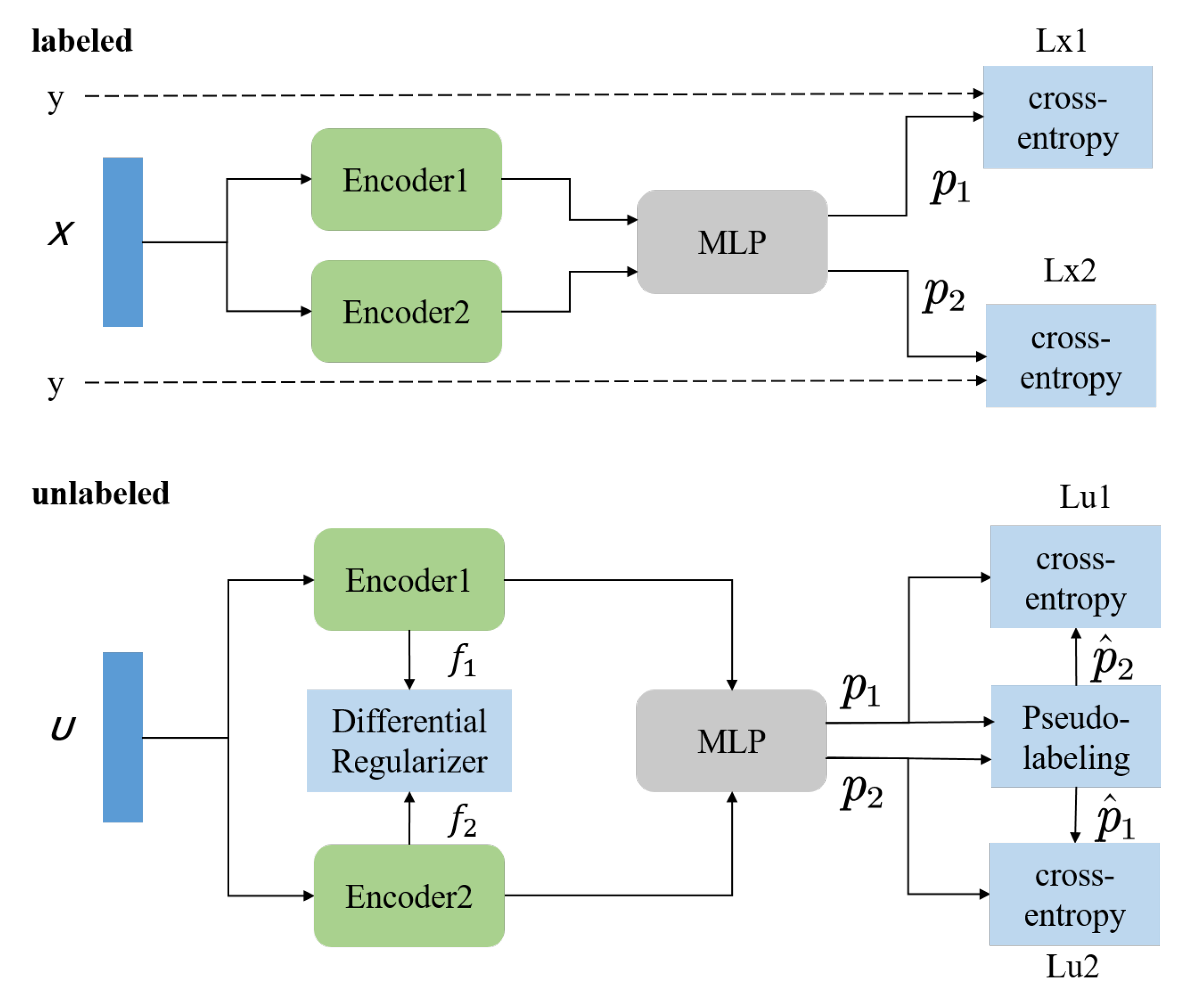
3.3.2. Dual Semi-Supervised Learning
| Algorithm 1 DSSL algorithm. |
 |
3.3.3. Regularization of DSSL
3.3.4. Loss Function of DSSL
4. Results
4.1. Features Selection
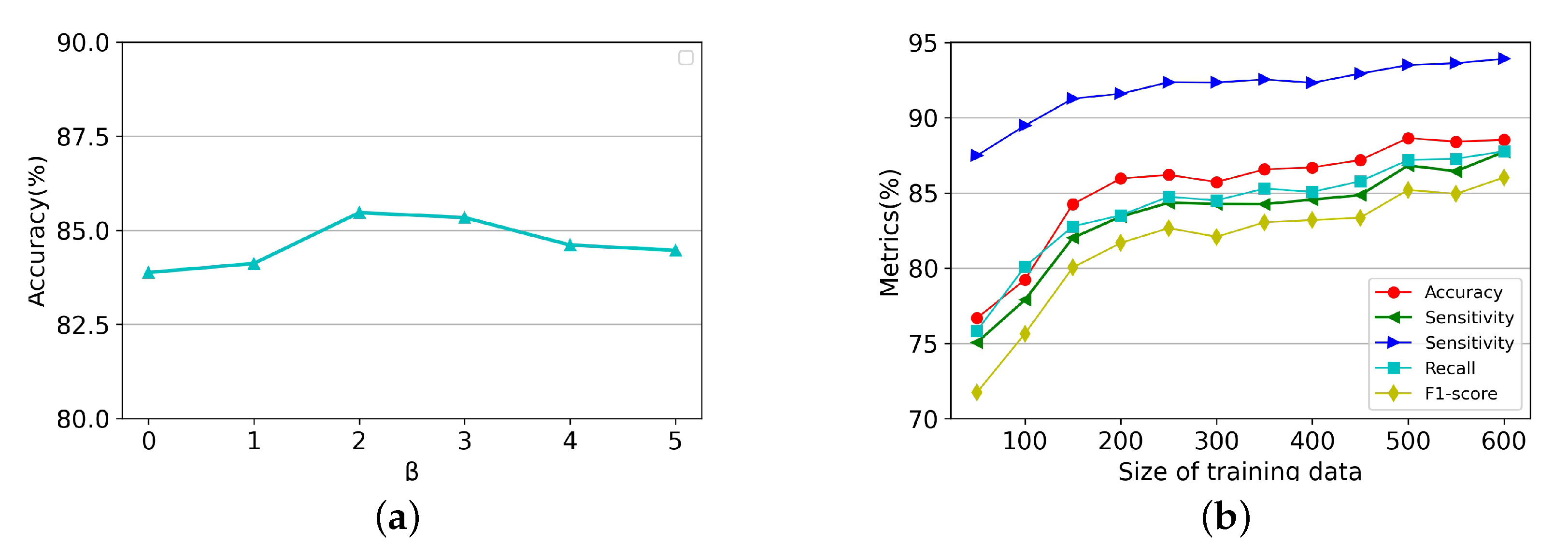
4.2. Implementation
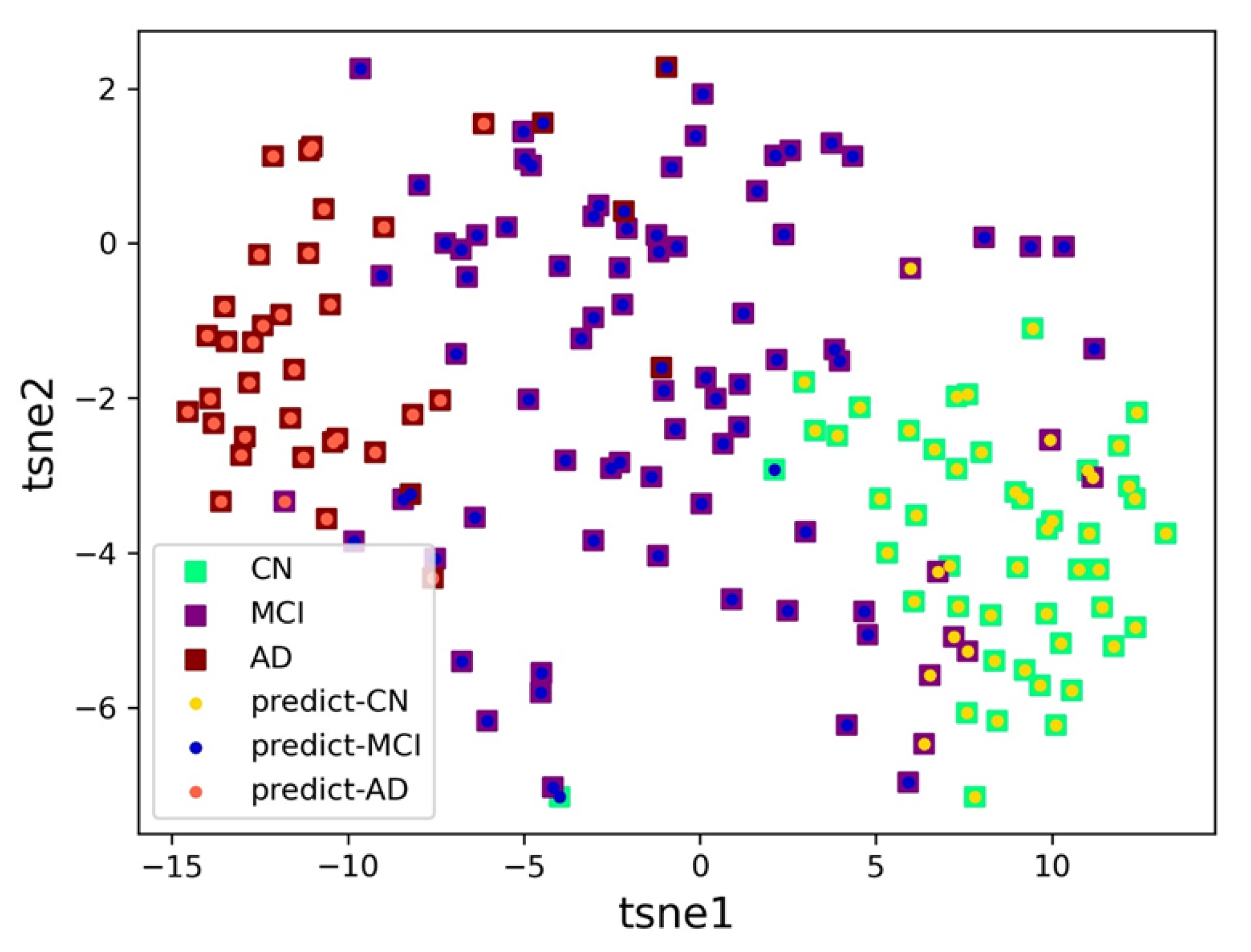
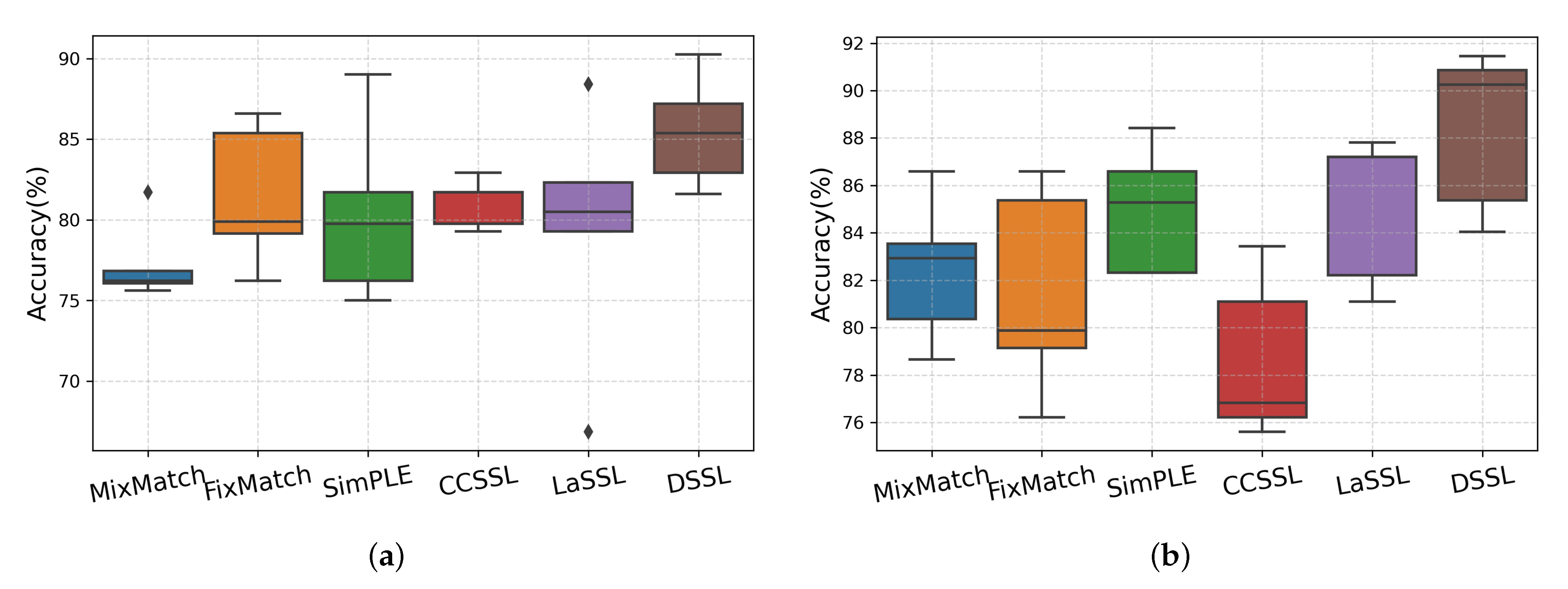
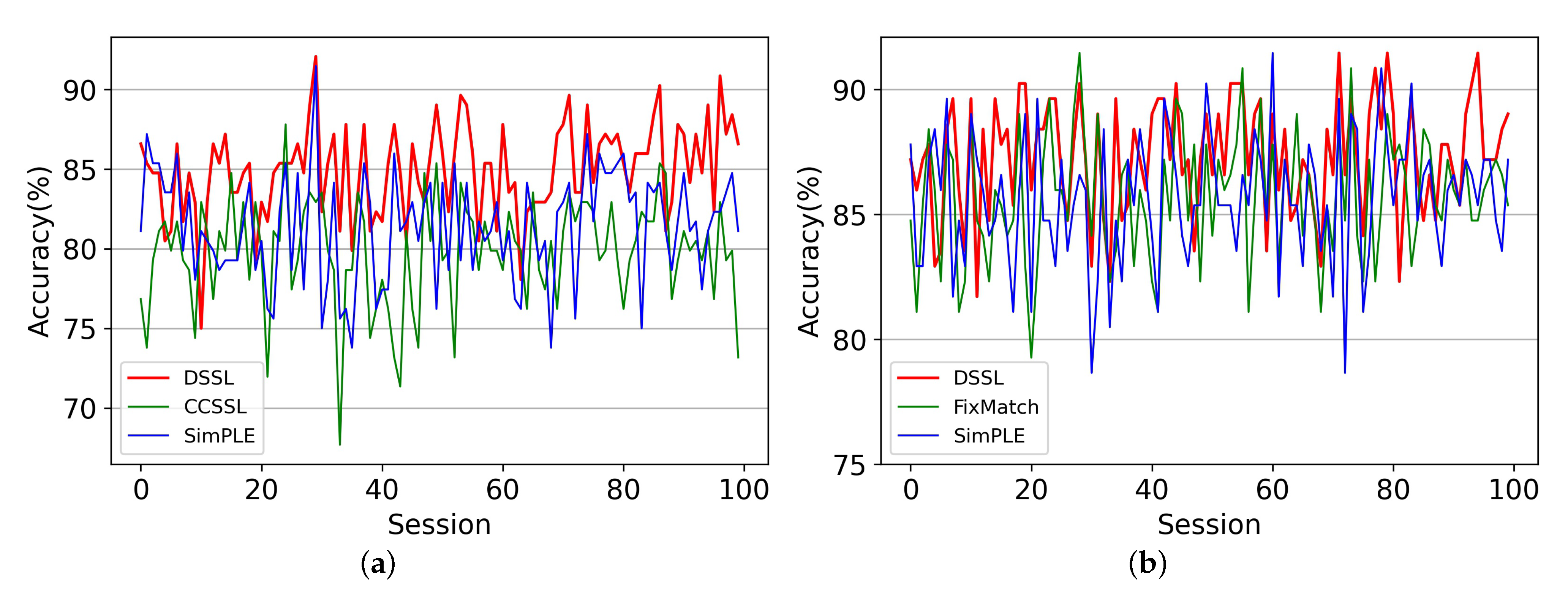
4.3. Results of Disease Classification
4.4. Comparison with Other Methods
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Neuropsychological Tests | |
|---|---|
| AQAS-cog | Total score of MMSE (1) |
| Q1: Word recall | CDR |
| Q2: Commands | CDR Sum of boxes |
| Q3: Constructional praxis | RAVLT |
| Q4: Delayed word recall | RAVLT Immediate recall |
| Q5: Object naming | RAVLT Learning |
| Q6: Ideational rraxis | RAVLT Forgetting delay |
| Q7: Orientation | RAVLT Percent forgetting |
| Q8: Word recognition | FAQ |
| Q9: Clarity of language | Q1. Manage finance |
| Q10: Comprehension | Q2. Complete forms |
| Q11: Word finding | Q3. Shop |
| Q12: Remembering test instructions | Q4. Perform games of skill or hobbies |
| Q14: Number cancellations | Q5. Prepare hot beverages |
| Total score of ADAS11 | Q6. Prepare a balanced meal |
| Total score of ADASMOD | Q7. Follow current events |
| MMSE | Q8. Attend to TV, books, or magazines |
| Orientation to place (5) | Q9. Remember appointments |
| Orientation to time (5) | Q10. Travel out of the neighborhood |
| Registration (3) | Total score of FAQ |
| Attention and concentration (5) | NPIQ |
| Recall (3) | Total score of NPIQ |
| Language (8) | GDS |
| Visual construction (1) | Total score of GDS |
Appendix A.2
References
- Chehrehnegar, N.; Nejati, V.; Shati, M.; Rashedi, V.; Lotfi, M.; Adelirad, F.; Foroughan, M. Early detection of cognitive disturbances in mild cognitive impairment: A systematic review of observational studies. Psychogeriatrics 2019, 20, 212–228. [Google Scholar] [CrossRef] [PubMed]
- Selkoe, D.J. Alzheimer’s disease. Cold Spring Harb. Perspect. Biol. 2011, 3, a004457. [Google Scholar] [CrossRef] [PubMed]
- Jack, C.R.; Bennett, D.A.; Blennow, K.; Carrillo, M.C.; Feldman, H.H.; Frisoni, G.B.; Hampel, H.; Jagust, W.J.; Johnson, K.A.; Knopman, D.S.; et al. A/T/N: An unbiased descriptive classification scheme for Alzheimer disease biomarkers. Neurology 2016, 87, 539–547. [Google Scholar] [CrossRef] [PubMed]
- Shi, Y.; Wang, Z.; Chen, P.; Cheng, P.; Zhao, K.; Zhang, H.; Shu, H.; Gu, L.; Gao, L.; Wang, Q.; et al. Episodic Memory–Related Imaging Features as Valuable Biomarkers for the Diagnosis of Alzheimer’s Disease: A Multicenter Study Based on Machine Learning. Biol. Psychiatry: Cogn. Neurosci. Neuroimaging 2020, 8, 171–180. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.S.; Kulkarni, P.; Galatzer-Levy, I.R.; Bigio, B.; Nasca, C.; Zhang, Y. Modern views of machine learning for precision psychiatry. Patterns 2022, 3, 100602. [Google Scholar] [CrossRef]
- Kruthika, K.; Maheshappa, H. CBIR system using Capsule Networks and 3D CNN for Alzheimer’s disease diagnosis. Inform. Med. Unlocked 2019, 14, 59–68. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, S.; Xia, K.; Jiang, Y.; Qian, P. Alzheimer’s disease multiclass diagnosis via multimodal neuroimaging embedding feature selection and fusion. Inf. Fusion 2021, 66, 170–183. [Google Scholar] [CrossRef]
- Fan, Z.; Xu, F.; Qi, X.; Li, C.; Yao, L. Classification of Alzheimer’s disease based on brain MRI and machine learning. Neural Comput. Appl. 2020, 32, 1927–1936. [Google Scholar] [CrossRef]
- Turkson, R.E.; Qu, H.; Mawuli, C.B.; Eghan, M.J. Classification of Alzheimer’s disease using deep convolutional spiking neural network. Neural Process. Lett. 2021, 53, 2649–2663. [Google Scholar] [CrossRef]
- Amini, M.; Pedram, M.M.; Moradi, A.; Ouchani, M. Diagnosis of Alzheimer’s disease severity with fMRI images using robust multitask feature extraction method and convolutional neural network (CNN). Comput. Math. Methods Med. 2021, 2021, 5514839. [Google Scholar] [CrossRef]
- Zhou, H.; He, L.; Zhang, Y.; Shen, L.; Chen, B. Interpretable Graph Convolutional Network Of Multi-Modality Brain Imaging For Alzheimer’s Disease Diagnosis. In Proceedings of the 2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI), Kolkata, India, 28–31 March 2022; pp. 1–5. [Google Scholar]
- Zhou, H.; Zhang, Y.; Chen, B.Y.; Shen, L.; He, L. Sparse Interpretation of Graph Convolutional Networks for Multi-modal Diagnosis of Alzheimer’s Disease. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022. [Google Scholar]
- Saleem, T.J.; Zahra, S.R.; Wu, F.; Alwakeel, A.; Alwakeel, M.; Jeribi, F.; Hijji, M. Deep Learning-Based Diagnosis of Alzheimer’s Disease. J. Pers. Med. 2022, 12, 815. [Google Scholar] [CrossRef]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef]
- Seo, E.H. Neuropsychological assessment of dementia and cognitive disorders. Korean Neuropsychiatr. Assoc. 2018, 57, 2–11. [Google Scholar] [CrossRef]
- Ewers, M.; Walsh, C.; Trojanowski, J.Q.; Shaw, L.M.; Petersen, R.C.; Jack, C.R., Jr.; Feldman, H.H.; Bokde, A.L.; Alexander, G.E.; Scheltens, P.; et al. Prediction of conversion from mild cognitive impairment to Alzheimer’s disease dementia based upon biomarkers and neuropsychological test performance. Neurobiol. Aging 2012, 33, 1203–1214. [Google Scholar] [CrossRef]
- Grassi, M.; Perna, G.; Caldirola, D.; Schruers, K.; Duara, R.; Loewenstein, D.A. A clinically-translatable machine learning algorithm for the prediction of Alzheimer’s disease conversion in individuals with mild and premild cognitive impairment. J. Alzheimer’s Dis. 2018, 61, 1555–1573. [Google Scholar] [CrossRef]
- Battista, P.; Salvatore, C.; Castiglioni, I. Optimizing neuropsychological assessments for cognitive, behavioral, and functional impairment classification: A machine learning study. Behav. Neurol. 2017, 2017, 1850909. [Google Scholar] [CrossRef]
- Battista, P.; Salvatore, C.; Berlingeri, M.; Cerasa, A.; Castiglioni, I. Artificial intelligence and neuropsychological measures: The case of Alzheimer’s disease. Neurosci. Biobehav. Rev. 2020, 114, 211–228. [Google Scholar] [CrossRef]
- Huang, Z.F.; Li, F.; Wang, Z.; Wang, Z. Interpretability of Deep Learning. Int. J. Future Comput. Commun. 2022, 11. [Google Scholar] [CrossRef]
- Bachman, P.; Alsharif, O.; Precup, D. Learning with pseudo-ensembles. In Advances in Neural Information Processing Systems 27 (NIPS 2014); Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2014; Volume 27. [Google Scholar]
- Sajjadi, M.; Javanmardi, M.; Tasdizen, T. Regularization with stochastic transformations and perturbations for deep semi-supervised learning. In Advances in Neural Information Processing Systems 29 (NIPS 2016); Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2016; Volume 29. [Google Scholar]
- Laine, S.; Aila, T. Temporal ensembling for semi-supervised learning. arXiv 2016, arXiv:1610.02242. [Google Scholar]
- Park, S.; Park, J.; Shin, S.J.; Moon, I.C. Adversarial dropout for supervised and semi-supervised learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Papernot, N.; Oliver, A.; Raffel, C.A. Mixmatch: A holistic approach to semi-supervised learning. In Advances in Neural Information Processing Systems 32 (NeurIPS 2019); Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2019; Volume 32. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Sohn, K.; Berthelot, D.; Carlini, N.; Zhang, Z.; Zhang, H.; Raffel, C.A.; Cubuk, E.D.; Kurakin, A.; Li, C.L. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Adv. Neural Inf. Process. Syst. 2020, 33, 596–608. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2019; pp. 3008–3017. [Google Scholar]
- Berthelot, D.; Carlini, N.; Cubuk, E.D.; Kurakin, A.; Sohn, K.; Zhang, H.; Raffel, C. ReMixMatch: Semi-Supervised Learning with Distribution Matching and Augmentation Anchoring. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Advances in Neural Information Processing Systems 30 (NIPS 2017); Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2017; Volume 30. [Google Scholar]
- Lee, D.H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Proceedings of the Workshop on Challenges in Representation Learning, ICML, Atlanta, USA, 16–21 June 2013; Volume 3, p. 896. [Google Scholar]
- Iscen, A.; Tolias, G.; Avrithis, Y.; Chum, O. Label Propagation for Deep Semi-Supervised Learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5065–5074. [Google Scholar]
- Hu, Z.; Yang, Z.; Hu, X.; Nevatia, R. SimPLE: Similar Pseudo Label Exploitation for Semi-Supervised Classification. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 15094–15103. [Google Scholar]
- Yang, F.; Wu, K.; Zhang, S.; Jiang, G.; Liu, Y.; Zheng, F.; Zhang, W.; Wang, C.; Zeng, L. Class-Aware Contrastive Semi-Supervised Learning. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14401–14410. [Google Scholar]
- Zhao, Z.; Zhou, L.; Wang, L.; Shi, Y.; Gao, Y. LaSSL: Label-Guided Self-Training for Semi-supervised Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022. [Google Scholar]
- Kueper, J.K.; Speechley, M.; Montero-Odasso, M. The Alzheimer’s disease assessment scale–cognitive subscale (ADAS-Cog): Modifications and responsiveness in pre-dementia populations. a narrative review. J. Alzheimer’s Dis. 2018, 63, 423–444. [Google Scholar] [CrossRef]
- Folstein, M.F.; Folstein, S.E.; McHugh, P.R. “Mini-mental state”: A practical method for grading the cognitive state of patients for the clinician. J. Psychiatr. Res. 1975, 12, 189–198. [Google Scholar] [CrossRef] [PubMed]
- Morris, J.C. The clinical dementia rating (cdr): Current version and. Young 1991, 41, 1588–1592. [Google Scholar]
- Rey, A. L’examen Clinique en Psychologie; University Press of France: Paris, France, 1958. [Google Scholar]
- Pfeffer, R.I.; Kurosaki, T.T.; Harrah, C., Jr.; Chance, J.M.; Filos, S. Measurement of functional activities in older adults in the community. J. Gerontol. 1982, 37, 323–329. [Google Scholar] [CrossRef]
- Kaufer, D.I.; Cummings, J.L.; Ketchel, P.; Smith, V.; MacMillan, A.; Shelley, T.; Lopez, O.L.; DeKosky, S.T. Validation of the NPI-Q, a brief clinical form of the Neuropsychiatric Inventory. J. Neuropsychiatry Clin. Neurosci. 2000, 12, 233–239. [Google Scholar] [CrossRef]
- Sheikh, J.I.; Yesavage, J.A. Geriatric Depression Scale (GDS): Recent evidence and development of a shorter version. Clin. Gerontol. J. Aging Ment. Health 1986, 5, 165–173. [Google Scholar]
- Schober, P.; Boer, C.; Schwarte, L.A. Correlation coefficients: Appropriate use and interpretation. Anesth. Analg. 2018, 126, 1763–1768. [Google Scholar] [CrossRef]
- Ghorbani, A.; Zou, J. Data shapley: Equitable valuation of data for machine learning. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 2242–2251. [Google Scholar]







| Characteristic | AD (n = 188) | MCI (n = 402) | NC (n = 229) | p-Value |
|---|---|---|---|---|
| Gender (M/F) | 99/80 | 257/143 | 119/110 | - |
| Age | 75.3 ± 7.5 | 74.8 ± 7.4 | 75.9 ± 5.0 | - |
| MMSE | 23.3 ± 2.0 | 27.0 ± 1.8 | 29.1 ± 1.0 | <0.001 |
| CDR | 0.7 ± 0.3 | 0.5 | 0 | <0.001 |
| FAQ | 13.1 ± 6.8 | 3.9 ± 4.5 | 0.1 ± 0.6 | <0.001 |
| ADAS1 | 6.1 ± 1.5 | 4.6 ± 1.4 | 2.9 ± 1.1 | <0.001 |
| RAVLT | 23.2 ± 7.7 | 30.6 ± 9.0 | 43.3 ± 9.0 | <0.001 |
| NPIQ | 3.5 ± 3.4 | 1.9 ± 2.7 | 0.3 ± 0.9 | <0.001 |
| GDS | 1.7 ± 1.4 | 1.6 ± 1.4 | 0.8 ± 1.1 | 0.14 |
| Feature Name | Absolute PCC | Feature Name | Absolute PCC |
|---|---|---|---|
| CDR-SB | 0.827928 | FAQFORM | 0.647591 |
| MMSETOTAL | 0.766936 | RAVLT_immediate | 0.629216 |
| ADASMOD | 0.743978 | FAQFINAN | 0.620305 |
| ADAS_Q4 | 0.721948 | FAQTRAVL | 0.595336 |
| FAQTOTAL | 0.691619 | FAQSHOP | 0.574347 |
| ADAS11 | 0.691199 | RAVLT_perc_forgetting | 0.561252 |
| FAQREM | 0.657881 | FAQMEAL | 0.550885 |
| ADAS_Q1 | 0.656050 |
| Passing Rate | Impurity Rate | Accuracy | |
|---|---|---|---|
| 0.25 | 100 | 18.55 | 82.05 |
| 0.5 | 100 | 16.48 | 84.12 |
| 0.75 | 99.67 | 16.45 | 85.1 |
| 0.85 | 98.95 | 16.58 | 84.24 |
| 0.9 | 97.79 | 15.33 | 85.47 |
| 0.95 | 95.31 | 14.32 | 85.22 |
| 0.97 | 93.36 | 13.16 | 85.47 |
| 0.99 | 87.64 | 10.88 | 85.22 |
| Pooling Layer | ACC (%) | SEN (%) | SPE (%) | REC (%) | F1 (%) | |
|---|---|---|---|---|---|---|
| Max + Max | 84.49 | 82.42 | 83.05 | 91.29 | 80.46 | |
| 60-label | Avg + Avg | 84.00 | 82.05 | 83.00 | 91.19 | 80.42 |
| Max + Avg | 85.47 | 83.77 | 84.14 | 91.82 | 81.92 | |
| Max + Max | 88.15 | 85.89 | 86.06 | 93.03 | 84.60 | |
| 120-label | Avg + Avg | 88.27 | 86.72 | 87.37 | 93.41 | 85.50 |
| Max + Avg | 88.40 | 86.99 | 87.07 | 93.20 | 85.53 |
| Method | ACC (%) | SEN (%) | SPE (%) | REC (%) | F1 (%) | Training Time (Minute) | |
|---|---|---|---|---|---|---|---|
| MixMatch [25] (2019) | 77.29 | 75.40 | 88.21 | 76.73 | 72.40 | 1.27 | |
| FixMatch [27] (2020) | 81.44 | 79.01 | 90.27 | 80.29 | 76.90 | 1.15 | |
| SimPLE [34] (2021) | 80.34 | 77.39 | 89.66 | 78.80 | 75.26 | 2.53 | |
| 60-label | CCSSL [35] (2022) | 81.07 | 79.74 | 89.99 | 80.05 | 77.11 | 2.48 |
| LaSSL [36] (2022) | 79.47 | 76.06 | 89.15 | 78.49 | 74.26 | 2.82 | |
| DSSL | 85.47 | 83.77 | 84.14 | 91.82 | 81.92 | 2.42 | |
| MixMatch [25] (2019) | 82.42 | 80.55 | 91.13 | 81.57 | 78.16 | 1.24 | |
| FixMatch [27] (2020) | 84.49 | 82.10 | 91.80 | 83.71 | 80.46 | 1.11 | |
| SimPLE [34] (2021) | 84.98 | 82.94 | 91.92 | 83.60 | 85.15 | 2.51 | |
| 120-label | CCSSL [35] (2022) | 78.64 | 76.03 | 88.83 | 76.92 | 73.23 | 2.42 |
| LaSSL [36] (2022) | 85.10 | 82.63 | 91.60 | 83.66 | 81.07 | 2.85 | |
| DSSL | 88.40 | 86.99 | 87.07 | 93.20 | 85.53 | 2.27 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Gu, X.; Hou, W.; Zhao, M.; Sun, L.; Guo, C. Dual Semi-Supervised Learning for Classification of Alzheimer’s Disease and Mild Cognitive Impairment Based on Neuropsychological Data. Brain Sci. 2023, 13, 306. https://doi.org/10.3390/brainsci13020306
Wang Y, Gu X, Hou W, Zhao M, Sun L, Guo C. Dual Semi-Supervised Learning for Classification of Alzheimer’s Disease and Mild Cognitive Impairment Based on Neuropsychological Data. Brain Sciences. 2023; 13(2):306. https://doi.org/10.3390/brainsci13020306
Chicago/Turabian StyleWang, Yan, Xuming Gu, Wenju Hou, Meng Zhao, Li Sun, and Chunjie Guo. 2023. "Dual Semi-Supervised Learning for Classification of Alzheimer’s Disease and Mild Cognitive Impairment Based on Neuropsychological Data" Brain Sciences 13, no. 2: 306. https://doi.org/10.3390/brainsci13020306