

Zero-Shot Relation Triple Extraction with Prompts for Low-Resource Languages

1
School of Information Science and Engineering, Xinjiang University, Urumqi 830046, China
2
Xinjiang Laboratory of Multi-Language Information Technology, Urumqi 830046, China
*
Author to whom correspondence should be addressed.
Appl. Sci. 2023, 13(7), 4636; https://doi.org/10.3390/app13074636
Submission received: 1 February 2023
/
Revised: 19 March 2023
/
Accepted: 4 April 2023
/
Published: 6 April 2023
Abstract
:Although low-resource relation extraction is vital in knowledge construction and characterization, more research is needed on the generalization of unknown relation types. To fill the gap in the study of low-resource (Uyghur) relation extraction methods, we created a zero-shot with a quick relation extraction task setup. Each triplet extracted from an input phrase consists of the subject, relation type, and object. This paper suggests generating structured texts by urging language models to provide related instances. Our model consists of two modules: relation generator and relation and triplet extractor. We use the Uyghur relation prompt in the relation generator stage to generate new synthetic data. In the relation and triple extraction stage, we use the new data to extract the relation triplets in the sentence. We use multi-language model prompts and structured text techniques to offer a structured relation prompt template. This method is the first research that extends relation triplet extraction to a zero-shot setting for Uyghur datasets. Experimental results show that our method achieves a maximum weighted average F1 score of 47.39%.
1. Introduction
Relation and triplet extraction (RE) is a critical topic in information extraction (IE), and it may be used for a variety of natural language processing (NLP) tasks [1,2,3]. The vast databases of labeled samples required by conventional approaches, on the other hand, are frequently expensive to annotate [4]. However, preceding zero-shot relation work does not necessitate the extraction of the whole relation triplet. Chen and Li [3] present zero-shot BERT, a unique multi-task learning approach, to directly estimate unknown relations without hand-crafted feature tagging. There are numerous methods in use currently to address the problems caused by data scarcity. Distantly supervised [4,5] methods are fast enough to construct large-scale corpora and corpus annotation is inexpensive, but the quality of annotation produced by this method is not as good as the results of manual human annotation. The work objective could also be written so that the label space is unrestricted.
However, since relation triplet extraction is a structured prediction problem rather than a sequence classification task, the existing formulations cannot be used in this manner [6]. John Koutsikakis et al. [7] present GREEK-BERT, a BERT-based language model for contemporary Greek that is monolingual. Xin Xu et al. [8] present an empirical investigation into the development of relational data extraction systems in low-resource environments. Based on recent pre-trained language models, they comprehensively investigate two methods for evaluating efficacy in low-resource settings: data augmentation technologies and self-training to generate more labeled in-domain data. Pundlik et al. [8] worked on a multi-domain Hindi dataset. The architecture described in the article [8] consisted of two stages. Yadav et al. [9] showed that Sentiment Analysis for the mixed Hindi language could be performed using three approaches. The first way was to use a neural network to classify previously known words.
Wikipedia [10] constructs this dataset using a snapshot of English Wikipedia. The titles of Wikipedia articles are considered brief texts, whereas the abstracts of all Wikipedia articles are used to build the associated lengthy documents. This dataset includes a total of 30,000 short texts and 1,747,988 long documents. This dataset is compiled by DBLP [10] using the bibliography database. The titles of computer science literature represent brief texts, whereas the abstracts of all published papers are collected to form the corresponding lengthy documents. This dataset consists statistically of 81,479 short readers and 480,558 long records. Programmable web [11] generates a real-world dataset for service recommendation and description augmentation. Fei Cheng et al. [12] provide an open-source natural language processing toolbox for extracting Japanese medical data. They create a pipeline system consisting of three components for identifying medical entities, categorizing entity modalities, and extracting relations. Existing relation extraction datasets for the Russian language are few and comprise a limited number of instances. Hence, D.I. Gordeev et al. [13] chose to develop RURED, a new Ontonotes-based sentence-level named entity and relation extraction dataset. The collection includes over 500 annotated texts and over 5000 labeled relationships. Leonhard Hennig et al. [14] present a German-language dataset, which is human-annotated with 20 coarse and fine-grained entity types and entity-linking information for geographically linkable entities. This first German-language dataset combines annotations for Named Entity Recognition and Relation Extraction. Ahmed Hamdi et al. [15] present the creation of the NewsEye resource, a multilingual dataset for named entity identification and linking, enhanced with attitudes towards named entities. The collection consists of diachronic historical newspaper articles published between 1850 and 1950 in French, German, Finnish, and Swedish.
Due to the lack of low-resource datasets, research on relation and triplet extraction has mostly been restricted to the English, German, French, Russian, Japanese, Finnish, Swedish, Arabic, and Hindi languages [11]. In this study, we present an alternate relation extraction method for a low-resource language (Uyghur) that can extract facts of new kinds that were not previously stated or observed. Despite the lack of annotated training examples, including the test relation labels, our method aims to extract triplets of the subject, object, and relation type from each sentence. Table 1 and Table 2 provide a task example and overview of task settings for easy comparison. This is the first research that, to our knowledge, extends relation triplet extraction to a zero-shot setting for Uyghur datasets. As a result, we suggest Relation Prompt, which redefines the zero-shot task as the production of new data for Uyghur languages. The fundamental idea is to use relational prompts to motivate a language model to produce an artificial training sample capable of expressing the necessary relations. These synthetic data can then be used to train another process of extracting a model of the triplet [16].
Overall, our significant contributions are as follows:
- In English, words and prepositions are separated by spaces, but in Uyghur, the entity and the suffixes following the entity are linked together. In Uyghur triplet extraction, entities and suffixes are not handled like Uyghur root extraction because entities may contain more than one word, so we have to consider the suffix of the last word in the entity.
- The Zero-Shot relation triple extraction dataset, known as Zero-Shot-Prompt-RE, is made up of Uyghur. In our collection, we have over 23,652 examples. There are 24 related classes that can each be an instance.
- This is the first research that, to our knowledge, extends relation triplet extraction to a zero-shot setting for Uyghur datasets.
- We use prompt-build synthetic relations to provide structured texts in order to make Zero-Shot-Prompt-Relation-Extraction.
2. Related Work
RE is a crucial pre-requisite job for creating large-scale knowledge graphs (KG), which can be used for automated responses, information retrieval, and other natural language processing (NLP) activities [17,18,19,20,21]. Previous papers on RE had a pipelined approach: first, all entities in the input phrase are identified using named entity recognition (NER), then, relational classification (RC) is applied to pairs of extracted entities [13]. Pipelined approaches typically have an issue with error propagation and ignore the connection between the two phases [20]. Ref. [21] provides a reading comprehension method in which one or more natural-language questions are associated with each relation slot. To improve the performance of relation classification systems, Ref. [22] performs zero-shot relation classification by using relation descriptions, current textual entailment models, and freely available textual entailment datasets. Ref. [23] proposes a unique dataset for Reading Comprehension (RC) for neural techniques in language understanding. Using GPT-3 as a case study, Ref. [24] shows that zero-shot prompts can significantly outperform those that use few-shot examples. This analysis motivates the rethinking of the role of prompts in controlling and evaluating powerful language models. Refs. [25,26,27] explore techniques for exploiting the capacity of narratives and cultural anchors to encode nuanced intentions. In natural language processing, prompting-based methods have shown promise in novel paradigms for zero-shot or few-shot inference [28]. Another advantage is adapting extensive language models to new jobs without needing somewhat expensive fine-tuning [29]. In order to combine many pathways and learn to share strength in a single RNN expressing logical composition across all relations, Refs. [30,31,32] present joint learning and neural attention modeling. However, such methods have many disadvantages for more difficult tasks such as triplet extraction [33,34]. Refs. [35,36] construct a Uyghur grammatical dictionary and provide extensive Uyghur grammatical information. Ref. [37] proposed a hybrid joint extraction model for supervised Uyghur datasets. To extend Uyghur RE research, Ref. [38] proposed a hybrid method to expand the Uyghur-named entity relation corpus. Sonali Rajesh Shah et al. [39] analyze, review, and discuss the methods, algorithms, and challenges researchers face when performing indigenous language recognition. The primary objective of this assessment is to comprehend the recent work undertaken in South Africa for indigenous languages. The trends in the field of SA are being uncovered by analyzing 23 articles. Machine learning, deep learning, and sophisticated deep learning algorithms were utilized in 67% of the reviewed publications. Twenty-nine percent of researchers have employed a lexicon-based methodology. SVM (Support Vector Machine) and LR (Logical Regression) outperformed all other machine learning approaches. CHENHE DONG et al. [39] provide a historical overview of deep learning research on natural language generation, highlighting the unique nature of the problems to be addressed. It begins with a contrasting generation with language comprehension, establishing fundamental concepts regarding the objectives, datasets, and deep learning methods. Following is a section of evaluation metrics derived from the output of generation systems, illustrating the possible performance types and the areas of difficulty. Finally, a list of open problems presents natural language generation research’s main challenges and future orientations. Nasrin Taghizadeh [40] proposed a cross-language method for relation extraction, which uses the training data of other languages and trains a model for relation extraction from Arabic text. The task is supervised learning, in which several lexical and syntactic features are considered. The proposed method mainly relies on the Universal Dependency (UD) parsing and the similarity of UD trees in different languages. Regarding UD parse trees, all the features for training classifiers are extracted and represented in a universal space. Yuna Hur et al. [41] suggest Entity-Perceived Context representation in Korean to provide a better capacity for grasping the meaning of entities and considering linguistic qualities in Korean.
3. Zero-Shot-Prompt-RE: Methodology
The majority of zero-shot research has been conducted in English. We provide a Uyghur-Relation-Prompt that employs relation types as prompts to produce Uyghur synthetic relation instances of target unknown relation types in order to extract triplets for unknown relation types in Uyghur-Zero-Shot-Prompt-RE. There are more research works on relation extraction using English. However, there needs to be more research on Uyghur, which belongs to a different language family to English and whose grammar is more complex with weaker letters and more or missing affixes. Therefore, this paper implements a rule- and template-based approach to Uyghur relation extraction research.
3.1. Task Definition
In English, words and prepositions are separated by spaces, but in Uyghur, the entity and the suffixes following the entity are linked together. In Uyghur triad extraction, entities and suffixes are not handled like Uyghur root extraction because entities may contain more than one word, so we have to consider the suffix of the last word in the entity. Uyghur-Zero-Shot-Prompt-RE aims to use relational and entity cues to learn and produce synthetic data from seen datasets, , and to extract triplets from unseen test datasets, . and are described as , where is the Uyghur sentence: “ئالمىرە بېيجىڭ ئۇنۋېرسىتىدا ئۇقۇيدۇ.—Almira is a student at Peking University” the seen relation is “educated at (P69)”—“ئالىي مەكتەپنى پۈتتۈرگەن (P69)”, T = (ئالمىرە، ئالىي مەكتەپنى پۈتتۈرگەن (P69) بېيجىڭ ئۇنۋېرسىتى،) is the output triplets, and R is the relation. “ئالمىرە—Alimire ” is a person’s name, “بېيجىڭ ئۇنۋېرسىتىدا— at Peking University” is a geographical named entity, a relation triple is defined as , which denotes the head entity—“ئالمىرە”, tail entity—“بېيجىڭ ئۇنۋېرسىتى + دا”, and relation type –“educated at (P69)”—“ئالىي مەكتەپنى پۈتتۈرگەن (P69)”, respectively. In the tail entity, “بېيجىڭ ئۇنۋېرسىتىدا—at Peking University”, the entity to be extracted should be Peking University, without the preposition. The seen and unseen relation type sets are represented as and , where and are the sizes of the known and unknown relation type sets, respectively.
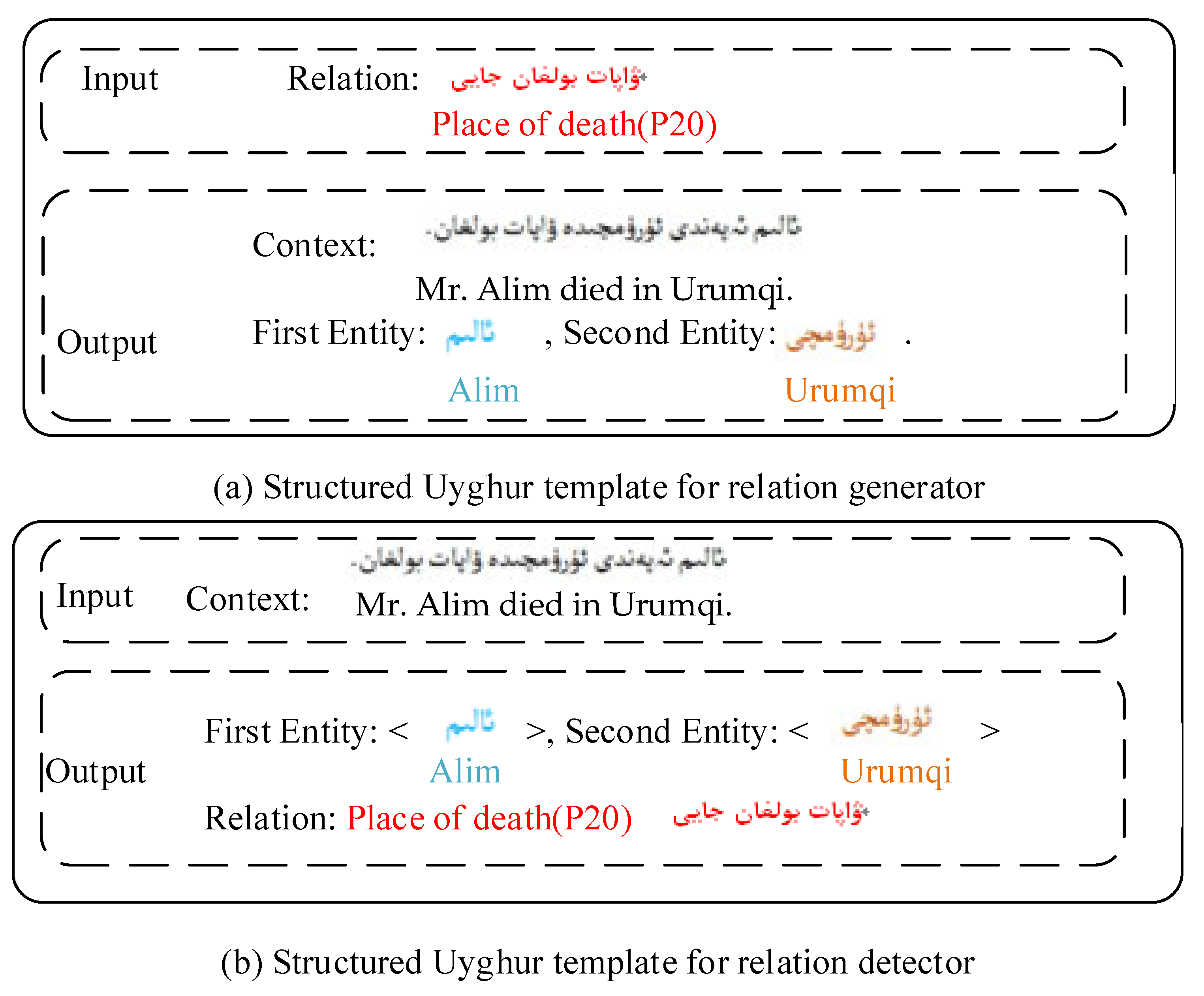
First entities, second entities, and relation labels are shown in blue, orange, and dark red, respectively, in Figure 1a,b. The relation generator (a) accepts the relation label as input and returns the context and entity combination as output. The relation extractor (b) accepts a phrase as input and returns a relation triplet consisting of an entity couple and a relation label.
Usually, we define the knowledge graph formally as , where denote the set of entities, relations, and facts, respectively. A fact is denoted as a triplet, T. The notation of the specific triadic relation extraction design and its description are shown in Table 3.
3.2. Relation Generator
By conditioning the language model on the target’s unknown relation types, we use relation prompts to produce synthetic sentences. Uyghur is a minority language with fewer data resources [42,43]. While using fine-tuning, the training cost can be meager: if the method of deriving feature vectors is used for transfer learning, the later training cost is light, the CPU is entirely stress-free, and no deep learning machine can perform it [36,37,38,39]. As regards what is suitable for small data sets, for cases where the dataset itself is small (thousands of sentences), it is not realistic to train an extensive neural network with tens of millions of parameters from scratch because the more significant the model, the greater the amount of data, and overfitting cannot be avoided. We propose the following algorithm to handle the Uyghur-Zero-Shot-Prompt-RE:
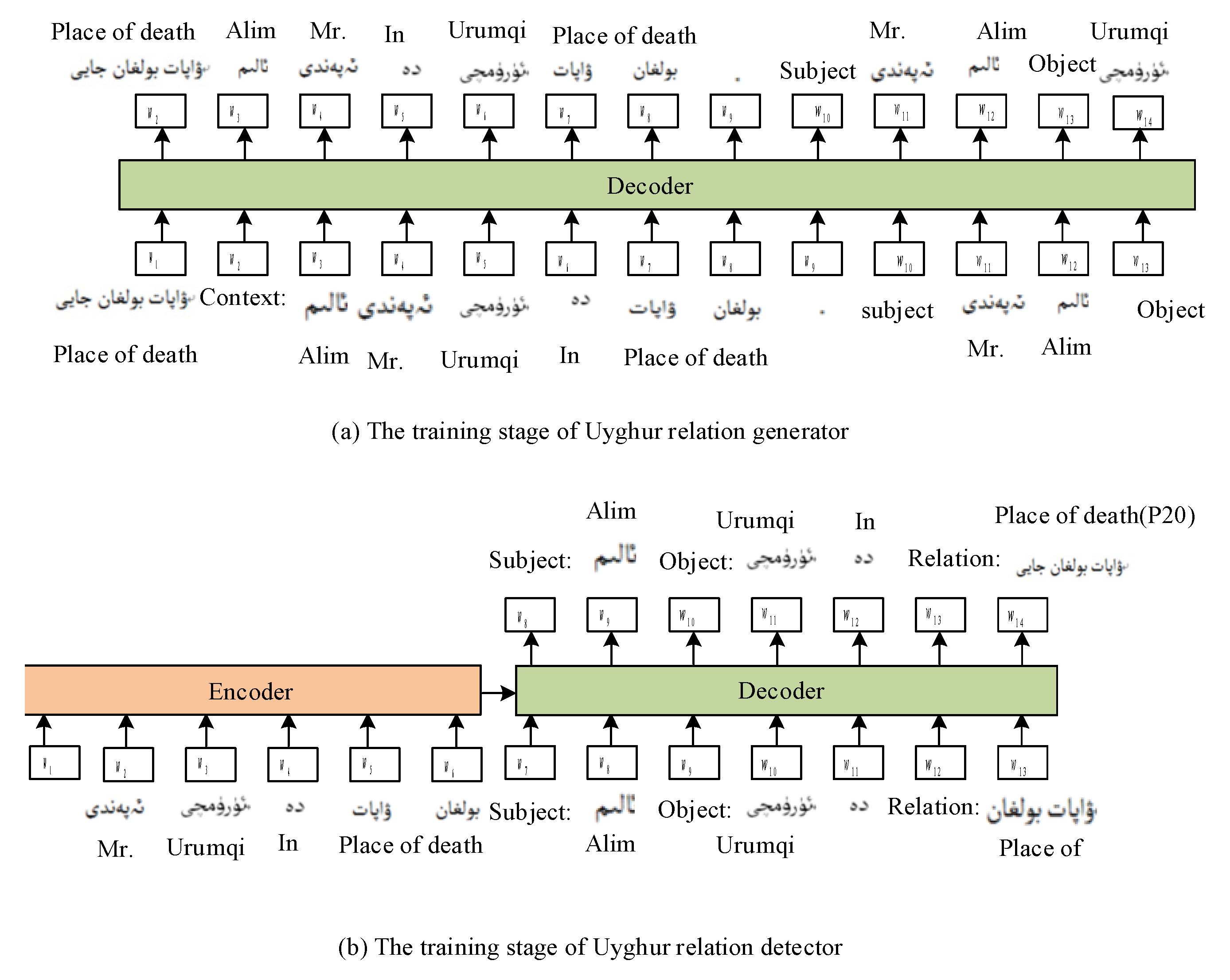
As shown in Algorithm 1, the is the Uyghur relation generator; the is the relation detector. As shown in Figure 1a, the relation takes an input: Relation: “label”, which is a structured prompt. The outputs are structured prompts in the form of context: “Mr. Alim died in Urumqi.—![Applsci 13 04636 i004]() ”, subject: “Alim—
”, subject: “Alim— ![Applsci 13 04636 i005]() ”, object: “Urumqi—
”, object: “Urumqi— ![Applsci 13 04636 i006]() ”. The probability of the next word given all the previous ones can be used to construct a statistical language model [10]. The purpose is to calculate the conditional generation probability for each sequence, :
”. The probability of the next word given all the previous ones can be used to construct a statistical language model [10]. The purpose is to calculate the conditional generation probability for each sequence, :
 ”, subject: “Alim—
”, subject: “Alim—  ”, object: “Urumqi—
”, object: “Urumqi—  ”. The probability of the next word given all the previous ones can be used to construct a statistical language model [10]. The purpose is to calculate the conditional generation probability for each sequence, :
”. The probability of the next word given all the previous ones can be used to construct a statistical language model [10]. The purpose is to calculate the conditional generation probability for each sequence, : Considering the alphabetic weakness of the Uyghur language and the multiple addition or loss of affixes, we use a prompt-based approach. Neural networks typically generate category probabilities using a “softmax” layer that converts the logit [44], , calculated for each category into a probability, , by comparing with other logarithms. The is the temperature, is the vocabulary size.
By dividing the output sequences based on the particular phrases “Context: Mr. Alim died in Urumqi.—![Applsci 13 04636 i007]() ”, first entity: “Alim—
”, first entity: “Alim—![Applsci 13 04636 i008]() ”, second Entity: “Urumqi—
”, second Entity: “Urumqi—![Applsci 13 04636 i009]() ”. The output sequence of the relationship generator is used to extract the relational triples. Suppose an error occurs on the decoding side of the relationship generator and an entity does not exist in the formed context. In that case, we discard the sample and continue to produce new data until the intended data sample is available.
”. The output sequence of the relationship generator is used to extract the relational triples. Suppose an error occurs on the decoding side of the relationship generator and an entity does not exist in the formed context. In that case, we discard the sample and continue to produce new data until the intended data sample is available.
 ”, first entity: “Alim—
”, first entity: “Alim— ”, second Entity: “Urumqi—
”, second Entity: “Urumqi— ”. The output sequence of the relationship generator is used to extract the relational triples. Suppose an error occurs on the decoding side of the relationship generator and an entity does not exist in the formed context. In that case, we discard the sample and continue to produce new data until the intended data sample is available.
”. The output sequence of the relationship generator is used to extract the relational triples. Suppose an error occurs on the decoding side of the relationship generator and an entity does not exist in the formed context. In that case, we discard the sample and continue to produce new data until the intended data sample is available.
| Algorithm 1: Zero-Shot-Prompt-RE for Uyghur |
| Input: Dataset = (sentence, triplets, relation types) |
| Output: Extracted Uyghur Triplets- |
| 2: Suffix = {دا،دە،تا،تە،نىڭ،غا،قا،گە،كە....} |
| 3: SELECT Entities with suffixes |
As can be seen from Figure 2, the second entity “ئۈرۈمچىدە = ئۈرۈمچى + دە —In Urumqi”, the correct result is the “ئۈرۈمچى—Urumqi”, without the “ دە—In” suffix.
3.3. Relation Detector
In this section, we use a sequence-to-sequence approach regarding NRE as a novel labeling problem, generated with greedy decoding [44,45,46,47]. We may create model outputs without any initial decoder input to predict a single relation triplet (subject, object, relation type) in a given sentence, s. If an object or relation type is invalid, we regard it as a null prediction for that sample. As shown in Algorithm 1, the prerequisite is that the set of visible relational types, , and the set of invisible relational types, , cannot intersect. is fine-tuned for the labeled dataset, , (line 6) after processing based on Uyghur entities and entity suffixes (line 1), and then reformulated on the synthetic sentences (line 8). The test sentences, , are then applied to predict and extract relation triplets, (lines 8 and 9). Our relationship extractor is not the same as a traditional relationship extractor, which is used as a prompt input sentence: “![Applsci 13 04636 i001]() ” in the form of “Context: s”. Additionally, the structured output form is “subject: , object: , Relation: ” with a single pair of entities, and , meeting the relation type, .
” in the form of “Context: s”. Additionally, the structured output form is “subject: , object: , Relation: ” with a single pair of entities, and , meeting the relation type, .
 ” in the form of “Context: s”. Additionally, the structured output form is “subject: , object: , Relation: ” with a single pair of entities, and , meeting the relation type, .
” in the form of “Context: s”. Additionally, the structured output form is “subject: , object: , Relation: ” with a single pair of entities, and , meeting the relation type, .Our method (Zero-Shot-Prompt-Uyghur-RE) accepts “Context:![Applsci 13 04636 i001]() , subject: , object: , Relation:” as decoder input and produces as relation type. As a result, because this modification influences model prediction, our solution naturally includes Zero-Shot-Prompt-RE.
, subject: , object: , Relation:” as decoder input and produces as relation type. As a result, because this modification influences model prediction, our solution naturally includes Zero-Shot-Prompt-RE.
, subject: , object: , Relation:” as decoder input and produces as relation type. As a result, because this modification influences model prediction, our solution naturally includes Zero-Shot-Prompt-RE.3.4. Extracting Uyghur Multiple Triplets
Uyghur is a multi-featured language, so in this section, we also suggest a generation decoding approach to increase zero-shot extraction performance for phrases with numerous triplets. For the Relation Prompt Production of synthetic data, each sample contains a single relation triplet [48,49,50,51,52,53]. Therefore, traditional relation extraction models are likely to perform poorly with our framework for multi-triplet Zero-Shot-Prompt-RE since they often presume that training data may include several triplets per sentence. There is a multi-turn question-answering inference approach [44] that may alleviate this issue. As a result, we offer Triplet Search Decoding, which enhances the relation extractor’s multi-triplet Zero-Shot-Prompt-RE [54].
When using a traditional relationship extractor [16] that takes a sentence cue as input and outputs a relationship category in an auto-regressive manner, multiple relationships cannot be resolved. Although our triplet search decoding can produce many lines, each of which corresponds to a distinct candidate-related triplet, we then filter the final output sequences using a probability threshold. Starting from the entity sequence “subject: ”, it follows from our template that the next generated token should be the first token of the subject, such as “Alim—![Applsci 13 04636 i002]() ”. The probability for the th potential token of the subject is represented as . The specific sub-sequence “object: ” is then formed after greedy decoding of the sequence. The first token of the second entity, such as “Urumqi—ئۈرۈمچى”, will then come next. The represents the probability of the initial token for the th tail entity. As a result, the generation is branched so that there will be an additional sequence for each head entity. The special sub-sequence “Relation:” is then generated after greedy decoding of the sequence. The initial token of the relation label, such as “death—
”. The probability for the th potential token of the subject is represented as . The specific sub-sequence “object: ” is then formed after greedy decoding of the sequence. The first token of the second entity, such as “Urumqi—ئۈرۈمچى”, will then come next. The represents the probability of the initial token for the th tail entity. As a result, the generation is branched so that there will be an additional sequence for each head entity. The special sub-sequence “Relation:” is then generated after greedy decoding of the sequence. The initial token of the relation label, such as “death—![Applsci 13 04636 i010]() ” in “Place of death—
” in “Place of death—![Applsci 13 04636 i011]() ”, will be the next token to be generated. We branch the generation so that there will be an additional sequence for each pair of subjects and objects. We only examine the likelihood of the first token because it can primarily predict the entity’s subsequent tokens [55,56,57]. The entire inference probability is represented as:
”, will be the next token to be generated. We branch the generation so that there will be an additional sequence for each pair of subjects and objects. We only examine the likelihood of the first token because it can primarily predict the entity’s subsequent tokens [55,56,57]. The entire inference probability is represented as:
 ”. The probability for the th potential token of the subject is represented as . The specific sub-sequence “object: ” is then formed after greedy decoding of the sequence. The first token of the second entity, such as “Urumqi—ئۈرۈمچى”, will then come next. The represents the probability of the initial token for the th tail entity. As a result, the generation is branched so that there will be an additional sequence for each head entity. The special sub-sequence “Relation:” is then generated after greedy decoding of the sequence. The initial token of the relation label, such as “death—
”. The probability for the th potential token of the subject is represented as . The specific sub-sequence “object: ” is then formed after greedy decoding of the sequence. The first token of the second entity, such as “Urumqi—ئۈرۈمچى”, will then come next. The represents the probability of the initial token for the th tail entity. As a result, the generation is branched so that there will be an additional sequence for each head entity. The special sub-sequence “Relation:” is then generated after greedy decoding of the sequence. The initial token of the relation label, such as “death— ” in “Place of death—
” in “Place of death— ”, will be the next token to be generated. We branch the generation so that there will be an additional sequence for each pair of subjects and objects. We only examine the likelihood of the first token because it can primarily predict the entity’s subsequent tokens [55,56,57]. The entire inference probability is represented as:
”, will be the next token to be generated. We branch the generation so that there will be an additional sequence for each pair of subjects and objects. We only examine the likelihood of the first token because it can primarily predict the entity’s subsequent tokens [55,56,57]. The entire inference probability is represented as:Unlike other decoding methods, such as beam search, triplet search decoding takes advantage of the particular triplet structure.
4. Experiments
4.1. Datasets
Uyghur Relation Extraction datasets for Zero-Shot-Prompt-RE are created by a distantly supervised Wikidata knowledge base and Wikipedia articles, as can be seen in Table 4. We use the same methodology as [3,50,58] to divide the data into known and unknown label sets randomly.
In our experiments, we have compared different sets of unknown relation types of size to confirm the effect of the size of the set of relation types on the experimental results.
4.2. Experimental Settings
Based on Uyghur Relation Extraction for Zero-Shot-Prompt-RE (UyRE-ZSP), the l-r is set at 3 × 10−4 and a batch size of 64. We employ the AdamW optimizer during the training procedure [45]. For each relationship, a set number of phrases will be generated. We fine-tune the pre-trained mBERT [38] for Uyghur, the relation extractor.
To evaluate ZSP RTE, we test triplet extraction separately for phrases with a single triplet and sentences with several triplets. To assess multiple triplet extraction, we use the Micro F1 metric, which is often employed in structured pre-diction tasks [51] and provides precision (P) and recall (R). As each phrase contains just a single possible triplet, the Accuracy metric is used to evaluate single triplet extraction (Acc.). We examine UyRE ZSP by [54] using the Macro F1 measure.
To evaluate the model’s performance for relational triple extraction [28], we introduced Precision (Prec.), Recall (Rec.), and F1-measures as evaluation criteria:
where indicates the total number of positive and anticipated positive labels and represents the number of tags that are negative and expected to be negative, FP represents the number of brands projected to be positive but negative. The number of positive but expected to be harmful labels is denoted by the symbol [28].
4.3. Main Experimental Results
Triplet Extraction: Table 5 compares Relation Prompt-Uyghur to the baselines on Zero-Shot-Prompt-Relation Triplet Extraction (ZSP_RTE) for the UyRE-ZSP datasets. Regarding accuracy and F1 metrics, our method consistently outperforms the baseline methods in single-triplet and multi-triplet evaluations. Uyghur is one of the most morphologically complex and adhesive languages, in which the composition of words and their meanings rely on complex forms of affixation to represent them. The affixes not only change the root word’s importance but also determine a word’s role in a sentence. Therefore, the correct separation of stems and affixes is necessary to represent the word’s true meaning as a whole correctly. Consequently, it requires extra processing of data; additional letters will be added or lost when the word root is extracted; this should be handled according to the Prompt to avoid the case of an extraction error.
We have conducted comparative experiments between Zero-Shot-Prompt-RE and the baseline method in Table 5. Our method consistently outperformed the baseline method in terms of accuracy and F1 metrics in both single triad and multiple triplet results [10,51]. We also note that Zero-Shot-Prompt-Relation Extraction (ZSP_RE) in Uyghur performs much better than a third-party Table Sequence [50,51,52], especially in multi-trigram extraction, suggesting that the Zero-Shot-Prompt-RE approach in Uyghur is practical. However, our proposed Uyghur entity and suffix processing, relation extractor, and decoder technique successfully resolve this difficulty by automatically listing and arranging many triples accurately at the time of inference, without the extracted entities carrying a suffix, as in previous work [39,44].
Relation Extraction: Zero-Shot-Prompt-RE for Uyghur includes information about entity pairs in the hints and supports zero-shot relation classification work without additional training. Table 6 shows that, compared to previous state-of-the-art ZS-BERT techniques [12], our approach maintains relatively good F1 performance for our relational classification when the set of unseen relational labels increases. It may be possible to scale better to larger sets of unseen tags based on relational hints, which is very friendly for applications of relational triad extraction in open domains. The reason for the low recall is that when the samples are labeled, most positive samples are mistakenly labeled as negative samples. This makes it harder for the model to learn from positive examples, which lowers the accuracy of negative samples while positive samples are predicted as negative samples. To solve the problem, the next step is to fix the samples that were wrongly labeled and watch the results to see if anything has changed.
5. Analysis
5.1. Ablation Study
The generated data’s accuracy is crucial to our Zero-Shot-Prompt-Relation Triplet Extraction (ZSP_RTE) technique’s success. Therefore, we contrast a variety of genuine and artificial data sets. We count the number of distinct words and other items in the texts. The accuracy of the data generated is critical to the success of our Zero-Shot Prompt-Relation Triplet extraction technique. Therefore, we compared the kinds of natural and artificial data samples and performed comparative experiments. Table 7 shows that the synthetic data sentences have more entities with a variety of unique components. However, the generated sentences have fewer individual words and less lexical diversity.
However, the generated sentences have a lesser vocabulary diversity. On the other hand, non-entity words account for the majority of the total uncommon words.
Our suggested Zero-Shot-Prompt-Relation Triplet Extraction approach relies significantly on the quality of the produced data. Thus, we examine a variety of samples of actual and fake data. Specifically, we count the unique words and items in the texts. We used the UyRE-ZSP validation set to produce five-label sentences and an equivalent number of synthetic phrases for comparison. Table 7 demonstrates that the created sentences include various unique items.
Nevertheless, the resulting phrases include fewer unique words overall, which may be explained by the fact that entity names are often unique. The generator language model has been exposed to many unique entity names during extensive pre-training. On the other hand, non-entity words account for the majority of the overall number of unique words. By employing prompts to condition the production of sentences explicitly for unknown connection labels, the output sentences may include less context-specific information.
Table 8 shows the results of an ablation study that was performed to test how well our decoding method and task-specific fine-tuning worked for the Uyghur visible relation set on the multi-triple recombination Zero-Shot-Prompt-Relation Extraction. The comparison was conducted on the UyRE-ZSP validation set, which contains ten invisible identifiers. This large performance disparity indicates that triplet search decoding is essential for Zero-Shot-Prompt-Relation Triplet Extraction for Uyghur with multiple triplets, implying that the enumeration and classification of associative triplet candidates are of adequate quality. Second, we observe that the relation extractor’s performance degrades significantly when the visible relation samples from the column set are not fine-tuned prior to the final fine-tuning of the synthetic samples generated by the invisible labels.
When the size of the unseen label set, , increases, our technique can retain a relatively good classification F1 performance, while Zero-Shot-Prompt-RE exhibits a more pronounced decline in performance.
5.2. Qualitative Analysis
Figure 3 shows a variety of real and created samples to demonstrate how the relation data generator generalizes to real-world relations. Real sentences and related labels were compiled from factual articles.
Given the relations “Mother—ئاپىسى”, “Spouse—جۆرىسى-”, and “Place of birth—تۇغۇلغان جايى.”, the generator can generate logical statements. It can also discover the proper semantic meaning of the relations. To test the generality of the relational data generator to relationships in the wild, we provide several actual and created examples in Figure 3. The connection labels and actual phrases were culled from articles of fact. With the relations “Mother—ئاپىسى”, “Spouse—جۆرىسى- “, and “Place of birth—-تۇغۇلغان جايى.”, the generator can detect the correct semantics of the relations and generate grammatically sound phrases. The produced head and tail entity pairs may often fit the specified relations and have similar contexts to the actual phrases. In the second instance of the connection ‘spouse’, however, the created entity pairings do not fit the relationship’s intended meaning despite the marriage relationship. In contrast, the connection implied by the produced words is more akin to “get married”. These results imply that a potential area for future development may be to make the head and tail entities created by the system correspond more closely to the specified connection.
5.3. Effect of Generated Data Size
We look into how the number of artificial samples affects how well the multi-triplet Zero-Shot-Prompt-Relation Triplet Extraction for Uyghur works.
Our Zero-Shot-Prompt-Relation Triplet Extraction method depends heavily on the quality of the generated data. Therefore, we compare the diversity of real and synthetic data samples. We measure the number of unique words and entities in the text. We used UyRE-ZSL validation set sentences with five unique tags and generated an equal number of synthetic sentences for comparison. Figure 3 shows that the diversity of unique entities is more significant for the generated sentences. However, the overall unique vocabulary diversity of the generated sentences is lower. These results may be because entity names are unique, and the generator language model has seen many unique entity names in large-scale pre-training. On the other hand, the overall unique vocabulary is mainly determined by the non-entity vocabulary. The diversity of contextual information in the output sentences can be constrained by generating sentences specifically for unseen relational labels using cueing conditions.
Table 9 shows the results of the evaluation, which is based on a UyRE-ZSP validation set with five and ten labels that are unseen. The F1 score goes up when the number of samples per label goes from 100 to 1500. However, increasing the generated capacity to a maximum of 1500 does not improve efficacy. This suggests that while synthetic data are advantageous for Zero-Shot-Prompt-RE for Uyghur, excessive quantities can result in overfitting due to noise.
5.4. Performance across Relations
To study how the performance varies across distinct relations labels, we evaluate single-triplet Zero-Shot-Prompt-RE for Uyghur on the UyRE-ZSP test set with m = 5, 10 unseen tags, respectively. Table 10 shows that the model can perform well for relations such as “sister—ئاچا سېڭىل ” and “ۋاپات بولغان جايى—place of death”.
However, it functions more inadequately for connections such as “Part of—بىر قىسمى ” and “مىللىتى—nationality.”
In order to investigate how the performance varies between different relationship labels, we evaluated the single triple ZeroRTE with five and ten invisible labels on the Wiki-ZSL test set. As can be seen in Table 10, the model performs well for m = 5 relations such as ‘‘Educated at— مەكتەپنى پۈتتۈرگەن’’ and ‘‘place of death’’, the model performs well for relations such as “Part of—بىر قىسمى ” and ‘‘Award received—مۇكاپاتقا ئېرىشكەن ” The model performs well for relations such as “Part of—بىر قىسمى ” and “nationality—دۆلەت تەۋەلىكى ” for m = 10, and worse for relations such as “Part of—ىر قىسمى ” and ‘‘Award received-مۇكاپاتقا ئېرىشكەن ” for m = 10. It performs worse for relations such as “Part of—بىر قىسمى ” and “nationality—دۆلەت تەۋەلىكى ”. These results suggest that Relation Prompt performs best for concrete relations to constrain the output context more effectively.
6. Conclusions
This paper describes the ‘Zero-Shot-Prompt-RE relational triple extraction for Uyghur’ job setting, which was made to get around the main problems with earlier task settings and encourage more research in low-resource relation extraction. To deal with Zero-Shot-Prompt-RE relational triple extraction tasks, we offer RelationPrompt and show that language models can use relation label prompts to create synthetic training data that can be used to create structured sentences. We present an effective and interpretable triplet search decoding approach to address the restriction of extracting many related triplets from a phrase. Using a multi-task learning structure and contextual representation learning quality based on the features of Uyghur entity words, cue learning embeds the input sentences well into the embedding space and significantly improves the performance. We also conducted extensive experiments to investigate different aspects of ZS-BERT, ranging from hyperparametric examples to case studies, ultimately showing that ZSP-RTE can consistently outperform existing relational extraction models in a zero-shot setting. In addition, learning effective relational embeddings using relational prototypes as auxiliary information may also help semi-supervised learning or few-shot learning.
In the future, we plan to apply this method to Knowledge Graph applications, including question answering, text classification, and event extraction.
Author Contributions
Conceptualization, A.H.; methodology, A.H.; software, A.H.; validation, A.H.; formal analysis, A.H. and T.Y.; investigation, A.H.; data curation, A.H.; original draft preparation, A.H.; writing, review, and editing, A.H., A.W. and T.Y.; supervision, A.W. and T.Y.; project administration, A.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Natural Science Foundation of Xinjiang Uyghur Autonomous Region of China (Grant No. 2021D01C079) and the National Key Research and Development Program of China (Grant No. 2017YFB1002103).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors would like to thank all anonymous reviewers and editors for their valuable suggestions to improve this paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Huang, S.; Liu, J.; Korn, F.; Wang, X.; Wu, Y.; Markowitz, D.; Yu, C. Contextual fact ranking and its applications in table synthesis and compression. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD), Anchorage, AK, USA, 4–8 August 2019; pp. 285–293. [Google Scholar]
- Zhang, Y.; Qi, P.; Manning, C.D. Graph convolution over pruned dependency trees improves relation extraction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 2–4 November 2018; pp. 2205–2215. [Google Scholar]
- Chen, C.; Li, C. Zs-bert: Towards zero-shot relation extraction with attribute representation learning. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 3470–3479. [Google Scholar]
- Mintz, M.; Bills, S.; Snow, R.; Jurafsky, D. Distant supervision for relation extraction without labeled data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Singapore, 2–7 August 2009; pp. 1003–1011. [Google Scholar]
- Riedel, S.; Yao, L.; McCallum, A. Modeling relations and their mentions without labeled text. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Bercelona, Spain, 19–23 September 2010; pp. 148–163. [Google Scholar]
- Chia, Y.; Bing, L.; Soujanya, P.; Luo, S. RelationPrompt: Leveraging Prompts to Generate Synthetic Data for Zero-Shot Relation Triplet Extraction. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; pp. 45–47. [Google Scholar]
- John, K.; Ilias, C.; Prodromos, M.; Ion, A. GREEK-BERT: The Greeks visiting Sesame Street Association for Computing Machinery. In Proceedings of the 11th Hellenic Conference on Artificial Intelligence, New York, NY, USA, 2 September 2020; pp. 110–117. [Google Scholar]
- Pundlik, S.; Dasare, P.; Kasbekar, P.; Gawade, A.; Gaikwad, G.; Pundlik, P. Multiclass classification and class based sentiment analysis for hindi language. In Proceedings of the 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 21–24 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 512–518. [Google Scholar]
- Mukesh, Y.; Varunakshi, B. Semi-supervised mix-hindi sentiment analysis using neural network. In Proceedings of the 9th International Conference on Cloud Computing, Data Science & Engineering (Confluence), IEEE, Noida, India, 10–11 January 2019; pp. 309–314. [Google Scholar]
- Tang, J.; Wang, Y.; Zheng, K.; Mei, Q. End-to-End Learning for Short Text Expansion. In Proceedings of the 23rd ACMSIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1105–1113. [Google Scholar]
- Shi, M.; Tang, Y.; Liu, J. Functional and Contextual Attention-Based LSTM for Service Recommendation in Mashup Creation. In IEEE Transactions on Parallel and Distributed Systems, Piscataway, NJ, USA, 6–8 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–10. [Google Scholar]
- Cheng, F.; Yada, S.; Tanaka, R.; Aramaki, E.; Kurohashi, S. JaMIE: A Pipeline Japanese Medical Information Extraction System. arXiv 2021, arXiv:2111.04261. [Google Scholar] [CrossRef]
- Gordeev, D.I.; Davletov, A.A.; Rey, A.I.; Akzhigitova, G.R.; Geymbukh, G.A. Relation extraction dataset for the russian. In Proceedings of the International Conference on Computational Linguistics and Intellectual Technologies “Dialogue”, Seoul, Republic of Korea, 20–22 July 2020; pp. 1–13. [Google Scholar]
- Hennig, L.; Truong, P.T.; Gabryszak, A. MobIE: A German Dataset for Named Entity Recognition, Entity Linking and Relation Extraction in the Mobility Domain. arXiv 2021, arXiv:2108.06955. [Google Scholar]
- Hamdi, A.; Pontes, E.L.; Boros, E.; Nguyen, T.T.H.; Hackl, G.; Moreno, J.G.; Doucet, A. A Multilingual Dataset for Named Entity Recognition, Entity Linking and Stance Detection in Historical Newspapers. In Proceedings of the SIGIR ‘21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 11–15 July 2021. [Google Scholar]
- Xin, X.; Chen, X.; Zhang, N.; Xie, X.; Chen, X.; Chen, H. Towards Realistic Low-resource Relation Extraction: A Benchmark with Empirical Baseline Study. arXiv 2022, arXiv:2210.10678. [Google Scholar] [CrossRef]
- Rami, A.; Andreas, V.; Ryan, M. Leveraging type descriptions for zero-shot named entity recognition and classification. In Proceedings of the ACL, Bangkok, Thailand, 1–6 August 2021; pp. 1516–1528. [Google Scholar]
- Yoshua, B.; Réjean, D.; Pascal, V.; Christian, J. A neural probabilistic language model. In Proceedings of the Fourteenth Annual Neural Information Processing Systems (NIPS) Conference, Denver, CO, USA, 27 November 27–2 December 2000; pp. 932–938. [Google Scholar]
- Cui, L.; Wu, Y.; Liu, J.; Yang, S.; Zhang, Y. Template-based named entity recognition using BART. In Proceedings of the Findings of ACL-IJCNLP, Bangkok, Thailand, 1–6 August 2021; pp. 1835–1845. [Google Scholar]
- Wei, Z.; Su, J.; Wang, Y.; Tian, Y.; Chang, Y. A Novel Cascade Binary Tagging Framework for Relational Triple Extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 1476–1488. [Google Scholar]
- Ye, H.; Zhang, N.; Deng, S.; Chen, M.; Tan, C.; Huang, F.; Chen, H. Contrastive Triple Extraction with Generative Transformer. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Virtual Event, 2–9 February 2021; pp. 14257–14265. [Google Scholar]
- Omer, L.; Minjoon, S.; Eunsol, C.; Luke, Z. Zero-shot relation extraction via reading comprehension. In Proceedings of the CoNLL, Vancouver, BC, Canada, 3–4 August 2017; pp. 333–342. [Google Scholar]
- Wang, Y.; Yu, B.; Zhang, Y.; Liu, T.; Zhu, H.; Sun, L. TPLinker: Single-stage Joint Extraction of Entities and Relations through Token Pair Linking. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 1572–1582. [Google Scholar]
- Wang, Y.; Sun, C.; Wu, Y.; Zhou, H.; Li, L.; Yan, J. UniRE: A Unified Label Space for Entity Relation Extraction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021; pp. 220–231. [Google Scholar]
- Yu, B.; Zhang, Z.; Shu, X.; Liu, T.; Wang, Y.; Wang, B.; Li, S. Joint Extraction of Entities and Relations Based on a Novel Decomposition Strategy. In Proceedings of the ECAI 2020—24th European Conference on Artificial Intelligence, Santiago De Compostela, Spain, 29 August–8 September 2020; pp. 2282–2289. [Google Scholar]
- Abiola, O.; Andreas, V. Zero- shot relation classification as textual entailment. In Proceedings of the First workshop on fact extraction and VERification, Brussels, Belgium, 1 November 2018; pp. 72–78. [Google Scholar]
- Laria, R.; Kyle, M. Prompt programming for large language models: Beyond the few-shot paradigm. In Proceedings of the CHI, Yokohama, Japan, 8–13 May 2021; pp. 1–10. [Google Scholar]
- Ding, B.; Liu, L.; Bing, L.; Canasai, K.; Thien, H.; Shafiq, J.; Luo, S.; Chunyan, M. DAGA: Data augmentation with a generation approach for low-resource tagging tasks. In Proceedings of the EMNLP, Online, 16–20 November 2020; pp. 6045–6057. [Google Scholar]
- Han, X.; Zhu, H.; Yu, P.; Wang, Z.; Yao, Y.; Liu, Z.; Sun, M. Fewrel: A large-scale supervised few-shot relation classification dataset with state-of-the-art evaluation. In Proceedings of the EMNLP, Brussels, Belgium, 31 October–4 November 2018; pp. 4803–4809. [Google Scholar]
- Das, R.; Nelakantan, A.; Belanger, D.; McCallum, A. Chains of reasoning over entities, relations, and text using recurrent neural networks. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; pp. 132–141. [Google Scholar]
- Huang, L.; Ji, H.; Kyunghyun, C.; Ido, D.; Sebastian, R.; Clare, V. Zero-shot transfer learning for event extraction. In Proceedings of the ACL, Melbourne, Australia, 15–20 July 2018; pp. 2160–2170.
- Ji, G.; Liu, K.; He, S.; Zhao, J. Distant supervision for relation extraction with sentence-level attention and entity descriptions. In Proceedings of the AAAI, San Francisco, CA, USA, 4–9 February 2017; pp. 2506–2512. [Google Scholar]
- Shang, Y.; Huang, H.; Mao, X. OneRel: Joint Entity and Relation Extraction with One Module in One Step. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2022, Dublin, Ireland, 22–27 May 2022; pp. 22–27. [Google Scholar]
- Yuan, Y.; Zhou, X.; Pan, S.; Zhu, Q.; Song, Z.; Guo, L. A Relation-Specific Attention Network for Joint Entity and Relation Extraction. In Proceedings of the Twenty Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 4054–4060. [Google Scholar]
- Fu, T.; Li, P.; Ma, W. Graphrel: Modeling text as relational graphs for joint entity and relation extraction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1409–1418. [Google Scholar]
- Abiderexiti, K.; Halike, A.; Maimaiti, M.; Wumaier, A.; Yibulayin, T. Semi-automatic corpus expansion for Uyghur named entity relation based on a hybrid method. In Proceedings of the 11th International Conference on Language Resources and Evaluation, European Language Resources Association, Miyazaki, Japan, 7–12 May 2018; pp. 1–5. [Google Scholar]
- Abiderexiti, K.; Maimaiti, M.; Yibulayin, T.; Wumaier, A. Annotation schemes for constructing Uyghur named entity relation corpus. In Proceedings of the 2016 International Conference on Asian Language Processing (IALP), Tainan, Taiwan, 21–23 November 2016; pp. 103–107. [Google Scholar]
- Aili, M.; Xialifu, A.; Maihefureti, M.; Maimaitimin, S. Building Uyghur dependency treebank: Design principles, annotation schema and tools. In Proceedings of the Worldwide Language Service Infrastructure, WLSI 2015, Lecture Notes in Computer Science, Kyoto, Japan, 22–23 January 2015; pp. 124–136. [Google Scholar]
- Gong, H.; Chen, G.; Liu, S.; Yu, Y.; Li, G. Cross-modal self-attention with multi-task pre-training for medical visual question answering. In Proceedings of the 2021 International Conference on Multimedia Retrieval, Taipei, Taiwan, 21–24 August 2021; pp. 456–460. [Google Scholar]
- Taghizadeh, N.; Faili, H.; Maleki, J. Cross-Language Learning for Arabic Relation Extraction. Procedia Comput. Sci. 2018, 142, 190–197. [Google Scholar] [CrossRef]
- Hur, Y.; Son, S.; Shim, M.; Lim, J.; Lim, H. K-EPIC: Entity-Perceived Context Representation in Korean Relation Extraction. Appl. Sci. 2021, 11, 11472. [Google Scholar] [CrossRef]
- Maimaiti, M.; Wumaier, A.; Abiderexiti, K.; Yibulayin, T. Bidirectional long short-term memory network with a conditional random field layer for Uyghur part-of-speech tagging. Information 2017, 8, 157. [Google Scholar] [CrossRef] [Green Version]
- Parhat, S.; Ablimit, M.; Hamdulla, A. A Robust Morpheme Sequence and Convolutional Neural Network-Based Uyghur and Kazakh Short Text Classification. Information 2019, 10, 387. [Google Scholar] [CrossRef] [Green Version]
- Halike, A.; Abiderexiti, K.; Yibulayin, T. Semi-Automatic Corpus Expansion and Extraction of Uyghur-Named Entities and Relations Based on a Hybrid Method. Information 2020, 11, 31. [Google Scholar] [CrossRef] [Green Version]
- Mike, L.; Liu, Y.; Naman, G.; Marjan, G.; Abdelrahman, M.; Omer, L.; Veselin, S.; Luke, Z. Bart: Denoising sequence-to-sequence pretraining for natural language generation, translation, and comprehension. In Proceedings of the ACL, Seattle, WA, USA, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Li, X.; Arianna, Y.; Chai, D.; Zhou, M.; Li, J. Entity-relation extraction as multi-turn question answering. In Proceedings of the ACL, Florence, Italy, 28 July–2 August 2019; pp. 1340–1350. [Google Scholar]
- Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the AAAI, Austin, TX, USA, 25–30 January 2015; pp. 2181–2187. [Google Scholar]
- Zheng, S.; Wang, F.; Bao, H.; Hao, Y.; Zhou, P.; Xu, B. Joint extraction of entities and relations based on a novel tagging scheme. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1227–1236. [Google Scholar]
- Tapas, N.; Hwee, T. Effective modeling of encoder-decoder architecture for joint entity and relation extraction. In Proceedings of the AAAI, New York, NY, USA, 7–12 February 2020; pp. 8528–8535. [Google Scholar]
- Giovanni, P.; Ben, A.; Jason, K.; Ma, J.; Alessandro, A.; Rishita, A.; Cicero, N.; Stefano, S. Structured prediction as translation between augmented natural languages. In Proceedings of the ICLR, Virtual Conference, Formerly Addis Ababa ETHIOPIA, Virtual, 26 April–1 May 2020; pp. 1–26. [Google Scholar]
- Miwa, M.; Sasaki, Y. Modeling joint entity and relation extraction with table representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1858–1869. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Mineapolis, MN, USA, 3–5 June 2019; pp. 4171–4186. [Google Scholar]
- Jiang, T.; Zhao, T.; Qin, B.; Liu, T. The role of “condition”: A novel scientific knowledge graph representation and construction model. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD), Anchorage, AK, USA, 4–8 August 2019; pp. 1634–1642. [Google Scholar]
- Hao, J.; Chen, M.; Yu, W.; Sun, Y.; Wang, W. Universal representation learning of knowledge bases by jointly embedding instances and ontological concepts. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD), Anchorage, AK, USA, 4–8 August 2019; pp. 1709–1719. [Google Scholar]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008; pp. 1247–1250. [Google Scholar]
- Dong, X.; Gabrilovich, E.; Heitz, G.; Horn, W.; Lao, N.; Murphy, K.; Strohmann, T.; Sun, S.; Zhang, W. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Doha, Qatar, 25–29 October 2014; pp. 601–610. [Google Scholar]
- Adam, R.; Colin, R.; Noam, S. How much knowledge can you pack into the parameters of a language model. In Proceedings of the EMNLP, Hong Kong, China, 16–20 November 2020; pp. 5418–5426. [Google Scholar]
- Wang, J.; Lu, W. Two are better than one: Joint entity and relation extraction with table- sequence encoders. In Proceedings of the EMNLP, Hong Kong, China, 16–20 November 2020; pp. 1706–1721. [Google Scholar]
Figure 1.
The Uyghur Relation Prompt structured templates.

Figure 2.
The Uyghur language training process for Relation Generator.

Figure 3.
Comparison of real and generated data.


{kind=link}
{kind=link}
{kind=link}
Table 1.
Task examples of triplet extraction.
| Sentence | Subject | Object |
|---|---|---|
| |  |
| Mr. Alim died in Urumqi. | Mr. Alim | In Urumqi |
In Table 1, Sentence, Subject, and Object refer to the sentence, first entity, and second entity, respectively.
Table 2.
Task parameters against our proposed Zero-Shot prompts retreated to triplet extraction.
| Task Setting | Input | Output | Supervision |
|---|---|---|---|
| Relation Classification | Full | ||
| Zero-Shot Relation Classification | Zero-Shot | ||
| Relation Triple Extraction | Full | ||
| Zero-Shot-Prompts Relation Triple Extraction | Zero-Shot |
In Table 2, refer to the sentence, first entity, and second entity, respectively.
Table 3.
Common symbolic descriptions in relationship extraction.
| Notation | Description |
|---|---|
| A knowledge graph | |
| Facts | |
| Sentence, Triplet, Relation | |
| A Uyghur triple of head, relation, and tail | |
| Seen datasets | |
| Unseen datasets | |
| The Uyghur relation generator | |
| The relation detector | |
| The set of seen relational types | |
| The set of unseen relational types | |
| The labeled unseen dataset | |
| The labeled seen dataset | |
| The conditional generation probability for each sequence | |
| The seen relation type sets | |
| The unseen relation type sets | |
| The sizes of the unseen relation type sets | |
| The sizes of the seen relation type sets |
Table 4.
Datasets statistics in Uyghur languages.
| Sentence-Length | Entities | Samples | Relations | |
|---|---|---|---|---|
| UyRE-ZSP | 20.8 | 20,742 | 23,652 | 24 |
Table 5.
Results for our method in different relation types in Uyghur languages.
| Method | Single Triplet | Multi Triplet | |||
|---|---|---|---|---|---|
| Acc. | Prec. | Rec. | F1 | ||
| m = 5 | Table Sequence [51] | 11.73 | 50.00 | 4.76 | 8.69 |
| NoGen [10] | 8.32 | 83.33 | 6.17 | 11.49 | |
| Relation Prompt [6] | 13.65 | 71.25 | 26.51 | 38.64 | |
| Zero-Shot-RTE for Uyghur | 13.28 | 73.97 | 30.17 | 42.86 | |
| Zero-Shot-Prompt-RTE for Uyghur (Our suggested model) | 16.35 | 69.23 | 35.29 | 46.75 | |
| m = 10 | Table Sequence [51] | 9.11 | 50.00 | 2.38 | 4.54 |
| NoGen [10] | 6.58 | 75.00 | 5.83 | 0.11 | |
| Relation Prompt [6] | 14.56 | 71.43 | 9.26 | 16.39 | |
| Zero-Shot-RTE for Uyghur | 11.54 | 76.25 | 31.69 | 44.77 | |
| Zero-Shot-Prompt-RTE for Uyghur (Our suggested model) | 16.48 | 78.46 | 33.95 | 47.39 | |
Table 6.
Results for our suggested method in Uyghur Zero-Shot-Prompt-Relation Extraction.
| Method | Prec. | Rec. | F1 | |
|---|---|---|---|---|
| m = 5 | R-BERT [51] | 88.40 | 13.40 | 23.28 |
| ZS-BERT [3] | 73.81 | 32.63 | 45.25 | |
| Relation Prompt [6] | 66.67 | 53.84 | 59.57 | |
| Zero-Shot-Prompt-RE for Uyghur (Our suggested model) | 70.89 | 57.55 | 63.35 | |
| m = 10 | R-BERT [51] | 88.73 | 12.67 | 22.18 |
| ZS-BERT [3] | 74.32 | 30.55 | 43.30 | |
| Relation Prompt [6] | 82.25 | 38.75 | 52.68 | |
| Zero-Shot-Prompt-RE for Uyghur (Our suggested model) | 82.02 | 48.39 | 60.87 |
Table 7.
Data diversity comparison.
| Model | Sentences | Entities | Words |
|---|---|---|---|
| Our Data | 2451 | 2859 | 10,356 |
| Generated Data | 2451 | 3122 | 7452 |
Table 8.
Ablation results of Uyghur multi-triplet extraction.
| Model | F1 | △F1 |
|---|---|---|
| Full method | 26.23 | |
| Uyghur Triplet Search Decoding | 12.33 | −13.9 |
| Extractor fine-tuning | 14.54 | −11.69 |
Table 9.
Effect of Uyghur generated data size On UyRE-ZSP.
| Generated Samples | F1 | |
|---|---|---|
| m = 5 | 100 | 19.56 |
| 200 | 23.24 | |
| 500 | 26.59 | |
| 1000 | 27.54 | |
| 1500 | 24.25 | |
| m = 10 | 100 | 23.15 |
| 200 | 26.54 | |
| 500 | 27.42 | |
| 1000 | 25.25 | |
| 1500 | 24.12 |
Table 10.
Separate evaluation on relation labels.
| Relation Labels | F1 | |
|---|---|---|
| m = 5 | Part of | 13.65 |
| nationality | 23.21 | |
| spouse | 25.65 | |
| Educated At | 39.87 | |
| Award Received | 15.63 | |
| sister | 28.25 | |
| Place of death | 42.68 | |
| m = 10 | Part of | 11.23 |
| nationality | 25.63 | |
| spouse | 36.52 | |
| Educated At | 38.23 | |
| Award Received | 39.25 | |
| sister | 41.58 | |
| Place of death | 44.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Halike, A.; Wumaier, A.; Yibulayin, T. Zero-Shot Relation Triple Extraction with Prompts for Low-Resource Languages. Appl. Sci. 2023, 13, 4636. https://doi.org/10.3390/app13074636
AMA Style
Halike A, Wumaier A, Yibulayin T. Zero-Shot Relation Triple Extraction with Prompts for Low-Resource Languages. Applied Sciences. 2023; 13(7):4636. https://doi.org/10.3390/app13074636
Chicago/Turabian StyleHalike, Ayiguli, Aishan Wumaier, and Tuergen Yibulayin. 2023. "Zero-Shot Relation Triple Extraction with Prompts for Low-Resource Languages" Applied Sciences 13, no. 7: 4636. https://doi.org/10.3390/app13074636
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.