
Metrics for Polyphonic Sound Event Detection

Abstract
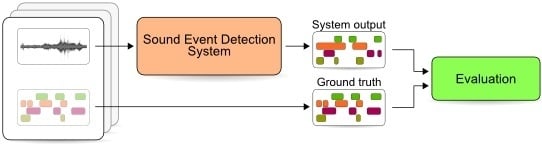
:
1. Introduction
2. Background
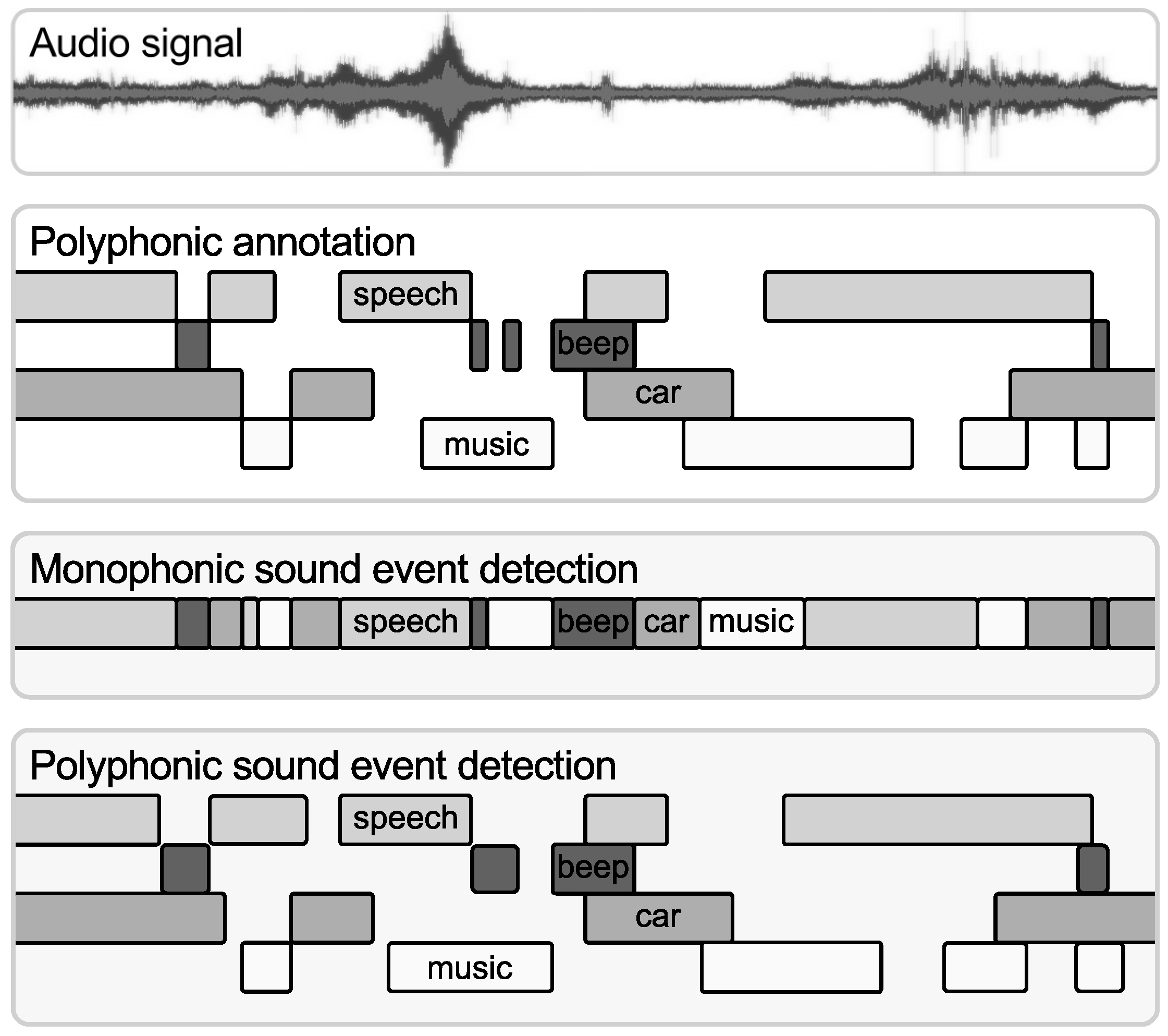
2.1. Classification and Detection of Sound Events
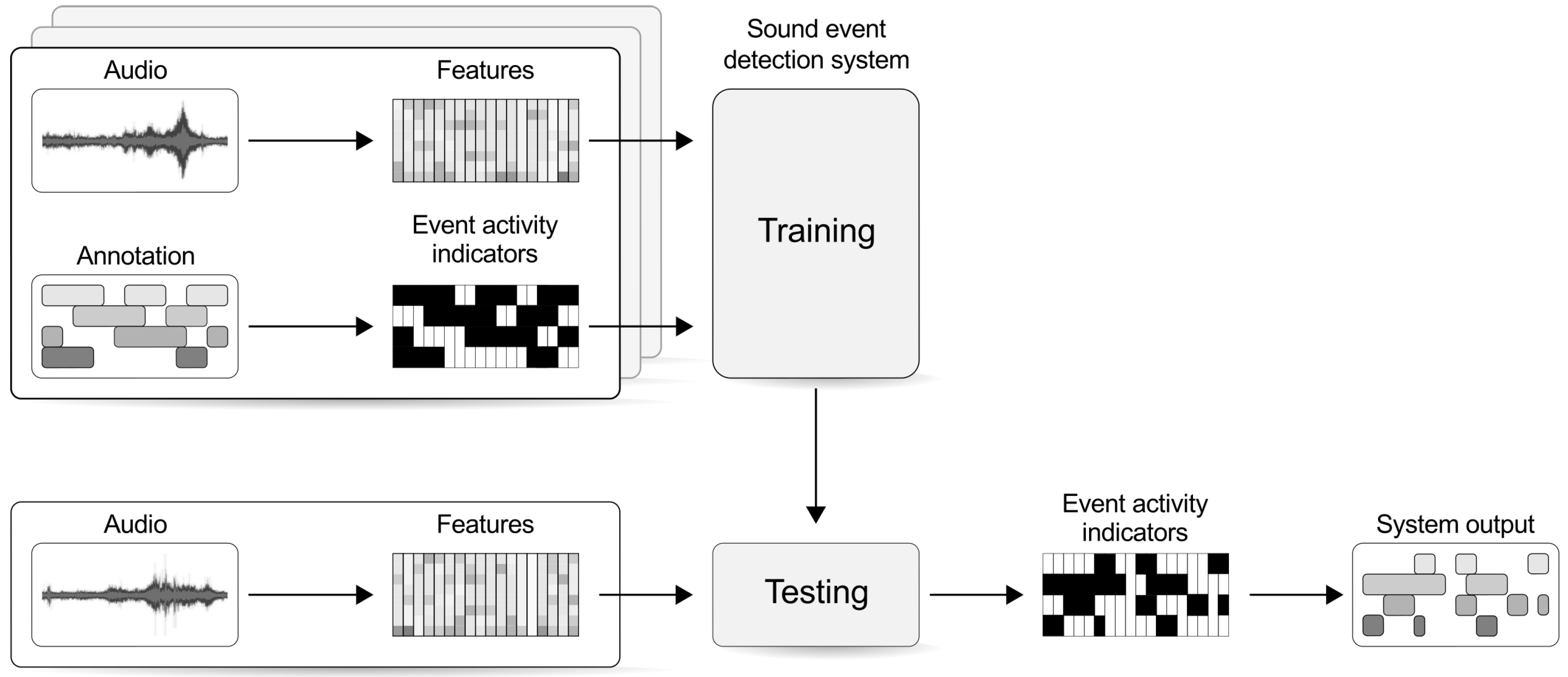
2.2. Building a Polyphonic Sound Event Detection System
2.3. Evaluation
3. Intermediate Statistics and Averaging Options
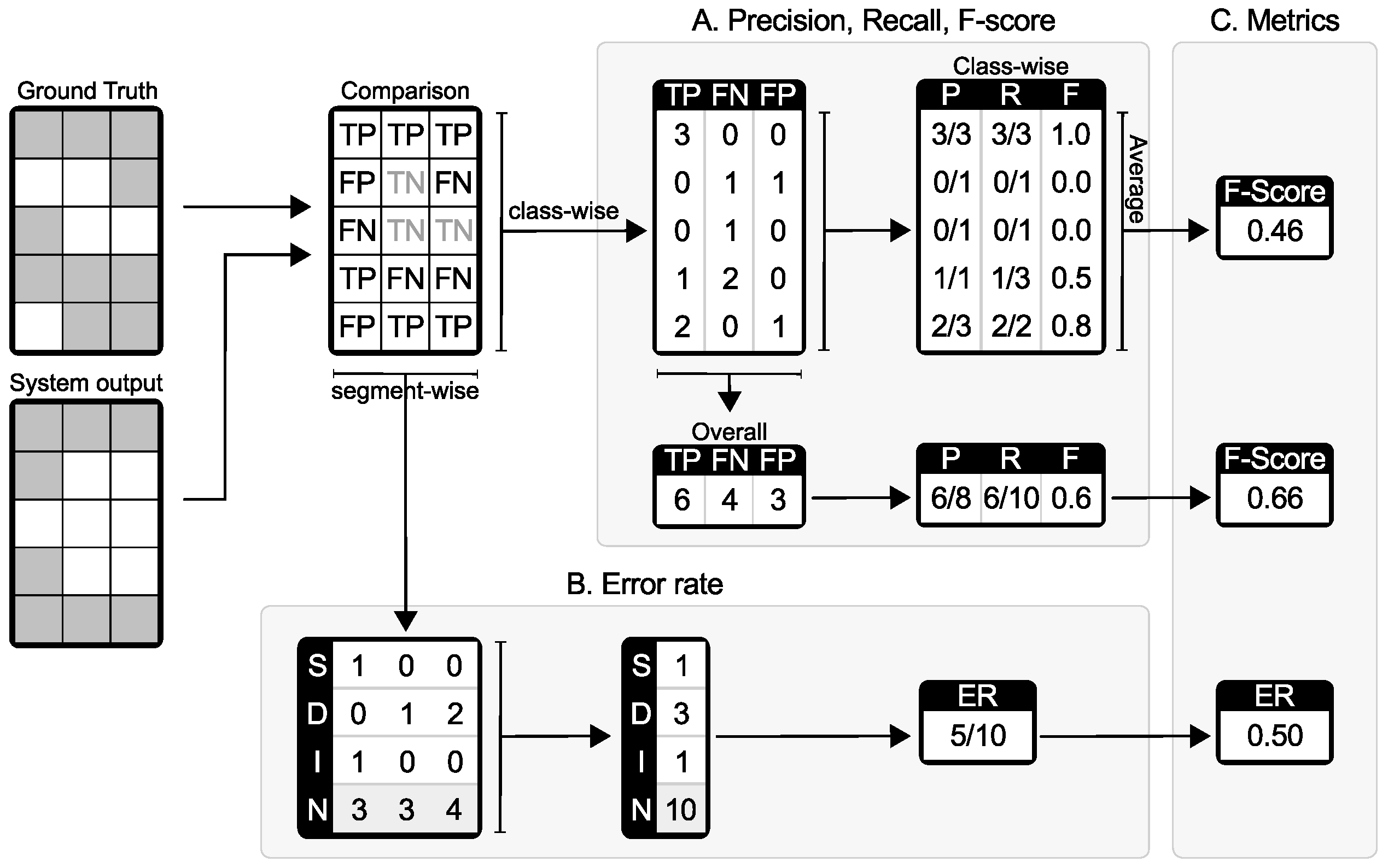
3.1. Segment-Based Metrics
- true positive: the reference and system output both indicate an event to be active in that segment;
- false positive: the reference indicates an event to be inactive in that segment, but the system output indicates it as active;
- false negative: the reference indicates an event to be active in that segment, but the system output indicates it as inactive.
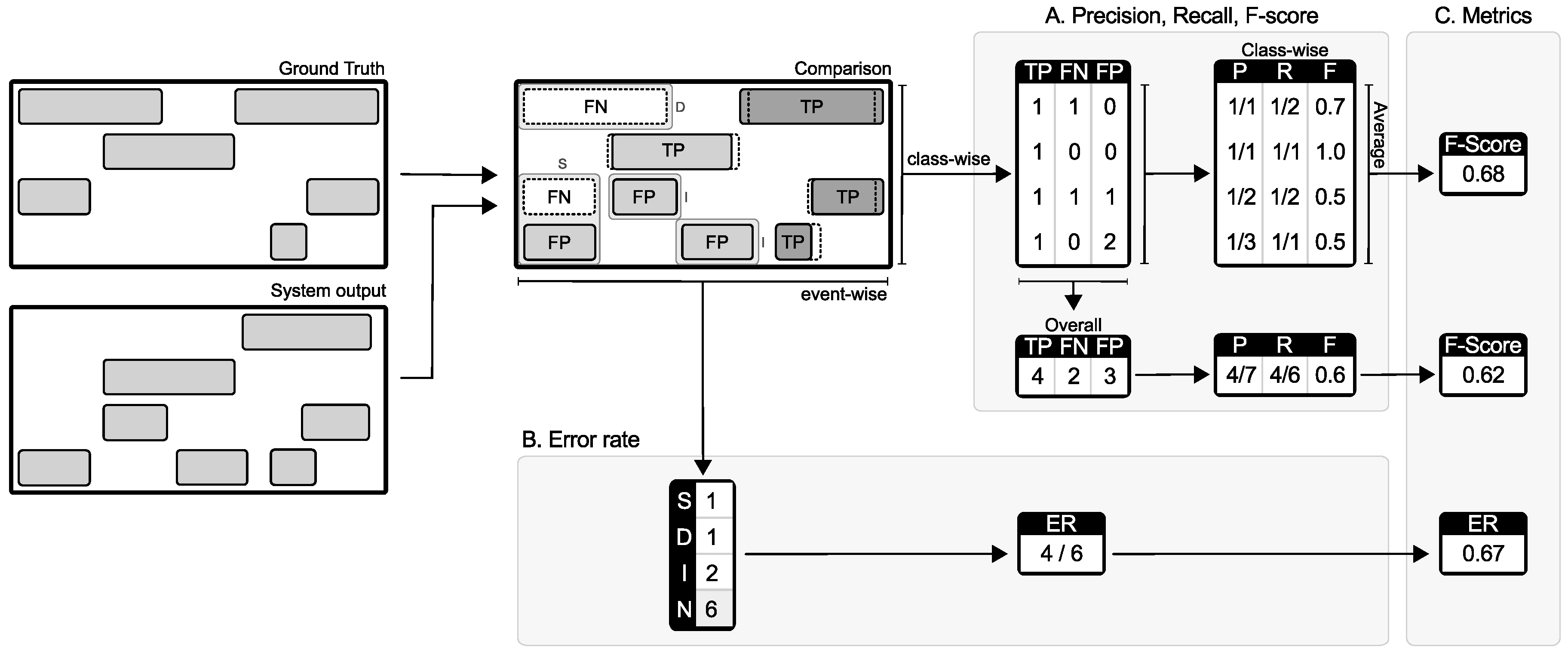
3.2. Event-Based Metrics
- true positive: an event in the system output that has a temporal position overlapping with the temporal position of an event with the same label in the reference. A collar is usually allowed for the onset and offset, or a tolerance with respect to the reference event duration.
- false positive: an event in the system output that has no correspondence to an event with same label in the reference within the allowed tolerance;
- false negative: an event in the reference that has no correspondence to an event with same label in the system output within the allowed tolerance.
3.3. Averaging Options in Calculating Metrics
3.4. Cross-Validation
4. Metrics for Polyphonic Evaluation
4.1. Precision, Recall and F-Score
4.2. Error Rate
4.3. Other Metrics
4.4. Toolbox for Sound Event Detection Evaluation
5. Choosing a Metric
5.1. Measuring Performance of a System
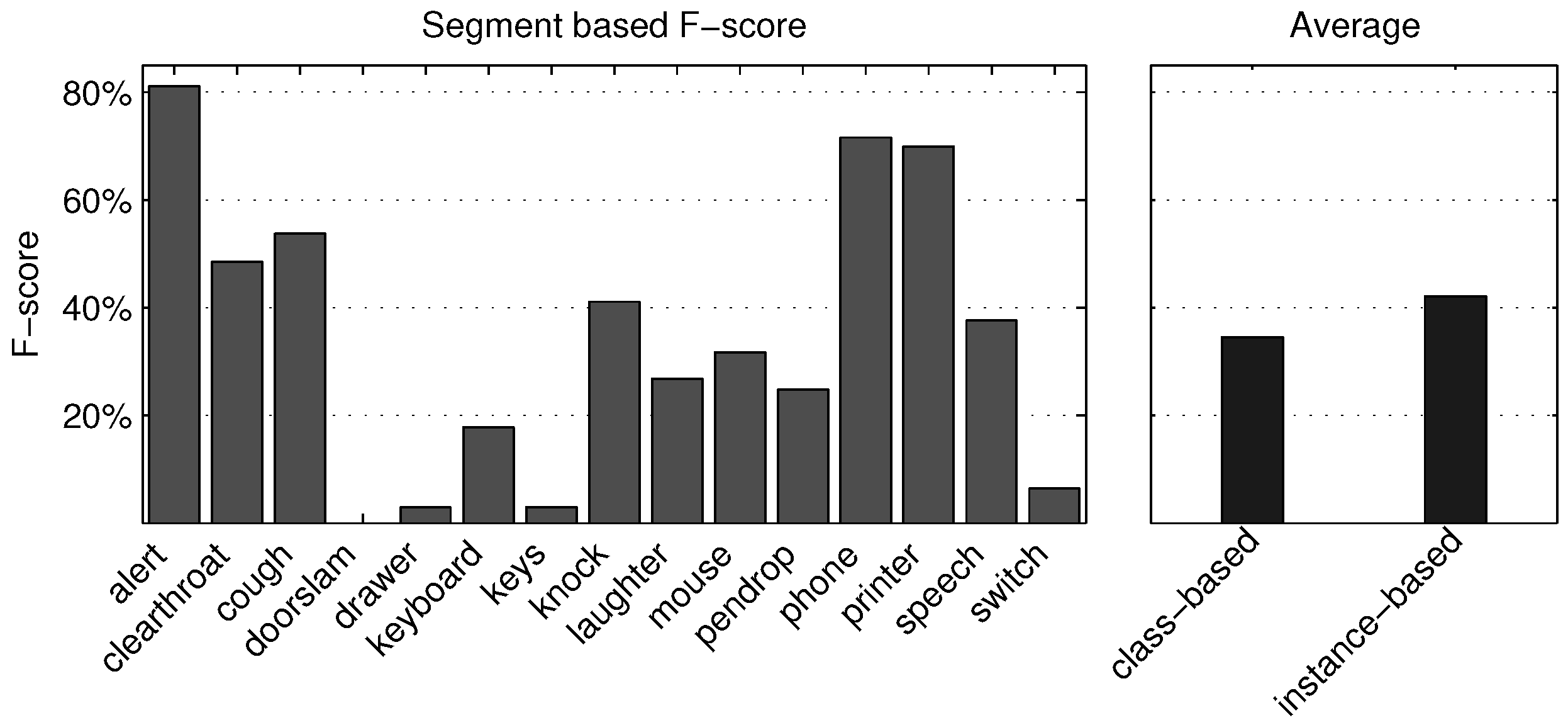
5.1.1. Segment-Based Metrics
5.1.2. Event-Based Metrics
5.1.3. Discussion
5.2. Comparing Performance of Different Systems
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Clavel, C.; Ehrette, T.; Richard, G. Events Detection for an Audio-Based Surveillance System. In Proceedings of the IEEE International Conference on Multimedia and Expo, Amsterdam, The Netherlands, 6 July 2005; IEEE Computer Society: Los Alamitos, CA, USA, 2005; pp. 1306–1309. [Google Scholar]
- Härmä, A.; McKinney, M.F.; Skowronek, J. Automatic surveillance of the acoustic activity in our living environment. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Amsterdam, The Netherlands, 6 July 2005; IEEE Computer Society: Los Alamitos, CA, USA, 2005; pp. 634–637. [Google Scholar]
- Foggia, P.; Petkov, N.; Saggese, A.; Strisciuglio, N.; Vento, M. Reliable detection of audio events in highly noisy environments. Pattern Recognit. Lett. 2015, 65, 22–28. [Google Scholar] [CrossRef]
- Peng, Y.T.; Lin, C.Y.; Sun, M.T.; Tsai, K.C. Healthcare audio event classification using Hidden Markov Models and Hierarchical Hidden Markov Models. In Proceedings of the IEEE International Conference on Multimedia and Expo, New York, NY, USA, 28 June–3 July 2009; pp. 1218–1221.
- Goetze, S.; Schröder, J.; Gerlach, S.; Hollosi, D.; Appell, J.; Wallhoff, F. Acoustic Monitoring and Localization for Social Care. J. Comput. Sci. Eng. 2012, 6, 40–50. [Google Scholar] [CrossRef]
- Guyot, P.; Pinquier, J.; Valero, X.; Alias, F. Two-step detection of water sound events for the diagnostic and monitoring of dementia. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), San Jose, CA, USA, 15–19 July 2013; pp. 1–6.
- Stowell, D.; Clayton, D. Acoustic Event Detection for Multiple Overlapping Similar Sources. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 18–21 October 2015.
- Cai, R.; Lu, L.; Hanjalic, A.; Zhang, H.J.; Cai, L.H. A flexible framework for key audio effects detection and auditory context inference. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1026–1039. [Google Scholar] [CrossRef]
- Xu, M.; Xu, C.; Duan, L.; Jin, J.S.; Luo, S. Audio Keywords Generation for Sports Video Analysis. ACM Trans. Multimedia Comput. Commun. Appl. 2008, 4, 1–23. [Google Scholar] [CrossRef]
- Bugalho, M.; Portelo, J.; Trancoso, I.; Pellegrini, T.; Abad, A. Detecting audio events for semantic video search. In Proceedings of the 10th Annual Conference of the International Speech Communication Association, Brighton, UK, 6–10 September 2009; pp. 1151–1154.
- Chu, S.; Narayanan, S.; Kuo, C.C. Environmental Sound Recognition With Time-Frequency Audio Features. IEEE Trans. Audio Speech Lang. Process. 2009, 17, 1142–1158. [Google Scholar] [CrossRef]
- Tran, H.D.; Li, H. Sound Event Recognition With Probabilistic Distance SVMs. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 1556–1568. [Google Scholar] [CrossRef]
- Dennis, J.; Tran, H.D.; Li, H. Combining robust spike coding with spiking neural networks for sound event classification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, QLD, Australia, 19–24 April 2015; pp. 176–180.
- Zhang, H.; McLoughlin, I.; Song, Y. Robust Sound Event Recognition Using Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, QLD, Australia, 19–24 April 2015.
- Zhuang, X.; Zhou, X.; Hasegawa-Johnson, M.A.; Huang, T.S. Real-world Acoustic Event Detection. Pattern Recognit. Lett. 2010, 31, 1543–1551. [Google Scholar] [CrossRef]
- Heittola, T.; Mesaros, A.; Virtanen, T.; Gabbouj, M. Supervised Model Training for Overlapping Sound Events based on Unsupervised Source Separation. In Proceedings of the 38th International Conference on Acoustics Speech, and Signal Processing (ICASSP 2013), Vancouver, BC, Canada, 26–31 May 2013; pp. 8677–8681.
- Mesaros, A.; Dikmen, O.; Heittola, T.; Virtanen, T. Sound event detection in real life recordings using coupled matrix factorization of spectral representations and class activity annotations. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, QLD, Australia, 19–24 April 2015; pp. 151–155.
- Espi, M.; Fujimoto, M.; Kinoshita, K.; Nakatani, T. Exploiting spectro-temporal locality in deep learning based acoustic event detection. EURASIP J. Audio Speech Music Process. 2015, 2015. [Google Scholar] [CrossRef]
- Grootel, M.; Andringa, T.; Krijnders, J. DARES-G1: Database of Annotated Real-world Everyday Sounds. In Proceedings of the NAG/DAGA Meeting, Rotterdam, The Netherlands, 23–26 March 2009.
- Stowell, D.; Giannoulis, D.; Benetos, E.; Lagrange, M.; Plumbley, M. Detection and Classification of Acoustic Scenes and Events. IEEE Trans. Multimedia 2015, 17, 1733–1746. [Google Scholar] [CrossRef]
- Poliner, G.E.; Ellis, D.P. A Discriminative Model for Polyphonic Piano Transcription. EURASIP J. Adv. Signal Process. 2007, 2007, 048317. [Google Scholar] [CrossRef]
- Detection and Classification of Acoustic Scenes and Events 2016, IEEE AASP Challenge. Available online: http://www.cs.tut.fi/sgn/arg/dcase2016/ (accessed on 5 January 2016).
- Mesaros, A.; Heittola, T.; Eronen, A.; Virtanen, T. Acoustic Event Detection in Real-life Recordings. In Proceedings of the 18th European Signal Processing Conference (EUSIPCO 2010), Aalborg, Denmark, 23–27 August 2010; pp. 1267–1271.
- Martinez, E.; Celma, O.; Sordo, M.; Jong, B.D.; Serra, X. Extending the folksonomies of freesound.org using contentbased audio analysis. In Proceedings of the Sound and Music Computing Conference, Porto, Portugal, 23–25 July 2009.
- Foster, P.; Sigtia, S.; Krstulovic, S.; Barker, J. CHiME-Home: A Dataset for Sound Source Recognition in a Domestic Environment. In Proceedings of the Worshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 18–21 October 2015.
- Heittola, T.; Mesaros, A.; Eronen, A.; Virtanen, T. Context-Dependent Sound Event Detection. EURASIP J. Audio Speech Music Process. 2013, 2013. [Google Scholar] [CrossRef]
- Cakir, E.; Heittola, T.; Huttunen, H.; Virtanen, T. Polyphonic Sound Event Detection Using Multi Label Deep Neural Networks. In Proceedings of the International Joint Conference on Neural Networks 2015 (IJCNN 2015), Montreal, QC, Canada, 31 July–4 August 2015.
- Dikmen, O.; Mesaros, A. Sound event detection using non-negative dictionaries learned from annotated overlapping events. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 20–23 October 2013; pp. 1–4.
- Temko, A.; Nadeu, C.; Macho, D.; Malkin, R.; Zieger, C.; Omologo, M. Acoustic Event Detection and Classification. In Computers in the Human Interaction Loop; Waibel, A.H., Stiefelhagen, R., Eds.; Springer: London, UK, 2009; pp. 61–73. [Google Scholar]
- Music Information Retrieval Evaluation eXchange (MIREX 2016): Multiple Fundamental Frequency Estimation & Tracking. Available online: http://www.music-ir.org/mirex/wiki/2016:Multiple_Fundamental_Frequency_Estimation_&_Tracking (accessed on 18 April 2016).
- Giannoulis, D.; Benetos, E.; Stowell, D.; Rossignol, M.; Lagrange, M.; Plumbley, M. Detection and classification of acoustic scenes and events: An IEEE AASP challenge. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 20–23 October 2013; pp. 1–4.
- Mesaros, A.; Heittola, T.; Virtanen, T. TUT Sound Events 2016. Available online: https://zenodo.org/record/45759 (accessed on 22 May 2016).
- Sebastiani, F. Machine Learning in Automated Text Categorization. ACM Comput. Surv. 2002, 34, 1–47. [Google Scholar] [CrossRef]
- Sechidis, K.; Tsoumakas, G.; Vlahavas, I. On the Stratification of Multi-label Data. In Machine Learning and Knowledge Discovery in Databases; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Geramny, 2011; Volume 6913, pp. 145–158. [Google Scholar]
- Forman, G.; Scholz, M. Apples-to-apples in Cross-validation Studies: Pitfalls in Classifier Performance Measurement. SIGKDD Explor. Newsl. 2010, 12, 49–57. [Google Scholar] [CrossRef]
- Rijsbergen, C.J.V. Information Retrieval, 2nd ed.; Butterworth-Heinemann: Newton, MA, USA, 1979. [Google Scholar]
- Dixon, S. On the computer recognition of solo piano music. In Proceedings of the Australasian Computer Music Conference, Brisbane, Australia, 10–12 July 2000; pp. 31–37.
- Ryynanen, M.P.; Klapuri, A. Polyphonic music transcription using note event modeling. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, New Platz, NY, USA, 16–19 October 2005; pp. 319–322.
- Sheh, A.; Ellis, D. Chord Segmentation and Recognition using EM-Trained Hidden Markov Models. In Proceedings of the 4th International Conference on Music Information Retrieval ISMIR, Baltimore, MD, USA, 27–30 October 2003.
- Mauch, M.; Dixon, S. Simultaneous Estimation of Chords and Musical Context From Audio. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 1280–1289. [Google Scholar] [CrossRef]
- Heittola, T.; Mesaros, A. sed_eval - Evaluation toolbox for Sound Event Detection. Available online: https://github.com/TUT-ARG/sed_eval (accessed on 22 May 2016).
- Japkowicz, N.; Shah, M. Evaluating Learning Algorithms; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Diment, A.; Heittola, T.; Virtanen, T. Sound Event Detection for Office Live and Office Synthetic AASP Challenge; Technical Report; Tampere University of Technology: Tampere, Finland, 2013. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Segment Length | F | ER | Sensitivity | Specificity | ACC | BACC | |
|---|---|---|---|---|---|---|---|
| 10 ms | class-based average | 34.5 | 0.87 | 27.3 | 99.5 | 96.7 | 63.4 |
| instance-based average | 42.0 | 0.76 | 29.7 | 99.5 | 96.7 | 64.6 | |
| 1 s | class-based average | 44.9 | 0.89 | 43.2 | 97.1 | 92.4 | 70.1 |
| instance-based average | 50.9 | 0.75 | 44.6 | 97.0 | 92.4 | 70.8 |
| Onset Only | Onset + Offset | ||||
|---|---|---|---|---|---|
| Collar | F | ER | F | ER | |
| 100 ms | class-based average | 7.5 | 2.10 | 4.7 | 2.10 |
| instance-based average | 20.7 | 1.74 | 8.2 | 2.11 | |
| 250 ms | class-based average | 10.5 | 2.25 | 4.1 | 2.10 |
| instance-based average | 30.8 | 1.49 | 10.1 | 2.06 | |
| Compared Systems | Segment-Based | Event-Based | Event-Based | |||
|---|---|---|---|---|---|---|
| Onset Only | Onset + Offset | |||||
| F | ER | F | ER | F | ER | |
| system A (NMF [28]) | 42.0 | 0.76 | 30.8 | 1.49 | 10.1 | 2.06 |
| system B (GMM [22]) | 68.5 | 0.49 | 10.7 | 1.42 | 4.4 | 1.62 |
| system C (HMM [43]) | 46.9 | 0.87 | 30.0 | 1.47 | 20.8 | 1.76 |
| zero-output system | 0.0 | 1.00 | 0.0 | 1.00 | 0.0 | 1.00 |
| all-active-output system | 15.4 | 10.93 | 0.0 | 1.44 | 0.0 | 1.44 |
| random-output system | 9.0 | 1.53 | 1.6 | 2.59 | 1.1 | 2.67 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mesaros, A.; Heittola, T.; Virtanen, T. Metrics for Polyphonic Sound Event Detection. Appl. Sci. 2016, 6, 162. https://doi.org/10.3390/app6060162
Mesaros A, Heittola T, Virtanen T. Metrics for Polyphonic Sound Event Detection. Applied Sciences. 2016; 6(6):162. https://doi.org/10.3390/app6060162
Chicago/Turabian StyleMesaros, Annamaria, Toni Heittola, and Tuomas Virtanen. 2016. "Metrics for Polyphonic Sound Event Detection" Applied Sciences 6, no. 6: 162. https://doi.org/10.3390/app6060162