1. Introduction
Automatic speech recognition (ASR) is capable of automatically converting speech signals into corresponding text sequences. With the continuous iterative development of deep learning techniques, end-to-end speech recognition models are gradually replacing the traditional Hidden Markov Model (HMM)-based speech recognition models. End-to-end speech recognition models are favored by more and more researchers because they simplify the overall model structure and training steps, and reduce the reliance on domain knowledge compared to traditional HMM-based speech recognition models. The most typical representative of end-to-end speech recognition models is Transformer [
1], which uses encoders and decoders with a multi-head attention mechanism to simplify the training and recognition process, accelerate parallel computation, and improve the accuracy of model recognition. Recently, Gulati et al. [
2] proposed the Conformer model, which uses a convolutional module to capture local content dependencies. Its shows better results on English datasets [
3] compared to other models such as Transformer and Transformer-XL [
4].
Although the Conformer end-to-end models have shown better results in the field of speech recognition and are widely used, they have also caused their own number of parameters to become larger and larger compared to Transformer. Some Conformer-based end-to-end speech recognition models have reached tens of millions of parameters, which also brings about problems such as higher computational complexity of the model, more resource consumption and large storage space. Therefore, it is important to build a lightweight end-to-end speech recognition model.
Many works have been carried out to study this. Winata et al. [
5] constructed the low-rank Transformer (LRT) using low-rank multi-head attention and low-rank feed-forward. Wang et al. [
6] used sparse processing for the computation of self-attention in the Conformer model to reduce the computational complexity on attention. In addition, MHA was used to carry out down sampling to improve the performance of the Conformer model [
7]. Li et al. constructed a low-rank feed-forward network module and a multi-head linear attention module to reduce the model parameters for the Conformer model [
8]. Ref. [
9] uses two approaches based on singular value decomposition (SVD) to solve the adaptation and personalization problems of DNN. Low-rank compression can compress the parameters of the model, but at the same time, it has an impact on the recognition accuracy of the model; moreover, to our best knowledge, few research works have investigated compression for Conformer’s multi-headed attention module.
There is a long-tail problem in most data sets. The long-tail problem has been extensively studied in computer vision [
10,
11]; for example, Tang et al. [
12] used causality to construct a balanced classifier to solve the long-tail problem in vision. Additionally, we found that there is a long-tail problem in the open-source Kazakh language dataset [
13], that is, high-frequency words occupy a small part of the dataset, while low-frequency words occupy the majority of the dataset. The uneven distribution of high-frequency words and low-frequency words makes the final recognition accuracy higher for high-frequency words that are adequately trained and lower for low-frequency words that are not adequately trained. At the same time, some low-frequency words may be incorrectly classified and recognized because of speech similarity, resulting in the overall low recognition accuracy of the final model [
14,
15]. To the best of our knowledge, few studies have explored the long tail in agglutinative languages.
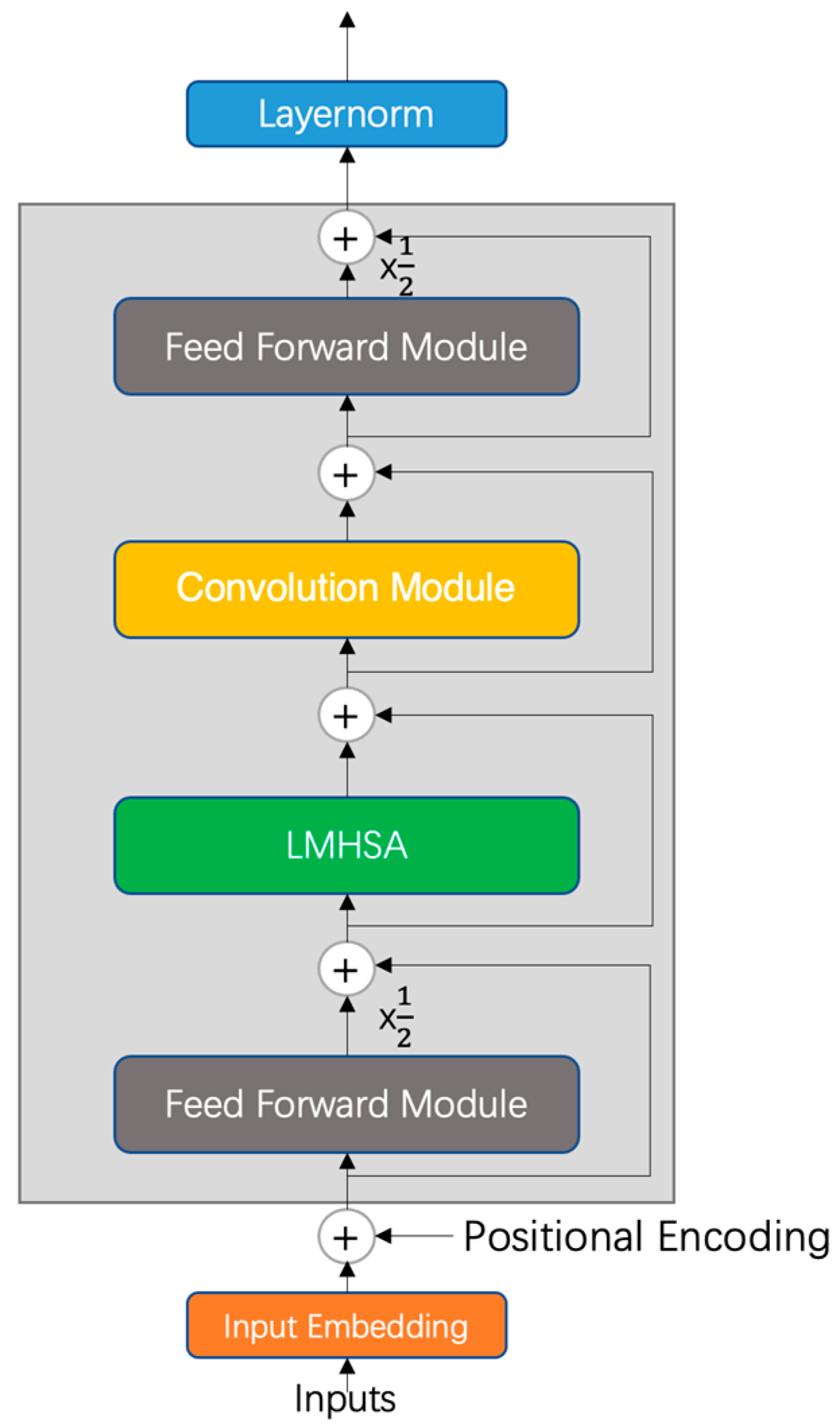
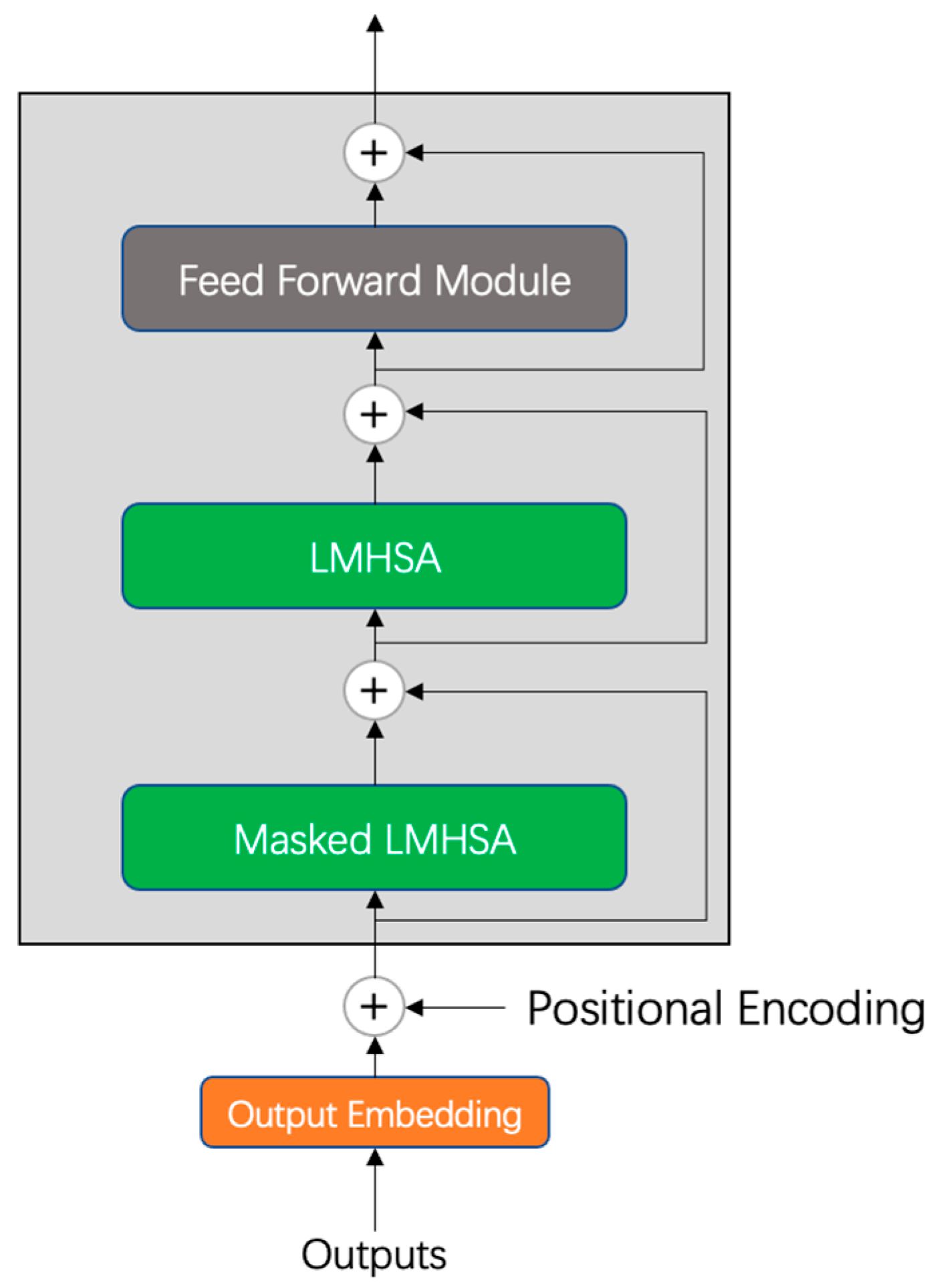
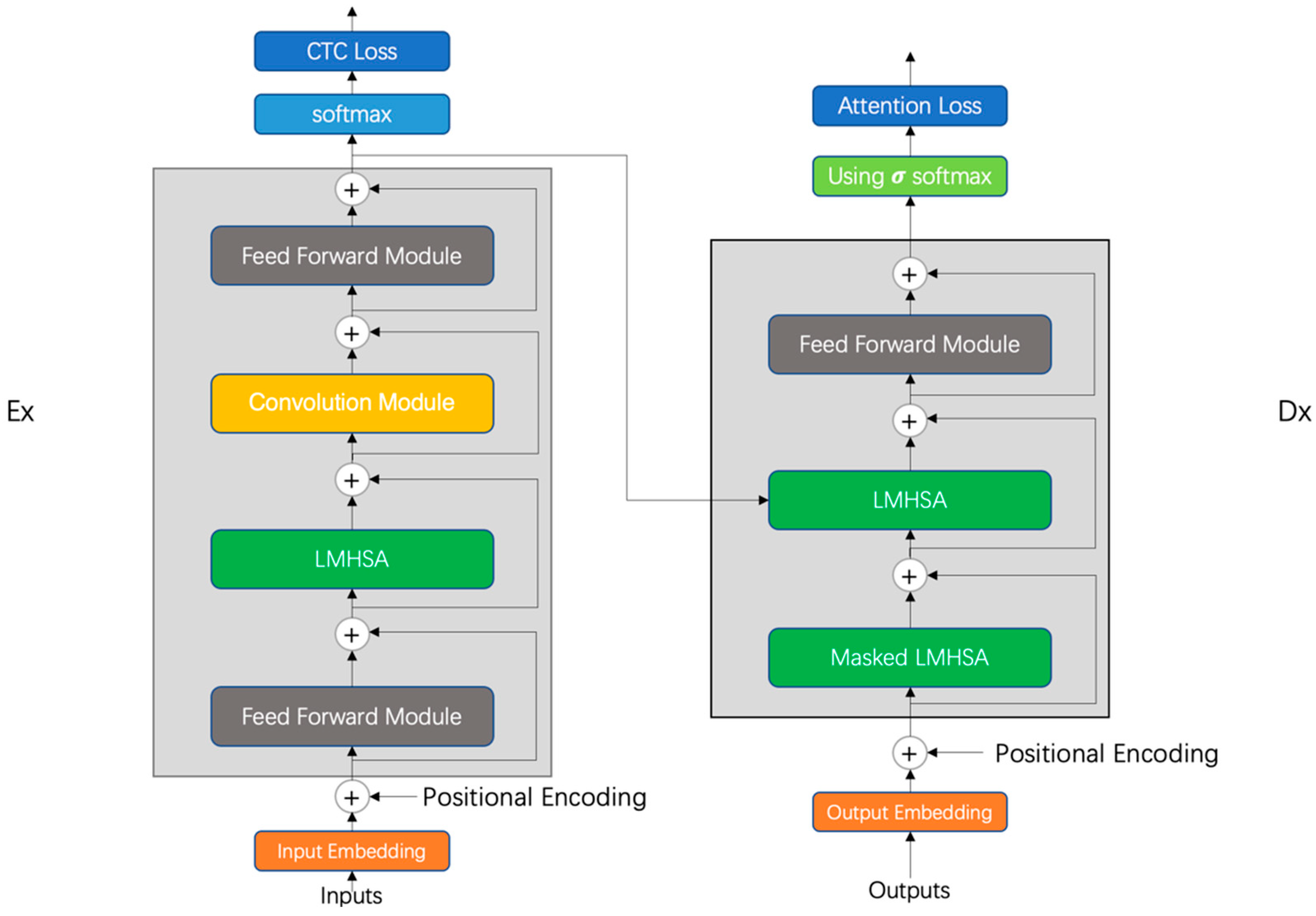
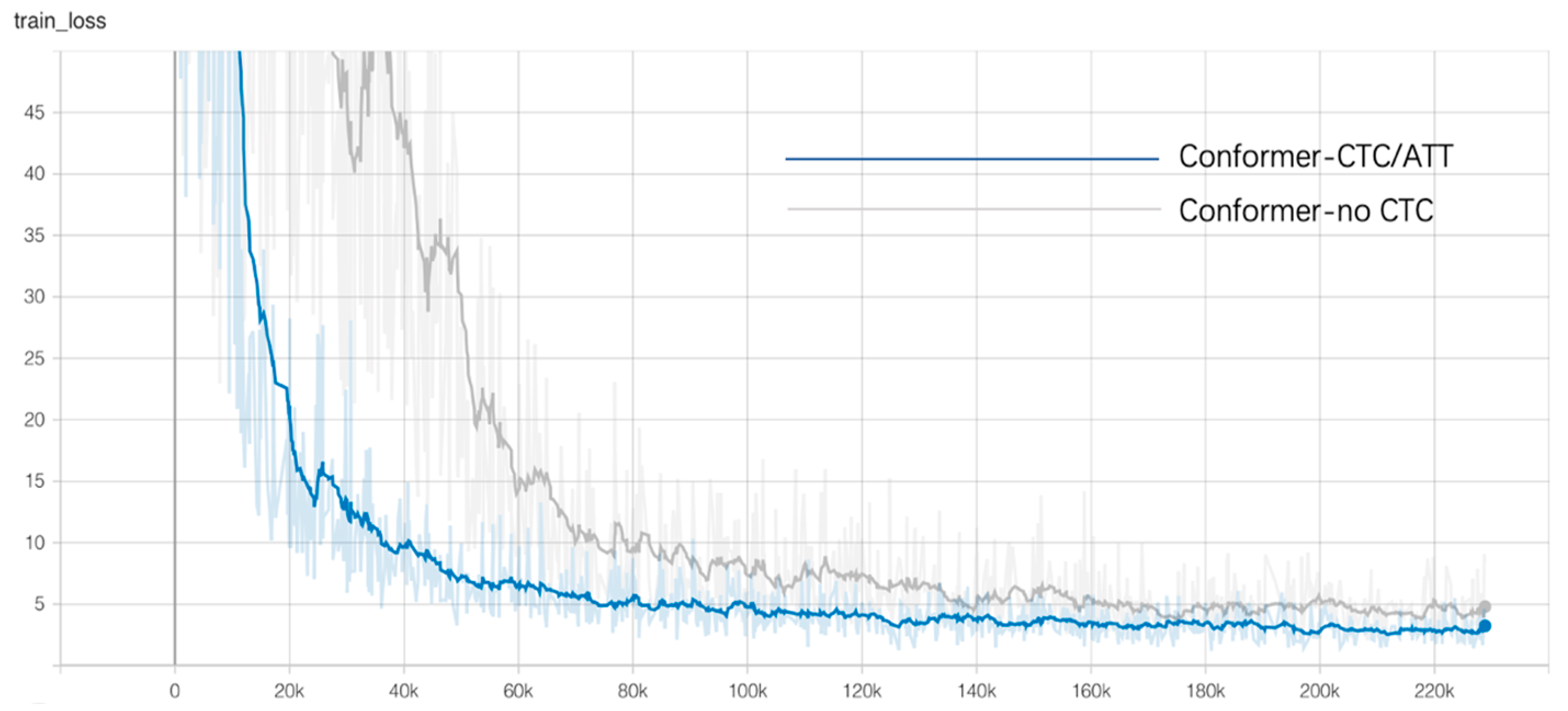
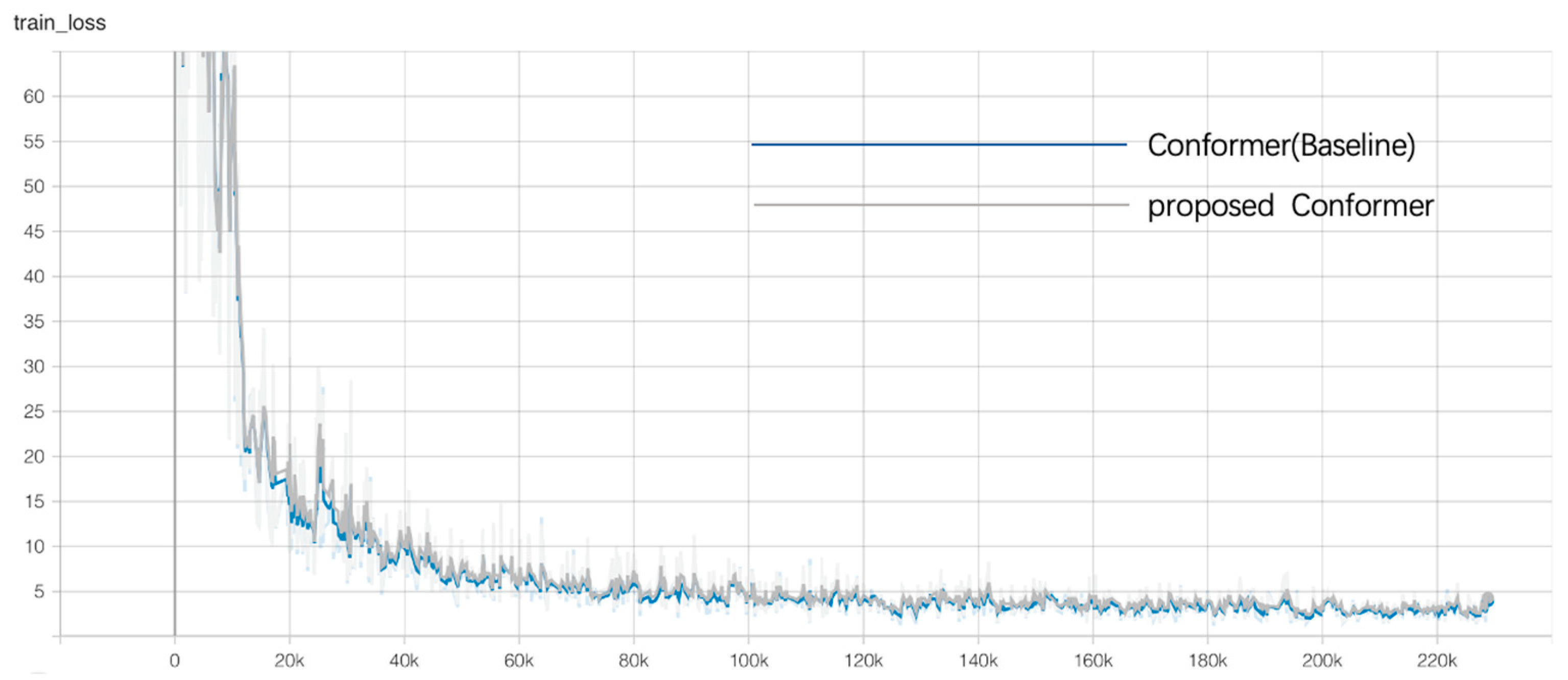
To address the above issues, we focus on constructing a lightweight but efficient Conformer speech recognition model, using low-rank approximation decomposition to reduce the number of redundant parameters of the multi-head self-attention module in the Conformer model and the memory size of the model, while keeping the model recognition accuracy and training time largely unchanged. The main innovations in this article are as follows. Firstly, we construct an encoder and decoder of low-rank multi-head self-attention modules, called LMHSA modules, in the Conformer model, and do not need to retrain the overall model during the compression process. Compression of the multi-head attention module using low-rank decomposition reduces the number of redundant parameters and the memory size of the model. Second, to effectively alleviate the long-tail problem in Kazakh, we used a softmax function with penalty factor to replace the original softmax function, called balanced softmax, to improve the accuracy of the model without increasing the training difficulty. Meanwhile, we investigate the best value of penalty factor in the Conformer model. Third, we use CTC as an auxiliary function in the Conformer model to build a hybrid CTC/Attention multi-task-learning training approach to help the model converge quickly. Fourth, we build a lightweight but efficient Conformer model, reducing the number of parameters and the storage space of the model while keeping the training speed and recognition accuracy largely unchanged. Experimental results on the KSC dataset show that the use of an LMHSA module can effectively reduce the parameters of Conformer, and the number of parameters of the model is reduced by 7.4%. The use of the balanced softmax function can effectively alleviate the long-tail problem in the Kazakh language, and the speech recognition word error rate (WER) is reduced by 0.15%. The multi-task efficient Conformer model using hybrid CTC/Attention compresses the final number of parameters of the model by 7.4% and the storage space of the model by 13.5 MB, while the overall training speed and word error rate remain largely unchanged.
The rest of this paper is as follows. In
Section 2, we briefly introduce the hybrid CTC/Attention end-to-end speech recognition model and its application to Kazakh, while we introduce the decomposition and the speech long-tail problem. The proposed method is described in detail in
Section 3.
Section 4 presents the environment configuration of the experiments and the introduction of the dataset.
Section 5 presents the experiments conducted with our proposed low-rank multi-head self-attention encoder and decoder, balanced softmax, and the final model structure scheme compared to the baseline model Conformer. In
Section 6, we summarize the work we have completed and present the outlook.
2. Related Work
End-to-end automatic speech recognition models are increasingly being investigated by researchers due to their simplified training process and time, and their ability to effectively improve the recognition accuracy of models. Currently, the mainstream end-to-end speech recognition models mainly include connectionist temporal classification (CTC) [
16,
17], the recurrent neural network transducer (RNN-T) model [
18,
19], and the attention mechanism-based encoder and decoder model [
20,
21]. Among the attention-based mechanism models, the most representative one is Transformer [
1]. Transformer uses a multi-head attention mechanism, increases parallel computation, and achieves good results in sequence modeling. Transformer, although more effective in extracting long sequence dependencies, performs poorly in extracting local features. For this reason, Gulati et al. proposed a new model, Conformer, which is a convolutional module to enhance Transformer’s learning in local features [
2]. The proposed end-to-end speech recognition framework based on Conformer has further improved the recognition accuracy of end-to-end speech recognition models and has also been widely used in the field of speech recognition [
22,
23]. The end-to-end model based on the attention mechanism is difficult to train due to its overly flexible alignment. Therefore, adding CTC to the decoder layer of the attention-based mechanism to assist in training not only helps the model converge quickly, but also improves the recognition rate of the model [
24,
25].
With the continuous development of deep learning techniques, end-to-end speech recognition is becoming more and more popular among researchers, but it also increases the number of parameters and storage space for models, which leads to higher resources and a longer training time for end-to-end speech recognition models. There are many research works investigating the reduction in the number of redundant parameters in end-to-end speech recognition models. Winata et al. proposed a method to compress large pre-trained models using non-negative matrix decomposition LSTM post-training compression [
26]. Kriman et al. proposed a QuartzNet model with one-dimensional temporal channel separable convolution to decompose the convolution [
27]. Mehrotra et al. proposed to compress the end-to-end speech recognition model using a low-rank decomposition method, with no reduction in word error rate [
28]. Winata et al. [
5] constructed a lightweight but effective end-to-end speech recognition model using low-rank decomposition in Speech-Transformer [
29]. In addition, common model compression methods include knowledge distillation [
30,
31] and pruning operations [
32], but knowledge distillation and pruning mostly require retraining of the model, and the training process is more complicated. To the best of our knowledge, most studies have focused on the feed-forward and convolutional layers in the network, and few studies have been conducted on the multi-head attention module, especially the multi-head self-attention module of the currently more advanced Conformer end-to-end speech recognition model. Therefore, in order to reduce the number of parameters and storage space in the Conformer model, we use low-rank decomposition to compress the multi-head self-attention module of the Conformer model for the study.
Speech recognition has been a relatively popular research object, but most research objects are mainly focused in resource-rich languages, such as Chinese datasets [
33,
34], English datasets [
35] and other datasets [
36,
37], and very little work has been conducted to study speech recognition of languages in Central and West Asia. The Kazakh language is currently used in two regions: the first is Kazakhstan and Mongolia, in which the Cyrillic alphabet is used; the second is the Xinjiang Uyghur Autonomous Region of China, in which the alphabet of Arabic origin is used [
13]. The Kazakh language in the Cyrillic alphabet is used as a modeling unit in this paper. The Kazakh language of Cyrillic alphabet has 42 letters, some of which are rarely used; the letters B, Ё, Ц, Ч, Ъ, Ь, Э, Щ, Ф, Һ, etc. only appear in loanwords. The research on Kazakh speech recognition is mainly focused on the following. Mamyrbayev et al. developed an end-to-end Kazakh speech recognition model based on RNN-T [
38]. Orken et al. developed an end-to-end Kazakh speech recognition model based on Transformer [
39]. Mamyrbayev et al. used different models for end-to-end agglutinative language (Kazakh) speech recognition for research training [
40]. The Mamyrbayev et al. study built a hybrid end-to-end Kazakh speech recognition model based on BLSTM using CTC [
41]. The above studies either only build a single speech recognition model for Kazakh, or the datasets they use are relatively difficult to acquire or are not open-source.
In addition, we found that the open-source Cyrillic Kazakh dataset suffers from uneven data distribution, i.e., high-frequency words contribute most of the training, while low-frequency words are rarely trained. As a result, the end-to-end speech recognition model always performs better recognition on high-frequency vocabulary, while the recognition accuracy decreases on low-frequency vocabulary, leading to the overall low recognition accuracy of the model. Recently, several approaches have been proposed in the field of speech recognition to solve the problem of uneven data distribution. The first, more common one is to improve the recognition of tail words by fusing language models in the end-to-end model. Toshniwal et al.’s study enables the model to recognize low-frequency words well when decoding by using a fusion language model [
42,
43,
44]. Secondly, in overcoming the problem of uneven data distribution in multilingual speech recognition tasks, Winata et al. [
45] attempted to improve the recognition rate of multilingual speech recognition by pre-training language models and using class priors to adjust the output of the softmax function. To alleviate the long-tail problem of single language in speech recognition, Deng et al. used a two-step training approach, i.e., representation learning and classification learning, in an end-to-end speech recognition model as a way to improve the recognition of low-frequency words by trying to add multiple loss functions (for example, by adding a softmax loss function with temperature in Transformer decoder) and pre-training the language model [
46]. Previous work studies have not explored the long-tail problem in single small language speech recognition.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}